國立臺灣大學電機資訊學院資訊網路與多媒體研究所 碩士論文
Graduate Institute of Networking and Multimedia College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
新議題在異質性社會網路上的傳播預測 Novel Topic Information Diffusion Prediction on
Heterogeneous Social Networks
洪三權
San-Chuan Hung
指導教授:林守德 博士 Advisor: Shou-De Lin, Ph.D.
中華民國 102 年 1 月 January, 2013
致謝
感謝家人在精神與物質上的支持,人過了 20 歲還能夠專心念書免於煩惱 經濟壓力煩惱,是件相當幸福且奢侈的事。
感謝林守德老師在研究上的教導,增進我對數據的敏感神經,使我學會從 數據當中觀察現象,並從中說出一個有道理的故事的方法;也感謝資訊網路與多 媒體研究所教過我的老師們,使我在資訊科學有所精進。
感謝社會系的劉華真老師於兩年前願意雪中送炭幫我寫推薦信,使我有進 入網媒所的條件。雖然很少再回社會系聽課,但在研究,或在生活當中,時常想 起社會系老師們當年在課堂上的教導。
感謝實驗室的夥伴, 與你們一起討論課業、做研究、玩耍,讓碩士漫長 兩年生涯增色許多。特別感謝 Tim 學長和 Weidong,謝謝你們願意和我討論,從 你們身上學到很多東西。
感謝 Python 的作者 Guido van Rossum 開發優雅且簡潔的語言,以及 Networkx 社群開發 Python Lib 的努力。缺乏 Python 和 Networkx 強大的火力支 援,研究的路途想必將會深陷於 Segmentation Fault 和 Memory 不足的幽暗深谷。
中文摘要
新議題的傳播預測是社會網路分析領域新興且重要的問題。新議題由於缺 乏過去的傳遞記錄,使得訊息的傳遞模式變得更加難以預測。相較於過去的研究,
我們提出更真實的實驗情境;此外,我們運用議題語義相似性,並結合異質性社 會網路的資訊,提出新的特徵值設計供機械學習的模型使用。根據實驗結果,結 合新模型與過去舊有的模型,在評鑑指標:「接收者操作特徵曲線下面積」有 3.51%的增進。
關鍵字:訊息傳遞預測、新議題、異質性社會網路、社會網路分析
Abstract
This work brings a marriage of two seemly unrelated topics, natural language processing (NLP) and social network analysis (SNA). Information diffusion prediction on novel topic is a challenging and important task in SNA, and we design a learning- based framework to solve this problem. Comparing to related work, we open the
scenario into a more realistic setting, and exploit the latent semantic information among users, topics, social connections, and heterogeneous social network information as features for prediction. Our framework is evaluated on real data collected from public domain. The experiments show 3.51% AUC enhancement from baseline methods.
Keyword: Information Diffusion Prediction, Novel Topic, Heterogeneous Social Networks, Social Network Analysis
Table of Contents
致謝 ... i
中文摘要 ... ii
Abstract ... iii
Table of Contents ... iv
List of Figures ... vi
List of Tables ... vii
Chapter 1 Introduction ... 1
1.1 Background ... 1
1.2 Contribution ... 4
1.3 Thesis Organization ... 4
Chapter 2 Related Work ... 5
2.1 Model-‐Driven Approaches ... 5
2.2 Data-‐Driven Approaches ... 6
2.2.1 Existing topic Information Diffusion Prediction ... 6
2.2.2 Implicit Topic Diffusion Prediction ... 6
2.2.3 Novel Topic Information Diffusion Prediction ... 7
Chapter 3 Methodology ... 11
3.1 Problem Formulation ... 11
3.1.1 Definition ... 11
3.1.2 Problem Definition ... 12
3.2 Intuition ... 13
3.2.1 User Level Design ... 13
3.2.2 Topic Similarity ... 13
3.2.3 Heterogeneous Node Type Cohesion ... 14
3.3 Feature Generation ... 15
3.3.1 User Behavior ... 15
3.3.2 Heterogeneous-‐Topic Estimating User Behavior ... 15
Chapter 4 Experiment ... 18
4.1 Plurk Data ... 18
4.1.1 Data Preparation ... 18
4.1.2 Diffusion Records ... 18
4.1.3 Heterogeneous Social Network ... 19
4.2 Corpus Processing ... 20
4.3 Cross Validation & Negative Sampling ... 20
4.4 Baseline ... 21
4.5 Evaluation Metric ... 22
4.6 Experiment Result ... 22
4.6.1 Single Feature Comparison ... 22
4.6.2 Feature Combination Comparison ... 24
Chapter 5 Conclusion ... 26
Chapter 6 Future Work ... 27
6.1 Time-‐Sensitive Model ... 27
Chapter 7 Reference ... 28
List of Figures
Figure 1 Female/Male Ratio X Topic Distribution ... 14
Figure 2 Edge Type ... 21
List of Tables
Table 4-1 Heterogeneous Node Type ... 19
Table 4-2 Single Feature Comparison Result ... 22
Table 4-3 Combination Comparison Result ... 24
Table 4-4 Leave-One-Out Experiment Result ... 24
Chapter 1 Introduction
1.1 Background
In recent year, microblog, such as Plurk and Twitter, has become more and more important as online service in daily life. According to Twitter official statistic report in 2006 [1], there were 140 million active users and 340 million Tweets (messages) a day, and the number has been still increasing. Similarly, Plurk is a popular microblog service in Asian with more than 5 million users [2]. Nowadays, microblog has become popular Internet service.
