行政院國家科學委員會專題研究計畫 成果報告
可攜式多媒體卡控制系統設計及其在電腦影音視訊上的應
用(3/3)
計畫類別: 個別型計畫 計畫編號: NSC91-2213-E-009-010- 執行期間: 91 年 08 月 01 日至 92 年 07 月 31 日 執行單位: 國立交通大學電機與控制工程學系 計畫主持人: 吳炳飛 報告類型: 完整報告 處理方式: 本計畫涉及專利或其他智慧財產權,2 年後可公開查詢中 華 民 國 92 年 5 月 12 日
第一章 前言
在資訊家電(IA)的發展越來越普及之際,如何使得原本屬於個人電腦範疇的 事務,能夠擴及到家電用品的領域上,一直是現在業界努力的方向,如最近當紅 由日本 Sony 公司出的 PS2 遊戲機,是一部具備電玩、上網以及 DVD 和 CD 播 放等功能的產品,由甫上市的熱賣情形看來,即可知資訊家電這個領域在未來的 潛力是不容小覷的。而在本報告中所提出的「 MP3 Recorder System」也是一個 定位在家庭中使用的產品。它具備有壓縮 MP3 的能力,也可擴充成 MP3 player。 更重要的是,它是 stand alone 的 IA,也就是不需要依靠個人電腦來操作的,這 對於不會使用或害怕使用電腦的人來說,提供了一個親切的人機介面,讓一般大 眾也可以簡易的壓 MP3 音樂以及享受聽 MP3 的樂趣。另外在這個系統中,我 們也有支援資訊保密的功能在裡頭,利用一種稱為 AES 的加密技術,讓壓縮好 的 MP3 再經過加密,擁有解密鑰匙的人,才能聽解密過後的 MP3 音樂,這對 於保護著作權會有正面的幫助。 我們認為發展一個無須依賴個人電腦,能夠做到壓縮MP3 及其他附加價 值,如 CD player、MP3 player 和快閃記憶卡的讀卡機以及擁有加密功能等,是 一個具有潛力的產品,因此本報 告便是探討此系統的設計方法。之後各章節我們 將陸續介紹此系統設計,所涵蓋的理論和方法,包含第二章的系統概述,第三章 的 MP3 編碼實作,第四章的 MP3 解碼實作,第五章的系統硬體設計,第六章的 系統韌體設計,第七章的結論與未來展望,以及最後的參考資料等,另外我們增 加了兩個附錄說明關於 MP3 在壓縮和解壓縮的細部內容,相信這對於想瞭解 MP3 的人來說,是非常具有價值的。第二章 系統概述
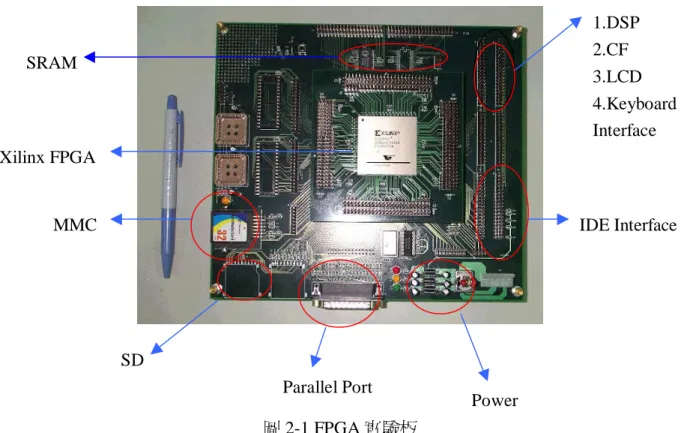
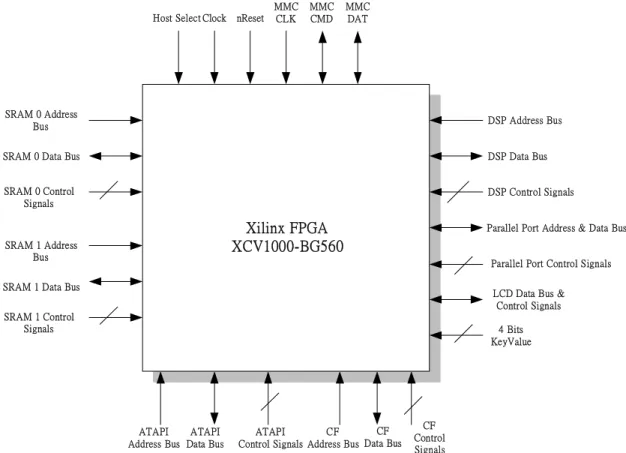
MP3 是 MPEG1 - Layer3 的簡稱,是一種針對 audio 設計的壓縮技術,從出 現以來一直受到愛好音樂人士的喜愛,原因在於經過 MP3 壓縮後,資料大小可 以大幅減少,將雙聲道 44.1k Hz 的 audio 以 128k bps 來壓縮,壓縮倍率可以 由(2-1)式算出。 11.025 128k 2 16 44.1k ( 2-1) 其中 44.1k 表示,audio 是每秒鐘 sample 類比音訊 44100 次所得到的。乘以 16 是指輸入的資料是以 16 位元為單位。乘以 2 則是表示資料來源為雙聲道。128k bps 則是表示經過 mp3 壓縮後,每秒鐘輸出 128k 位元的資料。由此得到壓縮比 為 11.025,若是 audio 的 sample 頻率和 MP3 的 bit rate 不同上述的話,壓縮比則 會有稍微的改變,但大致上 MP3 壓縮比約落在 10~12 這個範圍內。但 MP3 風行 的因素,絕不只是因為檔案小的緣故,更重要的是壓縮後的音樂品質,和一般 CD 上所聽到的相差不多,正常情況下,一般人無法分辨出兩者的差異,這是在 於 MP3 壓縮技術裡採用了聲響心理模型來模擬人耳的聽覺。利用人耳聽覺感知 上的遮蔽效應,來達到聽起來不失真的效果。 接下來我們來看這個系統是如何規劃的,如圖 2-1,發展的環境是一個我們 自行設計,以 FPGA 為基礎的電路板,我們使用 Xilinx Virtex系列的 XCV1000 BG560-4 這顆 FGPA,它是存放第五章要介紹的硬體電路的核心。在板子上除了 FPGA 外,在控制所有硬體電路的 host 方面,我們規劃了二種:如圖 2-2 的 TI 5146 DSP 和 PC 的 parallel port。在壓縮 MP3 的音訊來源方面,我們規劃了一組 IDE 介面,可以藉由排線外接光碟機進來。在儲存壓縮好的 MP3 音樂的裝置上,我 們規劃了 Secure Digital Card(SD)、MultiMediaCard(MMC)、CompactFlash(CF)等 三種快閃記憶卡的 Socket 進去,這三種卡都是目前市面上最受歡迎的之一。
圖 2-1 FPGA 實驗板 在人機介面方面,則規劃有一個如圖 2-3 的 4 x 4的鍵盤和 16 x 2 的文字型 LCDM。除此之外,電路板上還有兩顆 64k x 16 的 SRAM 和一顆 512k x 8 的 Flash ROM,這是給硬體電路設計所需要時用的。在電源方面使用了三顆 regulator, 分別可以穩壓在 5V、3.3V 和 2.5V,提供 FPGA 和其他週邊電路所需要的電壓。 最後還有一個 FPGA 的 download 電路,當硬體程式寫好並合成、繞線完之後, 我們可以把最後的檔案藉由 Xilinx 的 Foundation 這套軟體燒到 圖 2-2 DSP EVM 圖 2-3 Keyboard+LCDM ROM 裡,每當板子一供給電源之後,FPGA 就會自動從 ROM 讀取資料進去內
IDE Interface MMC SD SRAM Xilinx FPGA Parallel Port Power 1.DSP 2.CF 3.LCD 4.Keyboard Interface Audio Output DSP Expansion Port LCDM 4x4 KeyBoard
部,不需要每次電源重開,就要從 PC download 一次,可以省去不少麻煩。 K ey B o a r d & L C D C D -R O M Co m p ute r C V DSP Xilinx XC V1000-BG 560-4 F GPA Board M M C S D CF P arallel P ort DS P Interface S D Internet (optional) (o p ti on al ) 圖 2-4 系統方塊圖 在瞭解電路板上有哪些資源可用之後,我們的系統方塊圖,如圖 2-4,希望 能達到的運作方式是,透過鍵盤的按鍵選擇光碟機裡的某一首歌曲,系統就能把 該首歌曲壓縮成 MP3 的檔案,透過 AES 加密後,以 FAT 的格式儲存資料到快閃 記憶卡之中。另外有些附加的功能:利用 IDE 介面控制光碟機,可以當成 CD player 或是可以當成以 parallel port和 PC 溝通的快閃記憶卡讀卡機,另外 DSP 內部程式也支援 MP3 解壓縮,因此也可以當成是一台 MP3 player。往後我們考 慮加入網路的功能,利用網路無遠弗屆的特性,增加我們 系統在輸入輸出上的多 樣化以及彈性,例如:當我們把 CD 音樂壓縮成 MP3 檔案之後,可以利用網路 回傳給遠端的其他主機。 在應用的領域方面,我們把這套系統定位在家庭中使用,也就是讓它成為家 電用品的一部分,讓不懂電腦的人,也可以輕易的把音樂 CD 壓縮成 MP3。另一 個應用點則是我們這個系統的 MP3 播放功能,可以取代汽車上的 CD 音響,因 為開車震動的關係,CD 音樂會有短暫停頓的現象發生,但是利用快閃記憶卡儲 存的 MP3,則完全不受震動的影響,因此在這裡,也頗具實用性。
最後我們把這個系統的功能與特色整理如下: ◆ 支援 32、40、48、56、64、80、96、112、128、160、192、224、256 kbps 等 13 種傳輸率的 MP3 音樂壓縮。 ◆ 即時播放 MP3 音樂。 ◆ 儲存裝置部分,支援最熱門的快閃記憶卡 CF 與 MMC,未來考慮增加 SD。 ◆ 音樂輸入部分,支援 IDE 介面,優點在於可輕易的和一般市面上買到的光碟 機連接,而不必擔心貨源被壟斷的問題發生。 ◆ 人機介面部分,支援文字型 LCD 顯示(如圖 2-5 和 2-6),與 4x4 鍵盤輸入。 ◆ 韌體控制方面,支援: 1. AES 加、解密。 2. FAT 16 檔案格式的讀、寫、刪除、檔案自動命名與格式化。 3.光碟機控制方面支援 PIO 模式讀取,與播放 audio 音樂。
◆ 支援 parallel port 的 EPP 模式,可以和個人電腦連結。
圖 2-5 LCD 顯示一 圖 2-6 LCD 顯示二
M P 3編碼原理介紹於附錄 A,本章將針對 MP3 編碼實作時所做的改良部分 加以敘述。
第一節 濾波器排(The Filter Bank)
觀察這 32 個濾波器的係數,即矩陣 M32×64 [1],發現它 們有著一些相同的特性— 對稱,利用這些特性可以降低運算量並省下一些記憶體空間。 M32×64 : (2 1)( 16)], 0~31, 0~63. 64 cos[ ] ][ [i k i k i k M 我們從兩個方向找到化簡濾波器係數 M32×64的方法:其一,32 個濾波器的 係數有著相同的對稱方式。其二, 32 個濾波器彼此間的關係。以下將一一說明: 首先,對 32 個濾波器而言,第 16 個係數皆為 1,第 48 個係數皆為 0。第 0~32 個係數以第 16 個係數為中心左右對稱;第 33~63 個係數以第 48 個係數為 中心左右差一負號對稱,如圖 3-1 所示。將經過上述化簡所得到的矩陣稱為 M’ 32×31,數學式歸納於下:
[ ] [32 ]
'[][ ]
[ 17] [79 ]
(3-2) ] ][ [ ' ] 16 [ ] 96 [ ] [ ] ][ [ ] 32 [ ] [ ] ][ [ ] 16 [ 1) -(3 31 ~ 0 i for ] [ ] ][ [ ] [ 30 16 15 0 47 33 15 0 63 0
