行政院國家科學委員會專題研究計畫 成果報告
整合及開發人工智慧與語言科技以輔助語文教學活動
研究成果報告(精簡版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 99-2221-E-004-007-
執 行 期 間 : 99 年 08 月 01 日至 100 年 12 月 31 日
執 行 單 位 : 國立政治大學資訊科學系
計 畫 主 持 人 : 劉昭麟
計畫參與人員: 碩士班研究生-兼任助理人員:莊宜軒
碩士班研究生-兼任助理人員:陳建良
碩士班研究生-兼任助理人員:張裕淇
碩士班研究生-兼任助理人員:蔡家琦
碩士班研究生-兼任助理人員:王瑞平
報 告 附 件 : 出席國際會議研究心得報告及發表論文
公 開 資 訊 : 本計畫涉及專利或其他智慧財產權,2 年後可公開查詢
中 華 民 國 100 年 12 月 27 日
中 文 摘 要 : 本年度之工作重點在於應用倉頡碼來判別形體相似的漢字,
配合語音相近漢字的資訊來建構一個有用的漢字學習輔助系
統。在計算語言學方面,我們繼續探索一些與機器翻譯相關
的研究議題。在自然語言處理技術的應用方面,我們觸及美
國財報的意見分析與個人網誌上的情緒分析。為了建構好的
電腦輔助教學系統,了解學習者的文字辨識、認知歷程是很
相關的議題,因此我們也與心理學家進行一些合作的研究並
且發表一些相關的論文。
在本年度計畫期間之內(2010 年 8 月到 2011 年 7 月,7 月至
12 月為等待參與國際學術研討會之參與時間和經費核銷)合
計發表一篇 ACM 期刊論文、四篇國際會議論文與五篇國內學
術會議論文。另有受本研究計劃之部分補助,目前已經被接
受但未正式發表之兩篇國際學術會議論文與一篇國內學術會
議論文。審稿中之論文有:國際學術會議論文三篇與國內學
術會議論文三篇。
以下就各主要研究方向摘要說明工作內容與相關成果。
延續過去一兩年的努力,我們持續於去年度擴大倉頡詳碼的
應用。我們把倉頡詳碼的概念延伸到簡體漢字,並且建立一
個雛型軟體。比較重要的成果是我們終於回頭整理過去幾年
發表於 ACL 和 COLING 的論文,並且把論文投稿於 ACM 的
TALIP 且獲得接受。這一部分的論文發表是:J1、IC5 和 IC6
(請參考文末之論文清單)。
我們延伸形音相近漢字的基礎研究,建構一個有心理認知理
論基礎的漢字學習遊戲,這一遊戲能夠真實的協助學童學習
漢字,目前已經實際用於台北市兩個國小。相關研究成果發
表於 IC3 和 DC3。
除了漢字遊戲之外,我們也嘗試研究一些認知與教育相關的
議題。我們研究漢字母與使用者的眼動軌跡,企圖了解眼動
軌跡與中文斷詞的關連,雖然沒有驚人的發現,但是已經將
成果發表於 IC4。我們結合文字分析技術與機器學習技術,
企圖分析高中一年級與二年級的英文閱讀測驗的文本難度,
結果尚稱不錯,研究過程與結果發表於 DC4。
雖然機器翻譯目前仍然不是我們的研究的主要目標,但是透
過以機器翻譯作為假想目標,來培養實驗室的基礎研發能
力,卻是一個不錯的手段。過去幾年我們陸續在這一方面有
一些努力。包含與師範大學曾元顯教授參與 NTCIR9 的
PatentMT 工作坊的競賽,雖然我們沒有全心、長期投入,但
是也沒有因此落入最後一名;甚至翻譯效果也沒有輸給沒有
適當訓練語料的一般翻譯軟體。在機器翻譯相關的議題方
面,過去一年我們建立詞彙對列的經驗,並且結合過去的相
關經驗,開始嘗試比較接近機器翻譯議題的動詞名詞組的翻
譯。這一方面的工作成果發表於 DC1 和 DC5。目前也已將部
份成果投稿於國際學術研討會。
在過去一年中,本研究計畫最顯著的成果在於結合自然語言
處理技術與機器學習技術來處理美國財報中的文字與數據的
關連性。我們利用自然語言技術抽取財報中的質性判斷的主
觀陳述,並且利用統計模型來比對這一些意見與經營數據的
關聯性。本研究成果榮獲 2011 年計算語言學會的碩士論文佳
作獎與 IEEE ICEBE 2011 年最佳論文獎。這一研究的成果目
前發表於 IC1 和 IC2。在達成這一文字意見探勘之前,本研
究計畫已經進行一些比較先導的探索工作,研究個人微網誌
中的情緒分析,並且將成果發表於 DC2 和 DC6。
本研究計畫所研究的核心技術雖然集中於自然語言處理與機
器學習技術的綜合應用,但是要為個別研究撰寫目的、研究
方法與成果之細節,因此謹以上述的綜合摘要報告本研究案
的綜合成果。個別研究成果的細節,煩請參閱所發表之論
文,如若無法下載論文,請與計畫主持人連繫索取論文。我
們僅附上所發表之 ACM 期刊論文和 IEEE ICEBE 論文作為代表
作品。
中文關鍵詞: 漢字學習輔助、閱讀認知歷程、意見分析、財報內容分析
英 文 摘 要 :
行政院國家科學委員會補助專題研究計畫
█ 成 果 報 告
□期中進度報告
整合及開發人工智慧與語言科技以輔助語文教學活動
計畫類別:█ 個別型計畫 □ 整合型計畫
計畫編號: NSC-99-2221-E-004-007
執行期間: 2010 年 8 月 1 日至 2011 年 12 月 31 日
計畫主持人:劉昭麟
共同主持人:
計畫參與人員:莊怡軒、陳建良、張裕淇、蔡家琦、王瑞平
成果報告類型(依經費核定清單規定繳交):□精簡報告 █完整報告
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
█出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、
列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢
執行單位:國立政治大學資訊科學系
中 華 民 國 2011 年 12 月 26 日
中文摘要 (Chinese abstract)
本年度之工作重點在於應用倉頡碼來判別形體相似的漢字,配合語音相近漢字的資訊來建
構一個有用的漢字學習輔助系統。在計算語言學方面,我們繼續探索一些與機器翻譯相關
的研究議題。在自然語言處理技術的應用方面,我們觸及美國財報的意見分析與個人網誌
上的情緒分析。為了建構好的電腦輔助教學系統,了解學習者的文字辨識、認知歷程是很
相關的議題,因此我們也與心理學家進行一些合作的研究並且發表一些相關的論文。
在本年度計畫期間之內(2010 年 8 月到 2011 年 7 月;7 月到 12 月期間為等待參與國際
學術研討會與經費核銷)合計發表一篇 ACM 期刊論文、四篇國際會議論文與五篇國內學術
會議論文。另有受本研究計劃之部分補助,目前已經被接受但未正式發表之兩篇國際學術
會議論文與一篇國內學術會議論文。審稿中之論文有:國際學術會議論文三篇與國內學術
會議論文三篇。
以下就各主要研究方向摘要說明工作內容與相關成果。
延續過去一兩年的努力,我們持續於去年度擴大倉頡詳碼的應用。我們把倉頡詳碼的
概念延伸到簡體漢字,並且建立一個雛型軟體。比較重要的成果是我們終於回頭整理過去
幾年發表於 ACL 和 COLING 的論文,並且把論文投稿於 ACM 的 TALIP 且獲得接受。這
一部分的論文發表是:J1、IC5 和 IC6 (請參考文末之論文清單)。
我們延伸形音相近漢字的基礎研究,建構一個有心理認知理論基礎的漢字學習遊戲,
這一遊戲能夠真實的協助學童學習漢字,目前已經實際用於台北市兩個國小。相關研究成
果發表於 IC3 和 DC3。
除了漢字遊戲之外,我們也嘗試研究一些認知與教育相關的議題。我們研究漢字母與
使用者的眼動軌跡,企圖了解眼動軌跡與中文斷詞的關連,雖然沒有驚人的發現,但是已
經將成果發表於 IC4。我們結合文字分析技術與機器學習技術,企圖分析高中一年級與二
年級的英文閱讀測驗的文本難度,結果尚稱不錯,研究過程與結果發表於 DC4。
雖然機器翻譯目前仍然不是我們的研究的主要目標,但是透過以機器翻譯作為假想目
標,來培養實驗室的基礎研發能力,卻是一個不錯的手段。過去幾年我們陸續在這一方面
有一些努力。包含與師範大學曾元顯教授參與 NTCIR9 的 PatentMT 工作坊的競賽,雖然我
們沒有全心、長期投入,但是也沒有因此落入最後一名;甚至翻譯效果也沒有輸給沒有適
當訓練語料的一般翻譯軟體。在機器翻譯相關的議題方面,過去一年我們建立詞彙對列的
經驗,並且結合過去的相關經驗,開始嘗試比較接近機器翻譯議題的動詞名詞組的翻譯。
這一方面的工作成果發表於 DC1 和 DC5。目前也已將部份成果投稿於國際學術研討會。
在過去一年中,本研究計畫最顯著的成果在於結合自然語言處理技術與機器學習技術
來處理美國財報中的文字與數據的關連性。我們利用自然語言技術抽取財報中的質性判斷
的主觀陳述,並且利用統計模型來比對這一些意見與經營數據的關聯性。本研究成果榮獲
2011 年計算語言學會的碩士論文佳作獎與 IEEE ICEBE 2011 年最佳論文獎。這一研究的成
果目前發表於 IC1 和 IC2。在達成這一文字意見探勘之前,本研究計畫已經進行一些比較
先導的探索工作,研究個人微網誌中的情緒分析,並且將成果發表於 DC2 和 DC6。
本研究計畫所研究的核心技術雖然集中於自然語言處理與機器學習技術的綜合應用,
但是要為個別研究撰寫目的、研究方法與成果之細節,因此謹以上述的綜合摘要報告本研
究案的綜合成果。個別研究成果的細節,煩請參閱所發表之論文,如若無法下載論文,請
與計畫主持人連繫索取論文。我們僅附上所發表之 ACM 期刊論文和 IEEE ICEBE 論文作為
代表作品。
英文摘要 (English abstract)
We worked on a relatively wide range of projects in the past year. We applied the ideas of
extended Cangjie codes to simplified Chinese characters, and built realistic applications. We
continued to explore selected issues in Machine Translation to strengthen our fundamental
technical power. Opinion mining became a major part of our work this year, and we attempted to
extract opinion patterns from person micro-blogs and US financial statements. On the front of
