Interactive Query Expansion Based on Fuzzy Association Thesaurus for Web Information Retrieval
Hahn-Ming Lee'
Department of Electronic Engineering National Taiwan University of Science and Technology' Phone: 886-2-273764 10 Fax: 886-2-27376424
43, Sec.4, Keelung Rd., Taipei 106, Taiwan E-mail: hmlee@,mail.ntust.edu.tw -
Sheng-Kang Lin', and Chiung-Wei Huang'
229 Jian-Shing Rd., Jungli City, Taoyuan County 320, Taiwan
.
Department of Electronic Engineering, Ching Yun Institute of Technology'
Abstract- In this paper, a fuzzy composition based association thesaurus with interactive query expansion for Chinese web information retrieval is proposed. The thesaurus is well arranged by means of an organization technique, so that terms in the association thesaurus offered as suggestions could be effortless for users to decide which to add. Then, the reformulated queries accompanied with some query modification methods are submitted to perform another round of searching. Two test collections were used to construct the association thesaurus in order to see how dataset criteria affect the constructed thesaurus. Experimental results show that a homogeneous collection would get in a robust thesaurus that is useful for interactive query expansion. Besides, two weighting schemes for query modification were also examined and the results show that there are some compromises of using them. At last, we concluded that interactive query expansion based on fuzzy association thesaurus achieves better performance in both precision and recall rate significantly.
I. INTRODUCTION
Nowadays, explosive growth of Web sites results in information overloading problem [ 1][2]. Many difficulties, such as word misusage of human beings, short queries in retrieval systems and ambiguities in Chinese word
j identification, would cause web search engines to reach their limitations. Query expansion can effectively alleviate the problem addressed above [3], and a number of approaches for information retrieval systems have been studied [5][6][7][8].
There are generically two categories among these techniques, global analysis and local analysis [9]. However, in all these automatic query expansion approaches, undesired terms may be selected by the system unexpectedly. Users have no control over which terms are more appropriate than the others are. Thus, in this paper, interactive query expansion is proposed in order to sieve out undesired terms.
In interactive query expansion, users are shown a list of terms suggested by the system after entering the initial query. Our approach is on the assumption that not every suggested term is good for query expansion; further investigation is preferable.
Through human-machine interaction, undesired terms will not be added to the query string. Also, our system will retrieve documents using the new query by a query-document similarity measure with/without a query weight. Then, the system will return a ranked list of documents with documents based on fuzzy relation composition that best match the query being ranked at the top.
11. SYSTEM ARCHITECTURE
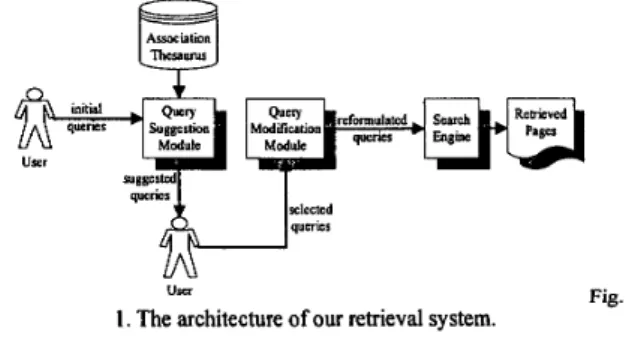
Fig. 1 sketches the architecture of our retrieval system.
The framework of our system is based on the popular vector space model [10][15]. Given an initial query, we first search the association thesaurus for additional related terms. These terms are then suggested to the user. After the user selection of which terms are more preferable for expansion, the system will modify the query according to some aggregation functions and query vector is generated consequently. Thus, our query expansion process can include additional information that a user is originally ignorant of and improve the retrieval performance of the system. It is noticeable that our query expansion subsystem is essentially composed of two parts, one is the association thesaurus construction phase and another is the human-machine interaction (query suggestion -+ user selection + query modification) phase.
Auociation
Fig.
uru
I . The architecture of our retrieval system.
A. Association Thesaurus
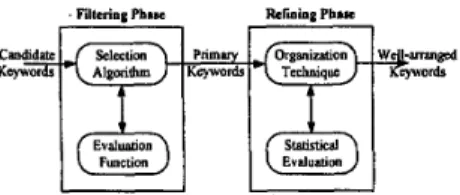
A large number of web documents are chosen as a sizable dataset. These documents have been manually classified into the same category as well. This is because manually classified documents have a high percentage of being correctly classified; as a result, documents within the same category would all cover topics in a certain subject area. The process of candidate keyword generation is shown as Fig. 2. Besides, the MMSEG system [12] is used in our system because it achieves very high percentage of accuracy in Chinese word extraction.