j j k k k j Y j Y j i M j Y j Y j i M Y k Y k Y k i M k Y k Y k i M Y k Y k i M i S 對每一個濾波器而言,原本需要 64 個乘法與 63 個加法(3-1 式)才能完成運 算,經過上述的化簡後,只剩下 31 個乘法與 62 個加法(3-2 式)。而矩陣的大小 也從原本的 32×64 變成 32×31。 接下來,再觀察 M’ 32×31中各濾波器之間的關係:M’[i][j] = | M’[31-i][j] |,for i=0~15,j=0~31。 其中 M’[i][j] = M’[31-i][j],for j = 0, 2, 4, 6, 8, 10, 12, 14, 17, 19, 21, 23, 25, 27, 29。 M’[i][j] = -M’[31-i][j],for j = 1, 3, 5, 7, 9, 1 1, 13, 15, 16, 18, 20, 22, 24, 26,28, 30。
A
k=16 k=48 × (-1) 32×64 k=0~15 k=33~47 32×31B
C
D
A
C
圖 3-1 M32×64的大小由 32×64 縮減成 32×31 根據上述特性,我們定義一個新的矩陣 M’’16×31(如圖 3-2 所示)與四個集 合 J1~J4: M’’16×31:M’’ [n][j] = M’[n][j],for n=0~15,j=0~30。 } 14 12, 10, 8, 6, 4, 2, 0, | { 1 j J 、J2{j |1,3,5,7,9,11,13,15}、 } 29 27, 25, 23, 21, 19, 17, | { 3 j J 、J4{j|16,18,20,22,24,26,28,30}。 接著,從(3-2) 式再繼續化簡:
30 ~ 16 i for ] 79 [ ] 17 [ ] ][ 31 [ ' ] 79 [ ] 17 [ ] ][ 31 [ ' ] 32 [ ] [ ] ][ 31 [ ' ] 32 [ ] [ ] ][ 31 [ ' ] 16 [ 15 ~ 0 i for ] 79 [ ] 17 [ ] ][ [ ' ] 79 [ ] 17 [ ] ][ [ ' ] 32 [ ] [ ] ][ [ ' ] 32 [ ] [ ] ][ [ ' ] 16 [ 2) -(3 ] 79 [ ] 17 [ ] ][ [ ' ] 32 [ ] [ ] ][ [ ' ] 16 [ ] [ 4 3 2 1 4 3 2 1 30 16 15 0 J J J J J J J J j j j Y j Y j i M j Y j Y j i M j Y j Y j i M j Y j Y j i M Y j Y j Y j i M j Y j Y j i M j Y j Y j i M j Y j Y j i M Y j Y j Y j i M j Y j Y j i M Y i S 然後令
3) -(3 15 ~ 0 n for ] 79 [ ] 17 [ ] ][ [ '' ] 32 [ ] [ ] ][ [ '' ] 16 [ ] [ 4 1 1
J J j Y j Y j n M j Y j Y j n M Y n T
4) -(3 15 ~ 0 n for ] 79 [ ] 17 [ ] ][ [ '' ] 32 [ ] [ ] ][ [ '' ] [ 3 2 2
J J j Y j Y j n M j Y j Y j n M n T 最後可以得到 S32 5) -(3 15 ~ 0 n for ] [ ] [ ] 31 [ ] [ ] [ ] [ 2 1 2 1 n T n T n S n T n T n S 根據 (3-1)式,原本需要 64×32=2048 個乘法與 63×32=2016 個加法才能得到 M32×64×Y64×1的結果。而化簡成(3-3)式~ (3-5)式之後,則只需要 31×16=496 個乘 法與 61×16+32=1008 個加法就能算出 S32×1。 另外,為了不增加 DSP 的負擔,我們並非直接呼叫 cos 函數來產生 M32×64 的數值,而是採用查表的方式,事先將 M32×64存放在記憶體中。因此經過化簡後, 所使用的記憶體空間也跟著變少了。原本需要 32×64=2048 words,最後後只剩下 16×31=496 words。 k=0~15 k=33~47 32×31A1
absA2
C1
C2
k=0~15 k=33~47 16×31A1 C1
圖 3-2 M’ 32×31的大小由 32×31 縮減成 16×31,M’’16×31原本 MP3 編碼所定義的量化運算式為 ) 0946 . 0 ) 2 ) ( int(( ) ( 0.75 4 n xrstepsizei i ix (3-6) 為了能夠降低運算量,將(3-6)式改寫成 16 3 75 . 0 2 ) ( ) ( stepsize i xr i ix (3-7) 由於量化後常常 distortion 還太大,所以必須對 xr(i)做調整 ifqstep i xr i xr() ( ) (3-8) 其中 2 _ 1 2 scale scalefac ifqstep 因為 ifqstep 也是以 2 為基底,所以可以和式(3-7)中以 2 為基底的部份做次方相 加即可。但如果 (3-8) 式中失真太大,可能造成 xr 累乘的次數不只一次,而定 點運算將難以處理這個問題。所以上述方法就能避開累乘,而以累加的方式取 代,如(3-9)式。 9) -(3 2 ) ( 2 ) ( 2 2 ) ( ) ( 16 expo16 75 . 0 16 _ 8 8 3 75 . 0 2 _ 1 16 3 75 . 0 i xr i xr i xr i ix scale scalefac stepsize scale scalefac stepsize 所以每常失真太大要做調整時,我們只要求(3-9)式中的 expo16 部份即可。 經過上述方法化簡後,編一首歌曲所需的時間只有原本的一半而已。因為量 化是 MP3 編碼中最耗費時間的部份,所以用有效率的演算法來處理,對整體速 度的提升有很大的幫助。 第三節 赫夫曼表的化簡
赫夫曼表所佔的記憶體空間實在不小,所以化簡赫夫曼 表是有其必要性的。 根據 ISO/IEC 1172-3 文件[1],在 table16~31 中,只有 table16 和 table24 有必要完 全儲存。因為 table17~23 和 table16 幾乎相同,差別在於 linbits 不同罷了,所以 只儲存 table16,並加上一些簡單的判斷,就能決定是用 table16~table23 中的哪 一個。同理,table24~31 也是一樣,所以這樣就可以省下不少空間。 索 引 最大值 索 引 可編碼之最大值 linbits 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 2 not used 3 3 5 5 5 7 7 7 15 not used 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 16 19 23 31 79 271 1039 8207 31 41 79 143 271 527 2016 8207 1 2 3 4 6 8 10 13 4 5 6 7 8 9 11 13 表 3-1 big_value region所用 32 個赫夫曼表的特性 另外一個省下赫夫曼表的方法是只儲存 table16 就可以,也就是說不需要 table24~31,因為 table16 和 table24 的差別是在於不同的統計特性下,可以有兩 種不同的 table 供選擇,這樣可以減少編碼後的位元數,讓其它失真較大的訊號 使用。但是經過我們的實驗證明,用 table16~23 即可完成 MP3 的編碼,而且歌 曲聽起來也沒有失真,這樣又可以省下不少記憶體空間。因為省下 table24 使得 原本赫夫曼表大約 5.8KB,省下 table 後所需空間為 4.7KB,大約省下 1KB 的記 憶體空間。
第四章 MP3 解碼實作
對系統而言,MP3 檔案的來源是外部的 Memory Card,所以當使用者欲播放 MP3 音樂時,系統會自所選定的 Memory Card 將音樂檔讀入解壓縮並從喇叭輸
出。如圖 4-1,在這一章中,我們將介紹後端的解決方法。
Decod er Buffer
Command from HID
Timer ISR Da ta from Memory Card PCM Sample Spe ake r 圖 4-1. MP3 Player 方塊圖 在網路上有許多在 PC 上驗證成功的 MP3 Decoder 原始碼,且大都可以免費 下載,我們修改這些原始碼,將其應用在我們的系統裡;接下來的小節中,介紹 一些使其應用在 DSP 上的解決方法。 第一節 資料來源以 16-bit word 為單位
對在 PC 上使用的 Decoder 而言,資料是一個 byte 接一個 byte 讀進程式裡使 用的 buffer 中,此時使用的 buffer 通常為 8-bit 寬度。但在 DSP 裡,不論是 IO 或是內部的暫存器都是以 16-bit word 形式存在,為了充分利用系統資源,我們 必須使用 16-bit 寬度的 buffer 來暫存資料。
在前端的韌體裡已有一組 256×16 的 buffer,資料來源可從 Memory Card而 來,而在後端的 Decoder 亦存在著一個 512×16 的 buffer,用來存在每個 frame 裡的 main_data(以上 MP3 位元串格式及定義請參考附錄 A),而 main_data 及 main_data 裡每個 part 在檔案裡的起始位置、結束位置、大小 等皆是以 byte 或 bit 為單位記錄在 side information 中,因此會有以下幾種自韌體 buffer 讀取 main_data 資料時的方法:
1. 自 buffer 讀取兩個 byte,即一個 word,此時可直接以記憶體搬移的方 法取得資料,並且將 buffer 指標指向下一個位置。
2. 從 buffer 內讀 1 個 byte,此 byte 為一個 word 裡的 upper byte,此時先 讀取整個 word,再利用 bit shift 將 upper byte讀出,buffer 指標停在原 處,並且必須有一旗標告知下次資料讀取時,必須從此 word 的 lower byte 開始讀。
