國立臺灣大學文學院圖書資訊學系 碩士論文
Department of Library and Information Science College of Liberal Arts
National Taiwan University Master Thesis
以視覺化標籤雲輔助圖書標記之使用者研究 A User Study of Using Folksonomic Tag Clouds as
an Aid to Book Indexing
梁文馨 Wen-Hsin Liang
指導教授:唐牧群 博士 Advisor: Muh-Chyun Tang, Ph.D.
中華民國 101 年 4 月
April, 2012
誌謝
從研究方向構思開始,到畢業論文撰寫完畢,唐牧群老師耐心傾聽我提出的 問題,協助我把研究方向具體化,並在撰寫論文期間提供寶貴意見,讓我能克服 撰寫論文的種種困難。除此之外,老師還鼓勵我參加博碩士生交流工作坊報告我 的論文,藉此培養我臨場應對的能力,增加我在正式口試時的信心。面對老師毫 無保留的傾囊相授,春風化雨之情,永銘於心。
除了唐牧群老師,也要感謝藍文欽、卜小蝶老師和曾元顯老師在百忙之中抽 空參與我的計畫書口試和學位論文口試,非常謝謝諸位老師對我論文的修正、建 議與鼓勵。
這份論文得以完成,還要感謝李冠輝、董冠伯兩位同學在課餘時間撰寫程式,
讓實驗系統順利上線。參與標記實驗的受試者以及惠玲、郁文兩位學姊,感謝你 們的熱心幫助,讓我體會到臺大學生的熱情。
另外要感謝同一個研究室的宜瑾在我撰寫論文的過程給予我的幫助,像是參 與前測實驗、統計分析教學、提醒我口試應該注意的事項,甚至介紹我許多好看 的電視劇與動畫,紓解撰寫論文時的寂寞;珮寧樂觀開朗的處事態度,讓研究室 增添不少歡樂的氣氛;和鈞湄聊天讓我忘記寫論文時的煩惱,有機會的話再一起 去吃拉麵;互相打氣加油和一起上體育課的珮雯,祝你順利提論文計畫書;提供 我 Word 小技巧,而且一起和貓咪先生拍照的書萍給我的鼓勵我會銘記在心,祝福 你未來有很好的發展。
最後感謝家人在我撰寫論文期間給予我的支持與鼓勵,我才能不畏艱難走到 寫誌謝的這一刻。
終於,我可以大聲的說「我畢業了」!!
摘要
本研究旨在嘗試以視覺化的角度探討標籤字體大小對於使用者標記行為的影 響,並在上述情況下,探討使用者選用的標籤品質是否較佳。
本研究建立兩種標籤雲介面,實驗組為有字體大小變化,控制組為無字體大 小變化,採用受試者內設計和拉丁方格法設計實驗。實驗組的標籤先以 TF-IDF 演 算法計算出標籤的權重,再依權重對應到標籤字體大小,隨機排列於標籤雲內;
而控制組的標籤沒有經過 TF-IDF 的計算,以固定的字體隨機排列於標籤雲內。
參與實驗的受試者在系統安排好的介面順序之下,皆會使用兩種介面,從標 籤雲內自由選用適合的標籤去標記指定書籍。受試者完成標記任務之後需接受研 究者的簡短訪談。另安排兩位專業圖書館員標記相同的書籍,所得結果作為使用 者選用的標籤品質評估基準。
本研究分析實驗結果與歸納訪談內容後,得到下述結論:受試者在實驗組與 控制組的標記行為有差異。從標籤被選用次數之分佈狀況來看,在實驗組的介面 裡,使用者傾向選用字體大的標籤,使得標籤被選用次數分佈較不平均;而在控 制組的介面裡,標籤被選用次數分佈較為平均。
受試者在實驗組與控制組中選用的標籤品質有差異。以館員選用的標籤評估 受試者在兩種介面裡選用的標籤品質,發現在實驗組的介面裡,受試者選用的標 籤與標籤名次接近館員選用的標籤和標籤名次。亦即在實驗組的介面裡,受試者 選用的標籤品質較高;而在控制組的介面裡,受試者選用的標籤品質不高。由此 判斷採用實驗組介面(有字體大小變化)標記書籍可以提升標籤品質。
關鍵字:視覺化;標籤雲;俗民分類法;標籤品質;實驗法;詞頻-逆向文件頻率
Abstract
The purpose of the study is to examine whether the users’ selection of tags is affected by the font size of the tags in a visual interface, and to examine whether TF-IDF weight based tag size visualization is more conducive to the quality of the tags they choose.
A book-tagging experiment was conducted with Latin square design where the participants were asked to use alternately two tag cloud interface to tag sixteen books, one without visualization, the other vary the size to tags based on their TF-IDF weight Thirty-six participants who had basic familiarity of these books took part in the experiment. After tagging the books, they were also asked to rank the importance of the tags they had assigned for each book. Two professional librarians were asked to tag and rank the same set of books, the result of which served as the benchmark for comparing the quality of the tags selected by participants.
The results showed a difference in the selected tags between visualization and non-visualization interfaces in terms of tag concentration. Tags selected using the visualization showed significant more uneven distribution as measured by Gini index and entropy. A correlation of tag size and tag selection was found where visualization was present, which indicated the impact of varying tag font size on the participants’
selection. A difference in the quality of the tags selected was also found. Using tags selected by librarians as quality criteria to evaluate the quality of users’ selected tags in two different groups, we found a significantly higher similarity between the tags selected by the librarians and the participants using the visualization interface.
Furthermore, the results also showed the effect of visualization was over and above the effect of users’ own knowledge.
