國立交通大學
工業工程與管理學系
博士論文
整合良率預估及缺陷樣式辨識之晶圓
缺陷診斷系統
Constructing a Wafer Defect Diagnostic System by
Integrating Yield Prediction and Defect Pattern
Recognition
研 究 生:趙豊昌
指導教授:唐麗英 教授
整合良率預估及缺陷樣式辨識之晶圓缺陷診斷系統
Constructing a Wafer Defect Diagnostic System by Integrating
Yield Prediction and Defect Pattern Recognition
研 究 生:趙豊昌 Student:Li-Chang Chao
指導教授:唐麗英 Advisor:Lee-Ing Tong
國 立 交 通 大 學
工業工程與管理學系
博 士 論 文
A DissertationSubmitted to Department of Industrial Engineering and Management College of Management
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Doctor of Philosophy
in
Industrial Engineering and Management
March 2009
Hsinchu, Taiwan, Republic of China
整合良率預估及缺陷樣式辨識之晶圓缺陷診斷系統
研究生:趙豊昌 指導教授:唐麗英 教授國立交通大學工業工程與管理學系
摘要
積體電路的製作技術日趨精密,然無論如何改善製程技術,其產品的良率 仍無法達到 100%。造成積體電路產品良率損失的最主要原因,乃是晶圓上產生 的缺陷。隨著晶圓面積的增大,缺陷出現群聚現象,以往常用之卜瓦松良率模式 (Poisson Yield Model)會因低估良率而不再適用。近年來,許多中外文獻針對晶圓 之缺陷群聚現象而提出一些良率模式,然而這些良率模式各有不完善之處。如: 負二項良率模式(Negative Binomial Yield Model)則因其中的缺陷群聚參數值過 於散亂,同時也可能為負值,而造成分析良率時的不便;複合卜瓦松良率模式 (Compound Poisson Yield Model)雖然預測的良率較卜瓦松良率模式準確,但模式 的建構卻相當複雜,較不易為業界所用。而 Jun et al.以迴歸分析法所建構之良率 模式,其模型之適配度與資料是否違反迴歸模型的假設都是值得考慮的。利用倒 傳遞網路構建之良率模式則必需經由適當地設定網路參數才能得到較佳的預測 結果。此外,目前半導體晶圓資料分析仍是以人工的方式分析晶圓上缺陷的空間 樣式來找出製程變異的可能原因。然而人工判定除了費時外,亦可能因誤判進而 影響偵測製程變異的準確性。有文獻提出一些晶圓缺陷樣式辨識方法來判定製程 是否異常,但皆有其不完善之處。因此,本研究的主要目的是要發展一個整合良 率預估模式及缺陷樣式辨識之晶圓缺陷診斷系統。本研究利用一般迴歸神經網路 (General Regression Neural Network, GRNN)來構建良率模式,並利用多類別支撐 向量機(Multi-class Support Vector Machines, Multi-class SVM)來構建一個晶圓缺 陷樣式辨識系統;最後整合成一個良率預估模式及缺陷樣式辨識之晶圓缺陷診斷 系統。本研究最後以模擬實驗來說明本研究所提之整合良率預估模式及缺陷樣式 辨識之晶圓缺陷診斷系統的可行性;並進一步與現有文獻所提之良率預估模式與 缺陷樣式辨識系統進行比較以驗證本研究的有效性與優越性。 【關鍵字】積體電路、缺陷、群聚現象、良率模式、一般迴歸神經網路、樣式辨 識、支撐向量機Constructing a Wafer Defect Diagnostic System by Integrating Yield
Prediction and Defect Pattern Recognition
Student:Li-Chang Chao Advisor:Lee-Ing Tong
Department of Industrial Engineering and Management
National Chiao Tung University
Abstract
Wafer yield is a highly effective means of evaluating the process capability of integrated circuit manufacturers. The defect number and cluster intensity of defects on a wafer are two critical factors influence wafer yield. As wafer sizes increase, the clustering phenomenon of defects increases. Clustered defects cause the conventional Poisson yield model underestimate actual wafer yield. The cluster parameter of the negative binomial model can be very scattered and negative when the model is applied to predict yield. Compound Poisson yield models are complicated. The degree of fitness for regression model must be considered when the regression methods are utilized to model the yield. Obtaining good prediction network requires substantial effort to identify the parameters of back-propagation neural network. Although some yield models consider the effects of defect clustering on yield prediction, these models have some drawbacks. Furthermore, the possible causes of process variation can be found out by operators through analyzing the defect pattern on a wafer. Judging the process by operators can waste time and the accuracy of process detecting can be influenced due to the erroneous conclusion. Although some recognizing methods for defect pattern on a wafer were proposed, these recognizing methods still have some flaws. This study presents a novel wafer defect diagnostic system that utilizes a general regression neural network integrating a multi-class support vector machines to predict the wafer yield and recognize the defect pattern on a wafer. A simulation study is utilized to demonstrate the effectiveness of the proposed method.
【Key Words】Integrated circuit, defect, clustering phenomenon, yield model, general regression neural network, pattern recognition, support vector machines
