國
立
交
通
大
學
生物資訊及系統生物研究所
碩
士
論
文
以模板導向方法建立蛋白質-蛋白質交互作用家族
Template-driven Approaches for Protein-protein
Interaction Families
研 究 生:林峻宇
指導教授:楊進木 教授
以模板導向方法建立蛋白質-蛋白質交互作用家族
Template-driven Approaches for Protein-protein Interaction Families
研 究 生:林峻宇 Student:Chun-Yu Lin
指導教授:楊進木 Advisor:Jinn-Moon Yang
國 立 交 通 大 學
生 物 資 訊 及 系 統 生 物 研 究 所
碩 士 論 文
A Thesis Submitted to Institute of Bioinformatics and Systems Biology College of Biological Science and Technology
National Chiao Tung University in partial Fulfillment of the Requirements for the Degree of Master in
Bioinformatics and Systems Biology
May 2009
Hsinchu, Taiwan, Republic of China
I
以模板導向方法建立蛋白質-蛋白質交互作用家族
學生:林峻宇 指導教授:楊進木
國立交通大學 生物資訊與系統生物所碩士班
摘
要
ABSTRACT (in Chinese)
將蛋白質分類成家族(family)可幫助研究者更深入瞭解蛋白質功能和彼此間的演化 關係。同樣地,因應蛋白質-蛋白質交互作用(protein-protein interaction, 簡稱PPI)資料的 快速增加(大部分來自高量高速篩選實驗),研究者為了瞭解新辨識出來的蛋白質-蛋白質 交互作用,迫切地需要快速且準確的方法將蛋白質-蛋白質交互作用分類成由同源蛋白 質-蛋白質交互作用(homologous PPI)所組成的家族。針對這個議題,我們提出了一個新 概 念 : 蛋 白 質- 蛋白質交互作用家族(PPI family) ,並分別以之建立PPISearch以及 SB-HomPPI兩種模板導向方法。PPISearch (http://gemdock.life.nctu.edu.tw/ppisearch)是一 個可迅速搜尋蛋白質交互作用家族的工具,同時也能合理地註解未知性質的蛋白質交互 作用,這些註解(annotation)的內容包括功能性區塊(domain)和生化功能(biochemical function)。本研究指出,當某蛋白質-蛋白質交互作用與其提問蛋白質對(query protein pair)
間具有顯著的序列相似性(BLASTP E-values ≤ 10-40)時,而且該交互作用也已被記錄在大 型PPI資料庫(包含來自 576 個物種的 290,137 筆PPIs)中,則此交互作用為該提問蛋白質 對之homologous PPI。我們的結果顯示,高達 88%和 69%的功能性區塊及生化功能註解 可以合理地由homologous PPI轉移至其提問蛋白質對。 然而仍有兩個問題。其一,我們建立的大型PPI 資料庫中每個物種的 PPI 數量並不 平均,少數的物種佔據大量的PPIs 紀錄,尤其以酵母菌(yeast)為最。其二,我們使用局 部序列比對工具(如 BLASTP)尋找同源蛋白質,會偏向具有長序列的功能性區塊,但此 區域並不一定參與交互作用。針對這樣的問題,我們結合PPI family 的概念和本實驗室 先前提出的「立體功能區域交互作用同源性對應(3D-domain interologs)」方法,建立一 個新的方法「SB-HomPPI」。SB-HomPPI 以異二聚體結構(heterodimer structures)之交互 作用界面(interface)做為模板,橫跨多個具有完整基因組的物種(如 Integr8 資料庫)來辨識
一個以結構為基礎之蛋白質-蛋白質交互作用家族(structure-based PPI family, 簡稱
SB-PPI family),此家族是由具有相似交互作用界面結構之同源蛋白質-蛋白質交互作用 (SB-HomPPIs)所組成。此方法論使用 Integr8 資料庫,可避免 PPI 資料庫造成的限制;
針對 interface,則可以修正 BLASTP 局部序列比對所造成的誤判。我們的結果顯示,
SB-PPI family (94%)與 PPI family (86%)在交互作用功能區塊對(domain pair)呈現出很高
的保留程度。類似的結果也出現在Gene Ontology (GO)註解對的保留程度分析上,同時
也發現SB-PPI family 高出 PPI family 超過 30%。綜合以上所述,交互作用功能區塊對及
II
Template-driven Approaches for Protein-protein Interaction
Families
Student: Chun-Yu Lin Advisor: Dr. Jinn-Moon Yang
Institute of Bioinformatics and System Biology National Chiao Tung University
ABSTRACT
Classifying proteins to families provides a description of the functional and evolutionary relationships of proteins. Likewise, as an increasing number of protein-protein interactions (PPIs) become available and high-throughput experimentsprovide systematic identification of PPIs, there is a growingneed for fast and accurate approaches to classify PPIs into families (i.e., a group of homologous PPIs) to understand a newly determined PPI. To address this issue, we proposed a concept "PPI family" to construct new template-driven approaches "PPISearch" and "SB-HomPPI". PPISearch is a tool (http://gemdock.life.nctu.edu.tw/ppisearch) that rapidly identifies PPI family and infers transferability of interacting domains and functions of a query protein pair. We identified homologous PPIs when these protein pairs have significant joint sequence similarity (BLASTP E-values ≤10-40) with the query sequences and were in the annotated database (290,137 PPIs in 576 species). Our results demonstrated that the transferability of conserved domain-domain pairs and conserved function term pairs between query pairs and homologous PPIs are 88% and 69%, respectively.
However, we found that the annotated database is dominated by few species, especially yeast, and the method of searching homologs by local alignment (i.e., BLASTP) has a bias in favor of the large domain but that may not involve in binding interface. For these questions, we combined the concept of "PPI family" and our previous study "3D-domain interologs" to construct the approach "SB-HomPPI". The SB-HomPPI identifies structure-based PPI family (SB-PPI family), which is composed of structure-based homologous PPIs (SB-HomPPIs), across multiple complete genomes (i.e., Integr8 database) by using the interfaces of heterodimer structures as templates. This approach uses the Integr8 database and emphasizes the interface to avoid the limitation of the annotated database and the bias of searching homologs by local alignment using BLASTP. Our results presented that SB-PPI family (94%) and PPI family (86%) are highly conserved in interacting domain pairs. Similarly, SB-PPI family was better (at least 30%) than PPI family in conservations of Gene Ontology (GO) term pairs. In conclusion, interacting domain pairs and GO term pairs are the highly conserved biological properties in family.
III
誌謝
這本論文的完成,背後是眾多良師益友的支持與協助,沒有你們的幫助,峻宇一人 是無法完成的。請容我向大家致上最深的感謝。 首先,峻宇何其幸運能受教於恩師楊進木教授,您對研究的熱忱及嚴謹,讓峻宇學 習到探索與發現的樂趣,以及正確的研究態度。此外,在生活及待人處事方面,您也讓 峻宇了解到許多該糾正的缺點及不足之處。在您的教導下,學生也感受到科學領域的廣 闊無邊,而您總是不厭其煩幫助學生找到正確的方向及目標,十分感謝您!峻宇真的獲 益良多。 感謝實驗室的學長姐們、同儕們以及學弟妹們:俊辰學長及宇書學長,感謝你們在 研究上帶我學習成長,更總是耐著性子聽我陳述,幫我歸納重點,在準備論文的時期, 更是不斷給予協助,沒有你們,峻宇不可能順利完成這本論文,真的真的很感謝你們! 其樺學長,感謝你在程式及網頁建置上不厭其煩的指導。阿甫學長、章維學長、PIKI 學長、志達學長、彥修學長以及敬立學長,感謝你們在研究上的給予的建議與幫助。怡 馨學姐感謝妳總是在大家煩悶時,默默為實驗室帶來歡笑與活力。還有我的同學們,力 仁、超哥、偉帆,大夥總是彼此幫忙及成長。最後,怡瑋、御哲及伸融,在生物知識及 程式方面也給了我很多的協助,感謝大家,你們都是我的良師益友。 在這兩年的研究所期間,家人一直是我最大的支柱。我親愛的父親林昆民先生,母 親葉淑燕女士,以及總是特地選我回家時回來陪我的老弟家宏,感謝你們一直以來的支 持與鼓勵,無論開心或難過,你們總是在背後支持著我,家永遠是我最溫暖的避風港。 當然,如同家人般,我最親愛的女友佳慧,在我低潮時陪我伴我,聽我訴苦,一直以來 陪我走過五年的歲月,在這條路上,有妳相伴,真好! 十分感謝熊昭教授、王雯靜教授以及黃鎮剛教授願意擔任峻宇的口試委員,給予指 導與學習的機會。峻宇在這兩年的研究所期間,得到太多人的幫助與支持,真的很幸運 來到 BioXGEM 這個大家庭,最後,致上峻宇最深切的感謝,感恩大家,謝謝!IV
Contents
ABSTRACT (in Chinese) ... I
ABSTRACT ... II
Acknowledgement (in Chinese) ... III
Contents ... IV
List of Tables ... VI
List of Figures ... VII
Chapter 1 Introduction ... 1
1.1 Background ... 1
1.2 Motivation ... 3
1.3 Thesis overview ... 6
Chapter 2 Methods and Materials ... 7
2.1 Overview of identifying PPI family ... 7
2.2 Homologous PPIs of a PPI family ... 10
2.3 The annotated PPI database ... 10
2.4 Annotations of homologous PPI ... 10
2.4.1 Transferability of domain-domain pairs ... 11
2.4.2 Transferability of Gene Ontology ... 11
2.5 Data sets for evaluating the approach of identifying PPI family ... 12
2.6 Overview of structure-based PPI family (SB-PPI family) ... 12
2.7 Structure-based homologous PPIs of a structure-based PPI family ... 17
2.8 3D-dimer template library and data sets for evaluating the predicting ability between the PPI family and SB-PPI family ... 17
2.9 Annotations of SB-HomPPI ... 18
2.9.1 Conservation of interactingdomain pairs ... 18
2.9.2 Transferability of Gene Ontology ... 19
2.10 Performance criteria ... 19
Chapter 3. Results and Discussions ... 20
3.1 The criteria for identifying PPI family ... 20
3.2 Conservation of domain-domain pairs and molecular function pairs in PPI family ... 21
V
3.3 Example analysis of PPI family ... 24
3.4 Limitations and biases of PPI family ... 24
3.4.1 Limitations of the annotated database for identifying PPI family ... 24
3.4.2 Biases of local alignment by BLASTP in searching homologs ... 25
3.5 The criteria for identifying SB-PPI family ... 34
3.6 Conservation of interacting domain pairs and GO term pairs in SB-PPI family . ... 35
3.7 Example analysis of SB-PPI family ... 37
3.8 Application of verify the large-scale PPIs ... 38
