圖書館個人化館藏推薦系統
78
0
0
全文
(2) 圖書館個人化館藏推薦系統 A Personalized Recommender System for Library. 研 究 生:余明哲. Student :Ming-Che Yu. 指導教授:柯皓仁 博士. Advisor:Dr. Hao-Ren Ke. 楊維邦 博士. Dr. Wei-Pang Yang. 國 立 交 通 大 學 資 訊 科 學 研 究 所 碩 士 論 文. A Thesis Submitted to Institute of Computer and Information Science College of Electrical Engineering and Computer Science National Chiao Tung University in partial Fulfillment of the Requirements for the Degree of Master in. Computer and Information Science June 2003 Hsinchu, Taiwan, Republic of China. 中華民國九十二年六月.
(3) A Personalized Recommender System for Library Student: Ming-Che Yu. Advisor: Dr. Hao-Ren Ke, Dr. Wei-Pang Yang. Institute of Computer and Information Science National Chiao Tung University. ABSTRACT Recommender systems are popularly being used in e-Commence to encourage consumers to purchase more products. In library, recommender systems can also be used to help patrons find collections to borrow, and increase the value of library. In this paper, we propose a personalized recommender system for library, which combines collaborative filtering and content-based filtering recommendation methods. We hope patrons can find books which fit their preferences through this personalized recommender system. In this recommender system, first, we use association mining to discover association rules between users and between books. Second, we take these associations rules to find user groups which have the same preference for collaborative filtering, and build representation model for content-based filtering. Finally, we use collaborative filtering to find a recommendations list which contains books collecting from other patrons’borrowing history, and we would re-rank this recommendations list by content-based filtering to cater to user’s preference. We implemented this recommender system on National Chiao Tung University (NCTU) library’s personalized information environment “myLibrary” (http://mylibrary.e- lib.nctu.edu.tw/), and the feedback received from users of library shows that most users satisfied with our recommendations.. Keywords: Recommender Systems, Personalization, Data Mining, Association Rules, Collaborative Filtering, Content-Based Filtering, Library. i.
(4) 圖書館個人化館藏推薦系統 A Personalized Recommender System for Library 研究生:余明哲. 指導教授:柯皓仁博士,楊維邦博士 國立交通大學資訊科學研究所. 摘要 推薦系統是網路商店上常運用的技術,主要用來提高顧客的購買慾望。我們將此技 術應用在圖書館上,希望能藉由個人化館藏推薦系統推薦給讀者圖書館中其有興趣的館 藏,幫助讀者使用圖書館資源。同時也希望圖書館這個新的館藏推薦服務能增加館藏的 利用率,並提高圖書館的價值。. 在本論文中,將利用資料探勘 (Data Mining) 中關聯規則探勘 (Association Mining) 的 技 術, 從讀者的借閱歷史檔 中找出頻繁項目集 (Frequent Itemsets) 和 關 聯 規 則 (Association Rules)。從這些探勘的結果中,分析得知讀者與讀者間和館藏與館藏間存在 的關係,由此取得讀者的興趣。接著先利用推薦系統中常用的協力式過濾 (Collaborative Filtering) 找出給讀者的推薦書目清單,再以內容導向過濾 (Content-Based Filtering) 的 方法將推薦清單依照讀者興趣做個人化的排序,最後能找出合適的館藏推薦給讀者。. 個人化館藏推薦系統目前實作於交通大學浩然圖書館的個人化資訊環境 myLibrary 中(http://mylibrary.e- lib.nctu.edu.tw/)。並且從收集回來的讀者回應中發現,這套系統的確 可以有效地依照讀者的興趣將館藏推薦給讀者。 關鍵字:推薦系統、個人化、資料探勘、關聯規則、協力式過濾、內容導向過濾、圖書 館. ii.
(5) 誌謝 感謝指導教授柯皓仁老師與揚維邦老師這兩年來在各方面的悉心指導。除了學業上 的教導外,也培養我獨立思考和研究的能力。常能適時地引導我研究方向,並在我遇到 困難時能指引方向,鼓勵我、給予我信心,使我不會徬徨無措、孤立無援。當我有所懈 怠時,也會不忘督促的責任給予提醒,使我在研究上能更上層樓。同時,生活上也給我 許多的啟示與照顧,帶給我這段人生中難得且珍貴的回憶。 實驗室裡的學長姐、同學和學弟,感謝你們陪我走過這段時間,給予我包容,不論 我高興或者不高興的時候伴在我身邊,聽我抱怨,替我加油打氣。在課業上常給予我很 多的幫助,而且時時關心我的生活,使我不感到孤單。尤其感謝葉鎮源學長,在論文上 提供我許多建議與協助。 還要感謝交通大學圖書館中館合計劃室、數位圖書資訊組和參考諮詢組中曾幫助過 我的朋友們,由於你們的幫忙使我能順利完成這篇論文。其中,蔡淑琴小姐提供我圖書 館的資料來源,劉玉芝小姐和湯春枝小姐給予我許多圖書館方面的指導和建議,在這邊 特別感謝她們。 最後,感謝我的父母親及家人能無條件地支持我,提供我一個能安心休息的避風 港,並且長久以來不斷地給我最溫暖的照顧,讓我能無牽無掛地順利完成學業。僅將此 篇論文獻給他們。 癸未年 孟夏. iii.
(6) 目錄 英文摘要 ..................................................................................................................................... i 中文摘要 ....................................................................................................................................ii 誌謝 ...........................................................................................................................................iii 目錄 ........................................................................................................................................... iv 表目錄 ........................................................................................................................................ v 圖目錄 ....................................................................................................................................... vi 方程式目錄 ..............................................................................................................................vii 第一章 緒論 ..............................................................................................................................1 第一節 研究動機及目的 ..................................................................................................1 第二節 研究方法與目標 ..................................................................................................2 第三節 論文架構 ..............................................................................................................6 第二章 相關研究工作 ..............................................................................................................7 第一節 推薦系統與電子商務 ..........................................................................................8 第二節 個人化推薦系統 ................................................................................................ 11 第三節 協力式過濾與關聯規則探勘 ............................................................................15 第四節 內容導向過濾與系統模型建立 ........................................................................17 第五節 圖書推薦系統 ....................................................................................................19 第三章 圖書館館藏推薦 ........................................................................................................27 第一節 協力式過濾的推薦方法 ....................................................................................27 第二節 內容導向的推薦方法 ........................................................................................39 第三節 結合協力式過濾和內容導向的推薦方法 ........................................................43 第四章 系統實作 ....................................................................................................................44 第一節 系統架構 ............................................................................................................44 第二節 前置處理 ............................................................................................................46 第三節 找出相關讀者群和建立館藏與讀者的表示法 ................................................48 第四節 產生推薦清單 ....................................................................................................52 第五節 系統在 myLibrary 上的呈現方式 .....................................................................55 第五章 館藏推薦滿意度評估 ................................................................................................58 第一節 收集讀者對館藏推薦的回應 ............................................................................58 第二節 計算讀者對館藏推薦的滿意度 ........................................................................59 第三節 結果分析 ............................................................................................................60 第六章 結論與未來研究方向 ................................................................................................63 第一節 結論 ....................................................................................................................63 第二節 未來研究方向 ....................................................................................................64 參考文獻 ..................................................................................................................................67. iv.
(7) 表目錄 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表. 1 以一本書為一筆交易的交易集 ....................................................................................27 2 代表具有相同興趣讀者群的頻繁項目集 ....................................................................28 3 以書籍為交易的交易集 ................................................................................................30 4 聚集過後以類別為交易分別不考慮次數和考慮次數的交易集 ................................30 5 項目集{3, 4}在各個交易集中的支持度 ......................................................................31 6 屬於相同類別的交易集 ................................................................................................32 7 將相同類別的書聚集起來的新交易集 ........................................................................32 8 以一個類別為一筆交易的交易集 ................................................................................33 9 單一項目的出現頻率 ....................................................................................................33 10 經過正規化處理後的交易集 ......................................................................................34 11 找出項目集{1, 2}的支持度.........................................................................................36 12 所有長度為 2 的項目集的支持度 ..............................................................................36 13 第二層中具有兩個項目的頻繁項目集 ......................................................................37 14 找出項目集{1, 3, 4}的支持度.....................................................................................37 15 找出項目集{2, 3, 5}的支持度.....................................................................................38 16 以書為交易項目的交易集 ..........................................................................................40 17 探勘第三層分類所需的交易集 ..................................................................................40 18 探勘第二層分類所需的交易集 ..................................................................................41 19 探勘第一層分類所需的交易集 ..................................................................................41 20 各階層分類探勘的最小支持度、最小確信值及最後關聯規則數量 ......................49 21 各階層所探勘出的關聯規則和確信值 ......................................................................49 22 包含讀者 3 的頻繁項目集 ..........................................................................................52 23 讀者借閱歷史 ..............................................................................................................53 24 讀者 3 在協力式過濾推薦裡得到的推薦數目 ..........................................................53 25 書的屬性向量表示式 ..................................................................................................54 26 推薦書目的新的推薦度和排序 ..................................................................................54 27 圖書館個人化館藏推薦系統各細部元件 ..................................................................57 28 系統滿意度調查結果 ..................................................................................................61. v.
