使用基頻資訊之國語分散式語音辨識系統
86
0
0
全文
(2) 使用基頻資訊之國語分散式語音辨識系統 The Mandarin Distributed Speech Recognition System Using Pitch Information. 研 究 生:魯柏暄. Student : Bo-Xuan Lu. 指導教授:王逸如 博士. Advisor : Dr. Yih-Ru Wang. 國立交通大學 電信工程學系 碩士論文. A Thesis Department of Communication Engineering College of Electrical Engineering and computer Science National Chiao Tung University In Partial Fulfillment of Requirements for the Degree of Master of Science in Electrical Engineering. June 2005 Hsinchu,Taiwan,Republic of China. 中華民國九十四年六月.
(3) 使用基頻資訊之國語分散式語音辨識系統. 研究生:魯柏暄. 指導教授:王逸如 博士. 國立交通大學電信工程學系碩士班. 中文摘要. 在本論文中,將在分散式語音辨認架構之標準-ETSI ES 202 212 XAFE 下, 建立國語語音辨認之效能評估。論文中共作了國語數字串及國語大詞彙連續語音 兩種語音辨認實驗。首先在實驗發現 ETSI 分散式語音辨認架構之基頻偵測器在 語音信號的訊噪比低於 10dB 時,ETSI 架構之基頻偵測器的效能嚴重變壞;這使 得國語語音辨識器在低訊噪比時,使用基頻資訊會比未使用基頻資訊的結果差; 在論文中提出了一個小幅修改 ETSI 架構之基頻偵測方法後,可以增進在低訊噪 比時的基頻偵測效能。論文中更藉由整合使用基頻資訊及未使用基頻資訊辨識器 之辨認分數,可有效增進環境雜訊下的國語語音辨識率。最後在國語數字串可獲 得 86.8%辨認率,在國語大詞彙連續語音可獲得 65.3%、45.4%的音節及字元辨認 率。. 關鍵詞: 分散式語音辨識、基頻偵測器 I.
(4) The Mandarin Distributed Speech Recognition System Using Pitch Information. Student: Bo-Xuan Lu. Advisor: Dr. Yih-Ru Wang. Department of Communication Engineering National Chiao Tung University. Abstract In the thesis, the performance of Mandarin digit-string and continuous large vocabulary Mandarin speech recognition were evaluated under ETSI ES-202-212 XAFE environment. First, the experimental results showed that the performance of the pitch detection algorithm degraded seriously when the SNR of speech signal was lower than 10dB. This makes the Mandarin speech recognizer using pitch information perform inferior to the recognizer without using pitch information in low SNR environments. A modification of the pitch detection algorithm is therefore proposed to improve the performance of ETSI’s pitch detector in low SNR environments. The recognition performance of Mandarin speech can be improved for most SNR levels by integrating the recognizers with and without using pitch information. Finally, 86.8% recognition rate can be achieved for Mandarin digit-string. 65.3% syllable and 45.4% character recognition rates can be achieved for Mandarin continuous speech.. Keywords: DSR, Pitch detection. II.
(5) 誌謝. 在研究所的這兩年中,最需要感謝的人就是陳信宏老師與王逸如老師,尤其 是王逸如老師每次都苦口婆心、不厭其煩的教導我,讓我學到了許多許多,在這 邊要跟老師說一聲「老師,您辛苦了!」;再來要感謝由於有聯發科的支持,讓 我們能順利進行研究。. 再來要感謝實驗室的學長、同學及學弟;智合及性獸學長,在我碰到問題時 由於有你們的幫忙,我才能順利解決,尤其要感謝性獸常常在幫我抓蟲;接著要 感謝我的同學們:順哥、隆勳、金翰、希群以及我們實驗室之花-佩穎,幸虧有 你們的陪伴,我才能順順利利地走完這兩年;還有可愛的學弟們,謝謝你們在我 最後的一年裡,常常帶給我們許多的歡樂;最後還要感謝輝哥,因為你讓我知道 了原來世界是這樣大的阿!. 最後我要感謝我的家人,以及我的女友,由於有了你們的支持,我才能夠努 力到現在,謝謝你們!!. III.
(6) 目錄 中文摘要...........................................................Ⅰ 英文摘要...........................................................Ⅱ 誌謝...............................................................Ⅲ 目錄...............................................................Ⅳ 表目錄.............................................................Ⅶ 圖目錄.............................................................Ⅸ. 第一章 導論.......................................................1 1.1 研究動機....................................................1 1.2 研究方向與主要成果..........................................2 1.3 章節概要....................................................2. 第二章 背景知識與基礎系統.......................................3 2.1 分散式語音辨認系統介紹......................................3 2.2 分散式語音辨識系統環境下國語連續數字串之辨認................6 2.2.1 語料庫................................................6 2.2.2 環境雜訊..............................................7 2.2.3 分散式語音辨識系統後級隱馬可夫模型之語音辨識器.......13 2.2.4 實驗結果.............................................16. 第三章 使用基頻參數的分散式國語連續語音辨識系統............20 3.1 分散式語音辨識系統中的基頻抽取.............................20 3.2 基頻在不同環境雜訊及不同的訊噪比之下的分析.................23 3.3 國語連續數字串之辨識---加入分散式語音辨識系統抽取的基頻 參數.......................................................28 IV.
(7) 3.3.1 實驗設定.............................................28 3.3.2 實驗結果.............................................30. 第四章 改良基頻參數抽取的方法.................................35 4.1 改良式分散式語音辨識系統之基頻參數抽取.....................35 4.2 改良式分散式語音辨識系統前級之基頻參數抽取器之效能分析.....36 4.3 國語連續數字串之辨識---加入改良式分散式語音辨識系統抽取 的基頻參數.................................................37 4.3.1 實驗設定與訓練模型建立...............................38 4.3.2 實驗結果.............................................39 4.4 國語連續數字串之辨識---整合沒有加入基頻參數的辨識器與加入改良 式分散式語音辨識系統抽取之基頻參數的辨識器.................44 4.4.1 實驗設定.............................................45 4.4.2 實驗結果.............................................46 4.5 國語連續數字串之辨識---使用乾淨語音的基頻參數之辨識器......48 4.5.1 實驗設定.............................................48 4.5.2 實驗結果.............................................48. 第五章 大字彙國語連續語音辨認.................................50 5.1 語料庫介紹---TCC300........................................50 5.2 大字彙國語連續語音之辨識---沒有加入基頻參數................51 5.2.1 實驗設定.............................................51 5.2.2 實驗結果.............................................54 5.3 大字彙國語連續語音之辨識---加入改良式的分散式語音辨識系統抽取 之基頻參數.................................................56 5.3.1 實驗設定.............................................56 5.3.2 實驗結果.............................................57 V.
(8) 5.4 大字彙國語連續語音之辨識---整合沒有加入基頻參數的辨識器與加入 改良式分散式語音辨識系統抽取之基頻參數的辨識器.............64 5.4.1 實驗設定.............................................64 5.4.2 實驗結果.............................................65 5.5 加入語言模型至使用改良式分散式語音辨識系統抽取之基頻參數的大 字彙國語連續語音辨識.......................................66 5.5.1 建立語言模型.........................................67 5.5.1.1 訓練語料及詞典.................................67 5.5.1.2 訓練語言模型的方法.............................69 5.5.2 基本辨識器加入語言模型之辨識分析.....................70 5.5.3 實驗結果.............................................71. 第六章 結論與展望...............................................72 6.1 結論.......................................................72 6.2 展望.......................................................73 參考文獻...........................................................74. VI.
(9) 表目錄. 表 2-1. 國語連續數字串語料庫......................................7. 表 2-2. 八種環境雜訊的音檔長度....................................8. 表 2-3. 加上環境雜訊的國語連續數字串內容介紹.....................14. 表 2-4. 語音特徵參數抽取之參數設定...............................15. 表 2-5(a) 國語連續數字串---乾淨語音訓練模式之辨識結果..............16 表 2-5(b) 國語連續數字串---複合情境訓練模式之辨識結果..............17 表 3-1(a) 基頻在地下鐵環境下不同訊噪比之分析.......................24 表 3-1(b) 基頻在嘈雜的人聲環境下不同訊噪比之分析...................24 表 3-1(c) 基頻在汽車環境下不同訊噪比之分析.........................24 表 3-1(d) 基頻在展覽會場環境下不同訊噪比之分析.....................25 表 3-1(e) 基頻在餐廳環境下不同訊噪比之分析.........................25 表 3-1(f) 基頻在街道環境下不同訊噪比之分析.........................25 表 3-1(g) 基頻在機場環境下不同訊噪比之分析.........................26 表 3-1(h) 基頻在火車環境下不同訊噪比之分析.........................26 表 3-1(i) 基頻在不同訊噪比之分析...................................27 表 3-2(a) 加入基頻參數後的國語連續數字串之乾淨語音訓練模式辨識結果.30 表 3-2(b) 加入基頻參數後的國語連續數字串之複合情境訓練模式辨識結果.31 表 3-3. 八種環境雜訊在兩個實驗中的進步情形.......................33. 表 4-1. 比較原本基頻參數抽取的作法與改進後基頻參數抽取的作法.....37. 表 4-2(a) 加入改良式分散式語音辨識系統抽取之基頻參數的國語連續數字串 辨認實驗中乾淨語音訓練模式之辨識結果............................39 表 4-2(b) 加入改良式分散式語音辨識系統抽取之基頻參數的國語連續數字串 辨認實驗中複合情境訓練模式之辨識結果............................40 VII.
(10) 表 4-3(a) 整合有由改良式的分散式語音辨識系統抽取之基頻參數以及不含基 頻參數的國語連續數字串辨識實驗中乾淨語音訓練模式之辨識結果......46 表 4-3(b) 整合有由改良式的分散式語音辨識系統抽取之基頻參數以及不含基 頻參數的國語連續數字串辨識實驗中複合情境訓練模式之辨識結果......47 表 4-4. 使用乾淨語音之基頻參數的國語連續數字串辨識中乾淨語音訓練模. 式之辨識結果....................................................49 表 5-1. 大字彙連續國語語音的語料庫...............................50. 表 5-2. 加上環境雜訊的大字彙連續國語語音內容介紹.................52. 表 5-3. 在測試語料中 8 種環境雜訊下之音節數.......................52. 表 5-4(a) 沒有加入基頻參數的大字彙國語連續語音辨識實驗中的乾淨語音訓 練模式之辨識結果................................................54 表 5-4(b) 沒有加入基頻參數的大字彙國語連續語音辨識實驗中的複合情境訓 練模式之辨識結果................................................55 表 5-5. 每個聲調的出現次數.......................................57. 表 5-6(a) 加入改良式的分散式語音辨識系統抽取之基頻參數的大字彙國語連 續語音辨識實驗中的乾淨語音訓練模式 1,515 個音節之辨識結果........58 表 5-6(b) 加入改良式的分散式語音辨識系統抽取之基頻參數的大字彙國語連 續語音辨識實驗中的複合情境訓練模式 1,515 個音節之辨識結果........59 表 5-7(a) 加入改良式的分散式語音辨識系統抽取之基頻參數的大字彙國語連 續語音辨識實驗中的乾淨語音訓練模式之聲調辨識結果................60 表 5-7(b) 加入改良式的分散式語音辨識系統抽取之基頻參數的大字彙國語連 續語音辨識實驗中的複合情境訓練模式之聲調辨識結果................61 表 5-8(a) 加入改良式的分散式語音辨識系統抽取之基頻參數的大字彙國語連 續語音辨識實驗中的乾淨語音訓練模式 411 個音節之辨識結果..........62 表 5-8(b) 加入改良式的分散式語音辨識系統抽取之基頻參數的大字彙國語連 續語音辨識實驗中的複合情境訓練模式 411 個音節之辨識結果..........63 VIII.
