碩士論文
Graduate Institute of Electronics Engineering College of Electrical Engineering & Computer Science
National Taiwan University Master Thesis
針對盲人輔助應用之電腦視覺演算法開發與硬體架構設計 Computer Vision Algorithm and Architecture Design for
Visually-Impaired Aid System
李嘉祥
Chia-Hsiang Lee
指導教授:陳良基 博士 Advisor: Chen, Liang-Gee, Ph.D.
中華民國 101 年 6 月
June, 2012
誌 謝
在實驗室的兩年中,是我人生最充實的日子,回首向來蕭瑟處,也無風雨也 無晴,從一開始懵懂無知的小研究生開始,經過必修課的作業海、投國際會議的 熬夜校稿、想破頭的研究題目尋找、沒日沒夜的寫程式碼、反覆找論文準備上台 報告、許多匆忙又充實的訓練,慢慢的開始可以獨當一面的做研究,提出自己的 見解與建議,對照兩年前什麼都不太會的我,這些轉變讓我很欣慰也很驕傲。而 碩士生涯的結束,意味著即將正式進入職場,在求學的旅程中,幫助過我的許多 夥伴們,在這麼短的篇幅裡面無法一一向你們致謝,只能用我最真誠的敬意來向 你們道謝,謝謝你們,感謝你們的陪伴。
首先,真的非常感謝我尊敬的指導教授-陳良基老師,從大學時期就對老師 的傳說略有耳聞,當兩年半前我決定考取電子所 ICS 組時,就私自暗許一定要跟 到陳良基老師,而當錄取研究所後便積極的與老師接觸,在得知老師願意收留我 當學生時,真的非常開心與榮幸,比起研究所或大學放榜更加興奮。在碩士生涯 中,老師不僅提供了我們最優渥的資源,在研究上,更給予我們精闢又深層的建 議,每次 meeting 時老師總會耳提面命的驅策,把精華毫不保留的傳授給我們。
除了研究方面,實驗室也舉辦或參加許多活動,例如實驗室出遊、聚餐、教師節 晚會、打羽球、跑台大校園馬拉松、歌唱比賽、欣賞音樂會,而老師也以身作則 從不缺席,在工作、家庭與休閒之間取得平衡。這兩年間,老師已經樹立了我未 來人生裡的典範,很感謝老師給予的一切身教與言教,老師的諄諄教誨我都會謹 記在心,謝謝老師。
再來要謝謝兩年間給予我許多教導的學長姐及同學。謝謝美麗又大方的直屬 學姐 Steffi 一路上給予我太多太多教導,從最基礎該如何做研究、簡報的技巧、
論文的寫作技巧,一直到獨立思考方向的培養,每次在我們的討論中總有許多令 人讚嘆的點子出現,沒有妳的教導,我一定無法成長這麼快速,謝謝妳。再來是 一起同甘共苦,熬夜寫 code 與修 paper 的 Denru,每次在凌晨一起離開實驗室時,
總能給我許多建議與鼓勵,細心的你是最可靠的夥伴,再來是認真負責的宣宏,
好佩服你每天準時 9 點上工,實驗室的大小事你總能輕鬆包辦,這次德國之旅也 都是你一手策劃,再來是風趣的吳謙,每次看到你就會覺得很開心,有種莫名的 喜感,跟你在一起總能得到許多歡笑,再來是俊廷,碩一感謝你的互相照料,我 們從課程分組到 IC 競賽總是同進退的夥伴,接著是熱心的乃夫,每次遇到事情 你總是第一個挺身幫忙,還有一民學長,總能為我解答許多疑惑,從工作站到實 驗室內務都是你管轄的範圍,還要感謝黃耿彥與蔣承毅,沒有你們的指導與幫忙,
我一定無法在碩二這年管理好工作站,還有從進實驗室來就一直指導我的學長姐 李育儒、陳韻宇、陳冠宇、賴彥傑,在你們規劃的新生訓練與一路指導下,才得 以度過懵懂無知的碩一生涯。
而當我們要畢業的同時,也要感謝學弟妹們的幫忙,感謝新一屆 superuser 致敬的幫忙,讓我在口試階段可以不用煩惱工作站的問題,接著是奕魁,我會努 力看完你推薦的漫畫,也感謝你在 RTL code 上面的分憂解勞,也感謝嘉臨,一 進實驗室就變成幕後的大總管,幫忙處理實驗室的雜務,還有集美麗與智慧與一 身的莞瑜,感謝妳的時相討論與精闢的見解,接著是博學多聞的強者小阿蔡,在 我心目中你是實驗室的小教授,還有實驗室許多的夥伴們,阿貴、吏芳、宗德、
松芳、致遠、東杰,謝謝你們的時相幫助,也祝你們在未來的研究路上一切順利。
最後要謝謝的是一路陪伴我的家人,爸爸媽媽從小就一直鼓勵我要努力念書,
你們提供我衣食無缺的生活,讓我無後顧之憂,也常常關注我的身體健康,每次 都會在電話中千叮嚀萬交代要早睡覺、多吃飯,謝謝你們,還有我的姐姐、外婆、
舅舅,有你們每一個人,我的人生才能如此完整,在我心中,你們是我的依靠,
我愛你們每一個人。當然還有我的女朋友,亞倩,這段時間常常讓你等待,每次 吃飯都要等到我的討論結束,常常已經過了正常時間了,謝謝妳還是在我身邊陪 我,每當痛苦煎熬的時間,看到妳就會讓我忘記所有煩惱,剛踏入社會的我們,
難免會碰到許多不如意,但是別忘了我們還有好多夢想在等著,希望人生的一切,
我們能夠攜手度過,不論開心難過,加油!再次感謝我所有陪伴我的家人與女友,
人生有你們真好。
謹以此文,獻給一路上陪伴我的師長、朋友、家人,期盼大家一切順利,謝謝。
李嘉祥 2012/8/12
中文摘要
近年來,在盲人輔助系統上,電腦視覺分析逐漸變為主流研究方向,在現階 段中,最普遍使用的盲人輔助系統為導盲犬與盲人手杖,然而,此種方式包含許 多缺點如不方便性及價格昂貴等,在社交的場合或是擁擠的環境中,此種輔助方 式極為不適用。此外,當盲人在行走於戶外環境時,它們無法提供環境的分析與 障礙物的偵測,相較之下,電子輔助系統是較為理想的解決方式,它們提供了更 多環境資訊與導航能力。然而最新的電子輔助系統較為笨重且功能受到限制,在 本篇論文中,我們設計了攜帶式視覺分析盲人輔助系統與視覺分析導航系統,此 系統幫助盲人行走並提供重要之環境資訊。
首先,我們發展出智慧型以深度圖(Depth Map)為基準之障礙物偵測系統,
此系統的高準確度使得盲人可以快速且輕易閃避障礙物,根據深度圖的切割 (Segmentation)與空間分布關係,我們提出的演算法可以高達 95%以上的準確度,
當障礙物被抓取之後,系統會提供障礙物的資訊例如深度、方向等,更進一步使 用物體追蹤演算法(Object Tracking)來記錄障礙物之方向與路徑的軌跡,藉此 可以預測障礙物未來動線以提早閃避,接著第二部份,為了使盲人了解環境資訊,
我們提出深度特性模型(Depth Characteristic Mode)來抽取環境資訊,例如:
道路、樓梯與牆壁,此功能可以使得盲人能更了解周遭環境,抽取出這些特定的 資訊來使得盲人安全的行走道路、攀爬樓梯、沿著牆壁行走等,在第三部份更透 過結合圖形辨識功能(Pattern Recognition),設計出以全球衛星定位系統 GPS (Globe Positioning System)為基準之視覺導航系統(Vision-based Navigation System),這使得盲人可以在陌生的環境中,更精確定位所在的位置,借此我們 可以達到更精確的導航功能,在論文最後,我們挑出了兩項在系統架構中最為耗 時的區塊來做硬體加速,使得此系統可以達到即時偵測的功能,此兩區塊分別為 圖形切割與型態學操作(Morphology),我們所用的製程為台積電(TSMC)提供之 65 奈米(nm)製程,此晶片可以操作在 200MHz 之頻率,所耗的功率為 56 毫瓦(mW),
速度,在最為複雜的情況下,也可以有 28 張每秒的處理速度。
總合來說,我們提出了一套的盲人輔助系統之演算法與硬體架構設計,其中 包含三大部分軟體演算法,分別為障礙物偵測、深度特性模型偵測與視覺導航系 統,並且對於其中運算量最高之部份做硬體加速,在 65 奈米製程下可使得整體 系統可以達到即時偵測之功能。
Abstract
Recently, vision technologies are gradually introduced to electronic aids to assist elder people or the visually-impaired. The most commonly used mo- bility tools - guide dogs and white canes, are inconvenient and expensive, and have limited usability in recognizing surrounding objects. Electronic vision-based visually impaired aids are smarter as navigation tools that can perceive rich visual information of the environment for the user. However, state-of-the-arts are too bulky and still reveal many limitations such as de- tecting distant objects in outdoor environments In the thesis, we design a wearable vision-based visually impaired traffic analysis and navigation sys- tem for the visually impaired. The system aims to assist blind persons from basic needs to advanced requirements in their lives.
First, we develop an intelligent depth-based obstacle detection system that allows blind avoid from from the obstacles easily. Then, to understand the environment, we propose a depth characteristic analysis system to help the blind get some information such as stair, road and wall. We also design a GPS-based visual navigation guide that combines recognition technology and the GPS function to provide higher accurate positioning result for the blind so that they can navigate independently even in an unfamiliar envi- ronment. Finally, we pick out the critical path in our system and design a new architecture to speed up the computational time. The chip is operated under 200MHz with 56mW in power consumption. Through our method- ologies, 2000 frame with 640∗480 resolution per second in general case and
i
28 frames per second in worst case. Totally speaking, we design a con- venient portable vision-based visually impaired aid system for the visually impaired.
