國 立 交 通 大 學
電信工程研究所
碩士論文
智慧型家用機器人使用之語者辨識系統
Speaker Recognition System for Intelligent
Home Robot
研 究 生:吳宜樵
指導教授:王逸如
博士
智慧型家用機器人使用之語者辨識系統
Speaker Recognition System for Intelligent
Home Robot
研 究 生:吳宜樵 Student:Yi-Chiao Wu
指導教授:王逸如 博士
Advisor:Dr. Yih-Ru Wang
國 立 交 通 大 學 電 信 工 程 學 系
碩 士 論 文
A Thesis
Submitted to Departmant of Communication Engineering College of Electrical and Computer Engineering
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master of Science in Communication Engineering
August 2011
Hsinchu, Taiwan, Republic of China
I
智慧型家用機器人使用之語者辨識系統
研 究 生:吳宜樵 指導教授:王逸如
博士
國立交通大學電信工程研究所碩士班
中文摘要
本研究探討語者辨識系統於智慧型家用機器人上以及家用環境內,所會面臨 的各式使用情境,並針對情境開發設計我們的語者辨識系統及註冊流程,以期使 用者能更方便直覺地使用本系統。此外,因為家用環境中通常富含各式雜訊,且 使用者在使用機器人時必定與機器人有一段距離,所以將文本獨立語者辨識前端 整合麥克風陣列、波束形成和空間濾波器的技術,以提高在雜訊環境下的強健 性。另一方面也考慮到在家用機器人中,與其他系統整合的可能性,在系統輸出 端則提供辨識結果有效與否的判定及信心指數,以利與其他使用者辨識系統整 合。最後為了更貼近家庭使用者的使用習慣與喜好,並降低所需註冊及測試語料 的秒數,而發展出可用任何語言輸入註冊文本資訊及註冊語料的文本相關語者辨 識系統。II
Speaker Recognition System for Intelligent
Home Robot
Student:Yi-Chaio Wu Advisor:Dr. Yih-Ru Wang
Department of Communication Engineering
National Chiao Tung University
Abstract
In this paper we present a speaker recognition system, which is specifically designed for intelligent home robot. The enrollment procedure of the system is designed to fit home scenarios and make it easier to be used. Besides, the performance of speaker recognition system degrades significantly in home environment because of reverberation, noise and the distant between speakers and microphone array. The spatial information from the microphone array, which couples with beam forming and spatial voice activity detection, makes the system more robust in the noisy environment. On the other hand, our system provides the confidence scores so as to be fused with other recognition results and achieve the integration of user recognition systems. Finally, in order to increase the convenience of using systems and reduce requirements of enrollment and test data, we develop a text-dependent speaker recognition system, which can be used in any language.
III
致謝
僅以此致謝記住所有曾在這趟旅途中,對我而言非常重要的人。陳信宏老 師、王逸如老師,江振宇、楊智合、黃信德學長,吳文良、賴智誠、許昱超、劉 銘傑、林彥邦、劉冠驛、鍾進竹等同學,電信系 98 級的各位同學好友,電信所、 電機系的學長姐、學弟妹,我的家人及所有幫助過我的人,沒有你們我不可能完 成這本論文。大恩不言謝,大家後會有期。IV
目錄
中文摘要... I Abstract ... II 致謝...III 目錄... IV 表目錄... VII 圖目錄... VIII 第一章 緒論...1 1.1 研究動機...1 1.2 文獻探討...2 1.2.1 文本獨立語者辨識...2 1.2.2 文本相關語者辨識...3 1.2.3 語者識別與驗證...4 1.3 研究方向...7 1.4 章結概要說明...7 第二章 文本獨立語者辨認系統簡介...9 2.1 語者辨認基本系統...9 2.1.1 參數抽取...9 2.1.2 通用背景模型訓練...10 2.1.3 語者註冊... 11 2.1.4 語者辨識...13 2.2 整合麥克風陣列...13 2.2.1 波束形成...14 2.2.2 語音端點偵測...14 2.3 實驗結果...16V 2.3.1 語者識別實驗語料及結果...16 2.3.2 整合麥克風陣列實驗語料與結果...18 3.1 語者身分驗證與信心指數...23 3.1.1 通用模型正規化...24 3.1.2 最大值正規化...26 3.1.3 幾何平均數正規化...27 3.1.4 信心指數曲線及門檻值...29 3.2 實驗結果...30 3.2.1 語者驗證實驗語料與結果...30 3.2.2 語者驗證信心指數...44 第四章 文本相關語者註冊設計...48 4.1 文本相關語者辨識系統...48 4.1.1 語者無關聲學模型之建立...48 4.1.2 語者註冊...49 4.1.3 語者辨識...50 4.2 註冊流程設計...51 4.2.1 語音輸入註冊資訊...51 4.2.2 混合語言註冊系統...53 4.3 實驗結果...53 4.3.1 訓練、註冊與測試語料...53 4.3.2 基礎文本相關語者辨識系統實驗...54 4.3.3 語音輸入註冊資訊的語者辨識系統實驗...56 4.3.4 混合語言語者辨識系統實驗...59 第五章 結論與未來展望...61 5.1 結論...61 5.2 未來展望...61
VI
參考文獻...62 附錄一:中文通關密碼文本...64 附錄二:英文及台語通關密碼文本...66
VII
表目錄
表 2.1:TCC300 語料資料統計表 ...16 表 2.2:語者辨識基礎系統辨識率...17 表 2.3:乾淨且經過波束形成註冊語料辨識率...20 表 2.4:乾淨經過波束形成及語音端點偵測處理之註冊語料辨識率...21 表 2.5:環境雜訊匹配辨識率...21 表 3.1:通用模型正規化法目標語者與封閉集合冒名頂替者分數分布統計...36 表 3.2:通用模型正規化法辨識正確及辨識錯誤的分數分布統計...38 表 3.3:最大值正規化法辨識正確及辨識錯誤的分數分布統計...40 表 3.4:幾何平均數正規化法辨識正確及辨識錯誤的分數分布統計...42 表 3.5:1 秒正規化方法選用及辨識結果信心指數平均值...44 表 3.6:2 秒正規化方法選用及辨識結果信心指數平均值...45 表 3.7:3 秒正規化方法選用及辨識結果信心指數平均值...45 表 3.8:正規化方法誤判集合匹配程度...46 表 4.1:基礎系統文本相關語者辨識率...54 表 4.2:基礎文本相關語者驗證封閉集合等錯率...55 表 4.3:基礎文本相關語者驗證開放集合等錯率...56 表 4.4:有文法限制音素序列辨識器辨識結果統計...57 表 4.5:語音輸入註冊文本資訊語者辨識系統辨識率...57 表 4.6:語音輸入註冊文本資訊語者驗證封閉集合等錯率...58 表 4.7:語音輸入註冊文本資訊語者驗證開放集合等錯率...58 表 4.8:新文法限制音素序列辨識器辨識結果統計...59VIII