(11) 表 5-9. 整合有由改良式的分散式語音辨識系統抽取之基頻參數以及不含基. 頻參數的大字彙國語連續語音辨識實驗中乾淨語音訓練模式之辨識結果..65 表 5-10. 詞典中之詞長分佈.........................................68. 表 5-11. 通用語料庫之詞數表.......................................69. 表 5-12. 在複合情境訓練、測試-人聲環境雜訊........................71. IX.
(12) 圖目錄. 圖 2-1. 分散式語音系統架構圖......................................4. 圖 2-2. 降低雜訊處理系統流程圖....................................6. 圖 2-3. 在乾淨語料中加入環境雜訊示意圖............................8. 圖 2-4. 八種環境雜訊的長時間頻譜.................................11. 圖 2-5. 八種環境雜訊的頻譜-時間圖(橫軸:時間;縱軸:頻率).....12. 圖 2-6. 八種環境雜訊在兩個訓練模式的比較.........................18. 圖 2-7. 不同的訊噪比在兩個訓練模式的比較.........................19. 圖 3-1. 分散式語音辨識前級估計基頻與語音狀態資訊系統架構.........21. 圖 3-2. 經過指數函數補償的基頻...................................22. 圖 3-3. 比較在乾淨語音與汽車環境雜訊中訊噪比為 0dB 的基頻值.......28. 圖 3-4. 八種環境雜訊的辨識結果比較...............................33. 圖 3-5. 不同的訊噪比的辨識結果比較...............................34. 圖 4-1. 改良式分散式語音辨識系統前級之基頻參數抽取的架構.........35. 圖 4-2(a) 在乾淨語音訓練模式中比較沒有加入基頻參數、使用 DSR XAFE 與 Modified XAFE 抽取之基頻參數的辨識結果....................41 圖 4-2(b) 在複合情境訓練模式中比較使用沒有加入基頻參數、DSR XAFE 與 Modified XAFE 抽取之基頻參數的辨識結果....................41 圖 4-3. 整合含有基頻參數以及不含基頻參數的辨識器之系統方塊圖.....45. 圖 5-1. LM 訓練流程圖.............................................67. 圖 5-2. LM 轉 Word-Net 之流程圖....................................70. IX.
(13) 第一章 導論 1.1. 研究動機. 由於科技產業的蓬勃發展,電子產品的功能日益強大,而體積卻是越做越 小,這不但是代表著人類的卓越的發明、創新的能力,同時這也為我們的生活帶 來了許許多多的便利;加上無線網路的進步,滿足了人們隨心所欲、隨時隨地交 流資訊的渴望。例如行動電話和筆記型電腦的普及,讓我們無論是在路上或是車 上,時時刻刻都能夠利用電子產品與網際網路接軌,可以接收或是發送資訊,尤 其是以行動電話的普及率更是高達到幾乎人手一機了;但是為了便利性、可攜帶 性,我們不斷的追求這些產品的輕薄短小,使得傳統式的鍵盤或按鍵輸入已經漸 漸不是最方便的輸入方式了,我們需要的是能夠更快速且能處理繁雜指令的輸入 介面。而使用語音當成輸入介面就是一個很好的方法。. 根據前面所述,若是使用語音作為新的輸入介面,勢必碰上許多問題:手持 設備(Handheld device)的體積太小,其計算能力以及儲存用的記憶體將嚴重 受限,使得我們要在手持設備上處理整個語音辨識的程序是有困難的。因此分散 式語音辨識(Distributed Speech Recognition; DSR)架構就此產生。分散式 語音辨識的想法是將整個語音辨識工作分成兩個部分:在手持設備(Client)上, 因為有許多限制,因此只做簡單的語音參數的抽取與壓縮,再將這些資料透過無 線通道傳送到遠端的伺服器(Server)執行語音辨識。也因為要透過無線通道來 傳遞資訊,無可避免的會有因多通道衰減造成(Multi-path fading)的群集錯 誤(Burst error)等;而且當使用者在使用手持設備的同時,會受到週遭環境 的影響,是造成使辨識率下降的最重要原因之一。. 1.
(14) 1.2. 研究方向. 本論文主要的研究方向在分散式語音辨識系統的架構下,建立國語連續語音 之辨識器;並且希望能夠加入基頻參數於國語連續語音辨識器中,以對抗環境雜 訊的干擾。本論文同時也提出了改良式的分散式語音辨識系統基頻參數抽取的方 法,此作法能夠有效的改進高訊噪比下之基頻偵測效能並提升辨識率。. 1.3. 章節概要. 第一章 導論:說明本篇論文的研究動機、研究方向及章節概要。 第二章 背景知識與基礎系統:介紹分散式語音辨認系統,並且做了一個國語連 續數字串辨認的實驗。 第三章 結合聲調辨識器與分散式語音辨識系統:說明如何建立一個加入由分散 式語音辨認系統抽取之基頻參數的辨認器,並且對分散式語音辨認系統 抽取之基頻參數所做的效能分析,以及實驗的結果分析。 第四章 改良基頻參數抽取方法:介紹的是如何改良分散式語音辨識系統之抽取 基頻參數的方法,使其應用在辨識器時,可以提升辨識率;並且分析比 較改良式分散式語音辨識系統抽取之基頻參數與原本的分散式語音辨 識系統抽取之基頻參數。 第五章 大字彙國語連續語音辨認:將對大字彙國語連續語音辨認比較其有使用 基頻參數與沒有使用基頻參數的差異。 第六章 結論與展望:對本論文的方法結果作結論,並說明未來改進的方向。. 2.
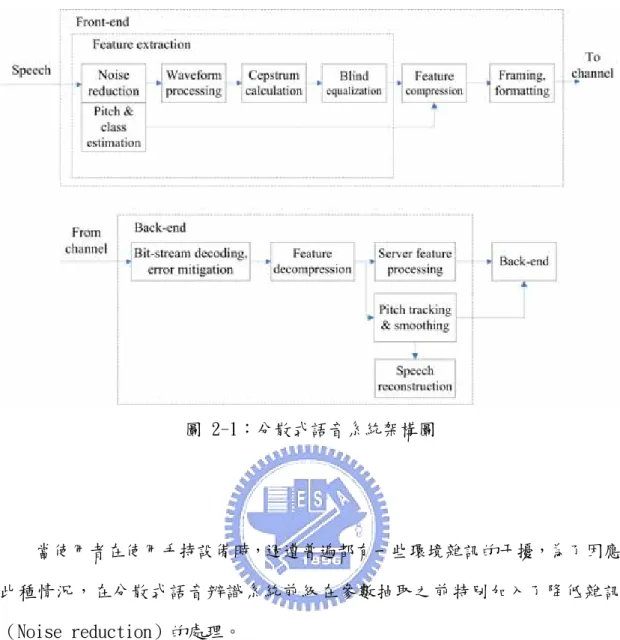
(15) 第二章 背景知識與基礎系統. 本章將會介紹分散式語音辨認系統,並且做了建立在分散式語音辨識系統, 多種環境雜訊下的國語連續數字串辨識實驗。. 2.1. 分散式語音辨認系統介紹. 分散式語音辨識系統主要的構想是來自:想要應用在手持設備可以使用語音 輸入更多更複雜的指令,但是手持設備又受限於其計算能力以及記憶體的不足。 因此分散式語音辨識系統的架構是將語音辨識分成兩個部分:在手持設備也就是 分散式語音辨識系統的前級(DSR front-end)接收語音輸入,繼而抽取語音的 特徵參數,經過壓縮、編碼,透過無線通道傳送到伺服器也就是分散式語音辨識 的後級(DSR back-end)端進行解碼以及辨識。本論文中之語言辨識前級是使用 歐洲電信標準協會編號202 212 V1.1.1(ETSI ES 202 212 V1.1.1)[1]之分散 式語音辨識系統前級的標準( Extended Advance Feature Extraction; XAFE), 圖 2-1則是歐洲電信標準協會編號202 212 V1.1.1之分散式語音辨識系統的架構 圖。. 3.
(16) 圖 2-1:分散式語音系統架構圖. 當使用者在使用手持設備時,週遭普遍都有一些環境雜訊的干擾,為了因應 此種情況,在分散式語音辨識系統前級在參數抽取之前特別加入了降低雜訊 (Noise reduction)的處理。. 在歐洲電信標準協會編號 202 212 V1.1.1分散式語音辨識系統前級中,降 低語音雜訊的處理方法是利用一個二階式維納濾波器(Wiener filter),如圖 2-2所示,這是一種能夠有效降低雜訊的方法,圖 2-2 顯示它的方塊圖,它是由 兩個串聯的維納濾波器組成,它們的輸出及輸入都是聲音的波形(Waveform)訊 號;第一個維納濾波器的輸入是未經處理且帶有雜訊的語音波形訊號,輸出的是 經過初步處理的語音波形訊號,它同時也是第二個維納濾波器的輸入波形訊號, 第二個維納濾波器輸出的是已除去大部分雜訊的波形訊號。在第一個維納濾波器 中包含了語音偵測的技術(Voice Activity Detection, VAD),用以進行雜訊 頻譜的估測(Noise spectrum estimation),第二個維納濾波器則假設經過第 4.
(17) 一個維納濾波器的處理,剩餘的加成性雜訊可以用白雜訊(White noise)近似, 不再含語音偵測技術。兩個維納濾波器都是隨著各個音框(Frame)內不同的雜 訊特性及訊噪比而設計的;首先依照不同頻率的訊噪比,得到線性頻率上維納濾 波器的係數(Linear-frequency Wiener filter coefficients),再將其通過 梅爾濾波器組(Mel filter-bank)以得到較平滑且和聽覺系統相關的梅爾維納 濾波器係數(Mel-warped Wiener filter coefficient),接著將此梅爾維納濾 波 器 係 數 作 梅 爾 反 離 散 餘 弦 轉 換 ( Mel-warped Inverse Discrete Cosine Transformation, Mel-warped IDCT),以得到在時域上的脈衝響應(Impulse response),最後再把目前音框中的波形訊號通過此脈衝響應以得到輸出的波形 訊號。在第二階維納濾波器輸出之前,有一個偏移補償(Offset compensation) 的區塊,用以移除輸出波形中的直流偏移量(DC offset)。. 圖2-2:降低雜訊處理系統流程圖. 在歐洲電信標準協會編號 202 212 V1.1.1的系統架構中,也訂定了偵測基 頻 的 方 法 , 其 用 途 可 以 用 來 做 聲 調 語 言 之 語 音 的 辨 識 ( Tonal language 5.
