國立臺灣大學電機資訊學院電機工程學研究所 碩士論文
Department of Electrical Engineering
College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
基於深度學習及遷移式學習之
機器人操作平板電腦虛擬鍵盤的視覺與動作協調系統 A Vision and Motion Coordination System Based on Deep
Learning and Transfer Learning for a Robot to Type Virtual Keyboards on a Tablet Computer
張邵瑀 Shao-Yu Chang
指導教授:鄭士康 博士 Advisor: Shyh-Kang Jeng, Ph.D.
中華民國 108 年 8 月 August 2019
口試委員會審定書
誌謝
能完成這本碩士論文,非常感謝我的指導教授鄭士康老師,在研究上老師給我 很多的空間去嘗試各種方法,並且提供給我一個非常難得的機會去使用機器人來 做這方面的實驗,除了理論知識外,老師也常常與我們分享一些做實驗與研究上的 一些要點與方法,讓我常常在找不到方向的時候可以再回到研究方法的起點再重 新調整問題的面向,也常常與我聊一些題目外新科技的閒談,也非常感謝老師在撰 寫論文的最後階段不斷地給予鼓勵與協助,讓這篇論文可以順利的完成。此外也感 謝口試委員袁世一教授,李弘毅教授所提供的寶貴意見,讓此篇論文更加完善。
感謝實驗室的夥伴,明臻、奕翔,學長瑞凱、子維、重源、昱佑、哲睿、士紘,
以及學弟兆鵬、鈞皓的 carry 讓我可以在研究的路上不孤單,在一天的辛勞後能夠 打一場大亂鬥。還有 607 的夥伴子樵、靖凱、立杰、振昊、韋廷、曉彤,還有禹謙、
克宣、浩宇、小皮、宜蓁,學弟妹宙穎、雲祿、蕭湧、景翔、洗宇、士彰、俊穎、
宜凡、怡彣,一起在洛聖都、咆嘯深淵和新體來回健身,感謝你們的陪伴讓我的碩 士生活除了研究以外多了更多精采。
更感謝我的家人。從小到大的栽培,對於我想做的事、想走的路都給予莫大的 支持與協助,有了你們才能順利地將這篇論文完成,謝謝你們。
張邵瑀 謹誌 2019/7/31
中文摘要
在本論文中,我們提出了一種新穎的視覺和運動協調系統機器人作為長期護 理長者的物理代理人操作鍵盤。要年長者去學習現代多樣化的應用程式是如何使 用是一項非常困難的挑戰,如果機器人可以為他們操作這些智慧裝置,勢必可以大 幅減少照護者的負擔。我們所提出的系統使用卷積神經網絡物件偵測來感知目標 按鈕位置,並通過深度神經網絡來控制其動作。我們設計了一個虛擬代理人 NAOgym,他負責管理機器人感知和運動模型之間的訊息交換。我們使用了基於 CNN 的視覺模型來偵測顯示在平板電腦上的目標按鍵與出現在視線中的觸控筆,
並且計算它們的相對位置和距離作為觀察到的高階語義信息。而基於 DNN 的運動 模型,將會根據結合了相對位置與物理代理人傳感器的狀態訊息,通過運動模型的 策略來產生下一個動作。另外,我們把注意機制應用在動作控制模型上,並將其受 專注的程度當作關節的運動速度,來加速強化學習演算法的訓練。在虛擬手臂環境 中,我們設計了像 NAO 一樣的手臂來評估訓練過程和效能,特徵的選擇對效能的 影響以及演算法對無須預先校准的假設。通過虛擬手臂進行實驗以評估所提出的 系統。實驗結果驗證了我們提出的概念。
關鍵字:機器學習,強化學習,機器人動作控制,NAO
ABSTRACT
In this work, we propose a novel vision and motion coordination system robot as a physical agent typing keyboard for elders in long-term care. It is a challenge for older people to learn how to use modern and diverse applications; if robots can operate these smart devices for them, it will inevitably reduce the burden on caregivers. Our proposed system uses convolutional neural network object detection to sense the position of the target button and control its motion through a deep neural network. We designed a cyber- agent, NAOgym, who manages the exchange of information between robot perception and motion models. We used a CNN-based model to detect the target buttons displayed on the tablet computer and the stylus pen that appeared in sight, and calculate their relative position and distance as the observed high-level semantic information. The DNN-based actor model will generate the next action through the policy of the actor model based on the state information combined with the relative position and the physical agent sensor.
In addition, we apply the attention mechanism to the motion control model and use the degree of concentration as the speed of the joint to accelerate the training of the reinforcement learning algorithm. In the virtual arm environment, we design an arm like NAO’s to evaluate the training process and performance, the features affection to the performance, and the calibration-free assumption of the algorithm. The experiments are conducted through the virtual arm environment to evaluate the proposed system.
Experiment results verify the conception we proposed.
Keywords: reinforcement learning, continuous robotic control, convolution neural network, NAO
CONTENTS
口試委員會審定書... i
誌謝 ... ii
中文摘要 ... iii
ABSTRACT ... iv
CONTENTS ... v
LIST OF FIGURES ... viii
LIST OF TABLES ... ix
Introduction ... 1
Objective and Motivation ... 1
Problem Statement... 3
Literature Survey and Related Work ... 3
Contributions ... 7
Chapter Outline ... 7
Background ... 8
Physical Agent: NAO ... 8
Introduction ... 8
Features ... 8
Broker ... 9
Programming Language ... 10
Computer Vision ... 10
Optical Character Recognition ... 10
YOLO ... 11
Robotic Motion Control ... 13
Virtual Environment ... 16
System Design ... 18
System Scheme ... 18
NAO core ... 19
Vision Model ... 20
Detection ... 21
Training Vision model on Our Task ... 22
Figure 3.4 Detecting pen tail and target button ... 22
Action Generator ... 23
Training Core ... 23
Virtual Arm Environment ... 23
Figure 3.6 Virtual arm environment ... 24
Attention DDPG ... 24
Experiment Design and Implementation ... 26
Experiment Platform... 26
NAO... 26
Physical Setup ... 27
Remote Computation System Setup ... 29
Virtual Keyboard on the Tablet ... 30
NAO gym package ... 31
Vision ... 32
Transfer Learning ... 32
Data Augmentation ... 33
Motion ... 37
Constraints on Joint Angles ... 37
Reward Engineering ... 38
State Observation ... 39
Attention Mechanism ... 40
Experiment Results and Discussion ... 42
Performance of Attention-OCR and YOLO ... 42
Attention-Based Actor ... 44
Performance in Virtual Arm v0 ... 46
Performance with Absolute Position ... 48
Performance with Randomized Arm ... 48
Type Single Character ... 50
Conclusion ... 51
References ... 52
Appendix ... 55
LIST OF FIGURES
Figure 1.1 From left to right are Boston Dynamics Atlas7, Kokoro Company Actroid8,
Honda ASIMO9 ... 4
Figure 2.1. NAO V5 [2] ... 9
Figure 2.2. Scheme of NAOqi [2]... 9
Figure 2.3. Attention-OCR Model structure [1] ... 11
Figure 3.1 Whole-system Scheme ... 18
Figure 3.2 NAO core system scheme ... 19
Figure 3.3 Diagram of inferring related position ... 21
Figure 3.4 Detecting pen tail and target button ... 22
Figure 3.5 Action Generator scheme ... 23
Figure 3.6 Virtual arm environment ... 24
Figure 4.1 NAO V5 [2] ... 26
Figure 4.2 Physical setup of the Nao robot ... 27
Figure 4.3 Press keyboard button by finger ... 28
Figure 4.4 Filled with foam tape between fingers and pen ... 28
Figure 4.5 Remote Computation System ... 29
Figure 4.6 Virtual Keyboard layout ... 31
Figure 4.7 Freeze front layers in prior epoch for transfer learning ... 33
Figure 4.8 Label data with CVAT ... 34
Figure 4.9 Cropped character button ... 35
Figure 4.10 Stylus pen image without a background. ... 36
Figure 4.11 The left images are augmented and synthesized by OpenCV. The image at the right side is inference result of the vision model. ... 36
Figure 4.12 The angle ranges of each joint ... 37
Figure 5.1 Detection result by Attention-OCR ... 42
Figure 5.2 The pipeline of Attention-OCR detection ... 43
Figure 5.3 The edge detection result enhanced by bilateral filter [38] ... 43
Figure 5.4 Detection result of the YOLO model ... 44
Figure 5.5 Virtual environment v0 outlay ... 45
Figure 5.6 The original reward data of each episode, green line is the original DDPG, the blue line is only applied attention mechanism, red line is applied attention and use the attention distribution as joint speed. ... 46
Figure 5.7 The performance curves of DDPG. The green curve is original DDPD, the blue curve has applied the mechanism described in 4.3.4, The red curve has applied the attention distribution as each joint speed. ... 47
Figure 5.8 The result of the added absolute position to the observed state... 48
Figure 5.10 Randomly set arm position at the initialization phase of each episode ... 49
