國立臺中教育大學教育測驗統計研究所
教學碩士學位暑期在職進修專班碩士論文
指 導 教 授:郭伯臣 博士
訊息量分階選取法之電腦適性測驗模擬
研究
研 究 生:陳曉竹 撰
中 華 民 國 九 十 九 年 八 月
中文摘要
電腦測驗題庫常被有心的補習業者或考生,想盡辦法拿到試題;當一群能力相近的 有心人同時考試,就更容易將過度曝光試題背起來。因此,如不能有效控制過度曝光試 題,進而將影響測驗的公平性。本研究分別提出「訊息量分階選取法」之選題策略,並 進行訊息量分階選取法、最大訊息法、鄰近法、考慮b 參數的 a 分層法四種選題策略 的比較,試圖找出在有效控制題庫試題最大曝光率,並且當題庫試題難度分布和受試者 能力分佈不相同時依然能有效控制題庫曝光率的選題方法。 根據模擬研究的結果發現:當受試能力的分布和題庫試題難度分布相近時,訊息量 分階選取法和鄰近法的能力估計誤差和曝光率的均勻度各有優劣,但訊息量分階選取法 的最大曝光率均為較低。當受試能力的分布和題庫試題難度分布不同時,訊息量分階選 取法是能在較少的能力估計誤差下有效控制曝光率的均勻度的方法,並且訊息量分階選 取法能有效降低題庫試題的最大曝光率。 關鍵詞︰電腦適性測驗、試題反應理論、選題策略、曝光率控制Abstract
Item exposure control is a critical issue for ensuring test fairness. When the item bank was used by examinees with similar ability, the problem of over-exposure of items can be expected. In this study, four methods, maximum information, information-stratified, Nearest-Neighbor and A_stratified with b blocking, were compared bared on for controlling exposure of items.
It was found when the distribution of item difficulty was matched to the distribution of student ability, information-stratified method and Nearest-Neighbor method performed quite similarly, and the highest exposure rate under inn method was lower than that under nn method. When the distribution of item difficulty is not matched to the ability distribution, the inn method resulted in lower RMSE of ability estimates, given the item exposure was well-controlled.
Keyword: computerized adaptive testing, item response theory, selection strategy, item exposure control.
目錄
第一章 緒論
1 第一節 研究動機 1 第二節 研究目的 2 第三節 名詞解釋 3第二章 文獻探討
5 第一節 試題反應模式 6 第二節 題庫的準備 8 第三節 測驗的起點 10 第四節 能力估計 11 第五節 試題選擇方法 12 第六節 終止標準 18 第七節 曝光率控管之相關研究 18第三章 研究方法
25 第一節 研究流程 25 第二節 訊息量分階選取法 26 第三節 研究設計 26 第四節 選題策略實施效能評估指標 31第四章 研究結果與討論
33 第一節 受試者能力分佈不同比較結果 33 第二節 受試者不同單點能力值下比較結果 44第五章 結論與建議
52 第一節 結論 52 第二節 建議 53參考文獻
54圖目錄
圖2-1 CAT 的流程 5 圖2-2 題庫的建立流程 9 圖3-1 研究架構圖 25 圖4-1 題庫 P1-t360的RMSE 41 圖4-2 題庫 P2-t360的RMSE 41 圖4-3 題庫 P1-t1440的RMSE 42 圖4-4 題庫 P2-t1440的RMSE 42表格目錄
表3-4-1 文獻資料之題庫參數範圍 29 表3-4-2 題庫種類代號表 30 表4-1 受試者能力值分布N(0,1)的 RMSE 34 表4-2 受試者能力值分布N(0,1)的 RMSE_sd 34 表4-3 受試者能力值分布N(0,1)的χ2 34 表4-4 受試者能力值分布N(0,1)的 rmax 35 表4-5 受試者能力值分布N(0,1)的 r>0.3 35 表4-6 受試者能力值分布N(1,1)的 RMSE 36 表4-7 受試者能力值分布N(1,1)的 RMSE_sd 37 表4-8 受試者能力值分布N(1,1)的χ2 37 表4-9 受試者能力值分布N(1,1)的 rmax 37 表4-10 受試者能力值分布N(1,1)的 r>0.3 38 表4-11 受試者能力值分布N(2,1)的 RMSE 39 表4-12 受試者能力值分布N(2,1)的 RMSE_sd 39 表4-13 受試者能力值分布N(2,1)的χ2 40表4-14 受試者能力值分布N(2,1)的 rmax 40 表4-15 受試者能力值分布N(2,1)的 r>0.3 40 表4-16 真實題庫P3、P4 的 RMSE 43 表4-17 真實題庫P3、P4 的 RMSE_sd 43 表4-18 真實題庫P3、P4 的χ2 44 表4-19 真實題庫P3、P4 的 rmax 44 表4-20 真實題庫P3、P4 的 r>0.3 44 表4-21 不同單點力值下題庫P1-t360 的 RMSE 45 表4-22 不同單點能力值下題庫P1-t360 的χ2 45 表4-23 不同單點能力值下題庫P1-t360 的 rmax 46 表4-24 不同單點能力值下題庫P1-t360 的未使用試題 46 表4-25 不同單點能力值下題庫P2-t360 的 RMSE 47 表4-26 不同單點能力值下題庫P2-t360 的χ2 47 表4-27 不同單點能力值下題庫P2-t360 的 rmax 47 表4-28 不同單點能力值下題庫P2-t360 的未使用試題 48 表4-29 不同單點能力值下題庫 P1-t1440 的 RMSE 49 表4-30 不同單點能力值下題庫P1-t1440 的χ2 49 表4-31 不同單點能力值下題庫P1-t1440 的 rmax 49
表4-32 不同單點能力值下題庫P1-t1440 的未使用試題 49
表4-33 不同單點能力值下題庫P2-t1440 的 RMSE 51
表4-34 不同單點能力值下題庫P2-t1440 的χ2 51
表4-35 不同單點能力值下題庫P2-t1440 的 rmax 51
第一章 緒論
本研究主要目的在於探討電腦適性測驗(computerized adaptive testing, CAT) 中,選題策略對測驗中影響能力值估計誤差與題目曝光率的影響,以提供在建置 題庫,發展適性測驗時能保障題庫的安全性,降低試題最大曝光率。本章第一節 為研究此問題之動機,第二節為本研究的目的,第三節針對本研究之名詞作概括 性的探討。
第一節 研究動機
電腦測驗題庫常被有心的補習業者或考生,想盡辦法拿到試題;當一群能力 相近的有心人同時考試,就更容易將過度曝光試題背起來。因此當一群能力平均 較高的有心考生,試圖記取考題時,選題策略對題庫試題最大曝光率控制成效在 CAT 的題庫安全是很重要的。電腦適性測驗的效率高出一般傳統的紙筆測驗許 多,而且還可以應用各種多媒體技術將影片、聲音、動畫等素材加到測驗中,現 今資訊硬體設備進步和普及的網路建置使得 CAT 廣泛應用在國內外著名的考試 或測驗中,例如:TOEFL、GRE、GMAT、美國軍職性向測驗(Armed Services Vocational Aptitude Battery; ASVAB)、護士證照考試(National Council Licensure Examination; NCLEX)等(陳柏熹,2006)。 在題庫試題的過度曝光下會使得題庫失去安全。如不能有效控制,當試題過 度曝光,受測者則容易施測到相同的試題使得題庫試題外流,一但外流題庫可能 無法再使用,必須重新建置新的題庫,而建立一個新題庫所費不貲,且要耗費許 多人力、時間等。因此能有效分散試題,使試題的使用率平均,可以有效降低題 庫中最大曝光率,對整體試題曝光率達到有效控制,以期達到提升題庫經濟效 益,且能避免有心人士竊取試題使得測驗不公平、不客觀。數增加同時鑑別度也逐步增加,能在維持良好的能力估計精確性下,同時提升低 a 值試題的使用率 (Chang & Ying, 1999; Hau & Chang, 2001)。雖然如此,一但 a、b 參數間的相關會使得 a 分層法的成效降低,當 a、b 參數間成正相關時,b
值會隨a 值越高的那層也越高,對於能力水準較低的考生而言,這樣的試題對他
的能力估計並無助益。(Chang & Ying, 1999)。而且 a 分層法無法有效控管試題的 的最大曝光率仍大於預設(Chang, Qian, & Ying, 2001; Leung, Change, & Hua, 2002)。為了降低 a 分層法各層間 b 參數的差異,Chang, Qian, & Ying (2001)提出
考慮b 參數的 a 分層法,希望能把各層中 b 參數的分配維持一致;優點是各分層 中的b 值分佈保持一致性,不會造成能力估計精準度的損耗。缺點是無法將試題 曝光率完全控制在可接受試題最大曝光率下。 而考慮b 參數的 a 分層法雖已經將 b 參數間納入分層的考慮因素,但是未能 將 c 參數納入分層考慮因素,如此可能造成分層中提供的訊息量並未能逐層遞 增。因此本研究提出在考慮將c 參數納入分層的因素下,並設定分階目標訊息量 的方法,將試題參數a、b、c 都同時納入的選題法。
