資訊學院
資訊科學與工程研究所
博 士 論 文
在影像與文字檔案中進行資料隱藏的技
術與應用之研究
A Study on New Techniques of Data Hiding in
Images and Text Documents and Their
Applications
研 究 生: 李義溪
指 導 教 授: 蔡 文 祥 博士
在影像與文字檔案中進行資料隱藏的技術
與應用之研究
A Study on New Techniques of Data Hiding
in Images and Text Documents and Their
Applications
研 究 生 : 李 義 溪
Student: I-Shi Lee
指 導 教 授 : 蔡 文 祥 博士 Advisor:
Dr.
Wen-Hsiang
Tsai
國 立 交 通 大 學 資 訊 學 院
資 訊 科 學 與 工 程 研 究 所
博 士 論 文
A Dissertation Submitted to
Institute of Computer Science and Engineering
College of Computer Science
National Chiao Tung University
in Partial Fulfillment of the Requirements for the Degree of
Doctor of Philosophy
in Computer and Information Science
July 2008
Hsinchu, Taiwan, 300
Republic of China
在影像與文字檔案中進行資料隱藏的技術與應用之
研究
研究生:李 義 溪 指導教授: 蔡文祥博士
國立交通大學資訊學院
資訊工程系
資訊科學與工程研究所
摘 要
本博士論文冀能領先全球研究,發展出將資料隱藏於影像及本文文字檔的 技術及其應用。本論文總共提出了10 種新方法,分別適用於黑白,灰階及彩色 影像,以及電子郵件,CP ++ P軟體程式,PDF和網頁等檔案類型。首先,本論文提 出二種新方法分別針對黑白及灰階影像,基於人眼視覺模型及動態規劃技術去降 低影像扭曲程度並增加資料被隱藏的容量。接著,本論文提出一種新方法可將大 量資料藏於BMP彩色影像中,本方法係利用色彩立體方塊及色彩叢集的觀念來 隱藏資料。然後,本論文提出一種利用特殊的ASCII控制碼將秘密訊息隱藏於電 子郵件中的新方法,這些特殊的ASCII碼顯示在Outlook Express與IE 網路郵件 的瀏覽視窗中是使用者看不見的。接著本論文提出二種將資料隱藏於原始程式的新方法。其中一種方法係利用資訊分享與驗證的技巧及人眼看不見的ASCII控制 碼來保護軟體程式的安全。另一種技術是應用於秘密通訊,同時可驗證隱藏訊息 真偽的新方法。更進一步,本論文提出二種利用特殊的ASCII碼將資訊隱藏於通 用的PDF檔中的新方法。其中之ㄧ應用於秘密通訊,另一個應用於驗證PDF檔的 真偽。最後,本論文提出二種新方法將資訊隱藏於大家常瀏覽的網頁中。其中之 ㄧ應用於秘密通訊,另一個應用於驗證網頁的真偽。二種方法皆是利用HTML檔 中各種不同的編碼系統的特殊空白碼。以上本論文提出之 10 種方法,皆為創新之 作, 且已投稿於國內外重要期刊。實驗結果顯示本論文提出的方法皆具有可行性 及實用性。
A Study on New Techniques of Data Hiding
in Images and Text Documents and Their
Applications
Student: I-Shi Lee
Advisor: Dr. Wen-Hsiang Tsai
Institute of Computer Science and Engineering
College of Computer Science
National Chiao Tung University
Abstract
In this study, data hiding techniques for image files and text documents and their applications are investigated, and totally ten methods are proposed for binary, grayscale, and color images, as well as email, software CP
++
P
program, PDF, and webpage files. First, two methods are proposed respectively for binary and grayscale images based on human vision modeling and dynamic programming to reduce the image distortion and increasing data hiding capacities. Also, a method is proposed for hiding large-volume data in BMP color images, based on the use of color cubes and the idea of color clustering. Then, a method is proposed for hiding secret messages in emails using some special ASCII codes which are invisible in the window of Outlook Express and IE Webmail browsers. Also proposed are two methods for data hiding in software programs. One is used for security protection of software programs by information sharing and authentication techniques using invisible ASCII control
codes. And the other is applicable to covert communication with the additional capability of authenticating the hidden secret message. Furthermore, two methods are proposed for data hiding in PDF files which are popular nowadays. One is useful for covert communication and the other for PDF file authentication, both using certain special ASCII codes. Finally, two methods are proposed for data hiding in web pages which are browsed by lots of people in the world. One method is proposed for covert communication and the other for authentication of web pages, both utilizing certain space codes of various coding systems applicable in HTML files. Experimental results show the feasibility and practicality of all the proposed methods.
Acknowledgements
I would like to express my sincere appreciation to my advisor, Professor Wen-Hsiang Tsai, for his patience and kind guidance throughout the course of this dissertation study. Appreciation is extended to Mr. Jiun-Tsung Wang for his programming support and helpful suggestions to my study on data hiding utilizing PDF files. Thanks are also extended to the colleagues in the Computer Vision Laboratory at National Chiao Tung University for their valuable help during this study.
Finally, I am so grateful to my wife and my parents for their love, support, and endurance. This dissertation is dedicated to them.
Table of Contents
0HTU 摘 要UT ...81Hviii 1HTU AbstractUT ... 82H x 2HTU AcknowledgementsUT...83Hxii 3HTUTable of ContentsUT...84Hxiii
4HTU
List of TablesUT...85Hxvi
5HTU
List of FiguresUT...86Hxviii
6HTU
Chapter 1UT TUIntroductionUT...87H1
7HTU
1.1UT TUScope of Data Hiding ResearchUT...88H1
8HTU
1.2UT TUMotivation of StudyUT...89H2
9HTU
1.3UT TUContributions of This StudyUT...90H4
10HTU
1.4UT TUDissertation OrganizationUT...91H6
11HTU
Chapter 2UT TUSurveys of Related Studies and Brief Descriptions of Proposed MethodsUT92H7
12HTU
2.1UT TUSurvey of Related StudiesUT...93H7
13HTU
2.2UT TUBrief Descriptions of Proposed MethodsUT...94H14
14HTU
Chapter 3UT TUData Hiding in Binary Images with Distortion-Minimizing Capabilities
by Optimal Block Pattern Coding and Dynamic Programming TechniquesUT...95H21
15HTU
3.1UT TUIdea of Proposed MethodUT...96H21
16HTU
3.2UT TUProposed Data Embedding ProcessUT...97H22
17HTU
3.3UT TUExperimental ResultsUT...98H37
18HTU
3.4UT TUConcluding RemarksUT...99H46
19HTU
Chapter 4UT TUData Hiding in Grayscale Images by Dynamic Programming Based on A
Human Visual ModelUT...100H49
20HTU
4.1UT TUIdea of Proposed MethodUT...101H49
21HTU
4.2UT TUCost Function for Distortion MeasurementUT...102H50
22HTU
4.3UT TUProposed Horizontal Data Hiding ProcessUT...103H55
23HTU
4.4UT TUProposed Data Recovery ProcessUT...104H64
24HTU
4.5UT TUExperimental ResultsUT...105H66
25HTU
4.6UT TUConcluding RemarksUT...106H73
26HTU
Chapter 5UT TUData Hiding in Color Images by Color Replacements with Reduction of
Image Distortion and Change NoticeabilityUT...107H76
27HTU
5.1UT TUIdea of Proposed MethodUT...108H76
28HTU
5.2UT TUDetailed Algorithms of Proposed Data Embedding and ExtractionUT...109H89
29HTU
30HTU
5.4UT TUConcluding RemarksUT...111H96
31HTU
Chapter 6UT TUData Hiding in Emails and Applications by Unused ASCII Control CodesUT
112H
98
32HTU
6.1UT TUIdea of Proposed MethodUT...113H98
33HTU
6.2UT TUProperties of Email SystemsUT...114H99
34HTU
6.3UT TUEmbedding ASCII Control Codes into EmailsUT...115H101
35HTU
6.4UT TUProposed Data Hiding Process for EmailsUT...116H104
36HTU
6.5UT TUProposed Data Recovery Process for EmailsUT...117H106
37HTU
6.6UT TUProposed Authentication Process for Email DocumentsUT...118H107
38HTU
6.7UT TUExperimental ResultsUT...119H109
39HTU
6.8UT TUConcluding RemarksUT...120H117
40HTU
Chapter 7UT TUSecurity Protection of Software Programs by Information Sharing and
Authentication Techniques Using Invisible ASCII Control CodesUT...121H119
41HTU
7.1UT TUIdea of Proposed MethodUT...122H119
42HTU