(8) 圖目錄 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 1 相關研究文獻 ..................................................................................................................7 2 一個兩層的分類樹 ........................................................................................................18 3 交通大學浩然圖書館館藏查詢使用者介面 ................................................................20 4 交通大學浩然圖書館館藏查詢結果呈現介面 ............................................................21 5 科幻圖書館藏的主題推薦 ............................................................................................22 6 科幻圖書館藏中的分類推薦-以“時空旅行”分類為例 .............................................22 7 個人化智慧型館藏查詢結果-以“資料庫”為書刊名關鍵字查詢 .............................23 8 個人借閱歷史查詢介面 ................................................................................................24 9 推薦相關館藏畫面 ........................................................................................................24 10 個人化智慧型查詢系統介面 ......................................................................................26 11 圖書館個人化館藏推薦系統架構圖 ..........................................................................45 12 協力式過濾需要的交易集 ..........................................................................................47 13 內容導向過濾需要的交易集 ......................................................................................47 14 相關讀者群的頻繁項目集 ..........................................................................................48 15 類別 312 的屬性向量表示式 ......................................................................................50 16 讀者的個人興趣向量 ..................................................................................................51 17 myLibrary 中“我的館藏”畫面......................................................................................56 18 系統推薦館藏的呈現畫面 ..........................................................................................56 19 設定個人興趣畫面 ......................................................................................................57 20 讀者滿意度回應畫面 ..................................................................................................58 21 Top N 的平均誤差值.....................................................................................................61 22 Top N 的排序分數度量值.............................................................................................62 23 Top N 的讀者平均滿意度.............................................................................................62. vi.
(9) 方程式目錄 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式. 1 文獻[8]中的權重給定公式....................................................................................18 2 項目集在每個交易中支持度的計算公式 ............................................................30 3 項目集於單筆交易內的支持度計算公式 ............................................................34 4 以取最小值為交集運算的支持度計算公式 ........................................................35 5 乏析資料探勘中項目集的支持度計算公式 ........................................................35 6 協力式過濾的推薦分數計算公式 ........................................................................39 7 書籍屬性向量表示式 ............................................................................................41 8 書籍屬性向量權重給定公式 ................................................................................42 9 讀者興趣向量計算公式 ........................................................................................42 10 內容導向過濾的喜好度計算公式 ......................................................................42 11 新的推薦分數計算公式 ......................................................................................43 12 讀者興趣向量修正公式 ......................................................................................51 13 平均誤差值計算公式 ..........................................................................................59 14 排序分數度量值計算公式 ..................................................................................59 15 排序分數度量值正規化計算公式 ......................................................................60. vii.
(10) 第一章 緒論 第一節 研究動機及目的. 圖書館長久以來一直扮演著傳承人類知識的重要角色。每一個圖書館都蘊藏著許多 的館藏、許多的資源和無數的智慧心血結晶,不但滿足一般人的求知慾,同時也提供了 後人學習及發展新技術的基礎。如果圖書館館藏資料能被妥善利用,一定能帶給人類社 會莫大的助益,萬一館藏資料乏人問津,那無疑地就是一種資源的浪費,是件相當可惜 的事情。. 1979 年美國 Pittsburgh 大學調查報告[7]中指出,圖書館的館藏資源僅有少數被有效 利用。原因之ㄧ是圖書館和使用者之間互動不足。往往圖書館扮演被動的角色,無法主 動提供資訊給使用者。例如當圖書館添購了新的館藏或增加新的服務,常常無法有效地 告知使用者相關的訊息,造成使用者不清楚甚至不知道圖書館有哪些資源可以利用。另 外,圖書館中的館藏,有部分屬於知名度比較高的熱門書,或者因為編排比較容易被使 用者取得的館藏,其使用率一直很高,導致使用者不易借閱到;但是事實上圖書館還有 許多相同類別且使用者感興趣的館藏沒有被借閱。由於使用者搜尋的技巧、習慣或找資 料的方向不同,使得圖書館中使用者有需要的館藏,沒被找出來利用。結果圖書館裡豐 富的館藏和服務因此被束之高閣而浪費掉了。這樣不但是圖書館資源的一種浪費,也是 使用者的損失。 圖書館的真正價值不在於優良的硬體設備或豐富的館藏,而在於其館藏的利用率。 也因此圖書館莫不致力於提升利用率以增加圖書館的價值。隨著時代的進步,提升利用 率的方法從以前較被動式的,如增加採購借閱率較高的館藏類別、設計良好的編目方式 和架位排列方式、採用方便有效率的館藏查詢系統等,也逐漸增加主動式的方法,如開 設一些改進使用者尋找資料的技巧或指導使用者利用圖書館館藏資源的訓練課程等,這. 1.
(11) 些無非都是在吸引使用者利用圖書館資源,以提升圖書館的利用率。在[28], [29]這幾篇 論文中,也提出以資料探勘 (Data Mining) 的技術和統計的方法,分析使用者的借閱歷 史資料,找出一些規則及有用的資訊,使圖書館能根據這些規則和資訊主動吸引使用者 到圖書館借閱館藏以提升館藏的使用率和借閱率,並且增強圖書館的經營與服務。而我 們在這篇論文中所提出的個人化館藏推薦系統也是一種偏主動式的方法來吸引使用者 使用圖書館資料。與[28], [29]比較,本論文提出的這套個人化館藏推薦系統,不僅能從 使用者以往的借閱歷史中找出館藏間的關連性,同時也會找出使用者間的關連性,並且 判斷出使用者的個人興趣。藉此來找出圖書館中使用者可能有興趣,但是卻還沒借閱過 的館藏,然後把這些館藏推薦給使用者,藉此來鼓勵使用者借閱館藏。希望藉由這樣一 種新的圖書館服務能提高圖書館的利用率,同時也增加圖書館的附加價值。. 第二節 研究方法與目標. 本論文提出的個人化圖書館館藏推薦系統,同時採用協力式過濾 (Collaborative Filtering) 和內容導向過濾 (Content-Based Filtering) 這兩個推薦方法。 協力式過濾的方法是一種最典型的推薦方法,自從 1992 年由 Goldberg 等人在[14] 中提出後就被廣泛採用在一般的推薦系統中,甚至在 1997 年 Resnick 和 Varian 提出推 薦系統 (Recommender System) [23]這個名詞之前,協力式過濾就是推薦系統的代名詞。 協力式過濾主要的概念是使用者利用同儕對某物品既有的評價來預期自己對該物品可 能的評價。這個想法就好像當我們要做某樣決定之前,會事先詢問一些有經驗的人,以 他們的意見做為決定的參考。 本篇論文將協力式過濾的概念應用在圖書館上,希望使用者之間能互相分享資訊, 每個使用者都是過濾代理人 (Filtering Agent),可以幫忙篩選館藏,提供別人借閱書籍意 見參考。而圖書館中每個使用者的借閱歷史可視為是給別人的館藏推薦清單,使用者可. 2.
(12) 以參考這些推薦清單,來挑選自己有興趣的館藏,而不用從圖書館眾多的館藏中盲目地 尋找。 不過若一個圖書館有上千名使用者,如果要使用者從這上千份推薦清單中挑選自己 感興趣的館藏,事實上的意義跟使用者要直接從館藏中挑選自己需要的館藏一樣困難且 麻煩。而且這麼多的推薦清單中,其實並不是每一份都是適合自己需要的,因為每個人 的興趣或目的不同,所以會借閱不同的館藏,分別產生有不同的借閱歷史和推薦清單, 而其中可能只有某部分清單是真正符合使用者需要的。因此我們這套系統還必須事先幫 使用者決定那些推薦清單是使用者需要或感興趣的,而不需要使用者每次都從這上千份 推薦清單中挑選。. 本論文用的方法是先? 使用者挑選和他有相同借閱興趣的其他使用者,稱之為“同 好” (Friends)。同好間因為借閱興趣類似,所以他們的借閱歷史,也就是本論文所認為 他們給其他同好的推薦清單,對使用者來說有比較高的參考價值。而認定有相同借閱興 趣的標準是依照使用者間借閱過相同館藏的數量,相同的館藏愈多時代表相同的借閱興 趣就愈高。當使用者相同的借閱興趣高過某一個標準時,我們就認定他們是“同好”。 找出有相同借閱興趣同好的方法,主要是採用資料探勘中的關聯規則探勘 (Association Mining),並且? 了配合圖書館特殊的資料類型,同時也參考了乏析式資料 探勘 (Fuzzy Data Mining) [17], [18]的方法。在實作上,則是採用[3]中所提出的以前序樹 (Prefix Tree) 為 基 本 概 念 實 作 的 Apriori [2] 演 算 法 來 找 出 頻 繁 項 目 集 (Frequent Itemsets),也就是找出有相同借閱興趣的使用者群。 內容導向過濾事實上比協力式過濾更早被應用在篩選資料上,通常內容導向過濾根 據使用者輸入的關鍵字,由系統來篩選出符合這些關鍵字或者符合這些關鍵字語意概念 (Semantic Concept) 的資料。一般內容導向過濾的方法都會運用到資訊擷取 (Information Retrieval) 的技巧來萃取出資料中的內容[27]。顧名思義,內容導向過濾主要是根據資料 的內容來篩選資料。這一點和協力式過濾相比是很明顯的不同,因為協力式過濾主要利 3.
(13) 用眾人的意見來篩選資料,完全跟資料的內容無關。但是內容導向過濾通常需要收集許 多系統中物件的內容資料,再利用一個模型 (Model) 根據物件的內容來替系統內的每個 物件建立各自的屬性表示式 (Representation),此模型通常是向量空間模型 (Vector Space Model),建出來的屬性表示式以向量表示。內容導向的方法因為實際考慮到物件的內容 屬性,所以系統中的物件利用各自的屬性向量表示式來比較彼此間相似度時,通常有相 當高的準確率。 但是在推薦系統中要找出一個適合的模型來描述整個系統,並且從每個物件中抽取 足夠的資訊來使系統中的每個物件都能各自的表示式並不容易。主因是在推薦系統中, 通常系統中的每個物件能提供的資訊並不充足。例如推薦書籍,可以獲得的資料只有作 者、出版社、出版日期、摘要等簡單的摘要資訊。只根據這些資料獲得的資訊很難建出 一個可以描述整個系統的模型,所以內容導向過濾的方法相對的比較難被應用在推薦系 統中。 在本論文提出的個人化圖書館館藏推薦系統中 ,採用的內容導向過濾是利用 Lawrence 等人在[8]中所提出來的方法來建立整個系統模型。[8]這篇論文主要目的是建 立一個超級市場中的推薦系統,? 每個消費者建立個人化的推薦清單當做購物時的參 考。[8]在建立內容導向過濾模型的作法是利用超級市場中的商品 分 類 樹 (Product Taxonomy) 為模型基礎,再探勘消費者的消費歷史資料,以找出分類樹中各個分類間的 關聯規則,藉此來替市場中每個商品和每個消費者建立各自的表示式。 超級市場的情境和圖書館頗為類似,在本論文中,我們利用圖書館中原本就有的書 目分類表為內容導向過濾的模型,再探勘使用者在圖書館的借閱歷史檔,找出書目分類 表中各個分類之間的關聯規則。這樣利用[8]中所提出的方法就可以替圖書館館藏推薦系 統中每本書和每個使用者找出各自的表示式。. 4.
