應用統計遮罩比對方法與統計決策規則於古籍手寫 文字之辨識
蔡殿偉 蔣德威 黃有評
大同大學資訊工程研究所 致理技術學院資訊網路技術系 大同大學資訊工程研究所
摘 要
我們提出了一個兩階段的分類方法,並佐以統計分析的技術,來辨識古籍 手寫文字。在訓練系統時,我們使用網格碼轉換方法,把每個訓練樣本中最重 要的離散餘弦轉換係數量化後,分配到一些網格中,使每一個網格代表一組具 有相同量化值的文字類別;同時,我們也以統計方法為每個文字類別產生一個 正遮罩和一個負遮罩。在辨識時,第一階段的粗分類先尋找與待辨識文字具有 相同量化值的網格;第二階段的細分類則使用統計遮罩比對方法,將它與該網 格中之所有文字類別的正、負遮罩逐一比對,再利用平均匹配機率之統計決策 規則,來挑選相似度最高的類別做為辨識的結果。我們使用古籍金剛經來進行 實驗,其結果証實了我們的方法非常適用於古籍手寫文字的辨識。
關鍵詞:光學文字辨識、離散餘弦轉換、遮罩比對方法、網格碼轉換。
USING STATISTICAL MASK MATCHING METHOD AND STATISTICAL DECISION RULES TO RECOGNIZING HANDWRITTEN CHARACTERS
IN CHINESE PALEOGRAPHY
Tienwei Tsai Te-Wei Chiang Yo-Ping Huang
Department of Computer Engineering Department of Information Networking Technology Department of Computer Engineering Tatung University Chihlee Institute of Technology Tatung University
Taipei, Taiwan 104, R.O.C. Taipei County, Taiwan 220, R.O.C. Taipei, Taiwan 104, R.O.C.
Key Words: optical character recognition, discrete cosine transform, mask
matching method, grid code transformation.
ABSTRACT
We present a two-stage classification approach, which is further en-
hanced by statistical techniques, to recognize regular handwritten charac-
ters in Chinese paleography. In the training phase, the grid code transfor-
mation method is applied such that each training sample is distributed to
the related grid according to the grid code derived from its most significant
DCT (discrete cosine transform) coefficients. Therefore, each grid consists
of the character classes with the same grid code. On the other hand, for the
purpose of fine classification, the statistical technique is also applied to
generate a positive mask and a negative mask for each character class. To
recognize an unknown character, the coarse classification is applied to ob-
tain its grid code in the first stage. In the second stage, the fine classifica-
tion that employs statistical mask matching is applied to match it against all
the masks of those classes belonging to the grid. Then, the class with the
highest similarity to the unknown character will be determined according to
the proposed statistical decision rule based on average matching probability.
We built an experimental system to recognize the Kin-Guan (金剛) bible. It is shown that our approach is effective in recognizing the handwritten characters of ancient calligraphers.
一、簡 介
