© 2004 TFSA (only used in first page)
Fuzzy Weighted Data Mining from Quantitative Transactions
with Linguistic Minimum Supports and Confidences
Tzung-Pei Hong, Ming-Jer Chiang, and Shyue-Liang Wang
Abstract1
Data mining is the process of extracting desirable knowledge or interesting patterns from existing tabases for specific purposes. Most conventional da-ta-mining algorithms identify the relationships among transactions using binary values and set the minimum supports and minimum confidences at nu-merical values. Linguistic minimum support and minimum confidence values are, however, more nat-ural and understandable for human beings. Transac-tions with quantitative values are also commonly seen in real-world applications. This paper thus attempts to propose a new mining approach for extracting linguistic weighted association rules from quantita-tive transactions, when the parameters needed in the mining process are given in linguistic terms. Items are also evaluated by managers as linguistic terms to reflect their importance, which are then transformed as fuzzy sets of weights. Fuzzy operations are then used to find weighted fuzzy large itemsets and fuzzy association rules. An example is given to clearly illu-strate the proposed approach.
Keywords: Association rule, data mining, weighted item, fuzzy set, fuzzy ranking, quantitative data.
1. Introduction
Knowledge discovery in databases (KDD) has become a process of considerable interest in recent years as the amounts of data in many databases have grown tre-mendously large. KDD means the application of non-trivial procedures for identifying effective, coherent, po-tentially useful, and previously unknown patterns in large databases [15]. The KDD process generally con-sists of three phases: pre-processing, data mining and post-processing [14, 26]. Among them, data mining plays a critical role to KDD. Depending on the classes of knowledge derived, mining approaches may be classified
Corresponding Author: Tzung-Pei Hong is with the Department of Electrical Engineering, National University of Kaohsiung, No. 700, Kaohsiung university Road, Kaohsiung, Taiwan, 811.
E-mail: tphong@nuk.edu.tw
Manuscript received 28 Aug. 2003; revised 1 Dec. 2003; accepted 21 June. 2004.
as finding association rules, classification rules, cluster-ing rules, and sequential patterns [10], among others. It is most commonly seen in applications to induce associ-ation rules from transaction data.
Most previous studies have only shown how binary valued transaction data may be handled. Transactions with quantitative values are, however, commonly seen in real-world applications. Srikant and Agrawal proposed a method for mining association rules from transactions with quantitative and categorical attributes [30]. Their proposed method first determined the number of parti-tions for each quantitative attribute, and then mapped all possible values of each attribute into a set of consecutive integers. It then found large itemsets whose support val-ues were greater than user-specified minimum-support levels. These large itemsets were then processed to gen-erate association rules.
Recently, the fuzzy set theory has been used more and more frequently in intelligent systems because of its simplicity and similarity to human reasoning [36, 37]. The theory has been applied in fields such as manufac-turing, engineering, diagnosis, and economics, among others [17, 23, 25, 36]. Several fuzzy learning algorithms for inducing rules from given sets of data have been de-signed and used to good effect with specific domains [5, 7, 13, 16, 18-21, 29, 31, 32]. Strategies based on deci-sion trees were proposed in [9, 11-12, 27-29, 33-34], and based on version spaces were proposed in [31]. Fuzzy mining approaches were proposed in [8, 22, 24, 35].
Besides, most conventional data-mining algorithms set the minimum supports and minimum confidences at numerical values. Linguistic minimum support and minimum confidence values are, however, more natural and understandable for human beings. In this paper, we thus extend our previous fuzzy mining algorithm [22] for quantitative transactions to the mining problems with linguistic minimum support and minimum confidence values. Also, items may have different importance, which is evaluated by managers or experts as linguistic terms. A novel mining algorithm is then proposed to find weighted linguistic association rules from quantitative transaction data. It first transforms linguistic weighted items, minimum supports, minimum confidences and quantitative transactions into fuzzy sets, and then filters weighted large itemsets out by fuzzy operations. Weighted association rules with linguistic supports and
confidences are then derived from the weighted large itemsets.
The remaining parts of this paper are organized as follows. Mining association rules is reviewed in Section 2. The notation used in this paper is defined in Section 3. A novel mining algorithm for managing quantitative transactions, linguistic minimum supports and linguistic minimum confidences is proposed in Section 4. An ex-ample to illustrate the proposed mining algorithm is given in Section 5. Conclusions and proposal of future work are given in Section 6.
2. Review of Mining Association Rules
The goal of data mining is to discover important asso-ciations among items such that the presence of some items in a transaction will imply the presence of some other items. To achieve this purpose, Agrawal and his co-workers proposed several mining algorithms based on the concept of large itemsets to find association rules in transaction data [1-4]. They divided the mining process into two phases. In the first phase, candidate itemsets were generated and counted by scanning the transaction data. If the number of an itemset appearing in the trans-actions was larger than a pre-defined threshold value (called minimum support), the itemset was considered a large itemset. Itemsets containing only one item were processed first. Large itemsets containing only single items were then combined to form candidate itemsets containing two items. This process was repeated until all large itemsets had been found. In the second phase, as-sociation rules were induced from the large itemsets found in the first phase. All possible association combi-nations for each large itemset were formed, and those with calculated confidence values larger than a prede-fined threshold (called minimum confidence) were out-put as association rules.
Srikant and Agrawal then proposed a mining method [30] to handle quantitative transactions by partitioning the possible values of each attribute. Hong et al. pro-posed a fuzzy mining algorithm to mine fuzzy rules from quantitative data [22]. They transformed each quantita-tive item into a fuzzy set and used fuzzy operations to find fuzzy rules. Cai et al. proposed weighted mining to reflect different importance to different items [6]. Each item was attached a numerical weight given by users. Weighted supports and weighted confidences were then defined to determine interesting association rules. Yue et al. then extended their concepts to fuzzy item vectors [35]. The minimum supports and minimum confidences set in the above methods were numerical. In this paper, these parameters are expressed in linguistic terms, which are more natural and understandable for human beings.
