建立一個各基因資料庫間的基因名稱導航與微陣列平台之註解系統:DIPLEX
96
0
0
全文
(2) 臺北醫學大學醫學資訊研究所 碩士論文. 建立一個各基因資料庫間的基因名稱導航與微陣列 平台之註解系統:DIPLEX Establishment of a web-based system for gene identifier navigation among databases and Microarray platform annotation:DIPLEX (Database Interrogation Platform for Gene Expression). 指導教授:李元綺、邱泓文. 研究生:陳彥臣 撰. 中華民國九十四年六月 June,2005. i.
(3) 誌. 謝. 感謝這兩年來承蒙李元綺老師和邱泓文老師的指導,讓我在生物資訊方面 學到非常多的東西,忍受我突發奇想的奇怪問題,並且給予我許多寶貴意 見,讓我受益良多。另外要感謝蔣以仁老師,蔣老師總會在百忙之中撥空 給予我在程式語言以及演算法上的指導,以及感謝楊騰芳老師在論文內容 的審閱與意見,使我能完成我的論文。此外還要感謝秘書姝茵(Joan)、千瑩 (Bebble)、佩珊(Sandy)、意露(Yihluh)的支持,在我鬱悶的時後一起唱歌, 與我分享好吃的點心,還要聽我抱怨。感謝同學宇瑄(Lillian)、雯雯(Kiss)、 宜芬(Yifen)、小泰(Ted)、小胡(thinkerh)、企鵝(amebajoe)、酷八(cool8)、學 姊雨婷(ntcnrain),平常大家一起吃飯聊天互相打氣,一起玩電玩,一起出 遊,幫我減少很多壓力,感謝大家。最後要感謝我的老媽,老媽在後面的 默默支持才能讓我無後顧之憂的專心唸書。. 於臺北醫學大學醫學資訊研究所 2005/07/4. ii.
(4) 目錄 __________________________________________________________________________. 頁數 標題 ....................................................................................................................... i 誌謝 ...................................................................................................................... ii 目錄 .....................................................................................................................iii 表目錄 ................................................................................................................ vii 圖目錄 ...............................................................................................................viii 中文摘要 ............................................................................................................. xi 英文摘要 ...........................................................................................................xiii 第一章 緒論 .................................................................................................... - 1 1.1. 前言 .............................................. - 1 -. 1.2. 研究動機 .......................................... - 3 -. 1.3. 研究目的 .......................................... - 8 -. 第二章 文獻探討及相關研究...................................................................... - 10 2.1. 基因資料庫探討 ................................... - 10 2.1.1 GenBank .................................................................................. - 10 2.1.2 UniGene................................................................................... - 12 2.1.3 LocusLink................................................................................ - 13 2.1.4 Reference sequence (RefSeq).................................................. - 13 2.1.5 OMIM...................................................................................... - 13 2.1.6 Entrez Gene ............................................................................. - 14 -. iii.
(5) 2.1.7 Gene Ontology......................................................................... - 14 2.1.8 HGNC...................................................................................... - 15 2.1.9 UniProt .................................................................................... - 16 2.1.10 SAGEmap.............................................................................. - 16 2.1.11 KEGG pathway database....................................................... - 16 2.1.12 Biocarta pathway database .................................................... - 16 2.2. 微陣列生物晶片 (Microarray) ...................... - 19 2.2.1 cDNA Microarray.................................................................... - 19 2.2.2 寡核苷酸微陣列 (oligonucleotide Microarray) .................... - 21 2.2.3 cDNA Microarray 和 oligonucleotide Microarray 之比較... - 23 -. 2.3. MatchMiner ....................................... - 25 -. 第三章. 材料、方法與架構....................................................................... - 27 -. 3.1. 資料收集、分析與處理 ............................. - 27 -. 3.2. DIPLEX 採用的技術 ................................ - 33 3.2.1 伺服器(Server)技術............................................................... - 34 3.2.2 資料庫系統(Database System).............................................. - 35 -. 3.3. DIPLEX 的架構、流程與方法 ........................ - 37 -. 3.4. 網站架構與演算法 ................................. - 39 3.4.1 3.4.2. 3.5. Gene ID Translate BOX ..................................................... - 42 Pathway Finder ................................................................... - 44 -. JSP 相關元件 ..................................... - 45 3.5.1 JfreeChart 產生統計圖的程式庫 .......................................... - 45 3.5.2 Jakarta-POI 處理 MS-Excel 的程式庫.................................. - 45 -. iv.
(6) 3.5.3 Jakarta-ORO 處理正規表示式的程式庫.............................. - 46 3.5.4 O’Reilly MultipartRequest 檔案上傳元件............................ - 47 第四章 系統實作.......................................................................................... - 48 4.1. DIPLEX 前期實作 .................................. - 48 4.1.1 4.1.2 4.1.3 4.1.4 4.1.5 4.1.6. 4.2. Single Gene Identifier Lookup ........................................... - 50 Multi Gene Identifier Lookup............................................. - 51 Batch Gene Identifier Lookup ............................................ - 52 Single Array Annotation ..................................................... - 53 Multi Array Annotation ...................................................... - 54 Pathway Search................................................................... - 55 -. 後期實作成果 ..................................... - 56 4.2.1 4.2.2 4.2.3 4.2.4 4.2.5 4.2.6 4.2.7. Gene Look Up..................................................................... - 57 Gene ID Translator ............................................................. - 59 Multiple Gene Annotation .................................................. - 60 UniGene Tracer................................................................... - 61 Gene Expression ................................................................. - 62 Pathway Finder ................................................................... - 64 GeneMatch.......................................................................... - 65 -. 第五章 討論與結論...................................................................................... - 66 5.1. 結果討論 ......................................... - 66 5.1.1 5.1.2. 5.2. Multiple Gene Annotation .................................................. - 66 GeneMatch.......................................................................... - 68 -. 結論 ............................................. - 69 -. 參考文獻 ........................................................................................................ - 70 中文參考文獻 .......................................... - 70 英文參考文獻 .......................................... - 70 -. v.
(7) 電子資料 .............................................. - 72 附錄 ................................................................................................................ - 73 附錄 1 - Database Schema ...................................................................... - 73 -. vi.
(8) 表目錄 __________________________________________________________________________. 頁數 表 1.2-1 Compare gene idietifiers in different database .................................. - 6 表 2.2.3-1 Microarray 比較表一 ................................................................... - 23 表 2.2.3-2 Microarray 比較表二 ................................................................... - 24 表 3.1-2 UG2LL 統計結果............................................................................ - 27 表 3.1-3 UniGene 和 LocusLink 交叉多重對應基因列表 .......................... - 28 表 3.2.1-1 伺服器端技術比較表 .................................................................. - 34 -. vii.
(9) 圖目錄 __________________________________________________________________________. 頁數 <圖 1.1-1 主要癌症死亡原因> ...................................................................... - 2 <圖 1-2-1 Gene Identifier Relationship> ......................................................... - 8 <圖 2.1-1 GenBank 格式範例>.....................................................................- 11 <圖 2.1.2-1 UniGene 資料格式> .................................................................. - 12 <圖 2.1.6 EntrezGene results for gene TP53> ............................................... - 14 <圖 2.1.7 Gene Ontology 分類樹狀圖>....................................................... - 15 <圖 2.1.8 KEGG cell cycle pathway map> ................................................... - 17 <圖 2.1.9 Biocarta cell cycle pathway map> ................................................. - 18 <圖 2.2.1-1 cDNA Microarray 實驗流程圖>................................................ - 20 <圖 2.2.2-1 Probe>......................................................................................... - 21 <圖 2.2.2-2 PM-MM>.................................................................................... - 22 <圖 2.2.2-3 Affymetrix probe design>........................................................... - 22 <圖 2.3-1 MatchMiner 資料表關連圖>........................................................ - 25 <圖 2.3-2 MatchMiner 可靠鍊序列(ChainOfResponsibility hierarchy)>.... - 26 <圖 3.1-1 資料處理流程圖 > ...................................................................... - 31 <圖 3.1-2 DIPLEX 資料關聯圖>................................................................. - 32 -. viii.
(10) <圖 3.2-1 以 web-based 為平台的資訊系統架構>..................................... - 33 <圖 3.2.2-1 基因對應資料之正規化>.......................................................... - 35 <圖 3.2.2-2 資料關聯圖> .............................................................................. - 36 <圖 3.3-1 DIPLEX 系統架構圖>.................................................................. - 38 <圖 3.4.1-2 Gene ID Translate BOX Algorithm Flow Chart> ...................... - 43 <圖 3.4.2 Pathway Finder Algorithm Flow Chart > ...................................... - 44 <圖 4.1-1 DIPLEX 首頁畫面>...................................................................... - 49 <圖 4.1-2 Single Gene Identifier Lookup search page> ................................ - 50 <圖 4.1-3 Single Gene Identifier Lookup result page > ................................ - 50 <圖 4.1-4 Multiple Gene Identifier Lookup search page > ........................... - 51 <圖 4.1-5 Multiple Gene Identifier Lookup result page >............................. - 51 <圖 4.1-6 Batch Gene Identifier Lookup search page >................................ - 52 <圖 4.1-7 Batch Gene Identifier Lookup result page > ................................. - 52 <圖 4.1-8 Single Array Annotation select page> ........................................... - 53 <圖 4.1-9 Single Array Annotation result page > .......................................... - 53 <圖 4.1-10 Multiple Array Annotation select page > .................................... - 54 <圖 4.1-11 Pathway Search page>................................................................. - 55 <圖 4.1-12 Pathway Search result page>....................................................... - 55 -. ix.
(11) <圖 4.2-1 DIPLEX 首頁畫面>...................................................................... - 56 <圖 4.2-2 Gene Look Up Page> .................................................................... - 57 <圖 4.2-3 Gene Look Up Result Page> ......................................................... - 58 <圖 4.2-4 Gene ID Translator Page> ............................................................. - 59 <圖 4.2-5 Gene ID Translator Result Page> .................................................. - 59 <圖 4.2-6 Multiple Gene Annotation Page> .................................................. - 60 <圖 4.2-7 Multiple Gene Annotation Result Page>....................................... - 60 <圖 4.2-8 UniGene Tracer Page> .................................................................. - 61 <圖 4.2-9 UniGene Tracer Result Page> ....................................................... - 61 <圖 4.3-10 Gene Expression Page> ............................................................... - 62 <圖 4.3-11 Gene Expression Result I Page> ................................................. - 63 <圖 4.3-12 Gene Expression Result II Page> ................................................ - 63 <圖 4.2-13 Pathway Finder Page> ................................................................. - 64 <圖 4.2-14 Pathway Finder Result Page>...................................................... - 64 <圖 4.2-15 GeneMatch Page>........................................................................ - 65 <圖 4.2-16 GeneMatch Result Page> ............................................................ - 65 <圖 5.1-1 Comparison of Different Array Type Annotation> ....................... - 67 <圖 5.1-2 GeneMatch Result of HG-U133A and Stanford Microarray> ...... - 68 -. x.