典藏書籍的數位化是一個具實際需求又有意義的工 作,更是一件極富挑戰性的研究題材。目前滿足這個需求 的方式一般是打字校對(如中研院二十五史的製作),或使 用辨識軟體針對現今之印刷書籍做自動辨識,然後予以人 工校對(如丹青版中英文文件辨識系統) [1]。然而,中國古 籍中的文字雖然大都以整齊的字體來書寫,但一方面手寫 文字的外型無法完全一致,另一方面它們的完整性已被許 多先天或後天的因素所破壞。例如,有些字雖然仍局限在 該字應有的範圍內,但筆畫卻有著不同的粗細程度。此外,
有些字也因為伴隨著其周圍的污點而使其形狀產生許多變 化,雖然對讀者而言仍可識別,但對電腦而言卻是一大考 驗。
一般而言,要將這些古籍轉換成文字檔案,必須利用 光學文字辨識(optical character recognition,OCR)技術。
OCR 技術可分為兩種截然不同的方法:統計方法 [2, 3] 與 結構方法 [4]。統計方法完全忽略文字的意義,它把描寫 文字的“黑點”視為統計上的“物件”或“變數”;結構 方法則把文字視為一連串的筆畫、直線和曲線的組合,它 嘗試利用書寫文字的過程來協助文字的辨識。對 OCR 而 言,雖然結構資訊長久以來都被認為是一個有用的特徵 [5,6],但在實用上卻很少演算法可以使用一致的方法來取 得文字的結構資訊,尤其對充滿各樣雜訊的古籍而言,更 難取得正確的結構資訊;因此,我們將採用統計方法來進 行古籍的辨識,並以實驗證明其可行性。
基 本 上 ,OCR 主 要 有 三 大 類 的 作 法 : 統 計 方 法
(statistical method)、結構化方法(structural method)和 類神經網路(neural network)。統計方法主要是萃取出待辨 識文字中比較穩定的特徵,利用統計的技巧,進行辨識。
統計方法較適用於待辨識文字品質較差時(如解析度較 低、不清楚、污損、變形),本論文所提之方法即屬此類,
特別適用於品質較差的古藉文字之辨識。至於結構化方法 則必須先透過文字細線化(thinning)等前置處理,取得文 字的骨幹結構,再依其結構進行辨識,圖形比對法[7]及隱 藏式馬可夫模型(hidden markov model) [10,17] 的 OCR 方 法即屬此類,適用於待辨識文字品質良好的情況。雖然基 於隱藏式馬可夫模型的方法已經用於解決連續式文字(如 英文)之辨識,然而手寫中文文字的辨識卻遠較字母文字困 難許多,其困難的原因主要有三:中文字集十分龐大、中 文字的結構遠較字母文字複雜,以及許多中文文字的形狀
類似。理論上,結構化比對法會有更佳的辨識率;但在實 際應用上,一方面受限於文字品質,另一方面又易受到筆 劃接觸與否的干擾。在另一方面,由於類神經網路容易實 作,所以成為一種普遍受歡迎的方法,但它的效果卻不如 基本的最近鄰居方法(nearest neighborhood method) [10],尤 其在辨識低劣品質的文字時更形遜色;此外,類神經網路 其先天上就不適於處理類別數量很多的中文識別應用,目 前僅應用於類別數較少的英文及數字辨識。
有關利用 OCR 辨識手寫中文字的調查研究請參考 [11],手寫文字的辨識可分為線上(online) [7]和離線(offline) [7, 8, 13, 17-19]兩個領域。線上辨識是利用寫字的時序動態 資訊,如筆畫數目、筆畫順序、每個筆畫的方向,以及每 個筆畫書寫的速度。相較於線上辨識,離線辨識的情形就 困難多了,因為它缺少了上述的資訊,而本論文所提出的 方法就是要解決離線辨識的問題。
事實上,將物件或樣式(pattern)分類至一組事先定義好 的類別已經引起廣泛的研究,也被應用在很多不同的領 域,如OCR、語音辨識和人臉辨識等。這些應用通常包含 了至少數百或數千種類別,因此如何取得可資區別的特徵 成為一個重要的課題。一般而言,我們可以將分類系統的 設計分成兩部份:特徵擷取和分類。為了提升分類的效率,
我們可將分類的過程再進一步分成兩個步驟:粗分類和細 分類。
雖然特徵的選取大幅影響分類的效果,但至今仍沒有 一個通則可以適用於所有的應用,它們都取決於設計者的 經驗、直覺或是智慧。為了設計一個通用的分類方法,使 其較不受個別專業領域的影響,以轉換為基礎(transform- based)的特徴擷取法是不錯的選擇。常見的幾種以轉換為 基 礎(transform-based) 的 特 徴 擷 取 法 主 要 有 : Fourier Transform、Cosine Transform、Wavelet Transform 及 Walsh Transform。其中 Cosine Transform 是由 Fourier Transform 衍生而來,利用將實偶函數取Fourier Transform 後仍為實 偶函數的特性,發展出較Fourier Transform 更簡易而有效 率 的 Cosine Transform 。 而 近 年 頗 受 矚 目 之 Wavelet Transform 其特色是可以將影像分解成數個階層的子波段 (subband),分別對應到不同解析度之近似(approximation)、
水平(horizontal)、垂直(vertical)、斜角(diagonal)等成份。至 於常被視為窮人之 FFT(fast fourier transform)的 Walsh Transform,是將一個函數變換成取值為+1 或-1 的基本函 數構成的級數,為一實數變換。相較於 Fourier Transform 之複數變換(需複數乘法)和離散餘弦轉換(discrete cosine transform, DCT)[14]之實數變換(需三角函數乘法),Walsh Transform 所要求的計算儲存量較少,運算速度也較快;然