Figure 5.10 The performance comparison of v0 and v2 virtual arm environment ... 49
LIST OF TABLES
Table 1. Performance on the COCO dataset[20] ... 12
Table 2 Augmentation parameters of keyboard ... 34
Table 3 Parameter of random affine of character button on COCO images ... 35
Table 4 Restricted range ... 38
Table 5 The reward setting ... 39
Table 6 Success rate of each virtual arm environment... 50
Introduction
Objective and Motivation
In the face of the growing elderly population, how to help seniors to have a good quality of life is a critical issue that must be solved in the future. With the advancement of medical technology, more and more countries in the world are gradually transforming into aging societies.
At the same time, consumer electronics equipment and IoT devices grow rapidly with the flourish advancement of technology nowadays, but the older people often encounter many difficulties in learning to use or understand those smart devices, even though there have been some personal assistant products like Google Assistance1, Alexa2, and HomePod3, which can help people to control those devices.
However, the variety of IoT applications makes the specifications and the software API hard to integrate. Thus, if we want to develop products to control all the electronic devices through the smart home assistant and IoT, the cost would be high. In the meanwhile, we have to consider not only to create/maintain programs according to the complicated organization of APIs for different applications and devices but also need to design various interfaces for different kinds of users, such as the elders not proficient in using 3C products.
Moreover, most of smart devices for a typical family nowadays were not with the full capability required for a real “smart home,” let alone to help the elders living alone and to be cared of for a long time. The goal of this study is thus to employ a robot agent
1 https://assistant.google.com/
2 https://www.amazon.com/Amazon-Echo-And-Alexa-Devices/b?ie=UTF8&node=9818047011
3 https://www.apple.com/homepod/
under such conditions to help the elders control various devices, smart or not, and reduce the load of the long term care staffs and family members of the elders, to facilitate a better life quality for both of the elders and their caregivers.
So, we believe that leveraging physical agents, some like a robot, to compensate the human resource of labor-intensive and non-critical long-term care job, with the help of some smart devices controlled and communicated by simple and different protocols, is a promising solution nowadays, before the invention of a universal smart device controlling all desired facilities with a unified protocol and software API architectures. Even with such an ideal device, we also argue that such a device can also be placed in a robot with some intelligence.
In this thesis, we propose a prototype system that can aid elders to manipulate tablet keyboard through a physical agent. Of course, not all devices may be connected to the tablet computer, but by typing the keyboard, we have already been able to do many things (including programming or surfing websites in the future, probably). Our work can be regarded as the first step in this direction.
Moreover, we implement a physical keyboard-typing agent that can type the virtual keyboard on a tablet. Hopefully, though not tested on real elders yet, this study may pave a way to developing simple UI/UX and help the elders such that they do not have to learn complicated operations on various devices, saving a lot of patience and time of the younger generation in teaching the elders.
The ultimate goal of our studies is to design a companion robot that can be a life partner of elders. Some researches indicated that the elders are less likely to reject emotionally humanoid robots in the size and appearance of a child. Therefore, we adopt
a child-like robot NAO4, developed by Aldebaran.
First of all, the proposed system needs to consider two tasks to allow the robot to type the virtual keyboard with its physical body: (1) Know the related positions of the target and robot arms. (2) Move the arm to the target position, and press the virtual target button on the device panel. Different from most previous works, where the whole system is trained together, we adopt a coordination system, with separate vision and motion modules to be trained separately, while work together to construct the whole robotic control workflow and achieve our goal. Since both modules are trained separately, kind of transfer learning may be applied for the vision model, and save a lot of training time and computational resources. In addition, the deep learning is adopted in the vision, the motion, and the coordination modules, with the help of Q-learning for the motion and coordination subsystems.
Problem Statement
The desired system is required to handle the following conditions: 1) Detect the target key position from vision signal, and calculate its relative positions from robot arms.
2) Move the arm to touch the target position with a pen-like object, or stylus, as a human doing to the device.
Literature Survey and Related Work
Researches on robotic control have a long history, which can trace back to a half- century ago. However, the concept of automaton has existed since the Middle Ages. At
4 http://doc.aldebaran.com/2-5/home_nao.html
that time, the skill was not regarded as a serious business and was just a hobby of high- level technicians like watchmakers, and the functions of the automaton are very simple5. As technology advances, the novel scientific theory and manufacturing process gradually improved. An 18th-century automaton maker Maillardet6, a Swiss mechanic, created an automaton capable of drawing four pictures and writing three poems. In spite of the existence of those pioneering works, the well-known concept of robot nowadays comes out with the science fiction novel: “I, Robot7” by Isaac Asimov in the 1950s. The humanoids that can act, as a human being is an ultimate fantasy liberating human resources.
With the growth of computer technology, the component of automaton changes from metal and gear to wire and motor. Moreover, the third wave of electronic technology has driven the need for automation throughout the world and benefited from Moore's law, so that the chips of the same size get more powerful than before. Therefore, we can make the robot smarter but smaller. Companies like Boston Dynamics8, Kokoro Company Ltd.9,
5 https://en.wikipedia.org/wiki/Automaton
6 https://en.wikipedia.org/wiki/Henri_Maillardet
7 https://en.wikipedia.org/wiki/I,_Robot
8 https://www.bostondynamics.com/
9 https://www.kokoro-dreams.co.jp/english/
Figure 1.1 From left to right are Boston Dynamics Atlas7, Kokoro Company Actroid8, Honda ASIMO9
Honda10, are committed to developing humanoid and get closer to our dreams.
