國 立 交 通 大 學
電機與控制工程學系
碩士論文
智慧型 DMA 應用於成本導向之語音處理器
晶片設計
A Cost-Effective Speech Processor Design and
Implementation Using Smart DMA
研究生:廖峻谷
指導教授:林進燈 教授
智慧型 DMA 應用於成本導向之語音處理器晶片設計
A Cost-Effective Speech Processor Design and
Implementation Using Smart DMA
研 究 生:廖峻谷
指導教授:林進燈 教授
Student: Chun-Ku Liao
Advisor: Chin-Teng Lin
國立交通大學
電機與控制工程學系
碩士論文
A Thesis
Submitted to Institute of Electrical and Control Engineering
College of Electrical Engineering and Computer Science
National Chiao Tung University
in partial Fulfillment of the Requirements
for the Degree of
Master
in
Electrical and Control Engineering
July 2006
Hsinchu, Taiwan, Republic of China
智慧型 DMA 應用於成本導向之語音處理器晶片設計
學生:廖峻谷
指導教授:林進燈 博士
國立交通大學電機與控制工程研究所
Chinese Abstract中文摘要
近年來嵌入式系統與消費性電子產品的迅速發展,造成產品週期愈來愈短, 而效能需求卻愈來愈高,如何兼顧成本及效能是個很重要的議題。目前定點數 16-bit DSP 的產值高達七成以上,低成本成為消費性電子產品很重要的一個關 鍵。這裡提供一個兼顧成本與效能的解決方案。本篇論文在以開發的智慧型 DMA 上(擁有乘加運算器的 DMA),改進定址模式與運算資料路徑,將它提昇為 DSP 運 算器,與已開發的通用嵌入式處理器整合成為 RISC/DSP 單核心處理器,並針對 特定的演算法,加入硬體加速器 IP,擴充處理器的應用範圍。此架構的優點在 於單核心處理器具有低成本的特性,相對於雙核心處理器而言系統複雜性低。為 了增強單核心處理器的運算效能,對於不同的演算法可搭配不同的硬體加速器, 本論文為了加速語音壓縮的演算法,特別針對向量量化的部份,設計一個能處理 多級編碼簿的向量量化單元,設計特色在於:(1)加入 M-L 搜尋法,增加量化的 精確度;(2)四級運算管線設計,提高計算吞吐量(throughput);(3)採用低成本 方式設計,運算元與智慧型 DMA 共用,且利用記憶體暫存量化資料,減少暫存器 的使用;(4)可由使用者參數設定量化環境,符合 IP 可重複使用的要求。本論文 提出ㄧ個兼顧成本與效能,語音運算導向的 RISC/DSP 單核心處理器。此晶片採 用 UMC 0.18μm 製程,晶片面積約 3.5x3.5 mm2 ,預估最大操作頻率在 100MHz。A Cost-Effective Speech Processor Design
and Implementation Using Smart DMA
Student: Chun-Ku Liao
Advisor: Chin-Teng Lin
Department of Electrical and Control Engineering
National Chiao-Tung University
Abstract
Recently the rapid growth of embedded system and consumer electronics has resulted in the decreasing product life cycle; the demand of efficiency, however, kept increasing. Therefore, how to balance the efforts spent between cost and efficiency became an urgent issue. In the present time, the 16-bit fixed-point DSP has achieved more than 70 percent of that of total DSP, hence low cost has turned into a key target of consumer electronics. This study presents a solution to look after both cost and efficiency. On the developed smart DMA(DMA with MAC), this thesis improves addressing mode and data path ,and promotes smart DMA to a DSP unit , then integrated it with developed general purpose embedded processor. This can achieve a unit-core processor with paralleled structure of RISC and DSP. In addition, this thesis presents hardware accelerator IP in accordance to a certain algorithm to expand the applied scope of the processor. The benefit of this structure is that unit-core processor possessed properties of low cost and one memory system with one set of developer, compared to dual-core one, the unit-core processor is less complicated in system. To improve the computing efficiency of unit-core processor, different algorithm can be collocated different hardware accelerator. Moreover, in
order to accelerate the algorithm of the speech compression, this thesis designed a unit of vector quantization which can process multistage codebook, specifically. The main features of this design are: (1)added M-L search methods to improve the accuracy of quantization; (2)Four-stage computing pipeline to raise throughput; (3)with the consideration of low cost, shared computing unit with smart DMA, and took advantage of memory to register quantification data to decrease the use of register; and (4)capability to set environment of quantification with parameters of user to conform to the demand of reusable of IP. In this thesis, we presented a speech RISC/DSP unit-core processor, which balanced the efforts spent between cost and efficiency. The chip has been integrated in the total area of 3.5×3.5mm2 by using UMC 0.18μm CMOS technology. The maximum clock frequency is 100MHz with a single 1.8V supply.
誌 謝
兩年的研究所生涯隨著論文的完成劃上了句號,這兩年間,要感謝許多人的 鼓勵和幫忙,使我獲得充實的專業能力並順利完成研究所的學業。 首先要感謝的是我的指導教授-林進燈老師。林老師是國內十分傑出的一位 教授,在不同領域內都有相當好的研究成果。感謝老師提供了很理想的研究環境 及正確的引導,使我在研究上非常順利。在老師悉心的指導下,讓我學習到解決 問題的能力及做研究應有的態度。 另外,最感謝資工系范倫達教授及鐘仁峰學長的教導,尤其是面臨畢業主題 方向模糊的壓力時,范教授在這上面給予我相當大的助力,而教授親切的態度及 學識的也讓我在討論論文時感到輕鬆而無壓力,獲益良多。此外在實驗室中,不 管大小疑難雜症,常常去請教仁峰學長,非常感謝學長不厭其煩地教導,使我增 進了對積體電路設計上的專業知識,開拓了我的視野。也感謝實驗室所有的夥 伴,得正學長、家昇、有德、庭緯、經翔、紹航、德瑋、智文、靜瑩、肇廷等, 感謝大家在研究上的互相扶持及鼓勵。 也感謝我的家人,父母廖見郎先生及洪玉蓉女士,你們的支持一直是我最溫 暖的後盾;哥哥姊姊峻毅、家沁謝謝你們包容我的煩躁,你們的鼓勵是我信心的 來源。 最後要感謝沛柔,陪伴我渡過這段辛苦的日子,這段時間有妳真的很重要, 謝謝!目 錄
中文摘要 ... iii
Abstract ... iv
誌謝 ... vi
目 錄 ... vii
圖 目 錄 ... x
表目錄 ... xii
第一章 緒論 ... 1
1.1 簡介 ... 1
1.2 論文架構 ... 7
第二章 智慧型 DMA 控制器介紹 ... 8
2.1 智慧型 DMA 傳輸模式 ... 8
2.2 智慧型 DMA 雙通道運算 ... 8
2.3 智慧型 DMA 控制器架構 ... 9