Keywords: Visual interfaces, Tag cloud, Folksonomy, Quality of tags, Experimental methods, Term Frequency-Inverse Document Frequency (TF-IDF)
目次
誌謝 ... i
摘要 ... ii
Abstract... iii
目次 ... iv
圖目次 ... vi
表目次 ... vii
第一章 緒論 ...1
第一節 研究背景與動機 ... 1
第二節 研究問題與目的 ... 4
第三節 研究範圍與限制 ... 5
第四節 名詞解釋 ... 6
第二章 文獻探討 ...9
第一節 詞頻(TF)與逆向文件頻率(IDF) ... 9
第二節 社會性標記與標籤 ... 12
第三節 標籤雲與視覺特徵 ... 17
第四節 標籤品質與評估方法 ... 21
第三章 研究方法與設計 ...27
第一節 受試者條件 ... 28
第二節 研究設計 ... 29
第三節 研究工具 ... 30
第四節 實驗流程 ... 37
第五節 資料分析與處理 ... 39
第六節 信效度策略 ... 44
第四章 研究結果與討論 ...45
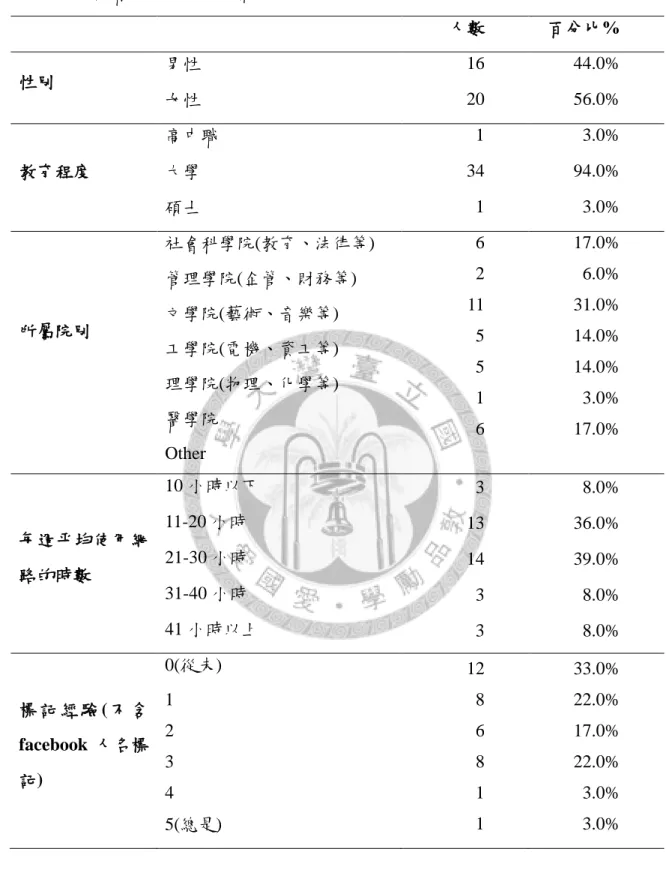
第一節 使用者基本資料 ... 45
第二節 標籤基本統計量 ... 49
第三節 標籤被選用次數之分佈狀況 ... 54
第四節 標籤品質 ... 67
第五節 小結 ... 75
第五章 研究結論與建議 ...78
第一節 研究結論 ... 78
第二節 研究建議 ... 84
參考文獻 ...86
附錄一 受試者實驗問卷 ...91
附錄二 館員實驗問卷 ...95
附錄三 參與實驗同意書 ...99
附錄四 受試者之實驗說明 ...100
附錄五 館員之實驗說明 ...102
圖目次
圖 2-1 標籤雲範例 --- 17
圖 3-1 網頁七種字體大小 --- 33
圖 3-2 實驗組(有字體大小變化)介面 --- 34
圖 3-3 控制組(無字體大小變化)介面 --- 35
圖 3-4 洛倫滋曲線(Lorenz Curve) --- 40
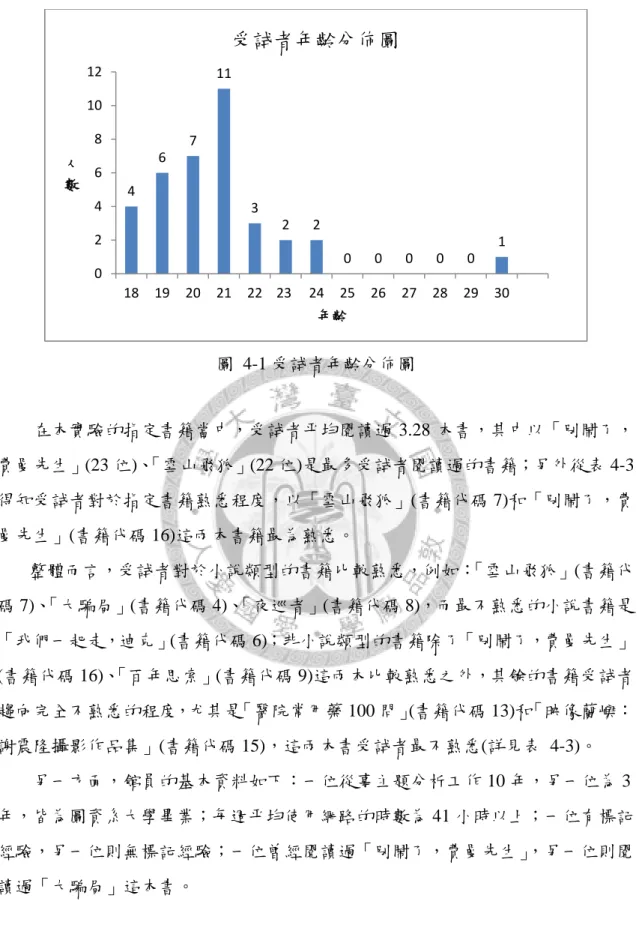
圖 4-1 受試者年齡分佈圖 --- 47
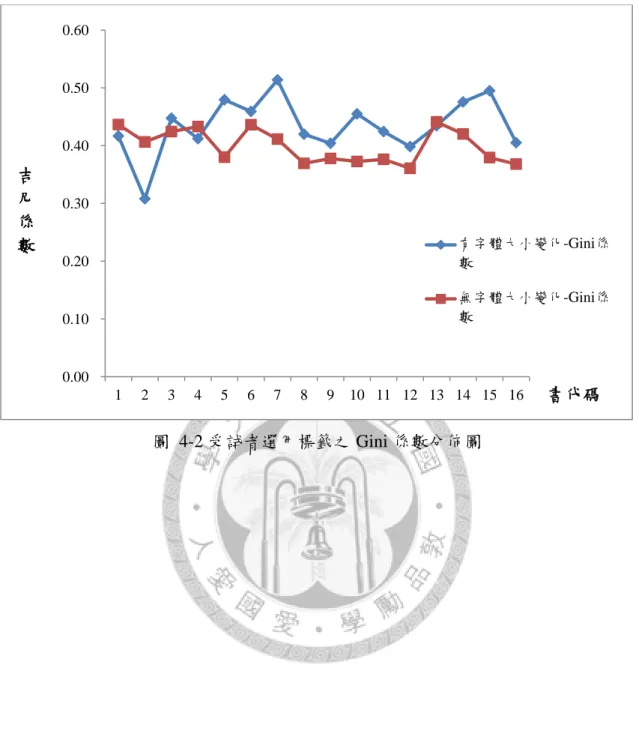
圖 4-2 受試者選用標籤之 Gini 係數分佈圖 --- 56
圖 4-3 不同介面中受試者選用標籤之 H(X)值 --- 59
圖 4-4 不同介面裡的受試者選用標籤個數比例之平均數 --- 63
圖 4-5 標籤字體大小與標籤被選用次數之間相關係數分佈圖 --- 66
圖 4-6 不同介面裡館員和受試者選用標籤的交集程度分佈圖 --- 71
圖 4-7 不同介面裡館員和受試者之間選用標籤名次的相關性分佈圖 --- 74
圖 4-8 分析模型 --- 76
表目次
表 3-1 四種介面順序 --- 29
表 3-2 指定書籍清單 --- 31
表 4-1 受試者年齡、閱讀指定書籍數量、標記經驗摘要表 --- 45
表 4-2 受試者背景與使用習慣分佈表 --- 46
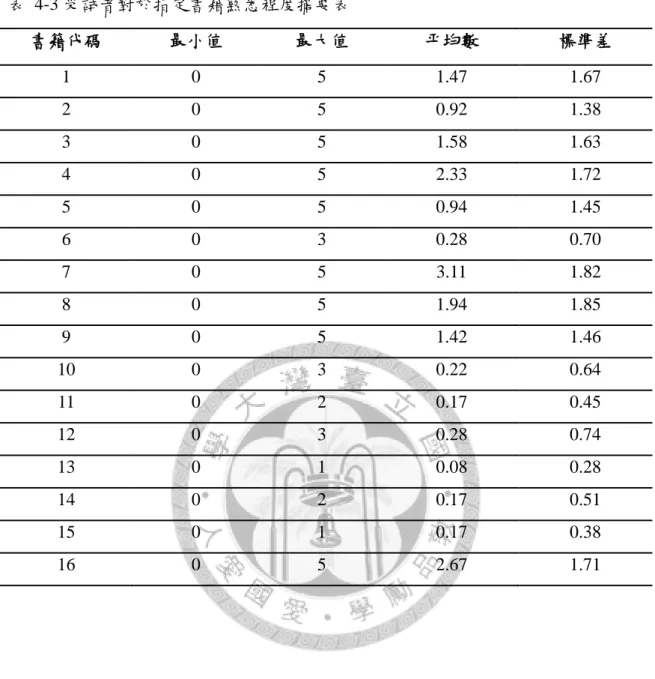
表 4-3 受試者對於指定書籍熟悉程度摘要表 --- 48
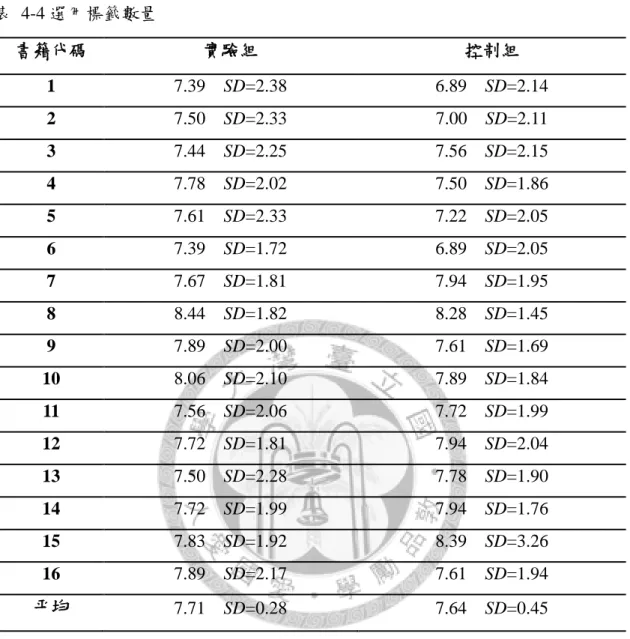
表 4-4 選用標籤數量 --- 50
表 4-5 相異標籤個數 --- 51
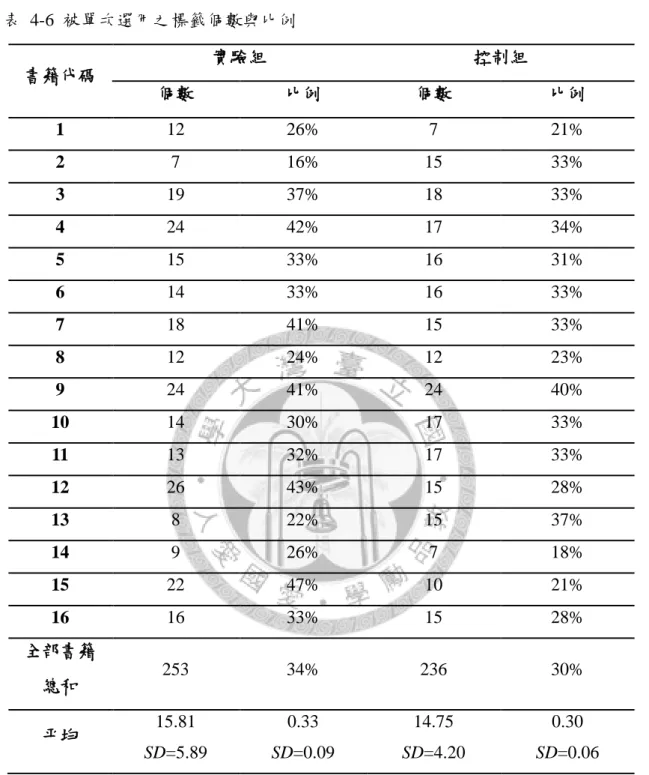
表 4-6 被單次選用之標籤個數與比例 --- 53
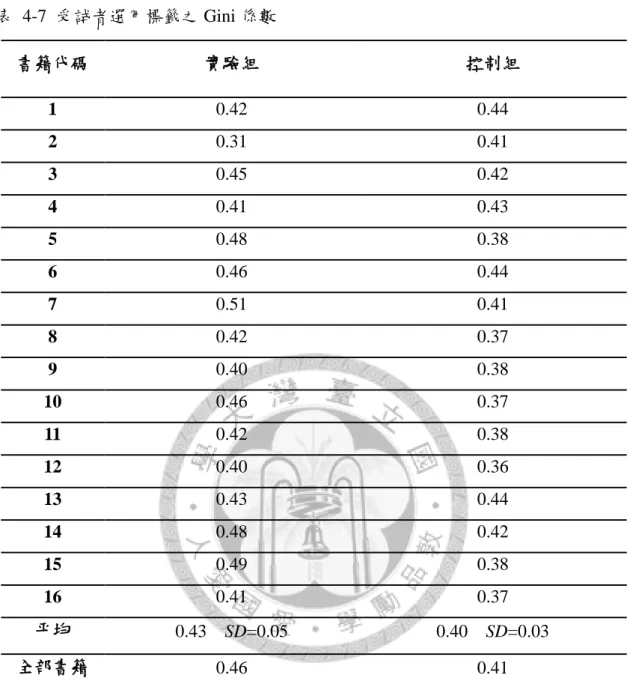
表 4-7 受試者選用標籤之 Gini 係數 --- 55
表 4-8 不同介面中受試者選用標籤之 H(X)值 --- 58
表 4-9 實驗組介面之受試者選用標籤個數比例 --- 61
表 4-10 控制組介面之受試者選用標籤個數比例 --- 62
表 4-11 標籤字體大小與標籤被選用次數之間的相關係數 --- 65
表 4-12 館員選用標籤和沒選用標籤的標籤個數、TF-IDF 值之平均數、TF-IDF 值之標準差 --- 68
表 4-13 不同介面裡館員和受試者選用標籤的交集程度 --- 70
表 4-14 不同介面裡館員和受試者之間選用標籤名次的相關性 --- 73
表 4-15 以標籤字體大小預測標籤被選用次數之多元迴歸分析摘要表 --- 77
表 5-1 研究結果總整理 --- 82
第一章 緒論
第一節 研究背景與動機
現今網際網路的趨勢以資訊分享、協同合作為主流,網路資源的組織方式也 從專業人員以事先制定的格式或分類架構,演變至一般使用者以自由建立標籤或 關鍵字組織高度異質化的網路資源。利用標籤或關鍵字的鏈結功能,除了讓使用 者方便搜尋到自己想要的資訊之外,其他使用者也能透過任何人所建立的標籤,
瀏覽各種類型的資源,促進使用者之間資源共享的目標。
由於具備社會性標記(social tagging)功能的網站逐漸增加,引起國內外圖書資 訊學界高度的關注,許多探討社會性標記的文獻也相應產生。從相關文獻中得知 社會性標記是以使用者參與為利基,支援個人化的資訊組織、搜尋和使用(Noruzi, 2006;Spiteri, 2007;Trant, 2009;卜小蝶、張淇龍,2009)。若與傳統資訊組織相 比,社會性標記比起傳統資訊組織更加開放,允許使用者運用群眾智慧(collective intelligence)並開啟向他人學習的機會,藉由標籤連結發掘其他意料之外(serendipity) 的資源(Mathes, 2004)。也因為社會性標記以相對主義(relativism)為基礎,即便使用 者在檢索或瀏覽過程所得到的資訊資源不夠精確與完整,也能讓使用者有滿足、
滿意的心理感受(Bianco, 2009)。
雖然社會性標記有上述優點,但是由使用者自由建立的標籤,基本上缺乏詞 性、詞意、字詞拼法,以及語意連結的機制。上述的詞彙問題,不僅難以聚集相 同概念的標籤,也會產生許多不必要的垃圾標籤(tag spam) (Guy & Tonkin, 2006;
Golder & Huberman¸ 2006;Noruzi, 2006;Spiteri, 2007;Peters & Weller, 2008;Bianco, 2009)。
為解決上述詞彙的問題,許多研究者提出解決的方法,例如:使用者依據事 先制定的詞彙規範來建立適合的標籤(Peters & Weller, 2008);選取適當的優選詞 (preferred term)以代替其他詞彙(Peters & Weller, 2008);加入外部參考資源有助於 使用者釐清標籤語意(Spiteri, 2007);透過控制詞彙建議機制幫助使用者建立適合的 標籤(Golub et al., 2009)。aNobii網路書櫃系統也在最近把使用者自由標記書籍的方 式改為讓使用者挑選已經設定好的控制詞彙,作為標記書籍內容的標籤。
針對上述提及的解決方法,使用者在選用控制詞彙或優選詞之前,必須先了 解、認同控制詞彙或優選詞所代表的意義,才能有效避免詞彙的問題;至於標記 過程中參考詞彙規範或是外部資源很可能會增加使用者的認知負擔。因此,本研 究參考 Harvey, Baillie, Ruthven & Elsweiler (2009)運用標籤雲輔助標記過程的研究 設計,並且以陳怡蓁(2010)所作的層面分類結構應用於社會性標記的研究中,受試 者在有無層面分類結構介面裡標記圖書作品所建立的標籤,作為標籤雲的素材。
本研究試圖以標籤雲輔助使用者標記圖書作品,減少使用者的認知負擔。