誌 謝
本篇論文得以順利完成,首先要感謝指導老師唐麗英教授的悉心指導,使 我在研究的過程中受益良多,謹此致上無限的感激。此外,感謝本系梁高榮老師、 科技管理研究所虞孝成老師、清華大學科技管理研究所黎正中老師以及國防大學 理工學院動力及系統工程學系王春和老師等人對本論文提出之建議與指導,使本 論文更臻完善,謹此致謝。 在博士班的生涯中,感謝與我一起分享喜悅,分擔憂愁的同窗好友,以及 同門的學弟妹,我會永遠記得與你們相處的這段美好時光。同時也感謝我目前的 服務學校致遠管理學院,能讓我在職進修以完成博士學位。 最後,僅以此論文獻給我的家人---偉大的母親,有您的付出才有今日的我, 由衷地感謝您;給予我精神支柱的太太,有你在背後默默地支持,我才能無後顧 之憂來完成學位;帶給我愉悅心情的兩個可愛小寶貝,你們讓我忘了一天的疲 憊,也讓我覺得付出有所代價;還有大哥、大嫂、大姐、二姐以及兩位姪女,有 你們大家的付出,我們家才能展現和樂融洽的氣氛,謝謝你們! 趙豊昌 謹誌於 交通大學工業工程與管理研究所 2009 年 3 月目 錄
第一章 緒論... 1 1.1 研究背景與動機... 1 1.2 研究目的 ... 3 1.3 研究限制 ... 3 1.4 研究架構 ... 4 第二章 文獻探討 ... 5 2.1 積體電路良率模式 ... 5 2.1.1 卜瓦松良率模式 ... 5 2.1.2 複合卜瓦松良率模式 ... 5 2.1.3 負二項良率模式 ... 6 2.1.4 使用迴歸分析法構建之良率模式 ... 8 2.1.5 類神經網路良率模式 ... 9 2.2 一般迴歸神經網路 ... 10 2.2.1 GRNN 網路架構 ... 10 2.2.2 GRNN 網路基本原理 ... 11 2.2.3 GRNN 的優點... 12 2.3 缺陷群聚指標 ... 13 2.3.1 負二項良率模式的群聚參數 ... 13 2.3.2 空間統計學之缺陷群聚指標 ... 13 2.3.3 無統計假設之缺陷群聚指標 ... 14 2.3.4 其他缺陷群聚指標 ... 15 2.4 缺陷樣式之辨識 ... 162.4.1 倒傳遞網路(Back-Propagation Neural Network, BPNN) ... 16
2.4.2 徑向基底函數(Radial Basis Function,RBF)神經網路 ... 18
2.4.3 支撐向量機(Support Vector Machines,SVM) ... 20
2.4.3.1 支撐向量分類(Support Vector Classify) ... 20
2.4.3.2 核函數(Kernel Function) ... 22
2.4.4 多類別支撐向量分類 ... 23
2.4.4.1 一對多(One Versus the Rest)分類法 ... 23
2.4.4.2 一對一(Pairwise)分類法 ... 23
2.4.4.3 DAG(Directed Acyclic Graph)分類法 ... 24
2.4.4.4 一次(Considering all Data at a Once)分類法 ... 24
第三章 研究方法 ... 25
3.2 本研究構建之良率模式 ... 28 3.3 本研究構建之晶圓缺陷樣式辨識系統 ... 29 3.4 整合良率預估及缺陷樣式辨識之晶圓缺陷診斷系統 ... 31 第四章 模擬驗證 ... 33 4.1 模擬實驗 ... 33 4.2 良率模式的比較... 36 4.2.1 各良率模式與缺陷數因子水準之關係 ... 39 4.2.2 各良率模式與群聚程度因子水準之關係 ... 43 4.2.3 各良率模式與群聚分佈面積因子水準之關係 ... 46 4.3 晶圓缺陷樣式辨識技術的比較 ... 49 4.3.1 各樣式辨識技術與缺陷數因子水準之關係 ... 51 4.3.2 各樣式辨識技術與缺陷群聚程度因子水準之關係... 54 4.3.3 各樣式辨識技術與群聚分佈面積因子水準之關係... 57 4.4 整合良率預估及缺陷樣式辨識之晶圓缺陷診斷系統 ... 60 第五章 結論... 65 參考文獻 ... 66
表
目
錄
表 2.1 積體電路良率模式彙整表 ... 7 表 2.2 不同值之下,負二項良率模式近似之良率模式及群聚現象 ... 8 表 2.3 值與 CI 值之比較... 15 表 4.1 245 片測試樣本的良率預估值與真實良率間之變異數分析 ... 38 表 4.2 5 種缺陷樣式下,各良率模式在 3 種設計因子的預估績效 ... 49 表 4.3 5 種缺陷樣式下,各辨識技術在 3 種設計因子的辨識績效 ... 60 表 4.4 10 片晶圓樣式之相關資訊 ... 64 表 4.5 10 片晶圓之 GRNN 預估良率與良率程度 ... 64 表 4.6 6 片晶圓之真實缺陷樣式與多類別 SVM 辨識之樣式 ... 64圖
目
錄
圖 2.1 GRNN 的網路架構 ... 10 圖 2.2 缺陷分布圖與兩軸的投影 ... 15 圖 2.3 BPNN 之網路架構 ... 17 圖 2.4 RBF 神經網路 ... 20 圖 2.5 最佳超平面 ... 21 圖 2.6 DAG 分類法處理 3 類別的分類 ... 24 圖 3.1 夾角與距離示意圖 ... 27 圖 3.2 群聚指標示意圖 ... 28 圖 3.3 本研究之 GRNN 良率模式架構圖 ... 29 圖 3.4 常見的晶圓表面缺陷樣式 ... 30 圖 3.5 本研究之多類別 SVM 晶圓缺陷樣式辨識系統架構圖 ... 30 圖 3.6 本研究之整合良率預估及缺陷樣式辨識之晶圓缺陷診斷系統構建流程圖 ... 32 圖 4.1- (a) 隨機樣式 ... 34 圖 4.1- (b) 牛眼樣式 ... 34 圖 4.1- (c) 弦月樣式 ... 35 圖 4.1- (d) 底部樣式 ... 35 圖 4.1- (e) 環狀樣式 ... 36 圖 4.2 245 片測試樣本的良率預估值與真實良率間之 RMSE 的比較 ... 38 圖 4.3 245 片測試樣本的良率預估值與真實良率間之散佈圖 ... 39 圖 4.4 隨機樣式時,各種良率模式之缺陷數因子水準與 RMSE 的關係 ... 40 圖 4.5 牛眼樣式時,各種良率模式之缺陷數因子水準與 RMSE 的關係 ... 40 圖 4.6 弦月樣式時,各種良率模式之缺陷數因子水準與 RMSE 的關係 ... 41 圖 4.7 底部樣式時,各種良率模式之缺陷數因子水準與 RMSE 的關係 ... 42 圖 4.8 環狀樣式時,各種良率模式之缺陷數因子水準與 RMSE 的關係 ... 42 圖 4.9 牛眼樣式時,各種良率模式之群聚程度因子水準與 RMSE 的關係 ... 43 圖 4.10 弦月樣式時,各種良率模式之群聚程度因子水準與 RMSE 的關係 ... 44 圖 4.11 底部樣式時,各種良率模式之群聚程度因子水準與 RMSE 的關係 ... 45 圖 4.12 環狀樣式時,各種良率模式之群聚程度因子水準與 RMSE 的關係 ... 45 圖 4.13 牛眼樣式時,各種良率模式之群聚分佈面積因子水準與 RMSE 的關係 ... 46 圖 4.14 弦月樣式時,各種良率模式之群聚分佈面積因子水準與 RMSE 的關係 ... 47 圖 4.15 底部樣式時,各種良率模式之群聚分佈面積因子水準與 RMSE 的關係 ... 48 圖 4.16 環狀樣式時,各種良率模式之群聚分佈面積因子水準與 RMSE 的關係 ... 49 圖 4.17 隨機樣式時,各種辨識技術之缺陷數因子水準與正確辨識率的關係 ... 52 圖 4.18 牛眼樣式時,各種辨識技術之缺陷數因子水準與正確辨識率的關係 ... 52 圖 4.19 弦月樣式時,各種辨識技術之缺陷數因子水準與正確辨識率的關係 ... 53 圖 4.20 底部樣式時,各種辨識技術之缺陷數因子水準與正確辨識率的關係 ... 53圖 4.21 環狀樣式時,各種辨識技術之缺陷數因子水準與正確辨識率的關係 ... 54 圖 4.22 牛眼樣式時,各種辨識技術之群聚程度因子水準與正確辨識率的關係 ... 55 圖 4.23 弦月樣式時,各種辨識技術之群聚程度因子水準與正確辨識率的關係 ... 55 圖 4.24 底部樣式時,各種辨識技術之群聚程度因子水準與正確辨識率的關係 ... 56 圖 4.25 環狀樣式時,各種辨識技術之群聚程度因子水準與正確辨識率的關係 ... 57 圖 4.26 牛眼樣式時,各種辨識技術之群聚分佈面積因子水準與正確辨識率的關係 .... 57 圖 4.27 弦月樣式時,各種辨識技術之群聚分佈面積因子水準與正確辨識率的關係 .... 58 圖 4.28 底部樣式時,各種辨識技術之群聚分佈面積因子水準與正確辨識率的關係 .... 59 圖 4.29 環狀樣式時,各種辨識技術之群聚分佈面積因子水準與正確辨識率的關係 .... 60 圖 4.30- (a) 隨機樣式 ... 62 圖 4.30- (b) 牛眼樣式 ... 62 圖 4.30- (c) 弦月樣式 ... 62 圖 4.30- (d) 底部樣式 ... 63 圖 4.30- (e) 環狀樣式 ... 63
