企業財務危機診斷模式之構建
葉忠興
中國文化大學國際企業管理學系博士班 11114 臺北市陽明山華岡路 55 號摘 要
近年來,由於企業環境經營巨變,造成整體經濟所面臨的狀況更加艱鉅,而企業財務危機 發生的可能性亦隨之提升。因此,建立一個有效的財務危機診斷模式,是當前學術界與實務界 的一個重要課題,本研究整合資料探勘與資料包絡分析建構模式方法,建構企業危機診斷分類 能力。此外,在探討企業危機的衡量指標上,本研究除了參考一般傳統財務性指標外,亦加入 了經營績效指標,希望能藉由更完整多元的企業資訊,來幫助企業本身評估其自身的真實價 值,並做出正確的決策。本研究經由約略集合理論針對所考量之衡量企業財務危機指標進行分 析,得知企業發生財務危機的原因,除了受到傳統財務構面指標的影響外亦受到經營績效指標 的影響。此外,整合資料探勘技術與經營績效指標所建構之企業財務危機診斷模式亦能確實有 效降低企業財務危機診斷誤判的情況,是以無論在學術研究或實際工作上,實有其相當的助益。 關鍵詞:資料探勘,企業財務危機,資料包絡分析,約略集合,支援向量機Predicting Financial Business Failures
C
HUNG-H
SINGY
EHDepartment of International Business Administration, Chinese Culture University 55, Hwa-Kang Rd., Yang-Ming-Shan, Taipei 11114, Taiwan, R. O. C.
ABSTRACT
Over the last few years, rapid changes in the global economic environment have increased the possibility of financial failures occurring. Therefore, constructing an appropriate financial distress diagnosis model has become a crucial task for the industry. The objective of this study is to investigate enterprise financial distress by integrating data mining with a data envelopment analysis (DEA) indicator. In addition to a financial indicator, the DEA indicator is also included in the model. The results indicate that the combined approach proposed in this study enables greater prediction accuracy and convergence speed compared to that of conventional data mining. Additionally, we discovered that the accurate diagnosis of enterprise financial distress is significantly influenced by both traditional financial indicators and the DEA indicator.
Key Words: data mining, financial distress, data envelopment analysis, rough set, support vector machine
一、導論