3. 在 word 裡的 upper byte 讀出後,必須先將 lower byte 讀出才能接著利用 方法 1 讀取整個 word。此時先讀取整個 word,再利用 bit and 將 lower byte 取出,並且將 buffer 指標指向下一個位置。
而在寫入軟體裡 buffer 時,已有以下幾種寫入的方法:
1. 寫入兩 byte 到 buffer,此時可直接以記憶體搬移的方法取得資料,並且 將 buffer 指標指向下一個位置。
2. 第一次寫入一個 byte 到 buffer,利用 bit shift 將 1 byte 資料存入 upper byte,buffer 指標仍停在原處,而下一次的寫入也必須為一個 byte,否 則會出現錯誤。
3. 第二次寫入一個 byte 到 buffer,利用 bit or 將資料存入 lower byte,經過 兩次的 byte 寫入才完成一個 word 的寫入動作,buffer 指標才能再指向 下一個位置。
I 2 第二節 利用定點運算加速解碼工作 在 PC 上,因為 CPU 速度非常快,因此對於比較複雜的浮點運算依然能夠 維持一定的處理能力。但在 DSP 上,雖然也具備了浮點運算處裡的能力,但因 為工作時脈僅能達到 160MHz,因此浮點運算對 DSP 而言是個很大的工作負擔,
因此為了達到 real time play的能力,我們利用 DSP 裡定點數運算的技巧,來取
代浮點運算,以加速解碼過程。
參考圖 B-1,解碼過程中需要用到浮點運算的地方包括了 Inverse quantization 及 Frequency to time mapping 兩個方塊,以下為取代浮點數運算的解決方法:
1. 在 Inverse quantization 裡,有一公式為 ]) [ ] [ )( _ 1 ( 2 1 ]) [ _ 8 210 _ ( 4 1 3 4 2 2 ]) [ ( ]) [ ( ] [ i pretab preflag i r scalefacto scale scalefac i gain subblock gain global i is abs i is sign i xr 先將其改為以下表示法:
8207 0 , 5 . 11 exp 4 1 5 . 88 where 2 abs 4exp 1 3 1 i is i is i is i xr 首先將 的動態範圍分為 10 個不等距的區間,利用區間內 線性逼近的方法,求出 的浮點值,在用量化的方法,以 16 bit 整數型態來表示其值。 接下來 的運算,則是先將其分為兩部分:
0 ,0.25 ,0.5 ,0.75
, 11 89 part. fraction the is and 2 of part integer the is where , 2 2 2 4exp 1 exp 4 1 F I -F I F I 首先, 利用 bit shift 的方法即可求得,再乘上 之後,利用 量化,將其以 16 bit 整數型態表示,並將量化係數儲存起來。2. 在 Frequency to time mapping 裡的 IMDCT 公式如下:
3 1 absisi exp 4 1 2
isi abs I 2
2 1
, for i 0~n-1 2 1 2 2 cos 1 2 0
n k k i k n i n X x where Xk is the frequency line, n is 12 for
short window, and 36 for long window. 其中的 cos 函數為浮點運算,我們以查表的方式取代之。
3. 在 Alias reduction 及 Subband thesis filter 裡會用到的 cos 數值,均以定 點表示。
第三節 音訊輸出裝置
在最後端的音訊輸出方面,因為必須以固定的 44.1KHz 輸出至喇叭,因此 我們利用一 buffer 當作緩衝器:
在解碼端,每解碼出一個 frame 之後,就將解碼出的 PCM sample 利用 circular 的方法一個 word 接一個 word 寫至 buffer,若欲寫入的位置尚未 被讀出,則暫停寫入的工作,直到此位置資料被讀出才能再寫入。 而在音訊輸出端,利用 Timer 中斷的方法,以 44.1KHz 的頻率用 circular
的方法將 buffer 內資料一一取出,並送至喇叭輸出。若解碼器無法達到 即時(real time)解碼的速度,會使得欲讀出的位置尚未被寫進資料,則 必須等到資料送達才能繼續播放,在聽覺上會產生延遲的感覺。
第五章 系統硬體設計介紹
第一節 前言
在這一章裡要談到的是這個系統裡的硬體架構,這個硬體是藉由 FGPA 來驗
證的,花了 XCV560-4 746 個 Slices,約佔了這顆 FPGA 6%的可用資源,若換算
成 gate count,相當於 11516 個,另花了 159 隻 I/O 接腳(FGPA 接腳的示意圖,
請見圖 5-3),設計出的電路最快可以跑到 25.476M Hz,由於這是一個驗證的雛
形,所以像是外掛的兩個 SRAM 以及 DSP,佔用了太多的 I/O(分別為 58 和 27 隻接腳),比較好的設計方法為找一個合適的 microprocessor 的 IP, SRAM也用 FPGA 內部提供的資源,搭配其他設計的硬體,來實現這個系統,這樣把所有的 東西整合在一顆 IC 裡頭,不僅大大節省了 I/O 的數目,更重要的是提高整體的 傳輸速度,也減少了雜訊的干擾,以完成 SOC(System-On-Chip)的設計,不過由 於我們沒有 microprocessor 的 IP 以及 Xilinx 內部 RAM 最大只能定址到 256(初期 驗證我們用到 512x8 的 RAM),所以這兩部分只好採用外接的形式來實作。圖 5-1 是 FPGA 內部電路的示意圖,它主要包含了一個 TI 的 54x DSP 的介面電路, DSP 藉由此介面負責控制所有的週邊。當然 DSP 還要負責最重要的 MP3 壓縮演 算法和 AES 加密,不過這不屬於硬體設計的範疇。而 FPGA 內部的功能則是 DSP 與週邊溝通的橋樑,裡面電路的設計,在接下來的小節裡,將介紹較重要的 MMC 和 Ping-Pong Buffer 部分。此外我們也整合了 EPP 電路進去,它在硬體電路發展 初期佔了一個很重要的角色,它替代 DSP 來當成 FPGA 端的 Host,透過 EPP 可 以把硬體的狀態傳回 PC 顯示,把資料寫成檔案到硬碟作比對。或是在 PC 上開 個檔案寫資料到硬體。等等許多開發初期的驗證都可以得到有效率的幫助。在電 路板上我們利用一條跳線,可以選擇 Host 是 DSP 或是 PC 的 parallel port,當 host 是 DSP 時,是系統的正常操作模式,若 host 是 EPP 時,則是系統的 debug 模式。
硬體部分的程式可以用圖 5-2 的結構來表示,其中較複雜的電路為 MMC controller 和 Ping-Pong Buffer 的設計,其餘較簡單的部分則不多作說明。
DS P or E P P Interface AT A P I Interface K eyB oard + LCD Interface M M C H o st Controller Re gister File S R A M Interface InterfaceSR A M FP GA T I 541 6 DS P or Pa rallel P ort
M ultiM ediaC ard
S R AM S RA M A T AP I C D-R O M LCD M 4 x 4 K e yB o a rd C F Interface C o m p a c tF la shCard 圖 5-1 FPGA 內部示意圖 DSP.VHD IDE.VHD LCD_KeyBoard.VHD Ping-Pong Buffer.VHD RAM256x16.VHD RAM256x16.VHD MMC_CMD.VHD MMC_DAT.VHD MMC.VHD CRC7.VHD CRC16.VHD MP3REC.VHD EPP.VHD CF.VHD 圖 5-2 MP3 Recorder Syetem 硬體程式之樹狀圖
Xilinx FPGA XCV1000-BG560 DSP Address Bus DSP Data Bus DSP Control Signals SRAM 0 Address Bus SRAM 0 Data Bus
SRAM 0 Control Signals
SRAM 1 Address Bus SRAM 1 Data Bus
SRAM 1 Control Signals
Host Select
Parallel Port Address & Data Bus
Parallel Port Control Signals Clock nReset MMC CLK MMC CMD MMC DAT ATAPI Address Bus ATAPI Data Bus ATAPI Control Signals CF Address Bus CF Data Bus CF Control Signals
LCD Data Bus & Control Signals
4 Bits KeyValue
圖 5-3 FPGA 接腳示意圖
這個模組主要的功能是作一個 MMC 的外部控制器,特性如上面方框中所 述,根據 MMC 的規格書,可知 MMC 只有 3 個腳位,CMD、DAT、CLK,其 中 CLK 是一個同步訊號,讓 MMC controller(FPGA端)可以在 CLK 的上升緣跟 MMC 作同步的溝通,包含讓 MMC 可以在 CLK 上升緣接收來自 FPGA 的 command 和 data,以及讓 FPGA 可以在 CLK 上升緣接收來自 MMC 送出的 response 和 data。因此除了輸出給 MMC 的這個同步訊號 CLK 之外,我們主要 要做的便是設計兩個電路,一個負責 CMD 腳位所有可能發生的時序,另一個則 負責 DAT 腳位所有可能發生的時序,這兩個電路我們分別給它一個名字,稱為 MMC_CMD.VHD 和 MMC_DAT.VHD ,它們的下層分別有個做錯誤偵測的電 路,分別是 CRC7.VHD 和 CRC16.CHD,這我們在之後會詳細介紹,架構在 MMC_CMD.VHD 和 MMC_DAT.VHD 這兩個電路之上的便是 MMC.VHD,它訂 定了 31 個暫存器,這些暫存器有些是提供底層電路要送出去給 MMC 的參數, 有些是控制底層電路操作模式使用的,其餘的就是暫存來自 MMC 的回傳值,它 們提供 host 關於 MMC 的狀態,讓程式可以來判斷如何執行。表5-1 列出 MMC.VHD 裡我們所定義的暫存器。 暫存器名稱 位址 屬性 說明
