國⽴臺灣⼤學⽂學院翻譯碩⼠學位學程 碩⼠論⽂
Graduate Program in Translation and Interpretation
National Taiwan University Master Thesis
聲⾳語調對聽眾注意⼒及中⽂同步⼝譯之影響 The Effects of Intonation on Listeners’ Attention and
Mandarin Chinese Simultaneous Interpreting 莊英里
Cristina Chuang 指導教授:郭貞秀博⼠
Advisor: Chen-Hsiu Grace Kuo, Ph.D.
共同指導教授:吳敏嘉教授 Co-advisor: Min-Chia Michelle Wu
中華民國 108 年 11 ⽉ November 2019
Acknowledgement
I would like to first like to express my deepest gratitude to my advisors, Grace and Michelle for all the help and support they have given me during this time. Thank you, Grace for your guidance and support despite your busy schedule. I have always enjoyed our meetings and you are truly a grace of God. Thank you, Michelle for giving me all the resources and help that I needed to finish this work. You changed my life in so many ways and I can never be grateful enough.
I would also like to sincerely thank Dr. Chia-chien Chang and Dr. Ya-lin Chen for their insightful comments and encouragement during the oral defense and throughout the writing process. Your passion for research is truly admirable and inspiring.
I truly appreciate the generosity that Prof. Danny Huang, Prof. Shan-shan Wang, and Amy Wu have shown me this year. Without your help and contribution, I would have never recruited so many participants.
Thank you, Jacky Siu and David Chuang for offering me your advice and experience. I am truly thankful to have had the helping hand of such brilliant thinkers.
Last but not least, I thank God for his abundant provision, for he gave me all the help and love I needed during what ended up being one of the toughest times of my life.
Thank you for placing people who believed in me when I could not believe in myself.
Thank you for giving me the wisdom and courage to strive forward when I only felt like giving up. Without you, I would not have been able to come this far.
Abstract
During the simultaneous interpreting (SI) process, interpreters are often not
visible to the audience and intonation is the most salient non-verbal element for
interpreters to convey the speaker’s message. Despite intonation’s crucial role, existing
research on intonation in the interpreting field have mostly focused on how intonation
affects the audience’s perception of the interpreter’s ability. There is very little
investigation about the role of intonation in speech communication and its effect on
listeners’ attention. The objectives of this research are to (1) uncover factors underlying
intonation in SI and study whether intonation can serve as a contextual cue in
Treisman’s attenuation theory (1960) and increase listeners’ attention; (2) investigate
how intonation may benefit future interpreting training and practice. This paper includes
a quantitative study (Part 1) and a qualitative study (Part 2). Part 1 is a dichotic test
participated by 132 subjects from National Taiwan University to explore whether a
lively intonation (wider F0 range) can enhance listening attention in Mandarin Chinese.
Part 2 is a questionnaire investigating 29 professional interpreters’ subjective evaluation
of intonation’s role in interpreting, the effects of monotony on their performance, and
The findings of this research prove that intonation can significantly enhance
listeners’ attention in Mandarin Chinese, especially for statement sentences. Results
also reveal that the majority of interpreters acknowledge intonation’s significance as a
non-verbal cue and believe it is crucial for effective delivery.
This research offers insights into the practice and training of interpreting,
establishing why and how intonation plays a decisive role in Mandarin Chinese SI.
Interpreting trainers should factor in intonation when selecting material for classroom
instruction in order to raise intonation awareness and explore the possibility of using
intonation as a strategy while performing Mandarin Chinese SI.
Key words: Simultaneous interpreting, intonation, monotony, listening attention,
contextual cue, Mandarin Chinese prosody
摘要
⼝譯員的語調(intonation)是同步⼝譯過程中傳達講者信息的重要⾮語⾔交際。
過去相關研究⼤多著重於⼝譯員的語調如何影響聽眾對於其⼝譯品質的評價,並
未探討語調在此過程中所扮演的⾓⾊以及其如何影響聽眾注意⼒。本研究指在了
解語調是否可作為崔斯曼在減弱理論(1960)中所提出的的⼀種情境提⽰(contextual
cue)提升聽眾注意⼒及語調如何影響⼝譯教學及實務⼯作。本研究第⼀部分為⼀
個雙⽿聽覺測試,共有 132 名受試者參與,實驗⽬的旨在了解語調變化(基本頻率
範圍)是否可以提升中⽂聽眾之注意⼒。第⼆部分則是針對 29 名專業⼝譯員進⾏
線上問卷調查,了解⼝譯員對於語調的重視程度、單調的講者是否會對其⼝譯表
現造成影響及⾯對此類型講者所採取的⼝譯策略。研究結果指出變化較為豐富的
語調可以顯著提升中⽂聽眾之注意⼒,尤其是增加其對於敘述句(statement
sentences)的理解及⼤部分⼝譯員都同意聲⾳語調是⼀個重要的⾮語⾔交際,能
夠協助其有效溝通。本研究透過證實聲⾳語調對於中⽂同步⼝譯之重要性為⼝譯
教學及實務⼯作帶來新的觀點:⼝譯教學⼯作者在篩選練習材料可以將講者的聲
⾳語調納⼊考量、提升學⽣對於聲⾳語調的意識,並將聲⾳語調作為⼀種⼝譯策
略。
Table of Contents
Chapter One Introduction... 1
1 3 4 1.1 Intonation in Simultaneous Interpreting... 1.2 Motivation... 1.3 Objective of the Study... 1.4 Organization... 5
Chapter Two Literature Review... 7
7 12 14 20 2.1 Intonation... 2.2 Intonation in Interpreting... 2.3 Intonation’s effect in Mandarin Chinese... 2.4 Intonation and Attention... 2.5 Summary... 23
Chapter Three Part 1... 25
3.1 Method... 25
3.1.1 Procedure...25
3.1.2 Material... 27
3.1.2.1 Stimuli Design... 27
3.2 Procedure... 30
3.3 Data Analysis... 31
3.4 Subjects... 31
3.5 Hypothesis... 32
3.6 Results... 33
3.6.1 Group scores for dichotic test... 34
3.6.2 Group Scores for Emotional Texts and Non-emotional Texts... 36
3.6.3 Observed common group mistakes... 43
3.6.4 Part 1 questionnaire results... 45
Chapter Four Part 2... 49
4.1 Method... 49
4.1.1 Procedure... 49
4.1.2 Material... 49
4.1.3 Subjects... 50
4.2 Results... 52
4.2.1 Interpreters’ View on Intonation’s Role in Mandarin Chinese
4.2.2 Monotony’s Effect on Interpreters During SI... 55
4.2.3 Strategies Applied when Interpreting Monotonous Speakers... 56
4.2.4 Should Interpreting trainers focus more on voice training?... 57
Chapter Five General Discussion... 59
59 65 69 5.1 Traffic Jam Theory: How Intonation Affects Listeners’ Attention.. 5.2 How Intonation Affects Listeners’ Attention in SI... 5.3 How Interpreters Perceive the Role of Intonation in Mandarin Chinese SI... 5.4 Implications of the Study ... 71
Chapter Six Conclusion... 76
76 78 6.1 Answering the research questions ... 6.2 Contributions of the study... 6.3 Suggestions for future research... 78
80 88 90 References... Appendix 1 Rating Survey for Part 1... Appendix 2 Passages used for Part 2 ... Appendix 3 Part 1 Questionnaire... 92
Appendix 4 Part 2 Questionnaire... 95
List of Figures
Figure 1. F0 of the final Tone2 (S: Statement; Q: Question) (Yuan, 2006, pg.26) ... 17
Figure 2. PRAAT graph of a lively version of “森林裡住著一隻狐狸” ... 28
Figure 3. PRAAT graph of a monotonous version of “森林裡住著一隻獼猴” ... 29
Figure 4. Average scores for Group LM, LL, ML, and MM ... 35
Figure 5. Average scores for Group LM and Group LL ... 35
Figure 6. Average score of Group ML and Group MM ... 36
Figure 7. Average group score of emotional texts and non-emotional texts ... 37
Figure 8. Average group score of question sentences. ... 38
Figure 9. Average group score of statement sentences. ... 39
Figure 10. Average group score of emotional texts. ... 40
Figure 11. Average group score of emotional texts with the emotion joy. ... 41
Figure 12. Average group score of emotional texts with the emotion sadness. ... 41
Figure 13. Average group score for emotional texts with the emotion fear. ... 42
Figure 14. Average group score for emotional texts with the emotion anger. ... 43
Figure 15. Subjects’ responds regarding intonation and their will to listen. ... 45
Figure 16. Experienced interpreters’ years of practice ... 51
Figure 17. Novice interpreters’ years of practice ... 51
Figure 18. Ratings of Essential Elements in SI ... 52
Figure 19. Ratings of Intonation’s role in SI ... 53
Figure 20. Diagram illustrating how subjects in Group LM process signals. ... 62
Figure 21. Diagram illustrating how subjects in Group LL process signals. ... 63
Figure 22. Diagram illustrating how subjects in Group MM process signals. ... 65
Figure 23. Group scores for the different emotional texts. ... 68
List of Tables
Table 1 The acoustic features of the four basic emotions obtained from Yuan (2002)'s
studies. ... 18
Table 2 The F0 features of English and Mandarin Chinese speech in the four basic
emotions (anger, fear, joy, sadness) obtained from Murray et al.’s and Yuan’s
studies. ... 18
Table 3 The different tests performed by the groups ... 26
Table 4 The F0 values of the lively vs. monotonous versions. ... 29
Table 5 The means and standard deviations of the monotonous and lively passages .... 30
Chapter One Introduction
1.1 Intonation in Simultaneous Interpreting
When simultaneous interpreting (SI) first debuted in the Nuremberg trials in 1945, it was shrouded with mystery and the world was fascinated by how interpreters could transfer one language to another in an effortless manner almost instantaneously as the speaker spoke (Seeber, 2015). Since then, an increasing number of national and international organizations have relied on SI to operate and communicate on a daily basis. In a
simultaneous interpreting setting, interpreters usually sit inside a booth and deliver rendered messages to the audience via a microphone while the audience listens through headsets. In most cases, the audience solely relies on the interpreter’s verbal language and paralanguage in order to comprehend the speaker’s speech. Since interpreters are often not visible to the audience, intonation, as one of the prosodic cues, is the most commonly used non-lexical feature to help interpreters deliver the emotional or attitudinal status of the speaker (Poyatos, 1997).
