國立臺中教育大學資訊工程學系碩士論文
基於 WordNet 與 SWRL 規則之知識本
體配對方法
An Ontology Match Approach Based
on WordNet and SWRL Rule
指導教授:徐國勛 教授
研究生:呂紹源 撰
中華民國 103 年 7 月
致謝
這篇論文的完成,我非常感謝許多曾經幫助過我的人,首先要感謝我的父 母,他們讓我能專心在自己的學業上,支持和鼓勵我,讓我能繼續學習順利取 得碩士學位。再來則是我的指導教授徐國勛老師,在碩士生涯中,老師不僅教 會我專業領域和研究上的技術和知識,還教會我們很多生活中處理事情的態度 和方法,也常常以學長們在業界的經驗告訴我們以後出社會工作該注意什麼, 真的讓我學習到非常多東西。在研究上遇到挫折和問題,老師也會給我們建議 和方向,讓我們有明確的目標繼續努力,我真的很喜歡老師的教學風格,非常 感謝老師這些年來的指導。再來感謝與我從大學一直到研究所都是同學的旻遇 在研究過程中一起討論研究中所遇到的問題,還有阿搞學長、冠霖學長雖然相 處時間不多你們就畢業了,但是在短短的時間內還是教會我很多事,也謝謝三 個學弟大佑、立青、承哲幫忙處理實驗室的雜務。最後感謝郁翔、柏寰、智皓、 明駿、宸勳、繼玄、政彥、碩搖、朝傑、鈺中、宏修、宗駿、元愷、小蔣、柏 誠、柏鈞、英麟、智忠、祥紳、洪爺等這些實驗室的學長、同學、學弟們,在 研究所這段期間帶給實驗室的歡樂氣氛,能認識你們真好,也特別感謝佳蓉陪 伴著我度過碩士班的嚴苛挑戰,感謝大家的支持和鼓勵,讓我的研究和論文能 順利的完成。摘要
近年來, 隨著 Web Service 越來越熱門在各種應用領域上,使得 Web Service 問題也受到許多學者關注,其中又以服務搜尋和服務配對問題較為熱門。在傳 統的服務配對方法中,大部分是以關鍵字為主的搜尋方式來找尋服務,但是光 靠關鍵字搜尋是無法有效幫助使用者找尋到適合自己的服務,為了解決這問題, 我們提出一個基於 WordNet 和 SWRL 規則之知識本體配對方法,將服務描述資 訊利用本體論建立對映關係進行配對,進而應用在服務配對上,讓使用者在找 尋服務上有更多的選擇,以滿足使用者在找尋服務時受單一關鍵字的限制而無 法匹配到適合自己的服務。 在本論文中,我們提出一個基於 WordNet 和 SWRL 規則的配對方法幫助使 用者能找到符合需求的服務,利用 WordNet 中豐富的詞彙庫透過擴充功能對使 用者提出的需求作擴充再搭配撰寫好的 SWRL 規則搜尋出使用者想要的服 務。 關鍵詞: 服務配對、本體論、網路服務、WordNet、SWRL I
Abstract
In recent years, the web service is becoming more and more popular in various application domains, which attracts many researchers to contribute efforts in this domain. Some people study on service search some on load balance. However, there are bottlenecks encountered in service matchmaking and service discovery. In traditional service matchmaking, most approaches use keyword-based methods for service discovery that may cause difficulties in meeting user’s demands. It will be limited to a single keyword by using keyword-based methods. In order to address the above problems, we propose a mechanism to match services based on WordNet, ontology and SWRL rules, in which WordNet are used to extend queries, ontology stores service description, service name and service attributes, and SWRL rules are used to extract implicit messages hidden in ontologies.
In this paper, we propose an Ontology match method based on WordNet and SWRL Rules, which improves the quality of the web service found by using WordNet and SWRL technologies.
Keywords: Service Match、Ontology、Web Service、WordNet、SWRL
目錄
摘要 ... I Abstract ... II 目錄 ... III 表目錄 ... V 圖目錄 ... VI 第一章 緒論 ... 1 1.1 研究背景 ... 1 1.2 研究動機與目的 ... 2 1.3 章節概要 ... 2 第二章 背景知識與相關研究 ... 4 2.1 相關研究 ... 4 2.2 背景知識 ... 5 2.2.1 WordNet ... 5 2.2.2 JWI ... 6 2.2.3 Ontology ... 7 2.2.4 Protégé ... 92.2.5 Semantic Web Rule Language(SWRL) ... 10
第三章 研究方法 ... 14
3.1 研究方法 ... 14
3.2 SWRL 規則 ... 17
3.3 Query Extension Based on WordNet(QEW) ... 19
3.4 本體論 ... 22
3.5 配對流程 ... 23
第四章 系統架構 ... 26
4.1 系統架構 ... 26
4.2 實作範例 ... 28
4.2.1 Query Extension Based on WordNet(QEW) ... 28
4.2.2 增加 SWRL 規則方法 ... 30 4.3 比較結果 ... 33 第五章 案例研究 ... 34 5.1 測試實驗 ... 35 5.2 驗證實驗 ... 36 5.2.1 方法比較 ... 36 5.2.2 方法驗證 ... 39 III
5.3 實驗討論 ... 44
第六章 結論與未來工作 ... 45 參考文獻 ... 46
表目錄
表 1 K-W(H) TEST 排序(Precision ratio) ... 40
表 2 Wilcoxon Rank Sum Test 排序(Precision ratio) ... 41
表 3 Wilcoxon Rank Sum Test 排序(Precision ratio) ... 41
表 4 Wilcoxon Rank Sum Test 排序(Precision ratio) ... 41
表 5 K-W(H) TEST 排序(Recall ratio) ... 42
表 6 Wilcoxon Rank Sum Test 排序(Recall ratio) ... 43
表 7 Wilcoxon Rank Sum Test 排序(Recall ratio) ... 43
表 8 Wilcoxon Rank Sum Test 排序(Recall ratio) ... 43
圖目錄
圖 1 詞彙矩陣概念圖(George A. Miller, 1990)[16] ... 6 圖 2 語意網語言階層[18] ... 9 圖 3 OWL Viz 示意圖 ... 10 圖 4 SWRL 呈現方式[Ian H, et al., 2004][20] ... 11 圖 5 SWRL 語言架構[Ian H, et al., 2004][20] ... 12 圖 6 本研究之 Overall architecture ... 15圖 7 Service Match Maker 主要功能 ... 16
圖 8 詞性參數設定... 20 圖 9 上、下義詞參數設定 ... 20 圖 10 WordNet 詞性對映圖 ... 21 圖 11 Query 擴充示意圖 ... 22 圖 12 本研究 Protégé 示意圖 ... 23 圖 13 知識本體配對循序圖 ... 24 圖 14 本研究方法架構... 26 圖 15 取得擴充資訊之程式碼 ... 29 圖 16 擴充之 Query ... 29 圖 17 QEW 搜尋結果 ... 30 圖 18 SWRL 規則虛擬碼 ... 31 圖 19 加入 SWRL 規則之搜尋結果 ... 32 圖 20 各領域之 TOP5 查準度 ... 35 圖 21 關鍵字搜尋之查準率及查全率 ... 37 圖 22 QEW 之查準率及查全率 ... 37 圖 23 加入 SWRL 規則之查準率及查全率 ... 38 圖 24 三種方法之查準率及查全率比較 ... 38 VI