2.3.1 通道控制器(Channel Controller)...10 2.3.2 暫存器組(Register Bank)...11 2.3.3 優先權仲裁器(Prioritizing Arbiter)...13 2.3.4 中斷處理(Interrupt)...13 2.3.5 算數運算邏輯單元(ALU)...142.3.6 多級向量量化單元(Multi-stage Vector Quantization)..15
2.3.9 周邊匯流排(APB - Advanced Peripheral Bus)...19
2.4 智慧型 DMA 控制暫存器 ... 20
2.4.1 來源暫存器(Source Register)...20 2.4.2 目的暫存器(Destination Register)...21 2.4.3 控制暫存器(Control Register)...21 2.4.4 配置暫存器(Configuration Register)...22 2.4.5 狀態暫存器(Status Register)...23 2.4.6 輸出暫存器(Output Register)...24 2.4.6 功能暫存器(Function Register)...24 2.4.7 智慧型 DMA 使用流程...24第三章
智慧型 DMA 運算控制器設計 ... 26
3.1 多級向量量化器設計 ... 26
3.1.1 原理 ...26 3.1.2 設計架構...29 3.1.3 控制輸入暫存器...303.1.4 流程控制單元(Address Generator Unit)...31
3.1.5 運算管線設計(Pipeline design)...33 3.1.6 比較器(Comparator)...34 3.1.7 數值表單元(Write Table)...34 3.1.8 最佳路徑選擇單元(Select M_Paths)...37 3.1.9 運作流程...37
3.2 蝴蝶運算器單元設計 ... 38
3.2.1 蝴蝶運算理論...38 3.2.2 架構 ...39 3.2.3 程式流程設定 ...41第四章 智慧型 DMA 控制器與 RISC 處理器的整合... 43
4.1 RISC 處理器 ... 43
4.1.1 RISC 處理器核心 ...43 4.1.2 RISC 處理器指令集 ...454.2 軟體開發環境 ... 48
4.3 整合 ... 50
第五章 驗證結果與晶片實現 ... 53
5.1 設計驗證與應用結果 ... 53
5.1.1 MELP 語音壓縮介紹 ...53 5.1.2 MELP 語音壓縮演算法複雜性分析 ...54 5.1.3 搜尋音高(Pitch Search)驗證...56 5.1.4 量化線性預估係數(LPC)驗證...59 5.1.4 快速傅立葉轉換(FFT)驗證...61 5.1.5 結論...635.2 晶片製作 ... 65
5.2.1 設計流程...65 5.2.2 合成結果...66 5.2.3 佈局與封裝...665.3 效能比較 ... 68
5.3.1 資料傳輸效能...70 5.3.2 資料運算效能...71 5.3.3 其他處理器比較...72第六章 結論 ... 75
參考文獻 ... 77
圖 目 錄
圖 1-1:RISC 與 DSP 規劃圖 ...2 圖 2-1:雙通道運算情形...9 圖 2-2:智慧型 DMA 的架構 ...10 圖 2-3:通道控制器架構圖...11 圖 2-4(a):智慧型 DMA 暫存器組的讀取時序圖...11 圖 2-4(b):智慧型 DMA 暫存器組的存取時序圖...11 圖 2-5:暫存器組示意圖...12 圖 2-6:優先權仲裁器(Prioritizing Arbiter)控制兩組匯流排...13 圖 2-7:中斷控制器連接狀態暫存器...14 圖 2-8:乘法器的使用情形...15 圖 2-9:ALU 單元 ...15 圖 2-10:運算管線與 ALU 使用情形...16 圖 2-11:蝴蝶運算單元與周邊的溝通...17 圖 2-12:透過記憶體選擇器的資料傳輸...18 圖 2-13(a):記憶體讀取時序圖...18 圖 2-13(b):記憶體存取時序圖...18 圖 2-14:APB 匯流排受控端介面 ...19 圖 2-15(a):APB 匯流排寫入時序圖 ...20 圖 2-15(b):APB 匯流排讀取時序圖 ...20 圖 2-16:智慧型 DMA 的使用流程...25 圖 3-1:三級向量量化器[18]...27 圖 3-2:三級向量量化器利用 M-L 法搜尋編碼簿(這裡 M=4) ...27 圖 3-3:多級量量量化使用 M-L 搜尋流程圖...28 圖 3-4:多級向量量化器架構圖...29 圖 3-5:多級向量量化器流程圖...30 圖 3-6:流程控制單元狀態圖...31 圖 3-7:運算管線時間圖...33 圖 3-8:數值表單元狀態圖...35 圖 3-9:數值表單元記錄下ㄧ級的輸入圖...36 圖 3-10:數值表單元輸出圖...37 圖 3-11:多級向量量化器與周邊運作流程圖...38 圖 3-12:8 點 FFT 圖 ...39 圖 3-13:蝴蝶運算圖...39 圖 3-14:多級向量量化器架構圖...40圖 3-15:蝴蝶運算單元架構...41 圖 3-16:FFT 運算分工情形 ...42 圖 3-17:利用 SDMA 計算 FFT 運算...42 圖 4-1:組譯器(Assembler)的用途...49 圖 4-2:圖形化介面組譯器(Assembler)...50 圖 4-3:RISC 處理器與智慧型 DMA 的整合 ...51 圖 4-4:RISC 處理器存取智慧型 DMA 暫存器-記憶體對映 ...52 圖 5-1:語音壓縮演算法特性比較[29]...54 圖 5-2:MELP 編碼解碼比例 ...54 圖 5-3:MELP 編碼各單元複雜度 ...55 圖 5-4:Quantization 內各單元運算複雜度 ...55 圖 5-5:處理器與智慧型 DMA 處理 Pitch 的分工情形...57
圖 5-6:Pitch Search C 程式與 Post-sim 結果 I...58
圖 5-7:Pitch Search C 程式與 Post-sim 結果 II...58
圖 5-8:多級向量量化 C 程式執行結果...60 圖 5-9:多級向量量化 Post-sim 結果...60 圖 5-10:512-FFT 各點數值表較 ...62 圖 5-11:晶片設計流程...65 圖 5-12:佈局及腳位圖...67 圖 5-13:208 CQFP 打線圖 ...67
表目錄
表 1-1:向量量化架構比較表...5 表 1-2:向量量化參數表...7 表 2-1:數位訊號處理運算的定址法表...9 表 2-2:來源暫存器(Source Register)...20 表 2-3:目的暫存器(Destination Register)...21 表 2-4:控制暫存器(Control Register)...22 表 2-5:配置暫存器(Configuration Register)...23 表 2-6:狀態暫存器(Status Register)...23 表 2-7:輸出暫存器(Output Register)...24 表 2-8:功能暫存器(Function Register)...24 表 3-1:控制輸入暫存器...31 表 3-2:控制輸入暫存器...32 表 3-3:控制輸入暫存器...32 表 3-4:架構修改前後誤差表...34 表 3-5:數值表單元狀態工作內容...35 表 3-6:控制輸入暫存器...36 表 4-1:資料搬移指令列表...45 表 4-2:算數邏輯運算指令列表...46 表 4-3:跳躍指令列表...47 表 4-4:其他指令列表...47 表 4-5:智慧型 DMAC 控制指令列表...48 表 5-1:Pitch Search 效能表 ...59 表 5-2:多級向量量化效能表...61 表 5-3:M Paths 量化路經結果表 ...61 表 5-4:512-FFT 含位元反轉效能表 ...63 表 5-5:智慧型 DMA 化簡複雜度表...64 表 5-6:合成後的資訊...66 表 5-7:晶片設計規格...68 表 5-8:與市面上 DMAC 做比較...69 表 5-9:資料傳輸效能表...70 表 5-10:位元反轉資料傳輸效能表...71 表 5-11:資料運算效能表...71 表 5-12:FFT 效能比較表 ...72 表 5-13:多級向量量化效能比較表...72表 5-14:多級向量量化效能比較表[33]...73 表 5-15:與 TI 的規格比較表...74 表 5-16:效能與成本比較表...74
第一章 緒論
1.1 簡介
近年來嵌入式系統與消費性電子產品的迅速發展,造成產品週期愈來愈短, 而效能需求卻愈來愈高,如何兼顧成本及效能是個很重要的議題。目前定點數 16-bit DSP 的產值高達七成以上,低成本成為消費性電子產品很重要的一個關 鍵。傳統上演算法的處理都是在雙核心系統上進行的,系統中的通用處理器用於 控制和管理功能,DSP 核心用於語音編解碼和高品質的演算法處理。雙核心處理 器如 OMAP 將 RISC 處理器與 DSP 數位訊號處理器整合在一顆晶片中,透過高效率 的分工合作,達成系統晶片的效能需求。這種架構常見於需要大量迴圈、向量運 算等應用中。將這類的運算交由 DSP 處理,可以發展較佳之平行化與最佳化演算 法,來提高整體效能。 在單一處理器上結合控制和訊號處理功能的單核心架構,相較於傳統雙核心 系統可以降低功耗和成本。如圖 1-1 所示,使用一個處理器可以簡化設計、減少 整合問題、縮短開發時間並降低風險,同時還能減少晶片週邊的數據傳輸。反之, 將 DSP 獨立出來的雙核心架構將涉及多個記憶體系統管理,以及 DSP 和處理器 核心之間的封包交換,且佔用的每個時脈週期都要消耗功率。而單核心處理器意 味著只有一個記憶體系統。使用開發環境時,若能只處理單一個工具鏈(tool chains)工具和工時方面以減少設計費用。此外,採用一個核心而不是兩個核心可 以減少核心和記憶體系統的晶片面積,因而降低晶片的成本,單核額外的成本來 自於硬體加速器或特殊功能的 IP,比起雙核心仍要少的多。本論文將採用單核 心的方式進行處理器設計來簡化系統,針對語音處理器需要的低成本要求。圖 1-1:RISC 與 DSP 規劃圖 精簡指令集處理器(RISC)架構特色在於區別存取指令和計算的指令,並擁有 多級管線架構,以一個時脈週期為單位執行指令,達到高時脈的處理速度。以運 算為導向的數位訊處理器(DSP)則不同於 RISC 的架構,指令集以記憶體相關與運 算效率為導向,例如濾波器的運算與快速複立葉轉換演算法。此外還擁有自己的 暫存器組,位址單元與運算器,數位訊號處理器有相當多特別的架構及定址法 [1],如環狀定址(Circular Addressing)、位元反轉定址模式(Bit-reversed Addressing)、零負擔(Zero overhead)迴圈、單一指令週期乘加運算等,並與 RISC 間有少量的暫存器共用。
