分散式無線感測器工作排程-使用賽局理論
64
0
0
全文
(2) 分散式無線感測器工作排程—使用賽局理論 指導教授:嚴力行 博士(教授) 國立高雄大學資訊工程學系. 學生:林哲民 國立高雄大學資訊工程學系. 摘要. 在無線感測網路中,存在數個感測器與目標物,目標物必須被感測器持續地監控。 每個目標物都會有被感測器覆蓋的等級需求,但同一時間並不需要所有感測器都開啟也 能滿足需求。這篇論文主要研究感測器如何進行工作排程而達到節省能源與延長整體系 統壽命的目的。傳統的方法多數是使用貪婪法則(Greedy)為主的啟發式(Heuristic)演算法 來求解。這裡我們利用賽局理論(Game Theory),由感測器自行選擇應該開啟電源,或 者進行休眠節省電源。我們證明了定義的賽局可以收斂至穩定狀態,效能模擬實驗證實 可以有效增加網路壽命。但賽局收斂至穩定狀態的時間必須視為一種成本,因此我們提 出兩種方法使賽局更快達到穩定狀態。由實驗結果可得知快速達到穩定狀態只會使網路 壽命稍微降低,效果非常好。. 關鍵詞:無線感測網路、賽局理論、潛力賽局、k-Coverage、Coverage problem. i.
(3) Distributed Work Scheduling for Wireless Sensor Nodes Using Game Theory Advisor(s): Dr.(Professor) Li-Hsing Yen Department of Computer Science and Information Engineering National University of Kaohsiung. Student: Che-Ming Lin Department of Computer Science and Information Engineering National University of Kaohsiung. ABSTRACT. In wireless sensor network, there are several sensors and targets. All targets have to be monitored by sensors. Each target has a coverage level requirement. The targets can satisfy requirements by opening a part of the sensors. The paper research how to schedule the sensors. The power consumption can be reduced, and the network life time can be extended. The traditional methods almost use the greedy methods and the heuristic algorithms to solve the problem. In this paper, we employ Game Theory to solve it. The sensor selects whether to open the power or not. We prove that the game we defined can converge to a stable state, and the simulation result show it can extend the network life time. But the time that a game converges to a stable state has to be regarding as a cost. We propose two solutions to get the stable state more quickly. By simulation result, reaching stable state quickly leads to the little reduction of the network life time. The result is very good.. Keywords:Wireless sensor network, Game theory, Potential game, k-Coverage, Coverage problem. ii.
(4) 目錄 目錄.......................................................................................................................................... iii 圖目錄........................................................................................................................................v 表目錄......................................................................................................................................vii 致謝........................................................................................................................................ viii 1. 簡介................................................................................................................................1 2. 背景知識與相關研究....................................................................................................4 2.1 感測器工作排程問題............................................................................................4 2.1.1 覆蓋的定義................................................................................................4 2.1.2 感測模型....................................................................................................5 2.1.3 感測器工作排程問題的定義....................................................................7 2.1.4 傳統感測器工作排程問題相關研究........................................................7 2.2 賽局理論(Game Theory).....................................................................................10. 3.. 4.. 2.2.1 賽局理論簡介..........................................................................................10 2.2.2 賽局的分類..............................................................................................12 2.2.3 賽局的定義..............................................................................................13 2.2.4 應用賽局理論於感測器工作排程相關研究..........................................16 感測器工作排程賽局設計與分析..............................................................................17 3.1 獨立時刻感測器工作排程賽局..........................................................................17 3.1.1 賽局基本設定..........................................................................................17 3.1.2 賽局運作例子..........................................................................................20 3.1.3 賽局的穩定性..........................................................................................25 3.1.4 賽局的實作..............................................................................................28 3.2 極大化覆蓋比例賽局..........................................................................................31 模擬實驗......................................................................................................................35 4.1 獨立時刻感測器工作排程賽局效能實驗..........................................................35 4.1.1 實驗環境設定(a) .....................................................................................35 4.1.2 加速收斂至納許平衡實驗......................................................................36 4.1.3 考量感測器剩餘電量實驗......................................................................38 4.1.4 無線感測系統壽命..................................................................................39 4.1.5 策略轉換次數..........................................................................................42 4.1.6 以非互斥集合分類感測器......................................................................44 4.2 . 極大化覆蓋比例賽局效能實驗.......................................................................47 4.2.1 實驗環境設定(b).....................................................................................47 4.2.2 滿足覆蓋等級需求比例..........................................................................47 4.2.3 策略轉換次數..........................................................................................50 iii.
(5) 4.2.4 不同系統壽命下的滿足覆蓋等級需求比例..........................................52 5. 結論..............................................................................................................................54 參考文獻..................................................................................................................................55. iv.
(6) 圖目錄 圖 2.1 覆蓋的定義分類............................................................................................................5 圖 2.2 感測範圍........................................................................................................................5 圖 2.3 感測能力模型(a) ...........................................................................................................6 圖 2.4 感測能力模型(b)...........................................................................................................6 圖 2.5 感測能力模型(c) ...........................................................................................................7 圖 2.6 感測器互斥集合與非互斥集合例子(a) .......................................................................8 圖 2.7 感測器互斥集合與非互斥集合例子(b).......................................................................9 圖 2.8 壅塞賽局......................................................................................................................16 圖 3.1 獨立時刻感測器工作排程賽局..................................................................................18 圖 3.2 目標物提供的利益值..................................................................................................19 圖 3.3 獨立時刻感測器排程賽局的運作例子(a) .................................................................20 圖 3.4 獨立時刻感測器排程賽局的運作例子(b).................................................................21 圖 3.5 獨立時刻感測器排程賽局的運作例子(c) .................................................................22 圖 3.6 以馬可夫鏈表示獨立時刻感測器排程賽局的運作例子..........................................23 圖 3.7 一步轉換機率矩陣......................................................................................................24 圖 3.8 目標物收到的強度......................................................................................................31 圖 3.9 強度函數......................................................................................................................32 圖 3.10 極大化覆蓋比例賽局................................................................................................32 圖 4.1 加速收斂速度方法的無線感測系統壽命關係..........................................................37 圖 4.2 加速收斂速度方法的策略轉換次數關係..................................................................37 圖 4.3 考量剩餘電量方法的無線感測系統壽命關係..........................................................38 圖 4.4 無線感測系統壽命與感測器數量的關係..................................................................39 圖 4.5 無線感測系統壽命與目標物數量的關係..................................................................40 圖 4.6 無線感測系統壽命與覆蓋範圍的關係......................................................................41 圖 4.7 無線感測系統壽命與覆蓋等級需求的關係..............................................................41 圖 4.8 策略轉換次數與感測器數量的關係..........................................................................42 v.
(7) 圖 4.9 策略轉換次數與目標物數量的關係..........................................................................43 圖 4.10 策略轉換次數與覆蓋範圍的關係............................................................................43 圖 4.11 策略轉換次數與覆蓋等級需求的關係....................................................................44 圖 4.12 無線感測系統壽命與感測器集合開啟時間的關係................................................45 圖 4.13 賽局數量與感測器集合開啟時間的關係................................................................45 圖 4.14 滿足覆蓋等級比例與感測器數量的關係................................................................48 圖 4.15 滿足覆蓋等級比例與目標物數量的關係................................................................49 圖 4.16 滿足覆蓋等級比例與覆蓋範圍的關係....................................................................49 圖 4.17 策略轉換次數與感測器數量的關係........................................................................50 圖 4.18 策略轉換次數與目標物數量的關係........................................................................51 圖 4.19 策略轉換次數與覆蓋範圍的關係............................................................................51 圖 4.20 滿足覆蓋等級比例與互斥集合個數的關係............................................................52 圖 4.21 策略轉換次數與互斥集合個數的關係....................................................................53. vi.
(8) 表目錄 表 2.1 囚徒困境......................................................................................................................11 表 4.1 實驗項目與參數設定(a) .............................................................................................36 表 4.2 實驗項目與參數設定(b).............................................................................................47. vii.
(9) 致謝 首先,我要感謝我的指導教授嚴力行老師,他在研究方向與論文題目的構思都給了 很多的建議。在撰寫論文時,老師也不厭其煩地一再幫我修改論文。同時也要感謝我的 口試委員王讚彬教授與謝欽旭教授,他們在百忙之中能夠仔細審閱我的論文。並且提供 了許多的意見使論文更加完善。 我也要感謝無線網路實驗室與其他實驗室的同學們平時的互相鼓勵與討論,在遭遇 挫折時才不至於放棄。這段時間內的相處的確讓我獲益良多。 最後我要感謝我的家人,讓我在物質方面不至於匱乏,可以專心在讀書與研究上, 最後終於能夠完成論文。. viii.
