整合資料在雲端環境上的分享與 隱私保護-以電子病歷資料為例 - 政大學術集成
54
0
0
全文
(2) 整合資料在雲端環境上的分享與 隱私保護-以電子病歷資料為例 Sharing and Protection of Integrated Data in the Cloud : Electronic Health Record as an Example. 研 究 生:楊竣展. Student:Juin-Jan Yang. 指導教授:胡毓忠. 國立政治大學 碩士論文. Nat. io. er. A Thesis. sit. y. ‧. 資訊科學系. Hu. 學. ‧ 國. 立. 政 治Advisor:Yuh-Jong 大. submitted to Department of Computer Science. al. n. v i n NationalC Chengchi University hengchi U. in partial fulfillment of the Requirements for the degree of Master in Computer Science 中華民國一百年七月 July 2011. 2.
(3) 整合資料在雲端環境上的分享與隱私保護 -以電子病歷資料為例. 摘要 由於電子化病歷逐漸取代了傳統的紙本病歷,在流通分享上面比傳統的紙本 病歷更加來的方便及快速,另外電子病歷的整合性,也是比傳統的紙本來的有效。 近年來雲端運算的發展,使得醫療系統在電子病歷上能夠更快速的發展,但是取. 政 治 大. 而代之的是卻是雲端運算所產生隱私權的問題,在快速發展的雲端運算環境中,. 立. 目前似乎無法完全確保資料的隱私性。即使現有的研究中可以讓資料擁有者表示. ‧ 國. 學. 自己的隱私偏好,卻因為設計時缺乏語意的考量,造成執行上有語意的落差。. ‧. 本研究將探討電子病歷存放在雲端環境上,設計一套三層整合平台系統並使用語 意化技術本體論整合來自多方的資料,達成在資料庫上使用 OWL2 作為整合的語. y. Nat. io. sit. 言,並在此整合平台進行本體論整合,能夠讓使用者可以從多方的醫療中心快速. n. al. er. 查詢整合的資料,經由整合平台的改寫,到下層的規範擷取到上層平台進行管理. Ch. i n U. v. 與落實動作,最終在資料庫查詢資料,達成整合分享的目標,並同時能夠兼顧資. engchi. 料擁有者的隱私期待,完成在雲端環境上資料分享、整合、隱私保護的目標。. 3.
(4) Sharing and Protection of Integrated Data in the Cloud : Electronic Health Record as an Example. Abstract The Electronic Health Records (EHRs) have replaced the traditional paper Health Records gradually and they are more rapid and more convenient in data sharing. Furthermore, the EHRs are also better than paper health. 政 治 大 In recent years, the rapid development of cloud computing can help 立. records when health records need to be integrated on the computer.. ‧ 國. 學. Health Information System to be more dynamic and provide a better service, but the problem of privacy is a critical issue. Although recent research. ‧. can let data owner expresses his own personal privacy preference in to. sit. y. Nat. policy to protect privacy, it is lacked of semantics and that will result. io. of policy.. al. er. in the gap between the real meaning of personal privacy preference and. n. v i n In our research, we willCusing semantic technology to express personal hen gchi U. privacy preference in to polices and also design the 3-layer integration platform to achieve semantics data integration so that polices can be. enforced without loss of real meaning of personal privacy preference and polices will have interoperability with others when we are using semantic data integration.. 4.
(5) 致謝. 首先感謝我的指導教授胡毓忠博士,因為教授才能讓我進入語意網 的領袖以及研究事物的方式,教授在課餘時間常常會給我許多學習的 機會以及不厭其繁的討論,都讓我學到了不少,並且在我研究生的兩 年中指點我方向,學生滿懷感謝。. 政 治 大. 另外實驗室的同學們更是我互相討論的好伙伴,不論是已經畢業. 立. 的學長弘毅、建輝、易修、宏傑在實做上或是研究方向都幫了我不少. ‧ 國. 學. 忙,特別是全實驗室一起出去玩的時候。協達與迪嶸則是我互相學習. ‧. 的好朋友;專班的世麒、郁婷、俊維,以及學弟妹雅玲、國平、穩男. Nat. sit. n. al. er. io. 滴我會牢記心頭的。. y. 都是陪我在研究的路上,並且提供了我許多寶貴的意見,這些點點滴. C. hen 最後,謹以此文獻給我摯愛的雙親。. gchi. i n U. v. 5.
(6) 目錄 第一章 ............................................................ 10 1.1 研究動機 ..................................................... 10 1.2 研究目的 ..................................................... 11 1.3 各章節概述 ................................................... 12 第二章 ............................................................ 13 2.1 HIPAA 法案 ................................................... 13 2.2 2.3 2.4 2.5. 雲端運算 ..................................................... 13 委外隱私權保護 ............................................... 14 規範的表達及落實 ............................................. 16 資料整合 ..................................................... 18. 政 治 大 第三章 ............................................................ 21 立 M L ........................... 21 3.1 X A C CCESS. ONTROL. ARKUP. ANGUAGE. 學. ‧ 國. E TENSIBLE. 3.2 AUDIT-BASED ACCESS CONTROL ....................................... 21 3.3 GOOGLE HEALTH .................................................. 22. ‧. 3.4 資料整合 ..................................................... 22 第四章 ............................................................ 24. y. Nat. sit. n. al. er. io. 4.1 研究架構設計 ................................................. 24 4.2 資料整合 ..................................................... 27 4.2.1 資料庫的整合 ............................................. 29 4.2.2 本體論的整合 ............................................. 30 4.2.3 重複資料的整合 ........................................... 32 4.3 隱私偏好的表示與落實 ......................................... 35 4.3.1 隱私偏好的表示 ........................................... 35. Ch. engchi. i n U. v. 4.3.2 規範的取得、管理與落實 ................................... 36 4.3.2.1 規範取得 ............................................. 36 4.3.2.2 規範管理 ............................................. 37 4.3.2.3 規範的落實 ........................................... 39 4.3.3 OWL2 RL 與 SWRL 的比較 .................................... 41 第五章 ............................................................ 43 5.1 資料整合的驗證 ............................................... 43 5.2 系統實作 ..................................................... 44 第六章 ............................................................ 47. 6.
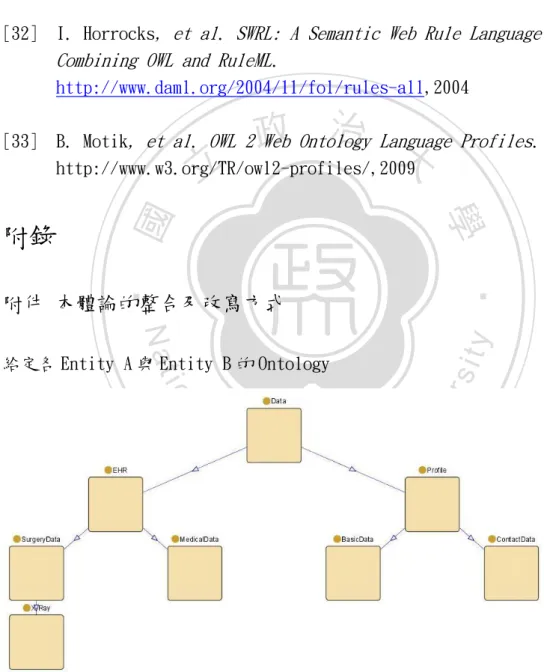
(7) 參考文獻 .......................................................... 48 附錄 .............................................................. 51 附件 本體論的整合及改寫方式 ...................................... 51. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 7.
(8) 圖目錄 圖 1 ACP 與 DHP 對於使用者的規範範圍 ................................ 17 圖 2 使用者要求資料流向使用者端 .................................... 18 圖 3 使用者要求資料,但資料不流向使用者端 .......................... 18 圖 4 在雲端環境上的醫療資料保護及分享模式 .......................... 25 圖 5 TisD 範例 圖................................................................... .............................................34 圖 6 本體論架 構................................................................... .............................................35. 政 治 大 圖 7 FETCH POLICY 概念圖 立........................................... 39. ‧ 國. 學. 圖 8 系統架構 ...................................................... 45 圖 9 本體論在 PROTEGE 編輯環境 ...................................... 46. ‧. 圖 10 網頁輸入介面 ................................................. 46 圖 11 ENTITY A 的本體論 ............................................ 51. y. Nat. sit. 圖 12 ENTITY B 的本體論 ............................................ 52. n. al. er. io. 圖 13 GLOBAL 的本體論 .............................................. 52. Ch. engchi. i n U. v. 8.
(9) 表目錄 表 1 本研究使用詞彙 ................................................ 24 表 2 SWRL 與 OWL2 RL 的比較 ......................................... 42. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 9.
(10) 第一章 導論 1.1 研究動機 電子化病歷逐漸取代了傳統的紙本病歷,在流通分享上面比傳統的紙本病歷 更加來的方便及快速,電子病歷的整合性,也是比傳統的紙本來的有效率。有了 電子病歷的整合,可以減少不必要的醫療資源支出及浪費,對於病人的治療也具. 政 治 大 揭露,對全球的醫療系統會有很大的幫助。然而,要如何保護電子化病歷,使得 立. 有幫助。一但電子病歷能夠快速的整合並且遵照個人的目的去使用、流通、分享、. ‧ 國. 學. 在網路上流通或分享這些病歷時,能顧及資料的安全性,並能確保符合資料擁有 者的隱私期待,而不至於過度的揭露,成為了一大挑戰及問題。. ‧. 個人的病歷是屬於個人資料的一部份,根據美國聯邦貿易委員會(Federal. sit. y. Nat. Trade Commission,FIP)所提出的合理訊息實踐原則(Fair Information. io. er. Practice Principle)[30],就提出了如何保護資料擁有者的個人資料,如下: (1)告知(Notice):即為必頇告知資料擁有者使用此資料的目的、範圍、及其影. n. al. 響。. Ch. engchi. i n U. v. (2)同意(Consent):當使用者告知資料擁有者之後,必頇提供讓資料擁有者決定 的權利。 (3)存取與參與(Access & Participation):資料擁有者有權利要求查閱自己的 資料,了解自身的資料被使用的情形,並且可以將這些資料加以修正。 這些原則可以讓資料擁有者在知情的情形下被使用資料。但是將場景換回醫 療系統來看,這些原則會太過於籠統。原因在於醫療是一個較複雜的學科,但也 是個人資料的一部分,而 FIP 並無特別提到在個人醫療資料中隱私權的保障。於 是在 1996 年美國通過了名為 HIPAA 法案(Health Insurance Portability and. 10.
