行政院國家科學委員會補助專題研究計畫成果報告
※※※※※※※※※※※※※※※※※※※※※※※※※※
※ ※
※
※
※
GSI 微處理機架構及功能分析
※
※
※
※
※
※※※※※※※※※※※※※※※※※※※※※※※※※※
計畫類別:■個別型計畫
□整合型計畫
計畫編號:NSC
89-2213-E-009-199-執行期間:89 年 8 月 1 日至 90 年 7 月 31 日
計畫主持人: 吳全臨 教授
計畫參與人員:江尚旻 國立交通大學
許鈺鼎 國立交通大學
黃印璽 國立交通大學
蔡長委 國立交通大學
饒書銓 國立交通大學
執行單位:國立交通大學資訊工程學系
中
華
民
國
90
年
7 月
31 日
GSI 微處理機架構及功能分析
計畫編號:NSC
執行期間:89 年 8 月 1 日至 90 年 7 月 31 日
計畫主持人: 吳全臨 國立交通大學資訊工程系教授
計畫參與人員:江尚旻 國立交通大學資訊工程系
許鈺鼎 國立交通大學資訊工程系
黃印璽 國立交通大學資訊工程系
蔡長委 國立交通大學資訊工程系
饒書銓 國立交通大學資訊工程系
摘要
當微電子技術可以將單晶片的電晶體數目推到十 億個左右時(即 Gigascale Integration, GSI),其在設計上 及應用上就必須有革命性的作法。傳統的單一處理機 (Uniprocessor)架構,可能變為不合適; 同時,在耗電、 速度、及連接方面也必需重新檢討。再者其應用的方 法也值得再思考,例如,我們可以把整個系統搬到晶 片上來,而形成所謂的系統晶片(System-on-a-Chip)。 一些傳統的英特爾(Intel)處理器的設計原則,可能要面 臨挑戰; 而平行處理架構也許要大行其道。很顯然地, 我們面臨一個架構斷層(Architecture Gap)。本文討論 GSI 微處理機架構及分析其功能。1. 簡介
由於面臨數十億個電晶體以上的單晶片的問世, 傳統的單一處理機架構,可能變得不合適;而在耗電、 速度及連接方面也需重新檢討。另外,應用在多媒體 的需求量越來越多,而可攜帶式的電子產品與行動計 算的新電器也已經十分普及,例如協助個人處理資料 與生活資訊的個人數位助理(Personal Digital Assistant, PDA)。再者,在新趨勢應用需求所形成的系統晶片 (System-on-a-Chip, SOC)蓬勃發展下,如何重新訂定微 處理機架構以因應 SOC 的需求,也是當前重要的考 量。因此,我們面臨所謂的 Gigascale Integration(GSI) 的挑戰。 雖然相關論談和研究中指出,GSI 將受限於理論上 (熱力學、量子力學、電磁學等)和實際應用上的限制, 其 中 包括 1)fundamental, 2)material, 3)device, 4)circuit and 5)system[10]。此外,在新的競爭趨勢下使得電子 資訊產業面臨一個危機:就是仍然不能掌握成熟的方法 來做 GSI 晶片的設計,因此在傳統微處理機和新興 SOC 設計需求中間存在一個令我們不得不重視的問 題— 架構斷層(Architecture Gap)。 影響現存的計算機架構的因素有很多,以現在的 半導體技術演進來說,許多專家預測在 2007 年以前, 將可以在一個晶片上製作超過十億個以上的電晶體, 當然,新的科技將會帶來許多新的問題,在通訊網路 應用的需求日益增加之下,人們更希望能夠提升通訊 的品質,希望能夠使聲音影像的傳輸大為增加,所以 多媒體的應用方面將會是影響現在計算機架構走向的 重要因素。2. 設計考量
當 VLSI 進展到數十億個電晶體在單一晶片上(GSI) 時,許多技術上的限制對 GSI 的效能有很大的影響, 如晶片面積、耗電、連接、時脈週期、匯流排等等。 而在微處理機結構盡最大努力下,必須面臨這些限制 做重新設計與考量,才能提供最高的效能和應用。 十億個電晶體(billion-transistors)世代的挑戰,最主 要的挑戰是如何配置這十億個電晶體,在一個架構的 那個部份須要多少電晶體,或是如何以效的利用這十 億個電晶體並整合成一個系統在一個晶片上,以求達 到所需的功能。以下是未來在製作十億個電晶體在單 一晶片時會遇到的最重大影響因素。 一、耗電問題(Power Consumption):我們知道, 越高的頻率,將導致越高的耗電量。為因應現在可攜 式電腦與行動計算上面的使用,有越來越多在低耗電 量問題上的研究,但是降低耗電量可能要降低處理機 的頻率,是個兩難的問題,所以低耗電量將是未來科 技演進後產生的重要問題。 二、記憶體延遲時間問題(Memory Latency):近來 相對於處理器以每年 60%的處理速度在成長,記憶體 的處理速度僅僅以 7%的小幅度在增加。這將使得處理 器與記憶體的距離越拉越遠。為了把這個距離補上,較好的記憶體階層架構例如緩衝器(write buffer)、快取 記憶體(caches)、主記憶體系統(memory system)、磁碟 輸 入 與 輸 出 子 系 統 (disk I/O subsystem) 與 互 相 連 線 (interconnection)的部份越顯重要。 三、利用平行度 (Exploiting Parallelism) :想要達 到高的表現,除了需要更高的技術,也需要更好的計 算機架構。要獲得更高的平行度以達到較好的表現可 以從硬體與軟體兩方面來著手。而以硬體的角度以及 根據應用需求而言,過去需要編譯器 (compiler)的支援 轉變為將編譯器的設計包含在計算機架構的設計當 中 , 以 求 達 到 高 度 的 指 令 層 平 行 度 (instruction-level parallelism),但因為如此,可能造成邏輯設計上更為 繁多,而繞線的數目也變的更為複雜,而使得延遲的 線路(delay path)更長。 四、設計複雜度(Design Complexity):上等的處理 機設計的複雜度、設計時間以及驗證,將會佔掉發展 費用的 40%,所以如果能夠簡化晶片中各個模組的交 互作用與減少有交互作用的模組數量將會簡化設計複 雜度,帶來更大的利益。 五、市場規模(Scale of Market):如果市場的規模 越大,則要生產的產品必定越多,所以設計出來的產 品必須跟現在市面上的現有產品有很明顯的優勢,這 也會影響到我們的設計。 根據以上的影響因素,我們依(1)應用需求, (2)耗電, (3)接線, (4)功能, (5)時脈週期, (6)匯流排, (7)電晶體個 數, (8)微架構內容等設計多維空間(Design Space),將 目前微處理機架構分類討論,比較並分析其優點及極 限,提供有系統的比較數據以發展未來 GSI 架構。
3. 分析比較現行架構