(12) 論 文 摘 要 論文名稱:建立一個各基因資料庫間的基因名稱導航與微陣列平台之註解 系統:DIPLEX 臺北醫學大學醫學資訊研究所 研究生姓名: 陳彥臣 畢業時間:. 93 學年度. 指導教授:李元綺. 第 2 學期. 臺北醫學大學醫學資訊研究所 助理教授. 協同指導教授:邱泓文. 臺北醫學大學醫學資訊研究所 副教授. 摘要: Microarray 和其他計算基因表現的技術通常會得到成千上萬的基因數據,正 確的基因註解資料可幫助生物醫學專家做更複雜的研究。然而,基因相關 資訊太過複雜,使得專家們對於手上大量的基因註解工作有很大的困擾。 這個工作的困難點,在於很難整理各個基因資料庫的 identifier 彼此間的對 應關係,來產生正確的註解資料。因此,我們開發 DIPLEX 來提供自動化 註解的服務,並整合基因表現數據與生化調控路徑(biochemical pathways) 資訊,幫助生物醫學專家做多樣化的研究。在類似的研究中以 NCI 所開發 的 MatchMiner 最為有名,而我們使用不同於 MatchMiner 的演算法,以 NCBI Entrez GeneID 為主要的 Identifier 來建立各資料之間的關聯,將使用者所輸 入的基因 identifier 轉為 Entrez GeneID,再以 Entrez GeneID 來擷取使用者 所需要的註解資訊。透過這樣的演算法,我們一併整合了 KEGG 和 Biocarta. xi.
(13) Pathway Database 的資料,統計出使用者所上傳的基因名單(Gene list)所 相關的 pathway。DIPLEX 建置在 http://bio.tmu.edu.tw/diplex/。. xii.
(14) Abstract Title of Thesis:Establishment of a web-based system for gene identifier navigation among databases and Microarray platform annotation:DIPLEX (Database Interrogation Platform for Gene Expression) Author:CHEN, YEN-CHEN Thesis advised by:CHIU, HUNG-WEN LEE, YUAN-CHII GLADYS Taipei Medical University, Graduate Institute of Medical Informatics. Abstract: Microarray and other gene expression technologies often result in hundreds and thousands of gene raw data; thus, correct and comprehensive gene annotations certainly will help the biomedical researchers interpret more complex work beyond gene lists. Since each gene has embedded valuable information among separate databases where the researchers often find difficult to access and not to mention to obtain the data in a convenient way. The big challenge for this project is the process to put together various identifiers from all databases and further to define the corresponding relationship between each identifier in order to produce correct annotations. As a result, we have developed a service tool DIPLEX (Database Interrogation Platform for Gene Expression) that offers the automatic annotation, the basic gene expression levels in normal tissues and carcinomas using public accessible microarray data, and the relevant biochemical pathways, in an aim to help the biomedical experts to make sense of each gene and the relationships among a gene list obtained from their research. The MatchMiner developed by NCI is one of the similar researches, and we use the most update data and different algorithm from MatchMiner, with NCBI Entrez GeneID as the main identifier to set up its relationship with all other databases. Gene identifier submitted by user will first be transferred into Entrez GeneID and all kinds of gene-related information can then be retrieved. xiii.
(15) according to the user’s need simply by clicking the functional keys. Likewise, user can also review the valuable gene expression level data in microarrays and allocate the position of each gene played in the pathways from KEGG and Biocarta. DIPLEX is located at http://bio.tmu.edu.tw/diplex/ .. xiv.
(16) 第一章 緒論. 1.1 前言. 癌症 (Cancer) 是全世界共同的問題,影響到每個人的健康。癌症是一種無法抑制成長 與擴散的細胞所造成,可能會影響到全身任何的器官。根據世界衛生組織 (WHO) 統 計,肺癌、直腸癌、胃癌一直是全世界癌症排名前五名,不分男性或女性。全世界男性 最容易得到的癌症為肺癌和胃癌,女性則為乳癌和子宮頸癌。世界衛生組織統計,每年 約有超過一千萬的人被診斷出患有癌症。預計到 2020 年,每年將會新增一千五百萬個 癌症病患,而每年死於癌症的人口將超過六百萬人。. 在台灣,衛生署公布 2004 年國人十大癌症死因,去年台灣地區每天約有 100 人死於惡 性腫瘤,平均每 14 分 27 秒就有一人因癌症而病逝,與 2003 年相較,肺癌超越肝癌, 成為國人癌症死亡第一名;男人得口腔癌、女人得乳癌死亡者偏年輕。統計資料顯示, 去年死於癌症的人數高達 3 萬 6357 人,創下歷年紀錄,女性乳癌與男性口腔癌的死亡 年齡明顯偏低,而口腔癌、結腸直腸癌、胃癌死亡率則顯著增加。<圖 1.1-1>去年十大 癌症分別為肺癌、肝癌、結腸直腸癌、女性乳癌、胃癌、口腔癌、子宮頸癌、攝護腺癌、 食道癌、胰臟癌等癌症,光是前三名的死亡人數就占了癌症死因的五成。罹癌死亡率的 增加幅度,以攝護腺癌最高,增加了 10.38%,其次為食道癌(9.9%) 、口腔癌(6.75%)、 胃癌(6.03%)以及結腸直腸癌(4.65%)。男性癌症死亡率為女性的 1.7 倍,兩性癌症 死亡平均年齡 66 歲,女性乳癌死亡年齡中位數為 54 歲,男性口腔癌死亡年齡中位數更 低,為 53 歲,與其他癌相較明顯偏低。93 年資料顯示,癌症主要侵襲 45 至 64 歲中年 人,每 10 名死亡的中年人,近四人死於癌症。國民健康局副局長趙坤郁表示,25 到 44. -1-.
(17) 歲的女性癌症,以乳癌、肺癌、大腸癌死亡率最高,尤其乳癌在 40 歲以後,死亡率明 顯升高。. <圖 1.1-1 主要癌症死亡原因>圖片來源-聯合報. 因此,全世界各國都在努力研究癌症,探究造成癌症的原因,早期診斷與有效的治療方 法。癌症可以說是細胞突變的結果,引起癌症的因素時常被稱為致癌因子 (carcinogen), 實際上一些引起癌症的突變是由於環境因素造成的,而其他的原因則是由於細胞 DNA 複製時自然發生的錯誤。所以,造成癌症的原因有大一部分被認為和遺傳基因有關。研 究癌症和基因之間關係的方法,主要有膠體電泳(gel electrophoresis)、微陣列生物晶片 (Microarray) 技術和基因表達序列系統分析( serial analysis of gene expression; SAGE )。 微陣列生物晶片 (Microarray) 技術更是被認為可對整個基因組 (genome-wide)檢驗病 變基因的最佳利器,目前已經被大量用來研究癌症基因表現 (cancer gene expression) 和 癌症的診斷與分類上面。. -2-.
(18) 1.2 研究動機. 微陣列生物晶片 (Microarray) 技術,是種能同時測量數千個,甚至上萬個基因表現的技 術,不但能增加效率,更降低了系統誤差的可能性。因此用微陣列生物晶片 (Microarray) 來測量各物種的基因表現,是近幾年來十分熱門的工具。尤其是在研究與疾病相關的議 題上,微陣列生物晶片的大量使用,對於疾病的分類、診斷、預測皆有極大的貢獻。但 是由於使用微陣列生物晶片 (Microarray) 的成本較高,非一般實驗室可輕鬆負擔,而且 Microarray 的實驗數據有很高的重複研究與利用的價值,因此有許多機構致力於 Microarray Data 的 收 集 管 理 與 制 訂 標 準 化 的 資 料 交 換 格 式 (MIAME: Minimum information abut a microarray experiment)[Brazma 2003],目前公認的是以 The Microarray Gene Expression Data (MGED) Society 所 制 訂 的 MAGE-ML (Microarray Gene Expression-Markup Language) [Brazma 2003]格式來存放 Microarray Data 為共同的標 準,並且公開散佈在網際網路上,例如:EBI (European Bioinformatics Institute)的 ArrayExpress [Rocca-Serra 2003] 、 Stanford University 的 SMD (Stanford Microarray Database) [Gollub 2003] 、 NCBI (National Center for Biotechnology Information) 的 GEO(Gene Expression Omnibus) [Edgar 2002] 、 密 西 根 大 學 的 ONCOMINE-Cancer Microarray Database [Rhodes 2004].耶魯大學的 YMD (Yale Microarray Database) [Cheung 2002]等。. Microarray Gene Expression 測 量 技 術 , 本 身 又 分 為 兩 種 技 術 , 一 種 是 cDNA Microarray ,普遍為一般研究單位所採用,另一種是 oligonucleotide Microarray 由 Affymetrix Corp.[Affymetrix]所研發,兩種技術的原理相同,但差別在晶片上的序列長短 不同,計算表現量的方式也不同,各有優點。因此,如果能把這兩種技術所得到的結果 拿來一起比較,當兩種 Microarray 同時得到一致的基因表現的結果一致時,我們則可 以更加確定該實驗的正確性;反之,兩種 Microarray 的結果不同時,我們則要考慮是 -3-.