(10) 1. 簡介 近年來,隨著通信技術,嵌入式計算技術和感測技術越來越成熟,感測器也擁有了 偵測、計算處理和無線傳輸通信的能力,因此無線感測網路(Wireless Sensor Network, WSN)逐漸吸引了人們的注意,它結合了感測技術、嵌入式計算技術和分散式資訊處理 技術。WSN 是由一個或數個資料收集器以及眾多的感測器所組成,感測器分佈在監視 區域進行資料的收集或監控,元件之間採用無線的方式進行溝通。WSN 可以從監視區 域中偵測和收集許多種類的資訊並且處理收集來的資訊傳回給使用者。為了達到大量散 佈的目的,感測器必須具備低成本、低耗電、小體積…等特性。感測器以隨機的方式散 撥在監視地區,主要目的在於監控人類較難以進入的區域。由於這些特色,WSN 可以 幫助人們在任何時間,地點和狀況下收集大量資訊。因此,它們被廣泛地使用在軍事領 域、環境監測、交通控制、健康照護、工業、災害預防…等,目前的應用以環境監測最 為廣泛,主要針對地震、氣壓、溫度、溼度…等加以監測。WSN 最早是由美國加州柏 克萊大學的一項研究計畫所提出,他們開發出與阿斯匹靈藥片大小相似的感測器,這項 計畫由美國國防部所資助,預定應用在軍事用途。例如在戰場上,以飛機在欲監控的敵 軍區域散佈大量的感測器,一段時間後,再派遣飛機將感測器的資料收回。這樣一來, 即使不派遣大量兵力進入敵方區域,也能進行敵軍情報的收集。 一些應用有嚴格的覆蓋等級(Coverage Level)需求,覆蓋等級表示了這個區域被監測 的程度(例:一個區域被監測多少百分比或被多少個感測器覆蓋)。然而,不同的應用 對於覆蓋等級的需求也不相同。舉例來說,對於家庭安全的應用,覆蓋等級的需求就比 較低,而對於戰場或化學污染區域監測的應用,就需要較高的覆蓋等級。即使是同一個 應用,在不同季節下的覆蓋等級需求也可能不同。所以感測網路的使用者可以針對自己 的應用環境設定所需的覆蓋等級。覆蓋等級的定義可以針對整個監視區域(Monitored Area)或某些特定目標物(Target)滿足即可,本篇論文研究的是後者。針對目標物的覆蓋 等級又可分為 1-Coverage、k-Coverage、Q-Coverage 三種。1-Coverage 要求每個目標物 1.
(11) 至少要被一個感測器所覆蓋, k-Coverage 要求每個目標物至少要被 k 個感測器所覆蓋, 而 Q-Coverage 假設每個目標物可以有不同的覆蓋等級需求。 同一時間內,即使不用讓所有的感測器打開,也可能可以滿足所有目標物覆蓋等級 需求。由於感測器的能源有限,所以我們希望讓感測器進行工作排程,以延長整體無線 感測系統的壽命(Network Life Time)。此處整體無線感測系統的壽命定義為所有目標物 滿足覆蓋等級需求的總時間。目前相關研究中,感測器工作排程的目標大致可分為兩 類,一是在滿足目標物覆蓋等級需求的前提下,設法極大化系統壽命,二是在已設定感 測網路工作總時間的情況下,極大化目標物滿足覆蓋等級需求的比例。本篇論文針對兩 類問題都提出一種解法。 Cardei等人[2]將感測器分為數個互斥集合(Disjoint Set),在某一時刻下只要開啟任 何一個集合都可以單獨滿足目標物的 1-Coverage需求,這樣一來極大化無線感測系統壽 命的問題即轉化成尋找更多互斥集合的問題。Cardei等人[3]研究極大化非互斥集合問 題,以線性規劃的啟發式(Heuristic)演算法和貪婪(Greedy)演算法來得到近似解。Li等人 [5]把Cardei等人定義的問題延伸至k-Coverage的覆蓋等級需求,他們用貪婪法則先選擇 周圍感測器密度最低的感測器,尋找到互斥集合後,剔除不必要的部份而得到近似解。 Chaudhary等人[4]將問題延伸至Q-Coverage的覆蓋等級需求,他們以貪婪法則先選擇剩 餘電量較高的感測器,再扣除不必要的感測器,反覆進行而得到解。 近十年來,賽局理論(Game Theory)被廣泛應用在無線網路資源分配的問題中,獲 得了不錯得成果。在覆蓋排程問題中,Ai等人[1]在給定感測網路工作總時間的前提下, 以賽局理論讓感測器自行選擇應該開啟工作的時段,目標在盡量提高整個區域的覆蓋等 級。Zhu等人[9]考慮比較精細的視覺感測器模型,利用賽局理論讓感測器自行決定所在 位置、焦距、角度等,方法較為複雜。 我們以一個分散式的方法來解決極大化系統壽命的問題。把任一時刻下的感測器工 作決策問題,視為一個獨立的賽局,因此一個完整的感測器工作排程被我們切割成若干 個小時段來處理。在任一時段,感測器會根據賽局理論選擇自己是否打開電源,使此時 2.
(12) 段中所有目標物都會滿足覆蓋等級需求。目標在延長感測網路的工作壽命。我們證明了 賽局的穩定性,每個賽局必定最終會停止在一個穩定狀態。最後考量了賽局在實作上可 能遇到的各種問題並提供解決方案。 針對極大化目標物滿足覆蓋等級需求的比例問題,在已經決定互斥集合個數的情況 下,我們讓感測器依照賽局理論自行決定應該加入哪個互斥集合。感測器們會互相觀察 對方的選擇,並且不斷轉換自己的選擇方案,最終停止在一個穩定狀態。最終各個互斥 集合就是排程後的結果,一個時間點只開啟一組互斥集合內的感測器。 模擬實驗極大化系統壽命部份,將我們的方法改變各項參數進行觀察,並且與傳統 得方法比較。可以發現我們的結果較優,且我們的方法是以分散式為基礎,在實作上較 可行。為了讓我們的方法更快到達穩定狀態,我們也提出了兩個方法進行實驗,結果確 實可加快速度。極大化目標物滿足覆蓋等級需求的比例部份,我們也改變各項參數進行 觀察。但由於採用的感測模型較為特殊,缺乏比較的對象,但可作為往後研究的參考。 這一章我們介紹了 WSN 的背景知識與應用、覆蓋問題、相關文獻的簡介以及我們 的研究方向。接下來第二章會針對覆蓋的定義、感測模型、何謂感測器工作排程問題、 賽局理論和相關文獻做詳細地背景知識介紹。第三章會探討我們如何把感測器工作排程 問題以賽局理論解決。第四章以程式模擬 WSN 的感測器工作排程問題,把我們的方法 與傳統方法做比較。第五章對整篇論文做總結,提出未來可發展的方向。. 3.
(13) 2. 背景知識與相關研究 這一章將針對感測器工作排程問題與賽局理論做介紹。第一部分首先說明感測器中 何謂覆蓋,接下來是感測器的感測模型有哪些,以及感測器工作排程問題的定義,最後 是介紹其他研究者對於感測器工作排程問題的傳統解法。第二部份首先簡介何謂賽局理 論,接下來是賽局的分類,以及如何定義一場賽局,最後是介紹其他研究者如何應用賽 局理論於感測器工作排程問題。. 2.1 感測器工作排程問題. 2.1.1 覆蓋的定義 以往的研究通常使用感測器監控一個「區域」(Area)或者一群「目標物」(Target)。 如 圖 2.1,如果是監控一個區域則又可分為 1-Coverage和k-Coverage兩種,在這裡 1-Coverage必須讓整個區域都被至少一個感測器覆蓋,k-Coverage則要至少被k個感測器 覆蓋。若是監控一群目標物,在 1-Coverage和k-Coverage的情況下,與前面所述相似, 只是改為目標物必須滿足覆蓋等級需求,Q-Coverage則是假設每個目標物可以有不同的 覆蓋等級需求,在這裡Q為一向量,表示每個目標物的的覆蓋等級需求值。在本篇論文, 我們以探討目標物覆蓋的k-Coverage為主。. 4.
(14) Coverage. Area Coverage. 1-Coverage. Target Coverage. k-Coverage. k-Coverage. 1-Coverage. Q-Coverage. 圖 2.1 覆蓋的定義分類. 2.1.2 感測模型 感測器可以分為同質性的(Homogeneous)或異質性的(Heterogeneous),同質性指的 是所有感測器在感測能力(Sensing Capability)、電量(energy capacity)、能源消耗力(power consumption)都相同,異質性則是有可能不相同。 感測器的感測能力模型可大致分為Unit-Disk、Probabilistic、Intensity三類。Unit-Disk 如圖 2.2、圖 2.3,目標物在感測器以半徑為r的圓形範圍內代表被此感測器覆蓋,在範 圍外則否。. r. sensor. 圖 2.2 感測範圍. 5.
(15) coverage. r. distance. 圖 2.3 感測能力模型(a) Probabilistic和Intensity如圖 2.2、圖 2.4,若目標物在感測器的覆蓋範圍內,根據目 標物與感測器的距離可得到一機率或強度,表示該目標物被感測的機率或強度。在圖 2.4,距離越遠機率或強度會呈線性下降,也可以使用圖 2.5的模型,機率或強度呈指數 下降。若是使用Probabilistic,可定義目標物被所有感測器感測的機率總和超過 1 就代表 此目標物可被感測。如果使用Intensity,可定義目標物被所有感測器感測的強度總和超 過一定值就代表此目標物可被感測。研究者可依照自己的需求來選擇要使用哪個模型。 本論文中我們使用了同質性的感測器,Unit-Disk模型和Intensity模型。. probability or intensity. r 圖 2.4 感測能力模型(b). 6. distance.