在 GSI 蓬 勃 發 展 的 趨 勢 下 , 從 超 純 量 (Superscalar) 、 多 引 線 (Multithreading) 、 多 純 量 (Multiscaling)的微架構方法,以及英特爾發展的 IA-64 架構等,能將現有表現提供更好的效能。 多線的處理機架構中,藉著多重引線提供額外的 平行度,將工作執行分為(1)將工作分割成引線並將引 線放在記憶體中(稱為虛擬引線);(2)選擇一個引線並且 將其交給擁有一些暫存器集合來執行(稱為實體引線)。 延伸成為同時多線(Simultaneous Multithread)的架構有 Compaq 的 Alpha 處理機、Sun 的 Java 處理機等。多純量架構是以超純量架構為基礎再利用其指令 間的平行度來設計完成的。為了將動態指令序列分割 成多個部份來執行而不是以一個部份來執行,多純量 架構採用多個超純量處理機在同一時間執行動態指令 序列的不同部份,每個超純量處理機可以在所屬的部 份指令中搜尋並執行其獨立的指令,和單一處理機比 較起來,明顯的增加系統的效能。 在 實 際 的 應 用 上 如 平 行 多 媒 體 處 理 機 (Parallel Media Processor) ,在單一晶片上整合多個平行運算單 元、指令執行以及記憶體架構[7]。而單一指令流多重 資料流像素處理機 (SIMD Pixel Processor) 則是一種將 平面焦點作影像處理的嵌入式架構系統,在與處理機 之間的存取使用一種區域陣列 (area-array) I/O 的方式, 可以在時脈週期和耗電兩方面的平衡考量下能提供更 高的效能[2]。在日益增多的嵌入式系統和行動裝置的 需求下,同時多線架構(SMT)的處理機可以提供比單 一引線的處理機較少的耗電[16]等等。
4.未來 GSI 架構
未來 GSI 架構針對各種不同的應用,整合處理機與系 統的架構,主要可以分為四個主流,將在以下四個小 節分別介紹。4.1.超大單一處理機系統晶片(Lar ge Unipr ocessor on a Chip)
4.1.1.超推測性處理機(super speculative pr ocessor s)
超推測性處理機透過積極的控制(aggressive control) 和資料的推測(data speculation) 以求達到高度的平行 度。保守的強烈相依模型(strong-dependence model)是 介由使用資料流圖(data-flow graph)與控制流圖(control-flow graph),透過指出內部指令相依與真實資料相依, 用來避免違反連續性的限制(serialization constraints)。 弱相依模型(weak-dependency model)是為了達到超推測 性處理機的積極平行度而提出的。包含以下的兩點: 一、如果推測可能有相依的情形發生,則不一定 要避免掉這種情形的發生。 二、如果推測可能有相依的情形發生而此時指令 已經在執行,則可以在影響整個機器的狀態之前,用 重置(recovery)的方式來復原系統。 這種模型的好處在於我們不必先完全了解程式的 語意,就可以遇先執行。 超流(Superflow)架構是另外以種接近超推測性微 架構的設計方式,利用很大範圍的推測技術,例如追 蹤 快 取 記 憶 體 (trace cache) 和 分 支 預 測 器 (branch predictor),來增進整體的流量,包括指令流,暫存器 資料流與記憶體資料流。 4.1.2. 路線處理機(Tr ace Pr ocessor ) 路線處理機是複製超純量管線(superscalar pipeline) 並使用控制與資料階層處理觀念來建立相連的處理元 素集。一個高階控制單元將指令流分割成小的路線 (trace),並用特別構造的快取記憶體,也就是線路快取 記憶體(trace cache)將這些線路儲存,而處理機一次攫 取並解碼一個線路,把一個線路當成一個單元。也就 是說,一個線路可以視為一個攫取與執行的基本單 元。這種架構必須要倚重預測器(predictor),因為我們 從原本指要定義比較簡單的指令控制流預測器(control
flow predictor),而現在得處理比較複雜的路線流控制 器(trace flow predictor)。這可以達到不用更改原本我們 輸入的程式,就可以達到比較快的執行速度。
4.2. 單一晶片多處理機系統(Multipr ocessor on a Chip) 4.2.1. 晶片多處理機(Chip multipr ocessor , CMP)
想要使用單一引線(single thread)的控制以求獲得 平行度將會在許多應用程式上產生限制,而且也很耗 研發的時間與費用,非常的不經濟。因此平行的使用 多個處理機核心來執行多引線(multiple thread)時,晶片 多處理機會使用相關簡單的單引線處理機核心,而每 一個簡單的單引線處理機核心的平行度也是相當適當 的設計。為保證硬體設計又快又簡單,在設計上我們 利用軟體來達到這種目的。因為晶片多處理機是真的 分成許多各別的處理機核心,而這種設計方式將可大 幅 降 低 內 部 繞 線 所 產 生 的 時 間 延 遲 (interconnection delay),這在十億個電晶體以上的設計,將會是十分嚴 重的課題。也因為這樣的設計,處理機核心的電路也 會簡化許多,所以如果想達到執行頻率的最佳化也容 易的多。而晶片多處理機的最大缺點為如果我們所執 行的目標程式是只有一個單一的引線,無法分成多引 線(multithread)的控制時,單一而且較複雜的架構就會 比晶片多處理機快很多。
4.2.2. 原質處理機(Raw pr ocessor , RAW)
這種原質處理機的基本構想為保持硬體上的簡單 設 計 , 而 針 對 各 種 應 用 程 式 的 需 要 來 設 計 編 譯 器 (compiler),以編譯器的編譯硬體,使得得到的硬體可 以適合客戶的須求。原質處理機是建立在一些簡易的 處理機架構之上,並複製這些架構,而每一個處理機 架構都擁有自己的指令流。而設計的主要概念是盡量 能夠在單一的晶片上置入越多的處理機越好,也就是 說越是簡單的架構,能夠置入的處理機數量越多,而 不是為了一些特殊的邏輯架構來製作一些硬體,這些 架構如暫存器改名單元(register renaming),指令排程單 元 (instruction scheduling) , 或 是 動 態 指 令 發 出 單 元 (dynamic instruction-issue)。而這些空下來的空間將可 以加大記憶體或是運算邏輯(computational logic),也可 以達到較高的執行頻率與減低驗證的複雜度。而原質 處理機是用軟體來製作的,這些分散的架構以可程式 化,而且有條理的整合線路來作相互連結,當然,還 包括可切換的內部連線控制。原質處理機很適合傳統 的科學應用計算,這種計算的有許多的資料流要處 理。 4.3. 系統晶片(system-on-a-chip, SOC) SOC 即在單一晶片上結合整個電腦系統(computer system) 如 處 理 機 (processor) 動 態 隨 機 存 取 記 憶 體
