行政院國家科學委員會專題研究計畫 成果報告
自網際網路抽取音譯詞組之研究 研究成果報告(精簡版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 97-2221-E-011-104-
執 行 期 間 : 97 年 08 月 01 日至 98 年 07 月 31 日 執 行 單 位 : 國立臺灣科技大學電機工程系
計 畫 主 持 人 : 楊英魁
計畫參與人員: 碩士班研究生-兼任助理人員:鐘晟航 碩士班研究生-兼任助理人員:林士山 博士班研究生-兼任助理人員:潘榮貴
報 告 附 件 : 出席國際會議研究心得報告及發表論文
處 理 方 式 : 本計畫可公開查詢
中 華 民 國 99 年 01 月 08 日
行政院國家科學委員會補助專題研究計畫成果報告
※※※※※※※※※※※※※※※※※※※※※※※※※
※ ※
※ 自網際網路抽取音譯詞組之研究 ※
※ ※
※※※※※※※※※※※※※※※※※※※※※※※※※
計畫類別:■個別型計畫 □整合型計畫 計畫編號:NSC 97-2221-E-011-104
執行期間: 97 年 8 月 1 日至 98 年 7 月 31 日
計畫主持人:楊英魁 共同主持人:
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
執行單位:國立台灣科技大學
中 華 民 國 98 年 12 月 27 日
行政院國家科學委員會專題研究計畫成果報告
計畫編號:NSC 97-2221-E-011-104 執行期限:97 年 8 月 1 日至 98 年 7 月 31 日
主持人:楊英魁 國立台灣科技大學 電機工程研究所
一、中文摘要
本 計 畫 提 出 三 種 自 動 學 習 架 構 (learning framework) 來處理自網際網路 中自動抽取 (automatic extraction) 音 譯詞組的問題。在自動抽取過程中可以透 過 中 英 文 字 詞 間 的 音 相 似 度 模 型 (phonetic similarity model, PSM) 來計 算音相似度,這裡所指的音相似度模型包 含混淆音矩陣 (confusion matrix) 及中 文 n-gram 語 言 模 型 (Chinese n-gram language model) 。使用這個音相似度模 型,音譯詞組自動抽取過程變成包含有『辨 識 (recognition) 』 及 『 驗 證 (validation) 』兩個步驟:首先,在辨識 過程,先找出一個英文字,然後在英文字 附近的上下文語境 (context) 中找出其最 有可能的中文候選詞 (candidate) ;其次 在 驗 證 過 程 中 , 經 由 假 設 檢 驗 (hypothesis test) 來篩選 (select) 候 選詞,以確認最後可能的音譯詞。在計畫 中 還 針 對 用 做 效 能 評 量 (performance evaluation) 的音譯詞組集合進行了統計 分析,以便對音譯的特性有更進一步了 解,進而更準確的模型化 (model) 音譯規 則,從而改善音譯詞組自動抽取的效能。
關鍵詞:音譯詞組,機器音譯,音相似度
模型,主動式學習 Abstract
This research proposes three learning frameworks for the automatic transliteration extraction from the Web. We formulate the machine transliteration process using a phonetic similarity model (PSM) which consists of phonetic confusion matrices and a Chinese character n-gram language model.
With the phonetic similarity model, the extraction of transliteration pairs becomes a two-step process of recognition followed by
validation: First, in the recognition process,
we identify the most probable transliteration in the k-neighborhood of a spotted English word. Then, in the validation process, we qualify the transliteration pair candidates with a hypothesis test. We also carry out an analytical study on the statistics of several key factors, such as lexical variation and phonetic variation, which result in casual transliteration, in English-Chinese transliteration to help formulation of the phonetic similarity modeling.Keywords: transliteration pairs, machine transliteration , phonetic similarity model, active learning
二、緣由與目的
