行政院國家科學委員會補助專題研究計畫成果報告
※※※※※※※※※※※※※※※※※※※※※※※※※
※
※
※
泛用型動態虛擬實境操控與運動復健輔助系統研發(1/3)
※
※
—總計畫
※
※
※
※※※※※※※※※※※※※※※※※※※※※※※※
計畫類別:□個別型計畫
■整合型計畫
計畫編號:NSC 90-2213-E-009-103
執行期間:90 年 08 月 01 日至 91 年 07 月 31 日
計畫主持人:林進燈 教授
共同主持人:李祖添、林昇甫、張志永、莊家峰 教授
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
執行單位:國立交通大學電機與控制工程研究所
中
華
民
國
91
年
7
月
31
日
行政院國家科學委員會專題研究計畫成果報告
泛用型動態虛擬實境操控與運動復健輔助系統研發
計畫編號:NSC90-2213-E-009-103
執行期限:90 年 08 月 01 日至 91 年 07 月 31 日
主持人:林進燈 教授 交通大學電控所
同主持人:
李祖添、林昇甫、張志永、莊家峰教授 交通大學電控所 摘要 本計畫的目標是發展一套運動復健 訓練的輔助控制系統,此系統主要是在 一個由電腦操控的六軸動作平台上建構 走步機或跑步機等運動訓練輔助機制, 配合聲光效果建立之虛擬實境,提供使 用者一個運動與訓練環境。其主要特色 在於運用感測資訊及操作者的選擇,以 電腦預測出使用者的體能與身心狀態之 型態(Pattern),進而改變輔助訓練的內容 與場景,期可以鼓勵使用者,達到進行 運動訓練的積極目的。此系統不但可作 為一般人士的運動、健身器材,尤其適 合提供給身心殘障人士一個更人性化及 具輔助性的復健空間與設備,並達到職 業重建的目的。 本年度此計畫共以五個子計畫完成 各自負責的項目,以下就分別陳述各子 計畫的進度狀況: 子計畫一:動態 VR 運動復健輔助系統 之行為轉換與即時模擬研究 一、計畫概述 在本計畫研發的系統中,操控員透 過操控界面下達指令,以操控系統中的 虛擬的運動訓練的輔助設備或載具。此 操控命令將被輸入所模擬之設備或載具 的精確物理模型中,以求得真實情況下 系統的反應。這些反應將透過本子計畫 的行為轉換與控制模組,而由六軸運動 平台、力迴饋模組及虛擬實境顯示器表 現出來,以讓操控員獲得身歷其境的感 受。這整個系統中,因為行為轉換模組 的設計扮演實際環境裡物體運動狀況以 及 虛 擬環 境 中操控員身體感受之間橋 樑,如何讓操控員有身歷其境的感受, 有賴於在動態模擬系統發展過程中,適 當的人(操控員)機(動態模擬器)溝通界 面及迴饋學習技術,以獲得最符合人類 感覺的行為轉換模式。本子計畫只要將 相 關 之運 動 行為提供給顯示子系統即 可。Stewart Platform 為一具有六自由度 運動能力之機械平台,但其運動範圍受 到其工作空間的限制,有些動作是無法 達成的,因此為了在其有限空間下模擬 出騎馬、飛機、輪船等交通工具時之運 動 感 覺 。 所 以 一 般 是 以 沖 淡 演 算 法 (Washout Algorithm)架構出對模擬器的 力的感受。在第一年的研究中,我們探 討了如下的四個課題:沖淡演算法級行 為轉換演算法、函數型類神經網路、訓 練者修正的加強式學習、以及模糊控制 器穩定設計與探討。我們簡述於下。 二、沖淡演算法級行為轉換演算法 本子計畫主要在於當虛擬系統接 收到控制命令,設法產生應有的運動行 為描述以及在模擬運動平台的運動行 為,以達到虛擬實境的目的。目前文獻 上對於如是的轉換是以 Washout 演算法 或 稱 Washout Filter 的方式來設計。 Washout Filter 的輸入為由數學運動模型 所求得的比例力與角速度。所謂的比例 力(Specific Force)是指單位質量所受的 非重力力。由向量的觀點來看的話,比 例力即是慣性加速度與重力加速度之 差,因此比例力可定義為f a g v v v − = 。在文獻中也有提出調適式的 Washout filter 如圖一為一調適式之 Washout filter,其 概 念 是 根 據 線 上 取 得 的 資 訊 去 調 整 Filter 中的增益。其主要是將平台的運動 和被模擬之運動之間的差異及平台特性 的考量來,架構出一性能指標。並經由 一最佳化的運算,來找出增益調適的法 則,由於指標函數及增益間之關係複雜及 即時的需要。一般都是以最陡下降法來 產生。如欲追隨之運動已知,則也可利 用最佳控制的概念,來直接尋找最佳之 線性 filter。此一調適演算法主要的功 能,即是要減低錯誤動作方式及使平台 儘量維持在原點。而在如圖一的架構中, 其斜傾處理的計算也有所改變。首先其 所利用的信號本身就不一樣。在調適式 架中由於是針對慣性座標軸,因此有許 多的運動的斜傾反應,也進入角度運動 環路中了。因此其在調適的考慮上也變 得非常複雜。 固定平台的虛擬實境主要是靠影像 部分來達成,當運動為直線定速時,如 是的模擬是相當不錯的,可是當運動路 徑是多變的時候,在轉彎加速或上下起 伏時,在固定平台上的感受就差很多。 若使用動作平台時,由於虛擬系統能設 法產生一些相對應的動作反應,使操作 者能感受到類似的感受力,此時在輔以 影像的虛擬,確實能使虛擬實境達到更 逼真的效果。可是當動作平台產生誤動 作時,整個系統的感受將是很不好的。 因此如何去設計好的動作,便是虛擬實 境系統中不可或缺。此一部分的設計一 般統稱為 motion cue。在我們的國科會研 究中(89-90 年度),我們取得美新科技一 組影片及對應的平台操控命令列,目前 我 們 在探 討 以資料庫的方式來建立的 motion cue 的對應法則。有關 motion cue 方面,我們也分析了一段雲霄飛車的影 片,企圖來了解一般在 motion cue 方面 的設計概念。可是這樣的資料庫再使用 上可能會很難,因為 generalization 的能 力是相當缺乏的。而且此資料庫的型態 是以函數為本質而不是點。在我們的研 究中我們將研究利用 Function Artificial Neural Network(FANN)來做 Motion cue 資料的建立。而在第一年的研究中,由 於其運動體就是操作者,所以其所需要 的動作平台的模擬反應較小,而且是可 預測的。因此在研究上我們將考慮在我 們 先 前研 究 中運動轉換資料庫的設計 上,運動轉換資料庫主要的概念是針對 已知的運動行程(如動態電影院),直接設 計平台動作的方式,由於此部分有些專 家的經驗,因此針對如是的資料庫,我 們可以累積經驗使之成為與被模擬機構 及平台機構無關的運動轉換法則,而為 了能達到知識粹取的過程,利用類神經 方式的建模是值得探討的,除了其能利 用 recognition without definition 的特質, 其將知識參數化,也可提供未來進一步 學習修正的依據。 圖一:調適式之 Washout filter 三、函數型類神經網路 (FFANN) 而在 motion cue 的記錄方面,我們 考 慮 使 用 函 數 型 類 神 經 網 路 來 記 錄 motion cue。在傳統的類神經網路,通常 以點對點的方式在時域當中進行系統的 建構。而所建構的網路以適應性網路進 行網路鍵結值的學習。近來,一種函數 型類神經網路架構已發表出來,函數型 網路架構使用數學的方式進行函數對函 數的輸出輸入對訓練網路之鍵結值。因 為 函 數型 網 路使用平行處理之數學計
算,可以快速估計出約略所需的輸出鍵 結值。由於它優異的函數近似能力,使 得我們可以將其運用在系統之頻域響應 當中。藉由前置的離散訊號處理以頻率 域替代傳統的時間域學習,並期望在噪 音的環境之下由在頻率域作業的優點, 而產生抑噪的功能;第二步,並將頻率 分解,由 FANN 的近似能力來學習,進 而追蹤期望訊號;第三步輸出並轉換為 時間域。這個架構可結合訊號處理的優 點(高速、抑噪),而達到我們想要的 結果。目前 FANN 正處於萌芽時期,其 中尚有以上一些缺點必須解決,對於週 期性的輸入便無法辨識,還有當期望輸 出上下限落差大,FANN 也無法學習, 及鍵結值的學習速度也在改進的範圍之 中。希望藉由我們提出的架構來改善以 上 所 提之 缺 點,並提升神經網路的效 能。FANN 以函數為輸出及輸入的類神 經網路。FANN 的架構及其學習效果等, 都是本研究所要探討的。長久以來,頻 域的脈衝特性使得傳統性的點對點網路 難以學習,在這當中還有頻域之中的複 數特性(大小及相位)需要比較精確的 比例才能使系統之輸出正確還原。在研 究中,我們以函數型網路為網路主體, 運用其良好函數近似能力去趨近受建構 系統之頻率響應;進行系統分析之後, 加上複數型學習網路機制,適當地調整 複數鍵結值並且保持相位的正確。為使 學習可以達到所期望的輸出,列舉三種 複數網路學習機制,其中兩種傳統學習 法 並 不能 正 確還原受建構系統時域輸 出。