3.8.1 Conservation of interacting domain pair ... 38
3.8.2 Conservation of GO term pairs ... 39
3.8.3 The performance of predicting PPIs using approaches of identifying PPI family and SB-PPI family ... 40
3.9 Application of identifying protein complex family ... 41
Chapter 4 Conclusion ... 44
4.1 Summary ... 44
4.2 Major contributions and future works... 45
References ... 47
Appendix A ... 51
VI
List of Tables
Table 1. The list of the numbers of proteins and PPIs in 11 common used organisms ... 5 Table 2. The PPI family search results [using the protein sequence pair of human TGFB3
(P10600) and TGFBR2 (P37173) as the query] ... 27 Table 3. The SB-PPI family search results (using the structural template of human TGFB3 and TGFBR2 heterodimer as the query) ... 29
VII
List of Figures
Figure 1. Comparison of protein family and PPI family. ... 2 Figure 2. Illustration of identifying a protein-protein family. ... 8 Figure 3. Overview of the PPISearch server for homologous protein-protein interaction search and conservation analysis using proteins σ1A-adaptin and γ1-adaptin as the query. ... 9 Figure 4. Illustration of identifying a structure-based protein-protein family. ... 14 Figure 5. Framework of the SB-HomPPI approach. ... 16 Figure 6. The RSS score distributions of the biological process (BP) and cellular component
(CC). ... 18 Figure 7. The relationships between joint E-value JE and the numbers of orthologous PPIs
(black) and homologous PPIs (red) derived from 290,137 annotated PPIs... 21 Figure 8. Evaluations of the PPI family. ... 23 Figure 9. Comparing the PPI family with the SB-PPI family using the PPI of human
transforming growth factor-beta3 (TGFB3; P10600) and TGF-beta type II receptor (TGFBR2; P37173) or their 3D heterodimer template (PDB code: 1ktz). ... 31 Figure 10. Comparison of searching results between PPI family and SB-PPI family of
transcription factor E2F1 (E2F1) and retinoblastoma-associated protein (Rb1). ... 33 Figure 11. The precision and recall of SB-HomPPI with Z-scores on the data set NR-563 and
the Integr8 database. ... 35 Figure 12. The distribution of the average consensus ratio of interacting domain pairs ... 36 Figure 13. The transferability (shared ratios) and conservation ratios of GO term pairs
between SB-PPI families and PPI families. ... 37 Figure 14. The comparison of precisions between two approaches of PPI family and SB-PPI
family. ... 41 Figure 15. The protein complex family of succinate ubiquinone oxidoreductase (PDB code:
1yq3). ... 43 Figure 16. The hypothesis of the hierarchical relationship between PPI families. ... 46
1
Chapter 1
Introduction
1.1
Background
Classifying proteins to families provides a description of the functional and evolutionary relationships of proteins, such as Pfam1 that classifies protein domains through multiple sequence alignments and profile hiddenMarkov models and PIRSF2 in that members are homologous and homeomorphic that sharing common ancestry and full-length sequence similarity with common domain architecture. Additionally, SCOP3 and CATH4 classify protein structures to families through homologous relationship in evolution.
In recent studies, interactions between proteins are critical to most biological function. To identify and characterize PPIs and their networks, many high-throughput experimental approaches5-6, such as yeast two-hybrid screening, mass spectroscopy, and tandem affinity purification, and computational methods (phylogenetic profiles7, known 3D complexes8, and
interologs9) have been proposed10. Some PPI databases, such as IntAct11, BioGRID12, DIP13,
MIPS14, and MINT15, have accumulated PPIs submitted by biologists, and those from mining literature, high-throughput experiments, and other data sources.
Recently, several PPI databases (e.g., IntAct and BioGRID) allow users to input one or a pair of proteins or gene names to acquire the PPIs associated with the query protein(s). Few computational methods16-17 applied homologous interactions to assess the reliability of PPIs identified by large-scale experiments. The discovery of sequence homologs to a known protein often provides clues for understanding the function of a newly sequenced gene. As these interaction databases continue growing in size, they become increasingly useful for analysis of newly identified interactions and classification of protein-protein interactions.
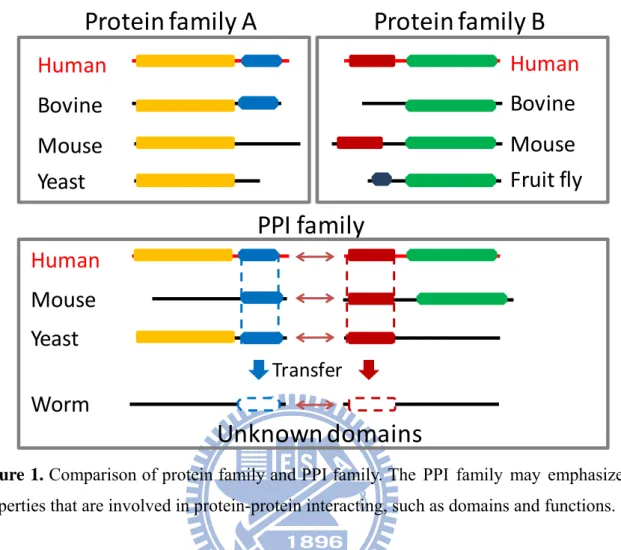
Figure 1. Comparison of protein family and PPI family.
Protein family A
Protein family B
Human
Human
Bovine
Mouse
Yeast
Bovine
Mouse
Fruit fly
2Human
PPI family
Unknown domains
Mouse
Yeast
Worm
Transfer
Figure 1. Comparison of protein family and PPI family. The PPI family may emphasize the
properties that are involved in protein-protein interacting, such as domains and functions.
Therefore, how could we classify PPIs into families? A PPI family may consist of a group of homologous PPIs. Comparing with the protein family, the PPI family may highlight the characteristics that are involved in protein-protein interacting, such as domains and functions (Figure 1).
In sequence level, we proposed the PPISearch server18 for searching homologous PPIs across multiple species and annotating the query protein pair. According to our knowledge, PPISearch is the first public server that identifies homologous PPIs from annotated PPI databases and infers transferability of interacting domains and functions between homologous PPIs and the query. PPISearch is an easy-to-use web server that allows users to input a pair of protein sequences. Then, this server finds homologous PPIs in multiple species from five public databases (IntAct, MIPS, DIP, MINT, and BioGRID) and annotates the query. Our results demonstrated that this server achieves high agreements on interacting domain-domain pairs and function pairs between query protein pairs and their corresponding homologous PPIs.
3
The structural information of interacting domains and atomic details for thousands of directly physical interactions between proteins are available19-20. There were many studies analyzed the PPIs on residue-based binding models and to derive domain-domain interaction (DDI) databases, such as 3did21, iPfam22, and DAPID23 using three-dimensional (3D) dimer protein structures recorded in Protein Data Bank (PDB)24. For predicting a PPI by searching a 3D-complex library to identify homologous templates of this pair of query protein sequences by accessing interface preference according to how they fit the known template structures, some methods have proposed by utilizing template-based methods (e.g., comparative modeling8,19 and fold recognition20). Despite the diversity of the strategies and algorithms used in these methods, they all focus on predicting the protein-protein interactions and seem to produce comparable results. For a query protein pair (or 3D-dimer template), these methods lack PPI families (i.e., paralogous PPIs in one species and orthologous PPIs across multiple genomes) for studying evolution of PPIs. In addition, it is time-consume (unfeasible) to query all protein pairs in multiple complete genomes (such as 6,352,363 proteins with 2,274 complete genomes in Integr825, having ~2.0×1010 possible pairs).