隨著頻繁的文化交流,外來的音譯名 詞不斷的湧入各種語言之中,因此在自然 語言處理 (natural language processing) 研究中,特別是在專有名詞辨識 (named entity recognition, NER) 、跨語言資訊 檢 索 (cross language information retrieval, CLIR) 、機器問答 (question answering, QA) 以及機器翻譯 (machine translation, MT) 等 方 面 , 機 器 音 譯 (machine transliteration) 扮演著重要 的角色。機器音譯研究乃是探討如何根據 發音特性 (pronunciation) 將一個字詞 (word) 從一個語言翻譯至另一個語言,這 種依照聲音翻譯 (translation-by-sound) 的方式簡稱為音譯。在這個研究中需要有 大量的音譯詞組 (transliteration pairs) 做為翻譯模型訓練 (model training) 之 用,因此大量的音譯詞組便成機器音譯研 究中不可或缺的資源。但是要收集大量的 音譯詞組則是費時費力,因此如何自動化 抽取大量的音譯詞組將是本計畫的研究重 點。
網際網路上實際包含著不同型態的文 字 語 料 庫 , 例 如 有 使 用 網 路 蜘 蛛 (Web spider) 蒐 集 而 來 的 網 頁 資 料 (web pages)、自網頁超連結 (hyperlink) 抽出來 的對比語料庫 (comparable corpus) 以及檢 索結果 (query results) 語料庫。其中對比 語料庫已經成功的應用於多種語言的詞彙 翻譯研究 ;而檢索結果語料庫則是指不斷
將 查 詢 關 鍵 語 送 往 網 際 網 路 搜 尋 引 擎 (web-based search engine) ,並將這些檢索 結果收集起來所得到的語料庫。其特色是 在 同 一 網 頁 中 會 出 現 許 多 的 檢 索 字 串 (query string) 以及其周圍文字,對於音譯 詞組抽取研究而言,也就是可能有多個音 譯詞組聚集在同一網頁中。透過這幾種方 式,可以快速的收集到大量的網際網路資 料。因為網際網路語料庫較平行語料庫涵 蓋更多的詞彙、更快速的更新而且可以較 低成本取得,因此,本計畫中的音譯詞抽 取實驗將使用這種語料庫。
為了自網際網路語料庫中抽取音譯 詞,本計畫將先提出一個中英文字詞間的 音相似度模型 (phonetic similarity model, PSM) ,這裡所指的音相似度模型包含混 淆 音 矩 陣 (confusion matrix) 及 中 文 n-gram 語 言 模 型 (Chinese n-gram language model) 。在自動抽取過程中使用 這個音相似度模型可以來計算字詞間的音 相似度,應用這個音相似度模型,因此音 譯詞組自動抽取過程變成包含有『辨識 (recognition) 』及『驗證 (validation) 』兩 個步驟:首先,在辨識過程,先找出一個 英文字,然後在英文字附近的上下文語境 中找出其最有可能的中文候選詞;其次在 驗證過程中,經由假設檢驗 (hypothesis test) 來篩選候選詞,以確認最後可能的音 譯詞。此外,在計畫中也針對用做效能評 量 (performance evaluation) 的音譯詞組集 合進行了統計分析,以便對音譯的特性有
更 進 一 步 了 解 , 進 而 更 準 確 的 模 型 化 (model) 音譯規則,進而改善音譯詞自動 抽取的效能。
三、研究結果與討論
機器音譯研究有兩類:音譯模型建立 (TM) 和音譯詞組抽取 (TE) 。本計畫所提 之 PSM 模型得利於這兩項研究,它採用了 音譯模型建立方法去處理音譯詞組抽取問 題。
音相似模型 (PSM) 是由依循吵雜通道 框 架 下 的 生 成 模 型 推 導 出 來 , 它 融 合 (fuse) 了多層次的知識來源,這些知識來 源包括有中文羅馬拼音、 語言學規則及音 素和音節。這個啟發是來自在音譯研究 上,研究人員努力找尋不同層次的知識來 源來處理音譯問題,舉例來說, 利用音相 似度來找尋音譯詞,以音素為單元的專有 名詞音譯,直接文字映射框架,在這個 PSM 模型下,在音譯詞抽取過程中有效的融合 了三個層次的知識來源。
在本計畫的實驗中,本計畫的方法可以 達到不錯的效能,但仍有改善的空間。因 此為了改善音譯詞組抽取效能,在此更進 一步研究 SET1 以及它的獨特音譯詞組的 一些特性。為了計算音相似度,中文字先 被轉換成音節,因此暸解音節轉換的複雜 度將有助於處理此問題。
在整個 SET1 中總共使用了 80,501 個 中文字,其中有 3,595 個不同的中文字;
而在中文獨特合格音譯詞組 (DQTPs) 中則 總共只有使用 7,902 ,其中有 1,210 個 不同的中文字,在這樣一個以中文為主的 中英文混合語料庫中中文字數幾倍於英文 字數,可以發現這樣的特性也增加了音節 對應的複雜度。另外中英文音節比例也反 映出 PSM 模型的複雜度,在整個 SET1 中 發現分別有 394 和 1,012 不同的中文及 英 文 音 節 ; 在 所 有 獨 特 合 格 音 譯 詞 組 (DQTPs) 中則分別有 333 和 824 不同的 中文及英文音節,換句話說,平均而言每 個中文音節大約可對應至 2.5 英文音節,
若以手工撰寫這些音節對應規則,這將是 一個極大的挑戰。在本計畫裡, SCM 及 PCM 等 PSM 模型參數可以有效的自語料庫中學 習得到,而不需以人工來建立。