因此我們依照系統所需還原及複數 網路特性去打造另一種學習法,結合原 有之函數型神經網路主體,為頻域中之 混合式函數型類神經網路。Algorithm 4 則為 Algorithm 3 的另一種變行。經由模 擬的結果可以明顯驗證函數型網路在頻 域展現出比時域更優良的性能,加以學 習機制的參與網路,頻域中混合式函數 型網路表現出速度快、高近似度、以及 強健度的效果。 四、訓練者修正的加強式學習 在本子計畫的研究中,我們也將從 事有關訓練者修正的加強式學習,主要 的 兩 個方 向 是在建模方面,另一則是 motion cue 的部分,主要的觀念乃是在虛 擬實境上,主要是要人的感受。因此當 操作者對於系統有認為不好的地方,我 們 希 望能 將 這一類的感受用於修正系 統,對建模部分而言,主要是對反應的 不真實性,加以修正,若是能建立這樣 的系統,則針對建模部分就可以只要建 一個簡單大致的模式,而後透過加強式 學習來使得模式反應更逼真,如是未來 對不同的系統開發可以不需要每一次都 要找一個所要開發系統的建模專家,而 只要有一對該系統反應狀況較熟悉的人 就可以了。同樣的,在 motion cue 設計 的部分,也是如此,只要一感受靈敏的 人,針對系統反應的評估,即可設計出 較精準而感受逼真的動態模擬系統。 圖二:加強式學習系統架構 在加強式的研究中,初步的架構如 圖二上,訓練者在運動平台上,針對平 台的反應來修正而修正分為部分,其一 為 Model 部分,而另一為 motion cue 部 分。在做法上,我們要研究訓練者的評 估在加強式學習中的效能。而系統對訓 練者其評估的不確定性,也是研究所需 要析的。這是因為對同樣的狀況,在不 同的時候,由於人類感受評估的不精確 性,其可能會有不同的評估值。而同時, 針對訓練者評估息的定義,也不必然和 事先設定的概念一致。因此如何的調適 評估信息的歸屬函數,及其在加強式學 習中的學習法則,都需要深入的探討與
研究。而目前我們加強式學習的架構是 以 SONFIN 的方式來使得每一網路的法 則數不需要那麼多,可是由於 SONFIN 的學習在使用 BP 下較慢,而使用 LS 方 法其所欲之輸出不知道,這些在研究中 我們都將加以探討。而在內部加強式信 號 的 產生 部 分,目前我們是以傳統的 Temporal Difference (TD)預估的方式來 進行。由於最近的研究大都使用遺傳演 算法,我們也會考慮使用,在未來的研 究 中 我們 將 更進一步的探討分析其結 果,同時也將納入類似 washout filter 的 概念以及段落分割之學習方面。最後, 由於如上二種加強式學習。在訓練者的 感受上似乎有不可分的現象。目前的概 念是先分別探討與學習,以便個別系統 能正確做加強式學習,若在分析中能正 確分割兩系統效應。則可據以做加強式 信號回饋的依據,若不能分割,則可考 慮將二系統直接合併。由於加強式學習 本來就是可用於較複雜,而不容易數學 化 的 系統 而 當系統參數化後,其利用 trial-and-error 的特質,也是可以架構出加 強式學習系統的。 五、模糊控制器穩定設計與探討
In traditional, the stability of a fuzzy system can be assured by finding a common positive definite matrix in a Lyapunov function. That matrix and the corresponding controller can be simultaneously found by solving a set of linear matrix inequalities (LMIs). However, LMI-based fuzzy static output-feedback gains are not obtained by traditional approaches for nonlinear systems with uncertainties or with time delays in the literatures. In this paper, a new approach will be proposed to stabilize nonlinear interval time-delay systems via static output feedback. This approach does not need to find a common positive definite matrix to guarantee the system stability. The verification process is via computing the matrix measure for each separate
subsystem. In this paper, we shall derive the stability conditions based on the matrix measures of the system matrices of the subsystems of a fuzzy model. We derive a new sufficient condition to ensure the stability of the following T-S fuzzy model
1 1 ( ) ( ( ))( ( ) ( )) ( ) ( ( ))( ( )) r i i i i r i i i t h t t t t h t t τ = = = + − =
∑
∑
x y A x D x y y C x &The static output feedback gains
j F ,
1, 2, ,
j= K , satisfy the following conditionsr
2( i i j k) i µ A +B F C <γ , , ,i j k=1, 2,K .,r if and only if 0 B I A A B)⊥( + −2 )( )⊥< ( i i Ti γi Ti , i=1,2,K,r, and ( ) (T T 2 )( ) i ⊥ i+ −i γi i ⊥< C A A I C 0, i=1,2,K,r. In this research, we have proposed a new robust fuzzy static output feedback controller design methodology for nonlinear interval time-delay systems with norm-bounded uncertainties and time delays. Finding an admissible solution to the matrix measure assignment problem can solve the problem of stabilizing controller design via static output-feedback for nonlinear interval time-delay systems represented by a T-S fuzzy model. The designed controller can indeed tolerate norm-bounded parametric uncertainties and against the effect of time delays. In the paper, we have shown that the matrix measure assignment problem is equivalent to an LMI feasibility problem. A sufficient condition for the existence of the fuzzy static output-feedback gain is obtained. Our approach does not need to find a common positive definite matrix for all rules and the verification of stability is very easy. Simulation results have verified and confirmed the effectiveness of the new approach in controlling a nonlinear interval time-delay system.
