DOI:10.6251/BEP.201803_49(3).0007
常用漢字部件的位置規則性與位置自
由度與其他文字特性相關之分析-以中
文部件組字與形構資料庫為基礎
*
曾千芝
陳學志
張瓅勻
國立臺灣師範大學 國立臺灣師範大學 教育心理與輔導學系 華語文教學系暨研究所胡中凡
陳修元
國立成功大學 臺北市立大學 心理學系 幼兒教育學系 漢字是由部件在二維的方形空間中排列而成。部件不但只會出現在特定幾種位置上(其可能出現 位置的數目即為位置自由度),並與某一特定位置有不同的關聯程度(其機率即位置規則性),例 如部件「扌」只出現在左側(如:換揮損搗撿擄等),而掌握這些組字規則的知識是識字教學的 重要環節。雖然如此,鮮少有研究檢視常用正體漢字部件出現在特定位置的機率,以及部件特性 與位置規則性之間的關聯。本研究採用陳學志、張瓅勻、邱郁秀、宋曜廷、張國恩(2011)11 種漢字結構,以及中研院的「五大字集部件表」的其中438 個部件,對「常用國字標準字體表」 (甲表)的4,808 漢字進行編碼。結果顯示:(1)平均每個部件只會出現在所有 22 種位置中的 2.66 種;(2)所有部件的平均位置規則性為 75.5%,且有 140 個(33%)部件只出現在一個特定 位置;(3)當部件屬於非常用字時,位置規則性越高。整體研究結果支持漢字部件的位置規律性, 文末並討論此結果在識字教學上的意涵與可能的應用方式。 關鍵詞:位置規則性、部件、組字知識、漢字、識字教學* 1. 本篇論文通訊作者:陳學志,通訊方式:[email protected]。 2. 本篇論文感謝國立教育部與臺灣師範大學「邁向頂尖大學計畫」的支持。 3. 本篇論文感謝吳阜融先生提供資料分析的協助。
文字字形的心智表徵是進行字詞認知解碼處理重要的基礎。例如:當兒童因字形表徵尚未完 整建立而造成字詞解碼無法達到自動化,產生認知資源過度耗費於字詞解碼,進而阻擋語意的理 解並且影響閱讀品質。固然過去許多研究發現聲韻處理為詞彙辨識的重要因素(Share, 1995; Stanovich, 2000),但越來越多證據顯示聲韻技巧不能單獨解釋詞彙辨識表現的發展,還需要其他 因素例如字形之「組字知識」技巧(orthographic skill)的增長(Cunningham, Perry, & Stanovich, 2001)。
部件是重複出現在不同漢字內的筆畫結構(Chen, Allport, & Marshall, 1996)。關於部件之「組 字知識」有兩項重要成分(鄭昭明、陳學志,1991;Ho, Yau, & Au, 2003):部件位置知識與功能知 識,前者強調特定書寫系統之規範,後者則涉及「字形-字音」與「字形-字義」的連結規則。在漢 字構字方法,形聲字佔常用漢字的 81%,由於形聲字包含提示整字語意與語音的部件,凸顯出部 件之功能知識的重要性(Li & Kang, 1993),因此部件功能知識受多數字彙處理研究者所重視(e. g., Feldman & Siok, 1997; Leck, Weekes, & Chen, 1995)。
至於部件位置知識方面,許多研究結果也顯示部件位置在識讀發展(e. g., Chen, Bukach, & Wong, 2013; Chen & Yeh, 2015; Taft, Zhu, & Peng, 1999; Wang, et al., 2009)與字詞辨識(e. g., 李虹、 彭虹、舒華,2006;洪儷瑜,2001;Chung, Tong, & McBride-Chang, 2012; Li, Shu, McBride-Chang, Liu, & Peng, 2012; Shu & Anderson, 1998)上的重要性。Li 等人用組字知識判斷作業來探討兒童的 識讀發展,該作業所測量之內容除了部件位置知識外,也納入部件辨識的測量。結果發現在控制 年級、視覺空間能力、聲韻覺識、唸名作業與詞素覺識作業的表現下,小學一、三年級生的組字 知識判斷作業分數對認字能力仍有顯著預測力,顯示部件位置知識在兒童識讀發展的重要性。在 字詞辨識方面,Chen & Yeh(2015)採用重複盲視(repetition blindness)的實驗派典,在快速呈現 一系列刺激中,觀察個體是否能夠正確指認出第二次呈現過的部件。該研究發現,相對於當部件 重複呈現在相同位置與具有相同部件功能時,如果所重複呈現之部件出現於不同位置,重複盲視 效果會顯著下降,而當該部件具有不同部件功能時則無視盲效果產生。這些結果均支持漢字中部 件位置編碼對字詞辨識具有其特定之影響。 固然部件功能知識與部件位置知識同為漢字重要之組字知識,但鮮少研究完整檢視部件位置 規則之相關特性,在正體漢字研究中,亦少有研究分析部件出現在特定結構位置的機率,並探究 部件特性與位置規則性之間的關聯。於識字教學方面,由於部件位置規則的抽取依賴字形資料庫 的頻次分析,識字教學者也難憑一己之力計算所有漢字部件位置規則,以編製適宜之教學材料。 回顧目前現有之漢字字形資料庫(莊德明、鄧賢瑛,2009;羅明、胡志偉、曾昱翔,2012;Chang, Hsu, Tsai, Chen, & Lee, 2015; Hsiao & Shillcock, 2006; Liu, Shu, & Li, 2007)可發現:現有資料庫在 部件位置的類別仍待更細緻的分類與分析,故本研究以中文部件組字與形構資料庫(陳學志、張 瓅勻、邱郁秀、宋曜廷、張國恩,2011)中的 11 種字形結構為基礎,從中細分出 22 種部件可能 出現的位置;並以「常用國字標準字體表」(甲表)所收錄之4,808 字為常用字範疇,計算每個漢 字部件的位置規則性(其出現於特定位置的機率)與位置自由度(其可能出現位置的數目),以深 入分析漢字部件與其可能出現位置間之關聯性,並且延伸分析與計算此關連強度與其他文字特性 之間的相關性。 一、部件位置規則與其心理實徵性 部件位置規則知識測驗常以假、非字作為題目,並且在實驗中呈現該類字,要求受試者進行 字彙判斷作業。此類研究假設:假字(其組字的部件符合該部件之位置規則)與非字(部件不符 合位置規則)之主要差別僅在於前者符合組字規則,後者則非;由於兩者皆為無意義字,也皆不 具音讀性,因此若存在對於兩者的辨識率差異,便能夠歸因此差異源自受試者對部件位置規則之 覺識。例如:鄭昭明(1981)在探討漢字認知歷程的研究中,發現符合部件位置規則但無具體意 義的「假字」,較不符合部件位置規則「非字」有較高的辨識率。
關於前述部件位置規則,不僅以成熟中文讀者(skilled Chinese readers)為對象的研究證實了 部件位置規則的心理實徵性(李宏鎰,2009;鄭昭明,1981; Ding, Peng, & Taft, 2004; Taft, et al.,
1999),關於較不成熟讀者(less skilled readers)的研究亦發現,早在國小階段,學童即已萌發部件位 置規則覺識(李虹等人,2006;洪儷瑜,2001;Shu & Anderson, 1998),且該覺識與識字能力之間 有顯著正相關(李虹等人,2006)。在一項利用部件組字遊戲所進行之研究中,也發現識字能力與 部件位置規則的關聯(Hong, Wu, Chen, Chang, & Chang, 2016),該研究的參與者為中文為第二語 言學習者,在作業中呈現一個部首盤(Chinese Radical Assembly Game),上面含括多個部件,研究 參與者需點選部件以組合成為真字。研究者安排兩種呈現方式,一種是將部件在部首盤上的呈現 位置與該部件最常出現在方形結構中的位置保持一致,以下稱部件規則組(例如:「舟」出現在左 側,「欠」出現在右側),另一種方式則將部件隨機散佈在部首盤中,稱為部件隨機組。同時,該 研究也將所有參與者依識字能力表現分為高分組與低分組。結果發現:部件規則組之識字能力高 分組較低分組有較佳的組字成功率,此二語學習者之研究亦支持母語者的研究結果。整體而言, 不論中文的精熟程度或母語背景,部件位置規則對中文讀者的漢字辨識歷程有一定程度的影響。 