基於關聯式分類技術之機車噴射引擎故障診斷輔助系統
蔡國彬
林文揚*
高雄大學資訊工程學系
[email protected]; *[email protected]
摘要 近來年所有 4 期環保法規的舊車款都已停止販 售,往後機車製造廠推出的新車款將採用和汽車類 似的噴射供油系統,與傳統引擎相較之下更加複 雜,很難單純依賴機師的經驗進行問題判斷,必須 仰賴輔助的系統。然而,現階段機車維修方式需透 過診斷器讀取 ECU 所判定的故障碼,由於 ECU 數據相當複雜,工程師根據測試經驗調整 ECU 的 參數需花費不少時間,並無一套完整系統輔助工程 師動態的參考歷史記錄做出更即時準確的診斷。 本研究以某機車製造公司的機車製造產線檢驗流 程作為研究標的,旨在建構一個機車噴射引擎故障 診斷輔助系統。我們的系統整合資料倉儲技術與資 料探勘方法,針對組裝生產線所收集、匯整的 ECU 數據,運用我們提出的改良自關聯式分類技術的 R-CMAR 演算法預作探勘處理,將探勘得到的故障 可能因素與故障代碼的樣式組合加以儲存於資料 庫系統中,進而建構出類似多維度分析的機車噴射 引擎故障原因線上診斷介面,可大幅度地降低工程 師調整時間、檢驗員的檢驗時間。 關鍵詞:機車噴射引擎、診斷輔助系統、關聯式分 類、資料探勘。 1. 前言 隨著全球溫室效應導致的氣候異常,降低 CO2 排放量已成為全球共同的責任,不僅汽車產業如 此,兩輪的機車產業也同樣責無旁貸。身為全球機 車密度最高地區之一的台灣,從 2007 年 7 月起開 始推動國家 5 期環保法規,迫使國內機車工業全面 噴射供油化,並自 2009 年起停售所有 4 期環保法 規的舊車款 [5]。往後機車製造廠推出的新車款將 採用和汽車類似的噴射供油系統,一旦進入噴射引 擎時代,機車要修引擎就不能只靠黑手的經驗,這 宣告了修機車已經進入電腦時代了。 現階段機車維修方式需透過診斷器讀取 ECU (Electronic Control Unit;微電腦控制器)所判定的故 障碼,但由於 ECU 數據相當複雜,目前並無一套 完整系統輔助工具可供工程師動態的參考歷史記 錄做出更即時準確的診斷,因此工程師是依據測試 經驗調整 ECU 的參數。此種方式會產生兩個問 題:一個是工程師需花費相當多時間進行測試與調 整;另一個是檢驗員進行檢驗時,每台車皆憑記憶 或翻閱維修手冊,導致效率不高。因此,若有一套 完善的機車噴射引擎故障診斷輔助系統,將有助於 提升維修率、降低維修時間。 本研究以某機車製造公司的機車製造產線檢 驗流程作為研究標的,旨在建構一個機車噴射引擎 故障診斷輔助系統。我們的系統整合資料倉儲技術 與資料探勘方法,針對組裝生產線所收集、匯整的 ECU 數據,運用我們提出的改良自關聯式分類技 術的 R-CMAR 演算法預作探勘處理,將探勘得到 的故障可能因素與故障代碼的樣式組合加以儲存 於資料庫系統中,進而建構出類似多維度分析的機 車噴射引擎故障原因線上診斷介面,可大幅度地降 低工程師調整時間、檢驗員的檢驗時間。 本論文其餘內容安排如下:第二節為背景知識 及相關研究,第三節為系統設計與架構說明,第四 節主要說明我們提出的 R-CMAR 探勘方法,第五 節為系統實作說明與實驗分析,第六節為結論與未 來研究方向。 2. 相關研究 據我們所收集的文獻顯示,目前有關機車噴射 引擎診斷的研究仍付之闕如。在學術界方面,目前 的研究多針對汽車引擎或傳統的機車引擎,主要可 歸納為兩大類: (1)發展引擎錯誤診斷的專家系統[1,3,8,9], 所採用的方法大多為建立專家的知識庫,結合案例 式推理(case-based reasoning)來判斷; (2)根據引擎噪音的訊號發展診斷的方法,所採 用的技術如模糊理論[2]、類神經網路[13,18,19, 24]、小波轉換(wavelet transform)[19,22,24]、主 成分分析(principal component analysis)[23]。在工業界方面,主要集中在發展診斷的軟引, 開發的廠商大致上可分二類: (1)ECU 製造商:由 ECU 原廠自行開發之診斷 軟體,只能診斷自家 ECU,適合於機車製造商、 改裝車業者,如德國西門子、台灣敦陽、美國 DELPHI 等; (2)軟體公司:由專門提供機車行維修相關軟體 的專業軟體公司開發,單一軟體可以診斷多品牌 ECU,適合於機車店頭業者,如極致摩托車科技、 東浥科技等。 3. 系統分析與架構設計 3.1 系統架構 如圖 1 所示,我們的系統是以資料倉儲[12]作 為資料的中心,提供前端的使用者進行 OLAP 分析 和關聯規則探勘。OLAP(線上分析處理,On-Line Analytical Processing)是一種能提供多維度以及快 速查詢的分析工具,具動態的多維度分析、複雜計
