國立臺東大學教育學系 教學科技碩士班
碩士論文
指導教授:李偉俊 博士
線上適性測驗系統之建置 以婦產科學為例
研 究 生: 張志芳 撰
中 華 民 國 九 十 九 年 七 月
國立臺東大學教育學系 教學科技碩士班
碩士論文
線上適性測驗系統之建置 以婦產科學為例
研 究 生: 張志芳 撰 指導教授:李偉俊 博士
中 華 民 國 九 十 九 年 七 月
謝 辭
論文終於完成了,離開校園十七年後因興趣而重新回到校園進 修,感謝慈濟醫院院方及同仁的支持才得以完成心願。回顧兩年的過 程,點滴在心頭。
在此要感謝指導教授李偉俊博士不厭其煩的指導和督促,並感謝 導師鄭承昌博士的細心關懷,讓我在學習及研究的過程中獲益良多,
本論文才得以順利完成。
同時感謝兩位口試委員黃振榮博士與郭達源博士,在百忙中抽空 參與計劃書及口試審查,並提供許多專業意見,讓論文得以在修訂後,
更為嚴謹及完整,在此表達謝意。
研究期間,特別感謝台北榮民總醫院婦產部趙灌中主任、花蓮慈 濟醫院婦產科朱堂元主任及台大醫院鄭文芳主治醫師的協助與幫忙,
使本論文的資料更完備及充實。
同窗、師長、好友、親人...要感謝的人太多了,限於篇幅無
法一一述說。最後,謹以此論文獻給我的家人,感謝他們在我學習過
程中無怨無悔的支持我,讓我無後顧之憂的投身課業中。
線上適性測驗系統之建置 以婦產科學為例
作者:張志芳 國立台東大學教育學系
摘要
本研究的主要目的建構婦產科學電腦化適性測驗,並探討不同群 體受試者在此線上測驗的能力估計情況。本研究同時結合試題反應理 論、題庫、及線上動態網頁技術,探討(1)如何建構線上電腦化適性測 驗系統,(2)題庫與線上適性測驗系統間如何有效運作及(3)對受試者進 行能力值估計。本研究所使用的測驗題目為醫學系五年級婦產科學的 教學內容及教學目標,草擬出 230 題婦產科學預試測驗。編製完成的 試題,經由四組不同群體的受試者進行預試,共回收 289 份有效問卷。
經預試後,測驗的題目先以 TESTER 2.0 進行傳統試題分析,刪除較差 的試題後選出優良試題後,再經 BILOG-MG 3.0 進行三參數模式(3PL) 估計後完成內含 155 題之「婦產科學適性測驗題庫」 。本研究建置線上 電腦化適性測驗系統,並由三個(傳統測驗、金字塔適性測驗、電腦化 適性測驗)子系統各自獨立組合而成。經由四組不同群體的受試者進行 測試。研究結果顯示,線上電腦化適性測驗系統能有效評估受試者的 能力值。
關鍵詞:題庫、婦產科學、電腦化適性測驗、金字塔、最大訊息量
Construct Obstetrics and Gynecology item bank and online computerized adaptive testing system
Chih-Fang Chang
Department of Education, National Taitung University
Abstract
The main purpose of this study was to construct the Obstetrics and Gynecology computerized adaptive testing, and to explore the ability scores of different groups of testees estimated by this online testing system.
Combining with item response theory, item bank, and online dynamic web page technology, this study discusses of how to (1) construct online computerized adaptive testing system, (2) operate the item bank and online adaptive testing system and (3) estimate ability scores of testees. The items used in this study were based on the teaching contents and objectives of Obstetrics and Gynecology. Based on which, a two-way specification table of Obstetrics and Gynecology was constructed. After searching through historical national examination questions and some specialized topics, 230 items were selected. After completing the preparation of items, four different groups of testee were arranged for pretest, a total of 289 valid questionnaires were collected. After the pretest, TESTER 2.0 was used for getting information from traditional item analysis. Items identified as not suitable were deleted. Then BILOG-MG 3.0 was used to calculate the three-parameter logistic model. As a result, Obstetrics and Gynecology adaptive testing item bank ended up with 155 items. In this study, the online computerized adaptive testing system is developed from three:
traditional testing, pyramidal adaptive testing and computerized adaptive testing. Four different groups of testees were invited to test the system for evaluation of its effectiveness. The results showed that the online computerized adaptive testing system can effectively assess the ability scores of testees.
Keywords: item bank, obstetrics and gynecology, computerized adaptive
testing, pyramidal adaptive testing, maximum information
目 次
第一章 緒論………1
第一節 研究動機………1
第二節 研究目的………2
第三節 名詞釋義………3
第四節 本研究的重要性………5
第二章 文獻探討………7
第一節 測驗理論………7
第二節 測驗與試題分析………10
第三節 題庫與電腦化適性測驗………15
第三章 研究方法………33
第一節 研究架構………33
第二節 研究樣本………35
第三節 研究工具………35
第四節 線上適性測驗之實施程序………50
第五節 資料處理………56
第四章 結果分析………59