(16) probability or intensity. r. distance. 圖 2.5 感測能力模型(c). 2.1.3 感測器工作排程問題的定義 同一時間內,可能只要開啟部分感測器,就可以滿足所有目標物的覆蓋等級需求。 由於感測器的能源有限,所以我們要進行感測器工作排程,同一時間我們只開啟部分感 測器,以延長整體無線感測網路系統壽命。整體無線感測網路系統壽命定義為所有目標 物或區域滿足覆蓋等級需求的總時間。目前相關研究中,感測器工作排程的目標大致可 分為兩類: . 一是在滿足目標物或區域覆蓋等級需求的前提下,設法極大化系統壽命。. . 二是在已設定感測網路工作總時間的情況下,極大化目標物的被覆蓋個數或區域的 被覆蓋範圍,這種情況下可能會有目標物或區域未達到覆蓋等級需求。. 2.1.4 傳統感測器工作排程問題相關研究 Cardei等人[2]研究的是目標覆蓋,他們在滿足 1-Coverage的前提下,欲極大化無線 感測網路系統壽命。他們將感測器分為數個互斥集合(Disjoint Set),在某一時刻下只要 開啟任何一個集合都可以單獨滿足目標物的 1-Coverage需求,這樣一來極大化無線感測 網路系統壽命的問題即轉化成尋找更多互斥集合的問題,因此覆蓋問題可被分為互斥集 7.
(17) 合與非互斥集合(Non-Disjoint Set)兩個方向的研究,這兩個方向均有學者在進行研究。. A r1 B r2 C r3 D 圖 2.6 感測器互斥集合與非互斥集合例子(a) 圖 2.6所示是一個例子,用來說明尋找互斥集合與非互斥集合的相異處。此處有四 個感測器 A, B, C , D 和三個目標物 r1 , r2 , r3 ,箭頭方向表示感測器可覆蓋的目標物,我們 假設 A, D 的剩餘電量可以開啟 1 單位時間, B, C 的剩餘電量可以開啟 2 單位時間,每 個目標物只需要 1-Coverage需求。若要尋找互斥集合,那麼結果可能是 A, C 、 B, D 各開啟 1 單位時間,則網路壽命就是 2 單位時間。若要尋找非互斥集合,那麼結果可能 是 B, C 、 A, C 、 B, D 各開啟 1 單位時間,則網路壽命就是 3 單位時間。若限制在 尋找互斥集合的情況下,很明顯地會出現電量無法完全利用的問題。以上是感測器在異 質性的情況(剩餘電量不同)下互斥集合無法完全利用剩餘電量,另一個狀況是在感測 器的數量無法被覆蓋等級需求k整除也會發生類似問題。. 8.
(18) 圖 2.7 感測器互斥集合與非互斥集合例子(b) 如圖 2.7,假設 A, B, C 的剩餘電量都可以開啟 3 單位時間,r1 需要 2-Coverage需求。 若使用互斥集合方法,可能會有四種答案分別是 A, B 、 A, C 、 B, C 或 A, B, C 開 啟 3 單位時間,這四種答案的網路壽命都是 3 單位時間。如果使用非互斥集合方法可以 得到 A, B 開啟 2 單位時間, A, C 開啟 1 單位時間, B, C 開啟 1 單位時間。則網路 壽命就是 4 單位時間。這是另一種互斥集合方法無法完整利用電量的情況。但由於極大 化互斥集合比極大化非互斥集合要來得簡單,所以許多學者會在此限制下研究。我們將 提出一個可適用於兩種情況下的方法。. Cardei等人[3]證明了極大化感測器非互斥集合問題是NP-Complete問題,他們提出 了利用線性規劃的啟發式(Heuristic)演算法和貪婪(Greedy)演算法來得到近似解。前者先 以線性規劃得到一線性上的最佳解,再慢慢去逼近最佳解得到一近似解。後者先選擇可 被感測器覆蓋數較少的目標物,再擇一感測器去覆蓋它,最終得到近似解。然而前者耗 費大量的運算時間但結果卻不如後者。. Li等人[5]研究的是區域覆蓋,他們在滿足k-Coverage的前提下,欲極大化無線感測 網路系統壽命。他們把Cardei等人[2]定義的尋找互斥集合問題延伸至k-Coverage的覆蓋 等級需求,並證明此問題是NP-Complete問題。他們證明此問題的上限值(Upper bound). 9.
(19) K 是 ,K是整個區域中被覆蓋等級最小的部份。他們用貪婪法則先選擇周圍感測器 k 密度最低的感測器,找到一組滿足k-Coverage的互斥集合後,再進行修剪(prune),把集 合中即使剔除後也不影響k-Coverage的感測器剔除,不斷重複最終得到近似解。. Chaudhary 等人 [4] 研究的是目標物覆蓋,他們將問題延伸至Q-Coverage ,在滿足 Q-Coverage 的前提下,欲極大化無線感測網路系統壽命。他們以 [3] 為基礎,推論在 Q-Coverage條件下此問題仍是NP-Complete問題。他們提出了以貪婪法則為基礎的啟發 式演算法,先選擇剩餘電量較高的感測器。選擇到的感測器集合扣除一個常數的單位電 量,所以調整常數大小就可以應用於尋找互斥集合與非互斥集合。 過去的感測器排程方法幾乎都是集中式演算法,我們希望研究出以分散式的方法來 解決。正好我們曾經有使用過賽局理論(Game Theory)於 802.11 AP 選擇機制,便想到利 用賽局理論解決感測器排程問題。賽局理論是一個以分散式為主,探討賽局中各個參與 者彼此的利益競爭與行動。我們將賽局理論用於感測器排程問題並且設計出一個只需稍 微修改就可變為互斥集合類排程方法與非互斥集合類排程方法的賽局。. 2.2 賽局理論(Game Theory). 2.2.1 賽局理論簡介 賽局理論又被稱為博弈理論或互動決策理論,在經濟學、電腦科學、生物學、軍事 戰略…等有著廣泛的應用,賽局理論提供了一套數理方法分析賽局中參與者(Player)們 的合作或競爭策略。在一場賽局中,選擇策略並進行競爭的代理人(Agent)我們稱為參 與者,參與者各自有不同的目標或利益。為了使自己的利益達到最大,他們會考慮對手 的各種可能行動方案,並且選擇對自己最有利或最合理的策略,在日常生活中的下棋類 遊戲就是一例。賽局理論就是這樣一門研究多人決策問題的方法,賽局中每一個人的決 策都會受到其他人的影響,它提供了有系統的方法來分析這種相互影響的策略。藉由形 10.
(20) 式化的推理來決定理性參與者所採取的策略,以及採取策略後所產生的結果。在賽局理 論中最有名的例子就是囚徒困境(Prisoner’s Dilemma)。 在某一件案子中警方逮捕了甲、乙兩位嫌疑犯,在問訊過程中嫌疑犯可以選擇「認 罪」與「沉默」兩個策略,根據他們的選擇,可能達到的結果可分為以下三類: . 兩人均選擇認罪,則兩人必須服刑 6 年。. . 兩人均選擇沉默,則兩人必須服刑 2 年。. . 其中一人認罪而另一人沉默,則認罪者作為汙點證人無罪釋放,另一人服刑 10 年。. 上述結果我們可以用表 2.1來表示之,表中(x, y)分別代表所甲與乙所需服刑的年數。 表 2.1 囚徒困境 乙. 甲. 認罪. 沉默. 認罪. (6, 6). (0, 10). 沉默. (10, 0). (2, 2). 由表 2.1我們可以發現,若參與者都是理性的且自私的,他們是不可能會選擇沉默 的,我們可以甲的立場說明之: . 若乙選擇認罪,則甲選擇認罪只要服刑 6 年,比沉默的 10 年要好。. . 若乙選擇沉默,則甲選擇認罪可無罪釋放,比沉默的 2 年要好。. 也就是說不論乙的選擇如何,甲選擇認罪都可以對本身得到較好的結果。這樣一來最後 兩人都會選擇認罪而達到 (6, 6) 的結果,這是因為他們都是以最大化自己的利益來行 動。事實上,我們可以發現(2, 2)是對整體而言最好的結果,但由於甲、乙兩人並無法 控制或預測對方的決策,因此不可能達到這個結果。當參與者只為自己的利益而行動, 卻會對整體得到較差的結果。賽局理論就是在研究參與者之間如何選擇策略而互相影 響,最終達到不同的結果。 對於某位參與者而言,所謂嚴格優勢策略(Strictly Dominant Strategy)指的是不論其 11.
(21) 他人的選擇如何,選擇此策略總是比其他策略得到較好的利益。因此若存在嚴格優勢策 略,參與者以理性角度勢必會選擇它。與其相對的是嚴格劣勢策略(Strictly Dominated. Strategy),不論其他人的選擇如何,選擇此策略總是比某一特定策略的利益較差,參與 者以理性角度絕不會選擇它。囚徒困境中的沉默就是一個嚴格劣勢策略,無論對方的選 擇如何,選擇沉默總是會比認罪要來的差。. 2.2.2 賽局的分類 賽局根據不同的基準有不同的分類,以下我們根據數個基準來分類賽局: . 以參與者是否合作區分:一般而言,賽局主要可分為合作賽局(Cooperative Game) 和非合作賽局(Non-cooperative Game),它們的差別在於參與者之間是否有一個具有 約束力的協議,如果有就是合作賽局,否則就是非合作賽局。這裡並不是說非合作 賽局中的參與者不能合作,如果賽局的設計者能夠讓參與者以理性自私進行賽局, 不以具有約束力的協議規範他們,而又能達到合作的結果,這也是可行的。由於合 作賽局理論遠比非合作賽局理論要來的複雜,在理論上的成熟度不如非合作賽局, 所以大部分人所談論的賽局理論是以非合作賽局為主。. . 以行動的時間序列性區分:可分為靜態賽局 (Static Game) 和動態賽局 (Dynamic. Game)。在靜態賽局中,參與者必須同時選擇他們的策略。而動態賽局是指參與者 選擇策略有先後的順序,且後行動的參與者可以觀察前面參與者的行動來判斷要如 何決策。 . 以參與者對資訊的了解程度區分:若每一位參與者完全了解其他參與者所可以選擇 的策略和利益我們稱為完全資訊賽局,若對於策略和利益了解不夠準確或者不是對 所有參與者都了解,稱為非完全資訊賽局。. . 以賽局進行次數區分:若賽局只進行一次稱為單次賽局,若賽局進行多次則為重複 賽局。 12.