第一章 緒論
1.1 研究背景與動機
半導體產業是我國目前重點發展的產業。依原料、生產/加工至產品產出, 半導體產業大致可區分為半導體材料(含化學品)、光罩、設計(含 CAD 軟體)、製 程、封裝、測試及設備等七個技術領域。半導體產品包括積體電路(Integrated Circuits, IC)、分離式(Discrete)元件和光電(Optoelectronic)元件等三大類,廣泛應 用於資訊、通訊、消費性電子、工業儀器、運輸及國防太空等領域[2]。 然而,無論如何改善積體電路的製作技術,其產品的良率仍無法達到 100%。造成積體電路產品良率損失的最主要原因,乃是晶圓上所產生的缺陷與 缺陷的群聚程度。這些缺陷一般可分為三類,即嚴重缺陷(gross defects),參數缺 陷(parameter defects)以及隨機缺陷(random defects)等[18]。嚴重缺陷是屬於相當 大的缺陷。例如,刮痕(scratches)、處置不當或尚未完全移除的光阻劑等所造成 的損壞;嚴重缺陷經常會造成良率的損失。參數缺陷是指會影響設備電氣參數(電 流、電壓、電阻…等)的缺陷。例如,一個晶片上由於雜質(dopant)不均勻的集中, 可能造成原先被視為相同的電阻器上卻有不同的電阻值;參數缺陷有時可能產生 良率損失,但它們較常引起一些可靠度問題(例如,設備在使用一段時間後,失 去了原先所設計的功能)。隨機缺陷乃是機遇性發生的缺陷,造成良率損失的隨 機缺陷又稱之為致命缺陷(fatal defects)或失效(faults)。 並非所有的製程缺陷都會造成良率的損失;製程缺陷是否會造成產品失效 乃是與產品的特性(例如,晶片面積、缺陷分布狀況、線寬大小、線路形狀…等) 有關。由於線寬大小與線路形狀所引起的良率損失,不易用機率模式來描述,所 以一般預測積體電路良率模式的文獻中,都著重於以晶片面積與缺陷分布狀況兩 參數來預測良率。 藉由特定的機率函數通常可以描述缺陷的分布情形,並進而建立產品之良 率與製程缺陷間的關係,即所謂的良率模式(Yield Model)。自 1960 年代開始就 有學者提出各種不同的良率模式來預估良率[14][37][41][45]。其中卜瓦松良率模 式(Poisson Yield Model)對於小晶片的良率預測效果較佳[6]。負二項良率模式 (Negative Binomial Yield Model)則對大晶片的良率預測效果較好;目前的積體電路工廠多採用負二項良率模式來預估良率[14]。複合卜瓦松良率模式[14]在良率 預測上亦較卜瓦松良率模式準確。Jun et al. [25] 利用一缺陷群聚指標 CI 與晶片 上的平均缺陷數建構出一個迴歸模式來估計晶圓良率;而其中之 CI 值能以均勻 的數值範圍來量化不同嚴重程度的群聚現象。還有一些利用類神經網路(例如, 倒傳遞網路)構建之良率模式也常被用來預估良率[1][4][42]。 Stapper[40]指出,當晶圓的面積增大時,晶圓上的缺陷並非呈現隨機性分 布,而是有群聚現象發生。這些群聚的缺陷通常分布在晶圓的邊緣[38]。缺陷群 聚現象使得卜瓦松良率模式會低估產品應有的良率。負二項良率模式中的缺陷 群聚參數值過於散亂,同時也可能為負值,這些都造成分析良率時的不便。複 合卜瓦松良率模式雖然良率的預測較卜瓦松良率模式準確,但模式的建構卻相 當複雜,較不易為業界所接受。Jun et al. [25] 以迴歸分析法所建構之良率模式, 其模式之適配度以及資料是否違反迴歸模式的基本假設都是值得考慮的。利用 倒傳遞網路構建之良率模式則必需經由適當地設定許多網路參數才能得到較佳 的預測結果。 目前在半導體晶圓缺陷資料分析方法中,大多是以人工的方式分析晶圓上 缺陷的空間樣式來找出製程變異的可能原因[28]。然而人工判定除了費時外,亦 可能因誤判進而影響製程變異偵測上的準確性。因此,如何構建一個有效的晶 圓缺陷樣式辨識系統一直受到學界與業界的重視。一般之晶圓缺陷樣式辨識主 要可分成三個領域:統計分析法、啟發式演算法以及人工智慧學習[31]。統計分 析法乃針對問題給定不同的分配假設以進行資料點的群聚現象分析,其目的在 於如何將空間上的資料點進行切割,以達到樣式分類辨識的目的[23]。啟發式演 算法通常利用柔性計算的方法(例如,基因演算法與模糊理論)來進行樣式辨識。 然而,基因演算法一般必頇付出相當多的努力於評估過程才能達到最佳解[7]。 而模糊理論的主要限制之一乃是其語意控制規則相當難產生;再者,必頇借重 一些專家的知識與經驗才能設計出一完善的模糊邏輯控制器[12]。人工智慧學習 乃藉由模仿生物神經系統的運算來達成資訊處理之目的,類神經網路即人工智 慧學習中一項常用的技術。然而,類神經網路技術的主要限制之一乃是其各項 網路參數必頇適度的設定才能得到較佳的結果[19]。近年來支撐向量機(Support Vector Machines,SVM)已廣泛應用在樣式分類辨識上,而且有好的辨識結果 [10][22]。例如:臉和手印身分驗証[49]、土地的覆蓋變化察覺[30]、國畫的辨識
與分類[24]、遺傳學的綜合症診斷分類[15]等。 缺陷之群聚現象可能造成良率模式低估晶圓良率;而晶圓的缺陷分布若呈 現特定樣式(pattern),亦可視為製程異常。因此,當一片晶圓出現中、低良率時, 應進一步診斷該晶圓表面的缺陷是否存在某種特定的缺陷樣式。為適切地反應出 產品的真實良率,並且能夠針對呈現特定樣式的晶圓做出正確的製程異常診斷, 有必要構建出一個能考慮到缺陷群聚現象與缺陷分布呈現特殊樣式的一個較精 密、正確但又計算簡便之整合良率預估及缺陷樣式辨識之晶圓缺陷診斷系統,使 業界能有效地用其來做出正確的製程異常診斷。
1.2 研究目的
針對缺陷群聚現象,鑑於過去學者提出之良率預估模式各有其不完善之 處;再者,為滿足學界與業界對建構一個有效的晶圓缺陷樣式辨識系統的需求。 本研究的主要目的即是要發展一個整合良率預估及缺陷樣式辨識之晶圓缺陷診 斷系統。本研究利用一般迴歸神經網路(General Regression Neural Network, GRNN)來構建良率模式,並利用多類別支撐向量機(Multi-class Support Vector Machines, Multi-class SVM)來構建缺陷樣式辨識系統;最後再將前述兩者整合成 一個良率預估模式及缺陷樣式辨識之晶圓缺陷診斷系統。本研究以模擬之晶圓缺 陷實驗來說明本研究所提之晶圓缺陷診斷系統的可行性;並進一步與中外文獻所 提之良率預估模式與缺陷樣式辨識系統進行比較以驗證本研究的有效性。1.3 研究限制
本論文的研究限制如下: 1. 晶圓上每個缺陷皆會影響產品的良率。缺陷數愈多即表示製程異常的狀況愈 嚴重。 2. 不考慮缺陷的大小與型態,只針對晶圓上的總缺陷數分析其對良率的影響。 3. 當製程處於管制狀態時,缺陷應隨機分布於晶圓表面。當缺陷群聚程度愈大 或缺陷分布所呈現的特定樣式愈明顯時,即表示製程異常的狀況愈嚴重。1.4 研究架構
本論文共分為五個章節,第一章為緒論,說明本研究之背景與動機、研究 目的、研究限制以及研究架構;第二章為文獻探討,介紹積體電路良率模式、 一般迴歸神經網路、缺陷群聚指標以及缺陷樣式之辨識;第三章為研究方法, 介紹本研究之特徵因子的選取、本研究構建之良率模式、本研究構建之晶圓缺 陷數診斷系統以及整合良率預估及缺陷樣式辨識之晶圓缺陷診斷系統;第四章 說明如何以模擬實驗來驗證本研究所發展的整合良率預估及缺陷樣式辨識之晶 圓缺陷診斷系統的可行性;第五章為本論文的結論。第二章 文獻探討
本章介紹各種積體電路良率模式、一般迴歸神經網路、缺陷群聚指標以及 缺陷樣式辨識之相關文獻。2.1 積體電路良率模式
自 1960 年代開始就有學者提出各種不同的良率模式來預估良率[14]。只要 求得良率模式中之各項參數(例如,缺陷個數、缺陷密度、晶片面積...等等),便 能夠得到相對的預估良率。以下便對各種良率模式以及利用迴歸分析法與類神經 網路所構建之良率模式做一介紹。 2.1.1 卜瓦松良率模式 卜瓦松良率模式[18]是由卜瓦松機率函數發展而來。使用此模式預估良率時 必頇符合下面兩個基本假設:1.