7.2UT TUProposed Program Sharing SchemeUT...123H121
43HTU
7.3UT TUSecret Program Recovery SchemeUT...124H125
44HTU
7.4UT TUDiscussions on Security ProtectionUT...125H128
45HTU
7.5UT TUExperimental ResultsUT...126H129
46HTU
7.6UT TUConcluding RemarksUT...127H130
47HTU
Chapter 8UT TUCovert Communication with Authentication via Software Programs
Using Invisible ASCII CodesUT...128H135
48HTU
8.1UT TUIdea of Proposed MethodUT...129H135
49HTU
8.2UT TUData Hiding Using Invisible CodesUT...130H137
50HTU
8.3UT TUSecret Hiding, Recovery and AuthenticationUT...131H138
51HTU
8.4UT TUExperimental ResultsUT...132H140
52HTU
8.5UT TUConcluding RemarksUT...133H140
53HTU
Chapter 9UT TUCovert Communication via PDF Files and PDF File Authentication by
Invisible CodesUT...134H144
54HTU
9.1UT TUIdea of Proposed MethodsUT...135H144
55HTU
9.2UT TUPrinciple of Encoding Message DataUT...136H146
56HTU
9.3UT TUMessage Hiding and Recovery for Covert Communication and
Experimental ResultsUT...137H149
57HTU
9.4UT TUPDF Authentication Process and Experimental ResultsUT...138H153
58HTU
9.5UT TUConcluding RemarksUT...139H158
59HTU
Chapter 10UT TUSecret Communication through Web Pages and Automatic Authentication
of Web Pages Using Special Space Codes in HTML FilesUT...140H160
60HTU
10.1UT TUIdea of Proposed MethodUT...141H160
61HTU
62HTU
10.3UT TUMessage Hiding and Experimental ResultsUT...143H165
63HTU
10.4UT TUAutomatic Authentication of Web Page Text ContentsUT...144H172
64HTU
10.5UT TUSecurity Consideration and Experimental ResultsUT...145H174
65HTU
10.6UT TUConcluding RemarksUT...146H178
66HTU
Chapter 11UT TUConclusions and Suggestions for Future ResearchUT...147H180
67HTU
11.1UT TUConclusionsUT...148H180
68HTU
11.2UT TUSuggestions for Future ResearchUT...149H181
69HTU ReferencesUT ... 150H 183 70HTU Publication ListUT...151H192 71HTU VitaUT ... 152H 194
List of Tables
Table 3.1 Proposed block pattern encoding table……….25
Table 3.2 An extraction table (table index B=0)………...36
Table 3.3 Statistics of three stego-images for proposed algorithms……….47
Table 3.4 Statistics of 19 stego-images processed by proposed DPA………..…48
Table 4.1 A block pattern encoding table proposed in this study……….…59
Table 4.2 An extraction table (table number T=0)………66
Table 4.3 Statistics of stego-images yielded by DPA using optimal encoding table…71 Table 4.4 Comparison of run times for four methods for grayscale images (in unit of sec.)………..71
Table 4.5 Comparison of PSNR values of the four methods for grayscale images (in unit of dB)………72
Table 4.6 Comparison of RS analysis results of the four methods for color images...73
Table 5.1 The colors in the (0, 0, 0)-th color cube with base color (r, g, b) = (0, 0, 0)………...81
Table 5.2 Color encoding table for the (0, 0, 0)-th color cube with base color (0, 0, 0)………...87
Table 5.3 Statistics of experimental results………..94
Table 6.1 ASCII control codes and description……….100
Table 7.1. ASCII control codes and descriptions………...120
Table 7. 2 Invisible character coding table……….121
Table 8.1. Invisible codes under various environments……….136
Table 9.1 ASCII codes selected for message representations in this study…………145 Table 9.2 Null space coding table for message “This is a covert communication
method”………..151 Table 10.1 Character representations in HTML……….164
List of Figures
Figure 1.1 Classification of data hiding techniques………...3
Figure 3.1 Illustration of block patterns and corresponding binary values………..…23
Figure 3.2 Division of input image into 2×2 blocks with separating linesPP(grids with bold boundaries are 2×2 blocks for data embedding)………27
Figure 3.3 An example of proposed data embedding process………..29
Figure 3.4 An example of proposed data embedding process………..32
Figure 3.5 Flowchart of the proposed data embedding process………...34
Figure 3.6 Flowchart of the proposed extraction process………38
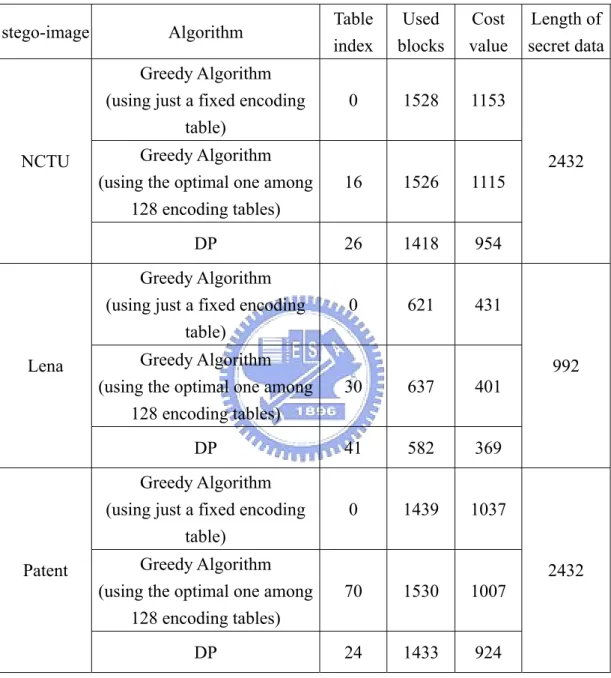
Figure 3.7 Input binary images, output stego-images with message data, and difference images. (a) Binary image “NCTU”. (b) Stego-image using greedy search and optimal encoding table. (c) Stego-image using DPA and optimal encoding table. (d) The difference image between (a) and (c) in which the white spots are difference pixels………39
Figure 3.8 Input binary images, output stego-images with message data, and the difference images. (a) Binary image “Lena”. (b) The stego-image using the greedy search algorithm and the optimal encoding table. (c) The stego-image using the DPA and the optimal encoding table. (d) The difference image between (a) and (c) in which the white spots are difference pixels……….41 Figure 3.9 Input binary images, output stego-images with message data, and
difference images. (a) Binary image “Patent.” (b) Stego-image resulting from greedy search and optimal encoding table. (c) Stego-image using DPA and optimal encoding table. (d) An enlarged part of difference image
between (a) and (c) in which the white spots are difference pixels……...43
Figure 4.1 Three grayscale images and their 8 corresponding bit planes (from left to right, original images, bpB0B, bpB1, bpB B2B, …, and bpB7B, respectively)………….50
Figure 4.2 Division of input image into 2×2 blocks with separating linesPP(grids with
bold boundaries are 2×2 blocks for data embedding)………58 Figure 4.3 An example of proposed data embedding process………..61 Figure 4.4 A cover image “House” with the size of 256×256 and its stego-image with
16440-bit message data embedded. (a) The cover image. (b) The
stego-image………67 Figure 4.5 Experimental results of three images. (a) The original images and their
corresponding bit planes (repeated from Figure 4.1). (b) The resulting three stego-images and their corresponding bit planes (from left, bpB0B, bpB1B,
bpB2B, …, bpB7B)………68
Figure 4.6 PSNR values of stego-image “Lena” using DPA……..……….72 Figure 5.1 An illustration of range sets of color cubes……….78
Figure 5.2 A color cube with 8 colors divided into four groups with base color (0, 0, 0)……82 Figure 5.3 Illustration of a 3D spherical coordinate system for use in even color
distribution……..………86
Figure 5.4 An example of color distribution in a color cube --- the 8 colors in group 3.………...…..87 Figure 5.5 An experimental result of message data embedding applied to Figure 5.1(a) with a 256×256 cover image and a 22900-byte message data…………....95 Figure 5.6 A second experimental result with a 256×256 cover image and a
22900-byte message………...95 Figure 5.7 A third experimental result of data embedding with a 512×512 cover image
and an 88200-byte message………96 Figure 5.8 A fourth experimental result of data embedding with a 512×512 cover