第一節 信度分析………59
第二節 效度分析………60
第三節 傳統測驗理論分析………60
第四節 試題反應理論分析………63
第五節 受試者測驗成績之平均數差異分析………66
第六節 受試者能力值估計之平均數差異分析………69
第七節 不同組別在婦產科學能力值的差異分析………72
第五章 結論與建議………73
第一節 結論………73
第二節 建議………75
參考文獻………77
附錄………79
附錄一 問卷調查………79
附錄二 題庫試題分析………81
附錄三 題庫參數表………126
附錄四 測驗訊息函數………141
表 次
表2–1 彈性測驗………24
表2–2 六個階層的分層適性測驗………25
表3–1 婦產科學雙向細目表………37
表4–1 測驗信度表………59
表4–2 難度指數P分析表………61
表4–3 試題分析表………61
表4–4 鑑別力評鑑標準………62
表4–5 鑑別度指數 D 分析表………62
表4–6 試題反應理論參數分析表………64
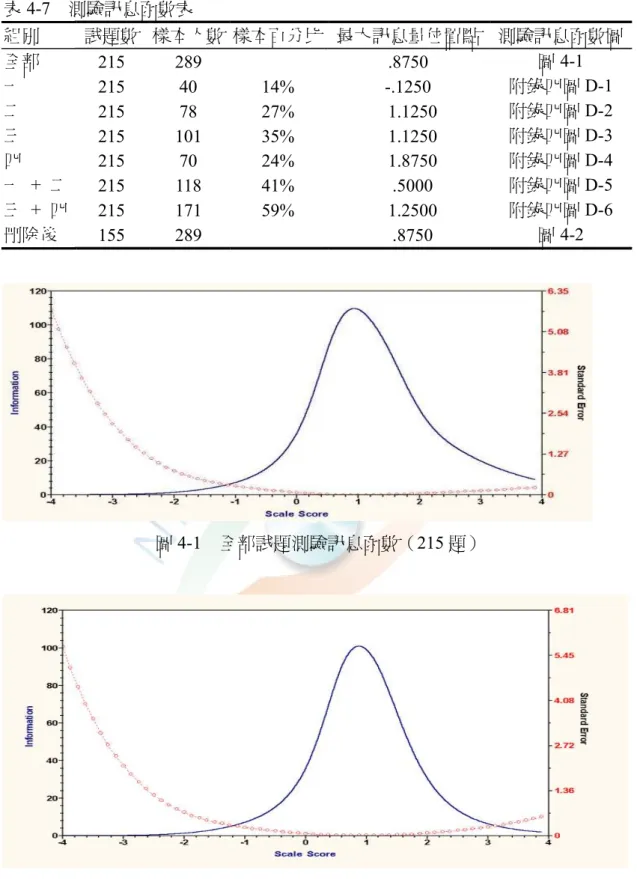
表4–7 測驗訊息函數表………65
表4–8 受試者測驗成績之平均數差異分析摘要表………67
表4–9 敘述性統計表………70
表4–10 受試者能力值(θ)估計之平均數差異分析摘要表………71
表4–11 變異數分析統計表………71
表4–12 各組別參與人數及能力值摘要表………72
表4–13 不同組別在婦產科學測驗表現的事後比較摘要表………72
圖 次
圖2–1 答對題數與能力值的關係圖 ………8
圖2–2 題庫發展流程圖………16
圖2–3 適性測驗策略………20
圖2–4 兩階段適性測驗………21
圖2–5 金字塔型適性測驗………22
圖2–6 Robbins-Monro 適性測驗………23
圖2–7 三參數試題特徵曲線及試題訊息曲線圖………25
圖2–8 電腦化適性測驗的簡易流程圖………28
圖2–9 對數近似值函數與能力估計值之間的關係………30
圖3–1 研究架構………34
圖3–2 研究工具發展流程圖………36
圖3–3 系統開發流程圖………39
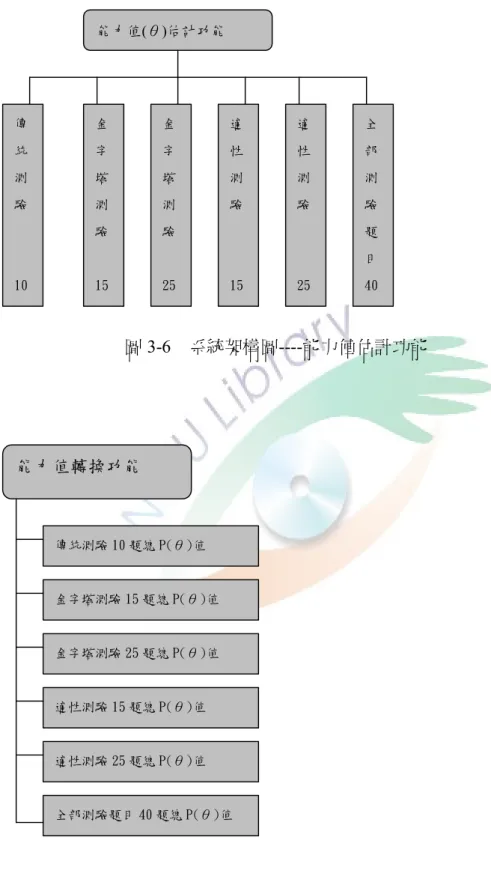
圖3–4 系統架構圖——數位測驗學習系統………40
圖3–5 系統架構圖——測驗功能………41
圖3–6 系統架構圖——能力值估計功能………42
圖3–7 系統架構圖——成績換算功能………42
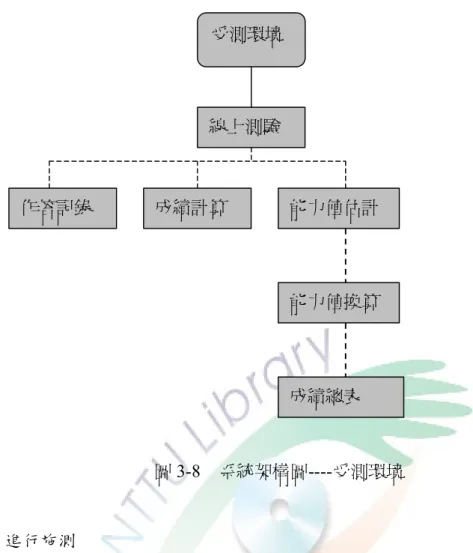
圖3–8 系統架構圖——受測環境………43
圖3–9 線上金字塔適性測驗施測簡易流程圖………45
圖3–10 金字塔適性測驗施測順序表………45
圖3–11 金字塔適性測驗試題分配表………46
圖3–12 線上電腦化適性測驗簡易流程圖………47
圖3–13 線上適性測驗施測程序圖………50
圖4–1 全部試題測驗訊息函數………65
圖4–2 正式題庫測驗訊息函數………65
第一章 緒論
本研究旨在結合古典測驗理論、試題反應理論、題庫、及資料庫管理技術等,
建構婦產科學電腦化適性測驗題庫,並探討 1.不同群體受試者對試題品質的影響,
2.試題經分析後,如何選擇及建置題庫,並作為適性測驗的基礎。3.題庫與線上適 性測驗系統間如何有效運作及估計受試者能力。本章共分四節,依次說明:「研究 動機」、「研究目的」、「名詞釋義」及「本研究的重要性」。
第一節 研究動機
「教、學、評、用」一直是教育的重大議題。
醫師臨床能力評量與專業執照考試制度的主要目的,在於確保醫師執照考試 能確實發揮其作用,確保醫療品質與維護民眾健康。近年來各國醫師考試改革之 主要發展包括:考試之種類與職權的統一與制度化、臨床表現能力評量的重視與 擴大電腦科技與實作評量技術的應用等。
醫學教育人士對於專業執照考試制度的批評一直持續存在,主要是擔心考試 技術不能有效評量受試者在專業素養、臨床實作、倫理道德及團體合作的能力。
而醫學院校及醫學生也以通過考試為目的的態度,減低對臨床學習的重視程度,
因而造成臨床經驗不足、醫病溝通技巧不良及臨床技能不熟等情況。
台灣醫界迷信資歷,並過度衍伸專科醫師的能力,而專科醫師也各自認為醫 學教育是他生而具有的專長,沒有真正下工夫去了解、學習及活用醫學教育的理 論與方法,造成測驗制度的僵化與便宜行事。台灣要發展醫學專業能力之評量制 度,其成敗關鍵在於是否能夠網羅學有專長的教育專家參與測驗的規劃及品質改 進(黃天祥、王維典,2005)。
隨著電腦科技的進步,測驗的電腦化已經是不可避免的趨勢(何榮桂, 1997)。 考選部於 91 年 8 月間,成立「採行電腦化測驗」專案小組,研修相關考試法規、
蒐集相關資訊並參訪國內相關試務機構,在不影響國家考試公正性、正確性、安 全性及效率性之要求下,配合考選部標準作業,而簡化試務流程、改進考試技術 (劉春明、鍾金燕,2007)。
考選部於 93 年 4 月 13 日至 15 日舉行之 93 年專門職業及技術人員特種考試 第 1 次航海人員考試開始正式實施至 99 年 1 月,業辦理 20 次專技人員航海人員 特考電腦化測驗考試與 6 次專技人員牙醫師、助產師、呼吸治療師、職能治療師、
獸醫師等 5 類科之電腦化測驗考試。而醫事放射師考試之電腦化測驗計畫將在民 國 99 年 7 月實施。
95 年 5 月 29 日考選部主辦「國家測驗發展趨勢與國家考試電腦化測驗研討
會」,國家考試電腦化測驗已是考選部之發展政策與長程規劃,而電腦適性測驗運
用在國家考試是考選部之長程規劃。雖然國外適性測驗技術發展多年,理論與技 術已成熟,其採行限制、民眾理解程度、命題作業、試題型態、實際考試措施及 相關法規等,在國內均須進一步深入探討,才能於國家考試施行電腦適性測驗。
因此,國內之電腦化測驗發展尚有可改進的空間。
在電腦化適性測驗中,由於挑選出適合受試者能力的試題讓他作答,只要一 半的試題數量就可以達到與傳統非適性測驗相同的測量精準度。所以電腦化適性 測驗是目前最新的測驗技術,因此目前國內外測驗的電腦化大多是以發展電腦化 適性測驗為最終的目標。
綜上所述,基於測驗是「教學評量」的一個重要過程,發展以網路技術為主 的測驗評量系統是未來數位學習的趨勢,本研究同時結合試題反應理論、題庫、
及線上動態網頁技術,試圖建立婦產科學適性題庫及發展線上適性測驗系統,並 透過適性測驗施測之結果,來印証適性測驗在醫學教育評量中之應用,以為將來 國內發展推廣醫學適性測驗之先期研究。
第二節 研究目的
基於上述研究動機,本研究旨在結合古典測驗理論、試題反應理論、試題與 測驗分析來檢視預試試題以及建立基本婦產科學題庫,並發展一個建構在全球資
訊網的「適性測驗系統」,以提供一個線上輔助教學測驗評量的平台,針對受試者
提供量身訂做的適性測驗。具體而言,本研究的目的如下:
壹、發展婦產科學適性測驗題庫;
貳、發展一套以 ASP.NET 技術為主的線上適性測驗系統;
參、評估線上適性系統成效。
第三節 名詞釋義
茲將本研究所涉及的重要名詞,分別界定如下:
壹、題庫(item pool、item bank)
題庫是指每道試題均經過編製、分析、系統編碼、測試、評論、修正、刪改 而建立起試題特徵資料的一群試題,並且可用來組成評量各種教學成果的工具。
動態的題庫主要是考慮新增試題的參數問題,利用不同時間所獲得的試題來進行 整個題庫之間的等化連結。
試題假如只是一群未依一定程序編製、分析、系統編碼的巿售題庫集或題庫 本,這些僅是將一堆試題(或考古題)彙整起來而已,並未能確知每道試題的可 用性,因此,嚴格說來,不能算是題庫,只能算是一種試題集。
