行政院國家科學委員會專題研究計畫 期末報告
基於物聯網技術之智慧型建築安全與綠能應用之研製--子 計畫二:基於物聯網異質感測器網路管理與雲端接取路由
技術之研究(I)
計 畫 類 別 : 整合型
計 畫 編 號 : NSC 100-2221-E-011-154-
執 行 期 間 : 100 年 08 月 01 日至 101 年 10 月 31 日 執 行 單 位 : 國立臺灣科技大學電子工程系
計 畫 主 持 人 : 呂政修
計畫參與人員: 碩士班研究生-兼任助理人員:陳其灃 碩士班研究生-兼任助理人員:陳政宗 碩士班研究生-兼任助理人員:李坤翰 博士班研究生-兼任助理人員:游敏杰
報 告 附 件 : 出席國際會議研究心得報告及發表論文
公 開 資 訊 : 本計畫涉及專利或其他智慧財產權,1 年後可公開查詢
中 華 民 國 101 年 10 月 31 日
中 文 摘 要 : 隨著各式異質設備日益發展下,各設備需有一仲介者來平衡 與協調,以有效提升感測設備間合作之效能。在智慧建築 中,各設備感測獨運作,而建築物周圍之約有數百至數千個 感測點,將所有設備點連接起來並使之可相互溝通(即為物聯 網),其工程極為複雜。OSGi(Open Service Gateway
Initiative)可作為一區域彙集平台,藉由收集各感測器之資 訊形成一區域物聯網路,而透過網際網路連接,可將區域的 異質感測物聯網路資訊彙集至遠端的雲端伺服器,以進行集 中式管控,因而、在各區域資訊彙集至雲端計算平台過程 中,排程與接取路由技術為一值得探討之議題。在這個計畫 中,我們將先建立以 OSGi 為基礎的物聯網異質感測網路平 台,提供彙集區域物聯網資訊的功能;再者、透過物聯網平 台與雲端計算平台的接取設計,可使區域物聯網資訊集中管 理;然而為使區域物聯網平台與雲端伺服器連接效能提升,
路由接取及容錯機制亦需詳加設計,進而達成物聯網異質感 測資訊於雲端系統管理之目的。
中文關鍵詞: 物聯網、OSGi、異質感測網路、雲端計算平台、接取路由 英 文 摘 要 : With the development of heterogeneous sensor devices,
all devices need a broker which can balance and coordinate these sensors to effectively enhance the cooperation among them. In a smart building, each sensor node independently functions. There are
normally hundreds or thousands of sensors around the building. Forming an Internet of Things (IoT) by joining such a large amount of sensors to cooperate and communication with each other is quite
complicated. OSGi (Open Service Gateway Initiative) can play a local aggregator platform by gathering all sensing information to establish a local IoT network.
Through the Internet, all information from distinct IoT platform can be reported to the remote cloud computing platform and be managed centrally.
Therefore, how to schedule and make the access routing to the cloud platform for collecting distributed information becomes an attractive
research topic. In this project, we plan to construct a local OSGi based platform for heterogeneous IoT sensor network management first. Furthermore, we plan to well design the cloud access mechanism to manage the local IoT information centrally. To facilitate
the efficiency of connection between the local IoT platform and the remote cloud computing platform, routing and fault tolerance schemes should be well designed to realize the purpose of managing IoT
information from heterogeneous sensor networks at the central cloud computing platform.
英文關鍵詞: Internet of Things (IoT); OSGi (Open Service Gateway Initiative); Heterogeneous Sensor Network; Cloud Computing Platform; Access Routing;
行政院國家科學委員會補助專題研究計畫 □期中進度報告
■期末報告
基於物聯網技術之智慧型建築安全與綠能應用之研製-子計畫二:基 於物聯網異質感測器網路管理與雲端接取路由技術之研究(I)
計畫類別:■個別型計畫 □整合型計畫 計畫編號:NSC 100-2221-E-011-154-
執行期間: 100 年 8 月 1 至 101 年 10 月 31 日 執行機構及系所:國立台灣科技大學電子工程系
計畫主持人:呂政修 共同主持人:
計畫參與人員:游敏杰、陳政宗、陳其灃、李坤翰
本計畫除繳交成果報告外,另含下列出國報告,共 _一__ 份:
□移地研究心得報告
■出席國際學術會議心得報告
□國際合作研究計畫國外研究報告
處理方式:除列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,■一年□二年後可公開查詢
中 華 民 國 101 年 10 月 31 日
2
一、研究計畫中文摘要:
隨著各式異質設備日益發展下,各設備需有一仲介者來平衡與協調,以有效提升感測設備間合作 之效能。在智慧建築中,各設備感測獨運作,而建築物周圍之約有數百至數千個感測點,將所有設 備點連接起來並使之可相互溝通(即為物聯網),其工程極為複雜。OSGi(Open Service Gateway Initiative)可作為一區域彙集平台,藉由收集各感測器之資訊形成一區域物聯網路,而透過網際網路 連接,可將區域的異質感測物聯網路資訊彙集至遠端的雲端伺服器,以進行集中式管控,因而、在 各區域資訊彙集至雲端計算平台過程中,排程與接取路由技術為一值得探討之議題。在這個計畫中,
我們將先建立以 OSGi 為基礎的物聯網異質感測網路平台,提供彙集區域物聯網資訊的功能;再者、
透過物聯網平台與雲端計算平台的接取設計,可使區域物聯網資訊集中管理;然而為使區域物聯網 平台與雲端伺服器連接效能提升,路由接取及容錯機制亦需詳加設計,進而達成物聯網異質感測資 訊於雲端系統管理之目的。
關鍵詞: 物聯網、OSGi、異質感測網路、雲端計算平台、接取路由
二、研究計畫英文摘要:
With the development of heterogeneous sensor devices, all devices need a broker which can balance and coordinate these sensors to effectively enhance the cooperation among them. In a smart building, each sensor node independently functions. There are normally hundreds or thousands of sensors around the building. Forming an Internet of Things (IoT) by joining such a large amount of sensors to cooperate and communication with each other is quite complicated. OSGi (Open Service Gateway Initiative) can play a local aggregator platform by gathering all sensing information to establish a local IoT network. Through the Internet, all information from distinct IoT platform can be reported to the remote cloud computing platform and be managed centrally. Therefore, how to schedule and make the access routing to the cloud platform for collecting distributed information becomes an attractive research topic. In this project, we plan to construct a local OSGi based platform for heterogeneous IoT sensor network management first.
Furthermore, we plan to well design the cloud access mechanism to manage the local IoT information centrally. To facilitate the efficiency of connection between the local IoT platform and the remote cloud computing platform, routing and fault tolerance schemes should be well designed to realize the purpose of managing IoT information from heterogeneous sensor networks at the central cloud computing platform.