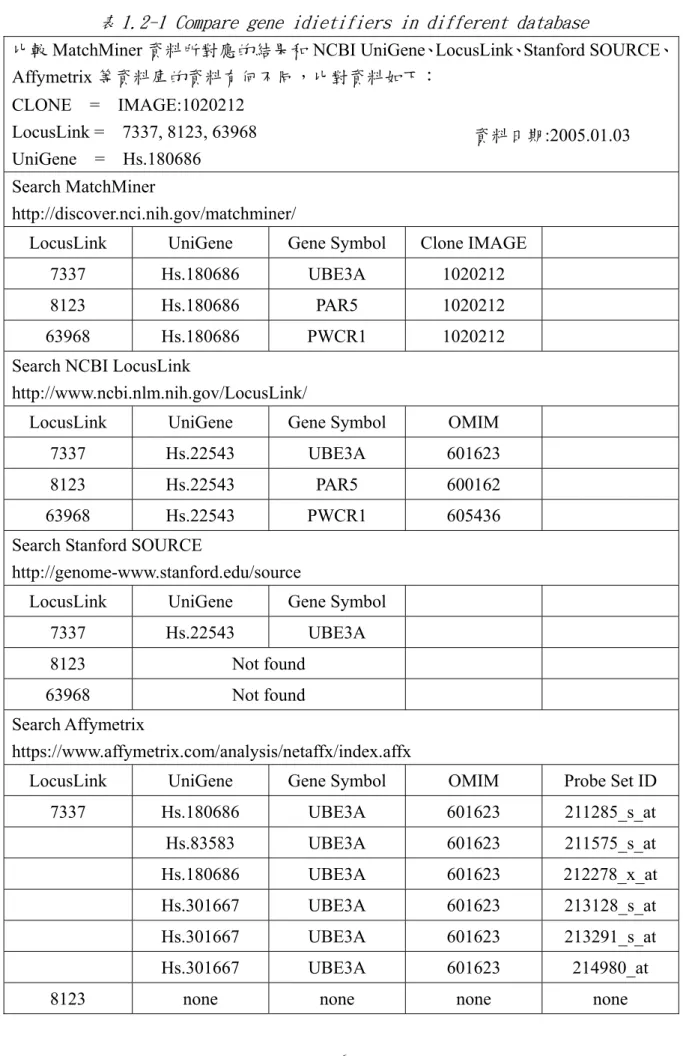
(19) 否採用這個數據,進而幫助我們有效地縮小尋找重要基因的範圍。基於這個想法,我們 收集並整理了類似想法的文獻資料,其中最具代表性的是 Lee 等人(2003)的研究[Lee 2003],他們利用兩種 Microarrays, cDNA VS. oligonucleotide, 同時對 NCI-60 cancer cells 進行研究,將兩種 Microarrays 的結果,利用減去平均值的方法做 Normalization 之後,再做階層式叢集 (hierarchical clustering) 觀察兩種 Microarray 實驗所得到的基因 表現模式 (gene expression pattern) 是否相同,並計算兩者之間的相關係數,結果證明兩 種 Microarray 的實驗數據可以得到相似的結果,具有高度相關性。由於 Microarray 本 身有實驗誤差的可能,如果能綜合比較兩種不同技術的 Microarray 的結果,可增加對基 因表現數據的可信度。. 因此,為了要將兩種 Microarray 的基因表現能對在一起比較,他們使用 Bussey 等人在 2003 年所發展的 MatchMiner [Bussey 2003] 這個工具,用來將 cDNA Microarray 每個 clone IMAGE ID (Microarray 上的每個基因都有一個 Identifier 可供辨識)所代表的基因和 oligonucleotide Microarray 每個 Affy Probe Set ID 所 代 表 的 基 因 作 對 應 , 使 兩 種 Microarray 的數據能做比較。. MatchMiner 是美國國家衛生院 (National Institutes of Health, NIH) 個國家癌症院 (Nation Cancer Institute, NCI) 所發展出來的一套功能強大的免費工具軟體,用來提供基 因和基因產物主要索引子( identifier ) 的轉換對應,被應用在 Microarray 的研究。使用 者可以輸入一個基因索引子表( list of gene identifiers ),使用 Merge 的功能尋找和第二個 基因索引子表中 overlap 的地方,可以是相同或是不同型態的索引子。也可以使用 Lookup 功能尋找對應的索引子,Ex. Affy ID to clone image ID。. 但是在實際上操作時,發現到有許多的 spots 無法對應。例如:Affymetrix chip 中 ID 為 1004_at 的 spot 應該要對應到 UniGene Hs.113816 這個基因叢集,但是在 MatchMiner 搜 -4-.
(20) 尋的結果卻是無資料,事實上卻是有資料可以對應起來的。搜尋 clone image:1020212 所 得到的對應結果,LocusLink ID 為 7337, 8123, 63968 三筆資料;UniGene ID:Hs.180686 為 舊 的 資 料 。 因 此 針 對 MatchMiner 、 Stanford SOURCE 、 NCBI UniGene 、 NCBI LocusLink、Affymetrix 等五個資料庫的內容進行比對,結果如表 1-2-1 所示。. 分析研究表 1.2-1 的搜尋結果,發現 MatchMiner 有幾個問題: 1. 資料老舊,MatchMiner 所搜尋到的 UniGene 為舊資料,沒有更新,而 UniGene 資料庫一至四星期內會更新一次,UniGene 可能會融合、改變、切割,使用者 必須自己再去查尋,造成困擾。 2. 資料不完整,並非如 MatchMiner 官方所說的包含完整的 Affymetrix array data。 3. 資料可能會誤導使用者判斷,Ex. clone image:1020212 在 MatchMiner 中對應到 UBE3A、PAR5A、PWCR1 三個基因,實際上 clone Image:1020212 並未歸屬於 這三個基因之中,原因是因為 MatchMiner 透過 UniGene 為主要的索引子轉換到 基 因 符 號(Gene Symbol) ,而 clone Image:1020212 和 這 三 個 基 因 對 應 到 的 UniGene 相同,但是 UniGene 並不是直接決定 clone image 與基因的對應關係, 只有間接關係。所以用 MatchMiner 搜尋的結果會使得該 clone Image:1020212 對應到這三個基因,使用者如果不注意可能會發生邏輯上的判斷錯誤,如圖 1.2-1 所示。. -5-.
(21) 表 1.2-1 Compare gene idietifiers in different database 比較 MatchMiner 資料所對應的結果和 NCBI UniGene、LocusLink、Stanford SOURCE、 Affymetrix 等資料庫的資料有何不同,比對資料如下: CLONE = IMAGE:1020212 LocusLink = 7337, 8123, 63968 UniGene = Hs.180686. 資料日期:2005.01.03. Search MatchMiner http://discover.nci.nih.gov/matchminer/ LocusLink. UniGene. Gene Symbol. Clone IMAGE. 7337. Hs.180686. UBE3A. 1020212. 8123. Hs.180686. PAR5. 1020212. 63968. Hs.180686. PWCR1. 1020212. Search NCBI LocusLink http://www.ncbi.nlm.nih.gov/LocusLink/ LocusLink. UniGene. Gene Symbol. OMIM. 7337. Hs.22543. UBE3A. 601623. 8123. Hs.22543. PAR5. 600162. 63968. Hs.22543. PWCR1. 605436. Search Stanford SOURCE http://genome-www.stanford.edu/source LocusLink. UniGene. Gene Symbol. 7337. Hs.22543. UBE3A. 8123. Not found. 63968. Not found. Search Affymetrix https://www.affymetrix.com/analysis/netaffx/index.affx LocusLink. UniGene. Gene Symbol. OMIM. Probe Set ID. 7337. Hs.180686. UBE3A. 601623. 211285_s_at. Hs.83583. UBE3A. 601623. 211575_s_at. Hs.180686. UBE3A. 601623. 212278_x_at. Hs.301667. UBE3A. 601623. 213128_s_at. Hs.301667. UBE3A. 601623. 213291_s_at. Hs.301667. UBE3A. 601623. 214980_at. none. none. none. none. 8123. -6-.
(22) 63968. Hs.302021. PWCR1. Search NCBI UniGene http://www.ncbi.nlm.nih.gov/UniGene/. 605436. 232976_at. 資料日期:2005.01.03. UniGene. LocusLink. Gene Symbol. Hs.22543. 7337. UBE3A. Hs.180686. Has been retired. Hs.83585. Has been retired. Hs.301667. Has been retired. Hs.302021. Has been retired. Search NCBI Entrez Gene http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=gene. 資料日期:2005.06.01. GeneID. UniGene. Gene Symbol. OMIM. Maps. 7337. Hs.22543. UBE3A. 601623. 15q11-q13. 8123. Hs.546847. PAR5. 600162. 15q11-q13. 63968. Hs.546847. PWCR1. 605436. 15q11.2. -7-.
(23) Clone ID IMAGE:1020212 UniGene Hs.180686. UBE3A PAR5A PWCR1 Gene Symbol <圖 1-2-1 Gene Identifier Relationship> Clone ID 和 Gene Symbol 都被 UniGene 所包含,. 但是 Clone ID 不一定等於 Gene Symbol,彼此只是間接關係並不相等。當 Input 輸入 Clone ID 時,透過 UniGene 所得到的 Gene Symbol 可能沒有或超過一個,因此只能當作參考。. 1.3 研究目的. 本研究是要發展一套基因數據表現與資料整合平台(Data Integration Platform for Gene Expression),用來整合研究 cDNA and oligonucleotide Microarray Data 以及 SAGE 的序列 標籤(Tag)資料,使得不同系統所產生出的基因表現數據得以相互比較。 系統目標如下: 1.收集整合基因相關 identifier 的資料,建置資料庫包含相關資訊。 2.提供批次(batch process)處理大量基因 list,提供基因 identifier 之間的轉換以 及產生註解資料。 3.建置基因表現數據資料庫,儲存經過篩選在網路上公開的基因表現數據,並. -8-.
(24) 提供視覺化的呈現。 4.整合建置 KEGG (Kyoto Encyclopedia of Genes and Genomes)和 Biocarta pathway database,提供批次處理基因 list 的功能,並統計使用者輸入的基因 list 與相關 pathway 之數目,並提供相關連結。 5.提供不同基因 identifier 的比對,如同 MatchMiner 的功能可用來讓不同技術 之 Microarray 的 identifier 可做對應,使不同技術的基因表現數據可做比較。. -9-.
(25) 第二章 文獻探討及相關研究. 本章主要探討建立微陣列整合平台 DIPLEX 所需要瞭解的基本知識,相關文獻和所使用 的技術研究。分成四個部分:一、基因資料庫探討;二、微陣列生物晶片 (Microarray); 三、MatchMiner。. 2.1 基因資料庫探討 (GenBank, UniGene, LocusLink, RefSeq ) 本節所探討之內容來源,節錄翻譯自 NCBI 官方網站上的定義和解釋。 2.1.1 GenBank GenBank®是美國 NCBI 基因序列資料庫,收集所有公開可用的 DNA 序列。截至 2004 年二月為止,GenBank 已包含了 32,549,400 筆 DNA 序列資料。GenBank 的資料使用標 準的生物邏輯辭彙集合(set of biological terms)來對基因序列註解,內容包含對該序列的 定 義 (Definition) 、 檢 索 號 碼 (Accession Number) 、 GI(GenInfo identifier) 、 關 鍵 字 (Keyword)、物種(Organism)、基因(Gene)、特性(Features)、編碼序列(Coding sequence; CDS) 如圖 2.1-1。GenBank 屬於 International Nucleotide Sequence Database Collaboration 的一 部分,該合作計劃由 DNA Data Bank of Japan (DDBJ) at NIG [Tateno 1998]、the European Molecular Biology Laboratory (EMBL) at EBI [Stoesser 1998]和 GenBank at NCBI [Benson 1998]所組成,這三個組織每日互相交換並更新資料庫中的資料,網址為 http://www.ncbi.nih.gov/GenBank/。 定義(Definition) 基因序列敘述的摘要,包含物種來源(source organism)、基因名稱/蛋白質名稱或是一些 序列功能敘述的資訊。 檢索號碼(Accession Number) Accession Number 是 GenBank 中每筆基因序列資料唯一且不重複的索引子(unique identifier),每一筆完整的資料通常會給一組包含英文字母(letters)和數字(numbers)的檢索 號碼(Accession Number),像是給一個英文字母後面再接著五個數字(e.g., U12345),或是. - 10 -.
(26) 兩個字母後面跟著六個數字 (e.g., AF123456),檢索號碼(Accession Number)永遠不會改 變。 但是,當該筆序列的資訊有更新的時候,或是有新版本的序列包含早期資料時,一個原 始的檢索號碼,可能變成新的檢索號碼的次檢索碼。 特性(Features) 每筆基因序列的長度、來源物種學名(scientific name)的總結,包含染色體位置(map location)、品種(strain)、殖株(clone)、組織型態(tissue type)等資訊。. < 圖 2.1-1 GenBank 格式範例 > 內容包含序列的定義 (Definition) 、檢索號碼 (Accession Number)、GI(GenInfo identifier)、關鍵字(Keyword)、物種(Organism)、基因(Gene)、特性 (Features)、編碼序列(Coding sequence; CDS)等。 - 11 -.
