國立臺東大學資訊管理學系 碩士論文
具有除錯延遲與測試心力函數之不完美 除錯軟體可靠度模型
Software Reliability Model Considering the Feature of Time-Delay
Fault-Removal and Testing Effort Function with Imperfect Debugging
研 究 生: 李嘉華 撰 指導教授: 廖國良 博士
中 華 民 國 一 零 三 年 六 月
I
謝誌
兩年的碩士時光,說長不長,說短不短。一直問自己,後不後悔當初選擇了 念研究所這條路,曾經後悔是真的,但不回頭繼續走完自己選擇的路,才是最對 得起自己的方式。在這兩年裡,學到了很多東西,自己的個性也變得獨力了許多,
因為一切的報告、作業、研究都要自己一個人完成,更讓自己的思考方式成熟了 許多。這些點點滴滴,將成為我一生中難以忘懷的回憶。
感謝我的指導教授廖國良老師,不管是學術研究的指導,還是生活經驗上的 教誨,都使我受益良多,在此致上最深的謝意。感謝口試委員謝昆霖老師和黃建 裕老師的諸多指導與建議,讓本論文內容更加的完善,在此由衷感謝。
感謝我家人、妹妹嘉玲給了我許多精神上的支持,讓我能順利完成課業。感 謝仙蕾一直以來的幫忙,從熟悉實驗室到論文進度的體諒,以及亭雅百忙之中給 予的幫助,衷心的感謝你們。感謝柏昌、羽庭、育帆、珮涵以及看館組夥伴們所 給予我的支持。還有這兩年來一直扶持著彼此的 103 級資管碩二的大家,在此一 併致謝。
最後,僅以此論文獻給這段日子曾經關懷與幫助過我的人,謝謝您們!
李嘉華 謹誌 國立臺東大學資訊管理學系碩士班 中華民國一零三年六月
II
摘要
隨著科技的發展,人類的生活越來越依賴在軟體系統上,軟體品質也漸漸得到了 重視,從而產生了軟體可靠度工程測量的相關技術。為確保軟體品質,許多專家 學者們針對軟體可靠度進行了探討和研究,並建立了相關的知識基礎以及推導出 許多軟體可靠度成長模型,以預測軟體的失效行為;當中又以非齊次卜瓦松過程 為基礎的軟體可靠度模型較為廣泛地應用在軟體可靠度工程中。本研究提出了一 個以非齊次卜瓦松過程為基礎的軟體可靠度成長模型,當中考慮了在軟體除錯過 程中發生的延遲現象與 S 型測試心力函數的概念,結合於錯誤偵測率函數,並於 故障內容函數中考量到了不完美除錯的可能性。模型建構完成後,透過多組實際 失效資料集,進行參數估計與模型評量,讓新模型與現有模型進行比較分析。分 析結果顯示,所提出之模型較現有模型在預測軟體失效行為上是擁有更準確的預 測能力。
關鍵字:軟體可靠度成長模型、非齊次卜瓦松過程、測試心力、除錯延遲、不完 美除錯。
III
Abstract
The strong development of technology makes humans rely more and more on software systems, software quality therefore playing an increasingly important role. To ensure software quality, experts has been studying and doing research on software reliability, creating relevant knowledge base and derive many software reliability growth models to predict the failure behavior of software systems, which has a big amount of models was based on Non-Homogeneous Poisson Process. In this study, we propose a software reliability growth model based on the Non-Homogeneous Poisson Process, considering the concept of S-Shaped Testing Effort Function and the feature of Time-Delay Fault-Removal into Fault Detection Rate function, along with the possibility of the Imperfect Debugging in Fault Content Function. In addition, numerical examples are given to verify the effectiveness of the proposed models, and compare to the existing ones in order to make sure if the new model had more accurate prediction capability. The results shows that the proposed model has more accurate capability in predicting the reliability of software systems.
Keywords: Software Reliability Growth Model; Non-Homogeneous Poisson Process;
Testing Effort; Time-Delay Fault-Removal; Imperfect Debugging
IV
目次
謝誌 ... I 摘要 ... II Abstract ... III 目次 ... IV 圖目次 ... VI 表目次 ... VIII
第一章 緒論 ... 1
1.1 研究背景與動機... 1
1.2 研究目的與範圍... 2
1.3 研究方法與流程... 4
第二章 文獻探討 ... 6
2.1 可靠度 ... 6
2.2 硬體可靠度 ... 7
2.3 軟體可靠度 ... 8
2.4 軟體可靠度成長模型 ... 9
2.5 測試心力 ... 14
2.6 除錯延遲 ... 18
2.7 不完美除錯 ... 19
2.8 學習曲線 ... 21
第三章 研究方法 ... 22
3.1 研究架構 ... 22
3.2 資料來源 ... 22
V
3.3 參數估計法 ... 23
3.4 模型評量準則 ... 24
3.5 模型建構 ... 27