CMD_WORD 1020h R/W 6 位元寬度,代表 0~63 的 command index,是提供
底層電路 MMC_CMD 的參數 ARG3~ ARG0 1021h~ 1024h R/W 下給 MMC 之 command 其中所需的 argument,是提 供底層電路 MMC_CMD 的參數 ‧支援 Multiple Block 及 Single Block 模式的讀寫 ‧傳輸速率:Multiple Block Read:400KB/sec Mu lt ip le B lo c k Wr it e:200KB/sec S ing le B lo c k R e a d:150KB/sec Single Block Write:100KB/sec
MB_LEN (L) MB_LEN (H)
1025h 1026h
R/W 設定 MMC multiple block mode 的長度
Control Register 1027h R/W Bit 7 : 0 表示 host 要 write MMC,
1 表示 host 要 read MMC
Bit 6 : 0 表示 data transfer 為 single block mode
1 表示 multiple block mode
其餘 bit 則保留未用 SEND CMD Register 1028h R/W 為一啟動 MMC_CMD 裡 state machine 的暫存器, 不管填入值為何,都會讓底層電路 MMC_CMD 發送出 48 位元的時序 STATUS Register 1029h R/W MMC.VHD 這個電路內部的狀態暫存器。 Bit0 :1 表示發送 command 出現 CRC 錯誤 Bit1 :1 表示 data 傳輸出現 CRC 錯誤
Bit2 :1 表示發送 command 包含接收 response 的 過程結束 Bit3 :1 表示讀寫 MMC 的過程結束 其餘 bit 則保留未用 48 位元的 command response Register 102Ah ~ 102Eh R 從 102Ah 至 102Eh 的 5 個 8 位元暫存器主要是依 序儲存前 40 位元的 response,最後的 7 位元 CRC 和 end bit 則不予以儲存 136 位元的 command response Register 102Fh ~ 103Eh R 從 102Fh 到 103Eh 的 16 個 8 位元暫存器主要是依 序儲存 136 位元的 response 裡頭的後 128 位元的 CID 或 CSD 表 5-1 MMC.VHD 電路裡定義的暫存器 表 5-1 裡的暫存器,關於 MMC_CMD.VHD 的是 CMD_WORD、ARG3~ARG0 這 5 個參數值,再藉由 SEND CMD Register把這些參數按照規格書[4]裡定義的 時序送出去給 MMC。而 response 則根據長度的不同,存在 102Ah~102Eh 或是 102Fh~103Eh 的暫存器裡。
而關於 MMC_DAT.VHD 的則是 MB_LEN、Control Register,分別是定義 data transfer 的長度為幾個 block,以及讀、寫 single block 或是 multiple block 等控制 MMC_DAT 裡的 state machine 的參數。
剩下的就是一個 status register,裡面可以讓 host 查詢到 command 或 data 傳 輸時是否有 CRC error,以及發送 command、接收 response、讀寫 MMC 內部資 料等過程是否已經結束,等 4 個狀態。
(一) CRC7.VHD 設計說明
bit0 bit1 bit2 bit3 bit4 bit5 bit6
data in
data out
圖 5-4 CRC7 generator/checker
在圖 5-4 我們可以看到 MMC_CMD.VHD 裡會使用的到一個編碼和解碼電 路,它的組成非常簡單,只有 7 個 Flip-Flop 和 2 個 XOR 而已,電路 reset 後,7 個 Flip-Flop 都為 0,操作的方法為,串列資料依序從 data in的地方輸入,每個 clock 來時,便依照箭頭的方向移動,當資料傳輸完畢,即暫停 clock 的輸入,7 個 Flip-Flop 內含的值就是一組錯誤檢查碼,這組錯誤檢查碼將附加在真正的資 料後面,傳遞給 MMC,MMC 內部也會有一個同樣的 CRC7 電路,用來檢查傳 輸過程中,資料是否發生錯誤,若傳輸過程無誤,則真正的資料加上 7 位元的錯 誤檢查碼,在通過 CRC7 電路後,會讓 7 個 Flip-Flop 的值都為 0,若是發生 7 個 Flip-Flop 的值有一個不為 0,則代表資料傳輸過程發生錯誤了。同樣的,在 MMC 回傳 response 給 FPGA 時,會在真正的資料後面附加一組錯誤檢查碼, FPGA 內部的 CRC7 電路也會依照前述的方法判斷是否有資料傳輸錯誤發生。 (二) CRC16.VHD 設計說明
data in
data out bit0 bit1 bit2 bit3 bit4 bit5 bit6 bit7bit8 bit9 bit10bit11bit12 bit13 bit14 bit15
圖 5-5 CRC16 generator/checker CRC16 的電路則如圖 5-5 所示,由 16 個 Flip-Flop 和 3 個 XOR 所組成的, 它的操作方法和 CRC7 是一樣的,差別在於 CRC7 是用在 MMC 的 CMD 腳位, 它的資料長度為 40 個位元,而 CRC16 是用在 MMC 的 DAT 腳位,它的資料長 度為 512 bytes。 (三) MMC_CMD.VHD 設計說明
這個部分的電路設計,主體是一個 state machine,它的功能為發送 48 位元 的 command 給 MMC,以及根據發送的 command 來決定 MMC 有無 response 和 response 的長度。首先我們看到圖 5-6,它是個下給 MMC 的 command 格式的示 意圖,第 1 個位元稱為 start bit,一定為 0,第 2 個位元用來指示資料的方向,1 表示 host 下 command 到 MMC,接下來 6 個位元是用來表示目前下的是第幾個 command,因此可以表示的範圍是介於 0 到 63 這些代號的 command。然後後面 緊接著 4 個 byte 的資料,分別表示 argument 3 到 argument 0,它最大的功用在於 指定 MMC 內部資料儲存的邏輯位址,由於共有 32 位元可以用來定址 MMC, 因此可以知道理論上 MMC 最大的容量可以支援到 232
=4G Byte,當然也有些 command 用不到這 4 個參數,因此這 4 個參數送出去什麼值就不重要了。緊接 著 argument 0 的是 7 位元的 CRC 錯誤檢查碼,用來讓 MMC 檢查 command 是否 有傳輸錯誤的情形發生,最後跟著 1 個位元,稱為 end bit,一定為 1,代表 command 已經發送結束了。
0 1 index argument 3 argument 2 argument 1 argument 0 CRC 7 1
6 bits 8 bits 8 bits 8 bits 8 bits 7 bits
圖 5-6 MMC command format
MMC 的 command response,從實際的內容來看,可以分成 5 種,但從硬體的角 度來看只有分成兩種而已,一種長度為 48 位元,另一種長度為 136 位元,所以 這個電路所要支援的便是在送出去 command 之後,判斷這個 command 是否有 response,若有則再判斷 response 的長度是 48 位元還是 136 位元,根據判斷的結 果,來控制 state machine 的運作流程。圖 5-7 列出 48 位元的 R1 type response 格 式,其餘的 R3、R4、R5 也都是跟 R1 屬於同一類型的,只不過內容不相同罷了, 不過這並不影響硬體的設計。圖 5-8 則列出 136 位元的 R2 type response 格式。
0 0 index card status CRC7 1
6 bits 32 bits 7 bits
圖 5-7 R1 type response
0 0 111111 CID or CSD Include internal CRC7 1
6 bits 127 bits
圖 5-8 R2 type response
不管是何種 type 的 response,回傳的第 1 個位元一定是 0,代表 strat bit,第 2 個位元一定是 0,表示現在 CMD 腳位的資料方向是由 MMC 回傳給 host,R1 type 接下來的 32 位元為記憶卡的內部狀態,R2 type接下來的 127 位元則為 CID 或 是 CSD,這儲存著記憶卡內部的許多重要規格和資訊。而不管是何種 type 的 response 最後也都跟著 1 位元的 end bit,表示 response 的結束。
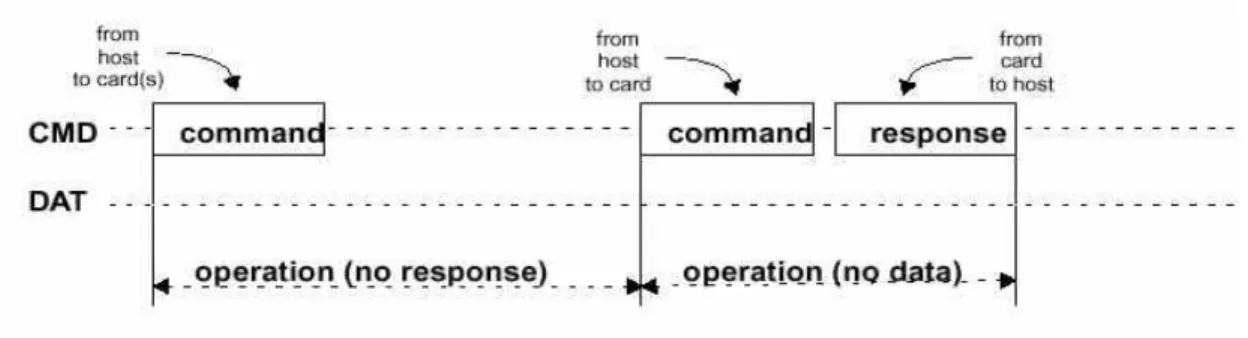
知道要發送的 command 和接收的 response 的格式後,圖 5-9 表示的就是 MMC 的 CMD 腳位會出現的兩種時序,左邊的是沒有 response 的 command,例如: command 0,右邊的是有 response 的 command,例如:command 17。