缺陷必頇呈均勻且隨機性分布。2.
缺陷密度為一固定常數。 在此假設下,卜瓦松良率模式為: P k e Y ( 0) (1) 其中,k 表每個晶片上的缺陷數, 表每個晶片上的平均缺陷數。 由卜瓦松良率模式可知,只要求得每個晶片上的平均缺陷數0,便可得到 良率。因此,卜瓦松良率模式擁有計算方便之特性。一般工業之品質管制的應用 上,在處理缺陷資料時,通常均假設缺陷的分布為卜瓦松分配;即缺陷呈隨機分 布。然而目前已有廣泛的報告指出,在 IC 製程中晶圓表面所產生的缺陷有群聚 的傾向[40]。很明顯的,這種群聚現象的發生破壞了卜瓦松模式的前提假設。 Cunningham[14]指出,當晶片面積小於0.25平方公分時,卜瓦松良率模式既 簡單又精確。但隨著晶片面積的增大,缺陷出現群聚現象的機率增加,卜瓦松 良率模式出現低估良率的情形。因此在預測較大面積之晶片的良率時,目前業 界多採用負二項良率模式。 2.1.2 複合卜瓦松良率模式 卜瓦松良率模式的基本假設是缺陷密度為一固定常數。但 Murphy[29]認為缺陷密度在各晶片,甚至各晶圓之間並不相同。他主張必頇以一個呈現常態的機 率函數 f(D)來取代。因此 Murphy 所主張的良率模式如下: 0 ) (DdD f e Y DA (2) 其中, D 表缺陷密度,A表晶片面積, f(D)表缺陷機率密度函數。式子(2)稱為 複合卜瓦松良率模式(Compound Poisson Yield Model)。
Murphy 認為利用高斯(Gaussian)分配來估計 f(D)相當合理。但由於無法整 合表示式,所以利用式子(3)之 triangular form 來近似 f(D)。亦即 0 0 0 0 0 0 2 0 2 , 0 2 , ) 2 ( 1 0 , ) ( D D D D D D D D D D D D D f (3) 其中, D 表缺陷密度,D0表平均缺陷密度。將上式(3)代入式子(2),可得 Murphy 良率模式為: 2 0 ) 1 ( 0 A D e Y A D (4) 自 Murphy 提出缺陷密度的觀念以來,陸續有學者以不同的機率密度函數 ) (D f 來建構積體電路良率模式,其相關資料彙整於表 2.1 [14][34]。 2.1.3 負二項良率模式 由 Stapper[39]所提出的負二項良率模式是業界常採用的良率模式。Stapper 以 Gamma 函數來描述式子(2)中之缺陷機率密度函數 f(D)。亦即將式子(5)之 ) (D f 代入式子(2), ) ( ) ( 1 D eD D f (5) 得良率模式如下: ) / 1 ( 1 0A D Y (6) 其中,D0表每單位面積之平均缺陷數,A表晶片面積,表群聚參數。
表 2. 1 積體電路良率模式彙整表 模式名稱 良率模式 缺陷密度分配 提出學者及年代 Poisson YeD0A - 1960 Murphy (Poisson-Triangular mixture) 2 0 0 1 A D e Y A D Triangular Murphy 1964 Poisson-Uniform mixture A D e DA 0 2 2 1 0 Uniform Murphy Seeds (Poisson-Exponential mixture) D A Y 0 1 1 Exponential Seeds 1967 Negative Binomial (Poisson-Gamma mixture) ) / 1 ( 1 0A D Y Gamma Stapper 1973 Half-Gasussian (Poisson-Half-Gaussian mixture) ) 2 ( ] ) 4 / exp[( 0 2 / 1 2 0 A D erfc A D Y Half-Gasussian Stapper 1991
Poisson- Weibull mixture
0 0 / 1 1 / 1 ! 1 k k k k k k A D Weibull -
Poisson- Rayleigh mixture
2 10/2 0 0 exp[( ) / ] 1 erfc D A A D A D Y Rayleigh Raghavachari et al. 1996
Poisson-Inverse Gaussian mixture Y exp
112D0A/1/2
Inverse GaussianRaghavachari et al. 1996 負二項良率模式之群聚參數 可以下列式子表示,亦即 ) ( 2 2 (7) 其中,表每個晶片上的平均缺陷數,2表晶片上缺陷之變異數。藉由選擇不 同的值,Gunningham[14]模擬了一些學者所提出的良率模式。表 2.2 列出在不 同的值之下,負二項良率模式近似的良率模式以及群聚情形。 負二項良率模式對大晶片的良率預測效果好;目前的積體電路工廠多採用
負二項良率模式來預估良率。然而,當利用式子(7)來求 值時, 值會顯得過 於散亂,同時也可能為負值(2可能小於),這些都會造成分析良率時的不便。 表 2. 2 不同值之下,負二項良率模式近似之良率模式及群聚現象 值 近似之良率模式 群聚現象 大約 10 ~ 卜瓦松模式 無 4.2 Murphy 一些 3 Dingwall 一些 1 Seeds 很多 2.1.4 使用迴歸分析法構建之良率模式
Jun et al.[25]提出一個缺陷群聚指標(Cluster Index, CI )。CI 可以式子(8) 來計算。 } , min{ 2 2 2 2 w s v s CI v w (8) 其中, v 和 2 v s 是vi的樣本平均數與樣本變異數, w 和 2 w s 是wi的樣本平均數與樣 本變異數;而vi和wi是 x 軸和 y 軸上的一組缺陷區間(defect intervals)。vi和wi的 定義如下: n i x x vi (i) (i1), 1,2,, (9) n i y y wi (i) (i1), 1,2,, (10) 其中,x 和(i) y 是x軸和y軸上第i小的缺陷座標。Jun et al.證明當缺陷的分布呈現(i) 隨機性時,群聚指標 CI 值會接近1;但假如缺陷的分布呈現群聚現象時,群聚指 標 CI 值會大於1。 Jun et al.所構建之預測良率的迴歸模型如下: CI e YK 0 1 2 (11) 其中,是每一晶片上的平均缺陷數, K 、0、1以及2是迴歸模型欲估計的 未知參數, 為誤差項並假設服從於平均數為0以及變異數為2的常態分配。Jun et al.將模擬資料透過Box-Cox最佳化程序[9]來估計迴歸模型的四項未知參數 K 、0、1以及2。在估計出迴歸模型的四項未知參數後,就可得到樣本的迴 歸方程式,並進一步利用樣本的迴歸方程式來做預測。只要計算出晶圓的 CI 值
及值後,就可代入樣本的迴歸方程式來預測此晶圓的良率。 但利用迴歸模型來做預測時,必頇先假設一個明確的函數式。而此函數式 的適配度是值得考慮的。再者,資料是否違反迴歸分析的基本假設亦是個問題。 最後,若資料不能能夠適配出一合適的迴歸方程式時,又必頇將資料做進一步 的轉換來做分析,而這些都造成在做資料分析時不便。 2.1.5 類神經網路良率模式
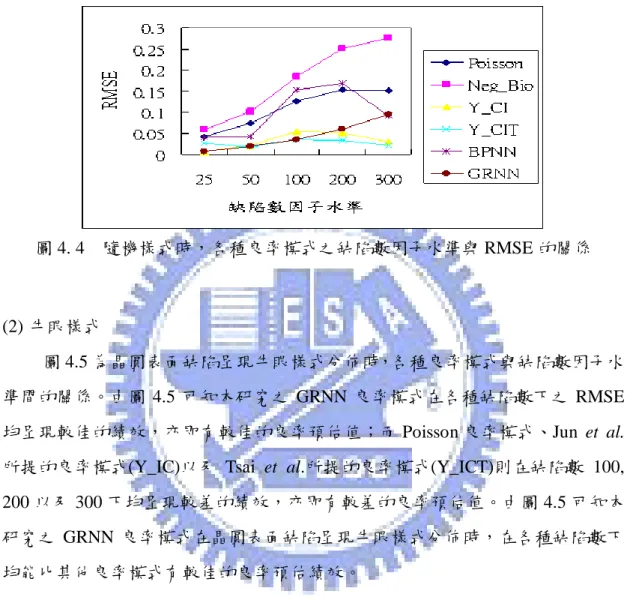
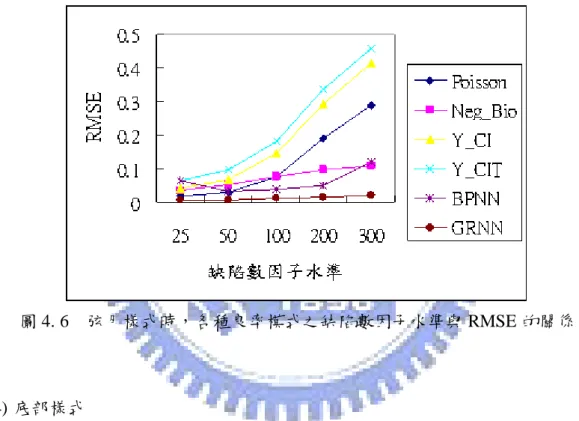
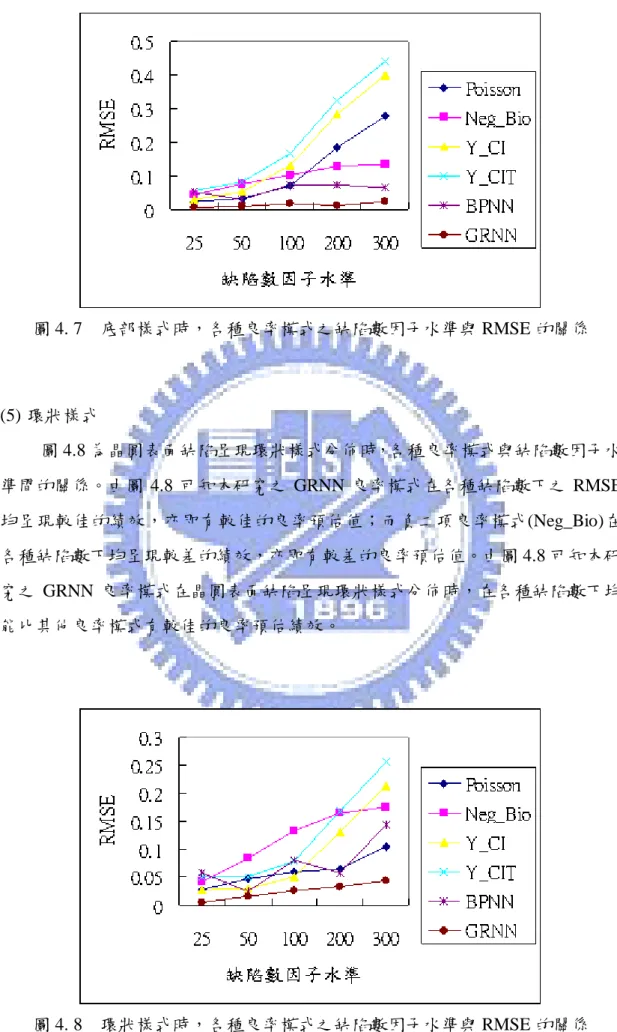
Tong et al.[42]以類神經網路的模糊自適應共振理論網路(Fuzzy ART)修正晶 圓上的缺陷群聚現象,直到缺陷分佈符合卜瓦松分配才停止,最後計算缺陷密 度,建立以卜瓦松分配為基礎的修正良率模式。此模式在預估良率上比卜瓦松 或負二項良率模式更為精確。但由於反覆地對每片晶圓進行群聚分類及測試工 作,仍有構建流程複雜之缺失。
李靜宜[1]以卜瓦松良率與Tong et al.[43]的一維轉軸群聚指標(CI )為輸R
入,利用倒傳遞網路(Back-Propagation Neural Network, BPNN)構建一個晶圓良率 預估模式。此模式能解決傳統卜瓦松良率模式未考慮到缺陷群聚的問題,且不 需複雜的統計模式即能精確的預測出晶圓的真實良率。但利用倒傳遞網路構建 之良率模式一般必需經由適度地設定許多網路參數(例如,學習速率、隱藏層數、 隱藏層單元數以及慣性項)才能得到較佳的預測結果。 Tsai et al.[44]考慮缺陷之夾角間距變異與距原點之距離間距變異而建構了 一缺陷群聚指標CI 來衡量晶圓上缺陷點的群聚程度;並將T CI 代入Jun et al.[25]T 所建構的良率模式來預估晶圓良率。藉由與Jun et al.所建構的CI 良率模式做比 較來驗證由CI 所建構的良率模式能精確地預估晶圓良率。但仍有與Jun et al.相T 同之迴歸模型適配度問題以及資料是否違反迴歸模型的基本假設都是值得考慮 的。 楊博欽[4]以缺陷總數與Tsai et al.[44]的群聚指標(CI )為輸入,應用自組性T