子計畫二:動態 VR 運動復健輔助系統 之智慧型感測與控制
一、計畫概述 本計畫為「泛用型動態虛擬實境操 控與運動復健輔助系統研發」整合計畫 之子計畫二,研發重點在於電動六軸動 作平台之設計與分析、運動訓練輔助機 制之感測與控制及操作者運動狀況之偵 測與分析。以之前本團隊所開發之油壓 式六軸動作平台的經驗為基礎,在本子 計畫裡,我們將繼續鑽研以馬達驅動(電 動式)之六軸動作平台的設計與分析,以 為整個動態運動訓練輔助系統的根基平 台。我們也將進行平台的硬體機構分析 並解決運動學、奇異點、工作空間等問 題,以達位置、速度及加速度控制等目 的。本子計畫的第二個重點在設計、開 發運動訓練輔助機制,以架設在動作平 台上,而構成即時動態運動訓練系統的 整 合 機構 。 我們將朝向泛用型機構設 計,以涵括如跑步、划船、騎馬等運動 訓練項目。我們也將研發此機構的感測 與控制技術。本計畫的第三個研究主題 是操作者運動狀況之偵測與分析,藉由 非侵入式檢測方式,瞭解運動員身心狀 況(如心跳、運動速度),以適當控制平台 及運動訓練輔助機制,達到輔助訓練效 果。本子計畫也將發展即時計算環境的 軟硬體,以達整體系統即時控制效果。 二、目前研究進度: 針對本子計畫所將陸續完成的三大 研究主題,在今年度本子計畫目前朝向 電動六軸動作平台的開發與分析、平台 嵌入式即時硬體單板之設計與發展、VR 跑步場景之開發、VR 投影技術之探討 等。以下就分別針對此幾個方向,來加 以說明目前進度狀況。 A. 電動六軸動作平台的開發與分析 在此部分的研究上,由於是要從無到 有,所以今年度我們從電動伺服馬達的 選定與控制、控制架構的設計、單軸平 台 的 載重 分 析等,都是目前的研究重 心,以下分述如下: u 電動伺服馬達的選定 為得知該採用哪款的伺服馬達,我 們假定所欲建構的電動六軸平台載重為 1000 公斤,再乘以 2 倍之安全係數得單 軸所需載重為 470 公斤。經計算結果得 知所需負載轉矩為 4.25 Nm與慣性矩為 18.6 Kg⋅cm2 。 最 後 查 閱 三 菱 MELSERVO-J2_SUPER 規格書,選定對 應 之 馬 達 類 型 如 圖 三 所 示 , 其 為 HC_SFS_153B (2000rpm/min)。 圖三:三菱 HC_SFS_153B 伺服馬達 u 電動伺服馬達的控制 在傳統的控制理論,控制器的設計 都是基於數學描述和系統方程式模型, 但是在現實世界中,當系統越來越複雜 時就很難以數學模型來描述,所以要再 使用傳統的控制理論去解決此類問題就 顯得極為困難。近年來陸續有研究者將 模糊控制器(Fuzzy Logic Control)運用到 各種自動控制系統,使控制器加入了日 常生活中的語意特質,其中的模糊規則 為匯集專家的經驗和操控法則。六軸平 台因其數學模式十分難以獲得,故利用 傳統的控制理論進行設計控制器時將需 花費很多時間調整控制器參數才能獲得 不錯的系統響應。為了解決此問題,我 們一開始選用利用模糊控制器為基本架 構來進行設計。 此外我們還進一步提出模糊滑動模 式控制(Fuzzy Sliding-Mode Control)設計 方 法 , 我 們 可 藉 由 滑 動 表 面 (Sliding Surface)的提出使模糊規則數目得以減 少,以利於設計與分析工作。這裡我們
使用模糊滑動模式控制後,將原先模糊 控制所需的 49 條規則減少至 7 條規則。 圖四展示所用之模糊滑動控制伺服馬達 系統。 u d θ t KTe l T ) ( 1 B Js s + θ Servomotor Drive Fuzzy Sliding-Mode Control
θ e fuzzy controller dt d rule modifier sliding surface function s 圖四:模糊滑動控制伺服馬達系統 u 單軸電動缸載重測試 我們所發展之單軸電動缸控制系統 架構圖,如圖五所示,控制演算法則經 由控制電腦執行後,經過數位/類比伺服 控制卡送出命令電流至驅動電路模組, 由驅動電路器送出驅動信號至電動伺服 馬達控制馬達正反轉與轉動角度,再經 由皮帶帶動整個單軸電動缸測試平台轉 換成直線型位置,最後檢測電動伺服馬 達的實際位置,作成位置迴授至控制電 腦以利閉迴路控制法則的執行。整個實 驗結果為驗證所設計控制器之系統強健 性,我們提供兩個測試條件如下: (1) 測試條件一(空載條件):將馬達轉 動直接帶動整個電動缸。 (2) 測試條件二(負載條件):在電動缸 平台上外加 375Kg 的負載。 這裡我們曾用業界中常用的 PID 控 制器來控制整個系統,其實驗結果發現 利用 PID 控制器時,不管測試條件一或 二均並無法有效地精確追蹤到我們所下 之控制命令。為了解決此問題,利用所 設 計 之 模 糊 滑 動 控 制 器 (Fuzzy Sliding-Mode Control)做比較,其實驗結 果發現利用模糊滑動控制器時,不管測 試條件一或二均可精確地追蹤到我們所 下之控制命令。此外為了方便隨時監控 電動缸之控制情狀,本子題也發展了一 適合且簡易的人機界面,透過這個人機 界 面 可以 讓 使用者更容易修改控制參 數、儲存資料及察看結果,如圖六所示。 控制電腦系統 控制演算法 電動伺服馬達系統 電動缸負載平台 控制電腦系統 控制演算法 電動伺服馬達系統 電動缸負載平台 圖五:單軸電動缸控 制 系 統 架 構 圖 圖六:單軸電動缸之人機界面執行畫面 B. 嵌入式即時硬體單板之設計與發展 一般控制系統中大多採用 DSP 或 8 位元的單晶片微處理器,然而由於其無 法支援作業系統的核心架構,所以用其 低階語言編譯出來的控制程式,修改程 序非常繁複,使系統發展性大為受限。 因此我們採用嵌入式控制系統為核心, 以 StrongARM 作為中央處理器,其可支 援 open source Linux 作業系統。而開放 式的程式碼不但可自由下載,並可依自 己的需要修改原始碼並重新編譯,大大 增進了整個系統發展應用軟體的效率。
目前我們採用以 Intel StrongARM 處理器為核心的 LART 嵌入式硬體,其
中 LART 是 由 全 名 Linux Advanced Radio Terminal 的字首組合而來,為一套 消耗不到 1W 功率即可達到 250MIPS 高 效能的嵌入式系統硬體套件,其包括一 塊主板、週邊裝置擴充板與網路卡,經 由 LART 嵌 入 式 硬 體 模 組 搭 配 ARMLinux 嵌入式作業系統來取代舊有 的工業電腦控制方式,此優點不僅可使 控制系統體積大幅減少,同時也便於在 作業系統上發展新的控制程式與未來控 制程式發展更具彈性,而嵌入式系統週 邊支援 TCP/IP 網路,使得先前發展的另 一塊 Stand Alone 單板-DSP 控制卡無法 連接 TCP/IP 網路的困境獲得解決。 接下來依序介紹在此嵌入式單板所 發展的一些主題與成果:1. ADDA 傳輸 介面。2. 嵌入式動態模擬控制系統。3. 整合成果與比較。 u ADDA 傳輸介面 圖五為 ADDA 電路系統方塊圖,由 於六軸動作平台是利用類比電壓訊號來 控制油壓伺服閥以決定軸伸長量,所以 要利用 LART 嵌入式單板控制六軸平 台,必須擴充設計六組的類比數位轉換 的介面,讓 LART 的數位訊號與平台的 類比訊號間做資料的傳遞。 整 個 ADDA 電 路 系 統 需 要 提 供 5V、+12V、-12V 的工作電壓,而 LART 主板的工作電壓則是在較低的 3.3V,在 5V 和 3.3V 間的訊號傳遞必須加入一個 電壓準位轉換的機制才不會造成電壓過 大系統損毀,或是電壓過小資料流失的 問題。圖七中虛線右半部代表 LART 主 板 之 工 作 電 壓 3.3V , 虛 線 左 半 部 為 ADDA 電路系統之工作電壓 5V。考慮當 LART 訊號送到 D/A 轉換器時,因為 3.3V 到達 5V 系統之
V
IH,資料閂鎖器(Latch) 會把 3.3V 的輸入數位訊號電壓拉到 5V 電壓準位送到 D/A 轉換器; AD 迴授訊 號傳回 LART 時,則是將數位訊號用可 變電阻分壓降到 3.3V 再由系統讀回。 數位轉類比的訊號是由六組 D/A 轉 換器分別控制六軸電壓訊號,所以在 D/A 轉 換 器各 需 加一組獨立的資料閂鎖器 (Data Latch) 來 鎖 住 各 軸 所 需 的 轉 換 資 料。在類比轉數位電路裡,先用一顆類 比多工器搭配 SA1100 上的三個 I/O port 來選擇讓第幾軸的類比訊號輸入轉換, 因此只需一顆類比轉數位轉換器即可完 成六軸電壓轉換動作。另外在這必須考 慮的是,A/D 轉換完的輸出 12-bit 數位資 料需經由 CPU 的 Data Bus 讀回系統處 理,而 CPU 的 Data Bus 乃雙向匯流排, 為了避免 CPU 的 Data Bus 在輸入與輸出 的值之間沒有協調好互相衝突,所以在 A/D 轉換器和 LART 的 Data Bus 間加上 一組三態緩衝器(Tri-State Buffer),在系 統尚未讀取資料前,AD 電路會被系統視 為一個高組抗元件。 Data Bu s latch D/A Data Bus Data Bus Data Bus GPIO B usBuffer Data Bus
A/D 3.3V 5V Intel StrongARM SA-1100 Data Bus axis voltage PEEL analog multi-plexer 6 ax i s vol tag e Addr Bu s GPIO Addr Bus 1 axis Addr Bus GPIO enable en ab le 圖七:ADDA 電路架構圖 u 嵌入式動態模擬控制系統 嵌入式動態模擬控制系統的發展主 要分成三層的巨觀架構,包括作業系統 控 管 的 核 心 層 (Kernel Space)、應用層 (User Space)和硬體裝置所屬的硬體層, 在數位類比介面卡硬體撰寫完成、網路 軟硬機制設置完備後,接著的工作就是 整合數位類比介面卡驅動程式並在應用 層發展網路連線程式與各種平台控制程 式(包括平台之姿態與腳長轉換的 Inverse Kinematics、發展模糊位置控制器、奇異 點狀況的規避等)。