(18) recognition)以及重建語音訊號(Speech reconstruction),所以在本論文中 將會利用歐洲電信標準協會編號202 212 V1.1.1所偵測的基頻資訊來做國語連續 語音的辨認。. 2.2. 分散式語音辨識系統環境下國語連續數字串之辨認. 在一套新的語音辨識系統架構中,一開始大多選定連續數字串的辨識工作, 因為連續數字串是有最多應用的一個語音辨識系統。在分散式語音辨識系統的環 境下,加上在分散式語音辨識系統的環境下,都會考慮環境雜訊對語音辨識效能 的影響。所以 AURORA-2 為例,它是由 TI-Digits 這套不含雜訊的英文連續數字 串的語料,並以人工處理的方式加上了八種環境雜訊而成的語料。在乾淨語音的 時候,辨識率已經高達 99.02%,但是加了環境雜訊之後,辨識率隨著訊噪比越 低,下降越快,平均從訊噪比 20dB 到 0dB 辨認率大幅降低了 30%[2]。在本論文 中將先建立一個在分散式語音辨識系統環境下國語連續數字串的基本辨識系統。. 2.2.1 語料庫. 在實驗中所使用的國語連續數字串語料庫,是一套由交通大學語音實驗室所 錄製的麥克風語料。表 2-1 列出此套語料的錄製方式,取樣頻率、句數,以及 語料統計特性。. 6.
(19) 表 2-1:國語連續數字串語料庫 錄製方式. 麥克風. 取樣頻率. 16 kHz. 編碼格式. 16 位元 PCM. 語料內容. 男性語者和女性語者各 50 人,每人 10 句,共 1000 句,6,438 個數字. 統計特性. 每句有 1~11 個數字不等,平均每句含有 6~7 個數字. 一般大眾使用的 GSM 手機,其內部對於聲音的取樣頻率,是依據傳統公眾 交換電話網路 ( PSTN ) 取樣頻率為 8k Hz 的標準。為了相容於此標準,使我 們的實驗更符合實際情況,所以將所取得的麥克風語料降頻 ( down-sample ) 為 8kHz。. 2.2.2 環境雜訊. 實際上當使用者在使用分散式的語音辨認系統時,系統的辨識率會受到使用 者週遭的環境雜訊影響,為了使我們的實驗與實際狀況更符合,所以要在語料中 加上環境雜訊。. 在本論文中,環境雜訊是採用 AURORA 2 中提供的環境雜訊[3],總共有八種 環境雜訊 ( 地下鐵、人聲、汽車、展覽會館、餐廳、街道、機場、火車站 ), 取樣頻率是 8kHz ,16 bit 的 PCM 檔案。表 2-2 表示每個環境雜訊的音檔長 度。. 7.
(20) 表 2-2:八種環境雜訊的音檔長度 地下鐵. 20:24. 人聲. 3:55:06. 汽車. 22:12. 展覽會館. 19:06. 餐廳. 4:46:12. 街道. 57:11. 機場. 2:59:29. 火車站. 2:59:29. 在加入環境雜訊時,是以乾淨語料的長度為基準,隨機選擇一段環境雜訊與 乾淨語料相同長度作相加的動作,但是八種環境雜訊的音長不盡相同,也不一定 會比乾淨語料還要長,所以又可以分成兩種情形: 1.乾淨語料的音長比環境雜 訊的音長短;2.乾淨語料的音長比環境雜訊的音長還長。. 當乾淨語料的音長比環境雜訊的音長短的時候,便是直接以乾淨語料的長度 為基準,隨機選擇一段與乾淨語料相同長度的環境雜訊,來與乾淨語料做相加的 動作;若是乾淨語料的音長比環境雜訊的音長還長的時候,先重覆環境雜訊,直 到環境雜訊的音長超過乾淨語料的音長,再以乾淨語料的長度為基準,隨機選擇 一段與乾淨語料相同長度的環境雜訊,來與乾淨語料做相加的動作。圖 2-3 以 圖示說明。在圖 2-3 中,S 為乾淨語料的音長,N 為環境雜訊的音長,L 是環境 雜訊上與乾淨語料相加區段的起始點。. 圖 2-3:在乾淨語料中加入環境雜訊示意圖 接著介紹當我們如何在乾淨語料中加上環境雜訊,並且控制訊噪比 8.
(21) (Signal-to-Noise Ratio, SNR)在某一定值的方法。首先要先計算乾淨語料以 及環境雜訊的平均能量 (Average Power),其中乾淨語料只計算有語音部份的平 均能量,環境雜訊只計算與乾淨語料相加部份的平均能量。平均能量可以下式表 示:. P=. 1 M. M. ∑ x (i ) 2. (2-1). i =1. P 為平均能量, M 為取樣的個數, x ( i ) 代表是第 i 個取樣點的振幅大小。. 在乾淨語料與環境雜訊相加時,想要控制訊噪比在某一定值,又因為訊噪比 為語音訊號與環境雜訊能量大小的比值,即為聲音振幅大小的比值[4],所以固 定乾淨語料振幅的大小,只調整環境雜訊振幅的大小;將環境雜訊的振幅大小乘 1. - SNR 2 ⎛P ⎞ 以 G = ⎜ S 10 10 ⎟ 倍,再與乾淨語料的振幅相加,即可控制乾淨語音訊號與環 ⎝ PN ⎠. 境雜訊相加後的訊噪比。. 1. ( ). SNR = 10 log ( PS ) -10 log PN'. 其中 PS =. 1 M. M. ∑ xS2 ( i ) , PN = i =1. 1 K. - SNR 2 ⎛P ⎞ ⇒ G = ⎜ S 10 10 ⎟ ⎝ PN ⎠. K. ∑ x (i ) i =1. (2-2). , PN' = G 2 * PN. 2 S. SNR 為乾淨語料與環境雜訊相加後的訊噪比, PS 代表乾淨語料的平均能量, PN 代表環境雜訊的平均能量, PN' 代表調整過後的環境雜訊的平均能量。. 9.
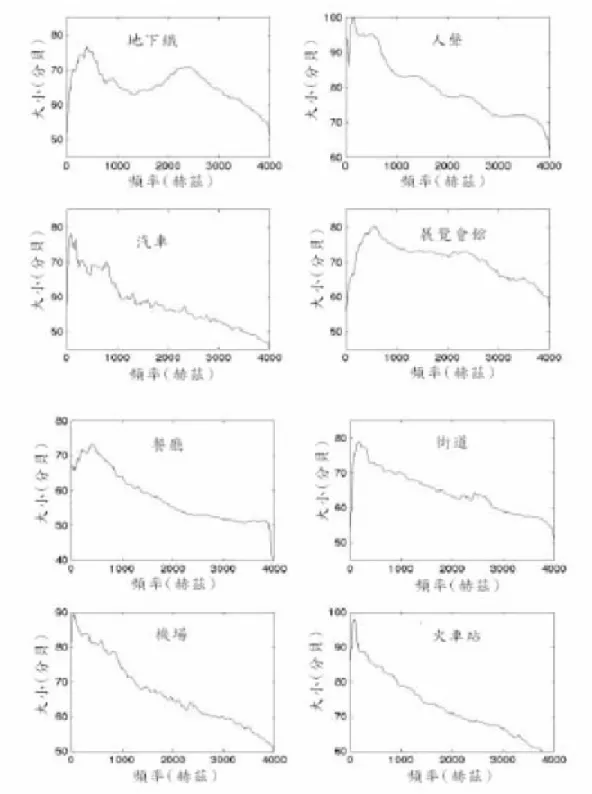
(22) 圖 2-4是各種環境雜訊的長時間頻譜(long-term spectrum)圖,由此圖可看 出:汽車雜訊、機場雜訊及火車站雜訊長時間平均頻譜在低頻處能量最高,隨著 頻率增加,能量逐漸減少,至4000Hz(二分之一的取樣頻率)時的能量大小和能量 最高處相差約有40dB;人聲雜訊、餐廳雜訊及街道雜訊的長時間頻譜特性大致和 前述三種類似,但高頻及低頻能量的差距不像前述三種雜訊明顯,且能量峰值的 位置亦較前述三種雜訊來的高;剩下兩種雜訊的特性則較為不同,地下鐵雜訊在 500Hz及2500Hz這兩處能量都有明顯峰值,展覽會館雜訊和其他雜訊相比之下, 其長時間頻譜則是較接近平坦的白雜訊特性。由圖 2-4只能觀察出各種雜訊長時 間平均後的特性,卻無法得知其特性是否穩定(Stationary)。圖 2-5 則是它們 的頻譜-時間圖(Spectrogram)橫軸及縱軸分別代表時間及頻率,較亮的顏色代表 較強的能量,由此圖較易了解雜訊的穩定性如何;由此圖我們看到較穩定的雜訊 (如:汽車雜訊及展覽會館雜訊)在任一時間點的頻譜都很接近其長時間頻譜;而 不穩定的雜訊(如:街道雜訊、機場雜訊及火車站雜訊),則隨著不同的時間點, 可能有著變動很大的頻譜特性,所以其長時間頻譜和實際上的雜訊特性是有較多 出入的。. 10.
(23) 圖 2-4:八種環境雜訊的長時間頻譜. 11.
(24) 圖 2-5:八種環境雜訊的頻譜-時間圖(橫軸:時間;縱軸:頻率). 12.
(25) 2.2.3 分散式語音辨識系統後級隱藏式馬可夫模型之語音辨識器. 在實驗中,分散式語音辨識系統後級採用隱藏式馬可夫模型 ( Hidden Markov Model, HMM )語音辨識器。隱藏式馬可夫模型的產生也可以分成只用乾 淨語料訓練,或是用加入不同的環境雜訊、以及不同訊噪比的語料做訓練,分別 對應到「乾淨語料訓練」和「複合情境訓練」這兩種訓練模式;而且依照各種訊 噪比加上八種不同的環境雜訊,按照所加環境雜訊的種類,分成 A、B 兩種測試 組合 ( Testing set ),其中 A 組所加入的環境雜訊是與訓練語料所加入之環境 雜訊匹配(Match) ,B 組所加入的環境雜訊與是訓練語料所加入之環境雜訊不匹 配(Mismatch) 。詳細內容如表 2-3 所示。. 在乾淨語音訓練模式中,將語料庫的十分之九當作訓練語料,其中男性語者 和女性語者各 45 人,每人 10 句,共 900 句,5,796 個數字;在複合情境訓練模 式中,因為語料數不夠的因素,所以將在乾淨語音訓練模式的 900 句的訓練語 料,重複使用兩次,總共 1,800 句訓練語料,再平均分為 20 組,每組中沒有重 複出現的句子,且每組分別是加入不同環境雜訊、不同訊噪比的情境。在兩種訓 練模式中,都是將語料庫的另外十分之一當作測試語料,男性語者和女性語者各 5 人,每人 10 句,共 100 句,642 個數字。同樣也是有語料數不足夠的問題,所 以將 100 句測試語料重複使用於各個不同的環境雜訊與不同的訊噪比的組合 中,總共有 49 組測試組,分別是八種環境雜訊與六種訊噪比合併組合的 48 組, 以及一組乾淨語料測試。. 13.