Keywords: Internet of Things (IoT); OSGi (Open Service Gateway Initiative); Heterogeneous Sensor
Network; Cloud Computing Platform; Access Routing;三、前言:
隨著生活品質進步,各種設備日益健全之情況下,在各系統間則需有一仲介者來平衡與協調,然 而此仲介者極為重要,它扮演一種系統間溝通之角色,在日常生活中總是需要一些設備來輔助我們,
使之方便、有效及快速達成目標,其為我們執著與期待的地方。在智慧建築中,各設備感測點可視 為一個別功能,因此一般個人或智慧建築周圍之設備點即可達到估計約一千至四千點左右,在如此 龐大之數字下,如須將所有設備點連接起來並使之可相互溝通(即為物聯網),其工程極為複雜,此
3
時則可藉由 OSGi(Open Service Gateway Initiative)作為一輔助工具並進一步達成所需之步驟。
物聯網(Internet of Things)為一類似區域網路之結構,它可將感測裝置裝載至各設備中(如電網、
鐵路、橋梁、隧道、公路...等等)並進一步透過特定程序、網際網路與管道將所有設備做連結,形成 一區域型之網路,如此一來各設備所在位置(電子標籤)或狀態都可透過管理中心控管,並可清楚知 道設備產品流向甚至可設計自動控制,讓各點間自動運作。在這個計畫中,我們將先建立以 OSGi 為基礎的物聯網異質感測網路平台,提供彙集區域物聯網資訊的功能;再者、透過物聯網平台與雲 端計算平台的接取設計,可使區域物聯網資訊集中管理;然而為使區域物聯網平台與雲端伺服器連 接效能提升,路由接取及容錯機制亦需詳加設計,進而達成物聯網異質感測資訊於雲端系統管理之 目的。
四、研究目的:
隨著網際網路的蓬勃發展,使得我們周遭有越來越多的設備或物品可以透過網際網路交換各式各 樣的訊息,除了本身構成網際網路互相連結的基礎設施,以及存取網際網路的終端設備,嵌入式系 統的發展也使日常生活中的種種產品可以透過網際網路連接。而在網際網路中交換的訊息也逐漸從 原本的二進位資料、文字到聲音、影像等,使得網路、資訊世界更加豐富,也使我們日常生活更少 不了網際網路的存在。
若依據其扮演角色的不同來劃分,則構成網際網路核心的部分便是互相連接的基礎設施,包含路 由器(Routers)、交換器(Switches)、伺服器(Servers)等,這些設施提供網際網路最基本的服務;連接至網際網 路的終端設備便可利用這些基礎設施達到互相連接的功能,並交換彼此的訊息,則這些終端設備便成為網際 網路核心之外緣部分,包含各式電腦、智慧型手機,以及透過嵌入式系統達到連線功能的其他設備,如智慧 電表(Smart meters)、電力線通訊設備(Power Line Communication, PLC)、物件標籤及讀取器;若是組合 這些網際網路的終端設備,便可延伸出許多應用領域,如家庭自動化系統(Home Automation, Domotic)、智慧電網(Smart Grid)、監視/警報系統、物件定位/追蹤系統,則這些應用都可以統稱為物 聯網(Internet of Things, IoT),意指構成網路的成員即為互相連接的物件。
但網路的發展快速,使這些由不同製造商生產的設備擁有多樣的連接方式、各種通訊協定或自有 的資料傳輸格式,勢必讓物聯網的整合更加複雜。於是為了縮短開發的生命周期,一個統一的國際 標準除了可減少不同開發商帶來的設備差異化,也使系統整合商能夠更快速的建立物聯網系統。不 幸的是,在物聯網發展十幾年期間,除了企業自有的標準外,尚未有國際的統一標準問世,使得許 多相關研究仍繼續在探討標準化的過程,包含系統架構、階層關係以及相關的核心技術、通訊協定 等。而在探討系統架構時,較少有研究探討在架構基礎上建立系統時實際需要運用哪些設計方法,
或是難以將系統架構與核心技術連結,使得在建立系統時仍缺乏統一性。於是本文將探討以服務為 導向架構(Service-Oriented Architecture)基礎下,以及使用較為熱門的網站(Web)建置方法,將物聯網 系統下的設備視為網站的各個服務,並提出明確定義的系統平台架構,使系統平台具有更好的整合 性、可擴展性以及彈性,而後透過實際建立的系統平台驗證架構的可行性。
五、參考文獻:
[1] G. L. Foresti, "A real-time system for video surveillance of unattended outdoor environments," Circuits
and Systems for Video Technology, IEEE Transactions on, vol. 8, pp. 697-704, 1998.
[2] M. Esteve, C. E. Palau, J. Martinez-Nohales, and B. Molina, "A video streaming application for urban traffic management," Journal of Network and Computer Applications, vol. 30, pp. 479-498, 2007.
4
[3] Y. Imai, Y. Hori, and S. Masuda, "Development and a brief evaluation of a web-based surveillance system for cellular phones and other mobile computing clients," in Human System Interactions, 2008
Conference on, 2008, pp. 526-531.
[4] T. Yu-Chee, W. You-Cbiun, C. Kai-Yang, and H. Yao-Yu, "iMouse: An Integrated Mobile Surveillance and Wireless Sensor System," Computer, vol. 40, pp. 60-66, 2007.
[5] P. Jung-Hyun and S. Kwee Bo, "A design of mobile robot based on Network Camera and sound source localization for intelligent surveillance system," in Control, Automation and Systems, 2008. ICCAS
2008. International Conference on, 2008, pp. 674-678.
[6]G. L. Foresti, "A real-time system for video surveillance of unattended outdoor environments," Circuits and Systems for Video Technology, IEEE Transactions on, vol. 8, pp. 697-704, 1998.
[7] M. Esteve, C. E. Palau, J. Martinez-Nohales, and B. Molina, "A video streaming application for urban traffic management," Journal of Network and Computer Applications, vol. 30, pp. 479-498, 2007.
[8] Y. Imai, Y. Hori, and S. Masuda, "Development and a brief evaluation of a web-based surveillance system for cellular phones and other mobile computing clients," in Human System Interactions, 2008 Conference on, 2008, pp. 526-531.
[9] T. Yu-Chee, W. You-Cbiun, C. Kai-Yang, and H. Yao-Yu, "iMouse: An Integrated Mobile Surveillance and Wireless Sensor System," Computer, vol. 40, pp. 60-66, 2007.
[10] P. Jung-Hyun and S. Kwee Bo, "A design of mobile robot based on Network Camera and sound source localization for intelligent surveillance system," in Control, Automation and Systems, 2008.
ICCAS 2008. International Conference on, 2008, pp. 674-678.
[11]"The Technical BSD Conference,"
http://www.bsdcan.org/2008/schedule/events/91.en.html
[12] Dinesh C. Verma “Data Backup Service”,Peer-to-Peer Networks, 2004
[13] Jepson, T.C.;"The basics of reliable distributed storage networks,",IT Professional,
[14] Wei Zhou; , "LAN-Free backup program design based on SAN,",ICNDS,2010
[15] Keeton, K.; Merchant, A.; , "A framework for evaluating storage system dependability," Dependable Systems and Networks, 2004
[16] Xu Wei; Wang Min; He Xiang; Xu Lu “A Self-Adaptive Backup System Based on Data Integration Mechanism,ICCIT 2008
[17] (Disaster Recovery Services)
http://www.fujitsu.com/tw/services/solutions/management/managedservice/disaster.html
[18] A. Chervenak, V. Vellanki, and Z. Kurmas. “Protecting file systems: A survey of backup techniques.”
In Proc. IEEE/NASA Conf. MSS, pp. 17 – 31, Mar. 1998.