Generally speaking, the robotic control would be to leverage complicated mathematic calculations to estimate the joint torques required to be exerted. For example, the robot ladder-climbing task of Siyuan Feng et al., 2013 [3] [4]. They calculate the complicated inverse dynamics (ID) and inverse kinematics IK [5] formulae, to compensate for the errors of motion. Also, X Xinjilefu et al., 2014 [6] designed a robot walking on flat ground and rough terrain with a steady-state Kalman filter [7], which also involves advanced mathematics.
The robotic control technology becomes very different from that with complicated mathematics recently. After the artificial neural network and reinforcement learning began to come to the public horizon, many researchers respond quickly, trying to leverage those technologies to conquer problems in their areas. This model-free approach naturally is another option of solving robotic control issues. Sergey Levine et al. 2016 [8] presented a system with a model that combines convolution neural network (CNN) and reinforcement learning to control a robot arm with features extracted by CNN and the policy optimized by supervised learning in the training process. Sergey Levine et al. 2018 [9] leveraged multiple identical robot arms and collected massive of vision data for two months to train the robot arm grasping office items, and get an impressive result of the task. Moreover, another advantage of those works is that they do not need calibration of the camera and robot.
However, those works are hard to reproduce for small-scale laboratory. The bottleneck is not in the model size or convergence of the model, but due to that their robots are very expensive and fragile (e.g., problems due to dozens of DOF arms they
10 https://global.honda/innovation/robotics.html
applied and the overheating of motors).
Thus, we consider on previous works in scales similar to ours. Qi Wan et al. 2015 [10] and Xiao Sun et al. [11] 2016 tended to use NAO to draw geometric shapes it saw.
One of the methods is to directly sample the joint angles by mapping them on a grid that they put on the table. The other is calculating the trigonometric function of each angle to transfer the end of the arm to the target position. This approach can draw the same shape as it saw. However, they must set the pen directly at a pre-assigned position in the beginning. This constraint is released in our work.
Instead of using paper and starting with the agent’s pen at a fixed position, our robot utilizes a tablet and can recognize the target position and press on it automatically after training. There is another work implemented on a tablet, on which NAO plays the tic-tac- toe game (Luis Calvo-Varela et al. 2016 [12]). They use OpenCV11 to process images and transfer the coordinates of arm positions in the same way as in Xiao [11]. However, the target it tends to operate is much bigger than ours, and their target detection uses only color separation to find the specific color block.
In order to “see” objects, the robot should have the ability to recognize the target.
However, object recognition consumes huge computational resources. Yann Philippczyk et al. 2016 [13] and Dario Albani et al. 2017 [14] applied a CNN inference model to NAO applications. Yann used a remote computation system to transfer the computational workload to an external device. Dario reduces the workload by preprocessing the image captured by NAO’s camera. However, as they admitted, computing resources are still insufficient.
11 https://opencv.org/
Contributions
Propose a novel scheme for a coordination system with vision and motion modules, and all are based on deep learning. Similar works before trained both modules together, and took a long time to train, which are also difficult to manage and maintain, since many works did have to be repeated for new tasks. Our vision and motion models are connected with high-level features. Such an approach can train both models simultaneously, and can even use vision model pre-trained, as the transfer learning concept. Such a framework makes it convenient to replace the vision or the motion modules by new state-of-the-art computer vision and/or new motion control algorithms. For the motion system, we developed an NAO gym virtual environment, on which new methods could be tested, increasing the developing speed and avoid damages of the robot due to improper commands.
Chapter Outline
The rest of this thesis is organized as the following: In the next chapter, we describe the background knowledge relevant to this work, including the specification of physical agent we applied, and the challenges of computer vision that we face in our system. We also describe the robotic control methods based on reinforcement learning. In Chapter 3, we describe the design of the proposed system, including the construction details and the workflows for each module. In Chapter 4, we introduce the implementation details and the training methods for the vision part and the motion part. Also given are the design of the experiments and the setup of the hardware environment. In Chapter 5, we demonstrate and discuss the experiment results. The last chapter concludes with suggestions on future works.
Background
Physical Agent: NAO
Introduction
We are to use interactive humanoid robots to help incapable people to use modern electronic devices. This study is focused on letting robots type keyboard command for people. To simplify the problem, we apply a medium-sized humanoid robots NAO [2]
developed by Aldebaran Robotics and SoftBank as the physical agent to physically executing the keyboard-typing actions in the real world.
NAO is a robot based on the Gentoo Linux system, on which we can develop applications using Python, C++, Java, or JavaScript. In addition to the programming language, Aldebaran Robotics also provides a relatively simple GUI development tool, Choregraphe.
Features
The sensors of NAO robot are with two cameras at mouth and forehead, microphones, touch sensors, infrared, bumpers, sonars, 3-axis gyrometers, and 3-axis accelerometer. Moreover, there are two loudspeakers on both sides of the head. For the motion of limbs, NAO has two joints at the head, six joints at each hand, two junctions at the pelvis, and five joints at each foot, 26 joints in total [2]. In addition, NAO has three fingers on each hand, which are not easy to control.
The programming framework for NAO is the NAOqi Framework, in which Aldebaran program their robots. It allows homogeneous communication between different modules, easy for programming, and simple for information sharing. Also, it is of cross-platform (Windows, Linux, MacOS) and cross-language (C++, Python, Java,
JavaScript) characteristics allow developers to create distributed applications they want.
Broker
The NAOqi [2] is a broker that runs on the NAO robot. After the operation system of NAO was booted, it loads autoload.ini to specify libraries it should load. There are one or more modules in a single library that use NAOqi to advertise their methods. The architecture is shown in Figure 2.2.
Figure 2.1. NAO V5 [2]
NAOqi
autoload.ini
[core]
albase launcher albonjour [extra]
framemanag er
leds sensors sudioout ...
libalbase.so
libmotion.so
libalbonjour.so
libalframemanager.so
libleds.so ALLeds
ALFrameMan ager ALBonjour
ALMotion ALLogger ALLogger
ALMemory insertData(...) getData(...) raiseEvent(...)
walkTo(...)
angleInterpolation(
...) getAngle(...)
setIntensity(...) fade(...)
Broke r
Libraries Modules Methods
Network Access
Figure 2.2. Scheme of NAOqi [2]
With our work, we use ALVideoDevice and ALMotion modules to obtain videos from cameras as NAO's vision input, and set torques for joints of arms as its action output by python's NAOqi package.
Programming Language
The develop language adopted to our work is Python 2.7. The reason is not only the abundant resources for machine learning in Python community but also the SDK of NAOqi supports only Python 2.7.
Computer Vision
The main objective tasks we want to handle are vision and motion of a physical agent.
For the vision, we use NAO's ALVideoDevice module to obtain the image stream of the camera in NAO's head. Then the first thing we have to process is to locate objects that the agent needs to interact. Object recognition is a large topic of Computer Vision (CV), and a bunch of methods exists to deal with different CV tasks, say, dozens of solutions may be available for dealing with a single problem. However, the Convolution Neural Network (CNN) [15] becomes dominant after the publication of AlexNet at 2012 [16].