近年來,由於企業環境經營巨變,造成整體經濟所面臨 的重況更加艱鉅,而企業財務危機發生的可能性亦隨之提 升。基本上,所謂的企業財務危機發生的因素,可涵蓋景氣 循環、管理不當、環境變遷,或者是突發重大情勢。企業財 務危機的發生不僅會導致公司股東或債權人權益的損失,更 可能引起上下游廠商的一連串財務問題。當企業發生財務困 難的初期,企業的營運大多會產生部份特別的徵兆,多數學 者認為企業在發生財務危機前,應該會有徵兆顯示企業經營 不善或周轉不靈的現象,而財務報表是企業整體的表現,因 此財務指標可以透視企業經營狀況與財務結構的變化。 由財務報表得知的財務比率可以反應出一些公司特 性,管理績效不佳是導致財務危機的主因(Gestel, Baesens, Suykens, Van den Poel, Baestaens, & Willekens, 2006),因 此,本研究認為公司經營的績效值是一個重要且可以反應管 理階層狀態的指標,所以採用公司的績效指標當作一個財務 危機診斷模式的變數。考量其他公司投入/產出的權重可以 得知公司的經營績效,藉由財務報表資訊來衡量公司績效是 困難的,而資料包絡分析法是一個衡量公司績效的良好工 具,它可以考量公司多個構面且處理多投入與產出,在本研 究中我們採用績效指標當作構建財務危機模式的變數。 財務危機的判別是一種分類的問題,最常被使用的統計 方法,包括區別分析(discriminant analysis)(Belkaoi, 1980)、 probit regression、logit regression(Ederington, 1985)。這些 統計方法往往必須滿足基本假設才能適用。因此不受限於統 計假設的資料探勘法逐漸興起,加上資訊科技的進步滿足了 系統大量計算的需求,故在實務上與學術研究上有越來越多 的專家學者採用資料探勘的方法來解決分類問題。而在做資 料探勘前,資料的淨化是相當重要的,包括了資料整理與處 理資料中不合於定義的數值,採用淨化後的資料再做分析, 才能得出更嚴謹及無誤的結果。資料探勘是在目前資料庫應 用的領域中,一項相當熱門的研究議題,其主要目的就是由 資料庫中將隱含的、先前不知道的、在有用的資訊萃取出來 的過程。資料探勘主要的貢獻在於它能由資料庫中獲取有意 義的資訊及對資料彙整出有結構的型態,作為企業做決策時 的參考。資料探勘包含了約略集合、支援向量機、決策樹與 類神經網路等,並且應用在各個不同層面上都有不錯的效 果。目前有學者採用約略集合(rough set)(Bose, 2006)、 支援向量機(support vector machine)(Shin, Lee, & Kim,2005)在財務危機研究上,並從中獲得一些有用的資訊與分 類效果。 約略集合能針對複雜的資訊做處理,可以獲得簡化與有 規則的資訊且它利用近似值的概念,可以表達模糊或不確性 很高的資料。透過約略集合理論,可以獲得相關的規則並用 以推導其他相關的資料,進行決策分析。其應用於財務危 機、社會科學、科學技術與工業工程方面,皆有不錯的分類 效果(Bose, 2006)。支援向量機在處理分類與預測方面的問 題都有不錯的表現,且廣泛的使用於不同領域,例如:影像 辨識、文字分類、生物科技等相關分類問題都有相當好的成 果(Kim, 2003)。因此,本研究將利用資料包絡分析多投入 與多產出的特質,整合資料包絡分析績效值導入約略集合與 支援向量機以進行財務危機公司的診斷。
二、財務危機相關研究
(一)企業財務危機之類型 Beaver(1966)首先對企業危機做出明確定義:即企業 宣告破產、公司債務違約、銀行透支、或未支付優先股股息, 此企業便稱企業危機。Altman(1983)指出企業經營失敗是 只投資實際的獲利率遠低於過去或當時類似的獲利率,而出 現虧損狀態。根據前人文獻,企業失敗過程與下列四事件的 發生有關連:股利支付的下降、債務契約的違反、困難債務 重整及會計師簽發經營有疑慮之保留意見。Lau(1987)採 用五個連續的階段描述公司財務情形,並評估某一企業進入 某一狀態之可能發生機率。這五階段分別為:財務穩定、停 止或減少股利支付、貸款支付的違約及技術違約性、受破產 法令的保護與破產清算。早期財務危機的原因及其認定的標 準,過去研究各有不同的解釋及定義,且早期研究多專注於 財務比率對危機公司分類的問題,近代則有一些考慮經營績 效的相關研究,因此,輸入變數的選取上,將財務比率、績 效值納入,對危機公司分類的正確率上,往往比不納入考量 來的高,我們希望能發展以財務比率與經營績效為基礎來對 財務危機公司做判別。 (二)財務危機的預警方法 Beaver(1966)首先利用單變量統計分析方法構建企業 財務危機診斷模式,掀起 40 年來未曾中斷的研究風潮。 