(26) 表 2-3:加上環境雜訊的國語連續數字串內容介紹 國語連續數字串語料庫 取樣頻率. 8 kHz 乾淨語音訓練. 訓練模式. 複合情境訓練. 音段數:900. 音段數:1,800. 環境雜訊: 無. 環境雜訊 : z 種類 : 地下鐵、人聲、汽車、展覽會館 z 訊噪比 : 20dB、15dB、10dB、5dB 和完全 乾淨 z 4 種雜訊乘以 5 種 SNR,共 20 種情境 A 組. 測試組合. B 組. 音段數 :2,800 環境雜訊 : 地下鐵 人聲 汽車 展覽會館. 音段數 : 2,800 環境雜訊 : 餐廳 街道 機場 火車站. 對於上述的每種環境雜訊,訊噪比都控制在 20dB、15dB、10dB、 5dB、0dB、-5dB 以及完全乾淨七種程度,並且對於每種雜訊的每 依個訊噪比程度都計算一組辨識結果. 本實驗使用的語音辨認參數是 12 維梅爾倒頻譜係數(Mel Frequency Cepstral Coefficients, MFCC),加上一維與二維的變化量,以及能量的一維與二維的變 化量,共 38 維特徵向量。表 2-4 列出特徵參數抽取過程中各項參數設定。其中 前五項是分散式語音辨識系統前級的標準設定,而語音特徵向量之選取則是後級 隱藏式馬可夫模型辨識器之設定。. 14.
(27) 表 2-4:語音特徵參數抽取之參數設定 取樣頻率(Sampling rate). 8 kHz. 音框長度(Frame window size). 25 ms. 音框平移量(Frame window shift). 10 ms. 預強調的轉換函數(Pre-emphasis). 1-0.9z -1 23 個濾波器. 梅爾濾波器組(Mel-frequency filter bank) 語音特徵向量(Speech feature vector). 38 維(靜態[12-MFCCs, log E ]、ㄧ次及二次動 態係數). 隱藏式馬可夫語音辨識模型的建立則詳述如下:首先建立國語數字從 0 到 9 的聲學模型,每個聲學模型設定為 8 個狀態(State) ,每個狀態含有 8 個混合高 斯數(Mixtures);除了國語數字的聲學模型外,還有兩個模型---靜音模型 (Silence model)與停頓模型(Short pause model) 的聲學模型,是用來描 述語音信號中靜音部分,其中靜音聲學模型是描述句首和句尾之靜音,設定為 3 個狀態,停頓聲學模型則用來描述字與字之間的靜音,設定為 1 個狀態,此狀態 允許跳躍(Skip),並且與靜音模型的中間狀態合併(Tying),兩個聲學模型中 每個狀態則含有 16 個混合高斯數。. 15.
(28) 2.2.4 實驗結果. 表 2-5(a)與表 2-5(b)分別列出乾淨語音訓練模式與複合情境模式下的辨 識結果。其中各種環境雜訊下之平均辨識率是依照 AURORA-2 平均辨識率的計算 方式,只對訊噪比 20dB 到 0dB 環境下的辨識率做平均。. 表 2-5(a):國語連續數字串---乾淨語音訓練模式之辨識結果 乾淨語音訓練 訊噪比 (dB). A組 地下鐵. 人聲. 乾淨. 汽車. 展覽會館 平均值. 98.1%. 20. 94.9%. 93.3%. 97.0%. 94.7%. 95.0%. 15. 90.3%. 91.7%. 95.6%. 91.4%. 92.3%. 10. 84.4%. 87.5%. 93.8%. 84.7%. 87.6%. 5. 66.7%. 77.4%. 86.0%. 70.6%. 75.2%. 0. 41.1%. 52.0%. 60.4%. 42.1%. 48.9%. -5. 16.4%. 20.1%. 19.9%. 15.4%. 18.0%. 平均值(20dB~0dB). 75.5%. 80.4%. 86.6%. 76.7%. 79.8%. 火車站. 平均值. 訊噪比 (dB). B組 餐廳. 街道. 乾淨. 機場 98.1%. 20. 90.0%. 95.5%. 90.5%. 95.3%. 92.8%. 15. 86.1%. 94.4%. 89.4%. 94.9%. 91.2%. 10. 80.7%. 87.4%. 86.6%. 90.3%. 86.3%. 5. 67.0%. 80.2%. 81.5%. 86.3%. 78.8%. 0. 48.6%. 48.3%. 57.2%. 65.4%. 54.9%. -5. 21.7%. 24.0%. 31.3%. 38.6%. 28.9%. 平均值(20dB~0dB). 74.5%. 81.2%. 81.0%. 86.4%. 80.8%. 八 種 環 境 雜 訊 及 五 種 訊 噪 比 的 平 均 值. 16. 80.3%.
(29) 表 2-5(b):國語連續數字串---複合情境訓練模式之辨識結果 複合情境訓練 訊噪比 (dB). A組 地下鐵. 人聲. 乾淨. 汽車. 展覽會館 平均值. 96.6%. 20. 95.8%. 96.9%. 97.2%. 97.2%. 96.8%. 15. 95.0%. 96.0%. 96.9%. 95.5%. 95.9%. 10. 89.1%. 93.0%. 96.1%. 91.1%. 92.3%. 5. 77.1%. 84.1%. 91.4%. 80.7%. 83.3%. 0. 48.0%. 62.0%. 68.1%. 52.7%. 57.7%. -5. 17.3%. 25.9%. 26.2%. 15.7%. 21.3%. 平均值(20dB~0dB). 81.0%. 86.4%. 89.9%. 83.4%. 85.2%. 火車站. 平均值. 訊噪比 (dB). B組 餐廳. 街道. 乾淨. 機場 96.6%. 20. 94.2%. 95.5%. 92.7%. 95.5%. 94.5%. 15. 94.1%. 95.0%. 94.7%. 96.0%. 95.0%. 10. 88.6%. 89.6%. 92.7%. 93.8%. 91.2%. 5. 78.5%. 84.6%. 86.3%. 90.5%. 85.0%. 0. 56.9%. 53.4%. 69.6%. 76.5%. 64.1%. -5. 25.7%. 27.4%. 40.7%. 46.7%. 35.1%. 平均值(20dB~0dB). 82.5%. 83.6%. 87.2%. 90.5%. 86.0%. 八 種 環 境 雜 訊 及 五 種 訊 噪 比 的 平 均 值. 85.6%. 從實驗結果中,我們可以獲得以下觀察: (1) 乾淨語音訓練模式的辨識率幾乎都是比複合情境訓練模式的辨識率還差,這 和我們的預期是一致的,因為複合式情境訓練模式所訓練出來的聲學模型跟 測試語料較匹配的原因;只有在沒有任何環境雜訊的測試情形下,乾淨語音 訓練模式的辨識率比複合情境訓練模式的辨識率好,這是因為此時複合情境 訓練模式所產生的聲學模型反而和測試語料存在較大的不匹配了。 (2) 火車站與汽車環境雜訊有比較多低頻聲音,所以對語音辨認的影響較小。. 17.
(30) (3) 比較在不同的環境雜訊之下,兩種訓練模式的差異。從乾淨語料訓練模式到 複合情境訓練模式,辨識率提高最多的是加了餐廳環境雜訊的情況,次之的 是加了展覽會館環境雜訊的情況;進步最少的是加了街道環境雜訊的情況。 如圖 2-6 所示。 (4) 兩種訓練模式都是隨著訊噪比越低,辨識率也會越低,當訊噪比低於 5dB 時,辨認率會急速下降;而且在訊噪比在 10dB 以上時,測試組合的 A 組的 辨識率,都比測試組合的 B 組還要高;但是訊噪比在 5dB 以下,情形便顛倒 過來,測試組合的 A 組的辨識率,都比測試組合的 B 組還要低。如圖 2-7 所示。. 95.0% 乾淨語料 90.0%. 複合情境. 85.0%. 辨識率. 80.0% 75.0% 70.0% 65.0% 60.0% 55.0% 50.0% 地下鐵. 人聲. 汽車. 展覽會館. 餐廳. 街道. 機場. 圖 2-6:八種環境雜訊在兩個訓練模式的比較. 18. 火車站.
(31) 辨識率. 100.0%. clean_A. 90.0%. clean_B. 80.0%. multi_A. 70.0%. multi_B. 60.0% 50.0% 40.0% 30.0% 20.0% 10.0% 0.0% 20. 15. 10. 5 訊噪比(dB). 0. -5. 圖 2-7:不同的訊噪比在兩個訓練模式的比較. 19. Ave.
(32) 第三章 使用基頻參數的分散式國語連續語音辨識系統. 從上一章中,我們知道在有環境雜訊的情況下,語音的辨識率會隨著訊噪比 越低而降低,而且在訊噪比為 5dB 以下時,辨識率下降的情況更為嚴重。為了減 緩這種情況發生,本章中我們將加上在歐洲電信標準協會編號 202 212 V1.1.1 的分散式語音系統架構中一項新的參數---「基頻」 ,相信如果將這項基頻參數使 用在辨識器中,對國語語音應當可以獲得辨識率的增益[5]。本章說明如何使用 分散式語音辨認系統中求得的基頻參數,建立一個帶聲調的國語連續數字串辨認 器,以及所做的實驗與分析。. 3.1. 分散式語音辨識系統之基頻抽取. 在這一節將先介紹歐洲電信標準協會編號 202 212 V1.1.1 的分散式語音系 統架構中基頻參數,是如何求得的。接著再介紹在聲調辨識器中所使用的基頻參 數。 在分散式語音辨識系統的前級中的「Pitch. & class estimation」,參考圖. 2-1,是用來估計基頻以及語音的狀態資訊。當語音信號數入,中間經過波形處 理(Waveform processing) 、計算頻譜及能量(Spectrum and energy computation; SEC),基頻以及是否為語音的預先估計(Pre-processing for pitch and class estimation; PP) ;梅爾濾波器組---用以得到較平滑且和聽覺系統相關的梅爾維 納濾波器係數,之後再經過語音偵測處理,得到哪一段是語音、哪一段不是語音 的資訊;低頻的雜訊偵測(Low-band noise detection; LBND)---偵測在低頻 中哪一個音框有背景雜訊,用以預先加強由 PP 求得的功率頻譜;然後在經由最 後的基頻估計(Pitch estimation; PITCH)得到最後的基頻值;最後再由「CLS」 20.
(33) 得到最後的語音狀態資訊。其系統方塊圖於圖 3-1。. 圖 3-1:分散式語音辨識前級估計基頻與語音狀態資訊系統架構. 在歐洲電信標準協會編號 202 212 V1.1.1 標準中,基頻軌跡的追蹤是在分 散式語音辨識系統的後級處理,如此可以補償一些由於傳輸錯誤所造成的基頻資 訊錯誤。. 在語音辨識器中,我們使用了連續隱藏式馬可夫模型(Continuous HMM), 必須將沒有基頻值的語音信號補一個非零的值,這樣才能夠避免基頻參數的觀察 機率發生不連續性的現象。所以本論文中將由 ETSI 202 212 V1.1.1 的 DSR 架構 中所求得的基頻參數,取其對數(log-F0) 。接著再利用指數函數(Exponential function) ,將補償(Interpolation)介於兩段語音中間屬於無聲音(Unvoiced) 的音框(Frame) ,以及每一個句子頭尾兩段沒有語音的音框[6]。補償第 n 個音 框非語音的基頻值,式子如下所示:. 21.