第二節 研究目的
本研究主要目的如下: 一、 提出新選題策略,有效控制試題最大曝光率。 二、 比較訊息量分階選取法、最大訊息法、鄰近法、考慮b 參數的 a 分層法 四種選題法,對能力估計與曝光率的影響。 三、 比較不同受試能力分佈下四種選題策略,對能力估計與曝光率的影響。 四、 比較不同大小題庫下四種選題策略,對能力估計與曝光率的影響。 五、 比較不同單點能力值下四種選題策略,對能力估計與曝光率的影響。第三節 名詞釋義
一、電腦適性測驗
電腦適性測驗是配合試題反應理論(item response theory, IRT),利用電腦
來實施測驗、適性選題、電腦計分、估計能力等問題的一種電腦測驗方式。 電腦依據受試者作答反應來估計受試者能力值,再依估計受試者能力值選擇 提供受試者能力值的較大訊息量的試題進行測驗;簡而言之就是答對後選擇 較難度較高試題,反之,則選擇難度較低的試題,直到終止條件成立。因此 電腦適性測驗比傳統紙筆測驗能在有效的能力估計時能節省較多試題。 二、試題曝光率
試題曝光率(item exposure rate)為試題再整體測驗中被使用的次數和測 驗長度的比值。題庫中通常具提供受試者訊息較高訊息量的試題較常被選 取,而常使用這些試題,則測驗的受試者較高的訊息量總合且估計精準度 高,但卻使得這些試題試題曝光率的過高,導致題庫之安全性與測驗公平性 受到質疑,所以電腦適性測驗在實際的應用上,試題曝光控制是一個重要的 議題。 三、試題最大曝光率 題庫中所有試題在電腦適性測驗中的曝光率最大值,以下以 rmax 為代 號。 四、試題訊息函數
試題訊息函數(item information function)可作為試題好壞的一個判定函 數。在某能力值的試題訊息,代表試題所能提供某能力值的訊息量,試題訊 息越高,其提供的訊息量越大,相對的能力值估計誤差越小。
五、偏移難度 當題庫試題為模式是一參數或二參數對數模式時,此時猜測參數為零, 試題的最大訊息量發生於能力值為難度參數值的點上;但當題庫試題為模式 是三參數對數模式,猜測參數不為零時,則試題提供最大訊息量能力點會產 生偏移,故稱此最大值發生點為偏移難度。 六、訊息量分階選取法 當測驗初期受試者能力估計尚未精準時,則選擇較小訊息量的試題;當 測驗終止前,受試者能力估計較精準時,則選擇較大訊息量的試題。使試題 選擇一目標訊息量分階逐題增加,故稱此選題法為為訊息量分階選取法 (information-stratified)。
第二章 文獻探討
本章概要介紹CAT 的六項基本要素(余民寧,1992)—包含試題反應模式、 題庫的準備、測驗的起點、能力估計、試題選擇方法、終止標準並介紹曝光率 控管,分別加以描述。CAT 的流程如圖 2-1 首先設定題庫試題參數的試題反 應模式建立題庫,決定受試者起始能力值依選題策略選題,接著在依受試者作 答反應估計受試者的能力值,如果未達終止條件則依估計能力在選試題給受試 者作答,直到終止條件成立。 圖2-1 CAT的流程 不成立 成立 題庫的準備 能力估計 作答反應 能力估計誤差與題庫曝光率效能評估 終止條件 試題選擇方法 設定試題反應模式 測驗的起點第一節 試題反應理論
試題反應理論又稱潛在特質理論(latent trait theory)為 CAT 主要理論基礎,係 利用數學函式來表示可觀察到的受試者的測驗作答情形及不可觀察到的潛在特 質之間的關係;期望以觀察的行為反應預測受試者的潛在特質(Hambleton & Swaminathan,1985)。
(一)試題反應的模式:以適用於二元化計分(binary or dichotomous scoring)的 測驗資料為主。IRT 以試題特徵函數表達受試者能力與測驗反應之間的關係,因 函數中所採用的參數不同分成:單參數包含難度度參數、雙參數包含難度度參數 及鑑別度參數以及三參數除了難度度參數及鑑別度參數再加入猜測度參數等三 種模式,而且都僅適用於二元計分的反應資料,也就是受試者做出正確答案時計
分為1,若為錯誤答案時則計分為 0(余民寧,1992)。
以下就以 CAT 最常採用的三參數對數模式(three-parameters logistic model, 簡
稱3PLM)來做說明。 三參數對數模式: ) ( exp 1 1 ) 1 ( i i b Da i i i c c u P − − + − + = = θ θ (2.1) i u:代表考生在第i題的作答反應,若考生答對第i題則ui=1,答錯則ui=0。 D:為一常數D=1.702。 exp:自然對數,exp=2.71828。 i :試題編號;i=1,2,3…n,n 是該測驗試題總數。 i a :第 i 題的鑑別度參數,它的值愈大表示試題對受試者之鑑別力愈強; 反 之,則鑑別力愈弱。a 參數表示試題特徵曲線之斜率,其理論值範圍 介於-∞與+∞之間。 i b :第 i 題的難度度參數,它表示試題特徵曲線位於能力量尺上之位
置,因假定受試者在能力量尺之能力值範圍為-∞至+∞,所以b 參 數之理論值範圍亦然。不過,受試能力值在實際應用上常限定介於 -3 至+3 之間; i c :第 i 題的猜測度參數,代表猜對之機率,它的值愈大表示不論受試能 力為高或低試題都容易猜對;值愈小,則不易被猜對。c 參數可表示試 題特徵曲線之左下漸近線(lower asymptote),其理論值範圍介於 0 與 1 之間,實際應用上過高之 c 參數常不被接受。 (二)試題訊息函數:其定義如下: ) ( ) ( )] ( [ ) ( 2 ' θ θ θ θ i i i i Q P P I = i=1,2,….,n (2.2) Ii(θ):代表試題i在能力為θ上所提供的訊息。 ) ( ' θ i P :在θ點上的Pi(θ)值的導數。 ) (θ i P 為能力θ在試題i上的試題反應函數,Qi(θ)=1−Pi(θ)。 余民寧(1992)論及 IRT 提出一個能夠用來描述試題或測驗、挑選測驗試題、 以及比較測驗的相對效能的實用方法,此方法需要使用試題訊息函數(item information function),作為建立、分析、與診斷測驗的主要參考依據。
(三)估計標準誤:其定義如下 ) ( 1 ) ( θ θ I SE = (2.3)
SE(θ)稱作估計標準誤(standard error of estimation),當I(θ)公式(2.2)值達到最
大時,SE(θ)值便達到最小,也就是說θ值的最大近似值的估計誤差最小,亦即此
時的θ的最大近似值估計最精確。Green, Yen& Burket(1989)研究指出影響估計標
準誤的三個因素: (1)測驗試題的題數:越多則估計標準誤越小。 (2)測驗試題的品質:試題的鑑別度高估計標準誤越小。 (3)試題難度與受試者能力間的配合度:越接近則估計標準誤越小。
第二節 題庫的準備
題庫試題都必須要含有選用試題反應模式包含的參數,無論使用何種試題反 應模式或選題方法,最重要的是要有一個試題難度分布均勻、符合標準的試題鑑 別度、低試題猜測度的優質的題庫。選題題庫大小會影響電腦適性測驗之效度與 效率(李茂能, 2000)。 題庫的建立,大部分是依據課程標準、教材大綱與其內容編寫而成的,建立 過程如圖2-2,可以分成下列十一個步驟:試題的編寫、預選試題、試題的校準與 銜接、更新題庫、試題編輯、評估測驗品質、測驗是否達預期的水準、執行考試、 評分、決策、研究與評鑑(許擇基、劉長萱,1992)。圖2-2 題庫的建立流程 否 是 預選試題 評估測驗品質 試題編輯 執行考試、評分 測驗是否達預期的水準 更新題庫 試題的編寫 試題的校準與銜接 決策、研究與評鑑
第三節 測驗的起點
CAT 是利用電腦來執行測驗、處理選題、計分、能力估計等方面的一種測 驗方式。在測驗時,CAT 根據受試者之作答反應資料來重新估計受試者能力值, 就此估計能力值依設定的選題策略,選擇適當的試題進行測驗;適性選題答對後 選擇較難試題,反之,則選擇較簡單的試題,直到估計值穩定並精確時,終止測 驗。常用於測驗起點的決定方式,有以下幾種(王寶墉, 1995;陳麗如, 1998) (1) 中等難度試題:假設受試者起始能力為中等能力,在題庫中挑選難度適中的 試題作為施測的起始題;中等難度試題開始,因試題有限,每位受試者都試 題易相同,題庫試題保密性需要考量。 (2) 依受試者之已知條件(年齡、學習、經驗或其他測驗結果)估算受試者能力 初始能力值,以決定測驗起始點。 (3) 自由選題:由受試者在接受測驗的時候,自行判斷設定自己的初始能力值, 以決定施測的起始題。 (4) 隨機選題:由電腦設定初始能力值隨機選題。(5) McBride & Martin(1983)提出 MM 演算法第一題從最適當試題五個試題中隨 機取,第二題從最適當試題四個試題中隨機選取,依此類推,第五題以後則 僅挑最佳的試題施測。 Lord(1977)即認為只要測驗的題數不少於 25 題的話,以那一個試題做為起 點的影響不大。
第四節 能力估計
常被使用的能力估計方法有兩種,一種是最大概似值估計法(MaximumLikelihood Estimators, 簡稱MLE) ,另一種是貝氏估計法(Bayesian procedure)。 MLE 主要是利用概似函數來進行能力估計,其估計效能很好,但是遇到
受試者全對或是全錯的答題組型無法估計,此時會產生能力值無法收歛而造成無 法估計的情形;受試者的反應組型異常時,例如:很容易的問題卻答錯而很困難的 問題卻答對時,也會產生能力值無法收歛而造成無法估計的情形;在測驗初期的 幾題中能力的估計值也會產生不穩定的情形。而貝氏估計雖然可以克服這些困 難,但是當事前分配的假設如果不當的話,會產生偏差的能力估計值(Wang & Vispoel, 1998)。 貝氏估計法需先假設事前分配(prior distribution),將事前分配與概似函數相 乘會得到一事後分配(posterior distribution),此事後分配的期望值當做能力估計值 稱為(expected a posteriori, EAP);而此事後分配所對應最大θ當做能力估計值稱為 (maximum a posteriori, MAP)。貝氏估計法雖可以估計受試者全對或是全錯的答題 組型,但若事前分配不正確則能力估計偏差將會很大(Baker & Kim, 2004)。本研