The terms “prosody” and “intonation” are often used interchangeably since prosody is generally regarded as a complex system of features including intonation (Cutler & Ladd, 1983). As Seeber (2015) succinctly defined, “intonation is the melody of a sentence that surpasses its grammatical form (p. 69).” Despite the lack of consensus on intonation’s definition due to its complex relation with other prosodic features such as rhythm and speech rate, most interpreting research has defined intonation as the pitch contour of an utterance (Ahrens, 2004; Seeber, 2001). Prosody, on the other hand, involves changes in fundamental frequency (F0), duration and amplitude. All these components interact with
2
one another to create a final product that surpasses the whole of its units (Beckman 1986;
L. C. Nygaard & D. S. Herold, L. L, 2009). In line with most of the previous work, intonation will be defined as the change in fundamental frequency (a.k.a. F0 range; the difference between the maximum F0 and the minimum F0) which is the major acoustic measurement in this paper and is used to facilitate the design of the first experiment (Holub, 2010; Langlet, 2012).
Researchers from the fields of linguistics have long studied the diverse functions and the role of intonation in speech production. Linguistic research has shown that acoustic features in non-lexical speech have a greater impact on listeners’ comprehension of speech attitude and emotion compared to verbal communication (Mehrabian & Wiener’s, 1967).
Intonation provides semantic information, conveying tense, emotion, and mood (Halliday, 1967; Shlesinger, 1994) and is perceived as a contextual cue, aiding participants to
comprehend the relationship among different actors, the intentions and emotions involved, and the context of the conversation (Steling,1992). Moreover, intonation is regarded as an integral part of communication since it provides grammatical functions to help listeners differentiate the syntactic structure of the sentence. Despite intonation’s crucial role in facilitating comprehension in speech communication, it has received surprisingly little focus in the field of interpreting (Holub 2010, Seeber 2015, Langlet 2013).
The existing literature studies on intonation in the interpreting field have mostly focused on how intonation affects audience’s perception of the interpreter’s ability (Moser, 1996). Little research has been done to investigate intonation’s role in the communication between the interpreters and the audience. Among the few studies on intonation’s role in SI, the empirical studies of Collados Aís (2001), Holub (2010), Holub and Rennet (2011) and
Lenglet (2013) have contributed to the ways in which intonation may affect listeners’
comprehension. Collados Aís (2001) investigated the impact of monotony, or the lack of intonation, on listeners’ ability to recall information by creating variations of the same text through reciting it with different levels of liveliness. Holub (2010) utilized the software PRAAT to replicate a monotonous version of the original text by flattening the F0. The results from both studies suggested a tendency of monotonous text hindering listeners’
comprehension. In addition, Holub and Rennet’s (2011) follow-up experiment revealed that intonation had more impact on listeners’ comprehension than fluency.
1.2 Motivation
In spite of the existing studies, the lack of consensus on how intonation and comprehensibility were defined in each study leaves the role of intonation in SI yet inconclusive. In addition, the lack of observation studying intonation’s relation with listeners’ comprehension show that almost none of the existing literatures have focused on explaining the mechanism behind such findings. Listening comprehension is a highly complex cognitive process; therefore, a more focused research investigating how, and to what extent, intonation may affect listeners’ comprehension would be necessary to avoid overgeneralized claims.
It is also important to mention that most of these experiments were conducted using stress-timed languages such as English and German (Holub,2010; Seeber, 2015) and there seems to be no comprehensive literature investigating the relation of intonation and comprehension in Mandarin Chinese within the interpreting field. Mandarin Chinese is a tonal language through which tones carry lexical and intonational meanings, hence
4
Mandarin Chinese demonstrates a greater average rate of F0 fluctuation (Eady, 1928).
Since Mandarin Chinese is a syllable-timed language, intonation’s effect on speech acts and discourse effects are expected to be different from those in stress-timed languages. This discrepancy between previous research shows a need for further investigation and data collection in order to understand intonation’s role in listener comprehension in Mandarin Chinese SI.
Attention is a multifaceted concept and psychological research has long studied the process which the perceptual filter screens the stimulus (Broadbent, 1958; Cherry, 1953;
Moray, 1959; Treisman, 1960). Broadbent’s early perceptual theory (1958) suggests that physical traits like loudness and pitch are the prime criteria in selective listening. In follow- up experiments, Treisman (1960) added that psychological factors such as one’s relevance to the message and contextual cues can also lower the threshold for signals to pass through.
If Treisman’s theory (1960) can also apply to a SI setting, then by exploring intonation’s role as a contextual cue may offer significant insight to how intonation affects listeners’
attention.
1.3 Objective of the Study
As previously mentioned, interpreters deliver messages to the audience using verbal language and prosodic cues. One of the most salient features of intonation is being a
contextual cue to help listeners understand the speech (Halliday, 1967; Shlesinger, 1994). It is therefore crucial that interpreters understand how prosodic features in their interpretation may serve as a double-edged sword— aiding them to deliver the message as powerfully as the speaker, or hindering them and altering the meaning of the original text. In spite of the
importance of intonation in speech communication, intonation’s role in listening attention is not completely understood and little research has been done to investigate intonation’s role in Mandarin Chinese in the interpreting field.
In order to fill in the gaps in the existing literature and offer insight for interpreting practice and pedagogical purposes, the current study attempts to address the following questions:
1. Can intonation (e.g., a wider F0 range), serve as a contextual cue as defined in Treisman’s attenuation theory (1960) and help increase listeners’ attention in Mandarin Chinese SI. If yes, then how?