標籤雲除了輔助使用者標記資源,減少標記過程所產生的認知負擔之外,通 常還伴隨著視覺特徵作為提示標籤的機制。一般而言是以使用者選用標籤的次數 (熱門性)來決定視覺特徵的醒目程度,即使用者選用次數越高的標籤是為熱門標籤,
其視覺特徵越明顯(Marinchev, 2006;Rivadeneira, Gruen, Muller & Millen, 2007;
Bateman, Gutwin & Nacenta, 2008)。上述文獻指出使用者在標記過程會受到視覺特 徵所產生的視覺影響(visual influence)。Bateman et al. (2008)的研究以標籤雲作為呈 現 視 覺 特 徵 的 平 台 , 探 討 九 種 視 覺 特 徵 對 於 使 用 者 產 生 視 覺 影 響 的 程 度 。 Rivadeneira et al.(2007)的研究中也探討標籤雲中的視覺特徵對於使用者記憶與認 知上的影響。以上研究皆證實視覺特徵的影響力,所以本研究進一步假設在標記 過程中,使用者會受到視覺特徵的影響改變其標記行為。
再者,選用次數高但不具區別力的熱門標籤會連結到許多資源,導致使用者 利用熱門標籤瀏覽資源時必須耗費許多精力才能篩選出相關的資源。因此,本研 究加入專指性的概念,藉由TF-IDF演算法計算的標籤權重,作為標籤字體大小(視 覺特徵之一)的變化依據,此有助於提升區別力高的標籤的能見度。
綜合上述的動機,本研究運用標籤雲輔助使用者標記圖書作品,從視覺特徵 的角度探討標籤字體大小是否會影響使用者的標記行為。再以TF-IDF演算法計算 的標籤權重作為標籤字體大小的變化依據,探討標籤字體大小是否會影響使用者 選用的標籤品質,以解決使用者建立的標籤過於雜亂的問題。
第二節 研究問題與目的
根據第一章的研究動機,本研究方法與設計以實驗法為主,建置兩種介面,
實驗組為有字體大小變化,控制組為無字體大小變化。每一位受試者皆會使用兩 種介面,並於標籤雲內選用適合的標籤標記指定書籍。再以量化分析方法評估標 籤字體大小是否會影響使用者的標記行為。除此之外,本研究將視覺特徵的變化 原理改為以TF-IDF演算法所計算出的標籤權重為依據。並借助館員在分類、索引 的專業能力,其選用的標籤作為標籤品質的基準。
在使用者不清楚標籤字體大小變化依據的情況下,本研究假設使用者會受到 標籤字體大小的影響,傾向選用字體大的標籤。再藉由館員的判斷能力證明字體 越大的標籤其品質越高,故以TF-IDF演算法作為字體大小變化依據的介面裡,使 用者選用的標籤品質較高的假設也會成立。
綜合上面的問題陳述,本研究提出以下具體的研究問題和假設:
研究問題一:在標籤字體大小的影響之下,使用者在不同介面裡的標記行為是否 有差異?
H1:標籤字體大小會影響使用者的標記行為,導致不同介面裡使用者選用標籤次 數之分佈狀況有差異,在實驗組介面裡使用者選用標籤次數之分佈狀況較為不 均。
H2:在實驗組介面裡,使用者選用字體大的標籤的機會較高。
研究問題二:在標籤字體大小的影響之下,使用者在不同介面裡選用的標籤品質 是否有差異?
H3:以 TF-IDF 演算法作為字體大小變化依據的介面裡,使用者選用的標籤品質較 高。
透過回答上述問題,本研究擬達成以下目的:
一、嘗試以標籤字體大小的影響力來引導使用者的標記行為。
二、嘗試以 TF-IDF 演算法所計算出標籤的權重,作為標籤字體大小的變化依據。
再從標籤字體大小的影響力探討使用者選用的標籤品質,試圖解決使用者建 立的標籤過於雜亂的問題。
第三節 研究範圍與限制
一、 研究範圍為有效驗證研究變項,並控制干擾因素的誤差,本研究採用人為安排的環境 進行實驗。參與本實驗的受試者,並非都是網路書櫃系統中的使用者,而且無法 驗證受試者是否有看過指定書籍,因此產出的實驗結果無法完全推估到網路書櫃 系統中使用者的標記結果。
本實驗主要是探討在標籤字體大小的影響之下,使用者在不同介面裡的標記 行為與選用的標籤品質是否有差異。至於採用品質高的標籤,是否就意味著在搜 尋特定書籍上有較好的表現?還須要配合實證研究才能了解。
二、 研究限制
(一)標籤字體大小的誤差
本研究中的標籤字體大小變化原理是以 TF-IDF 演算法計算出的標籤權重,對 應到 HTML 語法中二到七號字體,但因為字體大小的區辨力不足,無法精確對應 到標籤權重,因此標籤字體大小反映標籤權重會有誤差。
(二)無法區分視覺化因素和 TF-IDF 演算法因素
本研究的自變項—標籤字體大小同時包含視覺化的因素和 TF-IDF 演算法的因 素,實驗結果雖顯示受試者的標記行為會受到標籤字體大小的影響,但是本研究 者無法區別是視覺化因素,還是 TF-IDF 演算法因素,導致受試者的標記行為會受 到標籤字體大小的影響。
(三)受試者的心智模型
本研究在實驗進行之前,有告知受試者推薦標籤字體大小的依據不是以標籤 的熱門性來決定。但是本研究並無法保證受測者是否能仍然會做出這樣的假設,
是故無法排除受試者對於系統所抱持的心智模型(mental model)或理論對其判斷及 行為的影響。
第四節 名詞解釋
一、社會性標記 (Social Tagging)社會性標記意指使用者在社群性與科技性融合的情境下,為網路資源建立標 籤(tag)的動作、行為與過程 (卜小蝶,2007;Trant, 2009)。使用者將適當的詞彙或 關鍵字連結至資源物件,有利於分享、發現、搜尋、瀏覽、過濾相關資源,除此 之外,在標記過程中,使用者可直接利用標籤來組織、管理個人資源(Trant, 2009;
Guy & Tonkin, 2006;Noruzi, 2006;Golder & Huberman¸ 2006;Xu, Fu, Mao & Su, 2006)。
二、標籤 (Tag;label)
基本上,標籤是使用者為了描述資源內容所建立的詞彙,連結資源主題與使 用者,反映使用者對於資源內容的看法,可說是使用者標記資源後產出的結果(Guy
& Tonkin, 2006;Noruzi, 2006;卜小蝶,2007)。
其他使用者可藉由標籤詞彙的涵義,理解資源內容表述的概念與面向(Noruzi, 2006;Guy & Tonkin, 2006;Fu, Kannampallil & Kang, 2010)。然而,產生標籤的方 式可分為三種:使用者自行建立、仿用其他使用者的標籤,或是從資源內容中擷 取關鍵詞彙(Sen et al, 2006;Voβ, 2007)。
三、標記者 (Tagger)
自由建立標籤描述資源內容的使用者(Voβ, 2007),通常不限定性別、身分、年 齡,只要是了解標籤與標記意義的人皆可稱之,本研究中參與實驗之受試者也可 稱為標記者。
四、標籤雲 (Tag cloud)
標籤雲又稱詞彙雲(word cloud)或是視覺化設計的加權清單(weighted list in visual design),將使用者產出的標籤集合或是描述網站內容的關鍵詞彙,按字母順 序排列,並且以標籤的字體大小、粗細或顏色之視覺特徵,反映每一個標籤或關 鍵詞彙的重要性或熱門程度(Sinclair & Cardew-Hall, 2008;Wikipedia, 2011)。標籤 雲最主要的用途是讓使用者可以立即了解資源內容主旨,以及藉由詞彙的超連結 瀏覽、發掘與該標籤相關的資源(Friedman, 2007;Rivadeneira et al., 2007)。
五、視覺特徵 (Visual Features;Visual Properties;Visual Characteristics)
標籤詞彙藉由文字屬性的視覺特徵反映標籤的重要性或熱門程度,文字屬性 的視覺特徵包括:字體大小、字體粗細、字體顏色,尤其是字體大小最為常見,
其他像是字體顏色飽和度、字母數量與寬度、字母包含的像素多寡也都屬於視覺 特徵(Rivadeneira et al., 2007;Bateman et al., 2008)。
六、標籤品質 (Tag Quality)
標籤品質是一個抽象概念,沒有統一的定義,但是相關文獻中提出「好的標 籤(good tags)」需具備的五種特質:1.涵蓋多個層面 2.高熱門性 3.最小努力原則 4.