We combine two concepts that are protein-protein interaction family (PPI family) and 3D-domain interolog mapping8 to identify structure-based homologous protein-protein interactions (SB-homPPIs) across multiple complete genome. The 3D-domain interologs is similar to "generalized interologs mapping". Our concept is defined as "Domain a (in chain A) interacts with domain b (in chain B) in a known 3D complex, meaning that their inferring protein pair A' (containing domain a) and B' (containing domain b) in the same species would be likely to interact with each other if two pairs, i.e., (A, A') and (B, B'), are homologous". Based on the new approach of "SB-homPPI", we could infer the interacting domain-domain pairs, function pairs (Gene Ontology annotations26), the binding models (e.g., hydrogen-bond interactions and conserved residues), couple-conserved residues and the evolution of the PPIs. In this study, we used 1,895 3D heterodimers and our scoring functions to infer 224,713 PPIs by searching on the Integr8 database.
1.2
Motivation
In biological systems, interactions between proteins are critical. Currently, the description of the functional and evolutionary relationships of proteins could be provided by classifying proteins to families (e.g., Pfam and SCOP). However, evaluation of the relationship between sequence homology and function is ambiguous, because no clear measure of functional
4
similarity exists in interacting protein pairs27-28. As interaction databases continue growing in size, PPI families may offer biologists to understand newly identified interactions and evolutionary relationship of homologous PPIs in a family.
To address this issue, we proposed the PPISearch server for searching homologous PPIs (i.e., PPI family) across multiple species and annotating consensus domain-domain pairs and molecular functions to the query protein pair. According to our knowledge, PPISearch is the first public approach that identifies homologous PPIs from annotated PPI databases and infers transferability of interacting domains and functions between homologous PPIs and the query. Our results demonstrated that this approach achieves high agreements on interacting domain-domain pairs and function pairs between query protein pairs and their corresponding homologous PPIs.
5
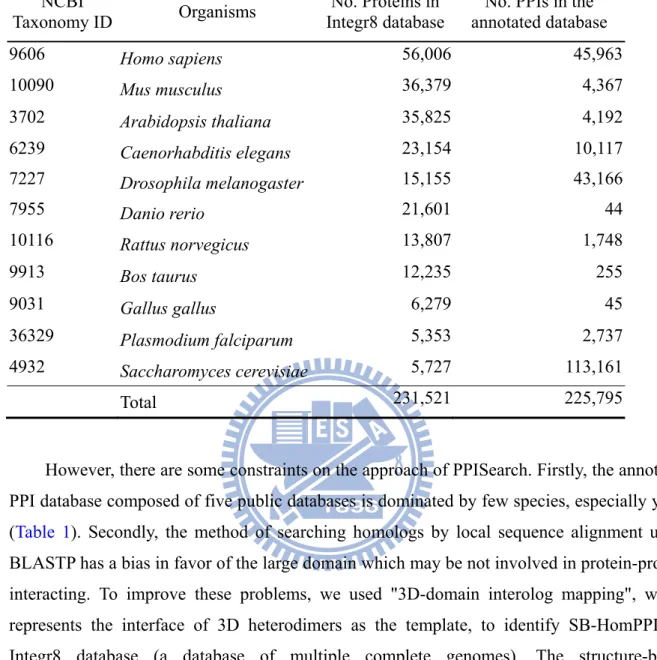
Table 1. The list of the numbers of proteins and PPIs in 11 common used organisms Table 1. The list of the numbers of proteins and PPIs in 11 common used organisms
NCBI
Taxonomy ID Organisms Integr8 databaseNo. Proteins in annotated database No. PPIs in the
9606 Homo sapiens 56,006 45,963 10090 Mus musculus 36,379 4,367 3702 Arabidopsis thaliana 35,825 4,192 6239 Caenorhabditis elegans 23,154 10,117 7227 Drosophila melanogaster 15,155 43,166 7955 Danio rerio 21,601 44 10116 Rattus norvegicus 13,807 1,748 9913 Bos taurus 12,235 255 9031 Gallus gallus 6,279 45 36329 Plasmodium falciparum 5,353 2,737 4932 Saccharomyces cerevisiae 5,727 113,161 Total 231,521 225,795
However, there are some constraints on the approach of PPISearch. Firstly, the annotated PPI database composed of five public databases is dominated by few species, especially yeast (Table 1). Secondly, the method of searching homologs by local sequence alignment using BLASTP has a bias in favor of the large domain which may be not involved in protein-protein interacting. To improve these problems, we used "3D-domain interolog mapping", which represents the interface of 3D heterodimers as the template, to identify SB-HomPPIs in Integr8 database (a database of multiple complete genomes). The structure-based protein-protein interaction family (SB-PPI family) consists of these SB-HomPPIs. Based on the binding models (e.g., hydrogen-bond interactions and conserved residues) of interfaces, we could infer couple-conserved residues and the evolution of the PPIs through multiple sequence alignments. Our results showed that the SB-PPI family between the 3D heterodimers and their corresponding SB-HomPPIs according to our results and the PPI family are highly conserved in interacting domain pairs and Gene Ontology (GO) term pairs.
6
1.3
Thesis overview
The thesis consists of the two studies "PPI family" and "SB-PPI family". Their frameworks were shown in Section 2.1 and 2.6, respectively. We first proposed the concept of identifying homologous PPIs across species to construct a web server, PPISearch. Moreover, we used case studies to present the limitations and biases of the PPI family (Section 3.8), and the improvements that used on the new approach to identify the SB-PPI family. We proposed evidence to demonstrate the conservation of interacting domain pairs and GO term pairs and predicting ability for PPI family and SB-PPI family. The reliable PPI family will be identified through combining PPI family and SB-PPI family and also help us to verify the reliability of the members in a family.
7
Chapter 2
Methods and Materials
2.1
Overview of identifying PPI family
In this section, we present the concept and the approaches of identifying protein-protein interaction family through sequence similarity (e.g., E-value and joint E-value). Figure 2 illustrates the concept of identifying protein-protein interaction family.
For this purpose, we define a group of homologous protein-protein interactions forming a PPI family. All homologous PPIs in the family are similar protein-protein interactions that share a common ancestry. The following steps show the details of the PPISearch server to search homologous PPIs of a query protein pair (A and B) (Figure 3A). This server first identifies the homologous families (A' and B') of A and B, respectively, with E-value ≤10-10 by using BLASTP to scan the annotated PPI databases (Figures 3B and C). All protein pairs of A' and B' are considered candidates of homologous PPIs. We selected homologous PPIs from these candidates, which are recorded in the annotated databases, and have significant joint sequence similarity [E-value ≤10-40, Equation (1)] between candidates and the query (Figure 3D). Then, we measured the conservation ratios of domain-domain pairs (DDPs; Pfam domains) and protein functions (Gene Ontology annotations) derived from these homologous PPIs of the query (Figure 3E).
Figure 2. Illustration of identifying a protein-protein family. Interacting proteins A B A’ B ’ Homologs Homologs Interacting proteins Interacting proteins A B A1’ A2’ B1’ A3’ B2’ A4’ B3’ Homologs Homologs Interacting proteins A1’ B1’ A2’ A3’ B2’ B2’ A3’ B3’ A4’ B3’ Species 1 Species 2 Species 2 Species 3 Species 1 Species 2 Species 3 A B PPI family Homologous interactions recorded in the annotated PPI databases
Figure 2. Illustration of identifying a protein-protein family. A protein-protein interaction
(A-B) is the query protein pair given by users. A' and B' are the homologs of proteins A and B, respectively. Two pairs, (A, B) and (A', B'), are similar. The homolog pair A'-B' are considered homologous interaction when it is recorded in the annotated PPI database (290,137 PPIs). The protein-protein family consists of all homologous interactions (e.g., A1'-B1' and A2'-B2') and the query pair.
Figure 3. Overview of the PPISearch server for homologous protein-protein interaction search and conservation analysis using proteins σ1A-adaptin and γ1-adaptin as the query.
Annotated databases (290,137 protein-protein interactions)
BLASTP E-value ≤ 10-10 BLASTP E-value ≤ 10-10
Homologous PPIs σ1A-adaptin of mouse (P61967) γ1-adaptin of mouse (P22892) A B C P61966 P61967 P56377 Q9DB50 Q9VCF4 P35181 P62743 P53680 O75843 O43747 Q86B59 Q9W388 Q9UPM8 Q12028 P17427 O95782 O75843 P61966 P61967 O43747 P56377 O75843 O43747 O43747 Q9DB50 O75843 Q9VCF4 P61966 Mouse Human Human Human Human Yeast Human Human Human Fruit fly Human Human Fruit fly Human Human Human Mouse Mouse Human Human Mouse Mouse Fruit fly Fruit fly Human Yeast Mouse Human
Domain-domain pairs Conservation ratio
14/14 = 1.0 13/14 = 0.93 2/14 = 0.14 Step 1: Query a pair of protein sequences
(A and B)
Step 2: Identify homologous protein
families (A' and B') of A and B,
respectively, with E-values ≤ 10-10using
BLASTP from annotated PPI databases
9 0.6 E 1/14 = 0.07 PF01602 PF02883 PF02296 PF07718 PF01217 PF01217 PF01217 PF01217 interacting domains
Step 4: Measure the conservation ratios
of all of domain-domain pairs (DDPs) and protein functions derived from these homologous PPIs of a query. The DDPs and function terms are considered as conservation if their ratios ≥ 0.6.
