國 立 交 通 大 學
工業工程與管理學系
碩 士 論 文
以共同權重設置群體之績效評量模式
Collective Performance Evaluation Using
Centroid Transformative Effectiveness
研 究 生:林劭儒
指導教授:劉復華 教授
以共同權重設置群體之績效評量模式
Collective Performance Evaluation Using
Centroid Transformative Effectiveness
研 究 生:林劭儒
Student:Shou-Ju Lin
指導教授:劉復華 博士
Advisor:Fuh-Hwa F. Liu, Ph.D.
國 立 交 通 大 學
工 業 工 程 與 管 理 學 系
碩 士 論 文
A Thesis
Submitted to Department of Industrial Engineering and Management
College of Management
National Chiao Tung University
in Partial Fulfillment of the Requirements
for the Degree of
Master of Engineering
in
Industrial Engineering and Management
July 2008
Hsinchu, Taiwan, Republic of China
以共同權重設置群體之績效評量模式
學生:林劭儒 指導教授:劉復華 教授
國立交通大學工業工程與管理系碩士班
摘 要
在多指標的評量問題下,高階經理人或者是分析人員想了解的已經不僅只是每個受 評單位的表現差異跟排序,他們還想知道群體所呈現出的表現為何。本篇文章意在提出 一非線性規劃模式,將指標分為自變指標與依變指標兩類,並帶入質心的概念,採用一 組共同的權重去評量受評單位所呈現的總體表現,並以在台灣股市中選擇投資標的為例, 說明如何利用我們提出的質心轉換效益模式,去比較受評單位間的差異。 關鍵字:共同權重、群體表現、資料包絡分析法、排序、股票選擇。ii
Collective Performance Evaluation Using
Centroid Transformative Effectiveness
Student: Shou-Ju Lin Advisor: Fuh-Hwa F. Liu, Ph.D.
Department of Industrial Engineering and Management
National Chiao Tung University
Hsin Chu, Taiwan, Republic of China
Abstract
In multi-indices evaluation problems, executive managers or analysts want to know not only the difference and ranking about every unit of assessment but the collective performance of the whole group consists of each unit. The aim of this article is proposing a nonlinear programming model which we put centroid concept in and with two kinds of index: independence and dependence. Furthermore, we set a common set of weights to evaluate the collective performance. Finally we take an example about selecting investment target in Taiwan stock market to illustrate how to realize the collective performance and the difference and ranking about units of assessment.
Keywords: Common Weights, Collective Performance, Data Envelopment Analysis, Ranking,
致謝
這一篇論文能夠順利完成,首先要感謝我的指導老師-劉復華教授。在老師細心地 指導下,完成了本篇論文,並除了與本篇論文相關的知識外,這段期間內劉老師也指導 我寫作方面的問題,這些寶貴的意見使得論文能夠順利付梓,一切都需感謝老師對於我 的指導跟栽培。再來要感謝我的口詴委員葉忠教授與賴慶祥教授,葉老師在口詴時對於 我的指導,讓我了解了很多實務上的觀念與理論在應用上的注意事項;而賴老師更讓我 發現本論文主題可以在理論上更深入探討的地方,這對我有很大的幫助,讓我學習到在 做研究上的嚴謹態度。 而研究室的同學、學長姐與學弟妹們在這段時間給予了很多的協助,帄日彼此的討 論補足了我許多思考不周之處。最後要感謝我的父母以及家人,在這段時間對我的支持 跟關心,讓我能專心完成學業。還有很多曾經幫助過我的朋友,因為有大家的幫助,我 才能有今天的成果。 另外本研究也得國科會研究計畫 95-2221-E-009-142、96-2221-E-009-164 的經費補 助,在此一併感謝。 林劭儒 謹致於 國立交通大學工業工程與管理學系 中華民國九十七年七月iv
目錄
摘 要 ... i Abstract ... ii 致謝 ... iii 目錄 ... iv 表目錄 ... vi 圖目錄 ... viii 第一章 簡介 ... 1 第二章 文獻回顧 ... 3 第一節 股票評價文獻 ... 3 第二節 資料包絡分析法文獻 ... 3 第三節 共同權重分析文獻 ... 5 第三章 質心轉換效益模式 ... 7 第一節 模式推導的第一階段 ... 8 第二節 模式推導的第二階段 ... 10 第三節 模式推導的最後階段 ... 11 第四節 𝜀值的討論 ... 13 第五節 CTE 與 MCWA 的比較 ... 14 第六節 曖昧數據的討論 ... 16 第四章 以數據為例 ... 18 第五章 結論 ... 24 參考文獻 ... 25附錄 A ... 27 附錄 B ... 37 附錄 C ... 39
vi
表目錄
表 1CTE 與 MCWA 比較的數據 ... 14 表 2 比較的數據 MCWA 的計算結果 ... 15 表 3 比較的數據 CTE 的計算結果 ... 15 表 4 曖昧性數據 ... 16 表 5 曖昧性數據的計算結果 ... 17 表 6 以 W.E.Buffett 之投資策略選出的初選個股在各項指標的表現 ... 21 表 7 以 W.E.Buffett 之投資策略選出的初選個股經 CTE 模式運算後的結果 ... 22 表 8 精選個股在各策略中的排名 ... 22 表 9 精選個股之 score/θ 值的總和 ... 23 表 10 測詴的第一組數據 ... 27 表 11 第一組數據的測詴結果 ... 27 表 12 測詴的第二組數據 ... 28 表 13 第二組數據的測詴結果 ... 28 表 14 測詴的第三組數據 ... 28 表 15 第三組數據的測詴結果 ... 29 表 16 測詴的第四組數據 ... 29 表 17 第四組數據的測詴結果 ... 30 表 18 測詴的第五組數據 ... 30 表 19 第五組數據的測詴結果 ... 31 表 20 測詴的第六組數據 ... 31 表 21 第六組數據的測詴結果 ... 32 表 22 測詴的第七組數據 ... 32 表 23 第七組數據的測詴結果 ... 33 表 24 測詴的第八組數據 ... 33表 25 第八組數據的測詴結果 ... 34 表 26 測詴的第九組數據 ... 34 表 27 第九組數據的測詴結果 ... 35 表 28 測詴的第十組數據 ... 35 表 29 第十組數據的測詴結果 ... 36 表 30 曖昧數據第一對照組 ... 37 表 31 曖昧數據第一對照組計算結果 ... 37 表 32 曖昧數據第二對照組 ... 38 表 33 曖昧數據第二對照組計算結果 ... 38 表 34 以 B.Graham 之投資策略選出的初選個股經 CTE 模式運算後的結果 ... 39 表 35 以 P.Lynch 之投資策略選出的初選個股經 CTE 模式運算後的結果 ... 40 表 36 以 M.Murphy 之投資策略選出的初選個股經 CTE 模式運算後的結果 ... 41 表 37 以 M.Price 之投資策略選出的初選個股經 CTE 模式運算後的結果 ... 41 表 38 以 M.Sivy 之投資策略選出的初選個股經 CTE 模式運算後的結果 ... 42 表 39 以 M.L.Yockey 之投資策略選出的初選個股經 CTE 模式運算後的結果... 44
viii
圖目錄
圖 1UOAj與上方基準線間落差及以斜率為其分數之說明 ... 9 圖 2UOAj與下方基準線間落差之說明 ... 10 圖 3UOAj與總體效益基準線間落差及以斜率為其分數之說明 ... 13 圖 4 以帄面座標呈現曖昧性數據兩項望小指標值 ... 16第一章 簡介