computer assisted language learning, we cooperated with psycholinguistic researchers to study
how native speakers learn Chinese characters.
During the course of this research, i.e., between August 2010 and July 2011, we published
one ACM journal article, four international conference papers, and five domestic conference
papers. In addition, at the time of this writing, we have two papers and one paper accepted by
international and domestic conferences, respectively. Moreover, six papers were under reviewed –
three for international and three for domestic conferences.
A brief summary for each major research direction of ours follows.
We have worked on the applications of Cangjie codes for a couple of years. In the past year,
we extended the work to simplified Chinese characters. We also found the time to collect past
achievements that we published in ACL and COLING, submitted the report to ACM TALIP, and,
luckily, had the paper accepted. Papers that described our findings are listed in J1, IC5, and IC6
(Please be referred to the publication list.).
Based on the experience and capability of recommending visually and phonologically
similar Chinese characters, we cooperated with psycholinguistic researchers to build a game for
learning Chinese characters. The game has been using by elementary schools in Taipei. The
research results were published in IC3 and DC3.
Reading is a fascinating process. We worked with a psychologist, Professor Tsai, to track the
eye movements of native speakers when they read traditional Chinese. We wondered whether
there would be any interesting relationship between the eye movements and the segmentation of
Chinese characters. The currents results, published in IC4, were not very decisive, and demanded
more research work.
For computer assisted Chinese learning, we also worked on the classification of short essays
used in the reading comprehension of high school students. The goal was to judge the grades of
the short essays that were used in the first four semesters of grade 10 and 11. We did not find a
method that perfectly find the correct answer, but have attempted to improve from the very first
version. Please be referred to DC4 for details.
Machine translation (MT) may be too tough for a small research group like ours. However,
targeting at MT issues, at least sometimes, helps us maintain the ambition and technical
competence. Working with Professor Yuen-Hsien Tseng of the National Taiwan Normal
University, we participated in the NTCIR9 PatentMT task in 2011. Although we did not spend a
lot of time and energy on the task, we did not perform poorly in the task, and was able to beat
another team. Interestingly, according to the estimation of the task organizers, our results would
have beaten Google, given that Google did not have the training data that we obtained from the
task organizers. Besides our participation in the NTCIR task, we nurtured our competence in MT
regularly, and had experience in word alignment and translation of verb-noun pairs. The results
had been published in DC1 and DC5, and some recent findings have been submitted for possible
publication in international conferences.
The most salient research results of our group are the mining of opinion mining in US
financial statements. We integrated techniques for natural language processing and machine
learning to find the opinion patterns in US financial statements in the form of multiple word
expressions (MWEs). Statistical models were then utilized to examine the relationships between
the MWEs and the financial ratios in the statements. This work received a 2011 Honorable
Mention Award for Master’s thesis by the Association for Computational Linguistics and Chinese
Processing, and results were published in IC1 and IC2. Before we completed this work, we had
started some explorative work. We analyzed the emotional ingredients in the short statements in
personal micro-blogs, and the results were published in DC2 and DC6.
Due to the wide variety of our work, we could not report the details of each of our projects
as demanded by the standard formats of the NSC final reports. Instead, we summarized the goals
and accomplishments of each projects above only, and provided our ACM and IEEE ICEBE
papers as the representative achievements. If the readers are interested in any of our projects,
please be referred to the papers listed in References. If papers cannot be downloaded easily,
please contact the principal investigator for the papers.