Step 5: Output homologous PPIs,
conserved DDPs and functions, and multiple sequence alignments across multiple species for the query
Step 3: Identify homologous PPIs which
are protein pairs of A' and B' and recorded in annotated databases with joint E-values (JE) ≤ 10-40. D P61967 Human Mouse P61966 O43747 Human Human P56377 O75843 Q86B59 Fruit fly Human Q9W388 Fruit fly Mouse Q9UPM8 Q9DB50 Human Fruit fly Q12028 Human Human P53680 O95782 Q9VCF4 Yeast P35181 Yeast P62743 P17427 Mouse Mouse … …
σ1A-adaptin family γ1-adaptin family
1.7e-134 1.7e-134 1.7e-134 1.7e-134 1.7e-129 1.7e-129 1.0e-128 1.0e-128 2.0e-124 2.0e-124 5.5e-73 6.5e-63 9.5e-55 6.0e-54 JE
Figure 3. Overview of the PPISearch server for homologous protein-protein interaction
search and conservation analysis using proteins σ1A-adaptin and γ1-adaptin as the query. (A) The main procedure. (B) Identify homologs of σ1A-adaptin and γ1-adaptin using BLASTP to scan the annotated PPI databases. (C) The homologous families of σ1A-adaptin and γ1-adaptin with E-values ≤10-10. (D) Homologous PPIs of the query. (E) Conservation ratios of domain-domain pairs derived from homologous PPIs.
2.2
Homologous PPIs of a PPI family
The concept of PPI family is the core of the PPISearch server to identify homologous PPIs and measure DDPs and functional conservations of a query protein pair (A and B). We define a homologous PPI as follows: (1) homologs of A and B are proteins with significant sequence similarity BLASTP E-values ≤10-10 9,29; (2) significant joint sequence similarity (JE ≤10-40) between two pairs, i.e., (A, A1') and (B, B1'), of the query protein pair (A and B) and their
corresponding homologs (A1' and B1') recorded in annotated PPI databases. This work
followed previous studies9,29 to define joint sequence similarity as
B A
E
E
E
J
=
×
(1)where EA is the E-value of proteins A and A1'; and EB is the E-value of proteins B and B1'.
Here, JE ≤10-40 is considered a significant similarity according to statistical analysis of 290,137 annotated PPIs and 6,597 orthologous PPI families collected from the PORC database25.
2.3
The annotated PPI database
We totally collected 290,137 PPIs as the annotated PPI database in that duplications were removed by using UniProt accession numbers from five public databases (e.g., 147,634 PPIs in IntAct, 18,529 PPIs in MIPS, 52,445 PPIs in DIP, 77,846 PPIs in MINT, and 150,827 PPIs in BioGRID). These PPIs were identified experimentally from 576 species.
2.4
Annotations of homologous PPI
A query protein pair and its homologous PPIs, which have significant sequence and joint sequence similarity, can be considered a PPI family. The concept of PPI family is derived from that of protein sequence family1 and protein structure family3. We believed that PPI families can be applied widely in biological investigations. Here, we assumed that the members of a PPI family are conserved on specific functions and in interacting domain(s). Using these conservations of query’ homologous PPIs, our server could be used to annotate the protein functions and DDPsof a query protein pair.
2.4.1 Transferability of domain-domain pairs
A query protein pair and its homologous PPIs can often agree on interacting DDPs. To measure the agreement of each DDP in a PPI family, we define the conservation ratio (CRDp) of a DDP p in homologous PPIs of a query protein pair i as
i p CRDp query of PPIs homologous of Number pair domain a with PPIs homologous of Number = (2)
Figures 3D and E show an example to calculate the CRD values of four DDPs. In addition, to statistically evaluate the transferability of DDPs between a query and its homologous PPIs, this study defines the shared ratio (SRD) of DDPs using CRDp and 290,137 annotated PPIs as query protein pairs. The SRD of DDPs against different ratio c is given as
∑
∑
∈ ∈ ≥ ≥ = Q i p i Q i p i c CRD D c CRD d SRD ) ( ) ( (3)where Q is a set of annotated PPIs in databases (here, the total number of PPIs in Q is 290,137); i is a query protein pair; di(CRDp ≥ c) is the number of DDPs with CRDp values exceeding c; and these DDPs are shared by the query i and its homologous PPIs. Di(CRDp ≥ c) is the total number of the DDPs with CRDp ≥ c, where DDPs are derived from homologous PPIs of the query i. Here, this work used a statistical approach to determine the threshold c (here, c=0.6) of CRDp to yield reliable DDP annotations with an acceptable level of Di. Please note that CRDp and SRD are computed from a query protein pair and a set of queries, respectively.
2.4.2 Transferability of Gene Ontology
We assumed that the members of a PPI family are usually conserved on specific molecular function, pathway, and cellular component. We utilize the Gene Ontology26 to annotate the molecular function, biological process, and cellular component of a query protein pair. To statistically evaluate the shared ratio of GO terms between the query pair and its PPI family (with N homologous PPIs), we define the shared ratio (SR) using the conservation ratio (CR=Na/N), where Na is the number of homologous PPIs with the same GO term in a PPI
family. The SR is given as
∑
∑
∈ ∈ ≥ ≥ = Q i i Q i i k CR P k CR T SR ) ( ) ( (4)where Q is a set of query pairs; Pi (CR≥ k) is the total number of the GO terms of query pair i when CR ≥ k; Ti (CR ≥ k) is the number of the shared GO terms of query pair i when CR ≥ k. The shared ratio of MFPs (SRF) is statistically derived from 290,137 annotated queries. Here,
k is set to 0.6.
2.5
Data sets for evaluating the approach of identifying PPI family
To evaluate the usefulness of the PPISearch for the discoveryof PPI family and for the annotations of a query proteinpair, we selected two query protein sets, termed HOM and ORT. For searching homologous PPIs, HOM and ORT data sets are used to assess performance of PPI family and to determine the threshold of joint E-valueJE [Equation (1)].
The HOM set includesall of 290,137 PPIs and the ORT set has 6,597 orthologous PPI families(14,571 PPIs) derived from the annotated PPI database and PORCorthology database. PORC data (putative orthologous clusters) were defined as orthologous families from Integr8 and CluSTr30 databases. These clusters contain all sequenced organisms (1,125 bacteria, 125 eukaryota and 50 archaea in the release 94). Each entry in PORC represents a cluster of genes grouped by the similarity of their longest protein product. According to the construction process of PORC, a gene cluster contains at most a single protein from a given species and a protein can be assigned to only a single cluster.
2.6
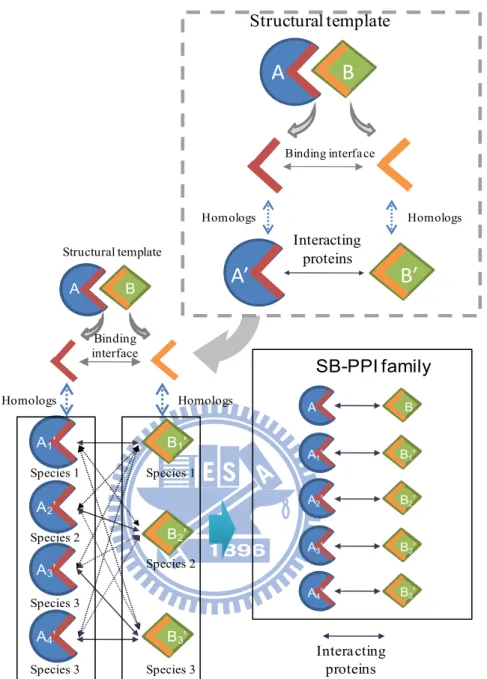
Overview of structure-based PPI family (SB-PPI family)
The structure-based protein-protein family (SB-PPI family) is extended from PPI family18 and 3D-domain interologs with structural template-based scoring function8. The 3D-domain interologs is defined as "Domain a interacts with domain b in the protein pair (A-B) of a known 3D complex, their inferring homologous protein pair A' (containing domain a) and B' (containing domain b) in the same species would be likely to interact with eachother." Figure 4 presents the approach of identifying SB-PPI family. We define a SB-PPI family consists of a
13
group of structure-based homologous protein-protein interactions (SB-HomPPIs). All PPIs in the family are similar protein-protein interactions that sharing a common ancestry and having similar binding model (i.e., significant interface similarity).
Figure 4. Illustration of identifying a structure-based protein-protein family.
A
B
Structural template Binding interface Homologs HomologsA’
B’
Interacting proteins A B Structural template Binding interface Homologs Homologs A1’ B1’ A2’ B2’ A3’ A4’ B3’ Species 1 Species 2 Species 3 Species 1 Species 2 Species 3 Species 3 Interacting proteins A B A1’ B1’ A2’ B2’ A3’ B3’ A4’ B3’ SB-PPI familyFigure 4. Illustration of identifying a structure-based protein-protein family. A 3D-dimer
template (A-B) is the query protein pair given by users. The domain a and b are the binding interface of A-B. Protein A' and B' that containing domain a and b are the homologs of proteins A and B, respectively. The homologous pairs A'-B' have similar binding model with the query pair A-B. The structure-based protein-protein family consists of all homologous interactions (e.g., A1'-B1' and A2'-B2') and the query pair.