(11) Accountability Act)[29]主要為保護病人病歷的隱私權,避免病歷被不當的使 用或揭露。儘管這項法案對於醫療隱私有了很大的幫助,也只能提供了一個最低 的保護,仍然無法就使用者本身的意願來提供保護。目前醫院雖然已有建立電子 病歷系統,但是在互通性上(interoperability)仍稍嫌不足。雖然已有如 HL7 標準幫助兩醫院之間流通分享電子病歷,但是流通出去的病歷是否遵守資料擁有 者的意願使用,可能就無法保證,所以在資料存放端的存取控管就非常重要。 近幾年雲端運算流行,網路服務變的更加方便,資料不限於只存本機端,是 放上雲端。這麼做的好處不但大大降低了醫院管理成本,也能比以前有更為快速. 政 治 大 靠性、資料放在雲端的安全性、隱私性、資料流至雲端的責任歸屬問題等等。本 立. 的分享流通病歷資料。然而背後會產生更多的問題。例如:雲端提供者本身的可. ‧ 國. 學. 研究希望設計一個架構足以保護使用者在雲端運算環境上的電子病歷隱私,並且 整合來自多方的電子病歷,更能夠讓資料擁有者選擇符合自己隱私期待的保護方. er. io. sit. y. Nat. 1.2 研究目的. ‧. 式,使得系統在做流通分享時,能夠保護資料擁有者的隱私。. 本研究的主要目的為當醫療資料經過資料擁有者同意之後存放在資料處理. al. n. v i n Ch 者的雲端運算環境上時,資料擁有者能夠制定醫療資料的個人隱私偏好,使得後 engchi U. 續使用者欲使用時,該規範能夠在電腦系統上落實,並且能夠在雲端環境上達成 資料整合,提供一個單一窗口讓使用者快速查詢到多個資料源的資料。主要的研 究方向如下: . 資料整合與規範框架整合:在各個醫院將資料放上雲端運算環境時,提供資 料整合可以讓使用者使用資料時,透過單一介面的查詢就能得到多個資料來 源的資料;除此之外各個醫院所設計的規範也必頇在資料整合時一併考慮進 來,達成規範語意的一致性。. . 共同資料的整合:在各個醫院中,會存在著共同資料的區域。此區域的資料. 11.
(12) 由於是由多家醫院所共同擁有的,因此在整合時若能將共同資料的區域分割 出來,會減少許多重複的資料與規範。 . 規範管理與落實:在經過資料與規範框架整合後,規範在系統終將具有一致 性的語意,但是由於共同資料區域的存在,規範必頇經過管理選擇出適合執 行的部分,並且使用語意化的技術將之落實。. . 實作三層式架構的系統,並且使用 Hbase 做為雲端儲存媒介實作驗證本研究 的可行性。. 1.3 各章節概述. 政 治 大 本文第二章是研究架構的背景說明;第三章則是對於相關研究說明;第四章 立. ‧ 國. 學. 會針對系統架構作完整的描述,並且針對規範表達落實與資料整合部分詳述;第 五章為研究方法的驗證與系統實作部分說明;第六章則為總結本研究。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 12.
(13) 第二章 研究背景 2.1 HIPAA 法案 HIPAA(Health Insurance Portability and Accountability Act)[29]是在 1996 通過的,原本為了提高行政效率所提出。法案分成兩個部份,第二部份提 到了隱私權保護。法案中提到了足以辨識個人的醫療資訊(Individually. 政 治 大. identifiable health information),這部份的資訊一但揭露,有可能造成病人. 立. 的隱私權侵害,因此這部份的資料必頇小心處理。. ‧ 國. 學. HIPAA 提供一個最低限度的保障,但是個人仍可以設計細部的隱私期待,以. ‧. 確保更符合個人隱私保護。例如個人可以禁止病歷資料流通至自己國家以外的區 域限制,而在不同地區也會有不同的保護程度。另外 HIPAA 法案僅僅提供醫療資. y. Nat. n. al. er. io. 2.2 雲端運算. sit. 料擁有者所具有的權利,但是仍缺乏一個方式能夠完整的表達這些規範。. Ch. engchi. i n U. v. 雲端運算的概念最早源自於分散式系統,將許多的主機串接在一起視為一個 大型主機來做運算,而現在的雲端運算也繼承了此一概念,但是與分散式系統不 同的是,雲端運算是一種新的商業模式。如同 Michael 等人所說 的”Pay-as-you-go”[23]電力系統一般,使用了多少量就付多少錢,若不需要 使用則可馬上停止,這跳脫了以往的概念,而轉變為『資源』的一種概念。資源 在此可以分成三種:IaaS(Infrastructure as a Service)、PaaS(Platform as a Service)、 SaaS(Software as a Service)。當使用者使用雲端運算時,他們不 需要去做維護的工作,也不需要去更新軟體,更不需要去了解這些使用者的資料. 13.
(14) 是如何被存放。也因此這些服務慢慢的開始被質疑。例如可靠性(Reliability)、 安全性(Security)、隱私性(Privacy)[21][18],其中隱私性更成了重要的議題。 因為雲端運算環境上的資料會不斷的分割、備分、等複雜的動作,這些動作 有時候可能會違反了使用者當時的隱私期待。此外在這些運作的過程中,雲端提 供者並不會主動告知以致使用者完全沒有選擇的權利。不同的資料如此被切割或 是備份、複製而分散在世界各地的資料,雲端提供者可能會違反一些地區性的法 律,如 EU Data Protection Directive[25],就明文禁止將歐盟居民的個人資 料流出歐洲大陸,而國際安全港法案(Safe Habor)[28]也只允許歐盟國家的資料. 政 治 大 並未提供的,因此在隱私保護的立場來看,雲端運算的隱私保護是必要的。本研 立. 流向美國來保障歐盟地區資料的安全性。這些使用者的隱私期待是目前雲端運算. ‧ 國. 學. 究將解決雲端運算上隱私權保護。. 2.3 委外隱私權保護. ‧. sit. y. Nat. 傳統的委外主要是聚焦在資料庫的委外。若某公司將資料庫委外出去後,會. io. er. 有適合的 API 可以讓某公司做查詢,並能新增、修改、刪除等動作。同樣的概念 也適用在雲端運算上,但雲端運算與傳統的委外有些差別:. al. n. v i n Ch 委外的形式:早期的委外可能聚集在資料庫、伺服器的委外,而雲端運算則 engchi U. . 從硬體的空間(Infrustructure)、編譯的平台(Platform)、甚至是軟體 (Software)都能進行委外,因此在形式上比早期的委外廣的多。 . 受委者與委外者的關係:早期的委外關係是長期的,兩者事先訂定合約,並 訂定服務層級協議(Service Level Agreement),因此關係較為靜態。雲端 運算則強調使用的彈性以及快速的擴充性,如同電力系統一般方便使用,也 因此關係較為動態。. . 虛擬化:早期的委外因為較靜態,因此在使用量、委外型式上都改變不大, 因此在資料庫委外時通常不需要虛擬化的參與。而雲端運算為了有不同的委. 14.
(15) 外型式外,還必頇具備彈性使用與快速擴充的特色,因此使用虛擬化的技術 達成這些目的。 DAS(Database As a Services)[5]的委外隱私權著重的是在資料完整性的確 保及不被其他惡意的一方不當使用的保護,因此有提出在存到 DAS 之前先自行加 密的做法。在委外的場景下,角色可以分成四種,分別為(1)委外者:可以是個 人資料擁有者,也可能是經過資料擁有者同意後得到資料的資料處理者,將資料 放入委外的資料庫。(2)使用者:需要使用該資料庫的人,透過特定查詢語言以 找到特定的資料。(3)使用者端:彙集使用者的查詢語言後將關鍵字轉換成先前. 政 治 大 (4)伺服器端:也就是受委者端。裡面的資料是已經經過資料使用加密過的,因 立 加密過的關鍵字,也就是 Schema 的轉換。. ‧ 國. 學. 此並不了解裡面存放的資料。. 資料擁有者將資料透過演算法加密過後,委外儲存到伺服器端,而後其他使. ‧. 用者會去對此資料庫做查詢,送出一道查詢語法至使用者端,使用者端經過先前. sit. y. Nat. 加密的演算法中,找出相對應的 Schema 將其轉換後傳送到伺服器端做查詢,得. io. er. 到的結果回傳回使用者端後,再經過解密最後回傳給使用者。如此可以確保在委 外的過程中資料的安全性以及只能由單一窗口(使用者端)進行查詢的動作,也提. al. n. v i n Ch 高了資料的保密性,但是資料的隱私性必頇再借助存取控管系統來確保每份資料 engchi U 的隱私期望被落實。另外,在雲端運算上若事先的加密會大幅度的喪失資料的可 用性。例如在雲端中的 PaaS 中,編譯程式本身需要程式碼,若事先將程式碼加 密後再上傳至雲端中,則 PaaS 會完全無法使用。 除此之外,雲端運算的資料庫儲存服務與一般的資料庫服務最大的差別在於 無法得知資料真正的存放位置;雲端運算透過虛擬化的技術將一台或多台實體主 機切成多個虛擬機器後提供給使用者,又因為可靠性、安全性等問題,會將資料 進行切割、備份等動作,所以無法得知真正的實體位置,因此隱私的問題也開始 變得重要;由於無法直接從多個雲端提供者中加入資料擁有者的隱私偏好,本研. 15.
(16) 究將從存取雲端資料的存取點進行隱私資料保護,確保每一次對雲端進行存取時 都滿足資料擁有者的隱私偏好。. 2.4 規範的表達及落實 隱私規範主要保護的為資料擁有者所擁有的資料,稱為個人足以識別的 資訊(Personally Identifiable Information,PII)。為了將了隱私偏好做更進 一步的分類,在歐盟的 PRIME Project 裡,提出兩種保護資料的規範分別是[13]: . 存取控管規範(Access Control Policy,ACP):定義了那一個主體(Subject). 政 治 大. 可以對一個受體(Object)進行存取的動作,並且帶上附帶條件(Condition),. 立. 它的主要元素如下:. ‧ 國. 學. Subject:表示欲進行存取的單位,可能是一個個體,也有可能是來自於一個 機構或是法人團體等等的單位。. ‧. Subject_claim:表示描述該主體具有的特徵例如持有特定數位簽章、年齡大. sit. y. Nat. 於 25 等等對主體所敘述的條件設定。. io. al. n. 服務. er. Object:表示被存取的單位,可能是個人病歷資料,也有可能是伺服器中的. i n C Object_claim:表示描述該受體具有的特徵。 hengchi U. v. Purpose:表示主體欲使用受體的目的。. Condition:表示該規範定義除了目的之外的其他條件,如義務、使用時間、 使用次數等等。 . 資料處理規範(Data Handling Policy,DHP):允許一個資料擁有者定義一條 規範允許自己的”個人足以辨識身分的資料”(PII)被使用的情形,它的主 要元素如下: Recipients:表示欲使用 PII 的使用者,也就是 Data user,在此 Recipients 可以為內部的服務提供者,或是外部未知的使用者。. 16.