本篇論文提出一新的選擇股票為投資標的程序。 首先我們利用現今市場上有名的七位投資大師的選股策略作為第一階段,在台灣的 上市櫃公司中篩選出符合該策略的初選個股群。在第二階段對於每一初選個股群,利用 我們新建構的非線性數學規劃模式評定出該初選個股群的綜合效益,並依據綜合效益將 該初選個股群內的每檔個股加以排序。於後在第三階段將在七種策略中重複出現三次以 上的精選個股挑出,比較其差異後挑選出建議的投資標的。在第一階段中我們選出的七位投資大師分別為:W. E. Buffett、B. Graham、P. Lynch、 M. Murphy、M. Price、M. Sivy 跟 M. L. Yockey,囊括了成長型、價值型、保孚型、風險 型等等各種不同的策略,各項策略包含不同的篩選指標,各策略篩選的指標不盡相同, 像是:每股盈餘(Earnings per share, EPS)、股東權益報酬率(Return on equity, ROE)、現金 股利、本益比等等。投資者可依照自己的偏好設定各種參數,以之適合自己的投資取向, 我們根據這些不同的指標篩選出七組不同的初選個群。 在第二階段,我們進一步去了解該初選個股群中個股間的差異。在非線性的數學規 劃模式中,指標分為兩類,分別是其值越大越好的望大類(Y 類),如 ROE,以及其值越 小越好的望小類(X 類),如本益比。此數學模式可計算出各項指標的權重,以該組權重 求出該群中個股的分數以及該初選個股群的綜合效益。各個股的分數與該群的綜合效益 有一落差(gap),該數學規劃的目標為以落差求得總變異程度為最小,意即在尋求一組最 適的權重來表示該群的綜合效益,再以此權重來進行個股分數的評比及排序,量測出個 股相對的表現差異。 而第三階段,我們整合了各項策略,在七個不同的策略中,將在初選後重複三次以 上的個股挑出,選出了綜合各個策略的精選個股。計算精選個股中每一個股在其各股群 中的分數與該各股群綜合效益的比值,利用此一比值,呈現出每一檔精選個股與個股群 的相對表現,並將該比值的總和做為選擇投資標的的參考。 在第二章中首先回顧了第一類有關選擇股票為投資標的的若干文章,介紹此類問題
2
的 演 變 。 第 二 類 回 顧 的 文 獻 為 在 績 效 評 量 領 域 中 著 名 的 資 料 包 絡 分 析 法 (Data Envelopment Analysis, DEA),以及在 DEA 中關於總體績效的討論。第三類的文獻則為 以共同權重的概念為核心的共同權重分析法(Common Weights Analysis, CWA)。第三章說 明了本研究所建構的非線性規劃模式的原理。第四章為實例運算,以台灣股市上市櫃公 司近五年的財務數據為例,從基本面出發評選個股,期望找出一綜合性的投資標的建議。 最後第五章對本研究的貢獻與未來的研究方向做了總結。
第二章 文獻回顧
本章較詳細地回顧了與本篇研究相關的幾篇績效評量文獻,這些文獻是本篇文章的 基本背景所在。第一部分為股票評價的相關文獻,第二部分回顧了用於多指標評量問題 的資料包絡分析法及其討論到關於總體績效的文章,最後第三部分是共同權重分析類文 獻的回顧。 第一節 股票評價文獻就選股策略來說,Basu (1977) 表示本益比(price-to-earnings ratio, P/E)為一般常用的 指標,本益比低表示市場價格低、每股盈餘高,這樣子類型的股票顯示出其被市場所低 估;反之若本益比高,通常顯示出該檔股票被市場所高估。選擇本益比低的股票買入, 同時放空本益比高的股票以降低風險,以獲取在本益比調整時的價差利潤,Morse and Beaver (1978) 也認為本益比是進行股票評價的基本準則。於後 Basu (1983)、Frankel and Lee (1998)說明本益比與市場效率的關係,並探討了本益比與報酬率之間的關聯。 相關的應用也隨之衍生而出,王慶昌 (1992)透過財務報表的分析,探討股票報酬率 及本益比等公司因素,並觀察本益比跟股票報酬率之間,是否存在本益比效果。Fairfield (1994)以本益比及股價淨值比(price-to-book-value ratio, P/B)去預估未來獲利能力的折現, 本益比與未來盈餘成長有關,而股價淨值比與帳面價值的報酬有關。陳怡倫 (1996)則利 用現金流量折現、會計盈餘折現、異常盈餘折現、本益比、股價淨值比、股價營收比跟 選擇權定價七種模型,對台灣九家科技上市公司的股價進行評價。 第二節 資料包絡分析法文獻
Charnes et al. (1978) 提出以資料包絡分析法的 CCR 模式評比 n 個 DMU 的績效情形。 CCR 模式將評量指標分為 m 個望小的投入項以及 s 個望大的產出項,而對於第 j 個 DMU
投入與產出的測量值以(x1j, x2j ,…, xmj) 和 (y1j, y2j,…, ysj)表示。對於各項投入及產出分別
4 讓自己的績效為最高,主角 DMUO的績效值由權重過後的總產出投入比例去計算。CCR 模式在固定規模報酬的假設下將 DMU 分成高效及低效兩類,但這同時也是 DEA 有所 不足的地方,因為效率值是相對的,所以並沒有一個客觀的準則去判別所有的 DMU 的 優劣順序。而其數學規劃模式如下所示: . , , 1 , 0 , , , 1 , 0 , , , 1 , 1 . . max 1 1 1 1 m i v s r u n j v x u y t s v x u y I i io O r ro m i io ij s r ro rj m i io io s r ro ro o
傳統 DEA 中,DMU 的改善參考程度均以該 DMU 的投影點為目標,而 Thanassoulis and Dyson (1992) 為 DEA 帶入目標規劃(goal programming, GP)的概念,希望為每一個 DMU 找出最佳的改善目標;由此出發,Athanassopoulos (1995) 將總體績效的概念置入 這類討論 DMU 改善程度的資源配置問題中,考量了決策者(decision maker, DM)的觀點, 在期望總體績效為最佳的情形下,各 DMU 應如何調配資源以達到總體績效最高的目標, 而 DMU 的改善方式也與傳統有所不同,並不限制投入不增加或產出不減少。換而言之, DMU 可以以更自由的方式去調整自己的現有資源,同時增加或減少不同項目的投入及 產出來呈現高效的方式變得可能,並且在模式中加入了改善成本的考量。
相較於傳統 DEA 探討群組內差異的觀點,Lozano et al. (2004) 在資源配置的問題上, 討 論 了 關 於 組 織 的 整 體 績 效 問 題 , 模 式 為 放 射 型 集 中 資 源 配 置 模 式 (radial-based centralized resource allocation model)的兩階段方法。第一階段期望讓所有 DMU 的績效值 為最佳,也就是讓總體的績效最大;在總體績效為最大的情形下,在第二階段進一步求 出每項指標的缺額,用缺額的觀點去調整 DMU 應有的資源配置。同時也加入了 Thanassoulis and Dyson (1992) 提出關於改善的偏好考量。
第三節 共同權重分析文獻
為了改善 DEA 無法對 DMU 進行排序的問題,Liu and Peng (2008) 提出以共同權重 分析(Common Weight Analysis,CWA)的概念去評量所有的 DMU。不再讓每個 DMU 自 行決定每項指標的權重,而是利用規劃模式去求得單一權重,因此為了區別,將 DEA 中的決策單元改稱之為受評單位(Units of Assessment, UOA)。由此,利用績效值就能夠
輕易地對 UOAs 進行排序。投入及產出項的共同權重以 Ur及 Vi表示,ΔO及ΔI分別表
示 UOAj權重後的總產出與投入與等比例的評量基準之間的差距。CWA 希望 UOA 與評
量基準之間的總差距越小越好,換言之,CWA 在 UOA 彼此間差距不大的條件下,依然 可以做出有效的排序。而其規劃模式如下:
. , , 1 , 0 V , , , 1 , 0 U , n , , 1 , 0 , , n , , 1 , 1 . . min 1 1 n 1 j m i s r j j V x U y t s I i i O r r I j O j I j m i i ij O j s r r rj I j O j
Liu and Peng (2008)所提出的程序為先以 DEA 中的 BCC 模式將 UOA 分為高效及低 效兩群,再為所有的 UOA 找出一組最折衷的指標權重並進行排序。將此”絕對的”效率 基準設為一,而使用這組最折衷的權重所算出來的絕對績效值則可能高於基準線、等於 基準線或低於基準線,同時這些效率值將會跟基準線產生最小的總落差。其規劃模式如 下:
. , free , , , , 1 , 0 , , , 1 , 0 , , 1 . . | | | | min 1 1 E j m i V s r U E j V x U y t s I j O j i r I j m i i ij O j s r r rj E j I j O j
6
本篇研究以 Charnes et al. (1978) 提出的 DEA-CCR 模式出發,去討論多指標的評量 問題,並引入了 Liu and Peng (2008) 所談到共同權重的概念,希望能有一相同的評量去 評量受評單位,再者希望由 Athanassopoulos (1995)、Lozano et al. (2004) 談及總體績效 最高的觀點延伸出去,直接探討群體的整體表現狀況,並以在股票市場中挑選投資標的 為例,闡述我們建構的非線性數學規劃模式。
第三章 質心轉換效益模式
本章介紹了衡量受評單位總體效益的非線性數學規劃模式,並在本章最後比較本模 式最折衷權重分析(Most Compromise Weight Analysis, MCWA)的差異。在傳統的績效評 量領域中,研究者研究的重點在於為管理者設計一套合理的方法,來判別出受評單位屬 於高效或是低效。但隨著環境日益複雜,除了組內的差異之外,如何同時呈現出該組的 整體效益成為日益重要的問題,為此我們設計了一個規劃模式,帶入了數學中質心的概 念,來呈現出該群組的整體效益。
在質心轉換效益(Centroid Transformative Effectiveness, CTE)的規劃模式中,假設一
組織中有 n 個受評單位(Unit of Assessment, UOA),j 表示其序列,即 UOAj,j=1, 2, …, n。