Microblog is a novel Internet communication service. Users can post a message to describe their present status with limited words (only 140 words per message allowed in Twitter). Besides, users can connect with each other in a follower-followee
relationship, where follower can subscribe interesting people as their followee such that they can read the message posted by followee instantly and response it. Moreover, there is some type information provided by users, such as gender and relationship status.
Thanks to the great popularity of microblog, large amount of data, especially heterogeneous social network and text content information, generated by microblog users can help researchers to study phenomena on social network. One of important problems is “diffusion prediction”: how is meme, information, or disease propagated on social network? Who will infect whom?
The diffusion prediction on social network has been studied for decades.
Generally, it can be divided into two categories: model-driven approaches and data- driven approaches. For model-driven approaches [3], such as Independent Cascade Model and Linear Threshold Model, these work design models to simulate cascading behavior, usually relying on intuition, without using historical diffusion records, the data about who propagate what to whom.
Researchers has exploited diffusion prediction problem by utilizing historical data; however, most of work [4]-[6] assumes that part of diffusion records of the predicted topics are known. In fact, such assumption is not always held in real world.
For example, there were little information diffusion records about “iPhone” before it was first released in 2007. Besides, it will be more practical and valuable if the unseen topic diffusion can be predicted. For instance, if a company could estimate the
propagation result of their new product on microblog, they can plan market strategy more precisely like sending coupons to expected high-influence users; if a political party can predict the diffusion result for their half-baked policy, they can send activity invitations to users who can help them to influence more audiences.
Recently, some work [2] starts to deal with the novel topic diffusion prediction problem. They exploit content and topology information for novel topic information diffusion prediction on homogeneous network; however, past work [2], [6] usually contain a strict constraint that there should be diffusion records in training data for predicted node pairs. The experiment scenario can be described as a “diffusion revival problem”: predicting whether past diffusion edges will reoccur in the future or not. But, the setting is unrealistic because of following reasons: To begin with, the data may be insufficient and incomplete such that some diffusion paths are missing in training data
but they may emerge in testing data. Besides, each topic has its novelty, and may bring up different type of curious users to discuss, so the novel topic diffusion edges may not overlap existing topic propagation records.
This work not only focus on novel topic diffusion prediction, but also, most different from past work [2], introduce a new task called “diffusion prediction on obscure networks”: predicting diffusion on not only existing edges but also unseen edges, the edges without records in past.
The problem is challenging. First, for novel topics, there are not diffusion records for inference. Second, it [2] has shown that some useful features for novel topic diffusion prediction usually based on past diffusion records; however, the predicted node pairs may have no data about that. Moreover, some users may be silent in training data and their data is not observable. Missing diffusion and user-behavior data may weaken the proposed features before.
In this paper, we propose novel features called User Behavior (UB) and
Heterogeneous-Topic Estimating User Behavior (HTB) to address above challenges. To estimating the diffusion potential in novel topic for users, it utilizes topic model to estimate the tendency from existing topic diffusion records. To cope with the lacking diffusion records problem, the proposed features are based on user level rather than pair level, because user level information is more sufficient than pair level. Besides, in the past [2], the framework was applied on homogeneous network, but in our work we taking on heterogeneous social network. For the silent users, we utilize heterogeneous node types information to estimate their tendency. The experiment results show that UB and HTB can help the state of the art model improve in a more realistic scenario.
1.2 Contribution
First, we introduce a new task of information diffusion prediction on novel topic, where we remove an assumption in the past that there should be diffusion records for predicted edges. We argue that the assumption is not realistic; instead, in real scenario, diffusion edges in novel topic may not exist in past diffusion records.
Furthermore, to tackle the problem, new features are introduced. We proposed features User Behaviors and Heterogeneous-Topic Estimating User Behavior based on topic similarity and heterogeneous node type information.
Besides, we design experiments to evaluate proposed models. The experiment shows that combining new and past features can improve performance for predicting novel topic information diffusion.
1.3 Thesis Organization
The thesis is organized as follows: in Chapter 2, related work of information diffusion prediction is introduced and reviewed. To tackle the problem, the approach we taken and the new designed features are introduced in Chapter 3, and the experiment setting and result on Plurk data are discussed in Chapter 4. Finally, this work is concluded in Chapter 5, and we propose future work in Chapter 6.