Fig. 2. Candidate keyword generation.
0-7803-7293-W011$17.00 Q 2001 IEEE 724 2001 IEEE International Fuzzy Systems Conference
1) Keywod Selection
Fig. 3 shows the block diagram of the proposed keyword selection process. There are two phases in our design:
jltering phase, which selects an optimal subset of candidate keyword set according to some evaluation function, and refiningphase, where keywords is well selected based on the statistical evaluation. Applying a threshold, terms’ TF-IDF [ l o ] measurements greater than this threshold are filtered to form a primary keyword set.
. Wtering ?hue Rehiap P b a
t
Fig. 3. Block diagram of the 2-phase keyword selection process.
2) E m Similarity
There are several interrelationships exist between terms in a thesaurus, such as BT (broader term), NT (narrower term), and RT (related term). However, it is hard to determine term relations automatically. Hence, we simplify all possible relations to one type of association relation. Terms with association relation are considered they are co-related rather than having a specific interrelationship between them.
Building an association thesaurus is based on the assumption that terms appearing concurrently within a given textual unit may be co-related in a way. Here, we define a whole document as a textual unit. The more frequently any two terms co-occur, the closer the two terms are [13]. For example, the terms ‘‘BE (stock)” and “&&& (fund)” often occur in the same document even in the same sentence, but they are not synonyms.
For each keyword $, we calculate its association with other keywords by using a composition between two fuzzy relations AJ and R. The resulting term-terms matrix B, states that to what degree a term associated with keyword 9.
BI 4 R
Fig. 4. Term-terms association matrix obtained from fizzy composition.
BJ is a lxn matrix that indicates the association degree between keyword 4 and other keywords. A, is a 1 xm matrix whose elements represent term-document relationship. R is a mxn matrix which includes all relationship of each term to each document. “ 0 ” denotes fuzzy composition based on the standard t-norms and t-conorms [14].
3) Keywon& Organization
Fuzzy composition approach is used to construct thesaurus.
Different operation used in fuzzy composition, such as max-min, max-product, and sum-product, will affect the order of terms in the ranked list. If only the top N terms in the list would be scanned, are there any strategies to generate a list according to these different fuzzy compositions? Thus, we refine the association thesaurus in the following steps. First,
determine a positive number N greater than N. For each term t, we extract the top N’ terms of t’s association list from different fuzzy compositions respectively. Then, leave duplicate terms while others are filtered out. Finally, nearly N terms concerning a term in the association thesaurus will be suggested to users in the querying process.
B. Query Expansion 1) Query Suggestion
The objective of our query suggestion module is to find a suitable candidate term list for users based on the concept-based query expansion method [8]. These terms should have the property of being similar to the entire query rather than to the individual query terms. Hence, in query suggestion, we need an evaluation hnction that measures the similarity between a term and the initial query composed of multiple terms. The query-term similarity value between the initial query q and a possible suggestion term tk, denoted by S(q,tk), can then be defined as follows, where fuzzy composition is used as similarity measure.
S(q,rt) = QQA: = ( c q l +oA: = s q , .(Al oA*T) (1)
/.I I
where A,, Ak represent term vectors for term rj and tk, respectively.
2) Query Mod$cation andsearching Model
After the human-machine interaction, the reformulated query q,, which consists of the initial query along with the additional selected terms, is obtained. The essential concept of the reformulated query, denoted as a vector Q,, can be expressed by:
Q. = t q , . A I . (2)
1-1
The normalized TF-IDF weighting scheme [I 11 is adopted to measure the query-document similarity. Based on this weighting scheme, two searching models, frst examined in [7], can be applied.
Query Without Weight
Let us consider a reformulated query qr and an arbitrary document d in the document set. The query-document similarity between qr and d, denoted by S(q, d), is defined as:
s(q, d ) = cq, x (g - 14, )
1-1
(3)
where
g-i&, =TF-DFvalueof termt,
rl,, =numberofoccwenwsof te’mr, indocumntd g,? =maximum term frequencyin document d
4, =numberof documentswhichcontainr, within thedocumentset m = total number of documents
8 Querywithweight
Since manually setting the weights of query terms places an extra burden to users, there is a demand that we have
725
to achieve it automatically. We consider each initial query term is equally weighted to be 1 and each additional expanded term is weighted according to its significance degree with respect to the initial query q.