為了支援日新月異的多媒體技術,如使用 VOIP 和 WiFi 技術的手機,商業應 用總量在 2009 年將達到 1.41 億部,許多設計公司爭相推出或研究新的解決方案 以滿足這種即將到來的市場需求。為了降低數位訊號處理器開發成本和複雜度 [2],因此,本論文在發展出的智慧型 DMA 控制器(Smart DMA Controller), 加入數位訊號處理的運算器,利用 DMA 有控管大量資料的特性,結合 DMA 資料傳 輸與數位訊號處理能力,可幫助處理器進行運算前資料排序[3]和記憶體相關的 RISC 控制 管理 DSP 演 算 法 處理 RISC/ DSP 控制管理 演算法 傳統雙核心劃分 雙核心,兩個記憶體系統 兩套工具鏈,高成本、高功耗 減少晶片成本 簡化開發工具 整合 RISC 與 DSP
定址模式,設定傳輸資料數,可以模擬 DSP 對固定 LOOP 的處理,節省處理器跳 躍指令的個數,減少因跳躍指令所帶來的負擔(penalty)。在 DSP 指令解碼方面, 使用 DMA 的控制介面來設定運算器的運作方式,仍屬於 RISC 架構的指令方式, 並不增加指令集複雜度。處理器與智慧型 DMA 的結合,為一個單核 RISC/DSP 架 構數位訊號處理器[2]。 ㄧ般數位訊號處理器(General Purpose DSP)在面對特定且複雜演算法時, 須對大量數據進行處理與計算,例如 3D 聲音處理和影像、語音的辨識等多媒體 演算法,但高階的 DSP 成本過高,其成效不如專業的特定用途 IC(Application -Specific IC;ASIC),因此需要特定的輔助運算器或硬體加速器[5][6],以提 高處理器的層級。利用矽智產觀念來輔助設計,矽智產的重複使用可有效降低設 計單晶片系統的複雜度,縮短晶片設計時程,提昇晶片設計的成功率。在智慧型 DMA 中,設計了ㄧ個能處理多級編碼簿的向量量化器,設計上符合 IP 的重覆使 用性與低成本目標[7],以解決處理器處理編碼簿時,需反覆且規律存取記憶體 所帶來的負擔。處理器在加上硬體加速器後,成為能快速處理特定演算法的高效 能處理器,兼顧成本與效能。 向量量化(Vector Quantization, VQ)的應用,隨著網際網路的蓬勃發展及 電腦相關科技的進步,已被廣泛地應用在語音及影像的編碼系統中,包含各種影 像、聲音、圖片等多媒體產品[8]。多媒體資料量龐大,資料壓縮愈突顯重要且 無法避免。向量量化技術在語音壓縮方面:網路電話VoIP的通訊協定G.723.1, 已實現為產業界產品,而美國國防部發展的保密通訊協定MELP[9]與MELPe[10], 分別有2.4Kbps與1.2Kbps的高壓縮率。在影像壓縮方面:已運用在多媒體系統、 高畫質電視、電傳系統(Teleconferencing Systems) 、影像資料庫管理(Image Database Management)、影像壓縮(Image Compression)、影像辨識(Identify) 等。
向量量化需從編碼簿中,比對每一個碼向量與輸入的向量,找出最接近輸入 向量的碼向量,然後將此碼向量的相對應編碼簿的索引值輸出,達到壓縮的目
的,而解碼端只要依據索引值去編碼簿找出相對應的碼向量,即能還原訊號,為 失真的壓縮方式(Lossy Compression)。此種逐一比較的方式 稱完全搜尋(Full Search)法,此法雖然簡單,且相較於其他的搜索法精確度最高,但是卻也是最 耗時、運算需求量最大的方法。近年來已有許多文獻提出不同的方式來加速碼簿 的搜尋,但缺乏經濟及有效率的使用實現在硬體電路。回顧硬體設計關於向量量 化的文獻,最早由Allen Gersho [11]提出7級管線的向量量化處理器架構,只能 處理完全搜尋,而Wang[12]利用心臟收縮電路(systolic architecture),用陣 列式的運算單元一起運算,達到高平行度與高吞吐量(throughput)的目的,但這 個方法卻也受到面積與精確度的限制,當編碼簿越大,需要的運算陣列也越大, 而陣列中每個運算單元受限於硬體複雜度,選用最小絕對值誤差(Mean Absolute Error)當失真誤差的量測,精確度不如最小均方誤差(Mean Square Error)。 Lee[13]利用有限狀態實現向量量化(Finite State VQ)的硬體,並用多條計算路 徑(Multipath)增加量化的精確度,但面積相當大。Zunino [14]利用階層式的搜 尋增進搜尋速度,在硬體設計上用4個最小絕對值誤差單元。 綜觀以上的向量量 化架構與收尋法,硬體複雜度相當高,並且當量化條件不同時,架構也勢必做調 整,並不符合IP的特性與要求。 這裡提出一個向量量化的架構,能進行完全搜尋或搜尋多級編碼簿的能力, 多級編碼簿的優點在於化簡編碼簿的大小;在失真量測方面,可以處理加權最小 均方誤差(Weighted Mean Square Error),並利用M-L搜尋法[15],加強多級向 量量化的精確度。此外,為了達到IP的使用性,可由使用者自行設定量化個數 (Order)、編碼簿級數(Stage)、編碼簿各級碼向量數(Level)與M-L搜尋路徑數(M Paths),以上參數的調整能使本論文的向量量化器應付各種量化的要求。最後為 了增加硬體運算吞吐量(throughput),設計四級的運算管線,相較於其他文獻的 設計方式,如表1-1。
表 1-1:向量量化架構比較表 Method C.L. Wang [12] C.Y. Lee [13] Zunino [14] Proposed
Architecture Systolic Parallel HW compute Parallel HW compute 4-Pipeline Design Distance Measure
MAE MSE MAE WMSE
VQ Type Full Search FiniteState VQ with MultiPath Search Hierarchical VQ MultiStage VQ with M-L Search Hardware Throughput 16 pixel/cycle 1 pixel/cycle 4 pixel/cycle 1 sample/cycle Gate count 300K (N=256,K=16) (256 MAE) 420K 42K (4 MAE unit) 26K 综合以上,智慧型 DMA 的主要設計特點如下: 1. 應用上支援廣泛的 I/O 系統,並有效率地處理資料流: 多媒體訊號處理需要有大量的資料流做為輸入輸出,因此必須設計一個 DMA 模組,支援匯流排結構,並對 I/O 進行大量資料移動、緩衝及控管的工作。對於 一些特殊應用,如影像語音壓縮(Image/Speech Compression),空間迴響器 (Reverberator)等演算法,需要大量的記憶體空間存放編碼簿或暫存濾波器的資 料,所以智慧型 DMA 也支援外部記憶體的連接。另外提供了五種定址模式,加快 傳輸的速率: z 遞增/遞減定址法(Increasing/Decreasing Addressing)
z 環狀定址法(Circular Addressing) z 鏡射定址法(Mirror Addressing) z 索引定址法(Index-based Addressing) z 位元反轉法 (Bit-Reverse Addressing) 2. 內建 ALU 單元,達到數位訊號處理器的效能: 加入 ALU 單元,配合各種定址法與資料路徑,效能可達數位訊號處理器 (DSP)。智慧型 ALU 運算單元與處理器的 ALU 做區隔,集中在需要多個指令週 期的運算,能與處理器平行運作。ALU 內部有多級除法器(DIV),乘加器 (MAC),柱狀位移器(Barrel Shift),輔助處理器運算特殊的指令。運算元搭 配各種定址法與資料路徑可進行各種數位訊號常見的運算[16]:
z DCT:Mirror + Index-based + Increasing Addressing + MAC z FIR:Increasing + Decreasing Addressing + MAC
z FFT:Bit-Reverse Addressing + Butterfly datapath + Shifter 3. 向量量化 IP,擴充處理器的應用範圍: 智慧型 DMA 加入向量量化 IP,使的處理器處理的範圍可延伸到各種影像 與語音方面的應用,提高處理器的層級。向量量化 IP 用有 IP 可攜性與重覆 使用性,可由使用者設定各種量化狀況,支援的向量量化參數如表 1-2。而 與其他文獻設計[12][13][14]比起來成本相當低廉。另外使用多條路徑,在 精確度上可以增進 2dB(SNR 比)。
表 1-2:向量量化參數表 Max. Support Distance Measure Weighted Mean-Square-Error Order 10 Stage 4
Level 256 (Every stage) CodeBook Size 1024 Codewords M Paths 8
1.2 論文架構
本篇論文中,第二章介紹智慧型 DMA 控制器的介紹,從硬體架構設計到 如何使用有詳細的說明。第三章說明智慧型 DMA 控制器的特殊運算設計,包 括加速 IP 的設計。第四章說明 VLIW 處理器的整合方式,及相關軟體發展及 如何應用。第五章詳述語音應用分析,包含模擬驗證方法及結果,晶片製作, 及測試效能的比較。最後,在第六章做總論。第二章 智慧型 DMA 控制器介紹
在智慧型 DMA 中有兩種特性,分別為負責傳輸記憶體與周邊資料的 DMA,另 一個為負責算術運算的數位訊號運算器。在傳輸方面,有連續資料傳輸及透過 LLI(Linked List Item)不連續資料傳輸,並且支援四種傳輸模式搭配匯流排 結構,可進行記憶體到記憶體、記憶體到周邊、周邊到記憶體、周邊到周邊的溝 通。在運算方面,提供柱狀位移(Barrel shift)、乘累加、除法等資料運算路徑, 可與處理器的 ALU 平行運算,為一個數位訊號處理器(DSP unit)。DSP 的輸入資 料由處理器設定兩個 32-bit 內部暫存器,當運算完會將結果存在通用暫存器 中,由智慧型 DMA 發出中斷給處理器取得。 智慧型的 DMA 的傳輸特性和運算特性可以結合,(1)利用智慧型 DMA 傳輸資 料的定址法,與 ALU 的乘加器合作,可進行雙通道資料記憶體向量運算,實現濾 波器的運算;(2)利智慧型 DMA 的位元反轉傳輸模式,在進行快速複立葉轉換前 先安排係數,再經由智慧型 DMA 裡 ALU 的資料路徑作蝴蝶運算;(3)進行編碼簿 搜尋時,利用智慧型 DMA 對外部記憶體周邊的溝通能力,協助向量量化加速器傳 輸編碼簿做計算。 本章介紹智慧型 DMA 控制器傳輸模式,運算模式及各單元的架構。