一致性 5.排除某些特定類型的標籤(Xu et al., 2006),從標籤具備的功能來看,一個 好的標籤必須有效率的幫助使用者瀏覽、搜尋、組織、分享、發掘相關資源,才 會是一個有意義(meaningful)、高品質的標籤(Noruzi, 2006;Guy & Tonkin, 2006;
Suchanek, Vojnovic & Gunawardena, 2008;Fu et al., 2010)。
在本研究中,以 TF-IDF 演算法計算標籤的權重,並假設權重越高的標籤其品 質也越高。
七、TF-IDF 演算法
TF-IDF(Term Frequency - Inverse Document Frequency)是一種常用於自動索 引與資訊檢索領域中的詞彙加權技術,是為一種統計方法。此演算法可分成兩個 部分。第一個部分是計算詞彙 k 在文件 i 內出現的次數,以公式 = 求得詞 彙之 TF 值;第二個部分則是計算在 N 個文件總數中,有詞彙 k 出現的文件數量,
帶入公式為 =log(
)求得詞彙之 IDF 值(Salton & McGill, 1983;Salton &
Buckley, 1988)。
一個完整的 TF-IDF 演算法是將 Term Frequency 與 Inverse Document Frequency 計算公式結合,以兩者個別獲得數值相乘的方式求得詞彙之 TF-IDF 值,也就是詞 彙權重來評估個別詞彙對於文件的重要程度。原則上,權重越高的詞彙僅在少數 文件內出現,具有區別文件內容的能力(Salton & McGill, 1983;Salton & Buckley, 1988)。
本研究運用 TF-IDF 演算法計算標籤的權重,並以標籤的權重決定標籤的字體 大小。
第二章 文獻探討
第一節 詞頻(TF)與逆向文件頻率(IDF)
一、 TF 與 IDF 概念的源起在自動索引研究與資訊檢索領域中,有許多計算詞彙權重的指標,以顯示詞 彙的重要性與辨識資源內容,或是成為索引詞的價值,其中又以 TF(Term Frequency) 和 IDF(Inverse Document Frequency)最為人所熟知。而這兩種方法源自於 Zipf(1949) 提出的「齊夫定律(law of Zipf)」:觀察個別詞彙在文章內的出現頻率,發現個別詞 彙的出現頻率和其排名存在著相乘等於常數的關係(as cited in Salton & McGill, 1983, p. 60)。除此之外,Luhn(1958)觀察使用者在書寫時運用詞彙的方式,發現某 些詞彙經常重複出現在文章中的現象(as cited in Salton & McGill, 1983, p. 60)。皆是 以詞頻作為測量詞彙重要性的基礎,進而衍生出測量詞彙重要性的相關指標。
經過不同領域學者的多次驗證,Kucera&Francis(1967)的研究中,得出有關於 詞彙使用的結論:文章內 20%的高頻率詞彙,負責 70%的詞彙使用率(as cited in Salton & McGill, 1983)。換言之,文章內詞彙的出現頻率是不均等的,而這種不均 等的現象,指出詞彙之間的差異,有助於找出具有區別力(resolving power、
discrimination)的詞彙,又能精確表達資源內容主旨,以利檢索或瀏覽效率的提升 (Salton & McGill, 1983)。總結來說,TF 和 IDF 都是基於詞彙的出現頻率來計算詞 彙權重的方法。
二、TF、IDF 與窮盡性、專指性的關係
從人工索引的角度來看,索引詞通常是由主題專家依據自身經驗與所受過的 專業訓練,從主題標目表中選擇一組事先複合過的控制詞彙,表達作品中最常被 談論的概念。在自動索引領域是以一般人在書寫時產生的經驗法則(重複重要概念,
和反覆使用相同詞彙的習慣)為依據(Salton & McGill, 1983),計算詞彙在文件內或 是文件之間的出現頻率作為決定索引詞的方法(Salton & Buckley, 1988)。
在選擇適當的索引詞之前,必須先考量到兩個索引描述特性:詞彙的窮盡性 (Exhaustivity)和詞彙的專指性(Specificity)。
詞彙的窮盡性(Exhaustivity)與索引詞的數量和索引詞涵蓋的層面範圍相關 (Sparck Jones, 1972;Salton & McGill, 1983;Soergel, 1994)。在人工索引的情況下,
學科專家藉由少量的索引詞表述作品內容,因此詞彙涵蓋的層面範圍較少,窮盡 性較低。而在自動索引的情況下,將文件中所有出現過的詞彙視為索引詞,涵蓋 的層面範圍也多,詞彙的窮盡性自然比在人工索引的情況下來的高(Sparck Jones, 1972;Salton & McGill, 1983)。
詞彙在單一文件中的出現頻率(詞頻 term frequency) 可作為決定索引詞的條件,
和詞彙的窮盡性有著間接的關係。舉例來說,假若設定索引詞的門檻為詞頻≧3,
假設 A 詞彙的出現頻率為 2:B 詞彙的出現頻率為 5:C 詞彙的出現頻率為 6,根 據設定的門檻,B 和 C 詞彙可作為索引詞,A 詞彙則不予採用,設定門檻的目的 是找出凝聚使用者共識的詞彙。
另一個索引描述特性:詞彙的專指性(Specificity),意指使用詞彙表達作品內 容的詳細程度,在人工索引的情況下,索引詞必須考量到能精準表達作品內容,
通常採用具有獨特性與排他性的詞彙作為索引詞。而在自動索引領域中,計算詞 彙 k 出現在文件集合中的次數決定詞彙的專指性。k 出現次數越多,則專指性越低;
k 出現次數越少,則專指性越高(Sparck Jones, 1972;Salton & McGill, 1983;Salton
& Buckley, 1988)。
在使用者自由標記的環境下,標籤並非全都可以作為描述書籍內容的索引詞,
因此本研究利用 TF-IDF 演算法計算出每一個標籤的權重。TF 和詞彙的窮盡性相 關,IDF 和詞彙的專指性有關聯。所以計算出來的標籤權重會考慮到詞彙的窮盡性
本研究計算個別標籤在單一書籍內被使用者標記的次數代表 TF 值。書籍總數 除以個別標籤在書籍集合中的出現次數取對數後為 IDF 值。兩值相乘之結果即為 個別標籤的權重,對應字體大小範圍,以字體大小顯示標籤權重的高低,探討標 籤字體大小是否會影響使用者的標記行為以及選用的標籤品質。
第二節 社會性標記與標籤
一、社會性標記的概念Social tagging 是 Web2.0 概念下的產物,著重於使用者導向的設計與體驗,以 及社群參與所集結的大眾智慧(O’Reilly, 2005),但是因為各個本研究切入的角度不 同,在文獻上又以各種名稱表示,例如:collaborative tagging、social classification、
social indexing(Yi & Chan, 2009),自然衍生出許多相似但不相同的定義,然而本研 究以 Trant (2009)對於 social tagging 的定義和卜小蝶(2007)對於 tagging 的解釋為主,
採用「社會性標記」作為 social tagging 轉譯的中文名稱。
社會性標記的基本概念以使用者為中心,在社群與科技交互影響的情境下,
為了個人組織、分類或是大眾分享的目的,主動建立標籤描述資源內容的過程,
過程中反映了使用者對於資源的看法和解讀,產生具有多元意義的標籤,總結來 說,社會性標記提供使用者自由組織、分享資源的途徑,彈性的反映多元文化與 新興概念,形成群眾智慧(Noruzi, 2006;Guy & Tonkin, 2006;Xu et al., 2006;Ding et al., 2009;Yi & Chan, 2009;Trant, 2009;Fu et al., 2010)。
二、使用者標記動機
從文獻上得知社會性標記可以有效促進資源發掘,以及資訊搜尋與瀏覽的功 能,同時也代表著另一種新形態的資訊組織方式,但是此新形態的資訊組織方式 並非由傳統資訊組織中的學科專家或是圖書資訊從業人員所主導,反而是由一般 使用者共同建立而成(卜小蝶、張淇龍,2009)。
至於刺激使用者自由產生標籤來組織、管理資源或是描述資源內容的理由,
又可稱為標記動機,大致上可分為兩種類型,一種是利己(selfish),另一種是利他 (altruistic),這兩種標記動機又可細分為四個類別。
第一,為了個人目的來標記自己擁有的資源;第二,以他人使用目的來標記 自己擁有的資源;第三,為了個人目的去標記其他人擁有的資源;第四,以他人 使用目的去標記其他人擁有的資源,由這四個類別可得知使用者的標記動機不一 定以利己為出發點,但是在一般標記系統上,大部分的使用者動機還是以「利己」
有學者進一步歸納出使用者的標記動機有以下六種,第一,記憶與情境連結 (Memory and Context):幫助使用者檢索特定的物件或是相關物件群組;第二,任 務組織(Task organisation):幫助使用者對於資源物件的搜尋任務更有組織性;第三,