演算法(Group Method of Data Handling, GMDH)構建一個晶圓良率模式。此模式 不需要任何統計假設,且可以構建出一個預測良率的數學方程式,實用價值甚 高。而在良率預測上也較業界常用的負二項良率模式和利用倒傳遞網路構建之 良率模式更為精確。但楊博欽所構建出的良率模式其數學方程式仍有太過冗長 的缺失。
2.2 一般迴歸神經網路
一般迴歸神經網路(General Regression Neural Network, GRNN)是 Specht [36] 於 1991 年所提出。GRNN 克服了機率神經網路(Probabilistic Neural Network, PNN)[5]只能處理分類的問題,不但能處理分類的問題,亦具有處理連續變數的 能力。GRNN 屬於監督式學習網路,因而適合預測、診斷等應用。 2.2.1 GRNN 網路架構 GRNN 是一個三層的網路,其網路架構如圖 2-1 所示,包括: (1) 輸入層:第一層為輸入層。輸入層的輸入單元(input unit)只負責分配變數給第 二層樣式層的樣式單元(pattern unit)。當有新的向量變數 X 進入網路後,此新 變數會減去原先內部儲存的訓練範例;然後將差量的平方值加總當成樣式層 單元的淨輸入。 (2) 樣式層(隱藏層):第二層為樣式層。樣式層由訓練樣式(training pattern)的各個 樣式所組成。樣式層單元的輸出使用非線性的轉換函數,一般為指數函數。 樣式層單元的淨輸入經由非線性的轉換函數後可得樣式層單元的輸出值。該 輸出值接著會被傳送到總和單元(summation unit)。 (3) 輸出層:第三層為輸出層。總和單元加總來自於樣式層單元的加權後輸出值 以形成第一項總和單元輸出值;同時總和單元加總來自於樣式層單元的加權 後輸出值與其所對應觀測值 Y 的乘積而形成第二項總和單元輸出值。輸出層 單元的輸出值即為第二項總和單元輸出值除以第一項總和單元輸出值,而此 亦為所對應觀測值 Y 的估計值。 圖 2. 1 GRNN 的網路架構
2.2.2 GRNN 網路基本原理
GRNN 與傳統的迴歸模式必頇先假設一個明確的函數式不同。GRNN 可利 用一個連續型的聯合機率密度函數(joint probability density function)來描述。假設
) , ( y f x 代表一已知的連續型聯合機率密度函數,其中 x 為一向量隨機變數,y 為 一隨機變數。令 X 為向量隨機變數 x 的某特定觀測值,則在 x=X 的條件下,y 的條件期望值(也可稱為 y 在 X 上的迴歸)可表示如下:
dy y f dy y yf y E ) , ( ) , ( | X X X x (12) 當 f x( ,y)未知時,可以觀測值(x, y)來估計。GRNN 利用無母數方法 Parzen[32] window 的方式來估計 f x( ,y)。其估計量f x( ,y) 可表示如下:
2 2 1 2 ) 1 ( 2 / ) 1 ( 2 ) ( exp 2 ) ( ) ( exp 1 ) 2 ( 1 ) , ( i n i i T i p p y y n = y f x x x x x (13) 其中 p 是 x 的維度,σ 是平滑因子參數, i x 和 i y 是一些樣本觀測值(x, y),n 是 樣本數。將式子(13)代入式子(12)可得式子(14)。
n i i i T i n i i i T i dy y y dy y y y Y y E 1 2 2 2 1 2 2 2 2 ) ( exp 2 ) ( ) ( exp 2 ) ( exp 2 ) ( ) ( exp ) ( ) | ( x X x X x X x X X X (14) 式子(14)可進一步簡化如下:
n i i n i i i D D y Y 1 2 2 1 2 2 2 exp 2 exp ) ( X (15) 其中,Di2 (Xxi)T(Xxi)。 GRNN 即是以式子(15)來求得觀測值 y 的估計值。 一般 GRNN 以指數分配為轉換函數,其轉換函數可表示如下: 22 2 2 exp ) ( i i D D f(16) 當一個新的向量變數 X 進入網路後,會減去原先內部儲存的訓練範例;然後將 差量的平方值加總當成樣式層單元的淨輸入。而樣式層單元的淨輸入經由式子
(16)之轉換函數後可得樣式層單元的輸出值。該輸出值接著會被傳送到總和單 元。總和單元加總來自於樣式層單元的加權後輸出值以形成第一項總和單元輸出 值,第一項總和單元輸出值可表示如下:
n i i D 1 2 2 2 exp (17) 。另一方面,總和單元加總來自於樣式層單元的加權後輸出值與其所對應觀測值 i y 的乘積而形成第二項總和單元輸出值。第二項總和單元輸出值可表示如下:
n i i i D y 1 2 2 2 exp (18) 。輸出層單元的輸出值即為第二項總和單元輸出值除以第一項總和單元輸出值, 此同於式子(15)所示的對應觀測值 y 之估計值。一般類神經網路的績效可以誤差項的均方根 (root-mean squared error, RMSE)來衡量。RMSE 可以式子(19)來求得。 n O A RMSE n i i i
1 2 ) ((19) 其中,n 表示訓練樣式的個數,Ai表示實際的輸出值,Oi表示實際輸出值的預測 值。本研究亦以 RMSE 來衡量各模式預測的績效。 2.2.3 GRNN 的優點 GRNN 有以下的優點: (1) GRNN 的網路學習過程為一次學習。因此它主要的優點是網路能夠快速的學 習 , 而 且 不 需 擔 心 類 似 BPNN[5][17] 過 度 訓 練 (overtraining) 或 訓 練 不 足 (undertraining)的問題。 (2) 針對稀疏資料(sparse data),當樣本數很大時,GRNN 亦能夠快速收斂到一個 最佳的迴歸面。 (3) 不像 BPNN 必需設定許多網路參數。例如,隱藏層數、隱藏層單元數、學習 速率(learning rate)以及慣性項(momentum)。GRNN 唯一要設定的參數是平滑 因子(smoothing factor) 值。如此便減少了類神經網路所為人詬病的參數設定 問題。 (4) GRNN 並不是利用最陡坡降法(gradient descent)來得到最佳解,因此減少了像
BPNN 可能只尋找到區域最佳解(local optimal)的機會。 因為 GRNN 有上述的優點,因此本研究利用 GRNN 來建構晶圓的良率預估 模式。
2.3 缺陷群聚指標
晶圓表面上缺陷群聚的嚴重程度可利用群聚指標來描述。目前較常用來衡 量缺陷群聚程度的群聚指標有負二項良率模式的 群聚參數、空間統計學的 M V 群聚指標以及無統計假設之缺陷群聚指標(Cluster Index, CI ),以下將分別 說明這些缺陷群聚指標以及一些國內文獻所提出的缺陷群聚指標。 2.3.1 負二項良率模式的群聚參數Stapper[39]以 Gamma 函數來描述 Murphy[29]良率模式中之缺陷機率密度函 數所得的負二項良率模式如式子(6)所示。其中,負二項良率模式之群聚參數 可 表示如下: ) ( 2 2 其中,表每個晶片上的平均缺陷數,2表晶片上缺陷之變異數。當利用上式 求值時,值會顯得過於散亂,同時也可能為負值(2可能小於 ),這些都會 造成分析良率時的不便。因此,Cunningham[14]建議以式子(20)來計算值。 ) ( 1 1 ) ( 2 2 avg avg (20) 其中,avg表平均每片晶圓上之每個晶片上的缺陷密度。 2.3.2 空間統計學之缺陷群聚指標 Tyagi與Bayoumi [45][46]應用空間統計學中之方格法來衡量晶圓上缺陷的 群聚現象。方格法是將所研究的區域(在本研究中即為晶圓的表面)劃分成若 干個面積相同的方塊,稱為方格(此處的「方格」在本研究中即為晶片),接著計 算出每一方塊內包含的「點」數(此處的「點」在本研究中即為缺陷)。最後經由 分析便可得知所研究區域內的「點」是呈現隨機分布或者有群聚現象的發生。 如果晶圓上缺陷呈現隨機分布,則表示其遵守卜瓦松分配。由於卜瓦松分配的 變異數等於平均數,亦即變異數與平均數的比值(Variance-Mean Ratio, V M )會 等於1;當點出現群聚現象時,則V M 值會大於1。此指標的缺點是在相同的點