試題集的功能就不如題庫,它無法用來組成評量各種教學成果的工具,更無 法配合電腦化適性測驗(computerized adaptive testing)的發展,成為電腦化題庫系 統,運用在等化(equating)分析、測驗編製、精熟測驗(mastery testing)、或診斷測驗 (diagnostic testing)等基礎應用的研究。
貳、電腦化測驗
電腦化測驗,顧名思義,是以電腦來輔助編輯試題、施測、計分、分析、報 告結果、與解釋的測驗方式。而線上測驗,更是能夠透過網路的雙向傳輸功能,
達到無遠弗屆的隨選施測(testing on demand)地步。它們不僅能夠節省測驗編輯和 施測時間,更能夠達到精確估計與報告受試者真正實力或潛在特質。
電腦化測驗可根據測驗理論基礎的不同,可分為適性與非適性兩類。
非適性的電腦化測驗(computer-based testing,簡稱 CBT),主要是以古典測驗 理論為依據,是一種將傳統紙筆測驗改成以電腦螢幕或網路當呈現介面的電腦輔 助施測方式。由於這種測驗不具有量身訂作的「因才施測」功能,所以不具適性 的本質。
從測驗理論來看,當測驗試題的困難度能夠適合受試者的能力時,這時測驗 所測量到的受試者能力最為精確。這種能夠適應個別化需求的測驗,便稱為「電
腦化適性測驗」(Computerized adaptive testing, CAT)。
電腦進行適性測驗的設計通常是由預期中等難度的試題開始施測,第二題及 後續試題則由受試者答題反應所決定。一般而言,若受試者答對前一題,下一題 電腦則會選擇稍難的試題施測;相反地,答錯下一題,電腦則會選擇稍微容易的 試題施測。當受試者表現達到某個事前決定的準確水準或已施測完畢程式設定的 最多試題,即停止施測。這種電腦化測驗即能夠針對不同程度的受試者及其不同 的作答速度,提供適合其能力作答的適當難度試題,以謀求估計受試者能力的最 大精確性,達到量身訂作的「因才施測」最高理想境界。
參、指數與參數
在教育測驗與評量中,指數、指標、參數名詞的使用,因各作者個人的解釋 而各異。為方便本研究的解釋,一律統一解釋如下。
傳統測驗中的難度(difficulty)等同難度指數(difficulty index)、難度指標;鑑別 度(discrimination)等同鑑別度指數(discrimination index)、鑑別度指標;試題反應理 論則為難度參數(difficulty parameter)、鑑別度參數(discrimination parameter)、猜測 度參數(pseudo-chance parameter)。
肆、位置分數
因金字塔型適性測驗的施測方式採固定分支方式,選題以單一試題為選擇單 位,受試者在任一階層只能對一道試題作答。以 15 階層的測驗而言,每位受試者 只需要作答 15 題,最後第 16 階為最後一階,是受試者最後到達的位置,由位置 所換算的成績,稱之為位置成績。分數的計算為 1601=0、1602=(1/15)=.06、
1603=(2/15)=.13、………、1615=(14/15)=.93、1616=(15/15)=1。
第四節 本研究的重要性
茲就本研究的重要性,分述如下:
壹、整合婦產科學適性題庫與適性測驗評量系統。
貳、探討題庫建置中試題的選擇與參數的估計。
參、探討不同測驗對受試者能力值估計之影響。
肆、探討適性測驗系統內參數設定對系統運作之影響。
伍、本研究為國內醫學教育適性測驗之先探研究。
第二章 文獻探討
本章文獻探討共分三節,第一節探討測驗理論並說明試題反應理論之基本概 念及假設,以為本研究建置線上測驗之依據。第二節則說明測驗的解釋與試題分 析的關係,以為本研究題庫選題之標準。第三節則說明題庫建立與試題反應理論 的關係,以為本研究建置題庫設計之依據。並探討電腦化適性測驗的歷史、組成 要素、優缺點、能力估計以及國外醫學應用,以歸納出本研究中適性測驗系統理 論上的基礎。
第一節 測驗理論
現代教育測驗評量中,測驗理論(test theory) 通常劃分為二大類:一為古典測 驗理論(Classical Test Theory, CTT),其理論基礎以真實分數模式(true score model) 為主;另一為當代測驗理論(modern test theory),由於其架構主要是以試題反應理 論(Item Response Theory, IRT)為骨幹,一般以試題反應理論來代表當代測驗理論。
古典測驗理論是以整份測驗(所有試題)的觀點,來解釋受試者測驗分數的意 義,所以任何單獨一題試題的得分,在解釋受試者能力上不具有任何意義及價值。
而當代測驗理論是以試題反應理論為骨幹所發展的測驗理論架構,主要是以個別 試題的觀點,來解釋受試者測驗分數的意義。
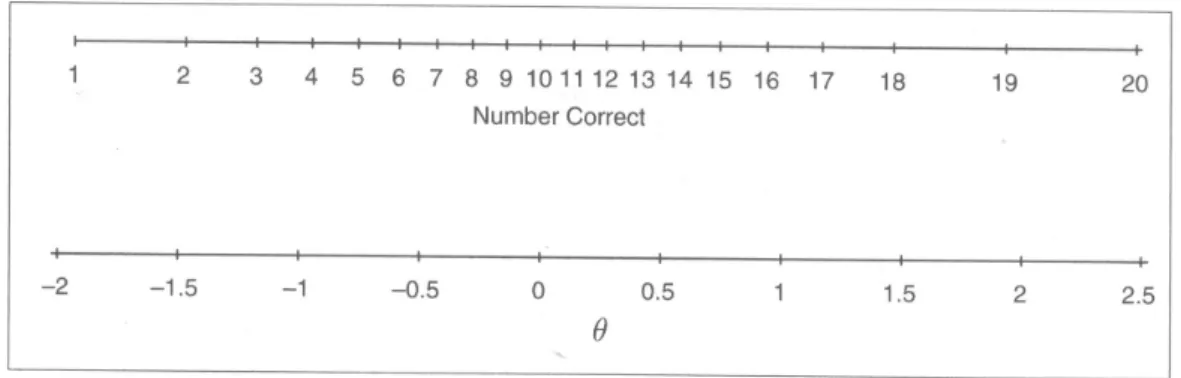
在古典測驗的分數等級解釋上,如以 10 題測驗試題之作答反應組型為例,1 是回答正確,0是回答錯誤,則甲(1111100000)、乙(000001 1111)、丙(1010101010)、丁(0101010101)四位受 試者的分數都是五分,但能力不相等,而分數等級有 11 等級(0~10)。同樣 作答反應組型以試題反應理論來解釋受試者的能力(θ)等級時,則有 1024 等級
(2^10)。如圖 2-1 所示,答對題數在量尺上是非等距的關係,而能力值(θ)
則是等距關係。
圖 2-1 答對題數與能力值的關係圖
資料來源:出自 DeMars(2010:17)
壹、試題反應理論的基本概念
自從 Lord(1980)發表第一本以「試題反應理論」為名的專書後,當代測驗理論 正式以試題反應理論為其理論中心架構,故當代測驗學者逐漸以試題反應理論一 詞代表當代測驗理論。試題反應理論的特點是以機率的概念來解釋受試者能力和 試題參數間之關係,亦即觀察受試者的反應和表現結果,再經數學模式的運算,
以推估受試者的能力(abilities)或潛在特質(latent traits)。此種用來表示試題特性的 連續性遞增數學模式稱之為試題特徵函數(item characteristic function,ICF)。試題 反應理論因翻譯的關係,又名題目反應理論、項目反應理論、試題作答理論等。
試題反應理論建立在兩個基本概念上:(1)受試者(examinee)在某一測驗試題上 的表現情形,可由一組因素來加以預測或解釋,這組因素便稱為潛在特質或能力;
(2)受試者的表現情形與潛在特質間的關係,可透過一條連續性遞增的函數來加以 詮釋,這個連續性遞增函數所形成的曲線便稱為試題特徵曲線(item characteristic curve,ICC)。
由於試題反應理論建立在理論假設嚴謹的數理統計學機率模式上,有關此理 論之研究報告與專書複雜深奧艱澀難懂,而且學術界的測驗理論學者大多是出身 自數學界或至少在數理統計學上訓練有素,他們對理論模式的探討,遠勝於對實 際應用的推廣,所以試題反應理論的發展雖然已經超過三十年,但在實際應用上,
並不為一般大眾所接受。因此要了解試題反應理論前先要了解它的基本概念及基
本假設,茲簡要解釋其基本概念如下(余民寧,2009):
一、試題特徵曲線(Item Characteristic Curve,ICC)
試題特徵曲線所代表之涵義是指受試者的某種潛在特質與他在某一試題上正 確反應之機率間的關係,這種潛在特質的程度愈高,代表受試者在某一試題上的 正確反應機率便愈大。在試題反應理論中,每一種試題反應模式(1PL、2PL、3PL) 都有其相對應之一條試題特徵曲線,此一特徵曲線通常包含一個或多個參數(a、b、
c)來描述該試題之特性及受試者之潛在特質;因此,當選用之試題反應模式不同,
則其具有之參數數目及其數值便有所不同,當然,其所畫出之試題特徵曲線便不 相同。
二、測驗特徵曲線(Test Characteristic Curve,TCC)