而,因其能量壓縮(energy compaction)能力較 DCT 弱,且 不像DCT 和頻率有直接關聯,因此在應用上不及 DCT 廣 泛。此外,由於DCT 本質上就有極佳的能量壓縮能力,能 將一個影像的特徵呈現在少數的幾個低頻係數,這樣的特 質使其特別適合粗分類法。本論文中,我們選用了在影像 壓縮時常用的技術-DCT 來進行粗分類。DCT 方法是把訊 號 經 由 運 算 將 空 間 域(spatial domain) 轉 換 為 頻 率 域 (frequency domain),也就是將數位影像轉換成另一種資料 格式的方法。由於DCT 具有良好的能量集中的特性,它將 大部份的能量集中在低頻部份;也就是說,大部份的能量 都保留在相對少量的DCT 係數中,也因此大量節省了儲存 資料所需的磁碟空間。在與文字辨識相關的文獻 [15]中指 出,約有84%的能量表現於 2.8%的 DCT 係數中,如此一 來可節省了97.2%的磁碟空間。
在第一階段中,我們利用網格碼轉換(grid code trans- formation,GCT)方法來進行粗分類。GCT 將每個物件的 DCT 係數量化成一個網格碼(grid code,GC),因此每個碼 就可被視為是一個群組,該群組包含了所有具備相同量化 值的文字類別。換句話說,在分類器的訓練階段,那些DCT 係數在某個既定範圍內的文字將會被區分為同一群組;那 麼在進行文字辨識時,可先將待辨識文字做DCT 轉換及量 化後,再找到具有相同量化值的網格,然後再對該群組中 的文字類別做進一步的細分類。
在進行細分類時,可分為空間域和頻率域兩種不同的 方 式 。 在 空 間 域 中 可 進 一 步 分 為 樣 板 比 對(template matching)和遮罩比對(mask matching)兩種方法;在進行比 對 時 又 可 再 細 分 為 統 計 方 法 和 匹 配 程 度(matching de- gree)。然而,若用一般直方圖(histogram)來統計某個灰階 值所出現的機率,則無法反映出該文字影像中的二維座 標;因此,不同的文字影像可能會具有相的直方圖,於是 我們採用統計遮罩比對(statistical mask-matching)方法,來 克服手寫文字外型不完全一致,以及古籍所面臨的污損問 題。
遮罩比對是在視覺樣式辨識(visual pattern recognition) 中非常普遍的一種技術,可以將它想像成把一個未知影像 經由一個遮罩投射到一個圖像感測陣列上,其反應將正比 於匹配的程度。基於這個觀念,可以將每個字產生一個遮 罩後儲存到電腦上,在進行文字辨識時即可與這些遮罩逐 一比對,其相符位元的個數愈高,表示匹配程度愈高;因 此 可利 用漢 明距 離(Hamming distance)來計算其相似程 度。然而,由於一個文字影像邊緣的雜訊或其難以預測的 變化,將使得所產生的遮罩變得不可靠。基於以上的原因,
我們提出了以統計為基礎的遮罩比對方法來進行細分類。
我們先利用每個字的訓練樣本產生一個正遮罩(positive mask)和負遮罩(negative mask),亦即把這些”同一字”(或 相同類別)的樣本重疊在一起後,計算每個位元呈現黑色 的機率,把機率超過某個門檻值的所有黑點集合起來就成 為正遮罩;同樣地,把所有呈現白色的機率超過某個門檻
值的白點集合起來就成為負遮罩。因此,我們將待辨識文 字與正、負遮罩比對來尋找最接近的類別以做為辨識的結 果。實驗證實我們所提出的兩階段分類方法,不但提升了 辨識的效率;在細分類時所使用的統計遮罩比對方法和統 計決策規則,也在古籍手寫文字的辨識上有很好的效果。
本論文除了本節的簡介之外,第二節對我們所提出的 兩階段分類方法做一簡要的敘述和分析。第三節介紹第一 階段的粗分類方法,第四節則進一步介紹第二階段的細分 類方法,以及所使用到的統計分析技術。第五節說明利用 金剛經進行實驗的結果。第六節則是針對本論文所做的結 論。
二、兩階段分類方法
在本節中,我們先簡要的說明分類問題,接著介紹所 提出之兩階段方法的整體架構。在隨後的兩節中,也將更 詳盡的介紹這個方法中的每個步驟。在進行分類時,我們 通常利用一組 D 個維度的特徵或屬性來代表一個樣式 (pattern),並將它視為一組 D 維的特徵向量(feature vec- tor)。分類的最終目的是希望將一個待辨識的樣式 x 歸類為 M 個可能的類別 (c1, c2,…, cM) 中的一類。
本實驗系統分為兩種模式:訓練模式及分類模式。在 訓練模式中,特徵擷取模組會找出最足以代表輸入樣式的 適當特徵,接著便利用這些特徵來訓練分類模組。在分類 模式中,訓練好的分類模組會根據相似度計算的結果,將 輸入樣式指定給樣式類別中的某一類。
為了獲得不同分類方法的優點,本系統將分類方法分 為兩階段:粗分類和細分類。在第一個階段中,我們使用 GCT 方法將最重要的 DCT 係數加以量化,並映射至一組 有限數目的網格中,其中每一個網格均與一個網格碼相對 應。在對一個未知類別的物件進行分類時,可以由其相對 應的網格碼擷取出一組範圍較小的候選類別。關於 GCT 的詳細內容將在第三節中介紹。第二階段的細分類則被用 來辨識從第一階段中所得到的候選類別,由於其範圍較 小,因此也提升了辨識的速率。至於是否因此而降低了辨 識的正確率,在第五節的實驗中有詳盡的討論。有關如何 使用統計遮罩比對方法來進行細分類,其詳細內容將在第 四節中介紹。圖1 為本分類方法的系統架構圖,其中預處 理模組(preprocessing module)主要包含了:文字切割(將文 件影像中的文字切割成單一文字的集合)、二色化(將文字 影像由灰階轉成黑白兩色)、去雜訊(將品質不佳的文字影 像之黑色筆劃中的白色空洞補平、並將白色背景上的黑色 雜點去除)、正規化(由於手寫文字的大小無法像印刷文字 般固定,會有些微差異,因此要透過簡單的幾何縮放將文 字大小調整成一致)。至於其他模組則將在隨後的章節中逐 一介紹。