2.1 智慧型 DMA 傳輸模式
與ㄧ般的 DMA 相同,智慧型 DMA 支援四種傳輸模式:記憶體到記憶體、記憶 體到周邊、周邊到記憶體、周邊到周邊。2.2 智慧型 DMA 雙通道運算
智慧型 DMA 支援四種定址模式包含遞增/遞減定址法、環狀定址法、鏡射定處理的運算。如圖 2-1 所示,設定通道控制器的傳輸模式與定址法,智慧型 DMA 便能同步從兩顆內建的記憶體讀取資料,讀入乘加器做運算。 圖 2-1:雙通道運算情形 底下介紹雙通道運算如何實現各種數位訊號處理,如表 2-1 所示 表 2-1:數位訊號處理運算的定址法表 運算 使用的定址法
DCT Mirror + Index-based + Increasing Addressing DWT Increasing + Decreasing Addressing
FIR Increasing + Decreasing Addressing
2.3 智慧型 DMA 控制器架構
智慧型 DMA 整體架構如圖 2-2,包含通道控制器、優先權仲裁器、暫存器組、 算術運算邏輯單元、中斷控制器及記憶體介面與多工器等,其說明如下:Channel Controller 0
╳
A C CChannel Controller 1
MAC
Channel Controller
Data
Bus
Data
Bus
圖 2-2:智慧型 DMA 的架構
2.3.1 通道控制器(Channel Controller)
通道控制器為 DMA 裡的主要部份,所有工作皆由通道控制器來控制。智慧型 DMA 內建兩組相同的通道控制器,只要匯流排不衝突,所有通道可同時運作;反 之,由匯流排仲裁器來決定優先權。若有需要,可增加多組的通道控制器,以提 高效率。通道控制器架構如圖 2-3 所示,由一組讀取控制器、寫出控制器和緩衝 器(FIFO)所組成,讀寫控制器採用有限狀態機(Finite State Machine, FSM) 實現,判斷緩衝器內是否已滿或有資料,來進行讀取或寫入的動作。 Source Register bank Destination Control Configuration ch1 ch0 Interrupt request MAC DIV Barrel Shift Memory interface Source Destination Configuration FIFO Channel controller FIFO1 Channel controller Prioritizing Arbiter APB Bus External RAM Butterfly Unit Muti-Stage VQ IPDSP feature DMA feature
Control
IPRegIn DSPRegIn DSPRegOut
圖 2-3:通道控制器架構圖
2.3.2 暫存器組(Register Bank)
智慧型 DMA 內部擁有十二組 32-bit 的暫存器組,而外界對智慧型 DMA 視為 一組 16x16 的記憶體。外界對內部存取的方式與記憶體相同,可採用記憶體映射 (Memory-maping)的方式整合。詳細每個暫存器的用法,會在下一節說明。
智慧型 DMA 暫存器組的讀取/寫入時序如圖 2-4(a)(b),所有的讀/寫動作由 時脈正緣觸發,配合 CEN 訊號(Low-active),當 WEN=1 時由給定的位址取出暫 存器的值;當 WEN=0 時,由暫存器輸入值寫入指定暫存器內。 圖 2-4(a):智慧型 DMA 暫存器組的讀取時序圖 Write Controller
FIFO
Read ControllerChannel Controller
Register Bank
APB Bus Data Bus APB Bus Data Bus CLK CEN WEN RegOut addr 1 2 1 2 t CLK CEN WEN RegOut addr 1 2 1 2 t ADDR圖 2-4(b):智慧型 DMA 暫存器組的寫入時序圖 暫存器組的周邊連接如圖 2-5 所示,左邊與處理器連接,此暫存器組被視為 處理器中記憶體的一部分,右邊連接通道控制器、算數運算邏輯單元與各個 IP 單元。 圖 2-5:暫存器組示意圖 Channel Controller 0 ALU Processor Channel Controller 1
Register
Source Source DSPRegOut Destination Destination Configuration Configuration Control Control Status DSPRegIn IpRegIn IPs CLK CEN WEN RegIn addr 1 2 1 2 CLK CEN WEN RegIn addr 1 2 1 2 ADDR2.3.3 優先權仲裁器(Prioritizing Arbiter)
由於通道控制器共用兩種匯流排(Data Bus and Peripheral Bus),若同時 使用匯流排會造成衝突的情況,因此,優先權仲裁器協調衝突的情況,決定優先 的順序。如圖 2-6 所示,兩組通道控制器 Channel Controller 0、Channel Controller 1,以 Channel Controller 0 的優先權較高。因此,當同時取用相 同匯流排的資料時,仲裁器會將優先權低的 Channel Controller 1 先暫停,待 優先權較高的通道控制器工作結束後,再將匯流排控制權交還給 Channel Controller 1。 圖 2-6:優先權仲裁器(Prioritizing Arbiter)控制兩組匯流排
2.3.4 中斷處理(Interrupt)
在暫存器組中的配置暫存器(Configuration Register),可設定中斷致能 (Interrupt Enable)。當中斷致能設定後,若通道控制器或算數運算單元工作 處理完畢,將立即發出中斷請求給處理器,並關閉通道處理器,中斷訊號為 Low-Active,並持續維持二個時脈周期。通道控制器和算術運算單元連接中斷控 制器,當寫出資料已結束,中斷控制器發出中斷要求,並寫入狀態暫存器中,如 圖 2-7 所示。Channel Controller 0
Channel Controller 1
Prioritizing Arbiter
Peripheral Bus Peripheral Bus Data Bus Data Bus圖 2-7:中斷控制器連接狀態暫存器
2.3.5 算數運算邏輯單元(ALU)
為了達到具有 DSP 的運算能力,在智慧型 DMA 內建算數運算邏輯單元(ALU)。 它與處理器 ALU 的區別是智慧型 DMA 裡的算數運算邏輯單元為幫助處理器計算多 個指令週期的運算,與和記憶體直接存取有關的指令。ALU 包含了四級除法器 (4-stage DIV) 、 柱 形 移 位 器 (Barrel Shifter) 及 乘 加 器 與 乘 法 器 (MAC and Multiplier)的設計。下面介紹 ALU 裡各個運算單元,與在運算中所扮演的角色。 ALU 擁有兩顆乘法器,與ㄧ個累加器。兩顆乘法器可以針對演算法應用,設 計相對應的資料路徑,有效率的處理各種特殊運算。如圖 2-8 所示,加權最小均 方誤、與蝴蝶運算裡的複數乘法、及 32-bit 乘法都是需要多個乘法的運算,使 用兩個乘法器可以縮短運算時間。 Channel Controller 0 Channel Controller 1 Interrupt Controller Interrupt Controller Status Register Interrupt0 Interrupt1
ALU: DIV Shifter Mul IPs: Butterfly MSVQ
圖 2-8:乘法器的使用情形 另ㄧ種運算模式為乘加器的使用,配合前面提到的定址法說明,可處理大量 繁複的數位訊號處理。乘法器為 16×16 bits 的有號數(Signed)快速乘法器, 輸出為 32-bit 的有號數。累加器寬度為 40-bit,以確保在加法過程中不會因溢 位導致結果錯誤。若溢位發生,錯誤會顯示在狀態暫存器內,並發出中斷通知處 理器。圖 2-9 表示 ALU 裡各個運算單元。 圖 2-9:ALU 單元
2.3.6 多級向量量化單元(Multi-stage Vector Quantization)
智慧型 DMA 配合內建的 ALU,設計了兩種種資料路徑:分別為多級向量量化 路徑與蝴蝶運算路徑。多級向量量化單元(Multi-stage Vector Quantization) 可以針對各種影像與語音壓縮編碼進行處理,並可由使用者設定參數,適合各種 Barrel SHIFTER 4-STAGE DIV MAC Multiplier ALUDMA ALU
WMSE Path Butterfly Path 32-bit Multiplier Complex Multiplier量化要求的向量量化編碼。
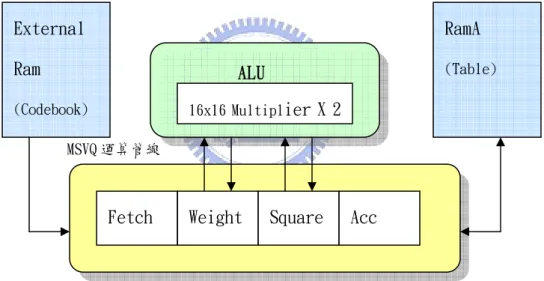
多級向量量化單元的核心為一個四級的運算管線,實現權重失真量測 (Weighted Distortion Measure)的運算,運算中使用到 ALU 裡的兩顆 16×16 bits 的有號數(Signed)快速乘法器,實現乘上權重(Weight)與平方(Square)的運算, 最後由一 40-bit 的累加器,計算失真結果。單元內的其他功能方塊為暫存器組 (Register Bank)、比較器(Comparator)、數值表單元(Write Table)、最佳 M_Path 輸出單元(Select M_Path),與流程控制單元(Address Generator Unit)。流程 控制單元與數值表單元分別與外部記憶體(編碼簿)以及內部記憶體(數值表)作 溝通。當運算結束後發中斷給處理器取值。圖 2-10 為多級向量量化運算管線與 ALU 使用情形。
圖 2-10:運算管線與 ALU 使用情形
2.3.7 蝴蝶運算單元(Butterfly Unit)
另ㄧ個智慧型 DMA 的資料運算路徑為蝴蝶運算單元(Butterfly Unit)。蝴 蝶運算單元可取代快速複立葉轉換(Fast Fourier Theorem)中,規律且繁複的蝴 蝶運算,有效的對許多常用到快速複立葉轉換的多媒體運算作加速。
蝴蝶運算單元的核心是複數乘法,利用 ALU 裡的兩顆乘法器可以在兩個指 ALU