Chapter 2
Related Work
In this chapter, we introduce the related work of information diffusion prediction, which has been studied for decades. Generally, it can be divided into two categories:
model-driven approaches and data-driven approaches.
2.1 Model-Driven Approaches
For model-driven approaches, such models focus on how to simulate the diffusion process, usually based on intuition. Independent Cascade Model (IC) and Linear Threshold Model (LT) [3] are well known diffusion simulating models that have been studied for years. The core idea of IC model is that active nodes propagate
information to inactive neighbor nodes with probability. If an inactive neighbor v is activated by an active node u, then v will try to active inactive neighbors. Similarly, LT model also assumes that the active nodes will influence their neighbors, but not in a probability way. In LT model, each node has it’s own threshold to become active. If one node is activated, it will propagate real value scores to neighbors. When an inactive node’s received score exceeds the threshold, it will become active.
Besides, Heat Diffusion Model (HD) [7] is also a diffusion model, inspired by the physic phenomenon, assuming that information is propagated from the “hot people”
to the “cold people”, just like heat flowing from high temperature points to cold temperature points. Analog to physic formula, HD model describes the heat flow as follows:
fi(t) is the heat of node i at time t, and α is the thermal conductivity, the heat diffusion coefficient. Similar to LT model, each node is also assumed containing its own
threshold in HD model. If one node receives heat exceeding its threshold, it will become active.
In sum, model-driven models focus mainly on simulating diffusion process rather than utilizing past record data. Model-driven models usually perform worse than data-driven models due to without learning process [2].
2.2 Data-Driven Approaches
2.2.1 Existing topic Information Diffusion Prediction
On the other hand, some work has started to utilize data such as social network topology, text content, and user behaviors in machine learning approach for information diffusion prediction. For instance, [4] and [5] combine social features and text content features to predict whether a message will be retweeted. Similarly, [6] proposed model to predict whether an URL will be diffused by a user; however, those work needs part of past records for topics causing it can not predict novel topic because the past records of novel topic are totally unknown.
2.2.2 Implicit Topic Diffusion Prediction
[8] proposed model can handle the novel topic evolution and discover following diffusion paths. The main difference between their work and this work is that their
model mainly handles implicit diffusion paths whose data are usually unavailable. In contrast, our work focuses on explicit diffusion paths prediction.
2.2.3 Novel Topic Information Diffusion Prediction
[2] dealt with novel topic diffusion prediction by utilizing content and social features. Given homogeneous social network and topic content information, they proposed four kind of features: User Information, Topic Information, User-Topic Interaction, and Global Information described as follows:
2.2.3.1 Topic Information
We extract hidden topic category information to model topic signature. In particular, we exploit the Latent Dirichlet Allocation (LDA) method [9],which is a widely used topic modeling technique, to decompose the topic-word matrix TW into hidden topic categories:
TW = TH * HW ,
where TH is a topic-hidden matrix, HW is hidden-word matrix, and h is the manually- chosen parameter to determine the size of hidden topic categories. TH indicates the distribution of each topic to hidden topic categories, and HW indicates the distribution of each lexical term to hidden topic categories. Note that TW and TH include both existing and novel topics. We utilize THt,*, the row vector of the topic-hidden matrix TH for a topic t, as a feature set. In brief, we apply LDA to extract the topic-hidden vector THt,* to model topic signature (TG) for both existing and novel topics.
Topic information can be further exploited. To predict whether a novel topic will be propagated through a link, we can first enumerate the existing topics that have been
propagated through this link. For each such topic, we can calculate its similarity with the new topic based on the hidden vectors generated above (e.g., using cosine similarity between feature vectors). Then, we sum up the similarity values as a new feature: topic similarity (TS). For example, a link has previously propagated two topics for a total of
three times {ACL, KDD, ACL}, and we would like to know whether a new topic, EMNLP, will propagate through this link. We can use the topic-hidden vector to generate the similarity values between EMNLP and the other topics (e.g., {0.6, 0.4, 0.6}), and then sum them up (1.6) as the value of TS.
2.2.3.2 User Information
Similar to topic information, we extract latent personal information to model user signature (the users are anonymized already). We apply LDA on the user-word matrix UW:
UW = UM * MW ,
where UM is the user-hidden matrix, MW is the hidden-word matrix, and m is the manually-chosen size of hidden user categories. UM indicates the distribution of each user to the hidden user categories (e.g., age). We then use UMu,*, the row vector of UM for the user u, as a feature set. In brief, we apply LDA to extract the user-hidden vector UMu,* for both source and destination nodes of a link to model user signature (UG).
2.2.3.3 User-Topic Interaction
Modeling user-topic interaction turns out to be non-trivial. It is not useful to exploit latent semantic analysis directly on the user-topic matrix UR = UQ * QR , where UR represents how many times each user is diffused for existing topic R (R ∈T),
because UR does not contain information of novel topics, and neither do UQ and QR.