image and an 88200-byte message……….96 Figure 6.1 Partial content of a cover email……….110 Figure 6.2 Partial content of the stego-email generated from Figure 6.1…………...111 Figure 6.3 Partial content of an embedded secret data file………111 Figure 6.4 Partial content of the extracted secret data file……….112 Figure 6.5 Partial content of a cover email………112 Figure 6.6 Partial content of the stego-email generated from Figure 6.5 before being
transmitted………113 Figure 6.7 Partial content of the stego-email received and displayed in IE………...113 Figure 6.8 Content of the original secret file………..114 Figure 6.9 Content of the extracted secret file………...114 Figure 6.10 Content of a stego-email for authentication before transmission……...115 Figure 6.11 Authentication result of “pass” after receiving a stego-email by Outlook
Express………115 Figure 6.12 Authentication result of “pass” after receiving a stego-email by IE…..116 Figure 6.13 Authentication result of “fail” after receiving the stego-email by IE. The
word “Lee” in the content has been modified to be “lee”………116 Figure 7.1 Illustration of invisible ASCII control codes in a comment of a source
program………..123 Figure 7.2 Experimental results of sharing a secret program………131 Figure 7.3 An experimental result of authenticating a destructed stego-program….134 Figure 8.1 An experimental result………..141 Figure 8.2 An example of authentication results…...……….143
appear to be white spaces (the first spaces in the 3rd and the 11th lines)……….146 Figure 9.2 Display of all ASCII codes in the window of Adobe Reader 8.1.2, in which the
width of A0 was set to be zero so that A0 becomes nonexistent (i.e., there is no space before the first comma in the 11th row, as compared with Figure 9.1)…..147 Figure 9.3 Invisibility of multiple A0’s at between-character locations………148
Figure 9.4 An experimental result of null space coding……….152
Figure 9.5 An experimental result for authenticating a PDF file………157
Figure 10.1 Appearances of nine space codes as white spaces in the window of the IE………164 Figure 10.2 Invisibility of space codes for the message “sky” in an HTML text…..169 Figure 10.3 The embedded secret data………...…171 Figure 10.4 An experimental result of authentication of a modified web page…….177
Chapter 1
Introduction
1.1 Scope of Data Hiding Research
Data hiding is a type of information hiding, emphasizing the purpose of embedding digital data behind multimedia of various forms. The multimedia into which data are hidden are called cover media, like cover image, cover text, etc., and the results are called stego-media, like stego-image, stego-text, etc. Applications of data hiding include at least the following.
(1) Copyright protection --- the data hidden are of the forms of watermarks like logos of companies, series numbers of products, etc.
(2) Covert communication --- the data hidden are secret messages sent from one site to another. Data hiding for the purpose of covert communication is sometimes called steganography. The goal of steganography is to arouse as little notice from observers of the stego-media as possible.
(3) Multimedia authentication --- the hidden data are authentication signals in various forms, created for the purposes of checking cover media’s fidelity, integrity, utilization rights, etc.
(4) Secret sharing --- the hidden data are parts of certain multimedia forms like text or image documents, and are taken as secret messages which are embedded into several shares in other forms of multimedia. Only a sufficient number of shares are collected can the secret message be recovered for inspection.
(5) Data association --- the hidden data are various information, like metadata, history, identification, etc., about the cover media. Data hiding in this way
facilitates close association of the data with the cover image for convenient preservation or transmission of the cover media.
(6) Digital rights management --- the hidden data need not always be invisible; on the contrary, we may embed a visible watermark on a video (like a movie) to prevent it form being watched by a customer paying no fee. More generally, data hiding may be used in applications of digital rights management, like pay movie control, video distribution management, limitation of watch times, etc.
A classification of the techniques of data hiding which are related to this dissertation study is illustrated in Figure 1.1.
In the following sections, the motivation of study is given in Section 1.2. The contributions of this study and the organization of this dissertation are reported in Sections 1.3 and 1.4, respectively.
1.2 Motivation of Study
Many data hiding techniques with images as cover media have been proposed. Most of the techniques were proposed for color and grayscale images because pixels in such images take a wide range of values and so are more proper for data hiding. Only a few techniques were proposed for binary images. In this study, we will investigate more efficient methods for hiding more data in binary images.
On the other hand, the cover media need not always be images. On the Internet, so many documents of formats other than images are being transmitted or displayed, like e-mails, web pages, freeware, etc. If we can hide data behind e-mails, for example, covert communication will be easily implemented. Authentication of e-mails is also possible to prevent receiving false or illegally altered messages. Furthermore, it is also desired to protect software from being stolen or illegal distributed. If we can hide data into the source programs, then possibly protection of
software copyrights is achievable. It is noted by the way that studies of data hiding in text contents are very few so far.
Data Hiding Copyright Protection Covert communication Multimedia authentication Secret sharing Data association Digitalrights management
Figure 1.1. Classification of data hiding techniques.
Most researches about data hiding in images lack serious considerations of image distortion reduction in stego-images. It is desired in this study to design new techniques of data hiding emphasizing optimality in image distortion reduction. In doing so, it is also hoped that human vision modeling may be considered, so that changes in the resulting stego-image can be less noticeable. It is noted here that most existing data hiding methods are conducted in the frequency domain and thus are useful for images compressed in the frequency domain like JPEG. For images of other types like BMP, appropriate data hiding methods need be developed. And this is also part of the goal of our study on data hiding in images.