究採用EAP 來估計受試者能力值。
第五節 試題選擇方法
1. 最接近難度法
選擇試題難度值bj最接近受測者能力估計值θ 的試題,作為下一階段
施測的試題(Reckase, 1973; Urry, 1970; Weiss, 1974);此種方法在計算上比
較簡約快速,其選題函數定義Fj為公式(2.5),選題時選擇尚未施測試題的 j F 值為最小的試題。 | | ) ( j j b F θ = θ − (2.5) 2. 最接近偏移難度法 當猜測度cj ≠0時,試題訊息最大值發生不在難度bj上,會產生偏移至
j m,最接近偏移難度法為選擇試題偏移難度最接近受試者能力估計值θ 的試 題,作為下一階段施測的試題。定義偏移難度mj(Birnbaum, 1968)為 ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ + + + = 2 8 1 1 log 7 . 1 1 j j j j c a b m (2.6) 則選題時選擇尚未施測試題的Fj(2.7)值為最小的試題。 | | ) ( j j m F θ =θ − (2.7) 3. 單點式最大訊息法 單點式最大訊息法是選擇對受試者目前能力值下能提供最大訊息量的 試題來施測,也就是選擇訊息函數(2.8)最大的試題,在此即選擇尚未施測且 公式(2.8)中Fj最大的試題,作為測驗施測下一階段施測試題。此種選題法可 使訊息量達到最大,由於訊息量與估計誤差是呈負相關(Lord, 1980),這種選 題方式可使每一位受試者的能力值估計精準度最佳。 ) ( ). ( )] ( ' [ ) ( 2 θ θ θ θ j j j j Q P P F = (2.8) 4、區間式最大訊息法 區間式最大訊息法使用區間能力值的題目訊息總值,來取代在單點能 力值的題目訊息量(Veerkamp & Berger, 1997)。區間式最大訊息法是選擇訊息 函數在信賴區間內的面積,選擇訊息量面積的最大,作為適性測驗下一階段 施測題目,故選題時選取尚未施測且選題函數(2.12)最大者。 θ θ θ θ θ d F u l
∫
= I ( ) ) ( j j (2.9) 其中 ) ) ( I 1.96 , ) ( I 1.96 -( ) , ( T T θ θ θ θ θ θl u = +5、KL 訊息法
(1)定義 KL 訊息
為定義真實能力值θ 與任意能力值0 θ間的距離(discrepancy),以改進 CAT
的估計誤差精準度 Cover & Thomas(1991)與 Kullback(1959)提出 KL 訊息
(Kullback-Leibler information; KL information),KL 訊息在真實能力值θ 距0
離θ越遠時,KL 值越大;反之,KL 值小。而當θ =0 θ 時,KL 訊息為 0;且 對各題目的總訊息有加法性。若作答反應為ui,第i題的KL 訊息定義為 ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ≡ ) ; ( ) ; ( log ) || ( 0 0 0 i i i i i u L u L E K θ θ θ θ θ (2.10) 其中Eθ0為對θ 的期望值,0 (θ; ) i(θ) 1 ui(θ) i u i i i U P Q L = − 為第i題的最大概似函 數,故KL 訊息亦可改寫為 ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − − − + ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ = ) ( 1 ) ( 1 log )] ( 1 [ ) ( ) ( log ) ( ) || ( 0 0 0 0 0 θ θ θ θ θ θ θ θ i i i i i i i P P P P P P K (2.11) (2)定義平均 KL 訊息指標 Chang 與 Ying 在 1996 年利用 KL 訊息的特性定義第i題的平均KL 訊息
指標(average KL information index)為
θ θ θ θ θ δ δ θ K d K n n n n i n n i
∫
+ − = ( || ) ) ( (2.12) 其中θ 為施測n n題後的能力估計值,δ 為平均值的計算區間大小。 n 此指標表示 KL 訊息在θ -n δ 與n θ +-n δ 間的區域面積,若n δ 值小,則指n 標(2.15)受Ki(θ ||θn)在θ 上的曲度(curvature)影響;若n δ 值大,則指標易受n ) || ( n i K θ θ 尾端值影響。故δ 應隨施測階段n n遞減到 0,並且區間(θ -n δ , nn θ +-δ )應包含n θ ,又因0 θ 的最大概似估計0 θ 為平均數為n θ ,變異數為0 ) ( 1 I(n) θ0 的近似常態分佈,故將區間設為
[
]
{
( ) 12[
( )]
12}
) ( , ) ( n n n n n n c I θ θ c I θ θ − + 其中常數c 依據收斂機率選擇。因I(n)為n 階,故可設 n δ 為 n c n = δ (2.13) 即第i題的平均KL 訊息指標為 θ θ θ θ θ θ K d K c n n c i n n i n n∫
−+ = ( || ) ) ( (2.14) KL 訊息法以此平均 KL 訊息指標選出最大訊息者,作為適性測驗的下 一階段施測的題目。 最大訊息法與KL 訊息法最大的差異在於使用訊息函數不同,最大訊息 法使用題目訊息函數(2.8),而 KL 訊息法採用 KL 訊息(2.14),而題目訊息函 數為真實能力值θ 的函數,KL 訊息為真實能力值0 θ 與任意能力值0 θ的函數, 因KL 訊息考量真實與任意兩能力值,計算公式較複雜且運算上較費時,當 0 θ =θ 時,KL 訊息函數的曲度即為題目訊息函數,兩訊息法相同有訊息的加 法性,可計算測驗的總訊息量。 6、鄰近法鄰近法(Nearest-Neighbors criterion, NN criterion; Cheng & Liou, 2003)為 考慮試題曝光率與能力估計精準度兩目標的折衷選題法,結合有較均勻曝光 率的最接近偏移難度法與高估計精準度的單點式最大訊息法,其實施步驟如 下:
其最大試題訊息Mj,其公式如下: ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ + + + = 2 8 1 1 log 7 . 1 1 j j j j c a b m (2.15)
[
]
[
2 2/3]
2 2 ) 8 1 ( 8 20 1 ) 1 ( 8 ) 7 . 1 ( ) ( j j j j j j c c c c a I Max M − − + + − = ≡ θ θ (2.16) 步驟二:設定非遞增整數n(k) k=1,2,…,L 步驟三:初始化能力值估計值θ (k) 步驟四:找新題n(k)個,其試題偏移難度 j m 最接近θ (k) 步驟五:選n(k)個試題中,有最大 j M 的作為下一題施測試題,重新估計 能力值為θ(k+1),回到步驟三,直到停止條件成立。 其中L 為施測試題數。當施測試題越多,能力估計值變動越小,估計越 接近真實能力值,但為降低其誤差,故在鄰近能力估計值能力值間選擇最大 訊息的試題,此表示當施測試題越多,估計越精準,則試題是否為最大訊息 的試題漸不重要,故非遞減整數n(k)可設為L,L-1,…,1,表示當施測題數越 多,則鄰近選題法越接近偏移難度選題法。 7、a 分層法(A_stratified)Chang & Ying(1999)在其研究中提出以鑑別度將題庫分層,用來降低高 鑑別度的試題曝光率,並增加低鑑別度的試題曝光。作法是在測驗開始的階
段,由於能力估計仍不精確,此時若使用高a 值的試題,對於能力估計的精
確性助益不大,反而會使高a 值的試題過度曝光;在測驗後期,能力估計趨
於精確,此時使用高a 值的試題,就能幫助提升能力估計的精確性。
層。 步驟二:將試題分入此K 層,根據 a 值由小到大排序,第一層包含最小的 a 值,第K 層包含最大的 a 值。 步驟三:由第k 層中選出nk個與能力估計值最接近難度的試題,並實施測驗 (n1+nk+…..+nk=L)。 步驟四:把測驗分成K 階段,k 由 1,2,...,K,重複步驟三。
8、考慮 b 參數的 a 分層法 (A_stratified with b blocking)
以GRE(Graduate Record Examination)數學測驗為例,a、b 參數間的相關
達.44。為了降低 A_STR 各層間 b 參數的差異,Chang, Qian, & Ying (2001)提
出考慮b 參數的 a 分層法,希望能把各層中 b 參數的分配維持一致。 考慮b 參數的 a 分層法的實施程序如下: 步驟一:先假設題庫中的試題數為N,測驗長度為 L,題庫分成 K 層。 步驟二:把試題依b 值由小到大分成 T 個區塊,每個區塊包含 K 道試題, 因此T=N/K(若 N 無法被 K 整除則做適當的調整)。第一區塊包 含b 值最低的試題,第 T 的區塊包含 b 值最高的試題。 步驟三:把每個區塊中的試題依a 值大小分成 K 層,每一層包含一到試 題,因此,對t 個區塊而言(t=1....,T)。第一層的 a 值為最低,第 K 層之 a 值為最高,此分層程序和 A_STR 相同。 步驟四:將每個區塊的第K 層合併為一層,k=1...,K。 步驟五:對應K 層,把測驗分成 K 階段,每個階段的施測題數應為 L/K 個試題。 電腦適性測驗的選題方法是依照受試者的能力估計值選出最適合其能 力的題目,而依不同的訊息量標準出不同的選題方法,在過往的研究中,Chen
