DOI:10.6245/JLIS.2013.391/602
以知識整合模型建置症狀查詢 就診科別推薦系統之研究
戚玉樑
中原大學資訊管理學系教授兼系主任 E-mail:[email protected]
陳滄堯
中原大學資訊管理學系助理教授 E-mail:[email protected]
洪智力
中原大學資訊管理學系副教授 E-mail:[email protected]
關鍵詞:知識分類;知識本體;推論;體徵症狀;疾病
【摘要】
知識分類是人類對領域的共同認知,利用結 構化方式建立系統性表達,以提供描述、解 釋、溝通、及推論。由於實務上的應用問題通 常涉及多種領域,因此如何建立它們的知識邏 輯 是 解 題 關 鍵 。 本 研 究 以 個 人 對 體 徵 症 狀
( signs & symptoms)的感知為例,探討藉由 知識分類及整合,最終能「查詢」特定醫療院 所的就診參考。本研究利用知識本體( ontology)
技術,發展所需的知識分類與解題模型,主要
的內容包括:( 1)釐清此議題的知識源內涵,
例如徵狀、疾病等知識分類;(2)將一般化 的知識源建置為「領域本體」,其內容是由共 通性的概念架構及實例共組而成,以利提供其
他領域在溝通時做為參考標準或術語;( 3)
以解題需要來發展各知識源之間的關聯與邏 輯,建立目標導向的「任務本體」,再依據各
概念的知識框架(schema),收集現況事實
為實例知識;( 4)最後,發展可推論解題的
「語意規則」,並以前述的事實知識為基礎,
推導隱含性知識。由實驗結果顯示:本研究發 展的知識模型整合程序,強調領域本體、任務 本體、及推論規則的模型設計,已初步達到解 決以體徵症狀查詢就診科別,也簡化後續知識 之維護及擴充,達到知識整合之效用。
緒論
本研究是關於發展一個具有推論能力的「知識庫 系統」,強調藉由知識分類、知識協同整合、知識推 論等學理,應用在解決實務問題的專家系統。我們 以人類的「疾病問題與應用」為中心,向前連結至 病友對體徵症狀(signs & symptoms,以下簡稱徵狀)
的感受認知、徵狀的學名、疾病的俗稱與學名對照 等,向後延伸應用則以判斷適當的醫療院所之就診
科別為目標。本研究以開發本體知識庫(ontological knowledge base)為核心,利用概念的分解、合併及 重組技術,探索事物之知識組成、定義邏輯關係、
及衍生知識的推導,這種針對「問題-解決」的架構 即為描述研究議題的知識模型。
在我們日常生活中,「疾病」始終伴隨在身旁,因 此我們自覺不陌生,也認為可掌握對徵狀的實際感 受、可利用「常識」來判斷徵狀或疾病的歸屬、以 及有能力在掛號時選擇對應的就診科別;然而,廖 俊凱(2012)所著的《90%的人生病都掛錯科》,反 映出現代人因醫療知識的不足,經常在就診時選擇 了錯誤的科別。另外,隨著網路掛號的普及,患者 必須在資訊不足的狀況下選擇掛號科別。雖然醫院 已提供類似對照表(lookup table)的查詢方式,提 供病患概略瞭解科別的內涵,但除了部分門診科別 的範圍明確外,許多門診的實際項目其實不易區別,
例如頭皮長東西該去掛內分泌、神經科或皮膚科?
而各醫院診所的規模也大不相同,門診科別可由十 幾類到數十類,因此當我們無從判斷時,只能先去 家醫科掛號,再轉介至適當之科別;再者,各醫院 在說明門診科別或疾病時,也常是學名(scientific name)及俗名(common name)併用或雜陳不一,
例如「腦血管疾病」,常見使用「腦中風」或「腦溢 血」等不同的術語名稱,這些學名及俗名混用,容 易造成資訊交換與系統設計的障礙。再者,醫政單 位所構想的聯合掛號系統,若使用術語名稱過於正 式,則容易與現況認知脫節,造成民眾不易理解;
另一方面,術語名稱若過於通俗,則易形成各自表 述,不同系統也因無標準可循造成資訊難以整合。
針對上述問題,宜以處理知識的角度著手,先行 歸納分析共通性的認知、原則、經驗,並以概念架 構代替實例來建立知識模型。因此,本研究利用知 識本體(ontology)的追本溯源學理,拆解與重組知 識的構成單元,應用邏輯來定義知識之間的關係,
再根據解題需要發展具推論能力的語意規則(semantic rules),最後結合已知事實成為知識庫,並做為解決 就診查詢之用。在系統建置方面,我們應用正規概 念分析法(Formal Concept Analysis, FCA)進行知識 素材分析,以知識本體語言(Web Ontology Language, OWL)及語意規則語言(Semantic Web Rule Language,
SWRL)為系統實作之表達技術,最後則是納入描 述邏輯推論器(如Pellet)、規則推論器(如 JESS)
作為解題的推論引擎,協助使用者進行知識推論。
簡言之,上述之各項技術將綜合運用於發展知識模 型及建置知識庫系統。本論文後續的內容安排如 下:文獻回顧一節對知識分類、本體及語意規則的 應用,以及徵狀、疾病等相關議題進行背景回顧;
知識模型的設計構想一節則包括了確認知識源類 型、對應關係與邏輯設計等;接著,本研究以系統 發展角度,說明知識本體的建構,主要依據知識工 程的發展程序進行,將模型分為領域、任務、規則 等三部分;個案實驗一節則以實例說明了開發實作 過程、驗證、與討論;最後為本研究的結論與未來 研究建議。
文獻探討
知識分類
「知識」是人類建立文明的重要基礎,任何創新 思維通常須以既有的知識為基礎,才能進一步衍生 新知識。知識通常來自於人類對領域的理解與感 受,包括心智或認知等過程,而這些具體化或抽象 化的共同認知,最後以結構化方式呈現知識內涵,
以協助知識能不斷傳承與再利用,所以學者將知識 定義為經驗、價值、情境資訊與專家洞見等的動態 混合,同時也是衡量及融入新經驗與資訊時的架構
(Davenport & Prusak, 2000)。Alavi 與 Leidner(2001)
分析知識的本質,指出資料-資訊-知識的連續性 分野角度:資料經過詮釋形成資訊,資訊經過驗證 為真則為知識,而知識呈現為文、圖、符號時又可 以被視為資料處理,因此知識為存在於使用者心智 中的概念化活動,而非僅是資料或資訊的集合。
Nonaka(1991)對於知識本質提出隱性知識與顯性 知識的區分:顯性知識是正式而有系統的知識,所 以易於溝通與分享;而隱性知識則有高度個人化的 特質,必須透過特定的程序才能將之顯性化,才能 成為確切可溝通、共享的知識。所以一般知識管理 流程在資料與資訊獲取後,便進入知識獲取的階 段,透過知識發掘與知識擷取等活動來獲取隱性知 識,進而進入顯性知識儲存、傳播及應用(Laudon &
Laudon, 2012)。
除了個人化特性的探討,Zack(1998)也將知識分 類為陳述知識(know-about)、程序知識(know-how)、
因果知識(know-why)、條件知識(know-when)與 關係知識(know-with),而這些知識也都可能轉譯 成顯性知識。例如,陳述知識是對於概念、類別、
描述的共同明確理解,是有效溝通與知識分享的基 礎,例如百科全書。而這些不同知識類別的存在也 說明了知識除了個人化,也因共同認知而具有其社 會性,並且隱含著邏輯(因果、條件、關係),可以 被推導處理,以發掘隱性知識及進一步的知識邏輯 應用。例如,維基百科便被視為一個大型顯性知識 資料庫,其中包含大量代表人類知識的詞條,而這 些詞條之間存在有語意上的相關性、階層與從屬關 係,因此可稱為一個知識的分類架構(taxonomy)
(Zirn, Nastase, & Strube, 2008),而每一個知識內容 領域也都有其獨特的知識分類結構。
「知識分類(knowledge categorization)」是將知 識單元由博而精的組織起來,類似分類學強調的階 層結構及從屬關係,有助於探索知識時的追本溯 源。在著名的生物分類法(biology taxonomy)中,
人類經由對「域、界、門、綱、目、科、屬、種」