(27) 2.1.2 UniGene 人類基因體計畫(Human Genome Project)的主要目標,是要完成人類完整基因體的定 序。但是只有其中的約 2%基因會轉譯成蛋白質,其他序列的功能仍舊不清楚。因此 NCBI 利用 GenBank 建立一個基本的基因圖譜 UniGene,用來表達基因實際的位置。 UniGene 是一個實驗中的系統,用來自動分割 GenBank 序列並分類到一個非重複 (non-redundant)序列片段集合中,成為一個基因的叢集(cluster),並且包含了大量的 EST (Expressed Sequence Tag) 和整段的 mRNA。每一個 UniGene cluster 代表一種特定已知的 或假設的人類基因,有定位圖(map location)和表達資訊以及同其它資源的交叉參考包括 是否有殖株(clone)。序列資料可以以叢集形式在 UniGene 網頁下載,完整的資料可以從 NCBI 的 FTP 站 ftp://ftp.ncbi.nih.gov/ 中的 repository/UniGene 目錄下下載,資料內容如 圖 2.1.2-1 所示,網址為 http://www.ncbi.nih.gov/UniGene/。 然而,有一點必須注意的是 UniGene 自動化序列叢集的程序 (procedures) 還在發展 中,所產生出來的結果可能隨著時間修正改善,大約每隔一個星期至一個月之間會更 新。一個 UniGene 叢集可能會和另一個 UniGene 叢集融合,或是被切割成好幾個叢集。 當資料改變時,原本的 UniGene ID 會被標上 retired,使用過的 UniGene ID 將不會再被 使用。 UniGene cluster ID. LocusLink ID. GenBank Accession Number. Clone image ID. <圖 2.1.2-1 UniGene 資料格式>節錄自 NCBI Human UniGene file “Hs.Data”的一部份,. 包含 UniGene ID、LocusLink ID、GenBank Accession Number 和 clone image ID。. - 12 -.
(28) 2.1.3 LocusLink LocusLink 提供一個單一的查詢介面,提供校正過的序列和遺傳位點(genetic loci)的描述 資訊。LocusLink 給每個基因一個固定的號碼,並且提供官方的命名(Gene Name)、簡稱 (symbol),別名(alias),Reference sequence (RefSeq),GenBank accession number,表型 (phenotypes),EC number,OMIM numbers,UniGene clusters,同源(homology),map locations,Gene Ontology information 和相關的網站資訊。LocusLink 是 NCBI, HGNC (HUGO Gene Nomenclature Committee), OMIM (Online Mendelian Inheritance in Man)和 其它組織的合作結果。LocusLink 目前包含 19 個物種,有人類(Human)、大鼠(Rat)、小 鼠(Mouse)、果蠅(Fruit Fly)、大腸桿菌(E. coil)等,可以被分開或合在一起查詢。完整的 資料可以從 NCBI 的 FTP 站 ftp://ftp.ncbi.nih.gov/ 中的 refseq/LocusLink 目錄下下載, LocusLink 的 服 務 在 2005 年 3 月 結 束 , 改 由 Entrez Gene 所 取 代 , 網 址 為 http://www.ncbi.nih.gov/LocusLink/ (2005 年 3 月以後自動轉到 Entrez Gene 的網頁)。. 2.1.4 Reference sequence (RefSeq) RefSeq 是 NCBI 資料庫的參考序列,為經過校正的非重複(non- redundant)序列集合,包 括基因組 DNA contigs(Group of clones representing overlapping regions of the genome),已 知 基 因 的 mRNAs 和 蛋 白 質 。 Accession numbers 用 NM_xxxxxx, NP_xxxxxx, 和 NC_xxxxxx 的形式來表示 mRNA, non-protein coding RNAs, protein。截至 2004 年 12 月 4 號統計結果,人類的基因數目為 23,452 個[Refseq statistics 2004],經過校正過的 RefSeq 存放在 GenBank,並會在 EntrezGene 中報告。完整的資料可以從 NCBI 的 FTP 站 ftp://ftp.ncbi.nih.gov/ 中的 refseq 目錄下下載。. 2.1.5 OMIM OMIM [ McKusick 1998 ]是 Online Mendelian Inheritance in Man 的縮寫,收集所有人類和 遺傳有關的疾病的資料庫。這個資料庫是由 Dr.Victor A. McKusick 和他在約翰霍普金 司(Johns Hopkins)大學的同僚,為 NCBI 所建立的一個遺傳疾病百科目錄,收集整理了 大部分已發表的遺傳相關疾病文獻,包含文字資訊和參考資料,並且提供 MEDLINE、 序列資料和其他 NCBI 的相關資源連結,每日更新。每一筆 OMIM 資料都給予一組唯一 不重複的六位數字,網址為 http://www.ncbi.nih.gov/omim/。. - 13 -.
(29) 2.1.6 Entrez Gene Entrez Gene [Donna 2005] 是 NCBI 針對特定基因資訊所建立的資料庫。Entrez Gene 未 包含全部已知或預測的基因,反而著重在整個基因組已定序完成的基因,這些基因目前 可能有團體正專門研究並釋放出大量的相關資訊,或者該基因正在被分析序列中。Entrez Gene 的報告內容自動和 NCBI Reference Sequence project(RefSeq)<圖 2.1.6>整合在一 起,並給予一個唯一穩定且可追蹤的索引數字 GeneID。內容包含(nomenclature, map location, gene products and their attributes, markers, phenotypes, and links to citations, sequences, variation details, maps, expression, homologs, protein domains and external databases),當資訊有變動時會及時更新。Entrez Gene 是 NCBI's LocusLink 向前踏出的 一大步,增加許多主要的分類的領域,並改進存取其它 NCBI tools 的效率。網址為 http://www.ncbi.nih.gov/ entrez/query.fcgi?db=gene/。. RefSeq information. <圖 2.1.6 EntrezGene results for gene TP53>. 2.1.7 Gene Ontology Gene Ontology project 的目的是為了建立了一套受到控制字彙,可用來解釋生物的基因 或蛋白質在細胞內所扮演的角色及生醫學方面的知識,同時這些字彙一直不斷的累積與 改變。Gene Ontology[Ashburner 2002] (以下簡稱 GO)主要由三個 Ontology 組成:biological. - 14 -.
(30) process, molecular function 及 cellular component,這三個 Ontology 底下包含更多的 Ontologies,並且用網路的結構串聯起來,再以樹狀分層(hierarchical tree)來呈現這些 Ontologies 之間的關係,每個 Ontology 都給予一組獨特的號碼。<圖 2.1.7>GO 的分類可 由三個方面來對基因或蛋白質解釋:cellular component 是構成在細胞內的特定元件, molecular function 是基因或蛋白質在分子功能上所扮演的角色,biological process 是基 因或蛋白質參與哪些生物過程。由於大部分真核生物有相似的生物邏輯功能(biological functions),經由 Gene Ontology 可利用已知物種的知識,解釋在其他物種所對應到基因 或蛋白質的功能。網址是 http://www.geneontology.org/。. <圖 2.1.7 Gene Ontology 分類樹狀圖>. 2.1.8 HGNC HUGO Gene Nomenclature Committee (HGNC)是第一個被正式授權幫人類基因的 Name 和 Symbol 命名的單位。在 HGNC 出現之前,基因的命名是混亂無章的,同一個基因可 能有十幾種講法,為了解決這個問題而出現 HGNC 這個組織。Genew [Wain 2004],Human Gene Nomenclature Database 是目前唯一提供人類全部正式認定的基因 Name 和 Symbol. - 15 -.
(31) 資 料 , 資 料庫 內 的 資料已 超 過 22000 筆 。 網 址 為 http://www.gene.ucl.ac.uk/cgi-bin/ nomenclature/searchgenes.pl。. 2.1.9 UniProt UniProt 是由 EBI(歐洲生物資訊所,位於英國劍橋南方的 Hixton)、SIB(瑞士生物資訊所, 負責維護 SwissProt)及 PIR(蛋白質資訊資源,位於美國喬治城大學醫學中心)共同發展 的。SwissProt [Gasteiger 2001] 是一個蛋白質序列資料庫,收集了許多完整的蛋白質序 列,整理了相關的資訊和完整的蛋白質註解資料,像是蛋白質的功能、2D、3D、4D 結 構、變異以及相關疾病資訊等,每個蛋白質均給予一個獨特的號碼。UniProt 的目的在 提 供 蛋 白 質 研 究 及 查 詢 相 關 資 源 , 並 延 用 SwissProt 的 蛋 白 質 號 碼 。 網 址 是 http://www.pir.uniprot.org/。. 2.1.10 SAGEmap Serial analysis of gene expression (SAGE),是一種可測量基因絕對表現量的方法。NCBI 為此建立了 SAGEmap 資料庫供線上查詢使用,SAGEmap (Lash 2000) 提供基因表現 量、Best tag 與基因的對照等資訊。與 Microarray 不同的是,Microarray 所測量出來的 基因表現量並非真實在細胞內的數量,SAGE 所測得的是真實表現量,而且可以找到新 基因(novel genes),缺點是所花費的時間及成本較高。 網址是 http://www.ncbi.nlm.nih.gov/sage。. 2.1.11 KEGG pathway database KEGG (Kyoto Encyclopedia of Genes and Genomes) pathway database 收集了很多調控路 徑(pathways)圖,這些調控路徑圖描繪出在不同 cellular processes 中的分子交互作用網路 (molecular interaction networks),包括 metabolism, membrane transport, signal transduction and cell cycle。<圖 2.1.8 >是 KEGG 中關於 Cell Cycle 的調控路徑圖,網址是 http://www. genome.ad.jp/kegg/。. 2.1.12 Biocarta pathway database Biocarta 是一間專賣實驗試劑的公司,但是他們免費提供專門繪製生化調控路徑. - 16 -.
(32) (biochemical pathways)的繪畫元件給生物醫學專家,這些專家可借此繪製出屬於他們專 業領域中知識彙整的調控路徑(pathways)。專家們將調控路徑(pathways)畫好後,上傳至 Biocarta 的網站之中,供全世界研究相關領域的人可以分享其研究成果或知識,並且在 調控路徑上的每一個基因或蛋白質的命名都依照 HGNC 組織的標準規定。在 Biocarta pathway database 中,調控路徑(pathways)的分類是依照英文字母排列,每個調控路徑 (pathways)都會註明作者名稱。目前為止,Biocarta pathway database 囊括了 355 個調控 路徑(pathways),並且持續增加中。因此,美國國家癌症研究機構(National Cancer Institute 簡稱 NCI)中的 CGAP(The Cancer Genome Project),也收錄了 BioCarta 所有基因及生化 調控路徑資料,提供研究癌症的學者更多相關資訊。<圖 2.1.9 >是 Biocarta 中關於 Cell Cycle 的調控路徑圖。Biocarta 的網址是 http://www.biocarta.com/。. <圖 2.1.8 KEGG cell cycle pathway map>. - 17 -.