User Space Kernel Space Hardware Layer Ethernet card Ethernet card AD&DA AD&DA Device Driver Device Driver TCP/IP TCP/IP Application (Network, Control, Inverse… … ) Application (Network, Control, Inverse… … ) RS232 RS232 Serial StandardSerial Standard command 圖八:軟硬體整合系統架構 u 整合成果與比較 圖九展示所完成之嵌入式單板實 體,而圖十則是進一步比較以前所用之 PC、DSP 單板以及目前所發展的 LART 嵌入式單板之優缺點。 圖九:LART 嵌入式硬體單板 ◆體積龐大 ◆價格昂貴 ◆多種作業系統支援 ◆豐富的通訊介面 工業電腦 ◆記憶體容量受限 ◆無法直接在單板上編譯程式 ◆豐富的通訊介面 ◆功能強大的ARMLinux作業 系統 ◆完整的硬體電路圖與自己設 計的ADDA介面卡 LART 嵌入 式控制硬體 ◆與平台只能靠RS232傳輸 ◆程式全用組語發展,移植性 不高 ◆記憶體容量受限 ◆較小的體積 ◆電路全為自行設計有完整電 路圖與DSP原始程式碼 DSP 控制卡 缺點 優點 控制硬體 ◆體積龐大 ◆價格昂貴 ◆多種作業系統支援 ◆豐富的通訊介面 工業電腦 ◆記憶體容量受限 ◆無法直接在單板上編譯程式 ◆豐富的通訊介面 ◆功能強大的ARMLinux作業 系統 ◆完整的硬體電路圖與自己設 計的ADDA介面卡 LART 嵌入 式控制硬體 ◆與平台只能靠RS232傳輸 ◆程式全用組語發展,移植性 不高 ◆記憶體容量受限 ◆較小的體積 ◆電路全為自行設計有完整電 路圖與DSP原始程式碼 DSP 控制卡 缺點 優點 控制硬體 圖十:控制硬體比較 C. VR 跑步場景之 開發 隨著電腦科技的快速進步,虛擬實 境(VR)這個名詞已從當初人們對它的陌 生發展演變而成現今炙手可熱的熱門技 術。市場上也出現愈來愈多發展相關的 軟、硬體,或者是利用此技術製作發展 的商品。而運動器材與虛擬實境的搭配 應用更是一項完美的結合,藉由虛擬實 境的聲光影像使消費者身歷其境,再搭 配軟體對於運動生理學及娛樂效果之輔 助功能,讓室內健身運動不再是枯燥無 味之運動,而是充滿著新奇、樂趣與資 訊的一項新興運動。 這裡此部分由於需要周邊軟、硬體 的適當搭配,故除了基於之前 VR 場景開 發的功力,積極開發出適當的跑步場景 外,更在另一個子計畫目標裡,我們將 拍攝真實外面影像,以融入 VR 畫面中, 而增加真實感。而在與周邊系統的搭配 上,除了在平台上適當搭建跑步機,我 們更結合運動強度的設定、虛擬路況參 觀、運動生理資料等,以增加使用者的 興趣及提高此系統各方面的功能(如圖十 一所示)。 圖十一:VR 跑步場景整合系統示意圖 D. VR 投影技術之探討 這個部分技術的探討主要是為了在
影像投射的呈現上,不會受限於場地、 投影機等。故我們首要目標是希望能夠 依照場地布置方式改變投影機的所在位 置、投射角度;此外更需依照所要投影 至投影曲面的影像去決定投影平面所需 呈現的畫面,故這裡投影曲面上的影像 希望可以是任意形狀,投影曲面也可以 隨意選擇(圖十二為投影概念示意圖)。我 們於圖十三~十五展示在不同曲面上的 放射面成像,圖十六與十七則展示轉動 投影機方向的放射面成像。 放射平面之高 投影機 投影曲面 放射平面 放射點 投影點 放射原點 圖十二:投影概念示意圖 圖十三:平面投影上的放射面成像 圖十四:圓柱投影上的放射面成像 圖十五:內凹球面投影上的放射面成像 圖十六:投影機向右偏轉時之球面投影 圖十七:投影機向下偏轉時之球面投影
子計畫三:動態 VR 運動復健輔助系統 之互動式實景影像設計與研發 一、計畫概述 本子計畫主要任務是應用立體實景 影像成像技術和虛擬實境顯像技術,令 使用者有身歷其境和賞心悅目的感受, 以增加使用者的興趣,而達到提昇訓練 的目的。本子計畫分三個年度進行,第 一年度係配合動態跑步機操控與互動式 實景影像展示系統之研發與設計,第二 年度係配合動態划船操控與互動式實景 影像展示系統之研發與設計,最後一個 年度係配合動態騎馬操控與互動式實景 影像展示系統之研發與設計。 基本上對每一個系統均是針對其個 別特性和需求,進行下列項目之研究:首 先 確 立適 合 主題之場景,並作實景記 錄。其次利用實景影像建立環境模型與 研究實景影像銜接合成技術,並由實景 影像序列建立立體實景影像且應用於虛 擬實境中。同時我們也進行操作者與捲 動播放互動關係之研究,探討操作者前 進方向與速度和六軸平台之運動姿態間 之關係。最後,針對大量的影像資料研 究其有效存取和播放的裝置。 總括來說,我們最終希望提供使用 者一個栩栩如生的視覺環境,且操作者 可與環境即時互動的影像系統。對於使 用 者 而言 , 他可以選擇路徑與速率快 慢,使用者的方向和速率變化由六軸平 台透過適當感應器讀取,然後傳送至本 子系統,本系統就會呈現出使用者所應 看到的 180 度景觀在使用者前方,並且 把地形起伏的資料傳送給六軸平台以修 正六軸平台的位置和提供適當的力回饋 給使用者。 本報告的第一部份是敘述這一個階 段研究計畫的目的,當中將從功能的角 度,再將本子計畫做更精細的劃分。其 次在第二部份將詳細說明研究發展及進 行步驟,當中將介紹本系統之規格與使 用之技術。最後的部份則是對於下年度 的展望。 二、本階段研究計劃之目的及成果 本研究報告為國科會整合性研究計 劃「泛用型虛擬實境操控與運動復健輔 助系統研發」中之子計劃三「動態 VR 運動復健輔助系統之互動式實景影像設 計與研發」的第一年期末成果報告。 在第一年度之內,本計劃巳達成上 列預定的 (1)固定路線,固定速率前進, 全平面地形,和 (2)固定路線,速率可 變,全平面地形二項目標。圖十八所示 是真實影像擷取系統,為降低成本及符 合一般大眾的真正情形所以採用三台市 售的低價位 DV (SONY TRV 18) 架設於 汽車頂,而這三台攝影機之距離和光軸 方向是可以測量得知的,所以事後可以 根据這些數據來進行 warping、mosaic、 或 view morphing 等影像處理的工做,使 得合成的畫面更加逼真。將 DV 架設於 汽車之上除了運動方便之外,亦可利用 汽車之避震系統減少攝影機之震動。 圖十八:影像擷取系統 取景之後,再把三台攝影機所錄得 的影像透過 IEEE 1394 介面以 AVI 格式 儲存於電腦硬碟之中成為基本素材。然 後使用 AVIedit (網路下載之 share ware ) 把 AVI 影 片 轉 為 一 連 串 的 靜 態 影 像 (BMP 檔)。圖十九所示即是左、中、右 三台攝影機在某一時間所攝得的三個畫 面。假設三台攝影機之相關位置在拍攝 之中不會改變,因此只要根據一組左、 中、右的照片來研究左、中和中、右的 相關點即可据此進行所有時間點照片接 合。除了剪裁接合之外,因為使用的 DV 採用自動調整光圈的模式,所以從圖十 九可以看出來,三張影像的亮度有明顯 的差異,所以必需把三張影像的亮度調
成一致,接合之影像才不會有不自然的 亮度變化。圖二十是經過指定相關點, 然後進行裁剪、調整亮度然後接合而成 的廣角影像。可以明顯看出亮度的變化 巳經做了大幅度的修正。 經過裁剪、調整、 接合等動作,把 左、中、右三張影像接合成一張廣角影 像, 重覆這個動作可以得到一連串的廣 角靜態影像,最後利用 AVIedit , 把一 連串的廣角靜態影像編輯成為一個 AVI 檔,再使用播放軟體,由 PC 送出訊號, 透過單槍投影機投射於螢幕上,即可得 到以實景為基礎的虛擬實境影像。關於 速度的調整可以從兩方面著手,一種是 在我們產生廣角靜態影像時,另外一種 方法是在轉換成 AVI 檔時,透過 Frame rate 的改變可以離線控制速率。 本系統規格如下(1)影像擷取:三台 SONY TRV18 數位攝影機。(2)影像格 式:靜態用 BMP 格式,動態儲存成 AVI 格式。(3)影像計算:一部 PC (Pentium 4, 1.8GHz)。(4)影像播放:以單槍投影機投 影至螢幕。 (a) (b) (c) 圖十九:(a)左側攝影機影像、(b)中央攝 影機影像、(c)右側攝影機影像 圖二十:接合並做亮度調整之廣角影像 三、研究發展及進行步驟 本子計劃是採用以真實影像為基礎 的方法,這種方法的優點是影像逼真, 其 主 要缺 點 是如果要記錄的環境結複 雜,則需要耗用相當大的記億体儲存空 間 才 能 夠 完 全 記 錄 下 這 個 背 景 。 M. Hirose[1]等人以 8 部攝影機來拍攝所需 的真實影像序列,我們則決定使用三台 一般用途的 DV 來拍攝,如此可以簡化 器材,降低成本,當然如果要達到相同 的影像品質,我們需要使用更多的影像 處理技術。影像格式目前一般的 DV 大 多使用 AVI [2]格式和 MPEG1 格式,為 了方便快速編碼和解碼,我們選擇用 AVI 格式,來儲存動態影像。 三部攝影機同步取得動態影像之 後,我們必需把這些相關的動態影像加 以剪輯、接合,以及加上必要的影像處 理技巧,最後再分割成三個畫面分別存 在三台 PC 硬碟之中。在攝影的當時也必 需同時記錄下地形的變化,這部份最簡 單的方法是使用足夠精確的「全球衛星 定位系統」或者利用立體影像重建的技 巧,但是後者需要複雜的計算以及較長 的時間。誠如上述所言,本子計畫需要 使用大量的影像處理技巧,以下將對主 要的部份加以介紹。 (一)AVI 格式[2]: AVI 格 式 是 由 美 國 微 軟 公 司 (Microsoft) 所 發 展 的 動 態 影 像 儲 存 格