第四章 資料分析與模型比較 ... 30
4.3.1 參數估計 ... 30
4.2 軟體失效數據 ... 32
4.3 範例測試與模型比較 ... 35
4.4 小結 ... 46
第五章 結論與建議 ... 48
5.1 結論 ... 48
5.2 建議 ... 48
參考文獻 ... 50
VI
圖目次
圖 1 程式碼行數與找到的錯誤數目之關係 ... 1
圖 2 研究流程 ... 5
圖 3 浴缸曲線 ... 7
圖 4 軟體可靠度與時間之關係 ... 8
圖 5 軟體可靠度成長曲線 ... 10
圖 6 偵測到之錯誤與已被移除之錯誤之間之關係 ... 18
圖 7 兩種類型之除錯環境 ... 20
圖 8 學習曲線 ... 21
圖 9 研究架構 ... 22
圖 10 新模型之曲線適配度(資料集一) ... 36
圖 11 DelaySshaped 之曲線適配度(資料集一) ... 37
圖 12 Y-TEF 之曲線適配度(資料集一) ... 37
圖 13 G-O 之曲線適配度(資料集一) ... 38
圖 14 新模型、DelaySshaped、Y-TEF 和 G-O 之曲線適配度比較圖(資料集一) ... 38
圖 15 新模型之曲線適配度(資料集二) ... 39
圖 16 DelaySshaped 之曲線適配度(資料集二) ... 39
圖 17 Y-TEF 之曲線適配度(資料集二) ... 40
圖 18 G-O 之曲線適配度(資料集二) ... 40
圖 19 新模型、DelaySshaped、Y-TEF 和 G-O 之曲線適配度比較圖(資料集二) ... 40
圖 20 新模型之曲線適配度(資料集三) ... 42
圖 21 DelaySshaped 之曲線適配度(資料集三) ... 42
VII
圖 22 Y-TEF 之曲線適配度(資料集三) ... 42
圖 23 G-O 之曲線適配度(資料集三) ... 43
圖 24 新模型、DelaySshaped、Y-TEF 和 G-O 之曲線適配度比較圖(資料集三) ... 43
圖 25 新模型之曲線適配度(資料集四) ... 44
圖 26 DelaySshaped 之曲線適配度(資料集四) ... 45
圖 27 Y-TEF 之曲線適配度(資料集四) ... 45
圖 28 G-O 之曲線適配度(資料集四) ... 45
圖 29 新模型、DelaySshaped、Y-TEF 和 G-O 之曲線適配度比較圖(資料集四) ... 46
VIII
表目次
表 1 NHPP 軟體可靠度模型均值函數之整理 ... 13
表 2 實際失效數據來源 ... 23
表 3 PL/I 應用程式測試資料 ... 33
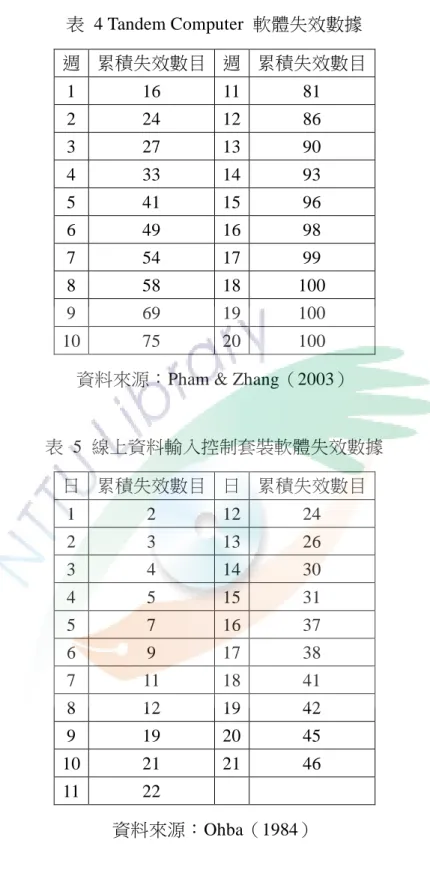
表 4 Tandem Computer 軟體失效數據 ... 34
表 5 線上資料輸入控制套裝軟體失效數據 ... 34
表 6 即時指揮控制系統測試數據 ... 35
表 7 新模型、DelaySshaped、Y-TEF、G-O 之參數估計結果(資料集一) ... 36
表 8 新模型、DelaySshaped、Y-TEF 和 G-O 之比較結果(資料集一) ... 38
表 9 新模型、DelaySshaped、Y-TEF、G-O 之參數估計結果(資料集二) ... 39
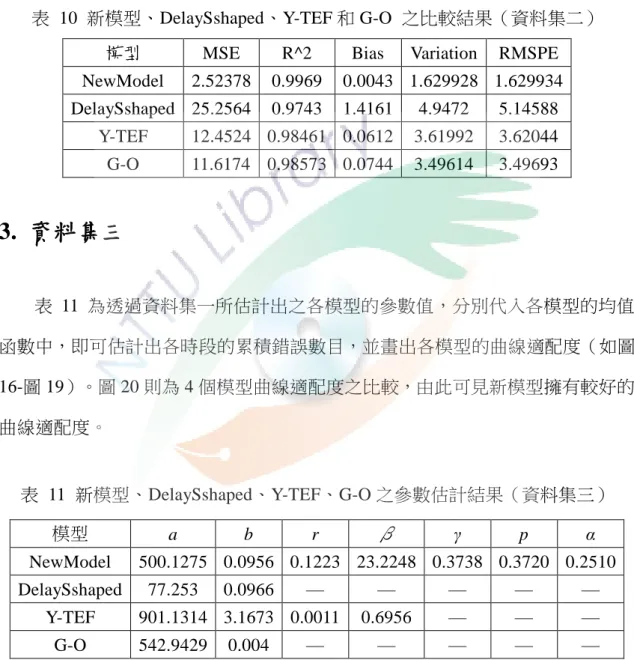
表 10 新模型、DelaySshaped、Y-TEF 和 G-O 之比較結果(資料集二) ... 41
表 11 新模型、DelaySshaped、Y-TEF、G-O 之參數估計結果(資料集三) ... 41
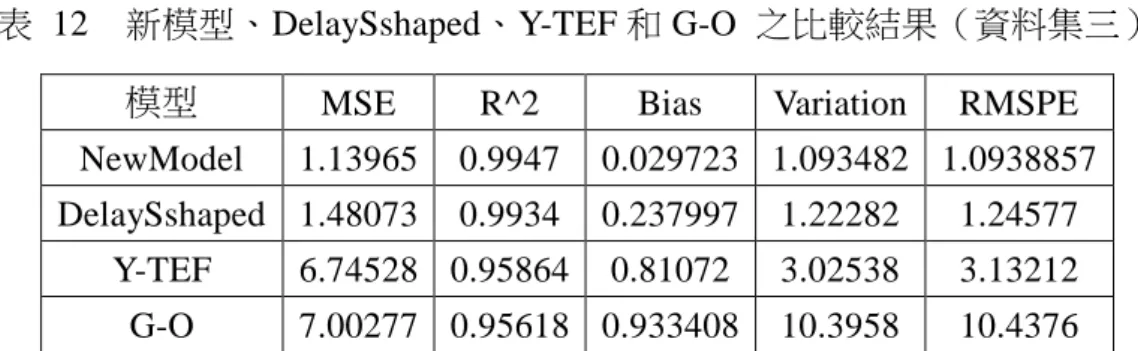
表 12 新模型、DelaySshaped、Y-TEF 和 G-O 之比較結果(資料集三) ... 44
表 13 新模型、DelaySshaped、Y-TEF、G-O 之參數估計結果(資料集四) ... 44
表 14 新模型、DelaySshaped、Y-TEF 和 G-O 之比較結果(資料集四) ... 46
1
第一章 緒論
隨著科技的發展與人類對軟體系統的依賴逐漸增加,軟體系統的品質也因此 開始扮演著越來越重要的角色。為了確保軟體品質,軟體開發人員會在軟體設計 完成後進行一系列軟體測試相關的工作。在這過程當中,軟體可靠度的定義逐漸 形成並開始成為軟體品質的象徵性指標。因此,許多專家學者們在過去幾十年來,
提出了許多軟體可靠度成長模型,以預測軟體系統的失效行為。
1.1 研究背景與動機
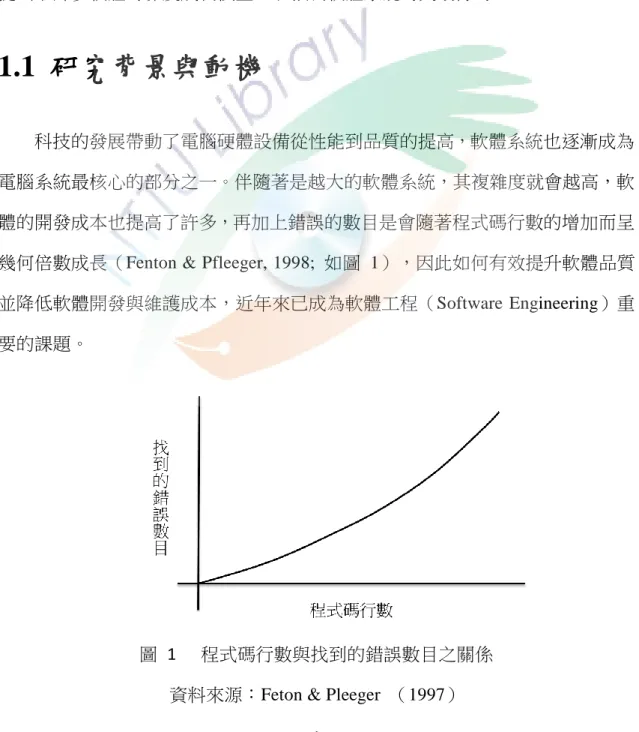
科技的發展帶動了電腦硬體設備從性能到品質的提高,軟體系統也逐漸成為 電腦系統最核心的部分之一。伴隨著是越大的軟體系統,其複雜度就會越高,軟 體的開發成本也提高了許多,再加上錯誤的數目是會隨著程式碼行數的增加而呈 幾何倍數成長(Fenton & Pfleeger, 1998; 如圖 1),因此如何有效提升軟體品質 並降低軟體開發與維護成本,近年來已成為軟體工程(Software Engineering)重 要的課題。
圖 1
程式碼行數與找到的錯誤數目之關係 資料來源:Feton & Pleeger (1997)
2
軟體可靠度研究在過去三十多年來,已有多位學者提出了各類軟體可靠度成 長模型(Software Reliability Growth Models, SRGMs)以評估軟體的可靠度。當 中又以非齊次卜瓦松過程(Non-Homogeneous Poisson Process, NHPP)為基礎之 模型居多。首次成功使用非齊次卜瓦松過程的概念來分析軟體失效行為是 Goel A.L. 與 Okumoto K. 兩位學者於 1979 年所提出的 G-O 模型。後來在此基礎上,
陸續有學者提出了很多基於非齊次卜瓦松過程之軟體可靠度成長模型(Goel &
Okumoto, 1979; Yamada et al., 1983; Yamada et al., 1986; Ho et al., 2003; Teng &
Pham, 2006; Huang et al., 2007; Zheng, 2009; Sharma et al., 2010; Khatri et al., 2012;
Kapur et al., 2012),主要目的為預測軟體開發完成後可能發生之失效行為。