On the other hand, it is also a goal of this study to devise new techniques for data hiding in text documents, which are still few so far. Such techniques will be very useful for daily uses because text documents like e-mails are popular and used or watched every day by humans worldwide, especially for the purpose of
steganography.
1.3 Contributions of This Study
In this study, we propose ten data hiding techniques for various applications of copyright protection, covert communication, authentication, and secret sharing. The processed file types include two major categories, namely, image and document. The former category includes binary, grayscale, and color images, and the latter type includes email, software program, PDF, and HTML (web page). The contribution of each of the ten techniques is described in the following.
(1) Data hiding in binary images --- the proposed technique has distortion-minimizing capabilities by optimal block pattern coding and dynamic programming techniques. Accordingly, not only more data bits can be embedded in an image block on the average, but the resulting image distortion is also reduced in an optimal way.
(2) Data hiding in grayscale images --- the proposed technique is based on dynamic programming and a human visual model with distortion-minimizing capabilities. The proposed method can predict the PSNR value of the resulting image according to the size of the data to be embedded before the embedding process starts.
(3) Data hiding in color images --- the proposed technique is based on color replacements with capabilities of reducing image distortion and change noticeability. Color cubes and the idea of color clustering are used for large-volume data hiding.
(4) Data hiding in emails and applications --- the proposed technique embeds data in emails via Outlook Express and IE by some unused and invisible ASCII control codes. Also described are two applications of the proposed data hiding technique,
covert communication via emails and authentication of emails.
(5) Security protection of software programs --- the proposed technique is based on information sharing and authentication using invisible ASCII control codes. These invisible codes are hidden in the camouflage program, resulting in a stego-program for a participant to keep. To enhance security, three security measures via the use of a secret random key are also proposed to prevent the secret program from being recovered illegally, authenticate the stego-program and check the stego-program whether it has been tampered with or not.
(6) Covert communication with authentication via software programs --- the proposed technique is also based on the use of invisible ASCII codes. Each binary message, after being encoded by certain ASCII codes and inserted at specific C++ program locations, becomes invisible in the source code editors. A scheme for tamper-proof authentication of the embedded message has also been proposed.
(7) Covert communication via PDF files --- the proposed technique is based on the use of special ASCII codes. A secret message, after being encoded by a special ASCII code and embedded at between-word and between character locations in the text of a PDF file, becomes invisible in the window of a common PDF reader, creating a steganographic effect for secret transmission through the PDF file. (8) Authentication of PDF files --- the proposed technique is based on the use of
invisible ASCII codes. To authenticate each word in a PDF file, a authentication signal composed of multiple non-breaking space codes is generated from the characters in the word and a random number. The authentication signal is invisible for common PDF readers, thus reducing the probability for the authentication signal to be tampered with.
(9) Secret communication via web pages --- the proposed technique is based on the use of some special space codes in HTML. These codes, like the ASCII code 20,
appear to be white spaces as well. Message hiding and recovery with security enhancement are also proposed.
(10) Automatic authentication of web pages --- the proposed technique is based on the use of multiple special space codes in HTML. The propose method is useful for checking automatically the integrity of the text content of a web page at the word level. Special space codes are used again as authentication signals with steganographic effects. Security enhancement techniques using secret keys and multiple word encoding are also proposed.
1.4 Dissertation Organization
In the remainder of this dissertation, a survey of related studies and a more detailed description of the ten proposed methods are given in Chapter 2. The proposed methods are described one by one in the subsequent chapters. In Chapter 3, the proposed method for data hiding in binary images is described. In Chapter 4, the proposed method for data hiding in grayscale images is presented. In Chapter 5, the proposed method for data hiding in color images is described. In Chapter 6, the proposed method data hiding in emails and some applications are described. In Chapter 7, the proposed method for security protection of software programs is presented. In Chapter 8, the proposed method for covert communication with authentication via software programs is described. In Chapter 9, the proposed methods for covert communication via PDF files and authentication of PDF files are described. In Chapter 10, the proposed methods for secret communication via web pages and automatic authentication of web pages are described. Finally, in the last chapter, conclusions of this study and some suggestions for future research are included.
Chapter 2
Surveys of Related Studies and Brief
Descriptions of Proposed Methods
2.1 Survey of Related Studies
Many data hiding techniques have been proposed while this dissertation study is dedicated to develop new data hiding techniques for various applications. Surveys of related studies on data hiding are described first in the following, followed by brief descriptions of the proposed methods.
2.1.1. Survey of Data Hiding in Binary Images
Many data hiding techniques have been proposed for a variety of applications of digital images in recent years [1-22]. Most of the techniques were proposed for color and grayscale images because pixels in such images take a wide range of values and so are more proper for data hiding. One simple method to data hiding in grayscale images is to use the LSB replacement technique to hide secret data or authentication signals. However, data hiding in binary images is a more challenging work. Because binary image pixels have drastic contrast, it is easier for humans’ eyes to find out pixel value changes in binary images. Therefore, it is more difficult to hide data into binary images than into color or grayscale images. Wu et al. [12] embedded secret data in specific image blocks that are selected with higher “flippability” scores by pattern matching. Manipulated flippable pixels on the image region boundary are then used to embed a significant amount of data without causing noticeable artifacts. Pan et al. [6] changed pixel values in image blocks, mapped block contents into the secret data, and used a secret key and a weight matrix to protect the hidden data. Given an
image block of size m×n, the scheme can conceal up to ⎣logB2B(m×n + 1)⎦ bits of data in
the image by changing, at most, two bits in an image block. Tseng and Pan [8] proposeda technique to alter an image bit into a new value identical to a neighboring one. It can yield better hiding effect within a binary image. Koch and Zhao [2] embedded a bit 0 or 1 in a block by changing the number of black pixels in the block to be larger or smaller than that of white ones, respectively. In [5, 11], secret data are concealed into dithered images by maneuvering dithering patterns. Tzeng and Tsai [9] encoded the edge features of binary images into 4×4 block patterns, and authenticated the images by pattern matching. Tzeng and Tsai [10] also proposed a new feature, called surrounding edge count, for measuring the structural randomness in a 3×3 image block, and defined “pixel embeddability” from the viewpoint of minimizing image distortion. Accordingly, embeddable image pixels suitable for hiding secret data can be selected. Wu et al. [14] used even-odd relationships of lengths of run pairs to embed information in binary images, and adjusted the length of each run to an even or odd value to represent the embedded bit value.
2.1.2. Survey of Data Hiding in Grayscale Images
Wang et al. [15] embedded an image in the fifth LSB bit plane of a cover grayscale image, and employed an optimal substitution process based on a genetic algorithm and a local pixel adjustment method to lower the distortion in the stego-image. Chang et al. [16] used dynamic programming to obtain an optimal solution for the LSB substitution method. Chan and Cheng [17, 18] presented an optimal pixel adjustment process to improve the image quality of the stego-image acquired by Wang’s schemes. Thien and Lin [19] proposed a method for hiding data in images digit by digit using a modulus function. The method is better than simple LSB substitution not only in eliminating false contours but also in reducing image
distortion. Lee and Chen [20] applied variable-sized LSB insertion to estimate the maximum embedding capacity by a human visual system (HVS) property, and to maintain image fidelity by removing false contours in smooth image regions. Liu et al. [21] presented a novel bit plane-wise data hiding scheme using variable-depth LSB substitution and employed post-processing to eliminate the resulting noticeable artifacts.