The features of objects that physical agents have to recognize are not only their categories but also locations of them. Our CV task is a subset of the object recognition task, often called Object Detection. We will discuss some of those methods in the following.
Optical Character Recognition
Optical Character Recognition (OCR) is the technique of classifying characters of one or more languages. In general, each key face is with an English letter in uppercase.
So finding the target key is the same as to find a character classification algorithm to
For our task, we adopted the most recent Attention-OCR [1] model. It combines CNN and RNN and LSTM units [17] to predict English sentences with all letters in one image. The core approach is to scan the sliced pixels and forward them through CNN layers. Then we pass the extracted features through LSTM layers to predict the character in each sliced image columns. Figure 2.3 shows the network structure. However, this approach needs lots of time in choosing candidate regions. The workflow pipeline is very inefficient even if we predict them together by concatenating all cropped button images (about 0.15~0.2 fps). The situations become even worse when we take a sliding window.
Hence, the OCR technique might be inappropriate for us, and we resort to other computer vision algorithms. The popular YOLO system is our final choice.
YOLO
You Only Look Once (YOLO) [18] [19] [20] is a CNN-based object detection algorithm. The feature extractor of YOLO is a Neural Network backbone Darknet
Figure 2.3. Attention-OCR Model structure [1]
developed by Redmon et al., 2016 [20]. With this structure, YOLO is about three times faster than other models like DSSD [21] and FPN [22]. A comparison of those methods are listed in Table 1. Since YOLO has much a higher FPS (frames per second) rate, it can be applied to real-time industrial applications such as pedestrian detection and automated image detections. YOLOv3 is the latest version released and has fixed some issues in its previous versions.
Table 1. Performance on the COCO dataset[20]
backbone AP50 Time (ms)
Two-stage methods
Faster R-CNN w FPN[22] ResNet-101-FPN 59.1 156
One-stage methods DSSD513[21]
RetinaNet [23]
YOLOv3 608 × 608 [20]
ResNet-101-DSSD ResNeXt-101-FPN Darknet-53
53.5 61.1 57.9
156 198 51
The end-to-end model architecture is the main reason of YOLO's efficiency. The early versions of CNN-based detection models, such as R-CNN [24], are based on pre- selection among thousands of possible regions extracted by CNN and classify those regions individually. Although these methods can avoid massive data slices caused by the sliding window, they still require considerable computation resources in post-processing of regions for recognition and classification.
The end-to-end model consists of the following work:
1) Divide the input image to 𝑆x𝑆 grids.
2) Calculate the confidence score and class of objects from 𝐵 bounding boxes, by formula 𝑐𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒 𝑠𝑐𝑜𝑟𝑒 = 𝑃𝑟(𝑂𝑏𝑗𝑒𝑐𝑡) ∗ 𝐼𝑂𝑈(𝑔𝑟𝑜𝑢𝑛𝑑 𝑡𝑟𝑢𝑡ℎ). If there is no object in bounding box, 𝑃𝑟(𝑂𝑏𝑗𝑒𝑐𝑡) = 0 , i. e. , the 𝑐𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒 𝑠𝑐𝑜𝑟𝑒 is zero.
Intersection Over Union (IOU) is the intersection area of predicted bounding boxes and
3) Utilize the five results (𝑥, 𝑦, 𝑤, ℎ, 𝑐𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒), each in the interval [0, 1], and scale them to calculate the bounding box of objects in the images. The elements 𝑥 and 𝑦 are the center coordinate of the bounding box, 𝑤 and ℎ represent the width and height of the bounding box. The YOLO approach bypasses the effort of moving a sliding window and dealing with sub-images cropped by pipeline algorithm. It improves the FPS to 5.5 in our system. The training detail will be described in Chapter 4.
Robotic Motion Control
In traditional robotics areas, engineers usually have to be proficient at some topics like control theory, motion planning, and robot locomotion. Moreover, the researchers also have to resort to complicated mathematical computations when developing the control process and fine-tuning the system. In recent years, machine learning has become a competitive alternative to designing a robotic control system.
Especially, recently, the combination of reinforcement learning (RL) and neural networks (NN) has brought massive success to learning policies for sequential decision- making. This approach has been quite successful in applications in simulated environments, such as playing Atari games with Deep Q-learning Network (DQN) (Mnih et al., 2015) [25], and defeating professional players at the complicated game of Go
(Silver et al., 2016) [26]. Other robotic tasks using RL and NN have also been reported, such as helicopter control (Ng et al., 2006) [27], screwing a cap onto a bottle (Levine et al., 2015) [28], and grasping office items (Levine et al., 2016) [9]. Thus, we decide to
apply this approach to our control problem. Basic background knowledge for RL and its combination with NN is introduced in the following.
In general, a reinforcement learning setup consists of an agent interacting with an environment 𝐸. At each discrete time step 𝑡, the agent receives an observation 𝑥𝑡 from
environment 𝐸, executes an action at and gets a reward 𝑟𝑡∈ ℝ𝑁. In our assumption, the value of actions 𝑎𝑡 ∈ ℝ𝑁. Let 𝑠𝑡 = (𝑥1, 𝑎1, … , 𝑥𝑡−1, 𝑎𝑡−1, 𝑥𝑡) describe a history of states.
Here a state at 𝑡 is a pair of an observation and an action. DQN addresses the challenge that the learning is suffered from the sequential and dependency of samples generated from exploring by replay buffer. Therefore, the history of states can be observed partially in the environment. We assume that only the current state in the state history can be observed, therefore 𝑠𝑡= 𝑥𝑡.
The behavior of an agent is defined by a policy, 𝜋, which maps states to a probability distribution over the actions, i.e., 𝜋 ∶ → . The environment, E, may also be stochastic.
Thus we model it as a Markov decision process, with a state space , action space = ℝ𝑁, an initial state distribution 𝑝(𝑠𝑡), probability of dynamic transitions 𝑝(𝑠𝑡+1|𝑠𝑡, 𝑎𝑡), and the reward function 𝑟(𝑠𝑡, 𝑎𝑡).
The returned reward value of a state is defined as the sum of discounted rewards from previous steps 𝑅𝑡 = ∑𝑇𝑖=𝑡𝛾(𝑖−𝑡)𝑟(𝑠𝑖, 𝑎𝑖) , where the factor of discounting the reward is 𝛾 ∈ [0, 1]. The action that policy 𝜋 chooses will affect the returned rewards and could be stochastic. The goal of reinforcement learning is to maximize the expected return from the starting distribution 𝐽 = 𝔼𝑟𝑖,𝑠𝑖~𝐸,𝑎𝑖~𝜋[𝑅1] by updating the policy. We define 𝜌𝜋 as the discounted state visitation distribution of a policy 𝜋.
The action-value function 𝑄 is a value estimate function commonly applied in many reinforcement learning algorithms (e.g., DQN in Mnih et al., 2015 [25]). It represents the expected value of the reward when executing an action 𝑎𝑡 in state 𝑠𝑡 with policy 𝜋:
𝑄𝜋(𝑠𝑡, 𝑎𝑡) = 𝔼𝑟𝑖≥𝑡,𝑠𝑖>𝑡~𝐸,𝑎𝑖>𝑡~𝜋[𝑅1|𝑠𝑡, 𝑎𝑡] (2.1) The Bellman equation (2.2) is a recursive relationship used in many reinforcement
learning approaches.