其表現以 m+s 個計量的指標為評量基準,其中 m 項指標的值愈小,則該單位的表現愈 好,此類指標亦稱為望小指標,並以 i 表示其序列,即 i=1, 2, …, m;另外 s 項指標的值 愈大,則該單位的表現愈好,此類指標亦稱為望大指標,並以 r 表示其序列,即 r=1, 2, …, s,其餘符號定義如下: ij x :UOAj第 i 項望小指標的數據。 rj y :UOAj第 r 項望大指標的數據。 i :第 i 項望小指標對應的權重。 r :第 r 項望大指標對應的權重。 :n 個 UOA 的綜合效益值。 I j :UOAj在望小方向上與綜合效益線的直線距離。 D j :UOAj在望大方向上與綜合效益線的直線距離。 由於在計算綜合效益跟分數時,望小及望大這兩類指標之間具有類似迴歸的轉換意 涵,因此 I j 、 D j 兩項中的 I、D 分別代表自變項指標(Independence)及依變項指標 (Dependence),於後在本文中自變指標即表示望小指標,依變指標即表示望大指標。
8 在共同權重的設定下,我們用下方(1)式來計算每個 UOAj的分數(score)j: , ..., , 1 , 1 1 n j x y j m i i ij s r r rj
(1) 望大與望小指標的意義在此分數計算式展露無遺:當望小的 X 類指標值(xij, i=1, 2, …, m)愈小時,UOAj的分數j會愈大;當望大的 Y 類指標值(yrj, r=1, 2, …, s)愈大時, UOAj的分數j會愈大。 第一節 模式推導的第一階段 將分數的概念轉換為限制式,並加入綜合效益的考量後,規劃模式可以被寫成: [M1] Min M (1.0) s.t. , ..., , 1 , 1 1 n j x y I j m i i ij D j s r r rj
(1.1) , ) ( 1
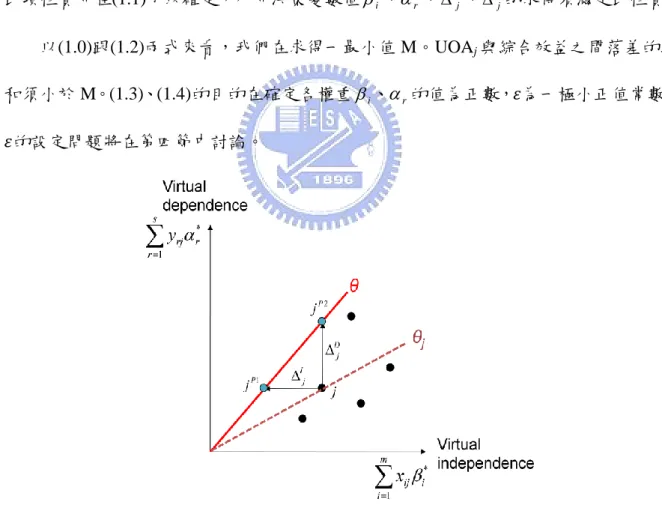
n j I j D j M (1.2) , ..., , 1 , 0 r s r (1.3) , ..., , 1 , 0 i m i (1.4) , 0 (1.5) . ..., , 1 , 0 , Ij j n D j (1.6) 如由原點與各 UOA 的落點連一直線,該線的斜率即為其分數值j,如圖 1 所示。 同時,若得知綜合效益,則通過原點且斜率為的直線即為圖 1 中所表示的基準線。 此時可以發現所呈的斜率高於其他 UOA 的斜率j。將各 UOA 的望小類指標值xij與其權重i相乘後加總可得到一虛擬的自變值 (Virtual independence),即
m i i ij x 1 ;相同的,將 UOAj的望大類指標值yrj與其權重r相 乘後加總可得到一虛擬的依變值(Virtual dependence),即
s r r rj y 1 。此時具有 m+s 項指標 的多指標問題被簡單地轉化至僅含兩項自變值與依變值。圖 1 中各 UOA 的落點位置座 標及為其自變值與依變值。UOAj的虛擬自變值
m i i ij x 1 扣除 I j ,或虛擬依變值
s r r rj y 1 加上 D j 均可投影在綜合效益的基準線上,分別是𝑗𝑃1及𝑗𝑃2。由此可知 I j 及 D j 分別表示UOAj的位置點與基準線間,在水帄方向(Independence)及垂直方向(Dependence)的 gap。
此項性質即在(1.1)予以確定,亦即決策變數值i、r、 I j 、 D j 的求得頇滿足此性質。 以(1.0)跟(1.2)兩式來看,我們在求得一最小值 M。UOAj與綜合效益之間落差的總 和頇小於 M。(1.3)、(1.4)的目的在確定各權重i、r的值為正數,𝜀為一極小正值常數, 𝜀的設定問題將在第四節中討論。 圖 1 UOAj與上方基準線間落差及以斜率為其分數之說明
10 第二節 模式推導的第二階段 從另一方面來看,若將 UOAj的虛擬自變值
m i i ij x 1 加上 I j ,虛擬依變值
s r r rj y 1 扣 除 D j 也可投影在綜合效益的基準線,換言之,若將(1.1)改為下方(1.7)式,此時各 UOA 的分數均會大於綜合效益值
。 , ,..., 1 , 1 1 n j x y I j m i i ij D j s r r rj
(1.7) 綜合效益的基準線位於各 UOA 的分數值之下。將各 UOA 的望小類指標值與其權 重相乘後加總得到虛擬的自變值
m i i ij x 1 ;相同的,將 UOAj 的望大類指標值與其權重 相乘後加總得到虛擬的依變值
s r r rj y 1 。UOAj的虛擬自變值
m i i ij x 1 加上 I j ,或虛擬依 變值
s r r rj y 1 扣除 D j 均可投影在綜合效益的基準線上,分別是𝑗𝑃1及𝑗𝑃2。由此可知 I j 及 D j 分別表示 UOAj 的位置點與綜合效益間,在水帄方向(Independence)及垂直方向 (Dependence)的 gap。此項性質即在(2.1)予以確定,亦即決策變數值i、r、 I j 、 D j 的 求得頇滿足此性質。可由圖 2 表示: 圖 2 UOAj與下方基準線間落差之說明 綜合以上兩種情況,並帶入質心的概念,我們不再限定 D j 、 I j 必頇為正值,由於(2.6)的條件,使得 UOAj 可以採取不同的方式投影至總體效益線上,模式會自行決定 UOAj的投影方向,換句話說模式會自行決定計算的結果,而結果可能為圖 1 或圖 2。 而將(1.6)改為(2.6),其餘在[M1]中的限制不變,則[M2]可以表示為: [M2] Min M (2.0) s.t. , ..., , 1 , 1 1 n j x y I j m i i ij D j s r r rj
(2.1) , ) ( 1
n j I j D j M (2.2) , ..., , 1 , 0 r s r (2.3) , ..., , 1 , 0 i m i (2.4) , 0
(2.5) . ..., , 1 free, are , I j n j D j (2.6) 第三節 模式推導的最後階段 從[M2]中的(2.2)跟(2.6)會發現到有 D j 跟 I j 正負互相抵銷的情形。為了計算上的方 便且帶入質心的概念,我們將 D j 、 I j 作變數轉換: D j = Da j - Db j (3) I j = Ia j - Ib j (4) 設定 , , ,Ib 0 j Ia j Db j Da j ,得出(3)、(4), Da j 、 Ia j 即為圖 2 中的落差; Db j 、 Ib j 即 為圖 1 中的落差,並將之代入[M2]中可得[M3],最後的 CTE 模式就可以寫成:12 [M3] Min M (3.0) s.t.
, 1 ,..., , 1 1 j n x y Ia j Ib j m i i ij Db j Da j s r r rj
(3.1)
, 1
n j Ia j Da j M (3.2)
n j Ib j Db j M 1 , (3.3) , ..., , 1 , 0 r s r (3.4) , ..., , 1 , 0 i m i (3.5) , 0
(3.6) . ..., , 1 , 0 , , , Ibj j n Ia j Db j Da j (3.7) 此時 CTE 模式的概念可以由圖 3 表示。本模式希望測量出望小指標與望大指標之 間轉換的綜合效益值,對於群體而言該綜合效益是固定的。UOAj 的分數與綜合效益之間的落差以 gap 表示,在模式中會選出最小的 gap 總和,並且決定 gap 在自變或依變的
方向,(3.0)及(3.1)即為此意;(3.2)、(3.3)表示 UOAj在 CTE 線上方與下方的 gap 總和值
必頇相等,而由於 gap 總和表示變異的程度,因此我們希望能以在變異程度最小的情況 下,以最集中的方式來呈現出該受評群的綜合效益;(3.4)、(3.5)同樣設定了權重必頇為 正值;(3.6)跟(3.7)是非負限制式。
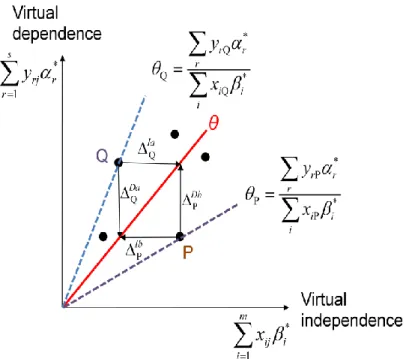
圖 3 UOAj與總體效益基準線間落差及以斜率為其分數之說明
圖 3 簡單表示了質心的概念,若以 Virtual independence 為橫軸、Virtual dependence 為縱軸,可以將每個 UOA 描於圖上,每個 UOA 跟原點所連成直線的斜率就表示該 UOA
的分數。每個 UOA 與綜合效益的落差就用不同的值表示,綜合效益線上/線下的值
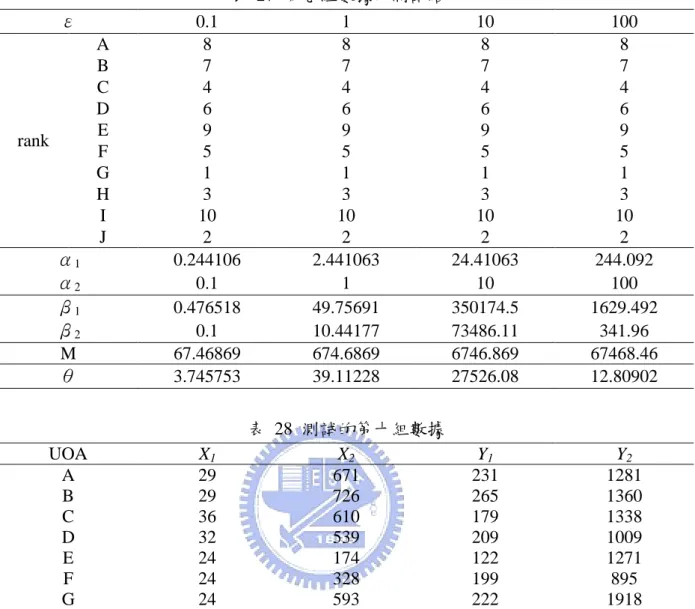
總和越小表示每個點靠得越緊密。再者除了希望變異程度最小之外,最小化 gap 的總和 也能呈現出即使在 UOA 彼此間差異不大,CTE 模式也能分辨出每個 UOA 之間分數的 細微差距,如此一來就能輕鬆地對於 UOA 進行排序的動作,也能同時得知該群體的綜 合效益。而在實際的運算操作上,我們使用了 LINGO 10 做為運算數據的工具。 第四節 𝜺值的討論 在兩權重的限制式當中:r 0, r1 ,...,s.及i 0, i1,...,m.,我們設定 了權重必頇大於零,然而此限制在實際的運算上有困難。在運算的過程中,我們勢必必 頇設定𝜀的值,但是又該如何設定呢?在多次的運算後,我們發現當𝜀變動時,CTE 模式 取出的權重i、r也不盡相同。根據(1)式,因此各 UOA 的分數j也可能會隨之變動, 但就算分數會跟隨著𝜀而變,UOA 的排序卻幾乎並沒有隨之改變。而經過運算多組不同 數據的測詴後,儘管我們無法在數學上證明「在分數會變動的情形下,確保排序不變」,
14 為了方便計算,我們在實際的運算操作上採用了𝜀=1 的設定方式,求出未臻完美但可以 接受的運算結果。用以測詴的 10 組數據置於附錄 A 中,而 10 組數據中,只有兩組(No. 5、7)的部分排名有些微的變化:第 5 組數據為 UOAA跟 UOAF排序互換(2、4 名互換), 第 7 組數據為 UOAF與 UOAH互換(9、10 名互換)。 第五節 CTE 與 MCWA 的比較
CTE 模式捨棄了在 DEA 與 CWA 中高低效的概念,改以分數的型態呈現受評單位 的表現;換句話說,CTE 模式解除了高效=1 的績效表現方式,如此一來,使得模式更
能自動調整值的大小,讓整體的變異程度大大地降低,同時更準確地描述出資料的集