This significance degree is determined by the query-term similarity value, which is defined in (3). The query-document similarity in this searching model can be defined as:
!f
= gqw,, x q, x ((0.5 + O . S ( - - L ) ) X # l o g m ) .
1-1 rf,. 4,
where
1, if tI is an initid query tam (4)
and other parameters are defined as those in (3)
After that, all documents are ranked according to their similarity values with respect to the reformulated query and then output this ranked list to users.
111. EXPERIMENTS
Since there are no standard Chinese text collections to evaluate systems up to date, we adopt some evaluation methods to point out our system’s characteristics and the potential benefits. In order to achieve sizable and representative requirements, we develope a spider program in advance to automatically collect online daily news from Taiwan’s leading news web site: China Times [20] from 07/01/1999 to 08/31/1999. One reason that we chose news pages as our test collections is that the vocabularies in news pages are used in a conscientious and careful way.
Additionally, news pages in China Times have been manually classified into their corresponding categories. Thus, documents in the same category might cover similar topics.
In this paper, we prepare two test collections with nearly equivalent scalar. One is a homogeneous collection covering topics in economic news (CT-Economy); another is a heterogeneous collection from six distinct categories (CT-Six).
Table I and Table II list the statistics of these two test collections in detail.
Table I
Table II
In practical design, we choose n = 1000 as selected keywords. Moreover, we set N = 30 to derive the suggestion term list. Three retrieval approaches are compared for retrieval effectiveness, namely initial query without query expansion (the baseline), interactive query expansion (IQE) without weight, and interactive query expansion (IQE) with weight. To form queries for test collections, four M.S. students majored in computer science were invited to make up queries.
Redundant queries and queries causing few relevant documents (less than 10) were removed.
A. Evaluatior Methocls
The query expansion process is evaluated using the well-known performance measures, precision and recall.
Precision (F‘) and recall (R) are defined as [ 15 1.
( 5 )
(6) Recision = Number of Documents Retrieved and Relevant
Number of Total Rehieved Documents
= Number of Documents Retrieved and Relevant Number of Total Relevant Documents
The performance is also evaluated with a combined measure of precision and recall, E, developed by Van Rijsbergen [3].
The evaluation measure E is defined as:
(1 + b’)PR
b’P+R (7)
where P stands for precision and R stands for recall. And b, ranges from 0 to infinity, is a measure of the relative importance of recall and precision.
Since E measure is inversely proportional to the performance, the F measure ‘is often used instead [16][17].
Here 0 I: F I: 1, and F is positively proportional to the performance.
E=I--
(1 + b’)PR F=- b’P + R
B. Results and Analysis
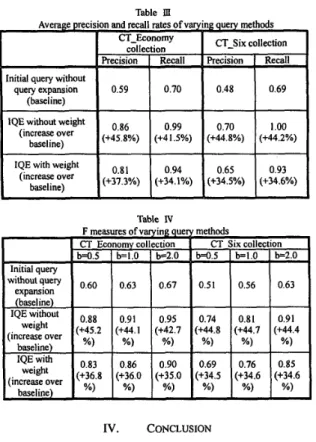
Table III lists the average precision and recall rates with performance improvement over the baseline approach being attached. It can be seen that IQE without weight achieves both high precision rate and high recall rate in CT-Economy collection. For IQE with weight, it also achieves high precision and recall rates but slightly lower than that of IQE without weight scheme. The reason that IQE with weight does not get better performance than IQE without weight might be: 1) the initial query string results in little retrieval response (means we have to broaden the query concept for further searching); 2) the query weight scheme used in this experiment is too conservative; it does not aggressively expand the initial query concept to a more suitable one.
The result of using another evaluation method, F measure, is listed in Table IV with b values at 0.5, 1.0, and 2.0, respectively. The results indicate again that both IQE without weight and IQE with weight perform better than initial query without query expansion scheme in terms of Rijsbergen’s combined measure. The performance improvement decreases as b value increases. These findings are understandable because when a user is getting more interested in recall over precision (b value getting large), the potential improvement on recall will be restricted due to the recall rate is higher than precision rate in baseline approach.
726
Average preci
Initial query without query expansion
(baseline) IQE without weight
(increase over baseline) IQE with weight
(increase over baseline)
Table III
R and recall rates of varying query methods CT-Economy
0.59 I 0.70 I 0.48 I 0.69 I
Table Iv
(+44.2%)
(+34.6%)
F measures of varying query methods
I Initial query
l w ~ ~ ~ ~ r y I 0.60
I
0.63I
0.67 I 0.51 1 0.56 1 0.63 1(increase over
Iv. CONCLUSION
In this paper, we propose an. interactive query expansion method, where a fuzzy composition based association thesaurus is adopted. After entering user initial query, a term suggestion list would be responded. The suggested terms are generated by using fuzzy relation compositions. However, not all of the suggested terms are suitable for query expansion.