Fetch Weight Square Acc 16x16 Multiplier X 2 External Ram (Codebook) RamA (Table) MSVQ 運算管線
的 Scaling 位移量,有效的處理資料範圍的問題。蝴蝶運算單元的輸入由兩顆內 部記憶體傳輸,內部記憶體 A 為輸入的資料,內部記憶體 B 為暫存正弦與餘弦函 數的係數,當運算完後將結果存回記憶體 A 準備給下ㄧ級做運算,並發中斷給處 理器。圖 2-11 為蝴蝶運算單元與周邊的溝通。 圖 2-11:蝴蝶運算單元與周邊的溝通
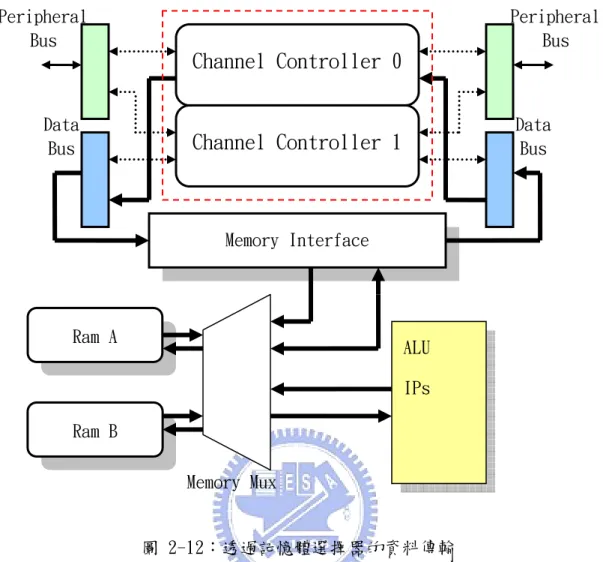
2.3.8 記憶體選擇器(Memory Mux)
智慧型 DMA 直接支援兩個 2KB(512×32-bit)的單埠高速同步記憶體,速度 可達 500MHz,每個記憶體包含 9 位元位址線,32 位元資料輸入/輸出線及讀寫控 制線,記憶體介面與內部記憶體資料傳輸連接方式如圖 2-12,記憶體讀取/寫入 使用相同的記憶體介面。記憶體多工器由控制暫存器的設定,觸發工作的模式; 當控制暫存器設定為通道致能時,智慧型 DMA 操作在傳輸模式或是雙通道運算, 記憶體掌控權交付給通道控制器;當控制暫存器設定通道除能時,智慧型 DMA 操作在運算模式,記憶體直接由算術運算邏輯或 IP 來溝通,如圖 2-12 所示。ALU
SHIFTER Multiplier MultiplierButterfly
Unit
RamA 輸入資料 RamB 暫 存 Sine 與 Cosine 係數圖 2-12:透過記憶體選擇器的資料傳輸 通道控制器可透過暫存器的設定(見 2.2 節)選擇要存取的記憶體。因此, 記憶體介面必須符合圖 2-13(a)(b)的存取時序。 圖 2-13(a):記憶體讀取時序圖
Channel Controller 0
Channel Controller 1
Peripheral Bus Peripheral Bus Data Bus Data Bus Memory Interface Ram A Ram B ALU IPs Memory Mux圖 2-13(b):記憶體寫出時序圖
2.3.9 周邊匯流排(APB - Advanced Peripheral Bus)
APB 匯流排為 ARM 的 AMBA(Advanced Microcontroller Bus Architecture) [17]架構下的一部分,其受控端介面訊號如圖 2-14 所示,並有簡單易用、省功 率的好處,主要應用在資料量不大,低頻寬的周邊裝置。內建一組音源介面 IC Sound Bus(I2 S)、與外部記憶體介面,最高支援八組周邊裝置,可擴充符合 APB 介面的周邊 IP,延伸處理器的應用範圍。 圖 2-14:APB 匯流排受控端介面 APB 匯流排時序如圖 2-15,一筆資料傳輸需要二個時脈周期,通道控制器直 接支援 APB 匯流排介面的訊號。
圖 2-15(a):APB 匯流排寫入時序圖 圖 2-15(b):APB 匯流排讀取時序圖
2.4 智慧型 DMA 控制暫存器
為了發揮智慧型 DMA 最大的效能,使用者必須設定其控制暫存器以達成傳輸 或運算功能,以下分別說明控制暫存器群組內各暫存器的功能與設定方式。2.4.1 來源暫存器(Source Register)
來源暫存器內部為 32-bit,對外為兩組 16-bit 可讀寫的暫存器。只要設定 來源暫存器後,其值會被保留,但來源位址會隨著實際的讀取位址而改變。來源 暫存器中高 16 位元用做特殊定址,低 16 位元用做資料定址,如表 2-2, 表 2-2:來源暫存器(Source Register) Bits High Source Register 15 Source Circular 0:circular / 1:mirror 14:7 Source Base 遞增(或遞減)位址數 6:0 Source Offset 區塊起始位置Bits Low Source Register
15 Source Device 來源裝置 0:Ram A / 1:Ram B 14:0 Source Address 來源位址
2.4.2 目的暫存器(Destination Register)
設定功能與來源暫存器相同,目的暫存器用在寫出的目標上。目的暫存器經 過設定,會保持設定過的值,但目的位址會隨著實際的寫出位址而改變。暫存器 位元排列如表 2-3 所示。
表 2-3:目的暫存器(Destination Register) Bits High Destination Register
15 Destination Circular 0:circular / 1:mirror 14:7 Destination Base 遞增(或遞減)位址數 6:0 Destination Offset 區塊起始位置
Bits Low Destination Register
15 Destination Device 目的裝置 0:Ram A / 1:Ram B 14:0 Destination Address 目的位址
2.4.3 控制暫存器(Control Register)
控制暫存器對外為兩組 16-bit 可讀寫的暫存器,只要設定控制暫存器,其 值會被保留,但傳輸資料數會隨著實際的寫出數目而減小。控制暫存器的高 16 位元部分為來源/目的區塊大小,低 16 位元為 DMA 控制,如表 2-4。
表 2-4:控制暫存器(Control Register) Bits Source/Destination Region Register 15:8 Source Region 來源區塊大小
7:0 Destination Region 目的區塊大小 Bits Control Register 15 Source Increase 來源位址遞增 14 Source Decrease 來源位址遞減 13 Destination Increase 目的位址遞增 12 Destination Decrease 目的位址遞減
11 Source Width 來源寬度(Reserved) Default =32 bit 10 Destination Width 目的寬度(Reserved) Default =32 bit 9:0 Transfer Size 傳輸資料數
2.4.4 配置暫存器(Configuration Register)
配置暫存器對外為一組 16-bit 可讀寫的暫存器,只要設定配置暫存器,其 值會被保留,但累加器清除(High-Active)會在設定後一個時脈周期改變成 Low;通道致能後,會在傳輸結束後,自動關閉。如表 2-5,其中 Function 為設 定智慧型 DMA 的運算功能,設定如下: 001:MAC: 雙通道乘加模式。 010:Shifter:柱狀位移模式。 011:DIV:多級除法器模式。 100:FFT:蝴蝶運算單元模式。 101:32-bit Multiplier:32 位元乘法模式。 110:MSVQ:多級向量量化單元模式表 2-5:配置暫存器(Configuration Register) Bits Configuration Register
15 Halt 暫停 14 Interrupt Enable 中斷致能 13:11 Source Peripheral 來源周邊(記憶體傳輸模式時無效) 10:8 Destination Peripheral 目的周邊(記憶體傳輸模式時無效) 7:6 Transfer Type 傳輸模式 5 Sequence Transfer 連續傳輸 4:2 Function 特殊功能 1 ACC Clear 累加器清除 0 Channel Enable 通道致能
2.4.5 狀態暫存器(Status Register)
狀態暫存器對外為一組 16-bit 僅能讀取的暫存器,包含兩個通道的資訊, 高位元為通道 1,低位元為通道 0。如表 2-6。 表 2-6:狀態暫存器(Status Register)Bits Status Register [15:8] Channel 1 / [7:0] for Channel 0 7 Interrupt 中斷
6 FIFO Full DMA FIFO 資料狀態已滿 5 FIFO Empty DMA FIFO 內無資料
4 FIFO Half DMA FIFO 資料狀態已達半數 3 Channel Select Channel 被選擇在工作模式 2:0 Error 錯誤狀態(累加器溢位發生)
2.4.6 輸出暫存器(Output Register)
智慧型 DMA 裡的 IP 如 MSVQ 單元以及 ALU 單元裡計算後的輸出,都存放在 輸出暫存器中;當進行雙通道的乘加運算時,輸出暫存器為一組 32-bit 可讀寫 累加器,僅能以 16-bit 寫入,以 32-bit 有號數讀出,內部為 40-bit 的暫存器。 如表 2-7 所示。 表 2-7:輸出暫存器(Output Register) 31:0 DSPRegOut SDMA 輸出
2.4.6 功能暫存器(Function Register)
功能暫存器對外為四組 16-bit 寫入的暫存器,負責設定智慧型 DMA 裡的運 算功能:當智慧型 DMA 進行 ALU 單元的運算時,功能暫存器為運算的輸入數值; 當智慧型 DMA 進行 MSVQ 單元運算時,功能暫存器為設定參數的輸入資訊;當智 慧型 DMA 進行 Butterfly 單元運算時,功能暫存器為記憶體的輸入位址,以及位 移量的設定。如表 2-8 所示。 表 2-8:功能暫存器(Function Register) Bits Function Register15:0 DSPIn1 15:0 DSPIn2 15:0 IPIn1 15:0 IPIn2
2.4.7 智慧型 DMA 使用流程
ALU IPs IPIn2 IPIn1 DSPIn2 DSPIn1 DSPReg Out器及功能暫存器設定後,配置暫存器必須最後一步設定,用以將通道致能。此時 可去處理其他工作,待中斷發生後,智慧型 DMA 處理的工作跟著結束。在設定暫 存器後,其值多會被保留下來,因此,若每次設定僅需選擇有改變的暫存器設定 即可。 Start Setting Register Source Register Destination Register Control Register Channel Enable Configuration Register Interrupt Occurred? End YES NO Do other thing Interrupt Occurred