自 SET2 及 SET3 語料庫中運用『先辨 識後驗證』演算法抽取出了大量音譯詞 組,這些抽取出來的音譯詞組形成了一個 雙語詞典,如果可以進一步分析這一個抽 取出來雙語詞典將有助於了解音譯特性。
以抽取出來的雙語詞典中的英文詞與 卡 內 基 美 隆 大 學 (Carnegie Mellon University, CMU) 發音詞典1及 Shorter 牛津英語詞典2比較,發現分別有 31.1% 及 47.8% 的英文字不在各自的詞典中,因此 使用 PSM 模型不僅可以從網際網路上抽取 出既新且真實音譯詞組,也獲得了大量新
____________________________________
的英文詞彙。監督式學習方法必須標記整 個語料庫以得到訓練樣本才可以進行音譯 詞組抽取;而使用非監督式學習方法,則 在無須標記訓練樣本的狀況下,可以快速 的抽取出新的音譯詞組,這比以純人工建 立音譯詞典3更有效率、此外, PSM 模型參 數如 SCM 、 PCM 及 CCM 也提供了每個英 文字詞的中文音譯變異機率資訊。
從本計畫的實驗結果發現,本計畫所提 出的 PSM 模型與規則式混淆音矩陣相比可 以有效的處理非正規音譯詞。以 CCM 為 PSM 模型參數進行音譯詞組抽取 (非監督 式) 所抽取出來的音譯詞組與經與 DQTPs 相比發現在 SET1 中有 68.48% 的非正規 譯音詞可以成功的被抽取出來,雖然抽取 出來的比例不低,但也顯示抽取非正規音 譯詞仍然是一項艱鉅的任務。主要的原因 是因為音譯受到文字、地區方言等因素影 響。另外,每一個語言的語音單元及發音 規則也有所不同。本文所稱的英文字詞並 不完全起源於是英文,也有可能起源於是 法文或義大利文。單一個字轉音 (G2P) 系 統對所遇到英文字並不完全有效,也就是 如果對於某一字源的文字使用針對其來源 的 G2P 可以得到較好的效能。從本計畫的 實驗也發現,中文羅馬拼音資訊有助於以 文字混淆音矩陣抽取音譯詞組。同樣地,
如果有這些文字起源資訊,將有助於提升 G2P 系統效能,而提升 G2P 系統效能後將
____________________________________
可改跨語言的音節對應,進而改善 PSM 模 型及音譯詞組抽取效能。從音譯詞組抽取 過程的錯誤分析發現,對於源自於韓文和 日文的英文字詞及其中文音譯詞,其抽取 檢出率是比較低的。這大概是因為目前的 PSM 模型主要還是從中英文語料庫中訓練 出來,因此尚無法抓住日文和韓文的羅馬 拼音規則。例如只有使用英文 G2P ,並不 容易將 “Matsuzaka" 與 "松阪" 連結 並對應起來。
在本計畫中,使用了自動語音辨識所 得到的混淆音矩陣來初始化 PSM 模型,
並以非監督式學習方式進行音譯詞組抽 取,從而得到與監督式學習非常接近的效 能。
本計畫的貢獻可以總結如下:
(一) 分析音譯詞組中所蘊含的音譯特 性,從統計的角度說明在英-中文音譯上的 困難度。例如敘述了在 SET1 中前六個單 獨輔音的省略比率,同時也發現不同型態 的單獨輔音在音節中間與尾端有不同省略 比例,將這個發現納入實驗中有助於改善 音譯詞組抽取效能,又例如發現加入語音 省略的規則式方法要比不加入語音省略的 規則式方法更好。同時也發現一個中文音 節平均可以對應 2.5 個英文音節,因此並 不容易以手工來撰寫這些音節對應規則。
這些問題都凸顯了非正規音譯所造成的問 題。
(二) 提出『先辨認後驗證』的音譯詞
抽取過程。辨認是透過動態規劃的搜尋策 略找出英文字詞並經中英文字詞的音相似 度計算,找出最有可能的中文音譯候選 詞,最後透過驗證也就是假設測試,確認 最有可能的中文音譯候選詞是否就是真正 的音譯詞。使用『先辨認後驗證』的音譯 詞抽取過程可以從不同的網路語料庫 (包 含一般網頁資料、超連結資料以及從網路 搜尋引擎收集回來的雙語摘要) 中來建構 中英文音譯詞典。因此提供了一個低成本 的替代方案可以從動態網頁中找出新的音 譯詞組。
( 三 ) 提 出 非 監 督 式 學 習 (unsupervised learning) 、主動式學習 (active learning) 等 兩 大 學 習 架 構 (learning framework) 來抽取音譯詞組。
非監督式學習利用自動語音辨識產生的混 淆音矩陣來提昇 (bootstrap) 初始的 PSM 模型,進而改善音譯詞組抽取效能。主動 式學習則篩選最富有資訊的樣本加以人工 標記,透過這種方式可大幅減少在監督式 學習 (supervised learning) 時需要人工 標記的樣本數量。使用這兩種學習演算法 都可得到與監督式學習非常接近到的效 能。
( 四 ) 提 出 利 用 中 英 文 詞 共 現 (co-occurrence) 資訊來抽取音譯詞的策 略。這個策略被用來改善初始的 PSM 模 型,進而改善整體的音譯詞組抽取效能。
從本計畫的實驗結果也確認了應用於 中英文音譯詞組的 PSM 模型的有效性,在 不失一般性的狀況下,這個架構同樣也可 以應用於其它語言對,諸如英-日文及英- 韓文等等。雖然在本計畫中實驗是先從中 文網頁開始,但也成功的擴充這個架構至 超連結文字語料庫上。
在本計畫中還發現,網際網路是一個 很生活化的語料庫,利用這個語料庫可以 來建構真實 (特別是非正規音譯詞) 的中 英文音譯詞典。善用這些音譯詞組,將有 助於跨語言檢索及專有名詞辨識等自然語 言處理研究。
四、重要參考文獻
E. Brill, G. Kacmarcik, C. Brockett. 2001.
Automatically Harvesting Katakana-English Term Pairs from Search
Engine Query Logs, In Proc. of NLPPRS, pp. 393-399.