𝑄𝜋(𝑠𝑡, 𝑎𝑡) = 𝔼𝑟𝑡,𝑠𝑡+1~𝐸[𝑟(𝑠𝑡, 𝑎𝑡) + 𝛾𝔼𝑎𝑡+1~𝜋[𝑄𝜋(𝑠𝑡+1, 𝑎𝑡+1)]] (2.2) If the target policy is deterministic, we can describe it as a function µ ∶ ← and avoid the inner expectation:
𝑄µ(𝑠𝑡, 𝑎𝑡) = 𝔼𝑟𝑡,𝑠𝑡+1~𝐸[𝑟(𝑠𝑡, 𝑎𝑡) + 𝛾𝑄µ(𝑠𝑡+1, 𝑎𝑡+1)] (2.3) The expectation is only related to the environment. Therefore, off-policy is possible for using transitions generated by alternative stochastic behavior policy 𝛽 to learn 𝑄µ. A commonly used off-policy algorithm is the Q-learning [29], using the greedy policy
µ (𝑠) = arg max
𝑎 𝑄(𝑠, 𝑎). Let’s the function approximators be parameterized as 𝜃𝑄. With 𝑦𝑡 as the label, we can approximately express,
𝑦𝑡 = 𝑟(𝑠𝑡, 𝑎𝑡) + 𝛾𝑄(𝑠𝑡,µ(𝑠𝑡+1)|𝜃𝑄) (2.4) and optimize it by minimizing the loss in (2.5).
𝐿(𝜃𝑄) = 𝔼𝑠
𝑡~𝜌𝛽,𝑎𝑡~𝛽,𝑟𝑡~𝐸[(𝑄(𝑠𝑡, 𝑎𝑡|𝜃𝑄) − 𝑦𝑡)2] (2.5) DDPG applied the replay buffer that allows the states to be used discretely. Also, we may leverage the use of mini-batches to make the process efficient. Transitions that in replay buffer 𝑅 is the tuple (𝑠𝑡, 𝑎𝑡, 𝑟𝑡, 𝑠𝑡+1). Therefore, the off-policy property of DDPG allows the algorithm to learn on uncorrelated transitions. Moreover, they use a separate target network and take a soft target update strategy to tackle the problem of stability when updating the target network. The major challenge of exploration when learning in continuous action spaces is adding noise sampled from a noise process to the actor policy. Algorithm 1 shows the entire reinforcement learning algorithm of DDPG [30].
Virtual Environment
A reinforcement learning agent will be designed in alternative ways, depending on how we want it to interact with the environment. In most cases of robot control, the researchers or engineers often leverage some development packages of GUI virtual environment like pyglet12, rviz13, MoJoCo14, or Gazebo15, to simulate how the robot interacts with the real world. There are three advantages to it. 1) Avoid the possible damage to the robot caused by its own actions in the real world. 2) Quickly restore the robot to the initial state that we want it to set up. This part is the most important of the
12 https://pyglet.readthedocs.io/en/pyglet-1.3-maintenance/
13 http://wiki.ros.org/rviz
14 http://www.mujoco.org/
Algorithm 1 DDPG algorithm
Randomly initialize critic network 𝑄(𝑠, 𝑎|𝜃𝑄) and actor µ(𝑠|𝜃µ) with weights 𝜃𝑄 and 𝜃µ.
Initialize target network 𝑄′ and µ′ with weights 𝜃𝑄′ ← 𝜃𝑄, 𝜃µ′ ← 𝜃µ Initialize replay buffer 𝑅
for episode = 1, M do
Initialize a random process for action exploration Receive initial observation state 𝑠1
for t = 1, T do
Select action 𝑎𝑡 =µ(𝑠𝑡|𝜃µ) + 𝑡 according to the current policy and exploration noise
Execute action 𝑎𝑡 and observe reward 𝑟𝑡 and observe the new state 𝑠𝑡+1 Store transition (𝑠𝑡, 𝑎𝑡, 𝑟𝑡, 𝑠𝑡+1) in 𝑅
Sample a random minibatch of transitions (𝑠𝑖, 𝑎𝑖, 𝑟𝑖, 𝑠𝑖+1) from 𝑅 Set 𝑦𝑖 = 𝑟𝑖 + 𝛾𝑄′(𝑠𝑖+1,µ′(𝑠𝑖+1|𝜃µ′)|𝜃𝑄′)
Update critic by minimizing the loss: 𝐿 = 1
𝑁∑ (𝑦𝑖 𝑖 − 𝑄(𝑠𝑖, 𝑎𝑖|𝜃𝑄))2 Update the actor policy using the sampled policy gradient:
∇𝜃µ𝐽 ≈ 1
𝑁∑ ∇𝑎𝑄(𝑠, 𝑎|𝜃𝑄)|𝑠=𝑠 ∇𝜃µµ(𝑠|𝜃µ)
𝑖,𝑎=µ(𝑠𝑖) |
𝑠𝑖 𝑖
Update the target networks:
𝜃𝑄′ ← 𝜏𝜃𝑄 + (1 − 𝜏)𝜃𝑄′ 𝜃µ′ ← 𝜏𝜃µ+ (1 − 𝜏)𝜃µ′ end for
end for
training phase for reinforcement learning since the model has to learn how to estimate what actions should take at the moment. 3) With a virtualized environment, we can smoothly migrate a reinforcement learning algorithm to a different task to evaluate if the algorithm robust enough to alternative problems.
The agent of our system receives the environment state for the physical agent, and the environment state is not only from real-world changes, but also includes the action that the physical agent takes. Action generator gathers the state from the vision model’s vision features and NAO core’s joint angle changes, as they are input to predict what reaction should it take. The robot control is related to a trajectory in continues action spaces for reinforcement learning. So we apply DDPG [30] as a model-free, off-policy actor-critic algorithm that can learn policies in the continuous, high-dimensional action spaces.
System Design
In this chapter, we describe the details of our proposed control system. The central concept of this thesis is the coordination between vision and motion of the physical agent.
System Scheme
Figure 3.1 shows the outline of the entire system, as it is composed of three sub- systems. The leftmost side is the agent perception, which is as an input component that receives data from the real world. Blocks in the right include an NAO core, a vision model, and an action generator. The NAO core is as a bridge between the agent perception and the action generator. The vision model extracts high-level features to the action generator.
Finally the action generator produces an action according to the input from agent perception, the vision model, and the learned policy, and then sending actions to NAO core.
Since the computation capability of NAO is insufficient for the whole end-to-end processes, a remote computer is adopted for processing all data in time. Thus, data for the NAO core system processes are both from the remote computer and the sensors of NAO.
The agent acquires the information from the environment via sensors and delivers raw data into a remote computer. After the raw data is processed, the image of vision
Agent
Perception NAO Core Vision
model Raw Data
Action Generator Vision Features
RGB Image
Joint Angle
Action Vector Action Command
Figure 3.1 Whole-system Scheme
information and the required torques for every joint as motion information will be fed into the vision model and the action generator separately. The vision model is responsible for obtaining the significant features from a vision state of the environment. Our vision model extracts the position of the touch component (the stylus) of the agent and the target button, and then we can estimate the reward through the related distance, and let the location of them as an environment state that could be referenced by action generators.