[19] A. Azagury, M. E. Factor, and J. Satran. “Point-in-Time copy: Yesterday, today and tomorrow.” In Proc. IEEE/NASA Conf. Mass Storage Systems (MSS), pp. 259–270, Apr. 2002
六、研究方法:
6-1 OSGi 框架(Framework):
OSGi 是一種 Framework,它建構於 JVM(Java Virturl Machine)之上,因此 OSGi 必須運作於作業 系統(Operating System)之中,其架構如圖 1 所示。
5
圖 1. OSGi 與 bundle 架構圖
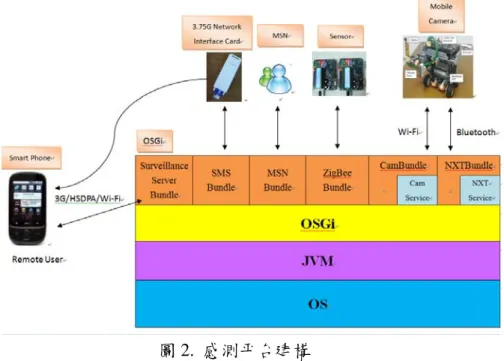
如圖 1 所示,作業系統(Operating System)運作於硬體(Hardware)之上,而 JVM(Java Virtual Machine)執行於作業系統之中,OSGi Framework 則是依賴於 JVM 之設定,bundle 則建構於 OSGi Framework 中,在 OSGi 裡我們對 bundle 分為兩區---sensor bundle 與 non-sensor bundle,其作用在於 區分感測功能(sensed function)及非感測功能(non-sensed function),並且可藉由加入 non-sensor bundle 讓 sensor bundle 功能更加完善,圖 2 為一感測建構平台。
圖 2. 感測平台建構
由圖 2 可知,用戶端透過 WI-FI 網路連結至感測平台,而在此有一 Surveillance Server Bundle,
透過它蒐集在感測平台上其他 bundle 資訊,然而 在這感測平台上則有著不同類型之 bundle,包含 SMS、MSN、溫度感測 sensor、行動監控...等等,並可藉由感測平台來控制所有 bundle 建構在此之上。
以行動監控為例,用戶端必須透過手機連線至 OSGi,並由 Framework 與機器人溝通以達到控制效 果,同時 Server 端會不斷的傳送影像至 OSGi,再由此 Framework 將影像送回手機,然而在控制機 器人之部分將以藍芽(Bluetooth)做資料傳輸,因它使用 2.45GHz ISM(Institute of Supply Management Manufacturing Index)之免費頻率,不必向 FCC(Federal Communications Commission)申請即可使用,
並適用於範圍大約 30 公尺內,在智慧建築中加入此應用最為合適。
6-2 物聯網異質感測網路平台(IOT Heterogeneous Sensor Network Platform):
6
感測系統架構圖如圖 3 所示,各搭配一個 Zigbee Slave 設備,並於 OSGi 服務平台上架設 Zigbee Master 設備與各個 Zigbee Sensor 節點溝通。
圖 3. 感測系統架構 此系統的感測目標具備下列功能:
1. 可偵測瓦斯、一氧化碳、二氧化碳、煙霧,一旦有任何一個事件發生,立即將訊息傳送到 OSGi 服務平台,OSGi 服務平台在透過網路將事件通知使用者事件發生
2. 可偵測大門及窗戶被打開之事件,即時將訊息傳送到 OSGi 服務平台,OSGi 服務平台在透過 網路通知使用者大門或是窗戶被打開之事件
3. 可偵測電器目前是否有電流超載的情況,一旦超出上限值,立即傳送訊息給 OSGi 服務平台,
OSGi 服務平台在立刻傳送給使用者,使用者獲知後,可透過網路遠端關閉電器。
6-2.1 感測模組(Sensor Bundle)
Sensor bundle 可裝載各種不同 Sensor 模組,在此就溫度感測作為範例並進行一系列之論述及探 討。溫度感測顧名思義即為可偵測溫度之設備,其感測方式極為多種包含 ADC 數據轉換、紅外線 溫度感測以及熱敏電阻感測...等等,然而有著各式各樣之感測方式卻沒有將各種感測統整,其實質 之功能將會受限,因此必須將他們連結起來,並建構成感測網路(Sensor Networks),相信在未來發展 中是必要的。
硬體設備 (Hardware) :
在建立一個無線感測網路中,首先最重要的就是瞭解在該感測網路中所使用的硬體設備,而這 些硬體設備都是以 ZigBee 無線感測網路為基礎所設計出來的,ZigBee 設備具有可靠度高、高擴充 性 以 及 省 電 等 特 性 , 此 外 根 據 設 備 使 用 的 用 途 不 同 共 可 分 成 兩 種 型 態 , 分 別 是 全 功 能 裝 置 (Full-Function Device,FFD)和精簡型裝置(Reduced-Function Device,RFD),FFD 之節點具備控制器 之功能提供資料交換,可稱得上是無線感測網路中的協調者,此外 FFD 除了做為一個協調者之外,
7
也能作為一個負責繞送訊息與提供連結的 Router;至於 RFD 則是只能單純地傳送資料給予 FFD 或 是從 FFD 接受簡單資料。
軟體架構 (Software) :
大部分的 ZigBee 設備的軟體架構都是建立在 TtinyOS 之上,其主要原因是 TinyOS 是一款自由 且開源的作業系統平台,且它主要是針對無線感測網路而設計的平台。如圖 4 所示,TinyOS 系統及 其應用程式皆是以 nesC(Network Embedded System C)程式所撰寫的,而 nesC 類似於 C 語言的語法,
但支持 TinyOS 的開發模型,其編寫的方式是基於一種組件的架構方式來編寫,組件可分為兩類:
模 組 (Module) 和 配 置 (Configuration) , Module 檔 (fileNameM.nc) 用 來 實 作 程 式 欲 執 行 的 內 容 ; Configuration 檔(fileName.nc)則用來描述在程式中會使用到的元件以及元件間的連結與關聯性。當我 們在設計一個程式架構的雛形時,我們可將自訂的組件視為主要的控制元件,其他則可皆視為輔助 工作的元件,接著我們則是要考慮元件相互連結溝通的 interface,也就是元件間溝通的管道,來完 成我們所需要的功能。
圖 4. TinyOS 平台架構圖[5]
Bundle 建置:
Bundle 的建置基礎是 JAVA 程式開發語言,因此當能夠透過 JAVA 將 ZigBee 感測設備所傳送的 封包解讀出來後,只要把我們所寫好的程式放入 Bundle 的框架裡即完成了一個 Sensor 的 Bundle,
在那之前我們需要了解 Bundle 的框架才能對 Bundle 的建置進行開發。一個 Bundle 裡會使用到三個 JAVA 檔,而這三份 JAVA 檔一個是用來實現此 Bundle 的功能,一個是 Bundle 啟動或停止時所需要 進行的工作,另一個則是當其他 Bundle 要使用此 Bundle 的功能時提供一個介面來供它調用,以簡 單的 HelloWorld 程式為例,首先我們先編寫出此 Bundle 所要實現的功能,接著再建一個新的 JAVA 檔作為讓其他 Bundle 能訪問的介面,最後則是用來啟動或停止此 Bundle 的程式檔,其中在 start 的 函式裡,除了啟動這個 Bundle 的同時我們使用 bundleContext.registerService( )來為我們這個 Bundle 進行註冊,使之能夠讓其他 Bundle 來調用它的功能,而在 stop 函式裡停止此 Bundle 的同時,我們 則使用 serviceRegistration.unregister()來註銷掉此 Bundle 所註冊的服務。
6-2 物聯網用戶端(IOT Client)
6-2.1 Smart Phone(Android Phone、iPhone、iPad)
8
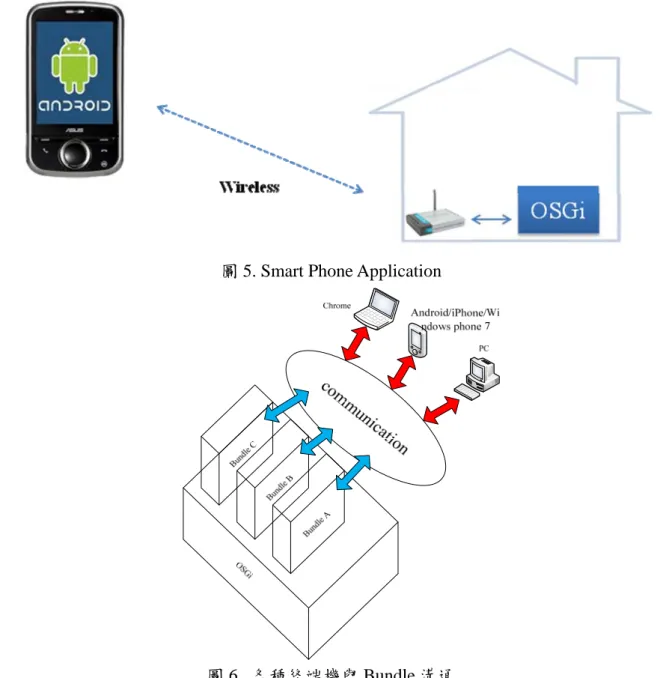
如圖 5 所示,在智慧型手機上開發應用程式,使其可透過 Wireless Network 接收 OSGi 傳送過來 的各式各樣訊息。手機可透過 Wireless Network 接收 OSGi 傳送過來的各感測(Sensor)設備的事件,
並可在手機螢幕上觀看各個感測(Sensor)設備的狀態。
圖 5. Smart Phone Application
圖 6. 各種終端機與 Bundle 溝通
基於 OSGi 服務平台上建立的 Bundle 之系統架構,如圖 6 所示,終端機與 Bundle 的溝通變得更 加重要,透過各種異質網路 GPRS、Wi-Fi、3GPP-LTE 或是目前最紅的 WiMAX 來作資料的傳遞,