(22) 2.2.3 賽局的定義 一場賽局 可以由下列數個部份所組成: . 參與者集合 P p1 , p2 , , pn (Player Set):賽局中所有參與者所組成的集合,也就 是囚徒困境中的甲、乙。n 代表參與者的總數,編號 i 的參與者以 pi 表示之。. . 策略集合 Si {s1 , s2 , , sm } (Strategy Set):賽局中參與者 pi 所可能選擇的策略所組成 的集合。囚徒困境例子中的此集合為{認罪、沉默} 。在囚徒困境中所有參與者所 能選擇的策略都相同,所以甲、乙擁有相同的策略集合,也就是任何 Si S j ,且. i j 。值得注意的是,也有個別參與者的策略集合不同的賽局存在,也就是 Si 可能 不等於 S j 。 . 策略組態 Y S1 S2 Sn (Strategy Profile):參與者選擇策略能達到的所有組合, 也就是囚徒困境中的(認罪、認罪)(認罪、沉默) (沉默、認罪) (沉默、沉默) 四種組合。. . 策略向量 C c1 , c2 , , cn (Strategy Vector):C Y ,其中 ci 為賽局中 pi 選擇的策略。 例如 pi 選擇了 s2 ,則 pi s2 。而所有人選擇的策略組合成一向量 C。. . 效用函數 ui C or ui ci , c i (Utility Function):參與者 pi 在某個策略向量 C 中所能 得到的利益,即囚徒困境中嫌疑犯所需服刑的年數。 ui 取決於 C,即一個策略向量 決 定 了 一 效 用 函 數 。 也 有 人 稱 為 報 酬 函 數 (Payoff Function) 或 代 價 函 數 (Cost. Function),囚徒困境的例子中嫌疑犯會希望服刑年數愈小愈好,因此稱代價函數較 為合理。不同研究者對此函數的命名與定義並不一致,本論文中我們希望效用函數 能愈大愈好,與囚徒困境的例子不同。 在非合作賽局中存在一種特殊的策略向量,在此類策略向量沒有任何一個參與者能 13.
(23) 因獨自改變策略而得到更大的利益,此類策略向量被稱為納許平衡(Nash Equilibrium) 或非合作平衡。. Definition 1. 納許平衡. 若 pi , i 1 n ,使得 ui ci , c i ui ci, c i ,則 C c1 , c2 , , cn 為納許平衡。. 納許平衡在學術上被證明是非構造性的(Non-Constructive),即是即使知道賽局中納 許平衡的存在,但卻不能指出以什麼構造演算法去達到納許平衡。上述所說的納許平衡 指的是純粹策略納許平衡(Pure Strategy Nash Equilibrium),還存在另一種納許平衡稱為 混合策略納許平衡(Mixed Strategy Nash Equilibrium)。純粹策略(Pure Strategy)是指參與 者只能選擇一個策略。而混合策略(Mixed Strategy)加入了機率的要素,參與者可能以 50 %的機率選擇策略一,另外 50%的機率選擇策略二,因此納許平衡的定義也會隨之改 變。混合策略被許多學者認為有嚴重的問題,這是因為沒有人能夠在沒有隨機數產生器 的幫助之下做出隨機的決定來。在本篇論文,我們以討論純粹策略為主。. Definition 2. Pareto optimal. 在一個賽局中,一組策略向量 C c1 , c2 , , cn 如果是 Pareto optimal 那麼若且為若. . . 不 存 在 另 一 組 策 略 向 量 C c1 , c2 , , cn , 使 得 i 1,..., n : ui C ui C 且 j 1,..., n : u j C ui C 。. Pareto optimal 通常是賽局的設計者最希望達到的目標,但參與者們自私的行動往 往會使結果落入納許平衡。我們可以經由效用函數的設計使納許平衡接近 Pareto optimal 或是等於 Pareto optimal。 有某一類的賽局被稱為潛力賽局(Potential Game)[7]。在潛力賽局中所有參與者想改 變決 策的動機可以用一個全域函數 (Global function) 來表示,稱為潛力函數 (Potential 14.
(24) function),而潛力賽局中至少存在一個潛力函數 ci , c i ,使得若 ui ci, c i ui ci , c i , 則保證 i ci, c i i ci , c i 。也就是說當 pi 從選擇策略 ci 轉換成選擇策略 ci 可獲得利益 時,潛力函數 的值也一定會獲得提升。. Definition 3. 潛力賽局(Potential Game). 如果一個賽局 是潛力賽局,那麼至少存在一個潛力函數 ,使得. pi P : ci , ci Si :: sgn ui ci, ci ui ci , ci sgn ci, ci ci , ci 。 if 0, 1 sgn( ) 0 if 0, 1 if 0. . 潛力賽局中存在某一種特例稱為確切潛力賽局(Exact Potential Game)。在確切潛力 賽局中如果參與者因改變策略而增加某個數量的利益,那麼潛力函數也可以提升同樣數 量的值。. Definition 4. 確切潛力賽局(Exact Potential Game). 如果一個賽局 是確切潛力賽局,那麼至少存在一確切潛力函數 ,使得 pi P : ci , ci Si :: ui ci, c i ui ci , c i ci, c i ci , c i 。. Monderer等人[7]證明了潛力賽局中必定存在純粹策略納許平衡,因此潛力賽局可以被 用來證明賽局中納許平衡的存在。. Rosenthal[8]提出了壅塞賽局(Congestion Game)。壅塞賽局中有多個factors,由數個 factors組成一策略,每一個策略都是factors的子集。如圖 2.8,參與者可以選擇策略一、 二,策略一包含了factor 1, 2,策略二包含了factor 2, 3。壅塞賽局命名於如果多個參與 者選擇到同一個factor ,那麼由factor 所形成的成本函數會隨著參與者的數量上升而降 低。壅塞賽局中參與者的效用函數是由各factor的成本函數所組成,若參與者選擇了策 15.
(25) 略一,那麼參與者的效用函數就是factor 1 和factor 2 的成本函數的總和。Monderer等人. [MS96]證明了所有壅塞賽局都屬於潛力賽局,即所有壅塞賽局都可以找到至少一個潛 力函數。. Factor 1 Strategy 1 Factor 2. Player Strategy 2. Factor 3. 圖 2.8 壅塞賽局. 2.2.4 應用賽局理論於感測器工作排程相關研究 Zhu 等 人 [9] 考 慮 比 較 精 細 的 視 覺 感 測 器 模 型 , 他 們 的 感 測 模 型 不 是 一 般 的 Unit-Disk,感測器可以設定角度與焦距,感測範圍類似扇形。利用賽局理論讓感測器自 行決定所在位置、焦距、角度等,從最近兩次的步驟選出較好的結果再進行下一次選擇。. Ai等人[1]研究的是區域覆蓋,他們在給定感測網路工作總時間的前提下,欲極大 化整個區域的被覆蓋面積(滿足 1-Coverage即被覆蓋)。他們以賽局理論模型化尋找互 斥集合問題。他們以感測器為參與者,互斥集合為可選擇的策略。效用函數定義為感測 器開啟所能獨自覆蓋的區域,與其他參與者重複覆蓋的不列入計算。讓感測器自行選擇 在哪個互斥集合能獨自覆蓋最多區域。最後他們證明了這是個潛力賽局和壅塞賽局. [8]。這個賽局的缺點在於感測網路工作總時間要如何取得,若設定太小或太大可能會 導致效率變差。. 16.
(26) 3. 感測器工作排程賽局設計與分析 針對極大化系統壽命問題,前人把感測器工作排程問題分為尋找互斥集合與非互斥 集合兩類,這裡我們想要設計能同時解決兩類問題的方法。我們把任一時刻下的感測器 工作決策問題,視為一個獨立的賽局,因此一個完整的感測器工作排程被我們切割成若 干個小時段來處理。在任一時段,感測器會根據賽局理論選擇自己是否打開電源,使此 時段中所有目標物都會滿足覆蓋等級需求,目標在延長感測網路的工作壽命。感測器在 某一時刻決定了自己的策略,這等同於找到了一組感測器集合。若我們設定這組感測器 集合會一次將電量耗盡,這就和尋找互斥集合問題相同。若我們設定這組感測器集合只 消耗開啟一回合的電量,那麼就可以應用在尋找非互斥集合問題。 針對極大化目標物的被覆蓋個數,我們把感測器做為參與者,讓感測器選擇互斥集 合作為策略。感測器將依照效用函數選擇要加入哪個互斥集合。已知互斥集合的個數, 目標在於增加滿足覆蓋需求的目標物個數。. 3.1 獨立時刻感測器工作排程賽局. 3.1.1 賽局基本設定 我們假設在監控區域內有 n 個感測器和 m 個目標物,感測模型使用 Unit-Disk,這 裡我們希望每個目標物都能滿足 k-Coverage,在此前提下要極大化無線感測網路系統壽 命。. 17.