等人(2000)比較單點式最大訊息法、區間式最大訊息法、後驗最大訊息法、 KL 訊息法與貝氏 KL 訊息法的估計精準度,以區間式最大訊息法與 KL 訊息 法在初始階段有較佳的估計精準度。陳俊宏(2004)比較最接近難度法、最接 近偏移難度法、單點式最大訊息法與區間式最大訊息法在能力估計的精準 度,顯示在題庫為單參數對數模式下,四種選題方法相同;二參數對數模式 下,將選題法區分為難度法與訊息法兩類,以訊息法較好;三參數對數模式 時,區間式最大訊息法較好。 a 分層法在測驗的初始階段,選用鑑別度較小的試題,當測驗題數增加 時,鑑別度也逐步增加,能提高a 值較低試題的使用率,同時仍能維持良好
的能力估計精確性(Chang & Ying, 1999; Hau & Chang, 2001)。雖然如此 a 分 層法卻無法有效控管試題的曝光率,其題庫中的最大曝光率仍大於預設 (Chang, Qian, & Ying, 2001; Leung, Change, & Hua, 2002)。此外,a、b 參數間
的相關也會影響a 分層法的成效。舉例來說,當 a、b 參數間成正相關時,a
值越高的那層,b 值也越高,對於能力水準較低的考生而言,這樣的試題對 其的能力估計並無助益。(Chang & Ying, 1999)。
Cheng & Liou(2003) 使 用 1990 年 美 國 國 家 教 育 進 展 評 量 (National Assessment of Education Progress, NAEP)數學測驗 622 題與 1992 年閱讀測驗 203 題的題庫資料,針對兩題庫各別依不同選題法選題與模擬 1000 名受試者 的作答情況,以20 題與 40 題為停止條件,以均方差評估估計精準度,以卡 方值評估試題曝光率的均勻程度,比較不同選題方法的估計精準度與試題曝 光率,以單點式最大訊息法與區間式最大訊息法精準度較高但曝光率較不均 勻;以最接近偏移難度估計精準度較低但曝光率較均勻;以鄰近法的估計精 準度與曝光率均勻度介於兩者之間,是較折衷的選題法,並顯示選題方法不 能兼顧估計精準度與曝光率均勻度。
試題曝光率較均勻,但損失能力估計誤較大的方法。鄰近法,為對於試題曝 光率均勻程度與能力估計誤差較折衷的方法。區間式最大訊息法與KL 訊息 法,為能力估計精準度高但損失試題曝光均勻度的選題方法。 最大曝光率是觀察題目的過度曝光程度,在以往的文獻中並未特別針對 降低題目的最大曝光率研究,故本研究提出訊息量分階選取法新的選題策略 加上最大訊息法、鄰近法、考慮b 參數的 a 分層法等四種選題策略進行估計 誤差與最大曝光率的評估。
第六節 終止標準
在正式施測之前,還要決定CAT的測驗終止方式。測驗結束方式最常見 的有固定題數終止與目標訊息量終止。固定題數終止是當受試者做完某個 既定的試題數量就停止,不過每個人的測量精準度可能會不同;目標訊息 量終止是當受試者的能力估計訊息量達到一個既定的標準後就停止,這種 方式可以確保對每個人能力估計得精準度都差不多,但每個人所接受的測 驗題數可能會不同。由於訊息量的概念較難被社會大眾所理解,因此固定 題數終止法是較多人採用的方式(陳柏熹,2005)。故本研究使用之終止條 件為固定測驗長度為30題。第七節 曝光率控管之相關研究
選題法選出試題後未達到被選試題分散而加入第二階段控管試題曝光率的方法有很多,如SH 法(Sympson & Hetter, 1985) 是實務上常使用的方
法,有許多學者將其作進一步延伸,以達到更完善的控管例如:SHC 法
(Chang, Ansley & Twu, 2002),此類方法雖能有效控管試題曝光率,但在實際
入時,該方法的控管成效便會大打折扣。另一種曝光率控管方法為不需先迭 代模擬曝光參數使用線上即時控管曝光率的方式,例如:SHO(朱怡君, 2005);SHOF(吳玫玲,2006),由於不需事先迭代模擬曝光參數即可線上
即時控管試題曝光率,將此類方法稱非迭代控管法,而將SH 法等相關方法
稱為迭代控管法。
在此,將題目曝光率定義測驗長度中每題使用的相對次數(Chang & Ying, 1999;Sympson & Hetter, 1985),如下
i er=(第i題被使用的次數)/N (2.17) 其中N 為受試者人數,若題目曝光率為 0.2,則表示 100 名受試者中就 有20 位受試者測驗過此題目。若 L 為平均的測驗長度或固定的測驗長度, 則平均曝光率為 n L er= / (2.18) 為顧及題目曝光率的均勻度,使題庫內的題目皆能被施測,期望題庫內 每題曝光率應接近於平均曝光率。 1、迭代控管法 (1)SH 曝光率控管法 P(S) :試題被選取的機率。 P(A) :試題被施測的機率。 P(A| S):試題在被選取下而被施測的機率。 EP:試題的曝光參數(exposure parameter)。 rmax:可接受試題最大曝光率。 若P(S) > rmax ,則令 P(A|S) = P(S) r max 藉此來壓低高曝光試題的出現機率;若 P(S) ≤ rmax ,則令 P(A| S) = 1,藉此來提高低曝光試題的出現機率。 實施步驟:
假設L 為測驗長度; EP 為曝光參數; rmax 為可接受試題最大曝光率。 步驟一:設定每一試題的EP 初始值為1。 步驟二:假設受試者目前施測到第j 題,依據受試者目前能力估計值,利用 最大訊息法選取下一道施測試題j+1 。從U(0,1) 中選取一亂數x , 若x ≤ EPj+1 ,則施測此試題;若x > EP j+1 ,則不再施測此試題。 步驟三:根據受試者施測完j+1 題的結果估計受試者能力值,重覆步驟二直 到施測完L 題。 步驟四:重覆步驟二與步驟三,直到所有受試者都施測完畢。 根據P(S) 來調整每一試題的EP 。 若P(S) > rmax ,則P(S) EP = ) ( max S P r ; 若P(S) ≤ rmax ,則EP = 1。 步驟五:找出L 道EP 最大的試題,將EP 值設為1。(此步驟係因若施測題庫 長度太短,將會有選不到施測試題的可能) 步驟六:將新產生的EP ,重覆步驟二至步驟五,一直到EP 穩定且P(A) 小 於rmax 。 SH 曝光率控管法若欲施測的母群體與迭代產生曝光參數的母群體不 同,研究發現對曝光率的控管將不如預期 (朱怡君,2005)。CAT 選題時, 一般採用最大訊息法,因此會造成高鑑別度題目過渡被選取,而低鑑別度題 目不易被選取,題庫的使用率較不高(Chang & Ying, 1999)。在極端能力區間 下的試題曝光率幾達100%(Chang & Ansley, 2003)。
(2) SHC曝光率的控管方法
方法:與SH 曝光率控管法相似,需先迭代曝光參數後再進行施測,不
同之處在於SHC 曝光率控管法針對不同的能力區間進行曝光參數的迭代。
假設N 為題庫長度;M 為能力區間分割數; EP 為曝光參數; rmax 為 可接受試題最大曝光率。 步驟一:將受試者能力分佈範圍切割成M 個區間。 步驟二:針對M 個能力區間,各給定 S 名均等分佈受試者,各區間分別使 用SH 曝光率控管法迭代產生各區間所對應的 EP 值。最後會形成一 個M × N 的 EP 矩陣。 將此M × N 的 EP 矩陣運用在實際的 CAT 施測上。選擇試題時,當 受試者能力估計值θ 落在區間 m (m = 1,2,3...M ),就使用區間 m 的 EP 來 控管試題的曝光率。 SHC 曝光率的控管方法不論受試母群體分佈為何,皆能將每個能力區間 的試題曝光率做良好的控管。EP 需要事先迭代產生,耗費相當多的時間與
運算資源,最大的缺點在於能力估計的損耗過大(Chang, Ansley, & Twu, 2002)。 (3)ASHC曝光率控管法 有鑒於SHC 能力估計的損耗過大,陳昇座(2007)提出ASHC 曝光率 控管法,以提高能力值估計精準度。ASHC 與SHC 曝光率控管法相似,須 先在不同能力區間先迭代曝光參數後再進行施測,不同之處在於ASHC 曝光 率控管法針對不同的能力區間給予不同的曝光率控管,以提升能力值估計, 針對受試者人數較多的能力區間,給予較嚴格的曝光率控管;受試者人數較 少的能力區間,給予較寬鬆的曝光率控管。ASHC1 法與ASHC2 法在能力 估計精準度上優於SHC 法,達到改進SHC法能力估計精準度的目的;ASHC2 在曝光率控管上,在試題曝光率平均值、未使用試題數指標,整體上效能最 佳;在受試者為常態分佈時,ASHC2 法的表現不遜於SHC 法(陳昇座, 2007)。然而此方法必須事先獲得受試者能力分佈情形以推算各能力區間曝
的過程,一旦施測情境與原先迭代曝光參數時的情境不同時,曝光參數便無 法有效控管試題曝光率,此外在偏態的情境下,ASHC 的最大曝光率有偏高 的現象(蔡篤松,2008)。 2、非迭代控管法 (1)SHO曝光率控管法 曝光參數以線上取得來取代SH 曝光率控管法須事先迭代產生,用來控 管下一位考生的試題施測機率,以達到曝光率線上控管。 實施步驟: 假設L 為測驗長度,P(S)為試題被選取的機率; EP 為曝光參數,rmax 為可接受試題最大曝光率。 步驟一:設定每一試題的EP 初始值為1。 步驟二:假設受試者目前施測到第j 題,依據受試者目前能力估計值,利用 最大訊息法選取下一道施測試題j+1 。從U(0,1) 中選取一亂數x , 若x ≤ EPj+1 ,則施測此試題;若x> EP j+1 ,則不再施測此試題。 步驟三:根據受試者施測完j+1 題的結果估計受試者能力值,重覆步驟二直 到施測完L 題。 步驟四:根據前面受試者的選題情形,計算出P(S) 來調整每一試題的EP 。 若P(S)> rmax ,則EP = ) ( max S P r ; 若P(S) ≤ rmax ,則EP = 1。 步驟五:找出L 道EP 最大的試題,將EP 值設為1。(此步驟係因若施測題庫 長度太短,將會有選不到施測試題的可能) 步驟六:將新產生的EP ,重覆步驟二至步驟五,一直所有受試者施測完 畢。 SHO 曝光率控管法免除 SH 曝光率控管法須事先迭代曝光參數。施測