算的能力,以及具時間導向,通常這些資料都是以 資料方體(data cube)的方式儲存[14]。由於絕大部分 的資料倉儲系統皆會提供此種分析工具,故本研究 直接採用現成的軟體,而非自行發展此部分的功 能。 另一關聯規則探勘工具是採用我們自行發展 的以關聯規則分類法[16]為基礎的探勘引擎,透過 此引擎,系統會根據分析者下達的查詢內容,由資 料倉儲中所記錄的 ECU 資料,產生各故障代碼與 ECU 檢測項目之間的關聯關係,了解導致故障發 生的可能原因,以進行後續更深入的分析與維修等 工作,這部份的設計將在第四節深入說明。 本節接下來的內容將敘述如何定義資料倉儲 的綱要結構、來源資料、資料的前置處理等,並以 實例說明 OLAP 工具在此系統所扮演的分析角色。 圖 1 系統架構圖 3.2 資料來源 我們以某機車製造公司的機車製造產線檢驗 流程系統(MES)資料作為資料來源,這些資料是由 機車製造廠於機車製造過程中所儲存,記錄每一部 機車於製造的各項檢驗數據(在本篇論文中我們將 以 ECU 數據為主)及故障內容,主要分三個部份: 1. 產品基本資料表:記錄產品各項基本資料, 如車號、機種代號等。 2. 檢驗數據表:記錄 ECU 資料的各項數據。 3. 維修登錄檔:記錄產品的維修內容。 ECU 的資料綱要結構(Table Schema)如圖 2 所 示,由六個關聯資料表組成。 1. BAS_CAR:記錄成車各項基本資料,如機 種代碼、製造日期。 2. BAS_MACHINE:記錄機種名稱、引擎代 號。 3. BAS_REPAIR_MASTER:記錄維修記錄表 頭檔,含維修日期、維修車號。 4. BAS_REPAIR_DETAIL:記錄單次維修代 碼 5. BAS_REPAIR:記錄維修代碼基本資料。 6. BAS_ECU_DETAIL:ECU 檢驗數據,含 車號、檢驗日期以及各項檢驗數據,如引 擎轉速、汽缸頭溫度、電瓶電壓等。 由於該公司噴射引擎機車是由 2011 年起才正 式生產,因此,本篇論文將以 2011 年起生產產品 為研究標的。 BAS_CAR CAR_NO MACHINE_ID MDF BAS_MACHINE MACHINE_ID ENGINE_ID DESCP BAS_REPAIR_MASTER REPAIR_MASTER_ID CAR_NO REP_DATE BAS_REPAIR_DETAIL REPAIR_MASTER_ID REPAIR_DETAIL_ID REPAIR_ID BAS_REPAIR REPAIR_ID REPAIR_NAME BAS_ECU_DETAIL CAR_NO CREATE_DATE T01 T02 T03 T04 T05 T06 T07 T08 T09 T10 T11 T12 T13 T14 圖 2 ECU 資料綱要結構 3.3 資料倉儲及架構 資料倉儲的綱要結構定義為建構資料倉儲的 首要工作,傳統上多採用星狀綱要[14]。然而,因 ㄧ個故障代碼可能與多種檢測項目有關,而每一個 檢測項目的問題也有可能導致多種故障,故二者間 關係是屬多對多,傳統星狀結構的多維度模式不能 表達此種關係。我們採用 Kimball 的方法[14],使 用中繼表來解決多對多的關係。圖 3 為我們定義的 ECU 資料倉儲綱要結構,其中包一個事實表、五 個維度表和兩個中繼表。 Testitem_value Testitem_name Testitem_id Testing_Dimension Testitem_id Testing_Group_id Testing_Group Error_id Error_group_id Error_Group Error_descp Error_id Error_Dimension Machine_descp Machine_id Machine_Dimension Engine_descp Engine_id Engine_Dimension ECU_DATA_FACT Error_group_id Testing_group_id Testing_date_id Engine_id Machine_id Day Month Year Testing_date_id Testing_Date_Dimension 圖 3 ECU 資料倉儲綱要結構 ECU_DATA_FACT 