計畫成果自評 (Self evaluation)
整體來說,以一個一年期的研究計畫新台幣 58 萬的研究經費來說,以上的成果應該算是超
過勉強交差的程度。在論文發表數量與質量兩方面都有中上的水準,並且建立一個真實可
用的軟體提供國小教學之用。
在人才培養方面,今年應屆畢業三位碩士班研究生,一位應聘於臺灣雅虎,一位應聘
於資訊工業策進會,一位入伍服役。整體來說算是合乎期待。
本年度至 2011 年 11 月發表之論文 (References)
(A) 期刊論文 (Journal articles)
J1. C.-L. Liu, M.-H. Lai(賴敏華), K.-W. Tien(田侃文), Y.-H. Chuang(莊怡軒), S.-H. Wu(吳世弘), C.-Y. Lee(李 佳穎). Visually and phonologically similar characters in incorrect Chinese words: Analyses, identification, and applications, ACM Transactions on Asian Language Information Processing, 10(2), 10:1-39, ACM, June 2011. (NSC-99-2221-E-004-007-) (NSC-97-2221-E-004-007-MY2)
(B) 研討會論文 (Conference papers)
國際學術會議 (international conferences)
IC1. Chien-Liang Chen(陳建良), Chao-Lin Liu, Yuan-Chen Chang(張元晨), and Hsiangping Tsai(蔡湘萍). Mining opinion holders and opinion patterns in US financial statements, Proceedings of the 2011
Conference on Technologies and Applications of Artificial Intelligence (TAAI'11), 62-68. Taoyuan, Taiwan, 11-13 November 2011. (EI) (NSC-99-2221-E-004-007) (NSC-100-2221-E-004-014)
IC2. Chien-Liang Chen(陳建良), Chao-Lin Liu, Yuan-Chen Chang(張元晨), and Hsiangping Tsai(蔡湘萍). Exploring relationships between annual earnings and subjective expressions in US financial statements, Proceedings of the IEEE International Conference on e-Business Engineering 2011 (ICEBE'11), 1-8. Beijing, China, 19-21 October 2011. (EI) (NSC-99-2221-E-004-007) (NSC-100-2221-E-004-014) (最佳論 文講)
IC3. C.-L. Liu, C.-Y. Lee(李佳穎), J.-L. Tsai(蔡介立), and C.-L. Lee(李嘉玲). A cognition-based interactive game platform for learning Chinese characters, Proceedings of the Twenty Sixth ACM Symposium on Applied Computing (ACM SAC'11), accepted. Taichung, Taiwan, 21-24 March, 2011. (EI)
(NSC-97-2221-E-004-007-MY2) (NSC-99-2221-E-004-007)
IC4. C.-L. Liu, J.-Y. Weng(翁睿妤), Y.-H. Chuang(莊怡軒), and J.-L. Tsai(蔡介立). An exploration of native speakers' eye fixations in reading Chinese text, Proceedings of the 2010 Conference on Technologies and Applications of Artificial Intelligence (TAAI'10), 66ԟ71. Hsinchu, Taiwan, 18-20 November 2010. (EI) (NSC-97-2221-E-004-007-MY2) (NSC-99-2221-E-004-007)
IC5. S.-H. Wu(吳世弘), Y.-Z. Chen(陳勇志), P.-C. Yang(楊秉哲), T. Ku(谷圳), and C.-L. Liu. Reducing the false alarm rate of Chinese character error detection and correction, Proceedings of the First CIPS-SIGHAN Joint Conference on Chinese Language Processing (CLP'10), 54ԟ61. Beijing, China, 28-29 August 2010. (NSC-97-2221-E-004-007-MY2) (NSC-99-2221-E-004-007)
IC6. C.-L. Liu, M.-H. Lai(賴敏華), Y.-H. Chuang(莊怡軒), and C.-Y. Lee(李佳穎). Visually and phonologically similar characters in incorrect simplified Chinese words, Proceedings of the Twenty Third International Conference on Computational Linguistics (COLING'10), posters, 739ԟ747. Beijing, China, 23-27 August 2010. (NSC-97-2221-E-004-007-MY2) (NSC-99-2221-E-004-007)
國內學術會議 (domestic conferences)
DC1. 莊怡軒、王瑞平、蔡家琦及劉昭麟。英文技術文獻中一般動詞與其受詞之中文翻譯的語境效用 (Collocational influences on the Chinese translation of non-technical English verbs and their objects in technical documents),第廿三屆自然語言與語音處理研討會論文集 (ROCLING XXIII),即將出版。 臺灣,臺北,2011 年 9 月 8-9 日。(中文內容) (NSC-99-2221-E-004-007) (NSC-100-2221-E-004-014) DC2. 莊怡軒、陳建良、劉昭麟及劉吉軒。失戀被動分手者情感挫折偵測之初探,第十五屆人工智慧與應 用研討會論文集 (TAAI'10),論文光碟。臺灣,新竹,2010 年 11 月 18-20 日。(中文內容) (NSC-97-2221-E-004-007-MY2) (NSC-99-2221-E-004-007) DC3. 李嘉玲、張裕淇、李佳穎及劉昭麟。結合認知理論之電腦輔助漢字教學遊戲,2010 台灣網際網路 研討會論文集 (TANET'10),論文光碟。臺灣,臺南,2010 年 10 月 27-29 日。(中文內容) (NSC-97-2221-E-004-007-MY2) (NSC-99-2221-E-004-007) DC4. 黃昭憲、郭韋狄、李嘉玲、蔡家琦及劉昭麟。以語文特徵為基之中學閱讀測驗短文分級 (Using linguistic features to classify texts for reading comprehension tests at the high school levels),第廿二屆自 然語言與語音處理研討會論文集 (ROCLING XXII),98ԟ112。臺灣,南投,2010 年 9 月 1-2 日。(中 文內容) (NSC-97-2221-E-004-007-MY2) (NSC-99-2221-E-004-007)
DC5. 黃昭憲、張裕淇、劉昭麟及曾元顯。以共現資訊為基礎增進中學英漢翻譯試題與解答之詞彙對列 (Using co-occurrence information to improve Chinese-English word alignment in translation test items for high school students),第廿二屆自然語言與語音處理研討會論文集 (ROCLING XXII),128ԟ142。 臺灣,南投,2010 年 9 月 1-2 日。(中文內容) (NSC-97-2221-E-004-007-MY2) (NSC-99-2221-E-004-007) DC6. 孫瑛澤、陳建良、劉峻杰、劉昭麟及蘇豐文。中文短句之情緒分類 (Sentiment classification of short Chinese sentences),第廿二屆自然語言與語音處理研討會論文集 (ROCLING XXII),184ԟ198。臺 灣,南投,2010 年 9 月 1-2 日。(中文內容) (NSC-97-2221-E-004-007-MY2) (NSC-99-2221-E-004-007)
附錄:發表論文之代表作
C.-L. Liu, M.-H. Lai(賴敏華), K.-W. Tien(田侃文), Y.-H. Chuang(莊怡軒), S.-H. Wu(吳世弘), C.-Y. Lee(李佳穎). Visually and phonologically similar characters in incorrect Chinese words: Analyses, identification, and applications, ACM Transactions on Asian Language Information Processing, 10(2), 10:1-39, ACM, June 2011.