(14) 找出每個物件的表示式後,接下來要找出系統內各個物件間的關係就相當容易,因 為系統中物件的表示式都在同一個空間中,所以要比較彼此間的關係通常只要一個計算 相似度的公式,就可以算出系統中物件間的相關程度。 因此在推薦系統中,若能夠建立使用者和推薦物品的屬性表示式分別代表使用者興 趣和物品屬性,就可以輕易地計算出使用者對推薦物品的喜好度,而不需要像協力式過 濾要參考其他人的意見。同時內容導向過濾也沒有像協力式過濾參考資料不足的問題, 因為在協力式過濾中需要的是眾人對推薦物品的評價,如果某物件太少人甚至根本沒有 人對其有評價,系統將無法為其做推薦。這個問題在內容導向過濾的推薦系統中不存 在,因為內容導向過濾的推薦系統中每個物件都是依照自己的屬性內容來建立表示式, 而要? 每個人找出推薦只要找出與使用者興趣符合度比較高的物件即可。而且因為以內 容導向過濾為主的推薦系統中每個人是以自己的興趣來建立個人的興趣表示式(興趣向 量),所以每個人的興趣向量都不盡相同,各有各自的特性,因此系統可以找出每個人 不同而只適合某個人的推薦,這使得採用內容導向過濾的推薦系統可以更具備個人化的 功能,推薦的東西更能符合個人的需求。 所以在本論文提出的個人化圖書館館藏推薦系統中,我們結合了協力式過濾和內容 導向過濾來產生推薦。利用協力式過濾? 使用者收集其他人的意見,幫助使用者篩選圖 書館的館藏,讓使用者可以更快速地找到有興趣的、甚至是以前從來沒想到或沒接觸過 的館藏。內容導向過濾則是用來進一步篩選之前以協力式過濾找出的推薦清單,藉以提 高推薦的準確度和使推薦具有個人化的功能;並且因為採用內容導向過濾的方法,所以 也能解決協力式過濾無法有效推薦新書[20]或冷門書的問題 (Cold-Start) [25]。 本論文提出的個人化圖書館館藏推薦系統的目標是希望能依據使用者的借閱歷史 來找出他們潛在的興趣,並依照興趣來替每個使用者推薦各自適合的館藏。期待經由這 樣一個新的圖書館服務,能吸引讀者更有效利用圖書館的資源,增加圖書館資源的利用 率,並且提高圖書館的價值。 5.
(15) 第三節 論文架構. 在這篇論文中,第二章將會介紹目前推薦系統發展的情況和推薦系統目前常應用到 的技術。第三章會把個人化圖書館館藏推薦系統所用到的協力式過濾和內容導向過濾分 別做詳細的介紹,並說明如何結合這兩種方法來提升推薦的準確度。第四章介紹交通大 學浩然圖書館的 myLibrary 上個人化圖書館館藏推薦系統實作的狀況。第五章則是評估 推薦系統效能,計算讀者對這個推薦系統所推薦的館藏滿意度。第六章為結論及探討個 人化圖書館館藏推薦系統未來可能發展的方向。. 6.
(16) 第二章 相關研究工作 推薦系統由於電子商務 (e-Commerce) 的發展而逐漸受到重視,各式各樣的推薦系 統為因應各種不同的需要而產生。目前推薦系統新的研究方法是加入資料探勘的技術, 其中最常用的是以資料探勘中關聯規則探勘 (Association Mining) 的方法找出交易集 (Transaction Set) 中隱含的知識 (Knowledge)、有用的資訊 (Useful Information) 和關聯 規則 (Association Rules),例如顧客與顧客間的關係、產品與產品間的關係或顧客與產 品間的關係等。圖 1 為這方面相關研究的文獻,主要分成推薦系統相關和關聯規則探勘 相關這兩部分。其中,推薦系統中的 Law01[8]和 LAR02[9]及關聯規則中的 Hong99[17]、 Han00[16]和 Tai02[28]這幾篇為本論文中特別有參考到的文獻。. Association Mining Han00 Agrawal94. Hong99. Tai02. Zaki00. Pei01. LK02. Hong03. Recommender Systems Konstan97. Lee02. Ko02. Resnick97. Del01. LAR02. Chen03. Bala97. Schafer01. Schein02. Cosley03. Gold92. Law01. Mobasher02. Mirza03. 2002. 2003. before 1999. 1999. 2000. 2001. 圖 1 相關研究文獻. 在本章中,我們將介紹目前推薦系統發展的概況。第一節中會先介紹推薦系統與電 子商務間的關係。第二節說明一般推薦系統的主要架構及設計考量。第三節和第四節分 別 描 述 推 薦 系 統 常 用 到 的 協 力 式 過 濾 (Collaborative Filtering) 和 內 容 導 向 過 濾 (Content-Based Filtering) 這兩種推薦方法。第五節介紹國立交通大學浩然圖書館中目前 已有且屬於推薦系統方面的功能。 7.
(17) 第一節 推薦系統與電子商務. 推薦系統目前應用最廣的領域在於電子商務上,主要用來提升消費者回店消費的機 率以增加其營業額。 由於近年來網際網路的興起,帶來了網路零距離的概念和前有未有的便利性,網路 逐漸成為另一個人們用來交換訊息和溝通的方式。尤其在網路技術成熟和基礎建設完成 之後,網路愈來愈深入人們的生活,使得愈來愈多的人開始學習使用網路,並且逐漸將 生活帶到網路上。在此同時很多商業行為也開始在網路上進行,各種電子網路商店林 立,消費者只要輸入網址馬上就被帶到網路商店裡,不但方便而且迅速,這創造了一個 新的且龐大的商機。網路不但縮短了消費者與商店間的距離,也縮短了消費者口袋和業 者口袋的距離。 網路市場這一塊大餅很快就被注意到並且激烈競爭,因為網路商店的設立成本低, 所以許多實體商店紛紛成立網路商店,增加一個窗口服務顧客同時多一個收入來源;甚 至更多的網路商店是沒有實體商店的純網路商店,只要少少的資本就可以在網路上租個 網頁空間做起生意來。而且網路商店因為成本低,所以有辦法壓低商品價格來跟實體商 店競爭,加上網路商店具有時間和空間上兩個最大的優點:在時間上的優勢是網路商店 可以 24 小時全天候甚至也是一年 365 天全年無休的營業。在空間上的優勢是其消費群 涵蓋全世界任何有網路的地方。所以在任何時間、任何地點,消費者只要上網就可以購 物。這些優點使得網路商店同時受到業者和消費者的喜愛。 不過網路商店雖然有那麼多的好處,但對於顧客和業者也各有其特有的缺點。對顧 客而言,網路交易的安全性是其在網路上消費的一個障礙;對業者而言,則是網路商店 太多、競爭太激烈,而且消費者的流動率很高。在這麼多的網路商店裡,如何吸引消費 者來你這家商店消費,甚至持續消費就是個重要的議題。而且實體商店和網路商店有一 點重要的不同在於網路商店沒有店員,沒有店員固然減少了人事上的費用,可是當顧客 8.
(18) 上門時沒有店員幫忙介紹商品、推銷商品、回答顧客的問題和給與顧客建議,商店和顧 客之間沒有互動,這無形中就減少了很多交易的機會。如果網路商店也僱請店員在網路 上跟顧客互動,說不定所花費的人事費反而比實體商店高。因為店員必須隨時在線上待 命,且網路上的客源數量不定,店員的數量難以拿捏。面對這個問題,其中一個解決的 方法就是建立一套具個人化的推薦系統,個人化的推薦系統可以取代店員部分的功能, 其中最重要的功能就是推銷商品、給予顧客購買上的建議,因此推薦系統逐漸被應用在 網路商店上,幫助網路商店的經營。 亞馬遜網路書店 (Amazon.com) 的執行長 Jeff Bezos 曾經說過: 『假如我在網路上有 三百萬個顧客,那我就應該有三百萬個網路上的商店。』(“If I have 3 million cus tomers on the Web, I should have 3 million stores on the Web”) [24],這句話突顯了網路商店個人化的 重要性。因為在實體商店中,當顧客找不到需要的商品或對商品有疑問時,都有店員會 給予協助,店員可以把店中符合顧客需要的商品展示給顧客選擇,並協助顧客完成交 易。但在網路商店中沒有店員的協助,當顧客瀏覽幾頁網頁找不到需要的商品時,馬上 會連上其他網路商店的網頁購買,顧客和交易就這樣輕易地流失了。所以每一家網路商 店都希望能把顧客需要的商品放在網頁上容易查詢到的地方,讓顧客覺得整家商店裡的 商品都是他所需要的,彷彿這家商店是專? 他所開設的一般。個人化 (Personalization), 又稱客製化 (Customization),剛好可以滿足這個要求。建立一個個人化的資訊環境 (Personalized Information Environment) 可以收集顧客的喜好 (Preferences) 及習慣,有助 於商店了解顧客的需求。當顧客留下愈多的個人資訊,商店就愈能提供符合顧客需求的 商品和服務以吸引顧客下次再度光臨,藉以提高顧客的回店率和忠誠度。顧客一旦再度 光臨又將會留下更多的個人資訊,讓商店更能滿足顧客的需要。如此可以提高顧客與商 店間的互動,之間形成一個良性循環。所以現在網路商店的一個重要資產就是顧客的個 人資料和興趣,誰掌握最多的顧客資訊,能提供最符合顧客需要的商品,誰就掌握了客 源。. 9.