(33) <圖 2.1.9 Biocarta cell cycle pathway map>. - 18 -.
(34) 2.2 微陣列生物晶片 (Microarray). 細胞的成長、功能和新陳代謝的運作,最基本的就是由 DNA 到蛋白質的過程,DNA 首 先轉錄成為 RNA,隨後 mRNA 再轉譯成為蛋白質。在人類基因體定序和註解完成之後, 基因體科學的下一步是分析轉錄體 (Transcriptome),也就是分析研究整個基因體的基因 表現狀況。微陣列生物晶片(Microarray)提供一個平行分析基因表現(Parallel Analysis of Gene Expression)的技術,可以同時偵測成千上萬個基因的表現程度。使用 Microarray 技 術來觀測人類組織、細胞株(Cell Lines)和物種的基因表現,在目前生物和醫學研究上已 經成為十分重要的工具。Microarray 本身又依照製造方式的不同分為 cDNA microarray 和寡核苷酸微陣列(oligonucleotide microarray)兩種。. 2.2.1 cDNA Microarray cDNA microarray 的製造方式是將 PCR 放大的 cDNA 片段(ESTs)高密度的點在玻片上, 平均每平方公厘上有 10-50 個點[Schena 1995],cDNA 片段的來源是由 cDNA 收藏庫中 挑選出來的選殖珠(clone)構成,每個選殖株有一組編號(clone ID)。cDNA 是 mRNA 反轉 錄為 DNA 後的基因片段(ESTs),已先行將不具轉錄功能的 intron 片段去除。. 實驗時,將兩組不同的 mRNA 樣本反轉錄為 cDNA 並標上螢光染色劑。一組是所要實 驗樣本的 mRNA,其所反轉錄的 cDNA 被標上 Cy5 螢光染色劑;另一組為參考組,其 cDNA 被標上 Cy3 螢光染色劑。將這兩組 cDNA 混合一起之後,放到 cDNA Microarray 做雜交(Hybridization),再用雷射光或是 CCD Camera 探查 Microarray 上面 Cy3 和 Cy5 信號的強度,所測出來強度的比率 Cy5/Cy3 ,為實驗組相對於參考組的基因表現程度, 完整流程如圖 2.2.1-1 所示。每次實驗處理方式不同,所得到結果的反應強度不同,然 後將結果進行生物統計的分析,通常可以用來測試已經建立的生物學假說[Brown 1999]。. - 19 -.
(35) <圖 2.2.1-1 cDNA Microarray 實驗流程圖>本圖取自聯合國糧食及農業組織。A.將樣本細 胞和參考細胞中的 mRAN 經過淬取出來,B.反轉錄為 cDNA 並染上螢光染色劑 Cy5 和 Cy3 後,C.將樣本和參考細胞的 cDNA 混和後,D.放到微陣列上做雜交(Hybridization), E.最後利用雷射光或 CCD Cramer 掃瞄基因的表現,將所得的數據放入電腦計算,以紅 黃綠色呈現基因表現比率(Cy5/Cy3)的高低。. - 20 -.
(36) 2.2.2 寡核苷酸微陣列 (oligonucleotide Microarray) 第二種用來平行分析基因表現的微陣列技術,是由 Affymetrix 公司所設計的寡核苷酸微 陣列(oligonucleotide Microarray) 又叫 GeneChip[Lockhart 1996;Lipschutz 1999],以下 簡稱 oligo array。Oligo array 並不如同 cDNA Microarray 由已定序的 cDNA 資料庫中選 擇 EST 來當作雜交(Hybridization)的點,而是利用電腦演算法運算後所設計出來。將已 知的或預測基因的基因序列,分成 11~20 個長度為 25-mer 足以代表該基因的片段作為 雜交的單位 Probe,如<圖 2.2.2-1 Probe>所示。Affymetrix 為每個基因片段 Probe 的集合 訂定一個 Probe Set ID。. 每個 Probe 實際上是由一對序列組成,完全配對的序列 Perfect match(PM)和只有一個鹼 基差異的序列 Mismatch reference(MM),設計用來計算短的核苷酸序列有交互雜交 (Cross-Hybridization)的情形。根據 MAS 5.0 pre-processing 的算法,PM 減掉 MM 訊號強 度平均的差異,所得到的結果代表基因的表現值,如<圖 2.2.2-2 PM-MM>所示。Probe 的製造方式是利用光刻蝕法( photolithography )和化學物質所合成出來的序列,利用這樣 的方式可使單位面積所能包含的基因數目更多,如圖 2.2.2-3 所示。. <圖 2.2.2-1 Probe>. 圖中 EXON 是 DNA 中真正會轉錄成 mRNA 的部分,oligonucleotide Microarray 用數個比 較短的序列(Probe)來代表一段完整的 mRNA,每個 Probe 實際上是由一對序列組成如< 圖 2.2.2-2 PM-MM>。. - 21 -.
(37) <圖 2.2.2-2 PM-MM>. 每 對 Probe 是 由 一 對 只 有 差 一 個 核 苷 酸 的 序 列 Perfect Match(PM) 和 Mismatch reference(MM)所組成,PM 和 MM 只有位在序列中間的核苷酸有差異,這樣可以避免 cross-hybridization,基因的表現量是計算同一個 Probe set 中所有 Probe 的 PM 強度減去 MM 強度的平均值。. <圖 2.2.2-3 Affymetrix probe design>本圖取自 Affymetrix Crop. http://www.affymetrix.com. - 22 -.
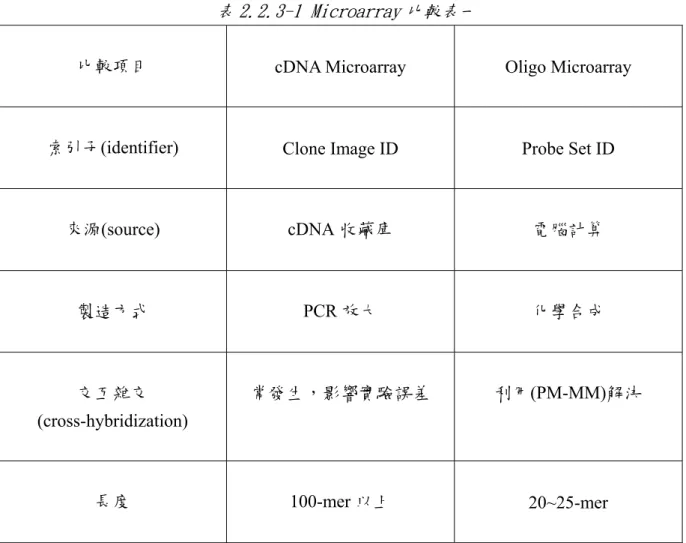
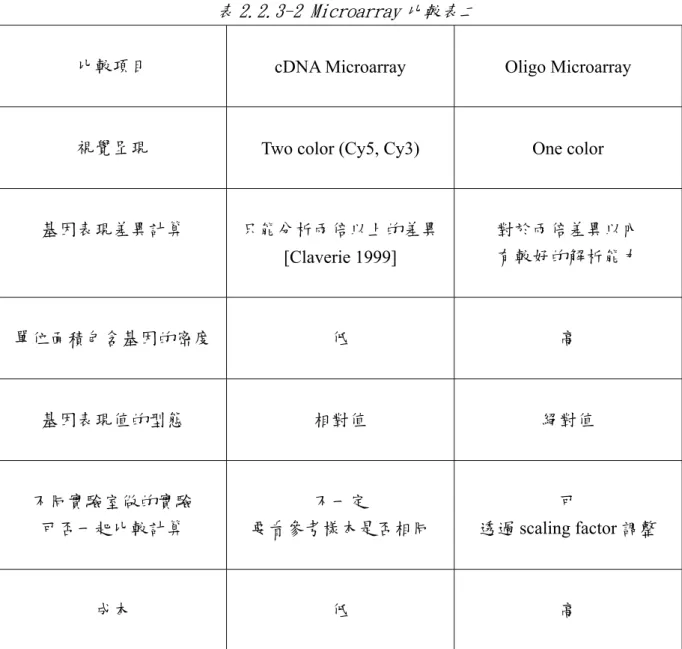
(38) 2.2.3 cDNA Microarray 和 oligonucleotide Microarray 之比較 cDNA Microarray 和 oligo Microarray 都分別有其優缺點,表 2.2.3-1 和表 2.2.3-2 整理了 兩種 Microarray 的主要差異。Microarray 實驗資料有很高的可再利用性,在研究疾病的 基因表現時,如果能這兩種 Microarray 的實驗結果結合在一起比較,則能得到更多精確 的基因表現資料。. 表 2.2.3-1 Microarray 比較表一 比較項目. cDNA Microarray. Oligo Microarray. 索引子(identifier). Clone Image ID. Probe Set ID. 來源(source). cDNA 收藏庫. 電腦計算. 製造方式. PCR 放大. 化學合成. 交互雜交. 常發生,影響實驗誤差. 利用(PM-MM)解決. 100-mer 以上. 20~25-mer. (cross-hybridization). 長度. - 23 -.
(39) 表 2.2.3-2 Microarray 比較表二 比較項目. cDNA Microarray. Oligo Microarray. 視覺呈現. Two color (Cy5, Cy3). One color. 基因表現差異計算. 只能分析兩倍以上的差異 [Claverie 1999]. 對於兩倍差異以內 有較好的解析能力. 單位面積包含基因的密度. 低. 高. 基因表現值的型態. 相對值. 絕對值. 不同實驗室做的實驗 可否一起比較計算. 不一定 要看參考樣本是否相同. 可 透過 scaling factor 調整. 成本. 低. 高. - 24 -.
(40) 2.3 MatchMiner MatchMiner 是美國國家衛生院 (National Institutes of Health, NIH) 國家癌症院 (Nation Cancer Institute, NCI) 所發展出來的工具,MatchMiner 主要分成三個功能: Interactive Lookup 轉換使用者所輸入的一個 ID 和的索引子類型(Identifier type)到另一個對應的索引 子類型,例如:將 UniGene ID 轉為 LocusLink ID。 Batch Lookup 功能和 Interactive Lookup 相似,提供使用者直接輸入一個 ID 列表的檔案,批次 做 Interactive Lookup 的功能。 Batch Merge 允許使用者輸入兩個不同索引子的 ID 列表檔案,找出這兩個檔案內所有 ID 所對 應到相同基因的列表。 MatchMiner 的資料來源主要來自四個地方:UCSC、UniGene、LocusLink、OMIM 和 Affymetrix Microarray HU95A、HU133A 的註解資料,圖 2.3-1 表示 MatchMiner 的資料 表關聯架構。. <圖 2.3-1 MatchMiner 資料表關連圖>. 圖中包含了四個資料庫(UCSC, UniGene, LocusLink, OMIM)和 Affymetrix Microarray 的註解資料(annotation),被分開存放在不同名稱的資料表,所有的資料表都和中間 的 Gene Index 資料表建立關聯性。. - 25 -.
