國 立 交 通 大 學
電信工程研究所
博 士 論 文
高效率之球型解碼演算法及其應用
Highly Efficient Sphere Decoding
Algorithm and Its Applications
研 究 生:黃崇榮
指導教授:李大嵩 博士
高效率之球型解碼演算法及其應用
Highly Efficient Sphere Decoding Algorithm and
Its Applications
研究生:黃崇榮
Student:
Chung-Jung
Huang
指導教授:李大嵩 博士 Advisor:
Dr.
Ta-Sung
Lee
國立交通大學
電信工程研究所
博士論文
A Dissertation
Submitted to Institute of Communication Engineering
College of Electrical and Computer Engineering
National Chiao Tung University
in Partial Fulfillment of the Requirements
for the Degree of Doctor of Philosophy
in
Communication Engineering
September 2013
Hsinchu, Taiwan, R.O.C.
高效率之球型解碼演算法及其應用
學生:黃崇榮
指導教授:李大嵩 博士
Chinese Abstract
國立交通大學電信工程研究所
摘要
多輸入多輸出系統中,高效率且低功率消耗之接收機的設計為關鍵議題之ㄧ。 在本論文中,吾人首先以K-Best 解碼器為基礎,提出一個適用於大型積體電路架 構的高性能球型解碼器。利用複數平面星座圖的規律特性來簡化路徑長度計算及 排序,達到省卻大量資料排序動作及路徑值的運算需求,進而實現一個高效率且 具有固定吞吐量的解碼器;更進一步針對傳統 K--Best 解碼性能的缺失,藉由所 提出的一種新型搜尋策略可提供接近於最大似然搜尋之解碼性能。接著,吾人針 對廣義之多天線之欠定系統,提出具有低解碼複雜度的解碼器。該解碼器包含了 兩個步驟:1.藉由所提出的高效率的平面候選點搜尋器將所有所需的候選點一一 找出。2.針對這些候選點集合進行平面交集的動作並配合動態半徑調整機制來快 速地找出該問題的解。接著,一個可與所提出解碼器結合之通道矩陣行向量的排 序策略亦被提出。進而提供低運算需求及近似最大似然搜尋的解碼性能。吾人亦 針對排序策略所對應的運算降低率提出一套系統化的數學分析分法。 最後,吾人 針對上傳鏈結系統之多點協同傳輸系統中的碼簿搜尋問題,提出具有極低運算複 雜度之演算法。首先,吾人根據矩陣運算理論,提出一個塊狀 QR 分解程序,能 順利將原搜尋問題轉化成尋找最長路徑之命題。接著,運用所提出的修正K-Best 解碼器便能以極低的運算量完成碼簿搜尋且仍保有極佳的系統性能。經由電腦模 擬驗證本論文所提出的演算法及架構皆能提供優越的解碼性能及較低的運算需 求,極適用於下世代之寬頻無線通訊系統。Highly Efficient Sphere Decoding Algorithm and Its
Applications
Student: Chung-Jung Huang
Advisor: Dr. Ta-Sung Lee
English Abstract
Institute of Communications Engineering
National Chiao Tung University
Abstract
In this dissertation, a low complexity near-ML K-Best sphere decoder is proposed as the first part. The development of the proposed K-Best sphere decoding algorithm (SDA) involves two stages. First, a new candidate sequence generator (CSG) is proposed. The CSG directly operates in the complex plane and efficiently generates sorted candidate sequences with precise path weights. Using the CSG and an associated parallel comparator, the proposed K-Best SDA can avoid the computational complexities in the large amount of path weight evaluations and sorting. Then a new search strategy based on a derived cumulative distribution function (cdf) and an associated efficient procedure is proposed. With the above features, the proposed SDA can provide near ML performance with the lower complexity than conventional K-Best SDAs. Afterwards, a novel decoder with low decoding complexity is proposed for underdetermined MIMO systems. The proposed decoder consists of two stages. First, an improved slab decoding algorithm is adopted to efficiently obtain valid candidate
optimal solution by conducting intersections on the obtained candidate set with dynamic radius adaptation. Furthermore, an optimal preprocessing technique is proposed from the geometrical perspective and the comprehensive analysis on the complexity reduction is also provided. The proposed decoder incorporating preprocessing scheme offers a low (non-exponential) computational complexity and near-ML decoding performance for underdetermined MIMO systems, particularly with large number of antennas and/or high-order constellations. Finally, a tree based codebook search algorithm for uplink (UL) coordinated multipoint (CoMP) systems is proposed. The codebook search issue can be reformulated as a tree search form and the solution can be obtained efficiently using a modified K-Best enumeration strategy. The proposed approach provides the advantage of low computational complexity and nearly the same performance of the exhaustive search algorithm, especially when the CoMP size is significant. Simulation results show that these proposed algorithms can significantly reduce the computational complexity and maintain system performance, which provide a promising solution for future wireless communication systems.
Acknowledgement
I wish to express my deepest gratitude for the guidance, support and constructive criticism to my advisor Dr. Ta Sung Lee, whose elegant way of approaching problems has considerably influenced my research and working style. I especially want to thank Dr. Wei-Ho Chung from Academia Sinica for many helpful suggestions, valuable comments and writing improvement.
I want to thank the all members of the Communication System Design and Signal Processing (CSDSP) Lab for sharing their knowledge and inspiring discussion.
I also thank my mother, parents-in-law, brothers and friends for their encouragement and continual support. Finally, I thank my adorable children CoCo and Jim and my lovely wife Amy, who always stood by me during frustrating and hard times, and without whom this work would not have been completed.