圖目錄
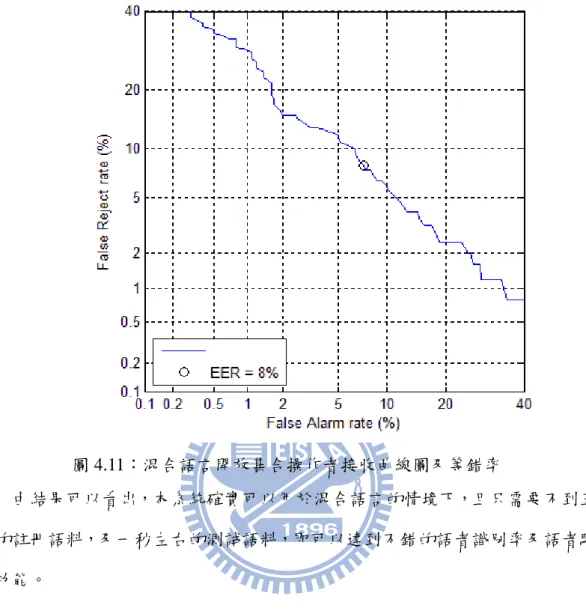
圖 2.1:通用背景模型訓練方塊圖...10 圖 2.2:語者註冊方塊圖... 11 圖 2.3:語者辨識方塊圖...13 圖 2.4:廣義旁瓣消除器...14 圖 2.5:語者辨識基礎系統辨識率...18 圖 2.6:麥克風陣列位置圖...19 圖 3.1:語者確認系統...23 圖 3.2:信心指數算法...29 圖 3.3:通用模型正規化法目標語者與冒名頂替者分數分布...30 圖 3.4:通用模型正規化法接收者操作特徵曲線圖...31 圖 3.5:辨識正確及辨識錯誤分數分布...33 圖 3.6:通用模型正規化法接收者操作特徵曲線圖...33 圖 3.7:最大值正規化法接收者操作特徵曲線圖...34 圖 3.8:幾合平均數正規化法接收者操作特徵曲線圖...34 圖 3.9:通用模型正規化法 1、2、3 秒目標語者與封閉集合冒名頂替者分數分布...36 圖 3.10:通用模型正規化法 1、2、3 秒接收者操作特徵曲線圖...37 圖 3.11:通用模型正規化法 1、2、3 秒辨識正確及辨識錯誤的分數分布 ...38 圖 3.12:通用模型正規化法 1、2、3 秒接收者操作特徵曲線圖...39 圖 3.13:最大值正規化法 1、2、3 秒辨識正確及辨識錯誤的分數分布...40 圖 3.14:最大值正規化法 1、2、3 秒接收者操作特徵曲線圖...41 圖 3.15:幾何平均數正規化法 1、2、3 秒辨識正確及辨識錯誤的分數分布...42 圖 3.16:幾何平均數正規化法 1、2、3 秒接收者操作特徵曲線圖...43 圖 4.1:聲學模型之建立流程...48IX 圖 4.2:文本相關語者註冊流程...49 圖 4.3:文本相關語者辨識流程...50 圖 4.4:註冊語料音節辨識...51 圖 4.5:註冊語料調適...52 圖 4.6:決定最佳音節辨識結果...52 圖 4.7:基礎文本相關語者驗證封閉集合操作者接收曲線圖...55 圖 4.8:基礎文本相關語者驗證開放集合操作者接收曲線圖...56 圖 4.9:語音輸入註冊文本資訊語者驗證封閉集合操作者接收曲線圖...57 圖 4.10:語音輸入註冊文本資訊語者驗證開放集合操作者接收曲線圖...58 圖 4.11:混合語言開放集合操作者接收曲線圖及等錯率 ...60
1
第一章 緒論
1.1 研究動機
本論文的目的在於能夠以人為出發點,發展出人性化的產品。而家用環境幾 乎為每個人共通擁有的使用情境,因此如何就目前各項日新月異的科技技術,確 切地發展出符合人們日常家庭生活需求的產品,是目前科技發展的重點。我們為 了能提供不同使用者利用最直覺的方式,使用智慧型家用產品裡各項客製化的服 務,所以發展語者辨識系統,讓使用者只需透過聲音,即可讓系統得知其身分, 並針對使用者而做出各式各樣適當的服務。 最基本的語者辨識系統,可以同時做到語者識別(speaker identification)找 出可能的語者排名,以及語者身分驗證(speaker verification)確認語者是否為其 所宣稱之人,並提供信心指數。而對於家用環境而言,使用者辨識使用的情境、 環境皆相當複雜多變,因此整合各項技術以提供更貼近人們生活的服務是必然的 趨勢。例如將語者辨識與語音辨識系統整合,對語音辨識系統提供語者資訊,以 增加其對於已知使用者情況下的辨識率;亦或是藉由語者辨識結合人臉辨識系 統,以發展更具強健性的使用者辨識系統;更進一步還可與各種個人工具軟體結 合,提供使用者客製化服務。 此外將使用範圍擴大到真實生活中,許多為了安全或是便利等因素的情境, 例如:車內環境,多人的會議室…,麥克風通常擺放在固定位置,離每個使用者 皆有一段距離,因此本論文將前端將整合麥克風陣列及波束形成(beam forming) 系統,並藉由探討如何處理經過麥克風陣列及波束形成系統的語料,以期能讓系 統在一般環境下能有不錯的辨識率,而未來還能更進一步地應用在例如:會議時 不同語者的語音歸檔;車內空間時,駕駛與其他成員的聲控系統;家內環境,每 個家庭成員所需客製化的服務提供等實際情況中。2
1.2 文獻探討
1.2.1 文本獨立語者辨識
文本獨立(text independent)語者辨識的技術有三個主要的分類【1】,第一 類也是最早的技術為使用長期統計(long term statistic)的語音參數,例如頻譜 或是音調等做為辨識依據。其概念在於將除了語者相關的聲學因子,其他像是不 同音節等所造成的聲學差異藉由平均的方式消除掉,只留下代表語者平均聲道 (vocal tract)形狀的長期頻譜平均值等語者相關的聲學參數。然而其壞處在於 需要相當長的註冊語料去產生穩定的長期統計模型,且丟棄了許多聲學上有用的 語者資訊。 第二類技術為將註冊語料分為幾個語音單元,並由這些單元的語音參數來為 每位語者訓練各自的語者模型,而在辨識時藉由比較測試語料中每群語音單元的 與每個語者模型中相對應語音單元的相似度,來分辨測試語料屬於哪一個語者。 此技術又可以再細分為兩種不同的切割語音單元的方式,分別為顯式分段 (explicit segmentation)與隱式分段(implicit segmentation)。顯式分段為在註冊 或辨識前,就先做語音辨識並以辨識結果切割出每個語音單元,但在【1】裡提 到先做語音辨識不僅增加計算量,且對於語者辨識的幫助不大,因此在文本獨立 的語者辨識範圍裡,比較常用的是隱式分段的方法。隱式分段是在訓練或辨識前 用非監督式分類法(unsupervised clustering)做語音單元切割,而每個分類是沒 有標籤的,所以並不需要依標籤個別訓練模型。而隱式分段下又有幾種形式,像 是分類樣板形式的向量量化編碼(vector quantization, VQ),就是將每個語音單 元所得的語音參數做分群,並用記錄每群頻譜樣版的碼本(codebook)來代表語 者,也就是每位語者的語音參數用其碼本去量化會有最小的量化誤差,並以此條 件來做語者辨識。向量量化雖然在有限詞彙裡的語者辨識效果不錯,但因其本質 較難以去代表每群內在真實情況裡的變異,所以在較大詞彙、噪音環境或是有通 道效應的文本獨立語者辨識裡,我們通常使用機率模型去提供一較佳聲學模型,
3
例如高斯混和模型(Gaussian mixture model, GMM)或是隱藏式馬可夫模型 (hidden Markov model, HMM)就常應用於文本獨立或文本相關的語者辨識。
第三類技術為使用鑑別式類神經網路(discriminative neural network),其特 點在於並非為每位註冊語者訓練各自的語者模型,而是找出分辨出所有註冊語者 最佳決策方程式。而其好處在於相對於為每位語者各自訓練模型,可以使用較少 的參數,但卻達到差不多辨識率。但其缺點在於,每當加入新的註冊語者,則整 個辨識模型都要重新訓練產生。 而在本篇論文裡我們選用屬於第二類中隱式分段的高斯混和模型來當作我 們的語者模型,因為在【1】裡面有提到,高斯混和模型是大家非常熟悉的且簡 單的模型,所以在計算上相當的方便。另一方面高斯混和模型可以簡單的用來模 擬任何機率分布,且即使原本的機率分布因資料量較小而不平滑,也可以透過用 高斯混和模型模擬的方式使其平滑。此外,許多語者相關的聲學特性,以及真實 地反映人類口腔等不同的特性,可以用高斯混和模型簡單的去代表。 因為是即時系統,所以不可能有大量的訓練語料,但很多語音基礎的特性因 為訓練語料的稀少,而無法全部涵蓋,使得我們的語者模型無法正確的代表出語 者相關與語者共通不同的特性,且少量語料可能對模型造成過適(over fitting) 的現象,這些缺點都會對辨識率造成很大的影響。為了解決此一問題,在【2】 裡面提到了,在系統建立前,用相對大量的訓練語料先行訓練一個通用背景模型 (universal background model, UBM),此模型涵蓋了大部分語者共同的聲學特 性,而在系統要註冊語者時,再用最大事後機率法則(maximum a posteriori probability, MAP)調適通用背景模型成為每位語者各自的高斯混和模型,如此語 者模型不但包含語者本身的聲學特性也包含語者間共通的聲學特性。
1.2.2 文本相關語者辨識
文本相關(text dependent)語者辨識因為其準確性與針對性,是目前在商業 化應用上最被廣泛使用的語者辨識技術。在【3】裡面提到,傳統的文本相關語4