圖 1 兩階段分類方法的架構
1. DCT 特徵擷取模組
DCT 是 近 年 來 廣 泛 應 用 於 影 像 壓 縮 的 一 種 技 術 [14],它可以將影像依照影像的視覺品質的重要性進行分 離或是分成光譜子波段(spectral subbands)。它使用 N 個正 交的實數基底向量,而每個向量的組成分子都是餘弦函 數。DCT 方法有著極佳的能量集中特性,並且在轉換過程 中只需要進行實數的處理。
在應用二維的DCT 時,一個 N×N 影像的頻譜(或是二 維DCT 係數) F(u, v)可由 f (i, j)所表示,其中 i, j = 0, 1, …, N-1,其定義如下
∑∑
−=
−
=
=
10 1 0
) , ( ) ( ) 2 ( ) ,
(
Ni N
j
j i f v N u v u
F
α α
2 ) ) 1 2 cos( ( 2 )
) 1 2 cos( (
N v j N
u
i
+ π + π
(1)其中
=
=
otherwise w (w for1 2 0 ) 1 α
我們注意到DCT 是一個單一轉換(unitary transform)。單位 轉換為一可逆之線性轉換,其核心(kernel)為一組完整、互 相正交之單位數基底函數。轉換的目標是將原訊號取樣間 之相關性打散,其結果為訊號的能量重新分佈,而且只集 中在很少數的幾個轉換係數。它也具有能量保存特性,也 就是說
( ) ∑∑ ( )
∑∑
−=
−
=
−
=
−
=
=
=
10 1 0 1 2
0 1 0
2
( , )
) ,
(
Nu N v N
i N
j
v u F j
i f
E
(2)其中E 是信號能量。
圖 2 字元影像“佛”的 DCT 係數
在等式(1)中,u 值和 v 值較小的係數與低頻成份有關,而 u 值和v 值較大的係數則與高頻成份有關。
對大多數的影像而言,其大部份的信號能量都是集中 在低頻,至於高頻係數則小到只會造成視覺上不易察覺的 變化,以致於可以忽略它們的存在;換句話說,DCT 有優 越的能量集中特性。圖2 顯示了尺寸大小為 48×48 的字元 影像“佛”的二維DCT 係數,係數的個數與像素的個數相 同。我們注意到其中大部份的信號能量均出現在左上角,
這些都是屬於低頻的係數。因此,我們可利用這些低頻的 係數來做為粗分類的特徵向量。
三、粗分類方法
在本節中,我們將介紹粗分類方法中所用到的量化模 組以及GCT 模組。
1. 量化
在網格碼轉換(GCT)之前必須先完成量化的工作。量 化是減少一個變數之可能值個數的過程 [16],從而減少需 訓練模式
訓練 樣本
測試 樣本
預處理 模組
預處理 模組
量化 模組
GCT 模組 GCT 模組
量化
模組 搜尋
候選類別 網格碼
排序 DCT
特徵擷取 模組
DCT 特徵擷取
模組 分類模式
粗分類 細分類
候選類別
計算 遮罩機率 刪除
重複網格碼
統計 遮罩比對
辨識 結果
F(u,v) 15 10 5 0 -5
10 20
30 u 40
10 20 30 40 v
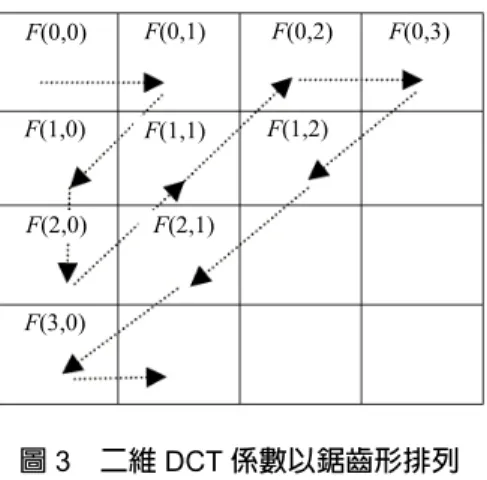
圖 3 二維 DCT 係數以鋸齒形排列
要用來代表它的位元數目。我們將使用下列方程式來把二 維DCT 係數 F (u,v)量化為 F’(u,v):
=
′ Q
v u v F u
F ( , )
) ,
( (3)
假設量化後之DCT 係數 F’(u,v)屬於 0, 1, .., q 其中的一 個量化值;那麼,F(u,v)的值域則被劃分成(q+1)個區間,
每一個區間相對應於一個量化的數值。這個量化的過程會 將高頻係數量化成零,故特徵向量的維度會因此而降低。
2. 網格碼轉換
在訓練階段時,先利用DCT 將每個訓練樣本的特徵擷 取出來,再利用等式(3)予以量化。量化之後的最重要的 D 個係數會被轉換成一個碼,我們稱之為網格碼(GC)。假設 有一樣本Oi,被量化為特徵向量[qi1, qi2, .., qiD],其中 qi1
是最重要的特徵,qi2是第二重要的特徵,以此類推。這些 項 目 以 鋸 齒 形(zigzag)的 順 序進 行排 序: F(0,0), F(0,1), F(1,0), F(2,0), F(1,1), F(0,2), F(0,3), F(1,2), F(2,1), F(3,0), F(3,1),…,以此類推 (請參考圖 3)。這個順序是由能量集 中特性所推導出,因為低頻的DCT 係數通常遠較高頻係數 重要。
此外,為了避免qij是負數,我們會將qij加上一個數字 kj,以便將qij轉換成一個正整數dij。kj是由所有訓練樣本 的量化特徵向量中的第 j 項所獲得的資料,其目的是利用 kj把第 j 個特徵的最小值轉換為 0。依照這個方法,物件 Oi 可 以 被 轉 成 一 個 有 D 個 位 數 的 網 格 碼 , 假 設 以
iD i
id d
d1 2
...
表示。這個過程便是我們所說的網格碼轉換。很明顯的,具有相同網格碼的訓練樣本都很相似,因此可 以將它們概略地歸為同一群組。在計算一個測試樣本之網 格碼時,其公式為dij=max(0, qij+kj);換言之,dij之最小值 為0。如此一來,可避免產生測試樣本之 dij值為負數的錯 誤。由於 GC 主要目的是進行樣本的分群,此一公式會使 (qij+kj)為負值之測試樣本被分類至和其特徵最相近之網格
空間(即(qij+kj)=0 所對應之網格)。從分群的角度而言,
將特徵相近的樣本分到相同的群組是十分合理的。請注 意,每一個網格碼可能對應到多個類別或者也可能無法對 應到任何類別。在進行分類時,與測試樣本具備相同網格 碼的類別會被列為候選類別;如果在資料庫中沒有任何類 別與之對應,則找鄰近網格碼之類別當成候選類別。