終端機方可以從桌上型 PC、Android Phone、iPhone、Windows phone 7…等手機到 google 最新發展 的 Chrome OS 作應用。
以下使用 ZigBee Bundle 與 Android Phone 為實例作介紹,在開發流程方面主要有四大步 驟:Protocol TCP/UDP、Set Socket、Set connection、Check and Application。
Protocol TCP/UDP :
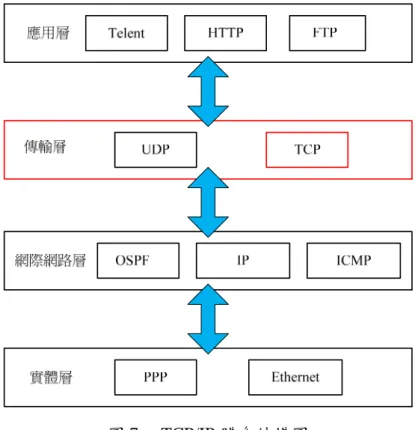
使用異質網路作資料傳遞時,首先要決定雙方的網路溝通協議,在 TCP/IP 體系結構圖中,如圖 7 所示,傳輸層中由 TCP 和 UDP 兩個重要的協定組成,此層的作用是完成 A 端與 B 端的通信。
TCP(Transmission Control Protocol)提供一種連線導向的可靠資料傳輸協定,而 UDP(User Datagram Protocol)採用一種不需連線的協定,提供不可靠的資料封包服務,例如:應用於 Peer to Peer,本實例
9
採用 TCP 協定作傳輸。
圖 7. TCP/IP 體系結構圖
Set Socket :
在 TCP/IP 協定規則中,可以採用 Socket 從事 TCP、UDP 等協議的程式設計,此外 Socket 還提 供一種原始通訊端機制,能夠讓開發者直接操控 IP 層,應用程式可以透過使用 Socket 介面實現資 料通信,以及資料封包的收發,而本實例介紹採用 Socket 作為網路溝通的方法,將網路連線簡化為 資料流(data stream)的概念,資料流在 client 端與 server 端各有一個接口(port),利用連接兩接口的纜 線作傳遞。
TCP 程式的 server/client 端開發流程可分類如下:
Server 端流程 (1) 通訊端建立:
使用 socket()函數,建立一個通訊端。
(2) 服務對應:
使用 bind()函數,為當前服務通訊端對應一個位址空間。
(3) 服務監聽:
使用 listen()函數,偵聽在指定連接埠。
(4) 處理新的連接:
使用 accept()函數,建立一條與客戶端當前來到來的通信連線。
(5) 資料收發:
利用已獲得的客戶通訊端標識,使用 send()和 recv()函數進行資料的收發工 作。
(6) 通訊端關閉:
假若通訊完畢,則使用 close()函數,關閉當前的通訊端。
Client 端流程
(1) 客戶端通訊端建立:
10
使用 socket()函數,初始畫一個通訊端。
(2) 發起連接:
使用 server 端的 IP 和連接埠填充 sockaddr_in 位址空間,同時使用 connect()函數向伺服器發起 連線。
(3) 資料收發:
假若連線成功,則使用 send()和 recv()函數進行資料資料收發。
(4) 通訊端關閉:
當通信完畢,使用 close()函數關閉通訊端。
Set connection :
Bundle 與終端機的連線主要透過 TCP 協定,建立 socket 作為網路溝通,而設定連線的方式主要 分如下三種:永久性持續連線、周期性間斷連線、觸發性連線,如圖 8 所示。
t t
T t
t t
T T
t t
持續性連線
週期性連線
T t
觸發性連線
T: Connection Time t: Send and Receive Data Time
圖 8. bundle 與終端機連線方式 (1) 持續性連線
永久性持續連線即 client 與 server 端在程式一開始便建立 socket 連線,且每隔 t 秒接收一次 data。
缺點為長時間建立連線可能會因為某些外在因素導致連線品質不穩定,最後中斷連線。解決方法 為設定中斷後等待時間再次連線,但是此方法並無法徹底解決因長時間連線而中斷的問題,若是 採用第二種連線方式周期性間斷連線即可改善第一種連線的主要問題。
(2) 週期性連線
週期性連線為 client 與 server 端在建立連線後每隔 T 秒鐘中斷連線一次,連線期間每隔 t 秒接收 data 一次,如此可減少長時間連線造成中斷的問題。
(3) 觸發性連線
透過終端機的 UI(user interface)上的按鈕或事件來觸發與 bundle 的網路連線,一旦觸發連線後雙
11
方便交換 data。缺點為無法從 bundle 端得知最新的訊息。
Check and Application :
從 bundle 端接收 data 後必須執行 data check 的動作,可利用 JAVA 語法中的 try catch 來捕捉例 外或是透過雙方事前的溝通決定傳遞訊息的格式,在應用方面可以把 sensor data 顯示在圖形化界面 上並配合虛擬 sensor 的變化來表示感測環境的異常。
6-3 系統架構實作:
在日常生活使用的各種設備中,以較常用的可分為兩大類型做區別:接收外在環境資料的感測 器(Sensor)以及可藉由控制信號對外在環境做出反應的驅動器(Actuator),則負責連接並整合、管理這 兩大類型設備的共同平台則由運算設備如個人電腦,以及網路設備構成,稱為閘道器(Gateway)或中 介器(Broker)。如此一來此通用架構便可描述大部分 IoT 系統以及其實際構成的成員,而在本計畫中 以 IoT 單元(IoT Unit)稱之,代表此架構即可成為一獨立運作之 IoT 系統,如圖 9 為 IoT Unit 實例。
Sensor 以及 Actuator 藉由不同的連接介質(Media)連接至 Broker,而因應設備連接型態的多樣 性,有時必須將 Media 予以轉換成 Broker 能夠支援之型式,則可藉由轉接器(Adaptor)將 Media 互相 轉換以連接至 Broker。Sensor 接收外在環境的資料後便輸入至 Broker 進一步處理,而可根據使用者 需求自動或手動下達指令至 Actuator 以做出反應。
圖 9. IoT 單元實例
Broker 將會蒐集來自 Zigbee 通訊協定構成的感測網路節點(Sensor nodes)之資料或來自以電力線 網路傳輸之網路攝影機(IP cam)影像分享至網路,藉由使用者指示或由 Broker 自動判斷制動機制向 機動設備或灑水系統下達命令,成為自動控制系統。藉由不同 Media 以及 Adapter 之搭配可解決硬 體設備連接型態之差異化。因 Broker 擔任 IoT Unit 整合之角色,故需藉由設計應用程式以接應不同 硬體設備。根據服務導向架構(Service-Oriented Architecture, SOA)模組化之設計,與硬體設備溝通之 應用軟體應能夠獨立運作、互相溝通且能夠重複使用,方能達到鬆散耦合之效果。故本計畫軟體架 構建立於 SOA 基礎之上,將一個硬體設備即對應一個軟體服務,並透過額外定義的其他服務可使軟 體具有擴充性及彈性。
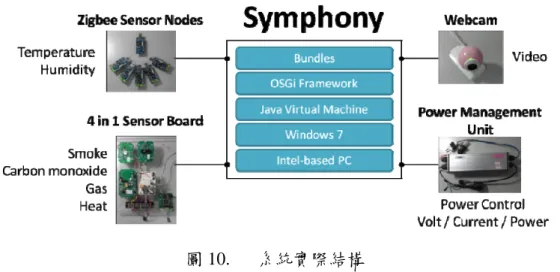
實作上,首先選定一較常見之家庭式監控系統做為建構目標,並且透過 SOA 與網頁服務逐步建 立通用系統平台以及與設備相對應之系統服務元件,如圖 10 所示為 Symphony 家庭監控系統之實際 結構,利用一般個人電腦以及無線路由器做為 IoT Unit 之 Broker,則將現有之設備以不同方式連接 至此。在此現有之設備皆以不同型態與 Broker 連接,以達到在建立 IoT 系同時所面臨之設備差異性。
網路攝影機(Webcam)以 USB 連接至個人電腦做為影像串流;電力線上管理單元(Power Management
12
Unit, PMU)則為電力線乙太網路,透過電力線路連接至路由器傳輸乙太網路流量,並可測量與之連 接電器之電氣參數,包含電壓、電流以及能耗,並能夠控制電器開與關;四合一感測板即利用現成 感測警報裝置配合單晶片系統以序列埠連接至個人電腦,並可利用電位差得知環境有無煙霧、瓦斯、
一氧化碳及高溫;Zigbee 為 IEEE 802.15.4 之通訊協定,則透過 USB 連接之協調器(Coordinator)與五 個感測節點(Sensor nodes)透過 Zigbee 協定傳輸各點溫度及濕度資料。
圖 10. 系統實際結構
Broker 為單純之個人電腦,故其已具備多樣化之輸入輸出介面,若將之改用體積小且較為省電 裝置如嵌入式系統,更可使系統具備可攜並更富彈性。於是本計畫將選擇 Java 做為可跨平台之開發 語言,且其於網路傳輸方面也較具其他語言在開發上帶來許多方便,如使用企業版(Java 2 Enterprise Edition, J2EE)之 Servlet 技術可順利以 MVC Model 2 網頁服務設計模式開發。本計畫選擇在家庭、