2. How will this study benefit future interpreting training and practice?
1.4 Organization
The present study is divided into five chapters. The first chapter Introduction explains the background of the research and specifies the purpose and importance of the study. The second chapter Literature Review presents an overview of the relevant literature in order to contextualize the research of this paper. The researcher will review studies on intonation, its effect in Mandarin Chinese, and studies related to intonation within the interpreting field. Then, the chapter will briefly discuss psychological studies regarding listening attention to explore the notion of intonation as a contextual cue. The third chapter Part 1 lays out the mechanism, purpose, design, and statistical results for the dichotic test while the fourth chapter Part 2 presents the details and results of a questionnaire investigating interpreters’ views on intonation. The fifth chapter General Discussion provides an analysis
6
and explanation of the data acquired from the quantitative and qualitative research from Part 1 and Part 2 in order to answer the research questions and the sixth chapter Conclusion recapitulates the purpose and importance of the study and highlights how it can benefit future interpreting practice and training.
Chapter Two Literature Review
The existing literature studies on intonation in the interpreting field have mostly focused on how intonation affects audience’s perception of the interpreting quality (see section 2.2 for review). The role of intonation in speech perception and its effect on listeners’ attention remains a relatively unexplored area. The aim of this chapter is to present an overview of the relevant literatures in order to contextualize intonation’s effect on speech production and explore the notion of intonation as a contextual cue. For this purpose, this chapter will include: (1) the notion of intonation and its diverse functions in the process of communication (2) interpreting studies on intonation (3) intonation’s role in Mandarin Chinese (4) the relation of intonation and attention. By building on these studies, this research aims to establish the importance of intonation serving as a contextual cue and explore its various effect on listeners’ attention.
2.1 Intonation
What is Intonation?
Recent studies have focused on prosody and discussed its important role in speech.
As Cutler stated (1997, p.141), “Prosody is an intrinsic determinant of the form of spoken language”. The definition of prosody often varies depending on the purpose of the research.
It is observed that the majority of the studies would define prosody as “the structure that organizes sounds” or “the synonym for pitch, tempo, loudness, and pause” (Cutler, 1997).
The term “prosody” is often used as a synonym for “intonation” since they both involve the measurement of fundamental frequency (F0) acoustically (Holub, 2010).
8
Although intonation has gained significant importance, it is crucial to note that there seems to be no single definition or shared consensus on how to describe intonation due to its varying features (Seeber, 2015). For instance, Beckman (1986) referred to intonation as
“a combination of the acoustic patterns of fundamental frequency, duration, amplitude, segmentation, and articulation”. Hargrove and McGarr (1994:16) viewed intonation as the
“communicative use of pitch”. Shlesinger (1994) characterized intonation with tones (pitch movement) and their features such as duration and speed. Similarly, Ahrens (2005) defined intonation as “the pitch contour of an utterance”. In addition, Seeber (2015) proposes that
“intonation is the melody of a sentence that surpasses its grammatical form”. It is important to acknowledge that intonation is composed of changes in F0, duration, and amplitude; all these components interact with each other to create a final product that surpasses the whole of its units (Crystal,1975). As mentioned before, the terms “prosody” and “intonation” are often used interchangeably due to its common features. Therefore, the most comprehensive definition of intonation is perhaps the definition provided by L. C. Nygaard, D. S. Herold, L. L:
“Prosody is the melody of speech, consists of intonation, rhythm, and relative
loudness and timing of components of an utterance and is instantiated primarily in the acoustic correlates of fundamental frequency, amplitude, and relative duration.” (L. C.
Nygaard, D. S. Herold, L. L, 2009, p.128)
Despite the lack of consensus on intonation’s definition due to its complex relation with other prosodic features, research on intonation within the interpreting field has mostly focused on “the changes of pitch” (Ahrens, 2004; Möbius et al.,1993; Seeber, 2001) or “the contour of fundamental frequency (F0)” in order to “establish correlation between
instrumentally measured frequencies and perceptual judgements” (Seeber, 2015). In line with previous work (Holub, 2010; Ahrens, 2004) intonation will be defined as “the range and variation of F0” in order to facilitate the design of the experiment.
The Effects and Functions of Intonation
In the process of spoken communication, extra linguistic elements such as
expressions, gestures, movements and proxemics provide rich communicative signals to listeners (Fantini, 1995). Studies on the effect of intonation have discovered two important functions of intonation: (1) intonation serves to clarify the structure of spoken language, and (2) intonation provides information on the psychological and attitudinal state of the speaker (Poyatos,1997).
Intonation contour helps the receiver disambiguate syllables, words and phrases.
Observations have showed that children and language learners use syllable duration and intonation contour to identify the syntactic structure of sentences (L. C. Nygaard, D. S.
Herold, L. L. Namy, 2009). For example, the end of a sentence is often marked by a lower pitch, which helps listeners distinguish whether the phrase is complete or not. Intonation also helps listeners differentiate questions from statements. In English, interrogative phrases that elicit either a “yes” or “no” response are often characterized by a rise in intonation in the end while complete statements show a falling pattern in intonation.
Intonation also helps provide information on the psychological state or attitude of the speaker. Prosodic cues help indicate speaker’s intentions and emotion (Bachorowski, 1999;
Scherer, 1994) and they also help listeners identify the speaker’s emphasis or focus in a
10
speech (Cohen, Douaire, & Elsabbagh, 2001; Liu, 1995). A wide range of studies have shown that emotional tone of voice may contribute to the semantic and linguistic
interpretation of words. Among them, Nygaard & Launders’ (2002) experiment discovered that homophones (bridal/bridle or die/dye) spoken with emotional prosody would lead the listeners to interpret words with an emotional meaning rather than a neutral meaning. Their experiment revealed that prosody contributes to the semantic comprehension of words, acting as a communicative signal, which facilitates one’s process of interpreting novel words. Nygaard & Lauders' (2002) experiment concluded that pitch, duration, and
phonation are correlated and paired with specific semantics. As a result, listeners utilize the relation of prosodic features and their associated meaning as semantic cues.
Though the association of intonation with particular meanings is unique to each community, some general rules can still be observed. For example, the pitch range tends to be wider at the beginning of a sentence while narrower and lower towards the end
(Vaissière,1983; Hargrove & McGarr, 1994). A wider pitch range also indicates interest whereas a narrower pitch range implies familiarity with the topic, boredom, or depression (Ladd, 1992; Seeber, 2015). All these examples show how intonation can prove syntactic and semantic meaning in speech communication.
Intonation as a Contextual Cue
Activities which help participants interpret an utterance in a particular scenario are referred as contextualizing language (Auer, 1992). These activities may include speech, mood, modality, topic, as well as the social relationship between speakers. Contextual cue is therefore defined as the mean which helps speakers contextualize language (Auer, 1992;
Tzeng et al.,2018). Though there is a wide range of studies related to contextualization, studies on non-lexical contextual cues like prosody and linguistic variations are most commonly explored and investigated.
It is observed that intonation acts as a formal cue and helps participants comprehend the relationship between different participants and also the intentions, emotions, and atmosphere of the conversation. These information help participants interpret the conversation in a more holistic manner and act as signals to highlight the contrast or sameness in speech; therefore, attracting participant’s attention to the cohesive relation of the conversation (Levinson, 2003; Steling, 1992). Intonation, as a contextual cue, acts like
“a knot in the handkerchief as a formal reminder of something” as Levinson (2003) succinctly defined.
Similarly, many early findings in psycholinguistics also highlight the role of prosodic features in speech recognition. Research has shown how a string of nonsense syllables is easier to recall if presented with sentence prosody than without (Cutler, 1997; Epstein, 1961). Furthermore, grammatical strings are only easier to shadow than ungrammatical strings if they possess sentence prosody (Cutler, 1997; Martin, 1968). Other research also found that nonsense utterances could be recalled and recognized more accurately if they were spoken with prosody, suggesting that prosodic features may “form part of the memory representation” which in turns helps listeners form the input (Speer et al.,1993; Culter, 1997). All the research has shown that prosody is crucial to speech communication and that prosody helps convey messages more efficiently (Cutler,1997).