(19) 所以推薦系統和個人化的功能常被運用在網路商店上,以提高業績收入。推薦系統 也逐漸加入個人化的功能,希望推薦出來的商品能更符合顧客個人的需求。目前比較有 名 且 有 個 人 化 推 薦 系 統 的 網 路 商 店 有 Amazon.comT M (http://www.amazon.com) 、 CDNOWTM (http://www.cdnow.com) 和 eBay.comT M (http://www.ebay.com) 等。 目前應用於網路商店上的推薦系統通常可分成兩種[11]。第一種是推薦購買頻率較 高的商品,例如書或影片之類,這些商品因為顧客購買的頻率較頻繁,所以主要用來推 薦的方法是由分析顧客購買的歷史紀錄,進而來推斷顧客的興趣、喜好,再由此來推薦 顧客喜歡或感興趣的商品。而這種推薦方式主要的技術在於分析顧客的興趣,通常用的 方法是資料探勘並且加入個人化的功能。 第二種系統則主要是推薦顧客購買頻率較低的商品,例如汽車、電腦、家庭劇院組 合之類的商品。針對通常購買這類商品的顧客,較無法得知其之前長期以來的興趣,而 且往往購買這些商品時都有顧客當時的特殊原因,如果採用以前的購買記錄來做推薦往 往無法達到預期的效果。所以這類推薦系統主要是用事先設定好的一些專家知識,依據 顧客購買當時的特殊需求,來推薦顧客當時最適合的商品。例如購買電腦時,對一個需 要做 3D 繪圖、影像處理的顧客,我們必須推薦一台有高階中央處理器和顯示卡的電腦, 而對一個主要用電腦來上網、做一些簡單的文書處理的顧客,則我們須推薦穩定性高或 價格較平價的電腦比較合適。在推薦這種購買頻率較低的商品時,主要採用專家系統 (Expert System)的技術。 根據圖書館的特性,圖書館館藏的流通相當頻繁,而且來借閱圖書館館藏的讀者通 常都是有長期的借閱習慣,所以比較接近於“購買頻率較高的商品”這一類的屬性。也因 此在本論文中我們主要用資料探勘的技巧來分析處理讀者的借閱歷史紀錄,並判斷讀者 的興趣所在,推薦給讀者感興趣的館藏資料。. 10.
(20) 第二節 個人化推薦系統. 推薦系統隨著電子商務而蓬勃發展,有相當多的研究和各式各樣的實作系統,同時 也有很多推薦系統已經實際在線上運作了。在[24]這篇論文中整理出了一般電子商務上 的推薦系統架構,主要把推薦系統分成三大部分,分別為輸入和輸出 (Functional I/O)、 推薦方法 (Recommendation Method) 和其他設計考量 (Other Design Issues),依序介紹 如下:. 2.2.1 輸入和輸出. 首先,第一部分的輸入和輸出指的是系統需要哪些關於顧客的資訊,以及推薦結果 如何呈現給顧客。在輸入這方面包含目標顧客的輸入 (Target Customer Inputs) 和社群資 訊的輸入 (Community Inputs) 這兩種。 目標顧客的輸入指的是顧客的興趣輸入,從顧客特意或不經意的情況下,系統可以 取得顧客的興趣。有幾種方式可以得到關於顧客興趣的資訊:. 1. 直接詢問顧客興趣 (Explicit Navigation):當顧客在網路商店上瀏覽時,直接要 求顧客填入或選擇他們有興趣的商品類別,明確指出他們的興趣所在。通常是 在顧客加入會員時,會要求顧客填入一些自己的興趣。 2. 網頁瀏覽記錄 (Implicit Navigation):由顧客瀏覽過的商品網頁有助於得知顧客 感興趣的商品種類。所以分析顧客在網站上的網頁瀏覽記錄,也可以判斷出顧 客的興趣。 3. 查詢關鍵字 (Keywords and Item Attributes):顧客查詢商品時所使用的關鍵字或 商品種類。 4. 商品評分 (Rating):顧客對使用過或購買過的商品的評價。 11.
(21) 5. 購買記錄 (Purchase History):顧客在商店裡曾購買過的商品和時間。 這些顧客所留下來的資訊,都透露著顧客的興趣和商品偏好。善用這些資訊,則推 測出來的使用者興趣將更貼近使用者的真正興趣。 社群資料的輸入指的是一般大眾對商品的喜好,在目標顧客的輸入中主要目的是取 得顧客的資訊,而社群資料的輸入則是想取得商品的屬性資訊。社群資料包含以下幾種:. 1. 商品屬性 (Item Attribute):包含商品所擁有特定的顧客群,和商品所屬的分類。 2. 熱門商品 (External Item Popularity):銷售量較高的商品,通常為一般大眾普遍 喜歡或在某些時節有特殊需要的商品。 3. 社群購買記錄 (Community Purchase History):由結合所有個人的購買記錄所組 成,可以找出商品銷售的趨勢和商品間的相似度,也是一種隱性的商品評分。 4. 商品評分和心得感想 (Rating and Text Comments):社群對商品的喜好程度及其 評論,有助於突顯商品價值。 收集個人和社群的輸入資訊加以分析,對了解顧客的興趣和分析商品的屬性有很大 的幫助,這些收集來的相關資訊都有助於使推薦系統能做出最合適的推薦。. 關於輸出部分,指的是要如何把推薦的結果呈現給顧客,通常是推薦系統中最後的 步驟,但也是最關鍵性的步驟。因為如果沒有用適當的方式把推薦呈現給顧客,那可能 會使顧客沒機會接觸到這些推薦,即使顧客得到推薦也會影響顧客對這些推薦的印象, 使得推薦無法達到預期的功效。推薦的輸出會根據商品不同的性質 (Type)、推薦的數量 (Quantity) 和呈現給顧客看的形式 (Look of Information)而有所不同。通常輸出的方式可 分為建議 (Suggestion) 和預期 (Prediction) 這兩種。建議是指給顧客一個未排序過的推 薦清單,讓顧客檢閱其中是否有符合需要的商品,避免因為清單中前幾個推薦不滿意而 使後面的推薦不被參考。而預期這種方法所給的推薦清單則是有排序過的推薦,甚至會 列出系統預期顧客可能的喜好程度,使顧客知道各個商品的推薦強度。 12.
(22) 2.2.2 推薦方法. 第二部分推薦方式指的是如何找出顧客感興趣的商品並列出推薦清單。推薦方法是 推薦系統的核心,方法的好壞直接影響了推薦結果的優劣。而因為需要的不同發展出多 種不同的推薦方法,常利用的方法如下:. 1. 基本檢索 (Raw Retrieval):網路商店上通常有基本的商品搜尋引擎,讓顧客輸 入關鍵字來找尋有興趣的商品。搜尋引擎可由顧客輸入的關鍵字列出所有相關 的 商 品 , 但 通 常 只 是 純 粹 的 字 串 比 對 , 所 以在 查 全 率 (Recall) 和 準 確 度 (Precision) 上都有所不足。 2. 人工選粹 (Manually Selected):由專家以人工方式建立推薦清單或分類清單,使 顧客可以依照自己的興趣選擇需要的清單參考。這種方式有相當高的準確度, 可是需要長期人工維護更新,無法及時提供資訊。 3. 統計分析 (Statistical Summaries):以統計的方法分析一般顧客的購買趨勢來做 推薦,也可以整理出熱門商品清單讓顧客參考。 4. 屬性導向 (Attribute-Based) 推薦:利用商品的屬性和顧客的興趣,比較之間的 關係,依此來判斷出顧客可能需要或喜歡的商品。 5. 商品間的關聯性 (Item- to-Item Correlation):商品間常會有某些關係存在,例如 可以找出常被一起購買的商品,當顧客購買某樣商品時,可以推薦給他其它常 被一起購買的商品。 6. 顧客間的關聯性 (User-to-User Correlation) :有些顧客因為購買習慣或興趣相 同,可以被歸類在同一個社群中。同社群內的顧客彼此之間可以分享資訊,互 相推薦商品。 這些推薦方法並無絕對的好壞,依照需求不同而各有存在的價值。這些方法除了可 以獨立運作外,也可以互相搭配使用來提升推薦的效果。例如在[8]中的推薦方法結合了 13.