3. Notation
The notation used in this paper is defined as follows.
n: the total number of transaction data; m: the total number of items;
d: the total number of managers;
u: the total number of membership functions for item
importance;
Di: the i-th transaction datum, 1≤i≤n; Aj: the j-th item, 1≤j≤m;
h: the number of fuzzy regions for each item; Rjl: the l-th fuzzy region of Aj, 1≤l≤h; Vij: the quantitative value of Aj in Di; fij: the fuzzy set converted from Vij;
fijl: the membership value of Vij in Region Rjl; countjl: the summation of fijl, 1≤i≤n;
max-countj: the maximum count value among countjl
values;
max-Rj: the fuzzy region of Aj with max-countj; Wjk: the transformed fuzzy weight for importance of
item Aj, evaluated by the k-th manager, 1≤k≤d; ave
j
W : the fuzzy average weight for importance of item
Aj;
α: the predefined linguistic minimum support value; β : the predefined linguistic minimum confidence
value;
It: the t-th membership function of item importance,
1≤t≤u;
Iave: the fuzzy average weight of all possible linguistic terms of item importance;
wsupj: the fuzzy weighted support of item Aj; wconfR: the fuzzy weighted confidence of rule R; minsup: the transformed fuzzy set from the linguistic
minimum support value α;
wminsup: the fuzzy weighted set of minimum sup-ports;
minconf: the transformed fuzzy set from the linguistic minimum confidence value β;
wminconf: the fuzzy weighted set of minimum confi-dences;
Cr: the set of candidate weighted itemsets with r
items;
Lr: the set of large weighted itemsets with r items. 4. The Proposed Algorithm
In this section, we propose a new weighted da-ta-mining algorithm, which can process transaction data with quantitative values and discover fuzzy association rules for linguistic minimum support and confidence values. The fuzzy concepts are used to represent item importance, item quantities, minimum supports and minimum confidences. The proposed mining algorithm
first uses the set of membership functions for importance to transform managers’ linguistic evaluations of item importance into fuzzy weights. The fuzzy weights of an item from different mangers are then averaged. Each quantitative value for a transaction item is also trans-formed into a fuzzy set using the given membership functions. Each attribute used only the linguistic term with the maximum cardinality in the mining process. The number of items was thus the same as that of the original attributes, making the processing time reduced [22]. The algorithm then calculates the weighted fuzzy counts of all items according to the average fuzzy weights of items. The given linguistic minimum support value is then transformed into a fuzzy weighted set. All weighted large 1-itemsets can thus be found by ranking the fuzzy weighted support of each item with the fuzzy weighted minimum support. After that, candidate 2-itemsets are formed from the weighted large 1-itemsets and the same procedure is used to find all weighted large 2-itemsets. This procedure is repeated until all weighted large itemsets have been found. The fuzzy weighted confidences from large itemsets are then calculated to find interesting association rules. Details of the proposed mining algorithm are described below.
The algorithm:
INPUT: A set of n quantitative transaction data, a set of
m items with their importance evaluated by d
managers, four sets of membership functions respectively for item quantities, item impor-tance, minimum support and minimum confi-dence, a pre-defined linguistic minimum sup-port value α , and a pre-defined linguistic minimum confidence value β.
OUTPUT: A set of weighted fuzzy association rules. STEP 1: Transform each linguistic term of importance
for item Aj, 1≤j≤m, which is evaluated by the k-th manager into a fuzzy set Wjk of weights,
1≤k≤d, using the given membership functions
of item importance.
STEP 2: Calculate the fuzzy average weight ave
j
W of
each item Ajby fuzzy addition as: ave j
W
=∑
= ∗ d 1 k jk W d 1 .STEP 3: Transform the quantitative value Vij of each
item Aj in each transaction datum Di (i = 1 to n, j = 1 to m), into a fuzzy set fij represented as:
) ( 2 2 1 1 jh ijh j ij j ij R f R f R f + + + L ,
using the given membership functions for item quantities, where h is the number of regions for Aj, Rjl is the l-th fuzzy region of Aj, 1≤l≤h,
and fijl is Vij’s fuzzy membership value in
re-gion Rjl.
STEP 4: Calculate the count of each fuzzy region Rjl in
the transaction data as:
∑
= = n 1 i ijl jl f count .STEP 5: Find max count max(countjl )
h 1 l j = =
− , for j = 1
to m, where m is the number of items. Let
max-Rj be the region with max-countj for item Aj. max-Rj is then used to represent the fuzzy
characteristic of item Aj in later mining
processes for saving computational time. STEP 6: Calculate the fuzzy weighted support wsupj of
each item Aj as: wsupj = n Wave j × −Rj max , where n is the number of transactions.
STEP 7: Transform the given linguistic minimum sup-port value α into a fuzzy set (denoted
min-sup) of minimum supports, using the given
membership functions for minimum supports. STEP 8: Calculate the fuzzy weighted set (wminsup) of
the given minimum support value as:
wminsup = minsup × (the gravity of Iave), where u I I u 1 t t ave
∑
= = ,with u being the total number of membership functions for item importance and It being the t-th membership function. Iave thus represents the fuzzy average weight of all possible lin-guistic terms of importance.
STEP 9: Check whether the weighted support (wsupj) of
each item Aj is larger than or equal to the fuzzy
weighted minimum support (wminsup) by fuzzy ranking. Any fuzzy ranking approach can be applied here as long as it can generate a crisp rank. If wsupi is equal to or greater than wminsup, put Aj in the set of large 1-itemsets L1.