Chien-Liang Chen(陳建良), Chao-Lin Liu, Yuan-Chen Chang(張元晨), and Hsiangping Tsai(蔡湘萍). Exploring relationships between annual earnings and subjective expressions in US financial statements, Proceedings of the IEEE International Conference on e-Business Engineering 2011 (ICEBE'11), 1-8. Beijing, China, 19-21 October 2011. (EI) (NSC-99-2221-E-004-007) (NSC-100-2221-E-004-014) (最佳論文獎)
國科會補助專題研究計畫項下出席國際學術會議心得報告
日期: 100
年 10 月 24 日
一、 參加會議經過及與會心得
十月十八日:上午在政治大學講授資訊檢索課程,中午下課之後立即前往機場。搭乘三點四十五
分之華航班機前往北京首都機場。抵達首都機場之後,換乘機場快軌、地鐵之後步行至投宿之飯
店。稍事休息,準備隔天之口頭報告與議程。
北京首都機場到市中心的連結現在已經相當完善,透過機場快軌的連結,外國旅客可以方便地在
離開機場之後進入市中心,然後再利用市中心的捷運系統到達主要的飯店。
十月十九日:上午之議程為開幕與兩場專題演講,下午有兩階段的論文報告,其中包含最佳論文
競賽,晚上則是晚宴。
開幕式中,議程主席報告本次會議投稿數量為 119 篇,大會論文之接受率為 21.8。這是第八屆
ICEBE 研討會,與會者來自全球五大洲。比起 ICEBE 初創時,這一研討會已經有相當的成長,
加上每兩年與 IEEE Conference on Commerce and Enterprise Computing 合辦,已經逐漸成長為 IEEE
中電子商務相關的主要研討會。
兩場專題演講中,第一場演講的主講者為澳洲 University of New South Wales 的 Benatallah 教授。
講者認為將來軟體服務的末端使用者有可能須要從是有限度的程式設計,來組合現在已經非常多
樣化的網路服務。第二場的主講者應為中國 IBM 研究中心的 Shen 博士,但是臨時有事所以派遣
另一研究員取代。講題是關於國內臺灣大學現在也在積極開發的 Internet of Things (IoT)的概念。
雖然是專題演講的內容,但是我個人不覺得要求末端使用者自己作有限度的程式設計的可能性。
服務提供者,應該將所欲提供之服務作最好的包裝,讓使用者就是使用者,而不必自己介入技術
的部分。如若不同服務的整合須要進一步整合,則可能有一些技術服務者可以作為中介,但是這
樣的能力需求不應該落到末端使用者的身上。
IoT 是一個很有趣的應用領域,跟早年 e-Business 一樣,將是影響國家基礎建設的重要基石。不
過我們可以思考一下,那一些服務真的能夠也須要 IoT 的概念。
下午的論文報告包含最佳論文獎的競賽,我們的論文也是五篇參賽論文之一。在包含參賽論文的
場次之中,有多位評審教授參與,因為須要實質評比參賽論文,所以問答相當踴躍。
我個人在最佳論文競賽之後的第二段場次擔任場次主席,該場次有五篇論文,論文的品質與報告
水準,都明顯地不如最佳論文的競賽論文,但是可以看出都是有所準備的好論文。有一些論文則
是報告者的英文有待改進,所以比較難以與一般與會者完成技術交流的目的。
計畫編號
NSC-99-2221-E-004-007
計畫名稱
整合及開發人工智慧與語言科技以輔助語文教學活動
出國人員
姓名
劉昭麟
服務機構
及職稱
國立政治大學資訊科學系教授
會議時間
100 年 10 月 19 日至
100 年 10 月 20 日
會議地點
北京市清華大學
會議名稱
(中文)
(英文) IEEE International Conference on e-Business Engineering 2011
發表論文
題目
(中文)
(英文) Exploring the relationships between annual earnings and subjective
expressions in US financial statements (最佳論文獎)
晚上的晚宴在清華大學的餐廳進行。原本是要頒發最佳論文獎,但是因故拖延到二十日的午宴。
晚宴中,大會頒發感謝狀給主辦單位的許多老師。也介紹了明年的會議地點與主辦單位。
十月二十日:上午持續有兩階段的論文報告,中午則是午宴與頒獎。
上午的論文報告的出席者多為國際學者,這或許是為了方便這一些學者先來參與晚宴,然後再次
日報告。報告內容的英文優於昨日下午,技術層次則約略相同。
午宴中頒發這一次最佳論文獎,入圍與得獎論文合計有五篇,政大的論文有幸脫穎而出,獲得唯
一的最佳論文獎。午宴持續到接近下午兩點才結束。
二、 考察參觀活動(無是項活動者略)
由於返國的班機預訂在八點起飛,而二十日中午的午宴到接近兩點才結束,因此實際上不可能參
與任何遠距的參觀活動。在搭機之前只有到天安門廣場旁邊參觀。當天中國國家博物館與三點就
閉館,因此改變原訂的參觀計畫;改到旁邊的中山公園。中山公園中正在展出辛亥革命百年紀念
的資料。可以靠到許多關於中國國民黨的資料。這樣的資料在過去或許不容易在天子腳下的北京
市看到,但是現在這些陳列似乎是很平常的,就好像我們在歷史課本中讀明史、清史一樣。
三、建議
四、攜回資料名稱及內容
會議論文光碟、最佳論文獎獎狀
五、其他
Exploring the Relationships between Annual Earnings and Subjective Expressions
in US Financial Statements
Chien-Liang Chen
Chao-Lin Liu
Yuan-Chen Chang
Hsiang-Ping Tsai
Dept. of Computer Science Dept. of Computer Science Dept. of Finance Dept. of Finance National Chengchi University National Chengchi University National Chengchi University Yuan Ze University
Taipei, Taiwan Taipei, Taiwan Taipei, Taiwan Taoyuan, Taiwan
[email protected] [email protected] [email protected] [email protected]
Abstract—Subjective assertions in financial statements influence the judgments of market participants when they assess the value and profitability of the reporting corporations. Hence, the managements of corporations may attempt to conceal the negative and to accentuate the positive with "prudent" wording. To excavate this accounting phenomenon hidden behind financial statements, we designed an artificial intelligence based strategy to investigate the linkage between financial status measured by annual earnings and subjective multi-word expressions (MWEs). We applied the conditional random field (CRF) models to identify opinion patterns in the form of MWEs, and our approach outperformed previous work employing unigram models. Moreover, our novel
algorithms take the lead to discover the evidences that support the common belief that there are inconsistencies between the implications of the written statements and the reality indicated by the figures in the financial statements. Unexpected negative earnings are often accompanied by ambiguous and mild statements and sometimes by promises of glorious future.
Keywords-Natural language processing, opinion mining, financial text mining, sentiment analysis, information extraction
I. INTRODUCTION
In recent years, researchers have implemented quantitative methods to investigate the relationships between financial performance and the textual content of the press. Loughran and McDonald developed positive and negative single-word lists, that better reflected the tone of U.S. financial statements (10-K filings), and they examined the linkage between textual statements and financial figures [15]. Antweiler and Frank studied the influence of the discussions on Internet message boards about 45 companies, which list in the Dow Jones Industrial Average, and their stock prices. They concluded that stock messages could help predict market volatility but not stock returns [1]. Li relied on the information in the texts of annual financial statements to examine the implications of risk sentiment of corporation's 10-K filings for stock returns and future earnings. Li found that risk sentiment is negatively correlated with future earnings and future stock returns [13]. Tetlock et al. used negative words contained in the financial press about the S&P 500 to show that the negative words are useful predicators for both earnings and returns [27].
Some researchers in opinion mining have employed different machine learning techniques. Pang et al. utilized the concept of naive Bayes, maximum entropy classification, and support vector machines to classify the sentiment of movie reviews at the document level [19]. Weibie et al. classified subjective sentences based on syntactic features such as the syntactic categories of the constituents [28]. Kim and Hovy used syntactic features to identify the opinion holders in the MPQA
corpus by a ranking algorithm that considered maximum entropy [11]. Choi et al. adopted a hybrid approach that combined CRF and the AutoSlog information extraction learning algorithm to identify sources of opinions in the MPQA corpus [4].
Unlike traditional models that considered individual words (unigrams) and "bag of words" [17], we attempt to automatically extract MWEs which could capture the subjective evaluations of the financial status of the corporation more precisely. Opinion patterns include opinion holders and subjective multi-word expressions (MWEs). For instance, the opinion patterns in the sentence "The Company believes the profits could be adversely affected" include opinion holder "The Company" and two subjective expressions: "believe" and "could be adversely affected".
Our leading contribution is to link positive and negative financial status with subjective multi-word expressions and to propound that the managements of the companies have an incentive to hide negative information but to promote positive information. First, we propose a computational procedure to model the text in financial statements which uses conditional random field models to identify opinion patterns. Second, we trained and tested the models with the annotated MPQA corpus [18] to tune and evaluate the CRF models. Third, we employed the best-performing CRF model that we found from a sequence of experiments to extract subjective opinion patterns in U.S. financial statements. Fourth, we employed multinomial logistic regression to verify whether the opinion patterns were indicative of the earnings of the corporations, and also designed a discriminative strategy to quantify the linkages between annual earnings and the use of subjective MWEs. Finally, using the algorithmically-identified MWEs, we examined whether companies indeed expressed different strengths of positivity and negativity for different earning outcomes, and we found that the companies inclined to use weaker expressions when mentioning negative results.