車載網路已成熟之 OSGi 為基礎建立系統。在 OSGi 之定義中,系統服務元件稱為 Bundle,可藉由 已定義之不同生命週期開發元件於啟動、停止等狀態時之行為。本計畫選擇使用體積較輕巧之 Eclipse Equinox 做為原形發展,並且透過內建之 Jetty 網頁容器將系統服務元件進一步開發成網頁服務形 式。本計畫實作系統之系統服務元件各別開發,如圖 11。
圖 11. 系統軟體平台構造
SymphonyUI 提供對外管理、存取介面以及負責控管其他元件生命週期,如圖 12 所示可利用瀏 覽器以拖拉方式管理可視化後各別的系統服務元件;而 SymphonyUtil 則可提供網頁美觀設計庫以及 利用 IoC/DI 抽象化之抽象介面,故其他服務元件必須依賴此元件提供其完整功能;最後四種設備因
13
其性質皆為 Sensor,故分別開發對應之服務元件。
圖 12. 使用者透過瀏覽器存取管理介面
以同一台個人電腦模擬擔任 IoT Portal 之角色與功能,用來連接不同 IoT Unit。使用者可利用智 慧型手機、筆記型電腦等手持裝置連接上網際網路後,以任何網路瀏覽器透過 IoT Portal 提供之存取 介面獲得目前系統中所有設備提供之視覺化資料,如圖 13。
圖 13. 使用者存取服務介面 七、結果與討論:
物聯網隨著行動網路的普及可演變成一個”Anytime,Anywhere”的應用服務,為增加物聯網應用 的彈性,在這個計畫中,我們提出一個以 OSGi 為基礎的物聯網異質感測網路平台,此架構可以手 持式裝置 (像是手機、筆記型電腦) 進行遠端監控,使用者不管何時何地只要能透過 GPRS、Wi-Fi、
UMTS (新興的 3GPP-LTE)、WiMAX 連上網路就能監控感測網路平台的各項資料,如溫度、濕度、
影像監控等。除此之外,由於我們有一台攝影機掛載在一個機械自走車上,遠端的使用者並可監 控到更廣泛的範圍。由於此應用透過異質網路橫跨於行動攝影機、OSGi 服務平台、監視端手機三 者之間,可提升計畫參與人員在異質網路上應用服務開發的問題分析與解決能力,並使得應用開 發當中可學習的相關的整合經驗,且提供不同的整合思維,提升在行動化網路軟體系統開發整合 解決方案設計上的競爭力。
14
由於物聯網設備可依特性分為 Sensor 及 Actuator 與環境互動,並透過服務導向架構定義,將 軟體元件明確定義並透過 MVC Model 2 及 IoC/DI 之著名設計模式,可使硬體與軟體接應、資料分 享至網路過程上更無阻礙。搭配不同定義之系統服務元件可使元件間相依性降至最低,並可直接 透過網路互相溝通交換資料,達成物聯網之設備間互相溝通之目的。因此擴充其他服務的彈性極 高,可以利用此概念去實作其他與物聯網相關的應用,如家庭式監控系統、遠距醫療系統等。
八、成果發表情形
計畫執行期間所發表之期刊論文如下:
M.-S. Lin, J.-S. Leu, K.-H. Li, and J.-L. C. Wu, “TABOA: Terrain-aware Beacon Order Adaptation Scheme in 3D Zigbee Sensor Networks,” IEEE Wireless Communications [SCI,EI]
M.-S. Lin, J.-S. Leu, K.-H. Li, and J.-L. C. Wu, “Zigbee-based Internet of Things in 3D Terrains,” Computers and Electrical Engineering (CEE), Elsevier [SCI,EI]
M.-S. Lin, J.-S. Leu, W.-C. Yu, M.-C. Yu, and J.-L. C. Wu, “BOB-RED Queue Management for IEEE 802.15.4 Wireless Sensor Networks,” EURASIP Journal on Wireless Communications and Networking 2011, 2011:107 doi:10.1186/1687-1499-2011-107 [SCI,EI]
計畫執行期間所發表之會議論文如下:
H.-Y. Shih and J.-S. Leu, 'Improving Resource Utilization in a Heterogeneous Cloud Environment,' The 18th Asia-Pacific Conference on Communications (APCC 2012), Jeju island, Korea, Oct. 15-17 2012. [EI]
J. Mora and J.-S. Leu, 'Intelligent Power Saving Technique for Mobile Devices,' The 18th Asia-Pacific Conference on Communications (APCC 2012), Jeju island, Korea, Oct. 15-17 2012. [EI]
J.-S. Leu and H.-J. Tzeng, “Received Signal Strength Fingerprint and Footprint Assisted Indoor Positioning Based on Ambient Wi-Fi Signals,” The 75th IEEE Vehicular Technology Conference (IEEE VTC 2012 Spring), Yokohama, Japan, May 6-9, 2012. [EI]
M.-S. Lin, J.-S. Leu, W.-C. Yu, K.-H. Li, and J.-L. C. Wu, “TBRA: Termites Based Routing
Algorithm in 3D Wireless Sensor Networks,” The 75th IEEE Vehicular Technology Conference
(IEEE VTC 2012 Spring), Yokohama, Japan, May 6-9, 2012. [EI]
1
國科會補助專題研究計畫出席國際學術會議心得報告
日期:101 年 10 月 20 日
一、參加會議經過
第 18 屆亞太通訊會議舉辦在韓國濟州島,主要探討有關電信與通訊網路技術,參 與人員包括有學術及產業領域等人士,為此領域每年交流的盛會,會議地點舉辦地 點大多在亞太主要都市,已有相當的舉辦歷史,每年吸引很多專家學者投稿,今年 有 381 篇投稿文章,接受了來自 30 個國家的 150 口頭報告論文與 55 篇海報論文。
計畫編號 NSC100-2221-E-011-154-
計畫名稱 基於物聯網技術之智慧型建築安全與綠能應用之研製-子計畫二:基於
物聯網異質感測器網路管理與雲端接取路由技術之研究(I) 出國人員
姓名 呂政修 服務機構
及職稱 台灣科技大學電子工程系/副教授
會議時間
101 年 10 月 15 日 至
101 年 10 月 17 日
會議地點 韓國濟州島
會議名稱
(中文)第 18 屆亞太通訊會議
(英文) The 18th Asia-Pacific Conference on Communications
發表題目
(中文)
1. 異質雲端環境中改善資源之使用率 2. 行動裝置上智慧型節能技術
(英文)
1. Improving Resource Utilization in a Heterogeneous Cloud Environment
2. Intelligent Power Saving Technique for Mobile Devices
2
本人於 10/15 搭機直達濟州島,立即前往會議舉辦地點,到達會場(Ramada Plaza Hotel)後即立刻參與會議,聆聽大會特地邀請工業界的專家介紹當前重點發展技 術,包含巨量資、雲端計算及智慧電視,獲得許多新的研究資訊,可謂收獲甚多。
本人的第一篇論文被安排於 10/15 下午的”Future Internet and Networks”Session 中 發表,第二篇論文被安排於 10/16 下午的”Green Optical Networks”Session 中發表,
順利完成口頭報告外並回答聆聽者的提問。本次會議的進行係採取「多軌制」(multi track)的方式,亦即同時有多篇論文或海報論文的發表,在研究上可給予新的激發。
個人並參與聆聽第二天大會安排的 keynote speech,其中來自中國清華大學 Prof.
Zhisheng Liu 與來自 Korea Telecom 的 Dr. James Won-Ki Hong 分享電信業者目前如何 進行綠能研究與營運上的挑戰,了解產學界專家對此議題的看法,讓曾在電信業者 工作過的我深覺心有戚戚焉之感,也產生一些未來可考慮發展的研究議題。此外、