(27) 圖 3.1 獨立時刻感測器工作排程賽局 如圖 3.1,我們把無線感測網路系統壽命分為數個回合。在任一回合下,我們將執行一 個賽局,賽局之間彼此獨立。執行過的賽局,開啟的感測器必須消耗一回合的電量。整 個系統會運作至無法使所有目標物滿足k-Coverage為止。若我們假設有 回合,則總共 有 個賽局 1 , 2 , , 。任一個賽局的定義如下: . 參 與 者 集 合 P p1 , p2 , , pn : 總 共 有 n 個 感 測 器 作 為 參 與 者 , 分 別 是. p1 , p2 , , pn 。 . 策略集合 Si {0,1}:所有參與者都可以選擇 0 或 1 兩個策略決定關閉或打開電源。 在定義效用函數之前,我們先定義若一個目標物被感測器覆蓋,感測器可得到的利. 益值為: if vt k g (t , vt ) 0otherwise. 18. (3.1).
(28) gain μ a vt k. 1. 圖 3.2 目標物提供的利益值 其中 vt ci 為目標物 t 的覆蓋等級, Rt 為可覆蓋 t 的感測器集合。如圖 3.2。當 vt 在 1 iRt. 至 k 的情況下,所有覆蓋 t 的感測器都可以得到 的利益值。若 vt 為 0,則沒有被任何感 測器覆蓋,所以也不會提供任何利益值。若 vt 大於 k ,超過了目標物 t 所需要的覆蓋等 級,因此目標物 t 也不提供利益值給覆蓋它的的感測器。這麼做是因為 t 已經滿足覆蓋 等級需求,即使更多個感測器覆蓋它也只是浪費電源。此外,目標物所提供的利益值 一定會大於感測器開啟一回合所消耗的電量成本 a ( a ),如此一來即使感測器開啟只 覆蓋了一個目標物,他也會執行開啟的動作,這是為了確保目標物能夠滿足k-Coverage。 . 效用函數 ui C or ui ci , c i :. g (t , vt ) a if ci 1 ui (ci , c i ) tTi 0 if ci 0 . (3.2). Ti 為感測器 pi 能覆蓋的目標物集合。若 pi 開啟( ci 1 ),它就會得到覆蓋範圍內的目標物 的利益值,將這些利益值加總並減去開啟一回合所消耗的電量成本作為效用函數。若 pi 關 閉 ( ci 0 ) , 它 將 不 會 得 到 任 何 利 益 值 , 但 也 不 必 消 耗 電 量 。 pi 希 望 達 到 max ui ci , c i ,所以 pi 會選擇利益值最大的策略。. 每個 1 , 2 , , 賽局一開始會預設所有感測器為關閉狀態。我們設定此賽局為動 態賽局,一次會有一個感測器決定或改變決策,不會有兩個感測器同時改變決策。並且 19.
(29) 設定此賽局為重複賽局,感測器可不斷根據其它感測器的選擇決定是否改變策略。直到 所有感測器都不想改變決策為止,也就是達到一個納許平衡。. 3.1.2 賽局運作例子 以下用一個例子來說明我們的賽局如何運作:. 圖 3.3 獨立時刻感測器排程賽局的運作例子(a) 如圖 3.3,有五個感測器 A, B, C , D, E 和三個目標物 r1 , r2 , r3 。我們假設每個感測器的 電量可供開啟一回合,只需讓目標物滿足 1-Coverage需求,預設所有感測器為關閉狀 態。首先開啟第一個賽局 1 ,假設感測器依照下列順序進行決策,以下依序說明感測 器進行決策的結果。 . 因 D 開啟可以覆蓋 r3 , D 計算開啟與關閉的效用函數分別為 a 和 0,所以 D 會 選擇開啟。. . 若 C 開啟可以覆蓋 r2 , r3 ,但 r3 會超過 1-Coverage 需求,故可得到 C 開啟與關閉的效 用函數分別為 a 和 0,所以 C 會選擇開啟。. . 若 B 開啟可以覆蓋 r1 , r2 ,但 r2 會超過 1-Coverage 需求,故可得到 B 開啟與關閉的效 用函數分別為 a 和 0,所以 B 會選擇開啟。 20.
(30) . 若 A 開啟可以覆蓋 r1 ,但 r1 已滿足 1-Coverage,故可得到 A 開啟與關閉的效用函數 分別為 a 和 0,所以 A 會選擇關閉。. . E 與 A 的情況類似, E 覆蓋的目標物都已滿足 1-Coverage,所以 E 會選擇關閉。. A-off r1 B-on E-off r2 C-on r3 D-on 圖 3.4 獨立時刻感測器排程賽局的運作例子(b) 圖 3.4為進行至此的感測器決策狀態,到這裡為止賽局 1 尚未結束,因為還未達到 納許平衡,所以我們重複進行賽局 1 。感測器決策如下: . 因為 C 發現即使關閉, C 覆蓋的目標物也會滿足 1-Coverage,所以 C 改變決策選擇 關閉。. . A 和 E 不改變決策選擇關閉,因為即使開啟也不會得到較高的效用函數。. . B 和 D 不改變決策選擇開啟。. 21.
(31) A-off r1 B-on E-off r2 C-off r3 D-on 圖 3.5 獨立時刻感測器排程賽局的運作例子(c) 如圖 3.5,我們得到一組集合 {B, D} ,這時已達到納許平衡,所有感測器皆不會想改變 決策,且所有目標物滿足 1-Coverage。接下來開啟賽局 2 ,依照相同規則,假設得到 集合 { A, C} , 3 得到集合 {E} 。由於所有感測器的電量已消耗殆盡,無法使目標物滿足. 1-Coverage,所以感測器工作排程到此結束。 在上述例子中,可滿足目標物 1-Coverage 的感測器互斥集合有 { A, C}、{B, D}、{E} 與 {B, C} 四組集合。這四組集合中,只需開啟一組即可滿足 1-Coverage。但我們可以發 現,{B, C} 是一組較差的集合,因為若開啟 {B, C},則 { A, C} 與 {B, D} 因電量不足皆無法 開啟。所以只能開啟 {B, C} 和 {E} ,則無線感測網路系統壽命僅為 2 回合。如果我們是 開啟 { A, C} 、 {B, D} 和 {E} ,就可以得到 3 回合的無線感測網路系統壽命。所以我們認 為 {B, C} 是一組較差的集合,應該要避免選到此集合。可惜的是以我們的賽局機制,有 可能會選到 {B, C} 。為了計算選到 {B, C} 的機率,我們使用馬可夫鏈(Markov chain)來表 示。上述例子雖然感測器都按照隨機順序來進行決策,事實上應該讓欲改變策略的感測 器們來競爭,讓它們爭奪改變策略的權利才適用於真實情況與馬可夫鏈。. 22.
(32) 1 00001. 1 1. 00011. 1 01001. 1/2. 11001. 1/2. 10001. 1/2 1/2. 1/3. 1/4. 1/4 10011. 01000. 1/4. 11000. 1/4. 10000 1/3. 1/4. 1/4 1/4. 11010. 1/3. 1. 1/3. 1/4. 1/4. 1/3. 10010. 1/5 1. 1. 1. 01100. 1/2. 11100. 1/2. 1/3. 10100. 1/5 01010. 1. 1. 1/2. 1/2 01110. 1/3. 1/3. 1/3. 00110. 10110 1/4. 1/4 1/4 00101. 1/3. 00100. 1/3 1/5. 1/5 1/2. 1/2. 00010 1/3 1/5. 00000 00111. 圖 3.6 以馬可夫鏈表示獨立時刻感測器排程賽局的運作例子 我們將感測器的開關狀態以二位元表示, 0 表示為關閉、 1 為開啟,則感測器. A, B, C , D, E 初始狀態由左至右表示為(00000) 。圖 3.6為感測器進行狀態變化的馬可夫 鏈。在這之中有(00001) 、 (01010) 、 (10100) 、 (01100)四個absorbing state,分別代表. {E}、{B, D}、{ A, C}、{B, C} 四種感測器集合開啟的狀態,而這四個狀態就是納許平衡。 我們關注的是(01100)這個較差的狀態的機率,從初使狀態(00000)到(01100)總 共有五條路俓,計算如下: . 1 1 1 (00000)→(00100)→(01100): 。 5 3 15. . 1 1 1 (00000)→(01000)→(01100): 。 5 3 15. . 1 1 1 1 1 (00000)→(00010)→(00110)→(01110)→(01100): 。 5 4 3 2 120 23.