12
2.2 Intonation in Interpreting
Intonation is an extensively studied subject in linguistics and psychology yet it has received surprisingly little interest in the field of interpreting. The studies of intonation in the interpreting field have mostly focused on how intonation may affect audience’s perception of the interpreter’s professional ability (Collados Aís, 1998; Moser 1996, Seeber, 2015; Lenglet, 2012;Zwischenberger, 2010). Only few authors conducted research related to prosody, or intonation in SI (Collados Aís, 2001; Holub, 2010; Seeber, 2015).
Moreover, the number of research examining the link between intonation and attention is even more limited.
Collados Aís (2001) designed a ten-minute source text in German and then made three versions of translation in Spanish: one with lively intonation and sense inconsistencies, one with lively intonation without sense inconsistencies, and one monotonous version without sense inconsistencies. Forty-two experts and fifteen interpreters were randomly divided into three groups to listen to one of the three versions and asked to rate the quality of the
interpretation and complete a comprehension test related to the content they heard.
Collados Aís discovered that the lively interpretations (with or without sense consistencies) received a significantly higher rating than the monotonous interpretation and this finding revealed that listeners tended to value intonation over accuracy. Though there was no significant difference between the comprehension score of the monotonous group and the two lively groups, Collados Aís claimed that the difference in scores between the groups suggested how monotonous intonation might negatively impact listeners’ attention.
However, the lack of acoustic measures and statistical data left this conclusion inconclusive.
Similarly, Holub (2010) investigated the impact of intonation on listeners’
comprehension and assessment of SI by simulating a real-life conference. She selected a specialized source text in English and recorded its SI in German. Unlike Collados Aís (2001), Holub used the software PRAAT to produce an artificial monotonous version of the content in order to control other speech parameters such as duration, pause, and amplitude.
Forty-nine economics students were divided into two groups to complete a comprehension and assessment test after listening to separate versions of the translation. The results indicated a moderate correlation between intonation and interpreting assessment, but a
“strong tendency that flattened fundamental frequency impedes comprehension.” (Holub, 2010, p.124)
In a follow-up experiment, Holub & Rennert (2011) used the same material from the Holub’s experiment (2010) to study how monotony and fluency would affect listeners’
comprehension. In addition to the source text and the monotonous text, they created two other versions: a non-fluent version with disfluencies such as pauses, repetitions, false starts, and consonant lengthening; and a monotonous text with disfluencies. Holub &
Rennert (2011) then studied listeners’ subjective and objective understanding of their comprehensibility. Findings revealed that poor fluency alone did not affect listeners’
objective comprehension. Moreover, monotony worsened listeners’ objective
comprehensibility even though it did not influence listeners’ subjective comprehension negatively. Judging on the results, Holub & Rennert (2011) concluded that poor fluency may lead to a worse impression of an SI performance yet monotony had the greatest impact in listeners’ comprehension.
14
Lenglet (2013) tested whether the peculiar prosody of SI, mainly the sentence segmentations and rising tone in the end of sentences, impacted listeners’ comprehension and perception of quality. Forty-nine economics students and thirty translation students were randomly divided into two groups to listen to two versions of interpretation. One was genuine SI while the other was a shadowing version that sounded like a prepared speech.
Listeners then filled a comprehension test and a questionnaire to assess their subjective evaluation of their comprehension and their perception of quality. Though the experiment proved how listeners link their perception of fluency and accuracy with better interpreting quality, the experiment revealed no significant difference in comprehensibility between the two groups.
From the literatures presented in this section, we find that intonation may influence listeners’ comprehension of the interpretation as well as their perception of the interpreting quality. The lack of the empirical studies on exploring the role of intonation in SI and on the effect of intonation on listener’s comprehension are still not completely understood. It is also worth mentioning that the majority of the experiments presented in this section were conducted in stress-timed languages and so far there is no interpreting research
investigating how intonation may affect Mandarin Chinese audience’s perception and comprehension of the interpreting. The discrepancy between previous research shows a need for further investigation and data collection in order to address knowledge gaps in the literature.
2.3 Intonation’s effect in Mandarin Chinese
In order to examine how intonation may affect listeners’ attention in Mandarin Chinese SI, it is important to understand the prosodic features of Mandarin Chinese and the role intonation plays in Mandarin Chinese speech production. This section will summarize the studies on Mandarin Chinese’s prosodic features, the relation between intonation and speech act, and the F0 features of Mandarin Chinese’s emotional speech.
Mandarin Chinese is a tone language where tones are lexically specified. Different F0 registers (or changes in F0 pitch) of a syllable have different meanings. There are four lexical tones in Mandarin Chinese which are often known as Tone 1 (high level tone), Tone 2 (mid-rising tone), Tone 3 (low-dipping one), and Tone 4 (high-falling tone). The F0 height and the F0 trajectory over a syllable are crucial components in tone production and perception. Aside from prosody at the lexical level, Mandarin Chinese also has a prosody at the utterance level. This second level of prosody is when F0 interacts with duration and amplitude over a phrase. Hence, the F0 in Mandarin Chinese reflects the interaction between tones and intonation (Yang, 2011).
In Chinese, tone and intonation are both presented in the F0 curves and therefore this is a great amount of questions regarding how Chinese intonation should be defined.
Some researchers explore intonation at the sentence level while others refer intonation to the F0 changes of prosodic units. Despite of their different focuses, most researchers acknowledge the fact that Chinese intonation patterns may occur repeatedly at the sentence level (Pan, 2012). It is also observed that as a tonal language, speeches in Mandarin
Chinese display a greater average rate of F0 change and fluctuation than in stress-timed languages such as English where F0 patterns are only prominent in certain lexical items (Eady, 1928).
16
Different intonations for sentences such as statements, exclamation sentences or questions are realized as different F0 changes and different discourse effects (Shih, 2000;
Thorsen, 1980; Garding, E. 1987). For example, declination effect, a gradual declination of F0 in a sentence which creates a downtrend tilt of intonation, is often regarded as an element of statement intonation (Shih, 2000; Pierrehumbert, 1980). In statement sentences, the pitch is typically higher in the initial position and lowered in the final position (Shih, 2000; Hirschberg & Pierrehumbert, 1986; Garding, E. 1987). In addition, a higher pitch followed by a downward trend of F0 can also signal the beginning of a new sentence (Shih, 1988; Liao, 1994). Declination effect is also prominent in post-focus sentences since focus in Mandarin Chinese is often marked by a sharp rise of F0 (Shih, 2000; Yuan, 2002).
Yuan (2006) investigated the characteristics of question intonation in Mandarin Chinese and how the question intonation differs from statement intonation. He observed that question intonation has a higher F0 contour than statement intonation. Question intonation also has greater strength of sentence final tones, resulting in a widening F0 intensity gap between the question intonation and the statement intonation toward the end of sentences. Generally speaking, question intonation shows higher F0 than statement intonation, especially for questions ending in Tone 2 (rising) syllables (See Figure 1). In addition, the F0 of the last syllable in Mandarin Chinese greatly affects listeners’
performance on identifying the question intonation and the statement intonation. The tone of the last syllable tends to only affect question intonation identification partly because the last syllable in a question is usually a question particle, such as ma and ne (Yuan, 2006).
Figure 1. F0 of the final Tone2 (S: Statement; Q: Question) (Yuan, 2006, p.26) The study demonstrated that for all subject, question intonation tended to be higher than statement intonation.
Intonation and Emotions
As mentioned before, intonation plays an important role in conveying vocal emotions.
Though the representation of different emotions with respective prosodic features has mostly focused on non-tone languages like English (Murray et. al., 1993), studies analyzing vocal emotions in tone languages like Mandarin Chinese are receiving increasing attention (Li, et al. 2011). In Chao’s (1933) studies, he studied how intonation, or expressive
intonation, conveys emotion in Mandarin Chinese. He proposed that expressive intonation is defined by the quality of the voice, the unusual degree of stress, and the general intensity and duration of the speech. Though emotional speech is the produce of different prosodic features, the researcher will only briefly present literatures which investigate emotional speech focusing on the variation of F0 contour for the purpose of the study.