式,它的原義是”Audio Video Interface”, 也就是說一個 AVI 檔案中影像和語音的 區塊是互相交錯存放的。這種動態儲存 格式是目前 PC 系統中最常見的,它也是 一 種 特 殊 的 RIFF(Resource Interchange File Format)。 (二) 彈性註冊方法(Elastic Registration) [5] [6]: 當兩張影像要接合時,我們必需先 找出分別位於兩張圖上的相關點。一般 的註冊方法只適用於被拍攝物体沒有太 大的失真或變形,其中以小波轉換的方
式可以得到相當好的效果。但是通常在 不同攝影角度所拍得的同一物体,往往 伴有相當程度的幾何變化,這種情況就 不適合使用一般應用於無形變的註冊方 法[6],而必需採用「彈性註冊法(Elastic Registration)」。H. Maitre 和 Y. Wu[5]使 用動態規劃演算法以及自回歸模型發展 出一種彈性註冊的方法可用於處理兩張 幾何結構發生變化的影像註冊問題。 (三) 根本矩陣(Fundamental Matrice)之計 算[3]: 假設對同一物体在不同角度、位置 分別攝得影像I 和0 I ,1 P 是0 I 上的一點0 而P 是1 P 在0 I 上相對應的點,若 F 是1 I0 和I 的根本矩陣,則1 P ,0 P 和 F 滿足下列1 方程式:
0
1 0FP
=
P
T , 此處 0 1 0 0,
1 1(1)
1
1
x
x
P
y
P
y
=
=
−−−−−−
所以根本矩陣隱含了I 和0 I 內景物的幾1 何 結 構資 訊 ,而這正是電腦視覺的關 鍵,所以計算出相對應兩影像之根本矩 陣一直是許多人研究的重要題目。如果 把 F 看成是 3 乘 3 的矩陣,則方程式(1) 可表為:[
0 0]
1121 1222 1323 11 31 32 331
0
1
(2)
f
f
f
x
x y
f
f
f
y
f
f
f
=
−−−−
或 0 1 11 0 1 21 1 31 0 1 12 0 1 22 1 32 0 13 0 23 330
(3)
x x f
y x f
x f
x y f
y y f
y f
x f
y f
f
+
+
+
+
+
+
+
+ = −−−−
在理想的情況下我們可以由測量 9 組P 和1 P 得出一個齊次線性系統,當中0 包含了 9 個類似方程式(3)的方程式,即 (1) (1) (1) (1) (1) (1) (1) (1) (1) 0 1 0 1 1 0 1 0 1 (9) (9) (9) (9) (9) (9) (9) (9) (9) 0 1 0 1 1 0 1 0 1 11 21 31 (1) (1) (1) 1 0 0 12 22 (9) (9) (9) 1 0 0 32 13 23 33 1 1 x x y x x x y y y x x y x x x y y y f f f y x y f f y x y f f f f = − 0 M M M M M M M M − −(4) 方程式(4)要有不為 0 的解,其係數 矩陣之秩數(rank)必需小於 9, 也就是行 列式值為 0。但在實際的測量中由於測量 的誤差,係數矩陣的行列式值不為 0,所 以無法求出有意義的非零解的 F 。在f33 不為 0 的情況下系統(4)可簡化為 (1) (1) (1) (1) (1) (1) (1) (1) (1) 0 1 0 1 1 0 1 0 1 (9) (9) (9) (9) (9) (9) (9) (9) (9) 0 1 0 1 1 0 1 0 1 11 21 31 (1) (1) (1) 1 0 0 12 22 (1) (1) (1) 1 0 0 32 13 23 1 1 1 1 1 1 x x y x x x y y y x x y x x x y y y f f f y x y f f y x y f f f − − − − = − − M M M M M M M (5) 1 1 1 −−− − − − 此時只要 8 組 () 1 ) ( 0 i i P P 和 即可解出 F 。但 是當 f 很小時所求出的根本矩陣就會33 因誤差太大而失去參考價值。 正因為根本矩陣如此重要又不易正 確求出,所以一直到今日都有人不斷地 提出更好的方法來估計根本矩陣。我們 通常把這許多求根本矩陣的方法歸納為 三大類:(1)線性的方法(Linear Methods) (2)疊代的方法( Iterative Methods) 和(3) 強健性的方法( Robust Methods)。實驗結 果顯示出,如果參考點適當地落在影像 當中,而相關性的問題又獲得解決,則 線性的方法可以達到相當好的效果。疊 代法可處理點位置含高斯雜訊的情形, 但這種方法對於不在影像當中的點會有 困難。強健法則可以應付位置的矛盾與 錯誤的配對。一般人的看法是使用特徵 分析( Eigen Analysis)的正交最小平方法 ( Orthogonal Least-Square)會比傳統的最 小平方( Least-Square)法有更好的結果。 但當把矩陣限制在 rank 為 2 且移除不在 兩 影 像 中 的 點 時 最 小 中 間 值 平 方 法 ( Least Median Square)是所有方法中估計 結果最正確的。 (四) View Morphing: 以影像為基礎的(Image-Based)虛擬 實境系統,如果要儲存的影像太多則會 有記憶体不足的問題產生。解決此問題 的方法之一是僅拍攝部份必需的場景, 其 餘 不同 角 度、位置所見的場景再以 View Morphing[4]的方式由現有的影像 產 生 ,如 此 可以省下大量的記憶體空 間,但需要付出的成本是計算時間,以 及 可 能 降 低 解 析 度 的 問 題 。 View Morphing 是由 Steven Seitz 和 Charles R. Dyer 所提出的影像處理技術。以圖二十 一為例,左邊的影像是照像機從左側拍 攝所得,右邊的影像是照像機從右側拍 攝得到的,我們可以利用這左、右兩張 照片加上 View Morphing 的技術,產生由 正中央拍攝時所應有的照片。 (a) Prewar p: 利 用 投 影 變 換 (Projective transformation) 把 既 有 的 兩 張 影 像 ) (I 、0 I1 轉換成兩張光軸平行的影像 ) ( 0 1 ∧ ∧ I I 、 。 (b) Mor ph: 其次使用線性內差法產生所要的 中間影像I 。∧s (c) Postwar p: 最後再用投影變換把中間影像I∧s 轉變為所要的I 。s 圖二十一:View morphing 圖二十二:Warping (五) Layered Depth Images:
如何利用 2D 的圖片建構出具有 3D 效 果 的圖 片 ,也是本子計劃的重點之 一,在諸多方法中,比較有效率的方法 稱為 Layered Depth Images (LDI)[7]。
每一張影像中的每個 pixel 除了其原有資 訊外再添加了深度資料,再由好幾張單 層的 depth image 來投射到我們想要的視 角所看到的平面上. 在 LDI 方法中。假如有兩個以上的 pixel 投射到同一個位置,我們便必須比 較它們的深度值,若深度的差異超過一 個上限,我們便增加一層新的 layer 來儲 存 ; 否則 便 以取平均的方式來儲存深 度。有了這些 layer 的資訊後便可將 2D 的圖片以較具立體化的感覺呈現給使用 者。 四、結論與未來展望 真實、即時、互動是本子計劃所要 追求的三大目標,首先依照本報告所規 劃的進度,配合動態跑步機拍攝完成(1) 固定路線、固定速率前進全平面地形之 場景和(2)固定路線、速率可變全平面地 形的場景。以目前的處理方式 (即播放 AVI 影片),因為影片是拍攝實際場景, 所以自然地有”真實”的感覺而且也可以 在 離 線的 情 況去模擬跑步者速率的改 變,算是可以做到離線狀況的互動,但 無法做到即時的互動。為了達到即時的 目的,必需變更架構,這將會是未來兩 年最大的挑戰。 關於場景製作有許多仍有改善的空 間。首先是顏色的調整,因為不同三台 攝影機的取景除了亮度會不同,其顏色 亦會有差異,故需加以調整。第二,由 於攝影機之光軸不平行,所攝影的物体 會有形變,另外同樣的物體成像大小亦 不同,所以會出現兩張照片(左、中或中、 右)無法完全接合的情況,這個問題可以 利用 Warping 或 View Morphing 的問題 加以解決。第三,可以加入背景音樂以 增加臨場感,這在 AVI 的格式中可以很 容易做到。第四,配合 Projection Matrix 的應用可以改變視線 (View Point) 營造 出上坡,下坡所看到的景物清況。 總結第一年度的做法,它的優點是 可以用很經濟的方法來製作栩栩如生的 場景,並且達到某種程度的互動,其主 要缺點是”即時性”的問題,這也是未來兩 年計畫的核心。 第二年我們將更進一步做到路線, 速率地形其中兩者可變的情況,而在最 後一年去除所有限制,達到路線、速率、 地形皆可即時互動的要求。此時由於要 傳送、計算的資料量均非常龐大,單純 以軟体的方法來進行將會很吃力,所以 需要藉助硬體系統的改進,軟、硬體相 輔相成來完成本計劃的最終目標。 五、參考文獻
[1] Yuichi Ohta and Hideyuki Tamura, Mixed Reality- Merging Real and Virtual Words, Springer-Verlag, pp. 183-197, 1999.