(23) 屬性導向推薦和顧客間的關聯性兩種方法,首先利用顧客間的關聯性來找出顧客可能感 興趣的推薦清單,再利用屬性導向推薦來對推薦清單排序,這樣找出來的推薦清單不但 參考了社群的意見,也相當符合個人的興趣。而在[9]中則提出了結合商品間的關聯性和 顧客間的關聯性的推薦方法以互補這兩種方法的缺點,當要對某位顧客做推薦時,如果 找不到相同興趣的顧客,無法用顧客間的關聯性做推薦時,就轉換成用商品間的關聯 性,從顧客的購買紀錄中判斷哪些商品顧客目前可能感興趣。 目前推薦系統在電子商務上的應用,比較偏重於個人化的功能,希望能根據每個使 用者不同的興趣分別給予使用者符合興趣的推薦。個人化推薦系統主要的方法分成兩 種,分別為協力式過濾和內容導向過濾。而在之前提到的方法中,商品間的關聯性和使 用者間的關聯性是協力式過濾推薦常用到的方法,而屬性導向推薦其實就是內容導向過 濾推薦的別名。協力式過濾和內容導向過濾這兩種方法將分別在本章第三節和第四節中 介紹。. 2.2.3 其他設計考量. 最後,設計一個推薦系統還必須考量到一些特別需求,依照各個網路商店不同的需 要分別做不同的設計,通常考量到的主要有個人化的程度 (Degree of Personalization) 和 如何把推薦送達 (Delivery) 給顧客這兩個方面。這些設計上的考量甚至會直接影響推薦 方法的選擇。 個人化的程度方面可分成三種,主要因為產生推薦的方法不同而有所差異。第一種 是無個人化 (Non-Personalized),例如只用一些統計摘要的方法所產生的推薦,每個人 所得到的推薦都是相同的。第二種是短期的個人化 (Ephemeral Personalization),這種個 人化主要是依據顧客最近的網頁瀏覽紀錄或選取了哪些商品,來推薦可能需要的商品, 這種方式大多採用內容導向過濾或利用資料探勘所找出的物品間的關係來做推薦。第三 種則是長期的個人化 (Persistent Personalization),這種方式會長期追蹤顧客的興趣,主 14.
(24) 要的推薦方式是利用顧客的歷史紀錄檔找出使用者和使用者間的關係,再利用協力式過 濾推薦。 而如何把推薦清單送達給顧客也是一個重要的議題,主要分成主動送出 (Push) 、 等候選取 (Pull) 和被動產生 (Passive) 三種。主動送出顧名思義是主動將推薦送給顧 客,通常採用電子郵件的方式。主動送出的優處是是可以直接且及時地把訊息送給消費 者,吸引顧客光臨,但也可能會被當成廣告信,引起顧客反感。等候選取則是可由顧客 自己決定何時要查看推薦。顧客可在瀏覽網站時,可自行點選檢視商店所推薦的商品, 讓顧客享有絕對的自主性。等候選取的困難在於需要引起顧客的興趣來點選瀏覽,所以 往往這種方法在應用上造成的效果不彰。第三種被動產生的方法則是當顧客的購物車裡 已經有某些商品時,可以根據這些商品來做即時的推薦。被動產生的方法因為直接跟顧 客互動,往往推薦的東西和顧客當時的需要接近,所以應用上的效果不錯。但是因為要 線上作業,所以特別要考量推薦執行的速度,避免? 了推薦而影響顧客瀏覽網頁的流暢 度,使顧客失去耐心。當然以上這三種方法可以互相搭配使用,主要還是依照商品的特 性、顧客群習慣和實際施行的效果。. 第三節 協力式過濾與關聯規則探勘. 協力式過濾可以說是推薦系統的前身,1992 年首先由 Goldberg 在[14]中提出,應用 於電子郵件分類系統 TAPESTRY 上。協力式過濾主要的想法是使用者之間可以利用彼 此已知的資訊,互相幫忙過濾出自己有用的資訊,就好像在我們做決定之前常會事先詢 問有經驗的人意見來當做決定的參考一般。協力式過濾在實作上常利用的方法是建立一 個顧客-商品的矩陣 (Customer-Product Matrix),或稱為評分矩陣 (Rating Matrix) [6], 矩陣中的值為顧客對商品的評分。從這個矩陣中可以得到顧客間的興趣相似度,藉著顧 客間的相似度和其他顧客對商品的評分可以預測出顧客對未評分商品的喜好程度。. 15.
(25) 而協力式過濾推薦近來常利用關聯規則探勘 (Association Rules Mining) [1] 的方 法,找出有用的關聯規則來當作推薦的依據。例如在[9]中就主要以關聯規則探勘所找出 的物品之間的關係 (Item Association) 及使用者間的關係 (User Associations) 這兩種關 聯規則互相搭配來做推薦。物品間的關係可以表現出哪些商品常常被一起購買,這些商 品之間可能隱含著某種關係而造成常被一起購買的現象,因此當顧客購買其中某樣商品 時,我們可以推薦給他其它也常常一起被購買的商品。而使用者間的關係則是要找出購 買習慣類似的顧客群。利用這些購買習慣類似的顧客群,當要對群中某個顧客做推薦 時,系統可以推薦給他同一群中其他人常購買的商品。例如若我們發現一群顧客常常購 買古典樂 CD,如果某天這群顧客中的某位來購買 CD,那我們可以將其所屬的顧客群中 其他人所購買過的古典樂 CD 推薦給他。 關聯規則探勘是資料探勘中的方法之ㄧ,經常運用於商品交易記錄資料庫上,針對 使用者的交易行為做分析,找出商品間的關聯規則。再根據這些關聯規則來決定搭配促 銷商品和商品架位等行銷策略,藉以提高交易量和營業額。例如:80%購買牛奶和果醬 的顧客也會同時購買吐司,就是一個典型的關聯規則。從 1993 年 Agrawal 提出從交易 資料庫中探勘出關聯規則的演算法[1]後,陸續有學者將關聯規則的概念應用到其他領 域,提出適用於該領域的演算法。. 關聯規則探勘主要分成兩個步驟:一、找出頻繁項目集 (Frequent Itemsets, Large Itemsets)。二、由頻繁項目集中歸納出關聯規則。由於第二個步驟,歸納出關聯規則, Agrawal 已經在[2]中提出有效率的演算法解決了,所以目前關聯規則探勘效率的瓶頸在 於第一步的找出頻繁項目集。早期的演算法找出頻繁項目集時常需要大量時間來產生和 檢查候選項目集 (Candidate Itemsets),這造成探勘的效率低落。因此? 了提高探勘的效 率解決這個問題,不需產生候選項目集的演算法便因應產生。 後來被提出的演算法大多主要著重在探勘效率的提升上,所以關聯規則探勘可粗略 依照是否產生候選項目集來區分成兩種[16]。需要產生候選項目集的有 Apriori [2]、 16.
(26) Pincer-Search[10]和[26]提出可處理大量資料的演算法 (Scalable Algorithms) 等,而不需 產生候選項目集的演算法有 FP-growth[19]和 H- mine [22]等。另外在[17], [18]中提出乏析 資料探勘 (Fuzzy Data Mining),專門處理量化 (Quantitative) 的資料。[15]則以 AprioriTid 演算法來實作乏析資料探勘。. 第四節 內容導向過濾與系統模型建立. 內容導向過濾的推薦方式,主要是從資訊擷取 (Information Retrieval) 的領域延伸 過來。這種方式會以物件的內容或屬性來替每個物件建立屬性向量,在判斷物件是否相 關時,常會以計算物件其向量間的餘弦 (Cosin) 值,也就是兩向量間的夾角大小來代表 相似度 (Similarity),如果代表這兩個物件的向量之間夾角小,則代表這兩個物件相關程 度高,反之則相關程度低。若以顧客和商品間的關係來看,我們可以把顧客和商品分別 用一物件表示,兩個物件間的向量夾角大小就是顧客對商品可能的喜好度。. 不過屬性導向的方法最大的困難在於如何建立一個模型 (Model) 來表示系統中所 有的物件。在[8]這篇論文中,提出了一種模型來替商品和顧客建立分別其屬性向量表示 式和興趣向量表示式。首先將所有的商品分成數類,建成一個有階層的分類樹,每個商 品屬於分類樹分類中的其中一類。假設最底層的分類有 1000 類,則這 1000 類事實上也 就是屬性向量中的 1000 個屬性,而每個物件其屬性向量中的值代表著它在各分類中的 權重。? 了要分析分類樹中每個分類之間的關係,所以利用關聯規則探勘找出分類樹中 每一層中分類之間的關聯規則。利用這些關聯規則,和權重給定公式,可以? 每一個商 品定義出其屬性向量表示式。 假設有一個分類樹如圖 2,第一層有 A, B, C 三個分類,而每個分類都有三個子分 類,所以第二層有九個分類,而所有系統中的物件都會以具有九個屬性的向量來表示, 而這九個屬性分別代表 A.1~C.3 這九個分類,各個屬性的值也就代表物件在各個分類的 關係權重。 17.
(27) Level 1. Level 2. A. A.1. A.2. B. A.3. B.1. B.2. C. B.3. C.1. C.2. C.3. 圖 2 一個兩層的分類樹. 之前顧客的購買記錄可以利用關聯規則探勘找出各階層分類間的關聯規則。假設找 到 A ⇒ B 和 A.2 ⇒ C.2 這兩條規則,而[8]定義的權重給定公式如下:. Ps( n). 1.0 1.0 = 0.5 0.25 0. if s = S ( n) if S(n) ⇒ s if C ( s) = C ( n) if C (n ) ⇒ C ( s) otherwise. ( within same subclass ) (within associated subclass) (subclass within same class) (within subclass of associated class). 方程式 1 文獻[8]中的權重給定公式. 其中 Ps(n)代表商品 n 在第二層分類 s 上的權重,S(n) 代表 n 所在的第二層分類,C(s) 和 C(n) 代表第二層的分類 s 和商品 n 所在的第一層分類。 從公式中我們可以知道如何去找出一個商品的屬性向量。首先將商品 n 所在的分類 S(n) 之權重設為 1;如果有關聯性規則表示可以從 S(n) 推廣到其他的分類 s,則 n 在這 些分類 s 的權重也是 1;此外如果商品 n 和分類 s 都同屬於某個第一層的分類下,則 n 在這個分類 s 下的權重為 0.5;如果商品 n 和分類 s 不屬於某個第一層的分類下,但是商 品 n 所在的第一層分類 C(n)和分類 s 所在的第一層分類 C(s),有 C(n) ⇒ C(s) 這樣的關 聯規則存在,則 n 在這個分類 s 的權重設為 0.25。至於其他的分類,n 在這些剩下分類 中的權重皆設為 0。 以一個屬於 A.2 這個分類的商品 k 為例,建立 k 的屬性向量之步驟如下:. 18.