18
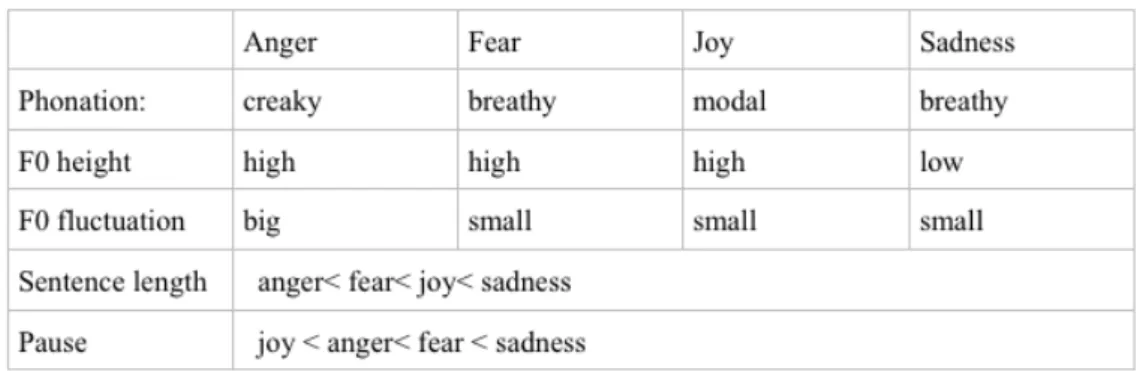
Yuan (2002) studied the acoustic realization of anger, fear, joy, and sadness in Mandarin Chinese by researching how speakers associate phonation, articulation and prosody with each emotion (See Table 1 and Table 2). Yuan concluded that joy is mainly realized on F0 while anger and fear were mainly realized on phonation. The F0 of joy was marked with a high intensity and great F0 fluctuation, while anger and fear were
characterized by a creaky and breathy phonation with narrower pitch range. Sadness, on the other hand, is a combination of phonation and intonation, marked by a low F0 with small fluctuation and a breathy phonation. Similar research also showed that the F0 magnitude (=
F0 range) of emotional speech in Mandarin Chinese were ranked as follow: anger > joy >
neutral > fear > sadness, indicating how active emotions demonstrated a larger F0 fluctuation compared to passive emotions (Li et al., 2011; Gu & Lee, 2007).
Table 1. The acoustic features of the four basic emotions obtained from Yuan (2002)’s studies.
Table 2. The F0 features of English and Mandarin Chinese speech in the four basic emotions (anger, fear, joy, sadness) obtained from Murray et. al.’s and Yuan’s studies.
From these observations, one can observe how intonation plays a crucial role in helping Chinese speakers communicate more effectively. The rising intonation at the end of a sentence shows question and doubt; a sentence with declination effect indicates
assuredness or completeness. Intonation is especially important for listeners to distinguish questions and statements and to interpret whether the sentence is a new topic or a post- focused sentence (Grice and Bauman, 2007). In addition, different moods and meanings can also be better conveyed through the fluctuation of intonations. However, one of the greatest features of Mandarin Chinese is that most of the changes of intonation were found in the sentence-final position. This is different from other stress-timed languages, such as English, where the intonation and pitch movement would mostly occur in the middle of the sentence (Pan, 2012). Since the intonation patterns of Mandarin Chinese are most
20
prominent in the tail of sentences, it is reasonable to suggest that speakers would pay most attention to the intonation of sentence-finals.
2.4 Intonation and Attention
Interpreters are communicators who interact between speakers, listeners, and other interpreters. Understanding the process of listening comprehension may enable interpreters to render messages more effectively and as a result, increase audiences’ engagement in the conference. It would also offer suggestions to how interpreters’ keep their listeners
“attended” regardless of all the other stimuli in the conference room. As mentioned before, listening attention is an integral part of listening comprehension due to the fact that the level of attention a person devotes may significantly impact the degree of information he or she can encode (Houston, D. M., & Bergeson, T. R, 2013). It would therefore be reasonable to assume that attention is the cornerstone to listening comprehension. In this section, the researcher will briefly review two of the most prominent attention theories and relate these concepts to intonation’s role in facilitating communication.
Attention is the action of processing incoming sensory information; it is selective, with limited capacity, and is reactive as well as deliberative (Posner, 1982; Driver, 2001; Musiek
& Chermak, 2015). This process “can either be controlled voluntarily by the subject, or it can be captured by some external event” (Roda, 2006, p.560). Simply put, attention is the process that enables and guides the incoming perceptual information (Roda, 2006) and research on attention is primary concerned with the process of prioritizing relevant information while neglecting irrelevant or interfering information (Chun & Wolfe, 2001;Lavie & Tsal, 1994). Most attention studies focus on two aspects: the degree of
control that the individual has over his or her attention and the external factors that may capture one’s attention (Chun & Wolfe, 2001; Roda 2006).
Broadbent’s early perceptual model (1958) is one of the most established theories and the foundation of many latter studies. He proposed two selection stages of perceptual stimuli: a pre-attentive stage and an attentive stage. In the pre-attentive stage, stimuli were assessed based on its relevance, loudness, and its frequency characteristics. In the attentive stage, stimuli were processed based on more abstract properties such as semantics.
Unattended stimuli at the pre-attentive stage would be completely filtered out and only stimuli which reaches the attentive stage would receive higher level of processing
(Broadbent, 1958; Roda, 2006). Nevertheless, latter studies showed that there were cases in which stimulus from the unattended ear could “break through” and interfere with the attended ear (Cherry, 1953). Treisman’s (1960) “attenuation theory”, a modification of Broadbent’s model, suggested that the unattended stimuli received a greater level of processing based on properties such as physical traits, relevance, and contextual cues.
Contextual Cue in Treisman’s Attenuation Theory
Treisman conducted a dichotic test in order to explore whether a contextual cue, or
“expectancy based on transition probabilities between words” (1960, p.1) would be a factor which influences how stimuli pass through the selective attention filter. In her experiment, Treisman recorded four different passages, each fifty words long, and the passages were randomized and put into pairs. Subjects would listen to two passages at the same time, one from each ear, while “shadowing”, or repeating what they heard on only one ear. In
between the twentieth and the thirty-fifth word, the passages would be interchanged from one ear to the other. In other words, subjects would hear the first part from passage 1
22
followed by the second part from passage 2 on one track, and the first part of passage 2 and the second part of passage 1 on the other track. Among the 18 subjects, 15 subjects
occasionally repeated one or more words from the wrong ear during the switch, and in retrospect, only one subject was aware that the passage had been switched to the other ear.
Treisman(1960) observed that the probability of this phenomena was highly linked with the transition probabilities between the passages. For example,
Passage in the left ear: “...I SAW THE GIRL/ song was wishing...”
Passage in the right ear: “…me that bird/ JUMPING in the street…”
(Words in capital letters were spoken by the subjects)
The experiment suggests that words with more contextual cues are more probable to pass the selective filter and be heard from the rejected ear, on the other hand, words with lower contextual cues will be “attenuated” rather than being absolutely filtered (Treisman, 1960).
Though the transition probability lowered the thresholds of words, but the filter still
operates in favor of the selected channel (the selected ear) and therefore subjects will return to the correct ear instead of shadowing to the end of the passage.
Treisman (1960) further explored the notion of a “dictionary” of known words in people’s mind. Within the dictionary, there are certain group of words that “have permanently lower threshold for activation”. For example, if the words “I sang a” were heard, the stored word “song” in the dictionary would have a considerably lower threshold, making it more likely to be activated, or heard. Other “important” words, such as one’s name, words that signal danger such as “fire, watch out, look”, are also contextually high and therefore more likely to be activated. This explanation provided a new perspective,
suggesting (1) the selective filter (Broadbent, 1958) selectively raises thresholds for stimuli from the rejected ear rather than serving as an all-or-none barrier and (2) in addition to
“physical” cues like pitch and loudness, the selective filter can also act according to the features of meaning.
In Treisman’s theory, contextual cue was mostly defined as the semantic and syntactic relevance between words. The role of how prosodic features may influence the filtering process was never answered. As mentioned previously, intonation is also regarded as a contextual cue, proven to have semantic and syntactic functions in speech, facilitating communication. Based on these literatures, the researcher would like to explore the notion of intonation serving as a contextual cue and the how it may increase listeners’ attention.