第一章 緒論
1.1 研究背景
隨著網際網路的發展,電子商務逐漸興起,網際網路儼然成為現代人生活中獲 取資訊的主要管道,而許多產業以往只以實體的方式經營,現在也開始逐漸重 視虛擬化的經營。當網路的資料漸趨龐大時,就出現了許多問題,包括資料負 載的問題、服務的配對等。其中在服務的配對上,因資料量龐大的關係可能導 致使用者在搜尋服務時,找到的服務與服務需求者所想要的不符,沒辦法讓服 務需求者找到合適的服務。而以往在服務的配對上,主要是以 UDDI(Universal Description, Discovery, and Integration)為主[1],但隨著 UDDI 中服務數量的增加, 服務需求者如何準確地找到想要的服務也成為重要的課題,目前在 UDDI 上主 要是以關鍵字為主的搜尋方式並無法有效的讓服務需求者找到適合的服務。因 此,在 1998 年 Web 的發明人暨 W3C 主席 Tim Berners Lee 提出了語意網 (Semantic Web)這個概念[2],語意網是現有網路架構的延伸,將資料內容的涵 義定義的更明確,使人們能有效的使用網路所帶來的便利,且語意網提供統一 的資料描述框架,使網路資源能整合在一起,並藉由連結到資訊本身的定義和 背景,使資訊內容的語意能被表示,進而更有效率的作資料存取和分析(Hjelm, 2001)[3] 。有鑑於此,本研究提出一個基於知識本體的配對方法,結合 WordNet 1和 SWRL 規則,讓服務需求者能找到符合需求的服務。
1.2 研究動機與目的
由於近年來 Web service 的數量和種類日益增加,如何讓服務需求者能準確地找 到想要的服務也成為了重要的研究議題,目前主要是以關鍵字為主的服務配對 和服務分類為主的搜尋方法,如 UDDI 等,但是在傳統的關鍵字搜尋上找尋服 務時,服務需求者會因為受到關鍵字的限制而無法找到想要的服務,所以 Tim Berners-Lee 在 1998 年提出了語意網(Semantic Web)這個概念,語意網的主要目 的是讓網際網路上的文件都能用標準的本體知識語言來表達,一方面達到知識 分享的目的,另一方面也能達到機器可讀性(machine readable),也就是讓電腦 可以讀的懂本體知識語言所描述的文件敘述,了解其語意內涵,而能進一步自 動替使用者作更精確的資料判斷與處理。所以本研究提出一個基於 WordNet 和 SWRL 規則的知識本體配對方法,將服務描述資訊利用本體論建立對映關係, 讓服務需求者在搜尋服務上不會受限於單一關鍵字而無法搜尋到適合的服務, 透過語意服務配對的方法,搜尋到更多適合的服務。1.3 章節概要
本論文架構如下: 在第二章將介紹本研究所使用到的技術方法和相關背景知識 以及服務配對上的相關研究;其中包含 Semantic Web Rule Language(SWRL)規則的語言架構和本體論相關知識介紹與 WordNet 知識庫等。第三章主要說明基 於 WordNet 和 SWRL 規則之知識本體配對方法作詳細的介紹。第四章說明本研 究方法之系統架構和各元件介紹,並以實例呈現和比較配對結果。第五章分成 測試實驗和驗證實驗兩部分,測試實驗我們使用 OWLS-TC4 作為我們的實驗樣 本並提出相關數據加以探討實驗結果;驗證部分則利用 Kruskal-Wallis (H)和 Wilcoxon Rank Sum Test 兩個方法來驗證其數據之間的可靠性。最後為本研究之 結論和未來之展望。
第二章 背景知識與相關研究
此章節主要介紹本研究所使用到之相關研究及技術,包括 WordNet、JWI、 Ontology、Protégé、SWRL 等,並且對學者所提出之相關研究方法作簡介。2.1 相關研究
近年來,由於網路服務日趨漸多,在服務配對上如何找到符合使用者需求的服 務也成為一大議題,而在以往以 UDDI 為主的配對方式[4-6],也因為服務的數 量和種類變多而無法滿足使用者需求,許多學者也提出基於語意的配對方法來 提升服務配對的準確度。在語意配對方法上也從許多不同觀點著手,包括架構 [7, 8]、演算法[9, 10]、Model[11, 12]等,都有助於改善配對的查準度和查全率 等。 G. Wang et al., [13] 提出一個基於改善語距和相似度演算法來提升服務配對的 查準度,文中提到以 Inheritor、Specialization、Generalization、The binary relation 四種關係為主的演算法來計算需求之間的相似度,但其演算法與 WordNet 所提 出的相似度計算比較起來,嚴謹度和完整度是不夠的。而在本文中是提出基於 WordNet 的方法來增加查準度的。 H. Fan et al., [14] 提出一個基於 SWRL 規則為前提配對方法來提升查準度,但 在這篇文章中,主要是利用 SWRL 格式定義出新的規則再結合 IOPE 配對流程 4的方式來配對服務,但在這方法中除了在撰寫 SWRL 規則上無法搭配現有的推 論引擎支援導致在撰寫規則上無法立即除錯外,也無法有效地與本體結合,這 樣無疑是使 SWRL 規則的優點無法發揮到最大限度。而在本文中,除了利用 OWL API 讓 SWRL 規則能和本體結合外,也搭配 Pellet 推論引擎,這樣不僅較 有利於撰寫規則,透過 SWRL 規則與本體的結合也能達到更佳的效果。
2.2 背景知識
本章節將介紹本研究所使用到的技術,依序是 WordNet、JWI、Ontology、Protégé、 Semantic Web Rule Language。
2.2.1 WordNet WordNet 是一部訊息豐富的語意知識庫[15],其中收錄了為數極多的詞彙。其 設計靈感源自於近代心理語言學和人類詞彙記憶的計算理論,提供研究者在計 算語言學,而在 WordNet 中,可分名詞、動詞、形容詞、副詞,這四個不同的 詞類,分別設計組合成同義詞集(synsets)的格式,呈現出最基本的詞彙概念, 在這當中以不同的語義關係連結各種不同的同義詞集,串成了 WordNet 的整體 架構,也呈現了 WordNet 整個面貌。 WordNet 最具特色之處是根據詞義而不是詞形來組織詞彙訊息,且它是按照詞 彙的矩陣模型組織的,如下圖 1 詞彙矩陣概念圖(George A. Miller, 1990)[16]所 示,同義詞集合(synonymy set)可看作是詞形(word form)之間一種具有中心腳色
的語義關係。 圖 1 詞彙矩陣概念圖(George A. Miller, 1990)[16] 圖 1 說明了 F1 和 F2 為同義詞,F2 為多義詞(一詞多義),詞義 M1 可用詞形(F1,F2) 表示。而在結構上它將所有的相同的語意集成 synset,並以 synset 為基礎進一 步連結語意之間的關係,如上位關係(hypernym)、下位關係(hyponym)、整體關 係(holonyms)及部分關係(meronyms)等。
目 前 WordNet 已 經 被 應 用 在 許 多 的 研 究 上 , 如 語 意 解 歧 (word sense disambiguation) 、 資 訊 檢 索 (information retrieval) 及 電 腦 輔 助 語 言 學 習 (computer-assisted language learning)等領域,儼然成為語意研究的共同標準。
2.2.2 JWI
JWI (The MIT Java WordNet Interface)為 MIT 所提出[17],是一套可存取 WordNet 的 Java API,可支援 1.6 到 3.0 間任意一個版本的 WordNet,而支援 WordNet 的 API 也很多,包括 JWNL 和 JAWS 等,會選擇 JWI 的原因是因為 JWI 對 WordNet 版本限制較不嚴謹,且 JWI 也較其它 API 活躍。
2.2.3 Ontology
本體論(Ontology)源自於哲學,主要用於探討「存在(Being)」的一門學問,本 體論常利用樹狀結構及關連的方式來表達現實之間的所有事物,並描述這些事 物之間的規則,” An Ontology describes basic concepts in a domain and defines relations among them” ,此句話定義了本體論是用來描述一個領域中的基本概 念及定義彼此之間的關係(Natalya F.N. et al., 2001) 。本體論是可以用來描述知 識,使機器能了解並使用這些知識。一般而言,本體論的構成要素有概念(Class)、 屬性(Slot)、實例(Instance)和原則(Axiom)(Natalya F.N. et al., 2001) ,說明如下: 1. 概念(Class): 用來描述特定領域的概念,也可稱類別。而一個概念可以有許 多個子概念,如景點、交通工具等可視為概念,而美食景點、觀光景點則 可視為景點的子概念。 2. 屬性(Slot): 在本體論中是用來描述概念或類別之間的關聯性,可以透過屬 性來分辨概念之間的差異,屬性又可分為資料屬性(Data property)和物件屬 性(Object property)。如住宿的地址、電話等都是資料屬性,而住宿的房型、 服務的類型就是物件屬性。 3. 實例(Instance): 在本體論中是概念或類別中的一個實際的例子,如長榮桂 冠就是飯店概念的一個實例。 7