為事實資料表,包含了由 五 個 外 來 鍵 (foreign key) 組 成 的 主 要 鍵 (primary key) : Machine_id 、 Engine_id 、 Testing_date_id 、 Testing_group_id、Error_group_id,分別連結三個 維 度 表 : Machine_Dimension( 車 子 的 機 種 ) 、 Testing_Date_Dimension( 車 子 的 檢 驗 日 期 ) 、 Engine_Dimension( 車 子 的 引 擎 ) 、 以 及 二 個 中 繼 表:Testing_Group、Error_Group,Count 欄位是 ECU_DATA_FACT 的量測值。 3.4 資料預處理 從 ECU 資料庫中檢測故障內容,並不是一件 容易的事,因為有很多問題待克服。首先,數據是 零散的,因為數據是直接從車子的 ECU 讀出,並 非所有數據對於故障檢測皆是有用的,而且數據為 連續數據,因此有必要對資料進行預處理,將需要 預處理的資料整理如下: 1. 無意義數據:因 ECU 數據相當多,並非每 個數據皆與故障原因有關聯,在此,我們 依據專家經驗,先保留六種數據觀察,引
擎轉速(rpm)、汽缸頭溫度(degC)、電瓶電 壓(V)、進氣感知器感測溫度(sdegC)、進氣 壓力(kpa)、含氧感知器電壓(mV)。 2. 連續數據離散化:我們將保留的數據進行 離散化作業,依據專家的經驗建議劃分了 幾個級別如圖 4。 3. 重覆記錄:在 ECU 資料庫中,有些車子可 能會有重覆記錄,因此重覆記錄應移除。 4. 不一致的記錄:例如‘引擎有異聲’跟‘引擎 鳥叫聲’,算是同一故障原因,故應將二種 原因合併成一種。 圖 4 離散化的級別 3.5 OLAP 由於 OLAP 具備多面向與計算快速的特性,故 非常適合在複雜、廣大的資料空間中,初步探測潛 在值得關注的資料區域。以本研究為例,從資深機 車維修者觀點看故障分析,故障原因多數會隨不同 機種、時間與屬性而異,惟有歷經長時間累積足夠 經驗才能快速作出判定,若我們能善用己建構出的 資料倉儲,搭配 OLAP 工具,將能協助維修者更快 速掌握值得分析的故障及可能的原因,再鎖定此故 障代碼或檢測項目,運用我們提供的探勘工具,深 入分析故障的原因。例如使用者可以根據年度與故 障兩個維度進行 OLAP 分析,了解發生機率高的故 障原因是否常發生於某些期間。由圖 5 的例子可得 知 2011 年故障代碼‘11’發生次數最高,因此為探討 發生機率高的故障原因是否與某些 ECU 檢測項目 有因果關係,所以篩選出故障代碼‘11’所對應的 ECU 資訊,如圖 6 所示。反之,使用者也可以針 對特定的檢測項目,觀察其伴隨的故障代碼出現的 頻率。由圖 6 得知‘D5’出現機率最高,因此可查詢 D5 所導致的故障代碼有那些,由圖 7 得知 D5 出 現故障 ‘11’的次數是最高的。 圖 5 2011 年故障次數 圖 6 2011 年故障代碼‘11’的 ECU 資訊 圖 7 2011 年 ECU 資訊‘D5’所發生的故障代碼 4. 噴射引擎故障規則探勘方法設計 4.1 診斷規則定義與量測指標 我們首先定義噴射引擎故障的診斷規則,每一 個診斷規則皆由一組 ECU 檢測項目與故障代碼所 組成,如下例: [電瓶電壓 < 14 無法發動] 其中‘電瓶電壓 < 14’表示 ECU 檢測項目,‘無法發 動’則是表示故障內容。 上述的規則在形式上可視為一種分類規則,規 則的右項‘故障碼’可視為是類別,而左項則為分類 的因子。 由 於 分 類 規 則 可 視 為 是 一 種 限 制 右 項 (constrained consequence)的關聯規則,故傳統上衡 量指標多採用關聯規則常用的支持度(support)與可 信度(confidence)[6, 7]。然而基於下列理由,我們未 完全採用此種指標: 1. 在實務上,有可能因為新產品剛上市,導 致支持度非常低,因為產品剛量產,所以 這種規則非常的重要; 2. 某項 ECU 資訊所導致的故障原因發生的 機率很低,但是在診斷中,卻要耗費相當 多時間,這種規則也非常重要。 在此我們加入在風險分析,特別是醫藥界中常 使 用 的 量 測 指 標 : 相 對 通 報 比 (Proportional Reporting Ratio , 簡 稱 PRR)[10] 與 通 報 勝 算 比 (Reporting Odds Ratio,簡稱 ROR)[17]。這兩個指 標的優點是不受限於觀察資料的筆數以及規則發 生的機率(即支持度),著重於被觀察事件的因果關 係相對於其他的項目組合的機率比值。其計算可以 簡單的 2×2 列聯表進行,以下列規則為例: [degC > 42, rpm > 5200 汽缸問題] 表 1 為此規則對應的 2×2 列聯表,表 2 為 PRR、 ROR 的公式及閥值定義。 4.2 演算法基本構想 我們所提出的演算法是採用關聯式的分類方 法,其概念最早是由 Liu 等人提出[16],將分類關