Table of Contents
Chinese Abstract ... i
English Abstract ... ii
Table of Contents ... v
List of Figures ... viii
List of Tables ... xi
Acronym Glossary ... xii
Notations ... xv
Chapter 1 Introduction ... 1
1.1 Basics of Multi-Antenna Systems ... 1
1.2 Basics of MIMO Decoder ... 2
1.3 Related Literature Review ... 4
1.4 Main Contributions ... 9
1.5 Organization of Dissertation ... 10
Chapter 2 Efficient Search Algorithm for Over- determined
MIMO systems ... 12
2.1 Overview ... 12
2.2 Signal Model ... 13
2.3 Proposed Sorting Algorithm and Hardware Architecture ... 18
2.3.1 Candidate Sequence Generator in Complex Plane ... 18
2.3.3 Complexity Advantages ... 28
2.4 Proposed Search Strategy for Near-ML Performance ... 29
2.4.1 Preprocessing with Column Permutation ... 29
2.4.2 Proposed Search Strategy ... 30
2.4.3 Joint 2-Layer ML Search Algorithm ... 34
2.5 Computer Simulation and Discussions ... 38
2.6 Summary ... 48
Chapter 3 Geometry Based SDA for Under- determined MIMO
systems ... 50
3.1 Overview ... 50
3.2 Signal Model for Underdetermined SDA ... 51
3.3 Proposed Decoding Algorithms for Underdetermined Systems ... 54
3.3.1 An Efficient Slab Search (ESS) Algorithm ... 55
3.3.2 A Multi-slab Sphere Decoding (MSSD) Algorithm ... 57
3.4 Proposed Preprocessing Technique for Complexity Reduction ... 60
3.4.1 A Preprocessing with Column Permutation ... 60
3.4.2 Complexity Analysis ... 64
3.5 Computer Simulation and Discussions ... 69
3.6 Summary ... 76
Chapter 4 Efficient Search Algorithm for Codebook Search in
Uplink CoMP Systems ... 77
4.1 Overview ... 77
4.2 Signal Model ... 78
4.4 Simulation Results ... 85
4.5 Summary ... 88
Chapter 5 Conclusions and Future Works ... 91
5.1 Summary of Dissertation ... 91
5.2 Future Works ... 92
APPENDIX ... 94
List of Figures
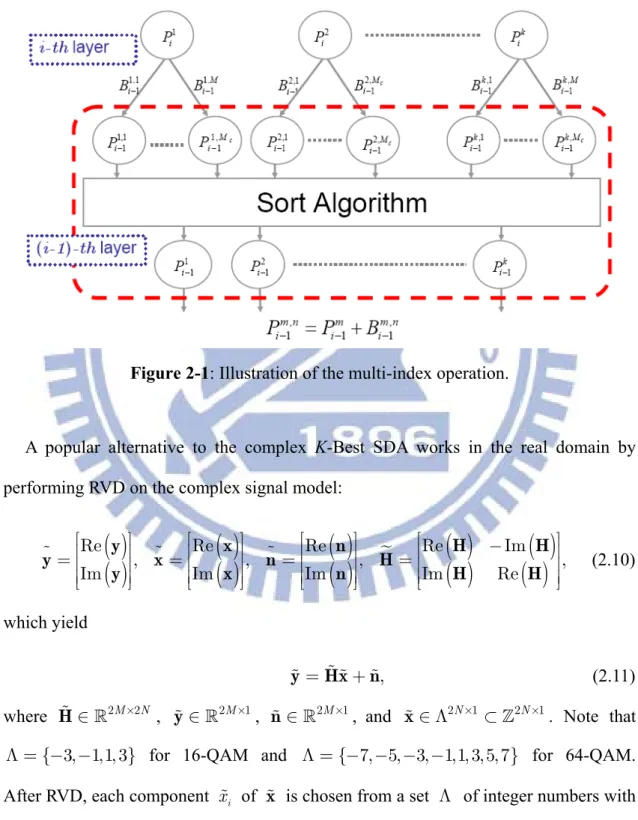
Figure 2-1: Illustration of the multi-index operation. ... 17
Figure 2-2: Modulo operation of the search center. ... 20
Figure 2-3: Partition of the search segments. ... 20
Figure 2-4: (a) Modulo unit of Re
( )
" i y . (b) Transformation unit of " , i M y . ... 23Figure 2-5: Hardware architecture of the candidate generator. ... 25
Figure 2-6: Illustration of the HPPC operations. ... 26
Figure 2-7: HPCC architecture. ... 27
Figure 2-8: Search constraints of the Nth layer with ' d = 1.1. ... 32
Figure 2-9: Cdf curves of 2 , , o i i r . (a) 4x4 MIMO channel. (b) 8x8 MIMO channel. ... 32
Figure 2-10: Geometrical relationship illustrating the adopted property ... 35
Figure 2-11: Performance of complex K-Best SDA for 4x4 MIMO systems. (a) 16-QAM modulation. K = 4 and 8 for complex K-Best SDA incoporating proposed CML strategy; K = 4, 8, and 12 for regular complex K-Best SDAs. (b) 64-QAM modulation. K = 4 and 12 for complex K-Best SDA incoporating proposed CML strategy; K = 4, 12, and 24 for regular complex K-Best SDAs. ... 41
Figure 2-12: Performance and complexity of SDA for 4x4 MIMO systems with 16-QAM modulation. (a) SER. (b) Complexity. K = 8 for K -Best SDAs. ... 42
Figure 2-13: Performance and complexity of SDA for 4x4 MIMO systems with 64-QAM modulation. (a) SER. (b) Complexity. K = 8 for K -Best SDAs. ... 43
Figure 2-14: Performance and complexity of SDA for 8x8 MIMO systems
with16-QAM modulation. (a) SER. (b) Complexity. K = 14 for K -Best SDAs. ... 45
Figure 2-15: Performance and complexity of SDA for 8x8 MIMO systems with
16-QAM modulation. (a) SER. (b) Complexity. K = 32 for proposed K -Best SDA; K = 32 and 52 for conventional K -Best SDAs. ... 47
Figure 3-1: Geometrical diagram of slabs with different y . ... 61
Figure 3-2: SER performance comparisons of SSD, ML and proposed decoder with
16-QAM modulation for various MIMO configurations. ... 71
Figure 3-3: SER performance and complexity comparisons of SSD, ML and proposed
decoder with 64-QAM modulation for various MIMO configureations. (a) SER; (b) Complexity. ... 72
Figure 3-4: Probability density function of ' M
y with various ordering rules with
16-QAM (4,2) MIMO configuration at SNR=15dB. ... 73
Figure 3-5: The comparison of the averaged complexity reduction ratio for various
ordering rules. ... 73
Figure 3-6: Performance and complexity comparisons of the proposed decoder
incoporated with and without greedy reordering scheme with 64 QAM
modulation ... 75
Figure 4-1: Illustration of centralized UL CoMP system model ... 79 Figure 4-2: Illustration of centralized UL CoMP system model. ... 80 Figure 4-3: Sum-rate performance and complexity of the proposed and exhaustive
search methods with Nt=4, Nr=4, M=3, P=1, d1=2, d2=3, and d3=4. ... 87
List of Tables
Table 2-1: LIST OF CANDIDATE SEQUENCES ... 22
Table 2-2: COMPUTATIONAL COMPLEXITY OF PROPOSED K-BEST SDA (EXCLUDING INTERFERENCE CANCELLATION) ... 37
Table 2-3: COMPUTATIONAL COMPLEXITY OF CONVENTIONAL K-BEST SDA IN REAL DOMAIN (EXCLUDING INTERFERENCE CANCELLATION) ... 38
Table 4-1: THE PROPOSED BLOCK QRDECOMPOSITION ... 88
Table 4-2: APROPOSED CODEBOOK SEARCH ALGORITHM USING K-BEST ENUMERATION ... 90
Acronym Glossary
3GPP third generation partnership project
AWGN additive white Gaussian noise
BS base station
BQRD block QR decomposition
CA carrier aggregation
CAS compare-and-select
cdf cumulative distribution function
CML conditional-ML
CoMP coordinated multipoint
CP central processor
CSG complex sequence generator
CSI channel state information
D-BLAST diagonal Bell laboratories layered space-time
DLSD double layer sphere decoding
ESS efficient slab search
FP Fincke and Pohst
GS Gram-Schmidt
GSD generalized sphere decoder
HPCC highly-parallel comparison circuit
ICI inter-cell intererence
LTE long term evolution
MIMO multiple-input multiple-output MISO multiple-input-single-output ML maximum-likelihood
MMSE minimum mean-square error
MSSD multi slab sphere decoding
MU multi-user
PDA plane decoding algorithm
pdf probability density function
PED partial Euclid distance
PSASR partial sum of achievable sum-rate
RVD real-value decomposition
RRH remote radio head
SDA sphere decoding algorithm
SE Schnorr and Euchner
SER symbol error rate
SIC successive interference cancellation
SINR signal to interference and noise ratio
SLA slab decoding algorithm
SNR signal to noise ratio
SSD slab sphere decoder
SVD singular value decomposition
UE user equipment
UL uplink
V-BLAST vertical Bell laboratories layered space-time
WiMAX Worldwide Interoperability for Microwave Access ZF zero-forcing
Notations
é ù⋅ ceiling operator ( )⋅ * conjugate operator { } E ⋅ expectation operator ë û⋅ floor operator( )⋅ † Moore-Penrose pseudo-inverse operator
[ ]⋅ rounding operator ( )⋅-1 inverse operator ( ) Q ⋅ quantization operator ( )⋅ T transpose operator C search radius H channel matrix r
N number of receive antennas
c
M constellation size
t
N number of transmit antennas
P transmit power
n noise vector
g average SNR at the receiver
x transmit signal vector
y received signal vector
m qk
H channel between the qth receiver and the kth UE in cell m
(m-1)P k+
(m-1)P k+
x
transmitted signal vector for the kth UE in cell m T
d number of total transmit data streams
sum
R achievable sum-rate
( )i
X the ith column of matrix X
{ }j i
X matrix consists of the ith column to of jth column of matrix X
( )
diag block diagonal matrix stacking operator
( )
tr trace operator
Chapter 1
Introduction
In this introductory chapter, background materials about multi-antenna systems and well-known decoding algorithms are presented. The following sections include the literature survey, dissertation contribution and overview of this dissertation.