(41) MatchMiner 用 來 解 析 索 引 子 的 核 心 演 算 法 , 採 用 的 是 一 個 即 時 的 可 靠 鍊 模 式 (ChainOfResponsibility pattern),用來結合不同搜尋順序的邏輯方法,並為每一個索引子 設定一個可靠鍊序列(ChainOfResponsibility hierarchy),圖 2.3-2 所示。. <圖 2.3-2 MatchMiner 可靠鍊序列(ChainOfResponsibility hierarchy)>. 圖中表示當索引子類型(Identifier type)為 IMAGE clone id 時,MatchMiner 所使用的資料 來自 UniGene,用 UniGene 為主索引子來轉換資料,所以會發生第一章 1.2 節所述邏輯 錯誤的情況。. - 26 -.
(42) 第三章 材料、方法與架構. 本章介紹如何建構『基因表現數據資料庫整合平台 DIPLEX』,分成三個部分。第一部 份介紹所使用材料的內容與來源,如何收集這些資料。對所收集資料處理的方法,包括 對資料內容切割、淬取、儲存、資料間對應分析、關聯式資料庫建置。第二部分介紹 DIPLEX 的架構流程、期望功能與做法。第三部分系統評估。. 3.1 資料收集、分析與處理 建構 DIPLEX 的首要工作,就是要收集完整的資料,DIPLEX 所需要的資料項目、來源、 檔案大小都整理在<表 3.1-1 基因索引資料來源表>中。接著,我們要瞭解這些資料之間 彼此的對應關係,因此要對資料進行統計的工作。首先,針對 UniGene ID 和 LocusLink ID 對應關係作統計,使用由 LocusLink 抓來的 loc2UG 檔案作資料的比對,統計結果如 <表 3.1-2 UG2LL 統計結果>所示 UniGene ID 和 LocusLink ID 的關係為多對多( M : M ) 的情況,發生交叉多重對應的情形詳列於<表 3.1-3 UniGene 和 LocusLink 交叉多重對應 基因列表>。. 表 3.1-2 UG2LL 統計結果 Hs.data 數量. UniGene 54,639. LocusLink. UG2LL. 1:1. 1:M. M:1. Cross. 23,653. 22,850 to 24,199. 21,076. 1,235. 546. 7. 本表說明在 UniGene 共有 54,639 筆資料,LocusLink 有 23,6543 資料,UniGene 有和 LocusLink 對應的資料筆數為 22,850 筆 UniGene 對應到 24,199 筆 LocusLink。其中 UniGene 比 LocusLink 為一比一情形的有 21,076 筆資料,一對多的有 1,235 筆資料,多對一的有 546 筆資料,另外有 7 筆資料有 UniGene 和 LocusLink 發生交叉多重對應的情形。. 其他資料的處理流程相同,資料之間的對應關係整理成<表 3.1-4 資料關聯表>,整個資 料處理的流程步驟如<圖 3.1-1 資料處理流程圖>所示。處理完資料間對應關係之後,接. - 27 -.
(43) 著就要進行建立資料庫的步驟。我們利用<表 3.1-4 資料關聯表>中的對應關係,畫出整 個資料庫正確的資料關聯圖如<圖 3.1-2 DIPLEX 資料關聯圖>,就可以建立 DIPLEX 所 需的正確資料庫架構。. 表 3.1-3 UniGene 和 LocusLink 交叉多重對應基因列表 UniGene. UG2LL. LocusLink. LL2UG. HUGO Gene Symbol. Hs.531478. 2312 400786. 2312. Hs.531478 Hs.531479. FLG. TRA@. Hs.74647. 6955 28755. 6955. Hs.74647 Hs.512100 Hs.512110 Hs.512112 Hs.534438. Hs.462589. 9220 399687. 9220. Hs.462589 Hs.462590. TIAF1. Hs.449585. 3535 3538 28831. 28831. Hs.449585 Hs.517453 Hs.517455. IGLJ3. Hs.459691. 5170 124216. 124216. Hs.459691 Hs.459699. None Available. Hs.499704. 84457 220965. 220965. Hs.499704 Hs.499705. FAM13C1. 953 Hs.444105 404033 None Available 404033 Hs.523177 本表中 UG2LL 欄位列出 UniGene 所對應到兩個以上的 LocusLink,LL2UG 欄位列出 LocusLink 對應到兩個以上的 UniGene。 Hs.523173. - 28 -.
(44) <表 3.1-1 基因索引資料來源表>. 附註. 檔案名稱. Human Array annotation. gene2go. 網址. Clone ID to GenBank Accession Number. ftp.ncbi.nih.gov. LL.out_hs ,gene2acc, gene2refseq. 資料來源. cumulative_arrayed_plates. GenBank detail. NCBI. ftp.ncbi.nih.gov. mim2loc. SAGE tag to UniGene. 資料項目. image.llnl.gov. gbest.seq. Gene Name/Symbol to LocusLink. Gene Ontology. NCBI. ftp.ncbi.nih.gov. Hs_long.best_tag Hs_short.best_tag. UniGene detail. www.affymetrix.com. LLNL. ftp.ncbi.nih.gov. All Data. Entrez Gene (LocusLink), Refseq. NCBI. ftp1.nci.nih.gov. Hs.Data. Uniprot detail. Affymetrix. Clone Image NCBI. www.gene.ucl.ac.uk. OMIM. NCI. ftp.ncbi.nih.gov. uniprot_sprot_data. Affy Probe Set ID. GenBank HUGO. SAGE. NCBI. ftp.uniprot.org. U95A-E, U95Av2, U133A/B, U133A 2.0, U133 2.0 plus etc.. Gene Name Gene Symbol. UniGene. ExPASy. LocusLink to Gene ontology number LocsuLink to GenBank OMIM ID to LocusLink. UniProt. - 29 -.
(45) <表 3.1-4 資料關聯表>. OMIM. Gene Symbol. UniProt. UniGene. GenBank. Entrez Gene (LocusLink) Gene Name. Identifier. 1:1. 1:1. 1:1. M:M. 1:1. 1:M. x x 1:1. 1:1. Entrez Gene (LocusLink) M:M x. 1:M. UniGene 1:1. 1:1. 1:1. 1:1. 1:1. 1:1. 1:1. x. x. 1:1. 1:1. 1:1. x. 1:M. Gene Symbol. x. M:1. 1:1. M:1. M:1. 1:1. GenBank 1:M. Gene Name. UniProt. M:1. 1:1. M:M. OMIM Clone ID Affy ID Gene Ontology. Clone. 1:M. M:1. x. Affy. 1:1. x. Gene Ontology. M:M. x. - 30 -.
(46) NCBI. LLNL. NCI. HUGO. ExPASy. Affymetrix. Web / FTP. 收集資料. 透過網站或 FTP 站點下載. 字串切割. 利用 Perl 程式切割所需 要的資料。. 統計對應關係. 統計資料間一對一、一 對多、多對一的關係。. 建立資料關聯表. 建立資料模型. DIPLEX 資料關聯. DIPLEX 資料關聯圖. <圖 3.1-1 資料處理流程圖 >. 資料透過 Web 或是 FTP 抓回來後,利用 Perl 所撰寫的程式對資料做淬取的動作,接著 統計資料間的對應關係,藉此建立資料模型。. - 31 -.
(47) M Affymetrix. M GenBank. 1. 1. CLONE. M. Gene Ontology. 1. HUGO (HGNC). M. UniProt M. 1. 1. 1 1. UniGene. M. M. EntrezGene (LocusLink) 1. M. 1 M. M. SAGE. Pathway. 1. OMIM. 一對一 一對多 多對多. <圖 3.1-2 DIPLEX 資料關聯圖> DIPLEX 資料庫中共包含 11 個資料表,以 EntrezGene(LocusLink)資料表為主,透過資料. 間的關聯性,串連所有資料表。. - 32 -.
(48) 3.2 DIPLEX 採用的技術. 1989 年瑞士日內瓦核能研究中心的 Tim Berners-Lee 等人,提出在網際網路上傳輸多媒 體文件的 World-wide web(WWW),目的是為了要整合世界各地研究人員所發表的多媒 體資料[Berners-Lee 1992]。加上各種瀏覽器(Browser)的問世,具有友善的操作介面,一 般大眾不需要瞭解專業操作方式既可使用,因此網際網路便開始蓬勃發展。而 WWW 的 技術不斷改良,由原本只能呈現靜態文字圖形的網頁,進步到現在動態的網頁如 Flash, 可以和使用者互動,並結合資料庫,使資訊系統(Information System)以新的不同方式呈 現,圖 3.2-1 呈現在 WWW 下的資訊系統架構。. Client. Server. Request. User. Browser. Web Server. Database. <圖 3.2-1 以 web-based 為平台的資訊系統架構>. 使用者在 Client 端透過 Browser 送 request 給 Web Server,Web Server 收到 request 後對後 端資料庫做處理,再把結果傳回給 Client 端。 以 Web-based 為平台的資訊系統,有幾個優點[Berners-Lee 1992]: 1. 使用者不受作業系統平台限制 2. 使用者介面一致 3. 使用者不需額外安裝軟體 4. 多媒體文件易於呈現 5. 系統維護改版容易 6. 操作介面簡單. - 33 -.
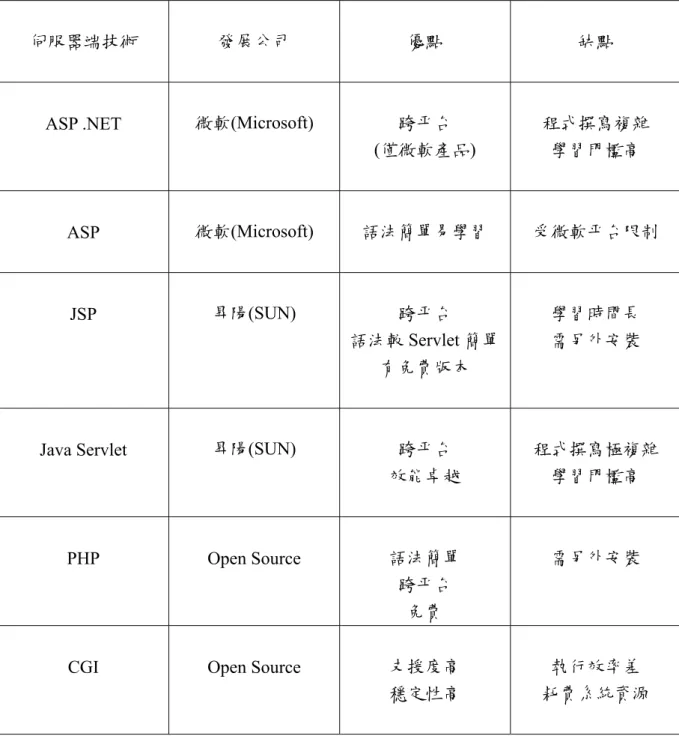
(49) 3.2.1 伺服器(Server)技術 拜電子商務發展所賜,網頁伺服器(Web Server)的技術不斷進步,目前主要的技術包括: ASP,ASP .NET,Java Servlet,JSP(Java Server Page),CGI,PHP 等。這些技術共同特 徵,是將程式碼內嵌在網頁之中,當使用者瀏覽網頁時並不會感覺到程式碼的存在,也 看不見原始碼,而且不需要客戶端瀏覽器的支援。表 3.2.1-1 綜合整理出伺服器技術的 優缺點。目前 DIPLEX 採用 JSP 技術。. 表 3.2.1-1 伺服器端技術比較表 伺服器端技術. 發展公司. 優點. 缺點. ASP .NET. 微軟(Microsoft). 跨平台 (僅微軟產品). 程式撰寫複雜 學習門檻高. ASP. 微軟(Microsoft). 語法簡單易學習. 受微軟平台限制. JSP. 昇陽(SUN). 跨平台 語法較 Servlet 簡單 有免費版本. 學習時間長 需另外安裝. Java Servlet. 昇陽(SUN). 跨平台 效能卓越. 程式撰寫極複雜 學習門檻高. PHP. Open Source. 語法簡單 跨平台 免費. 需另外安裝. CGI. Open Source. 支援度高 穩定性高. 執行效率差 耗費系統資源. - 34 -.