Given no propagation record about novel topics, we propose a method that allows us to still extract implicit user-topic information. First, we extract from the matrix TH
(described in Section 2.2.3.1) a subset RH that contains only information about existing topics. Next we apply least square method to derive another user-hidden matrix UH:
UH = (RH \ URT)T = ((RHT RH )-1 RHT URT)T
Using least square method, we generate the UH matrix using existing topic information. Finally, we exploit UHu,*, the row vector of the user-hidden matrix UH for the user u, as a feature set.
Note that novel topics were included in the process of learning the hidden topic categories on RH; therefore the features learned here do implicitly utilize some latent information of novel topics, which is not the case for UM. Furthermore, our approach ensures that the hidden categories in topic-hidden and user-hidden matrices are identical.
Intuitively, our method directly models the user’s preference to topics’ signature (e.g., how capable is this user to propagate topics in politics category?). In contrast, the UM mentioned in Section 2.2.3.2 represents the users’ signature (e.g., aggressiveness) and has nothing to do with their opinions on a topic. In short, we obtain the user-hidden probability vector UHu,* as a feature set, which models user preferences to latent categories (UPLC).
2.2.3.4 Global Information
Given a candidate link, we can extract global social features such as in-degree (ID) and out- degree (OD). We tried other features such as PageRank values but found them not useful. Moreover, we extract the number of distinct topics (NDT) for a link as
a feature. The intuition behind this is that the more distinct topics a user has diffused to another, the more likely the diffusion will happen for novel topics
This work contains an assumption that the proposed model only predicts the existing edges that edges with diffusion records in past. We remove the assumption and find that proposed useful features in [2] can not cope with the unseen edges prediction problem, so we introduce new design features for enhancement in following chapter.
Chapter 3 Methodology
In this chapter, we formally define a few key concepts and a novel task of information diffusion, and then we introduce a learning-based method to tackle this problem. We adopt a machine learning approach, and proposed two further features:
User Behaviors and Heterogeneous-Topic Estimating User Behaviors.
3.1 Problem Formulation
3.1.1 Definition
3.1.1.1 Heterogeneous Social Network
A heterogeneous social network is a graph G = (V, E, NT, nt) where V is a set of nodes, E is a set of edges among V, NT is a set of node types, and nt is a mapping from node to it’s node type. In a heterogeneous social network, a node corresponds to a user and an edge relates to a connection between user i and j. The edges direction can be undirected or directed, and in our setting edges are directed.
NTY = {TY1,TY2,TY3...TYN} is the set of node types, TYi = {tyi,1, tyi,2...tyi,ki} is a set of type value for a specific node type i. nt maps each user u to a tuple of node type values.
For instance, in Plurk data NTY is {Gender, Location, Relationship, Default_Lang }, and a user node type tuple may be {“female”, ”Taiwan”, “single”, “zh_TW” }.
3.1.1.2 Topic Words & User Words
A topic means a keyword or a set of keywords discussed by users highly, like
“iPhone5” or “earthquake”, with related word distribution P(w | ti)w∈W, and topic words means a set of topics word distribution representing in a matrix form
TW = (P(wj| ti))i, j.
Similarly, user words means a set of users’ word distributions represented in a matrix form UW = (P(w j| ui))i, j.
3.1.1.3 User Behavior and Diffusion Records
User behavior means that users perform specific actions with c times in a
specific topic t on microblog. Especially we focus on two actions: the number of posting a message mc and the number of responding messages rc, and they are described as M = {(v,t, mc) | v ∈ V,t ∈ T} and R = {(v,t, rc) | v ∈ V,t ∈ T}.
Diffusion records are the sets of diffusion recording how many times c one user u diffusing a specific topic t to another user v, which is described as
D = {(v, u, t, c) | v, u ∈ V;t ∈ T} .
3.1.2 Problem Definition
Give a heterogeneous social network G, user words UW, and a topic set T. TN is the set of novel topics whose diffusion records and user-behavior are unknown, and TR
is the set of the rest of topics whose diffusion records and user-behavior are given, i.e.
MT
R, RT
R and DT
R are given. It is also assumed that the topic words TW is given no matter TN or TR. The goal is to predict whether a user u will diffuse a novel topic t ∈ T
information to a user v. Note that it is not assumed that DT
Rshould have the diffusion records of u and v; besides, MT
R and RT
R may not have data of u or v.
3.2 Intuition
The proposed features are developed on following intuition: user level design, topic similarity and heterogeneous node type coherence. Here we discuss the reasons behind the intuition.
3.2.1 User Level Design
We design features on user level rather than pair level, because pair level features will have no information about unseen edges. In realistic situation, the
predicted edges may not have diffusion records causing some features proposed before, like TS, DF and NDT, to be zero.
Therefore, the features we proposed are based on user level. That is, the features use only node behavior data, more sufficient than edge behavior data, to cope with the problem.