本人並參與聆聽一些有關於與個人研究較相關的感測網路議題的論文發表,了解到 一些新的研究結果。議程結束後並於濟州島這極具觀光盛名的幾個著名景點參觀,
感受一些異國風情。於當地 10/17 晚上搭回程的飛機,於晚上 20:30 抵達台灣。
二、與會心得
亞太通訊會議或許不算是大規模會議,但會議主持單位相當用心,安排許多實務
上的專家分享實際上的案例,讓會議不致只是學術上的討論,這可讓學者專家可更
務實的研究一些可用的技術,而透過發表自己的研究成果,有機會可取得與會人士
的不同看法,且會議中眾專家學者發表的內容大部分都是最新成果且經過審查,相
互分享與討論可刺激新的思考模式,對於目前網通技術蓬勃發展的研究有很大的助
益,另外,在交流過程中因此會議而認識各國一些從事類似研究的專家學者,將有
3
助於未來可能的跨國合作,透過國際會議的交流可拓展了自己的視野,實有助於自 己研究實力之提升,本人非常感謝國科會提供本人參加本次會議的機會。
三、發表論文摘要(全文如附)
1. Improving Resource Utilization in a Heterogeneous Cloud Environment
Cloud computing features a flexible computing infrastructure for large-scale data processing. MapReduce is a typical model providing a logical framework for cloud computing and Hadoop, an open-source implementation of MapReduce, is a common platform to realize such kind of parallel computing model. Normally, a cloud computing service comprises many heterogeneous commodity machines. The original resource arrangement policy in Hadoop only focuses on the logical resources, such as free slot number, without considering the physical workload of comprehensive computing resources, such as the CPU utilization, network bandwidth, memory usuage on each working node. This paper aims at dispatching the computation load to all processing nodes in the cloud computing environment by considering the physical workload on each node so as to prevent bias in arranging computation resources and hence improve the overall computing performance in a heterogeneous cloud environment.
2. Intelligent Power Saving Technique for Mobile Devices
Power saving in mobile devices has become a very studied topic nowadays. Enhancing user experience through intelligent techniques that help to extend battery lifetime is today’s goal for many manufacturers and developers. Different approaches to improve power consumption have focused on improving the hardware used, the operating system, and/or the applications performance; however, this study’s focus is to design an intelligent software framework. After a throughout evaluation of the power consumption in different modules of the phone, in order to identify which modules consume power the most, a reinforcement learning method is proposed to effectively deal with this issue by granting/denying access to the user of executing battery-draining tasks.
四、建議
希望國科會能繼續鼓勵國內研究學者參與國際會議,以增廣見聞,除可有新的研 究外,並可廣為台灣宣傳研究實力。
五、攜回資料名稱及內容
USB 隨身碟內含會議論文集及紀念背包。
Improving Resource Utilization in a Heterogeneous Cloud Environment
Hsin-Yu Shih
Department of Electronic Engineering National Taiwan University of Science and Technology
Taipei, Taiwan [email protected]
Jenq-Shiou Leu, Member, IEEE Department of Electronic Engineering National Taiwan University of Science and Technology
Taipei, Taiwan [email protected]
Abstract—Cloud computing features a flexible computing infrastructure for large-scale data processing. MapReduce is a typical model providing an logical framework for cloud computing and Hadoop, an open-source implementation of MapReduce, is a common platform to realize such kind of parallel computing model. Normally, a cloud computing service comprises many heterogeneous commodity machines.
The original resource arrangement policy in Hadoop only focuses on the logical resources, such as free slot number, without considering the physical workload of comprehensive computing resources, such as the CPU utilization, network bandwidth, memory usuage on each working node. This paper aims at dispatching the computation load to all processing nodes in the cloud computing environment by considering the physical workload on each node so as to prevent bias in arranging computation resources and hence improve the overall computing performance in a heterogeneous cloud environment.