15
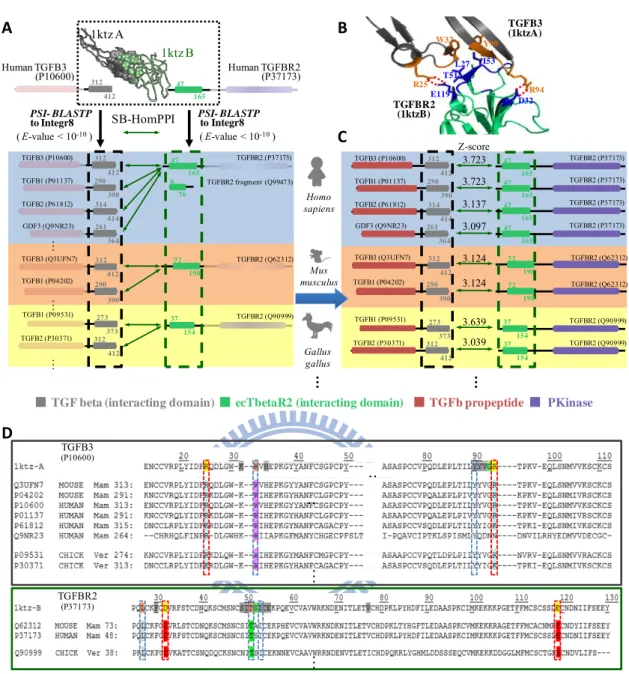
Figure 5 shows the framework of identifying SB-HomPPIs of the 3D-dimer template utilizing 3D-domain interolog mapping. We first identifies the homologous families (A' and B') (Figure 5A) of a 3D-dimer template T (Figure 5B), which has proteins A and B (with interacting domains a and b), with significant sequence similarity (PSI-BLASTP E-values ≤ 10-10) searching in the Integr8 database (6,352,363 protein sequences in 2,274 species). All protein pairs of A' and B' (with interacting domains a and b) are considered the SB-HomPPIs (a SB-PPI family) of the template T if their interfaces have significant interface similarity with the template T (Figure 5C) (See Section 2.7). For a SB-PPI family, we can measure the conservation ratios of domain-domain pairs (DDPs) and Gene Ontology annotations, including molecular function (MF), biological process (BP) and cellular component (CC). Additionally, the multiple sequence alignments of interfaces further provide the analysis of co-evolution in contact residue pairs in interfaces (Figure 5D).
Figure 5. Framework of the SB-HomPPI approach. 261 364 1ktz A 1ktz B Human TGFBR2 (P37173) A 312 412 47 165 Human TGFB3 (P10600) B TGFB3 (P10600) 312 412 TGFBR2 (P37173) 47 165 314 414 TGFB2 (P61812) 290 390 TGFB1 (P01137) 312 412 TGFB2 (P30371) 37 154 TGFBR2 (Q90999) 273 373 TGFB1 (P09531) 312 412 TGFB3 (Q3UFN7) 72 190 TGFBR2 (Q62312) 290 390 TGFB1 (P04202) TGFBR2 (P37173) 47 165 TGFBR2 (P37173) 47 165 72 190 TGFBR2 (Q62312) 37 154 TGFBR2 (Q90999) 312 412 47 165 TGFBR2 fragment (Q99473) 8 76 290 390 Homo sapiens 37 154 TGFBR2 (Q90999) 312 412 72 190 Mus musculus … … C Z-score 3.723 3.723 3.137 3.124 3.124 3.639 3.039 R94 D32 W32 Y90 L27 T51 E119 R25 TGFBR2 (1ktzB) TGFB3 (1ktzA) I53 SB-HomPPI TGFb propeptide
TGF beta (interacting domain) ecTbetaR2 (interacting domain) PKinase
TGFBR2 (P37173) TGFBR2 (Q62312) 314 414 290 390 ( E-value < 10-10) PSI- BLASTP to Integr8 ( E-value < 10-10) PSI- BLASTP to Integr8 TGFB3 (P10600) TGFB1 (P01137) TGFB2 (P61812) GDF3 (Q9NR23) TGFB3 (Q3UFN7) TGFB1 (P04202) TGFBR2 (P37173) 47 165 261 364 GDF3 (Q9NR23) 3.097 D TGFBR2 (P37173) … .. TGFB3 (P10600) … Gallus gallus …… … 312 412 273 373 TGFB2 (P30371) TGFB1 (P09531) ..
Figure 5. Framework of the SB-HomPPI approach. (A) A known 3D-dimer template structure
(PDB code 1ktz) which identified their homologs (E-value ≤ 10-10) of TGFB3 and TGFBR2 and 204 PPI candidates (B) The interface and some interactions of the template (PDB code: 1ktz). (C) SB-PPI family uses the structural template-based interface similarity scoring function to evaluate these 204 PPI candidates and 28 structure-based homologous PPIs with significantly interface similarity (interface sequence identity ≥ 25%, and contact residue identity ≥ 25%, Z-score ≥ 3) in six species are selected to comprise the SB-PPI family of the template 1ktz. Here, 8 PPIs are selected from Homo sapiens, Mus musculus, and Gallus gallus. (D) SB-HomPPI utilizes two multiple sequence alignments of structure-based homologous PPIs for interface evolution analysis. Hydrogen bond: red dotted box; Hydrophobic cavity: blue dotted box.
2.7
Structure-based homologous PPIs of a structure-based PPI family
We define a SB-HomPPI as follows: (1) Homologs of binding domains in proteins A and B are proteins with significant PSI-BLASTP E-value ≤ 10-10; (2) An interacting candidate is regarded as a SB-HomPPI if its significant interface similarity (interface sequence identity ≥ 25%, contact residue identity ≥ 25%, and Z-score ≥ 3) and it ranks in the Top 25 in one species. This work followed our previous studies to define homologs and similar binding model8,18. The binding affinity Z-score of a SB-HomPPI (proteins A1' and B1') of a template T
(proteins A and B) is defined as
AB AB B A E E Z σ > < − = 1' 1' (5)
where EA1' B1' is the sequence-interface similarity score of the SB-HomPPI proteins A1' and B1';
<EAB> and σAB are the mean and standard deviation of sequence-interface similarity scores of
10,000 random interfaces in a decoy set of the template T, respectively. EA1' B1' is given as
cons sim SF vdw B A E E E wE E ' = + + + 1 ' 1 (6)
where Evdw and ESF are the interacting van der Waals energy and the special interacting bond energy (i.e. hydrogen-bond energy and electrostatic energy), respectively, using four knowledge-based matrices8. Esim is the sequence similarity score and the Econs is the couple-conserved residue score of the SB-PPI family of template T.
2.8
3D-dimer template library and data sets for evaluating the
predicting ability between the PPI family and SB-PPI family
We used the data set of 1,894 heterodimers (i.e., 3,788 protein sequences, called NR-1894) from the Protein Data Bank (PDB) released in Feb 24, 2006 as the 3D-dimer template library. This set was derived from our previous study8. Additionally, we selected a non-redundant set, called NR-563, to evaluate conservations of interacting domain pairs and GO term pairs and performance of prediction. This set consisted of 563 heterodimer complexes selected from the NR-1894 according to their SCOP interacting-domain pairs. At least one chain of these complexes has different SCOP family.
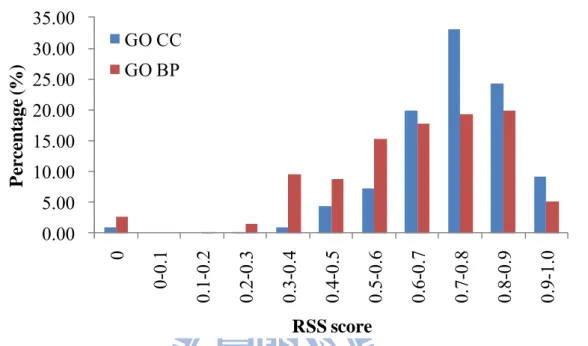
We used the annotated PPI database (290,137 PPIs) as the positive PPIs. Among 290,137 PPIs, 173,277 interactions can be used to calculate relative specificity similarity (RSS scores)31 of GO terms of BP and CC. The BP and CC RSS scores of 23,929 (13.81%) and
3,294 (1.90%) interactions, respectively, are less than 0.4 (Figure 6). Here, we considered a protein pair as a negative PPI if its BP and CC RSS scores are less than 0.4.
Figure 6. The RSS score distributions of the biological process (BP) and cellular component (CC). 0.00 5.00 10.00 15.00 20.00 25.00 30.00 35.00 0 0-0.1 0.1-0.2 0.2-0.3 0.3-0.4 0.4-0.5 0.5-0.6 0.6-0.7 0.7-0.8 0.8-0.9 0.9-1.0 P ercen ta g e ( % ) RSS score GO CC GO BP
Figure 6. The RSS score distributions of the biological process (BP) and cellular component
(CC). Among 290,137 PPIs recorded in the annotated database, 173,277 PPIs having both BP and CC annotations are used to calculate the BP and CC RSS scores. There are 23,929 (13.81%) and 3,294 (1.90%) PPIs with low BP and CC RSS scores (≤ 0.4), respectively.
2.9
Annotations of SB-HomPPI
A heterodimer structure and its SB-HomPPIs, which are significantin sequence and interface similarity (binding model similarity), can be considereda SB-PPI family. Here, we assume that the membersof a SB-PPI family have similar binding models and are conserved on interactingdomain pair(s) and biological properties.