情境異動(母群體、題庫)下,依然能有效做曝光率的控管,施測前期 SHO 產 生的曝光參數較不穩定,曝光率的控管成效不如施測後期來的好。(朱怡君, 2005)
(2)SHOF曝光率控管法
Chen & Liao (2005) 建議將 Freeze 程序(Revuelta & Ponsoda, 1998)加
入SHO 中,以提高曝光率控管的效能。Freeze 是一個嚴格的曝光控管程序, 只要試題的曝光率大於rmax,Freeze 便會停止施測該試題,直到其曝光率 小於或等於rmax,才恢復該試題的施測。 實施步驟: 假設L 為測驗長度,P(S)為試題被選取的機率。 EP 為曝光參數,r 為可接受試題最大曝光率。
若P(A) >rmax ,則EP = 0 試題停止選用(Freeze)
步驟一:設定每一試題的EP 初始值為1。 步驟二:假設受試者目前施測到第j 題,依據受試者目前能力估計值,利用 最大訊息法選取下一道施測試題j+1 。從U(0,1) 中選取一亂數x , 若x ≤ EPj+1 ,則施測此試題;若x> EP j+1 ,則不再施測此試題。 步驟三:根據受試者施測完j+1 題的結果估計受試者能力值,重覆步驟二直 到施測完L 題。 步驟四:根據前面受試者的選題情形,計算出P(S) 來調整每一試題的EP 。 若P(A) > rmax ,則EP = 0 (Freeze)
若P(S)>rmax ,則EP = ) ( max S P r ; 若P(S) ≤ rmax,則EP = 1。 步驟五:找出L 道EP 最大的試題,將EP 值設為1。(此步驟係因若施測題庫 長度太短,將會有選不到施測試題的可能)
步驟六:將新產生的EP ,重覆步驟二至步驟五,一直所有受試者施 測 完畢。 透過Freeze 的嚴格控管,SHOF 改善線上控管法在施測初期曝光控管不 穩定的情形,且具有較低的測驗重疊率及較高的題庫使用率,並維持良好的 能力估計準確性(吳玫玲,2006)。SHOF 雖然整體曝光控管成效不錯,但 若針對各個能力水準來看,其成效可能不盡理想(蔡篤松,2008)。
第三章 研究方法
本章分為第一節介紹研究流程、第二節介紹研究工具、第三節介紹訊息 量分階選取法、第四節介紹研究設計、第五節控制方法效能評估指標等五節。第一節 研究流程
圖3-1 研究流程圖 研究動機 設定研究情境 研究目的確立 產生模擬資料 初始選題 設定選題策略 模擬作答反應 能力估計 能力估計誤差與曝光 率效能評估 撰寫研究報告 電腦適性測驗模擬第二節 訊息量分階選取法
本研究提出適性測驗之訊息量分階選取法選題步驟如下: 一、訊息量分階選取法(information_stratified) 步驟一:設定題庫選題訊息量範圍 i_max,L 為施測試題數、k 為施測到第 k 題、j 為題庫試題編號 Mk= i_max/L*k ( 3.1) k=1,2,…,L ) ( ). ( )] ( ' [ ) ( 2 θ θ θ θ j j j j Q P P I = | ) ( | ) ( j k jk I M IM θ = θ − (3.2) 步驟二:初始化能力值估計值θ (k) 步驟三:找新題n(k)=L-k+1,n(k)個,其試題IM jk最小 步驟四:隨機選n(k)個試題中一題施測試題,重新估計能力值為θ(k+1) 步驟五:回到步驟三,直到停止條件成立。第三節 研究設計
本研究主要研究工具為 MATLAB7.1,MATLAB 是一個相當強大的數值分 析模擬軟體,不僅在數值分析能力達到一流水準,外在圖形影像上的處理更是相當 強大,具有語法簡單易用、矩陣運算能力佳及繪圖功能強大等優點。MATLAB 亦 為一個完備的整合性系統,提供了豐富的函式庫,讓方便程式撰寫。故本研究使 用此軟體為研究工具,做為模擬電腦適性測驗與繪製統計圖。 本研究設定的受試者能力情境有二:探討受試者能力分佈不同為 N(0,1)、 N(1,1)、N(2,1) 的情境及不同單點能力值下的情境兩種,分別在不同情境下來評估四種選題策略在曝光率控管的成效: 一、受試者能力分佈不同為 N(0,1)、N(1,1)、N(2,1)研究設計 (一)模擬參數題庫測驗選題策略比較 (1) 測驗初期選題策略 隨機選題法 (2) 選題策略 最大訊息法(mi)、鄰近法(nn)、考慮 b 參數的 a 分層法(ab)、訊息 量分階選取法(inn)等四種選題策略。 (3) 題庫參數及題庫大小 題庫參數範圍變化三種(表 3-4-1)P1、P2,題庫大小有 360 題、1440 題;題庫種類代號表(表 3-4-2)。 (4) 受試者人數 10000 人 ,受試者能力分佈 N(0,1)、N(1,1)、N(2,1) (5) 測驗長度 30 題 (二)真實擬參數題庫測驗選題策略比較 (1) 測驗初期選題策略 隨機選題法 (2) 選題策略 最大訊息法(mi)、鄰近法(nn)、考慮 b 參數的 a 分層法(ab)、訊息 量分階選取法(inn)等四種選題策略。 (3) 題庫參數及題庫大小 真實題庫參數範圍變化 P3、P4 題庫大小有 240 題;題庫種類代號表 (表 3-4-2)。
(5) 測驗長度 30 題 (三)題庫P1、P3 為試題鑑別度參數比較密集的題庫;題庫P2、P4 為試題鑑 別度參數比較分散的題庫 二、不同單點能力值下研究設計 (1) 測驗初期選題策略 隨機選題法 (2) 選題策略 最大訊息法(mi)、鄰近法(nn)、考慮 b 參數的 a 分層法(ab)、 訊息量分階選取法(inn) 等四種選題策略。 (3) 題庫參數及題庫大小 題庫參數範圍變化四種(表 3-4-1)P1、P2,題庫大小有 360 題、1440 題;題庫種類代號表(表 3-4-2)。 (4) 受試者人數 1000 人單點能力 -3、 -2、 -1、 0、1、 2 、3 七 項 (5) 測驗長度 30 題
三、模擬資料產生 CAT 與傳統紙筆測驗的不同在於必須建立一個含有 IRT 測驗試題參數 的題庫,題庫中之參數必須以共同量尺來表示,才能有一致的單位。適性測 驗之效度與效率,與選題題庫大小具有密切關係(李茂能,2000)。 表3-4-1 文獻資料之題庫參數範圍 作者(年代) 難度參數 鑑別度參數 猜測度參數
Philip E. Cheng & Michelle Liou (2000) range (-2.325, 3.061) mean = .024 range (.452, 2.502) mean = 1.194 range(0, .373) mean = .124
Philip E. Cheng & Michelle Liou (2003) range (-2.325, 3.061) mean = .024 range (.321, 4.260) mean = 1.360 range (0, .373) mean = .124 郭伯臣(2006) range (-3.49,2.055) mean =-.859 range (0.659,2.631) mean = 1.527 range (.074 , .335) mean =.206 郭伯臣(2006) range(-2.316,2.220) mean b =-.492 range (.473,3.542) mean a = 1.726 Range(.102 , .419) mean = .199
根據表3-4-1 題庫參數範圍本研究將進行之有題庫參數範圍變化有六種(表 3-4-2),題庫大小有 360 題、1440 題,設計如下(表 3-4-2): 表3-4-2 題庫種類代號表 難度參數 猜測度參數 鑑別度參數 題庫大 小 代號 360 題 P1-t360 U(0.3017, 2.3593) mean = 1.194 1440 題 P1-t1440 360 題 P2-t360 模擬 題庫 N(0,1) U(0,0.25) U (0.321, 4.260) mean = 1.360 1440 題 P2-t1440 range (-3.49,2.055) mean =-.859 range (.074 , .335) mean =.206 range (0.659,2.631) mean = 1.527 240 題 P3-t240-7 29(註1) 真實 題庫 range (-2.316,2.220) mean =-.492 range (.102 , .419) mean = .199 range (.473,3.542) mean = 1.726 240 題 P4-t240-7 76(註2)
註1:真實能力值為題庫產生時同時估計之受試者 729 位能力值,平均值為 0、 最大值為2.842、最小值為-3.728。 註2:真實能力值為題庫產生時同時估計之受試者 776 位能力值,平均值為 0、 最大值為2.328、最小值為-3.894。 上述研究利用MATLAB 7.1 模擬 CAT、進行能力估計誤差評估與曝光 率控制效能評估。資料產生部分是以研究者自行撰寫模擬程式。重複模擬50 次求平均。
第四節 選題策略實施效能評估指標
一、 能力估計效能利用真實能力值θ0與估計能力值θ的均方根差(root mean squared error, RMSE),評估 CAT 系統對受試者能力估計的準確度。 RMSE 的定義如下:
∑
= = N 1 j 2 j 0j- ) ( N 1 RMSE θ θ (3.3) θ :考生 j 的模擬真實能力值 0j θ :考生 j 的估計能力值 j N :受測考生總人數 RMSE_sd:為重複 50 次模擬 RMSE 的標準差。 二、 曝光率控制效能評估指標 1. 試題曝光率的均勻度(χ2 ) 每題之曝光率的期望值為平均曝光率,故利用Pearson 的卡方值為試 題曝光率是否呈現均勻分配的效能評估公式如下:i er=(第i題被使用的次數)/N :其中N為受試者人數,若試題曝光率 為0.2,則表示 100 名受試者中就有 20 位受試者測驗過此試題。若 L 為 平均的測驗長度或固定的測驗長度,則平均曝光率為 n L er= / ,為顧及試題曝光率的均勻度,使題庫內的試題皆能被施測,期 望題庫內每個試題曝光率應接近於平均曝光率。