(dynamic random access memory, DRAM)和輸入輸出子 系 統(I/O subsystem),整合了記憶體(包括 DRAM、 flash),類比核心模組(analog cores),各樣不同功能的 IP Blocks 及最上層的處理器(processor cores)及邏輯運 算單元(logic unit)等等。 製程技術的進步,已經進入到了深次微米(Deep Sub-micron) 的 製 程 , 容 許 一顆晶 片上可負載 更多的 gate 及電晶體,且可使得整個設備具有可攜性。SOC 的實現,讓原本只有硬體架構的系統可以融入更有彈 性的軟體設計;再者,將大部份的核心(core)放在一塊, 可以使得整體的頻寬增大,提高系統的效能,此意謂 著各個核心或 IP Block 之間的訊號傳遞不再需要經過 複雜及大量的 I/O buffer 及 system board 線路。
4.3.1. 智 慧 動 態 隨 機 存 取 記 憶 體 (Intelligent RAM, IRAM) 隨著科技的演進,處理機與記憶體的加塊速度卻 不層比例,使得處理機比記憶體快的多,產生了距 離,這也讓記憶體延遲時間與低記憶體頻寬的問題越 顯嚴重。智慧動態隨機存取記憶體的基本精神使是把 動態存取記憶體(DRAM)作到單一晶片上,以改善這個 影響處理機表現的因素,而不是使用靜態存取記憶體 (SRAM)來彌補處理機與記憶體之間的斷層。主要著眼 於在同樣的晶片面積的前提下,動態隨機存取記憶體 能夠比快取記憶體置入多 30 至 50 倍的單位數量。這 種做法的主要優點有三: 一、將記憶體置於單一晶片之上將可以使用很寬 的介面來提高記憶體的頻寬與降低記憶體的延遲時 間,同時也省去了接腳(pad)與排線(bus)的時間延遲。 二、因為從處理機核心到外部電路的存取次數減 少了,耗電量也相對的減少。 三、智慧動態隨機存取記憶體可有擁有多許多倍 的有效率介面(stream-lined interface),因為這些連續的 線是直接連到處理機核心來擴大基本輸入輸出的頻 寬,而不是透過有限制的接腳(pins)來和記憶體溝通。 然而,這種設計的方式將使的當記憶體大小不固定 時,設計的結果也要跟著改變。 4.3.2. 在 多 媒 體 通 訊 網 路 的 應 用 (Application on multimedia communication networ k)
由於目前 SOC 在影音多媒體通訊網路方面的設計 應用很多,而在通訊網路方面的重要特色已經發展成 為 點 對 點 連 續 資 料 流 的 即 時 處 理 (real-time processing),這與傳統的應用程式多用一般資料的向量 處理是迥然不同的,讓我們將這些特色明細如下: 一、即時回應(Real-time response):多媒體通訊需 要即時回應,有的時後為了能夠使輸出的資料更為流 暢,不惜丟掉一些來不及處理的資料,特別是在即時 影像傳輸的方面。
二 、 連 續 媒 體 資 料 型 態 (Continuous-media data type):多媒體應用程式的輸入資料多由一群取樣類比 訊號(sampling analog signal)的資料流所構成,這有別 於傳統應用程式處理非連續的資料。
三、顯明精細資料平行度(Significant fine-grained data parallelism):在以往的計算機架構上,多針對提高 指令層的平行度來做設計,以應傳統的程式需要,著 眼 於 高 度 的 超 存 量 指 令 發 出 (SuperScaler instruction issue) ,指令預測(instruction prediction) 或是預先攫取 (instruction prefetch)方面的硬體設計,非依序執行(out of order execution),暫存器改名(register renaming)等。 然而,在訊號與圖形處理方面卻是需要處理十分大量 相同資料型態的計算機硬體,所以如果使用 SIMD 的 方式來作硬體的設計能夠得到比較大的資料平行度, 也就是更寬的資料路徑。
四 、 支 援 引 線 平 行 度 (Parallelism for supporting threads):許多多媒體應用程式是由一些具有時間限制 的引線所組成的。這些引線將會帶來相當高的頻率, 很 深 的 管 線 (deep pipeline) 和 硬 體 方 面 多 引 線 (multithread)處理機和對稱(symmetric)多處理機。
五、高指令區域性(High instruction locality)以致小 迴圈(small loops):訊號與圖形的處理應用方面,小迴 圈的執行佔了主要的執行時間,所以如果能使迴圈的 執行速度增快將大幅增加整體的表現。
六、高記憶體頻寬(High memory bandwidth):許多 的媒體應用程式有非常大的資料量或是工作集,這就 是說在系統需要很高的記憶體頻寬前提下會遭受長時 間的記憶體延遲,但是快取記憶體對此現象並不會帶 來利益,資料的預先攫取或是資料往處理機核心傳遞 將會是更有效率的影響因素。 七 、 擴 充 資 料 的 重 組 (Extensive data reorganization):在 SIMD 的架構上,資料的重新組織 是必要的,因為這可以有效的提高純量架構的速度。 另外要再提的是,執行這些應用程式所須要的處理機 比較不算是一般用途的處理機,而且特別為訊號處理 而設計的。透過簡單架構的支援,新技術將整合處理 動態資料到一般性處理機的能力,使得在一般性處理 機在多媒體密集處理的能力上帶來明顯的增進。 此外,在 SOC 的架構上,探討其整顆晶片的耗電 大致上是以時派功率損耗(clock power consumption)為 主要耗電來源。SOC 即是包含多個 IP module 所組成, 而各個不同的 IP 其所需要的時脈也不盡相同。在這不 同的架構組合之下,需要不同的時脈驅動方式(clock driving method) : 在 此 提 出 兩 種 方 式 : (1) 單 一 驅 動 (Single Driver Scheme) (2)分散式驅動(Distributed Driver Scheme)[4]。
SOC 內各個 IP 模組的連線在未來是一個非常重要 的議題,就以往的 IC 設計而言,影響延遲的主因已經 由 邏 輯 閘 延 遲 (gate delay) 變 成 現 在 的 線路延遲(wire delay),更何況在 SOC 架構之下,連線(interconnection)