II. FINANCIAL DATA AND CORPORA
The financial statements used in this work are U.S. SEC 10-K filings of public companies downloaded from the EDGAR database [6]. We also used annual quantitative information about the companies from the Compustat database [23]. Opinion patterns were extracted from the financial statements of 324 U.S. companies for the years between 1996 and 2007, and we merged two different data sources (EDGAR and Compustat) by matching company names and dates (The matching table is provided by Sufi [25]). After eliminating the data with missing values, the number of data items was reduced from 2102 to 1421 to produce what may be describe as a "small dataset". In robustness test, we expanded our sample size from 1421 to 22780 which sample included reports of 6534 U.S. companies
ranging from the year 1996 to 2007, and the data with missing values also be dropped.
The task of the identification of opinion patterns was conducted at the sentence level by using the MPQA corpus [18]. We used the corpus to train the opinion patterns identification model and selected tagging labels which included five different aspects of labels "agent", "expressive-subjectivity", "objective speech event", "direct-subjective" and "target". The IOB format is employed (Ramshaw and Marcus [21]). In Table 1 "according to" is tagged as "B-objective speech event" and "I-objective speech event" in sequence, where "B" stands for the first word of a phrase and "I" stands for the internal word of a phrase. The single word "believe" is both the first and the internal word of a segment, and would be tagged as "B-direct-subjective".
III. OPINION PATTERN IDENTIFICATION:CRFMODELS This section explains how we attained our linguistic features and built the opinion patterns identifications with linear chain CRF models. The CRF models would be evaluated by the MPQA corpus in section V and also would be applied to the extraction of subjective expressions in the financial statement. A. CRF models and feature sets
The identification of opinion patterns is viewed as a sequential tagging problem which necessitates the incorporation of morphological, orthographical, predicate-argument structure, syntactic and simple semantic features to train the linear-chain conditional random field (refer to Lafferty et al. [12] for use of the linear-chain CRF model). The task of the processing of the feature values of the linguistic features was completed using the Stanford NLP toolkits [24], ASSERT semantic role labeler [3] [20] and CGI Shallow parser [10] for linguistic features. B. Morphological and orthographical features
Original token (f1): we separated the words in a sentence by both the white space and punctuation and also kept the original form without further processing. Lemmatization (f2): the tokens above may contain many syntactic derivations and pragmatic variations since the different parts of speech of the words derived from the same lemma word are semantically equivalent, and the lemma word usage can reduce the complexity of feature spaces. Initial words, words all in capitals or with first character capitalized (f3): in English, abbreviations of words or words all in capitals are probably all or part of the name of specific entities. Word with alphabetic letters and numbers mixed (f4): it is observed that some organizations tend to have a name with alphabets and numbers mixed for ease in memorized (e.g., the U.S. company “3M”). Punctuation (f5): the punctuation in sentences functions best in marking boundaries of semantic units that separate different phrases or clauses.
C. Predicate-argument structure features
The predicate-argument structure (PAS) has been successfully implemented in labeling semantic roles. The PAS
is a structure that captures the events of interest and the participant entities involved in events that correspond to predicate and arguments, respectively. Generally speaking, the predicate is usually a verb that conveys the type of event. Position of predicate (f6): arguments are usually near the predicate, especially agent and patient (subject and object of verb). Before or after predicate (f7): the arguments before or after the predicate perform different types of semantic roles. For example, in the sentence “Peter chases John”, since the predicate is “chases” and two arguments, Peter (arg0) and John (arg1), correspond to agent (Subject) and patient (object), respectively, it can be concluded the relative position of the arguments from the predicate has an influence on the semantic roles while the syntactic categories are the same. Voice (f8): whether the predicate is active or passive voice that can affect the type of arguments. In the sentence “John is chased by Peter” the predicate changes the voice, and the tense of verb is modified and both sequences of arguments are changed. Considering relative position from predicate and voice makes the resolution of the opinion holders more feasible.
D. Syntactic features
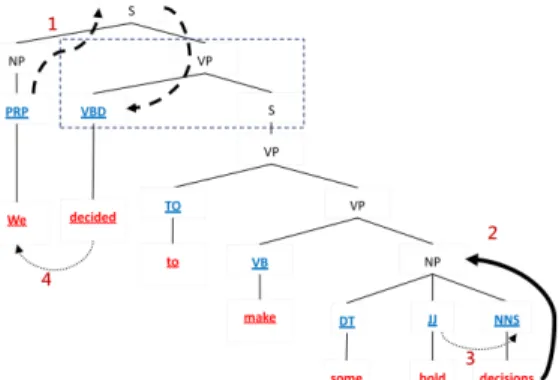
Sub-categorization of predicate (f9): the feature is the verb phrase sub-structure that expresses the VP sub-parse tree structure where predicate located. The Dash frame in Figure 1 indicates that the sub-categorization of “decided” is “VPÎVBD-S”. The function of the feature is to analysis the phrase or the clause that follows predicate, and it increases the ability in discriminating between arguments. Head word and its POS (f10): the features are the syntactic head of the phrase and the syntactic category of the head. Different heads in a noun phrase can be used to express different semantic roles. If the head word is “he” or “Bill” rather than “computer”, then the probability that the noun phrase is the opinion holder increases. The Collins’ head word algorithm is adopted for head word recognition [5]. We also included the head word and head word’s POS of the parent node and grandparent node for considering the contextual syntactic features in the linear data. Syntactic category of phrase (phrase type, f11): different semantic roles tend to be realized by different syntactic categories. The opinion holders are usually the noun phrases and sometimes prepositional phrases, and subjective expressions tend to be verb phrases. The syntactic categories of the word or the phrase are not pure linear data which has been expressed in tree structure, i.e., the phrase type of the word “decisions” in Figure 1 is NNS while the phrase type of “some bold decisions” is NP. We traced only three syntactic categories of non-terminal nodes upward from the parent of the leaf nodes if the head word
Table 1 A sample sentence and annotations of the MPQA According to Datanalisis' November poll, 57.4 percent of those polled
feel as bad or worse than in the past. MPQA annotation labels Opinion
holder 1 According to: objective speech event. Datanalisis' November poll: agent; Opinion
holder 2
57.4 percent of those polled: agent; feel: direct-subjective;
of parent phrase is such leaf node. For example in Figure 1, because the head word of the NP “some bold decisions” is “decisions” and the head of the VP “make some bold decisions” is “make”, the noun “decisions” would be the phrase type only NNS and NP without VP. In contrast, the verb “make” contains VB, VP and VP in sequence. Syntactic path and partial path (f12): the path helps predict the semantic labels. The syntactic path feature describes the syntactic relation from constituent to the predicate in the sentence with the syntactic categories of the node which is passed through. In Figure 1, the path from “We” to “decides” can be represented as either “PRP↑NP↑S↓VP↓VBD” or “NP↑S↓VP↓VBD” depending on whether the syntactic type is PRP or NP of word “We”. The partial path is the part of the syntactic path which contains the lowest common ancestor of the constituent and predicate (e.g., the lowest common ancestor is S in the sentence, so the partial path can be reduced to “PRP↑NP↑S”).