Computer Vision Algorithm and Architecture Design for Visually-Impaired Aid System
Chia-Hsiang Lee
Advisor: Liang-Gee Chen
Graduate Institute of Electrical Engineering National Taiwan University
Taipei, Taiwan, R.O.C.
August 14, 2012
Contents
1 Introduction 1
1.1 Introduction . . . 1
1.2 The Development of impaired Aid system . . . 3
1.3 Main Contribution . . . 4
1.4 Thesis Organization . . . 7
2 Intelligent Depth-Based Obstacle Detection 9 2.1 Introduction . . . 9
2.2 Proposed Framework . . . 11
2.2.1 3D-sensor . . . 12
2.2.2 Object Segmentation . . . 12
2.2.3 Obstacle Extraction . . . 14
2.3 Experimental Results . . . 16
2.4 Conclusion . . . 17
3 Depth Characteristic Analysis 23 3.1 Introduction . . . 23
3.2 Road Characteristic Analysis . . . 23
3.3 Wall Detection . . . 27
3.4 Stair Detection . . . 31
3.5 Conclusion . . . 32 i
4 Position Reconstruction by Street-View Recognition 35
4.1 Introduction . . . 35
4.2 The Proposed Positioning System . . . 37
4.2.1 Approach Overview . . . 37
4.2.2 Street View Recognition . . . 38
4.2.3 Position Estimation . . . 38
4.3 Experimental Results . . . 42
4.4 Conclusion . . . 45
5 Hardware Architecture 49 5.1 Introduction . . . 49
5.2 Hardware Design Challenge . . . 49
5.3 Proposed Hardware Architecture . . . 51
5.4 Chip Implementation . . . 55
6 Conclusion 59
Bibliography 62
List of Figures
1.1 Different applications on computer vision. . . 1 1.2 Traditional navigation aid for the visually impaired - guide
dogs and white canes. . . 4 1.3 Our proposed electronic aid for the visually impaired. . . 5 2.1 Segmented images. The left frame of each pair is a complete
image and the right frame of each pair is the ROI. The image pairs on the first row shows the noisy-segmented result. The second row image pairs presents the noise-reduced segmenta- tion result. . . 12 2.2 Pixel distribution of depth values on the chair (a) and the
floor (b). . . 15 2.3 Obstacle detection within 1.5m (left) and 2m (right) alarm
range. . . 16 2.4 Indoor results. Robustness test in the house within 2m alarm
range. . . 17 2.5 Indoor results. Robustness test in the house within 1.5m
alarm range. . . 18 2.6 Indoor results. Robustness test in the convenience store
within 1.5m alarm range. . . 19 2.7 Outdoor results. Robustness test in the campus within 1m
alarm range. . . 19 iii
2.8 Obstacle detection of bicycle in darkness. The Right frame of each image pair is the depth image and the left frame of each image pair is the RGB color image. The first row and the second row of image pairs are taken in the same place at
different timestamps. . . 20
2.9 System flow diagram. . . 21
3.1 General Road Model. . . 24
3.2 General formula for road model. . . 25
3.3 The failed road detection with different view angle θ and distance Yw in [1], the blue region is the detected road. . . . 26
3.4 Sketch map of the proposed road model and the simplified equation in road detection. . . 27
3.5 Comparison between the proposed method(right side) and the original method(left side). The blue region is the detected road. . . 28
3.6 False alarm of wall detection by Eq. 3.2. The small stick of pink region is the detected wall. . . 29
3.7 The wall detection algorithm after using area filter Eq. 3.2. The small stick of pink region is detected wall. . . 30
3.8 The interlaced planes in depth image. . . 31
3.9 The right side is the final results of stair detection and the left side is the corresponding interlaced planes in depth image. 32 4.1 The scenario of incorrect positioning estimation . . . 36
4.2 Sign shapes under different view-angles . . . 39
4.3 Geometric relationship between the object distance and the projected width in the image plane . . . 39 4.4 Definition of the user orientation, pattern angle, and view angle 42 4.5 Accuracy comparison between GPS and the proposed method. 43
v 4.6 Comparison of the error rate in SR estimation . . . . 44 4.7 The information on the GPS map and the corresponding rec-
ognized shop signs in the video frame . . . 45 4.8 Path estimation by different methods . . . 45 4.9 System flow diagram . . . 47 5.1 The profiling result. Percentage of each algorithm in the
visually-impaired aid system. . . 50 5.2 The sketch map of the proposed basic computational unit. . 51 5.3 The sketch map of the proposed basic computational block
by 8∗8 pixels. . . . 53 5.4 The sketch map of upper level block and the scan direction. 55 5.5 The comparison of processing time to the similar work [2]. . 56 5.6 The memory usage of the computational block. There are
8 256∗128 SRAMs in our architecture. The access of each computational block only need one clock. . . 58
List of Tables
5.1 The characteristics of segmentation algorithm under different block size N . . . . 52 5.2 The comparison of segmentation algorithm between the cur-
rent implementation and our proposed method. . . 56 5.3 Chip summary. . . 57
vii
Chapter 1 Introduction
1.1 Introduction
Figure 1.1: Different applications on computer vision.
