第一章. 緒論
隨著科技進步、國際市場間的藩離消失及顧客的需求改變等種種因素,使 企業的目標、方法以及基本的組織規則,不能再一成不變,企業不再是大量生 產以滿足市場需求,而是為了滿足顧客需要而採多樣性的產品變化,為因應環 境的變化,企業若沒有適當的應變策略,很可能無法生存。因此,有遠見的現 代企業、政府機關都積極的思考如何才能增強自已的競爭能力,希望能將成本 降至最低、並盡量縮短處理各種事件的時間,以適應瞬息萬變的社會。 而在企業、政府機關中,存在有許多的流程(business processes),這些流 程便是由組織中眾多的成員所共同參與,利用企業的資源來協力執行。組織便 是透過這些流程的執行來達成組織的目標(business goal)。因此,這些流程品 質的良寙,代表了組織中資源的使用方式、服務品質、競爭力的優劣。因此, 如何了解、進而改善企業的流程就變得非常重要了。所以,近年來,改造企業中的程序流程(Business Process Reengineering) 受到許多企業的重視,並有許多企業紛紛投入此一行列,例如:GM、Pepsi、U.S. Sprint、AT&T、IBM 等[Mana94]。然而,流程的改造,顧及其牽動組織的範圍大, 人力資源有限,必須經過多方面的評估與考量,方可成行。尤其對規模較大, 動輒含有上百甚至上千個的活動流程,改變流程的策略不太能輕易實施。基於 以上種種原因,如何尋求科技的幫助,使改變流程變得更為可行、有效,便成 為當前重要的課題。 而工作流程管理,便是起源於利用資訊科技對工作流程的支援,目的在促 進工作間的協調,使工作流程更具效率與彈性。由於電腦與電腦網路的普及, 原本皆由人負責的工作流程,現在可由電腦控管,不但有效率,且更方便追蹤 與修改。因此,目前有許多領域對於工作流程的相關研究、技術皆感到莫大興 趣。 本研究便是著眼於利用資訊科技對流程的支援,希望藉由所搜集工作流程 的各式資料,從中萃取相關資訊,以協助流程定義之修改,提昇流程的工作品 質,使企業的運作便為順暢、資源利用更有效率。
第二章. 研究動機與目的
隨著全球性的發展,現今的企業必須對於變革有著快速反應的能力,以便 能迅速的提供新的服務、發展新的產品,同時改善生產力、提高品質以及降低 成本的花費。企業流程改造,為許多企業視為達成這些目標的一大利器。 根據 Davenport 和 Short 的定義,「流程改造」是設計並且分析組織內與 跨組織的工作流程[Dave93],主要可以分為以下 5 個步驟: 1. 認清與了解企業中流程的整體目標。 2. 找出需要改造的流程。 3. 了解並評估現有的流程,避免犯下同樣的錯誤。 4. 腦力激盪來提出新的流程。 5. 測試並部署新的流程。 從上述步驟,可以很容易看出,要進行流程改造,必須先了解、找出目前 既有的流程,從而進行分析、改造。然而,要找出既有的流程並不容易[Hamm93]。 再者,對改造流程的工作人員而言,要找出既有的流程,通常就代表了一連串 與管理者、員工、各種不同群體工作人員的許多會議與溝通協調,時間、人力 成本甚為可觀。而且,不同的改造人員,所繪出的企業流程,並未標準化,可 能會有許多不同之處。所以,一個有趣的問題:是不是可以藉由某些架構機制、 方法演算,來自動找出組織中的既有流程呢?本研究的主要動機便是著眼於此--透過資訊科技的幫助,自動找出組織中的既有流程。 進一步思考,組織中的既有流程,可能是以人工、半自動化或自動化的方 式執行,當這些流程執行時,組織裡通常會留下一些記錄,這些記錄以各種不 同的方式存在。例如,以一些人工紙上作業留下記錄。當流程執行時,會有工 作進度表以記錄、稽核工作的執行時間、進度,收集這些工作進度表,就可以 得到目前既有流程執行的時間資料。 或者有一些專案管理工具,可以在既有流程執行的過程中,自動地留下一 些事件(event)、時間的記錄。如[Brad94]的研究中,即設計了流程監督工具 (process monitor),來記錄流程執行過程中,所發生的事件及其時間。