雖已發展有一段時間,但由於研究者對軟體失效的觀察角度不同,導致所建 立之模型不具有普遍通用性,目前尚未發展出一套全面性且能準確預測軟體失效 行為之軟體可靠度模型,因此,本研究將嘗試以非齊次卜瓦松過程為基礎,建構 一軟體可靠度成長模型,作為評估軟體可靠度之參考依據。
1.2 研究目的與範圍
軟體可靠度(Software Reliability)是一項重要的軟體品質指標。隨著電腦系 統的普及與系統功能的規模擴大,可靠度的概念漸漸得到重視,做好軟體可靠度 的預測即可有效提高軟體測試的結果。許多專家學者也因此針對軟體可靠度進行 了許多的探討與分析,並發展出相關的理論與知識,應用於實務中。一般來說,
軟體開發人員在軟體開發完成後,會進行軟體測試來確保軟體品質。在這過程中,
軟體當中所存在的錯誤將被發現、修正和移除。然而,現有軟體可靠度成長模型 當中大多數假設失效發生時,軟體中的錯誤將立即被發現,接著立即被移除,這 顯然是不符合實際狀況的。通常一個軟體系統發生故障等情形,軟體測試人員需 要一定的時間尋找導致此故障的錯誤,而當找到該錯誤之後,軟體測試人員又要
3
花一定的時間進行修正,因此從偵測到錯誤到最後錯誤的修正和移除,會有一定 的時間延遲。若能將此延遲現象考慮到軟體可靠度模型當中,或許能在軟體測試 過程中更準確的預測軟體失效。
另外,會影響軟體測試結果還有一項重要的因素,為測試心力(Testing Effort, TE),即軟體測試過程所消耗之各項資源,可以以一函數呈現。早期的軟體可靠 度成長模型大多不考慮 TE,或是把 TE 假設為隨著時間的消耗率為一常數(Lyu, 1996; Pham, 2000),此不合理的假設多多少少影響了軟體可靠度成長模型對於軟 體失效的預測結果。因此若能準確的掌握 TE 隨著時間變化對軟體測試所造成的 影響,將可提高軟體可靠度模型於軟體測試的測試結果。
在現有軟體可靠度成長模型中,以非齊次卜瓦松過程所建立的模型較為廣泛 地應用在軟體可靠度工程中。此類模型把測試過程當成是一種表示為均值函數
(Mean Value Function, MVF)的計數過程(Counting Process),確定均值函數 即可估計出軟體的可靠度,當中也考慮了許多概念,包含:完美除錯(Perfect Debugging)環境下的 NHPP 可靠度成長模型、不完美除錯(Imperfect Debugging)
環境下的 NHPP 可靠度成長模型,考慮測試覆蓋率(Testing Coverage)的 NHPP 可靠度成長模型等等(Pham, 2006)。NHPP 模型最大的優點在於其自身之可組 合性,只要透過不同組合之錯誤偵測率函數與故障內容函數即可建構出各種不一 樣的可靠度成長模型,且皆能充分呈現出可靠度隨著時間所產生的變化(Lai &
Garg, 2012)。然而,在這些軟體可靠度成長模型當中,大部分只考慮單一概念 或因素至模型中,較少有模型會結合兩三種概念進行建構,加上早期軟體可靠度 成長模型大多數假設軟體測試階段之除錯過程中錯誤將被完全移除且不會再產 生新的錯誤,種種不合理之假設讓現有軟體可靠度成長模型減少了本身對軟體失 效行為的預測準確度。
因此,本研究的目的為結合除錯延遲(Time-Delayed Fault-Removal)與測試 心力函數兩者之特性至錯誤偵測率函數中,以及於故障內容函數中考量到了不完
4
美除錯的可能性,以建構新的軟體可靠度成長模型,並評估其是否擁有更佳的預 測軟體失效行為的能力。
1.3 研究方法與流程
本研究將以非齊次卜瓦松過程為基礎,結合除錯時間延遲觀點與測試心力
(Testing Effort)的概念至錯誤偵測率函數中,並於故障內容函數中考量到了不 完美除錯的概念,以建構軟體可靠度成長模型,藉此評估其是否能夠更準確的預 測軟體失效行為。模型建構完成後,將透過多組歷史實際失效數據,讓新模型與 現有模型進行比較分析,以觀察新模型是否擁有更佳的預測軟體失效結果的能 力。
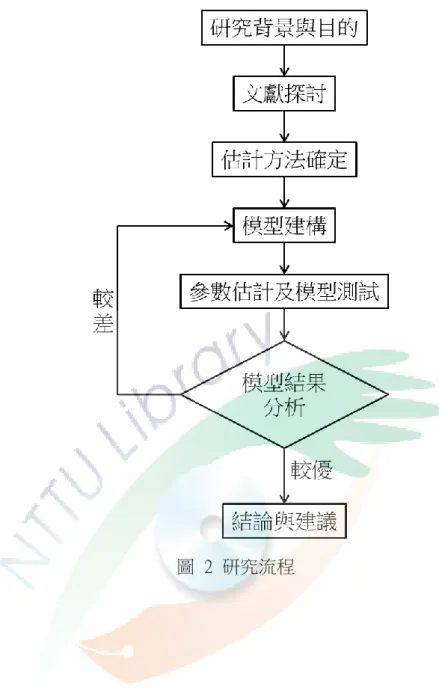
本研究基本架構為:第一章先針對研究問題界定研究動機、目的與範圍;第 二章則整理可靠度、軟體可靠度與軟體可靠度成模型之相關文獻;在第三章中決 定求解方法;第四章模型建構部分則以 NHPP 模型為基礎,結合延遲與測試心力 的概念;模型建構完成後即進行測試與分析,若分析結果不佳或不合理,則進行 數學模式的修正與檢討,直至模型無誤後,再進行模型標準之比較,最後在第五 章提出結論與建議。本研究流程如圖 1 所示。
5
圖 2 研究流程
6
第二章 文獻探討
2.1 可靠度
可靠度(Reliability)的定義最早由美國國防部於1952成立的顧問小組AGREE
(Advisory Group on Reliability of Electronic Equipment)所提出,只出可靠度為 某樣物品的特性,於既定的時間內,在特定的使用(環境)條件下,執行特定性 能或功能,圓滿成功達成任務的機率,簡寫為R。從質性觀點來看,可靠度可被 定義為某樣物品保持其功能的可能性(Birolini, 2007)。除此定義外,各國之專 業機構對可靠度也有類似的定義。歐洲品管組織 (European Organization for Quality Control. EOQC)於1965年針對可靠度提出的定義為:「在需要的時候,
產品在規定的環境下成功地執行其功能一段時間的能力的量度,以機率來量測 之」。另外英國標準學會(British Standard Institution, BSI)則定義可靠度為:「物 品在規定的條件下執行需要的功能一段時間的機率」(彭鴻霖, 2000)。
當系統無法在指定時間與條件下成功執行其功能即為「失效」,其變化情形 可用浴缸曲線(Bathtub Curve)來表示(圖3)。其主要分為三個階段:適應期
(Initial Period)、使用期(Operating Period)與磨耗期(Wear-Out Period)。在 適應期裡,由於還是系統初期,可能會由於設計不佳或品管不良等問題,使失效 率初始值偏高,但也會隨著使用時間而慢慢下降;在使用期時,系統漸漸處於穩 定狀態,失效率的成長也因此變的比較緩慢;而最後在磨耗期時,系統發生失效 的機率會隨著時間而快速增加,主要原因可能因為長時間系統損傷的累積(郭思 吟,2009)。
7
圖 3 浴缸曲線
資料來源:Klutke et al. (2003)
另外,可靠度又可分為軟體可靠度與硬體可靠度。硬體可靠度發展較早,因 此衡量技術已相當成熟,強調的是失效數據的分析。軟體可靠度發展較晚,強調 的是模型的假設與參數的解釋。以下分別為硬體可靠度與軟體可靠度之說明。