Finish the Job Start Setting Register Source Register Destination Register Control Register Channel Enable Configuration Register Interrupt Occurred? End YES NO Do other thing Interrupt Occurred
Finish the Job
第三章 智慧型 DMA 運算控制器設計
本章介紹智慧型 DMA 與其他 DMA 相異的特色,利用內部的算術運算邏輯單元 (ALU),搭配各種傳輸定址模式與資料路徑,達到具有數位訊號處理(DSP)的效 能。以下將介紹智慧型 DMA 的特殊運算功能,包括多級向量量化資料路徑設計及 蝴蝶運算資料路徑設計。3.1 多級向量量化器設計
本節介紹多級向量量化的設計,包含多級向量量化理論、M-L 搜尋法及設計 架構及硬體使用方法。3.1.1 原理
多級向量量化器(Multistage Vector Quantization)在 1982 年由 Juang 與 Gray 提出[18]。每個向量 x 先由一個粗略的向量量化器量化xˆ1=Q x[ ],量化的 誤差即為e1= − 。接著量化的誤差 ex xˆ1 1由另ㄧ個向量量化器量化eˆ1=Q e[ ]1 ,重 複上述的過程。根據使用幾級的向量量化器,每一級皆產生出一個編碼簿的索引 值,這些索引值即為量化後的結果。在解碼端,解碼器利用這些索引值,在碼簿 中找出相對應的向量,即可得到重建後的訊號。圖 3-1 表示 3 級向量量化的編解 碼過程。
圖 3-1:三級向量量化器(I 定義為第i I 個量化器 index)[18]
M-L 搜 尋 法 多 級 向 量 量 化 器 , 也 稱 為 樹 狀 搜 尋 多 級 向 量 量 化 器 (tree-searched multistage vector quantiser),在 1993 由 LeBlanc 提出[19]。 相較於傳統循序的收尋,他使用更佳的搜尋演算法。在 MSVQ 的第一級量化器, 選擇擁有最小失真測量的 M 個碼向量,將 M 個碼向量與原輸入係數的差值即為第 一級量化器的量化誤差,這 M 個碼向量誤差將傳送至第二級的量化器,即產生出 M 條量化路徑。在量化器的最後ㄧ級,這 M 條路徑將得到 M 個最後的量化誤差值, 此時最佳的量化路徑即為誤差最小者。圖 3-2 與圖 3-3 表示 M-L 搜尋過程及流程 圖。 圖 3-2:三級向量量化器利用 M-L 法搜尋編碼簿(這裡 M=4) Vector Quantiser 1 Vector Quantiser 1 Vector Quantiser 1
Decoder 1 Decoder 1 Decoder 1
x
- + 1 ˆxe
1ˆe
1 - + 2 e ˆe 2 1I
I2 I 3 1 ˆxˆe
1 ˆe 2ˆx
+ + + Encoder Decoder Min Overall Distort 1 2 3 4 4 1 2 3 4 1 3 2Pre_stage_error
Find overall minimum Select the path
Choose the last stage min. error
END of m loop Compute difference vector The next stage input
Compute min_d , min_i Find the min. D[r] and recode the min. index r Compute other_stage_error D[r]= 2 [ ] n Wn Xn X n ∧ −
∑
Stage
Compute difference vector Subtract the M candidate code vector and original input for being the next stage input Compute first_stage_M_best Find the first M min. error Compute first_stage_error D[r]= 2 [ ] n Wn Xn X n ∧ −
∑
M path
END of stages loop
END F i r s t s t a g e O t h e r s t a g e s
3.1.2 設計架構
圖 3-4 為多級向量量化單元,架構圖包含流程控制器、運算管線、比較器、 控制輸入暫存器、數值表單元、最佳路徑選擇單元,其說明如下: 圖 3-4:多級向量量化器架構圖 圖 3-5 表示多級向量量化器流程圖,使用者在控制暫存器設定量化環境後, 由流程控制器解碼,再進行位址的發配。流程控制器控制 4 個迴圈的流程,內層 迴圈實現加權均方誤差(WMSE);Level 迴圈循序抓取編碼簿的碼向量進行運算; Stage 迴圈抓取下ㄧ級的編碼簿;Path 迴圈進行 M-L 搜尋的實現。比較器選擇 External RAM (Codebook) Square Address generator ACCUMULATOR COMPARATOR Write Table Fetch Abs. Sub. RISC RamA (table) Write DiffBuffe Quantization Weight Select M_PATH WMSE Pipeline M_Path Multi-stage Channel Controller Control signal PreFetch APB Bus # Level M Order Input Buffer Diff Buffer Weight Buffer 控制/輸入暫存器WMSE 最小者,將誤差存到記憶體中,當成下ㄧ級的輸入。數值表單元負責暫存 資料,由圖可知,他控制下ㄧ級輸入與量化路徑表的暫存,暫存到記憶體中,以 減少暫存器的使用。最後由最佳路徑選擇單元選出誤差最小的路徑,交由數值表 單元輸出。 控制暫存器 流程控制器 流程控制器 WMSE 4級運算管線 數值表單元 數值表單元 比較器 Stage Level Order Path 編碼簿 輸入暫存器 最佳路徑選擇 記憶體 暫存 下ㄧ級輸入 量化路徑表 量化索引值輸出 控制迴圈流程 控制記憶體存取 解碼 圖 3-5:多級向量量化器流程圖
3.1.3 控制輸入暫存器
控制輸入暫存器為 4 組 16-bit 暫存器組,負責設定系統的參數與待處理的 資料。各暫存器的內容如表 3-1 所示,Next_Stage Buffer 用在多級編碼簿的情 形,代表下一級的輸入;Weight Buffer 則用在加權失真量測上(weighted mean squared error),若系統為 MSE(mean squared error),則 Weight Buffer 預設 值為 1。表 3-1:控制輸入暫存器 控制參數
Control Register 使用者自定 Order 數、Level 數、M Path 數 輸入暫存器
Input Buffer 向量量化係數
Next_Stage Buffer 下一級的向量量化係數 Weight Buffer 權重係數
3.1.4 流程控制單元(Address Generator Unit)
流程控制單元為一個位址產生器(Address Generator),負責控制系統的各 個運算流程,由一個 FSM(Finite State Machine)實現,共有 8 個狀態,狀態圖 如 3-6。各個狀態的工作說明在表 3-2。 圖 3-6:流程控制單元狀態圖 Ready Get_Level Update_Order Update_Level Update_stage Update_m Idle finish
表 3-2:控制輸入暫存器 狀態名稱 工作內容 Get_Level 對控制暫存器解碼,得到 Level 數的資訊 Update_Order 產生 Oder 位址 Update_Level 產生 Level 位址 Idle 等待忙碌訊號,數值表單元正在記錄 Update_stage 產生 Stage 位址 Update_M 產生 M paths 位址 Finish 送出完成訊號,結束工作 流程控制單元有 4 個計數器,依據控制暫存器設定的 4 個參數值:Order、 Level、Stage 及 M,決定 4 個迴圈的次數,當最內層迴圈 Update_Order 的計數 器數到 Order 次時,狀態就會跳至 Update_Level,將 Update_Level 狀態裡的計 數器加ㄧ,以此類推至 Update_Stage 與 Update_M 狀態。Idole 狀態發生在換下 ㄧ級 Update_Stage 時,數值表單元會記錄上ㄧ級的各種資訊及下ㄧ級的輸入來 源,此時流程控制單元進入 Idle 狀態等待數入資料準備完成。 為了掌控各單元間的操作,流程控制單元共產生 6 組控制訊號,分別控制與 驅動各個功能方塊,6 組控制訊號的內容如表 3-3 所示。 表 3-3:控制訊號 控制訊號 Enable_acc 累加器開始累加 Enable_compare 驅動比較器 Enable_recode 開始紀錄數值表 Enable_final 趨動比較器選擇最佳 M_Path Enable_output 輸出最後的索引值
3.1.5 運算管線設計(Pipeline design)
多級向量量化單元的核心為一個四級運算管線(4-stage pipeline)的設 計,為實現 WMSE(weighted mean squared error)計算,每一級在一個 clock 週 期進行一個運算,並將結果儲存在暫存器中準備給下ㄧ級使用,資料及控制訊號 經由管線進行同步傳送。利用管線同步運算的架構,以及每級運算時間平均的特 性,多級向量量化單元可達到較高的資料處理能力,相對於在相同時脈下以循序 電路實現。 運算管線運作與暫存器傳送時間圖如圖 3-7 所示。 圖 3-7:運算管線時間圖 Fetch 級運算兩個輸入來源的絕對值差;Weight 級運算差值的權重,這裡與 演算法不同的是,在 Square 級前先做了權重的運算,這是因為考量到數值的特 性,當 16-bit 絕對值差值接傳送到 Square 級運算,輸出須以 32-bit 儲存及傳 送給 Weight 級做乘法,如此則需一個 32-bit 乘法器或是多浪費一級作 32-bit 的乘法。為減少設計面積及考量到權重的係數特性,即使經過定點化後仍很小, 各係數可正歸化在 1 到 2 間,誤差最小,所以先乘上權重並傳送其號數(Sign) 至 Acc 級,再經過平方,這樣只需做 16-bit 的乘法動作。得到平方值後,依權 重係數的正負號,進行累加或是累減運算,輸出為 40-bit 的 WMSE 值。 Time 0 1 2 3 4 Fetch 1 1 A −B A2−B2 A3−B3 A4−B4 A5−B5 Weight - 1 1 1 w A −B w A2 2−B2 w A3 3−B3 w A4 4−B4 Square - - 1 1 1 W A −B W A2 2−B2 W A3 3−B3 Acc - - - 1 1 i i i i W A B = −