Recently, more and more computer vision technologies enable different innovative applications those were unfeasible before, such as surveillance
1
systems, intelligent vehicles, interactive games, robotic vision and portable vision, shown in Fig. 1.1. Intelligent vehicle technology commonly applies to car safety systems. It provides real-time information to the user who expects the system to assist in determining the best cruise travel. The required techniques on this applications are visual detection and tracking for on-road vehicles to estimate distance from preceding vehicles or pedes- trians. Interactive game like XBOX with Kinect brings fun to our daily life. Future surveillance systems offer people an extensive portfolio of in- novative features and systems for security. In these systems, video analysis will become important or even basic features to support intelligent func- tionalities, such as automatic detection of threats and abnormal behavior or violence. As to augmented reality, it is one of the most exciting tech- nologies in the near future. Recognition technology is employed to locate positions of target objects and track them to render virtual 3-D graphics.
Thus, people are able to interact with virtual objects in a real scene. For robot applications, vision is a basic ability for the robot to complete its tasks or even make decisions based on what they see. Images captured from front-mounted cameras of the robot are analyzed to sense its surroundings and build the related spatial relationship. Today, the mainstream of gam- ing is designed for human-computer interactive mechanism. Based around a webcam-style add-on peripheral for the gaming console, it enables users to control and interact with the gaming machine without the need to touch a game controller, through a natural user interface using gestures and spoken commands. Wearable vision also has great potentials in the future. With the increased attention to human health-care in this age, visual techniques are gradually introduced to electronic aids to take care for elder people or the visually-impaired. These devices serve as a pair of artificial eyes for users, and visual recognition techniques assist users in detecting obstacles and help them walk around safely. To sum up, with the advance of computer
3 vision software algorithms as well as the development of hardware platforms, we can imagine that innovative and smart computer-vision systems will go mainstreams and greatly benefit human lives in coming years.
1.2 The Development of impaired Aid sys- tem
Wearable vision, which can be applied to augmented reality and visually impaired electronic aids, is one of the main attractive potentials to assist people in the future. There are 284 million visually impaired people in the world. Visual impairment leads to loss of independence in performing many routine and life-enabling tasks. For the visually impaired, navigating city streets or neighborhoods has constant challenges. As shown in Fig. 1.2, most such people still must rely on a very rudimentary technology - a simple cane - to help them make their way through a complex world. Tools such as the white cane with a red tip are widely used to improve mobility. A long cane is used to extend the users range of touch sensation. It is usually swung in a low sweeping motion, across the intended path of travel, to detect obstacles. However, techniques for cane travel can vary depending on the user and the situation. Some visually impaired persons do not carry these kinds of canes, opting instead for the shorter, lighter identification (ID) cane. Still others require a support cane. The choice depends on the individuals vision, motivation, and other factors.
A small number of people employ guide dogs to assist in mobility. These dogs are trained to navigate around various obstacles, and to indicate when it becomes necessary to go up or down a step. However, the helpfulness of guide dogs is limited by the inability of dogs to understand complex directions. The human half of the guide dog team does the directing, based upon skills acquired through previous mobility training. In this sense, the
Figure 1.2: Traditional navigation aid for the visually impaired - guide dogs and white canes.
handler might be likened to an aircrafts navigator, who must know how to get from one place to another, and the dog to the pilot, who gets them there safely.
Many researchers were working to develop ultrasonic [3], laser [4], or vision sensors [5] to further enhance user confidence about mobility. In [6], the most famous electronic aids for blind persons are reviewed and classified based on how the travel instructions are sent to the subject, including audio feedback [7], tactile feedback [8], and others without interface [9].
1.3 Main Contribution
To provide a feasible and robust visual recognition and navigation system in computer vision, we put our strength in developing a highly efficient and robust navigation aid for the visually impaired. Our primary goal is to give a hand to those who is in need of portable vision assistance devices. Fig. 1.3 presents functionalities of the proposed system. The whole work can be di- vided into three parts: depth characteristic analysis, intelligent depth-based obstacle detection, and GPS-based visual navigation guide. First, we design an depth characteristic analysis system to assist blind persons to understand the environment. This system aims to achieve high accuracy in detecting the road, wall and stair. Second, to support safe travel guides for blind
5 persons, we propose a robust intelligent depth-based obstacle detection sys- tem to detect dangerous static obstacles in a dynamic environment. Lastly, a GPS-based visual navigation guide based on street view recognition is designed to provide precise positions of users when the blind travel in an unfamiliar place. In brief, the system supports functions from basic needs of blind people to their advanced requirements in a daily life.
1. Intelligent Depth-Based Obstacle Detection
3. Intelligent Visual Navigation
GPS Information 2. Depth Characteristic Analysis
Road, Wall and Stair Detection
Different Obstacles
Figure 1.3: Our proposed electronic aid for the visually impaired.
In the first part. The algorithm, intelligent depth-based obstacle de- tection, aims to assist the blind in detecting obstacles with distance infor- mation for safety. Obstacle extraction mechanism is proposed to capture obstacles by various object proprieties revealing in the depth map. With analysis of the depth map, segmentation and noise elimination are adopted to distinguish different objects according to the related depth information.
The proposed system can also be applied to emerging vision-based mobile applications, such as robots, intelligent vehicle navigation, and dynamic surveillance systems. Experimental results demonstrate the proposed sys- tem achieves high accuracy. In the indoor environment, the average detec- tion rate is above 96.1%. Even in the outdoor environment or in complete darkness, 93.7% detection rate is achieved on average.