Beaver 利用二分類檢定法(dichotomous classification test), 按照不同年度將樣本企業之特定財務比率值由大排到小,從 數值中找一個分界點,使分類錯誤百分比達到最小(及無母數統計之 Mann-Whitney-Wilcoxen 檢定法)。他不但開創了 使用統計方法研究企業危機的先例,所採用的正常企業搭配 危機企業的配對方法,也奠定日後研究者實驗設計的模式。 隨著經濟環境的變遷及交易型態的改變,傳統的統計方法似 乎不能精確診斷企業財務危機。在預警方法上,傳統的單變 量與多變量分析是最常被應用於財務診斷模式中。但是這些 統計方法往往需要滿足特定的統計假設(例如資料符合常態 分配)才能適用,因此,不需針對資料組合有任何統計假設 的人工智慧方法因運而生,再加上資訊科技的進展可以提供 資料大量運算的需求,因此,學術上與實務上越來越多的專 家與學者試著採用人工智慧方法解決問題,目前已有學者採 用約略集合(Bose, 2006; Jostarndt & Sautner, 2008)、支援向 量機(Jostarndt & Sautner)於財務危機公司分類的問題,並 獲得相當不錯的分類正確率,因此,本研究亦嘗試採用上述 兩種方法對財務危機公司做分類。 (三)輸入變數的選取 在輸入變數的選取上,早期研究大多採用多變量統計方 法的主成分分析、因素分析及逐步選取方法選取重要的輸入 變數,這些變數往往因應資料的可取得性而多著重於企業財 務資訊(由其是財務比率的資訊),鮮少使用營運面與市場 面的資訊,故分類正確率沒有辦法大幅提升。 本研究採用財務比率及考量營運面的績效指標作為輸 入變數,以探究模式分類的效果,有關過去學者研究財務危 機診斷模式相關文獻彙整如表 1。
三、研究方法
(一)資料包絡分析法(Data Envelopment Analysis, DEA) 資 料 包 絡 分 析 法 是 由 Charnes, Cooper, and Rhodes (1978)根據 Farrell(1957)所建立的 Cobb-Douglas 有母 數效率前緣分析法,依循並修正 Farrell 原始對於減少投入 成本的概念,所建構的投入或產出導向的無母數效率前緣分 析法,具有無須先預設生產或成本函數。DEA 基本模型包 括「CCR 模式」(charnes, cooper and rhodes model) 與「BCC 模式」(banker, chames and cooper model)。CCR 模式強調「固 定規模報酬假設」,亦即每增加一單位投入,就會使產出增 加一單位。假設有 n 個決策單位(decision making unit, DMU),對於 DMUk 可建立評估模式如下(Boussofiane,
Dyson, & Thanassoulis, 1991):
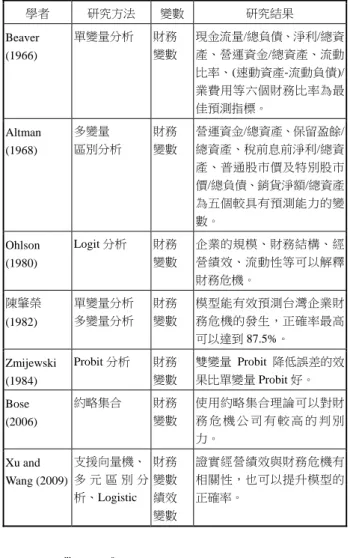
表 1. 財務危機診斷模式文獻回顧 學者 研究方法 變數 研究結果 Beaver (1966) 單變量分析 財務 變數 現金流量/總負債、淨利/總資 產、營運資金/總資產、流動 比率、(速動資產-流動負債)/ 業費用等六個財務比率為最 佳預測指標。 Altman (1968) 多變量 區別分析 財務 變數 營運資金/總資產、保留盈餘/ 總資產、稅前息前淨利/總資 產、普通股市價及特別股市 價/總負債、銷貨淨額/總資產 為五個較具有預測能力的變 數。 Ohlson (1980) Logit 分析 財務 變數 企業的規模、財務結構、經 營績效、流動性等可以解釋 財務危機。 陳肇榮 (1982) 單變量分析 多變量分析 財務 變數 模型能有效預測台灣企業財 務危機的發生,正確率最高 可以達到 87.5%。 Zmijewski (1984) Probit 分析 財務 變數 雙變量 Probit 降低誤差的效 果比單變量 Probit 好。 Bose (2006) 約略集合 財務 變數 使用約略集合理論可以對財 務 危 機 公 司 有 較 高 的 判 別 力。 Xu and Wang (2009) 支援向量機、 多 元 區 別 分 析、Logistic 財務 變數 績效 變數 證實經營績效與財務危機有 相關性,也可以提升模型的 正確率。 s r r m i i S S 1 1 ( min (1) rk r j ij S y Y t s.