的階層架構,很容易獲得知識在分類上的差異,例 如「小麥」與「檜木」二種植物,小麥的知識鏈可 溯源自禾本科、禾本目、單子葉綱、被子植物門等,
而檜木則溯源自柏科、松柏目、松柏綱、松柏門等。
因此,知識分類提供我們對領域的描述、解釋、溝 通等功能外,更可應用於知識檢索與推論。然而,
現況的實務問題通常不是單一知識源可解決,例如 探討植物如何生長的問題,除了植物知識外,顯然 也需要如土壤、空氣、水等不同的領域知識。因此,
整合跨領域知識是解題的關鍵工作。在單一知識領 域中,知識檢索只能利用上下階層的繼承說明從屬 關係,但在跨領域的知識架構中,藉由定義知識的 組成或描述與其他知識的關係,不同領域內的知識 單元因而橫向連結起來。
知識與本體技術
知識本體也稱為本體論或領域知識本體,它是源 自於哲學上探究萬事萬物的「存在」問題,強調以 系統化方式分析事物如何形成的學說。Feigenbaum
(1977)的研究是最早將知識表達觀念介紹到專家
系統中,他認為知識系統的效能是取決於專家對知 識表達方式及精確程度,因此表達方式逐漸成為發 展知識庫的研究領域之一。而隨著研究知識庫領域 的日益蓬勃,參與這個階段的角色分工也更為精 確,Walczak(1998)即曾指出:知識表達逐漸定義 為知識工程人員如何將擷取的知識,選擇某種型式 予以定型化至資訊系統的過程。目前常用的表達方 式包括法則式、邏輯式、語意網路、框架式及本體 技術等方法。
近年來,資訊科技已廣泛應用知識本體於塑模事 物的概念組成(戚玉樑、蔡明宏,2007),許多學者 也詮釋知識本體在資訊科技的意義,例如 Guarino
(1997)曾指出知識本體是特定領域的知識概念 集,用於表達概念、關係、與實例物件;Uschold &
Grueninger(1996)也曾提出知識本體為正式且明確 的規格,用於描述對事物共同一致的概念;Richards 與 Simoff(2001)則認為知識本體為描述領域概念 的階層架構與建立知識庫的框架。綜上所述,知識 本體是一種建構知識模型的方法,將特定領域的知 識予以概念化、階層化及邏輯化,因此本體可視為 定義完整的知識分類架構(Chandrasekaran, Josephson,
& Benjamins, 1999),使得知識更容易演繹與歸納,
在應用面則是藉由已知的顯性關係,推導未知的隱 性關係,因此具有知識推論的效能。近年來,知識 本體技術已在各項領域廣泛應用,例如在圖書資訊 類的期刊中,阮明淑與溫達茂(2002),介紹知識本 體技術在建構知識的用途及未來在知識管理的應 用;劉文卿與馮國卿(2003),認為知識本體包含了 比索引典更為廣泛的語意關係,其概念定義方式更 為明確,因此以既有之索引典發展金融業務相關之 知識本體。Chi 與 Chen(2009)利用知識本體將組 織職掌的內涵經驗,建置為知識模型,用於派送網 路新聞文件至相關部門;周濟群、戚玉樑與曾建勛
(2012)利用文字探勘技術,發展「公司治理」的 領域知識,並以本體架構呈現,以利提供會計或其 他領域的再利用。
網際網路標準組織(World Wide Web Consortium, W3C)為統一知識本體的發展,已於 2003 年公布本 體語言(OWL)為發展知識本體的正式規範,目前 許多編輯及推論工具已相繼推出,進一步提供開發
者建置OWL-based 知識本體的支援環境(Chi, Hsu,
& Yang, 2006);因此,OWL 已成為建立知識系統最 常用的技術之一。另一方面,Berners-Lee、Hendler 與Lassila(2001)曾提出著名的「Semantic Web Stack」
(語義網堆疊),將發展知識本體所需的支援技術以 堆疊層次呈現,其中在知識本體的架構上,須再加 入邏輯層與語意規則層,前者執行「概念層」的知 識推論,主要是利用描述邏輯(Description Logic, DL)定義概念的正規語意,後者則是用於支援「實 例層」的事實推導。近年來,語意規則語言(SWRL)
已逐漸成熟,為維持原來OWL 在邏輯的可判定性,
SWRL 須結合至 OWL 中,具體作法是將規則設定 為公理(axiom::=rule),並以 Horn-like 規則格式表 達。簡言之,SWRL 可結合現行 OWL-based 的知識 本體,執行對實例層之實例,進行隱含性知識的推 論(O’connor et al., 2005)。
體徵症狀與疾病的分類
相較於醫事專業人員,一般民眾對於醫學知識仍 停留在通俗認識的程度,因此對於徵狀的描述、疾 病名稱、門診科別的意義等,都存在不同的稱呼或 理解,也形成設計資訊系統的障礙。幾項關於疾病 在資訊應用的研究,例如網路掛號或聯合門診查詢 等,主要議題集中在資料標準與資訊整合(孫漢屏,
1991;廖玉里,2002;高誌鍵,2010;陳樂惠、林 鼎舜,2011)。另一方面,由於疾病與人類息息相關,
因此是我們最關心的日常話題與生活科學;有關疾 病的描述、分類與定義,更可溯及至古代的人類文 明,因此疾病知識是相對成熟的科學之一。在醫學 上,體徵(signs)與症狀(symptoms)都是描述疾 病的重要依據,通常「體徵」是由醫護人員或經由 測量工具發現,而「症狀」是指病患的主觀感受。
舉例而言,感冒的元素若包括咳嗽、頭昏及體溫超 過38 度,則咳嗽、頭昏是感冒的症狀,而體溫超過 38 度是感冒的體徵。
在疾病相關的參考文獻部分,我們主要是以官方、
法人組織或書籍的資料為主,例如參考聯合國世界 衛生組織(World Health Organization, WHO)贊助 的「國際疾病傷害及死因分類標準」(International
Statistical Classification of Diseases and Related Health Problems),它是提供編號的分類系統,對疾病與徵 兆、症狀、異常、不適、社會環境與外傷等所做的 分類。而在疾病的分類部分,過去是以「國際疾病 分類第九版臨床修訂」(International Classification of Diseases, Ninth Revision, Clinical Modification, ICD-9-CM)
為主,內容包括疾病及處置分類系統;近年來則是 以「國際疾病與相關健康問題統計分類第十版臨床 修訂」(International Statistical Classification of Disease and Related Health Problems, Tenth Revision, Clinical Modification, ICD-10-CM)(World Health Organization [WHO], 2004),其中ICD-10-CM 只含疾病碼,處置 部分則列於PCS。目前行政院衛生署也致力推動及 應用國際疾病分類第十版ICD-10-CM/PCS 於臨床疾 病分類及中文版編譯(行政院衛生署中央健康保險 局,2013)。簡言之,症狀與疾病分類均有充足之素 材,本研究將以參考ICD-10-CM 為主,另參考關於 疾病分類與徵狀之解說書籍(Kahan & Smith, 2007;
安藤幸夫、西尾剛毅,2006;黑瀨巖,2005)。
知識模型之整合設計
疾病與一般民眾息息相關,但疾病也屬於專業科 學(醫學)的範疇,一般民眾與醫事從業人員在專 業知識上,顯然有極大程度的落差,因此對於症狀 描述、疾病名稱、門診科別意義等,普遍存有學名、
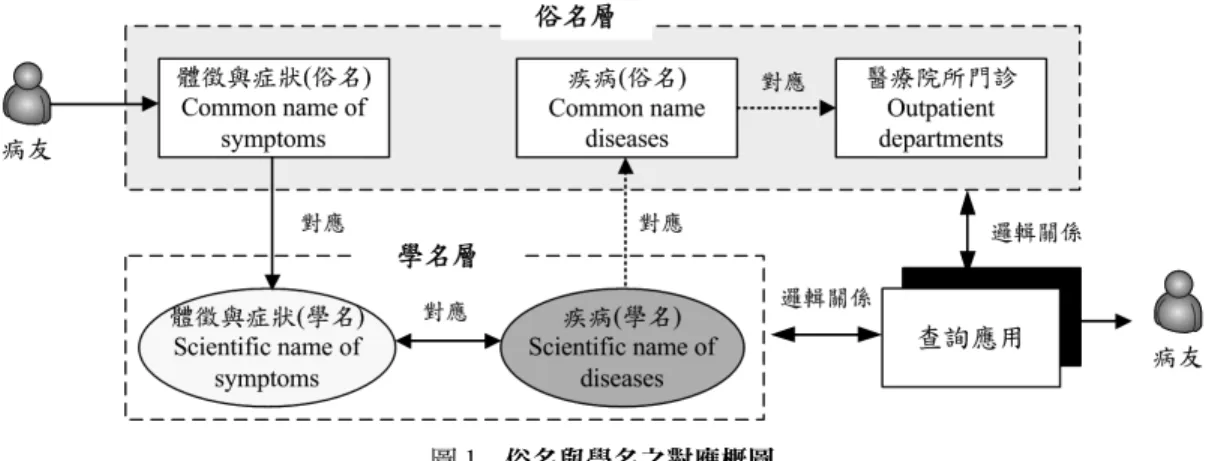
俗名混用的情況,甚至於在知識內涵存在認知差 異。如圖1 所示,疾病議題的發展與衍生應用都與 病友(民眾)相關,因此須同時納入俗名及學名至 系統才能發揮效益。本研究在模型的設計構想中,
首先將學名與俗名分開建立,再以「對應」關係串 聯,此部分之對應將藉由 has-a 關係建立,以協助 連結俗名與學名之間的關係,並提供問題與解決的 基礎依據。圖1 的俗名層,病友可將自我感知的徵 狀,利用通俗術語描述;而學名層部分,系統利用 徵狀、疾病的正式學名來運作,這些學名扮演知識 交換與串聯;在查詢與輸出部分,須加入解題的邏 輯關係與知識推論,最後再以民眾能理解的通俗術 語表達。