(33) . 1 1 1 1 1 (00000)→(10000)→(11000)→(11100)→(01100): 。 5 4 4 2 160. . 1 1 1 1 1 (00000)→(10000)→(11000)→(01000)→(01100): 。 5 4 4 3 240. 得到(00000)到(01100)的機率為. 1 1 1 1 1 0.1521 ,我們可以利用 15 15 120 160 240. 馬可夫鏈的一步轉換機率矩陣(One-step Transition Probability Matrix)來驗證是否正確。. 圖 3.7 一步轉換機率矩陣 如圖 3.7,我們將馬可夫鏈由小至大編號後找出一步轉換機率矩陣 P , P 中第一列 第一行為(00000)移動一步到(00000)的機率、第一列第二行為(00000)移動一步 到(00001)的機率,以此類推算出整個 P 。系統一開始的狀態分佈機率表示為 p 0 , 從初始狀態移動 x 步在各狀態的機率為 p x 。我們可以利用. p x P x p 0 T. (3.3). 來計算 p x 。我們把 p 0 定義為 [1 0 0 0]T ,使用 MATLAB 進行計算發現 p x 在 x 5 後就會收斂致(00001)、(01010)、(10100)、(01100)這四個狀態,機率. 分別為 0.5、0.175、0.1729、0.1521。其中(01100)狀態和我們所計算的機率是一樣的, 表示我們的結果正確,選到 {B, C} 這個較差的狀態機率並不高。 24.
(34) 依照我們的定義,若結束一個賽局後,被選中的感測器集合開啟到電源耗完,那麼 就與[2]提出的尋找互斥集合問題相同。若被選中的感測器集合只開啟到消耗一回合電 量,那麼就可應用在尋找非互斥集合問題,並且可調整開啟的時間長短進行觀察。所以 我們的方法可塑性相當高,稍微調整即可適用在兩種問題。. 3.1.3 賽局的穩定性 由上例中我們可以發現每個賽局 1 , 2 , , 都會停止在一個納許平衡,事實上在 賽局理論中,並不是每種賽局都有納許平衡存在。這裡我們將證明幾件事,第一是我們 定義的所有賽局都是確切潛力賽局,第二是利用確切潛力賽局證明賽局中必定存在納許 平衡,最後證明任一個賽局的納許平衡必定會滿足 k-Coverage。. Theorem 1 獨立時刻感測器工作排程賽局中任一個賽局 1 , 2 , , 均是確切潛力賽局。. 證明 Theorem 1: 考慮下列函數 . m. vt. . v 0. . (C) g (t , v) w a t 1. (3.4). n. (3.4) w 為此賽局中開啟的感測器數目,也就是 w ci 。只要證明此函數為確切潛力函 i 1. 數 , 就 代 表 此 賽 局 為 確 切 潛 力 賽 局 。 所 以 我 們 必 須 證 明 pi P : ci , ci Si :: ui ci, c i ui ci , c i ci, ci ci , c i 。. 若感測器 pi 是由開啟轉變為關閉,也就是 ci 1 轉變為 ci 0 ,那麼被感測器 pi 覆蓋 的目標物原本的覆蓋等級 vt 會變為 vt 1,我們可以得到效用函數 ui 與函數 的變化量如 下: 25.
(35) ui (ci , ci ) ui (ci , c i ) 0 g (t , vt ) a tTi a. (3.5). (3.5)式中 g (t , vt ) 0 是因為若 g (t , vt ) 0,那麼 g (t , vt ) 必定會大於 a,這樣一來 pi tTi. tTi. tTi. 就不可能會從開啟轉為關閉,所以可知 g (t , vt ) 0 。 tTi. . . m vt 1. m. vt. . v 0. . (ci , ci ) (ci , c i ) g (t , v) ( w 1) a g (t , v) w a t 1. . t 1. v 0. m vt 1. m vt 1. m. g (t , v) g (t , v) g (t , v ) a t 1 v 0. t 1 v 0. t 1. (3.6). t. a. m. (3.6)式中 g (t , vt ) 0 是因為 pi 會由開啟轉變為關閉,那麼代表即使 pi 開啟也無法得到 t 1. m. 任何目標物提供的利益值,所以可知 g (t , vt ) 0 。 t 1. 若感測器 pi 是由關閉轉變為開啟,也就是 ci 0 轉變為 ci 1,那麼被感測器 pi 覆蓋 的目標物原本的覆蓋等級 vt 會變為 vt 1,我們可以得到效用函數 ui 與函數 的變化量如 下:. ui (ci , ci ) ui (ci , c i ) g (t , vt 1) a 0 tTi . g (t , v 1) a tTi. t. m vt 1 m vt (ci , ci ) (ci , ci ) g (t , v) ( w 1) a g (t , v) w a t 1 v 0 t 1 v 0 . g (t , v 1) a tTi. (3.7). (3.8). t. 由(3.5)-(3.8)可得 pi P : ci , ci Si :: ui ci, c i ui ci , c i ci, ci ci , c i ,所 以我們證明了確切潛力函數的存在,得證此賽局是確切潛力賽局。 26.
(36) Theorem 2 獨立時刻感測器工作排程賽局中任一個賽局 1 , 2 , , 均存在納許平衡。. 證明 Theorem 2: 這裡我們使用反證法,首先假設在某個賽局 中不存在納許平衡,由於策略組態 Y 為有限集合,那麼必然可以找到一串策略向量的狀態變化 Ci C j Ck Ci ,使 得 Ci C j C k C i 。 但 不 可 能 存 在 一 個 潛 力 函 數 使 得. Ci Ci ,因此這是矛盾的,所以我們可知必定存在納許平衡。. Theorem 3 獨立時刻感測器工作排程賽局中任一個賽局 1 , 2 , , 的納許平衡必定會滿足. k-Coverage。. 證明 Theorem 3: 令 為達到納許平衡, 為滿足 k-Coverage,我們必須證明 為真。這裡也使 用反證法。先假設 為真,也就是說我們可以得到一納許平衡的策略向量 C 且不 滿 足 k-Coverage 。 但 依 照 我 們 定 義 的 效 用 函 數 , 如 果 存 在 任 一 目 標 物 t 不 滿 足. k-Coverage,那麼必然會有一感測器 pi Rt 為了提升效用函數(覆蓋一個目標物可得到 效用函數 a 0 )而開啟覆蓋它。因此 C 一定不是納許平衡,與假設矛盾,所以可知. 為真。. Theorem 4 獨立時刻感測器工作排程賽局中任一個賽局 1 , 2 , , 的納許平衡均是 Pareto. optimal。. 27.
(37) 證明 Theorem 4: 存在一組納許平衡 C c1 , c2 , , cn ,假設 C 不是 Pareto optimal,那麼必定存在另. . 一 組 策 略 向 量 C c1 , c2 , , cn. . , 使 得 i 1,..., n : ui C ui C 且. j 1,..., n : u j C ui C 。也就是說 C 可以經過一連串的策略轉換到達 C 且滿足上述. 條件。第一, C 可能因為多個感測器開啟而到達 C 嗎?這是不可能的,由於 C 是納許 平衡,所有目標物都滿足 k-Coverage,任何感測器開啟只會造成效用函數下降(由 0 變 為 a )。第二, C 可能因為多個感測器關閉而到達 C 嗎?這也不可能,感測器關閉效 用函數會從至少 a 降為 0。第三, C 可能因為多個感測器開啟且多個感測器關閉而 到達 C 嗎?只需從關閉的感測器來看就與第二點相同,因此仍然不可能。考慮上述三 點 C 不可能存在,得證。 這裡我們雖然證明任一個賽局 1 , 2 , , 的納許平衡均是 Pareto optimal,但這並 不代表最後排程完的結果會是最好的。策略向量 C 是 Pareto optimal 只是表示在單一個 賽局中相對於其他策略向量 C ' 而言, C 算是比較好的。而一個賽局中會有許多的納許 平衡,這些納許平衡都是 Pareto optimal。. 3.1.4 賽局的實作 我們考慮如何把這個賽局的運作方式實做到真正的無線感測網路系統上。由我們設 計的賽局可知若要計算效用函數必須知道 vt 的值。也就是對於某個感測器 pi 而言,必須 知道同時監測某個目標物 t Ti 的其他感測器 p j Rt , p j pi 是否開啟。由於目標物本身 並不能記錄並通知感測器自己的覆蓋等級,所以必須依賴感測器之間的溝通來獲得這個 資訊。要解決這問題可以用以下的方法,第一當我們假設感測器無法獲得位置資訊時, 感測器的通訊範圍(Communication Range)可以設定為覆蓋範圍的 2 倍。如此一來,只要 感測器欲開啟或關閉電源時先進行廣播(Broadcast),廣播的訊息內容包含感測器編號、 28.
(38) 覆蓋到的目標物標號及開啟或關閉狀態,覆蓋到相同目標物的其它感測器就可以收到訊 息而得到完整的資訊。第二若感測器可以由 GPS 獲得位置資訊,假設有一台 BS(Base. station)可與所有的感測器通訊,感測器將自己的位置及開關狀態傳送至 BS 由進行廣 播,其它感測器就可以根據位置判斷是否有覆蓋到相同目標物。 當感測器的通訊範圍小於覆蓋範圍的 2 倍時,可能會發生目標物已被覆蓋,但其它 感測器無法得知的狀況。這樣其它感測器計算效用函數時會少算目標物的覆蓋等級而可 能開啟造成浪費電源的情況,會使整個系統的壽命減少。反之,當感測器的通訊範圍大 於覆蓋範圍的 2 倍時,雖然對結果不會有影響,但考量到實際上增大通訊範圍應該需要 消耗較多的電量,感測器的壽命也會因此減少。 前面所述的賽局與例子在同一時間點只能由一個感測器改變決策,若是覆蓋到相同 目標物的感測器同時改變決策,我們就無法保證會停止在納許平衡,可能就無法到達一 個穩定狀態。為了避免有多個感測器同時改變決策。我們可以設定感測器要改變決策前 必須先等待倒數一段 backoff time,時間長短隨機產生並限制在某個值以下。若在此時 間內沒有其它感測器改變決策,就進行決策改變動作,並將決策結果廣播出去。若在此 時間內收到其它感測器改變決策的廣播,就將倒數值保留至下次欲改變決策時再使用。 另外,我們考慮是否可以多個感測器同時改變決策。我們有注意到沒有覆蓋到相同 目標物的感測器是可以同時改變決策的,這是因為它們並不會因為其它感測器改變決策 而影響到它們的效用函數。 由於賽局中感測器是以分散式執行自己的決策,感測器之間的溝通就成了一項應該 要納入考量的成本。我們原本的設定是每個感測器都有相同的機率爭取到轉換策略的權 利,反覆轉換策略後會到達納許平衡。我們思考要如何能夠更快地達到納許平衡。第一, 我們讓轉換策略能夠提升最多效用函數的感測器擁有優先權,期望可以讓目標物早點滿 足覆蓋等級需求。實作方式只要讓感測器的 backoff time 與提升的效用函數值呈反比即 可。但是這扼殺掉了反覆改變決策的變化性。第二種方法是感測器的提升的效用函數值 愈大,backoff time 的隨機數值範圍就愈小。這樣一來即可達到需求又不失變化性。我 29.