更是重要。在此有一新的 Bus 架構更是適用於 SOC 連 線 , 即 分 割 匯 流 排 (Segmented Bus ) 架 構 [12] 。 Segmented Bus 的優點是在大部份的時間中,只有部份 的匯流排是正在運作的,所以可以節省耗電,同時每 個叢集是獨立的,所以可以增加產能(throughput)。 因為 SOC 的盛行,使得設計趨向於以巨集為基礎 (macro-based)方法。這種方法使得在做邏輯驗證及邏 輯運算更加有利。在此,IBM 提出了三個對連接核 心、函式庫的匯流排架構,即:(1)Processor Local Bus (PLB); (2)On-Chip Peripheral Bus (OPB); (3)Device Control Register (DCR) Bus[13]。
在 SOC 製程中,由於是混合各式各樣的 IP blocks 或 cores ,logic unit 等等,所以在 SOC 的製作中,必須 有一個經過混合分析,都適合每一個 IP 的製程。例 如,DRAM 的製程不一定符合金屬層的製程。因此尋 求一個混合式且都符合不同技術的製程平台是發展 SOC 架構的一個重要議題。[5] 上面的分類是針對現今所存在的處理機及採用的 架構所預測的未來 GSI 架構的方向。由上面的分類可 以很清楚的看到未來一旦出現十億個電晶體的晶片 時,晶片上可能的架構會是處理單一複雜工作的處理 機(如(一)),或是由多個相同的單一處理機所組成的一 顆處理機,利用 Multi-threading 或 Multitasking 來達到 高 效 能 的 平 行 處 理 ( 如 (2)) 。 或 者 是 大 家 所 熟 知 將 RAM、I/O sub system、及 processor 放在同一個晶片上 的 SOC(如(3))。
4.4. Reconfigur able System 4.4.1. GARP 在 GSI 的廣大範疇之中,我們選出一個較具潛力 且有強大功能的系統來介紹,也就是 Reconfigurable system 中的 GARP 系統. 現在大多數的系統都會應用現成的 FPGA 來做為 特定應用程式的晶片來加速成品的效率;而一般而言 這種架構之下的 Bus System 大多都是依靠 I/O bus 來溝 通彼此之間的資料.然而雖然使用 FPGA 有其好處然 而有時它的低頻寬郤成為了有能力執行高速傳速之系 統的瓶頸.鑑於此,Garp 的出現正是可以解決這樣的 問題使得系統執行起來更加地流暢.實際上的 Garp System 是利用一個和處理器更為密切的 reconfigurable hardware 來 解 決 資 料 流 頻 寬 上 的 不足,當然,這個 reconfigurable hardware 當然是以特定應用程式運算為 主的晶片. GARP 的架構大致上可分為兩個部份,一為主要 處理器,這裡的處理器是以 MIPS 處理器為主而另一 部 份 則 是 撘 配 一 顆 Reconfigurable Hardware , 此 Reconfigurable hardware 主要是用來加速一般運算使用 為目的;在此,要發展此架構有幾個重點是我們必須 要注意的:
一 . 花 在 傳 輸 處 理 器 暫 存 器 和 reconfigurable hardware 的 多 餘 時 間 是 必 須 且 可 接 受 的 , 畢 竟 reconfigurable hardware 是我們所注重的,且發生這種 浪費時間的情況亦不多. 二.如同上面所說的,reconfigurable hardware 才 是我們的重點,鑑於此,我們必須允許它和記憶體做 直接的溝通,就好像是 DMA 一樣,並不需要處理器 多餘的關懷,否則處理器將成為一個嚴重的瓶頸. 三.為了配合程式運算,reconfigurable time 必須 短且迅速. 提供 reconfigurable hardware 和記憶體系統之間較 寬的匯流排不僅能提供快的資料傳輸,在此,亦可以 使 reconfiguration 的時間更有效率;Garp 有提供能處 理 reconfigurable hardware 的特定指令,處理器可依需 求載入所需的狀態至 reconfigurable hardware 以達到特 定的運算結構. 一般而言,reconfigurable hardware 運算時可分為 下列四個步聚 一.載入 configuration state 二.利用 coprocessor 指令拷貝初始狀庇暫存器至 reconfigurable hardware 三.開始執行,如果 configurable hardware 正在 執行其它運算則必須等候 四.將結果拷貝回處理器 發展一個新的架構,編譯器是絕對少不了的重 點,一個好的編譯器可以把一個具有高效能的系統發 揮得淋漓盡致.Garp 的編譯程式是以標準的 ANSI C 為主,所以編譯器選擇了既有的 SUIF C 編譯器來將 GARP 系統效能發揮到極致.一個新的架構當然會有 新的問題產生,針對 GARP 此架構,編譯器首要面臨 的挑戰即是如何利用 GARP 中的 reconfigurable array 來 加速運算.在此有兩個非常重要的問題:其一為如何 將程式放到 reconfigurable array 內執行,且合乎陣列的 規格要求;其二為如何開發程式的平行度,使得管線 化工作更加地有效率. GARP 遇到的問題同樣也發生在 VLIW 這個架構 身上,所幸 VLIW 已發展出一套較有系統的編譯流 程,也順利地解決了程式大小及平行度的問題. 要如何使得 GARP 更有效率?有下列普遍使用的 方法可以使得 GARP 在編譯或執行程式上更加順暢. 首 先 舉 出 的 是 “Speculative loads”,和某些架構一 樣,GARP 為了使程式本身更具有平行度,加了一些 硬體或軟體演算法對程式本身做預測,當然這些預測 本身後面也是有相當的風險,不過這些軟硬體足以彌 補錯誤發生時所造成的傷害;再來就是大家最常見的 管線化,故名思義,管線化也是為了開發更多的程式 平行度,使程式執行的速率能以倍數的增加;最後一 個方法則是利用硬體來模擬存取記憶體系統,這種做 法使得原本得用 reconfigurable array 來做的事轉稼到這 特別的硬體身上,這種做法讓 reconfigurable array 不需 花時間去控制存取記憶體系統,且可用來做其它的 事,可以說是事半功倍. 目前為止,reconfigurable hardware 大多是一些理 論和數據組合出來的架構,然而要將它製成可以使用 的晶片還是有一段路要走;再者,以 Moore’s Law 觀 點來看,Silicon size 的密度和電晶體的數目逐漸增加 中,加上製程的進步,Gigascale 的晶片系統已是不可 擋 的 趨 勢 了 , 趁 著 這 個 優 勢 , 發 展 出 具 有 Reconfigurable 的晶片系統應該是指日可待了. 4.4.2. RAW 現今 CPU 的架構中,像超純量(superscalars)因為 本身是利用硬體來做到 dynamic resolving instruction dependency 而進一步達到 parallelism,使得它已接近 performance 及 complexity 的極限。不但耗費硬體資 源,和 resolving 本身也有一定的難度,因此這個系統 設計上的瓶頸,要讓超純量的平行度再提升是一件很 難的工作。 而 RAW 這 個 系 統 是 一 個 強 調 簡 單 及 wire-efficient 的架構。它在硬體方面能夠隨著 VLSI gate 密 度的成長而保持成長,不會受到系統設計上的限制。 除此之外,RAW 藉著 compiler 的 static schedule 來達到 優質的 parallelism performance。