把能力值不同的受試者得分點連接起來而構成的曲線,便是能力不同的受試 者在某一試題上的試題特徵曲線,把測驗中各試題的試題特徵曲線加總起來,便 構成測驗特徵曲線。
三、試題獨立(item-independent)
當某一種試題反應模式適用於某種測驗資料時,一些試題反應理論的基本特 性也會跟著產生。經由不同組別的試題估計所得的受試者能力估計值,除了測量 誤差外,不會受所使用的不同組別測驗試題之影響,亦即,它是試題獨立的能力 估計值。
四、樣本獨立(sample-independent)
經由不同族群之受試者估計所得的試題參數值,除了測量誤差外,不受參與 測驗之受試者族群的影響,亦即,它是樣本獨立的試題參數估計值。
五、試題反應理論的「不變性」(invariant)
試題獨立及樣本獨立的兩種特性,在試題反應理論中稱為「不變性」,這些不
變性是把試題之訊息(information)考慮在能力估計的過程中。不管受試者來自何種 族群,只要他們具有相同的能力,則他們正確反應某一試題的機率便相同;由於 某特定能力之受試者,答對某一試題的機率是由試題參數所決定,因此試題參數 對這兩族群之受試者而言也必定相同。
六、估計標準誤(standard errors)
試題反應理論針對每一位能力不同的受試者,在能力值估計時,提供其測量 的估計標準誤,這不同於古典測驗理論假設所有受試者都有單一誤差估計值。
貮、試題反應理論的基本假設
任何一條試題特徵曲線所代表的意義是,受試者答對某一試題的機率,是由 受試者的能力值(θ)和試題的參數值(a、b、c、)所共同決定。因此,試題反應理論 在具有下列幾項基本假設的前提下,才能對測驗資料進行分析(余民寧,2009)。
一、單向度(unidimensionality):試題反應理論中的各種反應模式都有一個共同假 設,那就是測驗中的每道試題都能測量到同一種單一共同之能力或潛在特質,這 便是單向度假設。適用於含有單一主要潛在特質的試題反應模式,便稱為單向度 模式。適用於含有多種主要潛在特質的試題反應模式,便稱為多向度
(multidimensional)模式。
二、局部獨立性(local independence):當影響受試者能力值估計的因素被固定不變 時,受試者在任何兩題試題上的反應,在統計學上而言,它們是獨立的;換句話 說,在考慮受試者的能力因素後,受試者在不同試題上的作答反應是沒有任何關 係存在。因此受試者的能力,才是唯一影響受試者在測驗試題上做正確反應之因 素。一般來說,當單向度假設獲得成立時,局部獨立性假設也會獲得成立。
三、知道——正確假設(know--correct assumption):如果受試者知道某一試題的正 確答案,他必然會正確回答該試題;如果他回答錯誤某一試題,則假設受試者必 然不知道該試題的正確答案。
第二節 測驗與試題分析
壹、測驗的品質
一個良好的測驗應具備陳英豪、吳裕益(1990)所述的適切性(relevance)、平衡 性(balance)、有效性(eff1c1ency)、客觀性(object1v1ty)、特殊性(specificity)、適當 的難度(difficulty)、良好的鑑別度(discrimination)、信度(reliability)、效度(validity)、
公平性(fairness)、非「速度性」(speededness) 等十一項品質。要了解一個測驗是否 具備上述各項品質,就必需對測驗結果進行分析。
貮、試題分析
所謂「試題分析」(item analysis)是指利用「品質分析」(qualitative analysis)與
「量化分析」(quantitative analysis),篩選出品質較佳的試題,這不僅有助於提高編 製測驗的品質,檢討改善編製測驗技能、實施補救教學及改進教學,並作為日後 使用或選取適切試題重編測驗之依據。一個測驗信度與效度之高低完全取決於試 題的品質,所以經由試題分析的技術,可提高測驗的信度與效度。
質的分析可由分析試題的內容和形式、有效命題原則、教學目標、內容效度 分析,以及編擬試題技術方面等評鑑工作來進行。量的分析主要分成傳統題目分 析及試題反應理論題目分析。以統計學方法來分析每個試題的特徵指標,傳統題 目分析內容包括難度、鑑別度、和誘答力。試題反應理論題目分析包括難度參數、
鑑別度參數、猜測度參數。
基本上,古典測驗理論所使用的難度與鑑別度,都是一種樣本依賴的指標,
亦即試題分析的結果會隨著所使用的樣本不同,而獲得不同的分析結果。
因此,傳統試題分析的結果,只是獲得一個暫時性的統計特徵指標,它們並 不是固定不變的特質。此外,像受試者人數的多寡、教育背景、能力水準、及教 學型態等因素,都可能影響試題分析的結果。這些限制在解釋測驗結果時必須特 別注意。
一、難度分析
難度以「通過比率」表示,以 1.計算全體受試通過或答對某題上通過的比率 或 2.計算高分組與低分組在某一試題上通過的比率來表示,試題愈容易,則通過 的比率愈高。
P 值愈大,試題愈容易;當 P 值大到 1 時,表示全部答對;當 P 值小到 0 時,
表示全部答錯。因此,P 值介於 0 到 1 之間。
以「通過比率」表示試題難度值乃屬於次序量尺(ordinal scale),只顯示難度的 等級順序或相對困難程度,無法進行四則運算比較,即數值間差異的涵義無法直 接進行有意義的比較。
二、鑑別度分析
試題在條件相等的情況下(例如:同樣的測驗情境、沒有猜題),能讓有能力、
會正確回答的受試者答對,而沒有能力、不會答的受試者答錯,則這種具有分辨 的功能,便稱為試題的「鑑別度」。
鑑別度之目的在了解試題具備區別受試者能力高低的程度,區別不同能力受 試者的功能愈強,則鑑別度愈高,表示愈能區別高低能力受試者的表現,即高分 組傾向答對,低分組傾向答錯。反之,試題具有區別不同能力受試者的功能愈弱(例 如:全部答對或全部答錯),則它的鑑別度便愈低。一道良好的試題,應具有較高 的鑑別度。
Noll、Scannell 和 Craig(1979)等認為鑑別度之最低標準至少為.25 以上,若低 於此最低標準者,可視為鑑別度欠佳或品質不良之試題。
三、誘答力分析
選擇題較其他試題類型,可再進一步進行誘答力分析,因為選擇題除了正確 選項外,還有數個誘答選項(不正確選項)。誘答具有吸引或迷惑某些知識不完整、
概念不清晰的受試者,若誘答能充分發揮功能,則能提升試題的鑑別度,因此選 擇題應強化誘答的編擬技巧與經驗。
分析不正確選項是否具有誘答功能,可探討高、低分組受試者在每個試題選 項選答的次數分配與比率,再加以判斷。選項判斷原則為 1.至少有一個低分組受 試者選擇任何一個不正確選項。2.選擇不正確選項的比率,低分組應高於高分組。
3.選擇正確選項的比率,高分組應高於低分組。
根據受試者在每道試題各選項上選答次數的結果判斷,若有違反上述原則 者,即表示該試題的某個不正確選項缺乏誘答功能,必須加以修改、潤飾、甚至 刪除,才能維持試題品質。
參、測驗的信度分析
庫李方法主要是依據受試者對所有試題的作答反應,分析其試題間的一致性 (inter-item consistency),以確定測驗中的試題是否都能測量到相同特質的一種信度 估計方法。因此,庫李方法對於所要分析的測驗試題有幾個基本假設:1.試題的計 分是使用二元計分方式;2.試題不受作答速度的影響;3.試題都是具有同質性,亦 即都測量到一個相同的因素(余民寧,2002)。
庫李方法的測量誤差,主要來自於測驗內容的抽樣誤差,特別是受到抽樣內 容的同質性(homogeneity)或異質性(heterogeneity)程度的影響很大。一般而言,當 測驗中的每道試題都能測量到相同能力或潛在特質時(即為內容同質性高),即表示 試題的測量功能間一致性愈高,信度將會愈大;反之,當測驗中試題具備測量到 兩種以上的能力或潛在特質時(即為內容異質性高),即表示試題的測量功能間愈不 一致,信度將會愈小(Anastasi,1988)。