4. 原則(Axiom): 是定義屬性(Slot)無法指出的關聯,這種關聯通常橫跨多個類 別,例如在房型的類別中,客戶可以選擇所有房型,但是 VIP 房型只有 VIP 可以選,即可利用 Axiom 來定義非 VIP 客戶不能選 VIP 房型。
再來介紹 OWL 版本,網路本體語言(Web Ontology Language, OWL)是由 W3C 制定[18],OWL 又分 OWL Lite、OWL DL、OWL Full 三種:
1. OWL Lite: 用於提供簡單類別屬性的使用者,支援基數(cardinality),只允 許基數為 0 或 1 ,OWL Lite 的優點在於複雜程度低、容易掌握,能夠快速 實現。
2. OWL DL: DL 表示敘述邏輯(Description Logic),支援需要再推理系統進行 運算的使用者,提供推理系統保證計算完全性(Computational),表示所有可 能的推理結果都能被計算出來和可決定性(decidability),他可限制當一個概 念為多個概念的子概念時,他不可以是另一個概念的實例,而 OWL DL 的 缺點在於與 RDF 不完全相容,需要在某方面進行擴展或加以限制。
3. OWL Full: 適用於不須計算保證的使用者,但對於 RDF 的語法支援最大, OWL Full 包含了 OWL 全部語言的成分,並取消 OWL DL 中的限制,允許 一個概念可同時表達為多個概念的集合,及許多集合的一個概念。而 OWL Full 優點在於不論在語法或語意上,都能提供最大的表達性,缺點是沒有 任何軟體能完全支援 OWL Full 所有推理的功能。
而上面這三種版本是由 DAML 和 OIL 所結合演變來的,OIL 是第一個將本體 論結合的描述邏輯語言,以 XML 和 RDF 來呈現,圖 2 為語意網的語言階層:
圖 2 語意網語言階層[18]
OWL 是基於這些標準語言發展而來的,OWL 和 OIL 一樣是以描述邏輯來呈現 概念之間的關係,並以 XML 格式來呈現,讓建置出的本體論能適用於開放式 的網路環境,達到共享和再利用的效果。
2.2.4 Protégé
Protégé 是一個免費且開放原始碼的本體編輯軟體,是由 Stanford University 團 隊所開發[19],開發語言是採用 Java,由於使用方便,Protégé 是目前最為廣泛 使用的本體編輯軟體,在許多不同領域上也有使用,如生物學、電子商務等。 而目前在網路上也有許多工具支援本體建置,如 OWL Viz、推論引擎等,在本 研究中是以 Pellet 這個推論引擎來進行描述邏輯推理的,OWL Viz 則是將本體
論以圖形化的方式來呈現。圖 3 為 OWL Viz 示意圖。
圖 3 OWL Viz 示意圖
2.2.5 Semantic Web Rule Language(SWRL)
SWRL[20]是一 種以語意 的方式呈 現規則的 一種語言 ,規則部 分概念是 由 RuleML 演變而來,是以 Web Ontology Language(OWL)為基礎的規則描述語言, 其目的是為了讓規則和 OWL 結合,透過與 OWL 的結合讓所要表達的語意更 加完整提供更強的表達能力,而目前 SWRL 也是 W3C 的一員。
SWRL 呈現方式可分兩種,分別是 XML 和 RDF ,使用 XML 的方式呈現是以 RuleML 加 OWLX 的方式描述,RDF 則是以 OWL 加 RDF 方式呈現,圖 4 為 SWRL 呈現方式。
圖 4 SWRL 呈現方式[Ian H, et al., 2004][20] 以 XML 方式呈現的好處有:
可透過 XSLT 將 OWLX 轉換為其他語法。 規則和本體論的 axiom 可以混用。
OWL 和 RuleML 互通性容易,現存的 RuleML 工具可繼續編輯 SWRL。 以 RDF 方式呈現的好處有: 由於 RDF 是直接使用語意網標準語言能直接與所建立的本體論進行結合,所以 不須轉換格式。 SWRL 內部的變數皆是 RDF 方式呈現,變數本身就是 RDF 形式,使變數對應 到本體論的工作較為簡單 SWRL 語言架構
SWRL 主要由四個部分組成,分別是 Imp、Atom 、Variable 和 Building 組成, 其語言架構如圖 5 所示。
圖 5 SWRL 語言架構[Ian H, et al., 2004][20]
Imp 包含 head 和 body,head 表示欲推論的結果,body 則是該推論的前提 條件,而 head 和 body 所使用的 instance 則是由 Atom 和 Variable 提供
Atom 是 head 和 body 的基本元素,在 head 中只允許一個 Atom 出現,而 在 body 中可以是多個 Atom 來組成
Variable 則是用於定義 Atom 中的變數,在 Atom 中包含許多限制,主要有 以下四種:
C(x) :C 是 OWL 描述。
P(x ,y) :P 是 OWL 的屬性,而 x、y 可以是變數(OWL individuals 或 OWL data value)。
SameAs(x, y) :x 和 y 相等。
DifferenceFrom(x ,y) :x 和 y 不同。
Building 用於定義 SWRL 中的各種邏輯比較關係。 下列為一條簡單的 SWRL 規則,我們將針對其作說明:
hasParent(?x, ?y) ∧ hasBrother(?y, ?z) → hasUncle(?x, ?z)
在規則中 hasParent(?x, ?y) 和 hasBrother(?y, ?z)為規則中的 Body 即為推論前提, hasUncle(?x, ?z)為 Head 即為推論結果,而括號內的 xyz 則為 Variable。 hasParent(?x, ?y)表示?x 有雙親?y,?y 有兄弟?z,所以透過這些前提我們就可以 得到?x 有叔叔?z 這樣一個結果。
第三章 研究方法
本研究提出的方法是將 WordNet 和 SWRL 做結合,使用者輸入 Query 後, 利用 JWI(Java WordNet Interface)從 WordNet 中取出資料並將取出來的資料對 Query 做擴充再與 SWRL 規則結合的方式來進行知識本體配對的工作。本章節 主要分成五部分進行探討,在 3.1 研究方法首先介紹和說明本研究之 Overall architecture,接著介紹我們的方法主要的元件 Service Match Maker 的功能和使 用的技術,3.2 介紹 SWRL 規則的定義並以例子的方式呈現和說明,3.3 介紹 Query Extension Based on WordNet(QEW)使用的技術和運作方式,3.4 本體論主 要介紹本體論的建置上我們所依循的標準和所建置的領域,最後 3.5 配對流程 部分利用循序圖說明在我們的方法中如何將使用者所發出的 Query 成功的搜尋 到相關的服務並完成知識本體配對。
3.1 研究方法
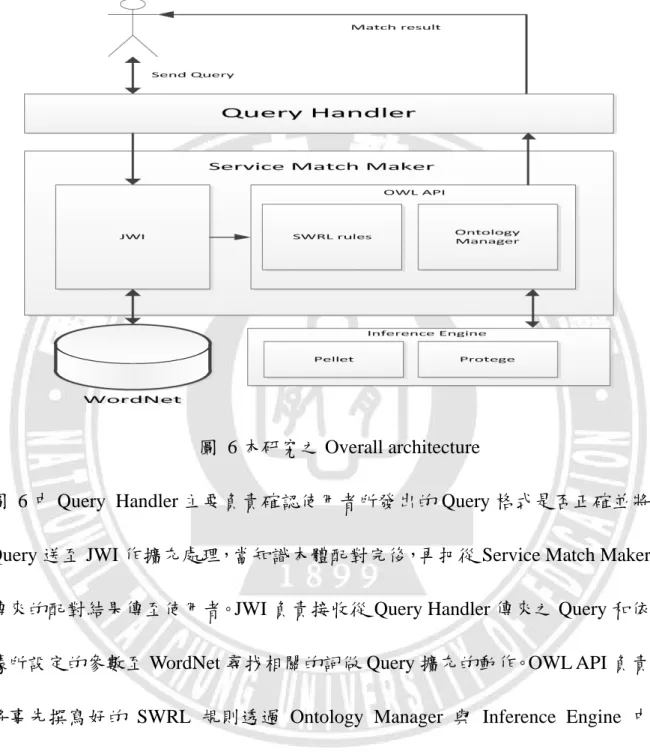
本研究是利用使用者所輸入的 Query 為搜尋條件,將 Query 透過 JWI(Java WordNet Interface)做擴充,此擴充方法我們命名為 Query Extension Based on WordNet(QEW) ,再加上我們寫好的 SWRL 規則透過 Service Match Maker 到 Inference Engine 中取出服務資訊進行知識本體的配對,最後再將配對到的服務 列出來供使用者選擇。 下面我們將介紹本研究之 Overall architecture 並說明各
元件之間的關係,如圖 6 所示:
圖 6 本研究之 Overall architecture
圖 6 中 Query Handler 主要負責確認使用者所發出的 Query 格式是否正確並將 Query 送至 JWI 作擴充處理,當知識本體配對完後,再把從 Service Match Maker 傳來的配對結果傳至使用者。JWI 負責接收從 Query Handler 傳來之 Query 和依 據所設定的參數至 WordNet 尋找相關的詞做 Query 擴充的動作。OWL API 負責 將事先撰寫好的 SWRL 規則透過 Ontology Manager 與 Inference Engine 中 Protégé 裡面的 Ontology 進行結合。Inference Engine 主要利用 Protégé 提供 Ontology 資訊和透過 Pellet 推理引擎來推論規則。