STEP 10: Set r = 1, where r is used to represent the number of items kept in the current large item-sets.
STEP 11: Generate the candidate set Cr+1 from Lr in a
way similar to that in the apriori algorithm [4]. That is, the algorithm first joins Lr and Lr
as-suming that r-1 items in the two itemsets are the same and the other one is different. It then keeps in Cr+1 the itemsets, which have all their
STEP 12: Do the following substeps for each newly formed (r+1)-itemset s with items (s1, s2, …, sr+1) in Cr+1:
(a) Find the weighted fuzzy set (Wfis) of s in
each transaction data Di as:
Wf Min(W f ) j j is s 1 r 1 j is = × + = , where j is
f
is the membership value ofre-gion sj in Di and j s
W
is the average fuzzyweight for sj.
(b) Calculate the fuzzy weighted support (wsups)
of itemset s as: n Wf wsup n 1 i is s
∑
= = ,where n is the number of transactions.
(c) Check whether the weighted support (wsups)
of itemset s is greater than or equal to the fuzzy weighted minimum support
(wmin-sup) by fuzzy ranking. If wsups is greater
than or equal to wminsup, put s in the set of large (r+1)-itemsets Lr+1.
STEP 13: If Lr+1 is null, then do the next step; otherwise,
set r = r + 1 and repeat Steps 11 to 13.
STEP 14: Transform the given linguistic minimum con-fidence value β into a fuzzy set (minconf) of minimum confidences, using the given mem-bership functions for minimum confidences. STEP 15: Calculate the fuzzy weighted set (wminconf)
of the given minimum confidence value as:
wminconf = minconf × (the gravity of Iave), where Iave is the same as that calculated in Step
9.
STEP 16: Construct the association rules from each large weighted q-itemset s with items (s1, s2, …, sq),
q≥2, using the following substeps:
(a) Form all possible association rules as fol-lows: j q j j s s s s s1Λ...Λ −1Λ +1Λ...Λ → , j = 1 to q.
(b) Calculate the fuzzy weighted confidence value wconfR of each possible association
rule R as: s s s s R W count count wconf j × = − , where
∑
= = = n 1 i is q 1 k s (Min f ) count k and ave s q 1 i s MinWi W = = .(c) Check whether the fuzzy weighted
confi-dence wconfR of association rule R is greater
than or equal to the fuzzy weighted mini-mum confidence wminconf by fuzzy rank-ing. If wconfR is greater than or equal to wminconf, keep rule R in the interesting rule
set.
STEP 17: For each rule R with fuzzy weighted support
wsupR and fuzzy weighted confidence wconfR
in the interesting rule set, find the linguistic minimum support region Si and the linguistic
minimum confidence region Cj with wminsupi-1
≤ wsupR < wminsupi and wminconfj-1 ≤
wconfR < wminconfj by fuzzy ranking, where: wminsupi = minsupi × (the gravity of I
ave
),
wminconfj = minconfj × (the gravity of I ave
),
minsupi is the given membership function for Si
and minconfj is the given membership function
for Cj. Output rule R with linguistic support
value Si and linguistic confidence value Cj.
The rules output after step 17 can then serve as lin-guistic knowledge concerning the given transactions.
5. An Example
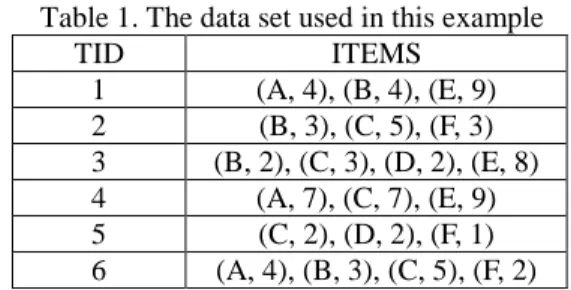
In this section, an example is given to illustrate the proposed data-mining algorithm. This is a simple exam-ple to show how the proposed algorithm can be used to generate weighted fuzzy association rules from a set of quantitative transactions. The data set includes six quan-titative transactions, as shown in Table 1.
Table 1. The data set used in this example
TID ITEMS 1 (A, 4), (B, 4), (E, 9) 2 (B, 3), (C, 5), (F, 3) 3 (B, 2), (C, 3), (D, 2), (E, 8) 4 (A, 7), (C, 7), (E, 9) 5 (C, 2), (D, 2), (F, 1) 6 (A, 4), (B, 3), (C, 5), (F, 2)
Each transaction is composed of a transaction iden-tifier and items purchased. There are six items, respec-tively being A, B, C, D, E and F, to be purchased. Each item is represented by a tuple (item name, item amount). For example, the first transaction consists of four units of A, four units of B and nine units of E.
Also assume that the fuzzy membership functions for item quantities are the same for all the items and are shown in Figure 1. In this example, amounts are represented by three fuzzy regions: Low, Middle and
High. Thus, three fuzzy membership values are produced
mem-bership functions. The importance of the items is eva-luated by three managers as shown in Table 2.
Figure 1. The membership functions for item quantities in this example
Table 2. The item importance evaluated by three managers
Assume the membership functions for item impor-tance are given in Figure 2.
Figure 2. The membership functions of item importance used in this example
In Figure 2, item importance is divided into five fuzzy regions: Very Unimportant, Unimportant, Ordinary,
Important and Very Important. Each fuzzy region is
represented by a membership function. The membership functions in Figure 2 can be represented as follows:
Very Unimportant (VU): (0, 0, 0.25), Unimportant (U): (0, 0.25, 0.5), Ordinary (O): (0.25, 0.5, 0.75), Important (I): (05, 075, 1), and Very Important (VI): (0.75, 1, 1).