2.9.1 Conservation of interactingdomain pairs
A heterodimer structure and its SB-HomPPIs often possess the sameinteracting domain pair(s) (IDP). To measure the IDP conservation of a SB-PPI family, we defined the consensus ratio (CRIDP) of a SB-HomPPI i in the heterodimer structure Q as
∑
∈ = Q i i i NIDP CIDP CRIDP (7)where CIDPi is the number of IDPs that is consensus between the structure Q and the SB-HomPPI i; and NIDPi is the number of IDPs of the structure i. Based on 359 heterodimer
structures and 14,095 PPIs (the annotated database) with IDPs annotated in iPfam database22, we statistically evaluated the consensus of IDPs between SB-PPI families and PPI families.
2.9.2 Transferability of Gene Ontology
Similar to PPI family, we assumed that the members of a PPI family are usually conserved on specific molecular function, pathway, and cellular component.We measured theconservation ratio and the shared ratio (described in Section 2.4.2) of a GO term pair in a SB-PPI family of a heterodimer structure i. Here,the shared ratio of GO MF, BP, and CC term pairs, which are statistically derivedfrom 281, 292, and 245 heterodimer structures with GO annotations, respectively, are utilized to estimate conserved GO term pairs shared by a SB-PPI family. In addition, we compared the transferability of Gene Ontology between PPI family and SB-PPI family.
2.10 Performance
criteria
We used precision and recall to measure the predicting ability of our two approaches (i.e., PPI
family of PPISearch and SB-PPI family of SB-HomPPI). The precision and recall show as
Positives False of number the Positives True of number the Positives True of number the precision + = (8) egatives N False of number the Positives True of number the Positives True of number the recall + = (9)
SB-HomPPI used the distribution between precision and recall to decide the threshold of
Z-score. This study also compared the distribution between the number of true positives and
the precision to assess the quality of PPI family and SB-PPI family.
20
Chapter 3.
Results and Discussions
In this study, we proposed two approaches (i.e., PPISearch and SB-HomPPI) of identifying
PPI family and SB-PPI family. According to our knowledge, PPISearch is first server to identify PPI family through the sequence similarity. Moreover, the SB-PPI family, using structural template-based scoring function of 3D-domain interolog mapping, is more conserved than the PPI family in interacting domain pairs and GO annotations. Firstly, we provided evidence of classifying PPIs to families and more details were shown in our previous study. Some case studies were used to present the potential limitations and biases of the PPI family. Secondly, we analyzed conservations of biological properties in PPI family and SB-PPI family, such as conservation of interacting domain pairs and molecular function. Finally, protein complexes are the fundamental units of macromolecular organization32. We applied our concept of PPI family and the approach of SB-HomPPI to construct protein complex family for determining functional modules of biological networks across multiple species.
3.1
The criteria for identifying PPI family
HOM and ORT were used to assess the PPISearch server in identifying homologous PPIs and orthologous PPIs, respectively, by searching the annotated PPI database (290,137 PPIs with 54,422 proteins). Figure 7 shows the relationships between JE values and number of orthologous PPIs (black) and homologous PPIs (red). The orthologous PPIs often have the same functions and domains. When JE ≤ 10-40, the number of orthologous PPIs decreases significantly; conversely, the number of homologous PPIs decreases more gradually than that at JE ≥ 10-40. This result showed that the proposed method is able to identify 98.2% orthologous PPIs with a reasonable number of homologous PPIs when JE ≤ 10-40. Based on our definition and criteria, there are 90,715 PPI families excluding two proteins of the PPI from different species, and these families consist of 93,406 PPIs in 174 species.
Figure 7. The relationships between joint E-value JE and the numbers of orthologous PPIs (black) and homologous PPIs (red) derived from 290,137 annotated PPIs.
Figure 7. The relationships between joint E-value JE and the numbers of orthologous PPIs
(black) and homologous PPIs (red) derived from 290,137 annotated PPIs.
3.2
Conservation of domain-domain pairs and molecular function pairs
in PPI family
To evaluate the transferability of DDPs and MFPs between a query and its homologous PPIs, we used the SRD [Equation (3)] and SR [Equation (4)]. The HOM set is used to evaluate the
utility of the PPISearch server in annotating the query protein pair. By excluding proteins without domain annotations from the query set, 103,762 PPIs are used to evaluate the transferability (SRD) of conserved DDPs between these query PPIs and their corresponding
homologous PPIs (Figure 8A). The transferability (SRF) of conserved functions between the
106,997 PPIs and their homologous PPIs is assessed by excluding proteins without molecular function terms of GO from the original query set (Figure 8B).
Figure 8A shows the relationship between conservation ratios (CRD) of DDPs and the SRD ratios. The SRD ratio increases significantly (solid lines) when the CRD increases and CRD ≤ 0.6. Conversely, the number of DDPs derived from 103,762 PPI families decreases
(dotted lines) as CRD increases. If the CRD is set to 0.6 and the joint E-value is set to 10-40
22
(green lines), the SRD is 0.88 (i.e., 88%) and the number of DDPs is 252,728. This result
demonstrated that members of a PPI family derived by PPISearch reliably share DDPs (or interacting domains). Additionally, similar results were obtained for transferability of conserved functions between homologous PPIs and the query (Figure 8B). The members of a PPI family have similar molecular functions, and SRF ratios are highly correlated with
conservation ratios (CRF) of MFPs. When the CRF is 0.6 and the joint E-value is 10-40 (green lines), the SRF is 0.69 (i.e., 69%) and the number of MFPs is 454,251.
These results revealed that the PPI family achieves a high SRD with a reasonable number
of DDPs when the joint E-value is set to 10-40. In summary, these experimental results demonstrated that this server achieves high agreement on DDPs and MFPs between the query and their corresponding homologous PPIs.
Figure 8. Evaluations of the PPI family. 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Conservation ratio of DDPs in homologous PPIs
S har ed r at io o f D D P s (S R D ) 0 50000 100000 150000 200000 250000 300000 350000 400000 N umb er o f d omai n p ai rs ( N D P ) SRD (logJE<-10) SRD (logJE<-40) SRD (logJE<-100) NDP (logJE<-10) NDP (logJE<-40) NDP (logJE<-100)
B
A
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Conservation ratio of MF pairs in homologous PPIsS ha re d ra ti o of M F p airs ( S R F ) 0 100000 200000 300000 400000 500000 600000 700000 N um be r of M F pa ir s ( N M F P ) SRF (logJE<-10) SRF (logJE<-40) SRF (logJE<-100) NMFP (logJE<-10) NMFP (logJE<-40) NMFP (logJE<-100)
B
Figure 8. Evaluations of the PPI family. (A) The relationships between conservation ratios of
DDPs with shared ratios of DDPs and with the number (dotted lines) of DDPs derived from 103,762 PPI families. The shared ratio of DDPs is 0.88 and the number of DDPs is 252,728 when the conservation ratio is 0.6 and joint E-value is 10-40 (green lines). (B) Relationships between conservation ratios of molecular function pairs (MFPs) with shared ratios of MFPs and with the number (dotted lines) of MFPs derived from 106,997 PPI families. The shared ratio of MFPs is 0.69 and the number of MFPs is 454,251 when the conservation ratio is 0.6 and joint E-value is 10-40 (green lines).
24
3.3
Example analysis of PPI family
Figures 3C and D show search results using σ1A-adaptin (UniProt accession number: P61967) and γ1-adaptin (P22892) of Mus musculus as the query. These two proteins are components of
the heterotetrameric adaptor protein complex 1 (AP-1), which medicates clathrin-coated vesicle transport from the trans-Golgi network to endosome33. According to the crystal structure (PDB code: 1w63)34, this protein pair is a physical interaction, but it is not recorded in the annotated PPI database. For this query, the PPISearch server identifies 14 homologous PPIs, a PPI family, from four species (human, mouse, fruit fly, and yeast). This PPI family has four DDPs (Figure 3E)—PF01217-PF01602 (CRD is 1.0), PF01217-PF02883 (0.93),
PF1217-PF02296 (0.14), and PF01217-PF07718 (0.07). Two DDPs (PF01217-PF01602 and PF01217-PF02883) with highest CRD ratios are the domain compositions of the query and
PF01217-PF01602 is the interacting domains34.
This server allows users to choose the JE threshold of homologous PPIs. For example, when JE is set to 10-100 (default value is 10-40), the number of homologous PPIs decreases from 14 to 10 by filtering out the last four PPIs (Figure 3D). These 10 homologous PPIs consistently include the two DDPs PF01217-PF01602 and PF01217-PF02883, each with a
CRD=1.0. Furthermore, users can choose the best match or number of homologous PPIs in a
species. In this manner, the PPISearch server is able to select the primary homologous PPIs of each species for specific applications, such as evolutionary analysis of essential proteins.
3.4
Limitations and biases of PPI family
There were some families which have numerous homologous PPIs from particular organisms but few homologous PPIs from some organisms, such as the family of transforming growth factor-beta3 (TGFB3) and TGF-beta type II receptor (TGFBR2). In these case studies, we found that the limitations and biases may be caused by the annotated database and the method of searching homologs by local alignment using BLASTP. In this section, we proposed some real cases to confirm these problems and the improvements for these limitations and biases.