圖1 俗名與學名之對應概圖
確認解題所需的知識類型
由於實務問題通常涉及包羅萬象的知識,過與不及 都會影響知識系統的績效,因此在發展知識模型前,
須限縮知識的類型與確認範圍。Grüninger 與 Fox
(1995)曾建議利用關鍵性問題方式(Competency Questions, CQs),針對議題的構成原因及解題的支 持元素,以類似腦力激盪方式,產生原則性的初始 項目,Chi(2009)也曾對知識導向之模型設計,建 議針對領域(domain)、應用(application)及使用 社群(community)等角度,先找出它們的交集做為 範圍,再利用正規概念分析法(FCA)界定知識之 間的依存關係。本研究融合前述學者的建議,先確 認此知識模型將以處理通俗的徵狀描述為前提下,
回應正規的學名徵狀、疾病等,再以邏輯推理可能 性較高之疾病,據以建議就診之醫院科別。具體作 法如下:
1. 以 CQs 獲取初始之知識項目,首先須將研究人 員聚集起來(包含本專案及醫事專業人員共五 人),探討問題與解決的相關項目,討論過程不 必拘泥在小細節,例如在討論過程中,疾病的 學名與俗名可列出非常多組的配對,重點不在 完整與否,而是找出共通的要點,最後研究人 員須總結為類似「建立疾病個別之學名俗詞對 應關係」的樣板,上述之作業藉由不斷的問題 與應答中,篩選與歸納適合的關鍵性問題至清 單中。以下為針對「徵狀查詢就診」問題,執 行CQs 並條列出相關聯的項目:
(1) 收集描述徵狀的通俗詞彙。
(2) 收集國內醫療院所在門診科別上的管理分類。
(3) 參考正規定義對徵狀建立學名分類。
(4) 參考正規定義對疾病建立學名分類。
(5) 建立徵狀與疾病之間的學名對應關係。
(6) 建立疾病與門診科別之間的對應關係。
(7) 建立徵狀與疾病個別之學名俗詞對應關係。
(8) 以實際情境建立門診分科與疾病的對應關係。
(9) 可依通俗的徵狀詞彙查詢徵狀學名及可能之 疾病。
(10) 可依主要徵狀篩選高風險之疾病。
(11) 可依高風險之疾病建議醫療院所的門診 科別。
根據上述的清單,知識類型(已畫底線者)包 括:徵狀俗名、徵狀學名、疾病俗名、疾病學 名、及門診分科等,另外則是聯繫它們關係的 經驗法則,例如徵狀知識、疾病知識、及醫院 門診知識等。
2. 以正規概念分析法(FCA)獲取知識項目之依 存關係,根據Ganter 與 Wille (1997)的研究,
FCA 是衍生自網格理論(lattice theory),利用 Formal Context 以三個欄位的
(
G, M, I)
公式表 示,其中 G 代表 Context 的物件群,M 代表 Context 的屬性集合,I 則是 G 與 M 之間的二元 關係,亦即一個物件g 及一個屬性 m,具有 gIm 或( g,m) I ∈
的關係。Formal Context 可衍生兩種重要的概念推導算式:屬性的內涵(intent)
及物件的延伸(extent),前者是指一組物件所 應共同具有的屬性集合,後者是指滿足特定屬 性 的 物 件 集 合 (Jiang, Ogasawara, Endoh, &
Sakurai, 2003)。在知識工程領域,FCA 常用於 分析知識組成,各項套裝工具已成熟普及,例 如TOSCANA, ConExp 等。利用 FCA 工具時,
通常由知識工程師會同領域專家共同探索知識 的組成,其中領域專家扮演知識的提供者及爭 議衝突時的決斷者。
在執行 FCA 分析時,通常先將參與的知識元素 分為物件(object)與屬性(attribute)二類,
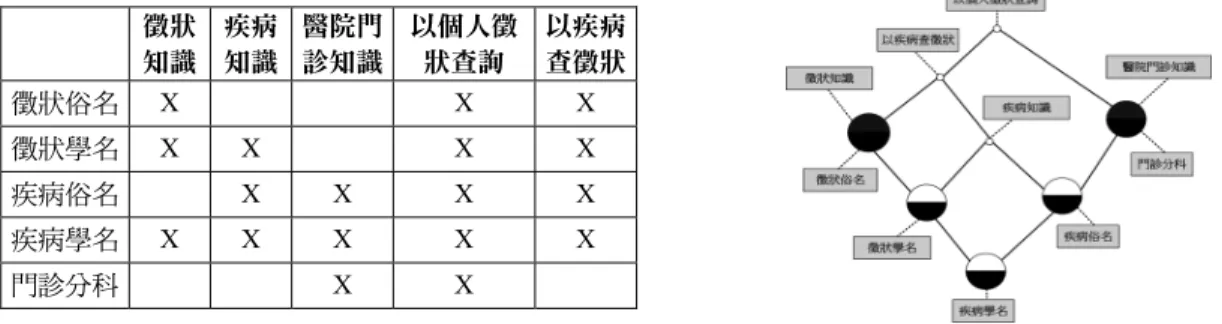
再以矩陣式的交叉表格(cross table)建立為 Formal context,如圖 2(A)所示:左方縱軸部分 為物件,使用徵狀之俗/學名、疾病之俗/學 名等較具體的知識,上方橫軸部分為屬性,表
示各項經驗或組合性的知識,例如疾病知識 等,二者如有關聯性則以’Χ’表示。在格線圖完 成後,FCA 再根據演算法計算未封閉或仍不完 整的知識概念,若開發者認定概念未封閉,即 代表具有新概念,須提供新的物件或屬性,使 知識內容更具完整性,此過程即為協助開發者 確認知識組成。圖2(B)為概念格線圖(Concept Lattices, CL)重新呈現概念分析的結論圖中標 示在節點上下的註記,分別為屬性與物件。格 線圖中得知屬性可透過繼承,延展包含於次階 層節點,亦即愈低層級的物件所擁的屬性愈 多,而較上層級的物件即為次層級物件的父類 別。正規化概念分析法與格線圖,不僅可釐清 知識擷取過程中複雜關係,亦可協助我們對建 置本體的階層化概念架構,值得注意轉換屬性 與物件至本體架構時,均須視為概念。
徵狀 知識
疾病 知識
醫院門 診知識
以個人徵 狀查詢
以疾病 查徵狀
徵狀俗名 Χ Χ Χ
徵狀學名 Χ Χ Χ Χ
疾病俗名 Χ Χ Χ Χ
疾病學名 Χ Χ Χ Χ Χ
門診分科 Χ Χ
圖2 (A)利用 FCA 建立 Formal context;(B)以概念格線圖呈現知識之關係
對應關係與邏輯設計
前述五項知識分類,包括徵狀俗名、徵狀學名、
疾病俗名、疾病學名、醫院門診等,須利用對應關 係予以連結,學名與俗名之對應是以一對多(1:N) 形式,而徵狀學名、疾病學名、醫院門診等關係,
是連結與衍生知識的核心,它們之間是以多對多 (N:M)形式呈現,為描述三者的邏輯關係,本研究 另外設計三項中介關係負責串聯知識概念,包括徵 狀知識、疾病知識、醫院門診知識等,以下說明三 者的定義:
( ) { }
( ) { }
( ) { }
{ }
⎧⎪
⎪⎪⎨
⎪⎪
⎪⎩
徵狀知識 :項「徵狀」寫成
疾病知識 : 項「疾病」寫成
醫院門診知識 : 項「醫院門診」寫成
∈
1 2 i
1 2 j
1 2 k
Symptom i S , S , ...., S
Disease j D , D , ...., D
Clinic k C , C , ...., C
i, j, k 1, 2, ...., N
為表達對應關係的邏輯矩陣,我們以{ Yij, Zjk}分別 表達「徵狀與疾病」、「疾病與醫院門診」的對應,
關係函數式分別為Yij=
(
Si, Dj)
, Zjk=(
Dj, Ck)
,邏輯矩 陣式如下,式(1)中之' '
φ
表示沒有可對應項目:因此,由徵狀到就診科別,即是二項邏輯矩陣進 行對應關係或是關係之間的串聯(conjunction),如 下列之式(2):
另一方面,由徵狀到就診科別,各類知識都是多 對多關係,易形成發散的知識對應,最終造成就診 科別數量可能過多,因此本研究把症狀再分為主要 症狀、伴隨(concomitant symptom)等二類,藉由給 予權數方式突顯其差異性,藉以區隔出高可能性之 疾病,進而收歛疾病、就診科別之數量。式(3)為計 算個別疾病之原始積分(DiseaseScore),設疾病的主要 徵狀、伴隨徵狀分別以ms, cs 表示,分別累計二項
徵狀的數量(i, j),再與對應之加權(wms, wcs)以內積 計算,二項徵狀最後加總為原始積分。
式 (4) 為 依 個 人 徵 狀 計 算 特 定 疾 病 的 程 度 值
(PDisease),設個人之徵狀與特定之疾病進行對應,
區分出主要徵狀、伴隨徵狀(分別以ms, cs 表示),
分別累計二項徵狀的數量(g,h),再與對應之加權 (wms, wcs)以內積計算,加總二項徵狀積分,再與特 定疾病的原始積分(DiseaseScore)相除,獲得之比值做 為相對性之程度值,若超過設定門檻值,即視為高 可能性之疾病。
φ φ
φ φ φ φ
φ φ
⎛ ⎞ ⎛ ⎞
⎜ ⎟ ⎜ ⎟
⎜ ⎟ ⎜ ⎟
⎜ ⎟ ⎜ ⎟
⎜ ⎟ ⎜ ⎟
⎝ ⎠ ⎝ ⎠
1 1 1 j 1 1 1 k
2 2 2 2
i 1 i j j 1
j
j jk
k i
.... ....