(34) (. ). log f [n] = 0. (. ). MAX ⎛⎜ log f [b] ⋅ e 0 ⎝. −α (n − b). (. ). ,log f [ g ] ⋅ e 0. −α ( g − n) ⎞ ⎟ ⎠. (式 3-1). 其中 b 是代表上一個有語音的音框編號,g 是下一個有語音的音框編號, α 是衰 減係數,在本論文當中設定 α = 0.95 。. 舉個例子來看經過補償後的基頻值,這個例子是加上地下鐵的環境雜訊,且 訊噪比設定在 20dB 的條件下。由圖 3-2 可看出基頻(F0)在經過指數函數補償 前與補償後的區別。. 350. 350 Interpolation. 300. Original. Freq (Hz). 250. 300 250. 200. 200. 150. 150. 100. 100. 50. er. si. ba. er. qi. 0. 50 0. 1 15 29 43 57 71 85 99 113 127 141 155 169 183 197 211 225 239 253 267 281. Frame 圖 3-2:經過指數函數補償的基頻. 22.
(35) 3.2. 在不同環境雜訊之基頻偵測分析. 為了要瞭解究竟在不同的環境雜訊以及在不同的訊噪比的條件之下 ,對分散式語音辨識系統之基頻參數的抽取有什麼影響。表 3-1(a)到表 3-1(h)中,分別表示八種不同的環境雜訊在六種訊噪比之下與乾淨環境下基頻資 訊的差異分析比較:在同一環境雜訊底下,六種不同的訊噪比分別與乾淨語料所 求出的基頻做的比較。其中,將基頻錯誤分成了三類,其中前兩種是偵測到有聲 音(Voiced)和無聲音(Unvoiced)的分類錯誤;第三類才是在有聲音的狀態下, 基頻參數求取的錯誤。 1.. U->V 判別錯誤:乾淨語音所求得的基頻屬於無聲音(pitch = 0),而加上 環境雜訊後的語音所求得的卻是有聲音的(pitch 有值)。. 2.. V->U 判別錯誤:乾淨語音所求得的基頻是有聲音的(pitch 有值),而加上 環境雜訊後的語音所求得的基頻卻是屬於無聲音(pitch = 0)。. 3.. V->V 相對錯誤:是指乾淨語音所求的基頻值( pitch ≠ 0 ),與加上環境雜 訊後的語音所求得的基頻值( pitch ≠ 0 )的相對錯誤。以均方誤差(Mean square error; MSE)表示兩者的相對錯誤,計算公式為. 1 MSE = N. 2. ⎛ Pi − Pi ' ⎞ ⎜ ⎟ (式 3-1) ∑ Pi ⎠ i =1 ⎝ N. 其中, P 為乾淨語音所求得的基頻值; P' 為加上環境雜訊後的語音所求得 的基頻值;i 是音框編號;N 是在這段語音的音框數。. 23.
(36) 表 3-1(a):基頻在地下鐵環境下不同訊噪比之分析 訊噪比 (dB). U->V. V->U. V->V 相對錯誤. 20. 1.84%. 7.84%. 0.087. 15. 1.15%. 11.48%. 0.119. 10. 0.38%. 19.41%. 0.200. 5. 0.25%. 38.85%. 0.404. 0. 0.09%. 70.05%. 0.719. -5. 0.09%. 94.10%. 0.947. 表 3-1(b):基頻在嘈雜的人聲環境下不同訊噪比之分析 訊噪比 (dB). U->V. V->U. V->V 相對錯誤. 20. 3.60%. 9.07%. 0.093. 15. 4.61%. 12.80%. 0.141. 10. 4.41%. 21.91%. 0.242. 5. 5.65%. 41.92%. 0.457. 0. 5.48%. 70.08%. 0.729. -5. 4.80%. 89.27%. 0.905. 表 3-1(c):基頻在汽車環境下不同訊噪比之分析 訊噪比 (dB). U->V. V->U. V->V 相對錯誤. 20. 2.29%. 10.44%. 0.108. 15. 2.89%. 16.30%. 0.182. 10. 2.56%. 29.06%. 0.336. 5. 2.36%. 53.70%. 0.604. 0. 2.46%. 78.93%. 0.839. -5. 2.39%. 94.00%. 0.958. 24.
(37) 表 3-1(d):基頻在展覽會場環境下不同訊噪比之分析 訊噪比 (dB). U->V. V->U. V->V 相對錯誤. 20. 2.35%. 7.44%. 0.081. 15. 1.38%. 10.18%. 0.111. 10. 0.82%. 15.40%. 0.168. 5. 0.47%. 30.78%. 0.322. 0. 0.43%. 62.68%. 0.648. -5. 0.48%. 93.57%. 0.942. 表 3-1(e):基頻在餐廳環境下不同訊噪比之分析 訊噪比 (dB). U->V. V->U. V->V 相對錯誤. 20. 4.27%. 7.90%. 0.084. 15. 4.99%. 11.43%. 0.121. 10. 5.16%. 18.89%. 0.200. 5. 6.66%. 36.64%. 0.396. 0. 6.30%. 63.95%. 0.671. -5. 6.38%. 87.07%. 0.892. 表 3-1(f):基頻在街道環境下不同訊噪比之分析 訊噪比 (dB). U->V. V->U. V->V 相對錯誤. 20. 2.88%. 8.47%. 0.094. 15. 3.71%. 13.10%. 0.144. 10. 4.08%. 21.95%. 0.244. 5. 4.22%. 40.53%. 0.450. 0. 3.40%. 70.86%. 0.739. -5. 3.01%. 86.80%. 0.894. 25.
(38) 表 3-1(g):基頻在機場環境下不同訊噪比之分析 訊噪比 (dB). U->V. V->U. V->V 相對錯誤. 20. 5.78%. 8.92%. 0.105. 15. 4.87%. 14.65%. 0.162. 10. 5.61%. 25.07%. 0.272. 5. 6.31%. 47.85%. 0.526. 0. 6.43%. 73.61%. 0.784. -5. 8.89%. 87.47%. 0.924. 表 3-1(h):基頻在火車環境下不同訊噪比之分析 訊噪比 (dB). U->V. V->U. V->V 相對錯誤. 20. 6.08%. 9.62%. 0.107. 15. 8.03%. 15.60%. 0.186. 10. 10.48%. 24.54%. 0.328. 5. 11.84%. 43.55%. 0.548. 0. 11.47%. 67.07%. 0.759. -5. 13.46%. 78.25%. 0.864. 從表 3-1 可以看到隨著訊噪比越低,V->U、U->V 的錯誤率會越來越高,且 V->V 基頻相對錯誤也會越來越大;在三種錯誤分析中,又以 V->U 的錯誤機率隨 著訊噪比下降,上昇的十分快,顯示出語音信號的週期特性非常容易受到環境雜 訊的破壞。也就是說訊噪比越低,基頻受到環境雜訊的影響會越大,所求得的基 頻也會越來越不可靠。在八種環境雜訊中,又以地下鐵、汽車、展覽會場受到的 影響最大。. 平均觀察八種環境雜訊在六種訊噪比的條件下所做的分析,只觀察基頻在不 同的訊噪比的不變化。結果在表 3-2 中。. 26.
(39) 表 3-2:基頻在不同訊噪比之分析 訊噪比 (dB). U->V. V->U. V->V 相對錯誤. 20. 3.64%. 8.71%. 0.095. 15. 3.95%. 13.19%. 0.146. 10. 4.19%. 22.03%. 0.249. 5. 4.72%. 41.73%. 0.464. 0. 4.51%. 69.65%. 0.736. -5. 4.94%. 88.82%. 0.916. 從表 3-2 中可以更加清楚地看到在不同訊噪比時的基頻錯誤變化,發現到在 訊噪比為 5dB、0dB 和-5dB 時,V->U 的錯誤率幾乎是倍數在增加,也就是說基頻 在這些條件下時,幾乎是訊噪比越低,基頻的資訊就會受到環境雜訊的影響而損 失一半。. 挑一句音檔當例子,分別比較在乾淨語音與汽車環境雜訊中訊噪比 0dB 的情 形下,由分散式語音辨識系統之基頻偵測器所求出的基頻值,音檔內容為--24827。如圖 3-3 所示。從中可以觀察到因為分散式語音辨識系統後級有做 Pitch tracking,會造成大部分由加入汽車環境雜訊在訊噪比 0dB 時求取的基頻區段整 段不見;而且其有求出基頻值之基頻區段的頻率會減半。. 27.
(40) 350 300 250 200 150 100. er. 50. si. ba. er. qi. 0 1. 19 37 55 73 91 109 127 145 163 181 199 217 235 253 271 289 Clean. Original. 圖 3-3:比較在乾淨語音與汽車環境雜訊中訊噪比為 0dB 的基頻值. 3.3. 加入基頻參數之國語連續數字串之辨識. 本章實驗是上一章實驗的延伸,主要是在所使用的辨認參數的不同,在這裡 多加入了基頻相關參數的資訊。最後會將辨認結果會再與上一章的結果做比較。. 3.3.1 實驗設定 本實驗用的語料庫是國語連續數字串;實驗設定分為乾淨語料訓練以及複合 情境訓練兩組模式,都與上一章實驗相同。. 在分散式語音辨識系統前級中的參數抽取的各項參數設定,皆與分散式語音 辨識系統前級的標準設定相同;而使用的語音參數除了 38 維梅爾倒頻譜係數之 外,還加入了基頻參數,以及一維、二維的基頻參數變化量,總共使用 41 維的 語音特徵向量。。. 28.
(41) 隱藏式馬可夫語音辨認模型的建立則詳述如下:首先建立國語數字從 0 到 9 的聲學模型,每個聲學模型設定為 8 個狀態,每個狀態含有 16 個混合高斯數; 除了國語數字的聲學模型外,還有兩個模型---靜音與停頓的聲學模型,是用來 描述語音信號中靜音部分,其中靜音聲學模型是描述句首和句尾之靜音,設定為 3 個狀態,停頓聲學模型則用來描述字與字之間的靜音,設定為 1 個狀態,此狀 態允許跳躍(Skip),並且與靜音模型的中間狀態合併(Tying),兩個聲學模型 中每個狀態則含有 32 個混合高斯數。. 29.
(42) 3.3.2 實驗結果 表 3-3(a)與表 3-3(b)列出加入基頻參數後的國語連續數字串之乾淨語音訓 練模式與複合情境訓練模式的辨識結果。. 表 3-3(a):加入基頻參數後的國語連續數字串之乾淨語音訓練模式辨識結果 乾淨語音訓練 訊噪比 (dB). A組 地下鐵. 人聲. 乾淨. 汽車. 展覽會館 平均值. 98.6%. 20. 96.4%. 97.7%. 98.0%. 97.4%. 97.4%. 15. 93.9%. 95.5%. 96.6%. 94.4%. 95.1%. 10. 88.0%. 90.5%. 89.9%. 89.3%. 89.4%. 5. 67.3%. 75.1%. 70.1%. 73.5%. 71.5%. 0. 34.7%. 40.8%. 36.1%. 38.5%. 37.5%. -5. 14.5%. 12.3%. 14.0%. 12.3%. 13.3%. 平均值(20dB~0dB). 76.1%. 79.9%. 78.1%. 78.6%. 78.2%. 火車站. 平均值. 訊噪比 (dB). B組 餐廳. 街道. 乾淨. 機場 98.6%. 20. 96.1%. 97.4%. 96.4%. 97.4%. 96.8%. 15. 93.9%. 95.6%. 94.9%. 95.8%. 95.1%. 10. 88.3%. 88.9%. 90.0%. 90.7%. 89.5%. 5. 70.9%. 76.5%. 74.3%. 75.6%. 74.3%. 0. 41.0%. 38.6%. 39.7%. 47.4%. 41.7%. -5. 15.0%. 17.8%. 16.7%. 25.2%. 18.7%. 平均值(20dB~0dB). 78.0%. 79.4%. 79.1%. 81.4%. 79.5%. 八 種 環 境 雜 訊 及 五 種 訊 噪 比 的 平 均 值. 30. 78.9%.