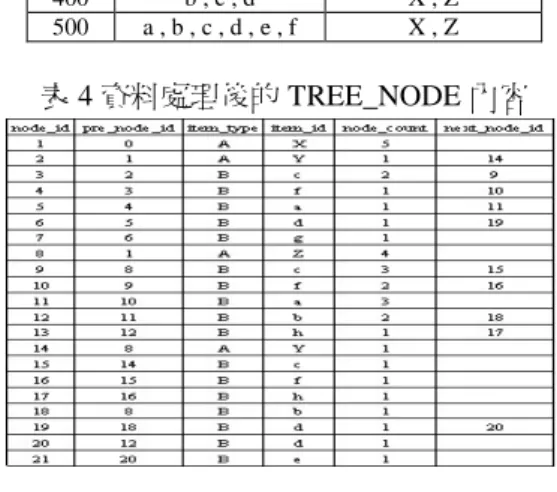
則視為是一種關聯規則,故可採用類似探勘關聯規 則的作法先找尋頻繁項目集,再由頻繁項目集產 生符合要求的分類規則。此後,陸續有學者提出改 良的方法[15,20,21,25],使得此種以關聯規則 為基礎的分類方法愈來愈受重視,並且成為一個有 影響力的分類方法。 表 1 指標範例 2 × 2 列聯表 汽缸問題 其他問題 degC > 42,rpm > 5200 a b a + b 其他檢測項目 c d c + d a + c b + d 表 2 指標公式表 我們的方法稱為 R-CMAR(Reverse CMAR), 是改良自 CMAR 演算法[15]採用類似著名的 FP-Growth 方法的 FP-tree 結構[11]。然而,為了能 快速支援使用者於線上進行交談式的探勘分析,我 們 採 取 類 似 OLAP 資 料 方 體 的 預 存 概 念 , 將 R-CMAR 所得到的規則樣 式預存於資料庫系統 中,當使用者下達探勘查詢時,便可由規則樣式庫 中快速生符合的規則。該方法具有幾個好處:(1) 採用類似 FP-tree 的樹狀結構可以有效壓縮資料 量,實驗證明我們的方法的壓縮效果遠優於 CMAR 所用的 CR-tree 結構;(2)結合資料庫系統己經很成 熟的索引和查詢處理能力,可有效支援線上探勘, 也有利於後續資料的維護。 4.3 資料結構 我們所採用的資料結構是改良自 CMAR 演算 法所用 CR-tree,之所以未直接採用 CR-tree 的理由 如下。如圖 8 所示,CMAR 是將產生的分類規則儲 存於 CR-tree 中,每條由根節點到儲存分類項目的 節點的路徑皆對應一條分類規則,例如此圖對應四 條規則為[a, c X],[a, b, c Y, Z],[a, b, d X, Z],[d X]。其缺點是當類別種類遠少於分類因 子項目時,對於常重複出現的類別項目無法進行有 效的壓縮,導致 CR-tree 的維護時間變長,也降低 探勘速度。 鑑於我們的 ECU 資料的故障碼種類遠低於檢 測項目值的種類,故上述 CR-tree 的缺點極為明 顯,故我們提出改進的方法,將代表故障碼的項目 置於樹狀結構的上層,而非如 CR-Tree 置於樹狀的 下 層 , 故 我 們 將 之 稱 為 RCR-Tree (Reverse CR-Tree) 。以圖 8 為例,其對應的 RCR-tree 如圖 9 所示。 Header Table Item link a b c d d (X:1) Root a b c (Y:1, Z:1) d (X:1, Z:1) c (X:1) Header Table Item link a b c d d (X:1) Root a b c (Y:1, Z:1) d (X:1, Z:1) c (X:1) 圖 8 CR-Tree 結構 Item_Header Item link a b c d d a b c d Class_Header Class link X Y Z X:3 Root Y:1 Z:1 Z:2 a b c Item_Header Item link a b c d d a b c d Class_Header Class link X Y Z X:3 Root Y:1 Z:1 Z:2 a b c 圖 9 RCR-Tree 樹狀圖 另外,我們將 RCR-tree 存於關聯式資料庫中, 其資料表的結構如圖 10,各表格說明如下: (1) TREE_NODE:記錄 TREE 的節點資訊,有 六個欄位
。