而硬體電路方面的設計,基本上就是在 CMD 腳位上,製造出這樣的時序, host 端在 MMC clock時脈的下降緣丟出資料,則 MMC 會在時脈上升緣接收到 資料,同樣的,回傳 response 時,MMC 也是在 clock 時脈的下降緣時丟出資料, host 就可以在時脈上升緣接收到資料了。 M M C _C M D .V H D R e g ister In p u t R e g iste r O u tp u t S ta rt se n d C o m m a n d S yste m C lo c k In p u t n R e se t C M D M M C C lo c k E n a b le C M D P ro c e ss F in ish C o m m a n d C R C e rro r 圖 5-10 MMC_CMD 的輸入輸出 最後來看圖 5-10,它是 MMC_CMD 這個電路的輸入輸出示意圖,圖中的 register input 是 MMC.VHD 裡頭為 MMC_CMD.VHD 所定義的暫存器,也 就是在 發送 command 前,host 必須把這些暫存器填入欲發送的值,這些值也就是參數, 就會依照時序送出了。而 register output 也就是 state machine 接收到的 48 位元或 136 位元的 response,輸出到上層的 MMC.VHD 裡頭,讓 host 可以讀取。當然這 個電路也會有 clock 和 reset 等基本的訊號,start send command則是啟動發送 command 的訊號。輸出訊號方面,CMD 則是對應到實際 MMC 的 CMD 腳位, MMC Clock enable 則是一個輸出到 MMC.VHD 的訊號,當發送 command、接收 response 的過程中,這個訊號為 1,其餘時刻則為 0,同樣的在下節裡介紹的 MMC_DAT 這個電路裡,也會有一個 MMC clock enable,當這兩個訊號其中一 個訊號為 1 時,系統的時脈就會接到實際 MMC 的 clock 腳位,當兩者都為 0 時, MMC 的 clock 腳位就為 0,這樣做可以減少硬體消耗的 power。剩下的兩個輸出 訊號,Command process finish 和 Command CRC error 便是接到上層的 MMC.VHD 裡頭的 status register 裡,用途如表 5-1。
(四) MMC_DAT.VHD 設計說明
MMC 在 DAT 腳位上傳送資料,主要有分成兩種模式,一種為 serial mode, 另一種則為 block mode,serial mode 和 block mode 主要差別是在於,用 serial mode 讀寫的資料長度沒有限制,資料讀取的長度取決於何時下達 stop transfer 這個 command,否則 MMC 會認為 host 還要讀寫資料,但是 block mode 一次讀寫的資料長度是可以設定的,一般來說我們習慣把一個 block 設定為 512 byte,這在配合檔案格式時 會比較方便,而在 block 長度設定後, MMC 每次傳輸資料便以 block 為最小單位,host 可以選擇下 single block 類 別的 command,一次只讀寫一個 block 長度的資料,也可以下 multiple block 類別的 command,一下讀寫好幾個 block 長度資料。而一個 block 的資料格 式如圖 5-11,起始有個 start bit 0,表示跟隨其後的為真正欲讀寫的資料,在 序列傳輸完 block length x 8 個位元後,緊接跟著 16 位元的 CRC,來檢查資 料傳輸過程中是否有錯誤發生,最後以一個 end bit 1,當作最後一個 block 資料傳輸結束的標記。
瞭解格式之後,我們來看傳輸資料的時序圖,從 MMC 讀資料和寫資料到 MMC 的時序有幾個不同點,首先我們看到圖 5-12 是從 MMC 讀取三個 block 出 來的示意圖,當 host 下 multiple block read 的 command 之後,不用等到 response 接收完,就可以在 DAT 腳位上等待收取資料了,每個 block 資料傳輸完畢,後 面都會緊跟著 16 位元的 CRC,同樣的情形,重複幾次就表示讀取幾個 block 的 資料回來,最後 host 要下 stop transfer 的 command 來結束整個讀取動作,但是一 旦下了 stop transfer 這個 command 後,正在傳輸中的資料會被破壞掉,這裡個人 認為是 MMC 本身設計上的一個缺點,不過這個問題稍後可以在設計 host 端的 硬體時解決掉。
圖 5-12 MMC multiple block read 示意圖
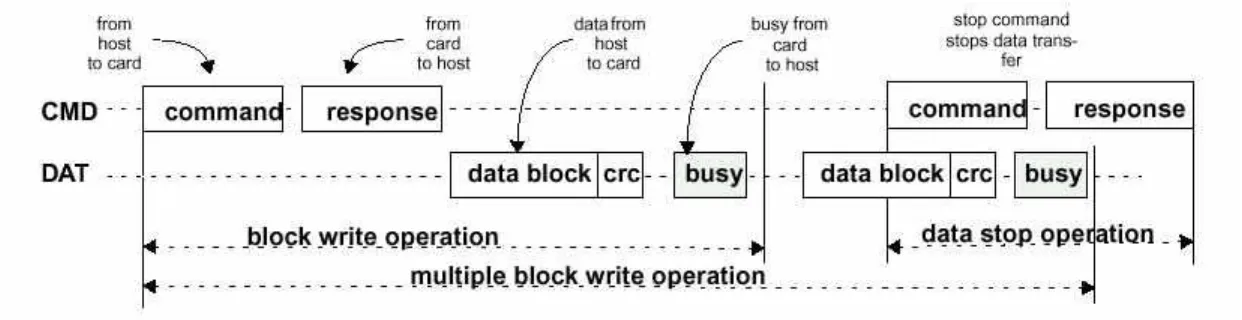
而在寫資料進入 MMC 的時序方面,則必須等到接收完 response 之後,才可以開 始寫資料,而每寫完一個 block 的資料之後,若資料傳輸無誤,則 MMC 會回傳 010,若傳輸檢查發現 CRC 有誤,則會回傳 101,因此 host 可以根據此點來判斷。 若資料傳輸無誤,由於 MMC 內部要把資料 program 到 flash memory 裡面,這需 要花一些時間,因此 MMC 會把 DAT 腳位拉 low,表示內部正在忙碌狀態,直 到資料被寫進去 flash memory 完畢後,DAT 腳位才會拉 high,結束一個 block 的 寫入動作,而 multiple block 的時序,就是重複上述的動作,直到 host 下 stop transfer 的 command 之後,才會結束整個 multiple block write 的命令。和 multiple block read 一樣,multiple block write在最後一個 block 資料還沒傳輸完畢時,就下 stop
transfer 的命令,會使得最後一個 block 的資料被破壞,因此關於這點,我們在設 計 host 的電路時,也有個解決辦法,這在稍後會介紹。
圖 5-13 MMC multiple block write 示意圖
MMC_DAT.VHD
Register Input Register Output
Satrt Data transfer DAT
MMC Clock Enable System Clock
nReset Buffer Input Full Buffer Output Full Buffer Data Bus Input
Bufferus Data Bus Output Write Buffer Strobe Read Buffer Strobe
MMC2BUF_DIR BUF2MMC_DIR
圖 5-14 MMC_DAT 的輸入輸出
由圖 5-14 我們可以看到 MMC_DAT 這個電路的設計需要的輸入與輸出,首先和 MMC_CMD 一樣的有個 register input 和 register output,register input 給的是控制 這個電路運作模式的訊號,包括:
‧Start:為一啟動訊號,當為 1 時,MMC_DAT 這個 state machine 就啟動,為 0 時,則關閉 state machine。
‧RnW:為一資料流動方向的指示訊號, 1 表示 state machine 走 block read 流程, 0 表示走 block write 的流程。
‧MB: 1 的話表示 host 要作 mulitple block 的 access,0 則表示 single block 的 access。
‧MB_LEN:為一個 16 位元的暫存器,表示 host 欲執行的 block 次數,最大可 支援到 65535 個 block 的 read/write。
Register output 則是輸出以下兩個訊號:
‧ DAT_CRC_ERR:1 表示資料傳輸過程發生 CRC error,0 則是傳輸正常。 ‧ MMCDATFsmClr :1 表示資料傳輸過程結束,0 則表示資料正在傳輸當中。
而除了必須要的 clock 和 reset 訊號之外,最重要的便是和 buffer 溝通的介 面,雖然我們實際上用到兩塊 buffer,但是由 MMC_DAT 這個電路來看就是一個 buffer 的介面而已,它輸出兩個非常重要的訊號給 MMC_DAT ,分別是 Buffer Input Full 和 Buffer Output Full,Buffer Input Full 為 1 時表示 buffer 內部還有資料 未被讀走,因此不能寫資料進去 buffer,若為 0,則表示可以寫資料進去 buffer。 Buffer Output Full 為 0 時表示,buffer 內部沒有資料可以被讀取,若為 1,才可 以讀取 buffer 的資料。在瞭解這兩個訊號的意思後,當 host 欲讀取 MMC 的資料 時,state machine 會判斷 Buffer Input Full 是否為 0,若是 0 才會執行讀取 MMC 的動作,否則就會一直等待。而當 host 欲寫資料到 MMC 時,因為資料是先被 寫入到 buffer 暫存的,所以 state machine 會判斷 Buffer Output Full 是否為 1,若 為 1,則表示要寫到 MMC 的資料已經都放置好到 buffer 了,若為 0,則表示 host 正在傳輸資料 buffer,因此 MMC_DAT 這個電路的 state machine 就要等待直到 buffer 裡的資料已經準備好了,才會繼續執行寫入的時序。當然和 buffer 介面溝 通,少不了 data bus和 read/write strobe 這些訊號,除此之外,MMC_DAT 還會 輸出兩個訊號,MMC2BUF_DIR 和 BUF2MMC_DIR,由字面上的意思我們可以 知道,這是一個方向的指示訊號,因為 DSP 和 MMC 的 host controller 這兩個電 路都會 access 到 buffer,所以要提供最上層的整合電路裡的多工器一個控制訊 號,來選擇實際上 buffer 是接到 DSP 還是接到 MMC 的 host controller。