(17) Action:欲對 PII 進行的動作,可能為存取,也有可能為備份等動作。 Purposes:欲對 PII 進行動作的目的。 Gen_condition:欲對 PII 進行動作所允許的狀況,例如動作時間只有白天允 許。 Provision:欲對 PII 進行動作前先行滿足的條件。如需要得到資料擁有者的 授權或是具備某種數位簽章等等。 Obligation:對 PII 進行動作後所必頇執行的條件,如存放三個月後刪除、 通知當事人等等。. 政 治 大 動作為存取,而且具備特定的目的時,此一規範便會屬於資料處理規範的範圍內。 立 由於這兩種規範具有部分交集,也就是當存取控管規範若為規定受體為 PII,. In tern al User. Service Provid er. Access Con trol al Policy. n. Ch. engchi. sit. y. Data Han d lin g Policy. io. Service. Nat. PII Data. Role. er. In d ivid ual. ‧. ‧ 國. 學. 兩種規範在動作為存取的情況下,所能規範的範圍如圖 1 所示:. i n U. v. 圖 1 ACP 與 DHP 對於使用者的規範範圍 從圖 1 中可以了解雖然 ACP 在保護 PII 的範圍中屬於 DHP 的集合內,在 Prime 中也提到有一些 ACP 是來自 DHP[22],但因為 ACP 所規範的範圍仍有其他資料或 是服務,因此並不能完全視為子集合。 假設資料已從資料擁有者端傳送至伺服器端,並且建立了 ACP 與 DHP。當使 用者欲使用系統內的 PII 資料時,首先經過 ACP 規範落實,這 ACP 可能某部分來 自於系統內部定義的,也有可能來自資料擁有者定義的 DHP。當 ACP 比較成功後, 該 PII 資料已經可以存取了,但使用者還必頇提供 DHP 的模板(Template)來與資 料擁有者所定義的 DHP 相比對,此比對並不是當下使用 PII 資料時所需要的比對,. 17.
(18) 而是使用者拿到 PII 個人資料後的後續動作(如分享、修改等)是否符合資料擁有 者當時規範的偏好。當 DHP 比較完成後,該 DHP 便會隨著 PII 資料留至使用者端, 如圖 2 所示。. ACP. ACP En force Cilen t. Server DHP. DHP En force Give PII, if All Perm it. 圖 2 使用者要求資料流向使用者端. 政 治 大. 反之,若使用者使用時並不會將 PII 資料流向使用者端,此時只需將 DHP. 立. 學. 束後不會將 PII 資料流到使用者端,如圖 3 所示。. DHP En force. Cilen t. ‧. ‧ 國. 當成 ACP 使用進行規範落實,允許後使用者可以直接在 Server 端進行操作,結. DHP. Nat. io. sit. y. Server. n. al. er. Op erate PII on Server, if All Perm it. Ch. engchi. i n U. v. 圖 3 使用者要求資料,但資料不流向使用者端. 2.5 資料整合 在關聯式資料庫的資料整合中,主要著重在 Schema 的整合,也就是對不同 點的 Local Schema 事先利用查詢語法 SQL 產生一組 View 表示該 Local Data. 18.
(19) Source 可供整合的部分;另外產生一個 Global Schema(Mediators),當使用者 做查詢時,Global Schema 會去對查詢語法在每一個 Local Data Source 進行查 詢語法改寫的部份,下到各個點去做查詢,最後將結果回傳給 Mediators[16], 再傳給使用者。Levy 的研究中提到了三種方式: 1.LAV(Local-As-View)[7]下層的 View 是由上層多個 View 組合產生的。因此 Local 所產生的 View 必頇要被 Global 所產生的多個或一個 View 所對應到。 2.GAV(Global-As-View) 上層的 View 是由下層多個 View 組合產生的。Global 所產生的 View 必頇要被 Local 所產生的多個或一個 View 對應到。. 政 治 大. 3.GLAV(Global-Local-As-View)一個上層 View 對應到多個下層 View 或多個上層. 立. View 對應到一個下層 View。. ‧ 國. 學. 三者主要差別在於 Global 與 Local 的對應角度,如 GAV 是以 Global Schema 為出發點,任何 Local Schema 必頇要想辦法產生 View 與 Global Schema 能夠對. sit. y. Nat. 造成系統很大的影響的。. ‧. 應[17],也就是因為這樣在 GAV 的架構下不同的 Data Source 的進入與退出是會. io. er. View 的產生有時會連帶產生一些限制,而這些限制又必頇使用一個方式搜 集到上層在合併時一併加以考慮,因此 Diego Calvanese 等人提出了在資料庫上. al. n. v i n Ch 層以本體論來做為合併的 Schema[1][2],也就是概念(Concept)的方式進行整合。 engchi U. 與先前不同的地方在於,使用本體論來做為整合的方式強調的是將概念(Concept) 與資料庫(Data)本身做抽離,利用本體論描寫多個資料庫的關係、限制概念,也 因此原先對應的方式也從 SQL Query to SQL Query 轉成了 SPAQRL Query to SQL Query,甚至在 2009 年更提出了以 OWL2 本體論語言做為整合語言的使用[2]。 而在本體論的整合中,主要注重於 Class 與 Property 彼此之間對應的關係; 對應的方式則有 Alignment 及 Merge。Alignment 為給定兩個本體論 A 與 B,以 A 作為主體,而讓本體論 B 對應到本體論 A 上。另一種 Merge 則是將兩個本體論合 併成一個大型的本體論。這兩種方式雖然在概念上不相同,但在實際的方法中都. 19.
(20) 強調在半自動化的整合。 在本研究中,規範的表達是以本體論描寫而成的,因此當系統進行資料整合 時,也將以 View 的方式進行資料的整合,但不同的地方在於,本研究採用本體 論描述一個 View 的存在。除此之外,也需一併的將規範框架整合,以達成規範 語意的一致性。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 20.
(21) 第三章 相關研究 3.1 eXtensible Access Control Markup Language eXtensible Access Control Markup Language(XACML)[10]是由 OASIS(Organization for the Advancement of Structured Information Standards)組織所提出對網路上的資訊進行存取控管的描述語言。XACML 以權限. 政 治 大 (what)、由誰(who)、在何時(when)、以那樣的方式(how)進行存取。而 Basel Katt 立 管理或授權管制為基礎,定義對於資訊存取的政策及規則,也就是何種資訊. ‧ 國. 學. 等人所提出來的 IHE-based System[3]即是 XACML 作為規範語言應用在醫療資訊 分享,主要解決了醫療資訊系統上進行外部存取時,滿足使用者的偏好。. ‧. 但由於使用 XACML 作為規範語言能表示僅為外部存取。換句話說,此規範無. sit. y. Nat. 法定義內部使用資料如何能被規範以滿足使用者偏好,因此離本研究與解決的問. io. er. 題仍有一段差距,除此之外 XCAML 語法結構是由 XML 的語法所寫成,因此在結構 的互通性上面是可行的,但是在語意上的互通,可能會產生語意不一致而導致錯. al. n. v i n Ch 誤情形發生,可能會造成存取控制的系統無法達成使用者的隱私期望。 engchi U 3.2 Audit-based Access Control. M.A.C. Dekker 等人所提出的由監視為基本架構的存取控管應用在醫療資訊 分享及保護上[11]。該系統所做的是將分散式系統間各個點所做的動作,如 Read(A,B)、Command(A,B,C1)等等的動作都在一個中央的 Log 端處理,而事後系 統管理者會去一一檢驗 Log 端所存的所有記錄是否合法,並要求執行這項動作的 一方提供證明已確保該動作是合法的。 雖系統確實能夠提供一個機制保護資料擁有者的隱私偏好,但是由於系統執. 21.
(22) 行動作後才會檢查 Log 裡的資料是否合法,除了時間點較晚無法確保資料符合隱 私之外,當無法證明執行動作時,也無法替已經執行的動作回復之前的狀態。. 3.3 Google Health Google Health 是近年來美國方便的醫療資訊整合服務[27],使用者可以自 行輸入個人目前的健康狀況,或是可以從一些大型醫院中直接引入在該醫院的個 人病歷資料,達到個人健康資料整合。同時也可以將目前更新的資料傳至各大醫 院內,使其更新資料,並有一個介面可以讓使用者分享此病歷健康資料給其他. 政 治 大 Google 將個人病歷資料放至雲端運算上,並且只有使用者允許的人才能使 立. 人。. ‧ 國. 學. 用。基本上已達到簡單的存取控管,但是對於允許的人該病歷資料該開放到什麼 程度,或是使用者可以存取的期限、範圍、責任與義務等等,Google Health 並. y. sit. al. er. io. 3.4 資料整合. Nat. 者規範較精確的隱私偏好。. ‧. 未提供這種方式,因此無法完全保護資料擁有者的隱私偏好,也無法讓資料擁有. n. v i n 在資料庫的整合中,LevyC 主要以使用 的方式進行資料庫的整合,整合 h e n g cView hi U. 的方式則有 LAV(Local-As-View)、GAV(Global-As-View)、. GLAV(Global-Local-As-View)等三種方式,三者主要的差別在於 View 與 View 的對應方式[7]。而 Diego 則提出了使用概念(Concept)的方式進行資料庫的整合, 其中整合方式則是使用 GLAV 的對應方式[2]。不同於 Levy 的方式,Diego 採用 不同於資料庫的描述語言進行概念與 View 的對應,稱為 Description Logic, 但也因為兩種不同的對應語言對應時,會造成描述能力上的落差,因此在 Diego 的研究中,又提出了 Schema Rewriting 步驟,能夠達成彼此間不同表達能力的 落差補足。. 22.
(23) 在本體論的整合中,Jérôme Euzenat 的研究中使用對齊的方式作為本體論 整合的方式[9]。對齊(Alignment)的基本概念為:給定兩個本體論分別描述相似 的概念,使用關係(Relationship)將一本體論的概念能夠校準到另一本體論為主 體上,使得進行校準動作的本體論裡的實例能夠被推論到為主體的本體論上。研 究中強調的是自動化(Automatic)與自主化(Autonomous)的本體論對齊,因此使 用的是比較兩者結構的相似性,也就是某一特定 Class 所擁有的 Property(Domain 及 Range)、Superclass、Subclass、Restriction 之間的互相 比較,而該 Class 所衍生的其他 Class(Superclass、Subclass 等等)則再需透過. 政 治 大 度的計算完成後,再依照相似的程度作手動的對應。 立. 遞迴的方式計算相似度,最後才能將所有的 Class 與 Property 計算完成,相似. ‧ 國. 學. 另一種本體論整合的方式則是使用合併(Merge),其中 PROMPT 方法[20]是由 史丹福醫療資訊學系所發展的,其合併兩個知識本體需要來自相同的領域。. ‧. PROMPT 合併本體論方法程序與 FCA-Merge 方法一樣為互動性的、人為介入的方. sit. y. Nat. 式,主要的合併程序區分為三個步驟:1.給予建議。2.決定衝突。3.提出解決衝. io. er. 突的策略。PROMPT 在本體論綱要(Schema)的細部整合方法主要是採用字串比對 與圖狀架構(Graph)對照的方式。在比較兩個本體論時,PROMPT 會依照字串比對. al. n. v i n Ch 所設定的參數以及類別在整個本體論中的圖狀架構位置來給與使用者合併的建 engchi U. 議。本體論綱要整合時,可以同時決定類別底下的實例是否要一起合併過去,因 此在綱要整合完成的同時一併完成實例的整合合併。與對齊方式不同的地方在於 合併是將兩個本體論合併成一個大型的本體論,而先前的兩個則不再使用,因此 本體論的合併不再去探討後續的對應問題(Mapping)。 雖然資料整合可以讓在多個 Data Source 的資料可以一次的被查詢出來,相 對了也多了份破壞資料隱私權的危機,由於多個點都可以在上層同時被查詢,因 此在存取控管方面必頇做的更謹慎、除此之外還必頇符合資料擁有者所期待的隱 私權。. 23.