3. 網格碼排序與刪除
所有的訓練樣本都將被 GCT 轉換成一個三元素數組 (triplet),即(Ti, Ci, GCi),其中 Ti是訓練樣本的代碼,Ci是 訓練樣本的類別代碼,GCi是訓練樣本的網格碼。為了增 加搜尋的速度,我們可先將這些網格碼依遞增方式排序。
此外,由於同一類別的訓練樣本會產生相同的網格 碼,可將這些重覆的網格碼刪除,以增加搜尋的效率,然 後建立一個查詢表(lookup table),讓每一個網格碼對應到 其相關的類別。當然,未對應到任何類別的網格碼應予以 刪除,以進一步提升搜尋速度。
綜合言之,在訓練階段時,先利用訓練樣本建立查詢 表,隨後進行測試時,則可根據測試樣本的網格碼找到候 選類別,然後再進行細分類。
四、細分類方法
在第二階段時,我們將使用統計遮罩比對方法來進行 細分類,以便從第一階段所選出的群組中找出與待辨識文 字最接近的類別。以下將進一步介紹對細分類方法。
1. 產生遮罩
遮罩比對方法可被視為樣板比對方法的一種變形。一 般而言,樣板比對是假設每個點的位置已經知道,其相似 度的測量只需計算每個點之取樣值的差異。因此,在使用 我們的分類方法之前,我們先使用幾何轉換來將包圍手寫 文字之矩形進行正規化,使得所有文字的外形的大小較為 一致。
由於每個文字的邊緣常因為書寫或掃描的雜訊而造成 各種不同的變化,因此我們採用統計的方法,將“同一字”
的所有樣本重疊後計算每一個點呈現黑色和白點的機率。
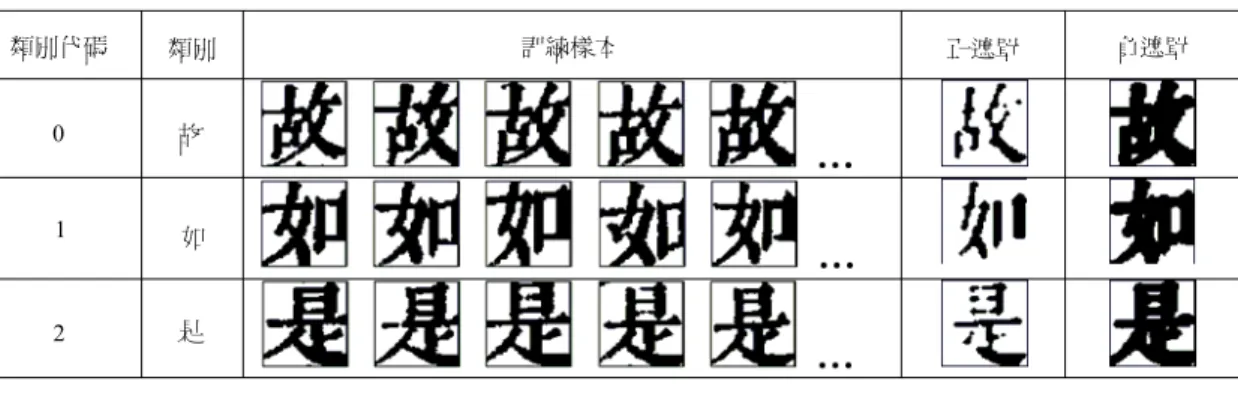
那些呈現黑色的機率大於門檻值的點集合在一起即產生正 遮罩,而呈現白色的機率大於門檻值的點集合起來即產生 負遮罩。例如,我們將金剛經中訓練樣本中的所有“故”
字重疊在一起,可得到圖4 的結果。由於那些不可靠的點 大都沿著字的邊緣,重疊次數愈多的點代表該點的可信度 愈高,我們把那些可靠的黑點集合來即產生“故”字的正 遮罩;把那些可靠的白點集合來即產生“故”字的負遮 罩。以同樣的方式可以產生圖4 中“如”和“是”兩個字 的正、負遮罩。
F(0,0) F(0,1) F(0,2) F(0,3)
F(1,0) F(1,1) F(1,2)
F(2,1) F(2,0)
F(3,0)
圖 4 一些正、負遮罩的例子
我們使用了兩個門檻值
θ
p和θ
n,用來分別定義可靠的 黑點和可靠的白點。例如當θ
p = 0.9 表示該點為黑點的機率 大於或等於90%,而θ
n = 0.9 表示該點為白點的機率大於或 等於90%。門檻值的設定主要取決於能否取得文字影像的 重要特徵,亦即能否產生清晰的正、負遮罩。門檻值設定 的好壞會影響到所產生之正、負遮罩的品質,也間接影響 到辨識的正確率。本論文的實驗中,產生正、負遮罩所使 用之門檻值θ
p和θ
n均設為0.8;依此門檻所得到之正、負遮 罩均相當清晰。2. 遮罩比對方法
首先假設文字影像和遮罩的大小相同,均為
n × n
的點陣圖。黑點表示在該點陣圖中其值為1 的點,白點則是 其值為 0 的點。令 Nb (f)表示點陣圖 f 中黑點的數目,且 Mb (f, g)表示點陣圖 f 和點陣圖 g 中均為黑點的數目。那麼,
一個待辨識文字x 和某個文字類別 ci的正遮罩(以
m
+i表示) 之間的匹配程度可定義為:) (
) , ) (
,
(
ib i i b
m N
m x m M
x d
+ + +
+
=
(4)同樣地,令Nw (f)表示點陣圖 f 中白點的數目,且 Nw (f, g) 表示在點陣圖f 和點陣圖 g 中均為白點的數目,那麼,一 個待辨識文字 x 和某個文字類別 ci的負遮罩(以
m
i−表示) 之間的匹配程度可定義為:) (
) , ) (
,
(
iw i i w
m N
m x m M
x d
−
− −
−
=
(5)在第四節中所提及的決策規則(一)和(二)就是使用遮 罩比對方法,實驗結果顯示,它的效果不如下一節所提出 的統計遮罩比對方法。
3. 統計遮罩比對方法
我們所提出的統計遮罩比對方法主要是由貝氏定理 (Bayes’ theorem)推導而來。而貝氏分類法(Bayes classifier) 乃是根據貝氏定理為基礎,用以判斷未知類別的物件應該 最接近哪一個類別。貝氏分類法的目標則是希望能透過機 率統計的分析,使誤差達到最小的一種分類方式。
假設某物件存在一個特徵值x,欲將它分類至 N 個可 能的類別(c1, c2, …, cN)之一。P(x) 表示該特徵值 x 出現的 估測機率,P(ci) 表示任意藉由亂數取出的特徵值恰巧落於 類別ci的機率,我們將之稱為事前機率(prior probability),
則根據條件機率(conditional probability),我們可將貝氏定 理表示為:
) (
)
| ( ) ( )
( ) ) (
|
(
P xc x P c P x P
x c x P c
P i
=
i∩ =
i i (6)其中,P (ci|x) 表示出現特徵值 x 時,又正好落於類別 ci的機率,我們將他稱為事後機率(posterior probability);
至於P (x|ci) 則表示落於類別 ci 的物件中,又正好發生特 徵值為 x 的機率。
現在,為了方便說明,我們增加以下兩個定義:
x
αi+和x
βi−。x
αi+表示待辨識文字x 和文字類別 ci的正遮罩之間 的匹配程度為α
,即d
+( x , m
+i) = α
。而x
iβ−表示待辨識文字 x 和文字類別 ci的負遮罩之間的匹配程度為
β
,即β
−
=
−
(
x,
mi)
d 。
假設有一待辨識文字x 可能屬於 N 個類別 (c1, c2, …, cN) 之一,若其與類別 ci的正遮罩匹配程度為
x
αi+,那麼x 在x
αi+的情形下,屬於類別ci的機率為:) (