Keywords-Cloud Computing, MapReduce, Large-Scale Data Processing, Hadoop
I. INTRODUCTION
With the explosive development of web applications, petabytes of data generated by various kinds of network applications are processed in the Internet. Cloud computing is developed to process massive data, such as distributed data sorting, log analyzing, machine learning and so on. Analyzing these huge volumes of data requires a scalable solution, MapReduce [1], is one well-known cloud computing model, features an efficient framework to analyze data in parallel with flexible job decomposition and sub-tasks allocation. MapReduce can be deployed on a large number of commodity machines and can automatically handle node failures.
Hadoop [2], a project maintained by Apache Software Foundation and an open-source implementation of MapReduce, is primarily used by Yahoo and also Facebook, Amazon and Baidu etc. Hadoop is a suitable platform to deal with various kinds of applications such as data mining and extraction on large-scale of data. In Hadoop, there are multiple Map and Reduce tasks in a
MapReduce job. Each task is a single unit of work that can be performed together with other tasks in parallel.
Assigning tasks to node assign is performed by a master node, which distributes tasks to slave nodes. Each slave node has a fixed number of Map and Reduce slots for executing Map and Reduce tasks. At any time, each slot can run only one task. Slot offers a simple abstraction of the available resources on a physical machine. The primary advantage of slots is the ease of implementation of the MapReduce programming model in Hadoop. However, this mechanism cannot fully exploit the processing capability among nodes especially in the heterogeneous environment due to the same slot setting. The original task assigning policy in Hadoop only considers the slot condition but not the workloads on each processing node for job dispatching where working loads should consider the CPU utilization, memory resources, network bandwidth, storage I/O and any other kinds of computation resources.
In this paper, we design a new resource-aware policy in Hadoop to improve the resource utilization among nodes in the cloud. We focus on a dynamic slot configuration according to the resource availability on all processing nodes carrying out Map/Reduce operations. In the initialization phase, the proposed scheme creates slots in Hadoop nodes, based on the number of computing cores on each machine. In the runtime phase, the proposed scheme adjusts the number of slots individually by considering workload instead of fixing the number of slots on each node. Comprehensive experiments show the proposed scheme can effectively improve resource utilization in a heterogeneous cloud environment.
The rest of this paper is organized as follows. We describe some related works and technical backgrounds in Section II and Section III. Section IV illustrates the proposed scheme to fairly utilize the node resources in the cloud. We then conduct some experiments to validate our design in Section V. Finally, a brief conclusion is shown in Section VI.
978-1-4673-4728-0/12/$31.00 ©2012 IEEE 185 APCC 2012
II. RELATED WORK
Exploiting the MapReduce model in cloud computing has drawn considerably more attention in recent years.
Many new studies on MapReduce related issues seek to improve MapReduce performance. Hadoop is a typical implementation for the MapReduce model. Since virtualization can provide benefits in cloud computing environment by enabling virtual machine migration to balance load across the nodes, some researchers deploy the Hadoop environment amount a lot of VM nodes [3, 4].
The authors in [3] proposed some optimization schemes to improve the performance of Hadoop cluster where the scheme in [4] focused on cloud storage optimization and only considered the CPU utilization to determine the load.
The authors proposed a multi-tiered application services in the Hadoop Distributed File System (HDFS) which allocates and releases resources in discrete units. When adding or removing a node, rebalancing stored data across the nodes is required.
Since the Hadoop cluster is connecting computation nodes by networks, a significant problem is data transportation. Data transportation is one of important issues to improve computation performance. When running jobs need to access the data not in the local storage, I/O on the node owning the data can become a performance bottleneck. The authors in [5] studied the issue about optimizing data transfers for MapReduce clusters. A Weighted Shufe Scheduling (WSS) mechanism has been proposed to schedule data at the shuffle transfer level, just like prioritizing a data transfer in order to lower job competition time.
Meanwhile, some researches focused on improving the performance of MapReduce processing by looking for a set of suitable configuration parameters. The authors in [6]
identified several factors affecting the system performance, including the I/O mode, how to parse records and how to schedule jobs. By studying how the job configuration parameters can affect the performance of Hadoop, the authors [7] proposed a scheme which can automatically tune the effective configuration parameters (e.g. the number of Map/Reduce slots, replication, block size, etc.) for MapReduce jobs to optimize the execution performance of an application. The authors in [8] studied the effect of the ratio of Map and Reduce slots for the overall computation performance and showed that the resource consumption and performance are dependent on the type of submitted job. A fingerprint based method to predict the resource consumption of a new job at hand is proposed to determine optimal values for configuring parameters of MapReduce by using a database containing similar resource consumption signatures of historical jobs.
Heterogeneity is bound to happen in organizations that own various generations of IT product purchase over different time. However, Hadoop does not perform well in a Heterogeneous environment [9]. In MapReduce, the authors in [10] noted that speculative execution can improve job completion time by 44%. To improve
MapReduce in a heterogeneous environment, a speculative task scheduler, Longest Approximate Time to End (LATE scheduler), chooses the tasks that take longest time to finish and launches speculative copies on fast machines. In addition, LATE limits the number of speculative tasks to significantly shorten the job completion time in the heterogeneous environment [11].
III. BACKGROUND KNOWLEDGE
A. MapReduce
MapReduce, introduced by Google in 2004, is one of the famous software frameworks to support distributed computing on massive data sets on clusters of computers.
It is widely used in various kinds of applications like distributed data sorting, log file analyzing and machine learning and so on. The main goal of MapReduce is to distribute the processing across many nodes to take advantage of parallel processing power. This is generally done by dividing the dataset into several chunks, and then processing those chunks in separate nodes.
A MapReduce job mainly consists of two phases, Map and Reduce. The input data-sets are split into independent chunks of default size. The Map task turns the chunk into a set of key-value pairs. One Map process is invoked to process one chunk of input data, and each Mapping operation is independent to each others. Then, the intermediate key-value pairs from the output of each Map task are collected and sorted by key, then transferred to the location where a Reduce process would operate on the intermediate data. Reduce tasks merge all intermediate values associated with the same intermediate key to form a possibly smaller data set. In other words, all key-value pairs with the same key complete at the same Reduce task.
MapReduce runs on a large cluster of commodity machines. A large server cluster can use MapReduce to sort petabytes of data in only a few hours. The parallelism also offers some possibility of fault-tolerant. If one Map task or Reduce task fails, the work can be recovered by rescheduling.
B. Hadoop
Apache Hadoop is an open-source implementation of the MapReduce programming model. Hadoop follows the master/slave architecture and consists of one master machine responsible for organizing the distribution of work, and a set of worker machine responsible for executing the work assigned by the master. Hadoop focuses on distributed storing and processing on massive data. It is designed to scale up from a single node to thousands of ones, with a very high degree of fault- tolerance.
In the Hadoop environment, the MapReduce framework consists of a single JobTracker on the master node and one TaskTracker per slave node in the cluster.
First, client applications submit jobs to JobTracker. Jobs are split into many tasks by default size. JobTracker communicates to the NameNode to determine the location
186
of the data, and then submits the Map or Reduce task to the chosen TaskTracker nodes. When the job is completed, JobTracker updates its status and stores the output data.
In Hadoop, resources are depicted by the concept of
‘slot’. On the other hand, each TaskTracker is responsible for a specific number of slots on each node. The slot number determines the max running number of tasks which are allowed to be run in parallel on that node at a time. The scheduling policy in Hadoop is based on the fixed slot number for the lifetime of each node. The slot number depicts the computation ability on the node and can be configured in an XML file.
Originally, JobTracker chooses the processing TaskTracker in the cluster by one rule - keeping the work as close to the data as possible. That is, when JobTracker tries to schedule a task with the MapReduce operations, it first looks for an empty slot on the same server that hosts the DataNode containing the processing data. If not, it allocates work to one TaskTracker nearest to the data with an available slot.