者辨識技術可以分為兩類。第一類為動態時軸校準(dynamic time warping, DTW),最典型的方法是由 Furui 在 1981 年提出的頻譜樣版比對(spectral template matching approach),用一序列的特徵參數向量去做為每位語者的樣板,並在測 試時藉由比對測試語料的特徵參數向量序列與每位註冊語者特徵參數向量序列 樣版的距離,決定辨識的結果;第二類為隱藏式馬可夫模型,在【3】、【4】裡都 提到本質上隱藏式馬可夫模型不是直接使用特徵參數向量序列做為樣板,而是對 語言中基本的音節或音素訓練成包含多個由高斯混和模型組成的狀態,且狀態之 間有方向性及轉移機率的一序列語音模型,所以較不易受到說話快慢等因素的影 響,比起動態時軸校準更能有效率的去代表文字相關的聲學模型。
1.2.3 語者識別與驗證
語者辨識系統主要可分為兩個基礎功能,分別為語者識別及語者驗證【3】。 語者識別就是在一個已知的註冊語者模型集合內,找出測試語料最有可能來自的 那位語者,所以又稱為封閉集合(closed set)辨識。而語者驗證則為確認使用者 是否為其所宣稱之語者,而冒名頂替的使用者(impostor)有可能是我們已知集 合的其它語者,或是來自於已知集合之外,所以又稱為開放集合(open set)辨 識。而其實兩個功能也可以看成同一個問題,也就是每當有使用者辨識時,系統 除了已知註冊語者之外還多了一個非已知註冊語者的選項。 而在【5】、【7】裡都提到任何的驗證問題,皆可視為統計假設檢定(statistical hypothesis testing)。統計假設一般有兩種形式,其一為虛無假設(null hypothesis) 是我們欲證明其為錯的假設,以H 表示;另一為對立假設(alternative hypothesis)0 是虛無假設的反面,以H 表示。而我們必須找出足夠的證據否定1 H ,否則就接0 受H 為真。而在【7】裡也提到不管是在語者辨識或是語音辨識,我們都必須要0 做離群值偵測(outlier rejection),對語者辨識而言就是驗證是否為冒名頂替的使 用者。一般辨識系統通常分成兩個階段,第一階段先將測試資料做模式分類 (pattern classification),第二階段再做離群值檢測。所以套用到語者辨識系統5
裡,則首先找出與測試語料最相似的已註冊語者模型,接著驗證其是否真的為這 個語者(屬於這個分群,H )0 ,亦或是冒名頂替的使用者(離群值,H )1 。
此外【7】裡提到在我們得知H 、0 H 的機率分布的前提下,根據奈曼-皮爾1
生引理(Neyman - Pearson lemma),最佳解為使用概似比檢測(likelihood ratio test, LRT)。概似比檢測的意義在於,比較兩種模型何者較適合詮釋我們的統計資料, 應用在語者辨識上,則是比較此語者的模型與非此語者的模型何者與我們的測試 語料較相近。因此其決策原則(decision rule)就是 0 1 , ( | ) , ( | ) hyp hyp X H p X X H p X η λ η λ > ∈ ≤ ∈ (1-1) 而寫成對數型式則為
( )
X logp X(
|λhyp)
logp X(
|λhyp)
Λ = − (1-2) 而一般情況中H 模型容易得到,也就是我們的語者模型,但要估計0 H 模型卻很1 困難,我們無法取得足夠的資料去完全估計H 模型,而在【2】1 、【6】、【7】裡提 到,有兩種主要的方法去估計H 模型,第一種以通用背景模型來代表,因此我1 們將語者辨識結果所得到的對數概似值減去語料對於通用背景模型的對數概似 值,才是我們概似比檢測的分數。而η 一般經由大量的實驗結果,畫出接收者操 作特徵(receiver operating characteristic, ROC)曲線,並依此訂定信心指數。在【9】 裡面稱此方法為通用模型正規化(World model normalization, WMN),其主要的 精神在於冒名頂替的使用者語料對於目標語者模型(target speaker model)與通 用背景模型的分數差距,應該是小於目標語者的語料對於目標語者模型與通用背 景模型的分數差距。而使用通用背景模型的好處,在於只需訓練一個通用背景模 型,即可代表所有或某一特定集合目標語者的對比假設模型,且另一方面此通用 模型還可以用於調適語者模型的辨識系統裡。
第二種方法則是使用一非目標語者的語者模型集合去代表H ,而這集合一1
6
(background speakers)【2】。同儕集合又可分為兩類,第一類為封閉同儕集合 (closed cohort set),假設我們現在有 20 位已註冊語者,則每一個語者模型其封 閉同儕集合則為其他 19 個語者模型,也就是對於目標語者而言,其他 19 位已註 冊語者為冒名頂替的使用者;第二類為開放同儕集合(open cohort set),如果我 們現在有 20 位已註冊位語者,則每個語者模型其開放同儕集合皆不與這 20 個已 註冊語者模型重疊,也就是對於目標語者而言,所有非註冊語者為冒名頂替的使 用者。應用到語者辨識系統上,則為系統所面對的兩類問題,第一類為已註冊語 者使用時,其辨識結果的正確性;第二類為非註冊語者使用時,系統是否可偵測 出其為冒名頂替的使用者。 兩種方法的比較上,因為目標語者與冒名頂替的使用者對於一包含完整語音 特性的通用背景模型所得之分數差異較小,因此用同儕集合來估計H 模型,或1 許能估計得較細微,而有較好的分辨效果。而在【10】裡面也提到,較有參考價 值的同儕集合是那些與我們的目標語者模型較靠近的模型,因其帶有較大的資訊 量,較能做為我們檢測的依據。在【11】裡面則提到,同儕集合人數數量在 10 個人以下,等錯率(equal error rate,EER)是小於通用背景模型,而在 15 個人 以後則高於通用背景模型。因人數太多反而造成混淆,語者模型之間的關係變得 複雜,所以反而不如用通用背景模型來得好。在【6】裡面也提到,同儕集合大 小的選法,是根據最大概似法則來選擇,假設我們希望用一大小為 M 的同儕集合 來估計H 模型,則找出在同儕集合中最接近目標語者的 M 個模型做為同儕集1 合。而同儕集合的大小對於開放同儕集合的影響較封閉同儕集合顯著,封閉同儕 集合的等錯率隨著同儕集合內語者模型的數量上升,很快即達到一收斂值,且等 錯率與模型數量少時差別不大。
此外【8】、【9】裡都提到了測試分數正規化(testing normalization, T-norm) 與平均值正規化(zero mean normalization, Z-norm)。平均值正規化是在系統運作 前利用同儕集合的語料當作冒名頂替使用者的語料,訓練出用來正規化的平均值
7 及標準差,目的是希望能獲得較好的整體臨界值(global threshold)η 。而測試 分數正規化則是在系統運作時,利用同儕集合裡的語者模型當作冒名頂替使用者 的模型,並使測試語料經過冒名頂替使用者的模型,訓練出用來正規化的平均值 及標準差,目的是希望藉此找出目標語者模型與冒名頂替使用者的模型之間的距 離是否夠遠,又或是多少的距離才算是夠遠。而在【8】裡面也提到,測試分數 正規化與平均值正規化相比的好處就是不會有訓練語料及測試語料間,可能因麥 克風、環境等因素而造成不匹配的問題。
1.3 研究方向
本論文目標為將系統建構在一般家用個人電腦上,包含完整的語者註冊及語 者辨識功能,且搭配設計過的註冊流程及文本, 使其能輕易的與其他需要得知 使用者身分的軟體整合。 基礎系統為文本獨立語者辨識系統,每位註冊語者在註冊時,將系統內的通 用背景模型調適成語者各自的高斯混和模型。辨識時,則用最大概似機率 (maximum likelihood)法則,找出最有可能辨識結果,並提供本次測試是否達 有效測試門檻及其信心指數。語者辨識系統前端與麥克風陣列及波束形成(beam forming)系統整合,並測驗其在各種情況下的辨識率,以期能增加語者辨識系 統的強鍵性。 接著本論文為更進一步增強使用者與系統的互動關係,且引入同樣常用於使 用者身分辨識的通關密碼,將使用隱藏式馬可夫模型發展文本相關語者辨識系 統,使用者可以用任意姓名註冊或是替系統取名字,並藉由此特殊通關密碼來做 語者辨識。1.4 章結概要說明
本論文的內容共分為五章: 第一章 緒論:介紹本論文之研究動機、研究方向、語者辨認的基礎方法。 第二章 文本獨立語者識別系統簡介:介紹本論文的文本獨立語者識別系統8 及其實驗數據。 第三章 文本獨立語者確認系統簡介:介紹本論文的文本獨立語者確認系統 使用之方法及其實驗數據。 第四章 文本相關語者註冊設計:介紹基於文本相關語者辨識系統,所設計 之註冊流程。 第五章 結論與未來展望。
9
第二章 文本獨立語者辨認系統簡介