RAW chip 由眾多相同的 tiles 所組成。每一個 tile 中 包 含 了 像 RISC 處 理 器 中 有 的 ALU 、 Registers Bank 、 Data 和 Instruction memory 還 有 一 小 部 份 的 configurable logic 用來調整 tile 內部的溝通。而 tile 與 tile 之間是用一個稱為 Switch Logic 的電路來做連接, 它負責連接本身 tile 與東西南北的 tile。Switch Logic 可 以經由 compiler 的產生的指令來做 static 的 program。 另外 RAW 也提供以 flow-control 的方式針對 compiler 無法決定的正確 static schedule 的情況作動態的調整 switch Logic。
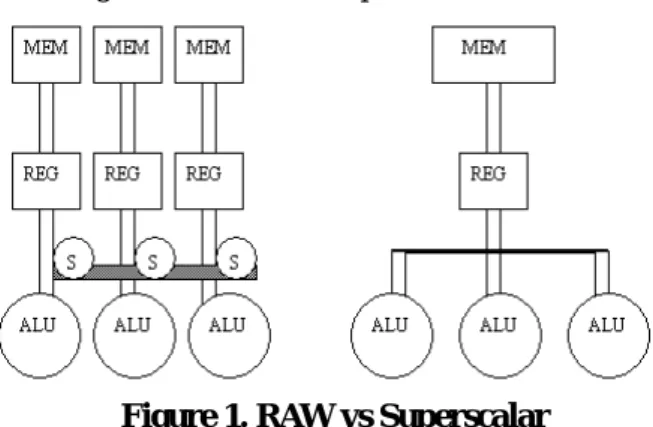
Figure 1.是 RAW 及 Superscalars 的比較圖。
RAW 的特色如下:
(1)Simple Replicated Tiles : RAW 由互相連結的 tiles 所構成。RAW focus 在保持每一個 tile 越小越好,
但是一個 RAW chip 上 tile 數量越多越好。可以藉由這 種優點來增加平行度及加快時脈速度。
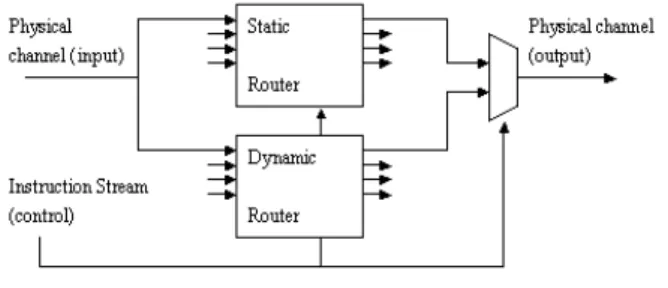
(2)Programmable Interconnect : Switch Logic 連接 tile 與 tile,這樣可以提供 tile 之間高頻寬以及低延遲通 訊 。 由 Figure 2. 可 看 到 physical wires 是 critical resource 。 Switch multiplexes 兩 種 不 同 的 logic network,分別是 static 及 dynamic network。
Static network 由 compiler 產生的指令控制,它將 switch input 連 接 到 正 確 的 output 位 置 。 因 為 communication patterns 是在 compile time 就完成,因此 不須要額外的 header interpretation,也就是沒有多餘的 routing overhead。若是有任何須要 communication 的動 作 卻 不 是 由 compiler route 及 schedule 的 , 則 使 用 dynamic network。經由 static 及 dynamic 的相互合作, 可增加 parallelism。
(3)Compiler System : RAW 的 compiler 目地是將以 high-level 語 言 所 寫 的 single-threaded (sequential) 或 multi-threaded (parallel) program map 至 RAW hardware。RAW 清楚的 parallel model 讓 compiler 能夠 直接的找出程式的 parallelism 並且描述它。
此 外,RAW 相較於其它架構有很多的優點: Tiles 間的溝通是藉由 interconnection 並且是 register level,因此 clock frequency 會較使用 global buses 的 chip 高。
(1)在 1 clock cycle 內所有 signal 所經過的距離不 會超過一個 tile 的寬度。
(2)Memory distributed across the tiles 將 降 低 memory bandwidth 的瓶頸並且在每一個 tile 中提供相當 低的 latency 至 memory module。
(3)大量的 distributed registers 將會減少 register renaming 的機率。
(4) 相 較 於 off-chip communication and DRAM latency,RAW 提供了 Higher internal switching speed。
(5)一個簡單的架構有利於快速進入市場。 (6)RAW 架 構 可 以 藉 由 調 整 FPGA-like configurable logic 成 為 multi-granular 來 達 到 FPGA computer 能夠做到的平行度。
(7)RAW 相較於 processor in memory 架構使用很 多小且低延遲的記憶體。
簡單的一句話就是 RAW 是一個由相同的 processing tiles 所構成的 software-exposed VLSI 架構。Compiler
system 能夠在 tile 間 static 的 schedule instruction-level parallelism。
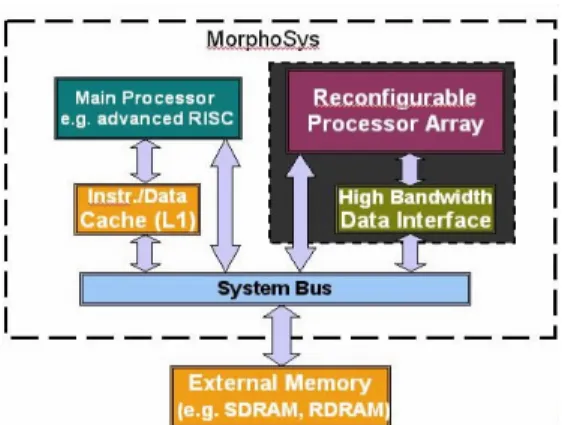