∑
2 1 i i i i W A B = −∑
註: 2 W =w A 與 B 分別為輸入向量與碼向量將 Weight 提前(Weight modify)所造成的 WMSE 結果與未修改前(Original Input)的比較如表 3-4,誤差值在 5%之內,與 SNR 的影響很小。 表 3-4:架構修改前後誤差表 SNR(dB) Original Input 57.243 Weight modify 56.335
3.1.6 比較器(Comparator)
當運算管線將 WMSE 數值計算完畢後,經由比較器選擇最小的誤差值,比較 器的設計為有號數(Sign)的比較,另外位了配合 M Paths 的演算法,這裡設計了 ㄧ個 threshold 暫存上ㄧ條 Path 的誤差值,下ㄧ條 Path 則需大於 threshold 下進行比較。3.1.7 數值表單元(Write Table)
數值表單元記錄各種數值暫存的路徑,由一個 FSM(Finite State Machine) 實現。其狀態流程圖如 3-8 所示,狀態工作內容如表 3-5 所示。
圖 3-8:數值表單元狀態圖 狀態名稱 工作內容 Ready 初始值設定 judge_condition 判斷該進入哪個 stage update_error 更新誤差值 recode_table(index) 紀錄各 stage 的索引值值 update_regfile 將最小 WMSE 的誤差當作下一級的輸入 idle 忙錄狀態 Final_compare 紀錄表完畢後,比較最後量化誤差大小,選擇ㄧ條最 好的 PATH,再將他的各級索引值輸出 表 3-5:數值表單元狀態工作內容 為了增加多級向量量化的精確度,例如表 3-6 所示,假設 M paths 數為 3, Stage 數為 2,為了求最佳的量化路徑,可用ㄧ張表紀錄各個路徑的索引值(index) 與最後ㄧ級的誤差值(error),比較每個誤差值的大小,選出最小的誤差值就是 最佳的路徑。假設 Error1 數值最小,可知最佳的量化路徑在 M1 上,此時輸出的 Ready Judge_condition Update_error Recode_tableI Update_regfile Idle Final_compare
索引值即為 Index1、Index2。
M1 M2 M3
S1 Index1 Index3 Index5
S2 Index2 Index4 Index6
Error Error1 Error2 Error3 表 3-6:控制輸入暫存器 數值表單元即記錄各個 M Paths 的資訊,為了節省暫存器的使用,這裡直接 將表的內容暫存到內部記憶體。數值表單元依據系統現在的狀態,寫入 M 個量化 路徑的索引值,與上一級的誤差值。當系統跑完一個 Stage 時,數值表單元會將 暫存在記憶體的誤差資訊取出,存在暫存器組裡當做下ㄧ個 Stage 的輸入。如圖 3-9 所示。 圖 3-9:數值表單元記錄下ㄧ級的輸入圖 當系統運算完畢後,由最佳路徑選擇單元(Select_M_Paths Unit)選出最佳 的向量量化路徑,數值表單元便將這個路徑上的索引值包裝成 32-bit 的數值, 輸出到智慧型 DMA 的暫存器組,由處理器取值,如圖 3-10 所示。 數值表單元 暫存器組 下ㄧ級的輸入 M 個量化路徑 上一級的誤差值 RAM A 下ㄧ級的輸入 Write Table
圖 3-10:數值表單元輸出圖
3.1.8 最佳路徑選擇單元(Select M_Paths)
將每條 Path 的最後ㄧ級誤差暫存,比較 M 組 Paths 的大小,輸出最小誤差 的路徑。3.1.9 運作流程
多級向量量化一個重要的步驟在於編碼簿的搜索,龐大的編碼簿不可能存放 在內部記憶體中,所以需要一個外部記憶體的周邊。智慧型 DMA 有ㄧ般 DMA 溝通 周邊的能力,對外的溝通介面為 APB 匯流排,傳輸符合標準協定。在編碼簿的設 計上,由於 APB Bus 的傳輸方式為兩個時脈週期傳送ㄧ筆資料,為了符合多級向 量量化單元中運算管線的機制,將兩筆碼向量存成 32 位元存放在一個記憶體位 置上,經由 DMA 傳送至向量量化單元中,如此運算管線就可以每個時脈週期抓取 ㄧ筆的碼作運算,如圖 3-11 所示。 數值表單元 最佳路徑選擇單元 索引值 Index2 索引值 Index1 RAM A 路徑 Path 1 索引值輸出 DSPRegOut SDMA 暫存器組圖 3-11:多級向量量化器與周邊運作流程圖 在處理器的設定上,如圖 3-11 所示的程式碼,利用指令設定智慧型 DMA 的 暫存器組,寫入 Level、Stage、Order 與 Paths 等參數,最後設定 MSVQ 功能致 能參數,系統便開始運作,此時處理器不必理會智慧型 DMA 的運作,可以進行其 他演算法的運算,當智慧型 DMA 運算完畢後,會發中斷給處理器取值。
3.2 蝴蝶運算器單元設計
本節將介紹蝴蝶運算器單元的設計。包括蝴蝶運算的理論、架構及其使用方 法。3.2.1 蝴蝶運算理論
快速複立葉轉換(Fast Fourier transform;FFT)在多媒體應用上非常常見, 詳細的 FFT 理論詳見[16],本章節介紹 FFT 理論的核心:蝴蝶運算。對於一個 8 點的時域分離的 FFT 形式(Decimation in Frequency)如圖 3-12 所示,共有 3 級,每級皆有 4 個蝴蝶的運算元,所以 8 點的 FFT 共有 12 個蝴蝶運算元,蝴蝶 運算元形式如圖 3-13 所示,此時 r j2 r N/
圖 3-12:8 點 FFT 圖 圖 3-13:蝴蝶運算圖
3.2.2 架構
設計一個蝴蝶運算的路徑,使用者只需輸入三個記憶體的來源位址,代表蝴 蝶運算的兩個輸入,與正弦餘弦的係數,設定完 DMA 的功能鍵後開始運算,此時 處理器負責控制與掌管 FFT 的流程,由智慧型 DMA 負責內部迴圈的計算。 蝴蝶運算單元裡的資料型態為 32-bit,其中低 16 位元為實部,高 16 位元 為虛部,這樣分配的優點在於節省記憶體空間,與加快存取的效率:對於一個 512 點的 FFT 運算,只需要 512 條記憶體位址線儲存複數的資料,ㄧ個時脈週期 可以得到實部和虛部的數值,處理完後再存成ㄧ個 32 位元的封包,在一個時脈 週期下存回記憶體。此外,為了符合定點化程式的需要,正弦餘弦係數常會做定 x[0] x[1] x[2] x[3] x[4] x[5] x[6] x[7] 0 NW
0 NW
0 NW
0 NW
-1 -1 -1 -1 0 NW
0 NW
2 NW
2 NW
0 NW
2 NW
1 NW
3 NW
X[0] X[1] X[2] X[3] X[4] X[5] X[6] X[7] -1 -1 -1 -1 -1 -1 -1 -1 r NW
(m-1)st Stage mth Stage -1點格式的調整,在與輸入進行複數乘法完後,必須要將格式復原,捨去額外的資 料。所以這裡設計用位移器來達到格式調整的目的,並可由使用者自行設定位移 量,增加蝴蝶運算單元的使用性。蝴蝶運算單元流程如圖 3-14。 圖 3-14:多級向量量化器架構圖 蝴蝶運算單元的架構圖如圖 3-15 所示,進行一次的運算只需 9 個時脈週期。 設定SDMA參數: -3個記憶體位址 -位移數 直接從記憶體 抓 取 資 料 與 Cosine/Sine係數 進 行 複 數 乘法 存回原來的記憶體位 址,給下ㄧ級作運算 進行複數 加法 由使用者設定 Scaling位移數
圖 3-15:蝴蝶運算單元架構
3.2.3 程式流程設定
蝴蝶運算單元在 FFT 運算中,由智慧型 DMA 操作,處理器負責流程的控管, 如圖 3-16 及圖 3-17 所示,處理器負責控制三層迴圈,以及蝴蝶運算輸入位址的 - 1 Cycles 2 Cycles 2 Cycles RAM1 RAM0 Re Im Re Im Cos Sin Re Im Re Im Cos Sin Re Im Re Im Re Im 2 Cycles RAM0 2 Cycles SHIFTER + - +計算,當蝴蝶運算在進行時,處理器開始計算下ㄧ筆的輸入位址以及計數器的運 作,達到處理器與計算單元分工的效果,大幅提升效能。 圖 3-16:FFT 運算分工情形 圖 3-17:利用 SDMA 計算 FFT 運算 LABEL:FFT (主迴圈:計算 FFT 級數) LABEL:LOOPI (次迴圈:ㄧ級裡有幾個蝴蝶運算) LABEL: ButterFly (內迴圈:蝴蝶運算) SDMAR 16,R4 (蝴蝶 Input 1) SDMAR 17,R8 (蝴蝶 Input 2) SDMAR 18,R5 (SinCos 位址) SDMAB 19,R11 (設定位移量) SDMAB 5,01000000_00_0_100_0_0 (蝴蝶單元致能) DMAOK (DMA 設定完畢) ... (計數器計算) ... (位址計算) JMBR R15,R4,ButterFly JNER R3,R1,LOOPI JNER R9,R10,FFT 設定智慧型DMA參數 RISC計算輸入位址 與Sine&Cosine表 位址 兩顆記憶體 的輸入位址 智慧型DMA計算 蝴 蝶 運 算 資 料 過 程 RAM A:計算資料 RAM B:Sine&Cosine RISC 計 算 迴 圈 計 數 器
第四章 智慧型 DMA 控制器與 RISC 處理
器的整合
智慧型 DMA 控制器搭配 RISC 處理器可以增強處理器的數位訊號處理效能。 因此,本論文利用實驗室發展的一個 32 位元精簡指令集架構(RISC)處理器核 心,並有快取記憶體控制器,與智慧型 DMA 控制器整合,為一個單核具有 DSP 平行架構的嵌入式處理器。以下章節將說明此精簡指令集架構處理器的特性、指 令集、軟體開發環境及如何與智慧型 DMA 做整合。4.1 RISC 處理器
實驗室發展的 RISC 訊號處理器擁有九級管線架構的設計[20][21],為一個 Unit-core 和 Multi-Ram 的處理器 IP[22][23]。當一個指令透過程式計數器 (Program counter)抓取進入處理器內部後,會先對該指令進行解碼,接著到 暫存器提取所需要的資料到 ALU 中執行,最後將結果存回暫存器或記憶體中。周 邊裝置的存取透過智慧型 DMA 來規劃,組譯器及處理器直接支援智慧型 DMA 的設 定及使用[24],周邊裝置(或 IP)可利用標準的 APB 規格掛上匯流排[25],將外 部的取樣訊號透過智慧型 DMA,將資料儲存在內部記憶體,或內部運算的結果送 到周邊裝置上輸出[26]。4.1.1 RISC 處理器核心