1.1 Basics of Multi-Antenna Systems
Next generation wireless communication systems are expected to provide users with higher data rate services for video, audio, data, and voice signals. Many innovative techniques have recently been proposed to improve the spectral efficiency and reliability of wireless communication links. Examples include coded multicarrirer modulation, smart antennas, multiple-input multiple-output (MIMO) technology and adaptive modulation.
Among these technologies, MIMO technology has attracted substantial research and industrial interests. The MIMO technology involves the use of multiple antennas at both sides to provide more reliable communication link and/or higher spectral efficiency[1-3]. The theoretical analyses show that the MIMO system capacity linearly increases with the minimum value of the number of transmitting and receiving antennas [2]. As a result, the MIMO technology has been recognized as one of the most promising solutions for future wireless communication systems. There are two underlying techniques in MIMO system: spatial multiplexing [6] and diversity techniques [3]. Spatial multiplexing offers a linear increase of data rate by transmitting multiple independent data streams at the same time.
Spatial diversity provides diversity gain to mitigate fading effects by using the multiple (ideally independent) copies of the transmitted signal. They are usually trade-offs in the two techniques which provide an effective and promising solution while achieving high-data rate and reliable transmission.
The MIMO technology has been widely adopted in the next-generation wireless communications such as IEEE 802.16 and Third Generation Partnership Project (3GPP), Long Term Evolution (LTE), and LTE-advanced (LTE-A) systems.
1.2 Basics of MIMO Decoder
Multiple-antenna systems employing spatial multiplexing increase the spectral efficiency. However, this improvement comes at the cost of an increased receiver complexity. Finding the well balanced trade-off between communications performance and implementation complexity in MIMO detection is one of the key challenges in the receiver design.
The optimal detector for MIMO systems is the maximum likelihood (ML) detector, which search all possible combinations of transmitted symbols. The number of possible combinations increases exponentially with the number of antennas and the size of the legal modulation symbol set. Therefore, it is difficult to be implemented at the receiver in practice. As a remedy, many suboptimal detection algorithms have been developed with desired trade-off between performance and complexity. They can be divided into the following classes.
Linear MIMO Detection
Zero-Forcing (ZF) and minimum mean square error (MMSE) filters apply linear operations to the received signal in order to restore the transmitted signal. These linear filters can be implemented at a low complexity; however, their communications
performance is poor. The MMSE filter considers the noise power in the interference cancellation and therefore shows a slightly better performance.
Successive Interference Cancellation
The successive interference cancellation (SIC) technique was initially adopted by the vertical Bell Laboratories layered space-time (V-BLAST) system [4] - [7-8]. In contrast to the basic ZF and MMSE filters, SIC detects the transmitted streams sequentially and then removes the interference of each detected stream from the received data before continuing the detection process. The performance of the SIC algorithm is generally better than ZF and MMSE filters.
Breadth-First Tree Search Algorithms
For further improvement of the communications performance, the MIMO detection problem can be mapped on a tree search. Tree search algorithms can be divided into breadth-first and depth-first search algorithms. Breadth-first algorithms can potentially provide a constant throughput with slight performance loss compared to an optimal
detection. Among these techniques, the K-Best enumeration strategy is the most popular
approach. While traversing the tree, the K-Best detector always retains the K best nodes
in each search level. This additional sorting operation causes extra computational complexity. In general, the decoding performance of breadth-first algorithms depends on the number of survival nodes chosen in each search layer.
Depth-First Tree Search Algorithms
The main idea of depth-first search is to apply pruning criteria to remove parts of the tree in the search to reduce the computational complexity. The typical sphere detectors can achieve the same decoding performance of ML detector with significant complexity reduction. Due to the nature of the depth-first search, their throughput is usually variable.
The sequential tree search order makes it difficult to parallelize the detection. There exist many sub-optimal variants regarding enumeration technique, pruning criterion, or simplified metric calculations to obtain desired trade-off between performance and complexity.
1.3 Related Literature Review
As the aforementioned, linear detection and SIC scheme are simple to implement, but their detection performance is far from optimal. ML detection is the optimal detection scheme, but its complexity grows exponentially with the size of the transmitted symbol alphabet and number of transmit antennas. To reduce the complexity of ML detection, the sphere decoding algorithm (SDA) has been introduced to achieve the same performance as ML detection with reduced complexity [9]-[12]. The SDA has received considerable attention as an effective detection scheme for MIMO systems.
The basic idea of the SDA is to locate the lattice point nearest to the received signal vector within a given sphere radius. In doing so, the SDA transforms the original problem into a tree search problem. Some candidate enumeration strategies have been proposed [9]-[12]. In the work by Fincke and Pohst SDA (FP-SDA) [9], [10], the radius is set as a scaled variance of the noise. If no lattice points satisfy the radius constraint, the algorithm increases the search radius and restarts the search. The Schnorr and Euchner SDA (SE-SDA) [12] is a variant of the FP-SDA. It shows that enumerating candidate symbols in ascending order based on their distance from the Babai estimate [13] (nulling-canceling solution) speeds up the tree search. This approach is likely to find the optimal solution faster than the FP-SDA and hence can reduce the computational complexity. With these efforts, the conventional SDA is still too
complex in the low SNR regime and its decoding throughput is not stable in general. Hence, it is not desirable for real time detection and hardware implementation. Previous works [14]-[16] proposed some architectures to explore the parallelism property of VLSI to improve the decoding throughput. These designs exhibit excellent performance in the higher SNR regime.
To overcome the drawbacks of the conventional SDA, the K-Best SDA has been
introduced in [17]-[19]. The K-Best SDA uses a breadth-first search and keeps the
K-Best candidates of each layer for the search of the next layer. Briefly, the main idea
of the K-Best SDA is to keep only K candidates which have the smallest path weights
as the most promising solutions. Hence, the decoding throughput of the K-Best SDA is
stable. Unfortunately, applying a sorting algorithm to find the K-Best candidates in
each layer requires many computational operations and a long decoding latency.
Moreover, the value of K must be large enough to achieve near-ML performance, and
this would increase the computational complexity, decoding latency, and implementation cost.
Sorting is a critical factor in reducing the complexity of a K-Best SDA. In [17] the
bubble sort algorithm is applied to conduct sorting. More efficient sorting algorithms [18], [19] have also been adopted to reduce computational complexity. Recently, a high
efficiency sorting architecture has been proposed, which can sort K values of partial
Euclidean distances in K/2 clock cycles [20]. It is found that the quick sort algorithm
[18] is not always more suitable than the bubble sort algorithm for a small value of K.