For the transaction data given in Table 1, the proposed mining algorithm proceeds as follows.
Step 1: The linguistic terms for item importance given in Table 2 are transformed into fuzzy sets by the
mem-bership functions in Figure 2. For example, item A is evaluated to be important by Manager 1, and can then be transformed as a triangular fuzzy set (0.5, 0.75, 1) of weights. The transformed results for Table 2 are shown in Table 3.
Table 3. The fuzzy weights transformed from the item im-portance in Table 2
Step 2: The average weight of each item is calculated by fuzzy addition. Take Item A as an example. The three fuzzy weights for Item A are respectively (0.5, 0.75, 1), (0.25, 0.5, 0.75) and (0.25, 0.5, 0.75). The average weight is then ((0.5, 0.75, 1) + (0.25, 0.5, 0.75) + (0.25, 0.5, 0.75)) / 3, which is derived as (0.33, 0.58, 0.83). The average fuzzy weights of all the items are calculated, with results shown in Table 4.
Table 4. The average fuzzy weights of all the items
ITEM AVERAGE FUZZY WEIGHT
A (0.333, 0.583, 0.833) B (0.583, 0.833, 1) C (0.417, 0.667,0.917) D (0, 0.167, 0.417) E (0.5, 0.75, 1) F (0.083, 0.333, 0.583)
Step 3: The quantitative values of the items in each transaction are represented by fuzzy sets. Take the first item in Transaction 1 as an example. The amount ‘4’ of A is converted into the fuzzy set (0.4/A.Low + 0.6/A.Middle) using the given membership functions (Figure 1). The step is repeated for the other items, and the results are shown in Table 5, where the notation
item.term is called a fuzzy region.
Step 4: The scalar cardinality of each fuzzy region in the transactions is calculated as the count value. Take the fuzzy region A.Low as an example. Its scalar cardinality = (0.4 + 0 + 0 + 0 + 0 + 0.4) = 0.8. The step is repeated for the other regions, and the results are shown in Table 6.
Step 5: The fuzzy region with the highest count among the three possible regions for each item is found. Take item A as an example. Its count is 0.8 for Low, 2.0 for Middle, and 0.2 for High. Since the count for Middle
M e m b e rs h ip v a lu e 1 0 0 1 6 1 1 L o w M id d le H ig h M e m b e rs h ip v a lu e 1 0 0 1 6 1 1 L o w M id d le H ig h Ite m q u a n tity M e m b e rs h ip v a lu e 1 0 0 1 6 1 1 L o w M id d le H ig h M e m b e rs h ip v a lu e 1 0 0 1 6 1 1 L o w M id d le H ig h Ite m q u a n tity O rd in a ry U n im p o rta n t U n im p o rtan t F Im p o rta n t Im p o rtan t Im p o rta n t E V ery U n im p o rta n t U n im p o rta n t U n im p o rtan t D Im p o rta n t Im p o rtan t O rd in a ry C Im p o rta n t Im p o rtan t V e ry Im p o rtan t B O rd in a ry O rd in a ry Im p o rta n t A M A N A G E R 3 M A N A G E R 2 M A N A G E R 1 M A N A G E R IT E M O rd in a ry U n im p o rta n t U n im p o rtan t F Im p o rta n t Im p o rtan t Im p o rta n t E V ery U n im p o rta n t U n im p o rta n t U n im p o rtan t D Im p o rta n t Im p o rtan t O rd in a ry C Im p o rta n t Im p o rtan t V e ry Im p o rtan t B O rd in a ry O rd in a ry Im p o rta n t A M A N A G E R 3 M A N A G E R 2 M A N A G E R 1 M A N A G E R IT E M W eight M em bership value 1 1 0.5 0.25 0.75
V ery U nim portant
U nim portant Im portant
V ery Im portant O rdinary 0 0 W eight M em bership value 1 1 0.5 0.25 0.75
V ery U nim portant
U nim portant Im portant
V ery Im portant O rdinary 0 0 F E D C B (0.25, 0.5, 0.75) (0.5, 0.75, 1) A MANAGER 3 MANAGER 2 MANAGER 1 MANAGER ITEM (0.5, 0.75, 1) (0.75, 1, 1) (0.25, 0.5, 0.75) (0.25, 0.5, 0.75) (0.25, 0.5, 0.75) (0.5, 0.75, 1) (0.5, 0.75, 1) (0.5, 0.75, 1) (0.5, 0.75, 1) (0.5, 0.75, 1) (0, 0.25, 0.5) (0, 0.25, 0.5) (0, 0, 0.25) (0.5, 0.75, 1) (0, 0.25, 0.5) (0, 0.25, 0.5) F E D C B (0.25, 0.5, 0.75) (0.5, 0.75, 1) A MANAGER 3 MANAGER 2 MANAGER 1 MANAGER ITEM (0.5, 0.75, 1) (0.75, 1, 1) (0.25, 0.5, 0.75) (0.25, 0.5, 0.75) (0.25, 0.5, 0.75) (0.5, 0.75, 1) (0.5, 0.75, 1) (0.5, 0.75, 1) (0.5, 0.75, 1) (0.5, 0.75, 1) (0, 0.25, 0.5) (0, 0.25, 0.5) (0, 0, 0.25) (0.5, 0.75, 1) (0, 0.25, 0.5) (0, 0.25, 0.5)
is the highest among the three counts, the region Middle is thus used to represent the item A in later mining processes. The number of item.regions is thus the same as that of the original items, making the processing time reduced. This step is repeated for the other items. Thus, “Low” is chosen for B, “Middle” is chosen for C, “Low” is chosen for D, “High” is chosen for E and “Low” is chosen for F.