社群信號( Social signaling):是一種讓使用者表達出自己喜好、感受、經驗給其他 使用者的管道;第四,社群貢獻(Social contribution):個人標記的資源有助於其他 使用者辨識資源內容,成為群體知識的一部分;第五,遊戲與競賽 (Play and Competition):可當作使用者之間用標記行為衍生出來的遊戲與競賽方式;第六,
意見表達(Opinion expression):傳遞使用者對特定資源內容的意見(Lamere, 2008),
除此之外,Marlow (2006)等人也分析前人研究,提出類似上述的六點動機:未來 檢索(Future retrieval)、貢獻與分享(Contribution and Sharing)、吸引注意力(Attract attention)、遊戲與競賽(Play and Competition)、自我表現(self presentation)、意見表 達(opinion expression),除此之外,標籤類型可視為不同使用動機所產生的標記結 果,換言之,使用者的標記動機會反映在標籤類型上(Golder & Huberman, 2006;
Marlow, Naaman, Boyd, & Davis, 2006;Munk & Mørk, 2007ab)。
不論標記動機是如何複雜,或是分成若干類型,總而言之,使用者的標記動 機不外乎是從利己或是利他兩大動機衍生出來,然而,標記動機雖然會影響使用 者選擇標籤,卻不是唯一的影響因素,而且在本研究中所設計的實驗之下,受試 者的標記動機是被本研究所控制,對於標籤集合和標籤品質的影響不大,因此,
使用者的標記動機不是本研究想要探討的問題之一。
三、標記行為特性與標籤被選用次數分佈現象
使用者在社會性標記系統中所產生的標籤,通常會受到其標記行為特性的影 響,產生特殊的標籤被選用次數分佈現象,以下從使用者標記行為以及標籤被選 用次數分佈現象兩大部分進行討論。
使用者的標記行為整體來看相當穩定,其原因如下:第一,使用者認為仿用 其他使用者的標籤是很合理且安全的決定,並從觀察其他使用者的行動而跟著行 動,有助於使用者不需花費過多的時間與精力來標記資源;這種基於社會保證原 則 (social proof) 下 的 社 群 模 仿 (social imitation) 行 為 , 形 成 社 群 凝 聚 力 (social cohesion),第二,同質性高的使用者群對於資訊內容有一致性的解讀,容易選擇語 意相似或相同的標籤,不僅造成標記行為上的穩定,也影響了標籤被選用次數分 佈與標籤類型。(Golder & Huberman¸ 2006;Sen et al., 2006;Munk & Mørk, 2007a;
Fu et al., 2010)。
以標籤被選用次數分佈現象來看,使用者在經過一段時間之後,會認同某些 詞彙是描述資源的最佳選擇,這些詞彙通常涵蓋廣義的主題範疇,在標記過程中 會優先採用這些詞彙來標記資源,導致這類詞彙的出現頻率很高,占有優勢地位,
其他較少被使用的詞彙,則處於次要地位,亦即少數標籤會被大多數使用者重複 使用,其餘的標籤在使用次數與使用人數上則會逐次下降,此現象稱之為「冪次 法則(power law)」(Mathes, 2004;Munk & Mørk, 2007a;Munk & Mørk, 2007b)。從 標籤分析為主的相關研究中發現,delicious、Flickr 網站上的標籤被選用次數分佈 是依循冪次法則,從單一文件中標籤被選用次數分佈現象得知,具有廣義主題範 疇的一般性標籤(例如:business、economics、politics)被使用的次數很高,占有很 高的比例,而其他較具個人性的獨特標籤則出現次數少,形成長尾分佈現象(Guy &
Tonkin, 2006;Golder & Huberman, 2006;Munk & Mørk, 2007a)。
儘管出現次數高的一般性標籤有助於一定程度的社群共識,有能發揮社會共 享的語意價值,但也因為一般性標籤被多數使用者所採用,標記於大多數的資源,
Munk & Mørk (2007a)兩位學者將此現象稱之為「過度表示(over-represented)」。然 而「過度表示」的現象造成使用者無法利用一般性標籤做更有效率的瀏覽和檢索 (Munk & Mørk, 2007a;Peters & Weller, 2008),因此,本研究綜合歸納使用者選擇
四、使用者選擇標籤時的影響因素
標籤是一種使用者創造的詮釋資料(metadata),用以提供資訊線索(information scent),連結使用者內心的想法和資源內容主題(Rader & Wash, 2008),然而,標記 過程如同索引過程一樣,會先對資源內容作概念分析,再以適當的標籤代表資源 內容主旨,不同的使用者會根據自己的需求或看法,對相同資源做不同的概念分 析,所採用的標籤自然也會不同,很顯然的,使用者之間很難對相同資源達成一 致性的解讀,反而會受到許多內在與外在因素的影響(Voβ, 2007)。
同理,當使用者在選擇標籤時,不只是個人內心的想法在影響使用者,還有 其他非個人性的因素參雜其中,影響使用者建立或是選擇適當的標籤來標記資訊 資源,有鑑於此,本研究統整了文獻上可能會影響到使用者選擇標籤時的因素,
分為社群性因素、個人性因素、標記系統功能與視覺特徵等四種影響因素。
(一) 社群性因素
標籤選擇過程中,使用者會仿用被其他使用者經常使用的標籤,或是觀察其 他使用者的標記行為,不但造成社群模仿行為並且凝聚社群智慧,讓標籤選擇比 例集中於某些特定標籤(Golder & Huberman¸ 2006;Sen et al., 2006;Munk & Mørk, 2007a;Fu et al., 2010)。除此之外,使用者之間的同質性也會影響標籤集合,反映 在標籤被選用次數之分佈狀況上(Golder & Huberman¸ 2006)。
(二) 個人性因素
除了使用者基於最小努力原則,傾向採用簡單、一般性的標籤之外(Munk &
Mørk, 2007a),使用者選擇標籤時會受到個人傾向的影響,包括使用者的個人興趣、
背景知識、使用標籤的偏好與信仰,甚至牽涉到使用者對於資訊科技的熟悉度。
使用者基於過去在其他標記系統中的使用經驗或是標記習慣,會影響未來的標記 行為,導致重複使用過去常用的標籤(Sen et al., 2006)。另外從 Rader & Wash (2008) 兩位學者所做的研究得知,delicious 的使用者在選擇標籤時受到個人資訊管理目的 的影響大過於社群影響因素,證明使用者在選擇標籤時的確會受到個人性因素的 影響。
(三) 標記系統功能因素
當使用者對於資源內容不熟悉的時候,可藉由標記系統中基於協同過濾技術,
自動推薦相關標籤的功能,或是基於標籤被使用的次數,推薦大多數使用者所採 用的熱門標籤,甚至是顯示使用者先前採用過的標籤,作為標記資源與建立標籤 時的參考,上述由標記系統所提供的參考建議標籤,會影響到使用者選擇標籤,
以及標籤選擇結果(Xu et al., 2006;Munk & Mørk, 2007a;Rader & Wash, 2008;
Suchanek, Vojnovic & Gunawardena, 2008)。
(四) 視覺特徵因素
一群相關的標籤在標記系統中藉由標籤雲的型態呈現,使用者會因為文字屬性 的視覺特徵,例如:字體大小、粗細、顏色上的變化,吸引其注意力並做為選擇 標籤的依據(Rivadeneira et al., 2007;Bateman et al., 2008),甚至有研究著重於其他 非文字屬性的視覺設計,例如:標籤雲版面設計的方式、標籤的排列方式與順序,
都會影響使用者選擇標籤或是辨識特定標籤的速度(Rivadeneira et al., 2007;Halvey
& Keane, 2007;Lohmann, Ziegler & Tetzlaff, 2009),相關研究中顯示視覺特徵越醒 目,越容易吸引使用者的注意。
藉由上述列出的影響因素,更能全面了解真實情形下的社群網站中的使用者 的標記行為與標籤選擇過程,是受到許多內在與外在因素的影響,導致特別的標 記行為或是特殊的標籤被選用次數之分佈狀況,然而本研究以實驗法為主軸,搜 集與分析實驗數據所作的結論,無法完全類推至真實情形下使用者的標記行為。
第三節 標籤雲與視覺特徵
一、標籤雲的概念與用途標籤雲是社會性標記系統常出現的功能之一,從本質上可解釋為一種社會性 導覽工具,協助使用者瀏覽相關資源(Dieberger, Dourish, Höök, Resnick & Wexelblat, 2000)。在名稱上除了標籤雲(tag cloud)之外,也可稱為詞彙雲(word cloud)、視覺化 設計的加權清單(weighted list in visual design)。三種名稱所代表的概念相同,是為 使用者產出的標籤集合或是描述網站內容的關鍵詞彙之視覺化描述(Rivadeneira et al., 2007;Sinclair & Cardew-Hall, 2008;Wikipedia, 2011)。
圖 2-1 標籤雲範例
資料來源:Friedman (2007).Tag Clouds Gallery: Examples And Good Practices.