Some efficient early-pruning schemes have been proposed in [18], [21] which eliminate the survival candidates that are unlikely to become ML solutions in the early search layers. The approach in [22] reduces the number of candidate nodes by adopting
dynamic K values according to the index of search layers. The above approaches can
due to that the ML solution can possibly be dropped.
To solve the above performance problem, the method presented in [23] always conducts the ML search in several preceding search layers, where ML search refers to an exhaustive search in a certain layer. In this case, the operation in the remaining
layers is the same as the conventional K-Best SDA. This approach is a special case of
the dynamic-K method, and increases complexity and power consumption significantly.
In general, it is not necessary to perform the ML search especially when the channel
condition is good. The method proposed in [24] chooses the optimal K dynamically
according to the channel condition. An approximated algorithm [25] has been proposed to estimate channel conditions in an efficient way. Nevertheless, these methods require complicated procedures and some extra circuits. To the best of our knowledge, there are no efficient mechanisms for deciding the number of layers in which the ML search is
conducted, or whether to perform the ML search under different K values and antenna
numbers.
Most of the SDAs developed so far work in the real domain using the real-valued decomposition (RVD) [17], [26]-[27]. Although the real domain approaches lead to better performance and lower complexity, they require more search layers than the complex domain approaches [28], [29]. To reduce the number of search layers, some novel search methods which operate in the complex plane have been proposed [30], [31]. These methods introduce errors when evaluating path weights, which achieves the goal of reducing complexity but sacrificing performance significantly. On the other hand, some communication systems require rotating the constellation by a pre-defined angle before transmitting symbols to achieve a higher diversity gain. In this case, conventional real domain SDAs cannot be adopted directly, and some extra and complicated techniques are needed. To tackle these issues, a new SDA directly performing in the complex domain is desired.
Afterwards, we will consider an underdetermined MIMO system commonly existing in multi-user (MU) uplink transmission of 3GPP LTE/LTE-A or Mobile WiMAX where the number of users exceeds that of receiving antennas at the base station and decoupling the spatial signals from these users encounters difficulties due to insufficient number of receive antennas. In this circumstance, conventional SDAs are unable to identify a unique solution for the underdetermined MIMO systems. To overcome the aforementioned drawback of SDA, certain novel decoders have been
proposed. First, the generalized sphere decoder (GSD) [42] performs an exhaustive
search on specified dimensions to find the ML solution. Its decoding complexity increases with the constellation size and the difference between transmit-receive antenna numbers. Based on GSD, other efficient decoders have been proposed, such as the regularized sphere decoder [43]-[45], tree-search approach [46], [47], double-layer sphere decoder (DLSD) [48], [49], and slab sphere decoder (SSD) [50], [51]. In [43], the authors convert the original problem into an overdetermined form by the regularization technique with a constant modulus constellation constraint, and then apply the conventional SDA to obtain a near ML solution. Later, the works in [44] reformulate this approach to remove the constant modulus constraint for generalized M-QAM systems. In [46], authors propose an efficient tree-search decoding algorithm for binary constellation systems and extend this algorithm to M-PSK systems in [47]. This modified algorithm needs to decompose the constellation into a weighted sum of QPSK constellations for M-QAM systems. As a result, the decoding complexity increases rapidly with the size of transmit-receive antenna number difference and/or constellation. The DLSD utilizes an outer sphere decoder to find a valid candidate set, and an inner sphere decoder to find the ML solution. The SSD adopts a geometrical approach for finding the valid candidate set to reduce the search complexity of DLSD. Both DLSD and SSD need to perform the conventional SDA sequentially, so their
complexity remains an issue. Besides, algorithms for coded MIMO systems [52], hybrid approach [53] or heuristic search method [54] tackle the MIMO system from
different perspectives. Comparing the results in [42]-[51], it is evident that the SSD
exhibits the lowest complexity for the large constellation and is thus chosen as a benchmark. Unfortunately, as shown in [51], the decoding complexity increases rapidly with the size of transmit-receive antenna number difference and/or constellation; therefore, developing efficient decoding algorithm is still an active research field for practical applications.
Finally, we intended to consider a codebook search problem in Uplink Coordinated multipoint (CoMP) systems. CoMP has been adopted in LTE-A to improve the cell average and cell edge throughputs [61]. It uses the cooperation between points in several cooperation groups to coordinate the transmission for inter-cell interference (ICI) alleviation and link quality enhancement. An attractive CoMP scheme referred to as centralized CoMP, is a full cooperation approach that involves full channel state information (CSI) and full data information for providing improved performances. The full cooperation scheme between base stations (BS) and remote radio heads (RRH) is applicable in LTE-A because of the dedicated fiber links. In uplink (UL) centralized CoMP systems, cooperating BSs forward received signals and CSI to a central processor (CP), which computes the corresponding precoder matrix for each user equipment (UE). Therefore, the CP needs to feed back the exact precoder matrix to each UE, which is inefficient and impractical. A codebook-based scheme that feeds back only the precoder matrix index (rather than the matrix itself) is adopted as a remedy in real applications. Centralized CoMP with MIMO has attracted significant attention, and there are numerous studies that focus on the optimal precoder design [62-63]. However, efficient codebook search algorithms for the aforementioned scenario are uncommon. It is noted that, to the best of our knowledge, the issue remains
scarce in the literature.
1.4 Main Contributions
The contributions of this dissertation are summarized as follows:
1. A simple and efficient complex domain candidate sequence generator (CSG) is proposed. By combining the proposed CSG with an efficient sorting architecture, the proposed decoder can significantly reduce path weight calculations and comparison operations without sacrificing detection performance. Moreover, to address the performance issue, a new search strategy that incorporates the ML search in the preceding layers under poor channel conditions improves the performance of the
proposed K-Best SDA even when the value of K is small. A judicious criterion is
proposed that helps determine fewer ML search layers. Furthermore, an efficient search procedure is also proposed that fully utilizes existing hardware elements. Combining
the above features, the proposed K -Best SDA exhibits lower complexity, excellent
performance, and is well-suited to real-time applications.
2. We further develop an efficient decoder from the geometrical perspective for he underdetermined MIMO systems. The proposed decoder consists of two stages. First, an improved slab decoding algorithm is adopted to efficiently obtain valid candidate points within a given slab. Next, a multi-slab based decoding algorithm finds the optimal solution by conducting intersections on the obtained candidate set with dynamic radius adaptation. Furthermore, an optimal preprocessing technique is proposed from the geometrical perspective and the comprehensive analysis on the complexity reduction is also provided. The developed procedure can be applied to any static ordering rule even in non-linear ordering rule for QR based MIMO decoder.
codebook search algorithm for UL CoMP systems. To break the interdependency among user equipments (UEs), a generalized blockwize QR decomposition procedure is proposed. By the proposed generalized block GS decomposition, the original codebook search problem can be reformulated as a problem of finding the longest path and be solved efficiently by conducting a tree search. To efficiently obtain this solution,
a modified K-Best algorithm is also proposed. The proposed algorithm provides a
significant improvement by one order of computational efficiency and provides a near ML performance compared to the exhaustive approach.
1.5 Organization of Dissertation
The remaining of this dissertation is organized as follows.
In Chapter 2, we will propose a low complexity near-ML K-Best sphere decoder.