文本獨立語者辨認為最基礎的語者辨認系統,可以廣泛地應用於各種情況。 本章將描述本論文所使用之文本獨立語者辨認系統,以及為了適應家用環境場而 將麥克風陣列整合入系統。2.1 節介紹本研究所採用的使用最大事後機率法則調 適語者通用模型的語者辨認系統;2.2 節介紹基礎系統前端整合線性麥克風陣; 2.3 節介紹語者識別及整合麥克風陣列實驗結果。2.1 語者辨認基本系統
整個語者辨識系統主要可分為註冊及辨識兩個階段,而註冊又包含了背景通 用模型的訓練及註冊語者模型,本節將依序介紹參數抽取、註冊及辨識。2.1.1 參數抽取
梅爾倒頻係數 (Mel-frequency cepstrum coefficients, MFCCs),因為其接近人 耳對語音區別性的特性,所以在語音或語者辨識系統裡被普遍地使用。而本論文 為了在即時系統裡可以有基本的抗噪效果,因此將所求出的梅爾倒頻係數再經過 RASTA濾波器 處理, 詳細過程 如下: 我們 由麥克風收錄取 樣頻 率8000赫茲 (Hertz)、取樣位元數為16位元的語料,音框大小(frame size)取240點、音框 位移(frame shift)取80點,首先將語音訊號做預強處理(pre-emphasis),如下式 所示:
( )
1 1 p H z = −αz− (2-1) 其中為了降低運算量,令α=0.9375=1-2-4。接著做256點的快速傅立葉(FFT)轉換 將訊號轉至頻域,然後通過一組20個「三角帶通濾波器」(triangular band pass filter),再經餘弦轉換(discrete cosine transform)後得到12維的梅爾倒頻係數。之後 將倒頻係數通過RASTA濾波器:( )
4 1 3 4 1 2 2 0.1 1 0.98 r z z z H z z z − − − − + − − = − (2-2)10
因為特徵參數軌跡(time sequence of spectral parameter)低頻部份通常受到通道效 應汙染較為嚴重,而RASTA為一帶通濾波器可用來壓抑特徵參數軌跡的低頻部 份,使其能達成去除部分通道效應的目的。最後求得26維的語音特徵參數,包含 了12維的RASTA-based MFCC,12維一階差量RASTA-based MFCC、1維一階 差量log energy以及1維二階差量log energy。
2.1.2 通用背景模型訓練
Feature extraction . . . VQ LBG EM UBM Speaker 1 training data Speaker N training data 圖 2.1:通用背景模型訓練方塊圖 一般的文本獨立語者辨識系統是利用高斯混合模型來做為每一個語者之語 音參數分布統計模型,但是通常無法對每位語者都取得大量的註冊語料,所以先 訓練一個通用背景模型,並使通用背景模型盡可能涵蓋語音信號中所有音素,以 求其能真正表現出語音訊號的語者無關的特性,再將通用背景模型調適為每位語 者的語音參數分布模型,如此可避免單一語者訓練及測試語料涵蓋音素不同時, 效能下降的問題。如【2】裡所示,一般論文通常用 512 維或是 1024 維的通用背 景模型,而每位語者再由其中挑選 64 維對於註冊語料概似值較高的高斯分布代 表,但在本文系統中為了降低運算量,通用背景模型直接訓練為 64 維。具體訓 練過程如圖 2.1 所示,先將 TC300 語料庫中 300 位語者,每位取 24 秒訓練語料 抽成語音參數後,做向量量化編碼做為 64 維通用背景模型的初始值,再依據 LBG (Linde-Buzo-Gray)演算法反覆更新碼本直到收斂為止。最後再使用最大期望 (Expectation-Maximization, EM)演算法對模型各項參數做調適。11
2.1.3 語者註冊
MAP adaptation UBM Speaker model Feature extraction Speaker adaptation data 圖 2.2:語者註冊方塊圖 如圖 2.2 所示,每位使用者註冊時,用系統麥克風錄下 24 秒註冊語料,語 料經過特徵參數抽取為 26 維 RASTA 參數後,對預先訓練好存在系統中的 64 維 通用背景模型,進行最大事後機率調適為使用者的 64 維語者高斯混和模型儲存 於系統中,並更新註冊名單以完成註冊。 假 設我 們要 依 觀 察到 的資 料 x 去評估一 未知的母體參 數(unobserved population parameter)θ ,而資料 x 的抽樣分布(sampling distribution)為 f( )⋅ 且存 在一θ 的事前分布(prior distribution)g( )⋅ ,則θ 的事後分布可表示為: ( | ) ( ) ( | ) ( | ) ( ) f x g f x f x g d θ θ θ θ θ θ θ ′∈Θ = ′ ′ ′∫
(2-3) Θ為g( )⋅ 的定義域。而最大事後機率法則可表示為:( )
MAP ( | ) ( ) ˆ argmax argmax ( | ) ( ) ( | ) ( ) f x g x f x g f x g d θ θ θ θ θ θ θ θ θ θ θ ′∈Θ = = ′ ′ ′∫
(2-4) 而在本論文中最大事後機率調適法則的做法是首先計算註冊語料對於通用背景 模型中每一個高斯分布的充份統計量(sufficient statistics),接著用新的充份統計 量及新的高斯混和模型參數去更新通用背景模型裡包含舊的充份統計量資訊的 各項參數,更新的方法為以一定的比例混合新的參數及舊的參數,比例則是由一 資料相關的係數α 決定。α 與新的充分統計量成正比,代表每一個高斯分布新的 充份統計量的可信度,如果充分統計量越高,則越多的註冊語料落在這一個高斯12
分布,可信度越高,新參數占得比例也越重。 具體的調適過程如下:
dimensional feature vector
D− X ,D×1 feature vector µi, covariance matrix i D D× Σ ,因此高斯分布機率為
( )
( )
(
) ( ) (
)
1 1/ 2 / 2 1 1 exp 2 2 i D i i i i p X X µ X µ π − ′ = − − Σ − Σ (2-5)而高斯混和模型和通用背景模型皆為M mixtures,feature vector X =
{
x1,...,xT}
,我們得到
(
)
( )
( )
1 Pr | j i i t t M j t j w p x i x w p x = =∑
(2-6) 接著利用Pr(
i x 和| t)
x 得到每一個高斯分布的充分計算量跟新的平均值(mean)t 及方差(variance):(
)
1 Pr | T i t t n i x = =∑
(2-7)( )
(
)
1 1 Pr | T i t t t i E x i x x n = =∑
⋅ (2-7)( )
2(
)
2 1 1 Pr | T i t t t i E x i x x n = =∑
⋅ (2-9) 為了控制新參數語就參數的平衡,我們利用充份統計量及比例因子γ 來計算調適 系數 w i α (用於權重)、 m i α (用於平均值)、 v i α (用於方差)。因為在【2】中提到 三個調適系數找出各自的最佳值與共用一個值對結果影響的程度微乎其微,所以 本系統將三個調適系數設為一致,且比例因子γ 設為經驗法則所得到的常數 16。 w m v i i i i i i n n α α α α γ = = = = + (2-10) 得到調適系數後,根據下列算式,我們就可以得到新的高斯混和模型參數:(
1)
new i i i i i n w w T α α = + − (2-11)( ) (
1)
new i iE xi i i µ =α + −α µ (2-12)13
( )
2( )
2(
)
(
2 2) ( )
2 1 new new i iE xi i i i i σ =α + −α σ +µ − µ (2-13) 然後因為我們假設高斯混和模型的每一個高斯分布之間是獨立的,所以他們的協 方差矩陣(covariance matrix)是一對角矩陣,所以展開後是一連串相乘,而取對數 之後是連加:( )
26 2 1 1 det log 2d d σ = =∑
(2-14) 而這些新的參數則組成新註冊語者的高斯混和模型。2.1.4 語者辨識