.... ....
Y = , Z =
: : .... : : : .... :
(S ,D ) (S ,D ) (D ,C ) (D ,C )
(S ,D ) (D ,C )
(S ,D ) .... (S ,D ) (D ,C ) .. .. (D ,C )
(1)
φ φ
φ φ φ φ
φ φ
⎛ ⎞ ⎛ ⎞
⎜ ⎟ ⎜ ⎟
⎜ ⎟ ⎜ ⎟
⎜ ⎟ ⎜ ⎟
⎜ ⎟ ⎜ ⎟
⎝ ⎠ ⎝ ⎠
I
1 1 1 j 1 1 1 k
2 2 2 2
i 1 i j j 1 j k
(S ,D ) .... (S ,D ) (D ,C ) .... (
.... ....
Y Z =
: : .... : : : .... :
.... ..
D ,C )
(S ,D ) (D ,C )
(S ,D ) (S ,D ) (D ,C ) .. (D ,C )
∩
(2)
=0 0
= ( ) ( )
=
⋅ + ⋅
∑
n∑
mScore i ms j cs
i j
Disease ms w cs w
(3)=0 0
( ) ( )
=
=⋅ + ⋅
∑
n g ms∑
m h csg h
Disease
Score
ms w cs w
P Disease
(4)
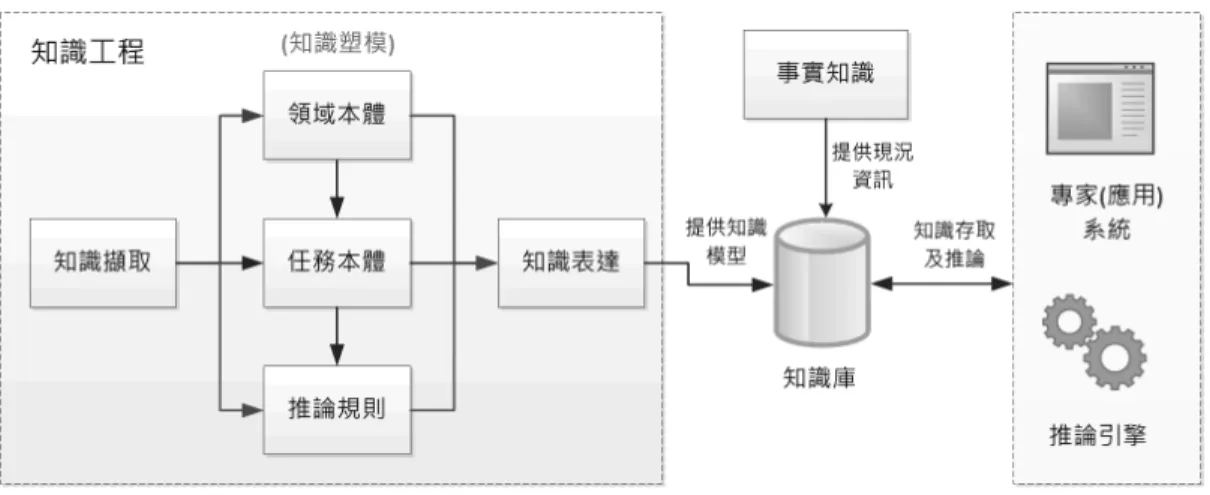
知識本體發展
為進一步實現前述之設計,本研究以建立知識庫 為目標,圖3 是知識系統設計的一般性概念圖,知 識庫是由知識模型與事實知識所組成,其中又以發 展模型為主要工作。本研究參考多位學者提出的知 識工程(knowledge engineering)開發建議(例如 Chi, 2009; Guarino, 1995; Noy & McGuinness, 2001),
經融合各項知識工程的主要精神,概略分為知識擷 取、知識塑模、知識表達等三項程序(如圖3),其 中之知識塑模部分應用知識本體技術,因此以建置 的角度再分為領域本體、任務本體、及語意規則,
最終輸出一個知識模型,此三項開發過程為本研究 的核心。簡言之,此模型建立由徵狀到就診科別的 概念定義、跨概念之間的關係定義、及推導隱含知 識所需的邏輯規則等。
圖3 知識系統設計概圖
建置領域本體
領域本體是解題所需的背景知識,通常是知識框架 或共同性的普遍認知,因此可視為知識的分類,提供 其他本體或系統做為標準術語或溝通之依據,此即為 知識之分享與再利用。在本體建置中,主從關係以 is-a 定義,以利呈現階層化或繼承的架構,前述分析 之知識源用於建立起始概念,例如徵狀學名、徵狀俗 名、疾病學名、疾病俗名、及門診分科等五項。本研 究目前以「消化系統」常見之疾病為實例收集對象與 實驗範圍,以下說明各概念及實例建置過程:
1. 在徵狀學名部分,參考國際疾病分類第十版及 Kahan 與 Smith(2007)之書籍資料,共建立 86 項實例。
2. 在徵狀俗名部分,收集文獻、書籍及網頁資料,
共整理223 項實例。
3. 在疾病學名部分,參考國際疾病分類第十版,
共建立52 項實例。
4. 在疾病俗名部分,收集文獻、書籍及網頁資料,
共整理107 項實例。
5. 在門診分科部分,整理國內相關之門診分科名 稱共44 項,另外建立 6 家不同規模之醫療院實 例備用。
建置任務本體
本研究的任務本體包含「知識法則」與「問題諮詢」
等二項上層概念,前者定義各知識源之間的邏輯關
係,再細分為「徵狀知識」、「疾病知識」、「醫院門診 知識」等三項子概念,後者是為查詢應用而設計,包 括:「個人徵狀查詢」及「疾病查詢」等二項子概念。
任務本體廣泛使用has-a 關係,用於表達一項概念擁 有其他某項概念,has-a 關係也常以 part of 表示。各 概念的內涵,例如邏輯定義、基本屬性、與概念之間 的關係等,須進一步依據問題解決的需要規劃細節項 目,除能限縮任務本體的範圍外,更提供執行知識系 統時,收集相關事實之依據。在屬性的定義中,依據 存放內容值的形式,可分為資料(data property)及 物件(object property),前者接受基本資料型態的資 料,後者限制使用特定概念下的實例;另一方面,屬 性「內容值」也可分為宣告值(asserted property)及 推論值(inferred property)等二種,以下分別說明各 概念的建置過程,其中「個人徵狀查詢」與「疾病查 詢」之設計構想與建置類似,本研究僅介紹「個人徵 狀查詢」概念之建置,以利後續之推論規則設計及個 案實驗更能聚焦說明。
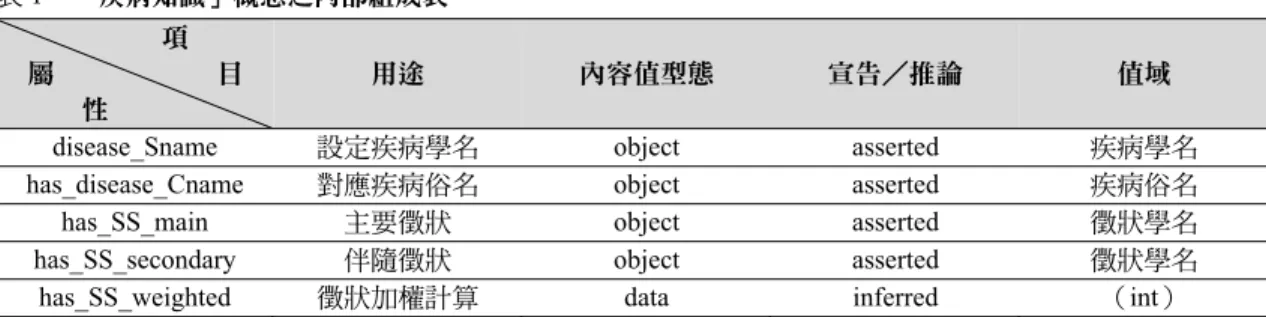
1. 在「疾病知識」概念中,主要是以「疾病」為中 心,定義疾病學名與俗名對應、疾病徵狀的程度 分類及利用徵狀數目計算原始積分。表1 共設計 五項屬性,包括:疾病學名(disease_Sname)、
疾病俗名(has_disease_Cname)、主要徵狀
(has_SS_main)、伴隨徵狀(has_SS_secondary)、
徵狀加權計算(has_SS_weighted)等,其中前 四項皆為object 及 asserted 形式,徵狀加權計算 須依前述式(3)之設計,另以撰寫規則方式獲 得加權值,此屬性定義為data 及 inferred 形式。
表1 「疾病知識」概念之內部組成表 項
屬 目 性
用途 內容值型態 宣告/推論 值域
disease_Sname 設定疾病學名 object asserted 疾病學名 has_disease_Cname 對應疾病俗名 object asserted 疾病俗名 has_SS_main 主要徵狀 object asserted 徵狀學名 has_SS_secondary 伴隨徵狀 object asserted 徵狀學名 has_SS_weighted 徵狀加權計算 data inferred (int)
2. 在「徵狀知識」概念部分,主要是以「徵狀學名」
為中心,分別對應至俗名、疾病學名。表2 設計三 項屬性,包括:徵狀學名(sign_symptom_Sname)、
徵狀俗名(has_SS_Cname)、疾病學名(has_
disease_Sname)等。三項屬性皆為 object 及 asserted 形式,詳細內容如表 2:
表2 「徵狀知識」概念之內部組成表 項
屬 目 性
用途 內容值型態 宣告/推論 值域
sign_symptom_Sname 設定徵狀學名 object asserted 徵狀學名 has_SS_Cname 對應徵狀俗名 object asserted 徵狀俗名 has_disease_Sname 對應疾病學名 object asserted 疾病學名
3. 在「醫院門診知識」概念部分,主要是以「醫 院」及「門診」二項知識為中心,對應至疾病 學名。表3 共定義:醫院名稱(hospital_name)、
門 診 科 別 名 稱 (clinic_name )、 疾 病 學 名
(has_disease_Sname)等屬性。三項屬性皆為 object 及 asserted 形式,詳細內容如表 3:
表3 「醫院門診知識」概念之內部組成表 項
屬 目 性
用途 內容值型態 宣告/推論 值域
hospital_name 醫院名稱 object asserted 醫院 clinic_name 門診科別名稱 object asserted 科別 has_disease_Sname 對應疾病學名 object asserted 疾病學名
4. 在「以個人徵狀查詢」概念部分,主要是由個 人描述徵狀俗名(has_SS_Cname)開始(定義 為object 及 asserted 形式),利用系統推論機制 或計算,獲取各項隱含性的知識。以下針對應 用問題設計相關屬性項目。表4 另外定義其他 之屬性均為object 及 inferred 形式,包括:徵狀
學名(mapping_SS_Sname)、疾病學名(mapping_
disease_Sname)、高風險疾病(high_risk_disease_