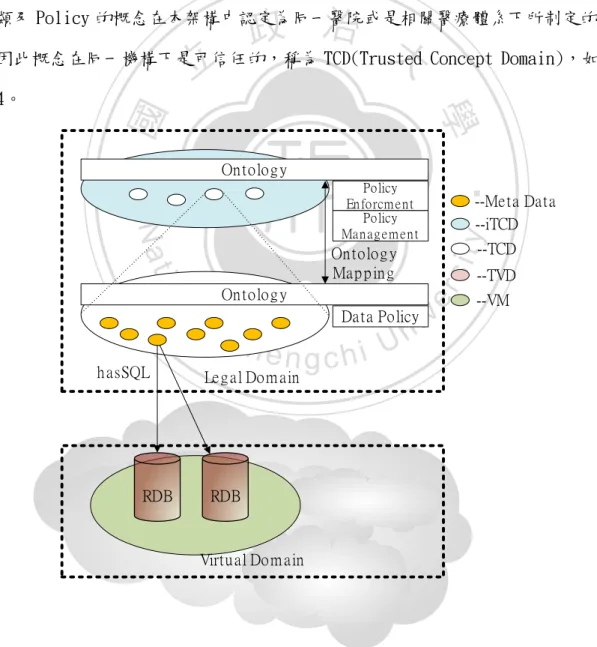
(24) 第四章 研究架構 4.1 研究架構設計 本研究欲採用三層平台整合式的架構,底層是的雲端環境上的資料庫,在此 資料庫存放的是實際的病歷資料;存於雲端虛擬機器的資料庫格式或是資料庫管 理系統則依不同的雲端提供者各自提供,因此本研究強調點為在資料庫存於雲端. 政 治 大. 環境之上進一步進行資料的整合與規範的落實,例如不同醫院雖有個別使用不同. 立. 的資料庫儲存管理系統以及各自的整合系統,但是本研究更能將不同醫院間的資. ‧ 國. 學. 料與規範整合,也就是在各自原有的系統上再次加值,達成系統間的整合。 架構會運用到的詞彙與簡要說明如下表所示:. Nat. y. 概念是彼此可信賴的。. a Trusted i v TCD 中彼此有交 l C intersection n在兩個 h e n g c h i U 集的概念。 Domain. n. iTCD. Trusted Concept Domain 在同一機構下,此領域的. sit. io. TisD. 說明. er. TCD. 總稱. ‧. 簡稱. Integrated Trusted. 將多個 TCD 整合成為整. Concept Domain. 合式的 TCD。. Meta Data. 代表一個實際資料存在 於一個 TCD 之中。. VD. Virtual Domain. 多個 Virtual Machine 所 形成的領域。. 表 1 本研究使用詞彙. 24.
(25) 因為資料庫是建築在雲端環境之中,無法得知該資料庫的真正位置,但透過 雲端虛擬化的技術後,資料庫至少會存在一種連結方式能夠讓使用者進入使用, 我們使用該連結方式做為進入資料庫的路徑,並且透過能查詢到結果的查詢語法 當成 Meta Data。 Meta Data 並不是表示真正的資料,而是描寫資料的特性、位置之描述資料 的資料。Meta Data 在架構中屬於 Concept Domain,因此我們使用本體論描繪出 各個 Meta Data 分類的概念,並將 Meta Data 放置適當的分類中,並且同樣使用 本體論描繪出 Policy 的概念,以及實際描寫某特定資料的規範;描繪出資料分. 政 治 大 因此概念在同一機構下是可信任的,稱為 TCD(Trusted Concept Domain),如圖 立 類及 Policy 的概念在本架構中認定為同一醫院或是相關醫療體系下所制定的,. ‧ 國. 學 Policy En forcm en t Policy Man ag em en t. On tolog y. sit. io. n RDB. --TCD. On tolog y Map p in g. al. --TVD. Data Policy. n U engchi Leg al Dom ain. Ch. --Meta Data --iTCD. y. Nat h asSQL. ‧. On tolog y. er. 4。. iv. --VM. RDB. Virtual Dom ain. 圖 4 在雲端環境上的醫療資料保護及分享模式. 25.
(26) 同樣的概念發生在雲端環境,本研究的資料庫也是儲存在雲端中可信任的虛 擬機器上,因此在資料庫層稱為 VD(Virtual Domain)。而 iTCD(integrated Trusted Concept Domain),則是同樣的使用本體論描繪資料與 Policy 兩個部分, 但是 iTCD 必頇整合來自下層 TCD 的本體論,而整合的準則採用齊頭式的整合, iTCD 與 TCD 的本體論在資料與 Policy 的本體論最上層的 Class 必頇一模一樣, 例如必頇共同要有 Meta Data 的 Class 名稱。 除此之外 iTCD 還必頇將各 TCD 中重複的資料一併考慮進來。換句話說,不. 政 治 大 頇要判斷,在整合時必頇確定有此情況出現,並且另行建立一個 TCD 特定為單獨 立. 同 TCD 同一份資料但是有不同的 MetaData 與不同的 Policy 描寫時的整合情況必. ‧ 國. 學. 兩個 TCD 中重複資料所描述的概念,稱為 TisD(Trusted intersection Domain), 在 TisD 單獨描寫重複的資料以及事前對兩 TCD Policy 進行整合。因此本研究將. ‧. 會在 iTCD 中的本體論個別描述 TCD 與 TisD 之間的關係,並且明確的指出那一些. sit. y. Nat. 不是 TisD 哪一些是,方便後續的規範管理及落實。資料整合將於下一節詳述。. io. er. 當架構整合好之後,使用者將會進入此平台使用整合服務,在此的使用者主 要可以分成兩種,一是一般外部的使用者,在醫療系統中,外部的使用者可能為. al. n. v i n Ch 其他的醫院,或是藥商、學術體系等為了特定的目的搜集滿足特定性質的病歷資 engchi U 料供外部使用;另一種則是資料擁有者本身,為了將所有在平台下的病歷資料存. 取出來供個人使用或是使用者為了特定目的必頇使用特定的病歷等個體使用。使 用流程如下: 1.使用者輸入 Request 後,系統會將 Request 透過改寫程序轉到各個下層 TCD 中進行查詢,找到符合條件的 Meta Data 以及相對應的 Policy,此步驟稱為 Meta Data and Policy Fetching。 2.找到相對應的 Meta Data 及 Policy 之後必頇要找出是否有同一筆資料但 是卻是由多個 TCD 或是 TisD 所描寫,並且有多個 Policy 所描繪的 MetaData,. 26.
(27) 此一步驟主要決定出資料應該由哪一條來自 TCD 或 TisD 的 Policy 進行落實,稱 為 Policy Management。 3.最後將經過 Policy Management 出來的 Policy 表示成可執行的規則語言, 並落實該 Policy,此一步驟稱為 Policy Enforcement 判斷出來結果後再回傳給 使用者。Policy 的各項動作將於 4.2 節詳述。 本研究預計採用的語言為 OWL2 RL。RL 為 OWL2 中的一個 Profile,然而在 其他 Profile EL 與 QL 中,也有各種有不同的表示能力,基本上三種 Profile 最大的差別在也於表達能力上,如 QL 不允許自身性的限制(self-restriction). 政 治 大 整合對應的描寫以及規範表達落實,前兩者使用較簡單的表達能力 EL 時能達到 立. 但 EL 與 RL 允許。在本研究中將會有三種情形使用 OWL2,分別是描寫本體論、. ‧ 國. 學. 最好的效能,後者因研究方法中有使用 Property 的串聯(Property Chain)及差 集(class negation )QL 及 EL 無法囊括之[33],因此統一使用 OWL2 RL 提供表. er. io. sit. y. Nat. 4.2 資料整合. ‧. 達能力。. 在本研究中,資料整合可以分為資料庫的整合與本體論的整合。在資料庫的. al. n. v i n Ch Diego 等人 整合中,早期 Levy 等人進行了許多以資料庫整合的研究,後續則有 engchi U. 以 Description Logic 做為資料整合的語言[1][2][16],取代以 SQL 作為整合語 言的方式,更能增加表達能力與限制,並以 GLAV 的方式整合。而本體論整合則 有兩種方式進行[29],分別是合併與調準。 兩種類型的整合雖然具有相似性,但不全然相同,因此研究將資料整合作為. 一般化的敘述。根據 François Goasdoué的研究中發現資料的整合主要可以分為 以下三個部分[17]: . Query Language:對於載體所進行的查詢語言,或是整合至中介層(Mediator) 上的查詢語言。在 Levy 的資料庫整合方式中,底層資料載體與中介層的查. 27.
(28) 詢語法均為 SQL、Diego 的資料庫整合方式中,底層資料載體查詢語法為 SQL, 而中介層的查詢語法則為 SPARQL、在本體論的整合中,資料載體與中介層 的查詢語法均為 SPARQL 或 DL-expression。 . View Language:產生一組集合稱為 View 並使用此 View 與上層中介層或是 下層載體最對應所使用的語言。在資料庫的整合中是以 SQL 作為 Database 產生 View 的語言,並以此 View 和上層中介層做對應。然而在現有本體論的 整合方式中,並沒有使用 View 的概念做整合,而是強調半自動化的將兩個 本體論結構上的整合,因此本研究仍然使用 View 的概念應用在本體論整合. 政 治 大 Query Rewriting:上層的中介層所使用的查詢語法,必頇透過一定的改寫 立 上,並以 DL-expression 作為 View Language。. . ‧ 國. 學. 方式對應到下層的查詢語法。查詢語法的改寫是與 Query Language、View Language 和對應方式有非常的關係。在兩者的查詢語言相同時,因為同一. ‧. 種語言的描述能力相同,因此不需要再次進行改寫,倘若兩者語言不同的情. sit. y. Nat. 況下,會因為表達能力的差異性,會造成查詢的結果不滿足 Complete 的概. io. er. 念,因此必頇進行 Schema Rewriting 的動作。例如 Diego 的資料庫整合方 式中,由於上層使用 Description Logic 表達能力上會產生具有隱含性的事. al. n. v i n C h Rewriting 的動作[2]。另外 實部分,因此必頇進行 Schema View 的對應方 engchi U. 式也會造成不同方式的 Query Rewriting。例如使用 LAV 作為對應方式時, 必頇使用演算法將上層的查詢語言轉成下層的查詢語言,例如 Bucket Algorithm[7]、miniCon Algorithm 等等,但若使用 GAV 最為對應方式時, 則只需展開(Unfolding)[24]即可完成改寫動作。. 本研究對於資料整合部分進行了文獻探討,並在資料庫整合與本體論整合分 開進行討論,在資料庫整合中,本研究使用了 Diego 的方式,以 Description Logic 作為整合的語言,並對於本研究架構進行了修改。在本體論整合方面,仍 然使用 View 的方式對於本體論進行整合,並與其他現有的方式做比較。兩者的. 28.