肆、優良試題的挑選標準
由難度與鑑別度的關係可知,要選擇優良試題,必須檢視不同的測驗目的而 定,不能一概等同視之。但是,不論是何種測驗目的,選擇優良試題的方法,仍 有其共通的標準,那就是:1.依據測驗用途:作為常模參照測驗的試題,多半是選 擇難易適中的試題,而作為效標參照測驗的試題,則應選擇具有教學內容代表性 的試題。2.依據試題效度:所選擇的試題必須能夠測量到它所要測量的能力目標。
3.依據試題品質:選擇鑑別度較高或教學敏感度指標較大的試題。簡單地說,上述 選擇試題標準的最終目標,在於確保組成測驗的每一道試題均是優良試題(余民 寧,2002)。
經過試題分析後,在鑑別度方面,已知試題鑑別度所代表的意義是試題品質 的優劣。而評鑑試題品質的優劣,是一種主觀的價值判斷,並沒有一致性的標準。
因此,比較常用的挑選標準,是「先挑出鑑別度較高的試題,然後,再從中挑選 出難度較為適中的試題」(郭生玉,2001)。
一般而言,作為常模參照測驗的試題鑑別度值是愈高愈好,但一般可接受的 最低標準至少.25 以上,低於此標準,則可視為鑑別度不佳或品質不良的試題(Noll, Scannell & Craig,1979)。
在難度方面,建議選擇難易適中(即難度接近.50)的試題為最恰當,因為試題在 難易適中時,它的鑑別度可以達到最大。不過,要從符合鑑別度挑選條件的試題 中,再找出所有的試題難度都接近.50 者,實際上是有困難的;因此,Ahmanan & &
Glock (1981)主張以.40 到.70 之間的難度作為選擇標準;Chase (1978)則主張以.40 到.80 之間的難度作為選擇題的挑選標準。一般而言,整份測驗的平均難度,還是 以接近.50 作為共同的選擇原則。
在進行優良試題的選擇時,雖然可以根據試題分析的結果作為選擇優良試題
的參考標準,但是,必須參考雙向細目表的詳細說明,以及兼顧教學評量的目標,
選出具有課程內容代表性(即內容效度)的試題,才能算是優良試題。
伍、解釋測驗結果的原則
解釋測驗結果時,除了要了解測驗目的及施測群體的特性外,還要注意到下 列各項原則(陳英豪、吳裕益,1990;余民寧,2002)。
一、測驗分數的解釋,需以使用該項測驗的特殊場合為依據。
二、測驗分數需以該測驗所測量的真正特質來解釋。
三、試題的鑑別度值低未必表示試題具有缺點。
四、內部一致性鑑別度不能表示具有外在效度。
五、試題分析資料為暫時性,而非固定不變的特質。
六、測驗分數需以其他的證據作為佐證。
七、解釋測驗分數時必須考慮到受試者身心狀況及家庭背景。
第三節 題庫與電腦化適性測驗
壹、題庫
題庫是指每道試題均經過編製、分析、系統編碼、測試、評論、修正、刪改 而建立起試題特徵資料的一群試題,並且可用來組成評量各種教學成果的工具。
動態的題庫主要是考慮新增試題的參數問題,利用不同時間所獲得的試題來進行 整個題庫之間的等化連結。McCallon 與 Schumacker (2002)對現代化電腦題庫的定 義,是指存有可即時提供正式考試所使用的試題庫,並運用電腦進行存取與組卷,
題庫中的每一試題均有必要的試題參數及特徵,同時也有內容分析及測驗目標。
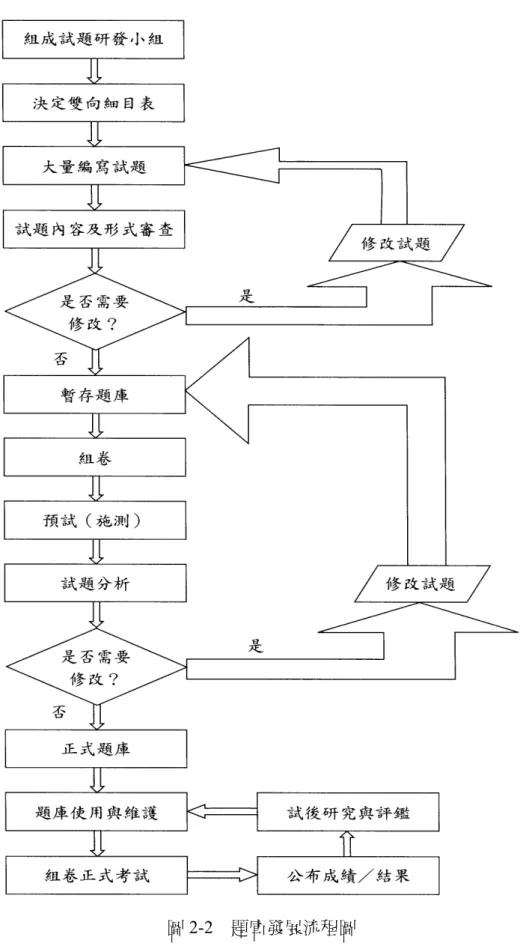
一、建立題庫的步驟
針對題庫的建立,一般可依據課程標準、教材大綱、雙向細目表的編寫而成,
它的建立過程,如許擇基、劉長萱等(1992)歸納為試題的編寫與修訂、選題預試、
試題的校準與銜接、更新題庫、測驗編輯、評估測驗品質、測驗是否達預期的水 準、執行考試、評分、決策、研究與評鑑等十一個步驟(如圖 2-2)。
二、題庫之品質
題庫品質,可分從題庫建立、影響品質因素和品質指標等三方面加以討論。
(一) 題庫的建立
以古典測驗或試題反應理論為基礎所建立之題庫,在程序上大同小異,大致 如下列幾個步驟:1.建立試題內容規格,2.試題撰寫,3.預試,4.試題分析並篩選 試題,5.題庫管理。在試題分析方法中,古典測驗理論以試題的鑑別度、難度與測 驗的信、效度做為題庫品質的參考指標;而試題反應理論則以難度參數、鑑別度 參數、猜測度參數、測驗訊息函數及相對效率做為描述題庫品質之指標。在測驗 編製完成之後,古典測驗理論必須進行建立常模和標準化的步驟,而以試題反應 理論為基礎之題庫則需運用等化連結的技術及理論,對題庫作進一步的擴充。
(二) 影響題庫品質之因素
影響題庫品質之因素可分為外在及內在因素兩大類。
外在因素方面包括:1.足夠經驗的測驗編製專家;2.充分的時間;3.充裕的經 費;4.能不斷預試及修正的循環編輯機制;5.眾多的受試者。在理想狀態下以試題 反應理論為基礎之題庫,應在各能力水準皆有充足數量的試題,而且各試題皆能 精確測量受試者之能力。但在題庫建立的實務上,難以建立理想的題庫,因此在 實務上妥協的方法為:1.將能力值限定於某範圍內;2.考慮經費及成本,題庫的規 模(總題數)、預試及修正的次數皆有適量的限制;3.當受試者為一群能力水準呈常 態分配者,需應用選題策略以改善試題受曝光率影響之情況。
內在因素方面,陳麗如等(1999)認為須考慮:1.試題內容與測驗目的配合程度;
2.題庫規模;3.參數(a、b、c 等參數)分配;4.試題曝光率。
圖 2-2 題庫發展流程圖
______________________________________________________________________
資料來源:出自余民寧(2009:243)
(三) 題庫品質指標
有關題庫品質的研究中,大多以試題參數為題庫品質之參考指標。在建立題 庫的實務過程中,經由受試者之作答反應組型資料,及試題分析軟體進行各試題 之參數估計,最後依研究者個人之經驗篩選出「優良」試題,以建立題庫。
一般而言,以試題反應理論為基礎之題庫,其品質管理策略之訂定,可將試 題參數(a、b、c)視為影響試題品質之主要因素。而不同題庫間之品質水準,常採 用測驗訊息函數(test information function; TIF)來加以比較( Hambleton &
Swaminathan, 1985)。
(四) 電腦化適性測驗題庫的特質
要發展電腦化適性測驗,首先要有一個具有試題反應理論為基礎之題庫,題 庫中之參數,必須以共同量尺來表示才能有一致的標準。
以試題反應理論為基礎之題庫,有下列特點(王寶墉,1995;陳麗如,1999;
余民寧,2009):
1.題庫的試題參數應包括鑑別度、難度及猜測度等三個參數。
2.難度參數應能涵蓋所有受試者的能力。
3.若能力介於±3 時,難度參數亦應介於±3 之間。
4.鑑別度參數應在 0.8 以上,若使用太高或太低的鑑別度參數時,亦應有理由。
5.猜測參數應在 0.3 以下。
6.題庫的題數最少在 100 題以上。
7.題庫中之試題都能測量到相同的能力或潛在特質。
當然,不同的測驗目的也會影響到題庫的試題參數之分佈範圍(特別是難度參 數)。例如,資優班學生甄選用的電腦化適性測驗題庫,其難度參數最好在 1.0 到 1.5 之間。鑑別智力不足用的電腦化適性測驗題庫,其難度參數最好在 -0.3 到 -1.0 之間,而測量一般常態分佈的群體之電腦化適性測驗題庫,其難度最好在±3,且 均勻分佈(陳麗如,1999)。
關於題庫的大小,理論上是越大越好。而且試題之難度參數要能配合受試者 的能力分佈。當鑑別度大,猜測參數小時,題庫內試題的總題數就不必太大,反 之,試題品質較差時,題庫則需要較大數量之試題。
三、題庫的評價
由於題庫的建立需要一定的經費和技術,一般來說,只有那些 1.經常需要進
行測驗的部門或團體;2.對測驗及評量有正確觀念的主管支持;3.充裕的經費;4.