分布下,可能會因方格選取的方法、形狀及大小的不同,而使得V M 值有相當
大的差異;再者,隨著晶圓缺陷密度的遞增,V M 值並沒有呈規則性遞增的特
性[45][46]。
2.3.3 無統計假設之缺陷群聚指標
Jun et al.[25]提出一個缺陷群聚指標(Cluster Index, CI )。群聚指標CI 的計 算方法是將一片晶圓上的n個缺陷的空間座標分別投影到X軸和Y軸上,如圖2.2 所示。由圖2.2可得知,投影後在X軸和Y軸上的座標點同時出現群聚現象才表示 該晶圓之缺陷具有群聚現象,如(d)所示;若投影後僅在Y軸或X軸上的座標點出 現群聚現象,如(b)、(c)所示;亦或投影後不出現群聚現象,如(a)所示;此兩者 之晶圓上的缺陷均不具群聚現象。 CI 可以下式表之: } , min{ 2 2 2 2 w s v s CI v w 其中, v 和 2 v s 是vi的樣本平均數與樣本變異數, w 和 2 w s 是wi的樣本平均數與樣 本變異數;vi和wi是 x 軸和 y 軸上的一組缺陷區間(defect intervals)。vi和wi的定 義如下: n i x x vi (i) (i1), 1,2,, n i y y wi (i) (i1), 1,2,, 其中,x 和(i) y 是x軸和y軸上第i小的缺陷座標。Jun et al. 證明當缺陷的分布呈(i) 現隨機性時,群聚指標 CI 值會接近1;但假如缺陷的分布呈現群聚現象時,群聚 指標 CI 值會大於1。Jun et al.透過模擬實驗得到群聚參數α值和群聚指標 CI 值之 間的相對關係,如表2.3所示。 值愈小代表群聚程度愈嚴重,而CI 值愈大代表 群聚程度愈嚴重;與 值相較, CI 值有較均勻的數值範圍來量化不同嚴重程度 的群聚現象,這是 CI 指標優於 指標的地方。然而經由模擬驗證發現,CI 指標 針對某些不同之缺陷分佈樣式,其群聚指標 CI 值卻相同[7]。因此 CI 指標針對 某些缺陷分佈樣式會有誤判的現象。
圖 2. 2 缺陷分布圖與兩軸的投影 表 2. 3 值與 CI 值之比較[25] 群聚現象 負二項良率模式的 群聚指標 無統計假設的 群聚指標 CI 無 10 或以上 0.85-1.00 些微 4.2 1.00-1.10 中等 3 1.10-1.25 嚴重 1 1.25-2.70 2.3.4 其他缺陷群聚指標 Tong et al.[43]將晶圓上的缺陷之二維座標投影至一維座標軸上。利用一維 轉軸的方法,對所有的缺陷在某特定角度的一維轉軸上做投影;並藉由計算在 該特定角度之軸上點的間距之變異係數的平方而得到一個指標值。然後改變轉 軸角度以計算出180個不同轉軸角度下的指標值。最後,計算這180個指標值的 平均值,即為一維轉軸群聚指標CI 。經由模擬與實際晶圓資料的驗證,R CI 指R 標確實較 CI 指標能更有效地偵測出不同的缺陷群聚程度。但CI 指標仍有無法R 辨別環狀樣式之缺陷分佈型態的缺失[7]。 許志瑋[3]利用各個缺陷與X軸第一象限之正值夾角的變異係數,以及各個 缺陷到座標原點之長度的變異係數,求得此兩變異係數的比值而定義一環狀群 聚指標。環狀群聚指標雖可補CI 指標無法辨認環狀缺陷群聚現象的缺失;然而R 環狀群聚指標只能偵測出環狀的缺陷群聚現象。若只看環狀群聚指標值將無法 判斷晶圓上缺陷的群聚程度。 Tsai et al.[44]利用各缺陷與X軸第一象限正值夾角之間距的變異係數平 方,以及各缺陷距原點座標距離之間距的變異係數平方,求得此兩變異係數平
方的最大值而發展出一缺陷群聚指標CI 。T CI 群聚指標值越大,代表群聚的現T 象越嚴重。CI 能以均勻的數值範圍來量化不同嚴重程度的群聚現象,更能偵測T 出環狀的缺陷群聚現象。
2.4 缺陷樣式之辨識
針對晶圓缺陷樣式辨識的方法,相關研究主要從統計分析法、啟發式演算 法以及人工智慧學習的觀點來分析[31]。統計分析法是假設落於晶圓上的缺陷符 合某種機率分配,進而以此分配的特性來進行資料點的群聚現象分析[23]。統計 分析法的目的在於如何將空間上的資料點進行切割,以達到樣式分類辨識的目 的。啟發式演算法是加入個人的專業知識來設定較佳的參數及演算程序,通常利 用柔性計算的方法(例如,基因演算法與模糊理論)來進行樣式辨識。然而基因演 算法一般必頇付出相當多的努力於適配函數與較佳解的選取評估過程上才能達 到最佳解 [7]。而模糊理論的主要限制之一乃是其語意控制規則相當難產生;再 者,必頇借重一些專家的知識與經驗才能設計出一完善的模糊邏輯控制器 [12]。人工智慧學習是以訓練樣本來建立網路模型,並以測試樣本來檢測所建之 網路模型的穩健性。類神經網路即人工智慧學習中一項常用的技術。以類神經網 路技術來做樣式辨識時,雖具有容錯能力的優點,但類神經網路技術的主要限制 之一乃是其各項網路參數必頇適度的設定才能得到較佳的結果 [19]。再者,所 選取的樣本需足夠且具代表性則是利用類神經網路技術的關鍵成功因素。 針對晶圓缺陷樣式辨識的方法,已有許多以類神經網路技術的辨識工具被 發展出來。其中,倒傳遞網路(Back-Propagation Neural Network, BPNN)是最具代 表性且應用最普遍的網路模式[5]。再者,徑向基底函數(Radial Basis Function, RBF)神經網路是一個較新穎但較少被應用的技術,而且能夠避免網路模式訓練 時間的冗長,以及增加網路學習的效率,並且已經成功的被應用在許多不同的領 域中[5][16]。基於此,本研究利用 BPNN 與 RBF 神經網路所建構之分類模式與 本研究所提之多類別 SVM 分類模式做晶圓缺陷樣式辨識準確率的比較。下面介 紹 BPNN、RBF 神經網路以及 SVM。2.4.1 倒傳遞網路(Back-Propagation Neural Network, BPNN) [5][17]
(1) 輸入層:輸入層單元被用來表示網路的輸入變數,輸入變數的數目依問題而 定,且輸入層單元使用線性轉換函數。
(2) 隱藏層:隱藏層單元被用來表現與輸入層單元間的交互影響,隱藏層單元的 數目通常以試誤法(trial and error)來決定。隱藏層單元使用非線性轉換函數, 而最常使用的非線性轉換函數為雙彎曲函數(binary sigmoid function),且可表 示如下: ) 1 ( 1 ) ( x e x f (21) (3) 輸出層:輸出層單元為網路輸出變數之表現。BPNN 利用網路輸出值與實際 輸出目標值間的誤差,以回饋方式來調整網路加權值直到最佳狀態為止。輸 出層單元的數目是依問題而定,並且使用非線性轉換函數。 BPNN 網路的計算過程分為前向(forward)與後向(backward)兩個階段。首先 輸入層單元接收到輸入的樣本資料後直接將它傳給隱藏層單元;隱藏層單元會將 加權後的資料加總並透過轉換函數而得隱藏層單元的輸出值;此輸出值進一步被 傳給輸出層單元。輸出層單元再以同樣的方法得到最終的網路輸出值,此階段為 網路的前向階段。而網路在比較網路輸出值與實際輸出目標值的差量值後,利用 此差量值再倒回去進行權重的調整,此為網路的後向階段。 圖 2. 3 BPNN 之網路架構 根據上述網路的計算過程,BPNN 網路演算法可描述如下: 步驟一:在某特定的範圍內將所有的權重值初始化成一個極小的隨機數值。 步驟二:以隨機方式選取一組訓練樣式(xp, tp),再利用前向階段方式計算各
層處理單元所對應的輸出值,並表示如下:
i q ji q i q j f O w O ( 1 ) q = 1, 2, .., Q (22) 其中,xp,表示第 p 個訓練樣式的輸入向量,tp表示第 p 個訓練樣式的目標向量, q j O 表示第 q 層之第 j 個處理單元的輸出,f 表示非線性轉換函數,且第一層的輸 入可表示如下: j j x O0 (23) 步驟三:利用網路最後一層(輸出層)之處理單元的輸出值 Q j O 與其所對應的 實際輸出目標值 tj 來計算輸出層各處理單元的差量值,此差量值如下: ) )( ( ' 1 j Q j Q j Q j f H O t (24) 其中, Q j 表示輸出層(第 Q 層)之第 j 個處理單元的差量值, Q1 j H 表示第(Q-1) 層之第 j 個處理單元的輸出值。 步驟四:利用步驟三所計算之輸出層各處理單元的差量值來計算前一層隱 藏層之各處理單元的差量值,此差量值如下: q ij j q j q j q j f H