Sname)、醫院門診(mapping_hostipal_clinic)
等。高風險疾病計算須依前述式(4)之設計,
另以撰寫規則方式獲得風險程度值,目前暫定 為0.5(此門檻值可依需求調整)。
表4 「以個人徵狀查詢」概念之內部組成表 項
屬 目 性
用途 內容值型態 宣告/推論 值域
has_SS_Cname 描述徵狀俗名 object asserted 徵狀俗名 mapping_SS_Sname 對應徵狀學名 object inferred 徵狀學名 mapping_disease_Sname 對應疾病學名 object inferred 疾病學名 high_risk_disease_Sname 計算高風險疾病 object inferred 疾病學名 mapping_hostipal_clinic 對應醫院門診 object inferred 醫院門診
建置推論規則
前述任務本體之概念設計中,部分屬性標示為「宣 告值」者,代表該屬性之內容值為隱含性知識,須 進一步利用推論機制獲得,例如表4 的徵狀學名屬 性(mapping_SS_Sname),代表由個案提供的「徵 狀俗名」去推導它的學名。本研究參考Chi(2010)
提出的規則分析表(rule analysis form)協助解題分 析,這個方法以表達式{Goal (inferred prop): Step1, Step2, .. .., Stepn}整理,模擬如何由需求者出發,並 向目標一步步探索,推進原則是每個步驟須使用已 知的事實,每個步驟須有序的串聯,直到抵達目標 為止。分析人員為協助系統開發人員理解規則的邏 輯設計,各步驟須儘量使用一般性的口語陳述,並 以條列方式呈現銜接順序:
{
Goal:由徵狀俗名推導徵狀學名(mapping_
SS_Sname)
Step1:建立「以個人徵狀查詢」概念,代入 個案(x);
Step2:由個案(x)的 has_SS_Cname 屬性,取 得徵狀俗名(y);
Step3:建立「徵狀知識」概念,代入個案(z) Step4:由個案(z) has_SS_Cname 屬性,取得 與Step2 相同的徵狀俗名(y)
Step5:由個案(z)的 sign_symptom_Sname 屬 性,取得徵狀學名(a);
Step6:徵狀學名(a)即為本問題的答案,須 置入mapping_SS_Sname 中。
}
在上述規則分析表中的’x’, ‘y’, ‘z’ , ‘a’等均為變 數,實作階段將由推論引擎代入相符的實例。開發 人員依據上述的步驟,轉換為「前提Æ結論」形式,
由於「前提」通常由多項單元(atom)串聯,再寫 成邏輯式"(atom1
ר
…ר
atomn)Æ
Consequence"的格 式,此處的atom 即為規則分析表中的 step。前述 Step1至Step6,可寫成式(5)。
其他規則可依上述「規則分析表」分別發展推導 步驟,各推論規則之設計用途如下:由徵狀俗名推 導疾病式(6);疾病的主要徵狀與個人徵狀相同即 為高風險疾病式(7);由徵狀俗名推導對應之醫院 門診式(8)。
以個人徵狀查詢(?x) ר has_SS_Cname(?x, ?y) ר 徵狀知識(?z) ר has_SS_Cname(?z, ?y) ר sign_symptom_Sname(?z, ?a) → mapping_SS_Sname(?x, ?a)
(5)
以個人徵狀查詢(?x) ר has_SS_Cname(?x, ?y) ר 徵狀知識(?z) ר has_SS_Cname(?z, ?y) ר has_disease_Sname(?z, ?a) → mapping_disease_Sname(?x, ?a)
(6)
以個人徵狀查詢(?x) ר mapping_disease_Sname(?x, ?y) ר mapping_SS_Sname(?x, ?z) ר 疾病知識(?a) ר disease_Sname(?a, ?y) ר has_SS_main(?a, ?z) → high_risk_disease_Sname(?x, ?y)
(7)
以個人徵狀查詢(?x) ר high_risk_disease_Sname(?x, ?y) ר 醫院門診知識(?z) ר has_disease_Sname(?z, ?y) → mapping_hospital_division(?x, ?z)
(8)
知識表達
知識表達是將前述知識模型轉換為系統可處理的 形式,隨著 XML 技術的成熟,知識表達也逐漸採 用註標語言,以期獲得再利用與分享的效益。由網 際網路標準組織發布的OWL,即為一種 XML-based 語言,各種支援工具也逐漸成形,使得 OWL 成為 目前最重要的知識表達規範之一(Horrocks, Patel- Schneider, & Van Harmelen, 2003; López de Vergara, Villagrá, & Berrocal, 2004)。另外,由史丹佛大學醫 學資訊中心所研發的Protégé 軟體,則是一項普遍使 用的OWL 編輯工具之一,除提供發展 OWL-based 的知識本體外,也做為知識系統的載台,提供各項
外掛模組(plug-in)銜接,例如圖形工具及推論引 擎(Noy et al., 2001)。簡言之,本研究利用 Protégé 來開發OWL-based 的知識本體。
圖4 為利用 Protégé 圖形工具呈現的知識模型,各概 念及屬性(關係)分別以方框及有向箭頭線表示,本 模型由owl:thing 起始,下轄領域本體及任務本體等二 群,圖中之淺色實線表示is-a 屬性,表示具有父子階 層的從屬關係;圖中之深色線為has-a 形式的屬性,即 為連結概念與概念之間的組合關係,它是經由分析研 究問題及構想如何解決而訂定的屬性(關係),其中 深色實線為須收集之可知事實(例如has_disease)、
深色虛線為待推論之知識(例如mapping_symptom)。
圖4 知識模型之概念與屬性關係
個案實驗
收集事實知識
有別於領域本體是以建立共通性知識內涵為主,
任務本體則是塑模特定議題的邏輯框架,因此在實 作時須依據框架項目收集事實知識。如前述表1 至 表 3,主要用於定義徵狀、疾病、醫院門診等的橫
向連結關係,因此在asserted 屬性中(共計十項),
須依經驗法則或實際情況提供事實,以下依概念逐 一說明:
1. 「徵狀知識」概念:每個實例以三項屬性,收 集徵狀相關之知識性描述(如圖5),包括收集 對應徵狀學名的俗名及疾病之知識,通常具有
「1 對多」的關係。
(1) 徵狀學名(sign_symptom_Sname):在領域本 體下的「徵狀學名」概念,選擇一個實例,
例如「上腹部疼痛」。
(2) 徵狀俗名(has_SS_Cname):在領域本體中 的「徵狀俗名」概念,選擇「上腹部疼痛」
徵 狀 的 對 應 俗 名 , 例 如 「 拉 肚 子 」、「 脹 氣 」 等 。
(3) 疾病學名(has_disease_Sname):在領域本體 中的「疾病學名」概念,選擇「上腹部疼痛」
徵狀的對應疾病,例如「急性胃炎」、「十二 指腸潰瘍」、「慢性胃炎」等。
圖5 事實知識之收集與編輯示意圖
2. 「疾病知識」概念:每個實例以四項屬性,收 集疾病之知識性描述,包括對應疾病學名的俗 名、主要徵狀、伴隨徵狀,通常具「1 對多」
的關係。
(1) 疾病學名(disease_Sname):在領域本體下的
「疾病學名」概念,選擇一個實例,例如「十 二指腸潰瘍」。
(2) 疾病俗名(has_disease_Cname):在領域本體 中的「疾病俗名」概念,選擇「十二指腸潰 瘍」的對應俗名。
(3) 主要徵狀:在領域本體下的「徵狀學名」概 念,選擇對應「十二指腸潰瘍」的主要徵狀,
例如「黑便與便血」、「十二指腸潰瘍」等。
(4) 伴隨徵狀:在領域本體下的「徵狀學名」
概念,選擇對應「十二指腸潰瘍」的伴隨 徵狀,例如「噁心與嘔吐」、「發燒」、「發 燒」等。