第三節 Ping-Pong Buffer.VHD 設計說明 Ping-Pong Buffer 這是一個在工業上常見到的設計方法,目的是加速資料的 傳遞速度,若我們的系統採用一個 buffer 的話,則當 buffer 被寫時,它就不能被 讀,或是被讀時,就不能被寫,這樣的話, access 到 buffer 的兩方,DSP 和 MMC host controller,在一方忙碌時,另一方則必須等待,這樣的作法是非常沒有效率 的,但若是採用雙 buffer 的操作之後,會發現等待的時間變短了。 Buffer0 Buffer1 DSP MMC hostcontroller Write Data Buffer0 Buffer1 DSP MMC hostcontroller Write Data Read Data Buffer0 Buffer1 DSP MMC hostcontroller Write Data 1st operation 2nd operation 3rd operation Buffer0 Buffer1 DSP MMC hostcontroller Read Data Final operation 圖 5-15 Ping-Pong Buffer 操作示意圖 由圖 5-15 中我們可以看到 Ping-Pong Buffer是如何運作的,以 DSP 要寫資料到 MMC 為例,第一次運作,DSP 把資料填入 buffer 0,此時 buffer 1 不動作,第二 次運作,DSP 把資料填入 buffer 1,此時 buffer 0 有之前已填入的資料,因此 MMC host controller 可以去 buffer 0 讀取資料然後寫入 MMC,第三次運作,一開始 buffer 0 是空的,buffer 1 是滿的,因此 DSP 填資料到 buffer 0,MMC host Controller
去 buffer 1讀取資料寫入 MMC,一直重複第二和第三次的操作動作,直到最後 一次的運作,在 buffer 0 的資料被 MMC host controller 讀走然後寫入 MMC 才算 結束 Ping-Pong Buffer 在 multiple block write mode 的操作。若是在 multiple block read mode的話,只要把圖 5-15 中虛線旁的 DSP 和 MMC host controller對調就 可以了。
關於 Ping-Pong Buffer 這個電路的設計,我們的 buffer 是使用 W26L010A 這 顆 SRAM,它的大小是 64Kx16,不過我們並不需要使用到這麼大的記憶體空間, 我們實際使用到的為兩個 256x16 的 buffer,之所以要使用這樣大小的 buffer,原 因是我們定義 MMC 一個 block 的大小為 512 byte,而 DSP 的 Data Bus寬度為 16 位 元 , 所 以 把 buffer 的 大 小 定 為 256x16 是 很 合 理 的 。 首 先 我 們 先 來 看 RAM256x16.VHD 這個電路裡的輸入輸出關係。圖 5-16 的右邊「Buffer Address」 是接到 SRAM 的 Address Bus,我們的設計是只要 buffer 被讀取或寫入一次之後, Buffer Address自動加一,這種定址方法省去了由韌體來指定 buffer 的位址,大 大減少了 access RAM 的時間。「 Buffer Data」這個雙向訊號線則是接到 SRAM 的 Data Bus,當外界要寫資料進入 SRAM 時,Din 會接到「 Buffer Data」,當外界要 讀取 SRAM 時,Dout 會接收來自「 Buffer Data」丟出的資料。「 BnUB」和「 BnLB」 則是 W26L010A 這顆 SRAM 的特有的功能,它可以讓使用者選擇要讀取 SRAM 的 Upper Byte 或是 Lower Byte,或是兩者皆要。靠的就是「BnUB」和「BnLB」 這兩個訊號,在我們的系統中要使用 16 位元的架構,所以「 BnUB」和「 BnLB」 都設為 0,表示 Upper Byte 和 Lower Byte 都要能讀寫的到。而「 BnOE」和「 BnWE」 分別就是 SRAM 的 Read 和 Write Enable,在這個電路裡,我們就直接把外界提 供的 Read 和 Write Enable 分別接到「 BnOE」和「 BnWE」。最後「 BnCS」為 SRAM 的 Chip Select,我們是直接給予 0,表示 enable 這個 SRAM。最後在 RAM256x16 這個電路裡有個非常重要的訊號就是「Buffer Full」這個輸出,當 buffer 的 256 個位址被填滿值之後,這個訊號就會維持為 1,表示 buffer 是在滿的狀態,直到 這 256 個位址裡的資料都被讀取走之後,這個訊號才會變為 0,這個訊號是提供
外界知道 Ping-Pong Buffer 內部儲存狀態的指標。 256x16 SRAM Clock nReset nOE nWE Read/Write direction Din Buffer Address Buffer Data BnUB BnLB BnOE BnWE BnCS Buffer Full Dout 圖 5-16 RA256x16.VHD 的輸入輸出 在瞭解單一 buffer 的操作特性後,我們來看兩個 buffer 如何達到之前敘述的操作 方式。在圖 5-2 的硬體程式樹狀圖裡,我們可以看到建構在 RAM256x16.VHD 之 上的就是 Ping-Pong Buffer.VHD,由 Ping-Pong Buffer的觀點來看,它是一個新 的 buffer,可以讀取也可以寫入,這是因為在這個電路裡,我們有 9 個多工器, 控制 buffer 0 和 buffer 1 一個對應到被讀取,另一個對應到被寫入,而這個控制 訊號我們把它稱為 BUFID,當 BUFID 為 0 時代表 buffer 0 是被寫入的,同時 buffer 1 就是被讀取的。相反地,若是 BUFID 為 1 時,buffer 1 就是被寫入的,buffer 0 就是被讀取的。在定義了 BUFID 這個訊號後,我們來看這 9 個多工器處理了哪 些工作。
0 1
BUFID Buffer 1 Data Bus Output
Buffer 0 Data Bus Output Ping-Pong Buffer Data Bus Output
圖 5-17 Ping-Pong Buffer 的第一個多工器
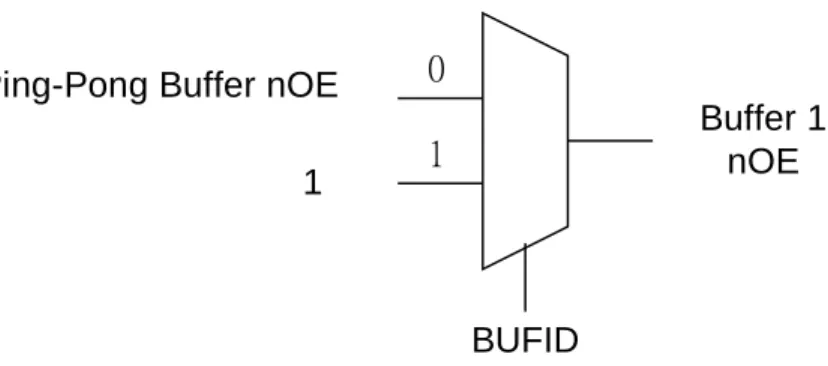
‧第一個多工器:是選擇 Ping-Pong Buffer 的 Data Bus 輸出是接到那個 buffer 當 BUFID 為 0 時,表示 buffer 1 的資料應該輸出,若 BUFID 為 1,則表示 buffer 0 的資料要被輸出。 0 1 BUFID Buffer 0 nOE 1
Ping-Pong Buffer nOE
圖 5-18 Ping-Pong Buffer 的第二個多工器
‧第二個多工器:是選擇 Buffer 0 的 nOE 訊號為何,當 BUFID 為 0 時,表示 buffer 0 是要寫入的,所以 buffer 0 的 nOE 訊號就為 1,若 BUFID 為 1 時,表示 buffer 0 是被讀出的,所以外界的 nOE 訊號要給 buffer 0 的 nOE。
0 1 BUFID Buffer 1 nOE 1
Ping-Pong Buffer nOE
圖 5-19 Ping-Pong Buffer 的第三個多工器
‧第三個多工器:是選擇 Buffer1 的 nOE 訊號為何,當 BUFID 為 0 時,表示 bu ffer 1是要讀出的,所以外界的 nOE 訊號要給 buffer 1 的 nOE,若 BUFID 為
1 時,表示 buffer 1 是被寫入的,所以 buffer 1 的 nOE 訊號要給 1。 0 1 BUFID Buffer 0 nWE 1
Ping-Pong Buffer nWE
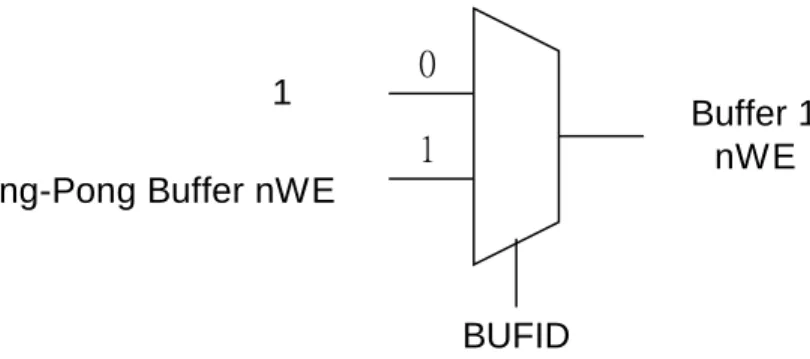
圖 5-20 Ping-Pong Buffer 的第四個多工器
‧第四個多工器:是選擇 Buffer0 的 nWE 訊號為何,當 BUFID 為 0 時,表示 bu ffer 0是要寫入的,所以 buffer 0 的 nWE 訊號就接到外界的 nWE,若 BUFID
為 1 時,表示 buffer 0 是被讀出的,所以 buffer 0 的 nWE 訊號要給 1。
0 1 BUFID Buffer 1 nWE 1
Ping-Pong Buffer nWE
圖 5-21 Ping-Pong Buffer 的第五個多工器
‧第五個多工器:是選擇 Buffer 1 的 nWE 訊號為何,當 BUFID 為 0 時,表示 buffer 1是要讀出的,所以 buffer 1 的 nWE 訊號就為 1,若 BUFID 為 1 時, 表示 buffer 1 是要寫入的,所以 buffer 1 的 nWE 要接到外界的 nWE 訊號。
0 1 BUFID Ping-Pong Buffer Input Full Buffer 0 Full Buffer 1 Full 圖 5-22 Ping-Pong Buffer 的第六個多工器
‧第六個多工器:是選擇 Ping-Pong Buffer 的 Input Full訊號由哪來,當 BUFID 為 0 時,表示 buffer 0 是要寫入的,所以 Ping-Pong Buffer 的 Input Full 訊號應 該接到 buffer 0 Full 這個訊號,若 BUFID 為 1 時,表示 buffer 1 是要寫入的, 所以就要選到 buffer 1 Full 這個訊號。 0 1 BUFID Ping-Pong Buffer Output Full Buffer 1 Full Buffer 0 Full 圖 5-23 Ping-Pong Buffer 的第七個多工器