j i n j ij ik X S X 1 -λj0; Si0; Sr0 r=1,…, s;i=1,…, m;j=1,…, n 由(1)式中可知投入與產出得以改善的空間,若 θ* =1 且 iS 、S 皆等於零時,則具有效率。Banker, Chanes, and r
Cooper(1984)放寬 CCR 模式固定規模報酬的前提假設, 即各 DMU 的規模報酬可能為遞增、遞減或固定,將(1) 式中加入 1 1 n j j 即為 BCC 模式。BCC 模式與 CCR 模式 的不同在於 BCC 模式改用變動規模報酬,並計算 DMU 的
純粹技術效率。DEA 模型所求得之每決策單位相對效率值 皆為大於 0 小於 1 之數值,當其效率值為 1 時,表示此決策 單位為相對有效率。 (二)資料探勘(Data Mining) 此部分將針對本研究所採用資料探勘中的兩種分類方 法-約略集合與支援向量機作介紹。
1. 約略集合理論(rough set theory, RS)
約略集合理論為波蘭 Pawlak 於 1982 年提出,最初為用 來處理有關不確定性、模糊性和粗糙性資料的數學工具。在 不斷發展與進步後,目前約略集合理論在人工智慧、資訊系 統分析和知識取得等方面有較佳的實務應用,也可以被使用 在擷取多維度屬性資料間的關聯性,故近年來逐漸被使用在 資料探勘領域中,對相當龐大與不完整的資料中進行分析與 找出有相關聯的資料。利用約略集合理論處理資料最大的優 點在於不需要預先處理資料,及能容易應用處理,現實世界 中有許多決策問題可以使用決策表的形式來表達,決策表也 是一種分類,其中的決策屬性相當於分類中的類屬性,分類 問題主要關注於對樣本完整的覆蓋,以及在保持分類能力不 變的前提下盡量得到一個優化的規則集。 而決策問題關注的是要如何使用較少的規則和屬性來得到 一個完整的決策規則集。對決策表的處理主要是對其進行簡 化和最小化,簡化包括屬性集簡化,也包含了對屬性值的簡 化和繁雜規則的刪除。 約 略 集 合 中 的 資 訊 系 統 可 以 表 達 為 S=(U,A,V,f) ; U={x1,x2,…,xn} 是樣本的有限非空全域集合(universe), 而 A=﹝a1,a2,…,an﹞為屬性的有限非空屬性集合;V 為屬性 值域, a A aU V V ;f:U×A→V 為一資訊函數,表示對每一個 aA,xU,f(x,a)Va。當資訊系統中屬性ACD,其中 C 為條件屬性集,D 為決策屬性集時,資訊系統也稱為決策 系統。 資訊系統中可能會有一些無異的屬性,所以對資訊系統 的簡化,找到資訊系統中知識的核心部份是相當重要的。為 了得到重要的屬性,我們必須進一步對資訊系統進行屬性的 縮 減 ( reduction of attributes )。 設 有 決 策 系 統 ) , , , (U C DV f S ,條件屬性集合 C 的約簡是 C 的一個非 空子集合 P。它滿足:1. aP,a 都是 D 不可省略的; 2. POSP(D) = POSC(D)。此時,則稱 P 是 C 的一個約簡,C 中所有約簡的集合記作 RED(C)。簡而言之,在相似的表達 中有一些屬性的特徵效果不明顯,可以刪除他們也不會對最 終結果有影響。基於知識最簡化的原則,這些對於樣本分類 無用的屬性應該予以逐步從資訊系統中剔除,去除多餘屬性 後,剩餘的屬性集合仍保持其等價關係。C 中所有不可省略 屬 性 的 集 合 稱 為 C 的 核 ( Core ), 記 為 CORE(C) , 則 CORE(C)= ∪RED(C),可以看出核可以解釋為知識最重要 部分的集合,進行知識萃取時不能夠刪除。
(三)支援向量機(Support Vector Machine, SVM) 近 幾 年 中 又 有 許 多 新 的 方 法 被 提 出 , 支 援 向 量 機 (support vector machine, SVM)是其中之一。支援向量機是 由 Vapnik 在 1995 年和 AT&T 實驗室團隊所提出的一個新方 法 , 它 是 來 自 統 計 學 習 理 論 中 結 構 化 風 險 最 小 誤 差 法 (structural risk minimization)。支援向量機主要是利用區分 超平面來分隔兩個或多同類別的資料,處理資料探勘中資料 分類的問題。支援向量機是由統計學習理論(statistical learning theory)衍生而成的學習演算法,從統計學習理論中 的簡易向量分類器(simple vector classifiers),逐漸發展為 超平面分類器(hyperplane classifiers),到目前大家所熟悉 的支援向量分類器,支援向量機在處理分類與預測方面的問 題都有不錯的表現,且廣泛的使用於不同領域。 支援向量機的參數設定對於分類器的正確率有相當大 的影響,所以如何調整支援向量機的參數來建立分類器就相 當 重 要 。 