∑
= − = n i i er er er 1 2 2 ( ) / χ (3.4) 若χ2值小,則試題曝光率為均勻分配,表示試題被充分的使用,故題庫使 用有效率。 2. 最大曝光率(rmax) 3. 曝光率大於.3 試題的題數(r>.03)。 4. 題庫中未使用試題第四章 研究結果與討論
第一節 受試者能力分佈不同比較結果
一、 受試者能力值分布N(0,1)結果 (一) 能力估計效能 在受試者能力為分布N(0,1)、測驗長度為 30 題,各選題法的 RMSE 於表4-1,以 P1-t360 為例,以 mi 法(0.148)與 inn 法(0.159)較小,nn 法(0.167) 次之,ab 法(0.216)較大;P2-t360、P2-t1440 也有此順序關係。P1-t1440 的 mi 法(0.121)較小, nn 法(0.134) 與 inn 法(0.140)次之,ab 法(0.191) 較大。 (二) 曝光率控制效能評估指標 1、 試題曝光率的均勻度 在受試者能力為分布N(0,1)、測驗長度為 30 題,各選題法的試題曝 光率的均勻度由表4-3 可知在 P1-t360、P2-t360、P1-t1440、P2-t1440 中 ab 的曝光率的均勻度均為最佳,在 P1-t360、P2-t360、P2-t1440 中 nn 法 曝光率的均勻度優於 inn 法,在 P1-t1440 中 inn 法曝光率的均勻度優於 nn 法,而 mi 法的曝光率的均勻度均為最差。 2、 最大曝光率 在受試者能力為分布N(0,1)、測驗長度為 30 題,各選題法的試題最 大曝光率由表4-4 可知在 P1-t360、P2-t360、P1-t1440、P2-t1440 中 ab 法 和inn 法的最大曝光率均為較低,在 inn 法次之, mi 法的均為最高。 3、 曝光率大於.3 試題的題數 在受試者能力為分布N(0,1)、測驗長度為 30 題,各選題法的試題 r>0.3試題r>0.3 的題數為較少,在 nn 法和 inn 法次之, mi 法的均為最多。 表4-1 受試者能力值分布 N(0,1)的 RMSE inn mi nn ab P1-t360 0.159 0.148 0.167 0.216 P2-t360 0.124 0.121 0.134 0.166 P1-t1440 0.140 0.121 0.134 0.191 P2-t1440 0.094 0.090 0.104 0.152 表4-2 受試者能力值分布 N(0,1)的RMSE_sd inn mi nn ab P1-t360 0.001 0.001 0.001 0.001 P2-t360 0.001 0.001 0.001 0.002 P1-t1440 0.001 0.001 0.001 0.002 P2-t1440 0.001 0.001 0.001 0.001 表4-3 受試者能力值分布 N(0,1)的χ2 inn mi nn ab P1-t360 32.613 67.520 22.835 6.089 P2-t360 35.693 55.206 16.803 4.454 P1-t1440 64.668 248.560 86.241 9.607 P2-t1440 107.790 217.170 67.845 10.105
表4-4 受試者能力值分布 N(0,1)的rmax inn mi nn ab P1-t360 0.384 0.652 0.484 0.388 P2-t360 0.343 0.575 0.425 0.274 P1-t1440 0.237 0.583 0.247 0.156 P2-t1440 0.232 0.570 0.244 0.127 表4-5 受試者能力值分布 N(0,1)的r>0.3 inn mi nn ab P1-t360 7.600 24.000 10.000 1.000 P2-t360 9.300 16.000 10.000 0.000 P1-t1440 0.000 12.300 0.000 0.000 P2-t1440 0.000 8.900 0.000 0.000 二、 受試者能力值分布N(1,1) 結果 (一) 能力估計效能 在受試者能力為分布N(1,1)、測驗長度為 30 題,各選題法的 RMSE 於表 4-6,以 P1-t360 為例,以 mi 法(0.168)與 inn 法(0.172)較小,nn 法 (0.1867)次之,ab 法(0.223)較大;P2-t360、P2-t1440 也有此順序關係。 P1-t1440 的 mi 法(0.137)較小, nn 法(0.151) 與 inn 法(0.153)次之,ab 法 (0.196)較大。受到受試者能力值分布和試題難度參數分布不相同,各種 情形的RMSE 一致均有增加的情形。
(二) 曝光率控制效能評估指標 1、 試題曝光率的均勻度 在受試者能力為分布N(1,1)、測驗長度為 30 題,各選題法的試題曝 光率的均勻度由表4-8 可知在 P1-t360、P2-t360、P1-t1440、P2-t1440 中 ab 的曝光率的均勻度均為最佳,在 P1-t360、P2-t360、P2-t1440 中 nn 法 曝光率的均勻度優於 inn 法,在 P1-t1440 中 inn 法曝光率的均勻度優於 nn 法,而 mi 法的曝光率的均勻度均為最差。 2、 最大曝光率 在受試者能力為分布N(1,1)、測驗長度為 30 題,各選題法的試題最 大曝光率由表 4-9 可知在 P1-t360、P2-t360、P1-t1440、P2-t1440 中 inn 法的最大曝光率均為最低,在ab 法和 nn 法次之, mi 法的均為最高。 3、 曝光率大於.3 試題的題數 在受試者能力為分布N(1,1)、測驗長度為 30 題,各選題法的試題 r>0.3 的題數由表4-10 可知在 P1-t360 中、P2-t360、P1-t1440 中 ab 法的試題 r>0.3 的題數為較少,在nn 法和 inn 法次之, mi 法的均為最多。P2-t1440 中 ab 法和 inn 法的試題 r>0.3 的題數為 0 題,在 nn 法試題 r>0.3 的題數為 2 題次之, mi 法的均為最多。 表4-6 受試者能力值分布 N(1,1)的RMSE inn mi nn ab P1-t360 0.176 0.168 0.187 0.223 P2-t360 0.150 0.147 0.158 0.178 P1-t1440 0.153 0.137 0.151 0.196 P2-t1440 0.114 0.110 0.126 0.165
表4-7 受試者能力值分布 N(1,1)的RMSE_sd inn mi nn ab P1-t360 0.001 0.001 0.002 0.002 P2-t360 0.002 0.001 0.001 0.001 P1-t1440 0.001 0.001 0.001 0.001 P2-t1440 0.001 0.002 0.001 0.001 表4-8 受試者能力值分布 N(1,1)的χ2 inn mi nn ab P1-t360 50.761 82.856 37.005 33.128 P2-t360 57.079 72.531 44.256 39.081 P1-t1440 107.550 284.540 121.250 66.366 P2-t1440 169.810 263.330 98.527 62.884 表4-9 受試者能力值分布 N(1,1)的rmax inn mi nn ab P1-t360 0.481 0.694 0.590 0.613 P2-t360 0.455 0.572 0.506 0.528 P1-t1440 0.305 0.689 0.464 0.370 P2-t1440 0.294 0.597 0.337 0.262
表4-10 受試者能力值分布 N(1,1)的r>0.3 inn mi nn ab P1-t360 27.000 37.700 11.100 9.800 P2-t360 33.500 35.000 24.900 22.500 P1-t1440 1.800 17.400 5.100 1.000 P2-t1440 0.000 10.900 2.000 0.000 三、 受試者能力值分布N(2,1) 結果 (一) 能力估計效能 在受試者能力為分布N(2,1)、測驗長度為 30 題,各選題法的 RMSE 於表 4-11,以 mi 法與 inn 法較小,nn 法次之,ab 法較大;受到受試者 能力值分布和試題難度參數分布不相同,各種選題法的RMSE 一致均有 增加的情形。 (二) 曝光率控制效能評估指標 1、 試題曝光率的均勻度 在受試者能力為分布N(2,1)、測驗長度為 30 題,各選題法的試題曝 光率的均勻度由表4-13 可知在 P1-t360、P2-t360、P1-t1440 中 inn 的曝光 率的均勻度均為最佳,在P2-t1440 中 nn 的曝光率的均勻度為最佳,inn 法次之;在P1-t360、P2-t360 中 ab 法曝光率的均勻度為最差,在 P1-t1440、 P2-t1440 中 mi 法曝光率的均勻度為最差。 2、 最大曝光率 在受試者能力為分布N(2,1)、測驗長度為 30 題,各選題法的試題最 大曝光率由表4-14 可知在 P1-t360、P2-t360、P1-t1440、P2-t1440 中 inn 法的最大曝光率均為最低,在ab 法和 nn 法次之, mi 法的均為最高。