Most of the above methods lack consideration of using precise human visual models in improving the data hiding effect. Instead, Wu and Tsai [13] presented a method based on the HVS by modifying quantization scales according to variation insensitivity from smooth to contrastive to improve stego-image quality. And Lie and Chang [22] presented an adjusted LSB technique with the number of LSBs adapting to the pixels of different grayscales.
On the other hand, some steganalysis techniques were developed to detect secret messages among stego-images. TLyu and Farid [23]T developed a universal blind
detection scheme to detect hidden messages in stego-images, which uses wavelet-like decomposition to build higher-order statistical models of natural images and adopts the support vector machine as an optimal classifier to separate stego-images from cover images. TThe method Tdemonstrates good performance on JPEG images and the
selected statistics is rich enough to detect hidden data in the results yielded by a very wide range of steganographic methods. In addition, to detect data hidden in LSBs in the spatial domain, it is observed that the basic LSB substitution method changes pixel values only between 2i and 2i + 1 in the i-th bit plane of the pixel value. This leads to an effective steganalytic technique, the RS method proposed by Fridrich, et al. [24], which not only can expose the presence of secret data but also can estimate the length of the embedded data.
2.1.3. Survey of Data Hiding in Color Images
Many techniques for data hiding in color images have been proposed in the past decade [1, 7, 27] which may be categorized into two major methods: the spatial-domain method and the frequency-domain method. In the former, secret data are directly embedded in the characteristics of the pixels of the cover image, and in the latter, the cover image is transformed first into frequency-domain coefficients, into which secret data are embedded. In general, the frequency-domain method is more robust against attacks while the spatial-domain method can hide more data. The previously-surveyed methods for data hiding in binary and grayscale images are conducted in the spatial domain. For the other method, related papers are very few unless the previously-surveyed methods are adapted to be applicable to color images, for example, by considering each color channel as a grayscale image. Tsai and Wang [28] proposed a data hiding technique for color images using a binary space partitioning tree, which partitions the RGB color space into voxels and embeds three message bits into each voxel.
2.1.4. Survey of Data Hiding in Text Documents
In contrast with other multimedia, digital texts contain less redundant information for embedding data. Most data hiding methods for digital text documents try to encode information directly into the text itself or into the text format. One way of into-text hiding is to exploit the natural redundancy of languages, and one way of into-format hiding is to adjust inter-word or inter-line space [29]. On the other hand, from the steganographic point of view, digital text documents can be classified into two types: hard-copy and soft-copy [27]. A hard-copy text may be treated as a binary image resulting from scanning a text document, while a soft-copy text may be regarded as an American Standard Code for Information Interchange (ASCII) text that
can be edited by a text editing software like Notepad.
For a hard-copy text, which is interpreted as a highly-structured image, information can be embedded into the layout or format of the image. Low et al. and Brassil et al. [30-31] presented text-based steganographic methods which use the distances between consecutive lines of texts or between consecutive words to hide information. If the space between two lines is smaller than a threshold, a “0” is represented; otherwise, a “1.”
In contrast with hard-copy texts and other digital media, soft-copy texts are more difficult to hide data due to the lack of redundant information. Even a slight modification, like rewriting a letter, may be noticed by a reader. However, huge amounts of text documents that people deal with daily on the Internet are essentially soft-copy texts in nature. Thus, the protection of digital rights of this type of text document becomes more and more important.
Bender et al. [27] proposed the use of infrequent additional spaces to form secret data and transmit them in soft-copy texts, including inter-sentence spacing, end-of-line spacing, and inter-word spacing in texts. For example, one space between words is taken to represent a “0” and two spaces a “1.” Wayner [32] proposed a method to use the context-free grammar to create secret text messages in cover files for covert communication; the secret message is not embedded in the cover file directly. And a receiver extracts the hidden message by parsing. A constraint is that the cover text should be a meaningful message; otherwise, a reader will doubt it.
Cantrell and Dampier [33] proposed to embed data into unused spaces in file headers. These spaces are invisible to usual users because they are disregarded when the files are opened. The spaces can be seen when examined at the byte level, but few users would do so. Johnson et al. [34] proposed another way to embed information in unused spaces that are imperceptible to an observer, which is based on the fact that
usually operating systems allocate more space than the need of a file and the result leaves some unused space to hide information. A third method is to create a hidden partition in a file system to embed information. The partition is not viewed normally. This concept has been expanded in a steganographic file system [35]. If a user knows the file name and the password, access to the file will be granted; otherwise, no evidence of the file will be revealed in the system of the hidden files.
Characteristics inherent in network protocols may also be taken advantage of to hide information [36]. For example, TCP/IP packets can be used to transmit secret messages across the Internet by embedding unused spaces in the packet header. Finally, Chang and Tsai [37] proposed a special space encoding to embed copyright information into the HTML text content. The bit “1” is encoded by inserting a so-called pseudo-space string “ ” before a real space, while the bit “0” is represented by a normal space between two words or sentences.
2.1.5. Survey of Data Hiding and Sharing in Software Programs
A survey about watermarking in programs can be found in Zhu, et al. [54]. Two methods have been identified: static and dynamic. The former inserts and extracts watermarks in program codes without running the program while the latter does the same in the execution state of a software object. Two respective examples are Venkatesan, et al. [55] and Collberg and Thomborson [56]. There exist other methods with digital text, sentence syntax, text typos, e-mails [1, 27, 53, 57-59] as cover media.
The concept of secret sharing was proposed first by Shamir [46]. By a so-called (k, n)-threshold scheme, the idea is to encode a secret data item into n shares for n participants to keep, and any k or more of the shares can be collected to recover the original secret, but any (k − 1) or fewer of them will gain no information about it. A
similar scheme, called visual cryptography, was proposed by Naor and Shamir [46] for sharing an image. The scheme provides an easy and fast decryption process consisting of xeroxing the shares onto transparencies and stacking them to reveal the original image for visual inspection. This technique has been investigated further in [48-50], though it is suitable for binary images only. Verheul and van Tilborg [51] extended the visual cryptography technique for processing images with small numbers of gray levels or colors. Lin and Tsai [52] proposed a digital version of the visual cryptography scheme for color images with no limit on the number of colors. The n shares obtained from a color image are hidden in n camouflage images which may be selected to have well-known contents, like famous characters or paintings, to create additional steganographic effects for security protection of the shares.
2.1.6. Survey of Data Hiding in PDF Documents
Portable Document Format (PDF) files [63] are popular nowadays, and so using them as carriers of secret messages for covert communication is convenient. Though there are some techniques of embedding data in text files [57-58], studies of using PDF files as cover media are very few, except Zhong et al. [64] in which integer numerals specifying the positions of the text characters in a PDF file are used to embed secret data.
For security, it is necessary to verify the authenticity of a file received from another party or kept for a long time in a certain environment, before the file is used for various purposes. This is the authentication problem of the file, which should be solved for protection of the file against unintentional changes and malicious manipulations. In the past, the information hiding method [1] has been adopted to solve this problem but most studies were about images [10, 66-71]. There is yet no investigation on the authentication of PDF files, though a related study about data
hiding in PDF files can be found in Zhong et al. [64]. Hiding data in documents other than PDF files have also been investigated [61-62].