下圖我們將介紹主要的元件 Service Match Maker,在 Service Match Maker 中主
要包含三個功能,如圖 7 所示:
圖 7 Service Match Maker 主要功能
圖 7 中顯示在 Service Match Maker 中包含了 SWRL rules、JWI、Ontology Manager 三個功能,當使用者輸入 Query 後,先透過 JWI 的方法擴充 Query 後, SWRL rules 透過 Pellet 推論引擎與 Inference Engine 中的 Ontology 結合推論出 新的關係,再以擴充後的 Query 為搜尋依據並利用 Ontology Manager 存取 Inference Engine 中 Ontology 的資訊進行知識本體配對。以下就各功能逐一做說 明:
SWRL rules: 是用來增加 Ontology 之間所隱含的關係進而獲取更多資訊, 開發者將 SWRL 規則撰寫好後加入到 Service Match Maker 中,再透過 OWL API 與 Inference Engine 中的 Ontology 結合產生新的關係,增加所搜尋的服 務。 再撰寫規則時,因為 SWRL 是使用本體論中所定義的詞彙和屬性進
行規則的編寫,且 SWRL 本身也是以 OWL 語法所編寫,所以 XML 文件 的優點也會符合 SWRL[20]。
JWI: 主要是用來將使用者所輸入的 Query 做擴充,在 Query 變多的情況下 配對服務找尋更多相符的服務供使用者選擇,而在此方面是透過 JWI(Java WordNet Interface)中的 IIndexWord()方法,將所需的參數設定好後,讓使用 者所輸入的 Query 到 WordNet 中取得相關資料再進行擴充,這些擴充後的 Query 就是我們搜尋知識本體時的依據。我們使用 WordNet 是因為它是一 部訊息豐富的語意知識庫[4]且在結構上它將所有相同的語意集成 Synset, 並以 Synset 為基礎進一步連結語意之間的關係,如上義詞、下義詞、整體 關係、部分關係等等, 且目前也有支援中文[21]。
Ontology Manager: 主要功能是用來存取和利用 Inference Engine 中的本體 論,藉由 Ontology Manager 除了能存取 Ontology 外,也能建立 Ontology、 individuals 等,也可透過本地端得 owl 檔和網路上的 URL 取得多個本體論, 讓搜尋的服務增加,讓使用者可選擇的服務增加。
3.2 SWRL 規則
SWRL 是以本體為基礎,以語意的方式定義法則的一種語言,SWRL 規則概念 則是由 RuleML[20]所演變而來,在 RuleML 中以 head 表示推論結果,body 表 示推論前提的型態也保留在 SWRL 中,所以 SWRL 可視為法則和本體的結合,
透過兩者的組合在撰寫法則時,可直接使用本體中所描述的關係和字詞,下列 為我們所建立的 SWRL 規則,其規則定義關係如下:
Store (Mike’s store)
HasService (Mike’s store, Sellbike)
Store 為我們所建立的一個概念(Class) ,所以表示有間商店叫 Mike’s store,而 HasService 為我們所建立的一個屬性(Slot) ,而在這屬性中是屬於物件屬性 (Object property)代表這家店有甚麼服務,所以表示 Mike’s store 有提供出售腳踏 車的服務,將前提(Body)寫好後透過 SWRL 規則的推論我們就可以得到 Mike’s store 有提供出售腳踏車的服務這個結論(Head)。
Body
Store (Mike’s store)
HasService (Mike’s store, Sellbike) Head
HasServiceSellbike(Mike’s store)
編寫好 SWRL 規則後,將規則加入 Service Match Maker 中,再透過 OWL API 和 Pellet 推論引擎將 SWRL 規則與 Inference Engine 中的本體論結合,最後再以 擴充後的 Query 為搜尋依據到 Inference Engine 中取得 Ontology 資訊並進行服 務配對。在服務的配對中我們是以字串擷取的方式來進行,當 SWRL 與 Inference
Engine 中的本體論結合後,透過 OWL API 將存在 Inference Engine 中的本體取 出後,再利用字串擷取的方式將與 Query 相符的資訊挑選出來供使用者挑選完 成配對。而我們在添加 SWRL 規則前,會先釐清使用者的需求和本體之間的關 係再來做 SWRL 規則的撰寫和加入,主要是針對使用者的回饋或較常使用的本 體來進行本體之間的分析和撰寫規則的動作,撰寫好後再將其 SWRL 規則加入 至 Service Match Maker 中。由於我們搜尋的依據是基於 WordNet 的方法來對 Query 作擴充的,但在擴充上因為參數設定的關係可能會導致擴充出的資料有 些是不符合原本使用者所輸入的 Query 意思,所以針對這個問題,我們利用 SWRL 規則中的 Built-Ins 來解決,例如 swrlb:notEqual、sqwrl:difference 等方法。 舉例說明,在本文的例子中我們以 Bike 作為我們的 Query,利用我們所設定好 的參數透過 JWI 擴充後會得到 bicycle、cycle、pedal、wheel 這些詞,但是在 wheel 一詞中也同義於 Car,所以會導致搜尋時可能會搜尋到與 Query 不相關的 結果,而在這例子中我們就會使用 SWRL 規則中的 sqwrl:difference 方式來區分 Car 中的 wheel 和 Bike 中的 wheel,讓搜尋時能更準確的判斷找出合適的結果。 透過這些方法的加入,能有效地將非相關的詞做區分,達到提升查準度的效果。 目前在本研究中 SWRL 規則主要是針對每一個不同的 Query 搜尋結果逐件個別 處理的方式加入。
3.3 Query Extension Based on WordNet(QEW)
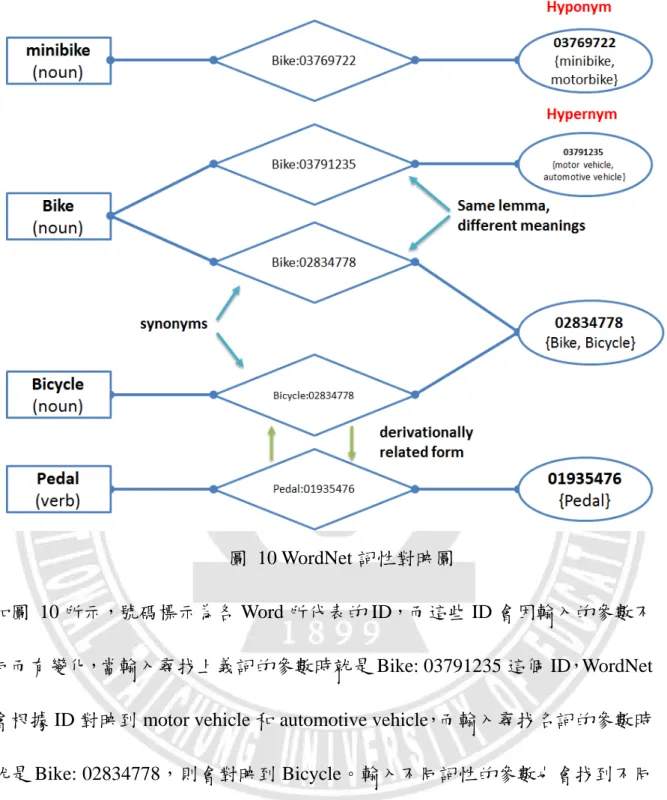
在 Query Extension Based on WordNet(QEW)方法中,我們主要是使用 WordNet 中的資料來做擴充的。WordNet 是一部訊息豐富的語意知識庫,其中收錄了為 數極多的詞彙,也包含很多功能,像是語句間相似度的計算等等,而在本研究 中主要是使用詞義的關係來做 Query 擴充,在詞性的部分主要分名詞、形容詞、 動詞、副詞、上義詞、下義詞等,在參數設定上我們也是以這六種詞類作為我 們對 Query 之擴充,其參數設定如圖 8 所示: 圖 8 詞性參數設定 圖 8 中分別為名詞、形容詞、動詞、副詞之參數設定,圖 9 為上、下義詞之參 數設定: 圖 9 上、下義詞參數設定 透過這些參數的設定,我們就可以得到相對應的詞。下面我們將以”Bike”作為 例子,圖 10 將簡單介紹 WordNet 是如何利用我們所輸入的參數對映到相關資 料。 20
圖 10 WordNet 詞性對映圖
如圖 10 所示,號碼標示為各 Word 所代表的 ID,而這些 ID 會因輸入的參數不 同而有變化,當輸入尋找上義詞的參數時就是 Bike: 03791235 這個 ID,WordNet 會根據 ID 對映到 motor vehicle 和 automotive vehicle,而輸入尋找名詞的參數時 就是 Bike: 02834778,則會對映到 Bicycle。輸入不同詞性的參數也會找到不同 的參數,如動詞就是 Pedal:01935476,會對映到 Pedal,依此類推。透過這樣的 方法我們就能利用 WordNet 取得所需的 Word 達到 Query 擴充的效果。在參數 設定的部分主要分名詞、形容詞、動詞、副詞、上義詞、下義詞等。
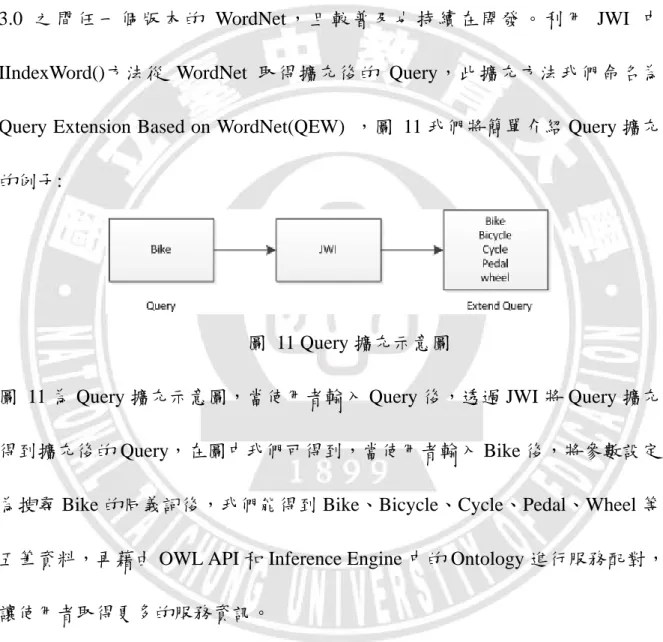
Query Extension Based on WordNet(QEW) 是將 Query 透過 JWI(Java WordNet Interface)做擴充,JWI(Java WordNet Interface)為 WordNet 其中一個 JAVA API, 我們會使用 JWI 的原因是因為它對 WordNet 的版本限制較小能支援訪問 1.6 到 3.0 之間任一個版 本的 WordNet ,且較普及也 持續在開 發。利用 JWI 中 IIndexWord()方法從 WordNet 取得擴充後的 Query,此擴充方法我們命名為 Query Extension Based on WordNet(QEW) ,圖 11 我們將簡單介紹 Query 擴充 的例子:
圖 11 Query 擴充示意圖
圖 11 為 Query 擴充示意圖,當使用者輸入 Query 後,透過 JWI 將 Query 擴充 得到擴充後的 Query,在圖中我們可得到,當使用者輸入 Bike 後,將參數設定 為搜尋 Bike 的同義詞後,我們能得到 Bike、Bicycle、Cycle、Pedal、Wheel 等 五筆資料,再藉由 OWL API 和 Inference Engine 中的 Ontology 進行服務配對, 讓使用者取得更多的服務資訊。
3.4 本體論
在本體論的部分,我們是使用 OWL API 來對 Inference Engine 中的 Ontology 做 存取和使用的動作,Inference Engine 我們是使用 Protégé 來做為建置本體論的
工具。先將我們需要的本體論加入,可加入本地端的 owl 檔也可以透過加入 URL 的方式取得網路上的本體論,而且也可同時加入多個本體論讓搜尋的服務增加。 在本體論建置中,我們是遵循 Natalya F. Noy 於 Ontology Development 101 中 所提出之本體開發步驟這個標準來建置的,其建置步驟為主要將本體論分為三 的層次 Top level、Middle level、Bottom level 建置。我們所建立的本體論其領 域為 Travel,主要以景點、服務的提供、美食為主,其中共包含 140 個 OWL Concepts、83 個 Object Properties 和 15 個 Datatype Properties。圖 12 為本研究 Protégé 示意圖。 圖 12 本研究 Protégé 示意圖
3.5 配對流程
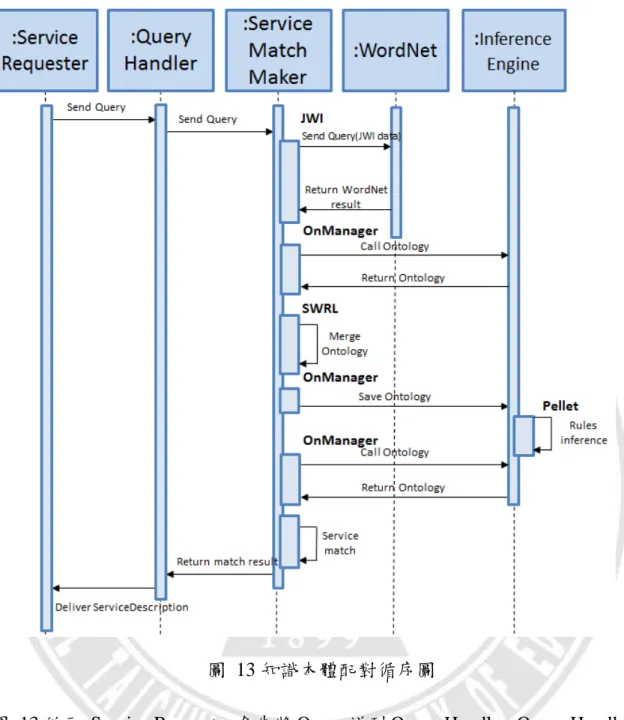
本節主要介紹從使用者發出 Query 後到配對服務成功的流程,再詳細說明每一 個元件之間的動作,下圖為知識本體配對的循序圖: 23圖 13 知識本體配對循序圖
如圖 13 所示,Service Requester 會先將 Query 送到 Query Handler,Query Handler 確認格式為完整的一個詞後,再將 Query 送到 Service Match Maker 中,當 Service Match Maker 中的 JWI 收到 Query 後,JWI 會將已收到的 Query 從 WordNet 中 取出與 Query 相關的詞,接著 Ontology Manager 會從 Inference Engine 中取出 Ontology 資訊,而事先撰寫好的 SWRL 規則會透過 OWL API 與 Inference Engine
中的 Ontology 做結合,再將結合後的 Ontology 存入 Inference Engine 利用 Pellet 做推論,此時 Service Match Maker 再利用 Ontology Manager 對 Ontology 進行 存取的動作,取得推論後的 Ontology 資訊,再以擴充後的 Query 為搜尋依據進 行配對,配對成功後,Service Match Maker 會將結果傳回給 Query Handler,Query Handler 在將服務的描述傳送到 Service Requester 做選擇服務的動作。
第四章 系統架構
4.1 系統架構
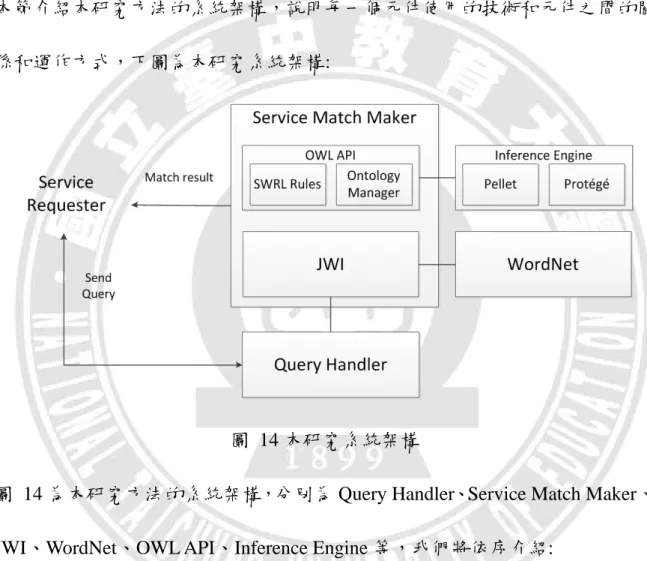
本節介紹本研究方法的系統架構,說明每一個元件使用的技術和元件之間的關 係和運作方式,下圖為本研究系統架構:
圖 14 本研究系統架構
圖 14 為本研究方法的系統架構,分別為 Query Handler、Service Match Maker、 JWI、WordNet、OWL API、Inference Engine 等,我們將依序介紹:
A. Query Handler
負責接收使用者所輸入的 Query,確認 Query 的格式是否為完整的一個詞,確 認無誤後,再將 Query 傳送到 JWI 進行 Query 擴充的步驟。
B. Service Match Maker
負責將已寫好的 SWRL 規則透過 OWL API 至 Inference Engine 結合本體論並利 用已擴充過的 Query 進行服務的配對,再將配對的結果呈現給使用者讓使用者 挑選合適的服務。OWL API 和 JWI 皆包含在 Service Match Maker 中。
C. JWI
JWI(the MIT Java WordNet Interface)為 MIT 提出,為一套可存取 WordNet,在 我們方法中,我們主要是利用它的擴充功能來使所輸入的 Query 能達到擴充的 效果。
D. WordNet
WordNet 主要是提供我們做擴充 Query 的資料庫,透過 JWI 到 WordNet 中獲取 我們所輸入 Query 的相關詞和上、下義詞,進而讓我們能使用擴充後的 Query 做配對服務用。
E. OWL API
OWL API 裡面主要包含 SWRL 規則和 Ontology Manager。SWRL 規則主要是 將本體論之間所隱含的訊息透過撰寫的規則呈現出來,加強服務的描述,讓使 用者能有更多的服務做選擇,挑選適合自己的服務。Ontology Manager 負責存 取 Inference Engine 中本體的資訊,也可建立本體等。
F. Inference Engine
Inference Engine 包括 Pellet 推論引擎和 Protégé。Pellet 推論引擎主要負責在 SWRL 規則撰寫的除錯和規則推論。Protégé 則為我們編輯和存取本體論的軟體, 所使用的版本為 4.3,且依照標準的建置本體論步驟建立出完整的 Domain
Ontology 並透過 Pellet 推論引擎結合 SWRL 規則增加本體論之間所隱含的訊息, 而我們所使用的 Domain Ontology 的領域為 Travel,其每一個 Ontology 都代表 著一個服務,且詳細的將服務資訊完整的描述。
4.2 實作範例
實作範例我們使用的本體論領域為 Travel,下面我們將分成兩個部分說明,一 為 Query Extension Based on WordNet(QEW)方法,另一部分為 QEW 再加上 SWRL 規則的方法。
4.2.1 Query Extension Based on WordNet(QEW)
在此章節會先介紹擴充功能的使用方法和所得到的執行結果,接著會再說明利 用這些所擴充出來的 Query 到 Inference Engine 中配對服務的方法和結果。
4.2.1.1 擴充功能
在一般關鍵字搜尋中就是以單一詞為主,在 QEW 的方法中是將使用者輸入的 Query 做擴充,透過參數的設定,擴充的部分包含此 Query 相關意思的詞,下 圖為 JWI 從 WordNet 中取得相關擴充資訊之程式碼:
圖 15 取得擴充資訊之程式碼
我們將參數設為尋找 Query 相關的詞,因為在 WordNet 中,” Bike”這詞沒有形 容詞和副詞,所以在我們的例子中,只會顯示名詞和動詞。下圖為搜尋結果畫 面:
圖 16 擴充之 Query
圖 16 中 Bike 為使用者所輸入之 Query,下面則為擴充後的結果,我們可得知 在擴充後的 Query 增加了四個關聯詞,再利用這些 Query 來搜尋服務,讓使用 者能以搜尋條件增加的前提下搜尋到更多相關或適合的服務。
4.2.1.2 QEW 搜尋結果
當取得擴充後的 Query 時,再以這些 Query 透過 Service Match Maker 到 Inference Engine 中進行服務的配對,配對結果如下圖:
圖 17 QEW 搜尋結果
透過 Service Match Maker 配對我們可從 Inference Engine 中匹配到符合這些 Query 的結果,在沒有擴充時搜尋,我們所得到的結果只有 Jason’s bike shop, 而擴充後我們所得到的結果除了原本的 Jason’s bike shop 之外還增加了 Joe’s bicycle store,所以透過這擴充的方法,讓使用者能不受單一關鍵字的限制,有 更多的服務選擇。 4.2.2 增加 SWRL 規則方法 在此章節,會先介紹我們所加入的 SWRL 規則如何撰寫並列出其例子和虛擬碼, 再加以說明解釋,在 4.2.2.2 的部分列出並說明所配對到的結果。 4.2.2.1 SWRL 規則加入 30