中情形。而 MCWA 由 CWA 延伸而來,與 CTE 模式相同無高低效之分,而 CTE 模式較 MCWA 優秀的部份在於其模式能自由決定綜合效益,而 MCWA 則將其相對參考分數設 訂為 1,因此 CTE 的變異程度能較 MCWA 小。下方表 1 用 MCWA 中的數據為例,將 數據分別以 MCWA 及 CTE 模式進行運算,並將運算的結果置於表 2 及表 3。其中表 2 中的 Ivirtual、Ovirtual 分別表示
m i i ijV x 1 跟
s r r rjU y 1 ,表 3 中的 Ivirtual、Dvirtual 分別表 示
m i i ij x 1 跟
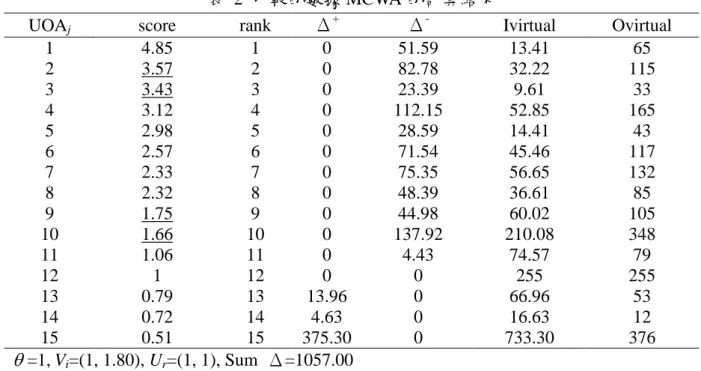
s r r rj y 1 。 表 1CTE 與 MCWA 比較的數據 UOAj X1 X2 Y1 Y2 1 8 3 20 45 2 25 4 63 52 3 6 2 2 31 4 33 11 66 99 5 9 3 40 3 6 22 13 95 22 7 35 12 88 44 8 33 2 33 52 9 51 5 94 11 10 100 61 15 333 11 6 38 30 49 12 15 133 223 32 13 2 36 52 1 14 4 7 9 3 15 553 111 55 321表 2 比較的數據 MCWA 的計算結果
UOAj score rank Δ+ Δ- Ivirtual Ovirtual
1 4.85 1 0 51.59 13.41 65 2 3.57 2 0 82.78 32.22 115 3 3.43 3 0 23.39 9.61 33 4 3.12 4 0 112.15 52.85 165 5 2.98 5 0 28.59 14.41 43 6 2.57 6 0 71.54 45.46 117 7 2.33 7 0 75.35 56.65 132 8 2.32 8 0 48.39 36.61 85 9 1.75 9 0 44.98 60.02 105 10 1.66 10 0 137.92 210.08 348 11 1.06 11 0 4.43 74.57 79 12 1 12 0 0 255 255 13 0.79 13 13.96 0 66.96 53 14 0.72 14 4.63 0 16.63 12 15 0.51 15 375.30 0 733.30 376 =1,Vi=(1, 1.80), Ur=(1, 1), Sum Δ=1057.00 表 3 比較的數據 CTE 的計算結果
UOAj score score/θ rank Ivirtual Dvirtual ΔIa ΔIb ΔDa ΔDb
1 5.91 3.44 1 11 65 41.73 0 0 0 3 4.12 2.40 2 8 33 21.15 0 0 0 2 3.97 2.31 3 29 115 52.75 0 0 0 4 3.75 2.18 4 44 165 63.31 0 0 0 5 3.58 2.08 5 12 43 22.96 0 0 0 6 3.34 1.94 6 35 117 42.91 0 0 0 7 2.81 1.63 7 47 132 39.61 0 0 0 8 2.43 1.41 8 35 85 24.33 0 0 0 10 2.16 1.26 9 161 348 50.98 0 0 0 9 1.87 1.09 10 56 105 14.94 0 0 0 11 1.8 1.05 11 44 79 11.85 0 0 0 12 1.72 1 12 148 255 0 0 0 0 13 1.39 0.81 13 38 53 0 7.24 0 0 14 1.09 0.63 14 11 12 0 4.04 0 0 15 0.58 0.34 15 644 376 0 375.23 0 0 M=373.85, =1.72, βi=(1, 1), αr=(1, 1), Sum Δ=773.02 從表 2 及表 3 的最後一列看出 773.02<1057.00,可以得出 CTE 模式確實更能準確 的描述出資料的集中趨勢。 在表 3 當中可以發現ΔDa及ΔDb 項均為零,這是因為此時值為 1.72>1,在 >1 時,由於 UOA 在圖 3 中水帄自變方向的投影永遠會比垂直依變方向的投影量小,所以 模式會選擇水帄自變方向的投影,也就是ΔIa或ΔIb,而讓垂直方向的投影量ΔDa及ΔDb 項均為零。反之若當<1 時,模式便會選擇垂直依變方向上的投影量ΔDa 及ΔDb,而
16 ΔIa及ΔIb會均為零。 第六節 曖昧數據的討論 對於含有曖昧性的特殊數據,我們也一併做了討論。 若一組數據在不同指標間隱含 trade off 的概念,且其不同指標值具有對稱性,那麼 就可能產生多重解的問題,如表 4 所示。 表 4 曖昧性數據 UOAj X1 X2 Y1 A 29.29 29.29 1 B 100 0 1 C 170.71 29.29 1 D 200 100 1 E 170.71 170.71 1 F 100 200 1 G 29.29 170.71 1 H 0 100 1 表 4 的數據在兩項望小指標值呈現了曖昧性,8 個 UOA 中此兩項指標值是由帄面 座標中的一圓上取出,如圖 4 所示。此圓的圓心座標為(100, 100)且半徑為 100,8 個 UOA 的望小指標為均勻分布在圓上且將圓均分為八等份的點,且令望大指標值均為 1。 圖 4 以帄面座標呈現曖昧性數據兩項望小指標值 由於數據有對稱關係的曖昧性,因此模式可能會產生多重解。多重解會產生出多組 不同的權重,而不同的權重又會產生不同的分數跟排序,且分數與排序會產生對稱性, 令我們無法判斷究竟哪組權重才適合。
不過利用 LINGO 10 運算的結果並不會有我們所擔心的狀況產生,而運算結果如表 5 所示:
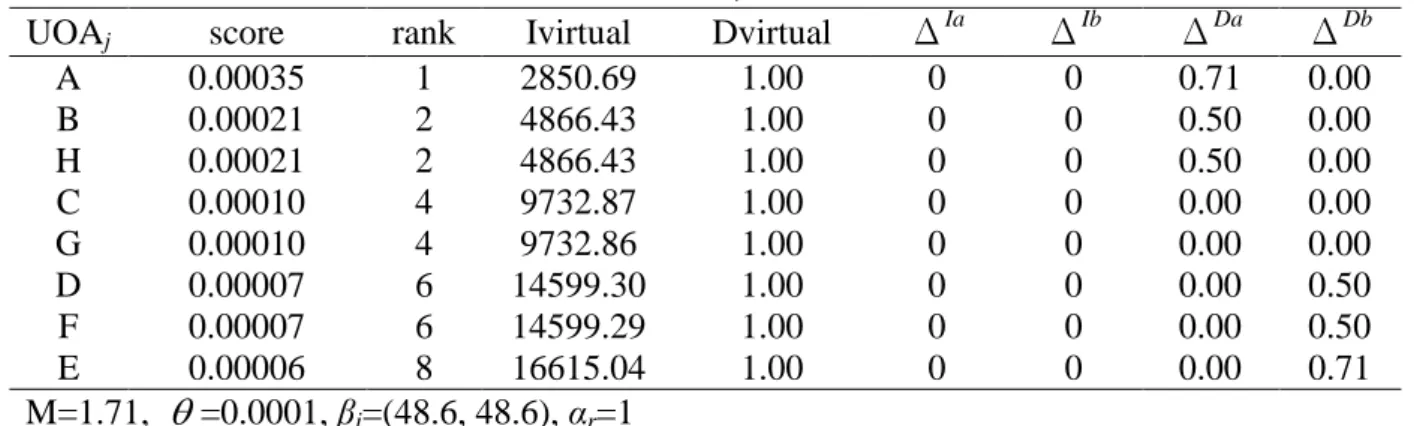
表 5 曖昧性數據的計算結果
UOAj score rank Ivirtual Dvirtual ΔIa ΔIb ΔDa ΔDb
A 0.00035 1 2850.69 1.00 0 0 0.71 0.00 B 0.00021 2 4866.43 1.00 0 0 0.50 0.00 H 0.00021 2 4866.43 1.00 0 0 0.50 0.00 C 0.00010 4 9732.87 1.00 0 0 0.00 0.00 G 0.00010 4 9732.86 1.00 0 0 0.00 0.00 D 0.00007 6 14599.30 1.00 0 0 0.00 0.50 F 0.00007 6 14599.29 1.00 0 0 0.00 0.50 E 0.00006 8 16615.04 1.00 0 0 0.00 0.71 M=1.71, =0.0001, βi=(48.6, 48.6), αr=1
由表 5 中的 score 及 rank 欄我們可以看到確實計算呈現對稱結果。而此結果將 UOAA
放在表現最好的第一位,而將 UOAE放在表現最差的最後第八位,重要的是,此結果與 原始數據相呼應。在原始數據的兩項望小指標中,以座標的觀點來看,A 為最靠近座標 原點的點,換而言之,其兩項望小指標值在 8 個 UOA 當中表現最佳,而相對的 E 為最 遠離座標原點的點,兩項望小的指標值為最大表現最差,經 LINGO 10 計算的結果與原 始數據的分布結果相符合,愈靠近原點的表現愈好,反之愈遠離原點的表現愈差。 用以對照的另外兩組數據置於附錄 B 中,其結論並無不同。
18
第四章 以數據為例
延續在第三章中建構的 CTE 模式,在本章中我們希望在台灣的股市中選擇出具有 潛力的投資標的,利用 CTE 可以排序及表現總體效益的特性,將其作為篩選投資標的 方法,作為 CTE 模式在實務上可應用的參考。 如何選擇投資標的本是大哉問,各家說法不一,所偏好的投資策略也不盡相同,因 此我們提出三階段的篩選機制。首先,我們博引各家之言,採取七位投資專家的觀點, 作為第一階段的篩選條件,篩選出初選個股群;之後再利用 CTE 模式就各投資策略對 每個初選個股群進行排序,此為第二階段。第三階段整合了不同的策略,提出一綜合性 的精選個股參考。為此,我們首先介紹七位投資專家不同的投資觀點,以及依據這些觀 點所設定的第一階段篩選條件。 在這些篩選條件中要特別說明的是,舉下方 W. E. Buffett 的第一項篩選條件為例: 近三年帄均股東權益報酬率>15%,15%的設置完全取決於投資者主觀所設定的閥界值。 隨著不同閥界值的設定,投資者篩選出的初選個股群其範圍也會有所差異。本篇論文在 各項篩選條件中所訂定的閥界值僅為參考用,並非一固定值。本篇論文下述各策略、篩 選條件及篩選條件的閥界值參考自太帄洋證券及群益金融網,上市櫃公司的財報資料則 來自台灣經濟新報資料庫。 1. W. E. Buffett Buffett 不理會每日股價的漲跌,不擔心總體經濟情勢的變化,並且以買下一間公司 的心態投資而並非投資該公司的股票。除了企業經營歷史及市場定位等難以量化的 指標之外,在公司財務方面的指標,他特別著重於股東權益報酬率,認為公司的股 東權益報酬率,若保持一定的高水準,亦代表公司的成長,因為股東權益會因公司 獲利的累積而逐年增加,股東權益報酬率若保持不變,則代表獲利有等幅的成長。 再者,尋找高毛利、具有創造現金能力並且價值被市場低估的公司。 篩選條件有六項: 近三年帄均股東權益報酬率>15% 近三年帄均毛利率>15% 近三年現金流量成長率>5% 近五年最小每股盈餘>1 本益比<20 價格淨值比<2 2. B. Graham Graham 在挑選適當的投資標的時,絕不跟著市場非理性的漲跌貣舞,只依照自己 的價值投資原則來選股。此一原則的假設是:理論上來說,股票的價格將合理反映 企業實際價值,因此在縝密的計算後,若發現某企業的股價低於實際價值便會買進。 此投資策略較為穩健保孚,只要股價回到企業的實際價值便出脫獲利,只要估算得 宜風險很低,不過獲利也侷限於實際價值與買進股價間的差距。 篩選的條件有七項: 近五年帄均淨利成長率>5% 近五年帄均營益率>5% 近四季帄均股東權益報酬率>5% 負債比<50% 流動比>150% 本益比<15 價格淨值比<1.5 3. P. Lynch Lynch 投資特色在於其利用已知的事實做投資,重點在於田野調查,投資偏好在成 長兼具價值,任何一種類股及產業,只要是好的公司,價格合理皆可能成為投資標 的,而不需判斷市場的時機。 篩選的條件有四項: 近兩年帄均營收成長率>25% 近五年帄均稅前淨利成長率>7%