(29) 整合方式將於下節詳述。. 4.2.1 資料庫的整合 根據 Diego 的資料庫整合方式中,是以 Description Logic 作為整合的語言 [1],並將資料本身放在下層的資料庫作為載體用,而上層所表示的則是概念的 整合與描述,因此,在整合中並不會將資料放置上層的中介層裡。主要包含以下 幾個步驟,以下將分別將步驟詳述,並且根據本研究架構進行修改: . 治 政 大 GAV 與 LAV 的一般化 料庫作為資料載體,並使用 GLAV 作為對應方式也就是 立 對應(Mapping):該研究是以 OWL2 作為上層整合的語言,底下則是使用資. 情形。. ‧ 國. 學. . 查詢改寫:由於 OWL2 的表達能力對於本體論中會出現一些隱含性的事實. ‧. (Inferred),一般來說隱含性的事實雖然可以使用推論引擎如 Pellet 推論. y. Nat. 出來,但是在查詢改寫的當下必頇要即時的判斷是否有隱含性的事實,該事. er. io. sit. 實必頇要一併的被找出來,目前則是尚未支援,因此必頇要採取的是手動性 的架構改寫(Schema Rewriting),在此使用的演算法為 CGLLR[15]。. al. n. v i n 由於該研究是採用 GLAV 的對應方式,也就是 GAV 與 LAV 的一般化情形,所 Ch engchi U. 以在查詢語法的改寫中,必頇要分開進行處理。GAV 的部分只需將該 View 直接. 進行展開(Unfolding)的動作即可,而 LAV 的部分則再需使用其他的演算法進行 處理,如 Minicon Algorithm、Bucket Algorithm。 在本研究議題的假設中,資料庫是不會有太大的變動性;此外在查詢語法改 寫的部分,上述研究使用的是 GLAV,因此必頇要將屬於 GAV 與 LAV 的部分分開 改寫,然而在 GLAV 的表達能力中仍會存在不屬於 GAV 與 LAV 的部分,也就是出 現多個 DL 敘述的連結對應到底下多個 SQL 的連結。在該研究中,尚未探討到此 部分,也未對 GLAV 的對應方式做限制,因此本研究將使用 GAV 作為底層資料庫. 29.
(30) 與上層 TCD 的對應方式。 本研究參考 Diego 的方式後,採用 GAV 的對應方式,而對應(Mapping)則採 用 DL 中的 Instance 對應到資料庫,原因在於資料庫本身並沒有如同 DL 描述能 力中階層的概念,使用 DL 是為了不同資料庫本身所產生的限制而所描寫的,如 果將這些限制都寫進 SQL 語法中,也就不需要使用 DL 的表達能力。另外,若使 用 DL 表達能力,則還頇進一步的進行 Schema Rewriting;除此之外在本研究中 因為使用的 GAV 方式對應,因此在本研究中,使用較簡單的方式即可達到目的, 若有 Meta Data 使用 GAV 對應到下層的資料庫,則該 Instance 就會具有一. 政 治 大 位置、資料表、及 SQL 語法等,如: 立. Datatype Property 為 hasSQL 連接一字串,表示 Meta Data 所對應到的資料庫. ‧ 國. 學. WHERE 1. SQL://somewhere:someTable SELECT some FROM some. ‧. 若 hasSQL 需要表示成從多個資料庫中擷取的形式,則可以表示成:. sit. y. Nat. SQL://somewhere:someTable SELECT some FROM some WHERE 1 UNION. io. er. SQL://someotherwhere:someTable SELECT someother FROM someother WHERE 1 本研究將 hasSQL 的個數限制(Cardinality)為 1,原因在於當系統判斷是否. al. n. v i n C時,必頇判斷此 兩個 Meta Data 為同一個 Data U 的值是否相同。例如 h e n g c h iPorperty. Meta Data A 具有 2 條 hasSQL、Meta Data B 具有 1 條與 Meta Data A 相同的 hasSQL Property 雖然在比對上會認為兩個 Meta Data 為相同,一旦需要讀取 Meta Data A 時還需要額外判斷使用哪一條 hasSQL 的值。但是需存取哪一方的 SQL 並不會 破壞資料擁有者的隱私期待,因此本研究不去探討此問題,故設定 hasSQL 個數 為1. 4.2.2 本體論的整合. 30.
(31) Jérôme Euzenat 的研究中使用對齊的方式作為本體論整合的方式[9]。然而 在本研究中,本體論數量不僅僅為兩個,而是可能多個本體論整合,若使用該方 式做整合,則頇對每兩個本體論進行對齊的動作,如此作法先後順序可能會影響。 再者選擇作為本體的本體論也是重要的考量,在本研究假設中,多個本體論作整 合時,選擇單一的本體論作為本體對齊與不同的本體論作為本體所呈現出來的結 果會大不相同,並且在後續的查詢語法改寫中變得更加困難。更進一步的,該研 究著重的是在於自動化與自主化的整合方式,才選擇使用相似度的比較,然而在 本研究假設中,多個本體論整合到上層本體論必頇完全對應,才有利後續的查詢. 政 治 大 對應成功,以及後續的改寫動作是否順利。 立. 語法改寫及規則判斷,因此本研究對於本體論的整合注重於彼此的結構是否完全. ‧ 國. 學. 另一種本體論整合的方式 PROMPT 在本體論綱要(Schema)的細部整合方法, 與對齊方式不同的地方,合併的方式是將兩個本體論合併成一個大型的本體論,. ‧. 而先前的兩個則不再使用,因此本體論的合併不再去探討後續的對應問題. sit. y. Nat. (Mapping),然而這與本研究的假設剛好相反。本研究架設本體論的整合為給定. io. er. 多個本體論,在上層建立起多個本體論的合併,並且建立起上層本體論與下層本 體論的對應,使得當上層的本體論有 Instance 時,可以被推論到下層本體論,. al. n. v i n Ch 以便在下層進行規範的取得,因此本研究將不使用本體論合併(Merging)的方 engchi U 式。. 本研究根據 Diego 研究方式中的整合框架本研究將對以下進行修改: 1. 對應方式:有別於資料庫的整合在下層的資料載體為資料庫,在本研究中欲 進行整合方式為本體論對本體論的整合,因此在 View Language 則使用 DL-Expression,以集合的概念產生 View,這與 SQL 的方式產生 View 截然不 同。SQL 可以透過 JOIN 的方式將不同的資料表結合在一起而產生 View,因此 資料表必頇要有 Foreign Key 的存在才能把兩個不同的資料表結合在一起, 例如:V1(x) := Tabkle1(w,y), Table2(y,x)其中 y 代表了 Foreign Key 的. 31.
(32) 存在,然而在 DL-Expression 中使用的是集合的概念,因此要將兩個概念連 結起來則透過 AND 或是 UNION 的方式即可。另外在對應的方式將採用 LAV, 原因在於第三層的 iTCD 主要為一個動態平台,在假設情境中,各個 TCD 可能 會動態的進入平台,或是離開,因此使用 LAV 的對應方式可以讓 iTCD 變動較 容易。 2. Instance 改寫:在原先的查詢請求為一道查詢語法,在本研究架構中,該查 詢將視為一個 Instance 的存在,原因在於查詢必頇經過隱私偏好規範的檢驗, 才有辦法進行查詢。因此查詢語法改寫在此將轉變成為上層的 Instance 透過. 政 治 大 的取得,並且再次對應到上層 iTCD 進行規範落。 立. Mapping 的方式被改寫到下層的本體論裡,進而在第二層各個 TCD 進行規範. ‧ 國. 學. 然而就集合的觀點檢視資料庫整合的 View 對應方式,在資料表之間的連結則 只使用了聯集(UNION)的方式,並未使用 AND,原先的 Query Rewriting Algorithm. ‧. 在本研究的整合方式中並不適用,因此改寫方式將如下所述:在先前對應的方式. io. er. 經由聯集或交集所形成的對應如:. sit. y. Nat. 中,採用 LAV 的對應方式,也就是下層的本體論各 Class 均是由上層本體論 Class. 𝐿𝑜𝑐𝑎𝑙_𝐶𝑙𝑎𝑠𝑠 ≡ 𝐺𝑙𝑜𝑏𝑎𝑙_𝐶𝑙𝑎𝑠𝑠1 ∪ 𝐺𝑙𝑜𝑏𝑎𝑙_𝐶𝑙𝑎𝑠𝑠2. al. n. v i n C h ∩ ∃𝐺𝑙𝑜𝑏𝑎𝑙𝑃𝑟𝑜𝑝𝑒𝑟𝑡𝑦. 𝐿𝑜𝑐𝑎𝑙_𝐶𝑙𝑎𝑠𝑠2 ≡ 𝐺𝑙𝑜𝑏𝑎𝑙_𝐶𝑙𝑎𝑠𝑠1 𝐺𝑙𝑜𝑏𝑎𝑙_𝑐𝑙𝑎𝑠𝑠2 engchi U. 其中,對應的運算原本研究僅使用等價(≡)作為 Class 之間的對應。在聯集中, 若有一上層 Instance 屬於 Global_Class1,則可以直接將該 Instance 改寫成屬 於 Entity_Class 之中,但是在交集之中,若有一上層的 Instance 屬於 Global_Class1 但不具有 GlobalProperty 其 Range 屬於 Global_Class2 則無法 直接改寫成 Instance。因此在 Instance 改寫中必頇將兩種不同的動作分開進行 改寫。. 4.2.3 重複資料的整合. 32.
(33) 在資料整合的過程中,可能會產生的情形就是在多個 TCD 整合到 iTCD 時, 會出現多個 TCD 中的 Meta Data 所對應到的資料庫資料為同一筆。在這情況下, 會出現兩種合理的解釋: 1. 資料擁有者為了方便起見在將資料提交到不同的 TCD 時,刻意地給定同一份 來源,因此就各個 TCD 來看,並不會知道該資料是與其他 TCD 重複的。 2. 另一為各個 TCD 為了資料共享的目的,如共同診療等目的,刻意將資料存在 相同的位置,因此各個 TCD 事先會知道與其他 TCD 重複的地方,然而在單一 TCD 的使用時,並不會將與其他 TCD 重複資料的情形考慮進來,在此情況下,. 政 治 大 TCD 之中,若資料與其他 TCD 表示可能會有另外一個 TCD 規範,因此必頇要 立. TisD 的存在是必要的,因為在單一 TCD 所規定的規範適用範圍只會挶限於該. ‧ 國. 學. 存在於一個兩者所交集的 TCD 是共同規範資料的部份,倘若不使用 TisD 進行 規範,可能會導致兩個 TCD 規範不一致甚至衝突,進而破壞使用者隱私偏好。. ‧. 第一種情形時,系統不需要去將重複資料進行整合,因為對於 TCD 來說是不. sit. y. Nat. 同的資料;就第二種情況來看,具有重複資料的兩個 TCD 必頇再建構另一種 TCD. io. er. 也就是 TisD,確保 iTCD 了解 TCD 間重複的區塊原因在於,當有重複的 Meta Data 存在並且 TCD 了解時,具有重複 Meta Data 的 TCD 會額外在 TCD 之間進行共同. al. n. v i n Ch Meta Data 的額外規範,這些規範是兩家 共同所遵守的,因此本研究將重複 e n gTCD chi U 的區域特別制定出來為 TisD,以減少 TCD 之間找到重複的資料與重複的規範落 實;TisD 與 TCD 結構相同,同樣需要使用本體論敘述資料與規範的概念,但與 TCD 不同的是,TisD 並不是真正存在於實體社會中的機構,而是兩個 TCD 中資料 交集的部分,因此並不會有單獨對於 TisD 進行存取的行為。當同一筆資料被多 個 TCD 所描述並且 TCD 也都瞭解此情況時,在規範的取得及落實無法像從單一 TCD 一樣,因此必頇 TCD 之間再找出交集部分,重新建構 TisD,如圖 5 所示。. 33.