The action generator predicts the action vector by the current state of vision information and joint angles. Both types of information can be obtained as the best result from actions executed. Finally, the NAO core converts the action vector to joint control commands as a motion signal that the physical agent should take. Thus, our physical agent will gradually approach the goal by the recurrence procedure.
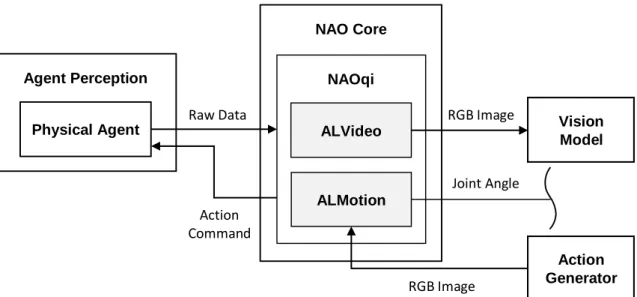
NAO core
NNAO core is the system that controls the physical agent movement: it bridges up the robot perception and action generator to the NAO physical agent or virtual environment. Aldebaran company has provided a cross-platform framework NAOqi that
Figure 3.2 NAO core system scheme NAO Core
NAOqi Agent Perception
Physical Agent ALVideo
ALMotion Raw Data
Action Command
RGB Image
Joint Angle
RGB Image
Vision Model
Action Generator
can let developers shift their major efforts from robot hardware control to the core algorithm. Figure 3.2 shows the scheme of the NAO core. NAO receives the state from the outer environment and sends the data from the joint angle sensors and the RGB image to the vision-model and action generator.
The raw data that NAO receives from the camera via ALVideo is an unsigned 8-bit integer array. NAO core converts the array to 3 channels of uint8 data type by the numpy16 package. After processing, the data would be a BGR image, and we swap the red and blue channels to make the vision model easy to infer the proper information from the RGB image. ALMotion module provides the torque information from joint sensors acquired by the action generator. The joint state from the agent is a value between –π and π. We concatenate the joint angles and vision features to a 1D tensor as the input to action generator.
The action vector generated from the action generator is a 5-dimension vector. NAO core receives the predicted action vector from the action generator; it will leverage the API setAngles of ALMotion modules to set the joint angles according to the action vector values. After that the action is executed by the physical agent, the new state, which includes changed joint angles and changes of the images, will be a new set of raw data fed into the NAO core for producing the next action.
Vision Model
We apply YOLOv3 [18], an object detection model that can predict the position and the bounding box of a target object. In order to make the control system capable of coordinating the vision and the motion modules, we need to provide sufficient
information as input to the whole system. In this case, our agent must have sufficient capacity to estimate the relative position and distance between the stylus pen and the target key button to determine the next move and solve the sparse reward problem [31].
Detection
Relative positions of a stylus pen and the target button are the primary vision feature that the action generator refers to produce action vectors. Figure 3.3 shows the flow chart of the related position inference process. After the vision model receives the RGB image from NAO Core, we resize the RGB image to a 416x416 image to fit YOLOv3 model’s input size, and the CNN model will then forward the data layer by layer to the final three pyramid-structural YOLO layers. The sizes of them are (𝑏𝑎𝑡𝑐ℎ, 52 × 52 × 3, 73) , (𝑏𝑎𝑡𝑐ℎ, 26 × 26 × 3, 73), (𝑏𝑎𝑡𝑐ℎ, 13 × 13 × 3, 73) respectively; here 𝑏𝑎𝑡𝑐ℎ is the numbers of images, 73 is the dimension of (𝑥, 𝑦, 𝑤, ℎ, 𝑐𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒) and the number of our data classes. We will concatenate them along the second dimension into a (𝑏𝑎𝑡𝑐ℎ, 10647, 73) tensor. In the evaluation mode, YOLOv3 model’s batch size will be
Vision Model
Positioning Detection NAO Core
YOLO
Candidate Positions
Position Computatio
n Target Filtering
Action Generator
RGB Image
Related Position
Figure 3.3 Diagram of inferring related position
1 for each frame that NAO captured. The second-dimension size 10647 represents the number of candidate bounding boxes. Then we filter out the target, excluding the less possible options. Finally, we merge overlapped candidate boxes by calculating IoU of them and send the calculated relative positions as an environment state to the action generator.
Training Vision model on Our Task
The objects we want to detect, the keyboard button and the stylus pen, are very different from the daily life photos used to train the YOLOv3 algorithm. In the meanwhile, it seems a waste to re-train the YOLOv3 program just using images of keyboards and stylus pens. Thus we apply transfer learning [32] to fine-tune the model while training.
First, we fix the previous layers of the CNN part and unlock them after several epochs.
The target classes that YOLOv3 was trained on are the COCO dataset [33]. However, the target pen and target key represented by a button are not included in it. So, we crop the buttons and pen images and synthesize them together with the COCO dataset images.
Besides that, we also mixed some full layout images of the entire keyboard with the letter button annotations labeled manually. The details will be discussed in Chapter 4.
Figure 3.4 Detecting pen tail and target button
Action Generator
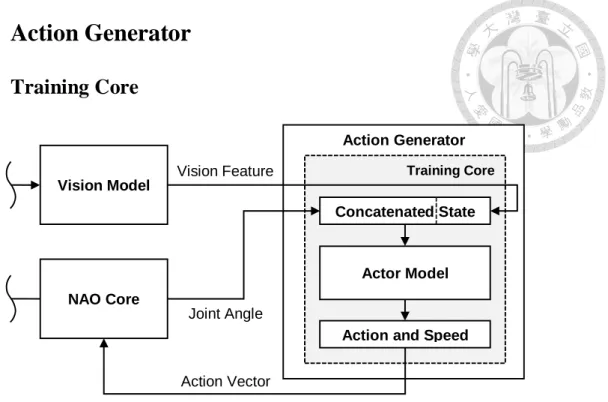
Training Core
The training core handles the reinforcement learning policy training process in our system. In general, there will be an agent and an environment in a reinforcement learning task. The primary role of an agent played in the algorithm is to execute actions generated by a reinforcement-learning actor model, and to receive the state of the environment after the action is executed. With this recurrent process to optimize the actor model, the training core is the role to execute this optimization process; Figure 3.5 shows the entire process.
In our system, the state is a tensor that concatenates vision feature and joint angles; and the action is specified by the joint angles and speed corresponding to each joint of the agent.
Virtual Arm Environment
First of all, our robot is not for industrial use, and the overheat situation appears frequently. Therefore, we expect the agent to learn what they are doing as soon as possible.
As mentioned before, it is safer and faster for training agents in virtual environments to estimate the RL algorithm. Thus, we develop a simple virtual arm environment to evaluate our assumption of the vision feature. The virtual arm environment is shown in Figure 3.6,
Action Generator Training Core Vision Model
NAO Core
Concatenated State
Actor Model
Action and Speed Action Vector
Vision Feature
Joint Angle
Figure 3.5 Action Generator scheme
where we colored the stylus pen as yellow and the target area with a blue box, and constrained the joint angle to be in the valid range that NAO moves its arms.