3. 「醫院門診知識」概念:每個實例以三項屬 性,收集門診之知識性描述,包括醫院名稱、
門診科別、疾病學名等,並以 1:1:N 的關係 呈現。
(1) 醫院名稱(hospital_name):至領域本體中的
「醫院」概念下,選擇一個醫院實例,例如
「臺北榮民總醫院」。
(2) 門診科別(clinic_name):至領域本體中的「科 別」概念下,選擇一個門診分科實例,例如
「大腸直腸外科」等。
(3) 疾病學名(has_disease_Sname):前述之醫院 及科別須依據實況對應可看診之疾病,例 如「急性胃炎」、「十二指腸潰瘍」、「慢性胃 炎」等。
由於各實例展開其連結關係後,將形成複雜的網 狀結構,因此實例數量與複雜度將成正比關係增 加,為使驗證可行及易於說明,本研究將上述之實 例限定在腸胃疾病的知識,徵狀、完成疾病、醫院 門診等知識法則的收集,實例數分別為 26 項、12 項、17 項。
知識推論實驗
本研究的知識推論主要在實例層進行,因此利用 撰寫SWRL 語意規則方式,藉由已知的事實,計算 隱含性知識。目前規則的推論引擎主要是使用JESS
(Java Expert System Shell),本研究在Protégé-OWL 的編輯平台上,嵌入隨插即用的SWRLTab 模組,
提供編輯及測試SWRL 規則。如圖 6 所示,由上至 下區分為二大區塊,上方為 SWRL 的「規則編輯 區」,前述的SWRL 規則須在此完成編輯,下方為
「JESS 引擎執行區」,提供執行規則的各項功能 操作。在操作區中,上方有六項查詢按鍵,當規則 推論執行後,各按鍵提供不同的細節資訊。下方的 三項功能鍵為主要的執行項目,由左至右分別為:
(1)將 OWL 及 SWRL 的內容轉換至 JESS 的語言 格式;(2)執行規則推論,JESS 在幕後進行邏輯運 算,推導隱含性知識,前述之六項查詢按鍵,即為 配合此功能鍵;(3)將推論結果寫回至 OWL 檔案 中,亦即更新知識庫。
圖6 Protégé 規則編輯與 JESS 推論引擎
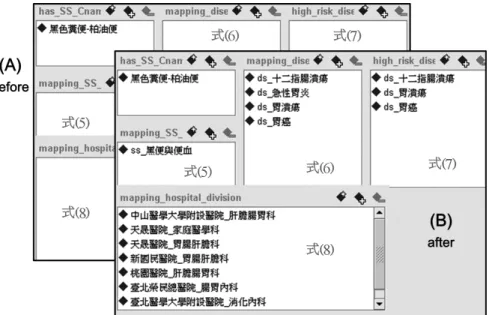
在完成前述之事實收集後,表4 設計的「以個人 徵狀查詢」概念,接受使用者給予個人感知的症狀 來查詢。如圖7(A)為執行規則推論前,在徵狀俗名
(has_SS_Cname)中置入「黑色糞便-柏油便」為例,
其他各屬性欄皆為待推論,本研究介紹之語意規 則,分別對應由式(5)求解徵狀學名、式(6)求 解相關之疾病名、式(7)求解高可能性之疾病、式
(8)以高可能性疾病查找醫院門診。圖 7(B)為利用
pJESS 規則推論引擎後之結果,原四項屬性欄皆獲 得推論值;本項工作是由外掛之語意規則引擎JESS
(Java Expert System Shell)完成,推論引擎首先將 知識庫的內容轉換為JESS 語言的格式,其次將語意 規則式(5)~式(8)導入進行邏輯運算,最後再 將推論結果覆寫回案中,亦即更新知識庫之屬性的 內容值。
圖7 (A)執行 JESS 規則推論引擎前;(B)執行 JESS 規則推論引擎後之結果
實驗討論
由於體徵症狀、疾病、門診科別、醫療院所等的 實例資料龐大,本研究僅就知識模型設計部分,以 局部實例驗證其解題之能力,特別是在前文所提的 關鍵性問題(CQs),例如依通俗的徵狀詞彙查詢徵 狀學名及可能之疾病、依主要徵狀篩選高風險之疾 病、依高風險之疾病建議醫療院所的門診科別等問 題,須利用執行JESS 規則引擎,獲得推論結果,比 較執行前後差異如圖7(A)與 7(B)所示。附錄 1 為 三項測試資料集,已由研究人員以人工方式整理;
此三項資料集的徵狀俗名,須提供知識庫做為問題 查詢的宣告資料,其餘各欄位將做為系統執行結果 的比較。由實驗結果顯示,三項測試結果均與人工 模擬作業的結果一致。由於本體的推論是在開放世 界假說下(open world assumption)進行,因此本研 究在定義解題之公理(axiom)時,特別將邏輯式以 封閉公理(closure axiom)形式撰寫,亦即所有推論 結果必定為各邏輯的合法推斷,不會做出定義範圍 以外的不當推論。
結論與研究建議
本研究以民眾對疾病徵狀的自我認知為例,探討 如何設計知識模型來解決問題,並進一步發展為應 用系統使用的知識庫,提供查詢不同醫療院所中的
正確就診科別。本研究導入本體相關技術做為建立 知識庫的設計,以知識庫的內容組成而言,可概略 區分為設計階段的「知識模型」及實作階段收集的
「事實知識」。我們將知識模型設計為領域本體、任 務本體、及語意規則共同組成,這個模型除定義解 題的邏輯架構外,也在應用階段做為收集不同事實 知識之依據,以下總結三項設計要點:
1. 領域本體:本研究針對徵狀、疾病、及門診科 別等,定義一般性的概念及實例,領域本體以 建置通用性的分類架構為原則,利用is-a 關係 建立具有階層性的從屬關係,協助定義領域知 識的框架。領域本體主要協助其他本體或系統 的溝通,特別是提供一致性的術語定義,本階 段分別建立實驗用的資料,包括86 項徵狀學名 實例、223 項徵狀俗名實例、52 項疾病學名實 例、107 項疾病俗名實例、44 項門診科別及 6 家醫院實例。
2. 任務本體:本研究針對研究解題建立「知識法 則」與「問題諮詢」二項概念,前者就徵狀、
疾病、門診等內涵知識,分別建立跨概念的對 應關係、從屬、及組成邏輯;後者則是為查詢 應用而設計,包括「以個人徵狀查詢」及「以 疾病查詢」等子概念。表1 至表 4 為上述各概 念的屬性定義,其中標示object 的屬性,用於
描述概念及概念之間的has-a 關係,它是任務本 體中最重要的知識定義;另一方面,屬性也可 依內容的獲得方式區分為 asserted 或 inferred,
其中標示 asserted 之屬性共計十項,須在實作 階段收集之現況事實,標示"inferred"之屬性共 四項,它們是設計做為解決問題之用,其內容 值雖暫時無法獲得,但可藉由其他已知事實得 佐證,由推論機制協助獲得。
3. 語意規則:在式(5)~式(8)中,針對部分 標示為 inferred 之屬性,發展求解的語意規 則,首先利用規則分析表以口語陳述方式,模 擬求解的邏輯與循序步驟,各步驟須是已知的 事實知識,最後再將規則分析表以邏輯式寫成 (atom1 Λ… Λ atomn)
Æ
Consequence)格式,規則 須由推論引擎執行推論。知識是結構化的資訊、經驗、價值和專家觀點的 融合,提供了評價和產生新的經驗和資訊的框架。
利用知識庫系統(knowledge base system)解題,通 常須以預先定義的符號或格式編輯,知識的格式因 經由事前分析而完整定義,新的事實只要依照格式 存放,即可依定義承襲既有的邏輯並進行知識推 論,除不須重複分析定義及程序,也不必再由程式 去轉換資料。由於知識庫系統強調對專業知識的塑 模能力,而不是資料處理的效率,因此較適合解決 知識密集(knowledge intensive)類型的問題。本研 究之疾病應用議題,即因為有相當大比例的工作,
須花費在塑模問題及定義邏輯關係上,因此本研究 採用建構知識庫系統的方式,並以知識本體原理做 為開發的方法、OWL 及 SWRL 為實際建置知識庫 的語言工具。
本研究融合學者在知識工程的建議步驟,應用於 建置知識本體,其中最主要貢獻是提出領域本體與 任務本體的構想,將知識模型區分為二類型並分別 發展。領域本體是以一般化的知識源為主,提供其 他領域在溝通時的參考標準或術語;任務本體則是 以解題需要來發展各知識源之間的關聯與邏輯。本 研究已建置解題之初步知識模型,並已給予實例資 料(事實知識)驗證該模型可行,然而如同人類的 心智認知及智慧,它可以不斷增加新的實例及向外 展延,以利達到更完整而週延的知識。因此,在前
述知識模型的基礎上,未來可針對醫療院所、徵狀、
疾病等之學名與俗名實例,再增加與擴充收集實例 資料,以利事實知識之完整。另一方面,本研究之 知識模型是以OWL-based 方式建置,依據註標語言 之特性,應可提供其他應用系統再利用與分享已建 置之模型與知識,例如聯合掛號系統、疾病查詢應 用等,皆是未來可再擴充之方向。