3.2.2 Topic Similarity
Intuitively, similar topics may attract similar group of people to discuss, and diffusion edges in past may revive in similar novel topics. For instance, people loving Apple’s products, like “iPhone4S” and “iPhone5”, may have interests in “iPhone6.”
To estimating diffusion potential in novel topic, we can amplify similar existing topic diffusion records data; meanwhile, reduce the influence of dissimilar topic data.
3.2.3 Heterogeneous Node Type Cohesion
Users with same type may have interest in similar topics. For example, male users may have more interest to engage in sport topics than in celebrity of celebrity gossip, but female users’ preference may be contrary.
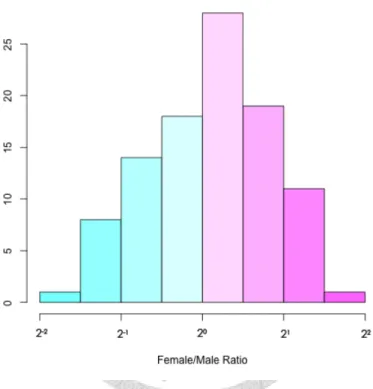
Figure 1 Female/Male Ratio X Topic Distribution
We calculate the statistic of female/male ratio X topic distribution. The x-axis is topic’s female/male ratio in log scale, and the y-axis is the count of responding topics.
Out of 100 topics, 59 topics’ female/male ratio is bigger than 1.0 and 41 topics’ ratio is smaller than 1.0, which means that nearing 60% topics are more attractive to female and 40% are more impressing to male. It shows that there are gender differences in topics.
Especially, in 20% topics the user number of one gender is more than double to the opposite gender, which means that the gender cohesion is strong in some topics. For
example, entertainment topics such as “Prince William and Kate” are more attractive to female users; in contrast, politic topics like “Su, Tseng-Chang (Taiwanese Politician)”
are more interesting to male user.
The result shows that the relationship between node types and topics may be insightful and useful for designing features.
3.3 Feature Generation
To deal with unseen edges prediction, we introduce two new user-behavior features: user message behavior (UM) and user response behavior (UR), and then incorporate topic information and heterogeneous social network information to refine User Behavior features called as Heterogeneous-Topic Estimating User Behavior (HTB).
3.3.1 User Behavior
User Behavior features describe one user’s tendency to post a message or to response messages. For a user, user message behavior (UM) and user response behavior (UR) are calculated by aggregating the number of posting messages and responding messages in existing topics; however, User Behavior features have no variance in each novel topic, so we proposed Heterogeneous-Topic Estimating User Behavior (HTB) to refine the feature.
3.3.2 Heterogeneous-Topic Estimating User Behavior
Heterogeneous-Topic Estimating User Behavior (HTB) comprises two parts:
using heterogeneous social network information to enhance user-behavior for missing data problem, and estimating user-behavior in novel topic with content information.
First, we assume nodes in same heterogeneous node type group share similar user-behavior information, and the group’s aggregated information can supplement individual feature if the group has consistent property. For a user u, the heterogeneous- enhanced user-behavior (HB) of u is described as follows:
HB(u, k,TY ) = (1−αTY (u),k)* Bu,k+αTY (u),k* BmeanTY (u),k
where TY(u) is user’s value of node type TY, k is the topic with diffusion records in training data, Bu,k is the user-behavior of u in topic k, BmeanTY(u),k is average user- behavior in topic k of TY(u) type nodes, and αTY(u),k is the confidence coefficient of node type value TY(u) information in topic k. The αTY(u),k is defined as follows:
αTY (u),k= 1− BstdTY (u),k
maxty∈TY(Bstdty,k) where BstdTY(u),k is the user-behavior standard deviation of TY(u) type nodes in topic k. The intuition is that if the distribution of user-behavior in node type value TY(u) is more concentrated, the average user-behavior of TY(u) is more believable.
Next, to estimate the user-behavior in novel topic knew, it needs to connect the relationship between existing topics and the novel topic by topic similarity information.
The main idea is to trust more on similar existing topics’ records but less on irrelevant topics’ records. For instance, to estimate one user’s user-behavior in novel topic
“iPhone 6”, user records of “iPhone 5” and “iPhone 4” are more believable than records of “Tsunami”. To do so, first, obtain the topic-hidden TH distribution by Latent Dirchlet Allocation (LDA) [9]. Second, calculate similarity on TH between existing topics and the novel topic, and we choose cosine distance as similarity score. Finally, to estimate the novel topic user-behavior, aggregate heterogeneous-enhanced user-behavior in
existing topics and weight it by the topic similarity. The whole process can be summarized as following formula:
HTB(u, knew,Ty) = tsim(knew, k)
k
∑ * HB(u, k,Ty)
where tsim(knew,k) is the topic similarity between knew and k in the topic-hidden distribution.
Chapter 4 Experiment
This chapter describes experiment details to evaluate the proposed model
effectiveness, and compare it with baseline models. Our goal is not to defeat the state of the art models totally; rather, our experiment design attempts to prove that our proposed features can enhance the state of the art models, and the performance in the realistic scenario will be best only when combining both together.