2.5 Summary
Despite the abundant amount of literature suggesting intonation’s crucial role in speech recognition and communication, there is little research investigating intonation’s influence on listeners within the interpreting field. Though past interpreting research has suggested that audience associate lively interpretation with professionalism and that a monotonous interpretation may have a negative impact on listener’s comprehension (Holub, 2010) and satisfaction (Moser, 1996), there is still scant literature and statistics to explain intonation’s role in SI and its effect on the audience. Moreover, a majority of the research studying intonation’s effect on listeners in SI have been conducted in stress-timed languages and almost no studies were investigated in Mandarin Chinese.
In order to overcome intuitive claims, the researcher hopes to build on Treisman’s (1960) attenuation theory to investigate whether intonation can serve as a contextual cue
24
and facilitate listeners’ listening process in SI. In other words, if intonation, as a contextual cue, can increase listeners’ attention, then it may offer a possible explanation to why monotony impedes listeners’ comprehension (Holub, 2010). Moreover, the experiments will be conducted in Mandarin Chinese in order to investigate the role of intonation in a tonal language SI. In conclusion, the researcher hopes to fill in the gaps in the literature by exploring how intonation may affect listeners’ attention and listeners’ subjective perception of the interpreting. The next section lays out the methodology for the two experiments conducted in order to answer these questions.
Chapter Three Part 1
Part 1 was a quantitative research conducted to explore the notion of intonation and its effect on listeners’ attention in Mandarin Chinese SI. The main purpose of the
experiment was to investigate whether intonation, as a contextual cue, can lower the threshold of listeners’ attention filter, and increase their attention when listening to interpreting.
The following section lays out the method and materials used for Part 1.
3.1 Method
3.1.1 Procedure
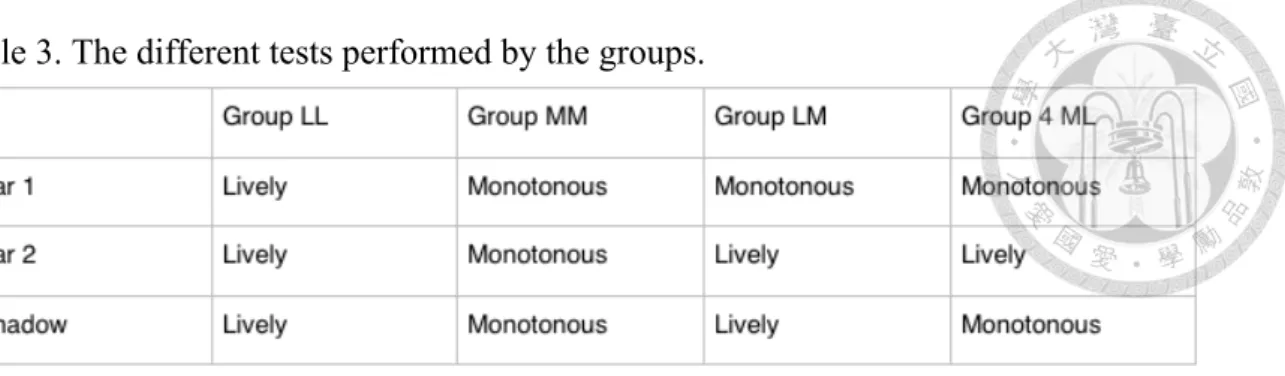
Part 1 utilized a dichotic listening test (Broadbent, 1958; Treisman, 1964) in which subjects were asked to shadow (i.e., repeat aloud) one of the two stimuli directed to both ears. By studying which ear (channel) subjects shadowed, one could distinguish which stimuli passed through the attention filter. There were four groups of subjects, and each performed a dichotic test listening to 16 pairs of passages (see Appendix 2). Group LL was exposed to two lively passages, Group MM to two monotonous passages, and both groups were asked to shadow a specific ear. On the other hand, Group ML and Group LM listened to a monotonous passage in one ear and a lively passage in another, and were asked to shadow the monotonous (ML) and the lively version (LM) respectively. Recordings were deliberately switched between ears and subjects were asked to shadow different ears in order to weaken the right-ear-advantage (REA).
26
Table 3. The different tests performed by the groups.
The experiment took place at NTU Foreign Language Teaching & Resource Center’s multi-media teaching rooms. The multi-media teaching rooms accommodated 50 students and each featured computers and the Sanako Lab 100 hardware system. The Sanako Lab 100 hardware was used to play the recordings on subject’s computers and also to record their answers. Subjects were given conference-used headsets to block outside sounds and disturbances, and to listen to the recordings. In addition, the microphone on the headset was used to record subject’s performance of the dichotic test.
A music file was first played for sound check and subjects were asked to ensure they heard sounds from both ears. After the researcher explained the instructions and assigned subjects to shadow a specific ear, they were asked to perform a practice trial in order to familiarize with shadowing. The practice trial recording contained five pairs of sentences which did not appear in the formal experiment. A slide presenting the sentences that should have been shadowed was then shown to the subjects after the practice trial in order to verify their understanding of the instructions. Students were asked to complete an online
questionnaire after finishing the dichotic test. The questionnaire contained questions (see Appendix 3) regarding their age, native language, hearing and psychological conditions, as well as their general reflection of the dichotic test. The entire procedure lasted within15
minutes and all subjects received sweets worth 50 New Taiwanese Dollars after completing the experiment.
3.1.2 Material
3.1.2.1 Stimuli Design
Reading Material
There were 16 pairs of passages used as the reading material in the experiment.
Among them, 8 pairs were coded as the “emotional text” because they contained emotional expressions such as ren-xing “willful”. The other 8 “non-emotional text” pairs did not contain any of the emotional expressions but varied with their sentence type – half of them were statements, and half of them were questions. (see Appendix 2). The emotional texts included four kinds of emotions: joy, anger, sadness, and fear.
All sentences were generated using the free-association method and adjusted in order to ensure they sounded natural. Each pair of sentences shared the same word length and level of word frequency. To contrast the presented pair of stimuli, each pair of sentences contained different keywords of one or two characters. All the keywords shared identical lexical tones in order to avoid the interference of tones. For example:
“東京航空明年將結束營業” (Tokyo Airline will stop operating next year)
“京都航空明年將結束營業” (Kyoto Airline will stop operating next year)
The keywords for the emotional texts were placed at the end or near the end of sentences in order to give listeners time to distinguish the emotion of the text. For example:
28
“你怎麼可以那麼過份!”(You have gone too far!)
“你怎麼可以那麼任性!” (You are too willful!)
A professional voice trainer recorded the 16 passages in two versions – one with a
monotonous tone and the other with a lively tone. The recording was made in a quiet room in a classroom of National Taiwan University (NTU) with the speech software PRAAT (Version 6.0.43; Boersma, P. & Weenink, D.,2018) installed on a laptop.
F0 Range of the Passages
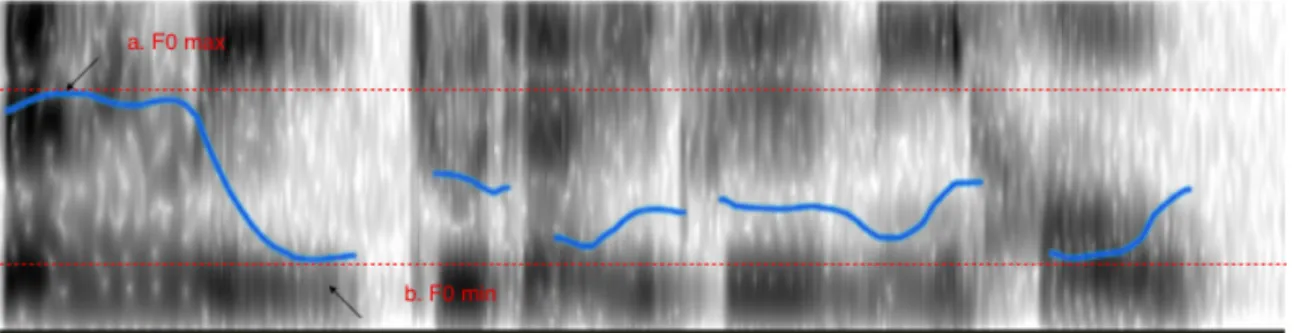
In line with the works of Ahrens (2004), and Holub (2010), intonation is defined as the f0 range. The f0 range is obtained by calculating the difference between the F0 max and the F0 min in each passage. Figure 2 shows the spectrogram of the passage “In the forest lives a fox” read in a lively tone. The blue line shows the pitch track. As demonstrated in the figure, the F0 max value was extracted from point a, and the F0 min value was extracted from point b. Figure 3 shows the spectrogram of the passage “In the forest lives a
macaque” read in a monotonous tone, which is a minimal pair passage of the one in Figure 2.