致謝
作者感謝行政院國科會提供專題研究計畫的經費 協助,計畫編號 NSC 99-2410-H-033 -028-MY3。
參考文獻
Alavi, M., & Leidner, D.E. (2001). Review: Knowledge management and knowledge management systems:
Conceptual foundations and research issues. MIS Quarterly, 25(1), 107-136.
Berners-Lee, T., Hendler, J., & Lassila, O. (2001). The semantic web. Scientific American, 284(5), 34-43.
Chandrasekaran, B., Josephson, J.R., & Benjamins, V.R.
(1999). What are ontologies, and why do we need them? IEEE Intelligent Systems, 14(1), 20-26.
Chi, Y.-L. (2009). A consumer-centric design approach to develop comprehensive knowledge-based systems for keyword discovery. Expert Systems with Applications, 36(2), 2481-2493.
Chi, Y.-L., & Chen, H.-C. (2009). Ontology and semantic rules in document dispatching. The Electronic Library, 27(4), 694-707.
Chi, Y.-L., Hsu, T.-Y., & Yang, W.-P. (2006). Ontological techniques for reuse and sharing knowledge in digital museums. The Electronic Library, 24(2), 147-159.
Davenport, T.H., & Prusak, L. (2000). Working knowledge:
How organizations manage what they know. Cambridge, MA: Harvard Business Press.
Feigenbaum, E.A. (1977). The art of artificial intelligence:
Themes and case studies of knowledge engineering.
Proceedings of Fifth International Joint Conference on Artificial Intelligence (pp. 1014-1029). Cambridge, MA.
Ganter, B., & Wille, R. (1997). Formal concept analysis:
Mathematical foundations. Secaucus, NJ: Springer -Verlag New York.
Grüninger, M., & Fox, M.S. (1995, August). Methodology for the design and evaluation of ontologies. Paper presented at the Workshop on Basic Ontological Issues in Knowledge Sharing, International Joint Conference on Artificial Intelligence, Montreal, Quebec, Canada.
Guarino, N. (1995). Formal ontology, conceptual analysis and knowledge representation. International Journal of Human Computer Studies, 43(5), 625-640.
Guarino, N. (1997). Understanding, building and using ontologies. International Journal of Human-Computer Studies, 46(2/3), 293-310.
Horrocks, I., Patel-Schneider, P.F., & Van Harmelen, F.
(2003). From SHIQ and RDF to OWL: The making of a web ontology language. Web Semantics: Science, Services and Agents on the World Wide Web, 1(1), 7-26.
Jiang, G., Ogasawara, K., Endoh, A., & Sakurai, T. (2003).
Context-based ontology building support in clinical domains using formal concept analysis. Journal of Medical Informatics, 71(1), 71-81.
Laudon, K.C., & Laudon, J.P. (2012). Management information systems: Managing the digital firm (Global.).
Edingburgh, England: Pearson Education.
López de Vergara, J.E.L., Villagrá, V.A., & Berrocal, J. (2004). Applying the web ontology language to management information definitions. IEEE Communications Magazine, 42(7), 68-74.
Nonaka, I. (1991). The knowledge-creating company.
Harvard Business Review, November-December, 162-171.
Noy, N.F., & McGuinness, D.L. (2001). Ontology development 101: A guide to creating your first ontology (Technical Report No. Stanford Knowledge Systems Laboratory Technical Report KSL-01-05 and Stanford Medical Informatics Technical Report SMI-2001-0880).
Stanford, CA: Stanford Knowledge Systems Laboratory and Stanford Medical Informatics Center.
Noy, N.F., Sintek, M., Decker, S., Crubézy, M., Fergerson, R.W., & Musen, M.A. (2001). Creating semantic
web contents with protege-2000. IEEE Intelligent Systems, 16(2), 60-71.