(43) 表 3-3(b):加入基頻參數後的國語連續數字串之複合情境訓練模式辨識結果 複合情境訓練 訊噪比 (dB). A組 地下鐵. 人聲. 乾淨. 汽車. 展覽會館 平均值. 96.3%. 20. 97.7%. 97.2%. 98.3%. 97.7%. 97.7%. 15. 96.1%. 96.7%. 97.4%. 97.8%. 97.0%. 10. 92.4%. 93.8%. 94.1%. 92.8%. 93.3%. 5. 78.7%. 83.2%. 80.8%. 81.9%. 81.2%. 0. 46.6%. 52.8%. 51.6%. 49.5%. 50.1%. -5. 17.8%. 19.3%. 18.9%. 15.4%. 17.9%. 平均值(20dB~0dB). 82.3%. 84.7%. 84.4%. 83.9%. 83.8%. 火車站. 平均值. 訊噪比 (dB). B組 餐廳. 街道. 乾淨. 機場 96.3%. 20. 96.4%. 98.0%. 95.6%. 97.5%. 96.9%. 15. 95.3%. 96.7%. 95.8%. 96.9%. 96.2%. 10. 92.4%. 91.3%. 91.7%. 92.4%. 92.0%. 5. 77.9%. 84.4%. 81.9%. 82.6%. 81.7%. 0. 50.5%. 48.8%. 52.0%. 60.6%. 53.0%. -5. 20.9%. 25.7%. 23.5%. 37.9%. 27.0%. 平均值(20dB~0dB). 82.5%. 83.8%. 83.4%. 86.0%. 83.9%. 八 種 環 境 雜 訊 及 五 種 訊 噪 比 的 平 均 值. 83.9%. 從實驗結果中,可以發現: (1). 比較乾淨語音訓練與複合情境訓練模式,在加入基頻資訊之後的實驗結 果:與沒有加入基頻資訊的實驗結果類似,一樣只有在沒有加入任何環境 雜訊的測試情形下,乾淨語音訓練模式的辨識率比複合情境訓練模式的辨 識率好;其他組的測試情況,都是乾淨語音訓練模式的辨識率比複合情境 訓練模式的辨識率還差。. 31.
(44) (2) 比較在不同的環境雜訊之下,兩種訓練模式的差異。從乾淨語料訓練模式 到複合情境訓練模式,辨識率進步最多的是在加了地下鐵環境雜訊的情 況,次之的是加了汽車環境雜訊的情況;進步最少的是加了機場環境雜訊 的情況。這個結果與沒有加入基頻資訊的實驗作比較,發現差異很大,所 以將在有加入基頻資訊的實驗結果與沒有加入基頻資訊的實驗結果中,將 八種環境雜訊的進步程度詳細比較,列於表 3-4 中。我們可以發現:沒有 加入基頻資訊前,進步最多的情形是在測試組合的 B 組,而前四名中有兩 個 B 組的,後四名中有兩個 A 組的;加入基頻資訊之後,進步情形的前四 名都是在測試組合 A 組當中,後四名則是在測試組合 B 組中,這跟預測的 情況是相同的,因為 A 組是屬於與訓練情境匹配的環境雜訊,B 組是屬於與 訓練情境不匹配的,所以 A 組進步的程度應該是要比 B 組多。 (3) 個別觀察八種環境雜訊的情況:在乾淨語音訓練模式—只有在地下鐵、展 覽會館跟餐廳這三種環境雜訊底下,有加入基頻資訊實驗的辨識率才會比 沒有加入基頻資訊實驗的辨識率高;其他五種環境雜訊都是有加入基頻資 訊實驗的辨識率比沒有加入基頻資訊實驗的辨識率還低,其中又以加入汽 車環境雜訊的情況的辨識率下降最多,次之的是加入火車站環境雜訊的情 況。在複合情境模式—在地下鐵、展覽會館跟街道這三種環境雜訊底下, 有加入基頻資訊實驗的辨識率才會比沒有加入基頻資訊實驗的辨識率高; 在餐廳這項環境雜訊的情況下是不變的;其他四種環境雜訊都是有加入基 頻資訊實驗的辨識率比沒有加入基頻資訊實驗的辨識率還低,其中又以加 入汽車環境雜訊的情況的辨識率下降最多,次之的是加入火車站環境雜訊 的情況與乾淨語音訓練模式一樣。如圖 3-4 所示。 (4) 訊噪比大於 5dB 時,加入基頻資訊的實驗結果幾乎都獲得比沒有加入基頻 資訊的實驗結果還高的辨識率;而在訊噪比 5dB 以下時,加入基頻資訊實 驗的辨識率幾乎都比沒有加入基頻資訊的辨識率還低,事實上與前一節基 頻抽取器效能之分析結果一致,在訊噪比越低時,基頻參數受到環境雜訊 32.
(45) 影響越大。整體的平均辨識率(20dB~0dB)都比沒有加入基頻資訊還要低。 如圖 3-5 所示。. 表 3-4 列出八種環境雜訊在兩個實驗中的進步情形從乾淨語音訓練模式到 複合情境訓練模式的進步情形。. 表 3-4:八種環境雜訊在兩個實驗中的進步情形 測試組合. A組. B組. 地下鐵. 人聲. 汽車. 展覽會館. 餐廳. 街道. 機場. 火車站. 有基頻. 8.15%. 6.01%. 8.07%. 6.74%. 5.77%. 5.54%. 5.44%. 5.65%. 沒有基頻. 7.28%. 7.46%. 3.81%. 8.74%. 10.74%. 2.96%. 7.65%. 4.75%. 圖 3-4,圖 3-5 分別是表示八種環境雜訊與六種訊噪比在沒有加入基頻資訊 的實驗(non-pitch)、有加入基頻資訊的實驗(pitch)以及乾淨語音訓練模式 (clean)和複合情境模式(multi)間的辨識結果比較。. 100.0% 90.0% 80.0% 70.0% 60.0% 50.0% 40.0% 30.0% 20.0% 10.0%. non-pitch clean non-pitch multi pitch clean pitch multi. 0.0% 地下鐵. 人聲. 汽車. 展覽會館. 餐廳. 街道. 圖 3-4:八種環境雜訊的辨識結果比較. 33. 機場. 火車站.
(46) 100.0% 90.0% 80.0% 70.0% 60.0% 50.0% 40.0% 30.0% 20.0% 10.0%. non-pitch clean_A non-pitch clean_B non-pitch multi_A non-pitch multi_B pitch clean_A pitch clean_B pitch multi_A pitch multi_B. 0.0% 20. 15. 10. 5 訊噪比(dB). 0. 圖 3-5:不同的訊噪比的辨識結果比較. 34. -5. Ave.
(47) 第四章 改良基頻參數抽取的方法. 從前一章中可以看到歐洲電信標準協會編號 202 212 V1.1.1 標準中所提出 的基頻偵測器在低訊噪比時,效能下降的很多,所以多加入了基頻這項資訊建立 辨認器,雖然在訊噪比較高的時候,可以有效的提升辨識率;但是在訊噪比較低 的時候,辨識率反而降低了。所以本章要介紹的是如何在小幅修改歐洲電信標準 協會編號 202 212 V1.1.1 標準中的基頻偵測器之前提下,改進基頻參數抽取的 方法,來增加辨識率。. 4.1. DSR 基頻參數抽取之改良. 原本分散式語音辨識系統抽取基頻參數的作法(ETSI XAFE)是先在前級接 收到語音信號經過波形處理後,做基頻的估計,然後在後級再做一次基頻資訊的 更正與軌跡的追蹤。可是在前級中,已經有針對降低環境雜訊做了兩次維納濾波 器,以獲得較為乾淨的語音訊號。於是便想要利用經過降低環境處理過後的語音 訊號來抽取基頻參數,如此一來在有環境雜訊時,應該可以得到更好的基頻參 數。改良式的參數抽取作法(Modified XAFE)就是在接收到語音信號後,先做 一次降低雜訊的動作,也就是先經過二階式維納濾波器降低雜訊的干擾後,再做 基頻參數估計;在分散式語音辨識系統的後級的部分,則是沒有改變作法。圖 4-1 是改良式分散式語音辨識系統前級之基頻參數抽取的作法的架構。. 圖 4-1:改良式分散式語音辨識系統前級之基頻參數抽取的架構 35.
(48) 其中加入信號補償方塊(Gain compensation)是因為分散式語音辨識系統中降 低雜訊處理的維納濾波器,會減弱語音信號的能量,而原 XAFE 的基頻偵測機制 中,會使用信號能量來做無聲音或有聲音的辦別。為了要補償能量的改變,所以 對每個音框,將經過降低雜訊處理之語音信號的平均能量與輸入之語音訊號的平 均能量作比較,得到兩個平均能量的比值,將經過降低雜訊處理之語音訊號的振 幅乘以兩個平均能量的比值開跟號,如此即可補償能量的改變。所以在信號補償 方塊中,信號振福放大值 g ( i ) 如下式所示:. . g (i ) =. Pinput ( i ). Preduction ( i ). (4-1). 其中 Pinput ( i ) 代表第 i 個音框輸入語音信號的平均能量, Preduction ( i ) 代表經過降低 雜訊處理之語音訊號的平均能量。. 4.2 . 改良式 DSR 之基頻參數抽取之效能分析. 對改良式分散式語音辨識系統前級之基頻參數抽取器作效能分析,我們同樣. 利用 3-2 節所定義的三項錯誤分析來評估改良式分散式語音辨識系統前級之基 頻參數抽取器的效能。. 36.