The proposed K-Best sphere decoding algorithm involves two stages. First, a new
candidate sequence generator (CSG), which operates in the complex plane and efficiently generates sorted candidate sequences with precise path weights, is proposed.
Using the CSG and an associated parallel comparator, the proposed K-Best SDA can
avoid performing a large amount of operations. Next, a new search strategy based on a derived cumulative distribution function (cdf) and an associated efficient procedure is proposed. By incorporating detection ordering into the proposed SDA, it can provide near ML decoding performance with a lower complexity requirement than conventional
K-Best SDAs.
In Chapter3, We further consider an underdetermined MIMO system and propose an efficient decoder from geometry perspective. The underdetermined MIMO systems can be found in the multi-user (MU) uplink transmission of 3GPP LTE/LTE-Advanced or Mobile WiMAX where the number of users exceeds that of receiving antennas at the
base station and decouples the spatial signals from these users encounter difficulties due to insufficient number of receive antennas. To tackle the problem, we will propose a geometry-based efficient decoder for underdetermined MIMO systems. The proposed decoder involves two stages. First, an improved slab search algorithm efficiently obtains valid candidate points within a given slab. Next, a multi-slab based decoding algorithm finds the optimal solution by taking intersections of the obtained candidate set with dynamic radius adaptation. By doing so, there is no need to perform SDA sequentially. The proposed decoder can thus provide near ML performance with much lower (non-exponential) complexity compared to the state-of-art methods. Furthermore, we propose an optimal preprocessing technique from the geometrical perspective and conduct comprehensive analysis on the complexity reduction. By introducing the proposed preprocessing scheme, the incorporated decoder can significantly reduce the decoding complexity in the low SNR regime without sacrificing performance. The advantage is useful and suitable for practical MU-MIMO operations.
In Chapter 4, we try to apply tree search techniques to solve codebook search problem in Uplink CoMP systems. CoMP techniques has been adopted in LTE-A to improve the cell average and cell edge throughputs. It uses the cooperation between points in several cooperation groups to coordinate the transmission for inter-cell interference (ICI) alleviation and link quality enhancement. We will propose an efficient codebook search algorithm to locate the optimal codebook set in centralized UL CoMP systems. The codebook search issue can be reformulated as a tree search
form and the solution can be obtained efficiently using a modified K-Best enumeration
strategy. The proposed algorithm can effectively perform precoder selection and maintain a significantly lower complexity compared to the exhaustive search method.
Finally, Chapter 5 concludes this dissertation and discusses future extensions of this research.
Chapter 2
Efficient Search Algorithm for Over-
determined MIMO systems
2.1 Overview
As the mentioned in Chapter 1, the K-Best SDA uses a breadth-first search and
keeps the K-Best candidates of each layer for the search of the next layer. Briefly, the
main idea of the K-Best SDA is to keep only K candidates which have the smallest path
weights as the most promising solutions. Hence, the decoding throughput of the K-Best
SDA is stable. Unfortunately, applying a sorting algorithm to find the K-Best
candidates in each layer requires many computational operations and a long decoding
latency. Moreover, the value of K must be large enough to achieve near-ML
performance, and this would increase the computational complexity, decoding latency, and implementation cost. For reducing the decoding complexity and obtaining
reasonable performance for practical applications, the selected value of K is usually
same as the constellation size. Therefore, how to trade off between performance and complexity is still an active research issue.
In this chapter, we will propose a simple and efficient complex domain candidate sequence generator (CSG) first. The CSG is developed based on the fact that neighboring points share the same candidate sequence in the complex plane, rendering the relevant rule invariant to constellation rotation. With a minor modification, the proposed decoder can be easily applied to wireless communication systems with constellation pre-rotation to obtain a larger diversity gain. By combining the proposed CSG with an efficient sorting architecture, the proposed decoder can significantly
reduce path weight calculations and comparison operations without sacrificing detection performance. Moreover, to address the performance issue, a new search strategy that incorporates the ML search in the preceding layers under poor channel conditions (i.e., channel matrix is ill-conditioned) improves the performance of the
proposed K-Best SDA even when the value of K is small. A judicious criterion is
proposed that helps determine fewer ML search layers than previous works [23], [27]. An efficient search procedure is also proposed that fully utilizes existing hardware elements. The procedure increases hardware utilization and significantly reduces
implementation cost. Combining the above features, the proposed K-Best SDA exhibits
lower complexity, excellent performance, and is well-suited to real-time applications.
2.2 Signal Model
Consider an MIMO system with N transmit antennas and M receive antennas. The
received signal vector is denoted as 1
1 2 T M M y y y ´ =éêë ùúû Î y , where y is the m
received signal at the mth receive antenna. Similarly, the transmitted signal vector is
denoted as 1 2 T N[ ] N x x x j é ù =êë úû Î x , where [ ]j :=
{
a +jb a b, Î}
is theset of Gaussian integers and x is the transmitted signal at the nth transmit antenna. n
The transmitted signal constellation is assumed to be either 16-QAM or 64-QAM.
Assume M ³N and that the channel responses are frequency-flat fading and remain
constant during a frame transmission. The channel matrix can be expressed as
1,1 1,2 1, 2,1 2,2 2, ,1 ,2 , , N N M M M N h h h h h h h h h é ù ê ú ê ú ê ú = ê ú ê ú ê ú ê ú ë û H (2.1)
Assuming that there is sufficient antenna separation at the transmit and receive sites, the entries of the channel matrix H can be regarded as i.i.d. complex Gaussian random variables with zero-mean and unit variance. The relationship between the received signal vector and the transmitted signal vector can be expressed as
,
y = Hx + n (2.2)
where n = ëêén1 n2 nMùûúT ÎM´1 is the i.i.d. complex additive white Gaussian
noise (AWGN) vector with zero-mean and covariance matrix 2I
M
s .
The optimal detector for MIMO systems is the ML detector, which searches all possible combinations of transmitted symbols via the following criterion [10]
2 ˆ arg min , S Î = -x x y Hx (2.3)
where S =ON denotes the set of all possible transmitted symbol vectors and O is
the modulation symbol alphabet set with a size of M . The computational complexity c
of ML detection grows exponentially with N. Therefore, it is difficult to be
implemented at the receiver in practice.
The basic idea of the SDA is to restrict the search region of the optimal solution to a smaller subset. Typically, the search region is constrained to the interior of a hyper-sphere of radius d centered around the received signal y as described by [10]
2
2 .
d ³ y-Hx (2.4)
First, performing complex QR-decomposition to the channel matrix produces
, é ù é ù ê ú ê ú ê ú ë û ê ú ë û 1 2 R H = Q Q 0 (2.5)
where Q1 ÎM N´ and Q2 ÎM´(M N- ) are unitary matrices, R is an N´N
into (2.4), we have
( )
2 2' ' ,
d ³ y -Rx (2.6)
where y' =Q y1H and
( )
d' 2 =d2- Q y2H 2.