二、部件位置的知識 (一)漢字部件可能出現的位置 本研究採用由下而上之研究取徑(bottom-up approach),以中文部件組字與形構資料庫為基 礎,精確計算漢字部件的位置規則。過去與正體漢字字形相關的資料庫,在部件位置的分類大多 過於簡化(莊德明、鄧賢瑛,2009;羅明等人,2012;Chang, et al., 2015; Hsiao & Shillcock, 2006; Liu, et al., 2007),例如:莊德明、鄧賢瑛建置漢字構形資料庫,採三種字形結構進行分析:水平、垂 直與包圍;但從心理實徵研究發現:僅三種字形結構的分類架構確顯不足。葉素玲、李金鈴、陳 洸民(1999)以成熟讀者為研究對象,進行漢字字形分類研究,該研究要求中文使用者依字形相 似性對中文字進行分類,並透過叢集分析(cluster analysis)歸納出五類字形結構:上下字、左右 字、P 型字、L 型字和包圍字,這五種字形結構於後續以中文讀者為研究對象之研究中獲得心理實 質性的支持(Yeh, 2000; Yeh, Li, Takeuchi, Sun, & Liu, 2003),尤其在成熟中文讀者上更是明顯;但 對於正處在識讀發展中之學童,此分類方式是否適合,卻值得商榷。
漢字字形結構複雜,漢字初學者不容易掌握,因此教學上宜強調細緻區分不同形構,以期提 升識字學習的成效,例如:華語教學研究者葉德明(1990)列出中文正體字至少有 11 種結構關係, 邢紅兵(2007)則界定出簡化字有 13 種空間結構。另一方面,對於漢字初學者處理複雜字形的研 究也發現學童視覺技巧的重要性;中文識字發展研究者一致地認為:視覺技巧(visual skills)是識 字能力的核心能力(Huang & Hanley, 1994; Lee, Stigler, & Stevenson, 1986; McBride-Chang & Zhong, 2003)。而探討個別差異的研究也發現,中文讀者的「中文詞彙辨識」與「視覺空間覺識」(visual-spatial awareness)之間的相關高於「中文詞彙辨識」與「音韻覺識能力」(phonological awareness)之間 的相關(Siok, Spinks, Jin, & Tan, 2009; Tan, Spinks, Eden, Perfetti, & Siok, 2005),上述研究顯示:相 對於英文閱讀的心理歷程,中文閱讀涉及較多字形屬性之處理,需要細緻精準地分析漢字字形。 有鑑於此,相較於過去字形相關資料庫,本研究採用更細緻的分類法來區分漢字字形結構,希冀 能將研究結果應用在部件位置規則的漢字相關教學。 目前涵蓋最多種結構關係的正體漢字資料庫為陳學志等人(2011)建置之「中文部件組字與 形構資料庫」。該資料庫拆解6,097 個漢字,歸納出 11 種結構:單獨存在、上下關係、左右關係、 左上包圍、右上包圍、左下包圍、上方三面包圍、左方三面包圍、下方三面包圍、四面包圍與兩 側夾擊。比較葉素玲等人(1999)與陳學志等人的字形結構分類,可發現兩者之分類架構不同: 陳學志等人的研究將獨體字也視為一種結構,並且增列五種結構:右上包圍(如:「司」)、上方三 面包圍(如:「同」)、下方三面包圍(如:「凶」)、左方三面包圍(如:「區」)與左右夾擊(如:「 夾」)。對於陳學志等人所增加之三面包圍之字形結構分類,相關視知覺研究發現:出現在這些結 構之包圍位置的部件(如:下方三面包圍結構之部件『凵』)若放置於其他被包圍位置(例如:上 方三面包圍)後,讀者可能有失去視覺重心之感;由於此類部件受到特定結構位置(即三面包圍 的字形結構)之侷限,因此,本研究預期此類部件具備高度的位置規則性。
如前所述,為了細緻地處理這11 種空間結構,本研究採階層化分析:將 11 種結構向上歸納 至4 大結構,向下界定出 22 種部件可能出現的位置,如圖 1 之樹狀組織所示。該 4 大結構為「單 獨型」、「對分型」、「包圍型」與「夾擊型」,而22 種位置因種類繁多複雜,以視覺化方式呈現(見 圖 1 之 22 個黃色區塊);由於本研究分析重點在部件組字之規則,因此出現在單獨存在結構的部 件不納入後續位置指標的分析。如圖1 所示,由左而右,由上而下共有 22 個部件可能出現的位置, 本研究於每個位置給予一固定編號,以便與後續分析內容相互對照,茲分述如下: 1. 垂直組合,包含 3 種位置:1 為座落於上方;2 為座落於上下之間;3 為座落於下方。假如 該字包含2 部件,則編碼 1 與 3。 2. 水平組合,包含 3 種位置:4 為座落於左側;5 為座落於左右之間;6 為座落於右側。假如 該字包含2 部件,則編碼 4 與 6。 3. 左上包圍:7 為座落於左上包圍結構中的包圍者的位置(亦即左上方):8 為座落於左上包 圍結構中之被包圍的位置(亦即右下方)。 4. 右上包圍:9 為座落於右上包圍結構中的包圍者的位置(亦即右上方);10 為座落於右上包 圍結構中之被包圍的位置(亦即左下方)。 5. 左下包圍:11 為座落於左下包圍結構中的包圍者的位置(亦即左下方);12 為座落於左下 包圍結構中之被包圍的位置(亦即右上方)。 6. 上方三面包圍:13 為座落於上方三面包圍結構中的包圍者的位置;14 為座落於上方三面包 圍結構中之被包圍的位置。 7. 左方三面包圍:15 為座落於左方三面包圍結構中的包圍者的位置;16 為座落於左方三面包 圍結構中之被包圍的位置。 8. 下方三面包圍:17 為座落於下方三面包圍結構中的包圍者的位置;18 為座落於下方三面包 圍結構中之被包圍的位置。 9. 封閉包圍:19 為座落於四面包圍結構中的包圍者的位置;20 為座落於四面包圍結構中之被 包圍的位置。 10. 左右夾擊:21 為座落於左右夾擊結構中被夾擊的位置;22 為座落於左右夾擊結構中之夾 擊者的位置。
圖1 22 種中文部件位置的組織圖 (二)最高位置規則性、位置自由度 在分析指標方面,陳學志等人(2011)的研究主要計算「最高位置規則性」,此指標的代表意 涵為某部件(簡稱部件 A)可能出現在一種以上的位置,而對於出現比率最高的位置,則稱該位 置是部件A 的「最高位置」,該比率稱「最高位置規則性」;這個指標所得之數據與分析時採用之 漢字範疇有相當高的連動性。該研究廣納 6,097 個正體漢字,其字庫採用來自 BIG-5 碼所界定的 5,401 個字與中央研究院中文詞知識庫小組(1993)所界定的 5,656 個字,此兩大資料庫所聯集而 得的字共計6,097 字。然而,根據王瓊珠、洪儷瑜、張郁雯與陳秀芬(2008)的識字量評估研究發 現:國小六年級生的識字量為3,300 字,國三生則是 3,700 字,因此,該研究採用之 6,097 個字實 包含大量的「非常用字」,並不適合用以研究學童的識字學習;也由於這些「非常用字」摻入字表 之後,勢必影響「最高位置規則性」的統計結果,因此本研究改採用「常用國字標準字體表」(甲 表)所收之4,808 個字。另外,在部件的定義上,為了與國家標準一致,本研究改採用中研院的「五 大字集部件表」(莊德明、鄧賢瑛,2009)。 另一方面,「最高位置規則性」可以描述部件在各種結構位置上的集中強度,但此指標對於分 散強度則比較不敏感,因此,本研究除採用陳學志等人(2011)「最高位置規則性」指標,還增加 了「位置自由度」的指標進行分析,此指標代表部件A 會出現在 22 種可能位置中的那幾種位置上 (其值介於1 至 22)。 (三)位置規則性、位置自由度與其他部件特性的關聯 如果某部件具有一定程度的位置規則性與低位置自由度,則代表該部件的位置並非完全隨機 散佈,而是會依循一定程度的規律,那麼進一步的問題是何種部件特性會影響此規律呢?此為過 去研究從未探討的問題。整體來說,部件特性包含形、音、義三方面,因此本研究透過迴歸分析, 在控制部件組字數與頻率下,比較何種部件的特性(形、音、義方面)會顯著影響出現位置規律
(即位置規則性與位置自由度),其中,所採用的形音義部件特性分別為筆劃(代表字形複雜度)、 是否為常用字(代表是否有音讀)、是否為部首。