(39) 們推測這兩種方法都可以更快達到納許平衡,但可能會帶來無線感測系統壽命的減少。 達到納許平衡的速度應該是第一種方法最快,但是也會減少較多的無線感測系統壽命。 第二種方法的效能則在兩者之間。模擬實驗可以證實我們的推測完全正確,而且只需減 少一些無線感測系統壽命,就可以使進入納許平衡的時間增快許多。 我們原本設計的賽局中沒有考量到感測器的剩餘電量,所以若感測器之間電量差異 很大可能會得到比較差的結果。這裡我們利用 backoff time 設計一個在賽局之外可以考 量剩餘電量的方法。讓感測器的 backoff time 與剩餘電量成反比,如此一來就可以讓剩 餘電量高的感測器先進行決策。剩餘電量較接近的感測器就容易分到同一集合,使浪費 的電量減少,無線感測系統壽命延長。模擬實驗證實我們的設計確實有效果。. 30.
(40) 3.2 極大化覆蓋比例賽局 這一節我們想要解決另一個問題,在已設定感測網路工作總時間的情況下,極大化 目標物滿足覆蓋等級需求的個數。感測模型採用了2.1.2提過的Intensity模型,目標物所 收到的信號強度與距離呈平方反比。如圖 3.8,目標物 r1 所收到的強度就是由感測器 A 、. B 來的強度總和,這裡k-Coverage的意義就改為目標物收到的強度超過k則滿足覆蓋等級 需求。. 圖 3.8 目標物收到的強度 感測器 pi 給予目標物 t 的強度我們以圖 3.9與(3.9)式表示,當兩者距離 di ,t 小於 1 時 目標物可以得到常數 的強度,當距離在 1 至 b 之間強度為. di2,t. ,當距離超過 b 則收不. 到任何強度。我們可以視為 pi 的覆蓋範圍為 b ,目標物在範圍內才能接收到強度。 I(di ,t ) 2 d i ,t 0 . if di ,t 1, if 1 di ,t b, if di ,t b.. 31. (3.9).
(41) 圖 3.9 強度函數. 圖 3.10 極大化覆蓋比例賽局 如圖 3.10,我們將感測器分類至互斥集合,已知有 h 個集合,同一時間只開啟一個 集合內的感測器。整個問題可以用一個賽局 來表示,賽局 的組成如下: . 參 與 者 集 合 P p1 , p2 , , pn : 總 共 有 n 個 感 測 器 作 為 參 與 者 , 分 別 是. p1 , p2 , , pn 。 . 策略集合 Si {1, 2,3, , h} :所有參與者都可以選擇參加集合 1 至 h 作為策略。 在定義效用函數前,先定義若目標物 t 接收到感測器 pi 的強度, pi 可得到的利益值. 為:. d if vt ci 1 k g (t , ci ) i ,t 0otherwise. (3.10)中 vt ci . I d 為目標物 t 所接收到的強度值總和,若強度值總和在. j 1,2,..., n and c j ci. j ,t. 32. (3.10). 0 至.
(42) 1 k 之間,則感測器 pi 可以得到給予 t 的強度 di ,t 作為利益值,也就是說給予的 強度愈多利益值愈高。感測器可獲得利益的目標物強度值總和要設定在 0 ~ 1 k 之 間是因為這裡的模型與 Unit-Disk 不同,不太可能會剛好滿足 k-Coverage。因此以 值 作為緩衝,即使目標物強度值總和超過一定量仍然可以獲得利益值。 . 效用函數 ui C or ui ci , c i :. ui (ci , c i ) g (t , ci ) tTi. (3.11). Ti 為與感測器 pi 距離 b 以內的目標物集合。感測器 pi 根據所選擇的策略 ci 收集覆蓋範圍 內的目標物利益值作為效用函數。 pi 會選擇能使效用函數達到最大的策略。 我們設定賽局一開始時感測器均為未選擇策略狀態,感測器們會爭奪選擇或轉換策 略的權利。我們設定此賽局為動態賽局,一次會有一個感測器決定或改變決策,不會有 兩個感測器同時改變決策。並且設定此賽局為重複賽局,感測器可不斷根據其它感測器 的選擇決定是否改變策略。直到所有感測器都不想改變決策為止,也就是達到一個納許 平衡。 我們可以發現賽局中總共有有 h 個互斥集合可供感測器選擇,但是 h 的大小究竟要 如何決定呢?若是 h 太大則許多目標物會無法滿足覆蓋等級需求,太小則網路壽命較短 而無效率。我們根據一些計算推論出一個適合的值。令 I total 為平均一個感測器給予覆蓋 範圍內的目標物們的強度總和, navg 為平均一個互斥集合有多少個感測器。. m k navg I total. (3.12). navg h n. (3.13). (3.12)式中目標物個數 m 乘以覆蓋等級需求 k 為所有目標物的覆蓋等級需求總和, 若要所有目標物都滿足覆蓋等級需求,它一定會小於等於感測器們給予目標物的強度總 33.
(43) 和。(3.13)式中平均一個互斥集合的感測器個數乘以互斥集合數就會等於感測器個數。. h. n I total mk. (3.14). 由(3.12)和(3.13)可以得到(3.14),我們可以得到 h 適當的大小。 另一個跟賽局有關的問題是覆蓋等級需求 k 的大小該如何決定,由於我們是使用. Intensity 模型,所以 k 的值要設定多少才適合並不容易決定。我們計算了平均而言一個 目標物可以從一個感測器得到多少強度來作為決定 k 的參考。由於感測器的覆蓋範圍為 一圓形,因此目標物落在與感測器距離 x 以內的機率為. Pr X x F x . x2 x2 b2 b2. (3.15). 將(3.15)式微分可得到目標物與感測器距離的機率密度函數(probability density function) 為. f x F x . 2x b2. (3.16). 根據(3.9)式與(3.16)式可以得到平均而言一個目標物可以從一個感測器得到的強度期望 值如下:. E[ X ] . . b. x 0 1. x 0. f x I x dx b. f x I x dx f x I x dx x 1. 2 2 1 xdx 2 dx 2 x 0 x 1 b b x 2 ln b b2 b2 . b. 1. 我們可以把(3.17)式作為一個參考值,把 k 設為它的倍數。. 34. (3.17).
(44) 4. 模擬實驗. 4.1 獨立時刻感測器工作排程賽局效能實驗 為了得知在3.1.4中我們所提出的加速收斂至納許平衡方法與考量剩餘電量方法效 果如何,我們將這兩種方法與原本只利用賽局理論設計出的方法進行比較。 為了了解我們的方法與傳統方法在效能上的差異,我們改變各項參數觀察各方法在 無線感測系統壽命的差異。另外對於我們的方法中,賽局進行多少次策略轉換才到達納 許平衡感到興趣,將改變各項參數觀察對平均策略轉換次數的影響。 我們將過去的方法進行分析,大部分都是以集中式貪婪法則為主。貪婪法則的選擇 規則可大致分為兩種。第一,優先選擇重要的感測器(most important sensor first, MISF), 這類感測器可以覆蓋某些較難被覆蓋到的目標物,從這類感測器先選擇可以減少重複覆 蓋的可能性。第二,優先選擇可覆蓋較多目標物的感測器 (maximum coverage first,. MCF)。大部分的方法就是以這兩種規則做選擇再進行修剪(prune)[5]的動作。我們的方 法將與MISF、MCF做比較。. 4.1.1 實驗環境設定(a) 我們在 600m×600m的區域中放置n個感測器與m個目標物。感測器以網格(grid)分 佈,目標物隨機分佈。目標物的放置位置在所有感測器均開啟的情況下至少要能滿足. k-coverage,以防止整個系統完全無法運作。所有感測器由關閉狀態開始進行賽局。如表 4.1我們每個實驗進行 500 次。實驗一將我們原本的作法與加速收斂至納許平衡方法進 行比較。實驗二為我們原本的作法與考量剩餘電量方法的比較。由於在實驗一、二可以 得到我們在實作上的設計確實有改善效能。所以實驗三至六,將我們改良過的設計與. MISF、MCF進行比較。以互斥集合分類感測器,分別改變感測器數量、目標物數量、 35.