The right-hand-side of (2.6) can be expanded as( )
2 2 2 ' ' ' , 1 2 2 ' ' , -1 -1, -1, -1 -1 2 2 2 '' 2 '' , 1, 1 -1 -1 , N N i i j j i j i N N N N N N N N N N N N N N N N N N N d y r x y r x y r x r x r y x r y x = = - -³ - = -= - + - - + = - + - +å
å
y Rx (2.7) where '' ' , , 1 N i i i j j i i j i y y r x r = + æ ö÷ ç ÷ =çç - ÷ ÷÷çè
å
ø . Define the path weight P and branch weight k B kof the kth layer as for for 1 0, 1 , , 1 k k k k P k N P P+ B k N ìï = = + ïí ï = + £ £ ïî (2.8) 2 2 '' , . k k k k k B =r y -x (2.9)
The path weight P is the partial Euclidean distance (PED)k which is a positive and
non-decreasing function of k. The iterative search for the candidates x xN, N-1, , , x x2 1
can be easily transformed into a tree search problem [10]. The decoding process of the
K-Best SDA can then be regarded as descending a tree in which each parent node has
c
M branches.
The main idea of the K-Best SDA is to keep only the K candidates with the smallest
path weights as the most promising solutions. The procedure of the complex K-Best
Step1:
(a). Set k = N. For each symbol in the complex-plane constellation, calculate PN =BN
.
(b). Choose those symbols having the K smallest paths. Step2:
(a). k ¬ -k 1
.
(b). Path Evaluation: For each partial symbol vector that survives the previous layer; for each symbol in the complex-plane constellation, calculate: Pk =Pk+1+Bk
.
(c). Sorting and candidate selection: Sort the KMc PEDs, and select K
partial nodes having the smallest PEDs among the entire candidate set
.
Step3:
If k =1
Output the vector with the smallest path weight as the estimated solution. Else
Go back to Step 2.
In (2.8)-(2.9), path weights are defined for a given candidate symbol x . When performing the decoding procedure of Step 2, multiple candidate symbols need to be evaluated concurrently for finding the optimal solution. Therefore, a multi-index notation is needed and Step 2 can be further elaborated as follows:
Let 1, 2, , K
i i i
P P P denote the K smallest PEDs in the ith layer, where
1 2 K
i i i
P £P ££P . In performing search in the (i- th layer, first conduct full 1)
path expansion from the K parent nodes to obtain KM branch weights c
1,1 1,2 1, ,1 ,2 , 1, 2, , 1c, , 1, 2, , 1 c M K K K M i i i i i i B- B- B- B- B- B- and PEDs 1,1 1,2 1, 1, 2, , 1c, , M i i i P- P- P- ,1 ,2 , 1, 2, , 1 c K K K M i i i P- P- P- respectively, where m n, i B and , 1 m n i
PED of the nth path expanded from the mth parent node. The associated PED of each
designated node can be evaluated according to , ,
1 1
m n m m n
i i i
P- =P +B- . Next, sort the
c
KM PEDs, and select K partial nodes having the smallest PEDs among the whole
candidate set. The above operations are illustrated in Figure 2-1
Figure 2-1: Illustration of the multi-index operation.
A popular alternative to the complex K-Best SDA works in the real domain by
performing RVD on the complex signal model:
( )
( )
( )
( )
( )
( )
( )
( )
( )
( )
Re Re Re Re Im , , , , Im Im Im Im Re é ù é ù é ù é - ù ê ú ê ú ê ú ê ú = ê ú =ê ú = ê ú =ê ú ê ú ê ú ê ú ê ú ë û ë û ë û ë û y x n H H y x n H y x n H H (2.10) which yield , = + y Hx n (2.11)where H Î2M´2N , yÎ2M´1, nÎ2M´1, and xÎ L2N´1 Ì2N´1. Note that { 3, 1,1, 3}
L = - - for 16-QAM and L = - - - -{ 7, 5, 3, 1,1, 3, 5, 7} for 64-QAM.
After RVD, each component x of x is chosen from a set L of integer numbers with i
c
detection problem can be solved in the real domain using the same K-Best algorithm.
This is denoted as the conventional K-Best SDA. In [28]-[29], it is shown that the
conventional K-Best SDA slightly outperforms the complex K-Best SDA and requires
lower complexity. However, the conventional K-Best SDA may not always be
applicable in some communications systems with special diversity features. Modified
K-Best SDA aim to reduce decoding complexity, but usually introduce performance
degradation, which is more significant in the complex domain [30]-[31]. These prompt
the development of a low-complexity and high-performance K-Best SDA directly
operating in the complex domain.
2.3 Proposed Sorting Algorithm and Hardware
Architecture
This subsection proposes a complex K-Best sphere decoder that achieves the same
performance as the conventional K-Best SDA with lower complexity. As described in the
previous procedural summary, the K-Best SDA involves three major operations: path
evaluation, sorting, and candidate selection. In the following, new algorithms for sorting and candidate selection will be developed to achieve the reduction in computations. The
path evaluation part remains unchanged so that the decoding performance of the K-Best
SDA can be maintained.
2.3.1
Candidate Sequence Generator in Complex
Plane
To search the symbols efficiently in the complex plane, it is useful to construct a table of candidate symbol sequences within a given region [14]. First, a primitive block is
defined to be a square block bounded by {1+j, 1-j, - +1 j, - -1 j}. The complex plane can be regarded as consisting of a lot of primitive blocks placed at equal distances. In Figure 2-2, a received symbol is located at y surrounded by four nearest i"
candidate symbols 41, 42, 49 and 50 in the constellation diagram. A candidate symbol
sequence, 49-50-41-42, can then be formed according to their distance from y in i"
ascending order. Consider then the square area centered at the origin and surrounded by the candidate symbols 27, 28, 35 and 36. Shifting the symbols 41, 42, 49 and 50 to the symbols 27, 28, 35 and 36 respectively, a location yi M", corresponding to y can be i"
identified. A new candidate symbol sequence, 35-36-27-28, can be identified likewise according to their distance from "
,
i M
y in ascending order. Apparently the relation in
terms of the distance from y to nearby candidate symbols remains unchanged after the i"
coordination transformation. On the other hand, since the symbols are placed symmetrically in the complex plane, once the relation between a received symbol and the associated candidate symbol sequence in one of the four quadrants is obtained, those in the other three quadrants can be readily derived. Next, Figure 2-3 shows quadrant I of the solid-line square area in Figure 2-2. The area is divided into 30 segments (we will explain how to partition the specified square area later). It can be verified that all symbols inside any given segment share the same candidate symbol sequence of k symbols, where
-1 1 3 5 -1 1 3 5 Q u a d ra tu re In-Phase
QAM Constellation
25 26 27 28 33 34 35 36 41 42 43 44 49 50 51 52Figure 2-2: Modulo operation of the search center.
Figure 2-3: Partition of the search segments.
For example, consider two symbols “c” and “d” inside segment 01, and evaluate the distances between all valid candidate symbols and the two points. It is straightforward to
" i
y
" , i My
1 Modulo 2 Add offsetverify that the resulting two candidate sequences are identical, i.e. {1+j, -1+j, 1-j,
-1- j, 1+ j3, -1+ j3, 3+ j, -3+ j, 3- j, -3- j, 1- j3}. For other segments, the same result applies.
Using the above properties, we can construct a table of candidate symbol sequences of the k nearest constellation symbols for all symbols bounded by
{1+j, 1-j, - +1 j, - -1 j} instead of generating approximated path weights
[30]-[31]. Due to the symmetry of 16-QAM and 64-QAM, a simple transformation
allows symbols in the region bounded by {1+j, 1-j, - +1 j, - -1 j} in
quadrants II, III, and IV to use the same table as quadrant I. Any symbol located within the bounded region is first mapped to quadrant I by a simple transformation. The transformed result acts as the search center for finding the k nearest candidate symbols by looking up the table of the symbol sequences, where k is a specified number. When the candidate symbol sequence
{ }
x is found, it can easily be transformed back to the ioriginal quadrant. Figure 2-3 shows the partition of the search segments in quadrant I and the corresponding symbol sequences are listed in Table 2-1, where k = 11 is chosen as an example. This table can be constructed in advance by the following off-line procedure:
First, the bounded square area by {1+j, 1, , 0 j } is divided into u2 grids, by (u-1)
equally-space horizontal and (u-1) equally-space vertical lines, where u is chosen
according to the required resolution. The corresponding distances between all valid
candidate symbols and the center of each grid, which represents all possible received symbols within, are then evaluated. Next, by using some sorting procedure, the associated candidate sequence of any possible received symbol can be determined.