4.1 Plurk Data
4.1.1 Data Preparation
First, 100 most popular topics (e.g., tsunami) are identified from Plurk
microblog site between 01/2011 and 05/2011 and related users posts and response are crawled. Then 100 topics are manually separated into 7 groups based on semantic meaning: disaster, URL sharing, entertainment, domestic politics, daily life, global politics, and sports.
4.1.2 Diffusion Records
The positive diffusion records are generated based on the post-response behavior.
That is, if a person x posts a message containing one of the selected topic t, and later there is a person y responding to this message, we consider a diffusion of t has occurred from x to y (i.e., (x, y, t) is a positive instance).
The dataset contains a total of 699,985 positive instances out of 100 distinct topics; the largest and smallest topic contains 117,201 and 1,102 diffusions respectively.
4.1.3 Heterogeneous Social Network
The underlying social network is created using the post-response behavior as well. We assume there is an acquaintance link between x and y if and only if x has responded to y (or vice versa) in at least one topic in training data. There are about 161971 nodes and 376578 edges in the network.
We collect Plurk public available user information as node type for each user:
gender, location, relationship, and default language. Note that status are self-reported by users; therefore, users can choose not to provide their status, and a few users’
information is missing because their accounts are expired. For the missing data, we add an “unknown” type for each node type. The following table summarizes four kinds of node types.
Node Type Description Size
(Include Unknown)
Gender (G) User’s gender 3
Location (L) User’s current location 210
Relationship (R) User’s current relation with others
status 11
Default Language (DL) Default language the user using 39 Table 4-1 Heterogeneous Node Type
4.2 Corpus Processing
Furthermore, the sets of keywords for each topic are required to create the TW and UW matrices for latent topic analysis; we simply extract the content of posts and responses for each topic to create both matrices. We set the hidden category number h = m = 7, which is equal to the number of topic groups.
We remove stop-words, use SCWS [10] for tokenization, and MALLET [11]
and GibbsLDA++ [12] for LDA.
4.3 Cross Validation & Negative Sampling
We use topic-wise 4-fold cross validation to evaluate our method, because there are only 100 available topics. For each group, we select 3/4 of the topics as training and 1/4 as validation.
We sample negative instances equal to the number of positive instances. To sample the representative negative instances, we divide the positive instances into three types and propose sampling method respectively.
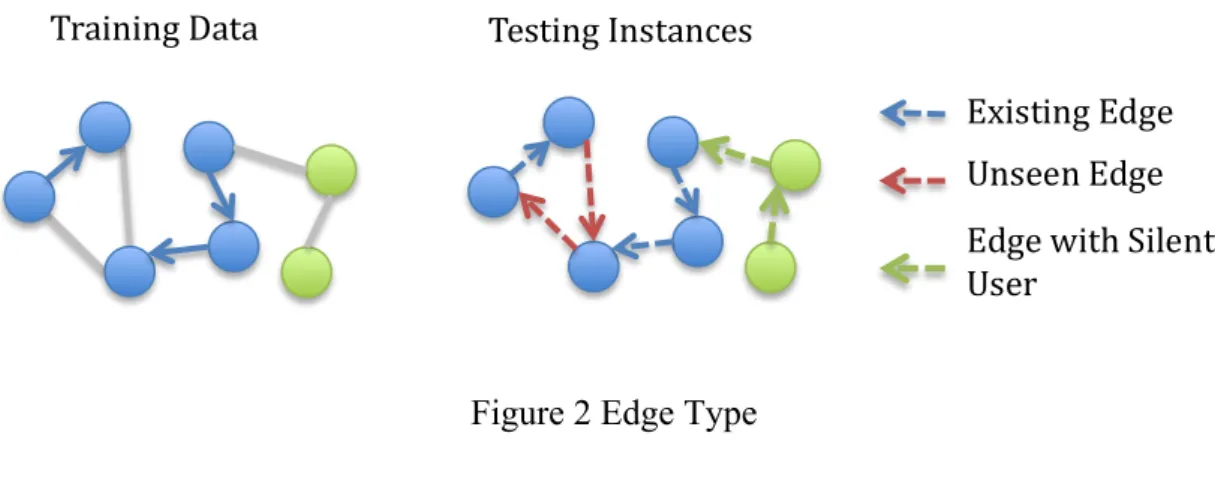
The positive instances (u,v) can be categorized into three types: “existing edges”,
“unseen edges”, and “edges with silent users”. Existing edges mean the edges with past diffusion records. If one user u and another user v did not diffuse information, but they both posted or responded others before, and then we call (u,v) as an unseen edge. If one of users or both users are silent in past, not posting or responding ever, we call (u,v) as an edge with silent users. The following figure shows three types of edges.
Figure 2 Edge Type
The same amount of negative instances for each topic (totally 699,985) is
sampled for binary classification. For each type of edges, to prepare the similar status to corresponding positive instance, we introduce three different negative sampling
methods.