2.2 硬體可靠度
硬體(Hardware)為系統的物理面。當考慮到硬體可靠度時,通常指的是元 件於實際使用狀況下的生命週期。硬體元件發生失效時,造成失效的元件將立即 被修復或更換,針對這些元件所做的測試主要是為了確定系統的平均故障間隔時 間(Mean Time Between Failure, MTBF)或系統的可靠度。MTBF 指的是系統或 裝備在操作或使用環境下發生失效之平均間隔時間,求解公式為:平均失效間隔 時間=累積操作時間/累積失效次數=1/失效率。硬體可靠度的基礎假設強調故障的 獨立性以及可靠度測量過程不會影響是效率(Beizer, 1984)。
8
2.3 軟體可靠度
軟體可靠度(Software Reliability)為影響系統可靠度的重要因素之一,其概 念由硬體可靠度而來,因此兩者擁有較多相同之處;軟體可靠度的定義為在一特 定的環境與時間內,軟體能夠正常運作而不發生失效(Failure)的機率(Lyu, 1996)。
錯誤(Fault)為系統中的一瑕疵(Defect),而當執行在特定環境下時,將產生 失效(Failure)(Musa et al, 1990)。隨著軟體執行時間的增加,發生失效的機 率也隨之增加,導致軟體可靠度降低(圖2)。而軟體可靠度又可分為兩種:確 定型(Deterministic)軟體可靠度模型與機率型(Probabilistic)軟體可靠度模型
(McCabe, 1976)。
圖 4 軟體可靠度與時間之關係 資料來源:Lyu(1996)
確定型軟體可靠度模型(Deterministic Software Reliability Model)可用來研 究程式中不同的運算子(Operators)與運算元(Operands),以及程式中的錯誤 數目與機器指令(Machine Instructions)數目(Pham, 2006)。機率型軟體可靠度 模型(Probabilistic Software Reliability Model)則把失效發生與錯誤移除等用機率
9
型時間來表示,區分成七種:植錯型(Error Seeding)、失效率(Failure Rate)、
曲線符合(Curve Fitting)、可靠度成長(Reliability Growth)、馬可夫架構(Markov Structure)、時間序列(Time-series)、非齊次卜瓦松過程(Non-homogeneous Poisson Process)(Pham, 2006)。
軟體失效大多是因為錯誤的程式碼所造成,而錯誤其實一直存在於軟體系統 當中,要等到含有此錯誤的程式碼被執行時,才會產生失效,此時錯誤才會被發 現。因此,必須進行軟體測試,以找出錯誤並進行修正。
數學模式可用來預測失效行為,透過一些參數估計方法可以針對數學模式進 行一些計算或預測,測試人員可把歷史實際失效數據代入數學模式中以進行計算,
亦可透過軟體產品與發展流程的內容屬性來確定模式的參數以進行預測,或直接 使用一些參數估計方法進行數學模式的計算(Musa et al, 1990)。
軟體可靠度模型是以隨機過程與機率分配來表示時間函數與系統參數(如失 效數目)之間的特性,期望藉由已知實際失效數據來評估模型參數並預測未來的 可靠度(Lyu, 1996)。其中包含三項活動:故障防範(Error Prevention)、錯誤 偵測與移除(Fault Detection and Removal)、測量以最佳化可靠度(Measurements to Maximize Reliability)(Rosenberg et al, 1998)。
目前軟體可靠度成長模型當中,多為軟體在測試階段中所發生的失效次數,
其中以非齊次卜瓦松過程(Non-Homogeneous Poisson Process, NHPP)為基礎所 建立的軟體可靠度成長模型較符合實際狀況。因此,本研究將針對以NHPP 為基 礎建立之軟體可靠度成長模型進行探討。
2.4 軟體可靠度成長模型
發展出可靠的軟體產品如今已成為軟體產業中非常重要的議題之一,如何讓 一套新軟體能在正常的狀況下達到使用者預期的功能而不會產生失效,是軟體開
10
發人員所面臨的重大問題之一。軟體可靠度模型也因此得到了廣泛的應用。軟體 可靠度模型從本質上看可分為兩種:一種是試圖從設計參數中預測軟體的可靠度,
又稱缺陷密度(defect density)模型,可從程式碼的特性、程式碼行數、輸入和 輸出的資料等之參考資料,計算出軟體內之錯誤數目;另一種則是從測試資料預 測軟體的可靠度,又稱軟體可靠度成長模型,此類模型試圖透過具有一定特性之 已知函數與歷史實際失效數據來預測未來的軟體失效行為(Wood, 1996)。
在現有的可靠度成長模型當中,有一大部分都是以非齊次卜瓦松過程為基礎 的。NHPP 通常用來描述失效趨勢(可靠度成長),並提供可有效描述測試過程 中軟體失效現象的分析架構,與畫出失效適配曲線,通常以指數型或 S 型曲線呈 現,來預測未來的失效數目(Yamada, 2014)。
圖 5 軟體可靠度成長曲線 資料來源:(Yamada, 2014)
透過建構軟體可靠度成長模型,測試人員即可有效預測軟體失效行為,以及 有效確保軟體系統發行之後的整體品質。此小節將介紹非齊次卜瓦松過程的基本
11
概念,以及以此過程為基礎所建構的軟體可靠度成長模型的整理表格,最後分別 針對 NHPP 除錯延遲和 NHPP 測試心力函數的軟體可靠度成長模型進行介紹。
2.4.1 非齊次卜瓦松過程軟體可靠度成長模型
非齊次卜瓦松過程(Non-Homogeneous Poisson Process, NHPP)模型把到時 間t為止所偵測的錯誤數目的呈現服從NHPP之形式{ ( ),N t t0}. NHPP模型的主 要目的是為了確定截止之時間t時所偵測到的錯誤數目之均值函數(Mean Value Function)(Pham, 2006)。
NHPP模型的基本假設為(Pham, 2006):
失效過程有一獨立增量(Increment)。(時間區間(t, t+s)中的失效數 目取決於目前時間 t 與區間 s 的長度,而不取決於過程的運作歷史。)
過程的失效率可獲得如下:
{ ( , )} { ( ) ( ) 1}
(t) t ( )
P t t t P N t t N t
t
恰好一個失效在
(2.1)
在小區間 期間,超過一個失效的機率是可以忽略的:
{ ( , )} ( )
P兩個失效以上在t t t t (2.2)
初始狀況N