另一方面,此部分的分析結果也具有識字學習上的意義。部件符合組字規則與否會影響學習 之難易:先前研究發現,當被學習的人造字符合表意透明度(Kuo et al., 2015; Zhang, Li, Dong, Xu, & Sholar, 2016)、表音一致性(Kim, Packard, Christianson, Anderson, & Shin, 2016; Lin & Collins, 2012)與表音規則性(Lin & Collins; Zhang et al.),會比不符合規則的人造字更易於學習。因此, 當部件位置規則性越高,也應該會越容易學習。除了符合組字規則與否之外,部件還有其他重要 的學習特性,像是筆劃多寡、是否為常用字、是否為部首、組字數、字頻,不僅會影響一個字是 否容易學習(Kuo et al.),甚至也會被用來決定其學習順序(曾昱翔、胡志偉、羅明、呂明蓁、呂 菁菁,2014)。然而,過去研究鮮少探討部件位置規則程度與其他重要的學習特性之間的關聯,因 此本研究探索當一個部件的位置規則性越高,其他有利於學習的特性一起出現之趨勢。 (四)不同位置之間的容納部件數(率) 漢字以形聲字居多,此種造字方法會造成部件在不同結構位置之間的差異。具體而言,形聲 字內不同位置會放置不同功能的部件,在一個字的左側或上方,通常放的是部首,在右側與下方 通常放的是該字的聲旁。然而,過去研究大多關注在位置表音與表意的功能,鮮少討論該位置的 其他基本卻是重要的訊息,例如:該位置可能出現幾種部件(即容納部件數),以及出現在該位置 部件的平均位置規則性,因此本研究針對這些指標進行計算。 三、部件位置的教學 回顧目前部件或組字知識教學,大多側重部件的表音與表意功能(胡永崇,2003;陳秀芬, 1999;秦麗花、許家吉,2000),而多數研究結果也支持其教學效果;相較之下,甚少有識字教學 研究是針對部件的結構位置知識(orthographic knowledge)進行訓練,尤其是外顯化的組字知識規 則之教學,例如:部件「疌」的衍生字有:婕捷睫,這三字的共通點即是「部件『疌』一定會出 現在右邊」。然而,在沒有資料庫為基礎的情況下,無法知道精確的部件位置規則,且要找出符合 與不符合規則之衍生的例字是相當耗時耗力,而教學者自行編製的教材可能也會因不同教學者的 經驗而有所偏頗。 四、本研究目的 部件位置規則不僅是漢字的重要特徵,也是識字發展過程中必須掌握的重要組字知識。然而, 對教學者而言,為識字教學漢字部件位置規則的教學材料所需心力是一大挑戰,為了提供完整與 精確的部件位置規則之學習材料,本研究採用陳學志等人(2011)的中文部件組字與形構資料庫 之11 種結構關係,以及中研院的「五大字集部件表」其中的 438 個部件(莊德明、鄧賢瑛,2009), 以竭盡式方式,全面分析「常用國字標準字體表」(甲表)的4,808 個漢字的部件位置規則。根據 資料庫的部件位置規則分析,本研究回答問題有四項: 1. 每個漢字部件的「最高位置規則性」為何?在「最高位置規則性」的分配又如何?哪些部 件具有較高的位置規則性? 2. 平均一個部件會出現在幾種位置(即平均「位置自由度」)?整體部件分配又如何? 3. 何種部件特性會與部件的「位置自由度」與「最高位置規則性」有關聯? 4. 每種位置可能出現幾種部件(即容納部件數)?每種位置的位置規則性高低?
方法
本研究根據「常用國字標準字體表」(甲表)所收之4,808 個正體字為常用字範疇,編碼每個 字所包含的部件與該部件的位置,竭盡式地分析漢字部件的位置規則性與位置自由度,詳細說明 如下。 一、常用字範疇 本研究之常用字範疇來自 1979 年於李鍌教授領導下,編成「常用國字標準字體表」(甲表) 的收字,共4,808 個字,由教育部發表之。依據黃富順(1994)的研究,我國一般成人日常生活所 需之基本字彙量為2,328 個字,因此,本研究採用的 4,808 個字對於現代的一般讀物已具有良好的 覆蓋率。 二、部件 本研究的部件採用中研院漢字構形資料(莊德明、鄧賢瑛,2009)的「五大字集部件表」,將 常用字4,808 字進行拆解,分析出 438 個部件。 三、位置的類型 本研究根據陳學志等人(2011)的 11 種字形結構,界定 22 種部件可能出現的位置。由於分 析重點在部件組字之規則,因此不納入單獨存在的部件(19 個);438 個部件減去 19 個部件為 419 個部件,此419 個部件即為本研究後續分析之基礎。 四、位置規則性與最高位置規則性 本研究的「位置規則性」分析採用陳學志等人(2011)研究中計算部件出現在「某個結構關 係的某個位置」中的比例,公式為:部件A 出現在某位置的「位置規則性」=(部件 A 出現在特 定位置的字數/部件A 的組字數)×100%。以部件「勿」為例,其所組出的 12 個字會出現在 4 種 可能的位置:有 7 個字(賜錫易剔惕蜴踢)出現在垂直結構中的下方位置,所以部件「勿」出現 在垂直結構中的下方位置之位置規則性=(7/12)*100% = 58%;有 2 個字(吻物)出現在水平結 構中的右側位置,所以部件「勿」出現在水平結構中的右方位置之位置規則性=(2/12)*100% = 17%;另有 2 個字(忽惚)出現在垂直結構中的上方位置,位置規則性也是 17%;最後在 1 個字 (刎)中,「勿」出現在水平結構中的左側,所以部件「勿」出現在水平結構中左側的位置規則性 =(1/12)*100% = 8%。由此可知「位置規則性」越高,該部件出現於特定位置的規則越強。 值得一提的是,本研究以分層拆解方式將整字字形拆解至部件層次,而上述「特定位置」是 指該部件所位在拆解層級中的位置。例如:「窺」的拆解方式是在第一層的拆解層級中拆解出上方 「穴」與下方「規」,第二層再針對「規」拆解出左邊「夫」與右邊「見」,因此「見」落在第二 層的左右拆解,屬於在右邊的位置。 在 419 個部件,每個部件都會出現在一個以上的位置,其中出現比例最高的位置則代表該部 件最常出現的位置,稱為該部件的「最高位置」,而部件出現在此位置的比率稱為該部件的「最高位置規則性」。以前述部件「勿」為例,在其所有可能出現的位置中,以下方位置的出現比率最高, 因此「勿」的「最高位置」為下方,「最高位置規則性」為58%。 五、位置自由度 「位置自由度」是指在4,808 字當中,某部件會出現在 22 種可能位置中的哪幾種位置上(其 值介於1 至 22)。位置自由度越高代表該部件可能出現的位置越多,越不侷限在特定位置。例如: 部件「辶」具有最低的位置自由度(等於1),代表它在出現位置上無任何自由,只會出現在一個位 置,即左下包圍;再例如:部件「香」的位置自由度等於2,代表它只會出現在 2 個位置,即下方 (馨)或左側(馥);部件「口」有高度的位置自由度(等於11),因為它可能出現在 11 種位置中, 比如上方(只)、上下之間(亨)、下方(否)、左側(吃)、右側(扣)、左上被包圍(右)、右上 被包圍(句)、上方三面被包圍(問)、四面包圍(獵)、四面被包圍(回)或左右夾擊(喪)。 六、各位置的「容納部件數(率)」 某位置的「容納部件數」代表在419 個部件中,可能出現該特定位置的部件種類數目;「容納 部件率」則是將「容納部件數」除以419(總部件數),數字越高代表該位置可能出現的部件種類 數越多。具體而言,位置L 的「容納部件率」計算方式=(位置 L 可能出現的部件種類數/419) ×100%。例如:出現在位置「左方三面包圍」的部件相當少,全部 419 個部件中只有部件「匸」 與「匚」,因此「左方三面包圍」的「容納部件數」等於2,「容納部件率」為 0.47%;相反的,位 置「右側」可以容納的部件種類則相當多,比如:史、丈、曳、內、欠、刂、瓜、失、申、皮、 丑、支、吏、共……等等,可預期「右側」位置具有高度「容納部件數(率)」。 七、筆畫數 本研究之筆畫數定義遵照教育部出版之「常用國字標準字體筆順手冊」(教育部國語推行委員 會,1999)。 八、出現頻次 「出現頻次」即每百萬字的出現次數,本研究之部件與漢字的出現頻次計算以中研院所公佈 之字頻(中央研究院中文詞知識庫小組,1993)為基礎。部件的出現頻次計算方式是將部件 A 所 組出之每個字的字頻相加。例如:部件「夷」在4,808 字中可組出 3 個字:「咦」、「姨」與「胰」, 它們的字頻分別為:7、11 與 2,因此,部件「夷」的出現頻次即是將這三個字的字頻相加(7+11+2) 為20。 九、常用字與否、部首與否 本研究以是否出現在4,808 個字中代表某部件是否為常用字的標準,此 4,808 個字來自「常用 國字標準字體表」(甲表)的收字。「非常用字」的部件大多不成字,無讀音;為「常用字」的部 件大多成字,有讀音。部首與否的標準則是依據國語活用辭典(周何,2008)所列之部首。