[2] John F. McGowan, AVI Overview,
http://www.jmcgowan.com/.
[3] J. Salvi, X. Armangue and J. Page, “A Survey addressing the Fundamental Matrix Problem,” Image Processing, 2001. Proceedings. 2001 IEEE International Conference, Vol. 2 , pp.209-212, 2001.
[4] Steven M. Seitz and Charles R. Dyer, “View Morphing,”
http://www.cs.wisc.edu/~dyer/vision.html/.
[5] Henri Maitre and Yifeng Wu, “A Dynamic Programming Algorithm for Elastic Registration of Distorted Pictures Based on Autoregressive Model,” IEEE trans on Acoustic, Speech, and Signal Processing, Vol. 37, No. 2, pp. 288-297, February 1989.
[6] Raymond J. Althof, Macro G. J. Wind, and James T. Dobbins, III, “A Rapid and Automatic Image Registration Algorithm with Subpixel Accuracy,” IEEE trans on Medical Imaging, Vol. 16, No. 3, pp.308-316, June 1997.
[7] Jonathan Shade, Steven Gortler, Li-wei He, Richard Szeliski, “Layered Depth Images, ” SIGGRAPH98 ,Computer Graphics proceedings, Annual Conference Series, pp231-242, July 19-24,1998.
子計畫四:動態 VR 運動復健輔助系統 之人機溝通介面及使用者情 緒瞭解 一、計畫概述 動態模擬系統之動態感覺,決定了 虛擬實境之逼真程度,但如何表示動態 模擬系統使用者之感覺概念,並傳遞給 行為轉換與控制模組(子計畫一)及六軸 運動平台、力回饋模組(子計畫二、三) 做適當的參數調整與控制,是本計畫之 重點。為了表示使用者的感覺概念,道, 以將操控者的使用感受忠實的告知子計 畫一與二進行模擬器的控制變數轉換及 後續階層式控制法則之設計,並藉此以 改善整個控制迴路及調整參數的方法, 而提高了模擬器的真實性,本計畫可視 為整個模擬器系統的高階回授單元。本 計畫之兩個主要子題: 計畫將發展出一 套即時之人情緒狀態判定系統及能與機 器系統做抽象式觀念感覺溝通與對映之 方法,下面是我們在這一年計畫中,對 以上兩方面所提出來實現方法的描述。 二、目前研究進度: (1) 人類表情與情緒的辨識 人類表情與情緒的辨識此子系統第 一部份為臉部特徵的選取。臉部特徵的 選取對於辨識人臉和臉部表情是很重要 的。人類臉部有些明顯的特徵如眼睛、 嘴巴、眉毛、臉部輪廓等等。在本計畫 中,我們擷取眉毛、眼睛及嘴巴作為主 要的特徵。我們以前的研究顯示,我們 首 先 使 用 粗 略 輪 廓 預 測 程 序 法 (rough contour estimation routine)以及我們所提 出 的 點 輪 廓 偵 測 法 (point contour detection method)這 兩 種 影 像 處 理 的 技 術,來擷取眉毛、 眼睛和嘴巴這三個特 徵器官的正確輪廓。由於使用粗略輪廓 預測程序法所得到的眉毛輪廓已經相當 精準,足夠做為辨識之用,故不用再加 強其輪廓。而使用粗略輪廓預測程序法 所得到的眼睛和嘴巴的輪廓不夠精準, 所以我們再使用點輪廓偵測法現正進行 臉部表情運動單元的分析 。圖二十三顯 示 30 個臉部特徵點;臉部特徵點可以用 來代表臉部的特徵。因此當我們得到了 這些特徵器官的精準輪廓之後,我們定 義臉部特徵點來描述這三個臉部特徵的 位置和形狀。接下來可由臉部特徵點組 成運動單元。由於運動單元可以用來描 述人類臉部基本的肌肉運動,所以臉部 快樂、生氣、與中性情緒狀態表情可以 藉 由 一放 射 狀函數基礎之神經網路辨 識,它的效果經過驗證可達 92﹪辨識 率,如圖二十四所示。 x y a19 a20 a22 a21 a17 a18 a1 a2 a15 a7 a13 a3 a5a11 a12 a6 a10 a4 a14 a8 a16 a23
a27 a25 a28 a24 a30 a26 a29 base/5 base/2 eyel/2 eyel base/4 base/4 a9 base/6 base (origin_x,origin_y) xb yb (0,0) 圖二十三:臉部特徵定義圖 圖二十四:藉由放射狀函數基礎神經網
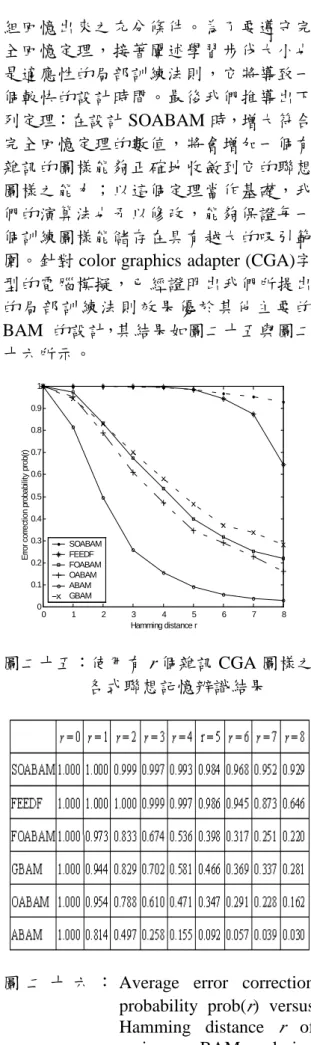
路辨識表情情緒狀態 (2) 人機系統溝通與與對映法 人機系統溝通與與對映之法 Takagi 等 人 係 利 用 關 聯 網 路 (Associate Memory; 簡 稱 AM ) 設 計 之 赫 比 式 (Hebbian)學習方法來建構之對映傳遞之 關係,但 AM 之兩對映是由(0,1)之串列 對映至 (0,1)之串列,與上述之感覺對 應,為 0~1 間的任意實數對映,我們初 步的研究其對映精確度很差。本計畫主 要是擴展並衍生觀念模糊集的概念,以 某一層的觀念節點的節點活性度值組表 示一個感覺概念,以機電整合受控體之 物理量為輸入層,感覺概念的溝通與學 習可由函數大約化之對映方法來執行感 覺概念之交流,以使電腦有感覺概念意 識與溝通的能力,而對於觀念節點溝通 所需之函數大約化,我們擬設計出一套 對映網路的裝置來進行,亦即在受控機 器中建立並學習某一感覺概念交流所須 之對映網路。第一年我們以 Kosko 之模 糊關聯網路 Fuzzy Associate Memory 設 計,所設計關聯網路(Associate Memory) 可 以 雙 向 聯 想 記 憶 (Bidirectional Associative Memory),簡稱 BAM,實現。 近來雙向聯想記憶已經在聯想記憶研究 當中扮演一個很重要的角色。非對稱式 雙向聯想記憶(Asymmetric Bidirectional Associative Memory)為雙向聯想記憶放 寬鍵結權重必須要對稱的限制之結果, 且相較於常見的雙向聯想記憶結構有較 好的記憶與回想效能。高階非對稱式雙 向 聯 想 記 憶 (High-Order Asymmetric Bidirectional Associative Memory)的記憶 容量比一階的好很多,然而新的高階聯 想記憶設計法卻很少被提出來。在本篇 論文裡,我們所關心的是設計具有最大 吸引範圍的二階非對稱式雙向聯想記憶 (Second-Order Asymmetric Bidirec tional Associative Memory)。將它延伸到 高階非對稱式雙向聯想記憶(High-Order Asymmetric Bidirectional Associative Memory)是有可能而且很簡單的。我們首 先推導出對於二階非對稱式聯想記憶的 鍵結權重矩陣能夠保證將所有標準圖樣 組回憶出來之充分條件。為了要遵守完 全回憶定理,接著闡述學習步伐大小也 是適應性的局部訓練法則,它將導致一 個較快的設計時間。最後我們推導出下 列定理:在設計 SOABAM 時,增大符合 完全回憶定理的數值,將會增加一個有 雜訊的圖樣能夠正確地收斂到它的聯想 圖樣之能力;以這個定理當作基礎,我 們的演算法也予以修改,能夠保證每一 個訓練圖樣能儲存在具有越大的吸引範 圍。針對 color graphics adapter (CGA)字 型的電腦模擬,已經證明出我們所提出 的局部訓練法則效果優於其他主要的 BAM 的設計,其結果如圖二十五與圖二 十六所示。 0 1 2 3 4 5 6 7 8 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Hamming distance r E rr o r co rr e ct io n pr o b a bi lit y p ro b (r ) SOABAM FEEDF FOABAM OABAM ABAM GBAM 圖二十五:使用有 r 個雜訊 CGA 圖樣之 各式聯想記憶辨識結果
圖 二 十 六 : Average error correction probability prob(r) versus
Hamming distance r of
schemes. 三、結論與討論: 一理想的虛擬實境系統,應能隨時 掌握操控者的情況與感受,並能讓操控 者與系統模擬器做直覺性的溝通,而讓 使用者有完全沈浸其中的感受,因此研 究發展任何虛擬實境技術時,使用者與 機器系統之間的互動與溝通為相當重要 的一環。本子計畫藉電子攝影機隨時紀 錄操控者臉部,藉影像處理技偵測出操 控者之情緒狀態,並建立操控者與模擬 器間的人性化溝通管道,以將操控者的 使用感受忠實的告知子計畫一與二進行 模擬器的控制變數轉換及後續階層式控 制法則之設計,並藉此以改善整個控制 迴路及調整參數的方法,而提高了模擬 器的真實性,本計畫可視為整個模擬器 系統的高階回授單元。本子計畫已發展 出一套即時之人情緒狀態判定系統藉線 上拍攝操控者臉部影像序列,由影像處 理技術偵測出操控者之臉部變化,進而 推敲操控者快樂、生氣、與中性情緒狀 態,它的效果經過驗證可達 92﹪辨識 率。在人機系統溝通與與對映方面,我 們 以 模 糊 關 聯 網 路 Fuzzy Associate Memory 設計,實現感覺概念交流所須之 對映網路,模擬證明我們所提出的局部 訓練法則效果優於其他主要的 BAM 的 設計。 四、參考文獻