足夠經驗的測驗編製專家;5.充分的時間等條件適合時,才能夠建立題庫成功。
(一) 題庫的優點
題庫能在各個領域上都得到廣泛的應用,是因為使用題庫有下列的優點(余嘉 元,1992):
1.對試題進行明確的分類。
2.將大量試題組織成具有結構性。
3.可以計算出試題的參數並刪除質量不好的試題,
4.對試題進行等化連結,擴增題庫的規模。
5.測驗試題組織靈活,對不同受試者提供不同的試題。
6.記錄每個受試者對試題的反應情況,輔助教師組織因材施教的訊息。
7.容易根據所感興趣的測量目標,組織試題。
8.得到足夠數量和測量目標有關的試題。
9.可以編製出高品質的測驗。
10.容易編製平行的測驗,也能夠根據編製者的要求,編製出不同難度的測驗。
(二) 建立題庫的缺點
余嘉元(1992)指出題庫的缺點,其主要的問題是專業技術層次要求高,並非每 一個使用者都能掌握題庫的建立、修改和使用技術,其次,題庫的建立是需要測 驗專家和電腦程式專家共同參與才能完成。
綜合上述之文獻分析可以歸納出,建立題庫是具有許多顯而易見的優點,並且 題庫可預期將來對測驗編製的重要性,同時也會節省編製測驗的時間與經費,尤 其是唯有高品質的題庫才能有高精確度的測驗,而這也是本研究必須建置題庫的 主要目的。
貳、電腦化適性測驗
一、適性測驗的歷史
最早應用適性測驗(即因材施測式的測驗方式)的例子,是以 1908 年 Binet 所作的智力測驗為代表(Weiss, 1985)。1960 年代末期,Lord 感覺到,對於低能力 與高能力的受試者而言,固定長度的測驗無法有效滿足這些受試者能力估計之需 求,因此才極力投入適性化測驗之研究。Lord 認為如果被挑選用來施測的試題都 能針對每位受試者之能力提供最大訊息量,則縮短測驗的長度,應該不會降低對 每位受試者能力的精確測量。理論上而言,每位受試者所接受的施測試題,應該 都會是不同的試題組合(余民寧,2009)。
適性測驗之發展可簡單依施測的方式分為五個階段,人工化(1905~1950 年代 後期)、結構式電腦化(1950 後期~1970 年代前期)、模式導向電腦化(1970 後期~1990 年代前期)、智慧化、診斷化(1990 後期~1990 年代後期)、遠距化(1990 年代後期~
迄今)(李茂能,2002)。但是要實施精確的適性測驗,唯有在電腦誕生後,才有普 及施行適性測驗的可能。因為現代科技的發達,日新月異,大容量記憶體可以貯 存數目龐大的測驗訊息、各種測驗、施測記錄及測驗分數,不斷更新的運算速度 可快速達到系統要求,因此在現代科技的推波助瀾下,電腦化適性測驗的發展愈 趨成熟。
二、適性測驗的類型
1900 年初期,Binet-Simon 在法國所發展的智力測驗,可以說是第一個適性測 驗(Weiss, 1983)。1951 年,Hick 整理出適性測驗的基本原則(De Ayala, 2009)。
兩階段式測驗 (two-stage testing)
適 性 測 驗
策 金字塔測驗
略 (紙筆或電腦施測)
固定分支選題策略 彈性測驗 (fixed-branching item selection)
分層適性測驗 多階段式測驗
(multistage testing)
貝氏估計策略 (電腦施測)
變化分支選題策略
(variable-branching item selection) 最大訊息量策略 圖 2-3 適性測驗策略
依據文獻指出適性測驗因分支結構的策略差異而構成不同的類型,主要分為 兩階段式測驗(two-stage testing)與多階段式測驗(multistage testing)兩大類(圖 2-3)。
在多階段式策略下可分為固定分支模式(fixed-branching )與變化分支模式
(variable-branching)。模式取決於試題之選擇方式,分為以數學為基礎的模式稱為 變化分支選題策略(variable-branching item selection),以結構為基礎的模式稱為固 定分支選題策略(fixed-branching item selection) (De Ayala, 2009)。固定分支策略又 可分為:金字塔測驗(pyramidal testing)、彈性測驗(flexilevel test)、及分層適性測驗 (stradaptive testing),可以使用紙筆或電腦施測。變化分支策略以試題反應模式為 其理論基礎,可分為貝氏估計策略與最大訊息量策略,主要使用電腦來進行施測。
De Ayala(2009)於書中指出 Cleary, Linn, & Rock 提出 two-stage test、Lord 提出 flexilevel test、Weiss 提出 stradaptive test 及 Larkin & Weiss 與 Lord 提出 pyramidal test 等適性測驗策略,玆描述如下。
(一) 兩階段適性測驗
兩階段適性測驗(two-stage adaptive testing),包括一個共同測驗及一個或一個 以上之分別測驗,共同測驗與分別測驗之間具有階層關係如圖 2-4。兩階段適性測 驗是一種分測驗與分測驗之間分支策略結構,第一部份共同測驗目的只是作為第 二部份的參考,稱之為「定路線測驗」(routing test),含有不同難度水準的測驗。
定路線測驗結果可對受試者能力進行粗略的評估,再依此評估給予適合受試者能 力之第二部份分別測驗。分測驗的試題通常由簡單容易至困難成線性排列,施測 的進度亦同。兩階段測驗中的分別測驗可用較少的試題對受試者提供較多的訊 息,進行施測的試題數目及所花的時間比傳統測驗少。
容易 困難
圖 2-4 兩階段適性測驗
(二) 金字塔型適性測驗
金字塔型適性測驗又稱為樹狀結構型(tree-structure)適性測驗,此種施測方式 採固定分支選題策略,選題以單一試題為選擇單位,受試者在任一階層只能對一 道試題作答(圖 2-5),位於金字塔頂端第一階層的試題(第 1 題)為中等難度,受試者 由該試題開始作答,如果答對,接下來就作答第 3 題(比第 1 題難),反之,如果第 1 題答錯,那接下來就作答第 2 題(比第 1 題簡單),回答完第二階層的試題之後,
繼續用相同的選題策略作答其餘各階層的試題。
以 15 階層其總題數為 120 題的金字塔測驗而言,每位受試者只需要作答 15 題。金字塔測驗是適性測驗中最常用的測驗方式。
綜而言之,金字塔型測驗的優點是(王寶墉,1995):
1. 充分運用貝氏策略。
2. 方便加入鑑別度參數及猜測度參數。
3. 適用於團體測驗。
+
+
+ +
容易 困難 圖 2-5 金字塔型適性測驗
1
2 3
(三) Robbins-Monro 適性測驗
Robbins-Monro 適性測驗與金字塔型適性測驗的施測流程極為類似,但架構上 稍有差異。除第一階層試題數目相同外,就同一階層試題數目而言,Robbins-Monro 適性測驗所需要的試題數目比金字塔型適性測驗多,第 K 階層需要的試題數為
2k (圖 2-6)。但在同一等級上,Robbins-Monro 所需的階層數少於金字塔型適性1 測驗,其優點在於能力估計時,能夠快速地達到收斂。所以從架構而言,
Robbins-Monro 適性測驗亦可稱為「減階增題式」程序。
+
+ +
+ + + +
容易 困難 圖 2-6 Robbins-Monro 適性測驗
(四) 彈性測驗(flexilevel test)
依彈性測驗策略,一個題數為 K 的彈性測驗,需要有 2K-1 的總題數。如表 2-1 所示,總題數為 75,每位受試者施測的題數為 38,即 K=38。假定所有試題已 依難度排列,題號越小,試題越簡單,題號越大,試題越難。
試題分成兩個分測驗群組,左分測驗為試題較簡單的群組,右分測驗為試題 較難的群組。左分測驗裡,試題難度由難至易由上往下排列,而右分測驗,其試 題難度則由易至難由上往下排列。
受試者一開始先接受中等難度之試題(例如第 38 題)施測,然後依其作答反應 之對或錯,來分別將其分枝至較難或較易的試題。如果答對 38 題,接下來是 39 題,如果答錯 38 題,接下來就是 37 題。只要是答對,接下來就是較難且尚未施 測的試題,答錯接下來就是較簡單且未施測的試題。測驗程序反覆進行到預設題 數的終止點便可停止施測。高能力者右邊答對較多,能力較低者左邊答對較多。