S. Brin and L. Page. 1998. The Anatomy of a Large-scale Hypertextual Web Search Engine, In Proc
. of 7
thWWW, pp. 107-117.
H.-H. Chen, W.-C. Lin, C.-H. Yang and
W.-H. Lin. 2006, Translating-Transliterating Named Entities
for Multilingual Information Access, Journal of the American Society for Information Science and Technology, 57(5), pp. 645-659.
D. A. Cohn, Z. Ghahramani and M. I. Jordan.
1996. Active Learning with Statistical Models, Journal of Artificial Research, 4, pp. 129-145.
I. Dagan and S. P. Engelson. 1995.
Committee-based Sampling for Training Probabilistic Classifiers, In Proc. of 12th
International Conference on Machine Learning, pp. 150-157.
J. Dean and M. Henzinger. 1999. Finding Related Pages in the World Wide Web, In
Proc. of 8
thWWW, pp. 389-410.
A. P. Dempster, N. M. Laird and D. B. Rubin.
1977. Maximum Likelihood from Incomplete Data via the EM Algorithm, Journal of the Royal Statistical Society, Ser. B. Vol. 39, pp. 1-38.
P. Fung and L.-Y. Yee. 1998. An IR Approach for Translating New Words from Nonparallel, Comparable Texts, In
Proc. of 17
thCOLING and 36
thACL, pp.
414-420.
F. Huang, Y. Zhang and Stephan Vogel.
2005. Mining Key Phrase Translations from Web Corpora, In Proc. of
HLT-EMNLP, pp. 483-490.
L. Jiang, M. Zhou, L.-F. Chien, C. Niu. 2007.
Named Entity Translation with Web Mining and Transliteration, In Proc. of
IJCAI, pp. 1629-1634.
D. Jurafsky and J. H. Martin. 2000. Speech and Language Processing, pp. 102-120, Prentice-Hall, New Jersey.
K. Knight and J. Graehl. 1998. Machine Transliteration, Computational Linguistics, Vol. 24, No. 4, pp. 599-612.
J. S. Kuo and Y. K. Yang. 2004.
Constructing Transliterations Lexicons from Web Corpora, In the Companion Volume to Proc. of 42nd ACL, pp.
102-105.
J.-S. Kuo and Y.-K. Yang. 2005.
Incorporating Pronunciation Variation into Extraction of Transliterated-term Pairs from Web Corpora, In Proc. of ICCC, pp.
131-138.
J.-S. Kuo, H. Li and Y.-K. Yang. 2006.
Learning Transliteration Lexicons from the Web, In Proc. of 44th
ACL, pp. 1129-1136.
C.-J. Lee and J.-S. Chang. 2003. Acquisition of English-Chinese Transliterated Word Pairs from Parallel-Aligned Texts Using a Statistical Machine Transliteration Model, In Proc. of HLT-NAACL Workshop Data
Driven MT and Beyond, pp. 96-103.
D. D. Lewis and J. Catlett. 1994.
Heterogeneous Uncertainty Sampling for Supervised Learning, In Proc. of ICML
1994, pp. 148-156.
H. Li, M. Zhang and J. Su. 2004. A Joint Source Channel Model for Machine Transliteration, In Proc. of 42nd
ACL, pp.
159-166.
W. Lam, R.-Z. Huang and P.-S. Cheung.
2004. Learning Phonetic Similarity for Matching Named Entity Translations and
Mining New Translations, In Proc. of 27th
ACM SIGIR, pp. 289-296.
W.-H. Lu, L.-F. Chien and H.-J. Lee. 2002.
Translation of Web Queries Using Anchor Text Mining, ACM TALIP, Vol. 1, Issue 2, pp. 159- 172.
A. McCallum and K. Nigam. 1998.
Employing EM in Pool-based Active Learning for Text Classification, In Proc.
of 15th International Conference on Machine Learning, pp. 350-358.
H. M. Meng, W.-K. Lo, B. Chen and T. Tang.
2001. Generate Phonetic Cognates to Handle Name Entities in English-Chinese Cross-Language Spoken Document Retrieval, In Proc. of ASRU, pp. 311-314.
J.-Y. Nie, P. Isabelle, M. Simard, and R.
Durand. 1999. Cross-language Information Retrieval based on Parallel Texts and Automatic Mining of Parallel Text from the Web, In Proc. of 22nd
ACM SIGIR, pp
74-81.V. Pagel, K. Lenzo and A. Black. 1998.
Letter to Sound Rules for Accented Lexicon Compression, In Proc. of ICSLP, pp. 2015-2020.
R. Rapp. 1999. Automatic Identification of Word Translations from Unrelated English and German Corpora, In Proc. of 37th
ACL,
pp. 519-526.G. Riccardi and D. Hakkani-Tür. 2005.
Active Learning: Theory and Applications to Automatic Speech Recognition, IEEE
Transactions on speech and Audio Processing, Vol. 13, No. 4, pp. 504-511.
R. Sproat, T. Tao and ChengXiang Zhai.
2006. Named Entity Transliteration with Comparable Corpora, In Proc. of 44th
ACL,
pp. 73-80.P. Virga and S. Khudanpur. 2003.
Transliteration of Proper Names in Cross-Lingual Information Retrieval, In
Proc. of 41
stACL Workshop on Multilingual and Mixed Language Named Entity Recognition, pp. 57-64.