[1] T. Takagi, A. Imura, H. Ushida, and T. Yamaguchi, “Conceptual fuzzy sets as a meaning representation and their inductive construction,”International Journal of Intelligent Systems, vol. 10,
pp. 929-945, 1995.
[2] F. L. Chung and T. Lee, “A new look at solving a system of fuzzy relational equations,”Fuzzy Sets and Systems,
vol. 88, pp.343-353, 1997.
[3] Cootes, T. F., C. J. Taylor, D. H. Cooper, and J. Graham, “Active shape models their training and application,”
Computer Vision and Image
Understanding,, Vol. 61, No. 1, pp. 38-59. 1995.
[4] P. Ekman, and W. V. Friesen, The Facial Action Coding System, Consulting Psychologist Press, San Francisco, CA, 1978.
[5] Huang, C. L., and C. W. Chen, ``Human facial feature extraction for face interpretation and recognition,” Pattern Recogni- tion, Vol. 25, No. 12, pp. 1435- 1444, 1992.
[6] Kobayashi, H., and F. Hara, “Analysis of the neural network recognition characteristics of six basic facial expressions,” in Proceedings of 3rd IEEE Int. Workshop on Robot and Human Communication, Nagoya, Japan, pp. 222-227, 1994.
[7] Lanitis, A., C. J. Taylor, and T. F. Cootes, ``Automatic interpretation and coding of face images using flexible models," IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 19, No. 7, pp. 743-756, 1997.
[8] Turk, M. A., and A. P. Pentland, “Eigenfaces for recognition," Journal of Cognitive Neuro-science, Vol. 3, No. 1, pp. 71-86, 1991.
[9] Yuille, A. L., P. W. Hallinan, and D. S. Cohen, “Feature extraction from faces using deformable templates,” International Journal of Computer Vision, Vol. 8, No. 2, pp. 99-111, 1992. [10] W. Pedrycz, “ Processing in
relational structures: Fuzzy relational equations,” Fuzzy Sets and Systems,
vol. 40, pp. 77-106, 1991.
[11] Y. F. Wang, J. B, Cruz, Jr., and J. H. Mulligan, Jr., “ On multiple training pairs for bidirectional associative memory ”IEEE Trans. on Neural Networks, vol. 1, pp. 275-276, Sept.
1991.
[12] T. Wang, X. Zhuang, and X. Xing, “Designing bi-directional associative memories with optimal stability, ”
vol. 24, pp. 778-790, May. 1994.
[13] H. Oh and S. C. Kothari, “Adaptation of the relaxation method for learning in bidirectional associative memory, ”IEEE Trans. on Neural Networks, vol. 5, pp. 576-583, July.
1994.
[14] Y. Wu and D. A. Pados, “ A feedforward bidirectional associative memory, ”IEEE Trans. on Neural Networks, vol. 11, pp. 859-866, July.
2000.
[15] C.-S. Leung, L.-W. Chan, and E. Lai, “Stability and statistical properties of second-order bidirectional associative memory, ”IEEE Trans. on Neural Networks, vol. 8, pp. 267-277, Mar.
1997.
[16] H. Shi, Y. Zhao, and X. Zhuang,“A general model for bidirectional associative memories,” IEEE Trans. on Syst. Man, Cybern. B, vol. 28, pp.
511-519, Aug. 1998.
[17] J. Park, C.-H. Kwon, and D. Park, “ An optimization-based design procedure for asymmetric bidirectional associative memories, ”IEEE Trans. on Neural Networks, vol. 12, pp.
169-170, Jan. 2001.
[18] F. L. Chung and T. Lee,“On Fuzzy
Associative Memory with
Multiple-Rule Storage Capa-city, ”
IEEE Trans. Fuzzy Syst., vol. 4, no. 3,
pp. 375-384, 1996.
[19] H.-C. Chang, H.-C. Chen, and J.-H. Fang, “ Lithology Determination from Well Logs with Fuzzy
Associative Memory Neural
Network, ” IEEE Trans. Geosci. Remote Sensing, vol. 35, no. 3, pp
773-780, 1997. 子計畫五:動態 VR 運動復健輔助系統 之人機溝通介面及使用者情 緒瞭解 一、中文摘要 本計畫提出一智慧型教導系統,以 指導使用者操作技巧。方法為學習由專 家或資深的訓練輔助員所提供有效率且 正確的操作運動技巧。學習方法主要以 類神經模糊網路來完成。目前我們已發 展出一具監督式學習能力之新型遞迴式 類神經模糊網路之架構設計及學習演算 法推導。此網路的特點為具有線上之架 構與參數學習之能力,並具高度學習能 力。經由測試及與其他遞迴式網路之比 較已驗證其優點。 關鍵詞:類神經網路、模糊網路、監督 式學習、線上學習 Abstr act
The project proposes an intelligent teaching system to guide user’s operation skill. The system is built by learning an efficient and proper exercising skill provided by experts or experienced operator. Learning is performed mainly by a neural fuzzy network. We have developed structure of a new type of recurrent neural fuzzy network and its learning algorithm. The network is characterized with on-line structure and parameter learning and owns high learning ability. After testing and comparisons with other recurrent network, we have verified the advantages of the proposed network.