For existing edges, negative instances of a topic t are sampled randomly based from existing topics’ diffusion records. For unseen edges, we sample two not silent users who are not connected in network. And for edges with silent users, if both users are silent users, we sample two other silent users from network randomly as a negative instance; if one user is silent user but the other is not, we sample a silent user and a user with diffusion records as a negative instance.
4.4 Baseline
In the following experiments, we compare User Behavior and Heterogeneous- Topic Estimating User Behavior with the proposed data-driven models in [2]: Topic Information, User Information, Topic-User Interaction, Global Features.
Training Data Testing Instances
Existing Edge Unseen Edge Edge with Silent User
4.5 Evaluation Metric
We choose area under ROC curve (AUC) [13] as evaluation metric; Testing instances are ranked based on their likelihood of positive, and compare it with the ground truth to compute AUC.
4.6 Experiment Result
4.6.1 Single Feature Comparison
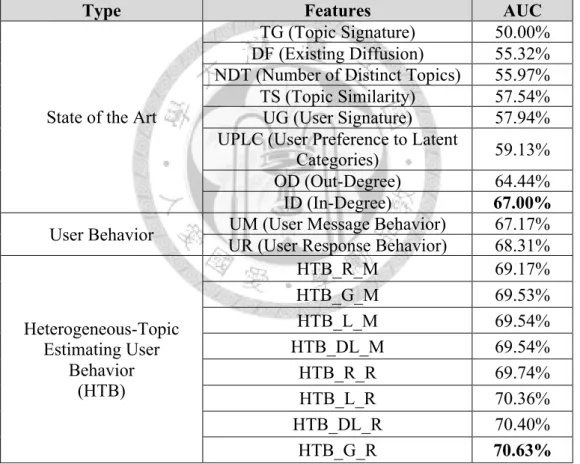
Type Features AUC
State of the Art
TG (Topic Signature) 50.00%
DF (Existing Diffusion) 55.32%
NDT (Number of Distinct Topics) 55.97%
TS (Topic Similarity) 57.54%
UG (User Signature) 57.94%
UPLC (User Preference to Latent
Categories) 59.13%
OD (Out-Degree) 64.44%
ID (In-Degree) 67.00%
User Behavior UM (User Message Behavior) 67.17%
UR (User Response Behavior) 68.31%
Heterogeneous-Topic Estimating User
Behavior (HTB)
HTB_R_M 69.17%
HTB_G_M 69.53%
HTB_L_M 69.54%
HTB_DL_M 69.54%
HTB_R_R 69.74%
HTB_L_R 70.36%
HTB_DL_R 70.40%
HTB_G_R 70.63%
Table 4-2 Single Feature Comparison Result
HTB is described as follows: for HTB_X_Y, X is the heterogeneous node type, and Y is the user-behavior type. For example, HTB_G_R uses gender as node type and responding action as user-behavior type.
To begin with, we attempt to compare different single features performance, so we evaluate each feature performance for novel topic information diffusion prediction.
Both user-behavior and heterogeneous-topic estimating user-behavior features outperform than the state of the art features. The best single feature is HTB_G_R:
heterogeneous-topic estimating user-behavior with gender as node type and responding action as user-behavior. Comparing with best single feature (ID) in baseline, HTB_G_R improve 3.63%, from 67.00% to 70.63%.
It [2] was showed that features exploiting users pair diffusion records, such as Existing Diffusion (DF), Topic Similarity (TS), and Number of Distinct Topics (NDT), have better performance than the others. Especially, TS was the best single feature before; however, those features do not perform well in our experiment scenario. In contrast, user level features, like HTB and ID, perform better. The reason is that users pair diffusion records may be missing in real scenario, which causes those pair level features’ performance decreasing.
4.6.2 Feature Combination Comparison
Type Features Combination AUC
State of the art
Features Single ID 67.00%
State of the art
Features TH+TS+ID+OD 69.43%
State of the art Features+
User Behavior+
HTB
TS+HTB_L_M+HTB_R_R 72.94%
Table 4-3 Combination Comparison Result
Besides, we compare features combination performance shown above.
Combining the state of the art features, User Behavior, and HTB, the best combination results in 72.94%, which outperforms than the state of the art single feature with 5.94%
and proposed features combination with 3.51%. It shows that HTB and User Behavior features can enhance performance of proposed features by [2].
Features AUC AUC - ALL
ALL (TS+HTB_L_M+
HTB_R_R)
72.94% -
ALL - TS 72.93% -0.02%
ALL - HTB_L_M 68.06% -4.89%
ALL - HTB_R_R 69.72% -3.23%
Table 4-4 Leave-One-Out Experiment Result
Moreover, we conduct a leave-one-out experiment on the best combination (TS+HTB_L_M+HTB_R_R), which comprising state of the art features and new features. The result shows that the combination is without redundancy; total performance will decrease if any one of the features is removed. Meanwhile, the
experiment result shows that HTB features importance. If HTB_L_M or HTB_R_R is removed, the total performance will decrease 4.89% and 3.32%; however, if TS is removed, the performance will just decrease 0.02%.