4.4.3. Mor phoSys Dynamically Repr ogr ammable Ar chitectur e(動態可重複程式化架構:適應計算的新趨 勢) (一)適應化晶片:這個晶片的目的是使的我們的電 腦能夠非常的配合我們所需要的應用,只要藉著動態 的規劃這個晶片,就可以讓我們的應用方面達到既快 又有效率的目的。 這個架構的提出,包含的幾個新的觀念: 1.動態可重複程式化架構必須在執行的時候因應 資料狀態的改變來作重複的程式化。 2.晶片上多個設定的路徑。 3.動態可重複程式化的記憶體陣列。 4.在 CAD 工具方面,也有所改變要有特殊的放置 (placement)與平面圖(floorplan)的運算方法,交互連線 的部分也是很重要的問題,因為連線有固定的型態。 5.在執行時的記憶體管理中心的設定,與系統表 現的量測與最佳化。 6.記憶體與執行資料流的動態再設定。 這個架構的產生,也產生對舊有架構的一些影響:1.系 統資源的分配變的比較容易。2.要讓晶片成為特殊用 途所用時,要調整比較簡單。3.在執行時,改變資料相依 的關係與功能以適應外部的環境,使的硬體可以成為 各種不同的應用的專屬硬體。 動態可重複程式化架構的優勢在於它可以適應的 應用方面廣泛,而且有較好表現,我們先拿一般用途 的運算機器做比較,雖然範圍更大,但是表現卻很 差。而 ASIC(Application-specific embedded systems)是 為某一特別的應用而製作,當然表現很好,但是他的 應用範圍就非常狹窄,也可以說是比較不經濟,所以 動態可重複程式化的新興架構成的最好的選擇,也讓 我們的設計變得更容易、更方便。 這個架構的名字叫 MorphoSys,可以先粗略的分 成三個部分:可重複設置的處理機陣列(Reconfigurable processor array),高頻寬資料介面(High-bandwidth data interface) , 與 主 流 處 理 機 (Mainstream processor) , 如 Figure 3.所示。
Figur e 2. Str uctur e of RAW switch
談到 MorphoSys 的運作方式,先了解他的資料來 源,從外部的 Main Memory Bank 經由一個在晶片內的 DMA 控 制 器 來 控 制 他 流 到 一 個 2blocks 、 16sets 的 context memory,而這個 DMA controller 則是由晶片內 的一個 TINY_RISC 的核心處理機(core processor)來控 制。而 TINY_RISC 如果要給可重複設置的單元陣列 (Reconfigurable Cell(RC) Array)資料的話,則要藉由控 制 DMA controller , 並 將 資 料 給 高頻寬的資料介面 (High-bandwidth data interface) 上 的 緩 衝 器 (Frame Buffer),藉由緩衝器將資料傳到可重複設置的單元陣 列,或是要求 context memory 將資料傳給可重複設置 的單元陣列。如 Figure 4.所示。
再來我們會談到 MorphoSys 的架構主要分成三個 部 分 : 可 重 複 設 置 的 陣 列 處 理機(Reconfigurable array processor):包含兩個部分 context memory
與 可 重 複 設 置 的 單 元 陣 列 (Reconfigurable Cell(RC) Array)。
1.高頻寬的資料介面(High bandwidth data interface): 包 含 兩 個 部 分 直 接 記 憶 體 讀 取 單 元 (DMA controller (Direct Memory Access, controller)) 與 緩 衝 器 (Frame Buffer)。
2.一般用途處理機(General purpose processor):包含 一 個 小 的 簡 化 指 令 集 核 心 處 理 機 (TinyRISC Core Processor)與資料快取記憶體(Data Cache) 。 這三個單元互相都有訊號的傳輸,但是在與外部 的單元部分,則是靠資料快取記憶體與高頻寬的資料 介面的緩衝器來與外部的主記憶體溝通。 我們先看可重複設置的陣列處理機(Reconfigurable array processor)的部分:
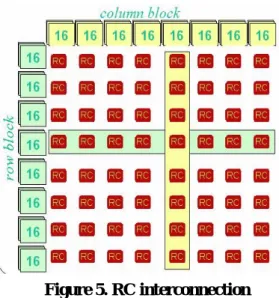
1. 可重複設置的單元陣列(RC array , Reconfigurable Cell Array): 8*8 個 RC array,也可以看成是 4 個 4*4 的 RCS,我們也稱他是 4 個 quads。
2. RC array 與 Context Memory 的關係: context memory 的 資 料 可 藉 由 廣 播 (Broadcast) 的 方 式 傳 到 每 個 Cell,把資料傳到某一列(row)或某一行(column), 再由某一列廣播到其他行,或是由某一行廣播到其
他列,所以我們把 Context memory 分成兩個區塊, 一 個 是 行 區 塊 (column blocks) 一 個 是 列 區 塊 (row blocks),共有每個區塊都有八組的 RC,也就是說 每個區塊控制一個列或是一個行,如此可以達到單 一指令多資料(Signal Instruction Multiple Data, SIMD) 的目的。
3. 4*4 RC array quad 的連線問題: 第一層是每個 RC 都 要 連 到 他 的 東 西 南 北 四 個 RC , 第 二 層 是 每 個 column 或是每個 row 的 RC 都需互相連線。
4. 整個 RC Array 就可以把四個 4*4 的 RC array quads 連起來,他們的連線方法是讓每個行都用垂直表現 巷道(Vertical express lanes),每個列都用水平表現 巷道(Horizontal express lanes),與三態緩衝器(tri-state buffer)來相連。
5. 每個 RC 的內部構造為兩個來源(source)的運算, source 可 由 資 料 匯 流 排 (Data Bus) 、 鄰 居 RC(Neighbor RCs)、暫存器(register file)這三個來源 而來,一個簡單的加乘法器(ALU,Multiple),移位 器(shift)與暫存器(register file)。
Figur e 3. Mor phoSys Ar chitectur e
我 們 再 看 一 般 用 途 處 理 機 (General purpose processor),他很單純,就是一個小的簡化指令集處
理機(TinyRISC),共切成 4 層:擷取層(Fetch Stage)、解 碼層(Decode Stage),執行層(Execute Stage),寫回層 (Write-Back Stage)。
最後談到高頻寬的資料介面(High bandwidth data interface)。緩衝器(Frame Buffer):分成兩個集合,每個集 合又分成兩個堆積(bank).Bank A 提供資料來源給 RC 的 source A,Bank B 提供資料來源給 RC 的 source B。 直接記憶體讀取單元(DMA controller (Direct Memory Access, controller)):由 TinyRISC 核心處理機控制,主記 憶體與緩衝器的資料直接溝通,也傳資料給 context memory。