現 近 最 使 用 頻 繁 的 是 格 子 點 演 算 法 ( grid algoruthm),本文使用格子點演算法找出支援向量機的最佳 參數,來建立支援向量機的分類系統,提高分類正確率。 1. 線性可分割 將訓練集設為 (x1, y1),…(xl, yl) xRn, y{1, -1},當中的 x為輸入變數,資料將會被一個超平面區分為兩類,一類為 1,另一類為-1,若該筆資料可以被正確區分,而每個分類 的最近向量(nearest vector)與該超平面間距離最大化,則 該超平面即為最適分割超平面。我們可以將超平面以(2) 式表示: l i b x w yi( , ) 1 , 1,..., (2) 所找到兩個最近方程式(2)的向量與其之間距離最大化如 下:
w w b x w w b x w x b w d x b w d b w p i y x i y x i y x i y x i i i i i i i i 2 , ( min , ( min ) : , ( min ) : , ( min ) , ( ) 1 , ) 1 , 1 , 1 , (3) 距離最大化(3)可表示為達成最小化 2 2 1 ) (w w ,採用 拉氏鬆弛法(Lagrange relaxation)將該問題表達為: ) 1 ] ) , [( ( 2 1 ) , , ( min 1 2 , y wx b w b w l i i i i b w (4) 因此,求得最適合的分割超平面為: ) , ( 2 1 * * 1 * s r l i i i i x x w b x y a w (5) 當中,x ,r xs是每個分類能滿足r,s0, yr1,ys1的 任何支援向量。我們可得到明確的硬式分類 (hard classifier) 如下:
w x b
x f( )sgn( , ) (6) 若考量無法完全被分類的情況,則軟式分類(soft classifier) 為(7)式:
1 : 1 1 1 : 1 1 ) ( , z z z :z z h where b x w h x f x (7) 2. 線性不可分割 在現實的世界裡會有無法準確將資料切割的情形, Vapnik(1995)導入和錯誤分類有關成本函數(cost fuction) 的觀念,以求得最適分割超平面,則可以表達為:
l i i C w w 1 2 2 1 ) , ( min (8) 0 . ,..., 1 , 1 ] ) , [( . where l i b x w y t s i i 其中i是錯誤分類的誤差項,C 是一個給定的參數值,根據 Minoux(1986)可得到拉氏鬆弛法如(9)式:
l i l i i i T i i i y w x b C w w 1 1 2 ) 1 ] [ ( 2 1 ) , (
l i 1 i i (9) 其中,為拉氏乘數。 3. 高維度空間的一般化-替代核心函式 當線性的分界(boundary)不合適時,支援向量機可以 將輸入向量 (x) 投射到掏維度的特徵空間 (z),採用一個非 線性的投射,支援向量機可以在特徵空間中建構一個最適分 割 超 平 面 。 此 非 線 性 的 投 射 常 用 多 項 式 核 心 函 式 (polynomial) K(x,x')[(x,x')1]d和 Gauss 徑向基核核心 函 式 ( Gaussian radial basis functionm, RBF )) exp( ) , (x x' rx x' 2 K 。因此,(10)式可表達為:
l i l j l k k j i j i j i y y K x x 1 1 1 ) , ( 2 1 min arg (10) 其中K(xi,xj)為核心函式,用以執行非線性投射到特徵空 間。四、研究設計
(一)研究設計流程 本研究先從相關文獻彙整出可能影響企業財務危機之 財務變數,接著使用約略集合約簡分類預測模型的研究變數 之後,並分別採用資料探勘中的約略集合與支援向量機建立 企業財務危機分類模式後,比較其分類正確率,接著比較考 量績效指標對型一錯誤及型二錯誤的影響,最後得到分類正 確率最佳之診斷模式。圖 1 為本研究之研究架構。 財務變數 DEA 績效值 圖 1. 研究架構(二)樣本選取 由於不同產業別,其財務結構及營運狀況的不同,在財 務危機診斷模式上,應該會導致不同的診斷模式。為了避免 不同產業採用同一個診斷模式而造成偏誤,本研究針對單一 產業,及電子資訊業(依台灣經濟新報所公告產業別為電子 資訊業者)進行分析。由於台灣股票市場電子類股之成交比 重平均高達五十以上,佔股票市場中大宗的投資標的。 