Chapter 5 Conclusion
Predicting information diffusion in novel topic is challenging: First, there are not diffusion records of novel topics for inference. Second, [2] has shown that the useful features for novel topic diffusion prediction usually based on past diffusion records; but, in real world, predicted node pairs may have no data about that. Furthermore, some users may be silent in collected data, and their data are limited so their behaviors become hard to predict.
We propose User Behavior and Heterogeneous-Topic Estimating User Behavior (HTB) to address above challenges. HTB is a set of user level features, which combines topic model for novel topic lacking records problem, and utilizes heterogeneous node types information to estimate the tendency of silent users in existing topics. Beside, we shift the experiment into a more realistic scenario by removing a assumption, and the experiment results show that User Behavior and HTB can help the state of the art model to improve 3.51% in the new scenario.
Chapter 6 Future Work
6.1 Time-Sensitive Model
To deal with novel topic lacking diffusion records problem, we focus on utilizing content information to connect between existing topics information and novel topics, and the experiment setting is based on topic-wise; however, it could be more complete if time information is considered.
We suggest two aspects that may be possible for enhancement: Topic Recency and Holliday Effect. Topic Recency means that the latest topic’s diffusion records are more believable than the older one’s. For instance, to estimate the diffusion path for the novel topic “HTC Butterfly”, a phone released in 2013, “HTC J” diffusion records are more believable than “HTC Aria” records, the former one released in 2012 and the latter one released in 2010. Besides, Holliday Effect means that some topics may resonate in specific time period. For example, technology companies, like Apple and Amazon, usually announce their latest products before Christmas, and products news may stimulate each other at that time, such as iPad mini and Kindle Fire.
Chapter 7 Reference
[1] “Twitter Blog: Twitter turns six,” blog.twitter.com. [Online]. Available:
http://blog.twitter.com/2012/03/twitter-turns-six.html. [Accessed: 30-Nov- 2012].
[2] T.-T. Kuo, S.-C. Hung, W.-S. Lin, N. Peng, S.-D. Lin, and W.-F. Lin,
“Exploiting latent information to predict diffusions of novel topics on social networks,” presented at the ACL '12: Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers, 2012, vol. 2.
[3] D. Kempe, J. Kleinberg, and É. Tardos, “Maximizing the spread of influence through a social network,” Proceedings of the ninth ACM SIGKDD
international conference on Knowledge discovery and data mining, pp. 137–
146, 2003.
[4] S. Petrovic, M. Osborne, and V. Lavrenko, “RT to Win ! Predicting Message Propagation in Twitter,” ICWSM, vol. 13, no. 513435, pp. 586–589, 2011.
[5] J. Zhu, F. Xiong, D. Piao, Y. Liu, and Y. Zhang, “Statistically Modeling the Effectiveness of Disaster Information in Social Media,” presented at the 2011 IEEE Global Humanitarian Technology Conference (GHTC), 2011, pp. 431–
436.
[6] W. Galuba, K. Aberer, D. Chakraborty, Z. Despotovic, and W. Kellerer,
“Outtweeting the twitterers-predicting information cascades in microblogs,”
presented at the Proceedings of the 3rd Workshop on Online Social Networks (WOSN 2010), 2010.
[7] H. Ma, H. Yang, M. R. Lyu, and I. King, “Mining social networks using heat diffusion processes for marketing candidates selection,” presented at the CIKM '08: Proceeding of the 17th ACM conference on Information and knowledge management, 2008.
[8] C. X. Lin, Q. Mei, Y. Jiang, J. Han, and S. Qi, “Inferring the Diffusion and Evolution of Topics in Social Communities,” mind, 2011.
[9] D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent dirichlet allocation,” Journal of Machine Learning Research, vol. 3, pp. 993–1022, 2003.
[10] Hightman, “SCWS - 簡易中文分詞系統 - hightman.cn,” hightman.cn.
[Online]. Available: http://www.hightman.cn/index.php?scws. [Accessed: 30- Nov-2012].
[11] McCallum and A. Kachites, “MALLET: A Machine Learning for Language Toolkit.,” mallet.cs.umass.edu, 30-Nov-2002. [Online]. Available:
http://mallet.cs.umass.edu. [Accessed: 30-Nov-2012].
[12] X.-H. Phan and C.-T. Nguyen, “GibbsLDA++: A C/C++ implementation of latent Dirichlet allocation (LDA),” gibbslda.sourceforge.net, 30-Nov-2007.
[Online]. Available: http://gibbslda.sourceforge.net. [Accessed: 30-Nov-2012].
[13] J. Davis and M. Goadrich, “The relationship between Precision-Recall and ROC curves,” presented at the Proceedings of the 23rd international conference
…, 2006.