1. Node_id:記錄節點編號,為流水號產生。 2. Pre_node_id:記錄此節點的父節點編號。 3. Item_type:記錄節點的種類,所存的內容 為檢測值或錯誤碼。 4. Item_id:記錄節點的內容,為檢測值代號 或錯誤碼。 5. Node_count:記錄項目出現次數。 6. Next_node_id:記錄同類別或同規則代碼出 現在下一個節點位置,以利資料探勘時所 用。 (2) CLASS_HEAD:記錄類別資訊及首次節點 位置,有四個欄位。 圖 10 RCR-tree 的關聯表格結構 指標 公式 閥值 PRR PRR1.96SE > 1 ROR ROR1.96SE > 1CLASS_HEAD Class_id Class_count Head_node_id Last_node_id TREE_NODE Node_id Pre_node_id Item_type Item_id Node_count Next_node_id ITEM_HEAD Item_id Item_count Head_node_id Last_node_id
)
/(
)
/(
d
c
c
b
a
a
d b c a / /1. Class_id:記錄錯誤代碼。 2. Class_count:錯誤碼出現次數。 3. Head_node_id:錯誤碼在 tree_node 中首次 出現的節點編號。 4. Last_node_id:錯誤碼在 tree_node 中最後 出現的節點編號。 (3) ITEM_HEAD:記錄屬性資訊及首次節點 位置,有四個欄位。 1. Item_id:記錄檢測值代號。 2. Item_count:檢測值出現次數。 3. Head_node_id:檢測值在 tree_node 中首次 出現的節點編號。 4. Last_node_id:檢測值在 tree_node 中最後 出現的節點編號。 我 們 所 提 出 的 演 算 法 , 稱 作 R-CMAR , R-CMAR 演算法分成二個階段:第一是 RCR-tree 建 構,第二是規則探勘。將在下面二節作詳細說明。 4.4 建構 RCR-tree RCR-tree 的建構方式類似 FP-tree 的建構方 式,主要有三個步驟: 1. 由資料倉儲中擷取相關的資料表,產生探 勘所需要的交易資料檔; 2. 掃瞄交易資料檔,計算每個分類因子項目 (檢測項目)及類別項目(錯誤碼)出現的次 數,並加以排序; 3. 掃瞄交易資料檔,依序讀入一筆資料,將 之排序後,存入 RCR-tree 的表格資料中, 若對應此資料的路徑已存在,則更新其次 數,反之則產生一新的路徑。 以表 3 的交易資料檔為例,其產生的 RCR-tree 的表格資料如表 4~6。 表 3 交易資料 序號 項目 類別 100 a , c , d , f , g X , Y 200 a , b ,c , f , h X , Z 300 c , f , h X , Y , Z 400 b , c , d X , Z 500 a , b , c , d , e , f X , Z 表 4 資料處理後的 TREE_NODE 內容 4.5 R-CMAR 的規則產生 在實際進行檢測時,使用者可透過本系統的探 勘查詢介面(詳細說明如第 5 節)輸入檢測的項目 值,以了解可能會導致的錯誤碼。我們提出的規則 產生方法有幾個步驟: 表 5 資料處理後的 CLASS_HEAD 內容
Class_id Class_count Head_node_id Last_node_id
X 5 1 1
Y 4 2 2
Z 2 8 14
表 6 資料處理後的 ITEM_HEAD 內容
Item_id Item_count Head_node_id Last_node_id
c 5 3 15 f 4 4 16 a 3 5 11 d 3 6 20 g 1 7 7 b 3 12 18 h 2 13 17 e 1 21 21 1. 探勘項目依據 ITEM_HEAD 的 Item_count 由小至大排序。 2. 將探勘項目從 TREE_NODE 作遞迴式由下 往上的尋找,將完全符合探勘項目的類別 捉出。 3. 合併符合類別的數量。 我們以 4.4 節建構的範例來作為探勘對象,假 設要探勘的項目為 ’c, a’,步驟如下: 1. ’c,a’,用 SQL 語法各自尋找 item_count, 結果再由小至大排序為’a、c’,SQL 語法 如下: select item_count from ITEM_HEAD where Item_id = ‘a’; select item_count from ITEM_HEAD where Item_id = ‘c’; 2. 先由’a’作探勘, 2.1 至 ITEM_HEAD 尋找初節點: select head_node_id from ITEM_HEAD where item_id = ‘a’; 結果應為‘0005’,設變數 ls_node_id = ‘0005’ select pre_node_id, node_count,