The second part is the depth characteristic analysis. This three functions in this part are road detection, wall detection and stair detection. Depth analysis has become a popular field in computer vision recently because of the accuracy and robustness. We proposed three powerful method for the visually-impaired aid system. Regardless of color variation, the proposed algorithm still work with high performance. The experimental results could also prove the robustness. In road detection algorithm, The detection rate is above 93% and the false alarm rate is 3.25%. In wall detection algorithm, there is about 94.05% detection rate and 2.3% false alarm rate. In stair detection, our proposed algorithm achieves 96.05% detection rate and 0.8%
false alarm rate.
The third part is the accurate positioning system based on street view recognition. Vision-based technique is employed for dynamically recogniz- ing shop or building signs on the GPS map. Two mechanisms including view-angle invariant distance estimation and path refinement are proposed for robust and accurate position estimation. Through the combination of visual recognition technique and GPS scale data, the real user location can be accurately inferred. Experimental results demonstrate that the proposed system is reliable and feasible. Compared with 20m error of position esti- mation provided by the GPS, our system only has 0.97m error estimation.
In the final part, the critical path, segmentation and morphology, in our system are picked out to discuss and design. We proposed a new archi- tecture and chip implementation with TSMC 65nm technology. The chip
7 is operated under 200MHz with 56mW in power consumption. Through our methodologies, 2000 frame with 640∗480 resolution per second in gen- eral case and 28 frames per second in worst case. Our proposed architecture achieves the high efficiency processing performance on frame rate and mem- ory usage.
1.4 Thesis Organization
Here shows the organization of the thesis. The overview of computer vi- sion technologies and emerging vision applications are illustrated in Chap1.
Chap2 begins to show the first work of the thesis- intelligent depth-based obstacle detection system. This chapter introduces the concept and algo- rithms of the analysis system. Chap3 presents the second work of the thesis - the depth characteristic analysis system. Chap4 illustrates the third part of the thesis - GPS-based visual navigation guide. Chip implementation and detailed design techniques are presented in chpater5. This chapter de- picts the functionalities and the specification it supports. Finally, chapter6 concludes the thesis.
Chapter 2
Intelligent Depth-Based Obstacle Detection
2.1 Introduction
With the advances of computer vision algorithms and the evolution of hard- ware technologies, intelligent vision systems have attracted increasing at- tentions in the age. Many mobile applications, including intelligent vehicle navigation, robotic vision, augmented reality, visually-impaired electronic aids, and dynamic surveillance systems, have the vision ability to fulfill spe- cific tasks. Owing to the maturity of 3D-sensors these years, depth-based systems have been adopted to solve many traditional computer vision prob- lems, such as object tracking [10], face recognition [11] and feature extrac- tion [12]. Omar Arif used the 3D-sensor to track and segment different objects in disparity layers [10]. Simon Meers proposed the depth-based face recognition with feature point extraction [11]. Peter Gemeiner presented a corner filtering scheme combining both the intensity and depth image of a TOF camera [12].
For mobile vision applications, obstacle detection and collision avoidance is an important or even basic feature to support useful information to the
9
user for safety. Recently, many works have been proposed to address this issue. These works can be divided into two categories: (1) non-depth-based obstacle detection and (2) depth-based obstacle detection approaches. For the first category, Long Chen proposed the saliency map obstacle detection [13]. This work extracted the visual attention region as an obstacle under certain thresholds. However, it could only be used in environments with few obstacles because the saliency map must be constructed with coherent characteristics. Zhang Yankun introduced an obstacle detection approach by using a single view image[14]. Based on edge detection for object seg- mentation, the assumption of the work is that the road surface is a plane without texture. For the second category, Cosmin D. Pantilie used mo- tion to detect obstacles for automotive applications [15]. According to his work, the pose of the stereo camera should be fixed in a certain angle and the environment would be restricted to the road. Pangyu Jeong presented a stereo-based real-time obstacle and road plane detector with adapting mechanism for various environments [16].
In this chapter, we propose a robust depth-based obstacle detection and avoidance framework based on computer vision technologies. Our sys- tem aims to assist the visually-impaired in obstacle detection for safety.
Compared with previous works [14][15][16], which focus on automotive or robot applications, with assumptions of fix height of camera positions, the proposed method enables free viewpoint of camera moving, which is more reasonable and further meet the specification of a head-mounted visually- impaired electronic aids. With analysis of different depth layers and object proprieties in the depth map, obstacles can be correctly detected and the corresponding distances from the user can be estimated. Since for many real mobile applications, only obstacles appearing within a small distance are potential threats to the user, we set the alarm range as 1-2 meters in this paper. Only obstacles exist in the alarm range will be reported to
11 remind the user. The proposed system could still work successfully even in darkness and outdoor environments. More than 10000 frames of each sequence taken in different environments are used to test the robustness of the proposed work. The experimental results prove that the proposed system achieves 96.1% and 93.7% detection rate on average in the indoor and outdoor environments, respectively.
The remainder of this topic is organized as follows. The objet segmenta- tion and obstacle extraction mechanism help to accurately locate appearing obstacles on the road are presented in Section 2.2. The experimental re- sults conducted with test sequences in different environments are provided in Section 2.3. Finally, some conclusions are drawn in Section 2.4.
2.2 Proposed Framework
Initially, a 3D-sensor is used to provide depth images as well as color images.
There are two stages to be performed. The first stage is object segmenta- tion. Edge detection on the depth image is used to find the discontinuous depth values in real-world environments. Then depth layers of the depth im- age are analyzed to distinguish different objects. We regard the pixels with similar depth values in neighboring locations as the same object. However, the segmented images are noisy. To overcome this problem, noise elimina- tion is performed with information of detected edges and pixel numbers.
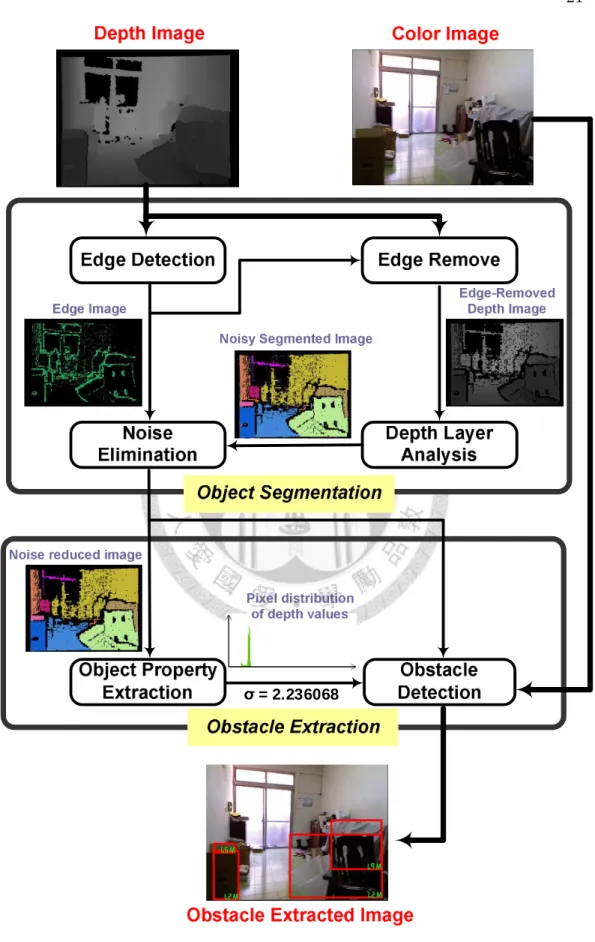
The second stage is obstacle extraction. Properties of detected objects are extracted to determine which ones belong to obstacles. Once obstacles are confirmed, they would be labeled with distance information far from the user. The system flow diagram is shown in Fig. 4.9.