0 0非齊次卜瓦松過程假設累積失效個數為N(t),其計數過程(Counting Process)
{N(t), t ≥ 0}可獲得如下(Huang et al., 2003):
(
)
Pr , 0,1, 2,
!
m t k m t
N t k e k
k
(2.3)
和
0 t
m t t dx (2.4)
12
其中,失效強度(Intensity Function)函數𝜆( )(或均值函數m(t))為軟體可 靠度工程文獻中所有NHPP模型的基本要素。
NHPP模型為假設失效強度與軟體內剩餘的錯誤數目成正比,且可透過求解 一下微分方程式而獲得(Pham et al., 1999):
dm t b t a t m t
dt (2.5) 其中,m(t)為截止之時間 t 時期望偵測到之錯誤數目,即均值函數;a(t)為 故障內容函數;b(t)為為每單位事件之錯誤偵測率函數。
若要考慮不完美除錯的機率,可於式(2.5)中加入參數p以預測錯誤被發現之 後成功被移除的機率(Kapur et al., 2011a):
( ) ( ) ( ) ( ) dm t a t m t pb t
dt (2.6)
藉由代入不同的a(t)與b(t)之數值,即可獲得不同的NHPP模型。表一為過去 三十年較有名之NHPP軟體可靠度模型均值函數的整理。
13
表 1 NHPP 軟體可靠度模型均值函數之整理
模型名稱 MVF(m(t))
Goel-Okumoto Model
1 bt
m t a e
a t a b t b
Delayed S-Shaped Model
21 1
1
m t a bt e bt
a t a b t b t
bt
Yamada Exponential Model
1 1
r e t
t
m t a e
a t a b t r e
Yamada Exponential
Imperfect Debugging Model
/ t bt
t
m t ab b e e
a t ae b t b
Yamada Linear Imperfect Debugging Model
1 1 /
1
m t a e bt b at
a t a t
b t b
Pham-Nordmann- Zhang Model
1 1 / / 1
1 / 1
bt bt
bt
m t a e b at e
a t a t
b t b e
Pham-Zhang Model
1 / / 1
1 / 1
bt t bt bt
t
bt
m t c a e ab b e e e
a t c a e
b t b e
資料來源:Pham(2003)
14
2.4.2 NHPP Goel-Okumoto 模型
Goel-Okumoto (G-O) 模型的基本假設為(Xie, 1991):
(1) 在時間t時,累積偵測到之錯誤數目服從卜瓦松分配(Poisson Distribution)
之形式。
(2) 所有錯誤彼此之間互相獨立且被偵測到的機會皆相同。
(3) 失效發生時,偵測到的錯誤會立即被移除且不會產生新的錯誤。
假設a t( )a 和b t( )b ,邊際條件(Boundary Condition)m(0)0 時,可 獲得:
( ) (1 bt)
m t a e (2.7) 失效強度則為:
( )t m t'( ) abe bt
(2.8)
2.5 測試心力
測試心力(Testing Effort, TE)指的是在測試過程中所消耗的各類資源,包 含人力、時間、CPU 執行時間等(Kuo et al., 2001)。早期的軟體可靠度成長模 型當中,大多不考慮 TE 或是假設 TE 隨著時間是一常數。此假設是不符合實際 狀況的,因此,近年來,專家學者們開始針對 TE 隨著時間而變化的情形進行探 討,並建構了考慮測試心力函數(Testing Effort Function, TEF)的軟體可靠度成 長模型,以更準確的預測軟體可靠度(Kapur et al, 2011b)。測試心力函數通常 可用兩種型態來呈現:Weibull-TEF 與 Logistic-TEF。而 Weibull- TEF 又可分為三 種:指數型曲線、Rayleigh 曲線與 Weibull 曲線,此型態之 TEF 函數可與多數實 際失效數據進行適配度之研究。近幾年來有一部分學者選擇使用 Logistic-TEF 以
15
代替 Weibull-TEF 的角色,應用於各種軟體可靠度模型中,且均可有效計算出測 試心理於軟體測試過程中對軟體可靠度的影響(Peng et al, 2014)。
2.5.1 瑞利測試心力模型(Rayleigh Testing Effort Model)
學者 Putnam 於 1978 年提出了應用了諾頓瑞利模型(Norden Rayleigh Model)
來計算測試心力的方式。透過實驗證明整體生命週期中的人力曲線是可以以一瑞 利曲線來表示(Kapur et al, 2011b):
1 at2W t e
(2.9)
其中:a 為1/ 2td2, 𝑑 為 a 是最大的時間點,W(t) 則是時間(0.t]內的累積測試心 力。
2.5.2 威布爾測試心力模型(Weibull Testing Effort Model)
曾有學者指出於測試生命週期期間所發生的瞬間測試心力之增加可用一威 布爾型分布來表示,及分為以下三種(Khatri et al, 2012):
指數型曲線:(0,t]期間累積測試心力可用指數型曲線來表示:
1 vt
W t e (2.10)
瑞利曲線:(0,t]期間累積測試心力可用瑞利曲線來表示:
2 1 2
vt
W t e
(2.11)
威布爾曲線:(0,t]期間累積測試心力可用威布爾曲線來表示:
16
1 vtcW t e
(2.12)
其中:𝛼 為軟體測試中所需花費的全部測試心力之數目,v, c 則為比例和模型參 數。
2.5.3 Logistic Testing Effort Function Model
學者 Parr 於 1980 年提出了可代替 Weilbull-TEF 且可更有效呈現軟體失效分 佈,稱其為 Logistic-TEF,於時間(0,t]期間累積測試心力為(Parr, 1980):
( ) 1 W t N
Ae t
(2.13)
其中,N 為為軟體測試中所需花費的全部測試心力之數目,α 為測試心力之 消耗率,A 為一常數。
在各種測試心力函數中,指數型曲線所呈現出來的結果是完全遵循測試時間 的變化(Kapur et al., 1994),因此本研究將嘗試將指數型曲線之測試心力函數加 入軟體可靠度模型的錯誤偵測率函數中,期望可以讓新模型更有效預測軟體失效 行為,並提供測試人員作為管理決策的參考依據。