在加入 SWRL 規則方法中,我們會事先將 SWRL 規則寫好在 Service Match Maker 中,當 Service Match Maker 接收到擴充後的 Query 時,SWRL 規則會先 和 Inference Engine 中的本體結合來增加本體之間所隱含的訊息,接著再透過擴 充後的 Query 做服務的配對,這樣除了原有的擴充 Query 作為搜尋依據外,還 增加了先寫好的 SWRL 規則讓使用者獲取更多的服務和相關訊息,下列為我們 所增加的 SWRL 規則和虛擬碼:
Store (Mike’s store) ^ HasService (Mike’s store, sellbike) →HasServiceSellbike (Mike’s store)
上面為我們所要加入至 Inference Engine 中的 SWRL 規則,其所代表的意思是 有一間商店名稱為 Mike’s store,而這間 Mike’s store 他有 Sellbike 的服務,所以 我們可以得知 Mike’s store 這個商店他有提供 Sellbike 這樣的一個服務。
圖 18 SWRL 規則虛擬碼
圖 18 為 我 們 例 子 中 所 撰 寫 的 SWRL 規 則 和 虛 擬 碼 ,
Declaration(Class(:HasServiceSellbike)) 為 我 們 所 要 新 定 義 的 ObjectProperty , Body 的 部 分 為 我 們 的 推 論 前 提 也 就 是 ClassAtom(:Store :Mike’s store) 和 ObjectPropertyAtom( :hasService :Mike’s store :Sellbike),Head 的部分則為我們 所推論出來的結果也就是 ObjectPropertyAtom(:HasServiceSellbike :Mike’s store), 透過推論引擎 Pellet,我們可以利用已知的前提 Body 來推論出新的結論 Head。
4.2.2.2 加入 SWRL 規則搜尋結果
將原本的 QEW 方法和 SWRL 規則透過 Service Match Maker 結合後,再進行服 務的配對,結果如下圖:
圖 19 加入 SWRL 規則之搜尋結果
圖 19 為加入 SWRL 規則後之配對結果。SWRL 規則透過 Service Match Maker 與 Ontology 的結合,再利用 QEW 為搜尋依據做配對服務,除了原有的 Jason’s bike shop 和 Joe’s bicycle store 兩個結果外,我們還可以得到 Mike’s store,讓使 用者有更多的選擇,而在撰寫例子的部分,我們也會針對使用者的 FEEDBACK 或較熱門的例子優先增加或修改。
4.3 比較結果
透過上述結果我們可以得知,在以 Bike 為 Query 的情況下,只以一般關鍵字搜 尋的情況下我們只能得到一個結果 Jason’s bike shop,結果受限於 Bike 無法搜 尋到其他相關的服務,再來我們透過 Query Extension Based on WordNet (QEW) 方法來做測試,透過 Query 的擴充除了原本的 Query “Bike”之外還能得到 Bicycle、Cycle、Pedal、Wheel 等四個 Bike 的同義詞,透過這些擴充的 Query 進行配對,除了原本的 Jason’s bike shop 之外,我們還可得到 Joe’s bicycle store, 所以 QEW 的配對方式讓使用者在搜尋上不在受限於關鍵字而找不到其他相關 的服務。最後我們再將 SWRL 規則加入到 QEW 的方法中做結合,利用我們所 撰寫好的 SWRL 規則透過 OWL API 與 Inference Engine 中的 Ontology 做結合, 讓原本的 Ontology 增加新的關係或關聯的服務,再利用 QEW 搜尋服務,除了 原本的兩個結果外,我們還可以得到 Mike’s store,所以利用 QEW 和加入 SWRL 規則的方法,是能有效提升服務配對的查準度和查全率的。
第五章 案例研究
本章節中我們主要分成測試實驗和驗證實驗兩部分,在測試的部分我們使用 OWLS-TC4 中的 ONTOLOGY 集合為實驗樣本,裡面共包含 Communication、 Economy、 Education、Food、Geography、Medical、Simulation、Travel、Weapon 九個領域的服務,並有 48 個測試需求和各自的相關服務,我們將從這 48 個測 試需求中隨機提取數個領域來做測試,列出 QEW 方法和加入 SWRL 規則方法 的查準度已 TOP-N 的方式來呈現進行比較,因為 QEW 是基於 WordNet 的一種 服務配對方法,所以在比較對象中我們挑選 QEW 方法來跟加入 SWRL 方法進 行比較,其結果將呈現在 5.1 章節。在驗證部分是套用我們所建立的本體論來 做為搜尋的依據顯示出關鍵字搜尋方法和我們所提出的方法比較,我們使用查 準度(Precision ratio)和查全率(Recall ratio),這兩項是在評估檢索成效中較常使 用的兩項指標。公式如下:
Precision ratio =Relevant service
Return service (1)
Recall ratio = Relevant service
Total service (2)
(1)為查準度(Precision ratio)之公式,(2)為查全率(Recall ratio)之公式。最後使用 統計學中 Kruskal-Wallis (H)和 Wilcoxon Rank Sum Test 兩個方法來驗證其資料 間是否有顯著差異。
實驗環境部分我們使用 ECLIPSE 作為 IDE 並使用 OWL API 搭配 JWI(Java WordNet Interface)作為搜尋引擎,資料來源我們分成兩部分。在測試方面從 OWLS-TC4 中的九個領域 48 個測試服務中隨機挑選 5 個不同領域中的服務作 為我們的搜尋依據。在驗證部分是使用我們自己所建立的本體論,使用的領域 是 Travel 並包含 140 個 OWL Concepts、83 個 Object Properties 和 15 個 Datatype Properties,使用的軟體是 Protégé4.3 版本作為我們建立和存取本體論的工具。
5.1 測試實驗
在測試部分,我們是使用 OWLS-TC4 來作為我們的實驗樣本,我們隨機挑選五 個不同領域的結果並列出 QEW 和加入 SWRL 規則之查準度,結果如下: 圖 20 各領域之 TOP5 查準度 由圖 20 我們可知在加入了 SWRL 規則之後的查準度和 QEW 比較下略為提升, 而在加入 SWRL 規則前我們會先釐清本體論之間的關係,再進行規則的撰寫和Economy Education Medical Travel Weapon
QEW 83 90 85 92 87 SWRL 92 95 88 95 91 83 92 90 95 85 88 92 95 87 91
TOP-5
QEW SWRL 35加入,讓本體論之間的隱含關係能透過 SWRL 規則的加入而呈現出來,達到搜 尋時能增加相關服務的連結進而提升查準度的上升。
5.2 驗證實驗
在驗證部分中,我們利用我們自己所建立的 ONTOLOGY 來做為搜尋依據並和 一般關鍵字搜尋(KEYWORD BASED)的方法來比較,並且針對我們所提出的方 法比較有無 SWRL 規則的差異並提出相關的數據和說明,再對這些數據利用統 計學中 Kruskal-Wallis (H)和 Wilcoxon Rank Sum Test 兩個方法來驗證其可靠性, 我們利用這兩驗證方法的原因在於我們所提出的母群體不是常態分布的且我們 的樣本屬成對,所以使用 Kruskal-Wallis (H)和 Wilcoxon Rank Sum Test 這兩種 無母數分析方法較其他驗證方法準確。 5.2.1 方法比較 我們可以從這三種方法中,比較出在查準度和查全率方面的差異,在針對這些 差異來分析其結果。 5.2.1.1 關鍵字搜尋 在關鍵字搜尋的方法中,利用我們所自行建立的本體論資料庫來進行配對,並 取二十次的搜尋作為基準,其結果如圖 21。 36圖 21 關鍵字搜尋之查準率及查全率
在圖 21 中,我們可得知利用關鍵字搜尋的方法再查準率方面平均是 39.7%, 而在查全率方面是在 39.5%左右,在查準度或查全率上都偏低。
5.2.1.2 Query Extension Based on WordNet
在我們所提出的方法中同樣取二十次的搜尋作為基準,首先為 QEW 的數據, 結果如圖 22。 圖 22 QEW 之查準率及查全率 在圖 22 中,我們可得知在 QEW 的方法中查準率平均為 74.1%,而在查全率方 面則平均為 73.35%,相較於關鍵字的搜尋,在查準率和查全率上都提升不少。 0 50 100 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
KEYWORD