Retrieved November 3, 2011, from
http://www.smashingmagazine.com/2007/11/07/tag-clouds-gallery-examples-and-good- practices/
綜合相關文獻對於標籤雲的敘述,可歸納出標籤雲的基本概念是標籤或關鍵 詞彙之集合。標籤詞彙不僅可以按字母順序排列,甚至可依標籤的重要性、相似 度或是隨機排序(Friedman, 2007),並且藉由字體大小、字體粗細、字體顏色等視 覺特徵,強調哪些是重要性高或是熱門程度高的標籤。再者,標籤雲通常是以標 籤被使用的次數(frequency of use),也就是標籤的熱門性來決定視覺特徵的醒目程 度。越常被使用的標籤,視覺特徵越醒目(Marinchev, 2006;Rivadeneira et al., 2007;
Bateman et al., 2008)。
根據現有文獻指出,標籤雲有三種用途,第一,標籤雲提供詞彙、資源物件、
使用者之間的動態超連結管道,除了幫助使用者瀏覽與找尋相關資源物件,具有 意料發掘其他標籤或資源的能力(serendipity) (Marinchev, 2006;Wu, Zubair & Maly, 2006;Bateman et al., 2008)。
第二,藉由標籤雲工具,可以得知標籤的建立者與其建立過的標籤,從標籤 了解標籤建立者的興趣與想法以連結有相同興趣、喜好的使用者,增進使用者之 間的互動(Marinchev, 2006;Wu et al., 2006)。
第三,標籤雲可視為一種與書籍內容相關的視覺化目次(table of content)與索引 (index),或是網站內容的類目清單,提供形成初步印象(impression)與辨識內容主 旨的管道(Rivadeneira et al, 2007)。
Harvey et al. (2009)的研究以實驗法為主。實驗分成兩個階段,第一階段以受 試者標記圖像建立的標籤形成標籤雲,在第二階段的實驗中,以第一階段形成的 標籤雲作為輔助第二階段的受試者標記圖像的工具,探討標籤雲如何影響受試者 的標記行為。經分析受試者選用的標籤後,證實標籤雲可以改善使用者的標記過 程,降低受試者在標記過程中產生的認知負擔,提升受試者之間選用標籤的共識 程度(Harvey et al., 2009)。由上述研究得知,在使用者不熟悉資源內容的情況下,
標籤雲是一項提供相關詞彙並且輔助使用者標記資源的工具。因此,本研究採用 標籤雲作為輔助受試者標記圖書作品的平台。
二、視覺特徵相關研究
標籤雲不僅是社會性導覽工具,也是一種文字集視覺化呈現(Rivadeneira et al, 2007),因此某些標籤根據其出現頻率而有視覺上的差異,一般情形下,標籤雲會 使用兩種以上的視覺特徵來引起使用者的注意,例如:同時改變字體大小與位置 上的變化,這個概念稱之為「視覺影響(visual influence)」(Bateman et al.,2008),然 而 , 從 相 關 研 究 中 發 現 使 用 者 不 會 仔 細 看 完 標 籤 雲 內 所 有 的 標 籤 (Weinreich, Obendorf, Herder & Mayer, 2006),反而是以瀏覽(scan)行為居多(Halvey & Keane, 2007),由此推知,使用者選擇標籤雲內的標籤,並非完全以標籤語意來決定,或 許有部分源自於視覺特徵的影響,必須利用實驗才能證明這個假設,回應本研究 問題。
目前關於視覺特徵的文獻,主要是探討由視覺特徵所產生的視覺影響力,研 究文獻中同時執行多項視覺特徵,釐清各項視覺特徵之間的關係,以及使用者受 到哪項視覺特徵的影響最甚,以下有幾篇文獻探討視覺特徵如何影響使用者選擇 標籤。
Rivadeneira et al. (2007)以兩階段的實驗探討視覺特徵對於使用者的影響,第 一階段藉由標籤字體大小、位置、與字體最大標籤的鄰近性三種變項檢驗使用者 記憶標籤的回收率,第二階段則調查標籤字體大小與標籤雲版面編排兩個變項在 印象形成與辨識上的影響,兩階段的實驗都顯示標籤字體大小強烈影響了使用者 在回收率、印象形成與辨識上的結果,表示標籤字體越大越容易被使用者注意與 記憶,至於其他視覺特徵對於回收率、印象形成與辨識上結果影響不大。
Halvey & Keane (2007)調查標籤雲在使用者找尋特定目標時,是否能發揮應有 效能,以六種不同介面型式,包括標籤雲形式、垂直與水平列舉形式、有無字母 順序排列供受試者找尋與選擇特定的標籤,研究結果指出,垂直與水平的列舉式 版面設計在找尋特定目標時的效能比標籤雲形式佳,字母順序可促進搜尋效能,
同時也指出字體大小強烈影響使用者找尋標籤的速度,字體越大的標籤越快速被 使用者發現。
Bateman et al.(2008)測量九種不同的視覺特徵如何影響使用者標籤選擇,採用 視覺特徵組合進行實驗,要求受試者從標籤雲選擇「視覺上最重要的標籤」,比較 每一種視覺特徵和期望值之間的標籤選擇比例,結果指出標籤字體大小和粗細對 於使用者的影響遠超過顏色飽和度、所包含的字母數量、像素多寡,以及標籤位 置等其他視覺特徵。
由上述研究得知,字體大小變化是最普遍的視覺特徵,也最能吸引使用者的 目光,因此本研究採用標籤雲的形式,以標籤字體大小作為唯一的視覺特徵,探 討標籤字體大小是否會影響使用者的標記行為。
第四節 標籤品質與評估方法
一、標籤的品質與判斷準則使用者在標記資源的過程,因為沒有固定的標籤規範而形成標籤在詞性與格 式上的差異,例如:單複數、縮寫字、名詞動詞、拼音差異、複合詞連接等基礎 詞性變化或是多樣的複合詞形式(Ding et al., 2009;Peters & Weller, 2008;Noruzi, 2006),除此之外,使用者之間依據自身背景知識對相同資源所做的解讀也有差異,
影響到使用者所採用的標記策略與標記深度,產生同義詞(synonym)、同形異義詞 (homonym) 、 一 詞 多 義 (polysemy) 等 歧 異 性 高 的 標 籤 (Spiteri, 2007 ; Golder &
Huberman¸ 2006;Noruzi, 2006)。
除此之外,本研究還歸納出影響使用者選擇標籤的因素,包含社群性、個人 性、標記系統功能和視覺特徵因素,也有可能導致上述提及的標籤詞彙問題,然 而,建立或選擇標籤是以使用者主觀判斷為基礎所產生的行為,因此,使用者對 於產出的標籤的品質是因人而異,也就是說,單就標籤詞彙在字形與字義上的歧 異,是無法有效判斷標籤品質的優劣。
因此,在評估標籤品質之前,必須先有判斷標籤品質的準則,以便檢驗標籤 集合裡的標籤品質,本研究以 Xu et al. (2006)提出「好的標籤(good tags)」的準則 說明標籤集合(set of tags)應該具備以下五種特質。
(一)涵蓋多個層面(high coverage of multiple facets)
一個好的標籤集合要涵蓋到資源物件的各個層面,隸屬不同層面的標籤有助 於聚集由不同使用者標記的相關資源物件。標籤集合內涵蓋的層面越多,使用者 越能快速找到特定的資源物件。
(二)高熱門性(high popularity)
高熱門性的概念類似傳統資訊檢索中的詞彙出現頻率(term frequency)。在單一 資源內,若特定的標籤被多數使用者所採用,則可作為辨識特定資源的索引詞,
也會增加後來的使用者採用相同標籤的機會。
(三)最小努力原則(Least-effort)
在描述資源時,藉由特定標籤所辨識的資源數量應該越少越好,如此一來,
使用者可藉由標籤快速瀏覽特定的資源,而標籤也發揮了辨識特定資源的能力。
(四)一致性、正規化(uniformity、normalization)
因為沒有共同的標準,所以使用者建立的標籤具多元性,甚至有採用不同的 標籤去代表相同概念的情況產生,我們可歸納出兩種形式的分歧現象,一個是語 法變異(syntactic variance),另一個是同義詞(synonym),標籤分歧現象一方面會產 生雜訊,另一方面卻可以增加回收率,因此為了中和分歧現象的好處與壞處,最 好的方法是允許使用者採用任何型式的標籤,連結標記系統內部權威性一致的表 達方式。
(五)排除某些類型的標籤(exclusion of certain types of tags)
因個人組織目的所產生的標籤,比較不能與其他使用者共享,因此基於大眾 分享使用的原則之下,這些因個人組織目的所產生的標籤最好予以排除。
歸納上述五點準則,得知標籤集合裡的標籤要能被大眾辨識,呈現資源的獨 特性,有效率的瀏覽、檢索、找尋相關資源,在語法和語意上也盡量呈現一致性,
並且要能被其他使用者理解與使用。除了有判斷標籤品質的準則之外,如何評估 標籤品質也相當重要,以下詳述相關文獻中提出的標籤品質評估方法。
二、標籤品質評估方法與測量項目
標籤品質評估方法大致上可分為三種類型,第一,直接性使用者回饋(explicit member feedback):使用者主動給予標籤正負面評價或評分(Sen Harper, LaPitz &
Riedl, 2007);第二,間接性系統使用數據(implicit system usage data):利用量化方 式,分析使用者標記行為數據,藉此推斷標籤的品質(Sen et al., 2007;Damme, Hepp