2.2.1 3D-sensor
The Time-of-Flight (TOF) camera has been widely used as the 3D-sensor recently. It provides each pixel with depth information in intensity values in real-time. In spite of physical limitations, it is reliable in general conditions.
In this paper, we use TOF camera to generate depth images and color images. The 640x480 resolution video inputs are tested in this work.
2.2.2 Object Segmentation
Figure 2.1: Segmented images. The left frame of each pair is a complete image and the right frame of each pair is the ROI. The image pairs on the first row shows the noisy-segmented result. The second row image pairs presents the noise-reduced segmentation result.
The purpose of the first stage is to segment each depth image into several regions, which represent different objects. The discontinuous depth values in the depth image measured by the TOF camera form the boundaries of objects in the real environment. Therefore, extracting points with discon-
13 tinuous depth values for edge detection is the first step. Let I(x) is the depth value of pixel x. We define m(xc, xi) as a binary variable, which rep- resents whether the difference of depth values between the center xcand its neighboring pixel xi is large than threshold TV or not. The representation is shown as follows.
m(xc, xi) =
1 if |I(xc) − I(xi)| > TV, 0 others,
(2.1)
To find out pixels on the object boundaries, we define E(xc) as a binary value, representing whether xc locates on one edge or not. Let N(xc) be the set of neighboring pixels of the center pixel xc. For the center pixel xc, once the number of its neighboring pixels, whose m(xc, xi) is equal to 1, is larger than a given threshold TN, the value of E(xc) would be set to 1. The equation is shown in Eq. 4.2.
E(x) =
1 if P
xi∈N (xc)
m(xc, xi) > TN, 0 others,
(2.2)
After all edges in the depth map are found, we eliminate them so that the depth image could be segmented more accurately. The next step in object segmentation is depth layer analysis. Compared with Watershed and Histogram-Based algorithm in segmentation, the concept of Region- Growing[17] is a more suitable method to separate objects in different depth layers and spatial locations. This algorithm spreads several seeds in the image plane and merges their neighbors iteratively. However, this algorithm is seed-dependent and it would fail if the initial seeds not ideally spread on objects. To overcome this defect, we modified the approach. Let every pixel initially be set as a seed, denoted as sx. These seeds would be merged into the same union Ai as their neighboring seeds N(sx) if the difference of their depth values is smaller than a threshold T . Then, multiple unions are
generated. Let Ai(sx) represents the seed set which contains the same union index i(sx). For each iteration, because of the scan order for processing the region growing step, a seed may not be merged within the union containing its neighbors with the nearest depth value. After one iteration, some seeds of N(sx) may have depth values with difference smaller than T but still do not belong to Ai(sx). Thus, we define the set of seeds as W . The representation is shown below.
W = {sx|∃s ∈ N(sx) : [I(s) − I(sx) < T ]Λ[i(s) 6= i(sx)]} (2.3) In our approach, every seed in W would be merged again with the region that has the most nearest mean of depth values. The equation could be represented as follows.
s0x = arg min
s∈N (sx)
¯¯
¯¯
¯¯
¯
I(sx) − P
sn∈Ai(s)
I(sn) card(Ai(s))
¯¯
¯¯
¯¯
¯
, (2.4)
Where the selected seed s0x is a neighboring seed to sx within the region that has the most nearest mean value of depth for all pixels inside. We iteratively renew the union index i(sx) until W ⊂ ∅.
The segmented image, however, is noisy because of the imperfect depth image measured by the TOF camera. Fortunately, noise usually has certain characteristics such as small number of pixels and sparse locations. The small regions with few pixel numbers and sparse locations near the edges usually represent the noise, which would be eliminated to guarantee the cor- rect segmentation. Fig. 2.1 show the comparison between a noisy segmented frame and a noise-reduced frame.
2.2.3 Obstacle Extraction
The purpose of this stage is to extract obstacles by object proprieties, such as standard deviation and the mean of depth values. The term ”obstacle” is
15 defined as moving and standing objects those appear within a certain alarm range, which is set as 1-2 meters far from the user in this paper. The alarm range could be adjusted according to different environments. Therefore, whenever obstacles occur within the alarm range, they will be captured and labeled with the estimated distance from the user.
(a) (b)
Figure 2.2: Pixel distribution of depth values on the chair (a) and the floor (b).
Intuitively, obstacles can be extracted among the detected objects by calculating the median or mean of depth values. This simple method is indeed able to extract all obstacles, however, it will cause high false-alarm rate when detecting the floor, which has low mean, is not what we aim to capture. In order to solve this problem, the standard deviation of each ob- ject should be extracted to distinguish whether it is floor or not. Since pixel distribution of depth values of the floor is scattered, its standard deviation would be larger than other objects. Fig. 2.2 shows the pixel distribution of depth values on the chair (Fig. 2.2-a) and floor (Fig. 2.2-b). Then, the threshold of standard deviation is established to remove the floor. There- fore, false alarm rate could be successfully reduced. The accurate road model would be introduced in Section 3. This road model could help us to extract the road accurately and increases the obstacle detection rate.
2.3 Experimental Results
Figure 2.3: Obstacle detection within 1.5m (left) and 2m (right) alarm range.
In our experiment, the TOF camera is used to capture depth images and RGB 3-channels multiple 8-bits color images. A user takes this camera and walks around. The two different alarm ranges, 1.5 and 2 meters, are tested in the same image in Fig. 2.3. All obstacles were detected successfully in the cluttered environment with light reflection. Fig. 2.4, Fig. 2.5 and Fig. 2.6 show more indoor results in different places. Fig. 2.7 presents the robustness of the system outdoors for 1 meter alarm range. In all the above environments, obstacles could be extracted. In addition, the proposed system also has good detection performance in dark environment.
Fig. 2.8 shows the successful detection of a bicycle which appears abruptly in darkness. In fact, moving objects, such as bicycles and cars can be considered as moving obstacles. These obstacles also bring potential threats to the user.