Finally, all these possible symbols are rearranged into several search segments such that each segment has the same candidate sequence. By this approach, it is easy to tackle any pre-defined constellation rotation during run-time processing. The following describes the run-time operation in detail:
Table 2-1: LIST OF CANDIDATE SEQUENCES Segment ID Candidate Sequence
01 1+j, -1+j, 1-j, -1- j, 1+ j3, -1+ j3, 3+ j, -3+ j, 3- j, -3- j, 1- j3 02 1+j, -1+j, 1-j, -1- j, 1+ j3, -1+ j3, 3+ j, -3+ j, 3- j, -3- j, 3+j3
: :
29 1+j, 1-j, -1+j, 3+ j, -1- j, 3- j, 1+ j3, -1+ j3, 3+j3, 1-j3, -1- j3 30 1+j, 1-j, -1+j, 3+ j, -1- j, 3- j, 1+ j3, 1-j3, -1+ j3, 3+j3,-1- j3
For any given search center " i
y in the complex plane, the CSG first rounds it to the
relative position "
, i M
y which lies inside the region bounded by
{1+j, 1-j, - -1 j, - +1 j}. This modulo operation is depicted in Figure 2-2:
Modulo operation of the search center. and the associated relationship is described as follows: For
( )
" Re y : i( )
(
( )
)
( )
( )
X_offset mod X_offest " " " " , Re Re ,2 Re Re i i i M i y y y y ì ê ú ê ú ï = + ï ê ú ê ú ï ë û ë û íï = -ïïî (2.12) For( )
" Im y : i( )
(
( )
)
( )
( )
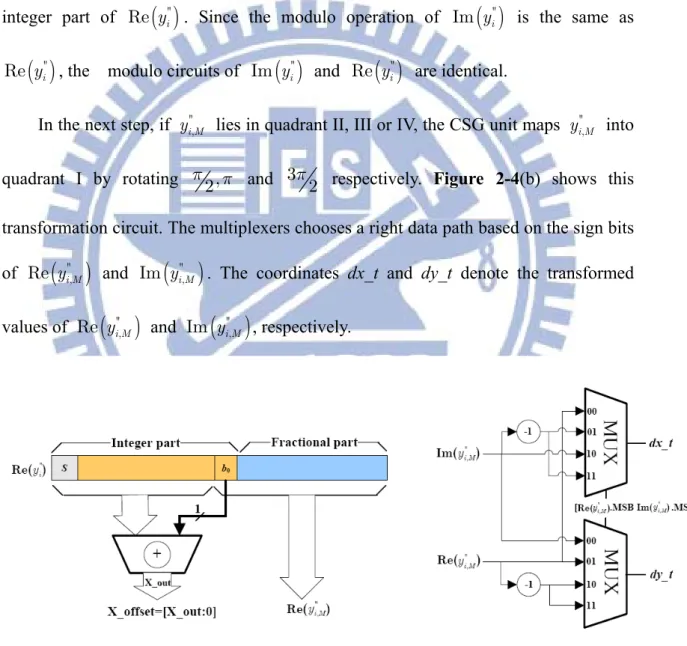
Y_offset mod Y_offest " " " " , Im Im ,2 . Im Im i i i M i y y y y ì ê ú ê ú ï = + ï ê ú ê ú ï ë û ë û íï = -ïïî (2.13)Figure 2-4(a) shows the modulo unit of Re
( )
" iy based on the 2’s complement
property, which is efficiently implemented by a single adder and a few bit manipulations. S is the sign bit (i.e. MSB) of Re
( )
"i
y and b is the LSB of the 0
integer part of Re
( )
" iy . Since the modulo operation of Im
( )
" iy is the same as
( )
"Re y , the modulo circuits of i Im
( )
" iy and Re
( )
" iy are identical.
In the next step, if " , i M
y lies in quadrant II, III or IV, the CSG unit maps " , i M
y into
quadrant I by rotating p p and 32, p respectively. Figure 2-4(b) shows this 2
transformation circuit. The multiplexers chooses a right data path based on the sign bits of
( )
",
Re yi M and
( )
" ,
Im yi M . The coordinates dx_t and dy_t denote the transformed
values of
( )
" , Re yi M and( )
" , Im yi M , respectively.Figure 2-4: (a) Modulo unit of Re
( )
" iy .(b) Transformation unit of " , i M
y .
The set (dx_t, dy_t) is sent to the candidate generator unit to generate the desired
identification (ID) and its corresponding candidate sequence are stored in ROM 1 and ROM 2, respectively, as shown in Figure 2-5, where the hardware architecture of the candidate generator is depicted. The found candidate symbol is first rotated into its original quadrant, and then the offset pair (X_offset, Y_offset) is added to the coordinates of the found candidate symbol. After the constellation restoration, the constellation boundary checker checks whether or not the found symbol lies inside the constellation boundary. If the found restored symbol is a legal one, the distance
calculator calculates the value of " 2
i i
y -x . Multiplying the value of " 2
i i
y -x by 2
, i i
r and adding the parent weight Pi+1 to the multiplied result, we obtain the path weight P i
of the found symbol. The CSG can efficiently generate the coordination pairs of valid candidates and the associated path weights according to their path weights in an ascending order for each given received symbol. From Figure 2-5, the major hardware cost of the CSG involves 3 multipliers, 12 adders, and 2 ROMs. The ROM sizes (number
of logic gates) are 2116 (ROM 1, with u = 32) and 731 (ROM 2), respectively, according
the Synposys® synthesis tools.
For any given symbol and its neighbors, which share the same candidate sequence,
the candidate sequence is generated from the k nearest constellation symbols by sorting
their relative distance to the search center, though these distance values are different for each different search center. The proposed CSG utilizes this property to generate a candidate sequence in ascending order, and calculates the associated path weights so as to avoid a heavy load of path weight evaluations and sorting. Based on this concept, we
can choose the appropriate k to fit the system requirement. The ROM size expands
quickly when a large value of k is chosen. To remedy this, we can divide k into a set
{ }
p 1 i i k = where = =å
1 p i iFigure 2-5: Hardware architecture of the candidate generator.
2.3.2
Architecture of Highly-Parallel Comparison
Circuit (HPCC)
The sorting operations in the K-Best decoder dominate the major complexity at each
search layer. Hence, sorting is a critical factor in reducing the complexity of the K-Best
SDA. The previously proposed CSG module can be applied to the K-Best SDA by
exploiting the inherent partial orders coming with the property of CSG. This can be
efficiently accommodated by applying the K-merge algorithm [30], [33]. For a more
practical implementation, an efficient architecture that can effectively reduce the sorting complexity is needed.