Attention DDPG
The algorithm deep deterministic policy gradient (DDPG) [30] we applied is an ideal approach to tackle our problem. Transit high dimensional arm joint to the limb end of the physical agent is a continuous-control task that DDPG is capable of handling.
Additionally, the DDPG algorithm is model free. Therefore, our work aims to fine-tune the DDPG with some problems we face.
In our assumption, from the relative positions, and the current joint angle form the state 𝑠𝑡, we can get an action from the deterministic policy 𝜇 by 𝑎𝑡 = 𝜇(𝑠𝑡). With the model-free characteristic, the algorithm needs no adjustment to evaluate the assumption.
We only have to change the action and state dimension for the input shape of the deep neural network with 𝜇 and 𝑄𝜇 . The vision state that the agent can observe is the pixel-
Figure 3.6 Virtual arm environment
wise distance between the key button center to the end of the stylus pen. The x-axis and y-axis distances would be normalized to the interval [−1,1], as the relative positions of each other.
Secondly, in a continuous control task, directly applying the angles generated by policy 𝜋 is usually unstable for the training phase. A common way to conquer this problem is to apply the 𝑡𝑎𝑛ℎ function at the last layer of the deep model and scale down the angle extent to a small range. We thus add an attention layer before the output layer and leverage the scale of the attention map as the scale down ratio of each joint. The concept is to let the more critical joint get more momentum to accomplish the action generated by the policy. We apply the self-attention [34] mechanism to enhance the training performance. The implement detail will describe in the next chapter.
Experiment Design and Implementation
Experiment Platform
NAO17
NAO is a robot based on the Gentoo Linux system, whose applications can be developed using Python, C++, Java, and JavaScript. In addition to the support of many programming languages, Aldebaran Robotics also provides a relatively simple GUI development tool, Choregraphe18. Figure 4.1 shows the appearance of NAO. The reason we choose NAO is that NAO looks like a child, which makes it suitable for applications like accompanying the elders for long-term care. Its human-like body also makes it possible to help incapable human for some simple jobs on 3C devices
Figure 4.1 NAO V5 [2]
17 https://www.softbankrobotics.com/emea/en/nao
18 http://doc.aldebaran.com/1-14/software/choregraphe/
Physical Setup
It is essential to create a safe and proper experimental setting for robots. Especially that the NAO robot is not as robust as robots for industry application. Some constraints have to be taken into considerations. First of all, in all experiments, we would set NAO to be in a sitting position to avoid overloading the motor at knees. However, the motors of knees still may overheat if NAO stays sitting for a long period. Therefore, we fix the fitness of each leg alternately to keep the body balance. Moreover, if the arm motor temperature is too high, NAO will be set to the rest mode to rest until the motor cools down. Additionally, a tablet computer that displays the virtual keyboard is placed in front of NAO. In this way, the NAO robot can see the state of the keyboard and its own hand movements, and touch the target position according to the visual information. The physical setup of the robot is shown in Figure 4.2.
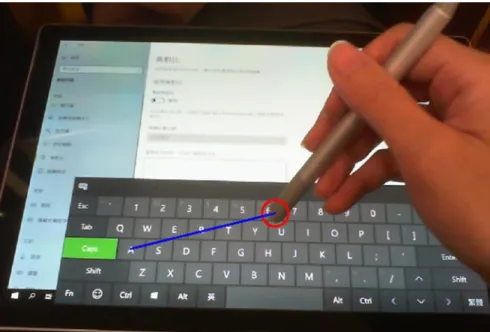
Another problem is that how can the NAO robot handle the stylus pen in hand. In the beginning, we made NAO extend its index finger and tried to use it to press a button on a regular physical keyboard, as shown in Figure 4.3.
Figure 4.2 Physical setup of the Nao robot
Figure 4.3 Press keyboard button by finger
Figure 4.4 Filled with foam tape between fingers and pen
Unfortunately, due to the fragility of NAO’s finger structure. This is not the best and safest choice. At the same time, how to hold the pen should be also taken into account.
We found it difficult for NAO to hold the pen properly, since the robot’s hand is made of just three fingers, and cannot hold the pen well. In order to avoid pen from sliding away, we filled with foam tape to bind NAO’s fingers and the pen together; it only tightened the hand holding the pen. The resultant hand and pen are shown in Figure 4.4.
On the other hand, if we use the physical keyboard, the distance information that we applied to conquer sparse reward will be less accurate. Therefore, we replaced the physical keyboard with a tablet to get the position where the stylus pen touches a tablet keyboard.
Remote Computation System Setup
A scheme of our remote computation setting is shown in Figure 4.5. The system consists of one remote computer (a desktop), one NAO robot, and one tablet.
Consider NAO’s embedded computer: one core 1.60 GHz CPU (Atom Z530) and only 1 GB RAM. Obviously, the computation resources of NAO are very restricted. So, a remote computer is introduced as the centralized computation unit of the whole system.
It is designed to infer the distance from the pen’s tail NAO hold and the target key button, and evaluate how we should change the joint angles of NAO’s hand to bring them to the
Physical agent
Cyber agent
Figure 4.5 Remote Computation System
same places. We also used the GPU on the remote computer to handle the relative heavy loaded training phase and to execute the inference work that consumes considerable RAM space and requires parallel computation.
The NAO robot is the physical agent of our task. It provides action and perception capability to interact with the real world. We process the images from NAO’s camera via the local wireless network and send a command to NAO’s hand to execute the action we want it to do.
The tablet will record the positions pressed by NAO in the training phase. The distance between the point pressed and the target key position will be used for evaluation of the reward.
We use a Microsoft Surface pro419 to display the virtual keyboard. In order to avoid extra transmission latency and unnecessary effort of remote computation, we also implemented a virtual keyboard internally on the remote computer and use remote desktop software to display the keyboard on the tablet with the same layout of the Surface Pro4.
In order to avoid the extra transmission latency and unnecessary effort of remote computation, we implemented a virtual keyboard on the remote computer and use remote desktop software to display the keyboard on the tablet with the same layout on Surface Pro4.