Feature extraction Speaker 1 model Speaker N model . . . M A X Result Score Confident measure Testing data 圖 2.3:語者辨識方塊圖 如圖 2.3 所示,辨識時使用者用系統麥克風錄下任意秒數的測試語料。語料 經過特徵參數抽取為 26 維 RASTA 參數後,對存在系統中的每個語者模型計算 概似值(likelihood),並找出最大概似值(maximum likelihood)的語者模型當作 辨識結果。系統輸出辨識結果排名,最大概似值分數以及信心指數,而信心指數 的算法將在第三章詳細介紹。2.2 整合麥克風陣列
考慮系統實際應用的環境中,必然會受到環境雜訊的干擾,因此我們嘗試將 系統前端輸入由原本的單一麥克風改為由四支麥克風組成的線性麥克風陣列,並 藉由麥克風陣列所提供的空間資訊加入波束形成技術,使得系統接收到經過純化 處理的聲音訊號,以期能降低環境雜訊所造成之影響。本節將介紹系統所結合的 波束形成和語音端點偵測(voice activity detection, VAD)技術及其應用於受雜訊 干擾的語者識別的實驗結果。14
2.2.1 波束形成
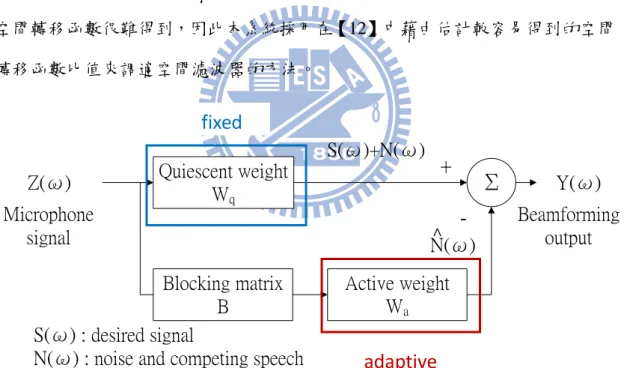
麥克風陣列常使用波束形成的方法為廣義旁瓣消除器(generalized sidelobe canceller),如圖 2.4 所示此方法為在獲得抵達方向偵測(direction of arrival, DOA) 提供的所需訊號的方向資訊後,藉由將麥克風接收訊號中的干擾部分分離出來, 並應用可適性權重向量將分離出來的干擾訊號與原始麥克風訊號相消,以達到聲 音純化的目的。而在【12】裡則提出,傳統廣義旁瓣消除器是在假設線性陣列模 型為裡想均勻的前提,即陣列訊號環境滿足窄頻訊號及遠場平面波的假設下,所 推導出來的最佳解,但在實際的語音訊號環境中,使用者大多離麥克風很近且訊 號多為球面波,並非如假設般單純,因此必須藉由估計聲源於空間中所經過的轉 移函數來調適廣義旁瓣消除器,以適應實際的語音訊號環境。但在實際應用中, 空間轉移函數很難得到,因此本系統採用在【12】中藉由估計較容易得到的空間 轉移函數比值來調適空間濾波器的方法。
Σ
Quiescent weight Wq Blocking matrix B Active weight Wa Z(ω) Microphone signal-+
Y(ω) Beamforming output S(ω)+N(ω) N(ω)^ S(ω) : desired signalN(ω) : noise and competing speech
圖 2.4:廣義旁瓣消除器
2.2.2 語音端點偵測
傳統的語音端點偵測作法為利用訊號短時間能量最大值與最小值之間差距 來訂定動態的偵測門檻值,並根據此值判定語音端點,但傳統方法在低訊雜比 (signal-to-noise ratio, SNR)或是常有突發性雜訊的環境,性能會大受影響,比adaptive
fixed
15 方說在家用環境中,除了目標使用者之外還有其他家庭成員不時說話聲的干擾, 則傳統方式易將家庭成員的聲音也當作我們想要的語音訊號。此外一般的語音端 點偵測的方法,並非使用麥克風陣列做為前端輸入,所以無法擁有空間上的資 訊,而空間資訊的好處在於可以更有效的消除雜訊的影響,以及在頻譜與時域之 外再加入空間亂度的資訊以幫助語音端點偵測。因此在【13】裡提出了基於廣義 旁瓣消除器的麥克風陣列處理結構,而發展出的空間語音端點偵測方法(spatial voice activity detection, SVAD),藉由估算目標對干擾比(target-to-jammer ratio, TJR)做為語音端點偵測的門檻值。 由圖 2.4 可看出廣義旁瓣消除器的結構分為上下兩個分支,而上分支包含想 要訊號的能量及干擾的人聲或雜訊的能量,下分支為分離出來的干擾人聲及雜訊 的能量及非常少量或是幾乎沒有的想要訊號能量,因此我們可以將想要目標訊號 的短時間能量近似為(
{}
⋅ 表示為短時間平均):( )
{
2}
Y t P ≈ ω (2-15) 而干擾訊號的短時間能量近似為:( )
2 N j P ω ∧ ≈ (2-16) 因此可得到目標對干擾比: 10 10 TJR=10 log Pt−10 log Pj (2-17) 並以此值做為語音端點偵測門檻值。利用此方法的好處在於,其所切割出的語音 訊號區段,是目標訊號能量大於干擾訊號能量的區段,而這些語音訊號區段對於 辨識而言是較可靠的區段。根據【13】裡的實驗結果可發現,此方法即使在訊雜 比-10dB 的情況下依然可以有相當準確的語音端點偵測,因此可適用於嘈雜且含 有非穩態干擾(non-stationary)雜訊的環境。16
2.3 實驗結果
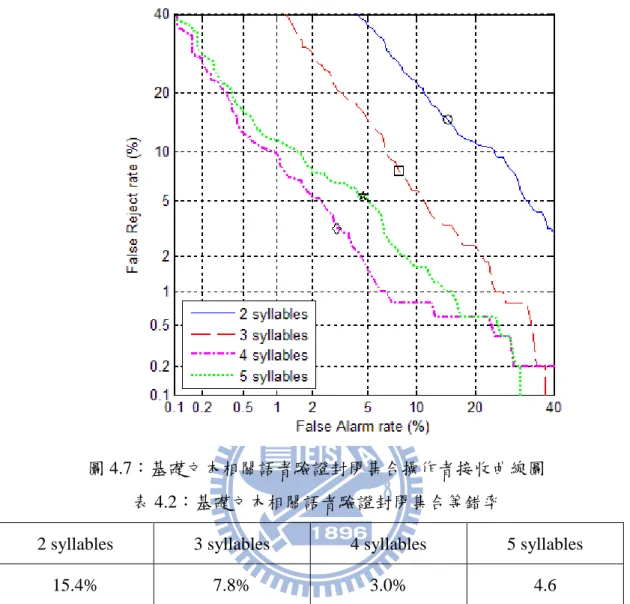
2.3.1 語者識別實驗語料及結果
本論文中使用 TCC-300 麥克風語音資料庫是由國立交通大學、國立成功大 學、國立台灣大學所共同錄製,中華民國計算語言學學會所發行,此語料庫屬於 麥克風朗讀語音,主要目的是為提供語音辨認研究,檔案統計資料如表 2.1 所示。 台灣大學語料庫主要包含詞以及短句,文字經過設計,考慮音節與其相連出現之 機率,共 100 人,每人錄製一句而成;成功大學及交通大學為長文語料,其語句 內容由中研院提供之 500 萬詞詞類標示語料庫中選取,每篇文章包含數百個字, 再切割成 3 至 4 段,每段至多 231 字,分別各 100 人,每人錄製一句朗讀來錄製, 且每人所朗讀之文章皆不相同。每個學校之語句取樣頻率皆為 16000 赫茲,取樣 位元數為 16 位元。音檔檔頭為 4096 位元組(byte),副檔名為*.vat。 表 2.1:TCC300 語料資料統計表 學校名稱 文章屬性 語者總數 總音節數 檔案總數 台灣大學 短文 男 50 男 27541 男 3425 女 50 女 24677 女 3084 總數 100 總數 52218 總數 6590 交通大學 長文 男 50 男 75059 男 622 女 50 女 73555 女 616 總數 100 總數 148614 總數 1238 成功大學 長文 男 50 男 63127 男 588 女 50 女 68749 女 582 總數 100 總數 131876 總數 1170 本實驗從語料庫中的交通大學及成功大學的部分隨機挑選 90 位語者男女各 半,並依其切割位置檔案去除音檔裡大於 0.5 秒的短停頓(short pulse)及靜音 (silence),接著將處理過的音檔轉為取樣頻率為 8000 赫茲,取樣位元數為 1617 位元的無檔頭 PCM 音檔供實驗之用。接著將 90 位語者分為 9 組,10 男、10 女 各 4 組及 5 男 5 女 1 組。每位語者各有 50 筆 1~6 秒測試語料,和一組 5~40 秒的 註冊語料。實驗時以各組為單位,做 10 人的語者識別,實驗結果如下表 2.2 及 下圖 2.5 所示。圖 2.5 的橫軸為測試秒數,縱軸為辨識率,每條曲線代表不同的 註冊秒數。 表 2.2:語者辨識基礎系統辨識率 註冊秒數 測試秒數 5 秒 10 秒 20 秒 30 秒 40 秒 1 秒 55.96% 67.51% 75.38% 79.07% 80.08% 1.5 秒 65.76% 76.78% 83.62% 86.71% 89.00% 2 秒 72.13% 82.98% 88.51% 90.87% 93.07% 3 秒 79.07% 89.47% 93.22% 94.82% 95.69% 4 秒 84.56% 91.80% 95.24% 96.36% 97.40% 5 秒 87.18% 93.64% 96.40% 97.22% 98.04% 6 秒 88.84% 95.02% 97.07% 97.76% 98.67%
18 圖 2.5:語者辨識基礎系統辨識率 由表 2.2 及圖 2.5 可以發現註冊秒數在超過 20 秒之後對辨識率所造成的影響 趨緩,而測試秒數在註冊秒數較長時大約在 3 秒之後對辨識率影響趨緩,但在註 冊秒數較短時辨識率隨著大於 3 秒的測試秒數上升較為明顯。由實驗結果可以發 現本論文基礎系統最有效率的操作點大約是註冊秒數 20 多秒、測試秒數 3 秒左 右。另一方面即使註冊秒數不長,只要測試秒數夠長依然可以有八成以上的辨識 率,對於在即時系統上的應用而言,使用者一開始並不需要太多時間註冊,而在 使用時多說幾次即可有不錯的辨識率。但若是在對反應時間有較高要求的應用 裡,增加註冊秒數可以達到一定效果,但還是無法大幅提升辨識率,因此對於這 些應用可能必須使用文本相關或其他方式來增加其強健性。
2.3.2 整合麥克風陣列實驗語料與結果
麥克風陣列的擺放方式如圖 2.6 所示,四顆數位麥克風彼此相距 7 公分排成 一線性陣列,而聲源方向為陣列正前方 30 公分處。麥克風收錄的訊號為取樣頻 率 8000 赫茲,取樣位元數為 16 位元的訊號。19 S