Figure 2. PRAAT graph of a lively version of “森林裡住著一隻狐狸”.
Figure 3. PRAAT graph of a monotonous version of “森林裡住著一隻獼猴”.
The patterns of the pitch tracks in the two figures are distinctive – the one of the lively version (Figure 2) shows more fluctuation and variation while the one of the monotonous version (Figure 3) is flatter. The F0 max of the lively version is 242.04 Hz and the F0 min is 100.4 Hz (F0 range = 141 Hz). The F0 max and F0 min are 136.87 Hz and 54.9Hz (F0 range = 82 Hz) for the monotonous version.
Table 4 shows the average F0 Max, F0 Min and the f0 range for the 16 lively and 16 monotonous versions of speech used in the experiment. A paired-two sample t-test shows significant difference in f0 range for the two versions of, more specifically, lively speech has wider f0 range (= 168.65 Hz) than monotonous speech (= 59.62 Hz); t (31)=6.13, P<0.001
Table 4. The F0 values of the lively vs. monotonous versions.
Rated Liveliness of the Passages
30
In order to further ensure the validity of the stimuli in listeners’ ears, the recorded passages were randomized and rated by 30 raters. The raters were asked to listen to the 32 pairs of passages and rate on a four-point Likert Scale, 1 being monotonous and 4 being lively (see Apendix 1). The results are shown in Table 5 below. The rating results ensures that the two versions prepared, monotonous vs. lively, were valid in naïve native listeners’
ears.
Table 5. The means and standard deviations of the monotonous and lively passages ratings.
Passages Means Standard Deviation
Monotonous 1.90625 0.857
Lively 3.404296875 0.723
3.2 Procedure
Subjects participated in a dichotic listening experiment in which they listened to two recordings simultaneously and their task was to shadow a specific ear. Loudness and duration of the two passages in the same trial were controlled. The loudness for all the recordings was set at 70 dB using PRAAT. The software AUDACITY (Version 2.3.0;
Audacity Team, 2018) was used to edit the passages’ duration and merge two mono tracks into one stereo recording. All the sentences were manipulated to ensure that the characters were played simultaneously controlled within 0.032 seconds time difference. A 1.18 second-pause took place between trials, giving subjects sufficient time to finish shadowing the previous sentence. The entire stereo-recording with 16 trials had a total length of one minute.
3.3 Data Analysis
A points system was designed to record the accuracy of the shadowing results. One point was awarded to the subject if the speech matched the passage of the designated ear.
On the other hand, if the subject did not shadow any characters from the assigned passage, or only shadowed part of the keywords, then no points were awarded. For example, if a subject was exposed to the passage pair: “東京航空明年將結束營業/京都航空明年將結 束營業” (Tokyo Airline will stop operating next year/Kyoto Airline will stop operating next year) and was asked to shadow the ear in which the passage was “東京航空,” then the subject would only receive one point if his or her response matched the keyword “東京.”
Any other answers such as 京都,東都, silence, or nonsense word that did not match the keyword would be regarded as failing to shadow the passage. The total number of points awarded was then calculated. Finally, a two-sample assuming equal variances t-test was used to determine whether subjects’ performance score was affected by intonation.
Data analysis for accuracy was assessed by counting the number of answers which matched the keyword of the designated passage. If the subject’s response matched the keyword, indicating he or she was shadowing from the right ear, the subject received 1 point. Any other answer which did not match the keyword would not be awarded any points. Subjects shadowed 16 pairs of passages and received a score between 0 and 16.
3.4 Subjects
32
132 subjects were recruited from National Taiwan University in Taipei, Taiwan.
Ninety-eight subjects are students from a course named Online English Program (OEP), twenty-three subjects are students attending a freshmen English course, and eleven subjects are students from an education practicum class. Data was incomplete for 26 subjects due to technical problems. 3 subjects were not included in the results because their native
language was not Mandarin Chinese.
A total of 103 subjects’ data were collected from four groups: Group ML (21), Group MM (34), Group LM (23), Group LL (25). All subjects had good hearing and no
psychological illness would affect their reactivity to the stimuli. Since students with
interpreting training would be able to shadow from a specific ear without being affected by the other ear, all subjects are students with no prior interpreting experiences.
3.5 Hypothesis
There were two general hypotheses concerning the performance of the dichotic test.
The first hypothesis is that intonation would lower the threshold of the attention filter (Broadbent, 1958; Cherry, 1953; Cutler, 1997; Treisman, 1960) making the lively sentences easier for subjects to recognize and shadow. Subjects shadowing the lively ear while
listening to the monotonous ear would score higher than other groups since it is easier to focus on the lively sentences and neglect the monotonous sentences. On the contrary, subjects listening to the lively sentences while shadowing the other ear would face most distraction since signals from the designated ear is more likely to be attenuated, allowing the lively sentences to pass through the filter. Therefore, it is hypothesized that Group LM
and Group ML will have the highest and lowest scores respectively. Subjects listening to either two lively or two monotonous passages would be exposed to two stimuli with equal chances of passing the attention filter, resulting in no significant difference between the scores of Group LL and Group MM. It is predicted that the scores of the 4 groups would rank as follow: LM > LL = MM > ML. If the hypothesis is accepted, we could conclude that intonation, as a contextual cue, can lower the threshold of the attention barrier and that the audience will more likely pay attention to a livelier SI instead of a monotonous SI.
The second hypothesis relates to the scores of the emotional texts. Since intonation facilitates the passing of information through the selective filter due to listeners’
“expectancy based on transition probabilities” (Treisman 1960, p.1), it is assumed that a lively intonation aligned with the context of the speech would be easier for listeners to process and therefore is more likely to be shadowed. The scores of the lively emotional texts would expect to be higher than the scores of the lively non-emotional texts (including both statements and questions). On the contrary, the scores of monotonous emotional texts will have the lowest score due to the mismatch between the intonation and the context. If the hypothesis is accepted, it suggests that intonation, as a contextual cue, plays a more important role in emotional texts compared to the non-emotional texts. This would highlight the audience tendency to listen more attentively to emotional texts than to the non-emotional texts when both were delivered in a lively manner.
3.6 Results
34
This chapter presents the results testing the two hypotheses. Performance was assessed by counting the total number of responses which matched the correct keyword, henceforth, “accuracy”. Section 3.6.1 lays out the performance of the four subject groups (LL, MM, LM, ML) who participated in the dichotic test, shadowing 16 pairs of passages.
Section 3.6.2 examines the accuracy results of the emotional and the non-emotional texts.
Section 3.6.3 scrutinizes the common mistakes and the questionnaire completed by subjects after the experiment.
3.6.1 Group scores for dichotic test
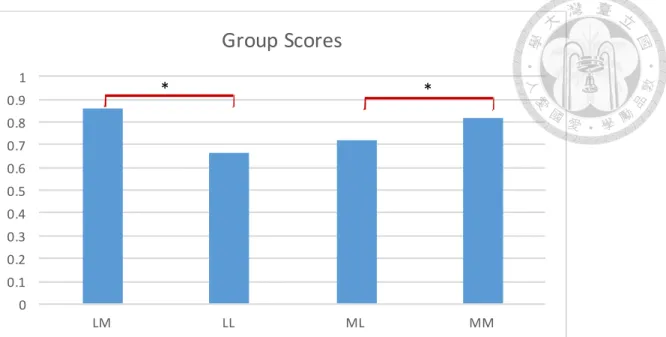
The group average scores are shown in Figure 4. An ANOVA test showed significant difference between the scores of the four groups (F (3,110)=5.923, p < 0.001). As shown in the figure, Group LM received the highest average score (M=0.86, SD=0.37), followed by Group MM (M=0.82, SD=0.2), Group ML (M=0.72, SD= 0.19), while Group LL received the lowest score (M= 0.67, SD= 0.11). This result rejects the null hypothesis of the 4 group scores ranking as LM > LL = MM > ML.