Virtual Keyboard on the Tablet
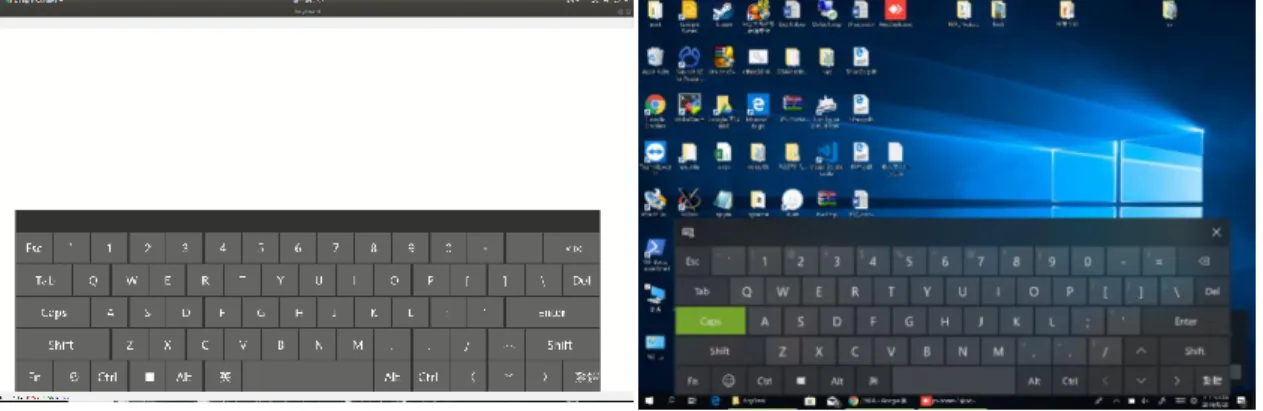
For training NAO agent to type a keyboard, we need some information that feedbacks from the environment. We used Python’s package pyglet to design a virtual keyboard similar to the keyboard outlay of the Surface Pro4 Tablet. When the tablet
screen is touched, the virtual keyboard program can probe the relative distance calculated by the xy-coordinates on the screen. Moreover, since our system’s computations are executed remote from the agent, large latency and extra coding jobs of communications between the internet should be avoided. We keep the virtual keyboard and reinforcement learning agent separately and use the remote desktop software (i.e., TeamViewer20, AnyDesk21, VNCviewer22) to simulate the real keyboard environment. Figure 4.6 shows the virtual keyboard and the original tablet keyboard appearance.
NAO gym package
Gym23 is a toolkit for developing or improving reinforcement learning algorithms announced by OpenAI. It supports teaching agents to react in a virtual environment built for them. Especially if the hardware devices are fragile or expensive, or the algorithm is in the early development phase. We leverage this toolkit to build a virtual environment, which integrates NAO Python SDK and a virtual keyboard that we developed previously.
Once we have constructed the environment, new algorithms or vision models can be used to improve the system, and we can directly replace any component of a cyber-agent in the environment.
20 https://www.teamviewer.com/tw/download/windows/
21 https://anydesk.com/zhs
22 https://www.realvnc.com/en/connect/download/viewer/
23 https://gym.openai.com/
Figure 4.6 Virtual Keyboard layout
Moreover, if some other people want to conduct similar researches or applications as we do, they can directly apply our NAO gym implementation to train their NAO robot.
The package mainly included the following APIs:
𝑟𝑒𝑠𝑒𝑡() function: Initialize the sitting pose and safely move the arm grasping a pen and move to the top of a tablet panel. It can also set the arm to an initial pose to make the pen visible to the agent. This function returns the state that concatenates arm angles and distances between the pen and the target position.
𝑠𝑡𝑒𝑝(𝑎𝑐𝑡𝑖𝑜𝑛) function: Convert an input action vector to the angle setting command and send it to the physical agent. Return the state of arm angles and the distance between the pen and the target position after executing the action.
𝑜𝑛𝑇𝑜𝑢𝑐ℎ() function: Monitor tactile sensors, or the deviation of the signal the joint sensor got and the command set to the robot body. We can leverage this event-detection capability to judge if the stylus touches the tablet screen.
𝑔𝑒𝑡𝑇𝑒𝑚𝑝𝑒𝑟𝑎𝑡𝑢𝑟𝑒() function: Monitor the temperature of each joint motor, if they get too hot, then set NAO to rest pose until the motor cools down.
Vision
Transfer Learning
Our framework is composed of a vision part and a motion part. Therefore, the vision model can be designed and trained independently. We applied the YOLOv3 [20] model and retrained the model with transfer learning [35]. First, we fixed the front layer of the model and trained with our data for five epochs. After that, we unfreeze all layers of the YOLO model and continue training as shown in Figure 4.7.
Data Augmentation
For training on our dataset to fit the distribution of the panel outlay, we use data augmentation to increase data samples to avoid overfitting. There are two approaches to augment our dataset. First, we use a computer vision annotation tool called CVAT[36]. It is a free, online interactive video and image annotation tool for computer vision. We use CVAT to label the keyboard layout with locations and bounding boxes of each letter button with two pictures of the tablet, as shown in Figure 4.8. Then we apply the random OpenCV-powered augmentation to the input images according to the specifications in Table 2.
Inputs (416, 416, 32) Convolution (416, 416, 32) Residual Layer (208, 208, 64) Residual Layer (104, 104, 128)
Residual Layer (52, 52, 256) Residual Layer (26, 26, 512) Residual Layer (13, 13, 1024)
Convolution 5L (52, 52, 128) Concatenate (52, 52, 384) Upsample Convolution (52, 52, 128)
Convolution 5L (13, 13, 256) Concatenate (26, 26, 768) Upsample Convolution (26, 26, 256)
Convolution 5L (13, 13, 1024) Darknet-53
FPN
Convolution (52, 52, 75) Convolution (26, 26, 75) Convolution (13, 13, 75)
Freeze
Inputs (416, 416, 32) Convolution (416, 416, 32) Residual Layer (208, 208, 64) Residual Layer (104, 104, 128)
Residual Layer (52, 52, 256) Residual Layer (26, 26, 512) Residual Layer (13, 13, 1024)
Convolution 5L (52, 52, 128) Concatenate (52, 52, 384) Upsample Convolution (52, 52, 128)
Convolution 5L (13, 13, 256) Concatenate (26, 26, 768) Upsample Convolution (26, 26, 256)
Convolution 5L (13, 13, 1024) Darknet-53
FPN
Convolution (52, 52, 75) Convolution (26, 26, 75) Convolution (13, 13, 75)
Unfreeze All Layer
Figure 4.7 Freeze front layers in prior epoch for transfer learning
The Bounding boxes will be tracked automatically and updated with the images.
Moreover, we leverage cropped letter button images to enhance the training process through randomly applying the affine transform to them and synthesizing them with the COCO dataset [33] images. The random affine parameters of the synthesis character are listed in Table 3. The cropped keyboard button are shown in Figure 4.9.
Finally, in order to detect the stylus pen correctly, we also have to produce some labeled data of it. We tried to use the CVAT tools again, by recording a short video that captures images of different view angles of the pen. However, the annotation job is tedious, and results of the captured image tend to have some afterimage caused by the angle changes.
Figure 4.8 Label data with CVAT
Table 2 Augmentation parameters of keyboard Augmentation Description
Translation +/- 10% (vertical and horizontal)
Rotation +/- 5 degrees
Shear +/- 2 degrees
Scale +400%/-10%
HSV Saturation +/- 50%
HSV Intensity +/- 50%
![Figure 2.1. NAO V5 [2] NAOqi autoload.ini [core] albase launcher albonjour [extra] framemanag er leds sensors sudioout ..](https://thumb-ap.123doks.com/thumbv2/9libinfo/9608776.634270/19.892.125.788.105.1158/figure-naoqi-autoload-launcher-albonjour-framemanag-sensors-sudioout.webp)
![Figure 2.3. Attention-OCR Model structure [1]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9608776.634270/21.892.285.622.541.1002/figure-attention-ocr-model-structure.webp)

![Figure 4.1 NAO V5 [2]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9608776.634270/36.892.349.579.580.980/figure-nao-v.webp)