(28) 1. 一開始 k 的表示式是一個具有九個屬性的向量,其中每個屬性的值都為零。 k = (0, 0, 0, 0, 0, 0, 0, 0, 0) 2. k 屬於 A.2 這個分類,所以 k 在 A.2 分類上的權重設為 1。 k = (0, 1, 0, 0, 0, 0, 0, 0, 0) 3. k 所在的分類 A.2 有一條關聯規則為 A.2 ⇒ C.2,所以 k 在 C.2 分類上的權重也 設為 1。 k = (0, 1, 0, 0, 0, 0, 0, 1, 0) 4. A.1 和 A.3 跟 k 都屬於 A 這個第一層分類之下,所以 k 在 A.1 和 A.3 這兩個分類 上的權重都為 0.5。 k = (0.5, 1, 0.5, 0, 0, 0, 0, 1, 0) 5. 又 k 所在的第一層分類 A 有一條關聯規則為 A ⇒ B,所以 k 在第一層分類 B 之 下的分類 B.1、B.2 和 B.3 這三個分類上的權重都可設為 0.25。 k = (0.5, 1, 0.5, 0.25, 0.25, 0.25, 0, 1, 0) 所以最後商品 k 的向量表示式為 (0.5, 1, 0.5, 0.25, 0.25, 0.25, 0, 1, 0),代表商品 k 的 屬性。將商品的表示式找出來之後,可據以建立顧客的表示式,最簡單的方式就是依照 顧客的購買記錄統計顧客消費過的商品,依照這些商品的表示式來建出顧客的興趣向量 表示式。之後可以利用這個模型,透過顧客和商品分別的表示式,來推測顧客對商品可 能的興趣程度。. 第五節 圖書推薦系統. 圖書館中事實上已經有許多推薦系統以各種形式存在,帶給讀者許多的便利性。以 下我們將以國立交通大學浩然圖書館為例,來舉出幾種目前圖書館中存在的推薦系統。. 19.
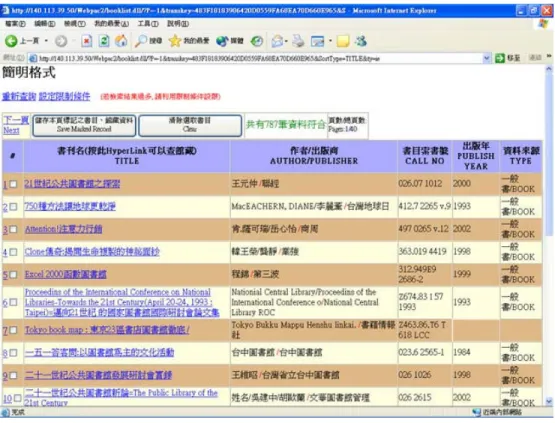
(29) 2.5.1 關鍵字搜尋. 關鍵字查詢是一般圖書館使用率最高的功能,通常使用者利用這個功能來找尋圖書 館中需要的館藏。圖 3 是浩然圖書館館藏查詢系統的使用者介面,其中提供有書刊名、 標題、作者、出版商等多達 11 種欄位來供使用者填入關鍵字來查詢。查詢的結果會呈 現出所有含有使用者輸入關鍵字的館藏,這些回傳的資料就相當於是查詢系統給予使用 者的推薦館藏,如圖 4 為以書刊名關鍵字“圖書館”的查詢結果。 但是關鍵字查詢通常只是單純的字串比對,若使用相同的關鍵字查詢,找出來的資 料都是一樣的。而且萬一使用不恰當的關鍵字搜尋,往往找到的資料不是過多就是過 少,無法達到讀者預期的需要。. 圖 3 交通大學浩然圖書館館藏查詢使用者介面. 20.
(30) 圖 4 交通大學浩然圖書館館藏查詢結果呈現介面. 2.5.2 主題式人工推薦. 當圖書館中某類館藏資料多到一定的程度,並且有專家的協助,有時候會把這類的 館藏以主題分類陳列。如圖 5 是浩然圖書館中一個以科幻圖書為主題的主題式推薦,在 這個例子中,主要的推薦是左方已經分門別類過的館藏,對科幻圖書有興趣的人可以很 方便地找到各種分類的科幻圖書。而圖 6 是點選左邊的“時光旅行”項目後出現的推薦清 單。圖 5 右方的查詢事實上仍是關鍵字查詢,只是在這裡的查詢會把搜尋類別侷限在科 幻圖書上。 主題式人工推薦最大的好處就是呈現出來的推薦準確度相當高,加上已經有經過專 家的分類,讀者可以很容易取得符合自己興趣的館藏,但缺點是需要人工長期維護以保 持更新。. 21.
(31) 圖 5 科幻圖書館藏的主題推薦. 圖 6 科幻圖書館藏中的分類推薦 -以“時空旅行”分類為例. 22.
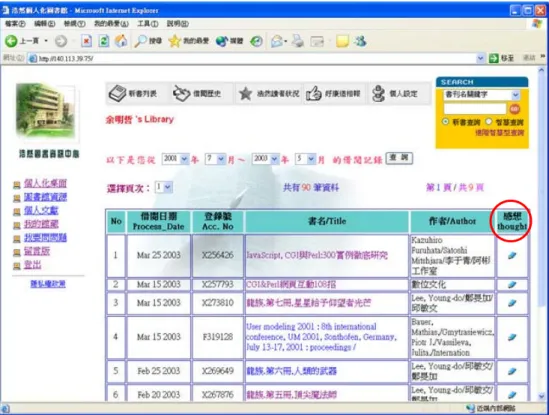
(32) 2.5.3 館藏間的關連性. 資料探勘的技術已經普遍應用在各領域,主要用來找尋大量資料中的規則性和關聯 性。現在這種技術也逐漸引入圖書館中,在[28], [29]這兩篇論文中就提出以資料探勘的 方法來找出館藏間的關聯性,找出哪些館藏經常會被讀者一起借閱。然後當讀者在查詢 館藏或者瀏覽自己的借閱記錄時,可以查看還有哪些館藏是常常一起被借閱的,藉此來 提高館藏的利用率。如圖 7 是以“資料庫”為書刊名關鍵字查詢館藏資料回傳的結果,圖 8 為某人的借閱歷史查詢結果。其中按下圖 7 中最右邊的“推薦”欄位或圖 8 中最右邊的 “感想”欄位,就可以看到該本書的關聯館藏,得知有哪些館藏常常跟那本書一起被借 閱,如圖 9 為“溫馨廚房咖啡屋”這本書的相關館藏資料。. 圖 7 個人化智慧型 館藏查詢結果-以“資料庫 ”為書刊名關鍵字查詢. 23.
(33) 圖 8 個人借閱歷史查詢介面. 圖 9 推薦相關館藏畫面. 24.
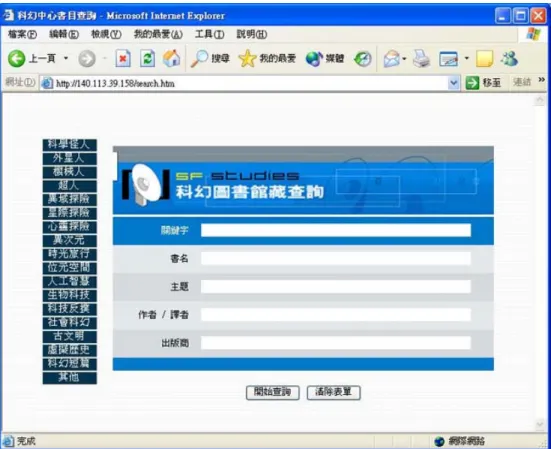
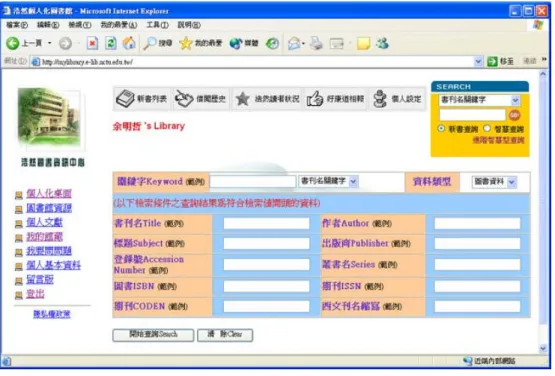
(34) 2.5.4 個人化的智慧型查詢. 在[30]中提到,圖書館面對與日俱增的數位或紙本資源,傳統的搜尋引擎已無法滿 足讀者的需求。因此[30]這篇論文將個人化資訊服務技術應用在圖書館上,建立一套個 人化數位圖書資訊環境-PIE@NCTU。 其中 PIE@NCTU 中最重要的改變是將館藏查詢系統採用個人化的智慧型查詢系統 (Intelligent Personal Search Engine) 以契合使用者的需求。這套具個人化的館藏查詢系統 會收集使用者搜尋時所用的關鍵字來判斷使用者的興趣,並且依此產生一些系統關鍵字 來代表使用者的興趣。另外使用者也可以自己增加關鍵字來告知系統自己的興趣所在, 或者自己選定有興趣的館藏類別。當使用者查詢館藏資料時,系統會利用系統判斷關鍵 字、使用者自訂關鍵字和使用者自選類別這三種資訊,來判斷使用者最需要的館藏,把 查詢結果先加以過濾和排序後再呈現給使用者。. 另外一個重要的功能是新書通告 (New Arrival Notice),當圖書館有新進館藏時,系 統可以根據使用者之前留下的個人興趣來判斷哪些新進館藏是使用者可能會感興趣 的,並將這些新進館藏的消息通知使用者。. 圖 10 為目前交通大學浩然圖書館的個人化智慧型查詢系統介面,查詢結果呈現方 式如圖 7 所示,其中上方的“二個燈”和“一個燈”表示和讀者興趣的符合度,燈數愈高代 表愈契合讀者興趣,最高為五個燈。. 25.