Table 5. The fuzzy sets transformed from the data in Table 1
TID FUZZY SETS
1 + Middle A Low A . 6 . 0 . 4 . 0 , + Middle B Low B . 6 . 0 . 4 . 0 , + High E Middle E . 6 . 0 . 4 . 0 2 + Middle B Low B . 4 . 0 . 6 . 0 , + Middle C Low C . 8 . 0 . 2 . 0 , + Middle F Low F . 4 . 0 . 6 . 0 3 + Middle B Low B . 4 . 0 . 6 . 0 , + Middle C Low C . 4 . 0 . 6 . 0 , + Middle D Low D . 2 . 0 . 8 . 0 , + High E Middle E . 4 . 0 . 6 . 0 4 + High A Middle A . 2 . 0 . 8 . 0 , + High C Middle C . 2 . 0 . 8 . 0 , + High E Middle E . 6 . 0 . 4 . 0 5 + Middle C Low C . 2 . 0 . 8 . 0 , + Middle D Low D . 2 . 0 . 8 . 0 , + Middle F Low F . 0 . 1 6 + Middle A Low A . 6 . 0 . 4 . 0 , + Middle B Low B . 4 . 0 . 6 . 0 , + Middle C Low C . 8 . 0 . 2 . 0 , + Middle F Low F . 2 . 0 . 8 . 0
Table 6. The counts of the fuzzy regions
ITEM COUNT ITEM COUNT ITEM COUNT
A.Low 0.8 C.Low 1.8 E.Low 0
A.Middle 2.0 C.Middle 3.0 E.Middle 1.4 A.High 0.2 C.High 0.2 E.High 1.6
B.Low 2.4 D.Low 1.6 F.Low 2.4
B.Middle 1.6 D.Middle 0.4 F.Middle 0.6
B.High 0 D.High 0 F.High 0
Step 6: The fuzzy weighted support of each item is calculated. Take Item A as an example. The average fuzzy weight of A is (0.333, 0.583, 0.833) from Step 2. Since the region Middle is used to represent the item A and its count is 2.0, its weighted support is then (0.333, 0.583, 0.833) * 2.0 / 6, which is (0.111, 0.194, 0.278). Results for all the items are shown in Table 7.
Step 7: The given linguistic minimum support value is transformed into a fuzzy set of minimum supports. As-sume the membership functions for minimum supports are given in Figure 3, which are the same as those in Figure 2.
Table 7. The fuzzy weighted supports of all the items ITEM FUZZY WEIGHTED SUPPORT
A (0.111, 0.194, 0.278) B (0.233, 0.333, 0.4) C (0.208, 0.333, 0.458) D (0, 0.044, 0.111) E (0.133, 0.2, 0.267) F (0.033, 0.133, 0.233)
Figure 3. The membership functions of minimum supports
Also assume the given linguistic minimum support value is “Low”. It is then transformed into a fuzzy set of minimum supports, (0, 0.25, 0.5), according to the given membership functions in Figure 3.
Step 8: The fuzzy average weight of all possible lin-guistic terms of importance in Figure 3 is calculated as:
Iave = [(0, 0, 0.25) + (0, 0.25, 0.5) + (0.25, 0.5, 0.75) + (0.5, 0.75, 1) +(0.75, 1, 1)] / 5
= (0.3, 0.5, 0.7).
The gravity of Iave is then (0.3 + 0.5 + 0.7) / 3, which is 0.5. The fuzzy weighted set of minimum supports for “Low”is then (0, 0.25, 0.5) × 0.5, which is (0, 0.125, 0.25).
Step 9: The fuzzy weighted support of each item is compared with the fuzzy weighted minimum support by fuzzy ranking. Any fuzzy ranking approach can be ap-plied here as long as it can generate a crisp rank. Assume the gravity ranking approach is adopted in this example. Take Item A as an example. The average height of the fuzzy weighted support for A.Middle is (0.111 + 0.194 + 0.278) / 3, which is 0.194. The average height of the fuzzy weighted minimum support is (0 + 0.125 + 0.25) / 3, which is 0.125. Since 0.194 > 0.125, A is thus a large weighted 1-itemset. Similarly, B.Low, C.Middle, E.High and F.Low are large weighted 1-itemsets. These 1-itemsets are put in L1 (Table 8).
Table 8. The set of weighted large 1-itemsets for this example ITEMSET COUNT A.Middle 2.0 B.Low 2.2 C.Middle 3.0 E.High 1.6 F.Low 2.4 Minimum support Membership value 1 1 0.5 0.25 0.75
Very Low Low Middle High Very High
0 0 Minimum support Membership value 1 1 0.5 0.25 0.75
Very Low Low Middle High Very High
0 0
Step 10: r is set at 1, where r is used to store the number of items kept in the current itemsets.
Step 11: The candidate set C2 is first generated from
L1 as follows: (A.Middle, B.Low), (A.Middle, C.Middle),
(A.Middle, E.High), (A.Middle, F.Low), (B.Low,
C.Middle), (B.Low, E.High), (B.Low, F.Low), (C.Middle, E.High), (C.Middle, F.Low), and (E.High, F.Low).
Step 12: The following substeps are done for each
newly formed candidate itemset in C2.
(a) The weighted fuzzy set of each candidate 2-itemset in each transaction data is first calculated. Here, the minimum operator is used for intersection. Take (A.Middle, B.Low) as an example. The membership val-ues of A.Middle and B.Low for transaction 1 are 0.6 and 0.4, respectively. The average fuzzy weight of item A is (0.333, 0.583, 0.833) and the average fuzzy weight of item B is (0.583, 0.833, 1) from Step 2. The weighted fuzzy set for (A.Middle, B.Low) in Transaction 1 is then calculated as: min(0.6*(0.333, 0.583, 0.833), 0.4*(0.583, 0.833, 1)) = min((0.2, 0.35, 0.5), (0.233, 0.333, 0.4)) = (0.2, 0.333, 0.4). The results for all the transactions are shown in Table 9.