表 2-1 彈性測驗
中難度,第 38 題 01 較易題,第 37 題
02 較易題,第 36 題 03 較易題,第 35 題
04 較易題,第 34 題 漸 05 較易題,第 33 題 容
: 易
:
:
:
: 33 較易題,第 05 題 34 較易題,第 04 題 35 較易題,第 03 題 36 較易題,第 02 題 37 較易題,第 01 題
01 較難題,第 39 題 02 較難題,第 40 題 03 較難題,第 41 題
04 較難題,第 42 題 漸 05 較難題,第 43 題 困
: 難
:
:
:
: 33 較難題,第 71 題 34 較難題,第 72 題 35 較難題,第 73 題 36 較難題,第 74 題 37 較難題,第 75 題
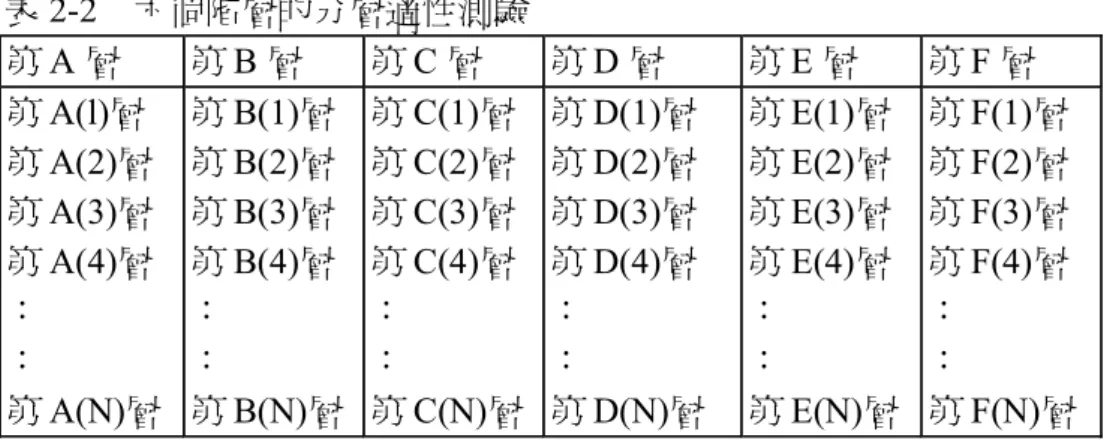
(五) 分層適性測驗(stratified-adaptive 或 stradaptive test)
如表 2-2 分層適性測驗是將測驗試題依其難度分為 K 個階層,每個階層的試 題難度相近,試題難度則由左至右遞增,鑑別力參數依序排列。
施測時可從任一階層的某一題開始(如從最中間階層開始),如果答對,接下來 就施測難度高一階層、尚未施測的試題。分層適性測驗每施測一題即換一階層。
則依其作答之「對」或「錯」而分支至左(較簡單)或右(較難)之階層,再從階層中 挑選受試者未曾做過之試題予以施測。測驗程序反覆進行,直至到達某一事先預 設之題數為止。
表 2-2 六個階層的分層適性測驗
第 A 層 第 B 層 第 C 層 第 D 層 第 E 層 第 F 層 第 A(l)層
第 A(2)層 第 A(3)層 第 A(4)層
:
: 第 A(N)層
第 B(1)層 第 B(2)層 第 B(3)層 第 B(4)層
:
: 第 B(N)層
第 C(1)層 第 C(2)層 第 C(3)層 第 C(4)層
:
: 第 C(N)層
第 D(1)層 第 D(2)層 第 D(3)層 第 D(4)層
:
: 第 D(N)層
第 E(1)層 第 E(2)層 第 E(3)層 第 E(4)層
:
: 第 E(N)層
第 F(1)層 第 F(2)層 第 F(3)層 第 F(4)層
:
: 第 F(N)層
(六) 試題最大訊息量(maximum information, Imax)
試題訊息曲線(Item Information Curve)圖(如圖 2-7 )的兩個主軸是試題訊息量 及能力二者,其外觀看似一條常態的鐘形對稱分配曲線,而試題訊息曲線最高點 的位置,對應在試題訊息量軸上便是試題最大訊息量(maximum information, Imax),對應在能力軸上則是試題所能最精確測量或估計出的受試者能力參數的估 計值。
圖 2-7 三參數試題特徵曲線及試題訊息曲線圖
假如電腦適性測驗的選題策略是最大訊息量,電腦會根據能力估計值,從現 有的測驗題庫中計算出每一試題的最大訊息量。一般而言,最大訊息量的試題能 對受試者的能力估計最有效。所以試題最大訊息量在個別試題上是“絕對"的最 大訊息量,但在電腦適性測驗的選題策略中,最大訊息量是“相對"的最大訊息 量。
上述各種適性測驗策略雖然各有其優點,但是在選題策略及計分的方法上仍 存有諸多的困難。在現代適性測驗的學術研究上,金字塔型適性策略運用的機會 較廣而且易於施行。電腦化適性測驗策略運用上,除使用金字塔型外,最大訊息 量及貝氏試題選擇法是最常使用之策略。
三、試題反應理論與電腦化適性測驗
根據文獻指出難易適中的試題,對估計受試者能力的精確性最為有效。而一 份測驗卷試題難度,很難滿足或適合每位受試者的能力水準,因此要使試題難度 隨受試者能力的不同(即個別差異化)而調整測驗方式,唯有採用適性測驗才有 施行之可能。由於試題反應理論中的試題反應模式,不受施測不同試題影響的能
力估計值(具有試題獨立的估計特性),也就是說不同的受試者考不同的試題,只
要試題性質相同,不同能力受試者之能力估計值可以被精確的估計出來,因此可 以互相比較。
在電腦化適性測驗裡,呈現給受試者的試題順序,是依據受試者在前一道(組) 試題上的表現好壞來作決定。在開始進行測驗時,先由電腦系統隨機呈現一道(組) 試題,在受試者作出反應之後,電腦便根據這些作答反應組型資料,估計出受試 者的初步能力估計值(initial ability estimate);然後,電腦會根據這能力估計值,從 現有的測驗題庫中挑選出最能對此能力水準之估計發揮最大貢獻的試題,一般而 言,能夠提供最大訊息量的試題,對受試者能力估計最有效。當呈現這試題給受 試者作答後,新的能力值便可估計出來;這種施測過程一直繼續下去,直到事先 預定之施測題數已測完、達到某種預定的能力估計值之測量精確性(即標準誤)、
或某種事前決定之標準已獲得為止,這時適性測驗便可終止。
由於適性測驗是根據受試者作答的好壞,下一個要呈現給受試者作答的試 題,便是對受試者能力估計精確性最有貢獻的最大訊息量之試題。因此,測驗的 長度便可以縮短,並且也不會犧牲任何的測量精確性;因為對於高能力的受試者,
可以不必給他相當容易的試題作答,對於低能力的受試者,也可以不必給他極度 困難的試題作答,因為低貢獻的試題對受試者能力水準之估計而言,只能提供極 為有限或絲毫沒有幫助的訊息。
四、電腦化適性測驗的施測條件
以試題反應理論為架構的適性測驗,是要配合試題的難度及受試者的能力水 準。為了達成這項目的,我們必須擁有一個已知每道試題特徵的試題庫,以便從 中挑選出適當的試題進行施測。
根據文獻綜合整理,電腦程式系統,要能完成下列的目的,才能達到精確施 行適性測驗的目標:
1.根據受試者的作答反應組型,估計受試者的能力值。
2.根據適性測驗的選題策略,有效挑選測驗題庫的試題給受試者作答。
3.受試者達到終止標準時,系統能自動停止施測。
4.在測驗完畢後,能夠準確估計受試者的能力值或轉換成績。
5.能即時給予受試者測驗的暫時結果。
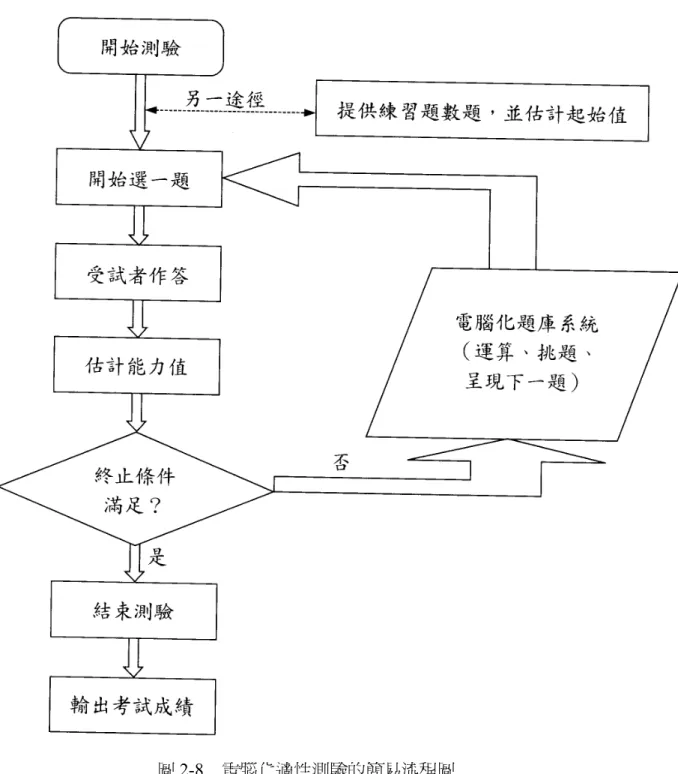
依余民寧(2009)(如圖 2-8)的電腦化適性測驗施測過程,主要包括的六個步驟為 挑選試題反應模式、準備電腦化題庫、起始策略(測驗起點)、繼續策略(選題方式)、
運算策略(能力估計)、終止策略(終止標準)等。並簡要描述如下:
1.決定試題反應模式:以選擇題型的測驗而言,三參數對數型模式是最常選用的模 式。
2.準備電腦化適性測驗題庫:電腦化適性測驗的發展首先要有根據試題反應理論所 建立的試題及試題參數特徵,並儲存在題庫中,題庫中之參數必須以共同量尺 來表示,才能有一致的單位。
3.起始策略:測驗起點(起始選題):應該先考那一道試題,是適性測驗所需面臨的 一件重要抉擇問題。常用的方法有:1.自難度適中的試題中隨機抽取一道試題;
2.完全隨機抽取一道試題;3.先調查受試者的背景,然後再決定出那一類的試題。
4.繼續策略:選題方式(適性選題):一般而言,常用的選題策略有三種:1.挑選能 對受試者能力估計提供最大訊息量的試題;2.利用貝氏試題選擇法,將受試者能 力分配看成是某種事先分配,計算受試者答對或答錯未用到的試題之事後變異 數,再挑選能夠使這種受試者能力事後分配之變異數為最小的試題,作為施測 的試題;3.挑選難度最接近受試者現階段能力估計之試題。
5.運算策略:能力估計:在適性測驗裡,受試者每答對一道試題,就得重新估計 一次受試者的能力值。而最大近似值估計法和貝氏估計法是適性測裡常用的兩 種能力估計方法。最大近似值估計法的估計效能很好,但遇到題數少或估計值
圖 2-8 電腦化適性測驗的簡易流程圖
______________________________________________________________________
資料來源:出自余民寧(2009:268)
無法收斂時,都會產生很大的問題;貝氏估計法雖能克服這些困難,但對事前 分配的假設如果不當的話,卻會產生有所偏差的能力估計值。