O’connor, M., Knublauch, H., Tu, S., Grosof, B., Dean, M., Grosso, W., & Musen, M. (2005). Supporting rule system interoperability on the semantic web with SWRL. In Y. Gil, E. Motta, V.R. Benjamins, & M.A.
Musen (Eds.), The Semantic Web - ISWC 2005 (pp.
974-986). Galway, Ireland: Springer.
Richards, D., & Simoff, S.J. (2001). Design ontology in context-a situated cognition approach to conceptual modelling. Artificial Intelligence in Engineering, 15(2), 121-136.
Uschold, M., & Gruninger, M. (1996). Ontologies:
Principles, methods and applications. The Knowledge Engineering Review, 11(2), 93-136.
Walczak, S. (1998). Knowledge acquisition and knowledge representation with class: The object-oriented paradigm. Expert Systems with Applications, 15(3/4), 235-244.
World Health Organization. (2004). ICD-10: International statistical classification of diseases and health related problems. Geneva, Switzerland: World Health Organization.
Zack, M.H. (1998). What knowledge-problems can information technology help to solve. In E. Hoadley
& I. Benbasat (Eds.), Proceedings of the Americas Conference of AIS (pp. 644-646). Baltimore, MD:
Association for Information Systems.
Zirn, C., Nastase, V., & Strube, M. (2008). Distinguishing between instances and classes in the wikipedia taxonomy. In Proceedings of 5th European Semantic Web Conference on the Semantic Web: Research and Applications (ESWC’08) (pp. 376-387). Springer -Verlag: Berlin, Heidelberg.
Kahan, S., & Smith, E. G.(2007)。表解疾病的徵象 與症狀(張晉銓譯)。台北市:合記圖書出版社。
(原著出版年:2004)
【Kahan S., & Smith, E. G. (2007). In a page signs &
symptoms (Jin-Quan Zhang Trans.). Taipei: Hochi.
(Original work published 2004)】
安藤幸夫、西尾剛毅(2006)。胃腸肝膽胰臟學習大 百科。新北市:瑞昇。
【Yukio, Ando, & Takeki, Nishio (2006). Weichang gandan yizang xuexidabaike. New Taipei: Rising.】
行政院衛生署中央健康保險局(2013)。國際疾病分 類第十版ICD-10-CM/PCS。檢自:http://www.nhi.
gov.tw/webdata/webdata.aspx? menu=23&menu_id
=957&webdata_id=3986&WD_ID=957
【National Health Insurance Administration Ministry of Health and Welfare (2013). International statistical classification of disease and related health problems, tenth revision, clinical modification, ICD-10-CM/PCS.
Retrieved from http://www.nhi.gov.tw/webdata/webdata.
aspx?menu=23&menu_id=957&webdata_id=3986&
WD_ID=957】
阮明淑、溫達茂(2002)。Ontology 應用於知識組織 之初探。佛教圖書館館訊,32,6-17。
【Yuan, Ming-Shu, & Wen, Dar-Maw (2002). Ontology yingyong yu zhishizuzhi zhi chutan. Information Management for Buddhist Libraries, 32, 6-17.】
周濟群、戚玉樑、曾建勛(2012)。以詞彙表為 基礎的知識本體雛型建構研究─以「公司治 理」領域知識為例。圖書資訊學研究,6(2),
37-81。
【Chou, Chi-Chun, Chi, Yu-Liang, & Tzeng, Jian-Shiun (2012). A research on how to construct the prototype of knowledge ontology based on glossary - Using the domain knowledge of “corporate governance” as an illustration. Journal of Library and Information Science Research, 6(2), 37-81.】
孫漢屏(1991)。類神經網路為基礎之智慧型醫院網 路掛號系統(未出版之碩士論文)。中國醫藥學院 醫務管理研究所,台中市。
【Sun, Han-Ping (1991). An intelligent appointment system based on the neural networks (Unpublished master’s thesis). Department of Health Service Administration, China Medical University, Taichung, Taiwan.】
高誌鍵(2010)。應用服務導向架構於網路掛號系統
─以某兩家醫院為例(未出版之碩士論文)。佛 光大學資訊學系,宜蘭縣。
【Kao, Chih-Chien (2010). Applying service-oriented architecture to online registration systems: Examples of
two hospitals (Unpublished master’s thesis). Department of Applied Information, Fo Guang University. Yilan, Taiwan.】
戚玉樑、蔡明宏(2007)。以文件為對象的概念萃取 程序建立知識本體的雛型架構。資訊管理學報,
14(3),47-66。
【Chi, Yu-Liang, & Tsai, Ming-Hung (2007). Knowledge acquisition approaches for building ontological conceptual prototypes in document. Journal of Information Management, 14(3), 47-66.】
陳樂惠、林鼎舜(2011)。運用 OWL 與 JessTab 建 構醫院門診推薦專家系統之研究。醫療資訊雜誌,
20(3),4-22。
【Chen, Le-Hui, & Lin, Ting-Shun (2011). The study of hospital clinic recommended expert system based on OWL and JessTab. The Journal of Taiwan Association for Medical Informatics, 20(3), 4-22.】
黑瀨巖(2005)。圖解消化系統的疾病與機制。新北 市:世茂。
【Iwao, Kurose (2005). Tujie xiaohua xitong de jibing yu jizhi. New Taipei: Coolbook.】
廖玉里(2002)。聯合網路掛號智慧代理系統之開發
(未出版之碩士論文)。國立陽明大學衛生資訊與 決策研究所,臺北市。
【Liao, Yu-Li (2002). The development of universal hospital web registry intelligent agents (Unpublished master’s thesis). Institute of BioMedical Informatics, National Yang-Ming University, Taipei, Taiwan.】
廖俊凱(2012)。90%的人生病都掛錯科:權威健檢 師教你看對醫生、做對檢查!臺北市:廣廈。
【Liao, Jun-Kai (2012). 90% de ren shengbing dou guacuoke: Quanwei jianjianshi jiao ni kandui yisheng, zuodui jiancha! Taipei: Guangxia.】
劉文卿、馮國卿(2003)。以 Metadata 為核心發展 金融機構 Ontology 之研究。圖書館學與資訊科 學,29(2),45-59。
【Liou, Wen-Ching, & Feng, Kuo-Ching (2003).
Developing the ontology for financial institutions based on standardized metadata. Journal of Library
& Information Science, 29(2), 45-59.】
附錄 1 本研究體徵症狀測試資料集
案例 徵狀俗名 徵狀學名 相關疾病 高可能性 之疾病
對應醫院門診
個人徵狀1 黑 色 糞 便
(柏油便)
黑便與便血 十二指腸潰瘍 胃癌
急性胃炎 胃潰瘍
十二指腸潰瘍 胃潰瘍 胃癌
天晟醫院_胃腸肝膽科;天晟 醫院_家庭醫學科;桃園醫院
_肝膽腸胃科;中山醫學大學 附設醫院_肝膽腸胃科;新國 民醫院_胃腸肝膽科;臺北醫 學大學附設醫院_消化內科;
臺北榮民總醫院_腸胃內科;
臺北醫學大學附設醫院_血液 腫瘤科;
個人徵狀2 想吐 解便不完全
噁心與嘔吐 便祕
急性胃炎 胃癌 腸阻塞
腸阻塞 天晟醫院_家庭醫學科;中山
醫學大學附設醫院_家醫科;
中山醫學大學附設醫院_大腸 肛門外科;新國民醫院_胃腸 肝 膽 科 ; 桃 園 醫 院 _ 消 化 外 科;桃園醫院_肝膽腸胃科;
臺北醫學大學附設醫院_消化 內科;臺北榮民總醫院_腸胃 內科
個人徵狀3 嘔吐 突發性上腹 部疼痛 大便中帶有 黏液
噁心與嘔吐 上腹部疼痛 慢性腹瀉
腸阻塞;十二指 腸潰瘍;胃癌;
急性胃炎;慢性 胃炎;胃潰瘍;
克隆氏病;大腸 癌;食道癌;潰 瘍性大腸炎
胃潰瘍 大腸癌
中山醫學大學附設醫院_肝膽 腸胃科;天晟醫院_家庭醫學 科 ; 新 國 民 醫 院 _ 胃 腸 肝 膽 科;桃園醫院_肝膽腸胃科;
中山醫學大學附設醫院_大腸 肛門外科;天晟醫院_大腸直 腸外科;桃園醫院_大腸直腸 肛門外科;臺北榮民總醫院_
大腸直腸外科;臺北醫學大學 附設醫院_血液腫瘤科;臺北 醫 學 大 學 附 設 醫 院 _ 消 化 內 科;臺北榮民總醫院_腸胃內科