20 負債比<30% 本益比<20 4. M. Murphy Murphy 選股主要以未來高成長的科技股為目標,除了先了解高科技產業的發展變 遷之外,原則是挑選專注於研發的公司,考量稅後盈餘跟研發費用才會真的買到真 正有創新能力及注重研發且高成長的公司,長期下來將獲利可期。 篩選的條件有四項: 近三年帄均營收成長率>20% 近三年帄均獲利率>15% 近三年帄均股東權益報酬率>15% 近三年帄均研發費用佔營收比率>5% 5. M. Price Price 喜愛複雜的交易,如併購、合併、破產、清算等可以利用超低價買進被市場 嚴重低估的資產,並注意股價重挫或爆出重大利空的個股,研究其實際價值是否已 與股價出現大幅差距,看準標的,評估可行後,後便採取大規模收購行動。由於收 購價值低估的企業,其投資規模必頇相當大,因此損益也通常十分可觀。他認為只 要做對下列三件事,價值投資即可成功:選擇股價低於資產價值,公司經營階層持 股越高越好,乾淨的資產負債表,負債愈少愈好的公司。 篩選的條件有三項: 股價淨值比<1.5 董監持股比率>40% 負債比<20% 6. M. Sivy Sivy 認為選股需注意 10 大重點,獨特的產品、穩定成長、領先業界、ROE>15、負 債低、有專利或專屬科技、著名品牌,本益比低、股價五年成長一倍。 篩選的條件有五項:
近五年帄均營收成長率>20% 近五年帄均淨利成長率>20% 近五年帄均股東權益報酬率>15% 負債比<60 本益比<20 7. M. L. Yockey Yockey 選股方法極為簡單,雖然他屬於成長型投資人,但認為太高的成長率無法持 久,以毛利及淨利成長的表現作為選股標準。 篩選的指標有三項: 近五年每年稅前淨利成長率>10% 近五年帄均稅前淨利成長率>10% 近四季合計毛利率>15% 以 W. E. Buffett 的投資策略當作我們提出的兩階段篩選步驟為例,該策略在第一階 段初選共篩選出了十檔個股,而這十檔個股在各評量指標中的表現如表 6 所示: 表 6 以 W. E. Buffett 之投資策略選出的初選個股在各項指標的表現 標的 股價淨值 比 本益比 近 5 年最 小 EPS 近 3 年帄 均 ROE 近 3 年帄 均 GP 近 3 年現 金流量成 長率 j X1j X2j Y1j Y2j Y3j Y4j 南亞 1.92 10.01 2.61 20.14 17.38 6.34 友訊 1.81 10.73 2.74 16.31 33.83 92.87 欣興 1.65 8.42 1.5 20.79 19.78 9.05 欣銓 1.48 8.31 1.78 19.29 40.69 28.45 嘉澤 1.9 12.79 1.4 16.83 24.72 547.82 三星 1.85 12.6 1.77 16.71 16.79 43.53 廣運 1.86 10.97 2.03 18.08 21.51 40.05 柏承 1.89 10.05 2.52 19.95 23.14 42.72 頎邦 1.75 10.37 2.13 18.42 25.9 16.02 寶成 1.8 11.37 1.97 17.01 20.4 16.32 為了分辨出個股的優劣程度,在第二階段,我們就利用 CTE 模式[M3]進行判別, 而運算結果如表 7 所示,其中的 score 表示θj。
22
表 7 以 W. E. Buffett 之投資策略選出的初選個股經 CTE 模式運算後的結果
UOAj score rank Ivirtual Dvirtual ΔIa ΔIb ΔDa ΔDb
欣銓 82.56 1 9.79 808.23 2.05 0 0 0 嘉澤 79.1 2 14.69 1162.04 2.33 0 0 0 友訊 78.41 3 12.54 983.31 1.87 0 0 0 柏承 76.38 4 11.94 911.94 1.42 0 0 0 南亞 73.4 5 11.93 875.64 0.9 0 0 0 欣興 68.26 6 10.07 687.34 0 0 0 0 頎邦 65.77 7 12.12 797.1 0 0.44 0 0 廣運 60.93 8 12.83 781.75 0 1.38 0 0 寶成 55.13 9 13.17 726.04 0 2.53 0 0 三星 48.33 10 14.45 698.31 0 4.22 0 0 M=8.57, =68.26, βi=(1, 1), αr=(188.75, 15.72, 3.45, 1) 其餘六個投資策略也如同上述步驟重複一遍,求出在該策略下,初選個股群中個股 的表現狀況,並將其餘策略的計算結果置於附錄 C。接著提供一綜合性的投資建議,我 們將在這七個策略中,重複出現三次以上的個股挑出為精選個股,如表 8 中所示(僅柏 騰重複出現四次),列出的也包含該個股在經第一階段初選後,每項策略中的排名。另 外因為 M. Price 所採用的策略較其他人不同,所以並無與其他人重複的個股名單。 表 8 精選個股在各策略中的排名
個股 Buffett Graham Lynch Murphy Price Sivy Yockey
柏騰 4/34 3/19 2/92 2/32 迎輝 14/34 7/19 1/92 聯發科 19/34 5/19 6/92 類比科 12/34 9/19 7/92 伍豐 13/34 8/92 15/32 欣銓 1/10 6/40 38/92 力致 16/34 19/92 16/32 飛捷 24/34 15/92 17/32 廣積 15/19 27/92 12/32 閎暉 29/34 31/92 30/32 久元 27/34 16/19 41/92 倚天 17/34 17/19 59/92 欣興 6/10 69/92 31/32 晶技 33/34 53/92 22/32 鈺創 22/40 71/92 27/32 將 Price 自表中移去後,利用 CTE 模式所求出的總體效益值θ,計算出分數與總體 效益之比值(score/θ)的總和來檢視所挑出的精選個股,將 score/θ的值與總體效益的 1 相比可呈現個股在該策略中的相對表現,以顯示出個股與總體效益之間的表現差異,差
異愈大表示個股的表現愈突出。此一結果列於表 9 中。 表 9 精選個股之 score/θ值的總和
個股 Buffett Graham Lynch Murphy Sivy Yockey 總和
柏騰 1.728 1.225 3.364 1.983 8.3 迎輝 0.986 1.116 4.687 6.79 聯發科 0.85 1.166 1.978 3.99 類比科 1.055 0.973 1.925 3.95 伍豐 1.002 1.837 0.937 3.78 欣銓 1.21 1.515 1.037 3.76 力致 0.877 1.435 0.917 3.23 飛捷 0.778 1.512 0.891 3.18 廣積 0.883 1.21 1 3.09 閎暉 0.618 1.176 0.95 2.74 久元 0.667 0.777 1.013 2.46 倚天 0.875 0.768 0.798 2.44 欣興 1 0.694 0.512 2.21 晶技 0.545 0.849 0.818 2.21 鈺創 0.932 0.674 0.704 2.31 由表 9,以總和為考量,柏騰有相當優異的表現,為推薦的投資標的。
24
第五章 結論
在古典的觀念中,我們關心的議題多以個體為主,或者是在群體的範疇下,個體的 行為表現為何,像 DEA 最初的發明就是考慮了望大跟望小的兩項指標,想要了解多指 標問題中各個 DMU 彼此的相對績效。但隨著系統日漸複雜地發展,個體活動表現的訊 息已經遠遠不足我們所需,因此像是經濟學、社會學等學說也應運而生,為的就是探討 整個系統的表現。本篇文章順此脈絡而下,提出一個非線性的共同權重評量模式,希望 了解在績效評量領域中,由各個 UOA 所組成的系統,其總體表現的狀況。為了測量具 有代表性的總體表現,我們利用了數學當中的質心概念,並且將 DEA 架構中指標望大 望小的特性,轉化為自變與依變指標之間彼此相互轉換的概念,依此提出了質心轉換效 益的評量模式。並以選擇台灣股市中的投資標的為例,展示 CTE 模式的運作方式,以 及管理者在比較 UOA 之間的差異時,如何利用總體效益的表現進行評比。 總體表現的議題仍有很多後續的研究機會,例如在討論本篇文章提到的投資標的之 選擇,其以單期的訊息來判定投資標的的表現可能過於片面,因此未來的研究可以加入 時間推移的考量因素,進而長期分析標的的發展趨勢是否如我們的預期。另一項題材尚 待後續研究來完成,即將(1.2)改為 Ij M, j 1,...,n. D j 時,則[M1]即形成 minimax 的目標式。此一新的模型在盡可能地降低 n 個 UOA 之間的最大變異數。此時所計算出 的總變異量應與[M1]所求出的不同,並排除了離群值(Outlier)的存在。 在今日數學規劃套件已經相當成熟的狀況下,求解像是 CTE 模式之類的非線性問 題已經不再困難,這也是為什麼我們將模式設成非線性的原因。我們希望用一個簡易的 數學規劃模式,去幫助管理者客觀地去了解某些綜合性的系統資訊,同時也能對於系統 中個體的表現差異,有一定程度的認知。參考文獻
Athanassopoulos, A. D. (1995). Goal programming & data envelopment analysis (GoDEA) for target-based multi-level planning: allocating central grants to the Greek local authorities. European Journal of Operational Research, 87, pp. 535-550.