(34) Police Bc. Police Bb. Police Ac. Police Cc. Police Aa. d escrib e d escrib e. d escrib e. d escrib e. d escrib e. ●Meta Data Cc. ● Meta Data b. ●Meta Data a ●Meta Data Ac. ●Meta Data Bc. TisD C h asSQL. h asSQL. TCD A. TCD B h asSQL h asSQL. h asSQL. ◆Data b. ◆Data a ◆Data c. 政 治 大. 圖 5 TisD 範例圖. 立. ‧ 國. 學. 舉例來說,若兩家醫院同時診療一位病人,某家醫院欲對該資料進行讀取, 也許可行,但若欲對該資料進行修改時,則需要另一家醫院的同意,或是兩家醫. ‧. 院必頇協商出特定規範,才能在此規範下使用。若換成本研究角度來看,則是由. sit. y. Nat. 單一個 TCD 進行存取以及從 iTCD 進行存取時,所涉及的規範也會不同,因此必. io. er. 頇要有 TisD 的存在。因此,當 TCD 欲在 iTCD 平台進行整合時,必頇了解目前是 否有已在 iTCD 的 TCD 而且是與自己有重複的資料,若出現此情形時,則頇再一. al. n. v i n Ch 次將重複的 TisD 加入 iTCD 中,已確保加入 的 Policy 並不會與其他 TCD 的 e n g c TCD hi U Policy 不一致甚至是衝突的情況發生。. 34.
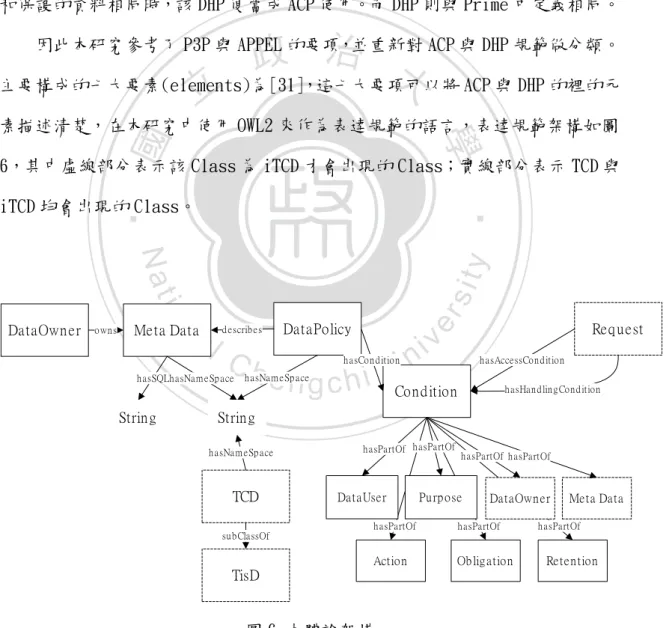
(35) 4.3 隱私偏好的表示與落實. 4.3.1 隱私偏好的表示 然而在本研究中系統僅僅有分享個人資料的動作,並沒有其他的服務,因此 ACP 就會成為 DHP 的子集合。本研究將 ACP 定義為:外部使用者欲對系統要求資 料,並且執行的動作為 Get 類別以及和欲使用資料與某一 DHP 的規範中執行動作 和保護的資料相同時,該 DHP 便當成 ACP 使用。而 DHP 則與 Prime 中定義相同。. 政 治 大 主要構成的七大要素(elements)為[31],這七大要項可以將 ACP 與 DHP 的裡的元 立 因此本研究參考了 P3P 與 APPEL 的要項,並重新對 ACP 與 DHP 規範做分類。. ‧ 國. 學. 素描述清楚,在本研究中使用 OWL2 來作為表達規範的語言,表達規範架構如圖 6,其中虛線部分表示該 Class 為 iTCD 才會出現的 Class;實線部分表示 TCD 與. ‧. iTCD 均會出現的 Class。. sit. al. n. Meta Data. Strin g. DataPolicy. d escrib es. Ch. h asSQLh asNam eSp ace. er. io. own s. y. Nat DataOwn er. v ni. e n g c h i UCon d ition h asCon d ition. h asNam eSp ace. Req uest h asAccessCon d ition h asHan d lin g Con d ition. Strin g h asNam eSp ace. TCD sub ClassOf. h asPartOf h asPartOf. DataUser. h asPartOf h asPartOf. Purp ose. DataOwn er. h asPartOf. h asPartOf. Action. Ob lig ation. Meta Data. h asPartOf. Reten tion. TisD. 圖 6 本體論架構 首先,每一個屬於 Meta Data 的 Instance 都代表著一個真正資料,真正的. 35.
(36) 位置則是使用 hasSQL 敘述透過何種方式能夠存取。Meta Data 的後續分類則由 各 TCD 各自決定。一條 Data Policy 描寫著一份或多份 Meta Data,而一條 Data Policy 具備一個 Condition,該 Condition 則是由不同的 Class 所組成,例如 DataUser、Action、Purpose,其中在 iTCD 中才會有 DataOwner 及 Meta Data 是因為 iTCD 並不知道 Request 會需要哪一些 Meta Data,因此必頇要將此情況 寫入 Condition 中;一條 Request 則是與 Data Policy 相同具有一個 Condition 組合,而分別用兩條 Property hasAccessCondition 與 hasHandlingCondition 分別表示兩種不同的 Condition,最後一條 Data Policy 與 Meta Data 都具備. 政 治 大 條 Data Policy 或 Meta Data 所屬的 TCD 以便進行 Policy 的選擇。 立. hasNameSpace Property 是因為後續在進行 Policy Management 時必頇要了解一. ‧ 國. 學. 4.3.2 規範的取得、管理與落實. ‧. 當 TCD 對應到 iTCD 以及增加了 TisD 後,並且 Data Policy 如同上一節所示. Nat. sit. y. 被定義清楚後,前置作業才算完成。當有後續的使用者經由上層的 iTCD 輸入. n. al. 主要分成三個步驟:取得、管理與落實。. 4.3.2.1 規範取得. Ch. engchi. er. io. Request 後,必頇把 Request 裡的元素與現有的 Data Policy 一一比對動作,這. i n U. v. 規範的取得(Policy Fetch):當使用者輸入 Request 時,必定需要輸入需要 使用的從 iTCD MetaData 取得的資料分類,藉由此分類我們可以分別對應到 TCD 中 Meta Data 的分類,將這些 Meta Data 找到,並且利用 Property"describes" 可以找到敘述這些 Meta Data 的 Data Policy,然而這些存在 TCD 中的 Data Policy 所含有的 Condition 組合詞彙乃是採用原有 TCD 中各個 Class 的分類詞彙,因此 必頇將取得的 Data Policy 中的 Condition 詞彙同樣透過對應的方式轉換到上層 iTCD 所整合的詞彙中。在上層詞彙對應成下層詞彙時,因為對應的方式是 LAV,. 36.
(37) 轉換的方式如同上一章所示;相反的,當下層詞彙對應成上層詞彙時,對應方式 剛好反過來,會變成 GAV 的對應方式,所以在轉換方始只需要採用 Unfolding 的方式即可。需要將滿足條件的 Meta Data 及 Data Policy 全部送回 iTCD 的原 因在於,當 TCD 在整合時會碰到重複性的資料存在,而重複性的資料極有可能是 兩家機構共同所擁有的,因此才會產生 TisD 描寫共同資料的規範,換句話說將 Data Policy 送回 iTCD 的原因也在於必頇讓 iTCD 判斷是否有出現 TisD 的情形, 以選擇符合的 Data Policy 執行。本研究將使用 DL-Expression 作為 Meta Data 與 Data Policy 的取得方式,取得方式如下:. 政 治 大 𝐹𝑒𝑡𝑐𝑃𝑜𝑙𝑖𝑐𝑦 ≡ 𝐷𝑎𝑡𝑎 𝑃𝑜𝑙𝑖𝑐𝑦 ⊓ ∃𝑑𝑒𝑠𝑐𝑟𝑖𝑏𝑒. 𝐹𝑒𝑡𝑐𝐷𝑎𝑡𝑎 立 𝐹𝑒𝑡𝑐𝐷𝑎𝑡𝑎 ≡ 𝐼𝑛𝑝𝑢𝑡𝐷𝑎𝑡𝑎𝐶𝑙𝑎𝑠𝑠. ‧ 國. 學. 第一條 DL-Expression 表示從 Request 中找出屬於 Meta Data Class 的 Instance 之所在 Class 當作 InputDataClass,因為在先前的對應中已經事先對. ‧. 應了 InputDataClass 在 TCD 中分別對應的 Class,在此不需要輸入對應的 Class,. sit. y. Nat. 而是會推論出下層哪一些 Class 是對應到 InputDataClass。第二條. io. 4.3.2.2 規範管理. al. n. Data 的。. er. DL-Expression 則是從取得的 MetaData 中找出 Data Policy 是描述這些 Meta. Ch. engchi. i n U. v. 當規範取得後,iTCD 必頇判斷是否存在同一份資料卻有多個 TCD 中 Data Policy 描寫,在此分成兩種情況,一為資料擁有者因為方便起見,刻意將存在 同一個地方的同一筆資料給數個 TCD 使用,因此 TCD 並不知道該資料是與其他 TCD 具有重複性質的;換句話說 TCD 也不需要遵守其他 TCD 的規範,因此在規範 管理上不需要處理此情況。另一種情形是 TCD 之間彼此事先知道重複的資料部分, 並且使用 TisD 將共同資料的部分額外規範,但是各個 TCD 間仍會有各自的 Data Policy 描寫同一份資料的情形。例如 TCD 內部可能規定某重複資料可以被讀取,. 37.