2.5.4 Yamada NHPP 測試心力函數模型
Yamada 測試心力函數模型(Yamada Testing Effort Function Model, Y-TEF)
的基本假設為(Yamada et al., 1986):
(1) 軟體系統隨機時間的故障是由系統中剩餘的錯誤所引起的。
(2) 當故障發生時,所引起故障的錯誤將被立即移除,以及不會產生新的 錯誤。
17
(3) 測試心力(Testing Effort)的輸出是以指數型曲線或Rayleigh曲線來表 示。
(4) 從時間(t, )到目前測試工作輸出階段的錯誤偵測期望值,與 軟體中剩餘的所有錯誤的期望值成比例。
根據以上假設,再將參數代如以下方程式中,以獲得模型的均值函數:
( )/ ( ) ( ( )) dm t w t r a m t
dt , (2.14)
( ) (1 rw t( ))
m t a e (2.15) 失效強度則為:
( ) ( ) rw t( ) t arw t e
(2.16)
Yamada 指 數 型 測 試 心 力 函 數 模 型 ( Yamada Exponential Testing Effort Function Model):
假 設 w(t) 為 時 間 (0,t] 內 累 積 的 測 試 心 力 , w t
et , 則 a t
a和
tb t re ,且邊際條件 m(t)=0 時,可得到:
1 1r e t
m t a e
(2.17)
Yamada Rayleigh 型 測 試 心 力 函 數 模 型 ( Yamada Rayleigh Testing Effort Function Model):
假 設 w(t) 為 時 間 (0,t] 內 累 積 的 測 試 心 力 ,w t
tet2/ 2 , 則a t
a和
t2/ 2b t rte ,且邊際條件 m(t)=0 時,可得到:
18
2 1 2
1
t
r e
m t a e
(2.18)
2.6 除錯延遲
在過去基於非齊次卜瓦松過程軟體可靠度成長模型中,通常會考慮到兩種狀 況:一則偵測到之錯誤將立即被移除、二則,較符合實際,即偵測到之錯誤數目 不會立即被移除,而是會隨著延遲效應因子形成延遲現象;圖 5 為偵測到之錯誤 與已被移除之錯誤之間之關係(Peng et al., 2008)。
圖 6 偵測到之錯誤與已被移除之錯誤之間之關係 資料來源:(Peng et al., 2008)
一個軟體的品質與可靠度只能透過減少軟體中的錯誤方能得到改善與提升,
錯誤排除過程可被視為極為重要的過程之一,換句話說,除錯延遲現象是直接影 響軟體可靠度的因素之一,因此除錯過程中發生的延遲現象應該要得到更多的重
19
視(Hwang & Pham, 2009)。此延遲現象通常以延遲效應因子 ( ) t 來呈現,主 要假設為期望移除之錯誤數目與期望偵測到之錯誤數目成正比(Huang & Lin, 2006)。
2.6.1 延遲 S型 NHPP軟體可靠度模型
延遲 S 型(Delayed S-shaped, DSS)模型的基本假設為(Yamada et al., 1983):
(1) 軟體在任何時間下的失效行為皆為系統中的錯誤所造成。
(2) 軟體的最初故障內容函數為一隨機變數。
(3) 第( k −1)次與第k 次失效發生的間隔時間取決於第( k −1)次失效發 生的時間。
(4) 失效發生時,偵測到的錯誤會立即被移除且不會產生新的錯誤。
假設a t
a 和
21 b t b t
bt
,且邊際條件m(0) = 0時,可得
1
1
btm t a bt e (2.19) 失效強度函數則為
t ab te2 bt (2.20)
2.7 不完美除錯
軟體系統是為了人類需求而設計出來的,就算再完美的系統也會發生失效的 時候,一般來說,軟體測試的目的就是為了偵測和修正全部隱藏在軟體系統內的 錯誤。但即使測試團隊計畫好整個測試階段、充分運用各種工程技術以及利用各 種不同方法,依然無法完全確保軟體發佈之後不會產生任何失效。在軟體發佈後,
20
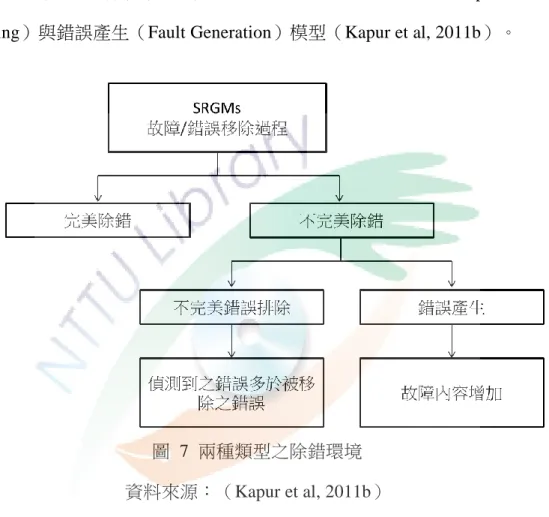
存在於軟體系統內的錯誤可分為三種:第一種是在整個測試過程中完全沒被偵測 到的錯誤;第二種是有被偵測到但沒被完全移除或修正的錯誤;第三種則是在修 正和移除舊錯誤時所產生的新錯誤。第一類錯誤可透過提升各種測試的效率與測 試覆蓋率等等而得到改善。第二和第三類錯誤在軟體可靠度文獻中,被歸類在不 完 美 除 錯 之 軟 體 可 靠 度 模 型 中 , 分 別 為 不 完 美 錯 誤 排 除 ( Imperfect Fault Debugging)與錯誤產生(Fault Generation)模型(Kapur et al, 2011b)。
圖 7 兩種類型之除錯環境 資料來源:(Kapur et al, 2011b)
早期軟體可靠度成長模型大多屬於完美除錯模型,即為假設除錯過程中,錯 誤皆可被順利移除且不會再產生新的錯誤,但在實際生活中這是不可能發生的,
因此,陸續有越來越多的學者針對不完美除錯軟體可靠度模型進行研究,並提出 了針對兩種不同型態之不完美除錯的狀況而發展的軟體可靠度成長模型(Goel, 1985; Kapur & Garg, 1990; Zeephongsekul et al., 1994 Ohba & Chou, 1989; Xie, 2003; Zhang et al., 2003; Lo & Huang, 2004; Kapur et al., 2006),使軟體可靠度模 型從此能更有效的應用在實際狀況下且能做出更準確的可靠度預測。
21
2.8 學習曲線
學習曲線(Learning Curve)又稱為經驗曲線(Experience Curve),可用一 條負斜率的曲線以表現之(如圖 8),其包含三個因素:經驗累積、技術進步與 規模效應(江文馨,2013)。
圖 8 學習曲線 資料來源:陳世坤(2005)
近年來軟體可靠度模型的研究中有越來越多學者考慮了學習效果對於整體 模型適配度的影響。隨著測試時間的增加,軟體測試人員會對軟體越來越熟悉,
除錯的經驗也隨即增加,因此助於減少軟體中的錯誤,提高了除錯的效率以及增 加軟體的可靠度。
22
第三章 研究方法
3.1 研究架構
本研究架構如圖 4 所示,首先透過文獻探討的部分進行確認用以建構模型的 參數,確認後即可進行模型建構。模型建構完成後,即可進行模型測試,利用參 數估計法估計出各參數以取得模型與失效數據之間的適配度。最後再與現有模型 比較,以觀察新模型是否能更有效的預測軟體失效行為。