The proposed system achieves high detection rate (DR) and low false alarm rate (FAR) indoors and outdoors. DR is defined as the total number of detected obstacles over the total number of existent obstacles in the alarm range. Our system achieves on average 96.1% DR in indoor cases and 93.7% DR in outdoor cases. FAR is defined as the total number of false
17
Figure 2.4: Indoor results. Robustness test in the house within 2m alarm range.
detected obstacles over the total number of real existent obstacles in the alarm range. The proposed system achieves less than 5.33% FAR in indoor cases and 5.62% FAR in outdoor cases. The results are obtained by testing more than 10000 frames of sequences in all kinds of environments.
2.4 Conclusion
In this chapter, we propose robust depth-based obstacle detection system for visually-impaired aid applications. The proposed system can be used to help the blind prevent from dangers and can also be adopted to many emerging mobile applications. This system achieves on average 96.1% and 93.7% detection rate in the indoor and outdoor environment, respectively.
Convincing results are demonstrated in diverse conditions. Environmental limitation is reduced by this framework. Even in darkness, the ability of
Figure 2.5: Indoor results. Robustness test in the house within 1.5m alarm range.
detection of the proposed system can still work successfully. In conclusion, we establish a practical framework for visually-impaired aid applications in obstacle detection.
19
Figure 2.6: Indoor results. Robustness test in the convenience store within 1.5m alarm range.
Figure 2.7: Outdoor results. Robustness test in the campus within 1m alarm range.
Figure 2.8: Obstacle detection of bicycle in darkness. The Right frame of each image pair is the depth image and the left frame of each image pair is the RGB color image. The first row and the second row of image pairs are taken in the same place at different timestamps.
21
σ = 2.236068
Figure 2.9: System flow diagram.
Chapter 3
Depth Characteristic Analysis
3.1 Introduction
Depth characteristic analysis play an important role in visually impaired aid system. This algorithm can help the blind to understand the environment including stair, wall and road. A lot of researchers were working to develop different algorithms in this field. In our work, we present three depth char- acteristic analysis technologies, that are road detection, wall detection and stair detection. The following section will detail the algorithm and show the experimental results. Section 3.2 shows the improvement of traditional road model and the robust result in our system. Section 3.3 introduces the stair detection algorithm. The final algorithm, stair detection will be introduced in section 3.4.
3.2 Road Characteristic Analysis
Road detection is an important problem with many applications, such as driver assistance systems, self-guided vehicles, robot navigation, visually impaired aid system or other safety applications. Stereo vision or depth sensor is one of the key components in road detection.
23
A traditional method for ground estimation is plane fitting, In [18] , the authors used RANSAC Plane Fitting to find the disparity of ground pixels.
In [19], the valid value in the depth map are extracted as ground plane if the value satisfy the constraint. In [20], a road detection algorithm is developed to utilize the road features called plane fitting errors.
Figure 3.1: General Road Model.
There are many researches in road detection in robotic navigation or driver aid system [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33].
In [1], the author present an efficient solution of fast stereovision based road scene analysis algorithm, which employs the ”U-V-disparity” concept to classify 3D road scene into relative surface planes and characterize the features of road pavement surfaces, roadside structures, and obstacles. Real- time implementation of disparity map calculation and ”U-V-disparity” clas- sification is also presented. In Fig. 3.1, the relationship between the user and the road plane fitted to a world coordination model. The transforma- tion shows in Fig. 3.2. This road model is suitable for car driver system in high detection rate because the view angle θ and the distance between the camera and the road plane Yw should be a constant. However, in our visually-impaired aid system, the view angle θ and the distance Yw is varied, we should consider this special issue and improve the algorithm with more robust formula. Fig. 3.3 shows the failed detection in different view θ angle
25
Figure 3.2: General formula for road model.
by [1]. The detected road with blue region less than the real road region because the view angle of user is not match to the initial value.
To overcome this problem, we proposed a new detection method with the gradient consistency. In road detection, we can image that the depth distribution should be continuous and the slope of distance must match to a certain constraint because road is a ”flat plane” from the near to the distant. According to this concept, the deviation can be represented by formula, as shown in Fig. 3.2 and Eq. 3.1. In advance, if the view angle incline with small value, Eq. 3.1 can be simplified to a short equation. The
Figure 3.3: The failed road detection with different view angle θ and dis- tance Yw in [1], the blue region is the detected road.
representation of this road model shown in Fig. 3.4.
dV dZw
=−Yw+ 2Zwsin θ cos θ
(Ywsin θ + Zwcos θ)2 (3.1)
With limiting the gradient constraint, the initial view angle θ and dis- tance Yw could change within a small range, that can tolerate the difference of view angle when the blind move around. The experimental results shown in Fig. 3.5. The left side is the original algorithm and the right side is our proposed method. In the comparison, the detected road, blue region, of our proposed method almost cover the whole area of road. In the left side, the mis-detection occurs when the view angle do not match to initial value. This improvement increases the detection rate from 53% to 93% and decreases the false alarm rate from 59% to 3.25%. In the experimental results, the proposed algorithm increases 40% detection rate and decreases 56% false alarm rate. This improvement is effective and the system become reliable to the blind.
27
m
hGround Ground Ground Ground
θ
aθ
hdddd
H H H H W W W W
Figure 3.4: Sketch map of the proposed road model and the simplified equation in road detection.
3.3 Wall Detection
Wall detection is another important depth characteristic analysis technol- ogy. When the system inform the obstacle to the blind, they will be sug- gested to get quickly out of the object. However, wall is a low threatened obstacle for the blind because it is static and flat. If we can extract the wall from the image, the suggested path will be more accurately and more robust. Therefore, in this section, we will introduce the algorithm for the wall detection.
There are some researches in wall detection of computer vision field [34] [35] [36].
The above researchers use edge, gradient or other characteristics in 2D im- age to extract the wall. These algorithms could help us to grab the wall area but not suitable in our system. The first reason is that the complexity
Figure 3.5: Comparison between the proposed method(right side) and the original method(left side). The blue region is the detected road.
is too high. In our system, we have only limited computational time to detect the wall. The second reason is that our system equips 3D sensor,
29 it can largely reduce the unnecessary calculation like coordination transfor- mation. Therefore, we proposed an high efficient wall detection algorithm in our system, that will be introduced in the following paragraph.
The characteristic of the wall is flat and with same depth value on the vertical direction. Therefore, we should check the depth distribution D(X, Ya) line by line in the 3D-image. If the depth is continuous with same depth with some threshold T , it will be label as a small stick of wall W (x).
Eq. 3.2 represents this processing.
W (x) =
1 if Y +TP
Ya=Y
D(X, Ya) = T , 0 others,
(3.2)
Figure 3.6: False alarm of wall detection by Eq. 3.2. The small stick of pink region is the detected wall.