根據我們的應用,先定出 RC array function, 經過 mView,會產生設定事件(configuration context),再經 過 mLoad 來產生事件庫(context library)。事件庫的資料 再用 mSched 轉成 VHDL 或其他硬體描述的檔案,經 過 Mulate 與 Morphosim 的 模 擬 後 , 就 可 以 寫 到 MorphoSys 的晶片上了。而我們寫的應用程式,必須 經過 MorphoSys “c” compiler 的編譯產生可執行檔來執 行。
MSched 是 kernel Scheduler,他要讓事件的再讀 取最小化,讓資料的重複使用率增高,而 RC 的運算 與資料的移動最大化,經過這些的需求,可以產生最 佳化的結果。 而這個架構的目標應用包含如下:影像處理:多媒 體影像壓縮、自動辨識、影響分析與醫學診療影像。 數位訊號處理:矩陣與陣列運算、FIR filters、Viterbi 編 碼解碼、FFT、DCT 與小波轉換。資料加密:DES、 IDEA、3-Way。 MorphoSys 設計方法在 CAD 工具上跟現有的要做 一個區別,TinyRISC 和 DMAC 可以用標準單位設計 (Standard Cell Design) , 可 是 RC Array 和 緩 衝 器 ,
context memory,資料快取記憶體與暫存器集,卻要用 客戶設計(custom Design),因為它的繞線是固定的(有 一定的規則),如果用一般 CAD 工具的繞線器,是繞 不出來的,而且慢又沒效率,所以我們用全客戶方式 的繞線,繞出來的結果小,而且又快。而電源訊號的 方式是用 H-tree 來繞線,最後做出來的設計延遲時間 為 10ns,面積為 1.5mm*1.0mm。 另外我們也可以合併多個 MorphoSys 而產生 meta-MorphoSys Architecture,這又是一個加強運算效能的 方法了。
5. 結論
可以預見的,未來的 IC designer 所要面對的問題將 與今日大大的不同,不論是在 chip 本身 core 的設計方 式或是 core 與外部各個 IP block 之間的聯繫,都將因 為硬體技術的發展,而面對前所未有的挑戰。不僅所 要考慮的層面因為技術層次的不同而有了重大改變, 單一晶片或是處理機的功能也將大大不同。設計者必 須以全新的觀念與思維來面對;另一方面,隨著硬體技 術突飛猛進,”電腦”或是所有的 電子設備(electrical device)都將對我們人類的生活產生越來越重要且不可 忽視的影響,人類的生活型態也將因為電腦系統能夠 達成的工作日益增加而產生重大的改變,一切都是因 為 GSI 時代的來臨,我們得以倚賴功能強大的卻輕薄 短小硬體設備來達成許多過去不敢想像的目標,不論 是在多媒體、通訊網路或是桌上型設備,能夠為人們 帶來的便利絕對是過去的我們無法觸及的世界。 不論是任何的系統晶片,或是 SOC 的整合,甚至 Reconfigurable System,目前都不算達到了真正成熟技 術的境界,因為硬體技術目前並沒有辦法看到邊界, 所謂的成熟技術也終將成為昨日黃花,而且世代交替 的速度也會越來越快,但是相關需要討論的課題卻是Figur e 6. meta-Mor phoSys Ar chitectur e
Figur e 5. RC inter connection
越來越多,不僅是因為硬體本身衍生出來的問題,應 用方面也將面對更多的可能性,身為現代資訊界的一 員,我們所要面對的挑戰正是無限寬廣卻充滿挑戰 性。每天都將會有新的技術或是應用問世,除了解決 其所衍生出來的新問題之外,如何將這些科技運用在 對於生活真正有益的方向才是最重要的課題。畢竟, 科技的本身若是不能跟人類的生活作結合,都將只是 沒有意義的符號和數字罷了。
參考文獻:
[1]Callahan,T.J.; Hauser, J.R.; Wawrzynek, J.," The Garp architecture and C compiler", Computer , Volume: 33 Issue: 4 , April 2000
Page(s):62-69
[2]Chai, S.M.; Gentile, A.; Wills, D.S.," Impact of power density limitation in gigascale integration for the SIMD pixel processor", Advanced Research in VLSI, 1999. Proceedings. 20th Anniversary Conference on, 1999, Page(s): 57 -71
[3]Chandra, A.; Chakrabarty, K.," System-on-a- chip test-data compression and decompression architectures based on Golomb codes ", Computer-Aided Design of Integrated Circuits and Systems, IEEE Transactions on , Volume: 20 Issue: 3 , March 2001 Page(s): 355 -368
[4]Chen, R.Y.; Vijaykrishnan, N.; Irwin, M.J., " Clock power issues in system-on-a-chip designs", VLSI '99. Proceedings. IEEE Computer Society Workshop On, 1999, Page(s): 48 -53
[5]Daeje Chin," Executing system on a chip: requirements for a successful SOC implementation", Electron Devices Meeting, 1998. IEDM '98 Technical Digest, International, 1998, Page(s): 3 -8
[6]Davis, J.A.; Venkatesan, R.; Kaloyeros, A.; Beylansky, M.; Souri, S.J.; Banerjee, K.; Saraswat, K.C.; Rahman, A.; Reif, R.; Meindl, J.D." Interconnect limits on gigascale integration (GSI) in the 21st century", Proceedings of the IEEE , Volume: 89 Issue: 3 , March 2001 Page(s): 305 -324