) ( )
| ) (
|
(
ii ii i
i
P x
c P c x x P
c P
+ +
=
+α
α α (7)
類別代碼 類別 訓練樣本 正遮罩 負遮罩
0 故
1 如
2 是
表一 不同決策規則之辨識率
候選項目個數 決策規則Top 1 Top 3 Top 10 PMD 76.16% 86.57% 90.79%
NMD 85.05% 91.44% 94.26%
PMP 82.23% 88.95% 92.96%
NMP 83.86% 90.03% 94.47%
AMP 87.87% 91.77% 94.80%
因此,只要知道類別ci的機率,類別ci中具有
x
αi+性 質的機率,以及所有樣本中具有x
αi+性質的機率即可推算 得到決策為類別ci之機率。同理,我們可以求得x 在x
iβ−的情形下屬於類別ci的機率為:
) (
) ( )
| ) (
|
( ii i
i i
i P x
c P c x x P
c P
−
−
− =
β
β β (8)
在第四節中所提及的決策規則(三)、(四)和(五)就是使 用統計遮罩比對方法。實驗結果顯示,決策規則(五)具有 最佳的效果。
4. 統計決策規則
為了決定待辨識文字 x 所屬的類別,我們定義了下列 五種決策規則:
(一) 正匹配程度(positive matching degree,PMD):
Exp(x) = arg max1 ≤ i ≤ N {
d
+( x , m
+i)
} (9)(二) 負匹配程度(negative matching degree,NMD):
Exp(x) = arg max1 ≤ i ≤ N {d−
(
x,
m−i)
} (10)(三) 正匹配機率(positive matching probability,PMP):
Exp(x) = arg max1 ≤ i ≤ N {
P ( c
i| x
αi+)
} (11)(四) 負匹配機率 (negative matching probability,NMP):
Exp(x) = arg max1 ≤ i ≤ N { P
(
ci|
xβi−)
} (12)(五) 平均匹配機率 (average matching probability,AMP):
Exp(x) = arg max1 ≤ i ≤ N
{
(
P(
ci|
xαi+) +
P(
ci|
xiβ−) ) / 2
}, (13) whereα = d
+( x , m
i+)
andβ = d
−( x , m
−i)
表二 在訓練後,每個網格所包含的文字
網格碼 所包含的文字
111 112 入 113 行 114 121 人八上
122 二三人入八丈大夫不又七上云今令立言 123 人又久大不十子尸乃今令少行住切言 124 下尸
131 二三人上止
… … 441 滅藐
442 毗勝無數緣耨隨雖藏薩離聽顯
443 陀限隋隨障那斯順實廢懈耨應斷薩離無羅 444 即阿降解斷無羅
在表一中的實驗結果指出決策規則 AMP 在辨識率的 表現比其他規則好。使用PMD 和 NMD 這兩種決策規則,
只將待辨識文字和所有正遮罩或負遮罩逐一比對,以匹配 率最高的正遮罩或負遮罩所對應的類別做為辨識的結果。
而PMP 和 NMP 這兩種決策規則另外使用貝氏分類法,來 推算在某個匹配程度
x
αi+或x
iβ−之下,落於類別 ci的機 率;AMP 則是取類別 ci的正匹配機率和負匹配機率的平均 值。因為 AMP 同時具備了使用統計正遮罩和統計負遮罩 的優點,使得它的表現比其他規則好。此時,若辨識結果 只給予一個候選目標時,其辨識率為87.9%:若給予 10 個 候選目標時,其辨識率可達94.8%。五、實驗結果
在我們的實驗系統中,我們從一本著名的古籍金剛經 中取出18,600 個樣本文字(共分 640 個類別,即 640 個不同 的文字),每個文字影像被轉換成一個 48×48 的點陣圖,其 中 1,000 個用來測試,其餘的做為訓練之用。在第一階段 時,每個樣本最重要的那些DCT 係數被量化後轉換成一個 網格碼。為了方便說明,我們初步以D 值等於 3 為例,若 量化參數Q 為 4 時,則網格的數目為 64。圖 5 顯示了每個 網格中所包含的文字類別的數目,表二則進一步顯示了部 份網格的內容;從此表中可看出同一網格中的文字外型都 有較高的相似度。例如,在網格 “131” 中包含了 “二”,
“三”, “人”, “上” 和 “止” 等文字,這些文字在外形上均有 些類似。為了選取適當的D 值,我們進行了以下的實驗。
表三 使用粗分類方法的資料減少率和辨識正確率
D 值 1 2 3 4 5 6
資料
減少率 0.402 0.500 0.512 0.592 0.593 0.732 辨識
正確率 0.993 0.984 0.983 0.977 0.977 0.960
表四 同時使用粗分類和細分類方法的辨識正確率
D 值 1 2 3 4 5 6
粗分類 0.993 0.984 0.983 0.977 0.977 0.960 粗分類
和細分類 0.805 0.806 0.805 0.803 0.803 0.803
表五 同時使用粗分類和細分類方法在不同 AMP 值時
的辨識正確率
AMP 值 0.1 0.2 0.3 0.4 0.5
辨識正確率 0.822 0.871 0.897 0.923 0.949 AMP 值 0.6 0.7 0.8 0.9 1.0 辨識正確率 0.980 0.989 0.998 1.000 1.000
圖 5 每個網格中的文字類別的數目