3.4.1 Limitations of the annotated database for identifying PPI family
In this study, we identified the PPI family through sequence similarity from the annotated database. Recently, there are rapidly increasing number of PPIs which are identified and
25
characterized by many high-throughput experimental approaches. Therefore, PPIs in the annotated database collected from five public databases (IntAct, BioGRID, DIP, MIPS, and MINT) have many PPIs derived from large-scale PPI identification. We compared the number of proteins in Integr8 database (6,352,363 protein sequences in 2,274 species), which integrated information about deciphered genomes and their corresponding proteomes, and the number of PPIs in the annotated database. Table 1 presents the number of PPIs and proteins in organisms that are commonly used in molecular researches. There are 56,006 proteins (24.19 % in 11 species) of Homo sapiens but only 45,963 PPIs (20.39 %). In contrast, 5,727 proteins
(2.47 %) and 113,161 PPIs (50.42 %) of Saccharomyces cerevisiae are recorded in Integr8
database and the annotated database, respectively. These results indicated that the annotated database was biased by PPIs of Saccharomyces cerevisiae. Conversely, the number of PPIs
from Homo sapiens in the annotated database is underestimated. Similarly, there are few PPIs
in Danio rerio, Bos Taurus, and Gallus gallus. Based on these results, we found that the
number of PPIs is underestimated in some organisms but overestimated in some organisms since we have merged the common used PPI databases. It meant the annotated PPI database is dominated by few species. On the other hand, there are more human PPIs than currently known from high-throughput and other experimental evidence35.
For improving this limitation, we used the Integr8 database as the new protein sequence database instead of original protein sequence database derived from the annotated database. Integr8, which is composed of complete genomes, reflects the genomic distribution of proteins in the nature but is not biased by few species.
3.4.2 Biases of local alignment by BLASTP in searching homologs
We used the tool of BLASTP that searching similar proteins by local alignment to identify homologs through sequence similarity (E-value ≤ 10-10). The PPI family of human transforming growth factor-beta3 (TGFB3) and TGF-beta type II receptor (TGFBR2), which is searching from the annotated database, consists of 23 homologous PPIs in human and only one homologous PPI in muse (Table 2). Otherwise, the SB-PPI family that using the template (PDB code: 1ktz36; TGFB3-TGFBR2) identified 4 and 2 homologous PPIs in human and mouse, respectively, among 28 SB-HomPPIs of six organisms from the Integr8 database (Table 3). More PPIs and organisms were included in this SB-PPI family than the PPI family. Additionally, Figure 9 shows the conservation of domain-domain pairs between PPI family
26
and SB-PPI family in homo sapiens and Mus musculus, and all of domain annotations are
assigned from Pfam database. The SB-PPI family emphasizes the interface of the template 1ktz has more conserved domain-domain pairs than the PPI family. According to the structural interface of 1ktz, TGFB3 binds with TGFBR2 through the TGF_beta domain and ecTbetaR2 domain. The TGF_beta domain and ecTbetaR2 domain are also considered as the interacting domain pair in the iPfam database. However, among these 24 homologous PPIs, there are only three homologous PPIs that also have the interacting domain pair in human (Table 2). The Activin_recp domain instead of the ecTbetaR2 domain in other homologous PPIs implied that these 21 homologous PPIs may not belong to this PPI family. We observed that sequence alignments of these homologous PPIs emphasize on the region of the PKinase domain which is the larger common domain of protein kinase (Figure 9).
Table 2. The PPI family search results [using the protein sequence pair of human TGFB3 (P10600) and TGFBR2 (P37173) as the query]
Protein 1 Protein 2
Species E-value Joint Rank UniProt
AC
Gene
name E-value Domain
UniProt AC
Gene
name E-value Domain
P10600 TGFB3 0.0 TGFb_propeptide TGF_beta P37173 TGFBR2 0.0 ecTbetaR2 Pkinase Homo sapiens 0.0 1 P61812 TGFB2 1e-129 TGFb_propeptide TGF_beta P37173 TGFBR2 0.0 ecTbetaR2 Pkinase Homo sapiens 3.2e-155 2
P01137 TGFB1 1e-82 TGFb_propeptide TGF_beta P37173 TGFBR2 0.0 ecTbetaR2 Pkinase Homo sapiens 1.0e-131 3
P10600 TGFB3 0.0 TGFb_propeptide TGF_beta P36897 TGFBR1 9e-63 Activin_recp TGF_beta_GS Pkinase Homo sapiens 9.5e-122 4 P10600 TGFB3 0.0 TGFb_propeptide TGF_beta P37023 ACVRL1 7e-52 Activin_recp TGF_beta_GS Pkinase Homo sapiens 2.6e-116 5 P61812 TGFB2 1e-129 TGFb_propeptide TGF_beta P36897 TGFBR1 9e-63 Activin_recp TGF_beta_GS Pkinase Homo sapiens 3.0e-96 6 P01137 TGFB1 1e-82 TGFb_propeptide TGF_beta P36897 TGFBR1 9e-63 Activin_recp TGF_beta_GS Pkinase Homo sapiens 9.5e-73 7 P01137 TGFB1 1e-82 TGFb_propeptide TGF_beta P37023 ACVRL1 7e-52 Activin_recp TGF_beta_GS Pkinase Homo sapiens 2.6e-67 8 O14793 MSTN 2e-27 TGFb_propeptide TGF_beta Q13705 ACVR2B 3e-76 Activin_recp Pkinase Homo sapiens 7.7e-52 9
P18075 BMP7 2e-21 TGFb_propeptide TGF_beta Q13705 ACVR2B 3e-76 Activin_recp Pkinase Homo sapiens 7.7e-49 10
P18075 BMP7 2e-21 TGFb_propeptide TGF_beta P27037 ACVR2A 3e-76 Activin_recp Pkinase Homo sapiens 7.7e-49 11
O95390 GDF11 4e-21 TGFb_propeptide TGF_beta Q13705 ACVR2B 3e-76 Activin_recp Pkinase Homo sapiens 1.1e-48 12
P22004 BMP6 2e-20 TGFb_propeptide TGF_beta Q13705 ACVR2B 3e-76 Activin_recp Pkinase Homo sapiens 2.4e-48 13
P22004 BMP6 2e-20 TGFb_propeptide TGF_beta P27037 ACVR2A 3e-76 Activin_recp Pkinase Homo sapiens 2.4e-48 14
P08476 INHBA 2e-19 TGFb_propeptide TGF_beta Q13705 ACVR2B 3e-76 Activin_recp Pkinase Homo sapiens 7.7e-48 15
P08476 INHBA 2e-19 TGFb_propeptide TGF_beta P27037 ACVR2A 3e-76 Activin_recp Pkinase Homo sapiens 7.7e-48 16
P12643 BMP2 4e-18 TGFb_propeptide TGF_beta P27037 ACVR2A 3e-76 Activin_recp Pkinase Homo sapiens 3.5e-47 17
Table 2. The PPI family search results [using the protein sequence pair of human TGFB3 (P10600) and TGFBR2 (P37173) as the query]
Table 2. The PPI family search results [using the protein sequence pair of human TGFB3 (P10600) and TGFBR2 (P37173) as the query] (Continued) Protein 1 Protein 2 Species Joint E-value Rank UniProt AC Gene
name E-value Domain a
UniProt AC
Gene
name E-value Domain
P09529 INHBB 5e-13 TGFb_propeptide TGF_beta Q13705 ACVR2B 3e-76 Activin_recp Pkinase Homo sapiens 1.2e-44 18 P09529 INHBB 5e-13 TGFb_propeptide TGF_beta P27037 ACVR2A 3e-76 Activin_recp Pkinase Homo sapiens 1.2e-44 19 P43026 GDF5 3e-12 TGFb_propeptide TGF_beta Q13705 ACVR2B 3e-76 Activin_recp Pkinase Homo sapiens 3.0e-44 20 P43026 GDF5 3e-12 TGFb_propeptide TGF_beta P27037 ACVR2A 3e-76 Activin_recp Pkinase Homo sapiens 3.0e-44 21 P18075 BMP7 2e-21 TGFb_propeptide TGF_beta Q13873 BMPR2 3e-61 Activin_recp Pkinase Homo sapiens 2.4e-41 22 P22004 BMP6 2e-20 TGFb_propeptide TGF_beta Q13873 BMPR2 3e-61 Activin_recp Pkinase Homo sapiens 7.7e-41 23 Q9Z1W4 Gdf11 4e-21 TGFb_propeptide TGF_beta P27040 Acvr2b 2e-76 Activin_recp Pkinase Mus musculus 8.9e-49 1 PPI family consists of 24 homologous PPIs of human transforming growth factor and its receptor, including transforming growth factor-beta3 (P10600 with interacting
domain TGF_beta) and TGF-beta type II receptor (P37173 with interacting domain ecTbetaR2) searching on Integr8 database. The threshold of the Joint E-value is set to 10-40. a Domain annotations of protein are assigned from Pfam database.