w 1 '( 1) q = Q, Q-1,…, 2。 (25) 其中, q1 j 表示隱藏層(第 q-1 層)之第 j 個處理單元的差量值, q ij w 表示第 q 層之 第 j 個處理單元與其前一層之第 i 個處理單元間的權重值。 步驟五:利用步驟三與步驟四所計算之各輸出層與隱藏層處理單元的差量 值來調整輸出層與隱藏層處理單元間的權重值,此權重值之計算如下: q ij old ij new ij w w w q = Q, Q-1,…, 2。 (26) 其中, q ij w 表示第 q 層之第 j 個處理單元與其前一層之第 i 個處理單元間的權重 變化值,且可表示如下: q j q i q ij O w 1 q = Q, Q-1,…, 2。 (27) 其中,表示學習速率。 步驟六:重複步驟二到步驟五直到誤差值之總和達到一可接受的水準為止。2.4.2 徑向基底函數(Radial Basis Function,RBF)神經網路
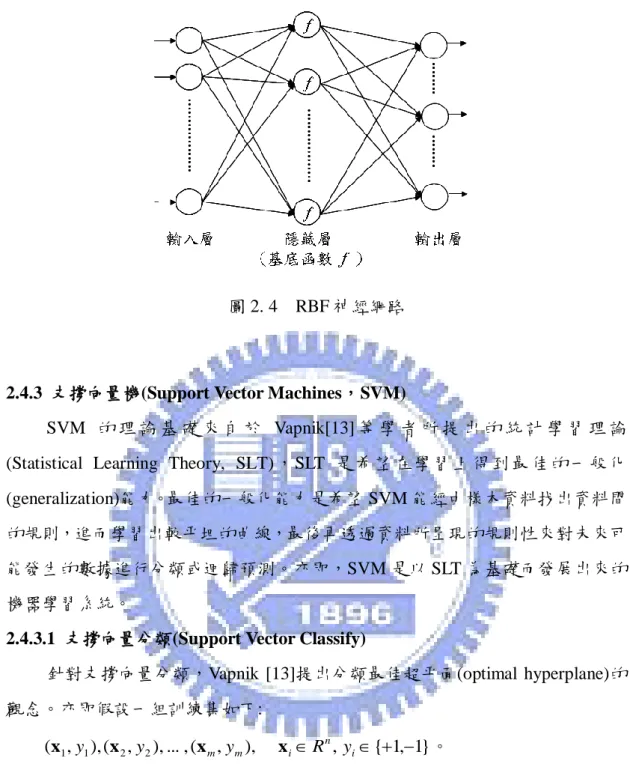
RBF神經網路[5][16]是監督式學習(supervised learning)網路模式的一種。 RBF神經網路之結構包含三層:輸入層(input layer)、隱藏層(hidden layer)及輸出
層(output layer),如圖2.4所示。網路的層與層之間有連接鍵以順向(forward)方式 相互連接,且各連接鍵皆含有一個權重值來代表輸入訊息的重要程度。在輸入層 部分,神經元的數目即為所欲輸入的變數個數;在隱藏層部分,隱藏層數目固定 為一層且一般以試誤法來求得神經元的最佳數目;在輸出層部分,神經元的數目 即為所欲輸出的變數個數。RBF的學習可分為兩個階段:第一階段為非監督式學 習,第二階段為監督式學習。在第一階段會先計算出訓練樣本與各個隱藏層結點 中心的距離,並以擁有最小距離的結點做為該訓練樣本所歸屬的隱藏層結點,進 而達成將訓練樣本聚類到隱藏層結點的目的。第二階段主要的目的是將隱藏層結 點的輸出值進行線性轉換,進而產生輸出層結點的輸出值,藉此達成將訓練樣本 對應到所屬輸出值的目的。 RBF神經網路之隱藏層結點被稱為kernel,並使用一組被稱為基底函數(basis function)的鐘型對稱函數作為轉換函數。最常被使用的基底函數為高斯核函數 (Gaussian kernel function),其基本型式可表示如下:
N j h j j p T j p j ] 1,2, 2 ) ( ) ( exp[ c x c x (28) 其中,h 為第j個隱藏層結點之輸出值,j x 為輸入向量,p c 為第j個隱藏層結點的j 中心,j則為第j個隱藏層結點的平滑參數(smoothing parameter),N代表隱藏層 結點的個數。由於高斯核函數的鐘型對稱特性,因此當輸入向量越靠近隱藏層結 點的中心時,經高斯核函數轉換出來的值就愈大;反之則愈小。而隱藏層結點的 平滑參數 乃用來表示在歸屬於該隱藏層結點訓練樣本的分散狀況。
RBF神經網路之輸出層結點使用通用差距法則(general delta rule)[5]來調整 連接鍵的權重值,進而求得輸出層結點的輸出值ok。ok可表示如下:
N j j jk k w h o 1 ) ( (29) 其中,ok為第k個輸出層結點的輸出值,w 為第j個隱藏層結點與第k個輸出層結jk 點的連接鍵權重值,h 為第j個隱藏層結點之輸出值,N代表隱藏層結點的個數。j 由式子(29)可知,輸出層結點的輸出值是由隱藏層與輸出層之間的連接鍵權重值 與隱藏層結點之輸出值進行線性組合而得,並非透過非線性的轉換函數而得。圖 2. 4 RBF 神經網路
2.4.3 支撐向量機(Support Vector Machines,SVM)
SVM 的 理 論 基 礎 來 自 於 Vapnik[13] 等 學 者 所 提 出 的 統 計 學 習 理 論 (Statistical Learning Theory, SLT),SLT 是 希望在 學習 上得 到最 佳的 一般化 (generalization)能力。最佳的一般化能力是希望 SVM 能經由樣本資料找出資料間 的規則,進而學習出較平坦的曲線,最後再透過資料所呈現的規則性來對未來可 能發生的數據進行分類或迴歸預測。亦即,SVM 是以 SLT 為基礎而發展出來的 機器學習系統。
2.4.3.1 支撐向量分類(Support Vector Classify)
針對支撐向量分類,Vapnik [13]提出分類最佳超平面(optimal hyperplane)的 觀念。亦即假設一組訓練集如下: } 1 , 1 { , ), , ( , ... ), , ( ), , (x1 y1 x2 y2 xm ym xiRn yi 。 此訓練集可被一個超平面區分成兩類。而超平面方程式可用兩個向量內積(dot product)的方式來呈現,如下所示: < w, x > + b = 0 (30) 其中,< , >為內積運算符號;w 為一組與訓練樣式向量 x 對應的權重向量;b 為 一門閥值(threshold)。若一個超平面能正確地分類一組訓練集,並且擁有離超平 面最近的向量xi距離此超平面間的距離最大的特性者,即為分類該組訓練集之最 佳超平面,如圖 2.5 所示。
圖 2. 5 最佳超平面[35] 由圖 2.5 可知,將 w 與 b 在尺度上做適度的調整可使得距離超平面最近的 訓練向量 x1與 x2滿足下列式子: 1 , 1 w x b (31) 1 , 2 w x b (32) 由式子(31)與(32)可得下式: || || 2 ) ( , || ||w x1 x2 w w (33) 其中,|| w 為權重向量 w 的長度。由式子(33)可得知,離最佳超平面最近的向量|| 與此超平面之間的距離為 || || 1 w ,一般稱為差數(margin)。為了求得最佳超平面(即 最大化差數),可藉由解下列二次規劃問題來達成。 , 2 1 ) ( . w w 2 Min (34) m i b y t s.. i(xi,w )1, 1,, (35) 此二次規劃問題可藉由解其對偶問題(dual problem)所形成的 Lagrangian 目標式 來達成。其中,Lagrangian 目標式如下所示: ), 1 ) , ( ( 2 1 ) , , ( 1 2
m αi yi i b b L w w x w (36) 其中,αi為 Lagrange 乘數(Lagrange multipliers)且αi 0。為最大化 Lagrangian目標式,可將式子(36)分別對 w 與 b 做偏微分進而推導得到下列式子:
m αiyi 1 , 0 (37) , 1
m α xiyi i w (38) 由式子(38)可知最佳超平面的向量解 w 可由該組訓練集展開而得。其中,擁有 0 i α 的訓練樣式向量xi即稱為支撐向量。將式子(37)與式子(38)代入式子(36)可 得對偶問題的最大化目標函式以及限制式如下: , , 2 1 ) ( . 1 , 1
i j m j i j i j i m i i y y W Max α x x (39) m i t s.. i 0, 1,, (40)
m αiyi 1 , 0 (41) 一旦求得目標函式的最佳解i,即可求得最佳超平面。而最佳超平面的決策函數 可表示如下: b y α x f m i i i
x ,x ) ( 1 (42) 若進一步考量訓練範例違反式子(35)的可能性,則可加入寬鬆變數(slack variable, i 0)來放寬限制式,並藉由解下列二次規劃問題來求得最佳超平面。 , 2 1 ) , ( . 1 2
m i i C Min w ξ w (43) m i b y t s.. i(xi,w )1i , 1,, (44) 0 i (45) 其中,C 為大於零的常數,且被稱為誤差項的懲罰參數;C 決定最大化差數(margin) 與最小化訓練誤差間的取捨。 2.4.3.2 核函數(Kernel Function) 前一小節所介紹的支撐向量分類是利用SVM的概念來解決線性分類問題。 然而,有些分類問題並非屬於線性可分問題,此時就必頇利用核函數將訓練樣式 向量x映射到一個高維度的特徵空間(feature space)中,於特徵空間建構最佳超平 面並將問題做線性的分類。目前常用的核函數為多項式(polynomial)核函數、徑向基底(radial basis)核函數以及類神經網路(neural network)核函數[26],如下所示: (1)多項式核函數:K(x,xi)x,xi d, (46) 其中,d 表示多項式的次方。 (2)徑向基底核函數:K(x,xi)exp( ||xxi||2), (47) 其中, 為參數且 0。 (3)類神經網路核函數:K(x,xi)tanh( x,xi ), (48) 其中,為參數且 0;為水平位移且R。 選擇適當的核函數K(x,xi)即可在特徵空間中訓練 SVM,並且求得最佳超 平面的決策函數,如下所示: b K y α x f i m i i