2.1.7. Survey of Data Hiding in HTML Documents
About hiding data in the HTML, Shirali-Shahreza [72] protects a Java applet in an HTML file from being copied by hiding a special 8-character string with a key within the Java applet. Wu and Lai [60] hide binary data in HTML files using various properties of tags, like attributes. Wu, et al. [73] use hash functions to compute digests of web page contents as watermarks. Chang and Tsai [37] insert extra white spaces in HTML text to encode bits for watermarking, as done by some commercial software [74].
There are very few studies on web page authentication using data hiding techniques so far. Zhao and Lu [75] generated watermarks of web pages based on principal component analysis and embed them by upper and lower cases of letters in HTML tags. The watermark was used to check the integrity of the entire web page. Wu et al. [73] designed fast fragile watermarks for web pages based on hash functions which generate digests of web pages quickly with case insensitivity. Two related studies can be found in [37, 60] which utilize properties of spaces, tabs, tags, attributes, etc., to encode and hide data bits into the HTML for purposes other than web page authentication. And some more general studies about data hiding can be found in [1, 76].
2.2 Brief Descriptions of Proposed Methods
In this dissertation study, we have developed totally ten methods, three for data hiding in various images with distortion reduction capability, one for data hiding in emails with capabilities of authenticating the hidden data, two for data hiding in source programs, two for data hiding in PDF files, and finally two for data hiding in
web pages. They are briefly described in the remainder of this section
2.2.1. Data Hiding in Binary Images with Distortion-Minimizing
Capabilities by Optimal Block Pattern Coding and Dynamic
Programming Techniques
The first method we propose is a new technique which embeds data into a binary image and minimizes the resulting image distortion in an optimal way. In a binary image, there are two distinct pixel values, 0 and 1, corresponding to black and white pixels, respectively. When data are embedded into a binary image, some image pixels used for data hiding will be changed from black to white or reversely. The pixel value changes will be called bit flippings in the sequel. To embed more data, more bit flippings may be conducted; however, the quality of the resulting image will also get worse. The bit flipping rates of most data hiding methods for binary images are about 50%. We propose a new data hiding method which has the capability to conceal up to
three data bits in a 2×2 block, resulting in bit flipping rates lower than 50%. The
method can thus be used to embed more data. This is achieved by a block pattern coding technique. On the other hand, while it is desirable to embed more data, the resulting image quality should be maintained in the mean time. For this purpose, two optimization techniques are proposed. The first is to use multiple block pattern encoding tables, from which an optimal one is selected for each input image. The second technique is to use a dynamic programming algorithm to divide the message data stream into appropriate bit segments for optimal data embedding in the image blocks in the sense of minimizing the number of bit flippings. As a result, the proposed method can achieve the goals of both increasing the embedded data volume and reducing the resulting image distortion. Furthermore, the method can be used to extract embedded data without referencing the original image.
2.2.2. Data Hiding in Grayscale Images by Dynamic Programming
Based on A Human Visual Model
The second method we propose is a new technique which embeds data into a grayscale image, based on the use of a new HVS model, to estimate the number of usable bits of each pixel in the cover image. Furthermore, a block pattern encoding method is proposed to embed up to three data bits in a 2×2 block of the bit planes without visible degrading of the stego-image quality. This is achieved by using two optimization techniques. The first technique utilizes multiple block pattern encoding tables, from which an optimal one is chosen for each input image; and the second technique uses dynamic programming to divide the message data stream into appropriate bit segments for optimal data bit embedding in the image blocks to minimize a cost function. Especially, the proposed method can predict the PSNR value of the stego-image according to the embedded data size before the embedding process is started. Moreover, the proposed method can extract embedded data without referencing the original image, and does not require post-processing to refine the stego-image quality.
2.2.3. Data Hiding in Color Images by Color Replacements with
Reduction of Image Distortion and Change Noticeability
The third proposed method is a new one for hiding data in RGB color images using color space partitioning and color encoding. The RGB color space is partitioned into non-overlapping, equal-sized color clusters, each being cubic in shape, called a color cube. The colors in each cube are used to represent fixed-length codes. Message data hiding is accomplished by replacing selected image pixels’ colors with closest ones in color cubes to embed corresponding codes representing the message bits. And data extraction is a reverse process of data embedding. To reduce image distortion, each color cube is designed to include a number of color groups, with all
colors in each group representing an identical code. The colors in each group are distributed as separately as possible in the cube, and color replacement at an image pixel is conducted by choosing as the replacing color the one in a group, which is
closest to the pixel’s color in the sense of Euclidean color distance. And to reduce the
noticeability of the resulting color changes, we select adaptively for use in data embedding those cubes whose colors are more scattered in the cover image (that is, the pixels whose colors are in these cubes are more separated mutually in the cover image), so that the color changes on these pixels will arouse less notice from the observer.
2.2.4. Data Hiding in Emails and Applications by Unused ASCII
Control Codes
The fourth proposed method is a new technique for data hiding in emails via Outlook Express and IE under the operating system of the tTraditionalTTChineseT version
of Microsoft Windows XP, service pack 2, 2002. The idea is based on the use of unused ASCII codes. Secret data are encoded by special ASCII control codes and embedded into cover emails by inserting the data into the text line ends in the body of a given email. These ASCII control codes, when displayed both by Outlook Express and IE, are invisible to the user, achieving the effect of steganography. Such invisible ASCII control codes were found out in this study by a systematic test of all the ASCII codes on various email server software systems and standards. The proposed data encoding technique is a combination of five coding rules found in this study, which insert special ASCII control codes into different places in email texts. The inserted codes will not change the meanings of the sentences in the cover email, neither causing any noticeable difference to the reader. Furthermore, hidden data can be extracted from a stego-email completely to recover the original email text content.
Also described in this study are two applications of the proposed data hiding technique, namely, covert communication via emails and authentication of emails. In the former application, security is enhanced by the use of a secret key, and in the latter, an authentication signal is generated from the cover email for email fidelity checking.
2.2.5. Security Protection of Software Programs by Information
Sharing and Authentication Techniques Using Invisible ASCII
Control Codes
The fifth proposed method is a new technique based on the use of some specific ASCII control codes invisible in certain software editors. By the use of the logic operation of “exclusive-OR,” each source program to be shared is transformed into a number of shares, say N ones, which are then hidden respectively into N pre-selected
camouflage source programs, resulting in N stego-programs. Each stego-program still
can be compiled and executed to perform the function of the original camouflage program, and each camouflage program may be selected arbitrarily, thus enhancing the steganographic effect.
To improve the security protection effect further, we propose additionally an authentication scheme for verifying the correctness of the contents of the stego-programs brought by the participants to join the process of secret program recovery. This is advantageous to prevent any of the participants from accidental or intentional provision of a false or destructed stego-program. The verified contents include the share data and the camouflage program contained in each stego-program.
2.2.6. Covert Communication with Authentication via Software
Programs Using Invisible ASCII Codes
The sixth proposed method is a new one for covert communication by embedding messages in source programs. A binary message, after being encoded into
some ASCII codes and embedded into certain C++ program locations, becomes
invisible in the source code editors of Visual C++ and C++ Builder under some
Windows OS environments, creating a steganographic effect. A tamper-proof authentication scheme for the embedded message is also proposed.