3、 曝光率大於.3 試題的題數 在受試者能力為分布N(2,1)、測驗長度為 30 題,各選題法的試題 r>0.3 的題數由表4-15 可知在 P1-t360 中、P2-t360、P2-t1440 中 ab 法的試題 r>0.3 的題數為較少,在nn 法和 inn 法次之, mi 法的均為最多。P1-t1440 中 inn 法的試題 r>0.3 的題數為 27 題最少,在 ab 法和 nn 法試題 r>0.3 的題 數為次之, mi 法的均為最多。 表4-11 受試者能力值分布 N(2,1)的RMSE inn mi nn ab P1-t360 0.253 0.250 0.265 0.275 P2-t360 0.254 0.253 0.264 0.272 P1-t1440 0.213 0.206 0.219 0.243 P2-t1440 0.186 0.184 0.195 0.221 表4-12 受試者能力值分布 N(2,1)的RMSE_sd inn mi nn ab P1-t360 0.002 0.001 0.003 0.002 P2-t360 0.001 0.002 0.002 0.003 P1-t1440 0.001 0.002 0.002 0.001 P2-t1440 0.002 0.002 0.002 0.001
表4-13 受試者能力值分布 N(2,1)的χ2 inn mi nn ab P1-t360 116.880 130.750 125.690 141.420 P2-t360 118.420 120.290 164.470 167.570 P1-t1440 298.220 432.630 365.290 399.120 P2-t1440 363.560 419.860 347.310 385.700 表4-14 受試者能力值分布 N(2,1)的rmax inn mi nn ab P1-t360 0.690 0.808 0.778 0.931 P2-t360 0.705 0.843 0.924 0.946 P1-t1440 0.506 0.762 0.793 0.882 P2-t1440 0.528 0.935 0.940 0.902 表4-15 受試者能力值分布 N(2,1)的r>0.3 inn mi nn ab P1-t360 37.000 38.500 34.000 29.500 P2-t360 36.000 38.700 31.000 30.000 P1-t1440 27.800 38.400 29.000 29.000 P2-t1440 34.900 36.800 31.000 28.000 綜合上述資料當在受試者能力分布和題庫試題難度分布相近時,inn 法和nn 法的 RMSE 和曝光率的均勻度各有優劣,但 inn 法的最大曝光率 均為較低;當在受試者能力分布和題庫試題難度分布不同時,inn 法的 RMSE 和曝光率的均勻度優於 nn 法,且 inn 法的最大曝光率均為較低。
由圖4-1、圖 4-2、圖 4-3、圖 4-4 中受試著能力分布情形與題庫試題參數 分布不同時RMSE 皆隨之提高,inn 法上升速度較緩。 0.000 0.050 0.100 0.150 0.200 0.250 0.300 inn mi nn ab N(0,1) N(1,1) N(1,2) 圖4-1 題庫 P1-t360 的 RMSE 0.000 0.050 0.100 0.150 0.200 0.250 0.300 inn mi nn ab N(0,1) N(1,1) N(1,2) 圖4-2 題庫 P2-t360 的 RMSE
0.000 0.050 0.100 0.150 0.200 0.250 0.300 inn mi nn ab N(0,1) N(1,1) N(1,2) 圖4-3 題庫 P1-t1440 的 RMSE 0.000 0.050 0.100 0.150 0.200 0.250 inn mi nn ab N(0,1) N(1,1) N(1,2) 圖4-4 題庫 P2-t1440 的 RMSE 四、 真實題庫P3、P4 結果 (一) 能力估計效能 在真實題庫P3、P4、測驗長度為 30 題,各選題法的 RMSE 於表 4-16, 以mi 法較小,nn 法與 inn 法次之,ab 法較大。
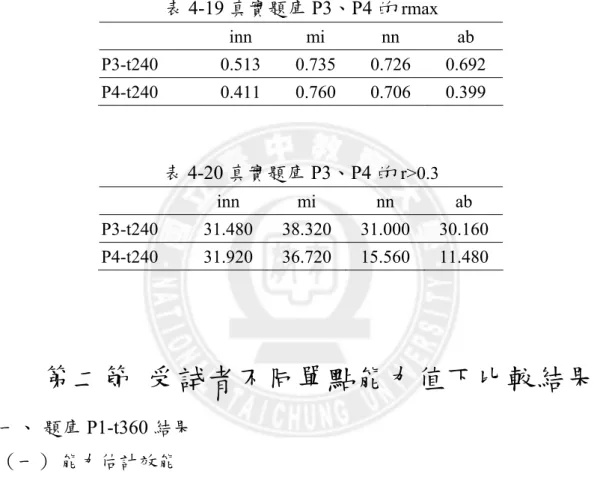
(二) 曝光率控制效能評估指標 1、 試題曝光率的均勻度 在真實題庫 P3、P4、測驗長度為 30 題,各選題法的試題曝光率的 均勻度由表4-18 可知在 P3-t240 中 inn 的曝光率的均勻度均為最佳, ab 法和nn 法次之;在 P4-t240 中 ab 的曝光率的均勻度均為最佳, inn 法和 nn 法次之, mi 法曝光率的均勻度為最差。 2、 最大曝光率 在真實題庫 P3、P4、測驗長度為 30 題,各選題法的試題最大曝光 率由表 4-19 可知在 P3-t240 中 inn 的試題最大曝光率為最低, ab 法和 nn 法次之;在 P4-t240 中 ab 的試題最大曝光率為最低, inn 法和 nn 法 次之, mi 法的試題最大曝光率為最高。 3、 曝光率大於.3 試題的題數 在真實題庫P3、P4、測驗長度為 30 題,各選題法的試題 r>0.3 的題 數由表4-20 可知在 P3-t240、P4-t240 中 ab 法的試題 r>0.3 的題數為較少, 在nn 法和 inn 法次之, mi 法的均為最多。 表4-16 真實題庫 P3、P4 的RMSE inn mi nn ab P3-t240 0.190 0.182 0.189 0.202 P4-t240 0.161 0.156 0.163 0.182 表4-17 真實題庫 P3、P4 的RMSE_sd inn mi nn ab P3-t240 0.006 0.004 0.009 0.006 P4-t240 0.006 0.006 0.005 0.006
表4-18 真實題庫 P3、P4 的χ2 inn mi nn ab P3-t240 31.267 53.476 42.792 39.304 P4-t240 24.626 40.585 24.437 15.050 表4-19 真實題庫 P3、P4 的rmax inn mi nn ab P3-t240 0.513 0.735 0.726 0.692 P4-t240 0.411 0.760 0.706 0.399 表4-20 真實題庫 P3、P4 的r>0.3 inn mi nn ab P3-t240 31.480 38.320 31.000 30.160 P4-t240 31.920 36.720 15.560 11.480
第二節 受試者不同單點能力值下比較結果
一、 題庫P1-t360 結果 (一) 能力估計效能 題庫 P1-t360 不同單點能力值下,各選題法的 RMSE 於表 4-21,mi 法在不同單點力值下均較小,ab 法在不同單點能力值下均較大;nn 法和 inn 法次之,而 inn 法的 RMSE 在受試者能力點除了-3 均小於 nn 法的 RMSE。(二) 曝光率控制效能評估指標 1、 試題曝光率的均勻度
表4-22 可知在受試者能力點 0、1、-1 下 ab 法的曝光率的均勻度均為最 佳, inn 法曝光率的均勻度次之,在受試者能力點 2、-2、3、-3 下 inn 法的曝光率的均勻度均為最佳, nn 法曝光率的均勻度次之,而 mi 法的 曝光率的均勻度在不同單點能力值下均為最差。 2、 最大曝光率 題庫 P1-t360 不同單點能力值下各選題法的試題最大曝光率由表 4-23 可 ab 法的最大曝光率均為最低。 3、 題庫中未使用試題 題庫 P1-t360 不同單點能力值下各選題法的未使用試題由表 4-24 中 inn 法的未使用試題為最少,在 ab 法和 nn 法次之, mi 法的均為最高。 表4-21 不同單點能力值下題庫 P1-360 的 RMSE -3 -2 -1 0 1 2 3 inn 0.324 0.221 0.155 0.146 0.150 0.193 0.284 mi 0.316 0.210 0.149 0.130 0.137 0.188 0.275 nn 0.320 0.231 0.172 0.154 0.161 0.204 0.293 ab 0.477 0.299 0.233 0.197 0.213 0.253 0.302 表4-22 不同單點能力值下題庫 P1-t360 的χ2 -3 -2 -1 0 1 2 3 inn 207.84 197.48 167.40 122.07 140.98 184.06 200.05 mi 270.58 259.58 267.52 239.40 248.72 259.69 275.41 nn 291.28 257.22 178.87 107.19 134.27 212.16 298.94 ab 231.16 207.75 90.99 44.78 86.78 156.06 275.74
表4-23 不同單點能力值下題庫 P1-t360 的rmax -3 -2 -1 0 1 2 3 inn 1.000 0.999 0.994 0.993 0.994 1.000 1.000 mi 1.000 1.000 1.000 1.000 1.000 1.000 1.000 nn 1.000 0.999 0.965 0.897 0.921 1.000 1.000 ab 0.999 0.991 0.757 0.445 0.665 0.887 1.000 表4-24 不同單點能力值下題庫 P1-t360 的未使用試題 -3 -2 -1 0 1 2 3 inn 44 42 39 36 35 39 38 mi 279 283 278 262 286 289 300 nn 284 256 230 165 208 272 301 ab 187 193 115 80 144 203 257 二、 題庫P2-t360 結果 (一) 能力估計效能 題庫 P2-360 不同單點能力值下,各選題法的 RMSE 於表 4-25,mi 法在不同單點能力值下均較小,inn 法在不同單點能力值下均次之,nn 法在不同單點能力值下均第三,ab 法在不同單點能力值下均較大。 (二) 曝光率控制效能評估指標 1、 試題曝光率的均勻度 題庫P2-t360 不同單點能力值下,各選題法的試題曝光率的均勻度由 表4-26 可知在受試者能力點 0、1、-1 下 ab 法的曝光率的均勻度均為最 佳, inn 法曝光率的均勻度次之,在受試者能力點 2、-2、3、-3 下 inn 法的曝光率的均勻度均為最佳, ab 法曝光率的均勻度次之,而 mi 法的 曝光率的均勻度在在受試者能力點0、1、-1 均為最差,nn 法的曝光率的 均勻度在在受試者能力點2、-2、3、-3 均為最差。