Table 3. The SB-PPI family search results (using the structural template 1ktz of human TGFB3 and TGFBR2 heterodimer as the query)
Protein 1 Protein 2
Species Z-score P / Nb Rank RSS of BPc RSS of CCd
UniProt
AC nameGene Domaina UniProt AC Gene name Domain
P17246 Tgfb1 TGFb_propeptide TGF_beta P38438 Tgfbr2 ecTbetaR2 Pkinase Rattus norvegicus 3.702 - 1 1.00 0.75 Q07258 Tgfb3 TGFb_propeptide TGF_beta P38438 Tgfbr2 ecTbetaR2 Pkinase Rattus norvegicus 3.702 - 2 0.86 0.75 P04202 Tgfb1 TGFb_propeptide TGF_beta Q62312 Tgfbr2 ecTbetaR2 Pkinase Mus musculus 3.124 - 1 0.90 0.00 Q3UFN7 Tgfb3 TGFb_propeptide TGF_beta Q62312 Tgfbr2 ecTbetaR2 Pkinase Mus musculus 3.124 - 2 0.84 0.66 P10600 TGFB3 TGFb_propeptide TGF_beta P37173 TGFBR2 ecTbetaR2 Pkinase Homo sapiens 3.723 P 1 0.89 0.46 P01137 TGFB1 TGFb_propeptide TGF_beta P37173 TGFBR2 ecTbetaR2 Pkinase Homo sapiens 3.723 P 2 0.89 0.48 P61812 TGFB2 TGFb_propeptide TGF_beta P37173 TGFBR2 ecTbetaR2 Pkinase Homo sapiens 3.137 P 3 0.92 0.55 Q9NR23 GDF3 TGF_beta P37173 TGFBR2 ecTbetaR2 Pkinase Homo sapiens 3.097 - 4 -e 0.00 Q66I23 tgfb3 TGFb_propeptide TGF_beta B0S5M2 ORF=DKEY-101K6.5-001 ecTbetaR2 Pkinase Danio rerio 4.034 - 1 0.37 - Q7ZZU7 tgfb1 TGFb_propeptide TGF_beta B0S5M2 ORF=DKEY-101K6.5-001 ecTbetaR2 Pkinase Danio rerio 4.016 - 2 0.37 - Q66I23 tgfb3 TGFb_propeptide TGF_beta Q58EQ1 tgfbr2 ecTbetaR2 Pkinase Danio rerio 3.753 - 3 0.37 - Q7ZZU7 tgfb1 TGFb_propeptide TGF_beta Q58EQ1 tgfbr2 ecTbetaR2 Pkinase Danio rerio 3.735 - 4 0.37 - Q9W6I7 lft2 TGFb_propeptide TGF_beta Q58EQ1 tgfbr2 ecTbetaR2 Pkinase Danio rerio 3.614 - 5 0.37 - Q7SZV4 tgfb2 TGFb_propeptide TGF_beta B0S5M2 ORF=DKEY-101K6.5-001 ecTbetaR2 Pkinase Danio rerio 3.338 - 6 0.37 - Q9W6I7 lft2 TGFb_propeptide TGF_beta B0S5M2 ORF=DKEY-101K6.5-001 ecTbetaR2 Pkinase Danio rerio 3.205 - 7 0.37 - Q7SZV4 tgfb2 TGFb_propeptide TGF_beta Q58EQ1 tgfbr2 ecTbetaR2 Pkinase Danio rerio 3.112 - 8 0.37 - P09531 TGFB1 TGFb_propeptide TGF_beta Q90999 TGFBR2 ecTbetaR2 Pkinase Gallus gallus 3.639 - 1 0.53 0.00 P30371 TGFB2 TGFb_propeptide TGF_beta Q90999 TGFBR2 ecTbetaR2 Pkinase Gallus gallus 3.039 - 2 0.53 0.55
Table 3. The SB-PPI family search results (using the structural template of human TGFB3 and TGFBR2 heterodimer as the query)
Table 3. The SB-PPI family search results (using the structural template 1ktz of human TGFB3 and TGFBR2 heterodimer as the query)
(Continued).
Protein 1 Protein 2
Species Z score P / Nb Rank RSS of BPc RSS of
CCd Uniprot
AC Gene name Domaina
Uniprot
AC Gene name Domain
Q4RLV8 ORF=GSTENG00032323001 TGFb_propeptide TGF_beta Q4SUT7 ORF=GSTENG00012314001 ecTbetaR2 Pkinase nigroviridisTetraodon 3.758 - 1 0.37 - Q4RFT1 ORF=GSTENG00035186001 TGFb_propeptide TGF_beta Q4SUT7 ORF=GSTENG00012314001 ecTbetaR2 Pkinase nigroviridisTetraodon 3.739 - 2 0.37 - Q4RPB2 ORF=GSTENG00031190001 TGFb_propeptide TGF_beta Q4SUT7 ORF=GSTENG00012314001 ecTbetaR2 Pkinase nigroviridisTetraodon 3.735 - 3 0.37 - Q4RR49 ORF=GSTENG00030322001 TGFb_propeptide TGF_beta Q4SUT7 ORF=GSTENG00012314001 ecTbetaR2 Pkinase nigroviridisTetraodon 3.567 - 4 0.37 - Q4RLV8 ORF=GSTENG00032323001 TGFb_propeptide TGF_beta Q4S0V9 ORF=GSTENG00025846001 ecTbetaR2 Pkinase nigroviridisTetraodon 3.496 - 5 0.37 - Q4RFT1 ORF=GSTENG00035186001 TGFb_propeptide TGF_beta Q4S0V9 ORF=GSTENG00025846001 ecTbetaR2 Pkinase nigroviridisTetraodon 3.477 - 6 0.37 - Q4RR49 ORF=GSTENG00030322001 TGFb_propeptide TGF_beta Q4S0V9 ORF=GSTENG00025846001 ecTbetaR2 Pkinase nigroviridisTetraodon 3.456 - 7 0.37 - Q4RPB2 ORF=GSTENG00031190001 TGFb_propeptide TGF_beta Q4S0V9 ORF=GSTENG00025846001 ecTbetaR2 Pkinase nigroviridisTetraodon 3.363 - 8 0.37 - Q4SBM1 ORF=GSTENG00020909001 TGF_beta Q4SUT7 ORF=GSTENG00012314001 ecTbetaR2 Pkinase nigroviridisTetraodon 3.265 - 9 - 0.00 Q4SVQ4 ORF=GSTENG00011872001 TGFb_propeptide TGF_beta Q4SUT7 ORF=GSTENG00012314001 ecTbetaR2 Pkinase nigroviridisTetraodon 3.263 - 10 0.37 - SB-PPI family consists of 4 positive and 0 negative PPIs of the structural template (PDB code 1ktz), including transforming growth factor-beta3 (chain A with interacting
domain TGF_beta) and TGF-beta type II receptor (chain B with interacting domain ecTbetaR2) searching on Integr8 database. The threshold of the Z-score is set to 3.0. a Domain annotations of protein are assigned from Pfam database.
b PPI is a positive (P, recorded in database) or negative case (N, RSS scores of BP and CC are less than 0.4).
c,d The relative specificity similarity (RSS) score, proposed by Wu et al., of Gene Ontology biological process (BP) and cellular component (CC), respectively. e The protein pair don’t have Gene Ontology annotation in BP or CC.
31
Figure 9. Comparing the PPI family with the SB-PPI family using the PPI of human transforming growth factor-beta3 (TGFB3; P10600) and
TGF-beta type II receptor (TGFBR2; P37173) or their 3D heterodimer template (PDB code: 1ktz). The detail information of members in PPI family and SB-PPI family are showed on the Table 1 and 2. The interacting domains (black and green dotted box) are more conserved in SB-PPI family than PPI family. The sequence alignment regions between TGFBR2 and its homologs (purple dotted box) in PPI family are not involved in protein-protein interacting.
Figure 9. Comparing the PPI family with the SB-PPI family using the PPI of human transforming growth factor-beta3 (TGFB3; P10600) and TGF-beta type II receptor (TGFBR2; P37173) or their 3D heterodimer template (PDB code: 1ktz).
ACVR2B (P27040) Joint E-value TGFB3 (P10600) 0.0 TGFBR2 (P37173) GDF11 (Q9Z1W4) 8.9e-49 9.5e-122 TGFBR1 (P36897) 9.5e-122 ACVRL1 (P37023) TGFBR2 (P37173) TGFB1 (P01137) 3.2e-155 TGFB2 (P61812) 1.0e-131 TGFBR2 (P37173) TGFB3 (P10600) TGFB3 (P10600) Structure-based
protein-protein interaction family
Protein-protein interaction family (TGFB3-TGFBR2)
1ktz A
1ktz B
TGFb propeptide
TGF beta (interacting domain)
PKinase
ecTbetaR2 (interacting domain)
Activin_recp TGF beta GS … TGFB3 (P10600) 312 412 TGFBR2 (P37173) 47 165 314 414 TGFB2 (P61812) 290 390 TGFB1 (P01137) 312 412 TGFB2 (P30371) 37 154 TGFBR2 (Q90999) 273 373 TGFB1 (P09531) 312 412 TGFB3 (Q3UFN7) 72 190 TGFBR2 (Q62312) 290 390 TGFB1 (P04202) TGFBR2 (P37173) 47 165 TGFBR2 (P37173) 47 165 72 190 TGFBR2 (Q62312) 37 154 TGFBR2 (Q90999) Homo sapiens Mus musculus … … Z-score 3.723 3.723 3.137 3.124 3.124 3.639 3.039 TGFBR2 (P37173) 47 165 261 364 GDF3 (Q9NR23) 3.097 Gallus gallus




![Table 2. The PPI family search results [using the protein sequence pair of human TGFB3 (P10600) and TGFBR2 (P37173) as the query]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8121048.165898/36.1263.129.1211.133.627/table-family-search-results-using-protein-sequence-tgfbr.webp)