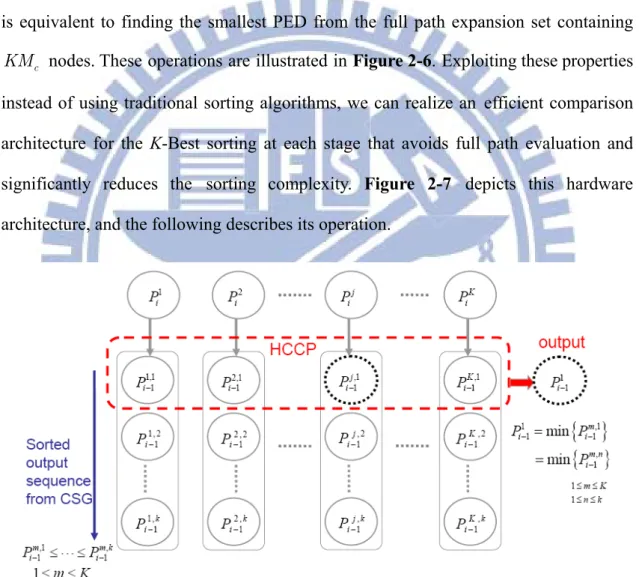
Recall the definitions of branch weights and PED in Section 2. Let 1 2
, , , K
i i i
denote the K smallest PEDs in the ith layer. After full path expansion, we have KM c PEDs 1,1 1,2 1, ,1 ,2 , 1, 2, , 1c, , 1, 2 , , 1 c M K K K M i i i i i i P- P- P- P- P- P- at layer i , where , 1 m n i
P- stands for the
PED of the nth path expanded from the mth parent node at layer i . Moreover, based on
the sorted results from the ith layer and the generated sequence from the proposed CSG
module, we have 1 2 K i i i P <P <<P and -,1< -,2 << -, 1 1 1 j j j k i i i P P P for each £ £
1 j k . Selecting the node with the smallest PED from the set
{
1,1, 2,1, , K,1}
i i iP P P
is equivalent to finding the smallest PED from the full path expansion set containing
c
KM nodes. These operations are illustrated in Figure 2-6.Exploiting these properties instead of using traditional sorting algorithms, we can realize an efficient comparison
architecture for the K-Best sorting at each stage that avoids full path evaluation and
significantly reduces the sorting complexity. Figure 2-7 depicts this hardware architecture, and the following describes its operation.
Figure 2-7: HPCC architecture.
The output sequence of the CSG module naturally forms a set in ascending order
according to the evaluated PEDs while performing the Nth layer search. We therefore
only need to conduct a single coordination transformation and K path weight
calculations. The generated results serve as the parent nodes of the next layer. To search in the (i - th layer, we first calculate 1)
{
1,1 2,1 ,1}
1, 1, , 1 K i i i
P- P- P- and feed them
into the HPCC. The candidate node with the smallest PED among these candidates is
obtained immediately after (K -1) compare-and-select (CAS) operations. If the
chosen node comes from the pth parent node, then the ,2
1 p p i i
P +B- PED is calculated,
overwriting the previously-chosen node. The node with the 2nd smallest PED is obtained
after log K CAS operations (only 2 log K results need be re-computed). Repeating 2
this procedure, we can successfully select K candidate nodes with the smallest PEDs
from the entire valid candidate set. The survival set acts as the parent nodes of the
(i -2) th layer. In searching the nodes in each layer, we use K coordination
operations. Note that the computational complexity of this approach is nearly fixed and
independent of the constellation size M of the transmitted symbols. Furthermore, the c
nodes in the survival set still exhibit an ascending order according to their PEDs. In the final search layer, i.e., the 1st layer, we only need to choose the node with the smallest
PED as the detection result. Hence, it takes only K coordination transformation, K PEDs
evaluations, and (K -1) CAS operations.
Compared with the winner path expansion method [34]-[35], the proposed architecture, which is also frequently found in Viterbi decoder for choosing the minimal path metric, can avoid performing unnecessary operations thanks to the property of
parallel computation. Moreover, it requires a smaller number of CAS (K -1) than
that of the conventional bubble sort method (K).
2.3.3
Complexity Advantages
Through the combination of the two proposed modules, we only need K coordination
transformations, (2K - PED evaluations, and (1) K-1 1)
(
+log2K)
CAS operations ineach layer to obtain K nodes with the smallest PEDs, regardless of the constellation size. These
PEDs only need to be calculated when they are fed into the HPCC. Hence the proposed architecture avoids exhaustive path weight evaluations as required in the conventional bubble sort architecture.
Previous methods attempt to reduce computational complexity by eliminating the number of visited nodes based on the probability or statistical properties of the additive noise. These methods provide an approximate solution, and barter decoding performance for complexity reduction. As an alternative, this chapter presents another way to reduce complexity with the premise of carrying on high quality decoding results. The proposed approach utilizes operation decomposition, reconstruction, and associated efficient
hardware architecture to select and evaluate only the most promising candidate symbols. The proposed method also significantly reduces computational complexity and provides an efficient solution with a nearly fixed throughput. These advantages are further enhanced when a larger constellation size is adopted. Although the proposed method incurs the extra cost of coordination transformation and restoration, it eliminates many path calculations and sorting operations, and provides the same performance as the
conventional K-Best SDA.
2.4 Proposed Search Strategy for Near-ML
Performance
One way to reduce the complexity of the conventional K-Best SDA is to choose a
smaller number of survival nodes in each layer. However, this can cause performance
degradation in term of error rate. Instead of choosing a sufficiently large K to achieve
the near-ML performance, a new search strategy is proposed. The proposed search strategy preserves all candidate symbols and performs the ML search in the preceding
layers when dealing with poor channel conditions. Only K candidates are kept for the
remaining lower layers. The following sections show how to determine the number of layers performing the ML search.
2.4.1
Preprocessing with Column Permutation
The channel matrix can be preprocessed with various techniques to reduce the
complexity of candidate search and/or improve the performance of the K-Best SDA.
Many preprocessing techniques can be used for this purpose, including column permutation [13], scaling [36] and lattice reduction [37]. In this chapter, column permutation is adopted, in which the permutation order is determined according to the
column norms of the channel matrix in ascending order. Given the QR decomposition of
the ordered channel matrix Ho =Q R , we characterize below the cumulative o o
distribution function (cdf) of the square of the diagonal entries of R denoted by o 2 , , o i i
r (see the Appendix A):
for i = 1
( )
(
) (
)
2 , , 1 1 1 0 0 ! ! 1 ! 1 ! o i i N r M k x M x r k N x F r e x e dx k N M -- - -= é ù ê ú = ê ú ⋅ - - ëå
ûò
(2.14) for 2£ £i N( )
( ) (
)
2 , , -1 -1 -1 -1 - -2 - - 1 -0 0 0 0 1 1 . ! ! o i i r i N i s M k M k M i i x x M x ii r k k x x F r C e e x e s s dxds k k = = é ù é ù ê ú ê ú = ê - ú ê ú ⋅ -ëå
û ëå
ûò ò
(2.15) where(
) (
!) (
!! 1 !) (
2 !)
. ii N C N i M i i i = - - - - (2.16)Comparing (2.14)-(2.16) with the results of [13], the ordering mechanism increases
2 , i i
E ré ùë û in the preceding layers, producing two main benefits. First, for a fixed K in the K-Best SDA, increasing 2
, i i
E ré ùë û in the preceding layers reduces the effective search
range of the candidates. This in turn reduces the probability of the ML solution being dropped in the preceding layers. Another benefit is that it constrains the growth of the tree and hence reduces search complexity.