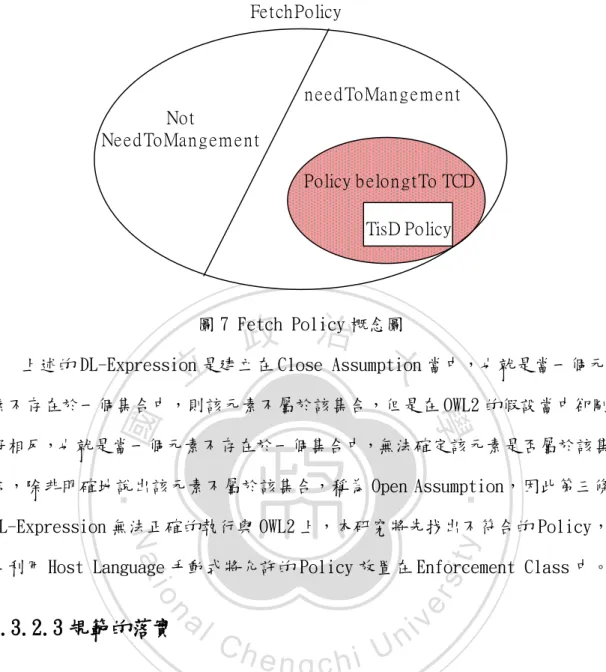
(38) 為了醫院的營運或是學術分析等目的;而 TisD 則規範範圍更廣,如允許在兩家 醫院同時診療的情況下對病歷資料進行增修等動作,當然 TCD 原有的 Data Policy 也會囊括之。在此步驟中對規範管理的概念為:”若重複資料的 Meta Data 中,其中有一份 Meta Data 來自 TisD 則就選用 TisD 所描寫的規範,否則不予處 理”。表達方式如下: 𝑝𝑜𝑙𝑖𝑐𝑦 𝑜 𝑎𝑠𝑁𝑎𝑚𝑒𝑆𝑝𝑎𝑐𝑒 𝑜 𝑖𝑛𝑣𝑒𝑟𝑠𝑒(𝑎𝑠𝑁𝑎𝑚𝑒𝑆𝑝𝑎𝑐𝑒) 𝑜 𝑡𝑐𝑑 ≡ 𝑏𝑒𝑙𝑜𝑛𝑔𝑠𝑇𝑜𝑇𝐶𝐷 𝑑𝑒𝑠𝑐𝑟𝑖𝑏𝑒𝑠 𝑜 𝑎𝑠𝑆𝑄𝐿 𝑜 𝑖𝑛𝑣𝑒𝑟𝑠𝑒(𝑎𝑠𝑆𝑄𝐿)𝑜 𝑖𝑛𝑣𝑒𝑟𝑠𝑒(𝑑𝑒𝑠𝑐𝑟𝑖𝑏𝑒𝑠). 政 治 大 FetchPolicy ⊓ not(∃needToManagement. (∃belongsToTCD. TisD)) 立 ≡ 𝑛𝑒𝑒𝑑𝑇𝑜𝑀𝑎𝑛𝑎𝑔𝑒𝑚𝑒𝑛𝑡. ‧ 國. 學. ⊔ ∃belongsToTCD. (not TisD) ≡ EnforcePolicy. 前面兩條表達方式是採用 OWL2 裡的 Property Chain,o 代表 Property 與. ‧. Property 之間的連接。第一條 Property Chain 是找到每一條 Data Policy 所屬. sit. y. Nat. 的 TCD,由於 TCD Class 只會在 iTCD 中出現,因此必頇在此時決定好。第二條. io. er. 則是同樣透過 Property Chain 找出那些 Policy 所描寫的 Meta Data 是具有重複 性質的。第三條 DL-Expression 則表示從第二條所找出的 Policy 中,有哪一些. al. n. v i n C h Policy 也沒有與屬於 所屬的 TCD 是不為 TisD 的,並且該 e n g c h i U TisD 的 Policy 有第二 條 Property Chain 所產生的關係。將這些找出來後不要,剩下的就是準備執行. 的 Data Policy 了。可以使用邏輯表示成(FetchPolicy − Policy belongsTo TCD) ∪ TisD Policy如下圖 7 所示:. 38.
(39) Fetch Policy. n eed ToMan g em en t Not Need ToMan g em en t Policy b elon g tTo TCD TisD Policy. 政 治 大 上述的 DL-Expression 是建立在 Close Assumption 當中,也就是當一個元 立 圖 7 Fetch Policy 概念圖. ‧ 國. 學. 素不存在於一個集合中,則該元素不屬於該集合,但是在 OWL2 的假設當中卻剛 好相反,也就是當一個元素不存在於一個集合中,無法確定該元素是否屬於該集. ‧. 合,除非明確地說出該元素不屬於該集合,稱為 Open Assumption,因此第三條. sit. y. Nat. DL-Expression 無法正確的執行與 OWL2 上,本研究將先找出不符合的 Policy,. io. n. al. er. 再利用 Host Language 手動式將允許的 Policy 放置在 Enforcement Class 中。. 4.3.2.3 規範的落實. Ch. engchi. i n U. v. 透過規範管理之後,得到的是需要被落實的規範,在此必頇先將 Request 進 行成兩類,一類為 Action 為 Get Class 之下的 Request,另一類則是 Action 為 Non-Get Class 之下的 Request,如果 Request 為 Get 則表示該 Request 除了需 要第一次的規範落實外,還必頇落實第二次 Data Handling 的規範,反之 Non-Get Request 則只需要一次規範落實即可。規範落實是先找到每一條 Policy 中 ConditionInstance 所存在的 Class,利用該 Class 作為一個 Condition 落實的 條件,例如範例 1 如果成為頇被落實的 Data Policy,即可表示成為:. 39.
(40) 𝑅𝑒𝑞𝑢𝑒𝑠𝑡 ⊓ ∃𝑎𝑠𝐴𝑐𝑐𝑒𝑠𝑠𝐶𝑜𝑛𝑑𝑖𝑡𝑖𝑜𝑛. ∃𝑎𝑠𝑃𝑎𝑟𝑡𝑂𝑓. 𝐷𝑜𝑐𝑡𝑜𝑟 ⊓ ∃𝑎𝑠𝑃𝑎𝑟𝑡𝑂𝑓. 𝑅𝑒𝑎𝑑 ⊓ ∃𝑎𝑠𝑃𝑎𝑟𝑡𝑂𝑓. 𝑃𝑟𝑒𝑠𝑐𝑟𝑖𝑝𝑡𝑖𝑜𝑛 ⊓ ≡ 𝑃𝑒𝑟𝑚𝑖𝑡 ∃𝑎𝑠𝑃𝑎𝑟𝑡𝑂𝑓. 𝐷𝑒𝑙𝑒𝑡𝑒 ⊓ ( ∃𝑎𝑠𝑃𝑎𝑟𝑡𝑂𝑓. 𝑁𝑜_𝑅𝑒𝑡𝑒𝑛𝑡𝑖𝑜𝑛 ). 因此,不同的 Data Policy 會被置換成不同的 DL-Expression,不同點僅在於 𝑎𝑠𝐴𝑐𝑐𝑒𝑠𝑠𝐶𝑜𝑛𝑑𝑖𝑡𝑖𝑜𝑛中的𝑎𝑠𝑃𝑎𝑟𝑡𝑂𝑓組合,在此先行將上述的 DL-Expression 表 示成. 政 治 大. 𝑅𝑒𝑞𝑢𝑒𝑠𝑡 ⊓ ∃𝑎𝑠𝐴𝑐𝑐𝑒𝑠𝑠𝐶𝑜𝑛𝑑𝑖𝑡𝑖𝑜𝑛. (∃𝑎𝑠𝑃𝑎𝑟𝑡𝑂𝑓. 𝑠𝑜𝑚𝑒𝐶𝑙𝑎𝑠𝑠),其中 someClass. 立. 表示由 Data Policy 所找到 Instance 存在的 Class。完整的規範落實表示如下:. ‧ 國. 學. 𝑅𝑒𝑞𝑢𝑒𝑠𝑡 ⊓ ∃𝑎𝑠𝐴𝑐𝑐𝑒𝑠𝑠𝐶𝑜𝑛𝑑𝑖𝑡𝑖𝑜𝑛. (∃𝑎𝑠𝑃𝑎𝑟𝑡𝑂𝑓. 𝐺𝑒𝑡). ‧. ≡ 𝐺𝑒𝑡𝑅𝑒𝑞𝑢𝑒𝑠𝑡. sit. y. Nat. 𝑅𝑒𝑞𝑢𝑒𝑠𝑡 ⊓ ∃𝑎𝑠𝐴𝑐𝑐𝑒𝑠𝑠𝐶𝑜𝑛𝑑𝑖𝑡𝑖𝑜𝑛. (∃𝑎𝑠𝑃𝑎𝑟𝑡𝑂𝑓. 𝑁𝑜𝑛𝐺𝑒𝑡). n. al. er. io. ≡ 𝑁𝑜𝑛𝐺𝑒𝑡𝑅𝑒𝑞𝑢𝑒𝑠𝑡. v. 𝑁𝑜𝑛𝐺𝑒𝑡𝑅𝑒𝑞𝑢𝑒𝑠𝑡 ⊓ ∃𝑎𝑠𝐴𝑐𝑐𝑒𝑠𝑠𝐶𝑜𝑛𝑑𝑖𝑡𝑖𝑜𝑛. (∃𝑎𝑠𝑃𝑎𝑟𝑡𝑂𝑓. 𝑠𝑜𝑚𝑒𝐶𝑙𝑎𝑠𝑠) ≡ 𝑃𝑒𝑟𝑚𝑖𝑡. Ch. engchi. i n U. 𝐺𝑒𝑡𝑅𝑒𝑞𝑢𝑒𝑠𝑡 ⊓ ∃𝑎𝑠𝐴𝑐𝑐𝑒𝑠𝑠𝐶𝑜𝑛𝑑𝑖𝑡𝑖𝑜𝑛. (∃𝑎𝑠𝑃𝑎𝑟𝑡𝑂𝑓. 𝑠𝑜𝑚𝑒𝐶𝑙𝑎𝑠𝑠) ≡ 𝐴𝑐𝑃𝑒𝑟𝑚𝑖𝑡 𝐴𝑐𝑃𝑒𝑟𝑚𝑖𝑡 ⊓ ∃𝑎𝑠𝐻𝑎𝑛𝑑𝑙𝑖𝑛𝑔𝐶𝑜𝑛𝑑𝑖𝑡𝑖𝑜𝑛. (∃𝑎𝑠𝑃𝑎𝑟𝑡𝑂𝑓. 𝑠𝑜𝑚𝑒𝐶𝑙𝑎𝑠𝑠) ≡ 𝑃𝑒𝑟𝑚𝑖𝑡 上述兩條 DL-Expression 先個別將兩種不同的 Request 分類後分開處理,若為 𝑁𝑜𝑛𝐺𝑒𝑡𝑅𝑒𝑞𝑢𝑒𝑠𝑡只需要執行第三條 DL-Expression 類型即可,反之則除了第一次 的 AccessCondition 需要比較外,HandlingCondition 還需要額外比較。. 40.
(41) 4.3.3 OWL2 RL 與 SWRL 的比較 SWRL(Semantic Web Rule Language) [32],是由 OWL 子語言 OWL DL 與 OWL Lite 以及 Datalog RuleML 為基礎的規則描述語言。郭弘毅在研究中便使用 SWRL 做為存取控管表達與落實的語言,並參考了 EPAL 的標準元素做為企業間資料隱 私偏好的表示,提供了以語意化技術表示及落實規範,使得在外部存取時能夠滿 足使用者偏好。SWRL 是採用 Instance 比對的方式進行推論。例如:爸爸的兄弟 是叔叔。可以用 SWRL 表示成:hasFather(? x, ? y) ∩ hasBrother(? y, ? z) hasUncle(? x, ? z)。在 OWL1 的表達能力中,是無法表示上述例子的概念的,但是. 治 政 在 OWL2 中即使有此能力可以表達 Property Chain 大 也增加了不少的限制[27]。 立. 1.Regular:任何的 Property Chain 必要要滿足 Regular 條件,也就是可以排出. ‧ 國. 學. 彼此 Property 的順序。例如:(1)𝑅 𝑜 𝑆 ⊆ 𝑅 (2)𝑆 𝑜 𝑆 ⊆ 𝑆 (3)𝑅 𝑜 𝑆 𝑜 𝑅 ⊆ 𝑇可. 之間的順序,造成 Undecidable。. Nat. y. ‧. 以得知一組順序S < R < T。若(1)R o S ⊆ S (2)S o R ⊆ R 則無法得知 S 與 R. er. io. sit. 2.Complex Property:在 Property Chain 中,裡面所使用的 Property 必頇為 Simple Property,也就是不為 Property Chain 所產生的 Property,如果在. al. n. v i n Property Chain 使用 Complex chain of C Property,則會造成”Property hengchi U Property Chain”,並且很有可能造成 Undecidable。除此之外,OWL2 還可以利 用 Class Expression 進行推論,而這部分推論的方式與 SWRL 則完全不同。Class Expression 是用集合的概念組成的,例如∃P. C 與∀P. C則分別表示 P Property 的 Range C Class 所形成的集合。相反的 SWRL 則無法表示集合的概念,而是單一 的 Instance 的比對,因此即使是單純比較是否為子集合,儘管在 SWRL 的表示可 以寫成ClassA(? x). ClassB(? x)與 Class Expression 的ClassA. ClassB所代表. 的意義仍然不同。 郭弘毅[26]在研究中便使用 SWRL 做為存取控管表達與落實的語言,而在 SWRL. 41.