Table 9. The weighted fuzzy set of (A.Middle, B.Low) in each transaction
TID A.Middle B.Low A.Middle ∩ B.Low 1 (0.2, 0.35, 0.5) (0.233, 0.333, 0.4) (0.2, 0.333, 0.4) 2 (0, 0, 0) (0.35, 0.5, 0.6) (0, 0, 0) 3 (0, 0, 0) (0.466, 0.666, 0.8) (0, 0, 0) 4 (0.266, 0.466, 0.666) (0, 0, 0) (0, 0, 0) 5 (0, 0, 0) (0, 0, 0) (0, 0, 0) 6 (0.2, 0.35, 0.5) (0.35, 0.5, 0.6) (0.2, 0.35, 0.5)
(b) The fuzzy weighted count of each candidate 2-itemset in C2 is calculated. Results for this example are
shown in Table 10.
Table 10. The fuzzy weighted counts of the itemsets in C2
ITEMSET COUNT ITEMSET COUNT
(A.Middle, B.Low) (0.4, 0.683, 0.9) (B.Low, E.High) (0.433, 0.633, 0.8) (A.Middle, C.Middle) (0.466, 0.823, 1.166) (B.Low, F.Low) (0.116, 0.466, 0.816) (A.Middle, E.High) (0.466, 0.803, 1.1) (C.Middle, E.High) (0.467, 0.717, 0.967) (A.Middle, F.Low) (0.066, 0.266, 0.466) (C.Middle, F.Low) (0.199, 0.6, 1) (B.Low, C.Middle) (0.834, 1.266, 1.567) (E.High, F.Low) (0, 0, 0)
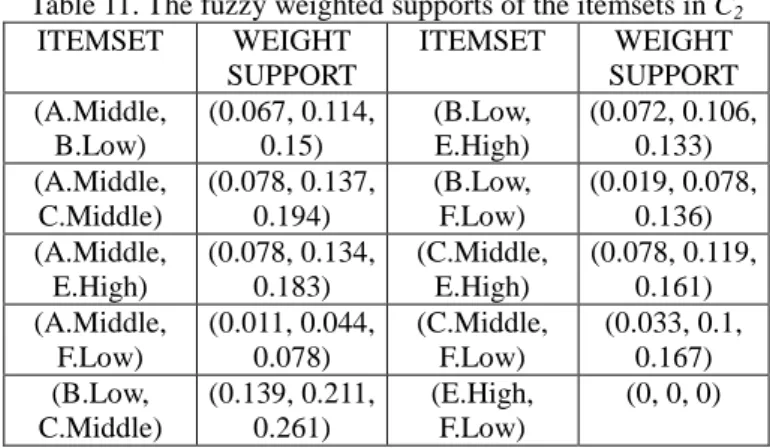
The fuzzy weighted support of each candidate 2-itemset is then calculated. Take (A.Middle, B.Low) as an example. The fuzzy weighted count of (A.Middle,
B.Low) is (0.4, 0.683, 0.9) and the total number of
transaction data is 6. Its fuzzy weighted support is then (0.4, 0.683, 0.9) / 6, which is (0.067, 0.114, 0.15). All the fuzzy weighted supports of the candidate 2-itemsets are shown in Table 11.
Table 11. The fuzzy weighted supports of the itemsets in C2 ITEMSET WEIGHT SUPPORT ITEMSET WEIGHT SUPPORT (A.Middle, B.Low) (0.067, 0.114, 0.15) (B.Low, E.High) (0.072, 0.106, 0.133) (A.Middle, C.Middle) (0.078, 0.137, 0.194) (B.Low, F.Low) (0.019, 0.078, 0.136) (A.Middle, E.High) (0.078, 0.134, 0.183) (C.Middle, E.High) (0.078, 0.119, 0.161) (A.Middle, F.Low) (0.011, 0.044, 0.078) (C.Middle, F.Low) (0.033, 0.1, 0.167) (B.Low, C.Middle) (0.139, 0.211, 0.261) (E.High, F.Low) (0, 0, 0)
(c) The fuzzy weighted support of each candidate 2-itemset is compared with the fuzzy weighted minimum support by fuzzy ranking. As mentioned above, assume the gravity ranking approach is adopted in this example. (A.Middle, C.Middle), (A.Middle, E.High) and (B.Low,
C.Middle) are then found to be large weighted 2-itemsets.
They are then put in L2.
Step 13: Since L2 is not null, r = r + 1 = 2. Steps 11 to
13 are repeated to find L3. C3 is then generated from L2.
In this example, C3 is empty. L3 is thus empty.
Step 14: The given linguistic minimum confidence value is transformed into a fuzzy set of minimum confi-dences. Assume the membership functions for minimum confidence values are shown in Figure 4, which are sim-ilar to those in Figure 3.
Figure 4. The membership functions for minimum confidences
Also assume the given linguistic minimum confidence value is “Middle”. It is then transformed into a fuzzy set of minimum confidences, (0.25, 0.5, 0.75), according to the given membership functions in Figure 4.
Step 15: The fuzzy average weight of all possible lin-guistic terms of importance is the same as that found in Step 9. Its gravity is thus 0.5. The fuzzy weighted set of minimum confidences for“Middle”is then (0.25, 0.5, 0.75) × 0.5, which is (0.125, 0.25, 0.375). M inim um confidence M em bership value 1 1 0.5 0.25 0.75
V ery Low Low M iddle H igh V ery H igh
0 0 M inim um confidence M em bership value 1 1 0.5 0.25 0.75
V ery Low Low M iddle H igh V ery H igh
0 0
Step 16: The association rules from each large itemset are constructed by using the following substeps.