Users must decide themselves whether to use them or not.
With the understanding of the real terms stored in the document database and their relationships, users may choose appropriate terms for a more effective searching.
Term suggestion increases the recall, while interaction enables users to attempt to not decrease the precision.
Experimental results show that interactive query expansion based on association thesaurus achieves better performance in both precision and recall rate significantly. Using interactive query expansion instead of automatic query expansion gives users a greater degree of control over the searching process in information retrieval. There is also some evidence to suggest that users may prefer the interactive method regardless of whether it improves performance.
REFERENCES
1 H. Berghel, “Cyberspace 2000: Dealing with Information Overload,” Communications of the ACM, 40(2), pp. 19-24, Feb. 1997.
2 A. Borchers, J. Herlocker, J. Konstan and J. Riedl,
“Ganging up on Information Overload,” Computer, pp.
106-108, Apr. 1998.
3 W.B. Croft, “What Do People Want from Information Retrieval?,” D-Lib Magazine, Nov. 1995, Available at httl,://www.dlib.o~dliblnovernber95/11 croft.html.
W.B. Frakes and R. Baeza-Yates, Information Retrieval:
Data Structures and Algorithms, Prentice-Hall, 1992.
R.C. Bodner and F. Song, “Knowledge-Based Approaches to Query Expansion in Information Retrieval,” Advances in Artificial Intelligence, Springer, New York, 1996.
L. Fitzpatrick and M. Dent, “Automatic Feedback Usin Past Queries: Social Searching?,” Proceedings of the .2&
Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR‘97), Philadelphia, PA USA, 1997, pp. 306-313.
7 M.C. Kim and K.S. Choi, “A Comparison of Collocation-Based Similarity Measures in Query Expansion,” Information Processing and Management, 35, pp. 19-30, Jun. 1999.
Y. Qiu and H.P. Frei, “Concept Based Query Expansion,”
Proceedings of the Id’ Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’93), Pittsburgh, PA USA, 1993, pp.
J. Xu and W.B. Croft, “Query Expansion Using Local and Global Document Analysis,” Proceedings of the 19”
Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’96), Zurich, Switzerland, 1996, pp. 4-1 1 .
10 G Salton, Automatic Text Processing: The Transformation, Analysis, and Retrieval of Information by Computer, Addison Wesley, 1989.
1 1 G Salton and C. Buckley, “Term Weighing Approaches in Automatic Indexing,” Information Processing and Management, 24(5), pp. 513-523, 1988.
12 C.H. Tsai, “MMSEG: A Word Identification System for Mandarin Chinese Text Based on Two Variations of the Maximum Matching Algorithm,” May 2000. Available at httD://m.fzeocities.com/haoS 1 O/mmseg!.
13 Y. Jing and W.B. Croft, “An Association Thesaurus for Information Retrieval,” Proceedings of RIA0 94, 1994, pp.
14 G.J. Klir and Bo Yuan, Fuzzy Sets and Fuzzy Logic:
Theory and Applications, Prentice-Hall, 1995.
15 G Salton and M. J. McGill, Introduction to Modem Information Retrieval, McGraw-Hill, 1983.
16 D.D. Lewis, “Evaluating and Optimizing Autonomous Text Classification Systems,” Proceedings of the 18‘’
Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’BS), Seattle, Washington, Jul. 1995, pp. 246-254.
17 Y.H. Tseng, “Solving Vocabulary Problems with Interactive Query Expansion,” Journal of Library and Information Science, 24(1), pp. 1-18, Apr. 1998.
18 M. Magennis and C.J. van Rijsbergen, “The Potential and Actual Effectiveness of Interactive Query Expansion,”
Proceedings of the 2dh Annual International AGM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’97), Philadelphia, PA USA, 1997, pp.
19 J. Koenemann and N.J. Belkin, “A Case for Interaction: A Study of Interactive Information Retrieval Behavior and Effectiveness,” Proceedings of CHI 96 International Conference on Human Computer Interaction, Vancouver, B.C.,Canada, 1996, pp. 205-212.
20 China Times, Available at http://www.chinatimes.com.tw/
4 5
6
8
160-169.
9
146-1 60.
324-332.
727