圖 9 研究架構
3.2 資料來源
本研究在模型建構完成後,將進行模型的參數估計與評估。透過引用過去學 者已公開發表的論文中所使用的數據,來進行模型的參數估計,並進行各模型之 比較分析。資料應用來源如表二所示。
23
表 2 實際失效數據來源
資料集 失效數據來源 應用文獻
一 即時指揮與控制系統 Ohba(1984)
二 Tandem Computers 之產品 Pham 和 Zhang(2003)
三 線上資料輸入控制套裝軟體 Ohba(1984)
四 即時指揮與控制系統 Musa(1987)
3.3 參數估計法
在模型建構完成後,需要進行模型套用在真實數據上的參數估計,以獲得模 型中所有未知參數(Parameters)之數值,進而計算出各模型之均值函數以及畫 出個模型之曲線適配度。在NHPP軟體可靠度成長模型參數估計方法當中較為廣 泛使用之兩種點估計方法分別為:最小平方估計法(Least Squares Estimation, LSE)
與最大概似估計法(Maximum Likelihood Estimation, MLE),以下為此兩種方法 的說明。
1. 非線性最小平方估計法
最小平方估計法(Least Squares Estimation, LSE)是使樣本觀察值與估計值 的差異之平方和為最小的估計方法(林惠玲、陳正倉,2008)。其公式如下:
2 2
( ˆ ) ( )
1
ˆ ˆ 1
n n
SSE y y y x
i i i i
i i
(3.1)
其中, 與 分別為第i個觀察值的自變數與依變數; ̂為第i個估計值;𝛼̂為 迴歸模型之截距(Intercept)的估計值; ̂為迴歸模型之斜率(Slope)的估計值。
透過微分方法對𝛼̂ 、 ̂ 進行微分,並令微分方程式等於零,即可求得迴歸模型 之參數值。
24
2. 最大概似估計法
最大概似估計法(Maximum Likelihood Estimation, MLE)的應用在於一般母 體之參數θ皆未知,因此,若能從母體抽出的隨機樣本中找到一估計值 ̂,且使此 組樣本發生之可能性為最大時,則此估計值 ̂即為最大概似估計值(程大器,2012)。
假 設 ( 1,? 2 ,?
,
X X Xn ) 為 抽自母 體 f(x;θ) 之一 組隨機 樣本, 則其 概似 函數
(Likelihood Function)即為此n個隨機變數的聯合機率分配f( )。因 參數θ 未知,故將此概似函數寫為
1 2, , , ;
1; 2;
;
;1 n
L f x x x f x f x f x f x
n n i
i
(3.2)
透過對概似函數L(θ)進行微分,並令微分方程式等於零且 2
2 0 d L
d
,即可 求得估計值 ̂。
由於最小平方估計法可簡便求出各未知之估計值,並令所求得之估計值和實 際值之間誤差的平方和為最小,因此,本研究主要透過最小平方估計法來求解個 模型之參數,並進一步畫出個模型之曲線適配度。
3.4 模型評量準則
建構軟體可靠度模型的最終目標為確定此模型是否可有效預測軟體的失效 行為,其中可透過比較模型所預測的失效數據與實際錯誤數據之間的差異。而專 家學者們常用來比較模型好壞的標準是以均方差(Mean Square-Error, MSE)、多 元判定係數(Coefficient of Multiple Determination, )、預測誤差(Prediction Error,
25
PE)、乖離率(Bias)、變量(Variation)、均方根預測誤差(Root Mean Square Prediction Error, RMSPE),以下將介紹此六種評估模型之方式,作為後續模型比 較之參考。
1. 均方差
模型比較主要是用來確認一個模型所預測出來的數值與實際失效的資料之 間的差異。均方差(Mean Square-Error, MSE)能計算出的預測值( ̂( ))與實 際觀察數據( )的公式如下:
21
( )
MS ˆ
E
k
i i
i
m t y k n
(3.3)其中:k為預測值的數量,n為模型中未知參數的數目。
MSE的值越低,表示適配誤差(Fitting Error)越低,代表模型的適配度越好
(Kapur et al., 1999)。
2. 多元判定係數
為了衡量解釋變數的解釋能力或迴歸方程式的適配度,將多元判定係數
(Coefficient of Multiple Determination, )定義為可解釋的差異(Sum of Squares Due to Regression, SSR)占總差異(Sum of Squares Total, SST)的比例。其公式 如下
2 SSR 1 SSE
R SST SST (3.4)
其中,SSR 代表可解釋的差異,SSE 代表隨機差異,SST 則為總差異。
2 1
(ˆ )
n
i i
i
SSR y y
; (3.5)26
2 1
( ˆ )
n
i i
i
SSE y y
; (3.6)2 1
( )
n
i i
i
SST y y
(3.7)的值在0到1之間,越大的值,代表模型的解釋能力越好(Kapur et al., 1999)。
3. 預測誤差
在任意時間i 下,實際失效次數與預測失效次數之間的差異,即稱為預測誤 差(Prediction Error, PE) 。
(m tˆ y ) P i
E i
i (3.8)
PE 的值越小,代表模型的適配度越好(Pillai & Nair, 1997)。
4. 乖離率
預測誤差的平均值為乖離率(Bias Ratio, Bias)。
1 n
PEi Bias i
n
(3.9)
Bias 的值越小,代表模型的適配度越好(Pillai & Nair, 1997)。
5. 變量
預測誤差的標準差即稱為變量(Variation),其公式如下
27
2Variation 1 1 PEi Bias N
(3.10)Variation 的值越小,代表模型的適配度越好(Pillai & Nair, 1997)。
6. 均方根預測誤差
均方根預測誤差(Root Mean Square Prediction Error, RMSPE)是用來測量預 測值與觀察值之間的接近程度,主要透過乖離率與變量兩者加以求得,其公式如 下
2 2
RMSPE Bias Variation (3.11)
RMSPE 的值越小,代表模型的適配度越好(Pillai & Nair, 1997)。
3.5 模型建構
3.5.1 問題描述