(a) All possible association rules are formed as fol-lows:
If A.Middle, then C.Middle; If C.Middle, then A.Middle. IF A.Middle, then E.High; IF E.High, then A.Middle; IF B.Low, then C.Middle; IF C.Middle, then B.Low.
(b) The weighted confidence values for the above possible association rules are calculated. Take the first possible association rule as an example. The fuzzy count
of A.Middle is 2.0. The fuzzy count of A.Middle∩
C.Middle is 1.4. The minimum average weight of
(A.Middle, C.Middle) is (0.333, 0.588, 0.833). The weighted confidence value for the association rule “If
A.Middle, then C.Middle ” is:
). 583 . 0 , 412 . 0 , 233 . 0 ( ) 833 . 0 , 588 . 0 , 333 . 0 ( 0 . 2 4 . 1 = ×
The weighted confidence values for the other associa-tion rules can be similarly calculated.
(c) The weighted confidence of each association rule is compared with the fuzzy weighted minimum confi-dence by fuzzy ranking. Assume the gravity ranking ap-proach is adopted in this example. Take the association rule "If A.Middle, then C.Middle” as an example. The average height of the weighted confidence for this asso-ciation rule is (0.233 + 0.412 + 0.583)/3, which is 0.409. The average height of the fuzzy weighted minimum con-fidence for “Middle” is (0.125 + 0.25 + 0.375)/3, which is 0.25. Since 0.409 > 0.25, the association rule "If
A.Middle, then C.Middle” is thus put in the interesting
rule set. In this example, the following six rules are put in the interesting rule set:
1. If a middle number of A is bought then a middle number of C is bought;
2. If a middle number of C is bought then a middle number of A is bought;
3. If a middle number of A is bought then a high number of E is bought;
4. If a high number of E is bought then a middle number of A is bought;
5. If a low number of B is bought then a middle num-ber of C is bought;
6. If a middle number of C is bought then a low num-ber of B is bought.
Step 17: The linguistic support and confidence values are found for each rule R. Take the interesting associa-tion rule "If A.Middle, then C.Middle” as an example. Its fuzzy weighted support is (0.078, 0.137, 0.194) and fuzzy weighted confidence is (0.233, 0.412, 0.583). Since the membership function for linguistic minimum
support region “Low“ is (0, 0.25, 0.5) and for “Middle” is (0.25, 0.5, 0.75), the weighted fuzzy set for these two regions are (0, 0.125, 0.25) and (0.125, 0.25,0.375). Since (0, 0, 0.125) < (0.078, 0.137, 0.194) < (0.125, 0.25,0.375) by fuzzy ranking, the linguistic support val-ue for Rule R is then Low. Similarly, the linguistic con-fidence value for Rule R is High.
The interesting linguistic association rules are then output as:
1. If a middle number of A is bought then a middle number of C is bought, with a low support and a high confidence;
2. If a middle number of C is bought then a middle number of A is bought, with a low support and a middle confidence;
3. If a middle number of A is bought then a high number of E is bought, with a low support and a middle confidence;
4. If a high number of E is bought then a middle number of A is bought, with a low support and a high confidence;
5. If a low number of B is bought then a middle num-ber of C is bought, with a low support and a high confidence;
6. If a middle number of C is bought then a low num-ber of B is bought, with a low support and a middle confidence.
The six rules above are thus output as me-ta-knowledge concerning the given weighted transac-tions.
6. Conclusion and Future Work
In this paper, we have proposed a new weighted da-ta-mining algorithm for finding interesting weighted as-sociation rules with linguistic supports and confidences from quantitative transactions. Items are evaluated by managers as linguistic terms, which are then transformed and averaged as fuzzy sets of weights. Fuzzy operations including fuzzy ranking are used to find large weighted itemsets and association rules. Compared to previous mining approaches, the proposed one directly manages linguistic parameters, which are more natural and un-derstandable for human beings. In the future, We will attempt to design other fuzzy data-mining models for various problem domains.
7. Acknowledgement
This research was supported by the National Science Council of the Republic of China under contract NSC94-2213-E-390-005.
8. References
[1] R. Agrawal, T. Imielinksi and A. Swami, “Mining
association rules between sets of items in large da-tabase,“ The 1993 ACM SIGMOD Conference, Washington DC, USA, 1993, pp.207-216.
[2] R. Agrawal, T. Imielinksi and A. Swami,
“Data-base mining: a performance perspective,” IEEE
Transactions on Knowledge and Data Engineering,
Vol. 5, No. 6, 1993, pp. 914-925.
[3] R. Agrawal, R. Srikant and Q. Vu, “Mining
associ-ation rules with item constraints,” The Third
Inter-national Conference on Knowledge Discovery in Databases and Data Mining, Newport Beach,
Cal-ifornia, 1997, pp. 67-73.
[4] R. Agrawal and R. Srikant, “Fast algorithm for
mining association rules,” The International
Con-ference on Very Large Databases, 1994, pp.
487-499.
[5] A. F. Blishun, “Fuzzy learning models in expert
systems,” Fuzzy Sets and Systems, Vol. 22, 1987, pp. 57-70.
[6] C. H. Cai, W. C. Fu, C. H. Cheng and W. W.
Kwong, “Mining association rules with weighted items,” The International Database Engineering
and Applications Symposium, 1998, pp. 68-77.
[7] L. M. de Campos and S. Moral, “Learning rules for
a fuzzy inference model,” Fuzzy Sets and Systems, Vol. 59, 1993, pp. 247-257.