next_node_id from TREE_NODE
where node_id = :ls_node_id;
設變數 ls_next_node_id = next_node_id 設變數 li_count = node_count
2.3 再至 TREE_NODE 由起始節點向上尋找: select pre_node_id, item_id, item_type, node_count
from TREE_NODE
where node_id = :ls_node_id;
設 ls_node_id=捉回的 pre_node_id,持續 2.3 的步驟,一直到 pre_node_id = ‘0’為 止,將取回的 item_id (item_type =’B’)組合
起來用陣列 find[n]暫存,和原探勘組’a、c’ 比對,若’ a、c’存在於 find[n],則將此次 探勘的類別、次數(li_count) 暫存於 F1。 2.4 判斷 ls_next_node_id 是否為 null,若不是
null 則設將 ls_node_id = next_node_id,再 執行一次 2.2。 2.5 再由 ‘c’作探勘,重覆 2.1~2.4 動作 2.6 將 F1 中相同類別,作次數的合計得 F2 2.7 可得下列規則: [a, c X:3] [a, c Y:1] [a, c Z:2] 5. 系統實作與實驗 我們的系統建構環境簡述如下:作業系統為 Windows XP SP3,使用的電腦為 Inter Core 2 Quad Q8400 2.66GHz 的處理器,主記憶體為 2GB,資料 庫系統為 Sybase 12.5,使用的程式開發工具為 Powerbuilder 6.5。 系統的診斷規則探勘操作畫面如圖 11 所示, 常用檢測項目排在最上方。由於我們在訂定了六種 檢測項目,因此使用者可自由選擇一至六種項目進 行探勘,將依次數排序,使用者可選擇不同指標排 序,並可以指定要產生的規則的前 k 筆。圖 12 為 系統的探勘結果畫面,使用者可對特定規則查看其 指標的詳細計算方式說明。 圖 11 規則探勘操作畫面 圖 12 規則探勘結果畫面 5.1 效能實驗 這個實驗的主要目的是了解我們的 R-CMAR 演算法的效能,我們從兩方面來探討:一是資料壓 縮比,我們與 CMAR 演算法所用的 CR-tree 比較; 二是針對規則樣式預存與不預存的探勘時間作一 比較。 由於我們目前所蒐集的實際資料筆數過少,無 法有效提供此實驗所需,故我們採用人造的方式來 產生測試資料。我們假設測試項目有 50 種,錯誤 代碼有 30 種,平均每台車有二個錯誤代碼,產生 的 ECU 檢測紀錄筆數分別設為 1000、3000、5000、 10000、20000、30000、40000。 圖 13 為 R-CMAR 與 CMAR 存放的規則樣式 所需的節點數之比較,由圖 13 我們可以得知,隨 著資料量愈來愈大,我們提出的 R-CMAR 演算法 明顯比 CMAR 壓縮效果要來得好,因為 R-CMAR 不僅針對分類因子作壓縮,也對類別壓縮,符合我 們在 4.4 節中的推測,由圖 14 可清楚看出壓縮比 率隨著資料筆數增加而增加,最後約在 50%~60% 左右。 圖 13 R-CMAR 與 CMAR 節點數比較 圖 14 R-CMAR 與 CMAR 節點數壓縮比率 另外,我們測試規則樣式預存與未預存的效 能,我們測試在 1000 筆資料時,兩者探勘的時間, 查詢所設的屬性數目(即檢測項目)分別設為 1~6。 由圖 15 很明顯可以看出,預存的執行時間皆在 1~2 秒完成,大幅領先未預存的時間(約 50 秒)。 5.2 有效性實驗 這個實驗的主要目的是檢驗我們的演算法的 有效性,檢驗方法是計算我們的方法所找出的規則 中,確實是的正確的比率(精確率)以及有多少比率 的已知規則被我們找出(召回率)。 我們目前所收集的資料筆數為 200 筆,每筆資 料保留六種 ECU 檢測項目數據,我們並將目前該