(50) 3.2.2 資料庫系統(Database System) 資料庫是整個資訊系統中最重要的一部分,不論在那個領域,資料都是最重要的資產。 沒有資料庫,整個資訊系統將毫無價值。資料的儲存最早以前是以檔案的方式儲存,後 來逐漸發展出階層式資料庫(Hierarchical Database)、網路式資料庫(Network Database)再 發展到現在的關聯式資料庫(Relational Database),發展已經到一個極致。目前的需求逐 漸變成可供交換的資料格式為主,關聯式資料庫已無法滿足現在的需求,因此出現了 XML 資料交換的格式,XML 本身除了當資料交換的格式之外,也可以充當資料儲存的 格式,因此市面上發展出結合 XML 和關聯式資料庫的解決方案。 在關聯式資料庫(Relational Database)中要儲存資料,需要先對資料畫出 ER Diagram (Entity-Relationship Diagram),找出資料之間的對應關係,經過正規化後切割成數個表格 (Table) 如圖 3.2.2-1。接著再利用所找出來的對應關係,建立主鍵(Primary Key)串連所有 的表格(Table)如圖 3.2.2-2,這就是所謂的關聯式資料庫。正規化的目的在避免資料重複 儲存、維護資料方便、使資料結構單純化,延長系統壽命。而我們想對資料庫的資料做 新增、刪除、查詢等動作,只需要利用 SQL 語法透過資料庫管理系統即可。. <圖 3.2.2-1 基因對應資料之正規化>. 原本的基因對應資料表中,Hs.22543、7337 和 UBE3A 不斷的重複出現,經過正規化後 分割為三個表格(UG2LL, LL2Symbol, LL2Affy),減少不必要儲存的多餘資料。. - 35 -.
(51) UG2LL LL2Symbol *UniGene *LocusLink M. 1. *LocusLink Gene Symbol. 1. LL2Affy. 1. *LocusLink GenBank Acc.. <圖 3.2.2-2 資料關聯圖>. 為基因對應資料正規化後之關聯圖,圖中的箭頭表示出每個基因資料表之間的對應關 係,一對一(1:1)、一對多(1:M)或多對多(M:M)的關係,星號(*)代表主鍵。一個好的正規 化結果,會避免關連圖內發生多對多的情形。在表格 UG2LL 中,因為 UniGene 和 LocusLink 是多對多的關係,為了避免資料重複,所以設定為雙主鍵。. - 36 -.
(52) 3.3 DIPLEX 的架構、流程與方法. DIPLEX 整個架構如<圖 3.3-1 DIPLEX 系統架構圖>所示,使用 Web-based Client-Server 架構建置,提供基因索引子的對應和基因表現數據查詢比對的功能。DIPLEX 使用 Linux 的自動工作排程系統 Cron 搭配 Perl 程式,定期自動更新基因索引子的資料,資料庫架 構在上一節已說明。系統的發展環境如下: 硬體部分: CPU :Intel(R) Pentium(R) 4 CPU 1700MHz RAM :1024MB H.D :240GB. PC. 軟體部分: 作業系統 :Debian Linux kernel 2.6.8 Web Server :Apache 2、JSP Server Tomcat 5.0.28 Database :MySQL 4 程式語言工具: Perl :資料淬取處理、儲存與統計。 JAVA、JSP :網站建置及資料庫管理搜尋。. - 37 -.
(53) <圖 3.3-1 DIPLEX 系統架構圖> DIPLEX 的 Data Collector 會自動定期去下載各個相關資料庫的資料包含 Swissprot, GeneOntology 和 NCBI 的 LocusLink , Unigene 及 OMIM,經過整理之後存放到 MySQL 資. 料庫中。使用者利用瀏覽器對 DIPLEX 進行資料搜尋的動作,DIPLEX 使用 JSP,Perl program,MySQL Database System 建置。. - 38 -.
(54) 3.4 網站架構與演算法 DIPLEX z z z. 主要分為七項功能,包含: Gene Look up:提供基因的相關資訊。 Gene ID Translator:提供基因 ID 轉換的功能,相似於 MatchMiner。 Multiple Gene Annotation:提供基因註解的功能。. z UniGene Tracer:提供查核手邊的 UniGene 是否過期。 z Gene Expression:提供基因在各個組織的表現量。 z Pathway Finder:提供搜尋統計基因相關的生化反應路徑。 z Gene Match:提供比對兩個基因 List 的交集。 整個網站的網頁架構如<圖 3.4-1>所示,分別列出每一項功能所相關的頁面網址,並區 分 HTML Page 和 JSP Page 以及處理目的。 HTML Page. JSP Page GLU.jsp GLU.jsp. Gene Gene Look Look up up page page GeneLookup.html GeneLookup.html. GIT.jsp GIT.jsp (General (General Process) Process) BGIT.jsp BGIT.jsp (Batch (Batch Process) Process). Gene Gene ID ID Translator Translator page page GeneIDTranslator.html GeneIDTranslator.html. MGA.jsp MGA.jsp (General (General Process) Process) MGA1.jsp MGA1.jsp (Display (Display HTML) HTML). Multiple Multiple Gene Gene Annotation Annotation page page GeneAnnotation.html GeneAnnotation.html. MGA2.jsp MGA2.jsp (Display (Display Excel) Excel) BMGA.jsp BMGA.jsp (Batch (Batch Process) Process) BMGA1.jsp BMGA1.jsp (Display (Display HTML) HTML). Index Index index.html index.html. UniGene UniGene Tracer Tracer page page UniGeneTracer.html UniGeneTracer.html. BMGA2.jsp BMGA2.jsp (Display (Display Excel) Excel). GE.jsp GE.jsp. Gene Gene Expression Expression page page GeneExpression.html GeneExpression.html. GE-I.jsp GE-I.jsp ~~ GE-IV.jsp GE-IV.jsp. SPF.jsp SPF.jsp (General (General Process) Process). Pathway Pathway Finder Finder page page PathwayFinder.html PathwayFinder.html. BSPF.jsp BSPF.jsp (Batchl (Batchl Process) Process). GMT-I.jsp GMT-I.jsp (Type (Type I)I). Gene Gene Match Match page page GeneMatch.html GeneMatch.html. GMT-II.jsp GMT-II.jsp (Type (Type II) II) GMT-III.jsp GMT-III.jsp (Type (Type III) III). <圖 3.4-1 DIPLEX SiteMap> 圖中右邊 JSP Page 底下括號內的 General Process,表示使用者直接在網頁中輸入資料,. 而 Batch Process 則是處理使用者上傳的檔案。. - 39 -.
(55) DIPLEX 是依照三層式(3-tier)架構建立,分別為 Presentation Layer、Business Layer、Data Layer。在<圖 3.4-2 三層式架構示意圖 A >和<圖 3.4-3 三層式架構示意圖 B >中,使用者 所使用到的功能皆包含一個重要元件『Gene ID Translate BOX』 ,這個元件就像一個黑盒 子一樣,只要丟基因 ID 進去,就會回傳所要轉換的 ID 回來,再由各功能所屬的 Middle Process Program 處理,最後輸出結果至 Result Page。<圖 3.4-2 三層式架構示意圖 A >中, 左邊 Presentation Layer 列出 DIPLEX 和 Gene Info Database 有關的四項功能。右邊的 Gene Info Database,整合了 2.1 節所述之相關資料庫的資料,包括:NCBI 相關 database、Gene Ontology、HUGO..等。. Presentation layer. Request Request. Business Layer. Data Layer. Index Index page page. Gene ID Translate BOX. Request Request. Gene Gene ID ID Translator Translator page page Gene Gene Match Match page page User. Multiple Multiple Gene Gene Annotation Annotation page page. Gene Info Database. Response Response. Gene Gene Look Look up up page page. Middle Middle Process Process Program Program. NCBI. GO. HUGO. Response Response. Result Result page page. etc.. <圖 3.4-2 三層式架構示意圖 A> 圖中『Middle Process Program』表示各程式的一個中繼處理概念,並非指一特定程式元 件。Gene Info Database 整合所有基因相關的資料。. - 40 -.
(56) <圖 3.4-2 三層式架構示意圖 B >中,左邊 Presentation Layer 列出 DIPLEX 三項功能,其 中『UniGene page』直接存取 Gene Info Database 判讀 UniGene 是否已被修正。 『Microarray Gene Expression page』經由 BOX 轉換 ID 後,由 Middle Process Program 存取 Gene Expression Database 後產生基因表現數據圖。『Pathway Finder page』則存取 Pathway Database。. Presentation layer. Request Request. Business Layer. Data Layer. Index Index page page. Request Request. UniGene UniGene Tracer Tracer page page Microarray Microarray Gene Gene Expression Expression page page User. Pathway Pathway Finder Finder page page. Response Response. Response Response. Gene ID Translate BOX. Middle Middle Process Process Program Program. Gene Info Database. Gene Expression Database. Pathway Database. Result Result page page. <圖 3.4-3 三層式架構示意圖 B> 圖中『Middle Process Program』表示各程式的一個中繼處理概念,並非指一特定程式元 件。Gene Info Database 整合所有基因 ID 相關的資料。Gene Expression Database 收集各 組織的基因在 Microarray 上的表現數據資料,包含 Normal 和 Cancer 兩種不同組織的細 胞。Pathway Database 收集了 KEGG 和 Biocarta 的 Pathway Map 與基因對應的資料。. - 41 -.