Based chunk (f13): the based chunk feature is a partial parsing structure. We represent the based chunk in IOB format which makes the segmentation of phrase boundary more precise. Subordinate noun clause followed verb and noun phrase before verb phrase (f14): since our phrase type feature is only three levels of syntactic category from the parents of parse tree leaf nodes, the macro syntactic structure information may be omitted if the parse tree is constructed deeply. In sentence “The management believed that …,” the subordinate noun clause following the verb “believed” is usually embedded with subjective expressions. We used the Stanford tregex toolkit to extract such patterns from the parse tree [24]. Syntactic dependency (f15): the feature is to capture the grammatical relation that includes three types of grammar dependency “subject relationship”, “modifying relationship” and “direct-object relationship”. The Subject relationship includes the “nominal subject” and the “passive nominal subject”, which correspond to the noun that is the syntactic subject of the active and passive clause; the modifying relationship consists of adjectival modifier or adverbial modifier, which can be any an adjectival (adverb) word that modifies the meaning of the noun (verb or adjective). The direct-object relationship indicates the noun that is the direct object of the verb. We utilized the Stanford dependency parser to get the dependency parse tree for the dependency features [24]. The opinion holders, opinion words in subjective expressions and opinion targets are correlated with the subject, modifying and direct-object relationship individually. In Figure 1, the label of the phrase “to make some bold decisions” is “expressive-subjectivity”, and we can observe that the opinion word in the phrase is “bold” with an adjective POS that modifies the noun “decisions”. Since the word “we” is the subject of verb “decides”, the identification of the relationship of the subject with the verb can be used to predict the opinion holders.
E. Simple semantic features
Named entity recognition (NER, f16): when utilizing the syntactic features, it is hard to distinguish the entity name from the other noun phrases. The NER can better identify the name of a person, who may be the opinion holder or the opinion target. Stanford NER [24] was employed to label the name of persons, organizations and locations. Subjective word and its polarity (f17): the subjective words which appear in sentences can help not only judging whether the sentence is an opinion sentence but also detect the opinion words in the labels
“expressive-subjectivity” and “direct-subjective”. The subjective words can be classified by two aspects which are the strengths of the subjectivity and the polarity. According to different levels of subjectivity, the strength can be either one of objective, weak subjectivity or strong subjectivity. Moreover, the weak and strong subjectivity can be further divided into positive, negative or neutral. The subjective word dictionary was manually collected by Wiebe [29]. Verb-clusters of predicate (f18): verbs with similar semantic meanings might appear together in the same document. In order to arrange the semantically-related verbs into one group, we use verb clusters to avoid the occurrence of the presence of rare verbs which would deteriorate the model performance. The ASSERT toolkit adopts a probabilistic co-occurrence model to cluster the co-occurrence of a verb into 64 clusters. The frame of the predicate in FrameNet (f19): We used the FrameNet [7] to query the name of the frame which a particular predicate belonged.
IV. LINKAGES BETWEEN EARNINGS AND SUBJECTIVE MWES We aim to investigate whether the subjective MWEs in the U.S. financial statements reflected the trend of firm’s earnings. We used multinomial logistic regression (Stata [26]) to explain the relationship between annual earnings and subjective MWEs and to infer its economic meaning.
A. Dependent variable: standardized unexpected earnings Our main concern in regard to the financial status of the company is each firm’s standardized unexpected earnings (SUE) which capture the trend of the firm’s earnings (following Li [13] and Tetlock et al. [27]). The SUE is viewed as the dependent variable of our research. The SUE for each firm in year t is calculated as,
(1) (2) Where is the earnings of the firm in year t, and the mean and volatility of unexpected earnings (UE) are equal to the mean ( ) and standard deviation ( ) of the unexpected earnings of each firm within a period of 12 years unexpected earnings. We transformed the SUE into three categories (Y) which are positive (1), no changed (0) and negative (-1), and the criteria is described as,
1, if
1, if
0, otherwise.
(3) Where is a constant that we set to 0.5. The reason for transforming the Y from a numeric dependent variable into a categorical variable is to avoid any minor changes in SUE disturbing the empirical results.
B. Explanatory variables: MWEf-idf and control variables The main explanatory variables in this study, an information retrieval weighting schema, was employed to quantify the MWEs. Moreover, other factors that have been traditionally considered as correlated with earnings are employed as control variables1. Further, the frequency of the occurrence of the
1
The control variables were the financial factors that relate with the SUE. The control variables include lag SUE (SUE of the previous year), BM ratio (natural log of dividing book value by market value), ROE (return on equity), accruals (earnings minus operating cash flow), size (natural log of market value), Dividend (cash dividend divided by book value) and Bankruptcy Score (Z-score) [23].
word expressions (MWEs) may be unable to well represent the relative importance of the MWE in the textual contents from different documents. To quantify the importance of the MWEs crossed documents, we proposed a variant multi-word expression frequency and inversed document frequency (MWEf-idf) weighting which extends the concept of the tf-idf (term frequency and inversed document frequency) weighting [17]. The formula is described as,
(4) While is the weighting of each MWE in each document. The notation of is the frequency of the MWE that occurs in the document; is the number of documents that contain the MWE; is the total number of the all documents. In information retrieval, the principle of the traditional tf-idf weighting is a vector space model that makes the weightings of frequent stop words close to zero as to weaken the influence of redundant terms in documents. Hence, we substituted maximum frequency of MWE with the constant and also multiplied by the constant to dilute the influence of the inversed document frequency. The two constants and were selected from empirical trials. We extracted subjective MWEs using the CRF model discussed in the previous section, and also employed information retrieval software Lucene [2] for efficiency in estimating MWEf-idf.
C. Multinomial logistic regression
The multinomial logistic regression predicts the occurrence probability of an event by fitting the data to logistic function and it is also one of the discriminative models that model conditional probability distribution | . The function form is represented as [9],
| ∑ ,
∑ ∑ , (5)
|
| ∑ , (6)
While is the log-odd ratio which selects the category 0 as a base category for comparison, c could be either of category 1 or category -1. The probability of category c can be estimated as formula (5) the cumulative density function of which is an S-curve that falls in the interval between 0 and 1. The explanatory
variable is a vector that consists of the control variables and MWEf-idf variables, while is the intercept and is the vector of the regression coefficients. The physical meaning of the significant coefficients is interpreted as: a positive coefficient means that the explanatory variable increases the probability of the category c, while a negative coefficient means the that the explanatory variable decreases the probability of the category c. D. Strategy of discriminative MWE identification
The discriminative model can predict the conditional probability | , given the explanatory variable vector and . However, some of the explanatory variables in vector would positively contribute to the conditional probability | , some would negatively contribute, and the others would not contribute at all. In order to identify the discriminative MWEs that are correlated with the SUE, we propose a strategy to rank the different level contribution of
each MWE to the conditional probability | in
Table 2. In order to infer the significance of the coefficients and the different signs of the coefficients, we defined the rank of the contribution R(c) as ranging from the 1st to the 5th, where
the 1st is the most likely discriminative indicator of the SUE and
the 5th is the least likely to be a discriminative indicator of the SUE. The different values of R(c) represent differences in the explanatory power of the MWE given the explanatory variable
and c. The strategy of Table 2 is elaborated as,
Goal: Find the R(c) of the MWE, given the vector of regression coefficients and p-values which were estimated by multinomial logistic regression.
Step 1: If both of the coefficients in category 1 and -1 are
significant (should be the same sign, BS) or insignificant, the MWE is not a discriminative explanatory variable; Otherwise, continue Step2. Besides, if both of the coefficients have the same sign (i.e., BS), the R(c) would be 4th; if not (i.e., NS), the R(c) will be 5th.
Step 2: If one of the coefficients in category 1 or -1 is
significant, the MWE is a discriminative explanatory variable. According to the coefficient signs of category 1 and -1, we can judge their R(c). If both of the coefficients in category 1 or -1 are significant and different signs, the R(c) will be 1st; if the coefficient sign of c is positively significant and the alternative coefficient is not significant, the R(c) will be 2nd; otherwise, the R(c) would be 3rd.