公司所提供已知的故障與形成原因,根據常見的 14 種故障碼分成 01~13 組已知規則。我們將演算 法所產生的規則,分別以兩種指標 PRR、ROR 的 閥值進行計算與過濾,將達到門檻的規則根據其故 障碼分成上述的 14 組,對各組計算其精確率及召 回率,結果如圖 16、17 所示。 0 10 20 30 40 50 60 1 2 3 4 5 6 檢測項目數 執 行 時 間 (秒 ) 預存 未預存 圖 15 預存與未預存的時間比較 由圖中可得知 PRR 與 ROR 值很接近,並且召 回率普遍比精確率要高,PRR 整體精確率為 68%, PRR 整體召回率為 82%;ROR 整體精確率為 69%, ROR 整體召回率為 82%。此現象與我們演算法中 將所有規則皆儲存有關,多數故障原因皆可以找 到,但精確率卻比較低;由於實際資料筆數收集尚 未足夠,因此,我們將在未來計劃中收集更多資料 進行實驗。 圖 16 使用 PRR 指標的精確率及召回率 圖 17 使用 ROR 指標的精確率及召回率 6. 結論與未來研究 在本研究中,我們建構一套機車噴射引擎診斷 輔助系統。為了可以快速回答使用者線上進行診斷 規則的查詢需求,我們提出 R-CMAR 演算法,以 R-CMAR 儲存大量 ECU 數據、故障資料,以提供 資料採掘之用,並且改善 CMAR 對於多重分類的 效能瓶頸,而且我們也使用預存規則樣式的方法, 結合資料庫管理系統的索引和查詢處理功能,加快 系統的回應時間。 從實驗的結果來看,我們提出的 R-CMAR 確 實能有效壓縮資料,而結合將規則樣式預存於資料 庫系統的方法確實能大幅降低使用者於線上進行 探 勘 查 詢 的 執 行 時 間 。 我 們 相 信 我 們 提 出 的 R-CMAR 方法不僅能適用 於噴射引擎故障的診 斷,也適用於其它欲進行多重分類的系統。未來我 們將進行的工作為: 1. 加入機車店頭的維護情況:使加盟之機車 店頭皆可使用同一平台,分享彼此的知識。 2. 整合 olap 與探勘工具:將我們自行開發的 探勘工具與 olap 工具進行整合。 3. 收集更多檢測資料進行 PRR 與 ROR 的精 確率及召回率實驗。 參考文獻 1. 周裕發,「知識結構在故障診斷維修之專家系統 的 應 用 - 以 台 灣 機 車 產 業 的 技 術 維 修 員 為 例」,國立清華大學碩士論文(2004)。 2. 曹立,「摩托車發動機配氣機構異響故障診斷的 研究」,重慶大學碩士論文(2002)。 3. 楊振興,「應用案例式推理建構機車維修管理系 統」,國立台北科技大學碩士論文(2002)。 4. 蘇隄,「企業建構資料倉儲的六項關鍵議題」, 電子化企業經理人報告,第 7 期,第 31–35 頁 (2000)。 5. 環 保 署 移 動 汙 染 源 管 制 網 http://mobile.epa.gov.tw/newsdetail.aspx?News_I D=24 。
6. Agrawal, R., T. Imielinski, and A. Swami, “Mining associationrules between sets of items in largedatabases,” Proc. ACM SIGMOD Int. Conf. on Management of Data, 207–216 (1993).
7. Agrawal, R.and R.Srikant,“Fastalgorithmsfor mining association rules in large databases,” Proc. 20th Int. Conf. on Very Large Data Bases, 487–499 (1994).
8. Al-Thani, A.T., “An expertsystem forcarfailure diagnosis,” World Academy of Science, Engineering and Technology, 12, 4–7 (2005). 9. Chen, G., M. Zhu, Y. Hu, B. Liu, L. Guan, G. Xu,
and H.Shi,“Study on engine faultdiagnosisand realization of intelligent analysis system,” Proc. IEEE Instrument and Measurement Technology Conf., 2, 1194–1197 (2005).
10. Evans, S.J., P.C. Waller, and S. Davis, “Use of proportional reporting ratios (PRRs) for signal generation from spontaneous adverse drug reaction reports,” Pharmacoepidemiol Drug
Safety, 10(6), 483–486 (2001).