6.終止策略:終止標準:終止適性測驗的方法,於施測前便定下標準,和適性選題 與能力估計有很密切的關聯。若以試題最大訊息量作為選題標準,只要累積已 測過之試題的訊息量,到達某種事先預定的標準後,便可終止。若以貝氏估計 法來選題,則可以估計能力之變異數小到某個預定的標準時,便可終止施測。
此外,也可以預設施測試題的上限及時間,只要達到終止標準,即使尚未達到 預定的標準,也可以終止施測,以避免無止境施測下去,浪費受試者及機構的 寶貴時間。
五、能力估計
(一) 最大概似估計法
在試題參數為已知情況下,只要得知受試者作答反應組型,即可針對某個固 定能力值,輕易算出其精確的近似值函數。凡是能夠使受試者的對數近似值函數 達到最高點的θ值,即被定義為該受試者θ值的最大概似估計值(maximum
likelihood estimator, MLE)。若把對數近似值函數與能力值θ畫成一個座標圖的話,
則對數近似值函數中的最高點,所對應到θ能力軸上的一個點(見圖 2-9 所示),該 點即為θ的最大概似估計值,記作(余民寧,2009)。
最大概似估計值無法由方程式中直接求出,必須求出近似值方程式的一、二 階導數,再套入 Newton-Raphson 遞迴估計程序(iteration procedure),才能把參數的 最大概似估計值求出。
當我們要進行受試者能力估計時,所謂的 Newton-Raphson 遞迴估計程序,其 實是在求解下列方程式的解:
1
m m
h
m
m
0,1, 2,....,2 2
ln
ln
a m
a
L h
L
1
( )( )
ln
(1 )
n
i ia ia ia i
a i ia i
a u P P c
L D
P c
,2 2
2
2
2 2 2
1
( )( )
ln
(1 )
n
i ia i ia ia i ia
a i ia i
a u c P P c Q
L D
P c
其中,
是指第 m 次的θ估計值,而
m
m1則是指第 m+1 次的θ估計值,所以,上 述方程式,是指在遞迴估計程序中,每下一次的估計值,是前一次估計值與一項微量校正項
h 之間的差值。而且,這個估計程序必須不斷進行,直至前後兩次估
m
圖 2-9 對數近似值函數與能力估計值之間的關係
______________________________________________________________________
資料來源:出自余民寧(2009:105)
計值之間差值的絕對值 hm
m1
m
0.001小於某個事前決定好的預設值(通 常都設 ε=0.001) 止,這時候,我們便說該估計值已經達到收斂的程度,而
m1便 是該估計方程式之解。在能力值估計過程中,必須不斷地遞迴進行,一直到估計值達到收斂為止。
用電腦進行運算,當估計值能夠收斂時,這估計值便是「收斂函數」(convergent function),這時候電腦程式一定可以估計出一個解答;假如估計值無法達到收斂 時,則此估計值便是「發散函數」(divergent function),電腦程式便會因為無法估 計出一個解答而無止境運算下去,直至當機為止。當估計值達到收斂時,已經收
斂的估計值
m1,即稱作「最大概似估計值」。在試題參數為已知的前提下所進行的能力值估計,則稱作「有條件的最大概似估計法」(conditional maximum likelihood estimation of ability)。
當受試者接受測驗的試題數目少、作答反應組型特異(aberrant)(即受試者答對 了相當困難和有鑑別度的試題,但是答錯了相當容易的試題),而且呈現非常態分 配時,程式在運算近似值(或對數近似值)函數時,因為所使用的起始值不同,而使 近似值(或對數近似值)函數收斂到「局部最大值」(local maximum),而不是收斂到
「整體最大值」(global maximum)的現象,此時的最大概似估計值,也就不會是一 個正確的估計數值(余民寧 2009)。Lord(1977)認為,只要測驗的題數不少於 25 題 的話,以那一道試題做為起點的影響不大。
(二) 能力量尺的轉換
能力量尺的轉換方法有兩大類:直線轉換(liner transformation)與非直線轉換 (non-liner transformation)。一種常用的轉換,即是將受試者的原始觀察分數(raw scores)除以受測總題數,以轉換成真實的百分比正確分數(true proportion correct score),並作為受試者領域分數(domain score)π之估計值:
1
( )
n
i
t Pi
t
n其中,t 為真實分數,π為領域分數,n 為總試題數。π的值域介於 0≦π≦1,如 同百分比分數介於 0 到 100%之間。
當受試者獲得極端分數時,即得分為 0 分(即全部答錯)或滿分(即全部答對) 時,最大概似估計法無法對能力值作出估計。雖然此時無法使用最大概似估計法 估計出精確的能力值,但是可以使用真實分數和領域分數的上下限數值(0 或 1),
作為受試者得分的依據(余民寧,2009)。
六、電腦化適性測驗的評價
電腦化適性測驗是利用電腦來施行測驗、處理選題、計分、能力估計等問題 的一種測驗方式。它的優點有下列幾項(吳裕益,1990;王寶墉,1995;余民寧,
2009):
1.能加強測驗的安全性,減少洩題之可能性。
2.對於試題類型的選擇更具彈性,能採用較新的題型。
3.無需使用答案紙。
4.縮短測驗長度、節省考試時間、減低監試的時間。
5.有個別測驗所具有的優點,能得到作答速度及過程等資料。
6.利用電腦建立試題和編製測驗,容易從題庫中找出並刪除不良的試題。
7.測驗過程靈活,具標準化過程,易於重覆施測,能及時提供回饋。
8.評量準確度高,計分方面減少誤差,並提供立即的計分和報告成績。
9.施測程序標準化減少測量標準誤。
10.依據需求來進行施測,試題難度配合受試者程度,適合每位受試者的作答速度。
11.降低某些受試者的考試挫折感,對某些受試者的作答動機有正面影響。
雖然電腦化適性測驗有上述的優點,但他也有不足之處,科技的發展雖日新
月異,但電腦化適性測驗的缺點也沒有多大的改變,吳裕益(1990)認為電腦化適性 測驗的缺點有:必須在電腦設備之下,依順序作答,不能跳答,就目前而言,仍 有某些題型無法使用(如申論題、作文等)。能力分數解釋較為困難。以及需要使用 者了解試題反應理論。同時,在結果解釋部份,受試者及家長可能無法完全理解 並接受測驗結果,特別是考試試題及題數不同,所得分數如何比較的問題。
七、國內適性測驗相關研究統計
統計 2004 年至 2010 年五月期間,國內博碩士論文研究以適性測驗為題的 72 篇中,以討論主題分類,數學有 30 篇,英文 2 篇,國文 1 篇,自然 1 篇,題庫 2 篇,演算法 6 篇,選題策略 4 篇,曝光率 12 篇,多向度 4 篇,實用性研究 3 篇,
其他基礎研究 13 篇,以年份分類,2004 至 2010 年則為 21、6、17、16、11、1、
0 篇,國內適性測驗研究以國小數學 28 篇為主,國中 2 篇,高職 1 篇;基礎研究 則以選題策略、曝光率共 16 篇為主。
由上述的統計數據中可發現,基礎研究及實用性研究約各佔一半,而實用性 研究以國小數學為主,高等教育及知識類佔極小數。基礎研究則以曝光率為主。
八、國外適性測驗在醫學上的應用
目前在世界各國,比利時(Belgium)於近年對適性測驗在一般醫學上的應用有 一些試驗性研究(Roex & Degryse, 2004),而加拿大的醫師考試則有部份使用適性測 驗(Huh, 2009),再者,根據韓國的 National Health Personnel Licensing
Examination(NHPLE) of the Republic of Korea 資料顯示,於 2008 年開始該機構有 意導入適性測驗於執照考試,並進行導入前之人才培訓及推廣工作(Huh, 2008)。
綜言之,本研究文獻探討的目的在於探討題庫建置中試題參數估計的基礎、
試題品質的分析、適性測驗系統選題策略的選擇及能力值估計之探究,以為研究 之基礎。