表三顯示在不同的D 值時測試樣本的資料減少率和辨 識正確率。注意這裡的正確率是指待辨識文字存在於所找 出的網格(群組)中的比率。由此可看出當 D 增加時,GC 的 位數增加,使得資料的減少率也增加,但同時辨識的正確 率卻隨之降低。D 值增加,意味著樣本空間被切割成更小 的單位,亦即單一網格碼所對應之網格空間變小了;網格 變小的結果是,落在此一網格空間內的訓練樣本字數變少 了;換言之,於分類過程中,經由此網格所取得之候選字 數變少了。候選字數變少的影響有二:一是資料減少率增 加;二是粗分類的正確率下降(因候選字變少,導致候選 字中包含受測字的機率下降)。這是一個取捨(trade-off)
問題,使用者可依其對速度和辨識率的需求,決定合適的 D 值。
接下來的實驗是用來驗証我們的細分類方法。細分類 的進行是從粗分類後所選出的群組中進一步找出待辨識文 字所屬的文字類別,即辨識出它是那一個字。表四顯示了 使用粗分類和細分類的結果,我們可以看出當D 增加時,
雖然粗分類的正確率降低,但進行細分類之後的最終正確 率並未因此而隨之降低;這個結果指出一個事實,追求高 的資料減少率並未使得細分類的辨識率降低。在這個實驗 中可得知當D 為 6 時,可得到最好的結果;此時在粗分類 時可減少了 73.2%的資料量,而在進行細分類後仍可保持 80.3%的正確率。
本論文之實驗系統是利用Microsoft Visual C++ 製作 程式碼,於Windows XP 的作業環境下進行實驗;硬體設 備為CPU 1.6GHz, RAM 704MB。測試結果為每個受測字 之平均辨識時間為 0.009751 秒(含大分類及細比對);即 每秒可辨識 102.5 個字。雖然最終正確率似乎不令人十分 滿意,但值得注意的是當 AMP 的值愈大時,其正確率就 愈高。表五顯示了我們的實驗結果,例如,當一個測試樣 本的AMP 值大於或等於 0.5 時,它的正確率可提高到 94.9
%。事實上,我們可以把 AMP 的值視為決策的信心度,較 強的信心度會得到較好的結果;因此,只要我們改善低信 心度的部份,就可提升整體的辨識率。
本論文所提出之方法造成文字辨識錯誤的原因主要來 自兩方面:(1) 受測文字本身的問題:文字影像本身破損 或包含過多的雜訊,導致辨識不易;(2) DCT 特徵的極限:
由於DCT 為通用的影像特徵萃取工具,其所取得之特徵可 能不若某些特別針對文字辨識設計的特徵萃取法所取得之 特徵來得優越。由於本論文的主要目的之一是希望能開發 一般通用的技術,以得到不錯(而非最佳)的辨識率為目 標,未來可將此一技術應用於其他相關的模型識別問題。
同時我們仍將繼續開發其他通用性的影像特徵萃取技術,
以進一步提升辨識率。
六、結 論
本論文提出了一個可移植於其他以樣板為基礎的影像 分類應用上之兩階段分類方法。為了提昇辨識的速率,在 訓練樣本時,先將每個文字影像進行DCT 轉換,然後利用 GCT 方法把 DCT 係數量化後歸類到一個網格上。在第一 階段粗分類時,先找出待辨識文字的 GC 碼,在第二階段 細分類時,只要比對相同GC 碼的群組中的類別,如此可 減少約73.2%的資料量。
第二階段的細分類是採用統計遮罩比對方法,這個方 法在使用信心度高於0.5 的 AMP 統計決策規則時,可將正 確率提升到 94.9%。此外,實驗結果也說明了辨識的正確 率不因為利用粗分類來減少資料量而有所降低。
綜合來說,這個方法應用在中文古籍手寫文字辨識 時,不論在效率或效果上都有很好的表現;由於不同型態 網格碼
文字類別之數目
300 250 200 150 100 50 0
112 122 132 212 142 222 232 242 312 322 332 342 412 432 442 422
的特徵在分類時常有互補的能力,因此我們仍將繼續研究 其他具高信心度的特徵,用來進一步改善分類的正確性。
符號索引
ci 文字類別
)
, ( x m
id
+ + 待辨識文字 x 和類別 ci正遮罩的匹配程度)
, (
xmid− − 待辨識文字 x 和類別 ci負遮罩的匹配程度 D 網格碼的位數
E 信號能量
Exp(x) 待辨識文字x 的匹配程度
f(i, j) 影像在座標 (i, j) 的像素值,i, j = 0, 1, …, N-1 F(u, v) DCT 係數,u, v = 0, 1, …, N-1
F’(u,v) 將DCT 係數 F(u, v)量化的結果,u, v = 0, 1, …, N-1
m
+i 類別ci的正遮罩m
−i 類別ci的負遮罩Mb(f, g) 點陣圖f 和點陣圖 g 中均為黑點的數目 N×N 影像大小
Nb(f) 點陣圖f 中黑點的數目 Nw(f) 點陣圖f 中白點的數目
Nw (f, g) 點陣圖f 和點陣圖
g
中均為白點的數目 Q 量化參數x 待辨識文字
x
αi+ 待辨識文字 x 和文字類別 ci的正遮罩之間的匹 配程度為α,即d+(x,m+i)=αx
iβ− 待辨識文字x 和文字類別 ci的負遮罩之間的匹 配程度為β,即d−(x,m−i)=β
θp 可靠黑點的門檻值 θn 可靠白點的門檻值
參考文獻
1. 顧 力 仁 ,「 古 籍 全 文 檢 索 系 統 」, 國 家 圖 書 館 , http://192.83.186.77/legacyweb (2005)。
2. Chiang, T. W., and Tsai, T., “A Statistical Mask-Matching Approach for Recognizing Handwritten Characters in Chinese Paleography,” Proceedings, IEEE International Conference on Systems, Man, and Cybernetics, Hague, The Netherlands, pp. 4717-4721 (2004).