2、 最大曝光率 題庫P2-360 不同單點力值下各選題法的試題最大曝光率由表 4-27 可 ab 法的最大曝光率均為最低。 3、 題庫中未使用試題 題庫 P2-t360 不同單點能力值下各選題法的未使用試題由表 4-28 中 inn 法的未使用試題為最少,在 ab 法和 nn 法次之, mi 法的均為最高。 表4-25 不同單點能力值下題庫 P2-t360 的RMSE -3 -2 -1 0 1 2 3 inn 0.357 0.182 0.129 0.102 0.115 0.163 0.258 mi 0.355 0.179 0.126 0.097 0.111 0.159 0.264 nn 0.358 0.189 0.137 0.111 0.129 0.168 0.264 ab 0.442 0.230 0.172 0.151 0.157 0.178 0.260 表4-26 不同單點能力值下題庫 P2-t360 的χ2 -3 -2 -1 0 1 2 3 inn 220.90 224.50 198.84 173.63 181.29 226.18 205.61 mi 261.95 268.06 249.63 238.64 251.49 272.50 247.70 nn 294.27 281.49 180.14 127.19 173.33 288.81 302.81 ab 261.96 235.92 121.11 63.96 113.36 253.69 292.31 表4-27 不同單點能力值下題庫 P2-t360 的rmax -3 -2 -1 0 1 2 3 inn 0.999 0.999 0.997 0.998 0.999 1.000 1.000 mi 1.000 1.000 1.000 1.000 1.000 1.000 1.000 nn 1.000 0.999 0.944 0.917 0.984 1.000 1.000
表4-28 不同單點能力值下題庫 P2-t360 的未使用試題 -3 -2 -1 0 1 2 3 inn 47 50 47 45 37 40 39 mi 272 279 278 270 278 290 295 nn 280 278 226 176 223 294 306 ab 206 183 132 107 135 242 286 三、 題庫P1-t1440 結果 (一) 能力估計效能 題庫P1-t1440 不同單點能力值下,各選題法的 RMSE 於表 4-29,mi 法在不同單點能力值下均較小,ab 法在不同單點能力值下均較大;nn 法
和 inn 法次之,而 inn 法的 RMSE 在受試者能力點除了 2、3 均大於 nn
法的RMSE。 (二) 曝光率控制效能評估指標 1、 試題曝光率的均勻度 題庫 P1-t1440 不同單點能力值下,各選題法的試題曝光率的均勻度 由表4-30 可知在受試者能力點 0、1、-1、2、-2 下 ab 法的曝光率的均勻 度均為最佳, inn 法曝光率的均勻度次之,在受試者能力點 3、-3 下 inn 法的曝光率的均勻度均為最佳, ab 法曝光率的均勻度次之,而 mi 法的 曝光率的均勻度在在受試者能力點 0、1、-1、2、-2 下為最差、nn 法的 曝光率的均勻度在在受試者能力點3、-3 下為最差。 2、 最大曝光率 題庫 P1-t1440 不同單點能力值下各選題法的試題最大曝光率由表 4-31 可 ab 法的最大曝光率均為最低。 3、 題庫中未使用試題 題庫P1-t1440 不同單點能力值下各選題法的未使用試題由表 4-32 中
inn 法的未使用試題為最少,在 ab 法和 nn 法次之, mi 法的均為最高。 表4-29 不同單點能力值下題庫 P1-t1440 的RMSE -3 -2 -1 0 1 2 3 inn 0.242 0.157 0.137 0.135 0.138 0.157 0.258 mi 0.233 0.138 0.116 0.112 0.117 0.141 0.242 nn 0.241 0.156 0.130 0.123 0.131 0.160 0.261 ab 0.325 0.238 0.199 0.181 0.187 0.207 0.289 表4-30 不同單點能力值下題庫 P1-t1440 的χ2 -3 -2 -1 0 1 2 3 inn 779.81 595.20 343.61 280.67 353.96 552.70 727.98 mi 1073.60 1018.90 962.43 926.09 962.09 1091.20 1155.80 nn 1167.10 687.37 401.21 363.45 396.40 627.58 1157.80 ab 846.21 357.73 110.27 70.43 137.92 426.73 1007.90 表4-31 不同單點能力值下題庫 P1-t1440 的rmax -3 -2 -1 0 1 2 3 inn 0.999 0.988 0.945 0.927 0.981 0.983 1.000 mi 1.000 1.000 0.999 0.999 1.000 1.000 1.000 nn 0.999 0.953 0.738 0.688 0.738 0.954 1.000 ab 0.991 0.646 0.275 0.228 0.428 0.662 1.000 表4-32 不同單點能力值下題庫 P1-t1440 的未使用試題 -3 -2 -1 0 1 2 3 inn 339 315 263 227 222 256 284 mi 1353 1352 1333 1329 1334 1353 1367 nn 1283 1246 1048 914 1011 1209 1311 ab 884 781 616 530 754 1060 1205
四、題庫P2-t1440 結果 (一) 能力估計效能 題庫P2-t1440 不同單點能力值下,各選題法的 RMSE 於表 4-33,mi 法在不同單點能力值下均較小,inn 法在不同單點能力值下均次之,nn 法在不同單點能力值下均第三,ab 法在不同單點能力值下均較大。 (二) 曝光率控制效能評估指標 1、 試題曝光率的均勻度 題庫 P2-t1440 不同單點能力值下,各選題法的試題曝光率的均勻度 由表4-34 可知在受試者能力點 0、1、-1、2、-2 下 ab 法的曝光率的均勻 度均為最佳, nn 法曝光率的均勻度次之,在受試者能力點 3、-3 下 inn 法的曝光率的均勻度均為最佳, ab 法曝光率的均勻度次之,而 mi 法的 曝光率的均勻度在在受試者能力點 0、1、-1、2、-2 均為最差,nn 法的 曝光率的均勻度在在受試者能力點3、-3 均為最差。 2、 最大曝光率 題庫 P2-t1440 不同單點能力值下各選題法的試題最大曝光率由表 4-35 可 ab 法的最大曝光率均為最低。 3、 題庫中未使用試題 題庫P2-t1440 不同單點能力值下各選題法的未使用試題由表 4-36 中 inn 法的未使用試題為最少,在 ab 法和 nn 法次之, mi 法的均為最高。 綜合上述資料當在受試者能力點靠近兩端時,inn 法的 RMSE 和曝光 率的均勻度優於nn 法,且 inn 法的未使用試題為較少;當在受試者能力 點靠近能力值0 時,inn 法和 nn 法的 RMSE 和曝光率的均勻度各有優劣, 但inn 法的未使用試題為較少。
表4-33 不同單點能力值下題庫P2-t1440的RMSE -3 -2 -1 0 1 2 3 inn 0.222 0.116 0.090 0.085 0.091 0.127 0.220 mi 0.222 0.110 0.087 0.077 0.086 0.122 0.217 nn 0.235 0.128 0.100 0.093 0.106 0.136 0.228 ab 0.278 0.182 0.152 0.145 0.150 0.178 0.233 表4-34 不同單點能力值下題庫P2-t1440的χ2 -3 -2 -1 0 1 2 3 inn 838.67 826.72 644.35 591.30 753.20 812.08 925.63 mi 1085.30 1091.40 1010.50 1014.30 1122.90 1075.50 1203.60 nn 1137.30 733.23 423.32 394.75 387.46 696.96 1176.20 ab 876.39 469.50 136.12 102.70 150.41 493.06 1014.40 表4-35 不同單點能力值下題庫P2-t1440的rmax -3 -2 -1 0 1 2 3 inn 0.998 0.997 0.978 0.987 0.995 0.999 1.000 mi 0.999 1.000 0.997 0.999 1.000 1.000 1.000 nn 0.997 0.973 0.771 0.786 0.773 0.913 1.000 ab 0.997 0.857 0.400 0.322 0.333 0.903 1.000 表4-36 不同單點能力值下題庫P2-t1440的未使用試題 -3 -2 -1 0 1 2 3 inn 474 484 430 386 434 479 503 mi 1319 1324 1322 1341 1341 1354 1375 nn 1263 1207 1077 1016 1053 1236 1310 ab 968 820 693 601 826 1111 1231