在現有軟體可靠度成長模型當中,雖已考慮到了許多不同的概念應用於不同 模型中,但大多都是一個模型一種概念,較少會結合多種概念於一個模型,減少 了模型本身對軟體失效行為的預測準確度。因此本研究將以非齊次卜瓦松過程為 基礎,結合除錯時間延遲觀點與測試心力的概念之錯誤偵測率函數,並於故障內 容函數中加入不完美除錯的特性,以建構出更廣泛的軟體可靠度成長模型,最後 再與現有的模型進行比較分析,以評估新提出的模型運用於實際失效數據時,是 否獲得更佳的預測結果。
28
3.5.2 符號說明
m(t) 均值函數,期望在t時偵測到之錯誤數目
λ(t) 失效強度函數;每單位時間內的錯誤觀測率
a(t) 故障內容函數;在時間t時軟體中的總錯誤數目,包含原有的錯誤
數目與後來產生的錯誤數目
b(t) 錯誤偵測率函數
a 軟體原有的錯誤數目
b 每單位時間的錯誤偵測率,0 b 1
γ 新模型的組合常數
r, β 測試心力函數中的參數, r > 0, β > 0 α 除錯過程中新錯誤出現率,0 1
p 錯誤成功移除機率,即完美除錯的機率
w(t) 時間(0,t]內累積的測試心力
3.5.3 模型建構
模型的基本假設如下:
(1) 錯誤偵測過程服從 NHPP 之形式。
(2) 當故障發生時,偵測到的錯誤可能不會立即被移除而會隨著延遲效應因子
ln 1 bt
t b
而產生延遲。
(3) 軟體最初故障內容函數為一隨機常數。
(4) 隨著測試心力強度(Testing Effort Intensity)變化之錯誤偵測率與軟體中剩 餘的錯誤數目成正比,且所有錯誤彼此之間互相獨立。
(5) 錯誤偵測率函數為透過一常數 γ 將除錯延遲與測試心力函數兩者之特性進行
29
組合,及錯誤偵測率函數可同時擁有除錯延遲與測試心力函數這兩種特性。
(6) 當軟體失效發生時,修正動作立即開始,故障成功移除的機率為 p,不成功 移除的機率為 1-p。
(7) 除錯過程中,不管錯誤是否有成功被移除,軟體系統將隨著不變機率 α 產生 新的錯誤。
根據以上假設,可獲得故障內容函數與錯誤偵測率函數如下:
a t a m t (3.12 和
1
1 1
1
1 1
t br e t
bt bt
b bt e be br e
b t t
br e
bt e bt e
(3.13)
其中,從(0,t]內累積之測試心力為W t( )r(1et) 。
將 a(t)與 b(t)代入方程式(2.5)中,並令邊際條件 m(0)=0,在針對方程式進行積分,
即可獲得模型的均值函數如下:
[1 ( (1 ) (1 ) (1 )) (1 )]1
a bt br e t p
m t bt e e
(3.14)
其中,當 p=1 與 α=0 時,新模型均值函數 m(t)將呈現完美除錯的狀態。若 γ= 1,
均值函數即為 Y-EXP-TEF 模型;而 γ= 0 時,則為 Delayed-S-Shaped 模型。
時效強度則為:
(1 ) (1 ) ( ) '( ) [ (1 ) (1 ) ]
(1 ) (1 ) (1 )
(1 ) (1 ) (1 ) e
br e t p
t m t bt e bt e
br e t
bt bt t
be bt e br e e
p t
br e bt e bt
(3.15)
30
第四章 資料分析與模型比較
為了評估新模型的有效性,本研究利用兩組實際失效數據來評估模型的參數 以及適配度,以進行模型評量準則的分析。
4.3.1 參數估計
本研究是最小平方估計法來進行模型的參數估計,以下將列出新模型的參數 估計方式,其他模型之算法與此類似。求出各模型之參數值之後,即可代入至各 模型的均值函數中,再來描繪出各模型的曲線適配度。
假設 a、b、r、β、γ、p、α 是透過 n 組觀察數據:
t m0, 0
, t m1, 1
, ( ,t m2 2),,
t mn, n
所決定的,其中 為時間
0,ti
內偵測到之總錯誤數目。透過最小平方估計法,即 可 獲 得 模 型 估 計 函 數 如 下 :
2
1
(1 ) 2
(1 )
1
( , , , , , , ) ( )
1 (1 ) (1 ) 1
i ti
n
i i
i
n p
bt br e
i i
i
MinM a b r p m m t
m a bt e e
(4.1) 透過分別對方程式(4.5)中的 a、b、r、β、γ、p、α 進行微分,並令其偏導數
(Partial Derivatives)等於零,即可獲得下列方程式:
(1 ) * 1-
1
(1 ) * 1
2 - 1- 1 1-
1 ( , , , , , , )
1 0
1 1
-
1 1
i ti
t
n p
bt br e
i i
i
bt br e p
m a bt e e
bt
M a b r p
a
e e
(4.2)
31
(1 ) 1
1
(1 ) 1
(1 )
(1 )
2 1 1 1
1
1 1
1 ( , , , , ,
1 1
1 1
, ) i ti
i ti
i i i ti
i ti
n p
bt br e
i i
i
bt br e p
i
bt bt t br e
i i
bt br e
i
a m a bt e e
bt e e
t e bt te r e e
bt e e
M a b r p
b
0
(4.3)
(1 ) 1
1
(1 )
(1 ) 1
(1 )
( , ,
2 1 1 1
1
1 1
1 1 0
1 , , , , )
1
i ti
i ti i ti
ti
n p
bt br e
i i
i
t br e
bt br e p
i bt br e
i
a m a bt e e
p b e e
bt e
M a b r p
r
e
bt e e
(4.4)
(1 ) 1
1
(1 ) 1
(1 )
(1 )
( , 2 1 1 1
1 , , , , , )
0
1 1
1
1 1
i ti
i ti
ti i
i ti
n p
bt br e
i i
i
bt br e p
i
br e
t
i bt br e
i
a m a bt e e
bt e e
p brt e e
b a b r
t e e
M p
(4.5)
(1 ) 1
1
(1 )
(1 ) 1
(1 )
( , 2 1 1 1
1
1 1 1
1 1
, , , , , )
0
i ti
i ti i ti
i ti
n p
bt br e
i i
i
bt br e
bt br e p i
i bt br e
i
a m a bt e e
bt e e
bt e e p
M a b r
bt e e
p
(4.6)