結果
本研究結果包含三個部分:一、最高位置規則性,包含:整體分配情形、每個部件的「最高 位置規則性」與具高度位置規則性的部件;二、指標「位置自由度」的分析結果,包含:整體部 件分配、屬於與不屬於常用字的部件分配;三、進行兩次多元迴歸分析,分析那些部件特性最能 夠預測部件的「位置自由度」與「最高位置規則性」。 一、最高位置規則性 表1 呈現所有 419 個部件的最高位置與最高位置規則性程度,圖 2 是部件在「最高位置規則 性」的分布長條圖,按5 級分類。由於 419 個部件在最高結構位置規則性的標準差為 22.9%,因此 本研究取一個標準差左右的20%作為分組的區間大小。 結果發現,位置規則性為100%的部件個數百分比最高(33.4%):419 個部件中,有 140 個部 件在組字時一定出現於特定位置;419 個部件的「最高位置規則性」平均數為 75.5%(SD = 22.9%), 採用字頻加權(by token;字頻依據中央研究院中文詞知識庫小組(1993))後為 76.9%(SD = 27.8%),改變並未太大。上述資料提供了漢字部件在位置規則程度上的客觀估計,而結果顯示多 數部件於出現位置具有高度規律性。 除了 419 個部件的最高位置規則性,分析結果也包含每個部件的符合/不符合最高位置規則 之衍生字,但因篇幅所限,表2 僅示例 8 個部件的分析結果。該表列舉 4 種最高結構位置:上方、 下方、左側與右側,在此4 種結構位置,再選出兩個部件作範例,這兩部件分別具有高程度/低程 度的最高結構位置規則性。此外,為了幫助學習者連結部件與其最高位置,圖3 以九宮格型態呈 現出現在各位置且位置規則性為100%的部件,圖 3 中的 N 之後放置的是非常用字,Y 之後放置的 是常用字,灰底部件代表出現在TOCFL(Test of Chinese as a Foreign Language)基礎級詞表中的 字。圖4 則放寬位置規則性的範圍,呈現不同位置下位置規則性介於 70-100%的部件。 圖2 5 級最高位置規則性的部件個數百分比分布圖(N = 419) 4.8% 24.8% 20.8% 16.2% 33.4%表1 419 個部件的最高位置與其位置規則性程度(按 5 級分類) 編 號 部件出現 的位置 位置 圖示 位置規則性 20-40% 40-60% 60-80% 80-99% 100% 1 上方 (5) (16) (15) (13) (30) 2 上下間 (2) (2) (1) (2) 3 下方 (7) (29) (16) (13) (21) 4 左側 (8) (15) (13) (29) 5 左右間 -- -- -- -- -- 6 右側 (42) (28) (19) (32)
表1(續) 編 號 部件出現 的位置 位置 圖示 位置規則性 20-40% 40-60% 60-80% 80-99% 100% 7 左上包圍 (3) (2) (5) 8 右 下 被 包圍 (1) (4) (3) (3) 9 右上包圍 (2) (1) (1) (5) 10 左 下 被 包圍 (1) (1) 11 左下包圍 (1) (1) (1) (4) 12 右 上 被 包圍 (1) (2) 13 上 方 三 面包圍 (1) (3) (2) 14 上 方 三 面被包圍 15 左 方 三 面包圍 (2) 16 左 方 被 三面包圍 17 下 方 三 面包圍 (1) 18 下 方 三 面被包圍 19 四面包圍 (1) 20 四 面 被 包圍 (1) 21 左右夾擊 (1) (2) 22 被夾擊 (2) (2) (1)
表2 最高位置為上方、下方、左側與右側的 8 個示例部件(每種位置下,高程度/低程 度位置規則性各示例1 個),及其最高位置規則性、符合衍生字與違反衍生字 部件 最高位置 最高位置規 則性 符合衍生字 違反衍生字 上方 1 書晝畫劃 上方 0.553 岌岑岩岸炭崁豈崇崑崔崖崙崩凱剴喘嵌嵐 惴揣湍催嵩微瑞嶄摧碳端徵皚踹嶺嶽徽繃 薇覬蹦顓懲癥巍攜巔巖黴 仙屹汕岐岔岡岫岱岳岷疝 峙幽舢剛峨峪峭峰島峻峽 訕密崆崎崛崢搗嶇綱嶝鋼 嶼癌豐巒豔 下方 1 爭崢掙淨猙睜箏諍錚靜 下方 0.4 毫髦撬橇 尾娓耗毯毽麾 左側 1 行彷役彼彿往征待徇很徊律後衍屐徐徑徒 屜得徘徙從御術徨復循街徬微衙徹銜履徵 德慫樅衛衝禦衡徽縱聳薇覆蹤懲癥黴衢 左側 0.585 軋軌軒軔斬軛軟軸軻軼軾較輊塹嶄慚漸輒 輓輔輕暫範輛輜輟輪輯輸輻輾轄轅轉轍轎 轔囀 軍庫陣連揮渾暈暉琿葷載 運漣蓮輝輦輩褲擊輿轂攆 繫鏈轟轡鰱 右側 1 次吹坎欣炊咨姿砍崁恣掀欲瓷軟厥嵌欺欽 款盜飲歇羨資嗽歉歌漱慾歐獗歙蕨諮歟蠍 蹶懿歡鱖 右側 0.556 仞紉軔韌澀 忍梁粱認 上方三面包圍(2) N: Y: 左方 三面 包圍 (2) N: 左上包圍(5) N: 右下被包圍(3) N: 上方(30) N: Y: 右上包圍(5) N: 左下被包圍(1) Y: Y: 左側(29) N: Y: 上下間(3) N: 左右夾擊(1) N: 右側(32) N: Y: 右上被包圍(2) N: Y: 左下包圍(4) N: Y: 下方(21) N: Y: 圖3 各位置下規則性為 100%的部件,共 140 個 註:括號內為個數,N 之後放非常用字,Y 之後放常用字,灰底部件代表可單獨或組合成 TOCFL 基礎 級詞表的字
圖4 各位置下規則性介於 70-100%的部件,共 273 個 註:括號內為個數,N 之後放非常用字,Y 之後放常用字,灰底部件代表可單獨或組合成 TOCFL 基礎 級詞表的字 二、位置自由度 圖5 與表 3 呈現 419 個部件在「位置自由度」之分布,並且增加常用字與否的變項(常用字 n = 252,非常用字 n = 167),以作為該部件常用字與否的標準。主要發現如下: (1)整體來說,特定部件會有限地出現在幾種位置,此發現來自於部件位置自由度的平均數 為2.66(SD = 1.99),表示雖有 22 種可能出現的位置,但平均而言,一個部件僅出現在其中 2~3 種位置。再者,從表3 的整體累加百分比可看出有 32.5%的部件固定出現在一種位置,56.1%的部 件只出現在兩種位置,71.1%的部件只出現在三種位置;此外,沒有任何部件會出現在所有可能位 置,即使是位置自由度最高的部件「口」,也只會出現在其中11 種位置,例如:占、叨、另、加、 亨、句、右、向、回、象、叵。 (2)從圖 5 與表 3 可知,常用字與否的部件有不同的分配情況,屬於非常用字的部件,呈現 較明顯的正偏態,比起常用字部件(M = 3.31,SD = 1.99),非常用字部件的位置自由度相對上較 低(M = 1.98,SD = 1.58)。對於位置自由度等於 1 的部件,也就是固定出現在一種位置的部件, 則大多屬於不成字部件。其中,非常用字部件數目(n = 87)是常用字部件(n = 49)的 2 倍左右。 N: N: N: N: N: N: N: N: N: N: N: N: N: Y: Y: Y: Y: Y: Y: Y: Y: N: Y: Y: Y:
圖5 各級位置自由度上部件個數的長條圖(N = 419) 表3 419 個部件在不同位置自由度與是否為常用字下的部件個數(%)與部件示例 位置 自由 度 非常用字的部件 為常用字的部件數 Total 個數 (%) 示例 個數 (%) 示例 部件數 累積% 1 87(52) … 49(19) ... 136(32) 32 2 42(25) … 57(23) ... 99(24) 56 3 22(13) … 41(16) … 63(15) 71 4 7(4) 47(19) ... 54(13) 84 5 2(1) 24(10) ... 26(6) 90 6 0(0) 17(7) … 17(4) 94 7 3(2) 6(2) 9(2) 96 8 2(1) 6(2) 8(2) 98 9 1(1) 3(1) 4(1) 99 10 1(1) 1(0) 2(0) 100 11 0(0) 1(0) 1(0) 100 sum 167 252 100 三、部件特性預測「位置自由度」與「最高位置規則性」的多元迴歸分析 透過多元迴歸分析,此部分探討哪些部件特性(預測變項)會與部件的「位置自由度」或「最 高位置規則性」(被預測變項)的高低特別有關。表4 是被預測變項與預測變項的平均數與標準差, 表5 為變項間的相關矩陣。
表4 被預測變項與預測變項的平均數與標準差 (N = 419) 變項 M SD 被預測變項 最高位置規則性 0.75 0.23 位置自由度 2.66 1.99 預測變項 筆畫數 5.33 2.89 部首與否 0.58 0.49 常用字與否 0.60 0.49 組字數 35.36 66.55 頻率 6805.00 15635.00 表5 被預測變項與預測變項的 Pearson 相關矩陣(N = 419) 規則性 自由度 筆畫數 部首與否 常用字與否 組字數 頻率 最高規則性 1 -.743** .044** -.133** -.341** -.179** -.184** 位置自由度 1 -.161** .311** .334** .503** .478** 筆畫數 1 -.018** .269** -.279** -.292** 部首與否 1 .145** .312** .245** 常用字與否 1 -.023** -.049** 組字數 1 .879** 頻率 1 **p < .01. 當被預測變項為「最高位置規則性」,多元迴歸分析的結果如表6,結果發現 5 個預測變項對 於「最高位置規則性」的總解釋力達到R2 = .166,F(5, 413)= 16.390,p < .001。進一步看各預測 變項的解釋效果,僅有「常用字與否」具有顯著的預測效力(t = -7.807,p < .001),其 Beta 值是 負的(β = -.369),表示當漢字部件屬於非常用字時,其最高位置的規則性越高。 當被預測變項為「位置自由度」,多元迴歸分析的結果如表7,結果發現 5 個預測變項對於「位 置自由度」的總體解釋力達到R2 = .408,F(5,413)= 56.969,p < .001。進一步看各預測變項的解 釋效果,5 個預測變項「筆畫數」、「部首與否」、「常用字與否」、「頻率」、「組字數」皆可顯著預測 「位置自由度」(依序t = -3.058、3.086、9.189、3.292、2.422,all ps < .05),其標準迴歸係數 Beta 值除了筆畫數為負的,其餘皆是正的(依序β = -.126、.125、.366、.267、.193),表示當漢字部件 筆畫數越少、是部首、是常用字、組字數越多、頻率越高,其位置自由度越高。 從以上結果推論,雖「位置自由度」與「最高位置規則性」有高度相關(r = -.743,p < .01), 但是兩者卻呈現不同且顯著的預測變項組合:當所有部件特性變項都可以顯著預測「位置自由度 」,只有「常用字與否」與「最高位置規則性」有顯著關聯。此結果表示高「位置規則性」與高「最 高位置規則性」的部件有不同的文字特性。當部件的「位置自由度」越高,代表該部件越會散佈在 方形結構的不同位置,這類部件的字形複雜度低(低筆畫數),並且本身具有語意與音讀上的完整 性(是部首與是常用字),並且曝光率也相當高(高組字數與高頻率)。另一方面,部件的「最高 位置規則性」僅與「非常用字」有緊密關聯,但與其他特性(組字數、頻次、部首與否與筆畫數) 關係較弱,因此在「非常用字」部件的學習上,即使有不利於學習之無讀音特性,仍可利用其高度 位置規則的特徵,以幫助記憶與習得。
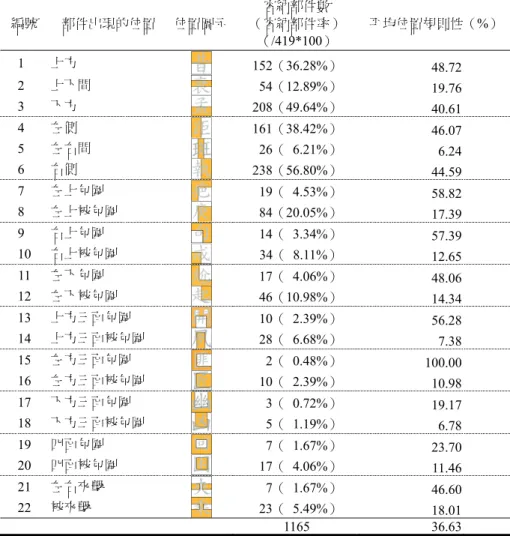
表6 部件特性變項對「位置規則性」之多元迴歸分析摘要表 未標準化係數 標準化係數 t 值 共線性統計量 B 之估計值 標準誤差 Beta 分配 允差 VIF (常數) .845 .027 31.485*** 筆畫數 .007 .004 .094 1.916*** .846 1.182 部首與否 -.016 .022 -.035 -.729*** .876 1.142 常用字與否 -.172 .022 -.369 -7.807*** .905 1.105 組字數 <.001 <.001 -.017 -.181*** .217 4.605 頻率 <.001 <.001 -.151 -1.594*** .225 4.447 R = .407,R2 = .166,調整後R2 = .155,F(5, 413)= 16.390*** ***p < .001 表7 部件特性變項對「位置自由度」之多元迴歸分析摘要表 未標準化係數 標準化係數 t 值 共線性統計量 B 之估計值 標準誤差 Beta 分配 允差 VIF (常數) 1.631 .192 8.484*** 筆畫數 -.085 .028 -.126 -3.058*** .846 1.182 部首與否 .493 .160 .125 3.086*** .876 1.142 常用字與否 1.452 .158 .366 9.189*** .905 1.105 組字數 .008 .002 .267 3.292*** .217 4.605 頻率 <.001 .000 .193 2.422*** .225 4.447 R = .639,R2= .408,調整後 R2 = .401,F(5,413)= 56.969*** *p < .05, **p < .01, ***p < .001 四、22 個位置的容納部件數(率)與位置規則性 「容納部件數(率)」的結果如表 8,結果發現右側「容納部件數」為 238,代表該位置可能 出現238 個部件,是所有位置中部件總數最多的,其「容納部件率」為 56.8%,表示一半以上的部 件都可能出現在左右結構的右邊。次高的是下方位置,其「容納部件率」為49.64%,表示近一半 的部件可能出現在上下結構的下方。此發現呼應漢字以形聲字最多的情形,且具有「左意右聲」 或「上意下聲」的特性,右側部件提供字音線索的功能,因為漢字的同音字多,平均四個漢字共 用一個發音(不計聲調),亦即每個漢字平均有三個同音字,所以可選擇的適合部件種類相當多, 例如:部件「工」、「公」、「弓」與「共」皆可為整字攜帶「ㄍㄨㄥ」的字音。至於所有位置中出 現部件種數最少的是左方三面包圍,只出現2 個部件。
表8 22 種位置下的容納部件數(容納部件率)以及其平均位置規則性 編號 部件出現的位置 位置圖示 容納部件數 (容納部件率) (/419*100) 平均位置規則性(%) 10 上方 152(36.28%) 48.72 20 上下間 054(12.89%) 19.76 30 下方 208(49.64%) 40.61 40 左側 161(38.42%) 46.07 50 左右間 026(06.21%) 06.24 60 右側 238(56.80%) 44.59 70 左上包圍 019(04.53%) 58.82 80 左上被包圍 084(20.05%) 17.39 90 右上包圍 014(03.34%) 57.39 10 右上被包圍 034(08.11%) 12.65 11 左下包圍 017(04.06%) 48.06 12 左下被包圍 046(10.98%) 14.34 13 上方三面包圍 010(02.39%) 56.28 14 上方三面被包圍 028(06.68%) 07.38 15 左方三面包圍 002(00.48%) 100.00 16 左方三面被包圍 010(02.39%) 10.98 17 下方三面包圍 003(00.72%) 19.17 18 下方三面被包圍 005(01.19%) 06.78 19 四面包圍 007(01.67%) 23.70 20 四面被包圍 017(04.06%) 11.46 21 左右夾擊 007(01.67%) 46.60 22 被夾擊 023(05.49%) 18.01 1165 36.63