一般而言,企業危機的狹義定義可以描述為破產、倒 閉、解散或清算等情事,而廣義的企業危機則可以涵括破產 及經營上的危機事件,為了明確定義危機發生與否,本研究 採用台灣證券交易所所訂的營業細則第四十九條、第五十條 及第五十條之一的規定,認定上市公司變更交易方式為全額 交割股或停止買賣以及終止買賣,列為危機公司。本研究的 研究期間為 2004~2006 年台灣上市櫃電子公司資料為實證 研究的測試對象。本研究之相關資料取自台灣經濟新報社, 由於資料包絡分析無法處理零和負值的數值,故刪除之,其 選取財務危機公司為樣本的標準如下: 1. 上市櫃電子公司。 2. 全額交割股。 3. 停止買賣以及終止買賣。 經由上述的標準篩選不符合及資料不全的樣本後,經過 篩選後,並找出資本額相近的相似產業進行一比一配對,總 計取得 74 筆觀測值,由於約略集合與支援向量機須將資料 分為訓練與測試組,先經由訓練資料得出分類模式,在導入 測試資料判斷正確性,為了以確保每筆資料皆能當作測試資 料,而且全部的測試樣本都是獨立的,不會受到極端值干 擾,故將樣本分成 k 個子樣本,輪流將 k-1 個以樣本當作訓 練樣本,剩下一個子樣本當作測試樣本,重複做 k 次建立模 型的工作後,取平均值可以平穩化資料型態,故本研究採用 5 組交互驗證法(5-fold-cross-validation)。 (三)應用環境
應用環境方面,約略集合採用 Rough Set Exploration System ver.2.2 軟體;支援向量機,採用 Chang and Lin(2001) 所設計的 SVM 軟體 Libsvm 進行分析。 為實際探討資料包絡分析法績效指標對企業危機產生 與否的影響,及驗證本研究所提之整合資料探勘法中的約略 集合與支援向量機對財務危機公司診斷之有效性。原則上, 我們將先透過資料包絡分析法求出各個公司的績效值,並透 過約略集合理論找出重要影響指標,再將所得出的重要指標 導入約略集合與支援向量機,並比較各個方法下對危機公司 診斷的精確性。
五、實證研究
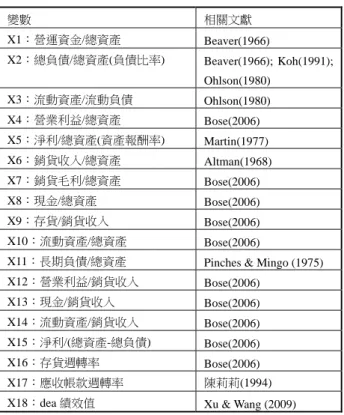
(一)DEA 分析 評估公司經績效的指標的變數有許多變數,由於本研究 的選取樣本是電子資訊產業,其產業環境變化性大(波動 高),而研究發展費是電子資訊產業維持競爭優勢所必須投 入之成本,故本研究的投入採用電子資訊產業經營績效的指 標,選取的投入項為當年度的固定資產總額、薪資費用、研 究發展費用;產出項為營業收入淨額,如表 2 所示。 (二)變數篩選 為了使分類的過程更有效、效果更好,並且在篩選完變 數後可以保留資料的原貌,本研究乃依據國內外學者所採用 之企業財務危機衡量變數為基礎進行選擇,選擇結果共包括 18 個變數(如表 3),經過約略集合作為篩檢變數的準則與 方法,所篩檢出的變數有 8 個:營運資金/總資產、總負債/ 總資產(負債比率)、淨利/總資產(資產報酬率)、流動資 產/總資產、流動資產/銷貨收入、淨利/(總資產-總負債)、 應收帳款週轉率、Dea 績效值。 由上述篩選過後的指標得知,資料包絡分析法的績效指 標也出現在重要指標之列。換言之,資料包絡分析法的績效 指標確實對企業財務危機有其影響程度。 (三)實證結果 彙總上述方法與績效指標,由表 4 可以得知,兩種分類 診斷模式都有不錯的分類診斷正確率,其中導入經營績效指 標導的約略集合對分類財務危機公司的效果高達 95.04%。 以上兩種分類方法在導入經營績效值對財務危機公司分類 診斷正確率皆有顯著提升,因此可得知公司的績效值為重要 的判別指標。以支援向量機在建構分類診斷模式的過程中, 對於資料的前置處理和硬體的效能,相對約略集合較為繁 瑣;但若只追求最高分類診斷正確率,且依賴電腦進行判 讀,則約略集合是最佳選擇。因此,本研究比較此兩種分類 表 2. 衡量經營績效值的投入與產出 投入 產出 當年度的固定資產總額 營業收入淨額 薪資費用 研究發展費用表 3. 原始變數表 變數 相關文獻 X1:營運資金/總資產 Beaver(1966) X2:總負債/總資產(負債比率) Beaver(1966); Koh(1991); Ohlson(1980) X3:流動資產/流動負債 Ohlson(1980) X4:營業利益/總資產 Bose(2006) X5:淨利/總資產(資產報酬率) Martin(1977) X6:銷貨收入/總資產 Altman(1968) X7:銷貨毛利/總資產 Bose(2006) X8:現金/總資產 Bose(2006) X9:存貨/銷貨收入 Bose(2006) X10:流動資產/總資產 Bose(2006)
X11:長期負債/總資產 Pinches & Mingo (1975) X12:營業利益/銷貨收入 Bose(2006) X13:現金/銷貨收入 Bose(2006) X14:流動資產/銷貨收入 Bose(2006) X15:淨利/(總資產-總負債) Bose(2006) X16:存貨週轉率 Bose(2006) X17:應收帳款週轉率 陳莉莉(1994) X18:dea 績效值 Xu & Wang (2009)