(45) 感測器覆蓋範圍、目標物覆蓋等級需求k等參數,並且觀察無線感測系統壽命和賽局收 斂至納許平衡的改變策略次數。 表 4.1 實驗項目與參數設定(a) 實驗編號. 感測器數量. 目標物數量. 覆蓋範圍(m). 覆蓋等級需求. 一 二 三 四 五 六 七. 150 500 200~400 300 300 300 300. 25 50 25 10~60 25 25 25. 150 150 150 150 100~200 150 150. 3 3 3 3 3 1~10 3. 針對以非互斥集合分類感測器,表 4.1實驗七研究一組非互斥集合開啟的時間長短 對於無線感測系統壽命會造成什麼影響。改變一組感測器集合開啟的時間長短由 1 單位 時間至 10 單位時間。. 4.1.2 加速收斂至納許平衡實驗 這裡我們針對 3.1.4 中所提 到的,更快地達到納許平衡的方法做實驗。 FBT(fixed. backoff time)是我們原本的作法,感測器設定backoff time為一段隨機時間,爭取到改變 策略的機率都相同。UBBT(utility-based backoff time)是感測器的backoff time與改變策略 所能提升的效用函數值成反比。UARBT(utility-aware random backoff time)是感測器的效 用函數提升越多,backoff time的隨機數值範圍就越小,因此得到改變策略的權利的機率 就較高。以下針對這三種方法進行實驗,實驗設定如表 4.1實驗一。我們使用互斥集合 分類感測器,並將感測器初始電量設定為可開啟 20 單位時間。 無線感測系統壽命方面,如圖 4.1 可以得到FBT > UARBT > UBBT。這是因為. UARBT和UBBT我們都有設定會往效用函數值增加較多的方向前進,這就抹煞了其他可 能較好的路線,可能有其他路線到最後會更好。但是結果說明這對於無線感測系統壽命 36.
(46) 的影響並不大,三種作法的結果都非常接近。. 120. 100. Network life time. 80. 60. 40. 20. 0. FBT. UBBT. UARBT. 圖 4.1 加速收斂速度方法的無線感測系統壽命關係. 40. The t imes of changing st rategies. 35 30 25 20 15 10 5 0. FBT. UBBT. UARBT. 圖 4.2 加速收斂速度方法的策略轉換次數關係 37.
(47) 策略轉換次數方面,如圖 4.2可以得到FBT > UARBT > UBBT。策略轉換次數越高 代表感測器需要溝通的次數越多,效能就會越差。UBBT和UARBT達到了我們希望加速 收斂速度的目標,這與我們的假設符合。UBBT在無線感測系統壽命只比FBT少 0.6%, 但在策略轉換次數卻可以減少 45.77%,可見UBBT的策略是相當成功。UARBT在無線 感測系統壽命比FBT少 0.2%,策略轉換次數減少 16.04%,效果還算不錯。. 4.1.3 考量感測器剩餘電量實驗 這裡我們針對3.1.4中所提到的,在感測器backoff time中考量剩餘電量的方法做實 驗。PABT(power-aware backoff time)是感測器的backoff time與它的剩餘電量成反比。將 我們原本的做法與PABT進行比較,實驗設定如表 4.1實驗二。我們使用互斥集合分類 感測器,並將感測器初始電量設定為在可開啟 10~40 單位時間中隨機分布,目的在於凸 顯PABT的特點。. 250. Network life time. 200. 150. 100. 50. 0. FBT. PABT. 圖 4.3 考量剩餘電量方法的無線感測系統壽命關係 由圖 4.3可以清楚得知,無線感測系統壽命PABT比FBT成長了 40%,可見我們的 38.
(48) 設計確實有效果。這樣在實作中加入考量剩餘電量方法的好處在於不必更改原本賽局設 計的理論與收斂等證明,利用實作中改變backoff time即可達到效果。. 4.1.4 無線感測系統壽命 這裡我們的方法結合了UBBT與PABT,令改變策略所能提升的效用函數值為 uincr , 感測器的剩餘電量為 psurplus ,將實作中的backoff time設定為 uincr (1 ) psurplus 。實驗 設定如表 4.1實驗三至六,將 設定為 0.2,以互斥集合分類感測器,感測器剩餘電量 設為 10~40 單位時間隨機分布,與MISF、MCF進行比較。. 200 UBBT+PABT MISF MCF. 180 160. Network life time. 140 120 100 80 60 40 20 200. 220. 240. 260. 280 300 320 340 The number of sensors. 360. 380. 400. 圖 4.4 無線感測系統壽命與感測器數量的關係 由圖 4.4可以看出當感測器數目增加,所有方法無線感測系統壽命也會上升,這是 因為更多的感測器可以進行工作排程,系統壽命也因此提升。不論感測器數量如何改 變,結果都是UBBT+PABT>MISF≒MCF。這是因為各個感測器剩餘電量不相同,而. MISF與MCF並未考量這個因素所導致。 39.
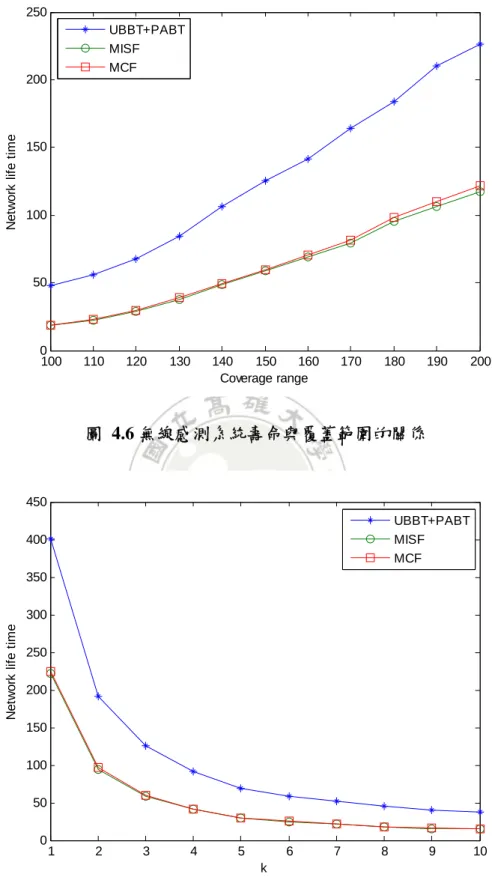
(49) 160 UBBT+PABT MISF MCF. 140. Network life time. 120. 100. 80. 60. 40 10. 15. 20. 25. 30 35 40 The number of targets. 45. 50. 55. 60. 圖 4.5 無線感測系統壽命與目標物數量的關係 如圖 4.5,當目標物數量增加,無線感測系統壽命會因此下降。這是因為更多的目 標物散落在較遠的地方,同一時間時要更多的感測器開啟,系統壽命才會變短。 由圖 4.6可知增加感測器的覆蓋範圍,可以提升無線感測系統壽命。這是因為每個 感測器可覆蓋的目標物變多了,所以更多的感測器可以進行休眠,只需要少部份的感測 器開啟,因而延長了系統的壽命。 在圖 4.7中,當增加目標物的覆蓋等級需求,同一時間就需要更多的感測器開啟來 滿足目標物需求,而使無線感測系統壽命下降。. 40.
(50) 250 UBBT+PABT MISF MCF. Network life time. 200. 150. 100. 50. 0 100. 110. 120. 130. 140 150 160 Coverage range. 170. 180. 190. 200. 圖 4.6 無線感測系統壽命與覆蓋範圍的關係. 450 UBBT+PABT MISF MCF. 400 350. Network life time. 300 250 200 150 100 50 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. k. 圖 4.7 無線感測系統壽命與覆蓋等級需求的關係. 41. 10.
(51) 4.1.5 策略轉換次數 這裡為觀察改變各項參數對平均一個賽局中感測器的策略轉換次數的影響,實驗設 定與4.1.4相同。. 50 45. The times of changing strategies. 40 35 30 25 20 15 10 5 0 200. 220. 240. 260. 280 300 320 340 The number of sensors. 360. 380. 400. 圖 4.8 策略轉換次數與感測器數量的關係 由圖 4.8可以得知改變感測器數目對賽局收斂至納許平衡的影響並不大。平均策略 轉換次數在 26~29 次之間,這是因為系統狀態由初始感測器全關閉至滿足k-Coverage只 需要一定量的感測器開啟,即使感測器增加影響也不大。 圖 4.9當目標物數量較少時,增加目標物數量使策略轉換次數提升較快,之後漸趨 平緩。這是因為當目標物數量較少時,目標物的密度較小,增加目標物容易需要多的感 測器來覆蓋它。當目標物數量增加,目標物的密度較大,即使增加目標物比較落在已經 開啟的感測器內,就不需多開啟感測器。. 42.
數據




+7





Outline
相關文件
Associate Professor of Department of Mathematics and Center of Teacher Education at National Central
The original curriculum design for the Department of Construction Engineering of CYUT was to expose students to a broad knowledge in engineering and applied science rather than
Associate Professor of Information Management Head of Department of Information Management Chaoyang University
Professor, Department of Industrial Engineering and Technology Management.
Professor, Department of Industrial Engineering and Technology Management.
Associate Professor of Information Management Head of Department of Information Management Chaoyang University
Department of Computer Science and Information Engineering, Chaoyang University of
EdD, MEd, BEd Adjunct Assistant Professor Department of Early Childhood Education Member, Centre for Child and Family Science The Education University of Hong