結論
部件位置規則在漢字組字知識扮演重要的角色,但卻少有針對部件位置規則的研究與根據研 究所發展之識字教學。部件位置規則的統計結果仰賴字形資料庫的頻次分析,然而,目前其他字 形資料庫(莊德明、鄧賢瑛,2009;羅明等人,2012;Chang, et al., 2015; Hsiao & Shillcock, 2006; Liu, et al., 2007)缺乏細緻的部件位置種類,因此無法提供識字教學精準且信而有徵的教學參考。為深 入掌握正體漢字的字形相關特性,本研究採用陳學志等人(2011)「中文部件組字與形構資料庫」 的11 種結構關係,以及中研院「五大字集部件表」其中 419 個部件(莊德明、鄧賢瑛,2009), 對「常用國字標準字體表」(甲表)的4,808 漢字進行編碼後,再計算每個部件的位置規則性以及 位置自由度,期可將本研究結果運用於識字教學中。 分析結果顯示多數的部件具有一定程度之位置規律。兩項重要的相關發現是:(1)419 個部件 的平均最高位置規則為75.5%;將此結果與常用形聲字中表音規則字佔 33.5%(Hsiao & Shillcock, 2006)、表意透明字佔約 36%(李孟峰,2011)的過去研究作粗略比較,部件在位置規則性相對較 高。(2)雖然漢字存有 22 種位置,但有 32.5%的部件(136 個部件)只會出現在一種位置上,而 平均每個部件只會出現2.66 種位置。從漢字部件位置具有高規則的結果,顯示於字彙處理歷程過程,部件位置訊息可能是有用的、可促進辨識的線索,此結果亦支持Ding 等人(2004)的多階層 交互激發模式(multi-level interactive-activation model),該理論強調字彙處理歷程中會形成位置敏 感(position-sensitive)的部件表徵。
另一方面,許多組字知識的教學法強調形聲字的構字方式,例如:「左部首右聲旁」、「上部首 下聲旁」。此教學方式雖可輔助學習者學到部件位置與功能的共變關係,但並未涵蓋所有部件的組 字規則,尤其是不成字部件,像是「 」或「 」;本研究結果發現,此類不成字部件的位置規 則性其實相當高,亦值得納入教學中。近期研究結果指出單獨學習部件位置規則的潛力(Chen & Yeh, 2015; Hong et al., 2016),例如:Hong 等人中文為第二語言學習者為研究對象,參與者需從部 首盤上選擇正確部件以組成真字,研究者操弄是否提示部件位置規則(即該部件出現在部首盤上 的位置與出現在漢字方形空間的位置是一致的)並觀察組字字數,再根據組字字數分為高低分組。 該研究結果發現:提示部首盤上的部件位置規則可消弭高、低分組原先在組字表現上的差異;也 就是說,對於低識字能力學習者,可透過學習外顯的組字知識規則,以促進組字的表現。連結該 研究結果與本研究之實務應用,在識字教學上,本研究之圖3、圖 4 可作為部件位置規則外顯化教 學之參考,以提升學習者的組字覺識(orthographic awareness)。 而本研究之多元迴歸分析結果,顯示部件位置規則、位置自由度和其他重要的漢字學習特性 之間有所關聯。主要發現有二:第一,非常用字的部件與其特定出現位置有強烈關聯。在華語教 學中,部件特性與教學順序密切相關,然而多數教師卻很少將部件特性(如:位置規則性)納入 考慮,例如:有些華語教學學者認為不成字部件應比起成字部件晚點教(黃沛榮,2003;鄧守信, 2009),這是因為不成字部件不具讀音,比起成字部件較難記憶與習得,故建議教學順序較後。但 是,有些不成字部件卻是相當高頻,因此具有優先學習的價值,例如:「勹」與「ナ」。是以,本 研究建議在不成字部件的教學時,應強調該部件的最高位置,將部件的位置規則視為記憶不成字 部件的關鍵特徵。第二,本研究發現:當部件的位置自由度越高,也會同時出現其他 5 項有利於 學習的特徵,包含:低筆畫數、為部首、為常用字、組字數越高與頻率越高,此結果表示高位置 自由度的部件同時也是應優先學習的部件。此外,本研究也發現包圍型位置的「容納部件數」相 當低,例如:左方三面包圍的位置,在所有 419 個部件中,只有兩個部件「匸」與「匚」會出現 在該位置,因此,教學時可直接教導「在左方三面包圍的位置,只會出現部件『匸』與『匚』」, 以有效地掌握包圍型位置會出現的部件。 一、本研究分析結果的延伸應用 本研究根據細緻區分的22 種位置來編碼 4,808 個常用字中的部件位置,據此資料,再延伸位 置自由度與位置規則性兩項精確指標並進行分析,所獲得的結果期可應用在假字與非字的製作 上,提升研究實驗結果的內在效度。假非字的應用廣泛,至少用在三方面重要研究:第一,作為 探討漢字字彙辨識歷程之研究的刺激材料(e. g., Chen et al., 2013; Chen & Yeh, 2015; Taft, et al.; 1999; Wang et al., 2009);第二,作為識字教學相關實驗的實驗材料(e. g., Kuo et al., 2015; Zhang et al, 2016);第三,作為評估學童組字知識發展相關研究的測驗題目(李虹等人,2006;洪儷瑜,2001; Chung et al, 2012; Li et al., 2012; Shu & Anderson, 1998)。
二、未來研究
本研究不足之處,也是未來研究需要再進一步發展的方向有三:(1)本研究僅聚焦字形層面 的組字知識,但是中文形聲字佔70-80%(Chen & Yeh, 2015),且部件表音或表義的字理分析在漢 字教學上極為重要(黃沛榮,2011);雖部件功能(表音與表意)並不穩定,但部件功能與位置有 共變關係,例如:「左形右聲」、「上形下聲」,因此,值得在未來研究中釐清在什麼位置下部件的 特定功能才會發揮;換言之,未來可在考量位置條件下,計算各部件的表音一致性、表音規則性
與表意透明度;(2)目前簡化字的使用人口佔多數,未來研究可延伸至簡化字與正體字在部件位 置規則的異同分析,也可使得中文部件的位置規則性探討更為完整;(3)最後,為將本研究結果 結合實務應用、提供漢字研究或教學相關人員查詢,未來可建構漢字部件之位置規則查詢平台, 以裨益漢字部件位置規則的識字研究與教學。
參考文獻
中央研究院中文詞知識庫小組(1993):新聞語料詞頻統計表:語料庫研究系列之二。台北:中央 研究院資訊研究所。[Chinese Knowledge and Information Processing Group. (1993). Corpus-based frequency count of characters in journal Chinese: Corpus-based research series (No. 1). Taipei, Taiwan: Acadimia Sinica Institute of Information Science.]王瓊珠、洪儷瑜、張郁雯、陳秀芬(2008):一到九年級學生國字識字量發展。教育心理學報,39 (4),555-568。[Wang, C. C., Hung, L. Y., Chang, Y. W., & Chen, H. F. (2008). Number of Characters School Students Know from Grade 1 to G9. Bulletin of Education Psychology, 39(4), 555-568.]