The R(c) of the MWE is the ordinal value that try to quantify how much of the strength which the MWE can
explain the conditional probability | . We
compared the R(c) of the MWEs in the financial statements between different SUE (i.e., c=1 or -1). Furthermore, the R(c) can provide supporting evidences that managements of the companies use different strengths of positive and negative statement when facing excellent or poor financial performance. In summary, we are able to find the relationship between the earnings of a firm and its discriminative subjective expressions, and can also use domain knowledge to interpret the economic meaning according to the R(c) of the MWE.
V. EXPERIMENTAL EVALUATION OF CRF MODELS This section includes the details about our experiments and the evaluation of the CRF models.
A. Design of the experiments
The design of the experiments is as following. Firstly, we
Table 2 Strategy of discriminative MWE identification Different significance scenarios c= -1 c= 1 R(c)
The MWE is not a discriminative indicator
of the SUE NS 5
th The MWE is a discriminative indicator of
the negative SUE (direct indicator) + - 1 st
+ NS 2nd
The MWE is a discriminative indicator which is either the positive SUE or not discriminative to SUE (indirect indicator)
- NS 3rd
The MWE is a discriminative indicator which is either the negative SUE or not discriminative to SUE (indirect indicator)
NS - 3rd
The MWE is a discriminative indicator of
the positive SUE (direct indicator) - + 1 st
NS + 2nd
The MWE is not a discriminative indicator
of the SUE (same sign) BS 4
th The significance of the MWE’s coefficients are represented as positively significant (+), negatively significant (-), not significant (NS) and both significant (BS). The correlated strengths of coefficients are represented as R(c) in the last column.
preprocessed the MPQA corpus for making sure that they could be parsed by the syntactic parser and were consist with IOB format. Secondly, we used the linguistic features discussed in Section III to extract the feature values. Thirdly, we chose feature sets by different linguistic characteristics and transformed them into CRF data format. Finally, we trained and evaluated the CRF with different data sets and parameters.
The CRF models were implemented using the MALLET toolkit [16]. We trained and tested the CRF models with feature set as previously discussed in Section II using 10325 sentences from the MPQA corpus, and the evaluation was performed on 30% of the holdout test data. The training iteration was 500 and the Gaussian variance was 10 with first-order CRF used. The model was evaluated with respect to token accuracy (a), precision (p), recall (r) and measure. The correct prediction of opinion labeling was defined as an exact match between the CRF predicted label and the MPQA annotated label of specific phrase sequentially. The definition of precision (p), recall (r) and measure is as fallowing,
p= the proportion of opinion labels predicted by the model is correct.
r= the proportion of correct opinion labels is predicted by the model.
(7)
While is the weight that controls the contribution percentage of precision and recall ( = 0.5). Another loose performance metrics is token accuracy (a) which compares whether the predicted label and annotated label of a single token are the same at token-level without considering the other tokens. B. Experimental results
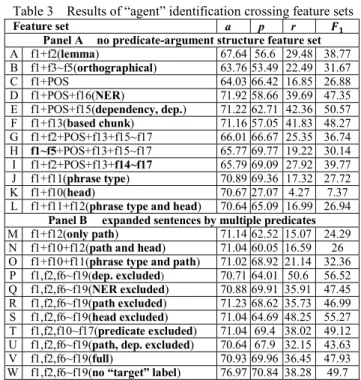
The feature set selection was applied to train and test the CRF models (Table 3). Since there may be more than one predicate in a sentence and some of the feature values related to different predicates may be different, we expanded one instance (i.e., one sentence data record) of the data (Panel A) into many instances with different feature values when there were more than one predicate in a sentence (Panel B).
We can observe from the feature set B (only orthographical features) that has the lowest token accuracy, and that there is a significant decrease in the recall about 6% in feature set H (orthographical feature added) when compared with feature set G. On the other hand, what orthographical feature can capture could be rendered by NER features and POS of token. Hence, all the other feature sets are excluded the orthographical features with the exception of set B and H. Although recall of J (phrase type) is unfavorable among the feature sets, its relatively higher precision is the reason why it is reserved for use in the following trials. The feature set K (head feature) has the lowest measure among all single feature sets which comprise tokens (f1) plus single feature in Panel A; besides, feature set S, which has excluded the head feature, enhanced the recall promisingly, but was also accompanied by a drop in precision; accordingly, the head is not a good indicator for detection of the phrase boundary; to use the head feature would allow the model to be conservative in predicting but would resulting in the lower recall when head feature included, so releasing the head feature (set S) makes the recall soar up.
In summary, we can conclude that feature sets with lemma, orthography, POS, phrase type and head are relatively inferior to feature sets with NER, syntactic dependency and based chunk
by observing the measures among feature set A, B, C, F, J and K when the features consist of f1 plus another feature. By comparing the performance among feature set G, H and I, the inclusion of feature f14 is better than inclusion of orthographical features under the condition that there is no predicate-argument structure situation. The measure of full feature set (V) is not significantly different from sets R, Q and T, but is explicitly higher than P, S and U; we can thus draw the conclusion that the exclusion of feature in NER and path from the full set would not affect the performance of the system but that the exclusion of the feature in head would.
In summary, we can conclude that feature sets with lemma, orthography, POS, phrase type and head are relatively inferior to feature sets with NER, syntactic dependency and based chunk by observing the measures among feature set A, B, C, F, J and K when the features consist of f1 plus another feature. By comparing the performance among feature set G, H and I, the inclusion of feature f14 is better than inclusion of orthographical features under the condition that there is no predicate-argument structure situation. The measure of full feature set (V) is not significantly different from sets R, Q and T, but is explicitly higher than P, S and U; we can thus draw the conclusion that the exclusion of feature in NER and path from the full set would not affect the performance of the system but that the exclusion of the feature in head would.
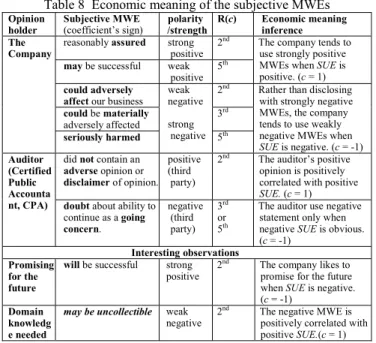
VI. EMPIRICAL STUDY OF EARNINGS AND SUBJECTIVE MWES A. Extraction of opinion patterns from financial statements
The main purpose of this section is automatically extracting the opinion holders and the subjective expressions in the financial statements by CRF models trained by the MPQA. We preprocessed the filings to extract footnote section and to remove redundant information: first, we removed the HTML tags, pictures, tables, front and sending matters and exhibitions and retained the useful item sections; next, we dropped the lines containing too many white spaces, symbols, numbers or non-meaning words (e.g., fragments left after elimination) by
Table 3 Results of “agent” identification crossing feature sets
Feature set a p r
Panel A no predicate-argument structure feature set
A f1+f2(lemma) 67.64 56.6 29.48 38.77 B f1+f3~f5(orthographical) 63.76 53.49 22.49 31.67 C f1+POS 64.03 66.42 16.85 26.88 D f1+POS+f16(NER) 71.92 58.66 39.69 47.35 E f1+POS+f15(dependency, dep.) 71.22 62.71 42.36 50.57 F f1+f13(based chunk) 71.16 57.05 41.83 48.27 G f1+f2+POS+f13+f15~f17 66.01 66.67 25.35 36.74 H f1~f5+POS+f13+f15~f17 65.77 69.77 19.22 30.14 I f1+f2+POS+f13+f14~f17 65.79 69.09 27.92 39.77 J f1+f11(phrase type) 70.89 69.36 17.32 27.72 K f1+f10(head) 70.67 27.07 4.27 7.37
L f1+f11+f12(phrase type and head) 70.64 65.09 16.99 26.94 Panel B expanded sentences by multiple predicates M f1+f12(only path) 71.14 62.52 15.07 24.29 N f1+f10+f12(path and head) 71.04 60.05 16.59 26 O f1+f10+f11(phrase type and path) 71.02 68.92 21.14 32.36 P f1,f2,f6~f19(dep. excluded) 70.71 64.01 50.6 56.52 Q f1,f2,f6~f19(NER excluded) 70.88 69.91 35.91 47.45 R f1,f2,f6~f19(path excluded) 71.23 68.62 35.73 46.99 S f1,f2,f6~f19(head excluded) 71.04 64.69 48.25 55.27 T f1,f2,f10~f17(predicate excluded) 71.04 69.4 38.02 49.12 U f1,f2,f6~f19(path, dep. excluded) 70.64 67.9 32.15 43.63 V f1,f2,f6~f19(full) 70.93 69.96 36.45 47.93 W f1,f2,f6~f19(no “target” label) 76.97 70.84 38.28 49.7
regular expression; finally, we adopted the LingPipe sentence model [14] to segment the filings into sentences to apply the opinion patterns identification model. The total number of sentences after preprocessing was 1.3 million. We selected 85,394 sentences on the condition that a sentence contained both financial positive/negative words and words with the MPQA labels “objective speech event” or “direct-subjective” (e.g., “believe”). The financial positive/negative words were collected by Loughran and McDonald [15], and all of them are unigrams. Finally, we chose 30,381 sentences of 85,394 sentences that can be processed by syntactic parser.