[8] K. C. C. Chan and W. H. Au, “Mining fuzzy
asso-ciation rules,” The Sixth ACM International
Con-ference on Information and Knowledge Manage-ment, Las Vegas, Nevada, 1997, pp. 10-14.
[9] R. L. P. Chang and T. Pavliddis, “Fuzzy decision tree algorithms,” IEEE Transactions on Systems, Man and Cybernetics, Vol. 7, 1977, pp. 28-35.
[10] M. S. Chen, J. Han and P. S. Yu, “Data mining: an
overview from a database perspective,” IEEE
Transactions on Knowledge and Data Engineering,
Vol. 8, No.6, 1996, pp. 866-883.
[11] C. Clair, C. Liu and N. Pissinou, “Attribute
weighting: a method of applying domain know-ledge in the decision tree process,” The Seventh
In-ternational Conference on Information and Know-ledge Management, 1998, pp. 259-266.
[12] P. Clark and T. Niblett, “The CN2 induction
algo-rithm,” Machine Learning, Vol. 3, 1989, pp. 261-283.
[13] M. Delgado and A. Gonzalez, “An inductive
learn-ing procedure to identify fuzzy systems,” Fuzzy
Sets and Systems, Vol. 55, 1993, pp. 121-132.
[14] A. Famili, W. M. Shen, R. Weber and E. Simoudis,
"Data preprocessing and intelligent data analysis,"
Intelligent Data Analysis, Vol. 1, No. 1, 1997, pp.
3-23.
[15] W. J. Frawley, G. Piatetsky-Shapiro and C. J.
Ma-theus, “Knowledge discovery in databases: an overview,” The AAAI Workshop on Knowledge
Discovery in Databases, 1991, pp. 1-27.
[16] A.Gonzalez, “A learning methodology in uncertain
and imprecise environments,” International
Jour-nal of Intelligent Systems, Vol. 10, 1995, pp.
57-371.
[17] I. Graham and P. L. Jones, Expert Systems –
Knowledge, Uncertainty and Decision, Chapman
and Computing, Boston, 1988, pp.117-158.
[18] T. P. Hong and J. B. Chen, "Finding relevant attributes and membership functions," Fuzzy Sets
and Systems, Vol.103, No. 3, 1999, pp. 389-404.
[19] T. P. Hong and J. B. Chen, "Processing individual
fuzzy attributes for fuzzy rule induction," Fuzzy
Sets and Systems, Vol.112, No. 1, 2000, pp.
127-140.
[20] T. P. Hong and C. Y. Lee, "Induction of fuzzy rules and membership functions from training exam-ples," Fuzzy Sets and Systems, Vol. 84, 1996, pp. 33-47.
[21] T. P. Hong and S. S. Tseng, “A generalized version
space learning algorithm for noisy and uncertain data,” IEEE Transactions on Knowledge and Data
Engineering, Vol. 9, No. 2, 1997, pp. 336-340.
[22] T. P. Hong, C. S. Kuo and S. C. Chi, "Mining as-sociation rules from quantitative data", Intelligent
Data Analysis, Vol. 3, No. 5, 1999, pp. 363-376.
[23] A. Kandel, Fuzzy Expert Systems, CRC Press, Boca
Raton, 1992, pp. 8-19.
[24] C. M. Kuok, A. W. C. Fu and M. H. Wong,
"Min-ing fuzzy association rules in databases," The ACM
SIGMOD Record, Vol. 27, No. 1, 1998, pp. 41-46.
[25] E. H. Mamdani, “Applications of fuzzy algorithms
for control of simple dynamic plants, “ IEEE
Pro-ceedings, 1974, pp. 1585-1588.
[26] H. Mannila, “Methods and problems in data
min-ing,” The International Conference on Database
Theory, 1997, pp. 41-55.
[27] J. R. Quinlan, “Decision tree as probabilistic clas-sifier,” The Fourth International Machine Learning
Workshop, Morgan Kaufmann, San Mateo, CA,
1987, pp. 31-37.
[28] J. R. Quinlan, C4.5: Programs for Machine
Learn-ing, Morgan Kaufmann, San Mateo, CA, 1993.
[29] J. Rives, “FID3: fuzzy induction decision tree,”
The First International symposium on Uncertainty, Modeling and Analysis, 1990, pp. 457-462.
[30] R. Srikant and R. Agrawal, “Mining quantitative
association rules in large relational tables,” The
1996 ACM SIGMOD International Conference on Management of Data, Monreal, Canada, June 1996,
pp. 1-12.
[31] C. H. Wang, T. P. Hong and S. S. Tseng, “Induc-tive learning from fuzzy examples,” The fifth IEEE
International Conference on Fuzzy Systems, New
Orleans, 1996, pp. 13-18.
[32] C. H. Wang, J. F. Liu, T. P. Hong and S. S. Tseng,
“A fuzzy inductive learning strategy for modular rules,” Fuzzy Sets and Systems, Vol.103, No. 1, 1999, pp. 91-105.
[33] R.Weber, “Fuzzy-ID3: a class of methods for
au-tomatic knowledge acquisition,” The Second
In-ternational Conference on Fuzzy Logic and Neural Networks, Iizuka, Japan, 1992, pp. 265-268.
[34] Y. Yuan and M. J. Shaw, “Induction of fuzzy
deci-sion trees,” Fuzzy Sets and Systems, 69, 1995, pp. 125-139.
[35] S. Yue, E. Tsang, D. Yeung and D. Shi, “Mining fuzzy association rules with weighted items,” The
IEEE International Conference on Systems, Man and Cybernetics, 2000, pp. 1906-1911.
[36] L. A. Zadeh, “Fuzzy logic,” IEEE Computer, 1988,
pp. 83-93.
[37] L. A. Zadeh, “Fuzzy sets,” Information and