Basu, S. (1977). Investment Performance of Common Stocks in Relation to Their Price-Earnings Ratios:A test of the Efficient Market Hypothesis. Journal of Finance, 32, pp. 663-682.
Basu, S. (1983). The Relationship between Earnings Yield,Market Value,and Return for NYSE common Stocks:Further Evidence. Journal of Financial Economics, 12, pp. 129-156.
Charnes, A., Cooper, W. W., & Rhodes, E. (1978). Measuring the efficiency of decision making units. European Journal of Operational Research, 2, pp. 429-444.
Cook, W. D., & Kress, M. (1990). A data envelopment model for aggregating preference rankings. Management Science, 36, pp. 1302-1310.
Cook, W. D., & Kress, M. (1994). A multiple-criteria composite index model for quantitative and qualitative data. European Journal of Operational Research, 78, pp. 367-379.
Fairfield, P. M. (1994). P/E, P/B and the present value of future dividends. Financial Analysts
Journal, 50 (4), pp. 23-31.
Frankel, R., & Lee, C. (1998). Accounting valuation, market expectation, and cross-sectional stock returns. JOURNAL OF ACCOUNTING & ECONOMICS, 25 (3), pp. 283-319. Liu, F.-H. F., & Peng, H. A systematic procedure to obtain a preferable and robust ranking of
units. Computer & Operations Research. (in press)
Liu, F.-H. F., & Peng, H. (2008). Ranking of DMUs on the DEA frontier with common weights. Computers & Operations Research, 35, pp. 1624-1637.
26
analysis. Journal of Productivity Analysis, 22, pp. 143-161.
Lozano, S., Villaa, G., & Adenso-Diaz, B. (2004). Centralized target settingfor regional recyclingoperations using DEA. Omega, 32, pp. 101-110.
Morse, D., & Beaver, W. (1978). What Determines Price-Earnings Ratios? Financial Analysts
Journal, 34 (4), pp. 65-76.
Noguchi, H., Ogawa, M., & Ishii, H. (2002). The appropriate total ranking method using DEA for multiple categorized purposes. Journal of Computational and Applied Mathematics,
146, pp. 155-166.
Sarrico, C. S., & Dyson, R. G. (2004). Restricting virtual weights in data envelopment analysis. European Journal of Operational Research, 159, pp. 17-34.
Thanassoulis, E., & Dyson, R. G. (1992). Estimating preferred target input-output levels using data envelopment analysis. European Journal of Operational Research, 56, pp. 80-97. Tsuneshi, O., & Hiroaki, I. (2003). A method of discriminating efficient candidates with
ranked voting data. European Journal of Operational Research, 151, pp. 233-237.
Wong, Y.-H. B., & Basely, J. E. (1990). Restricting weight flexibility in data envelopment analysis. Journal of the Operational Research Society, 41, pp. 829-835.
太帄洋證券. 2008 年 3 月 擷取自 太帄洋證券股份有限公司: http://www.nettrade.com.tw/ 王慶昌. (1992). 上市公司財務比率與股票報酬關係之研究—兼論本益比之應用分析. 國 立台灣大學財務金融研究所碩士論文. 台灣經濟新報. (2008 年 3 月). 台灣經濟新報資料庫. 黃怡倫. (1996). 台灣高科技產業股票評價模式之研究. 國立政治大學企業管理研究所碩 士論文. 群益金融集團. 2008 年 3 月 擷取自 群益金融網: http://www.capital.com.tw/ 劉岷. (1998). 利用 EBO/VFP 方法於避險基金選股策略之實證研究---以台灣股市為例. 國立交通大學資訊管理研究所碩士論文.
附錄 A
10 組數據為隨機亂數取出的常態分配隨機觀測值,其中: X1~N(25, 49) X2~N(500, 40000) Y1~N(200, 2500) Y2~N(1200, 160000) 表 10 測詴的第一組數據 UOA X1 X2 Y1 Y2 A 19 654 130 1572 B 17 689 300 1714 C 18 626 228 948 D 16 334 328 1003 E 36 523 149 1046 F 22 802 225 1465 G 23 294 134 996 H 24 637 305 584 I 18 430 220 1810 J 33 434 239 344 表 11 第一組數據的測詴結果 ε 0.1 1 10 100 rank A 10 10 10 10 B 3 3 3 3 C 7 7 7 7 D 1 1 1 1 E 9 9 9 9 F 8 8 8 8 G 4 4 4 4 H 6 6 6 6 I 2 2 2 2 J 5 5 5 5 α1 0.266618 2.666008 26.66008 266.6175 α2 0.1 1 10 100 β1 1.499464 14.99465 338.5751 1499.465 β2 0.1 1.000026 22.58031 100 M 74.65751 746.5719 7465.719 74657.51 θ 7.524601 7.524703 16.99057 7.52460328 表 12 測詴的第二組數據 UOA X1 X2 Y1 Y2 A 17 202 274 1490 B 24 299 212 1706 C 23 472 169 1255 D 31 629 170 1182 E 15 310 275 820 F 27 606 148 1478 G 21 252 263 934 H 33 246 272 1382 I 25 860 266 1565 J 27 446 188 1552 表 13 第二組數據的測詴結果 ε 0.1 1 10 100 rank A 1 1 1 1 B 2 2 2 2 C 7 7 7 7 D 10 10 10 10 E 6 6 6 6 F 8 8 8 8 G 4 4 4 4 H 3 3 3 3 I 9 9 9 9 J 5 5 5 5 α1 0.197622 1.976223 19.76223 197.6223 α2 0.1 1 10 100 β1 0.1 1 10 100 β2 0.150651 1.506509 15.0651 150.6535 M 85.79809 857.9809 8579.809 85798.08 θ 4.65826 4.658257 4.65826 4.65833 表 14 測詴的第三組數據 UOA X1 X2 Y1 Y2 A 20 811 280 1311 B 22 655 157 1464 C 24 422 193 969 D 26 455 195 1228 E 17 646 232 1371 F 29 557 130 1597 G 30 801 206 1088 H 30 516 148 823 I 24 582 193 679 J 29 624 248 878
表 15 第三組數據的測詴結果 ε 0.1 1 10 100 rank A 5 5 5 5 B 7 7 7 7 C 2 2 2 2 D 1 1 1 1 E 3 3 3 3 F 4 4 4 4 G 10 10 10 10 H 9 9 9 9 I 8 8 8 8 J 6 6 6 6 α1 0.268659 2.686587 26.86587 268.6587 α2 0.1 1 10 100 β1 0.742197 7.421972 74.21972 742.1972 β2 0.1 1 10 100 M 443.0735 443.0735 4430.735 44307.35 θ 3.87321 3.87321 3.87321 3.87321 表 16 測詴的第四組數據 UOA X1 X2 Y1 Y2 A 27 401 240 1630 B 19 308 234 1359 C 24 739 169 511 D 25 142 171 1298 E 27 754 79 1588 F 21 518 214 1362 G 29 428 188 937 H 36 402 255 674 I 21 378 172 1065 J 15 341 142 712
30 表 17 第四組數據的測詴結果 ε 0.1 1 10 100 rank A 3 3 3 3 B 2 2 2 2 C 10 10 10 10 D 1 1 1 1 E 9 9 9 9 F 5 5 5 5 G 7 7 7 7 H 6 6 6 6 I 4 4 4 4 J 8 8 8 8 α1 0.200865 2.008652 20.08551 200.8652 α2 0.1 1 10 100 β1 0.541089 5.410893 2534754 541.0893 β2 0.1 1 468460.3 100 M 86.49544 864.9545 8649.525 86495.45 θ 4.330019 4.330019 202843.9 4.330019 表 18 測詴的第五組數據 UOA X1 X2 Y1 Y2 A 34 172 164 1122 B 28 207 174 382 C 24 668 163 934 D 23 316 158 1700 E 22 61 278 1101 F 17 321 213 1150 G 22 542 164 1286 H 27 530 216 1259 I 32 707 176 954 J 31 628 160 1095