S. Wan and C. M. Verspoor. 1998.
Automatic English-Chinese Name Transliteration for Development of Multilingual Resources, In Proc. of 17th
COLING and 36
thACL, pp.1352-1356.
C. Zhang and T. Chen. 2002. An Active Learning Framework for Content-based Information Retrieval, IEEE Transactions on Multimedia, 4(2), pp. 260-268.
9
1
參加 ICAI2009 研討會心得報告
報告人: 楊英魁 2009.07.14
時間: 2009 年 7 月 13 日 ~ 2009 年 7 月 16 日 地點: Las Vegas, USA
報告內容:
這次在 Las Vegas, USA 為期四天所舉行的研討會 The 2009 International Conference on Artificial Intelligence (ICAI2009),是學術界在人工智慧與控制領域上重要的一次會議。ICAI2009 是 WORLDCOMP09 (The 2009 World Congress in Computer Science, Computer Engineering, and Applied Computing)中 25 個研討會之一。由於它的重要性,所以有另外九個與人工智慧領 域有關的研討會一起舉行。總共有來自全球不同領域的超過兩千三百個專家學者參與,氣氛熱 絡,連當地旅館都不容易定到,每位 Keynote Speaker 都是在人工智慧領域裡大師級的人物。
參加這次 ICAI2009,主要是去發表一篇由國科會所支持研究的成果論文:A CMAC Learning Approach Based on Grey Relational Ananlysis。發表此論文時,大約有 70 幾位專家學者參與 討論,氣氛對非常熱絡,對此論文所提出的方法與理論,與會者都極為肯定。
這幾天期間,與各地學者專家深入討論各個不同的領域,受益良多,也能正確的掌握目前 人工智慧的領域,尤其是每天第一場的 keynote speech 更是精采。主講者不但學術豐富,有幽 默感,而且明確指出今後在此領域上可以進行的幾個方向,足以當作最好的參考。
參加此研討會,不但有機會與來自世界各地的學者專家廣泛討論,相互切磋,也因此更確 定目前所進行的研究方向是正確的。而且同時可以參加六個相關研討會,真是不虛此行
2
A CMAC Learning Approach Based on Grey Relational Analysis
Po-Lun Chang1 and Ying-Kuei Yang2, Jin-Fang Liu2
No 43, Sec 4 , Keelung Road ,Taipei , Taiwan
Department of Electrical Engineering
National Taiwan University of Science and Technology, 106 Taipei, Taiwan e-mail:
1[email protected],
2[email protected]
Abstract - Learning and convergence are the two issues being most concerned in the research area of Cerebellar Model Articulation Controller (CMAC). This paper proposes to incorporate grey relational analysis with number of learning to obtain an adequate and appropriate learning rate for improving CMAC convergence. Additionally, this paper also proposes that the amount of weight adjustment to a memory cell of an addressed hyper cube must be proportional to the learned input area, grey relational grade and inverse of number of learning instances to minimize the learning interference. A credit apportionment approach is thus derived for implementing this idea to achieve fast and accurate learning performance. The results of the experiments conducted in this study clearly demonstrate that the proposed approach provides a more accurate learning mechanism and faster convergence.
Keywords: CMAC, learning interference, credit apportionment, learning instances, grey relational grade
1. Introduction
There were numerous studies employing Cerebellar Model Articulation Controller(CMAC) model in various applications [1][2][3]. In the relational papers dealing with CMAC, Chiang and Lin had proposed to embed the Gauss function into CMAC model to improve learning accuracy [4]. Sayil and Lee presented a maximum error algorithm that adopted the neighborhood training concept to accelerate CMAC convergence [5]. Horváth and Szabó presented the generalization features and enhanced strategy of the CMAC model [6]. Lin and Chiang had proposed some convergent features of CMAC [7]. However, the performance of these approaches in terms of convergence was inadequate and could not effectively satisfy the requirements of real-time applications [8][9][10].
In related research on learning rate and accuracy, Su、Tao、Hung[8][9] and Lu、Chang[11]
employed credit assignment to reform the CMAC learning strategy. However, the acceleration of learning speed takes place only during early learning cycles. Further, the lack of adaptive learning rate has caused an unstable system. Lu and Chang [11] applied credit assignment concept to the mapping hyper cubes of inputs and their neighborhood states to increase learning speed and accuracy. This approach unfortunately failed to achieve significant improvement [9][10].
In addition, the existent effect of learning interference reduces learning performance and
accuracy during this phase [8][9][10][11]. Therefore, this paper proposes a novel learning framework that employs the concept of credit assignment based on grey relational grade, the trained input area, the
3
number of trainings, and the concept of adaptive grey learning rate in a CMAC model in order to mitigate the influence of learning interference so that the learning speed and output accuracy can be effectively improved. During the learning phase, the grey relational coefficient is calculated for each input state after a learning iteration. An appropriate grey learning rate is then derived by incorporating the calculated grey relational coefficient with the number of learning iterations. Then the credit distributed to an addressed hyper cube is in inverse proportion to the number of trainings.