(49) 表 4-1:比較原本基頻參數抽取的作法與改進後基頻參數抽取的作法 訊噪比 (dB). ETSI XAFE. Modified XAFE. U->V (%). V->U (%). V->V 相對錯誤. U->V (%). V->U (%). V->V 相對錯誤. 20. 3.64. 8.71. 0.095. 2.68. 8.74. 0.097. 15. 3.95. 13.19. 0.146. 2.78. 13.20. 0.144. 10. 4.19. 22.03. 0.249. 3.15. 21.41. 0.240. 5. 4.72. 41.73. 0.464. 3.98. 39.05. 0.433. 0. 4.51. 69.65. 0.736. 4.21. 63.96. 0.679. -5. 4.94. 88.82. 0.916. 5.72. 84.18. 0.872. 同樣也可以從表 4-1 觀察到:在 ETSI XAFE 中 V->V 的判別錯誤率也與 V->U 的錯誤率有相同的現象,隨著訊噪比下降而增加,尤其是在訊噪比在 10dB 以下, 下降得更嚴重;改良後的基頻參數抽取方法在訊噪比 15dB 以後的相對錯誤,有 比原本的基頻參數抽取方法下降的緩慢。所以我們僅對原本歐洲電信標準協會編 號 202 212 V1.1.1 的分散式語音辨識系統前級的架構做小幅改良,即可大幅降 低原本分散式語音辨識系統標準中基頻資訊所受環境雜訊的影響。. 4.3. 國語連續數字串之辨識---加入改良式分散式語音辨 識系統抽取的基頻參數. 經由上一節證實,本論文所提出的改良式分散式語音辨識系統前級之基頻參 數抽取器,並沒有大幅更改原來分散式語音辨識系統前級的架構,由前一節之分 析可以發現:改良式分散式語音辨識系統前級之基頻參數抽取器可以將基頻偵測 的效能提高。接著將使用改良式分散式語音辨識系統前級之基頻參數抽取器應用 於國語連續數字串之辨識器中。 37.
(50) 4.3.1 實驗設定與訓練模型建立 本實驗用的語料庫都是國語連續數字串;實驗設定也都分為乾淨語料訓練以 及複合情境訓練兩組模式。訓練模型也是有 12 個聲學模型,10 個國語數字的聲 學模型,每個聲學模型設定為 8 個狀態,每個狀態含有 8 個混合高斯數;還有兩 個聲學模型:靜音聲學模型 3 個狀態、停頓聲學模型 1 個狀態,每個狀態含有 16 個混合高斯數。. 38.
(51) 4.3.2 實驗結果 表 4-2(a)、表 4-2(b)分別是加入改良式分散式語音辨識系統抽取的基頻參 數的國語連續數字串辨認實驗中的乾淨語音訓練模式以及複合情境訓練模式的 辨識結果。. 表 4-2(a):加入改良式分散式語音辨識系統抽取之基頻參數的國語連續數字 串辨認實驗中乾淨語音訓練模式之辨識結果 乾淨語音訓練 訊噪比 (dB). A組 地下鐵. 人聲. 乾淨. 汽車. 展覽會館 平均值. 98.4%. 20. 95.3%. 97.7%. 97.7%. 96.0%. 96.7%. 15. 93.3%. 93.9%. 96.4%. 93.6%. 94.3%. 10. 86.9%. 89.1%. 92.2%. 88.8%. 89.3%. 5. 71.0%. 75.2%. 77.7%. 75.4%. 74.8%. 0. 44.1%. 47.8%. 51.9%. 47.7%. 47.9%. -5. 15.0%. 18.2%. 17.8%. 15.3%. 16.6%. 平均值(20dB~0dB). 78.1%. 80.7%. 83.2%. 80.3%. 80.6%. 火車站. 平均值. 訊噪比 (dB). B組 餐廳. 街道. 乾淨. 機場 98.4%. 20. 92.4%. 96.6%. 93.8%. 96.3%. 94.8%. 15. 90.3%. 95.5%. 92.7%. 94.2%. 93.2%. 10. 80.2%. 87.9%. 88.3%. 86.0%. 85.6%. 5. 66.4%. 78.2%. 76.6%. 73.8%. 73.8%. 0. 43.2%. 46.4%. 50.9%. 54.8%. 48.8%. -5. 20.3%. 20.9%. 18.9%. 33.6%. 23.4%. 平均值(20dB~0dB). 74.5%. 80.9%. 80.5%. 81.0%. 79.2%. 八 種 環 境 雜 訊 及 五 種 訊 噪 比 的 平 均 值. 39. 79.9%.
(52) 表 4-2(b):加入改良式分散式語音辨識系統抽取之基頻參數的國語連續數字 串辨認實驗中複合情境訓練模式之辨識結果 複合情境訓練 訊噪比 (dB). A組 地下鐵. 人聲. 乾淨. 汽車. 展覽會館 平均值. 97.0%. 20. 97.7%. 98.1%. 98.0%. 97.7%. 97.9%. 15. 96.4%. 96.7%. 98.0%. 97.7%. 97.2%. 10. 93.5%. 94.2%. 95.6%. 93.8%. 94.3%. 5. 81.2%. 83.3%. 86.0%. 84.3%. 83.7%. 0. 51.4%. 59.4%. 59.0%. 61.5%. 57.8%. -5. 20.9%. 21.0%. 22.0%. 21.0%. 21.2%. 平均值(20dB~0dB). 84.0%. 86.3%. 87.3%. 87.0%. 86.2%. 火車站. 平均值. 訊噪比 (dB). B組 餐廳. 街道. 乾淨. 機場 97.0%. 20. 96.3%. 97.7%. 96.6%. 97.0%. 96.9%. 15. 94.7%. 97.4%. 95.6%. 97.0%. 96.2%. 10. 91.0%. 92.7%. 93.6%. 93.8%. 92.8%. 5. 79.3%. 84.1%. 82.9%. 83.8%. 82.5%. 0. 56.5%. 56.1%. 60.0%. 64.5%. 59.3%. -5. 21.2%. 27.7%. 28.4%. 39.3%. 29.2%. 平均值(20dB~0dB). 83.6%. 85.6%. 85.7%. 87.2%. 85.5%. 八 種 環 境 雜 訊 及 五 種 訊 噪 比 的 平 均 值. 85.9%. 比較沒有加入基頻參數、加入改良式分散式語音辨識系統抽取之基頻參數與 加入分散式語音辨識系統抽取之基頻參數的實驗結果,將分別比較在乾淨語音訓 練以及複合情境訓練模式,比較結果列於圖 4-2(a)、圖 4-2(b)。. 40.
(53) 乾淨語音訓練模型之比較 100.0% 90.0% 80.0% 70.0% 辨識率. 60.0% 50.0%. Non-pitch_A 40.0%. Non-pitch_B. 30.0%. Pitch_A. 20.0% 10.0%. Pitch_B Modified_A Modified_B. 0.0% 20. 15. 10. 5 訊噪比(dB). 0. -5. Ave. 圖 4-2(a):在乾淨語音訓練模式中比較沒有加入基頻參數、使用 DSR XAFE 與 Modified XAFE 抽取之基頻參數的辨識結果. 複合情境訓練模式之比較 100.0% 90.0% 80.0% 70.0%. 辨識率. 60.0% 50.0% 40.0% 30.0% 20.0% 10.0%. Non-pitch_A Non-pitch_B Pitch_A Pitch_B Modified_A Modified_B. 0.0% 20. 15. 10. 5 訊噪比(dB). 0. -5. Ave. 圖 4-2(b):在複合情境訓練模式中比較使用沒有加入基頻參數、DSR XAFE 與 Modified XAFE 抽取之基頻參數的辨識結果. 41.
(54) 從實驗結果中,可以得到以下觀察: (1) 比較加入改良式分散式語音辨識系統抽取之基頻參數與加入原本分散式語音 辨識系統抽取之基頻參數的實驗結果:在乾淨語料訓練模式中---測試組合 A 組在訊噪比 10dB 以上的辨識率幾乎都是加入改良式分散式語音辨識系統抽 取之基頻參數比加入原本分散式語音辨識系統抽取之基頻參數還低,只有在 汽車雜訊在訊噪比為 10dB 情形中,辨識率是加入改良式分散式語音辨識系統 抽取之基頻參數比加入原本分散式語音辨識系統抽取之基頻參數還高;訊噪 比在 5dB 以下的辨識率都是加入改良式分散式語音辨識系統抽取之基頻參數 比加入原本分散式語音辨識系統抽取之基頻參數還高。測試組合 B 組中,不 只在訊噪比 10dB 以上的實驗結果都是加入改良式分散式語音辨識系統抽取 之基頻參數比加入原本分散式語音辨識系統抽取之基頻參數還低,還包括了 在訊噪比為 5dB 時,在餐廳與火車站的環境雜訊中也是加入改良式分散式語 音辨識系統抽取之基頻參數比加入原本分散式語音辨識系統抽取之基頻參數 的辨識率還低;其餘的情況就都是加入改良式分散式語音辨識系統抽取之基 頻參數比加入原本分散式語音辨識系統抽取之基頻參數的辨識率還高。在乾 淨語音訓練模式情況中,整體的相對錯誤減少率(Error reduction rate) 為 4.8%。 在複合情境訓練模式中---測試組合 A 組中,就只有汽車環境雜訊在訊噪 比為 20dB 以及展覽會館在訊噪比為 15dB 時,辨識率是加入改良式分散式語 音辨識系統抽取之基頻參數比加入原本分散式語音辨識系統抽取之基頻參數 還低;其他的情形,包括乾淨語料測試,都是加入改良式分散式語音辨識系 統抽取之基頻參數比加入原本分散式語音辨識系統抽取之基頻參數的辨識率 還要高。在複合情境訓練模式情況中,整體的相對錯誤減少率為 12.4%。 綜合來說,加入改良式分散式語音辨識系統抽取之基頻參數的確是比加 入原本分散式語音辨識系統抽取之基頻參數的辨識率高,相對錯誤減少率為 8.6%。 42.
(55) (2) 比較加入由改良式分散式語音辨識系統抽取之基頻參數與沒有加入基頻參數 的實驗結果:乾淨語音訓練模式---測試組合 A 組在訊噪比 10dB 以上時都是 加入由改良式分散式語音辨識系統抽取之基頻參數比沒有加入基頻參數的辨 識率高;在訊噪比 5dB 以下時,則否,而 A 組的平均辨識率則是加入由改良 式分散式語音辨識系統抽取之基頻參數比沒有加入基頻參數的實驗高。測試 組合 B 組在訊噪比 15dB 以上時都是加入由改良式分散式語音辨識系統抽取之 基頻參數比沒有加入基頻參數的辨識率高;在訊噪比 10dB 以下時,則否,而 B 組的平均辨識率則是加入由改良式分散式語音辨識系統抽取之基頻參數比 沒有加入基頻參數的辨識率低。在乾淨語音訓練模式情況中,整體的辨識率 是加入由改良式分散式語音辨識系統抽取之基頻參數比沒有加入基頻參數的 辨識率低。在複合情境訓練模式情況中,整體的相對錯誤減少率為 1.6%。 複合情境訓練模式---測試組合 A 組除了在訊噪比-5dB 的情況,其餘的 都是加入由改良式分散式語音辨識系統抽取之基頻參數比沒有加入基頻參數 的辨識率高,而 A 組的平均辨識率則是加入由改良式分散式語音辨識系統抽 取之基頻參數比沒有加入基頻參數的實驗高。測試組合 B 組在訊噪比 10dB 以上時都是加入由改良式分散式語音辨識系統抽取之基頻參數比沒有加入基 頻參數的辨識率高;在訊噪比 5dB 以下時,則否,而 B 組的平均辨識率則是 加入由改良式分散式語音辨識系統抽取之基頻參數比沒有加入基頻參數的實 驗低。 上述結果是因為在高訊噪比時經過二階式維納濾波器的信號會改變信號 波形進而破壞信號的週期特性;但在低訊噪比時,二階式維納濾波器移除較 多的環境雜訊,而造成基頻偵測的改進。 綜合來說,加入改良式分散式語音辨識系統抽取之基頻參數的辨識結果 還是比沒有加入基頻參數的辨識率低。. 43.