Precision ratio Recall ratio
0 20 40 60 80 100 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
QEW
Precision ratio Recall ratio
5.2.1.3 加入 SWRL 規則之方法 我們在 QEW 方法中在加入 SWRL 規則進行測試,結果如下圖: 圖 23 加入 SWRL 規則之查準率及查全率 由圖 23 中,我們可得知加入了 SWRL 規則後查準率平均為 79.35%,而查全率 平均為 77.5%,跟 QEW 規則比較查準率大約上升了 2%左右而查全率則上升 3% 左右,所以說明了再加入 SWRL 規則後其查準率和查全率是較優於 QEW 的。 綜合上述所提出的資料,我們整理出一張比較表,如圖 24 所示: 圖 24 三種方法之查準率及查全率比較 在圖 24 中,我們可得知在使用關鍵字搜尋方法中其查準率和查全率是遠低於 0 20 40 60 80 100 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
SWRL
Precision ratio Recall ratio
0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00%
Precision ratio Recall ratio
KEYWORD QEW SWRL
語意搜尋方法的,在 QEW 和加入 SWRL 規則方法中其查準率和查全率又略微 增加,由此可知再加入 SWRL 規則後是有助於增加搜尋的查準率和查全率的。
5.2.2 方法驗證
驗證方面我們利用圖 21、圖 22、圖 23 中的數據並分成查準度(Precision ratio) 和查全率(Recall ratio)兩個部份,每一部分都包含 Kruskal-Wallis (H) Test 和 Wilcoxon Rank Sum Test 兩個方法的驗證。 Kruskal-Wallis (H) Test 為三組資料 比對,KEYWORD、QEW 和 SWRL。Wilcoxon Rank Sum Test 為兩兩資料比對, 包括 KEYWORD 和 QEW,KEYWORD 和 SWRL,QEW 和 SWRL 三種組合, 詳細內容如下 5.2.2.1 查準度(Precision ratio) 甲、 Kruskal-Wallis (H) Test 在查準度(Precision ratio)部分,我們使用圖 21、圖 22、圖 23 中的樣本作為依 據,包含 KEYWORD、QEW 和 SWRL 三個方法各 20 個,結果如下: 39
(%) 表 1 K-W(H) TEST 排序(Precision ratio)
表 1PR 之 K-W(H) TEST 排序中我們依 Kruskal-Wallis (H) test 的方法做排序並
利用公式來進行計算,我們假設 H0 為三組資料間沒有顯著差異 H1為三組資料 間有顯著差異,並以顯著水準α=0.05 來檢定,其結果如下:
K – W =
12 𝑁(𝑁+1)∑
𝑇𝑗2 𝑛𝑗 𝑘𝑘 𝑗=1-3(
𝑁𝑁 +1) =
K – W =
12 60(60+1)(
211.52 20+
7242 20+
894.52 20)-3(60+1)
= 41.4325
K – W >
𝑋𝑋
𝑘𝑘−1,𝑎𝑎2= K – W >
𝑋𝑋
2,0.052=
41.4325>5.991 REJECT H0透過 Kruskal-Wallis (H) test 我們可 REJECT H0,證明在這三組資料中是有顯著
差異,而不是隨機造成的。
乙、 Wilcoxon Rank Sum Test
我們再使用 Wilcoxon Rank Sum Test 方法對其兩兩驗證,其結果如下: 表(2)(3)(4) Wilcoxon Rank Sum Test 排序(Precision ratio)
表 2 表 3 表 4 我們以顯著水準α=0.05 用 Wilcoxon 方法來檢定,得到結果為:
Z =
𝑆𝐵−𝑛1(𝑛1+𝑛2+1)/2 �𝑛1𝑛2(𝑛1+𝑛2+1)/12Z
0.05=1.645 表 2 部分 𝑆𝐵=608.5 n1=20 n2=20 Z=5.3694>1.645 REJECT H0 表 3 部分 𝑆𝐵=610 n1=20 n2=20 Z=5.41>1.645 REJECT H0 表 4 部分 𝑆𝐵=494.5 n1=20 n2=20 Z=2.2857>1.645 REJECT H0透過 Wilcoxon Rank Sum Test 我們可以得到三種的結果皆為 REJECT H0,代表
在這三組資料中是有顯著差異,而不是隨機造成的。
(%)
(%)
5.2.2.2 查全率(Recall ratio)
甲、 Kruskal-Wallis (H) Test
接著我們進行查全率(Recall ratio)驗證的部分,一樣是三個方法各取 20 個樣本 作為依據,結果如下表:
表 5 K-W(H) TEST 排序(Recall ratio)
表 5 中我們依 Kruskal-Wallis (H) test 的方法做排序並利用公式來進行計算,我
們假設 H0為三組資料間沒有顯著差異 H1為三組資料間有顯著差異,結果如下:
K – W >𝑋𝑋𝑘𝑘−1,𝑎𝑎2 = K – W >𝑋𝑋 2,0.052
=
40.8381>5.991 REJECT H0透過 Kruskal-Wallis (H) test 我們可 REJECT H0,證明在這三組資料中是有顯著
差異,而不是隨機造成的。
乙、 Wilcoxon Rank Sum Test
透過 Kruskal-Wallis (H) test 我們可 REJECT H0,我們再使用 Wilcoxon Rank Sum
Test 方法對其兩兩驗證,其結果如下:
表 (6)(7)(8) Wilcoxon Rank Sum Test 排序(Recall ratio)
表 6 表 7 表 8 我們以顯著水準α=0.05 用 Wilcoxon 方法來檢定,得到結果為: 表 6 部分 𝑆𝐵=610 n1=20 n2=20 Z=5.41>1.645 REJECT H0 表 7 部分 𝑆𝐵=610 n1=20 n2=20 Z=5.41>1.645 REJECT H0 表 8 部分 𝑆𝐵=477.5 n1=20 n2=20 Z=1.8258>1.645 REJECT H0
透過 Wilcoxon Rank Sum Test 我們一樣可得到 REJECT H0,代表在這三組資料
中是有顯著差異,而不是隨機造成的。
(%)
5.3 實驗討論
綜合以上資料和討論,我們可得知在 QEW 的情況下在查準度(Precision ratio) 和查全率(Recall ratio)上較沒這麼理想,但是加入 SWRL 規則後在查準度 (Precision ratio)和查全率(Recall ratio)上都有較優異的表現,而在驗證方面我們 也提出了兩個無母數的分析方法 Kruskal-Wallis (H)和 Wilcoxon Rank Sum Test 來驗證,從上述可得知透過這兩種驗證方法,可以看出無論從三組比較或者是 兩兩比較上都可得到他們之間的關係是有顯著差異的,而不是隨機造成的。
第六章 結論與未來工作
本研究提出一個基於知識本體的配對機制,利用 Query 擴充的方式,將使用者 所輸入的 Query 進行擴充,再加入 SWRL 規則與 Inference Engine 中的 Ontology 做結合產生新的關係,使服務的配對上不受限於單一的關鍵字做搜尋,實驗結 果和驗證也證明透過這樣的方法對於配對的查準度和查全率上是有幫助的。未 來工作方面我們會建立更完整的服務資訊,建立本體論對映關係,如服務的詳 細資訊、圖片等及使用者回饋機制,透過回饋機制來建立更完整服務和 SWRL 規則。而在本研究中 SWRL 規則主要是針對每一個不同的 Query 搜尋結果逐件 個別處理的方式加入,但往後當規則變多時我們會以領域和 Built-Ins 這兩項來 做分類,將 SWRL 規則做更有系統地彙整,進而從中獲取新的資訊。而目前研 發 Protégé 的 Stanford University 團隊也提出線上的本體論編輯系統 WebProtégé, 除了更簡單的編輯系統外還可將所建立好的本體論直接供其他人使用或與其他 開發者協作建立更完整的本體論,所以我們往後也將在 WebProtégé 中建立本體 論。
參考文獻
[1] M. van Steenderen, "Universal Description, Discovery and Integration," SA Journal of Information Management, vol. 2, 2000.
[2] T. Berners-Lee, J. Hendler, and O. Lassila, "The semantic web," Scientific american, vol. 284, pp. 28-37, 2001.