(57) 3.4.1. Gene ID Translate BOX. DIPLEX 最重要的核心就是『Gene ID Translate BOX』,所有的功能皆要透過這個 BOX 來轉換基因的 ID,<圖 3.4.1-1 Gene ID Translate BOX Algorithm>描繪出 BOX 所用的演 算法流程,<圖 3.4.1-2>舉例詳細說明演算法的流程。BOX 所能接受的 Input Type 有 10 種,包括:EntrezGene、UniGene、Gene Symbol、Clone IMAGE、Gene Ontology、SwissProt、 OMIM Number、GenBank Accession、RefSeq、Affy Probe Set ID。Output Type 有 13 種, 包含 Input Type 以及 SAGE Tage、Maps、Aliases 等。. OMIM. GenBank RefSeq. Microarray Clone Image ID Affy Probe Set ID. GenBank Accession NO.. Gene ID Translate BOX. HGNC Gene Symbol Gene Name. Entrez GeneID. Report Report. Retrieval. SAGE Tag. Gene Identifier Translation Result. UniGene ID General Link Connect to Entrez GeneID SwissProt. Gene Ontology. <圖 3.4.1-1 Gene ID Translate BOX Algorithm> Middle Process Program 輸入資料到 BOX 後,BOX 會先判斷輸入為何種 Type,轉為 Entrez GeneID,再以 Entrez GeneID 回頭做 Retrieval 的動作。圖中藍色箭頭表示有直接 對應到 Entrez GeneID,紫色線表示其它對應路徑。. - 42 -.
(58) Gene ID Translate BOX. Microarray Clone Image ID Affy Probe Set ID. GenBank Accession NO.. Input Data. Map to UniGene. No. Yes Is UniGene exist?. No Is RefSeq exist?. Is geneID exist?. No Yes No Is geneID exist?. Unknown EST. Yes. Map to RefSeq. Yes. Map to Entrez Gene ID. Yes. No Is geneID exist?. Map to Entrez Gene ID. <圖 3.4.1-2 Gene ID Translate BOX Algorithm Flow Chart> 當輸入的是 Clone Image ID 或是 Affy Probe Set ID 時,會先轉為 GenBank Accession NO,接著判斷是否有對應到 Entrez GeneID,若沒有則再判斷是否有對應到 RefSeq ID, 再經由 RefSeq ID 接著判斷是否有對應到 Entrez GeneID,若沒有對應則再判斷是否有對 應到 UniGene ID,再經由 UniGene ID 對應到 Entrez GeneID,沒有對應則為 Unknown EST。演算法所有的路徑中,透過 UniGene 所產生出對應 Entrez GeneID 的結果,由於 UniGene 本身有可能會變動,其可信度較低,有錯誤的疑慮,因此需要定期更新。. - 43 -.
(59) 3.4.2. Pathway Finder. Pathway Finder 整合了 KEGG 和 BioCarta pathway database 中所有的 pathway maps, KEGG pathway database 目前包含有 179 張 pathway maps,和大約 2,926 genes 相關; Biocarta pathway database 則包含有 355 張 pathway maps,和大約 4,654 genes 相關。透 過 DIPLEX 的 Pathway Finder,使用者輸入一串基因 List 後,可搜尋到所有和基因 List 有關的 pathway maps,並且會計算出有多少基因在哪張 pathway map 上。Pathway Finder 的演算法流程如<圖 3.4.2>所示。. Pathway Finder Create array for maps. Counting total pathway No.. Gene ID Translate BOX. No Is geneID in map?. GeneID. Gene List. Yes Yes No. Counting and put GeneID into array. Next?. User Input Data. Show maps. <圖 3.4.2 Pathway Finder Algorithm Flow Chart >. 使用者輸入基因 List 後,透過 Gene ID Translate Box 將輸入的基因轉為 Entrez Gene ID, 在判斷是否有 Gene ID 和 Pathway Map 有關,並且計算相關基因的個數,最後 show 出 結果。. - 44 -.
(60) 3.5 JSP 相關元件. 在開發 DIPLEX 的過程中,需要許多特別的功能在 JSP 本身並沒有提供,例如產生統 計的圖形、把結果輸出成為 Excel 格式讓人下載、提供使用者上傳檔案、資料內容格式 判讀等功能,如果需要一一自行設計,則將會浪費很多時間,因此使用網路上免費提供 的套件縮短開發流程,以下介紹在 DIPLEX 中所使用到的 JSP 套件。. 3.5.1 JfreeChart 產生統計圖的程式庫. JfreeChart 是一個免費的 Java class library 用來產生各種常用的統計圖,包含: • • • • • • • • • •. pie charts (2D and 3D) bar charts (regular and stacked, with an optional 3D effect) line and area charts scatter plots and bubble charts time series, high/low/open/close charts and candle stick charts combination charts Pareto charts Gantt charts wind plots, meter charts and symbol charts wafer map charts. 專門設計給 Java application, applet, servlets 和 JSP 使用,並提供完整的 source code,網 址為 http://www.jfree.org/jfreechart/,DIPLEX 所使用的版本是 jfreechart-1.0.0-rc1.tar.gz , 下 載 後 解 壓 縮 至 任 意 目 錄 中 , 將 目 錄 中 的 jfreechart-1.0.0-rc1.jar 和 jcommon-1.0.0-rc1.jar , 複 製 到 %JAVA_HOME% /jre/lib/ext/ , 並 修 改 環 境 變 數 CLASSPATH 後,即完成安裝。. 3.5.2 Jakarta-POI 處理 MS-Excel 的程式庫. POI project 開發的目的,是要提供一個純粹的 Java API 用來存取 Microsoft Office 的檔.
(61) 案格式,例如 Word、Excel 等。我們可以利用 POI 開發出可輸出 Excel 檔案的程式,也 可讀取 Word 的文件。POI project 的網址為 http://jakarta.apache.org/poi/,DIPLEX 所使用 的版本是 jakarta-poi-1.5.1-final-bin.zip,下載後解壓縮至任意目錄中,將目錄中的 build 目錄下的 jakarta-poi-1.5.1-final-xx.jar,複製到 %JAVA_HOME% /jre/lib/ext/,並修改環 境變數 CLASSPATH 後,即完成安裝。. 3.5.3 Jakarta-ORO 處理正規表示式的程式庫. Jakarta 的 ORO 程式套件,提供我們在 Java 底下使用與 Perl 相同的正規表示式(Regular Expression),增強文字比對處理的能力。正規表示式(Regular Expression)是一種描述, 用來表示某種樣式或者若干樣式的組合。例如,如果有一個使用者輸入的字串,如 「IMAGE:12345678」 ,想知道使用者輸入的格式是否為 IMAGE : xxx(xxx 表數字),而且 要區分大小寫,這該如可判斷? 這時候,可能解決的方法是先「取得第一個字元」,再利用「A ~ Z」ASCII 值的範圍來 判別這個字元,再接著抓後面的字元做判斷。如果輸入的格式種類很多,那這個程式碼 就會寫的很複雜了。有人就發展出一套「字串樣式比對的描述性語言」,用來: 檢查某字串是否完整對應到某樣式 (核對) ─ 例如某字串是否符合 E-mail「帳號@網域名稱」的格式 在某字串中找尋對應樣式的子字串 (搜尋) ─ 例如在一篇文章中找出有關「達文西」二字的字串部份 由字串中取出對應到某樣式的字串 (取代) ─ 例如將文章中有關「達文西」三字的字串取代為「忍者 」三字的字串。 簡單的來說,就是利用「正規表示式 Regular Expression」來進行字串的比對及處理。 要取得 ORO 套件,可從 http://jakarta.apache.org/oro/ 中下載,DIPLEX 所使用的版本是 jakarta-oro-2.0.8.zip,下載後解壓縮至任意目錄中,將目錄中下的 jakarta-oro-2.0.8.jar, 複製到 %JAVA_HOME% /jre/lib/ext/,並修改環境變數 CLASSPATH 後,即完成安裝。. - 46 -.
(62) 3.5.4 O’Reilly MultipartRequest 檔案上傳元件. 在網頁中要提供使用者上傳檔案的服務,會遇到到一些複雜的檔案編碼問題,因為在使 用者端和伺服器端所使用的編碼格式不同,伺服器端無法直接取得使用者所上傳的檔案 內容,因此我們須要借助歐萊禮(O’Reilly)公司所開發的 MultipartRequest 套件,來提供 使用者上傳檔案的服務,MultipartRequest 套件可在 http://www.servlets.com/cos 中下載。 DIPLEX 所使用的版本是 cos-05Nov2002.zip,下載後解壓縮至任意目錄中,將目錄中下 的 cos-05Nov2002.jar , 複 製 到. tomcat5/common/lib/ 和. tomcat5/webapps/ROOT/. WEB-INF/lib/ 底下,即完成安裝。複製到 %JAVA_HOME% /jre/lib/ext/ 底下可能無法 找到該元件。. - 47 -.
(63) 第四章 系統實作. DIPLEX 的開發過程分為兩期:DIPLEX 前期的目標,在建立完整的資料庫架構與基本 功能成形。後期的目標,著重在功能整合與使用者介面的設計上面,並新增幾項功能, 以下介紹前後期的成果。. 4.1 DIPLEX 前期實作. DIPLEX 初步的架構,建置在 http://bio.tmu.edu.tw:8080/diplex/。 DIPLEX 提供六個基本功能: 1.. Single Gene Identifier Lookup 提供單一基因索引子對應轉換的功能. 2.. Multi Gene Identifier Lookup 功能和 Single Gene Identifier Lookup 相似,提供一次大量輸入基因索引資料。. 3.. Batch Gene Identifier Lookup 提供上傳檔案做批次查詢的動作。. 4.. Single Array Annotation 查詢 DIPLEX 中已儲存的微陣列註解資料,或是使用者上傳的微陣列資料。. 5.. Multi Array Annotation 查詢比較不同微陣列之間交集、聯集、差集基因的註解資料。. 6.. Gene Pathway Search 查詢和基因相關的 Pathway 資料。. - 48 -.
(64) <圖 4.1-1 DIPLEX 首頁畫面>. - 49 -.
數據

+5



Outline
相關文件
莊子美學中所呈現的「開放性系統」, 試圖來彌合菁英系統與庶民 系統之間的落差, 因為社會的穩定維繫於庶民教育體系的建立。毫
1.提高接收資料的速度 2.降低資料傳輸速度 接收端RX接收資料的速度低於發.
課程利用雲端學習平台 OpenEdu 從最基礎開始說明 Python 的語 法與應用,配合 Quiz in Video
數位計算機可用作回授控制系統中的補償器或控制
利用一些基本的 linear transfor- mations 的變化情形, 我們學習了如何將一個較複雜的 linear transformation 拆解成一些較 容易掌握的 linear
推理論證 批判思辨 探究能力-問題解決 分析與發現 4-3 分析文本、數據等資料以解決問題 探究能力-問題解決 分析與發現 4-4
The study samples are students’ quiz grades , homework assignments (paper homework and English homework) and six comprehensive examinations.. It’s our hope that these conclusions
結 果發現這個新解跟greedy choice一樣好 (也是一個 最佳解) 或者發現這個新解更好 (矛盾, 所以最佳解 裡面不可能沒有greedy