We chose feature set W (Table 3) which showed the highest precision in unseen data. In Table 4, there are top 8 frequent participant entities and their subjective expressions above sample sentences. 2
B. Empirical results of small dataset
We investigated which subjective expressions would be
2
We replaced every token in the sentences with their lemma word and then substituted the names of persons, organizations and locations with PERSON, ORG. and LOC., correspondingly.
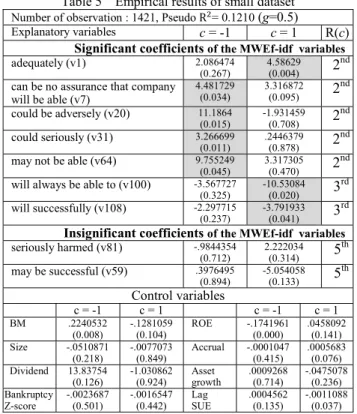
positively or negatively correlated with the SUE by testing the sign of the significant regression coefficients. In Table 5, we found that the significant negative MWEs (v7, v20 and v64) are expressed more mildly than the significant positive MWEs (v100 and v108) given the context of U.S. financial statements (i.e., the words “will” and “always” are stronger than “might” and “could” in subjective strength). Also, the MWE “seriously harmed” is the strongest negative. Accordingly, strongly negative MEWs seldom occur in financial statements when not necessary, and the low frequency of their occurrence may be the reason for the presence of the insignificant coefficients. The words “may” and “might” not only impair the strength of subjectivity but also cause one to feel uncertainty leading to an increase in one’s sense of insecurity, so the MWE “may be successful” is not significant.
C. Robustness test of using large dataset
The robustness test included (1) an expansion of data scale from 1421 to 22780 observations, (2) an addition of MWEf-idf variables usage (from 113 to 174 variables), (3) the variation of different thresholds, i.e., g = 0.5 or 1.0, and (4) correction of the standard error estimators of coefficients with Huber-White sandwich estimators. The Huber-White sandwich estimators were utilized to consider the issue of the heteroscedasticity and the failure in meeting the normality assumption [9] [26]. The point estimators of the coefficients will not be changed but interval estimators will be changed (because of the standard error estimator changed) while applying the Huber-White sandwich estimators.
In Table 6 and Table 7, we used different thresholds to differentiate positive SUE and negative SUE from no changed SUE (i.e., g=0.5 or 1.0). We were able to induct the following patterns under large data scale scenario: (1) the unigram word “adequately” cannot stand up to the robustness test. When the conditions of the robustness test become more conservative, the significance of the coefficients is lessened. (2nd to 5th) (2) Since the threshold g stands for the conservative sensitivity that
Table 4 Opinion patterns extracted from 10-K filings
Top 8 frequent phrases
Agent list Freq. Subjective expression list Freq.
We 8249 may not be able 140
the company 1840 may not be recoverable 137 the ORG. 948 reasonably assure 62
management 606 may be impaired 55
the 408 substantial doubt 51
It 394 would not be able 49
company 328 may not be successful 48 PERSON 249 would become exercisable 45
Table 5 Empirical results of small dataset
Number of observation : 1421, Pseudo R = 0.1210 (g=0.5)
Explanatory variables c = -1 c = 1 R(c)
Significant coefficients of the MWEf-idf variables
adequately (v1) 2.086474
(0.267) 4.58629(0.004) 2 nd can be no assurance that company
will be able (v7) 4.481729 (0.034) 3.316872(0.095) 2 nd could be adversely (v20) 11.1864 (0.015) -1.931459(0.708) 2 nd could seriously (v31) 3.266699 (0.011) .2446379(0.878) 2 nd may not be able (v64) 9.755249
(0.045) 3.317305(0.470) 2 nd will always be able to (v100) -3.567727
(0.325) -10.53084(0.020) 3 rd will successfully (v108) -2.297715
(0.237) -3.791933(0.041) 3 rd
Insignificant coefficients of the MWEf-idf variables seriously harmed (v81) -.9844354 (0.712) 2.222034(0.314) 5 th may be successful (v59) .3976495 (0.894) -5.054058(0.133) 5 th Control variables c = -1 c = 1 c = -1 c = 1 BM .2240532 (0.008) -.1281059 (0.104) ROE -.1741961(0.000) .0458092(0.141) Size -.0510871 (0.218) -.0077073 (0.849) Accrual -.0001047(0.415) .0005683(0.076) Dividend 13.83754 (0.126) -1.030862 (0.924) Asset growth .0009268(0.714) -.0475078(0.236) Bankruptcy
Z-score -.0023687 (0.501) -.0016547 (0.442) Lag SUE .0004562(0.135) -.0011088(0.037) We present partial of the MWEf-idf variablesfrom 113 variables (v1~v113) in the regression. The regression coefficients are significantly different from 0 while the p-value in parentheses are less than 0.05. The category 0 is base category which means no change in unexpected earnings. The correlated strengths of coefficients are represented as R(c) in the last column.
Table 6 Robustness test with g=0.5
Number of observation : 22780, Pseudo R = 0.0387
Explanatory variables c = -1 c = 1 R(c)
Multi-word expressions weighting (MWEf-idf) variables Significant coefficients of the MWEf-idf variables can successfully (v13) 1.00347 (0.406) 2.557169 (0.021) 2 nd reasonably assured (v120) -.3462077 (0.476) .7800411 (0.044) 2 nd did not contain an adverse opinion or
disclaimer of opinion (v49)
-3.729337
(0.416) 6.766385 (0.029) 2 nd could adversely affect our business (v23) 1.134901
(0.043) .5821329 (0.261) 2 nd could be materially adversely affected
(v33)
-1.110985
(0.019) -.2283351 (0.621) 3 rd may adversely impact our business (v77) -8.827469
(0.005) -1.002978 (0.602) 3 rd will be successful (v157) .7972535 (0.042) .3325742 (0.382) 2 nd may be uncollectible (v90) 7.782796 (0.135) 12.42345 (0.027) 2 nd
Insignificant coefficients of the MWEf-idf variables may be successful (v88) -4.291141 (0.238) -5.740041 (0.125) 5 th seriously harmed (v122) -.1906548 (0.711) (0.070) .84506 5 th doubt about ability to continue as a going
concern (v51)
-3.963982
(0.499) .3394289 (0.954) 5 th