2. CMAC Architecture
The basic structure of a conventional CMAC model [1] is shown in Figure 1. A CMAC model quantizes the learning space into several discrete states that serve as input states of the CMAC model and are represented as set S in Figure 1. Each input state is mapped from indexed memory A to the corresponding real memory cells W that store the input states information and are summed to produce actual output value. A mapping block is a hyper cube between axes. The total hyper cubes are real memory cells that store relational information regarding addressed input states.
S1
Sk
S A
W
∑
l e a r n i n g
s p a c e m e m o r y i n d i c e s
m e m o r y c e l l s
y a c t u a l o u t p u t
∑
yˆ t a r g e t o u t p u t + e r r o r −
Figure1. Basic structure of a CMAC model
If there are Nh hyper cubes in which each input state maps to Ne hyper cubes, then theactual output is shown in following Equation (1). The ys denotes the actual system output for input state s,
T
a is the indexed vector, and w is the memory cell vector.
s(1)
During the learning phase, the error of actual output value to the desired output value is uniformly distributed to regulate and train the memory cells of a CMAC model. The weight relation between before and after trainings of a memory cell is shown in Equation (2).
( 1)
( ) ( 1)
,
( T i )
i i s s
j j s j
w w a y
α
N e∧ −
− −
= + ⋅ ⋅ a w
(2)
In Equation (2), s denotes an input state, w( )ji represents the weight of j-th hyper cube in the training iteration of number i, as j, is an index vector for input state s and hyper cube of number j,
1
2
,1 ,2 , ,
1
[ , , , ] h
h
h
N T
s s s s N s s j j
j
N
w
y a a a w a w
w
=
⎡ ⎤
⎢ ⎥
⎢ ⎥
= = =
⎢ ⎥
⎢ ⎥
⎢ ⎥
⎣ ⎦
∑
L a w M
4 (ys Ts ( 1)i )
∧ − a w − denotes the learning error, α represents learning rate, and each input state corresponds to
Ne hyper cubes.
3. A Novel Learning Framework
The goal of this study is to propose the concept of credit assignment [9][10] that incorporates the grey relational grade with adaptive learning rate to achieve better learning performance for a CMAC model.
3.1 Grey Relational Analysis
Grey relational analysis is a method for measuring similarity [10]. Assuming a reference sequence x0 =
{
x0(1),x0(2),...,x0(n)}
with m comparison sequences xi ={
xi(1),xi(2),...,xi(n)}
, i=1,2,..., m, then the grey relational coefficient between x0 and xi at the k-th state is defined as follows [1][10].( )
max 0
max
0( ), ( ) min( )
Δ
⋅ + Δ
Δ
⋅ +
= Δ
ξ ξ
k kx k x c
i
i
(3)
where c(x0(k),xi(k)) is termed as the grey relational coefficient,Δ0i(k)= x0(k)−xi(k), ξ∈(0,1] denotes the distinguishing coefficient to control the resolution between Δmax and Δmin, max maxmax 0i(k)
k
i Δ
=
Δ ,
and min minmin 0i(k)
k
i Δ
=
Δ .
Once the grey relational coefficients are determined for all n states, their weighted average, termed grey relational grade, can be calculated by
( )
[ ]
∑
=⋅
=
n
k
i k
i w cx k x k
x x g
1
0
0, ) ( ), ( )
( (4)
where wk denotes the weighting factor of the grey relational coefficient c
(
x0(k),xi(k))
and1 =1
∑n=
k wk . Generally, wk =1n is selected for all k.
By above descriptions, the grey relational coefficient and grey relational grade are two effective parameters for analyzing the difference and similarity measures of actual system outputs to their corresponding target outputs during the learning phase of a CMAC model.
3.2 Grey Learning Rate
If the learning rate of CMAC is set to a larger value during the learning phase, then CMAC could be faster convergence, but with lower accuracy and possibly unstable phenomenon. On the other hand, if the learning rate of CMAC is set to be smaller, then CMAC could result in slower
convergence but with better accuracy and less risk of reaching unstable situation.
Assume that input space is partitioned into n states and target function yˆ to be learned is known, then the desired system output for a specific input state, say sk, k=1,2,...,n, can be mathematically expressed as yˆ k( ). These n desired outputs can be calculated to form a reference sequence as y∧ ={yˆ(1),yˆ(2),...,yˆ(n)}. To analyze the grey relation between the desired outputs and their corresponding actual outputs, the comparison sequence that is generated using the actual output of the
5
CMAC at every state is denoted asy
= {
y( 1 ),
y( 2 ),...,
y(
n)}
. According to Equation (3), the grey relational coefficient for input state sk in a single comparison sequence can be written as follows.max max min
) )) (
( ˆ ), (
( Δ + ⋅Δ
Δ
⋅ +
= Δ
ξ ξ k k
y k y GRC
y
(5)
whereΔy(k)= y(k)−yˆ(k) , max max y(k)
k Δ
=
Δ , min min y(k)
k Δ
=
Δ and
1 )) ˆ( ), ( 1 (
max min
≤ + ≤
Δ + Δ
k y k y ξ GRC
ξ .
Because both Δmax and Δmin are constant values for a CMAC model, the grey relational coefficient increases with decreasing output error (k)
Δy .