李宏鎰(2009):認字困難學童之文字表徵。中華心理衛生學刊,22(1),51-66。[Lee, H. Y. (2009). Character Representations of Child with Chinese Character Recognition Disability. Formosa Journal of Mental Health, 22(1), 51-66.]
李孟峰(2011):國小學童對於中文字形音義結構之認知與發展。國立臺灣師範大學教育心理與輔 導學系碩士論文。[Li, M. F. (2011). The Development of Orthographic Awareness of Chinese Characters for Taiwanese Elementary School Students (Master's dissertation). National Taiwan Normal University, Taipei, Taiwan.]
李虹、彭虹、舒華(2006):漢語兒童正字法意識的萌芽與發展。心理發展與教育,22(1),35-38。 [Li, H., Hong, P., & Shu, H. (2006). A Study on the Emergence and Development of Chinese Orthographic Awareness in Preschool and School Children. Psychological Development and Education, 22(1), 35-38.]
邢紅兵(2007):現代漢字特徵分析與計算研究。北京:商務印書館。[Xing, H. B. (2007). Analysis and Calculation of Modern Chinese Characters. China, Beijing: The Commercial Press.]
周何(2008):國語活用辭典。台北:五南。[Zhou, H. (2008). Mandarin Dictionary. Taipei, Taiwan: Wunan.]
洪儷瑜(2001):中文字視知覺測驗。台北:心理。[Hung, L. Y. (2001). The Test of Visual Perception of Chinese Characters. Taipei, Taiwan: Psychological Publishing.]
胡永崇(2003):國小四年級閱讀困難學生識字相關因素及不同識字教學策略之教學成效比較研 究。屏東師院學報,19,177-216。[Hu, Y. C. (2003). The Related Variables in Chinese Characters
Learning and the Effectiveness of Different Instructional Strategies of Chinese Characters on Fourth-grade Elementary Students with Reading Difficulties. Journal of Pingtung Teachers College, 19, 177-216.]
秦麗花、許家吉(2000):形聲字教學對國小二年級一般學生和學障學生識字教學效果之研究。特 殊教育研究學刊,18,191-206。[Chyn, L. H., & Sheu, J. J. (2000). A Study of the Effects of Teaching Phonetic-Radical Characters on Second-Grade Normal Students and Students with Learning Disabilities. Bulletin of Special Education, 18, 191-206.]
教育部(1979):4808 個常用字。未出版之字表。取自教育部終身教育司網站:http://ws.moe.edu.tw/ 001/Upload/1/relfile/6490/38921/25d230a9-b497-4de5-bef3-a6d54b4667eb.xls,2016 年 5 月 26 日。[Ministry of Education (1979). 4,808 Most Frequently Used Chinese Characters. Retrieved, 26/5, 2016. from http://ws.moe.edu.tw/001/Upload/1/relfile/6490/38921/25d230a9-b497-4de5-be f3-a6d54b4667eb.xls]
教育部國語推行委員會(1999):國語文教育叢書18:常用國字標準字體筆順手冊。台北:教育部。 [National Languages Committee (1999). Chinese Language Education Series 18: Commonly Used Standard Character Stroke Order Manual. Taipei, Taiwan: Ministry of Education.]
莊德明、鄧賢瑛(2009):漢字構形資料庫的研發與應用。中研院資訊所文獻處理實驗室。取自中
研院資訊所文獻處理實驗室網站:http://cdp.sinica.edu.tw/service/documents/T090904.pdf.,
2016 年 5 月 26 日。[Chuang, D. M., & Deng, X. Y. (2009). Design and application of a Chinese character database. Report of Chinese Document Processing Lab. Retrieved, 26/5, 2016. from http://cdp.sinica.edu.tw/service/documents/T090904.pdf.]
陳秀芬(1999):中文一般字彙知識教學法在增進國小識字困難學生識字學習成效之探討。特殊教 育研究學刊,17,225-252。[Chen, H. F. (1999). The Study of Instruction of General Orthographic Knowledge of Chinese Characters on Elementary Students with Word-Recognition Difficulties. Bulletin of Special Education, 17, 225-252.]
陳學志、張瓅勻、邱郁秀、宋曜廷、張國恩(2011):中文部件組字與形構資料庫之建立及其在識 字教學上之應用。教育心理學報,閱讀專刊,43,269-299。[Chen, H. C., Chang, Li. Y., Chiou, Y. S., Sung, Y. T., Chang, K. E. (2011). Chinese Orthography Database and Its Application in Teaching Chinese Characters. Bulletin of Educational Psychology, Teaching Chinese Characters. Bulletin of Educational Psychology, 43(Special Issue on Reading), 269-299.]
曾昱翔、胡志偉、羅明、呂明蓁、呂菁菁(2014):從文字屬性檢驗小學國語課本生字之學習順序 的恰當性。教育心理學報,46(2),251-270。[Tseng, Y. H., Hu, C. W., Lo, M., Lu, M., & Lu, C. C. (2014). Examining the Appropriateness of Teaching Sequence of Chinese Characters in Chinese Elementary School Textbooks. Bulletin of Education Psychology, 46(2), 251-270.]
黃沛榮(2003):漢字教學的理論與實踐。台北:樂學書局。[Huang, P. J. (2003). Teaching and Learning Chinese Characters: Theory and Practice. Taipei, Taiwan: Lexis Book.]
黃沛榮(2011):論漢字教學相關的基礎研究。台灣華語文教學,11,16-24。[Huang, P. J. (2011). Fundamental Research on Teaching Chinese Characters. Taiwan Journal of Chinese as a Second Language, 11, 16-24.]
黃富順(1994):我國失學國民脫盲識字標準及脫盲識字字彙之研究。國立臺灣師範大學成人教育 研究中心專題研究報告。[Huang, F. S. (1994). A Study on the Standard of Literacy and Literacy Character List on Out of School Nationals. Report of Adult Education Research Center, National Taiwan Normal University, Taipei, Taiwan.]
葉素玲、李金鈴、陳洸民(1999):中文字型分類系統的再確立:類別與字數的控制。中華心理學 刊,41(1),65-85.[Yeh, S. L., Li, C. L., & Chen, H. M. (1999). Classification of the Shapes of Chinese Characters: Verification by Different Predesignated Categories and Varied Sample Sizes. Chinese Journal of Psychology, 41(1), 65-85.]
葉德明(1990):漢字認知基礎-從心理語言學看漢字認知過程。台北:師大。[Yeh, T. M. (1990). Cognitive Basis of Chinese Characters-On the Cognitive Process of Chinese Characters from Psycholinguistics. Taipei, Taiwan: National Taiwan Normal University Press.]
鄧守信(2009):對外漢語教學語法。台北:文鶴。[Teng, S. S. (2009). A Pedagogical Grammar of Chinese. Taipei, Taiwan: Crane Publishing.]
鄭昭明(1981):漢字認知的歷程。中華心理學刊,23,137-153。[Cheng, C. M. (1981). Perception of Chinese Character. ACTA Psychologica Taiwanica, 23, 137-153.]
鄭昭明、陳學志(1991):漢字的簡化對文字讀寫的影響。華文世界,62,86-104。[Cheng, C. M., & Chen, H. C. (1991). The Influence of the Simplification of Chinese Characters on the Reading and Writing. Chinese world, 62, 86-104.]
羅明、胡志偉、曾昱翔(2012):C-CAT2:中文正體與簡體字、構字部件及鄰近字分析軟體。中 華心理學刊,54(2),243-252。[Lo, M., Hue, C. W., Tseng, Y. H. (2012). C-CAT2: A Computer Software Used to Analyze Traditional and Simplified Chinese Characters, Character Components and Neighbors. Chinese Journal of Psychology, 54, 243-252.]
Chang, Y. N., Hsu, C. H., Tsai, J. L., Chen, C. L., & Lee, C. Y. (2015). A psycholinguistic database for traditional Chinese character naming, Behavior Research Methods, 48(1), 1-11.