30cm
mic1 mic2 mic3 mic4
7 cm 圖 2.6:麥克風陣列位置圖 原始語料由 9 位男性語者各念”阿凡達”(機器人的初始名字)5 次。因為語 料稀少,所以採用交叉測試的方式,每位語者依序由五個音檔中挑選四個音檔串 聯在一起做為註冊語料,剩下的那一個音檔則做為那組註冊語料的測試語料。而 我們將註冊語料經過處理後分為 4 大類,因此每個分類的語料會有 5 組註冊語 料,4 類分別為:1.乾淨且經過波束形成處理但未經過語音端點偵測處理的語料; 2.乾淨且經過波束形成及語音端點偵測除去靜音的語料;3.混人聲(babble)雜 訊、訊雜比為 15dB 經過波束形成及語音端點偵測除去靜音的語料;4. 混飛機聲 (F16)雜訊、訊雜比為 15dB 經過波束形成及語音端點偵測除去靜音的語料。 因為經過語音端點偵測除去靜音的語料長度幾乎變為原本的一半,而最大事後機 率調適法則會依據調適語料的長短調整新舊資料的權重,所以我們將有除去靜音 的註冊語料複製為原本兩倍長度以示公平。 測試語料則分為 6 大類,每類再分為 0dB、5dB、10dB、15dB 等 4 種訊雜 比語料,每種語料有 5 組共 45 筆測試語料。6 類分別為:1.混人聲雜訊但未經過 波束形成及語音端點偵測處理的第二支麥克風語料,代號 Babble;2.混人聲雜訊 經過波束形成但未經過語音端點偵測處理的語料,代號 Babble+BF;3.混人聲雜 訊經過波束形成且經過語音端點偵測除去靜音的語料,代號 Babble+BF+VAD; 4.混飛機聲雜訊但未經過波束形成及語音端點偵測處理的第二支麥克風語料,代 號 F16;5.混飛機聲雜訊經過波束形成但未經過語音端點偵測處理的語料,代號
20 F16+BF;6.混飛機聲雜訊經過波束形成且經過語音端點偵測除去靜音的語料,代 號 F16+BF+VAD。 而實驗共分為四個階段,第一階段為利用乾淨註冊語料及乾淨測試語料做語 者辨識,因為註冊與測試的音檔內容皆為”阿凡達”,所以實驗結果的辨識率為 100%;第二階段為利用乾淨且經過波束形成處理但未經過語音端點偵測處理的 註冊語料,及六類測試語料做語者辨識,下表為實驗的結果。 表 2.3:乾淨且經過波束形成註冊語料辨識率 NOISE SNR Babble Babble +BF Babble +BF +VAD F16 F16+BF F16+BF +VAD 0dB 22.2% 31.1% 35.6% 20.0% 33.3% 33.3% 5dB 20.0% 33.3% 75.6% 24.4% 35.6% 68.9% 10dB 31.1% 35.6% 91.1% 26.7% 44.4% 88.9% 15dB 35.6% 42.2% 97.8% 40.0% 55.6% 100.0% 由表 2.3 的結果可以看出波束形成是有些微的效果,由其是在訊雜比在低時 較為明顯,而語音端點偵測除去靜音的效果則較為顯著,在 0dB 時雖然提升辨 識率的幅度較小,但在 5dB 之後幾乎都提升了一倍的辨識率,這結果可以看出 波束形成對於語者辨識系統的幫助有限,但使用麥克風陣列所提供之空間資訊去 做語音端點偵測在訊雜比不高的情況下依然能對辨識率有顯著的幫助。接著第三 階段我們探討利用乾淨且經過波束形成及語音端點偵測處理除去靜音的註冊語 料,及六類測試語料做語者辨識的結果,以期能更深入了解空間語音端點偵測對 於語者辨識的影響。
21 表 2.4:乾淨經過波束形成及語音端點偵測處理之註冊語料辨識率 NOISE SNR Babble Babble +BF Babble +BF +VAD F16 F16+BF F16+BF +VAD 0dB 17.8% 17.8% 46.7% 13.3% 13.3% 40.0% 5dB 31.1% 24.4% 95.6% 15.6% 15.6% 77.8% 10dB 44.4% 31.1% 100.0% 15.6% 22.2% 95.6% 15dB 53.3% 44.4% 100.0% 26.7% 28.9% 100.0% 由表 2.4 的結果可以看出靜音含量較少的註冊語料,對於同樣是靜音含量較 少的測試語料有著較好的辨識率,但對於含有靜音的測試語料則會更容易受到不 同的雜訊的影響而有差異度相當大的辨識率。因此由結果可以推測,如果系統的 語音端點偵測做得非常準確,即使訊雜比只有 5dB 依然能有不錯的辨識,但如 果測試語料含有雜訊及較多靜音時,幾乎不含靜音的註冊語料強健性較差,且在 不同雜訊間的辨識率變化相當大。最後第四階段我們探討利用與測試語料混相同 雜訊且訊雜比為 15dB、經過波束形成及語音端點偵測處理之註冊語料,及六類 測試語料做語者辨識的結果,以期能了解環境雜訊匹配與否對語者辨識的影響。 表 2.5:環境雜訊匹配辨識率 NOISE SNR Babble Babble +BF Babble +BF +VAD F16 F16+BF F16+BF +VAD 0dB 17.8% 20.0% 28.9% 11.1% 17.8% 33.3% 5dB 20.0% 20.0% 84.4% 17.8% 20.0% 93.3% 10dB 22.2% 22.2% 100.0% 22.2% 28.9% 100.0% 15dB 28.9% 24.4% 100.0% 26.7% 33.3% 100.0% 由表 2.5 可以看出不論使用混人聲雜訊或是飛機聲雜訊之註冊語料,對於相
22 對應雜訊且未經過語音端點偵測除去靜音之測試語料的辨識率,明顯不如乾淨的 註冊語料,而對於相對應雜訊且經過語音端點偵測去除靜音之測試語料辨識率, 則隨著雜訊不同與乾淨的註冊語料互有高低。由這三個實驗結果,我們可以得到 在雜訊環境下使用麥克風陣列做為前級之語者辨識系統,空間語音端點偵測有無 是影響其辨識率關鍵的結論,且有麥克風陣列提供空間之資訊,及使在訊雜比只 有 5dB 的嘈雜環境裡,使用空間語音端點偵測對語料做處理後,依然可以有不 錯的語者辨識率。
23
第三章 文本獨立語者確認系統
完整的語者辨識系統除了包含對於已註冊語者辨別身分的功能之外,還必須 包含偵查是否為非註冊語者的能力。更進一步地,語者辨識系統與其他使用者身 分識別系統(例:人臉辨識系統)結合時,還必須賦予辨識結果一個量化的分數, 也就是所謂的信心指數,以利多個系統融合出一個共同的辨識結果。3.1 節將介 紹系統計算門檻及信心指數的方法;3.2 節記錄實驗結果。3.1 語者身分驗證與信心指數
在本論文中如圖 3.1 所示,我們將語者身分驗證問題分成兩個階段: 語者辨識系統 測試有效判定 信心指數 辨識排名與信 心分數 無法辨識身分 超過門檻值 未達門檻值 測試語料 圖 3.1:語者確認系統 第一階段,系統依據辨識結果判定此次辨識是否有效。必須被判定為無效的情況 包括非註冊語者使用系統,以及辨識錯誤的結果。判定無效的結果則跳過第二階 段,直接輸出無法辨識使用者身分。判定有效的結果,則在第二階段賦予每個排 名一個信心指數,信心指數為一個介於 0 到 1 之間的數值,代表系統對於這辨識 結果的信心程度。 而我們將這兩階段視為統計假設檢定,H0 代表已註冊語者使用系統,或是 辨識正確的假設,而 H1則代表其對立假設。在已知 H0、 H1的機率分布條件下, 則根據奈曼-皮爾生引理,最佳解為概似比檢測。而其決策規則(decision rule) 為 : 第一階段 第二階段24 0 1 , ( | ) , ( | ) hyp hyp X H p X X H p X η λ η λ > ∈ ≤ ∈ (3-1) 其對數形式為:
( )
X logp X(
|λhyp)
logp X(
|λhyp)
Λ = − (3-2) 註冊語者為已知,因此我們可以藉由註冊語料得到 H0的機率分布,但如何去估 計 H1 就成了重點。本節我們將介紹三種估計 H1的方法及其實驗的結果,3.1.1 介紹使用通用背景模型做為 H1,稱為通用模型正規化;3.1.2 介紹以第二名的語 者做為同儕集合去估計 H1,稱為最大值正規化(maximum normalization);3.1.3 介紹以除了第一名以外所有註冊語者做為同儕集合去估計 H1,稱為幾合平均數
正規化(geometric mean normalization)。而我們先分別利用這三種方法及實驗語 料得到辨識正確與辨識錯誤語料的分數Λ
( )
X ,抑或是目標語者與非目標語者的 分數Λ( )
X ,並藉由分析分數分布而得到最佳的門檻值以及賦予辨識結果信心指 數的函數以供即時系統使用。3.1.1 通用模型正規化