診斷模式,提供資訊使用人依自身需求選擇合適的分類演算 法。比較兩種診斷模式針對測試樣本診斷後之結果(包含資 料包絡分析法績效值為投入變數),彙整如表 4。 型一錯誤是指正常公司沒有被正確地分類,因此型一錯 誤表示公司財務正常,卻被錯誤分類為財務危機,遭分類錯 誤的樣本數佔財務正常公司數的比率即為型一錯誤;而型二 錯誤是財務危機公司沒有被正確分類,而型二錯誤是指公司 有財務危機,被錯誤分類為財務正常公司,分類錯誤的樣本 佔正常公司的比率即為型二錯誤。一般而言,型二錯誤對投 資大眾與債權人而言所造成的後果較為嚴重,若能有效降低 型二錯誤發生率,即可降低投資大眾與債權人的風險。測試 結果如表 5 及表 6,從表 5 及表 6 發現透過經營績效值可以 表 4. 兩種方法的診斷結果(單位:%) 約略集合理論 支援向量機 組別 含有 DEA 未含 DEA 含有 DEA 未含 DEA 第一組 93.8 87.5 100 86.6 第二組 93.8 81.2 80 80 第三組 93.8 87.5 80 73.3 第四組 100 81.2 81.2 86.6 第五組 93.8 87.5 81.2 75 平均 95 84.9 84.5 80.3 表 5. 測試結果-含績效值(單位:%) 約略集合 (含績效值) 支援向量機 (含績效值) 組別 型一 錯誤 型二 錯誤 型一 錯誤 型二 錯誤 第一組 0 14.3 0 0 第二組 0 14.3 20 0 第三組 0 14.3 20 0 第四組 0 0 20 0 第五組 0 14.3 20 0 平均 0 11.4 16 0 表 6. 測試結果-未含績效值(單位:%) 約略集合 (未含績效值) 支援向量機 (未含績效值) 組別 型一 錯誤 型二 錯誤 型一 錯誤 型二 錯誤 第一組 11.1 14.3 13.3 0 第二組 22.2 14.3 20 0 第三組 11.1 14.3 20 6.7 第四組 22.2 14.3 13.3 0 第五組 11.1 14.3 12.5 6.2 平均 15.5 14.3 15.8 2.5 降低型二錯誤的發生率,故得知經營績效指標不僅是影響企 業財務危機的重要變數也是降低投資大眾風險的重要依據。
六、結論與建議
近年來,由於企業環境經營巨變,造成整體經濟所面臨 的重況更加艱鉅,而企業財務危機發生的可能性亦隨之提 升,若公司發生財務危機,不僅對公司有嚴重的傷害,更導 致投資人重大損失並嚴重危害金融體制的秩序,所以社會必 須付出相當大的資源來彌補企業所造成的傷害,因此,診斷 企業財務危機是一個極為重要的課題之一。 過去學者有關企業財務危機的相關研究,在變數方面大 多強調財務變數(蔡碧徽、黃鈺萍,2010),但卻往往忽略 了經營績效對企業財務危機的影響,因此本研究在變數選取 上特別採用經營績效的變數;而為了克服傳統統計方法的缺 點,所以採用資料探勘的方法,它可以克服傳統方法的缺 陷,並且沒有特殊的限制條件,因此,本研究嘗試將資料探 勘的方法結合經營績效值應用於診斷財務危機公司比較之 研究。 研究結果顯示,財務危機公司分類之正確率以約略集合 最好,其次為支援向量機。此外,比較加入經營績效變數是否會提升財務危機公司診斷正確率,研究結果顯示加入經營 績效變數之分類診斷正確率較佳,故可得知績效值為財務危 機診斷的重要變數。 本研究的變數大多來自台灣經濟新報社,因為部分樣本 及相關變數的缺乏,並對樣本做一些篩選,所以得出的樣本 數比較少,而且使用的資料為歷史資料,但是經濟型態日新 月異,財務危機的發生機會也相對提升,後續的研究者可以 採用其他更具有辨別能力的方法,並找出更具代表性的變 數,使財務危機公司分類正確性大大提升,並對投資大眾有 更多的保障。
參考文獻
陳莉莉(1994)。財務困難預測模式中分割點之探討—以台 灣上市公司為例。國立交通大學管理科學研究所碩士 論文,未出版,新竹。 陳肇榮(1982)。運用財務比率預測財務危機之實證研究。 國立台灣大學商學所碩士論文,未出版,台北。 蔡碧徽、黃鈺萍(2010)。財務危機預測模型之比較分析。
當代會計,11(1),51-78。Altman, E. I. (1968). Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. Journal of
Finance, 36(1), 589-609
Altman, E. I. (1983). Corporate financial distress: A complete
guide to predicting, avoiding and dealing with bankruptcy. New York: John Wiley and Sons.