[3] J. Hjelm, Creating the semantic Web with RDF: professional developer's guide: John Wiley & Sons, Inc., 2001.
[4] K. Yeom, J. Park, and M. Moon, "Registry and Discovery of Services with Variability based on 2-level UDDI," in Parallel and Distributed Processing with Applications Workshops (ISPAW), 2011 Ninth IEEE International Symposium on, 2011, pp. 305-310.
[5] H. Mezni, W. Chainbi, and K. Ghedira, "An autonomic registry-based SOA model," in Service-Oriented Computing and Applications (SOCA), 2011 IEEE International Conference on, 2011, pp. 1-4.
[6] K. Tamilarasi and M. Ramakrishnan, "Design of an intelligent search engine-based uddi for web service discovery," in Recent Trends In Information Technology (ICRTIT), 2012 International Conference on, 2012, pp. 520-525.
[7] M. Liu, W. Shen, Q. Hao, J. Yan, and Q. Gao, "A multi-level matching framework for semantic web services in collaborative design," in Computer Supported Cooperative Work in Design, 2008. CSCWD 2008. 12th International Conference on, 2008, pp. 392-398.
[8] S. A. Ludwig, "Fuzzy match score of semantic service match," in Fuzzy Systems, 2008. FUZZ-IEEE 2008.(IEEE World Congress on Computational Intelligence). IEEE International Conference on, 2008, pp. 193-199.
[9] M. A. Kamalabad, F. Mardukhi, N. Nematbakhsh, and M. N. Dehkordi, "Evaluating the similarity of web service policies using flexible parameter matching," in Measurement, Information and Control (MIC), 2012 International Conference on, 2012, pp. 1000-1005.
[10] K. Kritikos and D. Plexousakis, "Semantic qos-based web service discovery algorithms," in Web Services, 2007. ECOWS'07. Fifth European Conference on, 2007, pp. 181-190.
[11] G. Guo, F. Yu, Z. Chen, and D. Xie, "A four-level matching model
for semantic web service selection based on qos ontology," in Information Science and Engineering (ISISE), 2010 International Symposium on, 2010, pp. 630-634.
[12] A. Zohali and D. K. Zamanifar, "Matching model for semantic web services discovery," Journal of Theoretical and Applied Information Technology, vol. 7, pp. 139-144, 2009.
[13] G. Wang, D. Xu, Y. Qi, and D. Hou, "A semantic match algorithm for web services based on improved semantic distance," in Next Generation Web Services Practices, 2008. NWESP'08. 4th International Conference on, 2008, pp. 101-106.
[14] H. Fan, Z. Wang, and W. Du, "SWRL rule based precondition and effects service matching," in Geoscience and Remote Sensing Symposium (IGARSS), 2012 IEEE International, 2012, pp. 495-498.
[15] G. A. Miller, "WordNet: a lexical database for English," Communications of the ACM, vol. 38, pp. 39-41, 1995.
[16] G. A. Miller, R. Beckwith, C. Fellbaum, D. Gross, and K. J. Miller, "Introduction to wordnet: An on-line lexical database*," International journal of lexicography, vol. 3, pp. 235-244, 1990.
[17] JWI , Java WordNet Interface. Available:
http://projects.csail.mit.edu/jwi/
[18] D. L. McGuinness and F. Van Harmelen, "OWL web ontology language overview," W3C recommendation, vol. 10, p. 2004, 2004.
[19] Protege. Available: http://protege.stanford.edu/
[20] I. Horrocks, P. F. Patel-Schneider, H. Boley, S. Tabet, B. Grosof, and M. Dean, "SWRL: A semantic web rule language combining OWL and RuleML," W3C Member submission, vol. 21, p. 79, 2004.
[21] Chinese WordNet. Available:
http://lope.linguistics.ntu.edu.tw/cwn/
![圖 2 語意網語言階層[18]](https://thumb-ap.123doks.com/thumbv2/9libinfo/7442072.109211/17.892.110.769.248.936/圖2語意網語言階層18.webp)

![圖 4 SWRL 呈現方式[Ian H, et al., 2004][20] 以 XML 方式呈現的好處有:](https://thumb-ap.123doks.com/thumbv2/9libinfo/7442072.109211/19.892.115.769.180.957/圖4SWRL呈現方式IanHetal242以XML方式呈現的好處有.webp)
![圖 5 SWRL 語言架構[Ian H, et al., 2004][20]](https://thumb-ap.123doks.com/thumbv2/9libinfo/7442072.109211/20.892.122.770.141.975/圖5SWRL語言架構IanHetal242.webp)