2.2.7. Covert Communication via PDF Files and PDF File
Authentication by Invisible Codes
The seventh proposed method is a new technique for covert communication, which embeds secret messages in PDF files. A message is regarded as a string of bits or characters, which are then encoded with a special ASCII code by binary or unitary coding. The results, after being embedded at the between-word or between-character locations in the text of a PDF file, are found in this study to be invisible in the windows of common PDF readers, creating a steganographic effect and achieving the purpose of secret communication.
The eighth method is proposed for authenticating PDF files using a special ASCII code A0. For each word in the text of a PDF file to be protected, an authentication signal composed of repeating A0’s is generated from the 8-bit ASCII codes of the characters composing the word as well as a random number. The signal is then embedded to the right of the word. These A0’s are invisible in the window of common PDF readers, enhancing the security of the embedded authentication signals. Without the key for use in generating the random numbers, malicious creation of a fake file is nearly impossible.
2.2.8. Secret Communication through Web Pages and Automatic
Authentication of Web Pages Using Special Space Codes in
HTML Files
embedding special space codes in the HTML files of web pages. These codes appear as white spaces in the web page, and so may be used to encode secret message bits with steganographic effects. The codes are the result of a thorough investigation of all possible coding systems which can be applied in the HTML file. There are many of such codes, and each of them may be used to encode at least three message bits, increasing the data hiding capability.
The last proposed method is a new automatic authentication technique for checking the integrity of web page text contents. The method, aiming to check the authenticity of each single word, is based on a data hiding technique which uses some special space codes as authentication signals. Such codes, which are found in this study to be multiple and appear identical to normal white spaces in web pages, are used to encode certain binary mapping results from the word contents. These codes are then taken to replace the between-word spaces in the HTML codes, resulting in good steganographic effects. Security enhancement has also been considered, and related problems are solved by the use of secret keys and a multiple word encoding scheme.
Chapter 3
Data Hiding in Binary Images with
Distortion-Minimizing Capabilities by
Optimal Block Pattern Coding and
Dynamic Programming Techniques
3.1 Idea of Proposed Method
In a binary image, there are only two pixel values, 0 and 1, and the corresponding pixels may be called black and white ones, respectively. When data are embedded in a binary image, the image pixels will be changed from black to white or from white to black. The distortion rate is 50% in general data hiding methods for binary images. The method which we propose in this study for data hiding in binary images is based on a block pattern coding technique and a dynamic programming algorithm. The method can be used to embed more data in a block of a binary image, and minimize the resulting stego-image distortion simultaneously.
In order to embed more data in a binary image, more pixels need be changed; however, the quality of the resulting stego-image will get worse. On the contrary, in order to maintain the quality of the resulting image, the amount of the embedded data should be limited. The proposed method is designed to be a compromise between the embedded data volume and the resulting image distortion. The method can extract embedded data without referencing the original image. It also has the merit of concealing up to three data bits in a 2×2 block by changing the smallest number of bits in a block. Contrastively, most existing methods for hiding data in binary images can embed only one or two data bits in a 2×2 image block [7, 10, 12].
In the remainder of this chapter, the proposed method for dealing with 2×2 image blocks is first described in Section 3.2. Some experimental results are shown in Section 3.3, followed by some cluding remarks in Section 3.4.
3.2 Proposed Data Embedding Process
The proposed method is designed to hide secret data behind binary images in random fashions controlled by secret keys. The method consists of a data embedding process and a data extraction process. In this section, the principles behind the proposed method are presented first, followed by the details of the proposed data embedding and extraction processes.
A. Encoding Block Patterns for Secret Data Embedding
In order to embed secret data into a binary cover image, every 2×2 block of the cover image is regarded as a pattern with a corresponding 4-bit binary value in this study, with each black pixel representing a bit 0 and each white one representing 1. An illustration is shown in Figure 3.1. Therefore, in a 2×2 block, possible binary values of the block pattern are 0000B2B through 1111B2B, where “0000B2B” means an entirely
black block while “1111B2B” means an entirely white one.
The main idea of the proposed data hiding method is based on the use of a block
pattern encoding table which maps each block pattern into a certain code for use as
hidden data with the code being up to three bits in length. And data embedding is accomplished by changing the block patterns so that the codes of the resulting blocks become just the input secret data to be embedded. A block pattern encoding table designed for use in this study is shown in Table 3.1. The idea behind the design of this table is described as follows. It is emphasized, by the way, that such a table is just one of the many possible ones usable for data hiding, and the proposed data embedding
process will choose from them an optimal one for each specific input image, as described later.
2×2 block pattern Corresponding binary value
bB1BbB2BbB3BbB4B
0101
Figure 3.1 Illustration of block patterns and corresponding binary values.
The number of possible patterns in a 2×2 block are 16. This number is much larger than the need to represent the two secret bits ‘0’ and ‘1’, so we may use multiple block patterns to represent a single secret value, allowing the possibility of choosing among the patterns an optimal one to replace the original image block in the data embedding process, thus reducing the resulting image distortion in the replaced block. Furthermore, we wish to embed more data in a block, and for this goal we may use a block pattern to represent more than one bit of secret data.
For example, we may use both the block pattern tB1B = 1101B2B and the pattern tB2B =
1110B2B to represent the two-bit secret value s = 00B2B. In this way, when we want to
embed, for example, the secret value s = 00B2B into a block B with pattern v = 0110B2B, we
have the two choices of block patterns tB1B = 1101B2 and tB B2B = 1110B2B instead of the
conventional case of just one, from which we can choose tB2B = 1110B2B to replace the
pattern v = 0110B2 Bof the block B, resulting in the smaller distortion of just a 1-bit error.
Note that if only the choice of tB1B = 1101B2B is allowed, then the error will be 3 bits
which mean a larger distortion in the replaced block. It is such allowance of multiple
bB1B bB2B
choices for block pattern replacement that achieves distortion reduction in the proposed method.
More generally, we group in this study the 16 possible block patterns in a 2×2 block B into distinct sets according to the entropy values E of the block patterns, where an entropy value E of a block pattern P is defined as follows:
E = − k
k
k p
p
∑
log2 = −pB0B logB2B p0B B − pB1BlogB2B pB1Bwith pB0B and pB1B being the occurrence probability values of black and white pixels
appearing in P computed as
pB0B = (number of black pixels in P)/4; pB1B = (number white pixels in P)/4.
A pattern P in a set with a higher entropy value E is presumably more random in its black and white arrangement, and so is more suitable for hiding more secret data without causing a noticeable change. There are three possible entropy values 0, 0.811, and 1 in a 2×2 block by the above definition, so we divide the 16 possible block patterns into three sets. The first set with the entropy value 0 has two distinct block patterns, one being the entirely white block, the other the entirely black. They are denoted as A and F in Table 3.1 and are used to represent the secret data of 1 and 0, respectively. That is, they encode the secret data of 0 and 1, respectively.
The second set with the entropy value 0.811 includes eight distinct block patterns, which can be classified into two classes, one class with each pattern including one black pixel and three white ones and the other class with each pattern including three black pixels and one white one. The first class, denoted as B in Table 3.1, includes four block patterns, and we use two block patterns of them to encode the secret value 00B2B, and the other two to encode the secret value 01B2B. When deciding which two
“mismatch reduction criterion” of making the two selected patterns less different in the number of mismatching pixel values when one of the two selected patterns is superimposed on the other. We use the four block patterns of the other class, denoted as E in Table 3.1, to encode the secret values 10B2B and 11B2B in a similar way.