During the processing time, each TaskTracker sends out heartbeat messages to JobTracker every certain time period to notice JobTracker that it is still alive. If JobTracker does not receive the heartbeat signals from TaskTracker because of node failure or timeout, the corresponding job would be rescheduled to another node.
JobTracker is responsible for scheduling the tasks on the slaves, monitoring TaskTracker and rescheduling the failed tasks. TaskTracker only needs to execute the Map or Reduce task that is issued by JobTracker.
IV. PROPOSED SCHEME
A. Slot-Core Ratio / Slot Configuration
In a typical Hadoop environment, JobTracker looks for any available slot on the computation node which owns the processing data or is close to the processed data. Each computation node initially creates a fixed and common slot number. By default, each node contains two Map slots and two Reduce slots. We found the default settings are too conservative and make Hadoop not fully utilize the resources, especially in a heterogeneous machine environment.
As the computer hardware performance revolutionizes in recent years, a Hadoop cluster with heterogeneous nodes could exhibit significant diversity in processing power among nodes. On the other hand, the slot number needs to be configured before initialization. To achieve better system performance, the slot number on each node should therefore be configured on a processor core basis to reflect the actual processing power. That means the number of slots should be proportional to the number of processor cores on each node.
Intuitively, as the Slot-Core Ratio (SCR) increases, more tasks can be executed in parallel on each node so that the throughput can increase due to the concurrent
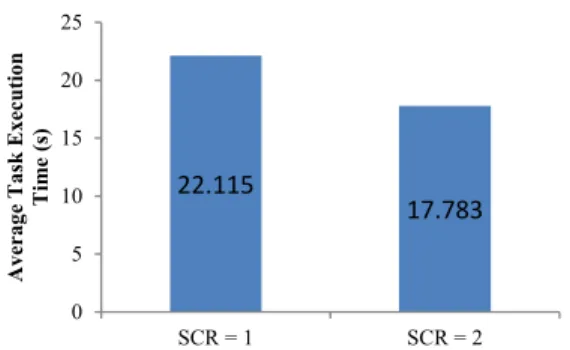
computation. For example, when a WordCount job with several tasks arrive at the node with dual cores, the average task execution time (the total task execution time divided by the number of parallel tasks) for SCR = 1 is higher than the one for SCR=2 due to the concurrent task execution as Fig. 1 shows. However, unlimited increasing the Slot-Core Ratio would prolong the task execution time caused by too much data-swapping or too much context- switching among tasks. An optimal SCR to reach better resource utilization should be found.
Figure 1. Parallel processing effect on a node with dual cores
B. Resource-Aware Task Assigning Scheme
Even if the slot number is configured optimally, the original task assigning policy only depends on the slot availability. When the TaskTracker on one node contains any free slots, it would get tasks assigned by JobTracker without considering the node’s current load. As the example shown in Fig. 2, each TaskTracker sends out its heartbeat messages to JobTracker to reassure its aliveness.
JobtTracker uses the empty slot information within the heartbeat message to determine how to assign tasks to TaskTracker.
If TaskTracker n informs TaskTracker through the heardbeat message that it still has two free slots but a non- Hadoop load occurs to cause a 100 percentages of CPU usage on the same node, JobTracker may still assign choose two tasks to TaskTracker n by the original task assigning policy even though the CPU is overloaded. If JobTracker assigns tasks to an overloaded TaskTracker, the whole job completion time might be prolonged since those tasks are processed by a heavy CPU. This fact is expected since the original TaskTracker does not consider the physical workload when assigning tasks to slots on each node.
22.115
17.783
0 5 10 15 20 25
SCR = 1 SCR = 2
Average Task Execution Time (s)
187
Figure 2. Task Assignment with a Non-Hadoop load
The workload on each node should consider many different system resources on one machine, including CPU, memory, storage, network and other kinds of resources.
Especially, the CPU utilization plays a significant role among all system resources.
V. PERFORMANCE EVALUATION
Our test bed is a heterogeneous Hadoop cluster consisted of five nodes. The detailed specifications for these nodes are shown in table I where four machines are with dual-core and one is with quad-core. The whole cluster system is executed on Ubuntu10.04 Linux OS. All nodes are connected via a gigabit Ethernet channel.
TABLE I. EXPERIMENT ENVIRONMENT Node
Name Core CPU CPU
Frequency Memory Storage M 2 i5-2520M 2.5GHz 4GB 100G S1 2 Core2Due P9700 2.8GHz 4GB 100G S2 2 Pentium Dual E2180 2.0GHz 2.5GB 100G
S3 4 i5-2400 3.1GHz 4GB 100G
S4 2 Pentium Dual E2140 1.6GHz 2.5GB 100G
Our test scenarios are billing each customer by aggregating the call records from different detail records (CDRs) files in different sizes. Two billing jobs are submitted into our Hadoop cluster and each job includes a large number of billing data. We prepare three different scales of input billing data including a 5.68GB file with 200,000,000 call records (5G), a 3.4GB file with 120,000,000 call records (3G), and a 1.13GB file with 40,000,000 records (1G). Then two jobs with their own files for billing calculation are simultaneously submitted to the heterogeneous Hadoop cluster with one minute gap.
A. Evaluating SCR-based Slot Configuration Scheme To compare the default slot configuration scheme which sets the slot number for each node as two to the proposed SCR-based one, we evaluate the average job execution time, averaged by the execution times of the two submitted jobs, on each scenario. In our SCR-based
scheme for this test case, we simply set the SCR as one.
That means the number of slots is the same as the number of cores on each node. Even though there is only one quad-core machine in our cluster, only this node has a different slot number. As the result shown in Fig. 3, the SCR-based scheme can outperform the default scheme with a shortened total execution time by 5% ~ 20%. A larger scale of input data can cause a more significant effect.
Figure 3. Average Execution Time Comparison for Default and SCR- based Schemes
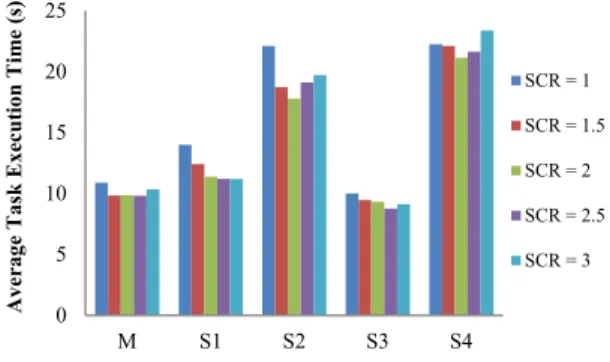
Typically, the number of slots can be more than the number of cores on each node. Intuitively, setting more slots on each node may increase the number of parallel processing tasks so that better performance can be achieved. However, the computation speedup cannot be infinitely increased due to the context switching overhead.
Hence we try different SCR values including 1, 1.5, 2, 2.5, and 3 to find an optimal configuration for the slot number on each node. As the results shown in Fig. 4, when the SCR is equal to 2 or 2.5, the system can reach a minimum average task execution time. If we keep increasing the SCR value, the average task execution time would increase since too many tasks request system resources and compete to each other.
Figure 4. Average Task Execution Time in term of Different SCRs on Different Nodes
0 50 100 150 200 250 300 350
Scenario 1
(5G/5G) Scenario 2
(5G/3G) Scenario 3 (5G/1G)
Average Job Execution Time (s) default
SCR-base (1x)
0 5 10 15 20 25
M S1 S2 S3 S4
Average Task Execution Time (s)
SCR = 1 SCR = 1.5 SCR = 2 SCR = 2.5 SCR = 3
188