11. Han, J., J. Pei, Y. Yin, and R. Mao, “Mining frequent patterns without candidate generation: A frequent-pattern treeapproach,”Data Mining and Knowledge Discovery, 8(1), 53–87 (2004). 12. Inmon, W.H. and C. Kelley, Rdb/VMS:
Developing the Data Warehouse, QED Publishing Group, Boston, Massachusetts (1993).
13. Kher, S., P.K. Chande, and P.C. Sharma, “Automobileenginefaultdiagnosisusing neural network,” Proc. IEEE Int. Conf. on Intelligent Transportation Systems, 492–495 (2001).
14. Kimball, R., L. Reeves, M. Ross, and W. Thornthwaite, The Data Warehouse Lifecycle Toolkit, John Wiley & Sons, New York (1998). 15. Li, W.M., J.Han,and J.Pei,“CMAR:Accurate
and efficient classification based on multiple class-association rules,”Proc. 1st IEEE Int. Conf. on Data Mining, 369–376 (2001).
16. Liu, B., W. Hsu, and Y. Ma, “Integrating classification and association rulemining,”Proc. 4th Int. Conf. on Knowledge Discovery and Data Mining, 80–86 (1998).
17. Morris, J.A. and M.J. Gardner, “Calculating confidence intervals for relative risks (odds ratios) and standardised ratios and rates,”British Medical Journal, 296, 1313–1316 (1988).
18. Paulraj, M.P., M. Majid, S. Yaacob, and M. Zin, “Motorbikeenginefaultsdiagnosing system using neural network,” Proc. Int. Conf. on Electronic Design, 1–6 (2008).
19. Paulraj, M.P., S. Yaacob, and M. Zin, “Entropy based feature extraction for motorbike engine faults diagnosing using neural network and wavelet transform,” Proc. 5th Int. Colloquium on Signal Processing & Its Applications, 47–51, (2009).
20. Thabtah, F., P.Cowling,and Y.Peng,“MMAC:A new multi-class, multi-label associative classification approach,”Proc. 4th IEEE Int. Conf. on Data Mining, 217–224 (2004).
21. Thabtah, F., P. Cowling, and Y. Peng, “MCAR: Multi-class classification based on association rule,” Proc. ACS/IEEE 2005 Int. Conf. on Computer Systems and Applications, 33 (2005). 22. Wang, W., Y. Kang, X. Zhao, and W. Huang,
“Study ofautomobileenginefaultdiagnosisbased on wavelet neural networks,” Proc. 5th World Congress on Intelligent Control and Automation, 2, 1766–1770 (2004).
23. Wu, H., M.Siegel,and P.Khosla,“Vehiclesound signature recognition by frequency vector principal component analysis,” Proc. IEEE Instrumentation and Measurement Technology Conf., 1, 429–434 (1998).
24. Wu, J.D. and C.H.Liu,“Investigation ofengine faults diagnosis using discrete wavelet transform
and neural network,” Expert Systems with Applications, 35(3), 1200–1213 (2008).
25. Yin, X.and J.Han,“CPAR:Classification based on predictiveassociation rules,”Proc. 3rd SIAM Conf. on Data Mining, 331–335 (2003).
AN ASSOCIATIVE-CLASSIFICATION
BASED MOTORCYCLE INJECTION
ENGINE DIAGNOSIS SUPPORT
SYSTEM
Kuo-Ping Tsai Wen-Yang Lin* Dept. of Computer Science and Information Engineering, National University of Kaohsiung [email protected]; *[email protected]
ABSTRACT
Recently, due to the fourth Environmental regulations, scooter manufacturers have to launch a new type of scooter with automobile-alike injection fuel supply system. Comparing with traditional engines, the diagnosis of injection engines are much more complex, hardly counting only on the experiences of the mechanicians. The current procedure for repairing a scooter uses a diagnostic device to read the defect code diagnosed by ECU. However, due to the complication of the ECU data, engineers have to spend a lot of time adjusting the ECU's parameters
based on their own experiences. There is no assistant system to help the engineers make a prompt and correct diagnosis. In this paper, we take a motorcycle manufacture in Taiwan as a case study, aiming to develop a motorcycle injection engine diagnosis support system. Our system integrates the data warehousing system that collects data derived from the ECU information and our own developed data mining method, R-CMAR, which is based on associative-classification technique. Incorporating the prestoring concept to store the candidate rules in DB, our R-CMAR can realize an OLAP-like multidimensional diagnosis environment and effectively reduce the efforts of the mechanician on parameters tuning and error diagnosis.
Keywords: Motorcycle injection engine, diagnosis support system, associative classification, data mining