RISC 架構處理器擁有 9 級管線架構,9 級管線包含程式計數與跳躍判斷模 組、指令抓取模組、程式碼記憶體模組、指令預測模組、指令解碼模組、暫存器 模組、及算數邏輯單元模組,以下分別描述其主要的工作簡述如下: 1. PC Counter/Branch Protect:在硬體架構最上層,目的是把程式計數器加一,並處理跳躍,最後決定程式計數器的值,並送到下一級指令抓 取(Instruction fetch)。
2. Cache:將 PC 位址傳到快取記憶體去抓指令,其中 PC 的位址線為 16-bit,傳回 RISC 指令為 32-bit,快取記憶體控制器架構為三級,因 此若搭配此 RISC 訊號處理器,則總級數為九級。 3. Instruction Fetch:這一級的目的是把程式計數器的值,轉成程式記 憶體的位址,送進下一級的程式記憶體去抓取指令。其中,由於有些指 令在 ALU 級時會需要處理中指令的程式計數器值,所以必須把程式計數 器值一級一級地傳下去,因此,程式計數器值會傳進下一級的暫存器。 在處理跳躍指令時,為了避免浪費跳躍指令發生後一個指令被抓取,設 定兩個訊號做為防止跳躍發生時的指標,用以表示現在的管線是否在 Stall 狀態,決定要不要執行該級動作。 4. Program Memory:將程式記憶體的位址經由硬體最上層的腳位傳到外部 的唯讀記憶體去抓指令,其中位址線為 16-bit,傳回 RISC 指令為 32-bit。 5. Instruction Decoder:這一級的目的是把指令依照對應的指令碼去做 解碼,指令中有兩個來源暫存器的位置,一個目的暫存器的位置。這些 位置可以對下一級的暫存器組取得來源運算元並提供未來 ALU 級寫回 的目的位置。內建兩組處理核心,所以也提供了指令去從兩個處理核心 中互相提取對方暫存器組的資料,方便資料的直接交換。 6. Register File : 處理核心有 32 個通用暫存器。設計有 13 個中斷暫存 器來處理外部中斷,暫存器組為 2 讀 1 寫的格式,負責提供解碼器所解 碼出的來源運算元值,並將 ALU 級算出的目的運算元寫回。在此模組 中,有很多連接 ALU 級模組的輸出信號,目的是把這些 ALU 級要用到的
7. ALU:本級功能是計算出邏輯或運算值,為了 Data forwarding 的實作, Data memory 及 Write back 這兩級隱含在 ALU 級內。Data forwarding 的機制是利用前面一級一級傳回的信號實作而成,目的是為了減少 RAW hazard。
除了以上基本的管線模組設計外,還有一些特殊硬體設計需求被強調出來 [27],包含以下五種說明:
1. 一個指令週期完成乘加運算。
2. Regular Loop Prediction: 數位訊號處理運算中有很多固定次數迴圈 的運算,利用一個良好的跳躍預測(Branch prediction),使處理器不 會有 Control hazard 造成的不必要 Stall。
3. 良好的 Data Forwarding 機制。
4. Condition Branch:預測採用 Prediction-untaken 方法設計。
4.1.2 RISC 處理器指令集
RISC 處理器指令集共分五大類:資料搬移、算數邏輯運算、跳躍指令、其 他類指令、智慧型 DMAC 控制類,列表如下:
資料搬移指令 :
表 4-1:資料搬移指令列表
Instruction Opcode Example Mode MOVRC 000001 MOV rd,data Direct MOVRR 000010 MOV rd,rs Reg-Reg MOVRM 000011 MOV rd,address Direct MOVMR 000100 MOV address,rs Direct MOVMRR 000101 MOV @rs2,rs Indirect
MOVRRM 000110 MOV rd,@rs Indirect MOVB 101111 MOVB rd,base(rs) Displacement MOVI 110000 MOVI rd,rs1(rs2) Index
MOVRMB 110001 MOV rd,address Direct-Second Ram MOVMRB 110010 MOV address,rs Direct-Second Ram MOVMRRB 110011 MOV @rs2,rs Indirect-
Second Ram MOVRRMB 110100 MOV rd,@rs Indirect-
Second Ram
RISC 處理器共提供 Direct、Reg to Reg、Indirect、Displacement (base add)、Index 五大類的定址模式。
算數與邏輯運算指令 :
表 4-2:算數邏輯運算指令列表 Instruction Opcode Example
ADDRR 001000 ADD rd,rs1,rs2 SUBRR 001010 SUB rd,rs1,rs2 MULRR 001100 MUL rd,rs1,rs2 ADDRC 000111 ADD rd,data SUBRC 001001 SUB rd,data MULRC 001011 MUL rd,data MACR 100111 MAC rd,rs1,rs2 MACC 110001 MAC rd,rs1,data ANDRR 001110 AND rd,rs1,rs2
XORRR 010000 XOR rd,rs1,rs2 INVR 010001 INV rd,rs
跳躍指令 :
表 4-3:跳躍指令列表 Instruction Opcode Example JMP 010010 JMP address
JMPR 010011 JMP @rs
JBE 010100 JBE rs1,address JNE 010101 JNE rs1,address JMB 010110 JMB rs1,address JLB 010111 JLB rs1,address JBER 011000 JBER rs1,rs2,address JNER 011001 JNBR rs1,rs2,address JMBR 011010 JMBR rs1,rs2,address JLBR 011011 JLBR rs1,rs2,address CALL 100011 CALL address
RET 011110 RET
Address 的部分也可以是 Label,組譯器會自動轉換成對應的位址。 其他指令:
表 4-4:其他指令列表 Instruction Opcode Example
SET 011100 SET A,rs
SHR 100000 SHR rs
SHL 100001 SHL rs
Instruction Opcode Example
ENDC 011111 ENDC
SET 指令是當 RISC 處理器沒有連接匯流排時,利用這指令可以設定兩個 16-bit 的 I/O port ,與外界溝通;INTOK 是處理軟體中斷的指令,利用這指令 可發出軟體中斷;SHR 將 rs 向右移一位元;SHL 將 rs 向左移一位元。
智慧型 DMA 控制相關指令 :
表 4-5:智慧型 DMAC 控制指令列表 Instruction Opcode Example SDMAD 100100 SDMAD data SDMAR 100101 SDMAR rs
GDMA 100110 GDMA rd
DMAOK 101001 DMAOK
GDMAR 101110 GDMAR rd,address
4.2 軟體開發環境
硬體設計外,處理器的軟體支援是相當重要,為此發展了圖形化介面的組譯 器(Assembler),提供機械碼(Machine code)的轉譯、程式記憶體(Program rom) 的產生、及錯誤資訊(Debug information),讓使用者能夠利用以上資訊來除錯 及產生Testbench。
Assembler Data Rom Machine Code Debug Information Testbench Assembler Assembler Data Rom Data Rom Machine Code Debug Information Testbench Testbench 圖 4-1:組譯器(Assembler)的用途 圖型化介面組譯器如下圖,使用 Visual C++完成演算法部分,使用 VB 做組 譯器的圖形介面,並用 dll 作連結,並提供編輯檔案的能力。當完成編輯檔案後, 須先經過 compile 的動作,確保無錯誤產生。最後經由 Build 的動作,產生所需 的檔案: z pop.txt:產生十六進位的程式碼,提供晶片測試的資料。 z bin.txt:產生程式記憶體的資料,提供模擬及後續測試必備的資料。
圖 4-2:圖形化介面組譯器(Assembler)
4.3 整合
本論文將智慧型 DMA 和 RISC 處理器做一個整合,用以驗證智慧型 DMA 的功 能,及整個系統的正確性,並驗證處理器加上智慧型 DMA 的功能,測試其效能。 如圖 4-3,RISC 處理器整合智慧型 DMA 成為一個系統,擁有多個共用匯流排。程 式記憶體為外接方式,內部兩個記憶體與智慧型 DMA 共用兩個資料匯流排。智慧 型 DMA 並支援周邊匯流排,增加整體的擴充性。
![圖 1-1:RISC 與 DSP 規劃圖 精簡指令集處理器(RISC)架構特色在於區別存取指令和計算的指令,並擁有 多級管線架構,以一個時脈週期為單位執行指令,達到高時脈的處理速度。以運 算為導向的數位訊處理器(DSP)則不同於 RISC 的架構,指令集以記憶體相關與運 算效率為導向,例如濾波器的運算與快速複立葉轉換演算法。此外還擁有自己的 暫存器組,位址單元與運算器,數位訊號處理器有相當多特別的架構及定址法 [1],如環狀定址(Circular Addressing)、位元反轉定址模式(Bit-reve](https://thumb-ap.123doks.com/thumbv2/9libinfo/8520756.186511/15.892.188.717.119.483/以一個濾波器的運算與快速複立葉轉換演算法此外還自己多特別Bitreve.webp)
![表 1-1:向量量化架構比較表 Method C.L. Wang [12] C.Y. Lee [13] Zunino [14] Proposed](https://thumb-ap.123doks.com/thumbv2/9libinfo/8520756.186511/18.892.124.770.129.782/表11向量量化架構比較表MethodCLWang12CYLee13Zunino14Proposed.webp)