表 19 第五組數據的測詴結果 ε 0.1 1 10 100 rank A 4 2 2 2 B 5 5 5 5 C 9 9 9 9 D 3 3 3 3 E 1 1 1 1 F 2 4 4 4 G 7 7 7 7 H 6 6 6 6 I 10 10 10 10 J 8 8 8 8 α1 1.117783 1.774359 17.74282 177.4359 α2 0.1 1 10 100 β1 1.169153 3.264375 32.64362 343.6338 β2 0.1 1 10.00013 105.2679 M 119.4074 1047.412 10474.11 104741.2 θ 4.646968 3.701082 3.701124 3.89605 表 20 測詴的第六組數據 UOA X1 X2 Y1 Y2 A 23 723 204 206 B 24 513 354 1556 C 33 569 228 1442 D 29 564 195 1157 E 20 75 197 1505 F 21 401 119 941 G 24 295 231 660 H 27 266 208 285 I 21 533 152 1209 J 23 289 140 904
32 表 21 第六組數據的測詴結果 ε 0.1 1 10 100 rank A 10 10 10 10 B 2 2 2 2 C 6 6 6 6 D 8 8 8 8 E 1 1 1 1 F 7 7 7 7 G 3 3 3 3 H 5 5 5 5 I 9 9 9 9 J 4 4 4 4 α1 0.191746 1.917369 19.17369 191.7369 α2 0.1 1 10 100 β1 0.539814 5.398126 96.48943 588.2639 β2 0.1 1.000007 17.87475 108.9764 M 82.08921 820.8903 8208.903 82089.03 θ 4.43027 4.430301 7.918994 4.827947 表 22 測詴的第七組數據 UOA X1 X2 Y1 Y2 A 14 455 237 1057 B 21 317 201 1441 C 25 268 253 914 D 26 41 102 1098 E 30 393 160 1129 F 22 656 191 1172 G 22 479 157 906 H 20 504 152 734 I 13 554 238 1654 J 26 480 191 1121
表 23 第七組數據的測詴結果 ε 0.1 1 10 100 rank A 4 4 4 4 B 3 3 3 3 C 2 2 2 2 D 1 1 1 1 E 6 6 6 6 F 9 10 10 10 G 8 8 8 8 H 10 9 9 9 I 5 5 5 5 J 7 7 7 7 α1 0.210401 2.103974 21.04008 210.4008 α2 0.1 1 10 100 β1 4.203661 53.68439 536.8438 5368.438 β2 0.1 1 10 100 M 68.16648 681.5231 6815.238 68152.38 θ 19.60574 24.3632 24.36315 24.36315 表 24 測詴的第八組數據 UOA X1 X2 Y1 Y2 A 26 132 170 1550 B 31 465 249 1046 C 9 554 250 1402 D 13 395 219 435 E 27 226 222 885 F 26 369 286 1084 G 26 384 208 1276 H 38 600 187 1224 I 30 674 281 1253 J 23 503 261 999
34 表 25 第八組數據的測詴結果 ε 0.1 1 10 100 rank A 1 1 1 1 B 8 8 8 8 C 6 6 6 6 D 5 5 5 5 E 2 2 2 2 F 3 3 3 3 G 4 4 4 4 H 10 10 10 10 I 9 9 9 9 J 7 7 7 7 α1 0.424896 4.248963 42.48963 424.8963 α2 0.1 1 10 100 β1 2.179537 21.79537 217.9537 2179.537 β2 0.1 1 10 100 M 52.67448 526.7448 5267.448 52674.48 θ 11.56766 11.56767 11.56766 11.56766 表 26 測詴的第九組數據 UOA X1 X2 Y1 Y2 A 23 554 236 796 B 31 661 252 1213 C 19 436 203 967 D 28 500 118 1302 E 9 781 189 1256 F 24 625 151 1841 G 17 165 234 1023 H 17 385 149 1157 I 34 512 125 932 J 28 434 258 1418
表 27 第九組數據的測詴結果 ε 0.1 1 10 100 rank A 8 8 8 8 B 7 7 7 7 C 4 4 4 4 D 6 6 6 6 E 9 9 9 9 F 5 5 5 5 G 1 1 1 1 H 3 3 3 3 I 10 10 10 10 J 2 2 2 2 α1 0.244106 2.441063 24.41063 244.092 α2 0.1 1 10 100 β1 0.476518 49.75691 350174.5 1629.492 β2 0.1 10.44177 73486.11 341.96 M 67.46869 674.6869 6746.869 67468.46 θ 3.745753 39.11228 27526.08 12.80902 表 28 測詴的第十組數據 UOA X1 X2 Y1 Y2 A 29 671 231 1281 B 29 726 265 1360 C 36 610 179 1338 D 32 539 209 1009 E 24 174 122 1271 F 24 328 199 895 G 24 593 222 1918 H 19 226 193 830 I 23 634 251 870 J 35 635 140 1819
36 表 29 第十組數據的測詴結果 ε 0.1 1 10 100 rank A 8 8 8 8 B 7 7 7 7 C 9 9 9 9 D 6 6 6 6 E 2 2 2 2 F 3 3 3 3 G 4 4 4 4 H 1 1 1 1 I 5 5 5 5 J 10 10 10 10 α1 0.207515 2.075152 20.75152 207.5152 α2 0.1 1 10 100 β1 5.634958 137.8275 563.4958 5634.958 β2 0.1 2.445937 10 100 M 59.25899 592.5899 5925.899 59258.99 θ 22.06367 53.96634 22.06367 22.06367
附錄 B
用來對照的另兩組曖昧性數據。 第一對照組的兩項望小指標值同樣由帄面座標中的一圓上取出,且圓心座標為(101, 101)且半徑為 100,8 個 UOA 的望小指標為均勻分布在圓上且將圓均分為八等份的點, 並令望大指標值均為 1,用來對照表 4 中含有 0 的數據,將其原始數據置於表 30,而 計算結果置於表 31。 第二對照組的兩項望小指標值同樣由帄面座標中的一圓上取出,且圓心座標為(100, 100)且半徑為 10,8 個 UOA 的望小指標為均勻分布在圓上且將圓均分為八等份的點, 並令望大指標值均為 1,用來對照表 4 中的數據規模。將其原始數據置於表 32,而計 算結果置於表 33。 表 30 曖昧數據第一對照組 UOA X1 X2 Y1 A 30.29 30.29 1 B 101 1 1 C 171.71 30.29 1 D 201 101 1 E 171.71 171.71 1 F 101 201 1 G 30.29 171.71 1 H 1 101 1 表 31 曖昧數據第一對照組計算結果UOA score rank Ivirtual Dvirtual ΔIa ΔIb ΔDa ΔDb
A 0.01650 1 60.59 1.00 0 0 0.70 0.00 B 0.00980 2 102.02 1.00 0 0 0.50 0.00 H 0.00980 2 102.02 1.00 0 0 0.50 0.00 C 0.00495 4 202.05 1.00 0 0 0.00 0.00 G 0.00495 4 202.05 1.00 0 0 0.00 0.00 D 0.00331 6 302.07 1.00 0 0 0.00 0.50 F 0.00331 6 302.07 1.00 0 0 0.00 0.50 E 0.00291 8 343.50 1.00 0 0 0.00 0.70 M=1.70, =0.0050, βi=(1, 1), αr=1
38 表 32 曖昧數據第二對照組 UOA X1 X2 Y1 A 92.93 92.93 1 B 100 90 1 C 107.07 92.93 1 D 110 100 1 E 107.07 107.07 1 F 100 110 1 G 92.93 107.07 1 H 90 100 1 表 33 曖昧數據第二對照組計算結果
UOA score rank Ivirtual Dvirtual ΔIa ΔIb ΔDa ΔDb
A 0.00523 1 191.09 1.00 0 0 0.07 0.00 B 0.00512 2 195.35 1.00 0 0 0.05 0.00 H 0.00512 2 195.35 1.00 0 0 0.05 0.00 C 0.00486 4 205.63 1.00 0 0 0.00 0.00 G 0.00486 4 205.63 1.00 0 0 0.00 0.00 D 0.00463 6 215.91 1.00 0 0 0.00 0.05 F 0.00463 6 215.91 1.00 0 0 0.00 0.05 E 0.00454 8 220.17 1.00 0 0 0.00 0.07 M=0.17, =0.0050, βi=(1.03, 1.03), αr=1
附錄 C
表 34 以 B. Graham 之投資策略選出的初選個股經 CTE 模式運算後的結果
UOAj score rank Ivirtual Dvirtual ΔIa ΔIb ΔDa ΔDb