( , ) ) ( 1 x x (49) 針對核函數,通常無法以自動的方式來選取並調整其對應的參數。因此必 頇嘗試不同的核函數,並調整其對應的參數來得到最佳的結果。針對非線性問 題,由於透過徑向基底核函數轉換所得的實驗結果很好。因此,非線性徑向基底 核函數是最常被使用的核函數[26];本研究亦以徑向基底核函數為 SVM 的核函 數。當使用徑向基底核函數的 SVM 技術來做分類時,懲罰參數 C 與參數 為最 重要的參數。利用格子搜尋(grid search)法可於交叉驗證(cross validation)中選取最 佳的(C, )參數組合,再將此參數組合用於訓練與測試資料中來得到最佳的結果 [11]。 2.4.4 多類別支撐向量分類 至目前為止所介紹的SVM是用於處理兩類別的分類問題。但許多實際問題上 所需處理的是多類別的分類問題。由於本研究乃藉由多類別SVM來進行多類別 晶圓缺陷樣式的分類,在此即介紹幾種多類別支撐向量分類法。2.4.4.1 一對多(One Versus the Rest)分類法
一對多分類法[8]在處理類別問題時,會產生m個兩類別的SVM,其中第i個 SVM的產生方式,是給定第i類資料的標註為{+1},而其他類別的所有資料的標 註則為{-1}。解一對多分類法之最佳化問題後可得到m個決策函數。而未知類別 資料x則被歸於具有最大決策函數值之類別。
一對一分類法[27]在處理m類別問題時,每兩類資料都會產生一個SVM。解 一對一分類法之最佳化問題後可得到 2 ) 1 (m m 個決策函數。而在決定未知類別資 料x時,一對一分類法採用投票(vote)策略[35]。最後將未知類別資料x歸於得票數 最高的類別;但若發生兩類別票數相等時,則任意選擇其中一類別為最後結果。
2.4.4.3 DAG(Directed Acyclic Graph)分類法
DAG分類法是學者Taylor所提出[33]。此方法在訓練階段與一對一分類法相 同。不同處在於測試階段,DAG分類法建立一個二元且無循環的有向圖來做分 類;其中包含 2 ) 1 (m m
個內部節點(internal node)和m個葉節點(leaf node),如圖2.6 所示。每一個內部節點都表示一個SVM,m個葉節點表示類別。而未知類別資料
x乃由根節點(root node)開始測試,再依據該SVM來決定下一層應歸於左邊或右
邊的內部節點,而最後到達的葉節點就是x的類別。
2.4.4.4 一次(Considering all Data at a Once)分類法
Vapnik[47]認為處理多類別的分類問題時,可將問題合併成單一的最佳化問 題而一次求解,不用處理多個最佳化問題。一次分類法在處理m個類別資料時, 會產生m個決策函數。其中第i個決策函數,可以區分類別為i的資料和其它所有 類別的資料。然而決策函數並非由m個最佳化問題各別求得,而是結合成一個最 佳化問題一次求解。在決定未知類別資料x時,一次分類法利用決策函數產生m 個值,x則被歸於具有最大決策函數值之類別。 由於一對一分類法的訓練時間較短[22],所以本研究所採用之多類別SVM 是利用一對一分類法的方式來進行多類別晶圓缺陷樣式的分類。 圖 2. 6 DAG 分類法處理 3 類別的分類
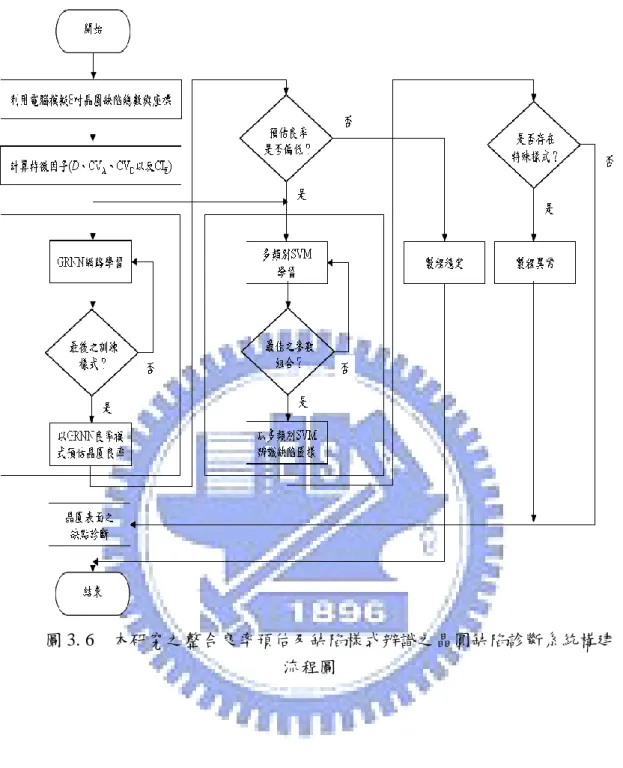
第三章 研究方法
本研究之主要目的是要發展一個整合良率預估及缺陷樣式辨識之晶圓缺陷 診斷系統。本研究利用一般迴歸神經網路(GRNN)來構建良率模式,並利用多類 別支撐向量機(Multi-class SVM)來構建缺陷樣式辨識系統;最後整合成一個良率 預估模式及缺陷樣式辨識之晶圓缺陷診斷系統。本研究以模擬之晶圓缺陷實驗 來說明本研究所提之整合良率預估及缺陷樣式辨識之晶圓缺陷診斷系統的可行 性;並進一步與中外文獻所提之良率預估模式與缺陷樣式辨識系統做比較以驗 證本研究的有效性與優越性。 本章共分為四小節,第一小節介紹本研究之特徵因子的選取,第二小節介 紹本研究構建之良率預估模式,第三小節介紹本研究構建之晶圓缺點樣式辨識 系統,第四小節介紹本研究構建之整合良率預估及缺陷樣式辨識之晶圓缺陷診 斷系統。3.1 本研究之特徵因子的選取
由於本研究是要發展一個整合良率預估及缺陷樣式辨識之晶圓缺陷診斷系 統。因此,當一片晶圓出現中、低良率時,應進一步診斷該晶圓表面的缺陷是否 存在某種特定的缺陷樣式。為利用 GRNN 來構建良率模式,並利用多類別 SVM 來構建缺陷樣式辨識系統,本研究乃以對晶圓良率有所影響的因素做為本研究之 特徵因子。 一般的良率模式為單位面積的缺陷密度與晶片面積的函數[14],其公式可表 示如下: ) , , (D AK f Y (50) 其中,D 表示單位面積的缺陷密度,A表示晶片面積,K 為晶片面積A的修正因 子。由式子(50)可知,單位面積的缺陷密度 D 為影響良率的因子之一,同時可以 用來描述晶圓上缺陷的群聚程度。因此,本研究擷取單位面積的缺陷密度 D 做為 本研究之特徵因子。 此外,本研究利用各個缺陷與 X 軸第一象限正值夾角的變異 CVA,以及各 個缺陷距原點座標距離的變異 CVD做為本研究之特徵因子,圖 3.1 為上述夾角與距離的示意圖。其中 CVA與 CVD的公式推導如下: 步驟一:計算晶圓上各缺陷座標與第一象限的 X 軸所成的正值夾角i,且公式 可表示如下: i i i X Y 1 tan ,i =1,2,…,n
(51) 其中,Xi為第 i 個缺陷的 X 軸座標,Yi為第 i 個缺陷的 Y 軸座標。再將i做遞 增排序後可得(i)。(i)表示排序後第 i 小的夾角,而夾角的間距Ai可表示如下: ) 1 ( ) ( i i i A ,i =1,2,…,n (52) 其中(0)為 0。 步驟二:計算晶圓上各缺陷座標到原點的距離Li,且公式可表示如下: 2 2 i i i X Y L ,i =1,2,…,n (53) 其中,Xi為第 i 個缺陷的 X 軸座標,Yi為第 i 個缺陷的 Y 軸座標。再將Li做遞 增排序後可得L 。(i) L 表示排序後第 i 小的距離,而距離的間距(i) Di可表示如下: ) 1 ( ) ( i i i L L D ,i =1,2,…,n
(54) 其中L(0)為 0。 步驟三:計算 CVA與 CVD,且公式如下所示: A S CV A A (55) D S CV D D (56) 其中, A 和SA表示Ai的樣本平均數與樣本標準差; D 和SD表示Di的樣本平均 數與樣本標準差。 當缺陷分佈呈現隨機分佈時,不論是夾角的間距或是距離的間距都會比較 一致,也就是說間距的變異會較小;當缺陷分佈有群聚現象時,不論是何種群聚 樣式都會造成至少一種間距的變異會增大。因此只要其中一種間距的變異大,便 認為此晶圓的缺陷呈現群聚現象。由此可知,夾角的變異 CVA與距離的變異 CVD 皆能反應缺陷的群聚現象,並進而可能影響晶圓良率。基於此,本研究擷取各個 缺陷與 X 軸第一象限正值夾角的變異 CVA,以及各個缺陷距原點座標距離的變
異 CVD做為本研究之特徵因子。 圖 3. 1 夾角與距離示意圖 最後,本研究提出一個新的指標來描述缺陷的群聚現象,並做為本研究之 特徵因子。以下即說明本研究所發展之群聚指標的建立過程及其優點。 本研究利用晶圖上缺陷的群聚分佈情形發展出新的缺陷點群聚指標 CIE。 CIE的計算公式如下:

![圖 2. 2 缺陷分布圖與兩軸的投影 表 2. 3 值與 CI 值之比較[25] 群聚現象 負二項良率模式的 群聚指標 無統計假設的 群聚指標 CI 無 10 或以上 0.85-1.00 些微 4.2 1.00-1.10 中等 3 1.10-1.25 嚴重 1 1.25-2.70 2.3.4 其他缺陷群聚指標 Tong et al.[43]將晶圓上的缺陷之二維座標投影至一維座標軸上。利用一維 轉軸的方法,對所有的缺陷在某特定角度的一維轉軸上](https://thumb-ap.123doks.com/thumbv2/9libinfo/8502981.185352/25.892.126.763.182.846/無統計假設群聚指標或以上缺陷至一維座標軸上利用一維轉軸.webp)
![圖 2. 5 最佳超平面[35] 由圖 2.5 可知,將 w 與 b 在尺度上做適度的調整可使得距離超平面最近的 訓練向量 x 1 與 x 2 滿足下列式子: 1, 1 wxb (31) 1, 2 wxb](https://thumb-ap.123doks.com/thumbv2/9libinfo/8502981.185352/31.892.135.758.103.855/最佳超可知將調整平面最近訓練向量滿足.webp)