(42) 中的執行是採用對於每一個存在於本體論的 instance 之間去做比較,因此當兩 者需要做比較時,只能單純判斷兩者是否屬於同一個 instance,並無法判斷兩 者是否滿足階層性的概念。例如在上一節中,若一條 Request 的使用資料為 Personal Data,在郭弘毅研究中,必頇要有一條允許使用 Personal Data 的 Policy,如果有一條 Policy 是允許所有 Data 的 Policy,在 SWRL 的比對中,兩 條 Policy 所用的 Instance 不同,因此該 Request 並不會被允許。OWL2RL 與 SWRL 的比較如下表所示 DL-Safe Undecidable SWRL. 是. 可能會有. OWL2 RL. 是. 不會產生. 立. Instance 比對. 是 治 沒有 政 大Class 是. 比對階層性 無法 可以. Expression. 表 2 SWRL 與 OWL2 RL 的比較. 學. 表達能力較弱。. ‧ 國. Class 比對. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 42.
(43) 第五章 系統實作與驗證 5.1 資料整合的驗證 在資料整合的研究中,特別點出了兩種資料整合時所具有的特性,分別為 Sound 以及 Complete[]。Sound 的定義為:給定兩個載體原始載體 *𝐷𝑎1 , 𝐷𝑎2 … , 𝐷𝑎𝑛 +與整合載體𝐷𝑏 並存在一個對應的關係 R,若給定查詢 Q 於. 政 治 大 於𝐷 所產生的結果為一集合(寫作 Q(𝐷 )),若滿足 Q(𝐷 ) ⊆ Q(𝐷 立. *𝐷𝑎1 , 𝐷𝑎2 … , 𝐷𝑎𝑛 +所產生的結果為一集合(寫作 Q(𝐷𝑎1 )∪ Q(𝐷𝑎2 ) … ∪ Q(𝐷𝑎𝑛 ))及 Q 𝑏. 𝑏. 𝑎1 )∪. 𝑏. Q(𝐷𝑎2 ) … ∪. ‧ 國. 學. Q(𝐷𝑎𝑛 ))則𝐷𝑏 滿足 Sound;反之,若 Q(𝐷𝑏 ) ⊇ Q(𝐷𝑎1 )∪ Q(𝐷𝑎2 ) … ∪ Q(𝐷𝑎𝑛 )),則𝐷𝑏 滿足 Complete;若同時滿足 Sound 與 Complete,即 Q(𝐷𝑎1 )∪ Q(𝐷𝑎2 ) … ∪ Q(𝐷𝑎𝑛 )). ‧. = Q(𝐷𝑏 )則稱為 Exact。在資料庫整合中,只頇滿足 Sound 即可[6],原因在於. sit. y. Nat. 一些位於原始載體的 Schema 未必會到整合載體上產生關係;由於資料庫的對應. io. er. 方式是採用 View 作為單位的,因此在原始載體未必會把所有的 Schema 都建構成 View,而導致從整合載體查詢的資料少於從原始載體查詢的資料。另外在 View. al. n. v i n 的對應上若原始載體所產生的CView View 本身就具有落差,也就是由於 h e與對應的 ngchi U View 本身的限制所產生的不一致性時,在查詢上也是會造成落差的。但是只滿. 足 Sound 在資料庫整合中仍認為是合理的,而最差的情況是指滿足 Complete 也 就是整合載體找出的資料在原始載體找不到。由於本研究目的涉及資料整合部份, 因此採用上述兩種特性驗證資料整合在本研究架構中,三層的架構是由兩個不同 方式的整合所組成的,若要證明此架構至少為 Sound 及兩個不同的整合方式分開 證明為 Sound 即可。首先底層的資料庫產生 View 之後,個別的 View 都會對應到 上層 TCD 的 Instance 中,也就是說在 TCDInstance 中的 View 與資料庫的 View 雖然是採用 GAV 的方式對應,但實際上在架構設計時就決定兩個 View 是完全相. 43.
(44) 同,並不會有出現 TCDInstance 的 View 是多個資料庫 View 組合產生,因此並不 會產生不同 View 限制的不一致性;然而在 GAV 的對應方式中,仍然會出現底下 層的 View 尚未被使用到,造成從 TCD 查不到的資料,在資料庫中可以查到,也 就是滿足了 Sound 特性。 在本體論使用 LAV 的對應方式下,使用 Class 代表一個 View 的產生,換言 之,View 與 View 之間的對應是採用 Class 與 Class 的對應。一般來說 Class 之 間的對應可以用五種字元代表,分別為:等價(≡)、包含於(⊐)、被包含於(⊏)、 包含於或等於(⊒)、被包含於或等於(⊑),若上層 Class 被包含於下層 Class 則. 政 治 大 了 Sound 特性,反之若上層 Class 包含於下層 Class 則表示滿足 Complete 特性。 立 表示,上層 Class 所產生的集合被包含於下層 Class 所產生的集合,也就是滿足. ‧ 國. 學. 在本研究假設中,Class 與 Class 的對應一慮採用等價(≡)主要原因在於在架構 進行 Policy Fetch 時,必頇透過 Request 使用 iTCD 設計 Meta Data Class 分類,. ‧. 對應到下層 TCD 後找出相對應的 Meta Data 與 Policy 並且將原先存在 TCD Policy. sit. y. Nat. Condition 中的 Instance 所屬的 Class 一併的找出後再次對應到 iTCD 中,換言. io. er. 之若要使此方式成立,必頇滿足(1)從 iTCD Meta Data 對應到 TCD Meta Class 滿足 Sound 特性。(2)TCD Meta Class 以及 Condition Class 對應到 iTCD 滿足. al. n. v i n Ch Sound 特性。由於採用 LAV 的對應方式,每一個進入平台的 TCD 中的所有 Class engchi U 都必頇要被 iTCD 對應到,並且使用等價運算元作為所有 Class 對應的運算元,. 因此每一個 iTCD Class 都會完整的對應到下層 TCD Class,同時滿足了 Sound & Complete。. 5.2 系統實作 本研究系統架構為幾個步驟,先給定各個 TCD、iTCD、TisD 的本體論並且將 這些彼此對應的關係也寫成本體論描述的概念,之後透過 Web Page 輸入 Request, 網頁將 Input 傳給 Java Core 執行 Fetch、Management、Enforcement 等動作後,. 44.
(45) 最後將允許的 SQL 語法回傳給 Web Page 最後經由 Web Page 進行資料庫查詢後 將結果回傳給使用者,架構如圖 6 所示。. 立. 政 治 大 圖 8 系統架構. ‧ 國. 學. 本體論的編輯本研究採用 Protege 4.1beta 版,Protégé是 Stanford 大學所 開發的本體論編輯軟體,其中第 4 版後開始支援 OWL2 的編輯語言,因此使用此. ‧. 軟體將 TCD、TisD、iTCD 的本體論根據第四章的 CLASS 建構並針對不同的 Class. Nat. sit. y. 進行分類;除此之外還必頇描繪出 TCD 與 iTCD Class 的對應關係,在此同樣使. n. al. er. io. 用本體論進行描述,本體論的編輯模式如圖 9 所示. Ch. engchi. i n U. v. 45.
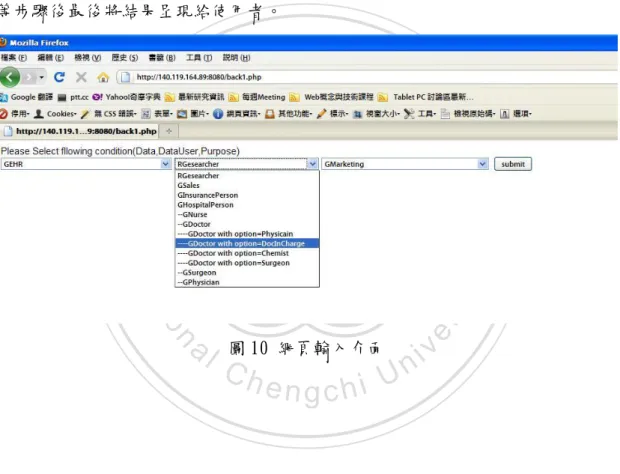
(46) 圖 9 本體論在 Protege 編輯環境 在 Java Core 本研究採用 Jena 2 Library 作為處理本體論檔案的 API,Jena 在先前是專門處理 RDF-Based 的 API,裡面除了具有對本體論查詢、修改之外, 另有支援多個推論引擎如 Pellet 等,在 Jena 2 之後開始支援 OWL2 的語法,並 大幅增加了系統效率,因此當 Request 透過系統網頁介面如圖 8 輸入時,使用者 可以根據 iTCD 所提供的詞彙進行輸入包括 Data、DataUser、Purpose 等各種 Condition,輸入後再經由 Jena 2 的處理包括 Fetch、Management、Enforcement 等步驟後最後將結果呈現給使用者。. 立. 政 治 大. ‧. ‧ 國. 學. n. i n U. 圖 10 網頁輸入介面. Ch. engchi. er. io. sit. y. Nat. al. v. 46.
數據


+5

Outline
相關文件
阿吉老師將簡介 micro:bit 開發程式環境,並分享 micro:bit 內建感測器程式編寫、數位/類比信號讀取及寫入,並了解 如何用 micro:bit 連接電子模組編寫程式進行機電整合。.
(B)Data Bus 是在 CPU 和 Memory 之間傳送資料,所以是雙向性 (C)Address Bus 可用來標明 Memory 或 I/O Port 位址的地方 (D)Data Bus 的長度和 Address
審查整理呈現資料:蒐集到的資料應先審核 是否完整、正確、合理與一致,然後利用敘
sort 函式可將一組資料排序成遞增 (ascending order) 或 遞減順序 (descending order)。. 如果這組資料是一個行或列向量,整組資料會進行排序。
說明:本題藉由羅馬史家 Ammianus Marcellinus 描述外族的兩則資料,檢測學生能否觀察
MOV reg,data reg ← data 轉移立即資料(data)到暫存器 reg 內 MOV dreg,sreg dreg ← sreg 轉移暫存器 sreg 的內容到暫存器 dreg MOV segreg,reg segreg ← reg
利用 Microsoft Access 資料庫管理軟體,在 PC Windows 作業系 統環境下,將給與的紙本或電子檔(如 excel
由於投訴人的上司對投訴人的工作表現不 滿,因此向投訴人發出一封警告電郵,並