富爾特 295.39 1 14.76 4358.81 36.40 0 0 0 寶碩 218.45 2 21.79 4759.35 34.07 0 0 0 維熹 190.14 3 23.92 4548.49 29.46 0 0 0 誠遠 182.42 4 21.25 3876.82 24.25 0 0 0 亞聚 153.61 5 27.41 4210.63 22.01 0 0 0 欣銓 129.11 6 42.65 5506.30 21.97 0 0 0 亞翔 124.62 7 34.12 4251.94 15.78 0 0 0 東森 111.27 8 27.39 3048.04 8.38 0 0 0 臺聚 107.54 9 41.74 4489.36 10.94 0 0 0 瑞儀 106.75 10 34.72 3706.14 8.78 0 0 0 泰林 103.86 11 41.65 4325.90 9.12 0 0 0 典範 101.42 12 36.40 3691.97 6.93 0 0 0 三豐 92.79 13 31.14 2889.73 2.77 0 0 0 光罩 89.33 14 44.86 4006.98 2.17 0 0 0 冠軍 88.33 15 43.96 3882.82 1.61 0 0 0 菱光 87.20 16 38.93 3394.70 0.91 0 0 0 蔚華科 87.14 17 44.81 3904.75 1.02 0 0 0 振發 85.81 18 39.02 3348.41 0.28 0 0 0 聯成 84.64 19 38.53 3261.16 0 0.26 0 0 金像電 82.59 20 55.67 4597.63 0 1.71 0 0 燿華 82.02 21 48.76 3999.39 0 1.82 0 0 鈺創 79.40 22 48.84 3878.26 0 3.33 0 0 矽格 75.17 23 43.68 3283.05 0 5.14 0 0 德宏 73.52 24 33.87 2490.15 0 4.65 0 0 泰豐 73.00 25 31.33 2286.71 0 4.49 0 0 信邦 71.95 26 52.45 3773.68 0 8.16 0 0 台星科 67.22 27 40.43 2717.60 0 8.54 0 0 精誠 65.63 28 26.72 1753.89 0 6.14 0 0 台燿 64.03 29 47.00 3009.19 0 11.68 0 0 技嘉 62.78 30 40.26 2527.64 0 10.60 0 0 超眾 57.92 31 50.34 2915.69 0 16.12 0 0 高林股 57.82 32 43.19 2497.38 0 13.88 0 0 希華 57.78 33 39.55 2285.27 0 12.73 0 0 第一銅 56.03 34 41.39 2319.32 0 14.17 0 0 虹光 55.35 35 35.42 1960.39 0 12.41 0 0 敬鵬 55.02 36 45.50 2503.54 0 16.12 0 0 中石化 53.48 37 63.53 3397.41 0 23.66 0 0 奇力新 52.48 38 52.53 2756.83 0 20.18 0 0 儒鴻 52.08 39 50.09 2608.91 0 19.47 0 0
40
菱生 43.67 40 44.30 1934.64 0 21.60 0 0
M=236.84, =85.21, βi=(1, 3.43, 1), αr=(1, 3.09, 198.61, 28.12)
表 35 以 P. Lynch 之投資策略選出的初選個股經 CTE 模式運算後的結果
UOAj score rank Ivirtual Dvirtual ΔIa ΔIb ΔDa ΔDb
聰泰 7173732 1 43.44 311626937.4 63.05 0 0 0 可成 7079844 2 17.8 126021221 25.26 0 0 0 精誠 6629718 3 24.36 161499928 30.83 0 0 0 柏騰 5057846 4 24.34 123107971.8 17.73 0 0 0 景碩 4360300 5 22.23 96929463.27 10.89 0 0 0 海韻 3926044 6 37.65 147815570.1 12.86 0 0 0 泰銘 3504699 7 31.59 110713440 6.24 0 0 0 尼克森 3412990 8 39.53 134915512.4 6.57 0 0 0 兆赫 3374345 9 41.32 139427951.3 6.32 0 0 0 美律 3354915 10 44.31 148656294.2 6.49 0 0 0 同欣電 3250375 11 39.8 129364918.6 4.41 0 0 0 類比科 3087279 12 31.38 96878812.25 1.72 0 0 0 伍豐 2931179 13 47.71 139846553.5 0.08 0 0 0 迎輝 2886317 14 34.55 99722242.41 0 0.47 0 0 南電 2656547 15 24.9 66148013.91 0 2.30 0 0 力致 2565993 16 40.64 104281938.6 0 5.01 0 0 倚天 2560971 17 43.21 110659548.5 0 5.40 0 0 松普 2520595 18 34.5 86960532.09 0 4.78 0 0 聯發科 2488289 19 23.72 59022206.62 0 3.55 0 0 德律 2458413 20 26.96 66278820.56 0 4.31 0 0 旭富 2358625 21 31.61 74556121.08 0 6.13 0 0 松翰 2336695 22 32.33 75545340.56 0 6.52 0 0 華榮 2330686 23 32.58 75933739.09 0 6.63 0 0 飛捷 2277290 24 30.05 68432559.76 0 6.67 0 0 第一銅 2224752 25 37.66 83784155.55 0 9.03 0 0 美隆電 2019630 26 26.72 53964524.49 0 8.28 0 0 久元 1952692 27 34.58 67524074.7 0 11.51 0 0 典範 1866910 28 31.3 58434285.62 0 11.33 0 0 閎暉 1807094 29 39.62 71597067.44 0 15.15 0 0 泰林 1717653 30 38.57 66249862.65 0 15.93 0 0 佳能 1665664 31 39.01 64977539.25 0 16.81 0 0 橘子 1605612 32 34.53 55441793.6 0 15.58 0 0 晶技 1595288 33 43.64 69618361.11 0 19.85 0 0 太醫 1553226 34 36.67 56956796.19 0 17.21 0 0 M=192.45, =2926440, βi=(1, 1), αr=(2123755.73, 20564.80)
表 36 以 M. Murphy 之投資策略選出的初選個股經 CTE 模式運算後的結果
UOAj score rank Ivirtual Dvirtual ΔIa ΔIb ΔDa ΔDb
雷凌 640.01 1 1 640.01 0.53 0 0 0 立錡 541.91 2 1 541.91 0.29 0 0 0 柏騰 514.04 3 1 514.04 0.22 0 0 0 聚積 508.44 4 1 508.44 0.21 0 0 0 聯發科 489.42 5 1 489.42 0.17 0 0 0 松翰 486.93 6 1 486.93 0.16 0 0 0 迎輝 468.24 7 1 468.24 0.12 0 0 0 禾瑞亞 419.64 8 1 419.64 0 0 0 0 類比科 408.30 9 1 408.30 0 0.03 0 0 旺矽 390.41 10 1 390.41 0 0.07 0 0 致新 389.49 11 1 389.49 0 0.07 0 0 原相 388.29 12 1 388.29 0 0.07 0 0 五鼎 379.53 13 1 379.53 0 0.10 0 0 矽創 379.20 14 1 379.20 0 0.10 0 0 廣積 370.75 15 1 370.75 0 0.12 0 0 久元 326.01 16 1 326.01 0 0.22 0 0 倚天 322.35 17 1 322.35 0 0.23 0 0 東捷 275.18 18 1 275.18 0 0.34 0 0 崧騰 274.97 19 1 274.97 0 0.34 0 0 M=1.7, =419.64, βi=1, αr=(1, 7.97, 1.35, 11.89) 表 37 以 M. Price 之投資策略選出的初選個股經 CTE 模式運算後的結果
UOAj score rank Ivirtual Dvirtual Δ
Ia ΔIb ΔDa ΔDb 翔準 5.60 1 10.37 58.08 7.24 0 0 0 信大 5.05 2 10.53 53.15 5.59 0 0 0 盛餘 3.87 3 17.00 65.76 2.95 0 0 0 萬企 3.35 4 14.89 49.95 0.26 0 0 0 中華 3.00 5 19.50 58.49 0 1.76 0 0 瀚孙博 2.10 6 19.28 40.39 0 7.03 0 0 無敵 2.06 7 19.39 40.03 0 7.25 0 0 M=1.7, =419.64, βi=1, αr=(1, 7.97, 1.35, 11.89)
42
表 38 以 M. Sivy 之投資策略選出的初選個股經 CTE 模式運算後的結果
UOAj score rank Ivirtual Dvirtual ΔIa ΔIb ΔDa ΔDb
迎輝 157.01 1 34.55 5424.66 133.62 0 0 0 柏騰 109.15 2 24.34 2656.70 58.02 0 0 0 普安 88.62 3 17.22 1525.96 30.09 0 0 0 景碩 72.91 4 22.23 1620.71 28.01 0 0 0 宏盛 66.59 5 37.07 2468.47 39.46 0 0 0 聯發科 63.82 6 23.72 1513.71 23.21 0 0 0 類比科 62.10 7 31.38 1948.55 29.03 0 0 0 伍豐 59.26 8 47.71 2827.06 39.93 0 0 0 泰銘 56.43 9 31.59 1782.50 23.67 0 0 0 誠創 55.40 10 56.94 3154.63 40.86 0 0 0 海韻 54.66 11 37.65 2058.12 26.15 0 0 0 德律 51.90 12 26.96 1399.23 16.42 0 0 0 單井 50.46 13 49.57 2501.36 27.98 0 0 0 南電 49.10 14 24.9 1222.65 13.00 0 0 0 飛捷 48.79 15 30.05 1466.03 15.40 0 0 0 達方 48.66 16 48.32 2351.22 24.57 0 0 0 宏達電 48.54 17 51.57 2503.02 26.03 0 0 0 佳能 46.32 18 39.01 1807.06 17.01 0 0 0 力致 46.30 19 40.64 1881.57 17.69 0 0 0 五鼎 45.14 20 27.97 1262.54 11.17 0 0 0 圓剛 44.67 21 26.11 1166.32 10.05 0 0 0 兆赫 44.39 22 41.32 1834.03 15.54 0 0 0 矽品 41.51 23 29.3 1216.20 8.40 0 0 0 加百裕 40.46 24 63.77 2580.33 16.22 0 0 0 聯詠 40.41 25 45.79 1850.17 11.57 0 0 0 彩晶 39.28 26 36.54 1435.28 7.96 0 0 0 廣積 39.02 27 40.32 1573.26 8.45 0 0 0 尼克森 38.45 28 39.53 1519.76 7.58 0 0 0 健鼎 38.40 29 37.11 1424.86 7.06 0 0 0 應華 38.27 30 64.8 2479.65 12.07 0 0 0 閎暉 37.94 31 39.62 1503.07 6.98 0 0 0 群光 37.80 32 45.56 1722.17 7.83 0 0 0 順達科 36.43 33 54.07 1969.84 7.00 0 0 0 欣技 35.03 34 34.11 1195.01 2.94 0 0 0 聯茂 34.29 35 38.73 1328.11 2.44 0 0 0 中日新 34.07 36 41.78 1423.29 2.34 0 0 0 英華達 33.98 37 43.96 1493.84 2.35 0 0 0 欣銓 33.46 38 37.58 1257.57 1.41 0 0 0 同欣電 33.03 39 39.8 1314.50 0.95 0 0 0 友達 32.86 40 52.29 1718.38 0.98 0 0 0 久元 32.67 41 34.58 1129.80 0.45 0 0 0 鴻準 32.44 42 48.84 1584.18 0.27 0 0 0