After finding out the candidate of wall, area filter should be applied to filter out the noise. Because in the real case, there are a lot of small planes on the object surface that will be detected by Eq. 3.2. Fig. 3.6
shows the false alarm of wall detection. We can find that the pink region of detected wall is obviously appear on the non-wall surface, that is why the area filter should be proposed to filter out this noise. In our experiments, we define the area of wall must larger than 3m2 and the equation can be represented as Eq. 3.3. In Sec.2.2, we have introduced the segmentation algorithm, thus, wall detection continue this method to determine whether each segmentation Sg extracted by Eq. 3.2 is wall or not. Fig. 3.7 shows the robust experimental results after using Eq. 3.3. The noise of small region that is not belong to the wall, successfully be eliminated by the proposed algorithm. This improvement achieves 94.05% detection rate and 2.3% false alarm rate.
Area = P
∀z∈Sg
NzZ2
f2 > 3m2 (3.3)
Figure 3.7: The wall detection algorithm after using area filter Eq. 3.2. The small stick of pink region is detected wall.
31
Figure 3.8: The interlaced planes in depth image.
3.4 Stair Detection
Stair detection is another important depth characteristic analysis technol- ogy. This algorithm can help the blind to go upstairs or downstairs if any stair locates in the vicinity to the blind. Similar to chapter 3.3, the tech- nology of depth analysis is reliable and efficient. Furthermore, the proposed algorithm can also inform the blind how far is the distance from the stair.
It is an useful information to the blind. In this section, we will introduce the stair detection algorithm by depth analysis.
There are some researches for stair detection in robotic system or com- puter vision field [37] [38] [39]. Similar to chpater 3.3, these researchers use edge, gradient or other characteristics in 2D image to extract the stair.
These algorithms could help us to grab the stair region but not suitable in our system. The same reason is that the complexity is too high, our application only have limited computational resource to detect the stair.
The second reason is that our system equip 3D sensor, it can largely reduce the unnecessary calculation like coordination transformation. Therefore, we proposed an high efficient stair detection algorithm in our system, that will be introduced in the following paragraph.
Stair usually contain a lot of small vertical and horizontal planes and these planes would cross each others. For example, the horizontal plane would locate beneath and under some vertical plane, this characteristic would regularly repeat in stair until the end. According to this characteris- tic, we can individually employ the detection algorithm in chapter 3.2 and chapter 3.3, then combining these two algorithms to determine if some re- gion detected by 3.2 and 3.3 is stair or not. Fig. 3.8 shows the interlaced image of vertical and horizontal planes, and Fig. 3.9 shows the final results of stair detection. The proposed algorithm achieves 96.05% detection rate and 0.8% false alarm rate.
Figure 3.9: The right side is the final results of stair detection and the left side is the corresponding interlaced planes in depth image.
3.5 Conclusion
We propose three depth characteristic analysis algorithm for road, wall and stair detection. These functions are useful to the blind when they are in the unknown environment. The proposed method use depth cue instead
33 of RGB cue, the traditional approach, to analyze the characteristics. The advantage is that the shape of object is usually invariable. For example, the appearance of wall usually be painted with different color, however, the shape of wall only be vertical and flat. That is why depth analysis is reliable in our system. The experimental results could also prove the robustness.
In road detection algorithm, Sec. 3.2, the detection rate is above 93% and the false alarm rate is 3.25%. In wall detection algorithm, Sec. 3.3, the detection rate is about 94.05% and the false alarm rate is 2.3%. In stair detection, Sec. 3.4, our proposed algorithm achieves 96.05% detection rate and 0.8% false alarm rate. In conclusion, we establish a practical framework for visually-impaired aid applications in depth characteristic analysis.
Chapter 4
Position Reconstruction by Street-View Recognition
4.1 Introduction
Self-localization is important in many applications, such as automatic vehi- cle or pedestrian navigation, robotic path planning, and visually-impaired electronic-aids. The GPS system, which provides localization and huge map scale, is widely utilized in these applications. However, GPS has a fatal defect, positioning inaccuracy, which may be caused by satellite masking, multipath or cloudy weather. The positioning error may increase up to 20 meters when the user moves in urban environments. For many applications, such as navigation services for pedestrian, robot or the visually-impaired, 20 meters is unacceptable. An example is shown in Fig. 4.1. If a blind person is guided by a GPS system to get to his destination, the inaccurate position would lead him toward the opposite direction. To overcome this problem, an accurate positioning system is important and must be a basic requirement of GPS-based systems for advanced applications.
Many works have been proposed to improve GPS accuracy. These works can be classified into three categories. (1) Several works utilized mathemati-
35
Wrong location by GPS Correct location Wrong navigation Correct navigation
Destination
Figure 4.1: The scenario of incorrect positioning estimation
cal models, such as Kalman filter [40], least square model [41] and frequency domain model [42], to eliminate the noise of positioning estimation and pre- dict the most possible location. In general, these models do not have good performance in urban environments because the satellite signal is signifi- cantly masked or reflected by crowded buildings. (2) There are also some works combining different sensors to acquire multi-type data. For exam- ple, Maya Dawood [43] proposed a vehicle localization system with fusion of an odometer, reckoning sensors, 3D models and visual recognition meth- ods. The approaches of the category are accurate but multi-type data fusion
37 from too many sensors makes the system more complex. (3) Some works [44]
[45] adopted visual recognition methods by tracking corresponding points across neighboring video frames for camera pose estimation. Shortages of these works are the assumption of the known initial location and error es- timations propagated during a longer period.
In our work, we propose an accurate and robust positioning system based on street view recognition. Our system is equipped with a GPS receiver and a digital compass to catch global map information and estimate the current user orientation, respectively. Vision-based recognition technique is employed to capture dynamic street views, such as shop or building signs, which are tagged within the GPS map. With the targeted signs around the user on the street, a view-angle invariant distance estimation mechanism is developed to infer accurate user locations. The proposed system can be applied to many advanced applications, such as robot self-localization, visually-impaired aids, augmented reality and general navigation on smart phones.
4.2 The Proposed Positioning System
4.2.1 Approach Overview
The main idea of our approach is to combine street view recognition with shops or building information tagged within the GPS map. The system flow diagram is shown in Fig. 4.9. There are one camera, the digital compass and the GPS receiver equipped with the proposed system. Our approach can be divided into two parts: street view recognition and position estima- tion. The aim of street view recognition is to recognize shop or building signs, which are also tagged on GPS map. In this stage, we utilize feature- based recognition method. Feature extraction and feature matching for the current frame of the input video are performed first. The following stage
is position estimation. It includes three main functionalities: view-angle invariant distance estimation, location reconstruction, and path refinement.
View-angle invariant distance estimation calculates the distance between the user and the recognized shop signs. Location reconstruction infers the location of the user based on geometrical relationship. Finally, path refine- ment is executed to correct the moving track of the user by considering both previous motions of the user and the estimated location at each timestamp.
4.2.2 Street View Recognition
In order to identify shops or buildings on the street while the user is moving, the technique of visual recognition is adopted. Firstly, SIFT [46] features, a local descriptor with good scale, rotation, and luminance invariance, are extracted from the input video. Next, for each feature in the input video, feature matching is performed to find the nearest neighbors among ref- erence images in the database. To speed up the processing time of the matching stage, kd-tree [47] is adopted as the index of the image database.