& Coenen, 2008;Bar-Ilan, Zhitomirsky-Geffet , Miller, Shoham, 2010);第三,間接 推測標籤品質的方式:以測量標籤語意相似度、相關度,以及標籤使用集中程度 推測標籤品質的優劣(Cattuto , Benz, Hotho & Stumme, 2008;Markines et al., 2009;
陳怡蓁,2010)。
以上敘述的標籤品質評估方法各有利弊,結合三種評估方法才能正確測量出 標籤品質的優劣,本研究試圖應用三種類型的評估方法回答本研究問題與驗證假 設。
(一) 直接性使用者回饋(explicit member feedback)
以 Sen et al. (2007)的研究為例,藉由使用者回饋機制獲得相關數據評估標籤品 質,總共有兩種獲取相關數據的方法。
第一,利用 MovieLens 電影推薦系統中的標籤評價機制,幫助使用者以最簡 便的點擊方式給予標籤正或負面評價,並且藉由標籤位置反映使用者對於標籤的 看法,點擊拇指向上(thumb up)圖示會提升標籤在清單上的位置代表正面評價增加,
點擊拇指向下(thumb down)圖示使標籤位置下降,若標籤的負面評價持續增加到一 個數量後,將不會出現在清單列表中,並以正面和負面評價機制組合成四種標記 介面進行實驗,探討評價機制產生的效用,以及對於標籤選擇方法的預測能力。
第二,發送線上問卷給 MovieLens 使用者,請使用者以五顆星的範圍評分被 五部電影採用的二十個標籤,所得的標籤評分結果作為標準數據集,用以評估文 獻中提出的三種預測標籤品質的選擇方法:(1)單一標籤使用次數(num-apps);(2) 單一標籤使用人數(num-users);(3)單一標籤搜尋或點擊人數(num-searches)。幫助 標記系統或是標記介面設計者更了解使用者對於標籤的喜好,提供更多正面評價 的標籤。
(二) 間接性系統使用數據(implicit system usage data)
在相關實證研究中,經常利用使用者標記行為數據來分析使用者產出的標籤 被選用次數之分佈狀況,和評估使用者產出的標籤品質,其中以 Bar-Ilan et al.(2010) 的研究為例,提出一套在使用者互動前後,對於標籤集合裡的標籤品質的量化評 估標準(quantitative assessment),包含了六個測量指標,評估使用者標記猶太文化 遺產相關圖片所產生的標籤集合中的標籤品質,六個測量指標如下:
(1) 標籤群組的大小(the size of the tag set):尤其是標籤數量越多的群組,象徵標籤 群組有較高的完整性(comprehensiveness)和可信度(reliability),有助於圖片檢索 的精確率(precision)和回收率(recall)。
(2) 所使用的個別相異、有區別性(distinct)標籤的數量:可用來測量標籤群組的多 樣性(diversity),有助於回收率。
(3) 在特定的標記模式中,有多少百分比的使用者運用出現頻率最高的標籤來標記 特定圖片:這代表大多數人對特定圖片上的特定標籤有高度的共識(maximum consensus)。
(4) 因為標籤所用字句不常見(nonconventional),或是使用者誤解或錯誤解讀而產生 讓某些標籤只出現一次,獨特標籤越多,表示大家對標籤群組的共識越少。以 每一個實驗組別所產生的相異標籤總數中,被單一使用者所標記的標籤比例作 為歧異度的量測。
(5) 定義單一標籤的共識分數(consensus score)為有多少百分比的使用者在特定的 互動模式和實驗組別中採用此標籤標記特定圖片。對於每一張圖片來說,至少 被標記過兩次(multiplicity two)以上的標籤才能算出平均共識分數。
比較互動前後和實驗組別之間的平均共識分數,若平均共識分數越高,越能反 映使用者之間對於標籤之間的相關性有高度共識。此項指標有助於改善圖片檢 索的精確度。
(6) 計算被至少百分之十的使用者採用的標籤數量,這些標籤是凝聚使用者共識的 標籤。
Damme et al. (2008)也提出三種標籤品質度量(quality metrics),以 delicious 為資 料集驗證所提出的標籤品質度量是否可以有效的檢測出高品質的標籤,其中兩種 標籤品質度量是屬於間接性系統使用數據類型,分別為:
(1)高頻率標籤(High Frequency Tags):計算單一資源中個別標籤的出現頻率並且加 以排序,選擇出現頻率最高的五個標籤,作為高頻率標籤的代表。
(2)標籤共識程度(Tag Agreement):特定標籤之出現頻率除以標記特定資源的總人 數,將相除後的結果乘上一百得出百分比的結果,以 50%為門檻,此數值越接近 100%代表標籤的共識程度越高,反之越接近 0%則表示標籤的共識程度越低。
(3)TF-IRF:先以 Markov Clustering(MCL)演算法作相似標籤的群集分析,以便建立 相似資源集合,再以 TF-IDF 公式為基礎,建立 TF-IRF 公式,標記的資源並非都 是文字性資源,所以在計算過程中必須將 TF-IRF 公式做一些調整,計算出標籤的 TF-IRF 權重,標籤的權重越高,越能代表標籤對於資源的重要性,標籤的品質也 相對的提高。
由上述文獻中得知,以系統使用數據為基礎的標籤品質評估方法,著重於計算 標籤在單一資源中的出現次數,或是在單一資源中選擇單一標籤的使用者比例來 評估標籤的品質。
(三) 間接推測標籤品質的方式
有別於前兩種類型的標籤品質評估方法,Cattuto et al. (2008)藉由圖形化的方法 發掘相關標籤,以標籤語意相似度、相關度的測量推測標籤品質。
例如:
(1)Co-Occurrence:計算兩個標籤之間連結(edge)的權重,代表兩個標籤之間的共現 關聯程度。
(2)Cosine Similarity:運用向量空間模型的概念計算兩個標籤之間的距離,顯示兩 個標籤同時發生在相似情境的關聯程度。
(3)FolkRank:在標籤、資源、使用者三點模式架構(three-mode structure)中,應用 網頁排名(PageRank)演算法評估標籤、資源、使用者之間的相關程度。
另外,在 Markines et al., (2009)的研究中以資訊理論、統計學、實際測量衍生出 的公式,例如:Jaccard 係數(Jaccard coefficient)、Dice 係數(Dice coefficient)、Cosine Similarity、Mutual Information 分別評估資源和標籤的相似度。
陳怡蓁(2010)以 2x2 多因子實驗設計同時操弄層面分類結構(有提供/無提供) 與作品文類(小說/非小說),探討層面分類結構應用在社會性標記的可行性,並且 評估使用者在有無層面分類結構介面標記圖書作品的成果和品質。上述研究採用 Jaccard 係數和 Gini 係數評估評估使用者標記圖書作品所建立的標籤詞彙相似度,
以及標籤使用集中程度。結果顯示有層面分類結構介面裡使用者建立的標籤詞彙 相似度和標籤使用集中程度,都比無層面分類結構介面來的高。代表層面分類結 構的確有助於提升使用者建立的標籤的品質。除此之外,Gini 係數也曾被用來評 估社群影響對於音樂市場的分佈狀況(Salganik, Dodds & Watts, 2006)。
本研究歸納上述相關文獻後,採用適合的指標評估不同介面裡使用者選用的標 籤品質。
第三章 研究方法與設計
本研究以實驗法為主軸,採用量化分析方法輔以簡短訪談獲取實驗結果和質性 資料回答以下兩個研究問題和四項假設。
研究問題一:在標籤字體大小的影響之下,使用者在不同介面裡的標記行為是否 有差異?
H1:標籤字體大小會影響使用者的標記行為,導致不同介面裡使用者選用標籤次 數之分佈狀況有差異,在實驗組介面裡使用者選用標籤次數之分佈狀況較為不 均。
H2:在實驗組介面裡,使用者選用字體大的標籤的機會較高
研究問題二:在標籤字體大小的影響之下,使用者在不同介面裡選用的標籤品質 是否有差異?
H3:以 TF-IDF 演算法作為字體大小變化依據的介面裡,使用者選用的標籤品質較 高。
本章包括以下節次:受測對象、研究設計、研究工具、實驗流程、資料分析 與處理、信效度策略等六個部分。
第一節 受試者條件
本實驗經由 BBS 看板、aNobii 網路書櫃的討論群組,以及 Facebook 中有關書 籍閱讀的粉絲頁為招募管道,徵求本實驗所需之受試者,並且限定受試者須符合 下列所有條件:
1.知道「標記」、「標籤」的概念與作用(標記是給予書籍或是圖片等資源一個或數 個關鍵詞的動作,標籤則是關鍵詞,其他使用者可以藉由此關鍵詞了解資源內容,
方便個人管理或是其他使用者瀏覽查詢相關書籍。)
2.曾經讀過兩本以上的指定書籍,並且對書籍內容有部分了解。
本實驗的指定書籍清單會隨招募廣告一併告知有意願參與的受試者,以利找 尋符合上述條件的受試者參與本實驗。
此外,本研究藉由館員(專家)在分類索引、主題分析上的專業,以人脈關係招 募兩位在圖書館從事主題分析工作一年以上的館員,標記相同的指定書籍。以兩 位館員互相討論後為每一本書選用的 4 到 10 個標籤,作為評估受試者選用標籤品 質的基準。