(35) 圖 10 個人化智慧型查詢系統介面. 以上這幾種圖書館所提供的推薦服務,都能提供給讀者搜尋資料上莫大的幫助。尤 其在現在許多圖書館都朝向電子圖書館 (e-Library) 或數位圖書館 (Digital Library) 的 方向前進,提供給讀者即時且便捷的服務是圖書館的首務。所以必須運用科技進步帶來 的新技術和新方法,藉以提升圖書館服務的品質並增加服務的項目,使圖書館跟上時代 逐漸成長進化。. 26.
(36) 第三章 圖書館館藏推薦 本論文圖書館個人化館藏推薦系統中所採用的推薦方法,是結合協力式過濾和內容 導向過濾這兩大方法。本章分別介紹這兩種方法如何應用在系統上,並說明如何結合這 兩個方法。. 第一節 協力式過濾的推薦方法. 在進行協力式過濾時,我們首先用關聯規則探勘找出使用者間的關係,希望藉以找 出具有相同興趣的使用者群。然後在具有相同興趣的使用者之間,推薦給彼此曾經借閱 過的館藏。 我們將每一本書當作一筆交易 (Transaction) ,而其中的項目 (Item) 為借過這本書 的人,例如現在有 A, B, C 三本書,和 1, 2, 3, 4, 5 這五個讀者。從這五個讀者的借閱歷 史檔中,可以建立一個交易集 (Transaction Set) ,其中每筆交易表示每本書曾被哪些讀 者借閱過。如表 1 中的第一筆資料代表 A 這本書曾被讀者 1, 2, 4, 5 這四個人借閱過, 第二筆資料代表 B 這本書曾被讀者 1, 3, 5 這三個人借閱過,其他筆資料以此類推。. 書. 借閱讀者群. A. 1, 2, 4, 5. B. 1, 3, 5. C. 2, 4, 5. 表 1 以一本書為一筆交易的交易集. 假設最小支持度 (Minimum Support) 為 2,則從表 1 的交易集經過關聯規則探勘 後,可以得到一些項目集 (Itemset),若項目集的支持度高於預設的最小支持度,即可稱 為頻繁項目集。這些出現在同一個頻繁項目集中的讀者群,就是我們想找出來的相同興. 27.
(37) 趣讀者群。如表 2 所示,在表 1 的例子中可以得到 3 個頻繁項目集,或稱為三個讀者 群,其中每一群裡的讀者彼此間具有相同興趣。. 群編號 頻繁讀者群 支持度 S001. 1, 5. 2. S002. 2, 4. 2. S003. 3, 5. 2. 表 2 代表具有相同興趣讀者群的頻繁項目集. 雖然用一般關聯規則探勘可以找出相同興趣讀者群,可是在圖書館的環境下卻遇到 兩個問題。第一個問題是在圖書館中,借閱同一本書的讀者在比例上不多,而利用一般 關聯規則探勘所找出來的相同興趣讀者群都是要曾借閱過多本相同書的讀者,這造成能 找出來的相同興趣讀者群不夠多,只佔全部讀者群中的一小部分。這種結果會嚴重影響 到後來的推薦,因為協力式過濾推薦需要從跟讀者有相同興趣讀者群中,找出其他讀者 常借閱的書來當推薦,萬一找不到跟讀者有相同興趣的讀者群,就無法? 讀者找出適合 的推薦。第二個問題是圖書館中大多數讀者借閱館藏的數量並不多,在[29]中曾指出在 交通大學浩然圖書館中約有 1/2 的讀者其借閱數少於 10 本,這使得在關聯規則探勘時必 須採用非常小的最小支持度,才能找出足夠的頻繁項目集。但是當最小支持度設太低時 便需要耗費大量的時間進行探勘,而且也常因此找出不恰當的頻繁項目集。 對於第一個問題,改善的方法是放鬆讀者屬於同一筆交易的限制。之前是以一本書 為一筆交易,所以讀者必須借閱過相同的書才會屬於同一個交易中,現在我們改以一個 類別為一筆交易,只要讀者曾借閱過這個類別中的任一本書就屬於同一筆交易中,亦 即,將原來的交易集中,屬於同一類書的交易聚集起來,形成一個以一個類別為一筆交 易的交易集。因為在圖書館中,如果某本館藏被借閱走了,則其他讀者就無法借閱了, 這時候通常讀者還是會借閱相同類別中其他相關的館藏。所以在圖書館這種環境下,要 判斷讀者是否跟其他讀者有相同興趣,只依讀者間有沒有借閱過相同的館藏來判斷兩人. 28.
(38) 是否興趣相同,在現實上太過嚴苛了,要是依照彼此之間是否借閱過相同類別的館藏來 判斷會顯得合理許多。基於上述理由,我們改變原本以一本書為一筆交易的形式,改成 以一個類別為一筆交易,只要借過同一個類別下任一本書的讀者,都視為興趣類似,而 可以放在同一筆交易中。 這樣的做法或許會降低最後所找出的相同興趣讀者群的準確性,因為只要是借過同 類別書籍的讀者則他們可以放在同一個交易中,而不像之前必須借過同一本書才能放在 同一筆交易中。這樣探勘出來的結果其意義是只要讀者常常借閱相同類別的書籍就會被 認定興趣相同,而非像之前必須常常借閱同一本的書籍才會被認定興趣相同。這樣其實 就是放鬆判斷讀者是否興趣相同的條件,所以可能會使最後出來的頻繁項目集(相同興 趣的讀者群)結果不像之前那麼精確。 但,如此做可以使改變後的交易集裡,屬於同一筆交易的讀者數變多,也就是交易 中的項目變多了,會有助於後續找出更多的頻繁項目集。因為這樣可以讓讀者更有機會 同時存在同一個交易中,而被視為具有相同興趣;使讀者間更容易產生關聯性,探勘時 可以找出更多相同興趣的讀者群,使之後系統可以替更多讀者做館藏推薦。 可是若以一個類別為一筆交易,將衍生另一個問題,聚集過後的交易中必須考慮其 中項目出現的次數。因為有些讀者在同一個類別中借過多本書,當交易聚集時這些讀者 會在新的同一筆交易中出現多次,這些出現的次數必須被保留,否則將造成支持度降低 及資訊的流失,違背原先聚集交易的目的。以表 3 為例,若書名第一碼英文字母相同為 同一類,聚集後可以分別得到考慮個數和不考慮個數的交易集如表 4,其中考慮個數的 交易集中每個項目 “:” 之後的數字代表個數。. 29.
(39) 書. 借閱讀者群. 書. 借閱讀者群. A.1. 1, 2, 5. D.1. 1, 3, 5. B.1. 1, 3, 4, 5. D.2. 1, 3, 4. B.2. 2, 3, 4. E.1. 4, 5. C.1. 2, 3, 5. E.2. 3, 5. C.2. 1, 3, 4, 5. E.3. 3, 4. 表 3 以書籍為交易的交易集. 類別. 借閱讀者群(不考慮次數). 借閱讀者群(考慮次數). A. 1, 2, 5. 1:1, 2:1, 5:1. B. 1, 2, 3, 4, 5. 1:1, 2:1, 3:2, 4:2, 5:1. C. 1, 2, 3, 4, 5. 1:1, 2:1, 3:2, 4:1, 5:1. D. 1, 3, 4, 5. 1:2, 3:2, 4:1, 5:1. E. 3, 4, 5. 3:2, 4:2, 5:2. 表 4 聚集過後以類別為交易分別不考慮次數和考慮次數的交易集. 在考慮次數的交易集中,計算項目集在每個交易中支持度的方法為找出項目集中所 有項目分別在交易中的出現次數,取其中最少的次數為其支持度。以計算長度? r 的項 目集 s 在交易 Di 的支持度 sup is 為例,公式如下:. sup is = min (sup is j ) 0< j ≤r. 方程式 2 項目集在每個交易中支持度的計算公式. 其中 sj 代表項目集 s 中第 j 個項目, sup is j 代表 sj 在交易 Di 中的次數(支持度)。例如在考 慮個數的交易集中,項目集{3, 4}於類別 C 中的支持度為 1,其算式如下:. sup {C3,4} = min(sup C3 , sup C4 ) = min( 2,1) = 1 30.
(40) 另外,表 5 將項目集{3, 4}分別在不考慮個數的交易集、考慮個數的交易集和交易聚集 前的交易集內的支持度列出。. {3, 4} 項目集出現次數 類別. 聚集後交易集. 聚集後交易集. (不考慮次數). (考慮次數). A. 0. 0. 0. B. 1. 2. 2. C. 1. 1. 1. D. 1. 1. 1. E. 1. 2. 1. 支持度. 4. 6. 5. 聚集前交易集. 表 5 項目集{3, 4}在各個交易集中的支持度. 在表 5 中,可以發現不考慮次數的交易集中,項目集 {3, 4} 得到的支持度為 4, 甚至比聚集前交易集中的支持度 5 少。因為不考慮次數交易集的類別 B 中,項目集{3, 4} 會失去支持度 1,反而造成支持度下降。而項目集 {3, 4} 在考慮次數的交易集中可以得 到 6 的支持度,比聚集前交易集中的支持度高。因為在考慮次數交易集的類別 E 中,項 目集 {3, 4} 不但沒有因為聚集的結果在交易 B 中失去支持度,而且在類別 E 中因為 3 和 4 都分別出現 2 次,所以 {3, 4} 的支持度提升為 2,比原來聚集前交易集中的支持度 增加 1。 再以另外一個例子來說明? 何聚集交易集可以增加找出的頻繁項目集。表 6 中假設 A.1, A.2, A.3 這三本書同屬於類別 A,則 A.1, A.2 和 A.3 可以聚集成新的交易如表 7。 其中類別 A 的借閱讀者群為取 A.1, A.2, A.3 這三本書的借閱讀者群聯集,並且保留原本 讀者出現的次數,在讀者編號之後符號‘:’後面的數字代表出現過的次數,也就是讀者在 這一個類別中借閱過的館藏數量。在表 6 和表 7 中,如果項目集後面有符號‘:’,則‘:’ 之後的數字代表那個項目集出現的次數,如果沒有則代表僅出現一次。 31.