Table 3.1 Proposed block pattern encoding table.
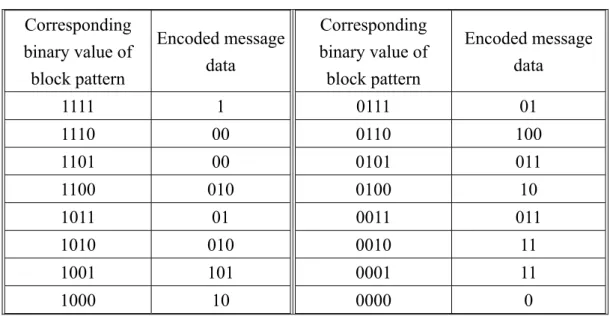
Type Block pattern Entropy value Corresponding binary value Encoded secret data A 0 1111 1 B1 0.811 1110 00 B2 0.811 1101 00 B3 0.811 1011 01 B4 0.811 0111 01 C1 1 0011 011 C2 1 0101 011 C3 1 1010 010 C4 1 1100 010 Type Block pattern Entropy value Corresponding binary value Encoded secret data F 0 0000 0 E1 0.811 0001 11 E2 0.811 0010 11 E3 0.811 0100 10 E4 0.811 1000 10 D1 1 0110 100 D2 1 1001 101
The last set with the entropy value 1 has six distinct block patterns. So far we have completed the encoding of all possible one-bit and two-bit secret values with ten patterns. So the remaining six patterns in the 16 ones may be used to encode three-bit secret values. But six patterns are not enough to encode all the eight three-bit secret
values, so we can only take care of some of them, following the aforementioned mismatch reduction criterion. In particular, we use two block patterns to encode each of the two 3-bit secret values 011B2B and 010B2B, and finally, the last two patterns to
encode the secret values 100B2B and 101B2B, respectively. The six patterns are denoted as
C1 through C4 and D1 and D2 in Table 3.1.
B. Sketch of proposed idea of data hiding
In the proposed data embedding process, the more data we embed in a 2×2 block, the worse the resulting image quality becomes. Therefore, we must control the number of destructed pixels in a block to reduce the resulting image distortion. The idea of the proposed data embedding process is sketched as four major steps in the following, which includes two folds of distortion minimization.
(1) Dividing the input image into blocks: We divide the input image into 2×2 blocks with every two neighboring blocks being separated by a 1-pixel-wide line, as shown in Figure 3.2. The 1-pixel-wide band around each 2×2 block is said to be the neighborhood of the block.
(2) Selecting a random list of embeddable blocks for data embedding: We then use a secret key K as well as a random number generator f to select randomly a sequential list of embeddable blocks. A block B is said to be embeddable in this study if the following two conditions are satisfied: (a) the neighborhood of B is not entirely black or white, (b) B has not been selected for data embedding yet. The way we adopt to generate the random list of embeddable blocks is as follows: (a) concatenate all blocks obtained in Step (1) above in sequence; (b) use K and f to generate sequentially a random number f(K), divide it by the total number of blocks, and take the remainder as a block number, denoted by N; (c) check block
an embeddable block is obtained; (d) append the obtained embeddable block to the end of the desired random list; (e) stop the process when a sufficient number of embeddable blocks for data embedding are obtained.
(3) Using multiple block pattern encoding tables for the first-fold distortion reduction: We generate all possible block pattern encoding tables and select an optimal one for use in the data embedding process, in the sense of introducing the least
distortion.
(4) Applying optimal search techniques for the second-fold distortion reduction: Finally we apply the dynamic programming technique to segment the input message data stream optimally into a series of codes and embed them in the input image, according to a cost function designed in advance for measuring the degree of the pattern change in each image block. This reduces the resulting distortion further in a global sense.
Figure 3.2. Division of input image into 2×2 blocks with separating linesPP(grids with
bold boundaries are 2×2 blocks for data embedding).
C. Use of Multiple Block Pattern Encoding Tables
tables, as mentioned previously in the third major step of the proposed data; embedding process, is based on the idea that a single encoding table will not be suitable for every binary image in the embedding process. If a binary image is destroyed very seriously in the data embedding process using Table 3.1, it will be necessary to use another table with other combinations of block patterns and encoded hidden data. For example, assume that a binary secret value v = 101B2B is to be
embedded into a sequence of three randomly selected image blockswith patterns 0000,0100, and 1111 by Table 3.1. The data embedding process using Table 3.1, as illustrated in Figure 3.3(a), will select optimally the block pattern type D2 = 1001, which encodes the three-bit secret value v = 101B2B, to replace the first selected block
with pattern 0000, resulting in reversing two bits. However, if we replace the encoded secret data of type A in Table 3.1 with those of type F, and replace those of all of types B1 through B4 with those of all of types E1 through E4, respectively, then we will get a new block pattern encoding table and the use of it to hide the secret value v = 101B2B will result in no bit reversing because here we can, as illustrated in Figure
3.3(b), select in sequence optimally the new pattern type F = 0000 (encoding the secret data of 1B2B) and the new pattern type E3 = 0100 (encoding the secret data of 01B2B)
to encode together the secret data v = 101B2B. This means that adaptive table generations
and selections for use in data embedding help distortion reduction indeed. More generally, by enumerating all possible ways for exchanging the encoded secret data of certain types in Table 3.1 with those of the other types, we can get 128 distinct block pattern encoding tables for selection in the data embedding process to minimize the distortion.
D. Proposed Distortion-Minimizing Cost Function and Search Techniques for
Optimal Solutions
The cost function proposed in this study for use in the proposed data embedding process to minimize image distortion is the total number of reversed bits in the resulting stego-image. In Table 3.1, block patterns can be used to encode one, two, or three secret bits. Correspondingly, we hide a binary secret value v by embedding the first one, two, or three bits in the prefix of v into a block.
To determine how many bits should be embedded, we may calculate first the cost function value for each of the three cases, and then replace the currently selected block with the block pattern which corresponds to the case with the minimum cost function value. This method provides a quick way for data embedding. However, it is actually a greedy search and not an optimal solution.
To see this, for example, for the previously-mentioned example in which the secret value v of 101B2B is embedded in three selected blocks with patterns 0000, 0100,
and 1111 by Table 3.1, by the above-mentioned greedy algorithm we first replace the block with pattern 0000 by the block pattern E3 = 0100 to embed two bits 10. The computed cost function value is 1 because a bit is reversed here. This cost is a local minimal one. Next, we replace the block with pattern 0100 by the block pattern A= 1111 to embed the last bit 1of v, and get a local minimal cost value 3. The total cost value is 4. Now, if we do not use the greedy algorithm from the beginning, and replace instead the first block with pattern 0000 by the block pattern D2 = 1001 to embed three bits 101 directly, then the total cost value will be reduced to 2 which is smaller than the previous total cost 4. This shows that there indeed exist at least one solution better than that found by the greedy method. Figure 3.4 illustrates the data embedding process for this example. This is also true for many other examples, as found by this study. And so the search of an optimal solution is meaningful, for which the proposed method is dynamic programming.
In the proposed dynamic programming algorithm (abbreviated as DP in the sequel), certain edit distances are defined to minimize the cost function, as described in the following. Assume that the input secret data value to be hidden is in the form of an n-bit string SB1B with SB1B[i] denoting its ith bit. Also, let the randomly selected blocks
for embedding the secret value be expressed as a list in the form of another string SB2B