第二節 研究設計
本研究主要的研究方法為實驗法,自變項為視覺特徵的變化,依變項為標籤 被選用次數之分佈狀況,以及使用者選用的標籤品質。自變項分成兩個類別:有 字體大小變化、無字體大小變化,以此建立兩種介面,實驗組為有字體大小變化,
控制組為無字體大小變化。
本研究採用受試者內設計與拉丁方格法,將書籍類型(小說與非小說)分成組四 個集合1,四個集合內所包含的書籍與書籍排序皆為固定,經自實驗組、控制組與 四個集合配對後產生四種介面順序(如表 3-1),每一個介面順序裡有兩個介面會顯 示字體大小變化,另外兩個介面則控制組,系統會依序指派受試者在其中之一的 介面順序裡標記書籍。
表 3-1 四種介面順序
實驗組(有字體大小變化) 控制組(無字體大小變化)
1 A C B D
2 B D A C
控制組(無字體大小變化) 實驗組(有字體大小變化)
3 B D A C
4 A C B D
1 將小說書籍分成 A、B 兩個等量的集合,每一集合包含 4 本小說書籍;將非小書籍分成 C、D 兩
第三節 研究工具
本實驗中採用的研究工具,包含標籤來源、指定書籍、標記系統、實驗介面、
實驗後問卷、實驗後訪談大綱、標籤清單,以下將敘述研究工具的建立過程。
一、 標籤來源
兩個實驗介面中的標籤雲,源自於陳怡蓁(2010)論文中所產出的實驗成果,原 先的研究以 2x2 多因子實驗設計同時操弄層面分類結構(有提供/無提供)與作品文 類(小說/非小說)這兩項因素,評估使用者標記圖書作品的成果與品質。
在陳怡蓁(2010)的研究裡總共有 32 位受試者參與實驗,每一位受試者依隨機 區組設計(randomized block design)指派至實驗組或控制組其中之一,標記與本研究 所採用相同的 16 本指定書籍。實驗組的介面中提供數個特定的層面欄位作為標記 的指引,使用者可依據欄位旁加註的文字說明理解層面欄位的定義,為每一本書 建立適當的標籤;控制組則是提供 10 個空白欄位讓受試者為每一本書自由建立標 籤,兩組共產生 3226 個標籤,實驗組中的受試者平均為每一本書建立約 8 個標籤,
而在控制組的受試者平均為每一本書建立約 5 個標籤。
本研究採用陳怡蓁(2010)論文裡有關標籤字形與字義的判定結果,並且將原先 實驗組和控制組內字形相同標籤的出現次數予以相加,共獲得 1546 個標籤,將 1546 個標籤配合在原先實驗中所出現的書籍,建立與 16 本指定書籍相關的 16 個標籤 雲,盡量避免標籤雲中不會出現字形相同的詞彙。
二、 指定書籍
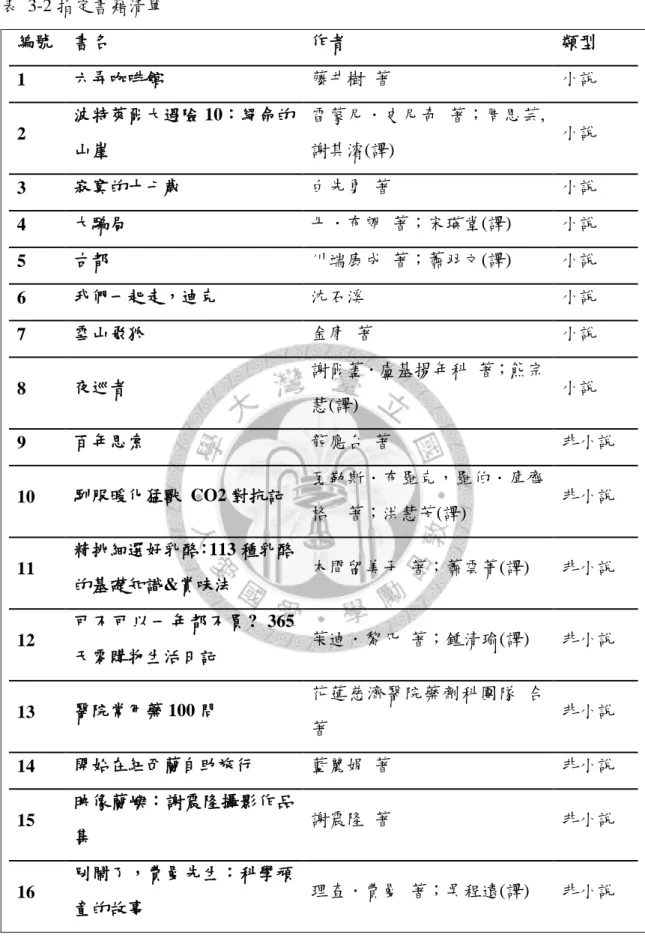
由於本研究是以陳怡蓁(2010)論文裡所產生的標籤作為組成標籤雲的元素,因 此,本實驗必須配合原先研究所採用的指定書籍,讓受試者可從標籤雲裡選用標 籤來標記書籍。原先研究的選書原則除了避免書籍選擇上的偏見,並考量到受試 者在時間與心力上所能負荷的程度,共選擇了 16 本書籍,包含小說與非小說書籍 各八本(詳見表 3-2)。
其中詳細的選書條件包含(1)選擇以中文撰寫或翻譯成中文的書籍;(2)避免內 容太過艱澀、專門之書籍;(3)避免全部選擇知名度高的書籍,以降低因書籍性質 與大眾認知所可能導致的偏差;(4)無法輕易區分為小說或是非小說類型的書籍不 予採用;(5)盡可能包含不同題材、類型、性質、年代的書籍,以增加指定書籍的
表 3-2 指定書籍清單
編號 書名 作者 類型
1 六弄咖啡館 藤井樹 著 小說
2
波特萊爾大遇險 10:絕命的 山崖
雷蒙尼.史尼奇 著;周思芸,
謝其濬(譯) 小說
3 寂寞的十七歲 白先勇 著 小說
4 大騙局 丹.布朗 著;宋瑛堂(譯) 小說
5 古都 川端康成 著;蕭羽文(譯) 小說
6 我們一起走,迪克 沈石溪 小說
7 雪山飛狐 金庸 著 小說
8 夜巡者 謝爾蓋.盧基揚年科 著;熊宗
慧(譯) 小說
9 百年思索 龍應台 著 非小說
10 馴服暖化猛獸 CO2 對抗記 瓦勒斯.布羅克,羅伯.庫齊
格 著;洪慧芳(譯) 非小說
11
精挑細選好乳酪:113 種乳酪
的基礎知識&賞味法 本間留美子 著;蕭雲菁(譯) 非小說
12
可不可以一年都不買? 365
天零購物生活日記 茱迪.黎凡 著;鍾清瑜(譯) 非小說
13 醫院常用藥 100 問 花蓮慈濟醫院藥劑科團隊 合
著 非小說
14 開始在紐西蘭自助旅行 藍麗娟 著 非小說
15
映像蘭嶼:謝震隆攝影作品
集 謝震隆 著 非小說
16
別鬧了,費曼先生:科學頑
童的故事 理查.費曼 著;吳程遠(譯) 非小說
三、實驗前問卷
本研究以 Google 文件製作線上問卷,在標記書籍之前會請受試者和兩位館員 填答不同的問卷,這份問卷調查受試者和館員背景,包含:性別、年齡(館員填答 的問卷以工作年數代替年齡)、學歷、學院別、平均每週使用網路的時數。採用李 克特(Likert Scale)六點量表型式調查受試者和館員先前的標記經驗,以及受試者和 館員對於指定書籍的熟悉程度(問卷詳細內容請參見附錄一和附錄二)。
四、標記系統
本研究採用自行設計標記系統進行實驗,標記系統以 Client-Server 的架構建立 系統,Client 部分是以 PHP 網頁程式語言設計標籤雲與實驗介面,Server 部分是由 Apache、PHP 設置一個支援 PHP 程式的 Web Server,並安裝 MySQL 資料庫提供 網站存取受試者選用的標籤。由資料庫後端記錄的資料欄位包含:受試者編號、
標記時間、書籍編號、介面編號、選用的標籤、標籤名次、標籤字體大小編號。
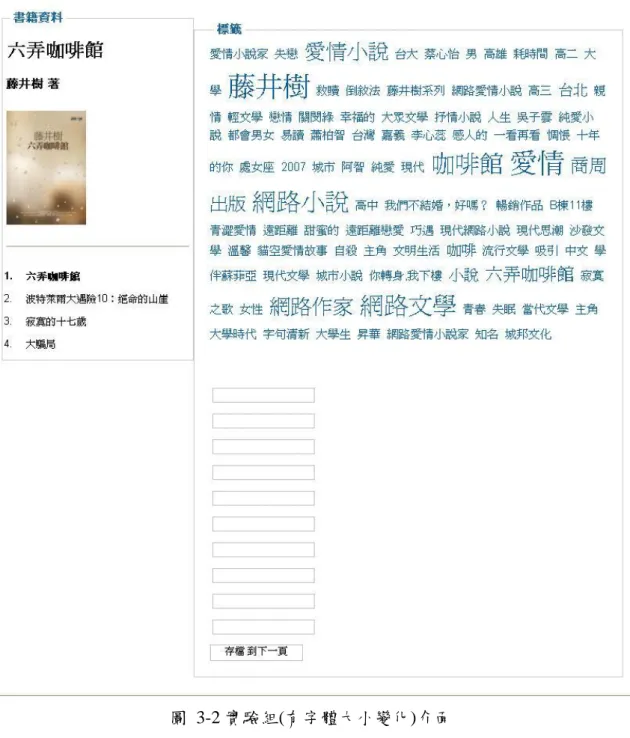
五、實驗介面
本實驗中四個階段的介面上的設計皆相同,包含下列四個部分:指定書籍資料、
書籍列、標籤雲、標籤輸入欄位(參見圖 3-2、圖 3-3、圖 3-4),分別敘述如下:
第一部分:指定書籍資料,包含書籍題名、書籍作者、書籍封面,有助於受試 者辨別書目資訊之用。
第二部分:書籍列,列出此階段所要標記的書籍,已標記過的書籍會以「@」
符號顯示在連結右側,提醒受試者此書籍已完成標記任務。
第三部分:標籤雲,兩個介面裡標籤雲內的標籤採用隨機順序排列。控制組內 的標籤無字體大小變化,實驗組以 TF-IDF 演算法計算的標籤權重,作為標籤字體 大小的變化依據,權重計算方式如下:
(1) TF=在每一本書裡個別標籤的出現次數
(2) IDF=LOG(N=16000/個別標籤在 16 本書裡的出現次數),原本應該以 N=16(指定 書籍數量)作為資源集合總數帶入公式。而本研究先前已分別採用 16、160、1600、
16000 等數字作為資源集合總數帶入公式,結果發現帶入 16000 之後所得到的 標籤權重對應到 HTML 語法的七種字體大小(參見圖 3-1)所產生的視覺效果最 好,字體大小之間的差距最明顯,故本研究將資源集合總數改為 16000。
每一個標籤的 TF 值和 IDF 值相乘之後所得到的標籤權重,對應到 HTML 語 法的七種字體大小,為了避免字體太小影響受試者選擇標籤,不考慮最小的一號 字體,只採用二號到七號字體,對應方式為事先算出標籤權重間距2,再將標籤權 重除以權重間距後取整數,並限定最大值為 7,最小值為 2。最後以像素(Pixel)方 式呈現標籤字體大小,原則上權重越高字體越大。
圖 3-1 網頁七種字體大小
資料來源:單維彰(2003)。HTML 教材:字型大小。檢索日期:2011 年 5 月 20 日,網址:http://libai.math.ncu.edu.tw/bcc16/7/html/b06.shtml
第四部分:標籤輸入欄位,受試者點擊標籤雲中的標籤,即出現在下方的空白 欄位,一個欄位放一個標籤,共 10 個欄位。欄位的順序代表名次,越上面的欄位 名次越高,受試者依個人對於書籍內容的認知,將越重要的標籤放在越上面的欄 位。
圖 3-2 實驗組(有字體大小變化)介面
圖 3-3 控制組(無字體大小變化)介面
五、實驗後訪談大綱
本研究在受試者完成所有標記任務之後,以事先擬好的問題為基礎與每一位 受試者做簡短訪談,訪談問題如下:
1.請問標籤雲內的標籤,對於您標記書籍時是否足夠?(請舉實例說明)
2.請問實驗介面中的標籤字體變化,是否會影響您標記書籍?是否有助於您標記書 籍?(請舉實例說明)
3.整體而言,您認為本實驗介面中,推薦標籤字體大小的依據(背後原理)為何?
本研究在兩位館員完成所有標記任務後,以事先擬好的問題為基礎,與兩位 館員一同進行簡短訪談,訪談問題如下:
1.請問您曾經讀過哪幾本指定書籍?曾經執行主題分析或編目過的書籍有哪些?
2.請問標籤清單內的標籤,對於您標記書籍時是否足夠?(請舉實例說明) 3.請問您標記書籍和排序標籤的原則或方法為何?(請舉實例說明)
4.請問您覺得在哪些書籍的標記過程中有確實符合窮盡性、專指性原則?(請舉實 例說明)
除此之外,本研究會觀察個別受試者或館員的標記過程,偶爾詢問其他的問 題,並且將受試者的回答錄音起來,轉譯為文字稿,藉此獲得受試者的真實感受 來解釋實驗結果。
六、標籤清單
本研究將實驗介面中 16 個標籤雲內的所有標籤,以 EXCEL 清單方式列出,
除標示書籍代碼之外不提供任何線索(包含標籤權重與標籤字體大小編號),此清單 作為專家選用與排序標籤時的依據。