對於本論文的即時系統而言,使用者使用時,系統並無任何的使用者資訊, 完全憑其語料及系統內事先註冊的模型來判斷每位語者的身分,因此首先必須判 定使用者是否為已註冊語者,接著判定辨識結果是否為正確,如果為錯誤的辨識 結果,其實也可以視為封閉集合的冒名頂替者。而通用背景模型正規化的概念, 就是認為辨識正確的語料對於目標語者模型及通用背景模型的相似度差異,是比 辨識錯誤的語料和非註冊語者的語料對於目標語者模型及通用背景模型的相似 度差異來得較為明顯。 具體的正規化流程如下,假設現在共有 N 位已註冊語者,且第 M 位註冊語 者為目標語者,而語者模型為λ ,n n= 1 S N;目標語者模型為λ ;通用背景S 模型為λUBM ;觀測資料O={
O1,...,Ot,...,OT}
共T個音框,則我們可以得到每筆測25 試語料對語者模型λ ,經過通用模型正規化後的對數概似值分數為: n
( )
1(
(
)
(
)
)
log | log | T t n t UBM t n p O p O O T λ λ = − Λ =∑
(3-3) 測試的實驗語料分成三類,第一類為目標語者的語料OS ={
O1S,...,OtS,...,OTS}
;第 二類為封閉集合的冒名頂替者語料On ={
O1n,...,Otn,...,OTn}
,n=1N∩ ≠n S;第 三類為開放集合的冒名頂替者語料(假設現在共有 K 位開放集合的冒名頂替者){
1,..., ,...,}
k k k k t T O = O O O ,k =N+1N+K。則我們可以得到三類分數,第一類為 目標語者語料對於目標語者模型得到的分數:( )
1(
(
)
(
)
)
log | log | T S S t M t UBM S S t S p O p O O T λ λ = − Λ =∑
(3-4) 第二類為封閉集合的冒名頂替者語料對於目標語者模型得到的分數:( )
1(
(
)
(
)
)
log | log | T n n t S t UBM n n t S p O p O O T λ λ = − Λ =∑
,n=1N∩ ≠n S(3-5) 第三類為開放集合的冒名頂替者語料對於目標語者模型得到的分數:( )
1(
(
)
(
)
)
log | log | T k k t S t UBM k k t S p O p O O T λ λ = − Λ =∑
,k=N+1N+K(3-6) 而根據第一類分數是應該被判定有效,二三類分數是應該被判定為無效的原則, 我們可以得到接收者操作特徵曲線圖,並藉由分析圖及找出其等錯率點來訂定門 檻值。 此外,更進一步地,除了冒名頂替者是該被判定無效的辨識結果外,辨識錯 誤的結果一樣是應該被判定為無效。因此我們將目標語者的語料對於目標語者模 型的分數,再分成辨識正確的分數:( )
1(
(
)
(
)
)
log | log | T SR SR t S t UBM SR SR t S p O p O O T λ λ = − Λ =∑
(3-7)26 及辨識錯誤的分數:
( )
1(
(
)
(
)
)
log | log | T SE SE t S t UBM SE SE t S p O p O O T λ λ = − Λ =∑
(3-8) 兩類,並依此原則訂定最終供即時系統使用的信心指數及門檻值。而辨識錯誤即 代表系統將使用者誤認為其他已註冊語者,因此對於被誤認語者而言,此辨識錯 誤也可以視為封閉集合的冒名頂替者。3.1.2 最大值正規化
最大值正規化的概念,即是認為辨識正確的語料對於目標語者模型的相似度 會大於辨識錯誤的語料和非註冊語者的語料對於目標語者模型的相似度。因此若 辨識結果第一名與第二名的分數差距越大,系統對於此結果為辨識正確結果的信 心度也越高。最大值正規化法也是討論第一名分數與其他名次分數分布的關係, 因此其出現封閉集合的冒名頂者的情況也即為辨識錯誤的情況。 具體的正規化流程如下,假設共有 N 位已註冊語者,則語者模型為λ ,n 1 n= S N;觀測資料O={
O1,...,Ot,...,OT}
共T個音框,我們可以得到測試語 料對於語者模型λ 的對數概似值分數: n( )
1(
(
)
)
log | T t n t n p O O T λ = Λ =∑
(3-9) 首先找出最高的分數:( )
arg max n n M = Λ O (3-10)( )
( )
1st O M O Λ = Λ (3-11) 接著找出第二高的分數:( )
( )
2 1 [ ]max
nd n n N n M O O = ∩ ≠ Λ = Λ (3-12) 最後我們可以得到經過最大值正規化的分數:( )
1( )
2( )
MAX O st O nd O Λ = Λ − Λ (3-13)27 而在這裡我們將語料分為兩類,第一類為已註冊語者語料
{
1,..., ,...,}
n n n n t T O = O O O ,n= 1 N 第二類為開放集合的冒名頂替者的語料(假設我們現在有 K 位開放集合冒名頂 替者){
1,..., ,...,}
k k k k t T O = O O O ,k=N+1N+K 因此可以得到三類分數,第一類為辨識正確的分數:( )
1( )
2( )
R nR nR nR MAX O st O nd O Λ = Λ − Λ (3-14) 第二類為辨識錯誤(對於被誤認的語者,則視為封閉集合的冒名頂替者)的分數:( )
1( )
2( )
E nE nE nE MAX O st O nd O Λ = Λ − Λ (3-15) 第三類為開放集合的冒名頂替者的分數:( )
1( )
2( )
I k k k MAX O st O nd O Λ = Λ − Λ (3-16) 也是根據第一類分數是應該被判定有效,二三類分數是應該被判定為無效的原 則,並藉由分析接收者操作特徵曲線圖及找出其等錯率點來訂定門檻值。3.1.3 幾何平均數正規化
幾何平均數正規化的概念,即是認為辨識正確的語料對於目標語者模型及其 他已註冊語者模型的相似度差異,是比辨識錯誤的語料和非註冊語者的語料對於 目標語者模型及其他已註冊語者模型的相似度差異來得較為明顯。因此若第一名 的分數大於其他名次分數的平均越多,系統對於此結果為辨識正確結果的信心度 也越高。此外由於此正規化法討論的是第一名分數與其他名次分數分布的關係, 因此其出現封閉集合的冒名頂者的情況即為辨識錯誤的情況,例:已有註冊語者 模型的使用者 A 使用系統時,被系統辨識為註冊語者 B,因此對於 A 而言此辨 識結果為錯誤的,而 A 同時也成為了冒名頂替 B 的使用者。28 具體的正規化流程如下,假設共有 N 位已註冊語者,語者模型為λ ,n 1 n= S N;觀測資料O=
{
O1,...,Ot,...,OT}
共T個音框,我們可以得到測試語 料對於語者模型λ 的對數概似值分數: n( )
1(
(
)
)
log | T t n t n p O O T λ = Λ =∑
(3-17) 首先找出最高的分數:( )
arg max n n M = Λ O (3-18)( )
( )
1st O M O Λ = Λ (3-19) 接著找出幾合平均數正規化項:( )
1( )
1 N n n n M G O O N = ∩ ≠ Λ Λ = −∑
(3-20) 最後我們可以得到經過幾合平均數正規化的分數:( )
1( )
( )
GM O st O G O Λ = Λ − Λ (3-21) 而在這裡我們將語料分為兩類,第一類為已註冊語者語料{
1,..., ,...,}
n n n n t T O = O O O ,n= 1 N (3-22) 第二類為開放集合的冒名頂替者的語料(假設我們現在有 K 位開放集合冒名頂 替者){
1,..., ,...,}
k k k k t T O = O O O ,k =N+1N+K (3-23) 因此可以得到三類分數,第一類為辨識正確的分數:( )
1( )
( )
R nR nR nR GM O st O G O Λ = Λ − Λ (3-24) 第二類為辨識錯誤(對於被誤認的語者,則視為封閉集合的冒名頂替者)的分數:( )
1( )
( )
E nE nE nE GM O st O G O Λ = Λ − Λ (3-25)29 第三類為開放集合的冒名頂替者的分數:
( )
1( )
( )
I k k k GM O st O G O Λ = Λ − Λ (3-26) 同樣根據第一類分數應該被判定有效,二三類分數應該被判定為無效的原則,並 藉由分析接收者操作特徵曲線圖及找出其等錯率點來訂定門檻值。3.1.4 信心指數曲線及門檻值
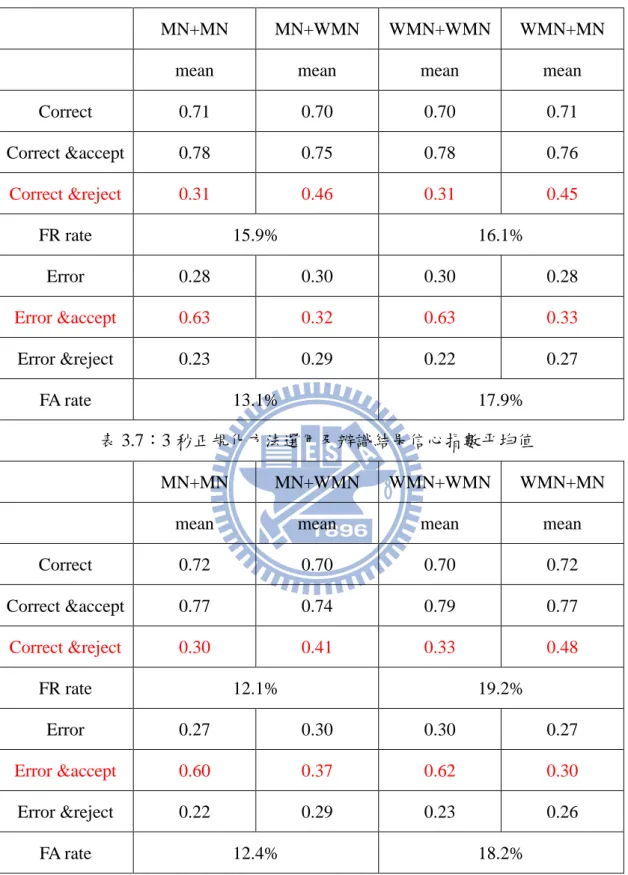