‧ 第七個多工器:是選擇 Ping-Pong Buffer 的 Output Full 訊號由哪來,當 BUFID 為 0 時,表示 buffer 1 是要讀出,所以 Ping-Pong Buffer 的 Output Full 訊號應 該接到 buffer 1 Full 這個訊號,若 BUFID 為 1 時,表示 buffer 0 要讀出,所以 就要選到 buffer 0 Full 這個訊號。
0 1 BUFID Buffer 0 Read/Write Direction 0 1 圖 5-24 Ping-Pong Buffer 的第八個多工器
‧第八個多工器:是選擇 buffer 0 的 read/write direction 訊號為何,當 BUFID 為 0 時,表示 buffer 0 是寫入,所以選 0,當 BUFID 為 1 時,表示 buffer 0 要 讀出,所以選 1。 0 1 BUFID Buffer 1 Read/Write Direction 1 0 圖 5-25 Ping-Pong Buffer 的第九個多工器
‧第九個多工器:是選擇 buffer 1 的 read/write direction 訊號為何,當 BUFID 為 0 時,表示 buffer 1 是被讀出,所以選 1,當 BUFID 為 1 時,表示 buffer 1 是被寫入,所以選 0。
最後 Ping-Pong Buffer 這個電路裡頭有兩個暫存器供 host 存取,一為位址 1000h 的 Buffer Data Register,這個暫存器是 host 讀取 buffer 的窗口,也就是讀寫資 料都是對應到這個暫存器。另一個為位址 1001h 的 Buffer Status Register,它提 供外界對於 Ping-Pong Buffer 內部狀態的一個指示,Bit 7 是
前述的 Ping-Pong Buffer Input Full 訊號,Bit 6 則是前述的 Ping-Pong Buffer Output Full 訊號,其餘 Bit 皆為 0。
第六章 系統韌體設計介紹
第一節 前言 在整個系統中,如果硬體是人的軀殼,那麼韌體就是人的靈魂了,可見它的 重要性,在我們的應用中, DSP 程式就是我們的靈魂,它不僅要處理壓縮、解壓 縮等演算法的工作,更要對系統的週邊作存取,包括光碟機、鍵盤、 LCD 和 CF、 MMC 等快閃記憶卡,在這章中,我們不談這些週邊的控制以及檔案系統,這在 報告最後所列的參考資料中,都可以找到更詳細的說明,我們主要針對 AES 加 解密演算法作說明以及系統在前後端資料長度不一的問題,提出一套合理的解決 方法。第二節 Advanced Encryption Standard (AES) 韌體程式設計說明
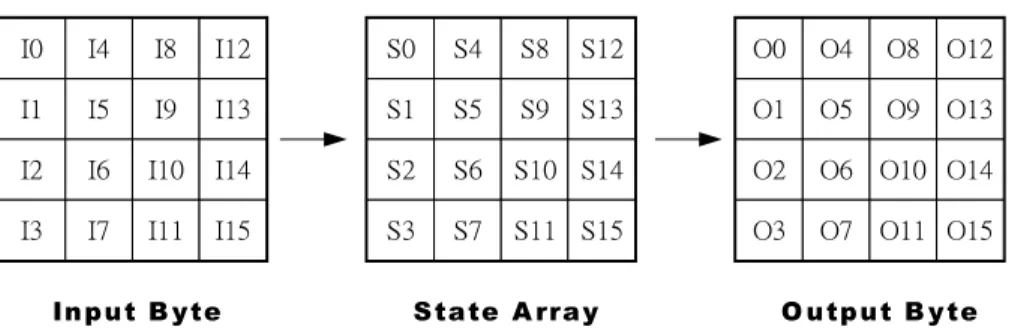
AES 這種加解密方法,是屬於傳統密碼系統,也稱為對稱金匙密碼系統, 主要是應用在電子資料上的,資料長度固定為 128 bit,鑰匙長度可為 128 bit、 192 bit、256 bit 三種,經過加密後資料長度不變,只是把原本有意義的資料,也 就是明文(plaintext)變成渾沌不清、無法理解的密文 (Ciphertext),當要把資料回復 成明文時,也是用同一把鑰匙解密的。AES 演算法所處裡的資料的最小單位為 byte,由 8 個 bit { b7 b6 b5 b4 b3 b2 b1 b0 } 所組成的,我們也可以用多項式 0 1 2 3 4 5 6 7x7 b x6 b x5 b x4 b x3 b x2 b x1 b b 來表示一個 byte,而在 AES 演算法 裡,所有的運算都是定義在有限場 GF(28 )裡,元素之間的加法,就是兩個元素作 exclusive OR 得到的結果,元素間的乘法就是把兩個元素先用多項式的形式表示 後,作多項式的相乘,再除以 m(x)=x8x4x3x1後取餘數,便是元素之間相 成的結果了。在 AES 演算法裡,資料的排列如圖 6-1,首先 128 bit 也就是 16 byte 的輸入資料依圖裡 index 的順序放在一個 4 x 4的陣列裡,經過一串反覆的處理 之後,最後以同樣的次序依序輸出。在加密的情況, input byte 就是明文,state array 裡存的就是加密過程中的暫存資料,output byte 就是密文。而在解密的情況, input byte 就是密文,state array裡存的就是解密過程中所暫存的資料,而 output byte 就是明文了。 I0 I1 I2 I3 I4 I8 I12 I5 I9 I13 I6 I10 I14 I7 I11 I15 S0 S1 S2 S3 S4 S8 S12 S5 S9 S13 S6 S10 S14 S7 S11 S15 O0 O1 O2 O3 O4 O8 O12 O5 O9 O13 O6 O10 O14 O7 O11 O15
Input B yte State A rray O utput B yte
Cipher( byte in[4xNb] , byte out[4xNb] , word w[Nb x (Nr+1 )] ) Begin byte State[4,Nb] state=in AddRoundKey(State,w) For(round=1;round<Nr;round++) { SubB yte(State) ShiftRows(State) MixColumn(State) AddRoundKey(State , w+Nb x round) } 而加解密過程中所使用到的鑰匙,也如同輸入資料一樣,放在一個有 4 列的陣列 裡,在這裡我們定義三個變數: Nb:輸入資料放的陣列裡的欄位數,由於輸入資料數為固定的 16 byte,陣列裡 每一個欄位有 4 個 byte,所以 Nb 為 4 Nk:鑰匙放的陣列裡的欄位數,由於鑰匙長度有 16、24、32 byte 3 種情況,因 此 Nk 有 4、6、8 三種可能。 Nr:Nr 為加、解密處理過程執行的回合數(number of round),這個數字和 Nk 有 關,如表 6-1。
KeyLength(Nk) Block size(Nb) Number of round (Nr)
AES-128 4 4 10 AES-192 6 4 12 AES-256 8 4 14 表 6-1 (Nk,Nb,Nr)次數對照表 瞭解這些後,我們用以下的 Pseudo Code 來表示加密和解密的過程,之後各小節 裡再去討論細部的 function 為何。
圖 6-2 Pseudo code for Cipher
在這個虛擬的加密程式裡,w 這個陣列存放著 Nb x (Nr+1)個 word(4 個 byte)的鑰 匙,每個回合的加密過程,取用不同位置裡的鑰匙來使用, w 陣列裡面的資料是 由一個稱為 KeyExpansion()的動作所產生的,詳細過程在之後會介紹。加密一開 始,把 input data 放在 state buffer 裡,再把 state buffer 裡的每個元素(byte)一一的 和 w 陣列裡的前 Nb 個欄位裡的資料作 exclusive OR,接著開始 Nr 個回合的處 理,由程式中我們可以看到,最後一個回合的處理,和前 Nr 個回合只有一個地 方不同而已,就是最後一個回合少了 MixColumn 這個動作,其餘的動作一樣, 每個回合的動作裡,都依序包含 SubByte、ShiftRows、MixColumn 和 AddRoundKey 等 4 級的處理。當 Nr 回合的處理結束後,state buffer裡的資料就是密文了。而 解密的過程則如圖 6-3 裡所示,和加密的過程剛好成一個對稱的關係,加密過程 裡的每個動作都有它的相對應的 inverse 動作,加密過程中先作的,在解密過程 中就後作,加密過程中後作的,解密過程中就先作,依此原則,就可以把先前的 密文還原成明文了。之後我們依序來討論各回合裡的詳細動作。 // Final Round SubByte(State) ShiftRows(State) AddRoundKey(State , w+ Nb x Nr) Out=state End
InvCipher (byte in[4 x Nb] , byte out[4 x Nb] , word w[Nb x (Nr+1)] Begin State=in // Final Round AddRoundKey(State,w+ Nb x Nr) InvShiftRows(State) InvSubByte(State)
For(round=Nr-1;round>0;round--) { AddRoundKey(State,w+ Nb x round) InvMixColumn(State) InvShiftRows(State) InvSubByte(State) } AddRoundKey(State,w) End
圖 6-3 Pseudo code for Inverse Cipher ‧KeyExpansion 說明
KeyE xpansio n的動作為利用長度為 Nk word 的 Cipher Key,然後根據圖 6-5 KeyExpansion 的 Pseudo code,產生長度為 Nb x (Nr+1)的 Key schedule,這個 key schedule 提供一開始 initial 和之後 Nr 次的 AddRoundKey 動作,所需要的 Key, 一開始 initial 時,從 key schedule 裡取前 Nb words 的 key,之後每次 AddRoundKey 執行時,就再向右取 Nb 個 key,直到 Nr 次 AddRoundKey 結束為止。 ... Initial 1st Round 2nd Round Nr th Round word= 4 byte
Nb words Nb words Nb words Nb words
...
...