During the learning phase, the output errors of input states should be also related to the inverse of the number of training iterations. Therefore, this paper proposes an adaptive regulation of learning rate, termed grey learning rate, that is based on the number of training iterations and grey relational
coefficients of input states in a CMAC model. During the i-th training iteration, the grey learning rate at the input state sk is proposed as follows.
)) ( ), ( ( )
(
) 1 (
) 1 ( _
k y k y GRC i
i
i k
grey ∧
−
α =
(6)
where GRC (i 1)(y(k),y(k))
− ∧ is the grey relational coefficient at state
s
k in the (i-1)-th training iteration. Initially, GRC(0)(y(k),∧y(k))=1 and grey_α
(1)(k)=1. When the training iteration i becomes larger, it means the systems has been trained more times already. Similarly, when the grey relational coefficient GRC becomes large, it means the system is closing to the final state. In these two cases, Equation (6) shows that the learning rate should be a smaller value. That is, the system is tuned by smaller changes to avoid any overshooting or instability.3.3 Grey-area-time Credit Apportionment
A hyper cube that includes more input states is more influenced by the learning interference during the learning phase. To mitigate this effect, the distribution of errors among the addressed hyper cubes must be proportional to the hyper cube creditability. The key information available for use as credit is the number of times a hyper cube has been updated [8][9]. In addition, conceptually, the accuracy of the stored weights in hyper cubes should increases with the number of input states during a learning phase. For this, the trained proportion of input states is proposed to be considered as one factor of creditability. Further, as discussed previously, an adaptive learning rate is necessary to avoid an unstable system. This means the grey relational grade in a hyper cube should be also a factor involving creditability of the hyper cube. Consequently, the number of updated times for hyper cubes, the trained proportion of input states and grey relational grade in a hypercube can be integrated to provide an indicator of hyper cube creditability. The credibility, termed grey-area-time, is defined as shown below.
∑=
−
−
×
× +
×
×
= +
−
− m
c
i i
i i
i
j GRG j a c t
j GRG j a j j t time area grey
1
1 ) ( )
(
1 ) ( )
) ( (
)) ( ( ) ( ) 1 ) ( ((
)) ( ) ( ) 1 ) ( ) ((
( (7)
6
where t( j) denotes the accumulative learning times of the j-th hyper cube, and m represents the number of addressed hyper cubes for an input state
s
k. Notice thatt
(c) must include the value 1 to prevent from dividing the equation by zero . a(i)(
j)
is defined as following Equation (8) and)
)(
( j
GRGi is defined as following Equation (9).
cube hyper the in states of number
states input trained of number j the
ai
max ) 1
)(
( = + (8)
wherea(i)(j) denotes the trained area proportion of input states in the j-th hypercube at the iteration i.
Notice that the numerator of Equation (8) must include the value 1 to prevent the value being zero.
∑=
− ∧
⎥⎦⎤
⎢⎣⎡
⎟⎠
⎜ ⎞
⎝
⋅ ⎛
= p
c
i c
i j w GRC yc y c
GRG
1
) 1 ( )
( ( ) ( ), ( ) (9)
where GRG(i)(j) represents the grey relational grade of the j-th hyper cube at present iteration i, and p is the number of addressed input states corresponding to the j-th hyper cube. Moreover,
w
c is the weighting factor of the grey relational coefficient ⎟⎠
⎜ ⎞
⎝
⎛ ( ),∧( )
)
( yc yc
GRCi and 1
1 =
∑= p
c wc . Normally,
c p
w =
1 for all p. Initially, GRG(1)(j)=1.Based on above discussions, this study modifies the weight updating formula in Equation (2) according to the grey-area-time credit assignment. That is, the Equation (2) is rewritten as
) ( )
( ( 1) ()
, ) 1 ( )
( w a y a w grey area time j
wji = ji− +α⋅ sj⋅ ∧s− Ts i− ⋅ − − i (10)
3.4 A Novel Learning Framework
Two key factors affecting the learning result of hyper cubes are: (1) the amount of error distributed to a hyper cube; and (2) the learning rate. Combining the previous discussions, the following Equation (11) shows how grey-area-time credit assignment and grey learning rate are
integrated together for better updating the weights of hyper cubes. The learning rate α of Equation (10) is replaced by
grey
_α(i)(k
) of Equation (6).) ( )
( ) (
_
() , (1) ()) 1 ( )
( w grey k a y aw greyareatime j
wji
=
ji−+
αi⋅
sj⋅
∧s−
Ts i−⋅ − −
i (11)A CMAC model using Equation (11) for its learning mechanism is termed as Grey-area-time
CMAC. In Equation (11), it is easy to verify that grey
_α(i)(k
)⋅grey
−area
−time
(i)(j
) does not exceed value 1 and gradually approaches value zero in the later cycles of learning phase.4. Simulation Results
In each experiment, results of four approaches of conventional CMAC, Time-Credit CMAC [8], Fuzzy-time-credit CMAC [9] and the Grey-area-time CMAC proposed in this paper are compared.