Chen, Y. P., Allport, D. A., & Marshall, J. C. (1996). What Are the Functional Orthographic Units in Chinese Word Recognition: The Stroke or the Stroke Pattern? The quarterly journal of experimental psychology, 49A (4), 1024-1043.
Chen, H., Bukach, C. M., & Wong, A. C. (2013). Early electrophysiological basis of experience-associated holistic processing of Chinese characters. PLoS One, 8(4), e61221.
Chen, Y. C., & Yeh, S. L. (2015). Binding radicals in Chinese character recognition: Evidence from repetition blindness. Journal of Memory and Language, 78, 47-63.
Chung, K. H., Tong, X., & McBride-Chang, C. (2012). Evidence for a deficit in orthographic structure processing in Chinese developmental dyslexia: An event-related potential study. Brain research, 1472, 20-31.
Cunningham, A. E., Perry, K. E., & Stanovich , K. E. (2001). Converging evidence for the concept of orthographic processing. Reading and Writing, 14, 549-568.
Ding, G., Peng, D., & Taft, M. (2004). The nature of the mental representation of radicals in Chinese: A priming study. Journal of Experimental Psychology: Learning, Memory, and Cognition, 30, 530-539.
Feldman, L. B., & Siok, W. W. T. (1997). The role of component function in visual recognition of Chinese character. Journal of Experimental Psychology: Learning, Memory and Cognition, 23, 776-781.
Ho, C. S. H., Yau, P. W. Y., & Au, A. (2003). Development of orthographic knowledge and its relationship with reading and spelling among Chinese kindergarten and primary school children. In C. McBride-Chang & H. C. Chen (Eds.), Reading development in Chinese children (pp. 51-71). London: Praeger.
Hong, J. C., Wu, C. L., Chen, H. C., Chang, Y. L., & Chang, K. E. (2016). Effect of radical-position regularity for Chinese orthographic skills of Chinese-as-a-second-language learners. Computers in Human Behavior, 59, 402-410.
Hsiao, J. H. W., & Shillcock, R. (2006). Analysis of a Chinese Phonetic Compound Database: Implications for Orthographic Processing. Journal of Psycholinguistic Research, 35, 405-426. Huang, H. S., & Hanley, J. R. (1994). Phonological awareness and visual skills in learning to read
Chinese and English. Cognition, 54, 73-98.
Kim, S. A., Packard, J., Christianson, K., Anderson, R. C., & Shin, J. A. (2016). Orthographic consistency and individual learner differences in second language literacy acquisition. Reading and Writing, 29(7), 1409-1434.
Kuo, L. J., Kim, T. J., Yang, X., Li, H., Liu, Y., Wang, H., Hyun Park, J., & Li, Y. (2015). Acquisition of Chinese characters: the effects of character properties and individual differences among second language learners. Front. Psychol, 6, 986.
Leck, K. J., Weekes, B. S., & Chen, M. J. (1995). Visual and phonological pathways to the lexicon: Evidence from Chinese readers. Memory & Cognition, 23, 468-476.
Lee, S. Y., Stigler, J. W., & Stevenson, H. W. (1986). Beginning reading in Chinese and English. In B. R. Foorman & A. W. Siegel (Eds.), Acquisition of reading skills: Cultural constraints and cognitive universals (pp. 123-150). Hillsdale, NJ: Erlbaum.
Lin, C. H., & Collins P. (2012). The effects of L1 and orthographic regularity and consistency in naming Chinese characters. Reading and Writing, 25(7), 1747-1767.
Li, H., Shu, H., McBride-Chang, C., Liu, H. Y., Peng, H. (2012). Chinese children’s character recognition: Visuo-orthographic, phonological processing and morphological skills. Journal of Research in Reading, 35, 287-307.
Li, Y. & Kang, J. (1993). Analysis of phonetics of semantic-phonetic compound characters in modern Chinese. In Y. Chen (Eds.), Information analysis of usage of characters in modern Chinese (pp. 84-98). Shanghai: Shanghai Education Publisher.
Liu, Y., Shu, H., & Li, P. (2007). Word naming and psycholinguistic norms: Chinese. Behavior Research Methods, 39, 192-198.
McBride-Chang, C., & Zhong, Y. (2003). A longitudinal study of effects of phonological processing, visual skills, and speed of processing on Chinese character acquisition among Hong Kong Chinese kindergartners. In C. McBride-Chang, & H. Chen (Eds.), Reading development in Chinese children (pp. 20-37). Westport, CT: Praeger.
Share, D. L. (1995). Phonological recoding and self-teaching: Sine qua non of reading acquisition. Cognition, 55, 151-218.
Shu, H., & Anderson, R. C. (1998). Learning to read Chinese: The development of metalinguistic awareness. In J. Wang, A. W., Inhoff, & H. C. Chen (Eds.), Reading Chinese script: A cognitive analysis (pp. 1-18). Mahwah, NJ: Lawrence Erlbaum.
Siok, W. T., Spinks, J. A., Jin, Z., & Tan, L. H. (2009). Developmental dyslexia is characterized by the co-existence of visuospatial and phonological disorders in Chinese children. Current Biology, 19, 890-892.
Stanovich, K. E. (2000). Progress in understanding reading: Scientific foundations and new frontiers. New York, NY: Guilford Publications.
Taft, M., Zhu, X., & Peng, D. (1999). Positional specificity of radicals in Chinese character recognition. Journal of Memory and Language, 40, 498-519.
Tan, L. H., Spinks, J. A., Eden, G. F., Perfetti , C. A., & Siok , W. T. (2005). Reading depends on writing, in Chinese. Proc Natl Acad Sci USA, 102(24), 8781-8785.
Wang, T., Li, H., Zhang, Q. L., Tu, S., Yu, C. Y., & Qiu, J. (2009). Comparison of brain mechanisms underlying the processing of Chinese characters and pseudo-characters: an event-related potential study. International Journal of Psychology, 45(2), 102-110.
Yeh, S. L. (2000). Structure detection of Chinese characters: visual search slope as an index of similarity between different-structured characters. Chinese Journal of Psychology, 42(2), 191-216.
Yeh, S. L., Li, J. L., Takeuchi, T., Sun, V. C., & Liu, W. R. (2003). The role of learning experience on the perceptual organization of Chinese characters. Visual Cognition, 10, 729-264.
Zhang, J., Li, H., Dong, Q., Xu, J. & Sholar, E. (2016). Implicit use of radicals in learning characters for nonnative learners of Chinese. Applied Psycholinguistics, 37, 1-21.
收 稿 日 期:2016 年 05 月 31 日 一稿修訂日期:2017 年 07 月 31 日 二稿修訂日期:2017 年 08 月 29 日 三稿修訂日期:2017 年 09 月 08 日 接受刊登日期:2017 年 09 月 14 日
Bulletin of Educational Psychology, 2018, 49(3), 487-511 National Taiwan Normal University, Taipei, Taiwan, R.O.C.
A Corpus-based Analysis of Radical Position and the
Degree of Freedom of Permissible Positions and
Examination of the Influential Radical Properties
Chien-Chih Tseng
Hsueh-Chih Chen
Li-Yun Chang
Department of Educational Psychology and Counseling Department of Chinese as a Second Language National Taiwan Normal University National Taiwan Normal
University
Jon-Fan Hu
Shiou-Yuan Chen
Department of Psychology Department of Early Childhood Education National Cheng Kung University Taipei Municipal University of Education Chinese characters are composed of radicals appearing in non-linear spatial configurations. Although the visual complexity of Chinese orthography has been widely recognized, the probability that a radical appears in a permissible position within a configuration is yet to be investigated. This understanding of what patterns of radicals are spatially arranged would be crucial for mastering Chinese orthographic knowledge. The present study aims to analyze the positions of 438 radicals extracted from 4,808 most frequently used Chinese characters according to 22 permissible positions. The results reveal three main findings. First,on average, each radical has 2.66 permissible positions. Second, 33% of the 438 radicals exhibit extremely high position-based regularity (i.e., they only appear in one particular position). Third, only the factor “non-character” could predict high position-based regularity. Overall, the findings spell out the statistical regularities underlying the composition of radicals and their arranged positions within different configurations. Supporting examples and the implications of these regularities for learning and teaching Chinese characters are offered and discussed.
KEY WORDS: Chinese character, Character learning and instruction, Othography, Position-based regularity of radicals, Radicals