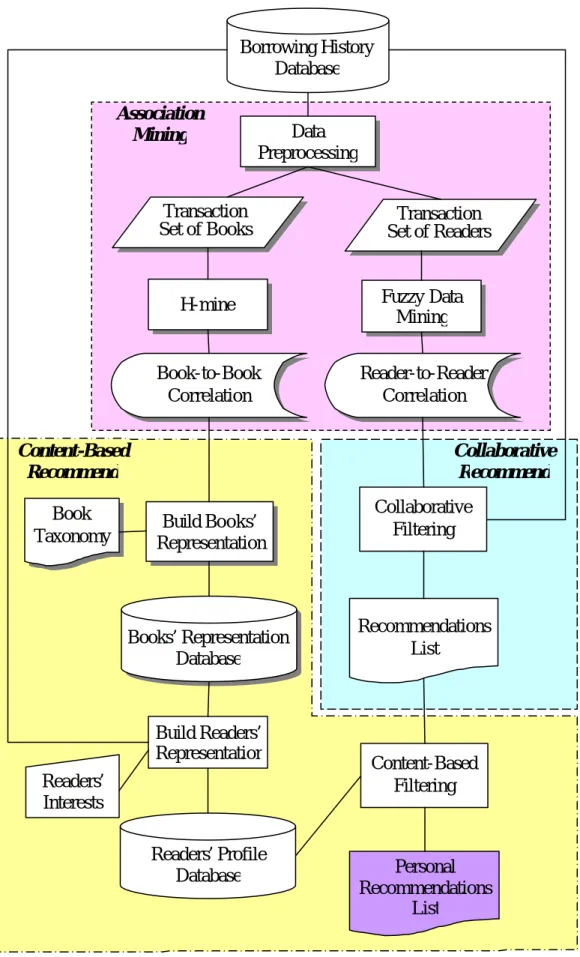
(41) 書. 借閱讀者群. 可產生的項目集. A.1. 1, 2, 3. {1}, {2}, {3}, {1,2}, {1,3}, {2,3}, {1,2,3}. A.2. 1, 2. {1}, {2}, {1,2}. A.3. 3, 4. {3}, {4}, {3,4} {1}:2, {2}:2, {3}:2, {4}:1, {1,2}:2, {1,3}:1,. 統計. {2,3}:1, {3,4}:1, {1,2,3}:1 表 6 屬於相同類別的交易集. 類別. 借閱讀者群. 可產生的項目集 {1}:2, {2}:2, {3}:2, {4}:1, {1,2}:2, {1,3}:2,. A. 1:2, 2:2, 3:2, 4:1. {1,4}:1, {2,3}:2, {2,4}:1, {3,4}:1, {1,2,3}:2, {1,2,4}:1, {2,3,4}:1, {1,2,3,4}:1. 表 7 將相同類別的書聚集起來的新交易集. 從表 6 和表 7 中發現,聚集後的交易集可以產生的項目集增加了。比較表 6 中書 A.1, A.2, A.3 和表 7 中類別 A 所能產生的項目集,類別 A 增加了 {1, 4}, {2, 4}, {1, 2, 4}, {2, 3, 4}, {1, 2, 3, 4} 這五個項目集。 有以上兩個例子,可以得知在聚集過後的交易集中有必要額外考慮次數,也就是必 需特別記錄讀者在這一個分類中曾借過的書籍數量,這樣才能確保不會造成支持度和資 訊的流失,並且能真正提高項目集的支持度,使探勘結果能找出更多的頻繁項目集,解 決原本因項目集的支持度不足而無法找出足夠頻繁項目集的問題。 而針對一般讀者借閱數偏少的問題,解決方法是將所有人的借閱數都經過正規化 (Normalize) 的處理,不再直接考慮讀者的借閱數,而是考慮讀者在每一分類中借閱的 比例。例如一個讀者總共借過 16 本書,其中有 8 本 A 類的書、6 本是 B 類的書和 2 本 是 C 類的書,則我們認為讀者的興趣 8/16 = 50%在 A 類,6/16 = 37.5%在 B 類,2/16 = 12.5%在 C 類。將每個讀者的借書數都轉成比例來表示之後,讀者在每類或每筆交易中 32.
(42) 出現的值都變成介於 0 與 1 之間,這樣一來不論讀者借書量的多寡,經過轉換後就都沒 有差別了。假設表 8 為以一個類別為一筆交易的交易集,我們可以找出其中每個項目的 支持度,亦即每個項目在交易集中的出現頻率,如表 9。轉換過後的交易集中,每個項 目在每筆交易中的值(權重),為該項目在每筆交易中出現的次數除以在交易集中總出現 頻率。例如讀者 2 在交易中的總出現頻率為 5,其原本在類別 A 的出現次數為 1,所以 讀者 2 在轉換後的類別 A 中的權重為 1/5 = 0.2,最後轉換完的結果如表 10 所示。表 10 為讀者 1, 2, 3, 4, 5 在 A, B, C, D, E 這五類中的興趣程度,而不論借閱數量多寡每個讀者 在這五類的總和(支持度)皆為 1。 類別. 借閱讀者群. A. 2:1, 3:1. B. 1:1, 2:1, 3:1, 4:2, 5:1. C. 2:2, 3:1, 5:2. D. 1:1, 2:1, 3:1, 4:2, 5:3. E. 1:1, 3:1, 4:2. 表 8 以一個類別為一筆交易的交易集. 讀者. 出現頻率. 1. 3. 2. 5. 3. 5. 4. 6. 5. 6. 表 9 單一項目的出現頻率. 33.
(43) 項目. 1. 2. 3. 4. 5. A B C. 0 0.33 0. 0.2 0.2 0.4. 0.2 0.2 0.2. 0 0.33 0. 0.17 0 0.33. D. 0.33. 0.2. 0.2. 0.33. 0.5. E. 0.33. 0. 0.2. 0.33. 0. 支持度. 1. 1. 1. 1. 1. 類別. 表 10 經過正規化處理後的交易集. 經過前述的聚集交易集並考慮項目數量及正規化項目數量這二種轉換之後,交易集 資料中每筆交易不再只包含項目,還必須多考慮每個項目各自有不同的權重。在此我們 採用[17]所提出的乏析式資料探勘,這種資料探勘的方法主要用來處理量化的資料 (Quantitative Data)。所謂量化的資料指的是一筆交易中,每個項目具有各自的權重值, 且每個項目具有的權重不盡相同。 而乏析式資料探勘和非乏析式資料探勘最大不同的地方在於計算支持度的方式。非 乏析式資料探勘在計算支持度時,如果計算的項目集中所有項目同時存在一筆交易中 時,則這個項目集的支持度就加一,代表這個項目集的所有項目同時出現一次。之所以 在非乏析式資料探勘中可以如此做的原因是,非乏析式資料探勘的交易中每個項目的權 重都視為相同,一般假設為 1。但是在乏析式資料探勘中,交易中的每個項目權重不見 得相同,所以必須用特殊的方法來處理。而在[17]提出的乏析式資料探勘中,計算支持 度的方式分成兩個步驟:. u. 步驟一:先計算具有 r 個項目的項目集 s 在每一個交易 D(i)中的值 f s( i) ,. f s(i ) = f si1 Λf si2 Λ...Λf sir 方程式 3 項目集於單筆交易內的支持度計算公式. 34.
數據
![圖 2 一個兩層的分類樹 之前顧客的購買記錄可以利用關聯規則探勘找出各階層分類間的關聯規則。假設找 到 A ⇒ B 和 A.2 ⇒ C.2 這兩條規則,而[8]定義的權重給定公式如下: ⇒=⇒==otherwise0 class)associatedofsubclass(within )()(if25.0class)same within (subclass)()(if5.0subclass)associated(within if0.1)subclasssamewithi](https://thumb-ap.123doks.com/thumbv2/9libinfo/8376025.177932/27.894.154.798.138.381/一個兩層規則⇒⇒C2這兩條規則而定義權重給定公式=⇒==.webp)
+5
相關文件
1999年10月,臺灣大學校長陳維昭教授與法鼓山 中華佛學研究所創辦人聖嚴法師正式締約,擴大 佛學網路資料庫的內容及工作範圍,並正式更名 為「佛學數位圖書館暨博物館」計畫 (Digital
「臺灣 OCLC 管理成員館聯盟」迄2021年已成立15年,現由本館擔任召集館。為使成員館瞭解 OCLC 與
Web of Science Core Collection(簡稱 WOS)為引用文獻索引資料庫,可同時檢索 Science Citation Index Expanded(簡稱 SCIE,即通稱的 SCI)、 Social Sciences Citation
典藏服務組張端桂編審及系統資訊組蔡玉紋組員參加土耳其柯克大學(Koç University)舉辦之 Istanbul International Library Staff Week
[r]
非採用國圖系統建檔之學校,若欲隱藏中英文摘要
博物館是一座城市歷史與文化的縮影,也是認識一座
巡迴於全國各縣市公共圖書館展示,巡展內容包括書展、海報等,從豐富的展品 及展書中呈現各國文化內涵,至今已巡展全臺超過 100 所公共圖書館,廣受各巡 展館好評,並於