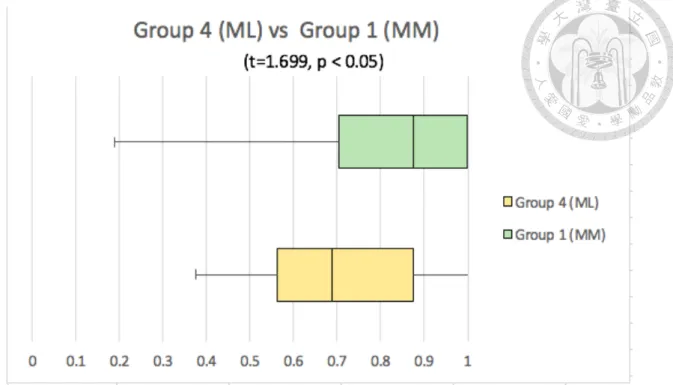
In addition, the post hoc t-tests were conducted to observe the between group
differences. The results revealed significant difference between LM and LL (t (46) =4.437, p <0.001) as well as between ML and MM (t (53) =-1.6997, p <0.05), but not between ML and LM.
Figure 4. Average scores for Group LM, LL, ML, and MM.
Figure 5 and Figure 6 demonstrate the groups whose scores were significantly different from each other.
Figure 5. Average scores for Group LM and Group LL.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
LM LL ML MM
Group Scores
* *
36
Figure 6. Average score of Group ML and Group MM.
The findings that there was no significant difference between the scores of Group ML and Group LM, and that the scores of Group LL was the lowest among the four groups reject the null hypothesis which predicted that Group LM and Group ML would have had the highest and the lowest scores respectively and that Group LL and Group MM would have shared a similar score.
3.6.2 Group Scores for Emotional Texts and Non-emotional Texts
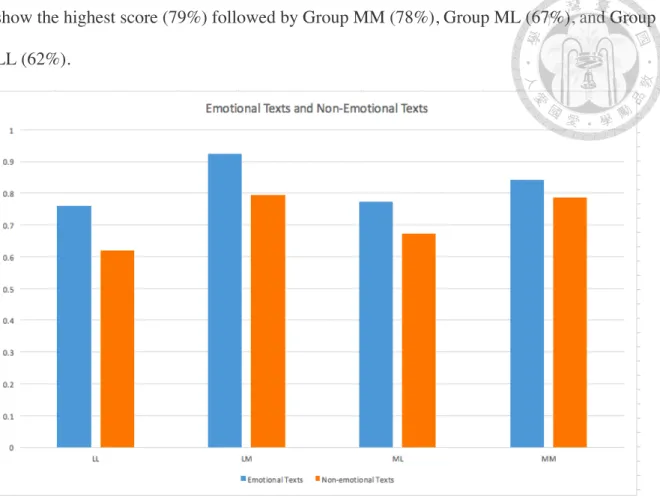
In this section, the scores for emotional texts and non-emotional texts are examined separately. The general pattern in scores of these two texts are demonstrated in Figure 7. It shows that the average score of emotional texts is higher than the score of the non-
emotional texts (including both statement and question sentences) in all four groups. For the emotional texts, Group LM show the highest score (92%) followed by Group MM (84%), Group ML (77%), and Group LL (76%). For the non-emotional texts, Group LM
show the highest score (79%) followed by Group MM (78%), Group ML (67%), and Group LL (62%).
Figure 7. Average group score of emotional texts and non-emotional texts.
Non-emotional text
Statistical results of the non-emotional text scores (i.e., the blue bars in Figure 7) showed that there is a significant difference between the experimental groups (LM, ML) and the control groups (LL, MM). A series of t-tests was conducted and the result revealed significant difference between Group LM and Group LL (t (382) =3.775, p <0.001) and between ML and Group MM (t (438)=-2.6782, p <0.01).
There are two sentences types in the non-emotional text, namely “statements” and
“questions”. Unlike English, statements and question sentences often have the same
structure in Mandarin Chinese. Since statements are often changed into questions by simply adding a sentence particle or raising the intonation at the end of the sentence, the researcher
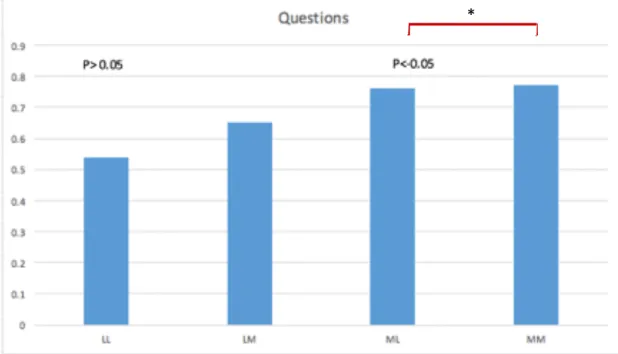
38
further investigated whether intonation would impede or facilitate listeners’ perception of question sentences. Further comparison analysis were conducted and the results showed that for “questions” type, there was only significant difference in the scores for Group ML and Group MM (t (218)=0.172, p <0.05) (see Figure 8). As for the “statement” type, significant differences were found between Group LM and Group LL (t (190)=4.342, p
<0.01) and between Group ML and Group MM (t (218)=3.578, p <0.01) (see Fig.9).
Figure 8. Average group score of question sentences.
*
Figure 9. Average group score of statement sentences.
Emotional texts
Statistical results showed that there was a significant difference between the two experimental groups (LM, ML) and the control groups (MM, LL). There was a significant difference between Group LM and Group LL (t (382)=4.461, p <0.001) and between Group ML and Group MM (t (438)=-1.793, p <0.05.)
* *
40
Figure 10. Average group score of emotional texts.
In order to see if scores of a particular emotion affected the results of the emotional text in general, scores of the four emotions were examined individually below.
Joy
A further analysis on the different sentences within the emotional texts indicated that only the LL and LM group showed significant score difference in terms of sentences with the emotion joy. Test revealed the first group’s result to be Group LM (M=0.93, SD=0.44) and Group LL (M= 0.76, SD= 0.24); t (94) =2.42, p <0.01 while the result of the second group revealed no significant difference; Group ML (M=0.73 , SD= 0.43) and Group MM (M=0.80, SD=0.39); t (108)=-0.867, p> 0.05 (see Fig. 11).
* *
Figure 11. Average group score of emotional texts with the emotion joy.
Sadness
The results were also similar for sentences with the emotion sadness, scores indicated that only the LL and LM group showed significant score difference, Group LL (M=
0.82,SD= 0.38) and Group LM (M=0.93, SD=0.24); t (94)=1.71, p <0.05; while Group ML and MM, Group ML (M=0.9 , SD= 0.29) and Group MM (M=0.88, SD=0.32); t
(108)=0.36, p> 0.05 showed no significant difference (see Fig. 12).
Figure 12. Average group score of emotional texts with the emotion sadness.
*
*
42
Fear
As shown in Figure 13, there were no significant difference in the two control and experimental groups for sentences with the emotion fear. Group LL (M= 0.74,SD= 0.44 ) and Group LM (M=0.82, SD=0.38); t (94)=1.01, p >0.05; Group ML (M=0.76 , SD= 0.43) and Group MM (M=0.86, SD=0.34); t (108)=1.42, p> 0.05.
Figure 13. Average group score for emotional texts with the emotion fear.
Anger
For sentences with the emotion anger, the results were extremely significant for Group LL (M= 0.72,SD= 0.45)and Group LM (M=1, SD=0); t (94)=4.18, p <0.001; and insignificant for Group ML (M=0.69 , SD= 0.46) and Group MM (M=0.80, SD=0.39); t (108)=1.41, p> 0.05 (see Fig. 14).