Example 1:
The target function is y
(
x) = sin
x/
x where –30<x<30. The distinguishing coefficient of grey relational coefficients is assigned asξ
=0.1. There are 10 training cycles. The root mean square error7
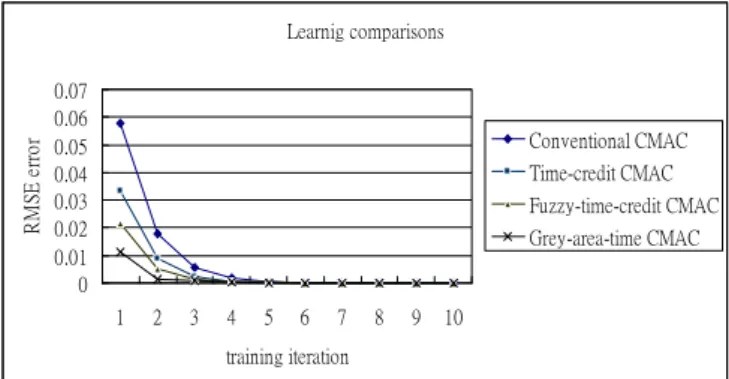
(RMSE) is employed for comparison. Figure 2 shows the performance of different CMAC models. It is observed in Figure 2 that the proposed Grey-area-time CMAC has the best performance. Furthermore, Grey-area-time CMAC has been stable and achieved convergence faster than other three methods.
Learnig comparisons
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07
1 2 3 4 5 6 7 8 9 10
training iteration
RMSE error Conventional CMAC
Time-credit CMAC Fuzzy-time-credit CMAC Grey-area-time CMAC
Figure 2: Learning comparison for different CMAC models
Example 2:
The target function is
z x y
( , ) (=x
2−y
2) sin 5x
where -1< x < 1 and -1< y < 1. The distinguishing coefficient is set to ξ=0.1. Learning comparison adopts root mean square error(RMSE). Figure 3 shows the performance for different CMAC models. It can be observed from Figure 3 that the proposed Grey-area-time CMAC results in less RMSE than other three models since the first learning cycle. Furthermore, the RMSE monotonically decreases in the Grey-area-time CMAC until it stabilizes after 9 learning cycles.
Learning comparisons
0 0.01 0.02 0.03 0.04
1 2 3 4 5 6 7 8 9 10
training iteration
RMSE error Conventional CMAC
Time-credit CMAC Fuzzy-time-credit CMAC Grey-area-time CMAC
Figure 3: Learning Comparisons for different CMAC models
5. Conclusions
This paper presents an enhanced strategy for creating a novel learning framework for the CMAC model. The accumulated frequency of updating to the hyper cubes [2][6], the trained proportion of input states and grey relational grade of hyper cubes are integrated into a measure of the credibility of the hyper cubes for each input state. This paper also considers the adaptive regulation of learning rate with the number of training iterations and grey relational coefficients in the CMAC model. The credit
8
apportionment is combined with the grey learning rate to improve system performance. The conducted experiments indicate that the proposed approach works well in terms of system stabilization, fast convergence and approximation to the target function.
References
[1] M. F. Yeh and H. C. Lu, “On-Line Adaptive Quantization Input Space in CMAC Neural Network”, IEEE International Conference on Systems, Man and Cybernetics, vol.4, 2002 [2] H. M. Lee and C. M. Chen, “Self-Organizing HCMAC Neural-Network Classifier”, IEEE
Transaction on Neural Networks, vol.14, no.1, pp.15-27, 2003
[3] J. C. Jan and S. L. Hung, “High-order MS_CMAC Neural Network”, IEEE Transaction on
Neural Networks, vol.12, no.3, pp.598-603, 2001
[4] C. T. Chiang and C. S. Lin, “CMAC with General Basis Functions”, Neural Networks, vol.9, no.7, pp.1199-1211, 1996
[5] S. Sayil and K. Y. Lee, “A Hybrid Maximum Error Algorithm with Neighborhood Training for CMAC”, IEEE Proceedings of the International Joint Conference on Neural Networks, vol.1, pp.165-170, 2002
[6] G. Horváth and T. Szabó, “CMAC Neural Network with Improve Generalization Property for System Modeling”, IEEE Instrumentation and Measurement Technology Conference, vol.2, pp.1603-1608, 2002
[7] C. S. Lin and C. T. Chiang, “Learning Convergence of CMAC Technique”, IEEE Transaction
on Neural Networks, vol.8, no.6, pp.1281-1292, 1997
[8] S. F. Su, T. Tao, and T. H. Hung, “Credit Assigned CMAC and Its Application to Online Learning Robust Controllers”, IEEE Transaction on System, Man, and Cybernetics-Part B:
Cybernetics, vol.33, no.2, pp.202-213, 2003
[9] Shun-Feng Su, Zne-Jung Lee, and Yan-Ping Wang, “Robust and Fast Learning for Fuzzy Cerebellar Model Articulation Controllers”, IEEE Transaction on System, Man, and
Cybernetics-Part B: Cybernetics, vol.36, no.1, pp.203-208, 2006
[10] Ming-Feng Yeh and Kuang-Chiung Chang, “A Self-Organizing CMAC Network With Grey Credit Assignment”, IEEE Transaction on System, Man, and Cybernetics-Part B: Cybernetics, vol.36, no.3, pp.623-635, 2006
[11] H. C. Lu and J. C. Chang, “Enhance the Performance of CMAC Neural Network via Fuzzy Theory and Credit Apportionment”, IEEE Proceedings of the 2002 International Joint