Keywor ds: Neural network, Fuzzy network,
Supervised learning, On-line learning 二、Motivation And Objective
The project aims at setting up an intelligent teaching system to guide and evaluate user’s operation skill. The role of the system can be regarded as an instructor. The development of the system relies on proper operation and exercising skill provided by experts. To learn expert’s knowledge and skill, a learning network and mechanism should be developed. Since the
operation of a person usually depends on previous states, a recurrent network is more suitable than a feedforward network for the learning task. For nonlinear system learning, the most commonly used model is the neural or neural fuzzy network. The performance of a neural fuzzy network has shown to be superior than a neural network. For this reason, in this project, a recurrent fuzzy network is proposed.
Some recurrent neural fuzzy networks have been proposed in the literature. In [1], a dynamic fuzzy logic system is proposed with multiple external output. In [2], a recurrent neuro-fuzzy model is proposed. In [3], a dynamic fuzzy neural network (DFNN) is proposed. In DFNN, the premise and defuzzification parts are static while the consequent parts of the fuzzy rules are recurrent neural networks with internal feedback and time delay synapses. For these recurrent neural fuzzy networks, one common characteristic is that the recurrence is achieved by including external feedback. To apply these networks to dynamic system processing problems, we still need to know the order of both the system. To conquer this problem, a TSK-type Recurrent Fuzzy Network (TRFN) [4] is proposed. In contrast to the aforementioned networks, in TRFN, the recurrent property is achieved by including internal feedback. The internal variables, derived from fuzzy firing strengths, are fed back to both network input and output layers in TRFN, and no a priori knowledge of the plant order is required. In TRFN, there are no rules initially, they are constructed by on-line structure and parameter learning. TRFN has the following advantages over a neural network: faster learning speed, higher learning accuracy, and each node and weight has its corresponding meaning. 三、Str uctur e and Lear ning of TRFN A. Structure of TRFN
In this section, structure of the TRFN (as shown in Fig. 27) is introduced. A network with two external inputs and a single output is considered here for convenience. This six-layered network realizes a recurrent fuzzy network of the following form:
Rule 1: IF x1(t) is A11 and x2(t) is A12 and h1(t) is G
THEN y(t+1) is a10+a11x1(t)+a12x2(t)+a13h1(t)
and h1(t+1) is w11 and h (t+1) is 2 w21
Rule 2 : IF x1(t) is A21 and x2(t) is A22 and h2(t) is G
THEN y(t+1) is a20+a21x1(t)+a22x2(t)+a23h2(t)
and h1(t+1) is w12and h (t+1) is 2 w22
where A and G are fuzzy sets, wand a are the consequent parameters for inference output h and
y, respectively. The consequent part for the external output y is of TSK-type and is a linear combination of the external input variables xand internal variables h, plus a constant.
To give a clear understanding of the mathematical function of each node, we will describe functions of TRNFN layer by layer. For notation convenience, the net input to the ith node in layer kis denoted by ui(k)and the output value by Oi(k).
Layer 1: No function is performed in this layer. The node only transmits input values to layer 2.
Layer 2: Two types of membership functions are used in this layer. For external input xj, the following Gaussian membership function is used,
(2) 2 (2) (2) (1) 2 ( ) exp j ij (1) i j j ij u m O and u O σ − = − =
where mijand σij are, respectively, the center and the width of the Gaussian membership function of the ith term of the jth input variable xj. For internal variable hi, the following sigmoid membership function is used,
(2) (2) (5) (2) 1 (2) 1 exp{ } i i i i O and u O u = = + −
Links in layer 2 are all set to unity.
Layer 3: The output of each node in this layer is determined by fuzzy AND operation. Here, the product operation is utilized to determine the firing strength of each rule. The function of each rule is 1 (3) (2) (5) 1 1 1 exp{ } n i j j i O O O + = = = + −
∏
* 1 2 (2) 1 ( ) exp ( ) (3) n j ij j ij O m σ = − − ∑
where n is the number of external inputs. The link weights are all set to unity.
Layer 4: Nodes in this layer perform a linear summation. The mathematical function of each node i is
∑
∑
= + + = + + = = n j i in j ij io n j j ij i a u a a x a h O 1 1 1 0 ) 4 ( ) 4 ( (4) where nis the number of external input variables, and aij, j=0,L,n+1, are the parameters to be tuned. Links from this layer to layer 6 are all equal to unity.Layer 5: The context node functions as a defuzzifier for the fuzzy rules with inference output
h. The link weights represent the singleton values in the consequent part of the internal rules. The simple weighted sum is calculated in each node,
∑
= = = r j ij j i i O O w h 1 ) 3 ( ) 5 ( (5) As in Fig. 27, the delayed value of hiis fed back to layer 1 and acts as an input variable to the precondition part of a rule. Each rule has a corresponding internal variable h and is used to decide the influence degree of temporal history to the current rule.Layer 6: The node in this layer computes the output signal y of the TRNFN. The output node together with links connected to it act as a defuzzifier. The mathematical function is
(3) ( 4) 1 (6) (3) 1 (6) r j j j r j j O O y O O = = = =
∑
∑
B. Learning of TRFNThe task of constructing the TRFN is divided into two subtasks: structure learning and parameter learning. The objective of the structure learning is to decide the number of fuzzy rules, initial location of membership functions, and initial consequent parameters. On the contrary, the objective of parameter learning is to tune the free parameters of the constructed network to an optimal extent.
Since there are no rules initially in TRFN, the first task in structure learning is to decide when to generate a new rule. Clustering on the external input
x, which represents the spatial information, is used as the criterion. Based on this concept, the spatial firing strength ( 2) 1 ( ) n i k k F x O = =
∏
2 2 1 exp ( ) [0,1] (7) n j ij ij j x m σ = = − − ∈ ∑
is used as the criterion to decide if a new fuzzy rule should be generated. For each incoming data x(t), find ) ( max arg ) ( 1 F x I i t r i≤ ≤ = (8) where r(t) is the number of existing rules at time
t. If FI <Fin(t), then a new rule is generated, where Fin(t)∈(0,1)is a pre-specified threshold that decays during the learning process. Once a new rule is generated, the next step is to assign initial centers and widths of the corresponding membership functions. Here, they are decided by
∑
= + + − ⋅ = = n j Ij Ij j i t r i i t r m x t x m 1 2 2 ) 1 ) ( ( ) 1 ) ( ( ) ( ) ( σ β σ (9)for i=1Ln , according to the
first-nearest-neighbor heuristic, where
0
≥
β decides the overlap degree between two clusters. The number of fuzzy sets in each external input dimension is equal to the number of fuzzy rules. Once a new rule is newly generated during the presentation of (x(t),y(t)) data, generation of the corresponding consequent node in layer 4 and context node in layer 5 follows. The initial constant value aioconnected to layer 4 is set to y(t), and the other aijparameters are assigned as small random signals in [-0.05, 0.05] initially. For the newly generated context node, its fan-in comes from all the existing rule nodes in layer 3. The initial link weights ware set as random values in [-1,1] to make the initial values of internal variables hlocate in the sensitive region of membership function G. This way, a quick parameter learning can be reached at the beginning. The output, h, of the new context node is fed back as input in the precondition part of the newly generated rule. With this setting, each rule has its own memory elements for memorizing the temporal firing strength history. Via repeating the above process for every incoming training data, a new recurrent rule is generated, one after another, and a whole TRFN is constructed finally.
As to the parameter learning, the real time recurrent learning is used. Detailed learning algorithm may refer to [4].
四、Results And Discussion
Suppose the control action sequence u provided by the expert is described by the following equation: ) 3 ( 2 . 0 ) 2 ( 01 . 0 ) 1 ( ) 1 ( 025 . 0 ) ( 72 . 0 ) 1 ( 2 − + − + − − + = + k x k x k x k u k u k u
where x denotes the state of the operated plant. To learn the mapping by TRFN, only the current state x and action u are fed as the network input. After 9000 time steps of training, there rules are generated and there are 33 network parameters in total. A test sequence is generated and the test result is shown in Fig. 28, and the root mean square (RMS) error is 0.0313. To show the effectiveness and efficiency of the recurrent part in TRFN, the performance of Elman’s recurrent neural network (ERNN) [5] is compared. There are five hidden nodes in ERNN and the number of network parameters is 54. The test RMS error for the test sequence is 0.078. That is, the performance of TRFN is better than that of ERNN.
五、Conclusion
An intelligent teaching system based on the proposed TSK-type recurrent fuzzy network