本論文中訂定第一階段門檻值的方式為,藉由每個正規化方法三種秒數的等 錯率點的分數值做為門檻值。而當實際使用時,系統將測試語料區分為小於 1.5 秒、介於 1.5 秒到 2.5 秒、大於 2.5 秒三個區間,不同區間的測試語料分別對應 到 1、2、3 秒測試結果等錯率點所算出的門檻值。 而第二階段賦予辨識結果信心指數的方式則如下圖所示,先利用大量實驗的 結果得到辨識正確分數的累積分布函數 F R(x),以及辨識錯誤分數的累積分布函 數 F E(x)。而信心指數曲線為經過 FR(x)-(1- FE(x))運算後得到的曲線,再將 Y 軸正 規化到 0 到 1 之間。曲線圖的 X 軸代表經過正規化方法後的辨識結果分數,Y 軸 代表信心指數(一個 0 到 1 的值)。實際使用時,每次辨識結果所得到的語者分 數經過正規化後,依其落在 X 軸的點找相對應的 Y 軸的點即為其信心指數。 圖 3.2:信心指數算法30
3.2 實驗結果
3.2.1 語者驗證實驗語料與結果
實驗語料為與語者識別實驗語料相同的 10 男、10 女各 4 組及 5 男 5 女 1 組 共 9 組的語料。每位語者使用 24 秒註冊語料,及 50 筆 1 秒測試語料,每筆語料 之間不重疊。 實驗分為兩個階段,第一階段先挑選其中 10 男、10 女各 1 組及 5 男 5 女 1 組共 3 組語料,在通用模型正規化法裡探討目標語者語料分數與冒名頂替者語料 分數的分布,及更進一步地在三種正規化方法下探討辨識正確的分數與辨識錯誤 (封閉集合的冒名頂替者)和開放集合冒名頂替者的分數分布。 圖 3.3:通用模型正規化法目標語者與冒名頂替者分數分布31 圖 3.4:通用模型正規化法接收者操作特徵曲線圖 圖 3.3 為 3 組所有目標語者語料分數以及封閉集合和開放集合冒名頂替者語 料分數經過通用模型正規化之後的分布圖。在我們系統的使用情境裡,因為文本 獨立的關係,系統並不知道使用者說話的內容,而每位語者使用時也並無宣稱自 己身分,因此在這個實驗裡所謂的封閉集合冒名頂替者,就定義為每次語者識別 後目標語者測試語料對於除了自己以外其他所有已註冊語者模行得到的分數,也 就是假設目標語者使用系統時宣稱自己為其他已註冊語者時的情況。由圖可以發 現封閉集合的冒名頂替者分數分布較為靠近目標語者分數,據推測是因為在全部 男生或女生的實驗組裡封閉集合的冒名頂替者為同樣性別,而開放集合的冒名頂 替者則有 3/4 為不同性別,才造成此差異,而這也影響到了兩者的等錯率,分數 分布距離較遠的開放集合冒名頂替者因其與目標語者分數分布重疊部分較少,所 以有比較低的等錯率。 對於家用機器人上所使用之文本獨立語者辨識系統而言,由於較常用於生活 幫手或是客制化服務的情境中且文本獨立的關係,因此系統並無任何關於使用者 的資訊,只能單憑其測試語料來辨別身分,而對於系統而言真正會出現的冒名頂
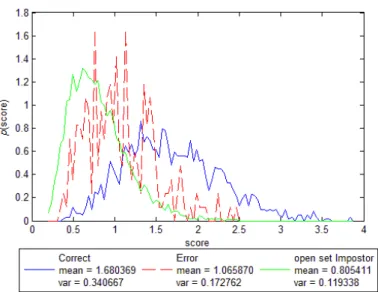
32 替者即為語者識別錯誤的結果及非註冊語者。接著我們將探討在三種正規化方法 下辨識正確、辨識錯誤和開放集合冒名頂替者之間分數分布的情況,以期系統能 偵測錯誤。而辨識正確的分數則是來自每筆目標語者測試語料對於其語者模型所 得到的分數中辨識結果正確的部分,辨識錯誤的分數則是來自每筆目標語者測試 語料對於其他已註冊語者模型所得到的分數中,超過該筆語料對於其自身語者模 型所得到的分數,而造成辨識錯誤的部分。 (a)通用模型正規化法 (b)幾合平均數正規化法
33
(c)最大值正規化 圖 3.5:辨識正確及辨識錯誤分數分布
34
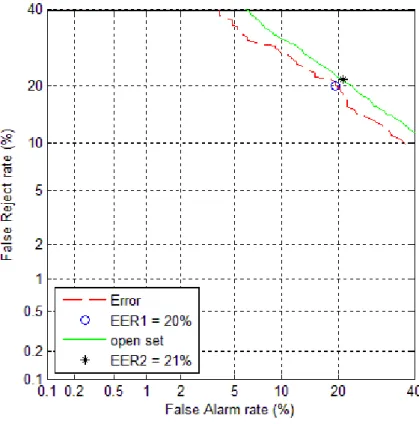
圖 3.7:最大值正規化法接收者操作特徵曲線圖
圖 3.8:幾合平均數正規化法接收者操作特徵曲線圖
由圖 3.5(a)可以看出辨識錯誤的分數確實與辨識正確的分數有所差別,但 重疊的部分卻比之前封閉集合冒名頂替者分數與目標語者分數重疊部分大得
35 多,因此由圖 3.6 可看出等錯率提高了不少。而開放集合的冒名頂替者與辨識正 確的分數分佈重疊的更少了,因此等錯率下降了些許。由這結果可以看出在通用 模型正規化法裡若以辨識正確與否當做判斷準則,則依照等錯率點所找出的門檻 值對於開放集合的冒名頂替者是相當有鑑別力的,而對於判斷是否辨識錯誤則有 20%左右的機率判斷錯誤。 由圖 3.7 及圖 3.8 實驗的結果可以看出幾何平均數正規化法對於判別辨識錯誤 的能力似乎較最大值正規化法和通用模型正規化法差上許多,但其辨別非註冊語 者的能力似乎略優於最大值正規化法,不過也還是遠輸於通用模型正規化法。此 外,由圖 3.5(b)我們可以發現最大值正規化法辨識錯誤以及非註冊語者的分數 分布非常相似,這也顯示了最大值正規化法的背後意義,在於如果第一名的分數 超過第二名越多,則辨識結果為正確的可能性越大。 綜合第一階段實驗的結果,通用模型正規化法對於辨識錯誤的判斷能力與其 他兩個方法相差不遠,而對於非註冊語者的判斷則優於其餘兩個方法。但非註冊 語者的分數分布較難以掌握,因為其語料變化較大也未知,在實驗時也無法完全 正確地去估計真正非註冊語者的模型,所以在真實情況時,是否能確實的拒絕未 註冊使用者,可能會受到許多未能事先掌控的因素大幅度影響。而且對於家用系 統的使用情境而言,大部分時間皆為已註冊語者使用系統,所以如何將辨識錯誤 的結果判定無效比拒絕非註冊語者的情境更常見,因此在第二階段實驗裡我們將 重點擺在三個方法的偵錯能力。此外在第一階段實驗確定這三個方法有一定的偵 錯能力之後,為了印證對於結果的推論具有一般性,我們將測試組數增加為 9 組,並測試不同秒數所造成的結果變異。每位語者一樣使用 24 秒註冊語料,而 測試語料則增加為 1、2、3 秒各 50 筆。 在第二階段實驗,我們首先觀察通用模型正規化法對於目標語者語料分數與 封閉集合冒名頂替者語料分數的分布,接著觀察三種正規化方法辨識正確與辨識 錯誤的分數分布。觀察通用模型正規化法對於目標語者語料分數與封閉集合冒名 頂替者語料分數的分布,是為了藉由了解目標語者對於自己的語者模型及對其他
36 註冊名單裡的語者模型所得到的分數分布,做為之後分析辨識正確及辨識錯誤分 數分布的參考。 圖 3.9:通用模型正規化法 1、2、3 秒目標語者與封閉集合冒名頂替者分數分布 表 3.1:通用模型正規化法目標語者與封閉集合冒名頂替者分數分布統計 測試秒數 分數 1 秒 2 秒 3 秒 目標語者平均值 1.04 1.04 1.04 目標語者方差 0.42 0.29 0.24 冒名頂替者平均值 -0.28 -0.28 -0.28 冒名頂替者方差 0.35 0.26 0.23 由圖 3.9 及表 3.1 我們可以發現不論測試語料的秒數為多少,目標語者與封 閉集合冒名頂替者分數分佈的平均值都差別不大,但方差則明顯的隨著秒數增加 而變小。這結果代表了當測試秒數越高,則兩類分數的分布越往其各自的平均值
37 集中,而重疊造成混淆的部分越來越小,因此等錯率也應該越來越小。此外重疊 部分在一定程度上與辨識錯誤率相關,因此隨著秒數上升辨識錯誤率下降,重疊 部分減少也是合理的情況。由下圖 3.10 也可以看出等錯率確實如預期般隨著秒 數上升而下降,但下降的幅度也隨著秒數趨緩,對照於語者識別率上升速度的結 果,也確實隨著秒數上升而趨緩。 圖 3.10:通用模型正規化法 1、2、3 秒接收者操作特徵曲線圖
38 圖 3.11:通用模型正規化法 1、2、3 秒辨識正確及辨識錯誤的分數分布 表 3.2:通用模型正規化法辨識正確及辨識錯誤的分數分布統計 測試秒數 分數 1 秒 2 秒 3 秒 辨識正確平均值 1.20 1.11 1.08 辨識正確方差 0.34 0.25 0.22 辨識錯誤平均值 0.36 0.37 0.40 辨識錯誤方差 0.19 0.11 0.10 接著觀察通用模型正規化法下辨識正確與錯誤的分數分布,由圖 3.11 及表 3.2 可以看出從目標語者分數分佈中拆出部分的辨識正確分數,及從封閉集合冒 名頂替者分數分布中拆出部分的辨識錯誤分數,也有著方差隨著秒數增加而變小 的特性,但兩分數平均值的距離卻隨著秒數增加而縮短。據推測應該是因為會造 成語者識別錯誤的語料,其分數必定是落於封閉集合冒名頂者分數分布與目標語
39 者分數分布重疊的區間,而隨著秒數上升重疊部分越來越小,所以依然辨識錯誤 結果的分數也必然越來越高。另一方面由表 3.2 可看出隨著秒數上升,目標語者 與封閉集合冒名頂替者各自分數的平均值幾乎不變,但目標語者分數中屬於辨識 正確的部分則越來越多,因此辨識正確分數的平均值則會隨著秒數上升而下降, 所以造成辨識正確語辨識錯誤分數平均值間的距離隨著秒數上升而縮短。由下圖 3.12 可以發現三種秒數等錯率幾乎是差不多的,會造成這樣的結果就在於雖然辨 識正確與辨識錯誤的分數分佈都因為秒數上升而方差下降,但其平均值也越來越 靠近,所以造成其重疊的部分並沒有因此減少。 圖 3.12:通用模型正規化法 1、2、3 秒接收者操作特徵曲線圖