After this step, hundreds of matching pairs for each frame in the input video are obtained. In addition, to remove false matching among match- ing pairs, RANSAC [48] is employed to filter outlier pairs. The RANSAC algorithm iteratively selects samples at random among matching pairs and estimates their homography matrix as the fitting model. Finally, the re- maining matching pairs which fit the model within a user given tolerance are the final answers and sent to the next stage.
4.2.3 Position Estimation
4.2.3.1 View-angle Invariant Distance Estimation
To estimate the user position, the first step is to calculate the distance between the recognized shop sigh and the user. Intuitively, the scale ratio
39 of the size of the shop sign in the input video frame to that in the database image, called SR, can be utilized to infer the distance. Fig. 4.2 shows the observation of different shapes of the shop signs under various view-angles from the user. From this figure, we can see that the pixel displacement of y-component keeps in a constant value even when the view-angle of the user changes. Thus, we define SR for each matching pair as shown in the following equation.
rij = |{y(fi) − y(fj)}/{y(Fi) − y(Fj)}| , (4.1) where rij is the SR between the i-th and j-th features. y(fi) is the y- component of the i-th recognized feature fi and Fi is the the corresponding feature of fi in the image database
Matching pair
Matching pair Feature Constant
Figure 4.2: Sign shapes under differ- ent view-angles
d1 d2 L
focal length
w1 Image Plane
Object Plane 1 Object Plane 2
w2 L
Figure 4.3: Geometric relationship between the object distance and the projected width in the image plane
However, shapes of shop signs under various view-angles are usually not perfectly transformed. The effect would cause the error of SR estimation.
Therefore, a spatial consistency filter is introduced to eliminate outliers with
extreme SR values. This filter calculates the average value of SR among all matching pairs. Next, the matching pairs with SR larger than the average value under a given tolerance would be removed. This process repeatedly proceeds until the percentage of inliers is larger than a given threshold. The screening condition could be represented as follows.
mkij =
1 if ¯
¯rij − Rk−1¯
¯ < p × Rk−1, 0 others,
(4.2)
where p is the tolerable error rate of Rk−1, which is the refined ratio in (k-1)-th iteration. mkij is a binary value which decides whether the i-th and j-th matching pair rij is inlier or not in k-th iteration.
The rij would be regarded as an inlier if it is closed to Rk−1. Otherwise, it would not be adopted in the next iteration and the corresponding mkij would be labeled as zero. After inliers are acquired, Rk, the value of R, could be updated as follows.
Rk = ( XN
i=2
Xi−1 j=1
mkijrij )/(
XN i=2
Xi−1 j=1
mkij ), (4.3)
where N is the total number of matching pairs and Rk would be iteratively refined until the following condition is reached.
XN i=2
Xi−1 j=1
mkij >= n(n − 1)/2 − an(an − 1)/2
= n(1 − a)(an + n − 1)/2,
(4.4)
where a is the tolerable error rate of outliers.
Eq. 4.2 eliminates extreme SR values. The Rk would be iteratively refined by preforming operations shown in Eq. 4.2 and 4.3 until the condition illustrated in Eq. 4.4 is reached. Next, SR values of the recognized shop signs are calculated and the corresponding distance from the user could also
41 be estimated by Eq. 4.5. The geometrical relationship is shown in Fig. 4.3,
d1 = w2
w1× d2 = R × d2, (4.5)
where d1 is the distance between the user and shop signs and d2 is the constant value stored in the image database. w is the pixel width of shop signs appearing in the video frame.
Refer to the d2 and R, d1 could be obtained and it would be sent to the next stage to reconstruct the user location.
4.2.3.2 location Reconstruction
In order to estimate current user location on the GPS map, the estimated distance between shop signs and the user should be combined with the in- formation of the user orientation. Fig. 4.4 illustrates definitions of the user orientation, pattern angle θpi and view angle θh. θh can be acquired by the digital compass. θpi, representing the pattern angle of the i-th recognized shop signs, can be calculated by the pixel position of the signs. Combining the user orientation, estimated distance from shop signs, and GPS informa- tion, the user location in the global map could be estimated by Eq. 4.6.
x = XN p
i=1
[ xpi− dicos(θh+ θpi)]/Np
y = XN p
i=1
[ ypi− disin(θh+ θpi)]/Np
(4.6)
where Np is the number of recognized sings. The xpi and ypi are the coor- dination of the i-th recognized signs which are stored in GPS database. If Np > 1, we calculate the mean of these reconstructed locations.
4.2.3.3 Path Refinement
Although the user location could be estimated in the previous stage, there is still small error of R. Therefore, Kalman filter is adopted to refine the
Camera center
pattern angle θpi View angle θh
North
The recognized shop signs
field of view The user
orientation
Figure 4.4: Definition of the user orientation, pattern angle, and view angle path. It can combine all estimations and previous status to predict the most possible position. In our work, the previous motion trajectory, GPS raw data, and the estimated distance from shop signs are combined to pre- dict accurate location of the user. The following equations are the main mathematical operations in Kalman filter.
ˆ
xt= Aˆxt−1+ But−1, (4.7) xt= ˆxt+ Kt(zt− H ˆxt), (4.8) where the ˆxtis the predicted user location according to the previous motion on t-th. The ut−1 is the previous motion trajectory of the user on (t-1)-th.
The xt−1 is the previous decision of user location. The zt is the GPS raw data and the reconstructed location presented in section 4.2.3.2. The Kt is the confident ratio for the predicted location.
4.3 Experimental Results
In the proposed work, real sequences captured from a CMOS front-mounted camera with 1920x1080 resolution video input are utilized. Firstly, a user
43 walks along several streets and his walking paths are recorded as correct an- swers. While the positioning information outputs from GPS, the proposed system is tested simultaneously with the GPS information. Two experi- ments are conducted to compare positioning accuracy between GPS and the proposed system.
02
468
1 0
1 2
14
1 6
1 8
2 0 1 3 1 6 1 9 1 1 2 1 1 5 1 1 8 1 2 1 1 24 1 2 7 1 3 0 1 3 3 1 3 6 1 3 9 1 4 2 1
The proposed algorithm coordination GPS coordination
Error(Meters)
Frames
Figure 4.5: Accuracy comparison between GPS and the proposed method.
The first experiment compares the error of location estimation calcu- lated by GPS and the proposed system. The experimental result is shown in Fig. 4.5. From this figure, we can see that estimated error of the pro- posed system is the same as GPS in first 16 frames. It is reasonable because there are few recognized shop signs utilized for location reconstruction in the beginning. As the number of shop signs appears in subsequent frames increases, the estimated errors of locations by the proposed system are be- low 2 meters. Compared with location information provided by GPS with 10 meters error on average, the proposed system significantly improves po- sitioning accuracy.
The accuracy of SR is important for distance estimation and location