圖 6-4 Key Schedule 示意圖
Key Schedule 的產生方法為,一開始,前 Nk word 的值由 Cipher Key 填入,之後 的 word 的值 w[i],由現在位置的前一個值 w[i-1]和前 Nk 個值 w[i-Nk],作 XOR 得到,不過有兩種情形例外,第一種:若遇到位置的 index 是 Nk 的整數倍時, 則 w[i-1]裡的 4 個 byte 要先經過一個轉換:[a0 a1 a2 a3] →[a1 a2 a3 a0],再經過
KeyExpansion ( byte key[ 4 x Nk ] , word w[ Nb x (Nr+1) ] , Nk ) Begin
i = 0
while(i<Nk)
w[i]=word[ key[4i] , key[4i+1] , key[4i+2] , key[4i+3] ] i++ end while
i =Nk
while( i< Nb x (Nr+1) )
word temp=w[i-1]
if (i mod Nk = 0)
temp=Subword( RotWord ( temp ) ) XOR Rcon[ i/Nk ]
else if( Nk = 8 and I mod Nk=4 )
temp=Subw ord(temp) e n d i f w [ i ]= w [ i-Nk] xor temp i + + end while End 一 個 稱 為 Subword 的 查 表 法 , 可 得 到 一 個 轉 換 值 , 這 個4-byte 值 和 Rcon[i]=[ xi1,{00} ,{00} ,{00} ]作 XOR 後得到的值,用來取代 先前的 w[i-1]。第
二種:當 Nk=8 時,若遇到位置的 index i 減去 4 是 Nk 的倍數的話,則 w[i-1]要 先經過 subword 查表得到一個 4-byte 的值,才能和 w[i-Nk]作 XOR。依照這個規 則去產生每一個 w[i]的值,就完成 KeyExpansion 的動作了。
圖 6-5 Pseudo Code for KeyExpansion
SubByt e是一個非線性的轉換,主要由兩個動作來達成的: (1) 因為每一個 byte 資料都可以視為是有限場 GF(28)裡的一個元素,所以每一個 byte 自然會有它的乘法反元素,第一步便是取得該數的乘法反元素。 (2) 得到乘法反元素之後,把該數代入底下的矩陣計算 0 1 1 0 0 0 1 1 7 6 5 4 3 2 1 0 1 1 1 1 1 0 0 0 0 1 1 1 1 1 0 0 0 0 1 1 1 1 1 0 0 0 0 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 0 0 0 1 7 6 5 4 3 2 1 0 b b b b b b b b b b b b b b b b
當 state buffer 裡的每一個 byte 都執行完上述兩個動作後,完成 Subbyte 的工 作了。不過我們會發現,若事先先把 0~255,也就是 GF(28)裡的每個元素都依照
上述方法先算好,加密程式在執行時,就只要用查表的方法,就可以很快的得到 結果了,而 DSP(或泛指一般 CPU)執行程式就可以節省許多時間了。
InvSubByte 的動作就是把 state buffer 裡的元素先代入上述矩陣的 inverse matrix 執行後,再計算其乘法反元素,就是結果了。同樣的,這些步驟也都是可 以 事 先計 算出 來的 ,因 此實 作時 ,也 是用 查表 的 方法 來替 代直 接計 算的 。 而 SubByte 和 InvSubByte 的表格在 AES 的規格書裡可以找的到。
這個步驟非常的單純,只是把 state buffer 裡的資料,依照不同的列,給予不同 的循環移動(cyclic shift),移動的規則為:第 0 列不移動,第 1 列向左循環移動一 位,第 2 列向左循環移動兩位,第三列向左循環移動三位。示意圖如圖 6-6。 0 , 0 S 0 , 1 S 0 , 2 S 0 , 3 S 1 , 0 S 1 , 1 S 1 , 2 S 1 , 3 S 2 , 0 S 2 , 1 S 2 , 2 S 2 , 3 S 3 , 0 S 3 , 1 S 3 , 2 S 3 , 3 S 0 , 0 S 1 , 1 S 2 , 2 S 3 , 3 S 1 , 0 S 2 , 1 S 3 , 2 S 0 , 3 S 2 , 0 S 3 , 1 S 0 , 2 S 1 , 3 S 3 , 0 S 0 , 1 S 1 , 2 S 2 , 3 S 圖 6-6 ShiftRows 示意圖
而 InvShiftRows 的動作也是把 state buffer 裡的資料,依照不同的列,給予不同的 循環移動,第 0 列不變,第 1 列向右循環移動一位,第 2 列向右循環移動兩位, 第三列向右循環移動三位。示意圖如圖 6-7。 0 , 0 S 0 , 1 S 0 , 2 S 0 , 3 S 1 , 0 S 1 , 1 S 1 , 2 S 1 , 3 S 2 , 0 S 2 , 1 S 2 , 2 S 2 , 3 S 3 , 0 S 3 , 1 S 3 , 2 S 3 , 3 S 0 , 0 S 3 , 1 S 2 , 2 S 1 , 3 S 1 , 0 S 0 , 1 S 3 , 2 S 2 , 3 S 2 , 0 S 1 , 1 S 0 , 2 S 3 , 3 S 3 , 0 S 2 , 1 S 1 , 2 S 0 , 3 S 圖 6-7 InvShiftRows 示意圖
Mixcolumn這個步驟是把 state buffer 裡的每個 column 視為一個 3 次項的多項 式,把這個多項式和{03}x3
+{01}x2+{01}x+{02}這個 3 次項的多項式相乘後,除 以 x4
+1 取餘數,再存入 state buffer 的同一個 column,當 state buffer 的 4 個 column 都做完這些動作後,便是 MixColumn 的結果了。不過在 AES 的規格書裡有提到, 上述的這些過程,可以簡化成下面的矩陣式子,把 state buffer裡的 4 個 column 代入運算後,也是得到相同的結果,寫程式時,便是以此矩陣實作的。 c c c c c c c c S S S S S S S S , 3 , 2 , 1 , 0 , 3 , 2 , 1 , 0 02 01 01 03 03 02 01 01 01 03 02 01 01 01 03 02 for 0cNb
至於 InvMixcloumn 的動作,則是把 state buffer 裡的 4 個 word 資料,當成是一個 3 次多項式的係數,把這個多項式和{0b}x3+{0d}x2+{09}x+{0e}這個多項式相乘 後取餘數,再存回 state buffer 裡,直到 state buffer 裡的 4 個 column 都做完這些 工作,就算完成 InvMixColumn 了。在 AES 的規格書裡也有提到上述的步驟, 可以簡化成一個如下的矩陣形式,實作時也是依照此矩陣來實現的。 c c c c c c c c S S S S e d b b e d d b e d b e S S S S , 3 , 2 , 1 , 0 , 3 , 2 , 1 , 0 0 09 0 0 0 0 09 0 0 0 0 09 09 0 0 0 for 0cNb ‧AddRoundKey
裡的每個元素作 XOR,就是 AddRoundKey 的結果了,Round Key 的取得就是從 Key schedule 裡,每次取 4 個 column 出來,就是該回合的 Round Key 了。
0 , 0 S 0 , 1 S 0 , 2 S 0 , 3 S 2 , 0 S 2 , 1 S 2 , 2 S 2 , 3 S 3 , 0 S 3 , 1 S 3 , 2 S 3 , 3 S 1 , 0 S 1 , 1 S 1 , 2 S 1 , 3 S l W WWllW11l2 Wl3 0 , 0 S 0 , 1 S 0 , 2 S 0 , 3 S 2 , 0 S 2 , 1 S 2 , 2 S 2 , 3 S 3 , 0 S 3 , 1 S 3 , 2 S 3 , 3 S 1 , 0 S 1 , 1 S 1 , 2 S 1 , 3 S b N round l 0roundNr 圖 6-8 AddRoundKey 示意圖 第三節 系統在前端資料長度不同之解決方法 在 mp3 壓縮的演算法中,是把輸入的訊號分成左右兩個聲道來處裡的,在
單一聲道中,每次壓 縮所需的最小單位為一個 frame,其中包含 1152 個 16-bit 的 PCM 訊號,而其中每 576 個 PCM 訊號稱為一個 granule。因此一個 frame 中含有 兩個 granule,稱為 granule 0 和 granule 1,encoder 先處理左聲道的 frame 再處理 右聲道的 frame,如此重複下去。但是在讀取光碟機的資料方面,一次讀取的基 本單位為 1176 word,而且資料是以「左右左右」的順序排列下去。 在圖 6-9 中的紅色方塊表示單一聲道的一個 frame,而綠色虛線箭頭的方向則是 光碟機被讀取出資料的順序。因此我們在 mp3 recorder system的前端資料取得 上,遭遇到兩個問題,第一為 mp3 壓縮的基本單位 1152 word 和光碟機讀取的基 本單位 1176 word 相差了 24 個 word。第二是 mp3 壓縮是左右聲道分開處理,但 光碟機讀取出的資料卻是左右聲道交錯著,因此在系統的韌體裡必須對 granule 0 granule 0 granule 1 granule 1 576 word Left Channel Right Channel 576 word 1152 word L R L R . . . . L R L R L R L R 24 word 1176 word 576 word 576 word 圖 6-9 MP3 recorder system 前端資料示意圖 前端資料的蒐集有套良好的機制,可以解決上述的兩個問題。在這裡我們提出了 藉由 circular buffer 的特性,可以完全解決前述的困難點。首先,circular buffer 就 是 一 種 特 殊 的 記 憶 體 定 址 方 法 , 我 們 指 定 某 一 塊 連 續 的 記 憶 體 空 間 作 為
circular buffer,對這塊記憶體作資料的讀、寫,是由該塊記憶體的起始點開始, 當定址到該塊記憶體的最後一個位址時,下一次讀或寫所定址到的位址就會回到 起始點了,就像是把記憶體繞個圓圈一樣。在我們的韌體中,設定了 circular buffer 為 1152 x 4 個 word 這麼長,原因有二:第一點,在於每次光碟機讀取出的資料 長度比 mp3 encoder 所需的 frame size 多 24 word,需要有多餘的記憶體空間來存 放這 24 word 的 PCM 資料。第二點,由於 mp3 encoder的程式要求每次皆把左 右聲道 frame 的資料準備好,也就是要把 1152 x 2=2304 word 的資料準備好,因 此要先讀取光碟機的資料到 circular buffer 兩次後(1176 x2),mp3 encoder 才能讀 取 circular buffer 一次,這樣會造成每次執行上述整個動作一次,circular buffer 就會多 48 word 的資料出來,但我們可以發現一個規則,由於 2304 除以 48 等於 48,也就是讀取光碟機 48 次(1176*2 稱為一次)之後,mp3 encoder 緊接著從 circular buffer 讀走第 48 次左右聲道的資料後,circular buffer 裡的資料剛好剩下 2304 word,這剛好滿足 MP3 encoder的需要,因此系統的韌體在讀取過 48 次光碟機 後,第四十九次就不必再從光碟機裡讀取資料出來了,照著此機制,就可以完全 解決 mp3 recorder system 在處理前端資料上遇到的問題了。