Banker, R. D., Chanes, A., & Cooper, W. W. (1984). Some models for estimating technical and scale inefficiencies in data envelopment analysis. Management Science, 30(9), 1078-1092.
Beaver, W. H. (1966). Financial ratios as predictors of failure.
Journal of Accounting Research, 12(1), 1-25
Belkaoi, A. (1980). Industrial bond ratings: A new look.
Financial Management, Autumn, 9(3), 44-51.
Bose, I. (2006). Deciding the financial health of dot-coms using rough sets. Information and Management, 43(7), 835-846. Boussofiane, A., Dyson, G., & Thanassoulis, E. (1991). Applied
data envelopment analysis. European Journal of
Operational Research, 52, 1-15.
Charnes, A, Cooper, W. W., & Rhodes, E. (1978). Measuring the efficiency of decision making units. European Journal
of Operational Research, 1(2), 429-444.
Chang, C. C., & Lin, C. J. (2001). LIBSVM: A library for support vector machines. Retrieved Software available at http://www.csie.ntu.edu.tw/~cjlin/libsvm.
Ederington, L. H. (1985). Classification models and bond ratings. The Financial Review, 20(4), 237-262.
Farrell, M. (1957). The measurement of productive efficiency.
Journal of the Royal Statistical Society General,120(3),
253-281.
Gestel, T. V., Baesens, B., Suykens, J. A. K., Van den Poel, D., Baestaens, D. E., & Willekens, M. (2006). Bayesian kernel based classificationi for financial distress detection. European Journal of Operational Ressearch,
172, 979-1003.
Lau, A. H. L. (1987). A five-state financial distress prediction model. Journal of Accounting Research, 25(1), 127-138. Jostarndt, P., & Sautner, Z. (2008). Financial distress, corporate
control, and management turnover. Journal of Banking &
Finance, 32(10), 2188-2204.
Kim, K. (2003). Financial time series forecasting using support vector machines. Neurocomputing, 55, 307-319. Koh, H. (1991). Model predictions and auditor assessments of
going concern status. Accounting and Business Research,
21(84), 331-338.
Martin, D. (1977). Early warning of banking failure. Journal of
Banking and Finance, 1(3), 249-276.
Minoux, M. (1986). Mathematical programming: Theory and
algorithms. New York: Wiley - Chichester.
Ohlson, J. A. (1980). Financial ratios and the probabilistic prediction of bankuptcy. Journal of Accounting Research,
18(1), 109-131.
Pinches, G., & Mingo, K. (1975) The role of xubordination and industrial bond ratings. Journal of Finance, 3, 201-206. Pawlak, Z. (1982). Rough sets. International Journal of
Parallel Programming, 11(5), 341-356.
Shin, K. S., Lee, T. S., & Kim, H. J. (2005). An application of support vector machines in bankruptcy prediction model.
Expert Systems with Applications, 28(1), 127-135.
Vapnik, V. (1995). The nature of statistical learning theory. New York: Springer-Verlag.
Xu, X., & Wang, Y. (2009). Financial failure prediction using efficiency as a preditor. Expert Systems with Applications,
36(1), 366-373
Zmijewski, M. E. (1984). Methodological issues related to the estimation distress prediction model. Journal of
Accounting Research, 22(Supplement), 59-82.