(56) 由上述兩點觀察結果,可以知道加入改良式的分散式語音辨識系統求取之基 頻參數辨識器雖然其效益的確比加入原本的分散式語音辨識系統之基頻參數的 辨識器要好,但是卻沒有比沒有加入基頻參數的辨識器好。因此我們便想到可以 結合兩個辨識器的優點,成為一個新的辨識器,在訊噪比 10dB 以上的語音以加 入改良式的分散式語音辨識系統求取之基頻參數辨識器為主;在訊噪比 5dB 以 下,以沒有加入基頻參數的辨識器為主,這樣組合而成的辨識器應該會有較好的 效能。. 4.4. 國語連續數字串之辨識---整合沒有加入基頻參數的 辨識器與加入改良式分散式語音辨識系統抽取之基頻 參數的辨識器. 因為比較過沒有加入基頻參數的辨識結果與加入改良式的分散式語音辨識 系統求取之基頻參數的辨識結果,發現訊噪比在 5dB 以下時,加入改良式的分散 式語音辨識系統求取之基頻參數反而會使辨識率下降。所以想要將沒有加入基頻 參數的辨識器與有加入經過降低雜訊干擾處理的辨識器整合成一個新的辨識 器,希望能夠提升所有訊噪比的辨識率。. 44.
(57) 4.4.1 實驗設定 首先分別將兩個辨認器辨識出來分數(Log-likelihood scores) ,依據所辨 認句子不同的訊噪比,給相對應的比重係數(Weight),再將乘上比重係數後的 分數相加,最後取分數最高的為辨識結果。當訊噪比越高,越信任所求得的基頻 參數,也就是越信任有加入基頻參數的辨識答案;反之, 訊噪比越低,越不信 任所求得的基頻參數,也就是越信任沒有加入基頻參數的辨識答案。若是沒有相 同的答案,則是依照訊噪比,當訊噪比在 10dB 以上時,就採用加入改良式的分 散式語音辨識系統求取之基頻參數辨識器的辨識答案;當訊噪比在 5dB 以下,就 採用沒有加入基頻參數的辨識器的辨識答案。以下面的式子表示:. S ' = ω ⋅ Swith _ pitch + (1 − ω ) ⋅ Swithout _ pitch. (4-2). 其中 S ' 代表整合後的辨識分數; Swith _ pitch 代表有加入基頻參數的辨識分數; S without _ pitch 代表沒有加入基頻參數的辨識分數。而 ω 是比重係數,其比重函式. (Weighting function)則是使用 Sigmoid 函數[7],如下式:. ω (d ) =. 1 1 + exp( −γ d + θ ). , γ =2.5、θ =19. (4-3). 圖 4-3:整合含有基頻參數以及不含基頻參數的辨識器之系統方塊圖. 45.
(58) 4.4.2 實驗結果 表 4-3(a)、表 4-3(b)分別是整合有由改良式的分散式語音辨識系統之基頻 參數以及不含基頻參數的辨識實驗中的乾淨語音訓練模式以及複合情境訓練模 式的辨識結果。. 表 4-3(a):整合有由改良式的分散式語音辨識系統抽取之基頻參數以及不含基 頻參數的國語連續數字串辨識實驗中乾淨語音訓練模式之辨識結果 乾淨語音訓練 訊噪比 (dB). A組 地下鐵. 人聲. 乾淨. 汽車. 展覽會館 平均值. 98.4%. 20. 96.0%. 97.5%. 97.8%. 96.3%. 96.9%. 15. 93.2%. 94.7%. 96.4%. 93.6%. 94.5%. 10. 87.7%. 90.2%. 93.8%. 89.9%. 90.4%. 5. 71.3%. 78.7%. 84.4%. 73.8%. 77.1%. 0. 43.6%. 52.8%. 60.1%. 45.2%. 50.4%. -5. 15.1%. 20.4%. 19.0%. 15.0%. 17.4%. 平均值(20dB~0dB). 78.4%. 82.8%. 86.5%. 79.8%. 81.9%. 火車站. 平均值. 訊噪比 (dB). B組 餐廳. 街道. 乾淨. 機場 98.4%. 20. 92.5%. 96.9%. 93.5%. 96.6%. 94.9%. 15. 91.6%. 95.5%. 92.7%. 95.0%. 93.7%. 10. 83.0%. 88.0%. 89.6%. 88.5%. 87.3%. 5. 69.0%. 83.0%. 81.5%. 83.5%. 79.3%. 0. 50.8%. 48.9%. 57.0%. 65.7%. 55.6%. -5. 22.1%. 23.8%. 29.6%. 37.5%. 28.3%. 平均值(20dB~0dB). 77.4%. 82.5%. 82.9%. 85.9%. 82.2%. 八 種 環 境 雜 訊 及 五 種 訊 噪 比 的 平 均 值. 46. 82.1%.
(59) 表 4-3(b):整合有由改良式的分散式語音辨識系統抽取之基頻參數以及不含基 頻參數的國語連續數字串辨識實驗中複合情境訓練模式之辨識結果 複合情境訓練 訊噪比 (dB). A組 地下鐵. 人聲. 乾淨. 汽車. 展覽會館 平均值. 97.0%. 20. 97.4%. 97.7%. 98.3%. 98.1%. 97.9%. 15. 96.4%. 96.4%. 97.7%. 96.9%. 96.9%. 10. 93.3%. 95.0%. 96.1%. 92.4%. 94.2%. 5. 79.6%. 85.4%. 90.0%. 82.1%. 84.3%. 0. 48.6%. 63.1%. 67.3%. 53.3%. 58.1%. -5. 17.8%. 24.8%. 24.5%. 15.3%. 20.6%. 平均值(20dB~0dB). 83.1%. 87.5%. 89.9%. 84.6%. 86.3%. 火車站. 平均值. 訊噪比 (dB). B組 餐廳. 街道. 乾淨. 機場 97.0%. 20. 96.1%. 97.2%. 96.0%. 97.2%. 96.6%. 15. 96.0%. 97.4%. 95.6%. 96.7%. 96.4%. 10. 91.7%. 91.3%. 94.4%. 94.6%. 93.0%. 5. 80.7%. 86.1%. 86.1%. 90.7%. 85.9%. 0. 58.7%. 55.3%. 67.5%. 75.1%. 64.2%. -5. 24.9%. 26.6%. 38.6%. 47.0%. 34.3%. 平均值(20dB~0dB). 84.6%. 85.5%. 87.9%. 90.9%. 87.2%. 八 種 環 境 雜 訊 及 五 種 訊 噪 比 的 平 均 值. 86.8%. 將此實驗結果與加入改良式的分散式語音辨識系統求取之基頻參數的實驗 結果比較可觀察到在乾淨語音訓練模式中,所有訊噪比的情況整合兩個辨識器的 實驗結果都比加入改良式的分散式語音辨識系統求取之基頻參數的實驗結果還 要好,其錯誤減少率為 10.56%。在複合情境訓練模式中,整體的錯誤減少率為 6.22%。. 47.
(60) 4.5. 國語連續數字串之辨識---使用乾淨語音的基頻參數 之辨識器. 這個實驗的目的是:假設當所求得的基頻參數沒有受到環境雜訊的影響時, 即所求得的基頻參數可靠性相當高,可以將這個實驗結果當作是此方法的上限 (Upper bound)。. 4.5.1 實驗設定. 梅爾倒頻譜係數是從加了環境雜訊後的語音訊號抽取的,而基頻參數是從與 加了環境雜訊後的語音訊號相對應的乾淨語料中抽取的。. 4.5.2 實驗結果 表 4-4 是使用乾淨語音之基頻參數的辨識實驗中的乾淨語音訓練模式的辨 識結果。從辨識結果中可以觀察到使用由乾淨語料中抽取的基頻參數之辨識器, 其辨識結果的確是在本論文中五個國語連續數字串的實驗中最好的。因此我們可 以將此實驗結果當作是加入基頻參數之辨識器的一個指標,也就是說如果我們所 抽取的基頻參數可以完全不受到環境雜訊的影響,便有可能達到此實驗的效果。 與表 4-2(a)比較,可以發現在低訊噪比時使用改良式分散式語音辨識系統求取 之基頻參數的辨識結果,其辨識率還是大幅下降,所以可以知道在低訊噪比時, 基頻偵測器還是有改善的空間。. 48.
(61) 表 4-4:使用乾淨語音之基頻參數的國語連續數字串辨識中乾淨語音訓練 模式之辨識結果 乾淨語音訓練 訊噪比 (dB). A組 地下鐵. 人聲. 乾淨. 汽車. 展覽會館 平均值. 98.4%. 20. 95.2%. 96.4%. 98.0%. 95.5%. 96.3%. 15. 91.6%. 95.0%. 96.1%. 93.9%. 94.2%. 10. 84.4%. 90.3%. 93.9%. 87.9%. 89.1%. 5. 71.2%. 77.4%. 89.1%. 74.3%. 78.0%. 0. 56.4%. 59.7%. 74.6%. 53.9%. 61.2%. -5. 36.3%. 36.8%. 50.0%. 24.6%. 36.9%. 平均值(20dB~0dB). 79.8%. 83.8%. 90.3%. 81.1%. 83.8%. 火車站. 平均值. 訊噪比 (dB). B組 餐廳. 街道. 乾淨. 機場 98.4%. 20. 95.6%. 96.0%. 96.9%. 97.2%. 96.4%. 15. 94.7%. 95.2%. 94.1%. 96.0%. 95.0%. 10. 86.0%. 87.7%. 91.0%. 94.4%. 89.8%. 5. 75.6%. 83.3%. 85.2%. 86.9%. 82.8%. 0. 56.9%. 62.9%. 67.5%. 75.6%. 65.7%. -5. 29.6%. 42.8%. 46.9%. 59.7%. 44.8%. 平均值(20dB~0dB). 81.8%. 85.0%. 86.9%. 90.0%. 85.9%. 八 種 環 境 雜 訊 及 五 種 訊 噪 比 的 平 均 值. 49. 84.9%.
數據


+7






相關文件
主頁 > 課程發展 > 學習領域 > 中國語文教育 > 中國語文教育- 教學 資源 > 中國語文(中學)-教學資源
(三)使用 Visual Studio 之 C# 程式語言(.Net framework 架 構 )、 Visual Studio Code 之 JavaScript 程式語言(JavaScript framework 架構) ,搭配 MS
(三) 使用 Visual Studio 之 C# 程式語言(.Net framework 架構) ,設計 各項系統程式、使用者操作介面,以及報表。. (四) 使用 MS
(三)使用 Visual Studio 之 C# 程式語言(.Net framework 架構)、Visual Studio Code 之 JavaScript 程式語言(JavaScript framework 架構) ,搭配 MS
第四章 連續時間週期訊號之頻域分析-傅立葉級數 第五章 連續時間訊號之頻域分析-傅立葉轉換.. 第六章
傳播藝術系 應用英語系 幼兒保育系 社會工作系. 資訊
中學中國語文科 小學中國語文科 中學英國語文科 小學英國語文科 中學數學科 小學數學科.
Researches of game algorithms from earlier two-player games and perfect information games extend to multi-player games and imperfect information games3. There are many kinds of