3. Jain, A. K., Duin, P. W., and Mao, J., “Statistical Pattern Recognition: A Review,” IEEE Transaction on Pattern Analysis and Machine Intelligence, Vol. 22, No. 2, pp.
5-37 (2000).
4. Wang, A. B., Fan, K. C., and Wu, W. H., “Recursive Hier- archical Radical Extraction for Handwritten Chinese Characters,” Pattern Recognition, Vol. 30, pp. 1213-1227 (1997).
5. Chang, F., Lu Y. C., and Pavlidis, T., “Feature Analysis Using Line Sweep Thinning Algorithm,” IEEE Transac- tion on Pattern Analysis and Machine Intelligence, Vol. 21, No. 2, pp. 145-158 (1999).
6. Suen, C. Y., Legault, R., Nadal, C., Cheriet, M., and Lam, L., “Building a New Generation of Handwriting Recogni- tion Systems,” Pattern Recognition Letters, Vol. 14, pp.
303-315 (1993).
7. Hsieh, A. J., Fan, K. C., and Fan, T. I., “Bipartite Weighted Matching for On-line Handwritten Chinese Character Recognition,” Pattern Recognition, Vol. 28, No.
2, pp. 143-151 (1995).
8. Mohamed, M., and Gader, P., “Handwritten Word Recog- nition Using Segmentation-Free Hidden Markov Model- ing and Segmentation-Based Dynamic Programming Techniques,” IEEE Transaction on Pattern Analysis and Machine Intelligence, Vol. PAMI-18, No. 5, pp. 548-554, (1996).
9. Alma'adeed, S., Higgens, C., and Elliman, D., “Recogni- tion of Off-line Handwritten Arabic Words Using Hidden Markov Model Approach,” Proceedings, 16th Interna- tional Conference on Pattern Recognition, Vol. 3, pp.
481-484 (2002).
10. Yan, H., “Comparison of Multilayer Neural Network and Nearest Neighbor Classifiers for Handwritten Digit Rec- ognition,” International Journal of Neural Systems, Vol. 6, No. 4, pp. 417-423 (1995).
11. Hildebrandt, T. H., and Liu, W., “Optical Recognition of Handwritten Chinese Characters: Advances Since 1980,”
Pattern Recognition, Vol. 26, No. 2, pp. 205-225 (1993).
12. Drouhard, J. P., Sabourin, R., and Godbout, M., “A Neural Network Approach to Off-line Signature Verification Us- ing Directional PDF,” Pattern Recognition, Vol. 29, No. 3, pp. 415-424 (1996).
13. Lee, S. W., “Off-line Recognition of Totally Uncon- strained Handwritten Numerals Using Multilayer Cluster Neural Network,” IEEE Transaction on Pattern Analysis and Machine Intelligence, Vol. PAMI-18, No. 6, pp.
648-652 (1996).
14. Tang, Y. Y., Tu, L. T., Liu, J., and Lee, S. W., “Offline Recognition of Chinese Handwriting by Multifeature and Multilevel Classification,” IEEE Transaction on Pattern
Analysis and Machine Intelligence, Vol. 20, No. 5, pp.
556-561 (1998).
15. Huang, L., and Huang, X., “Multiresolution Recognition of Offline Handwritten Chinese Characters with Wavelet Transform,” Proceedings, International Conference Document Analysis and Recognition, pp. 631-634 (2001).
16. Jacobs, C. P., Simard, Y., Viola, P., and Rinker, J., “Text Recognition of Low-resolution Document Images,”
Proceedings, 8th International Conference on Document Analysis and Recognition, Vol. 2, pp. 695-699 (2005).
17. Wallace, G., “The JPEG Still Picture Compression Stan- dard,” Communications of the ACM, Vol. 34, No. 4, pp.
30-44 (1991).
18. Chiang, T. W., Tsai, T., and Lin, Y. C., “Progressive Pat- tern Matching Approach Using Discrete Cosine Trans- form,” Proceedings, International Computer Symposium, Taipei, Taiwan, pp. 726-730 (2004).
19. Gray, R. M., and Neuhoff, D. L., “Quantization,” IEEE Transaction on Information Theory, Vol. 44, No. 6, pp.
2325-2383 (1998).
2006 年 01 月 02 日 收稿 2006 年 03 月 03 日 初審 2006 年 06 月 06 日 複審 2006 年 08 月 15 日 接受
![圖 1 兩階段分類方法的架構 1. DCT 特徵擷取模組 DCT 是 近 年 來 廣 泛 應 用 於 影 像 壓 縮 的 一 種 技 術 [14],它可以將影像依照影像的視覺品質的重要性進行分 離或是分成光譜子波段(spectral subbands)。它使用 N 個正 交的實數基底向量,而每個向量的組成分子都是餘弦函 數。DCT 方法有著極佳的能量集中特性,並且在轉換過程 中只需要進行實數的處理。 在應用二維的 DCT 時,一個 N×N 影像的頻譜(或是二 維 DCT 係數) F(u, v)可由](https://thumb-ap.123doks.com/thumbv2/9libinfo/9126553.410848/4.892.138.758.144.341/兩階段分類方架構DCT特徵擷取模組DCT是近年來在應用時一個.webp)