[7]Fritts, J.; Wu, Z.; Wolf, W.," Parallel media processors for the billion-transistor era", Parallel Processing, 1999. Proceedings. 1999 International Conference on, 1999, Page(s): 354 -362
[8]Hauser, J.R.; Wawrzynek, J." Garp: a MIPS processor with a reconfigurable coprocessor", Field-Programmable Custom Computing Machines, 1997. Proceedings., The 5th Annual IEEE Symposium on , 1997 Page(s): 12 -21
[9]Hounsell, B.I.; Arslan, T.," Programmable multiplierless digital filter array for embedded SoC applications", Electronics Letters , Volume: 37 Issue: 12 , 7 June 2001 Page(s): 735 -737
[10]Meindl, J.D." Gigascale integration: is the sky the limit?", IEEE Circuits and Devices Magazine , Volume: 12 Issue: 6 , Nov. 1996 Page(s): 19 -24, 32
[11]Meindl, J.D. " Interconnect limits on gigascale integration (GSI)", Plasma- and Process-Induced Damage, 2001 6th International Symposium on , 2001 Page(s): 1 -1
[12]Ohmi, T.; Sugawa, S.; Kotani, K.; Hirayama, M.; Morimoto, A. ," New paradigm of silicon technology", Proceedings of the IEEE , Volume: 89 Issue: 3 , March 2001 Page(s): 394 -412
[13]Remaklus, W.," On-chip bus structure for custom core logic designs ", Wescon/98, 1998, Page(s): 7 -14
[14]Seng, J.S.; Tullsen, D.M.; Cai, G.Z.N.," Power-sensitive multithreaded architecture", Computer Design, 2000. Proceedings. 2000 International Conference on, 2000, Page(s): 199 -206
[15]Shi Yuanyuan; Liu Jia; Liu Runsheng," Single-chip speech recognition system based on 8051 microcontroller core ", Consumer Electronics, IEEE Transactions on , Volume: 47 Issue: 1 , Feb. 2001 Page(s): 149 -153
[16]Singh, H.; Ming-Hau Lee; Guangming Lu; Kurdahi, F.J.; Bagherzadeh, N.; Chaves Filho, E.M. " MorphoSys: an integrated reconfigurable system for data-parallel and computation-intensive applications", Computers, IEEE Transactions on, 2000, Page(s): 465 -481
[17]Vahid, F.; Givargis, T.," Platform tuning for embedded systems design", Computer, Volume: 34 Issue: 3 , March 2001 Page(s): 112 -114
[18]Waingold, E.; Taylor, M.; Srikrishna, D.; Sarkar, V.; Lee, W.; Lee, V.; Kim, J.; Frank, M.; Finch, P.; Barua, R.; Babb, J.; Amarasinghe, S.; Agarwal,A." Baring it all to software: Raw machines", Computer, Page(s): 86 -93 [19]Weinhaudt, M.; Luk, W.," Memory access optimisation for reconfigurable systems", Computers and Digital Techniques, IEE Proceedings- , Volume: 148 Issue: 3 , May 2001 Page(s): 105 -112
[20]Yan Zhang; Wu Ye; Irwin, M.J.," An alternative architecture for on-chip global interconnect: segmented bus power modeling", Signals, Systems & Computers, 1998.
Conference Record of the Thirty-Second Asilomar Conference on Volume: 2, 1998, Page(s): 1062 -1065 vol.2
[21]Zarkesh-Ha, P.; Meindl, J.D.," Optimum on-chip power distribution networks for gigascale integration (GSI)",Interconnect Technology Conference, 2001. Proceedings of the IEEE 2001 International , 2001 Page(s): 125 -127