收集這 些自動記錄下來的事件時間記錄,也可以得到目前既有流程執行的時間資料。 在這些被記錄下來的資料裡,其實隱含著許多流程的相關資訊,如果可以透過適當的方法,是不是可以由這些歷史資料中找出既有流程的定義呢? 再則,目前市面上已有一些工作流程管理系統、工具,可以依據使用者給 定的流程定義,實際執行流程,當然也可以留下流程實際執行過程的相關資訊。 然而,使用者一開始所定義的流程並不見得完全正確,或者隨著環境的變遷、 條件的改變,實際上的流程執行已與原有流程定義不相符。這時,是不是也可 以由這些工作流程管理系統、工具,所實際記錄下來的流程執行相關資訊,來 找出目前既有、實際的流程定義呢? 因此,由這些人工紙上作業、專案管理工具、工作流程管理系統所記錄下 來的資料中,我們應該可以收集到許多與流程相關的資訊。如何利用這些資訊, 解決前述不易找出既有流程的問題,便成了本研究的目標。 回應前述的研究動機,本研究的主要目的是:利用所記錄下來的歷史資料, 透過演算法的萃取,自動化地找出流程的定義,以提供專家或改造人員參考, 使得流程的模式化,更為容易。對於工作人員而言,也可以在更短的時間內, 以更少的人力、資源、更有效率地找出企業既有流程,以為進一步分析、改造 之用。 本研究論文分為七大章。第一章與第二章,敘述研究背景與研究的動機、 目的,讀者可以從中了解本研究的研究概念。第三章是相關研究,說明萃取流 程定義演算法的相關文獻。第四章則闡述本研究所採用的流程模式(process model)和萃取演算法,讀者可以由此章了解本研究的方法架構與演算法。第五 章則說明本研究對於錯誤資料(noise)的處理方法,以使演算法更具實用性。第 六章,則以演算法實作雛形系統,並與其它演算法進行效能比較評估。第七章, 總結研究成果及未來研究的方向。綜合以上所述,將各章的關係以圖 2-1 表示。
圖<2-1> 第一章 緒綸 第二章 研究動機與目的 第三章 文獻探討 第一節 流程表示法 第二節 萃取流程演算法 第四章 萃取演算法 第一節 流程模式 第二節 控制流萃取演算法 第三節 控制條件萃取演算法 第五章 錯誤資料處理 第四節 時間複雜度 第六章 演算法效能評估 第七章結論 第三節 綜合比較
第三章.文獻探討
目前已有一些研究,對於流程萃取方法進行探討,但這些方法所使用的流 程模式、表示法各有不同。因此,本研究首先於第一節流程表示法,敘述常見、 或於不同萃取方法中,所使用的流程表示法。第二節萃取流程演算法,則分別 針對這些流程萃取方法進行分析。並綜合比較各萃取方法的特性、缺點於第三 節綜合比較。第一節 流程表示法
流程表示法是用來表達某一特定流程,方便使用者了解這個流程的方法, 因此流程表示法必須選取簡單、清楚的描述方式。表示方法有下列數種被提出:1.以溝通為基礎的表示法(Communication based Methodologies)[Geor95]: 這個方法以”Action Model”為代表[Memo93]。它是將每一個流程或活動都 視為是一執行者(Performer)和一客戶(Customer)間的溝通。而溝通又可分 為四階段: 準備、協商、處理和接受,流程中的活動全部以這四種型態來 表示。 2.以活動為基礎的表示法(Activity-based Methodologies)[Geor95]:這種 表示法著重在描述流程中各組成活動間的關係,而非人與人之間的溝通。 如圖 3-1 是一個生病求診的流程。 圖<3-1>
3.以有限狀態圖 FSM(Finite State Machine)表示流程的方法[Cook95]:這 種表示方法是由流程執行的事件(event)和狀態(state)來表示,如圖 3-2 所示。圖 3-2 是一個電腦中心提供服務給使用者的流程,圖中的 S1、S2… S7 是狀態,而如 R-SR、F-T… L-SR 便是事件。其中,若流程位於狀態 S1,在 事件 R-SR 發生後,會改變流程的狀態,而成狀態 S2(這個電腦中心,在收 到使用者要求後,準備進行處理)。也就是說,以 FSM 圖來表示流程時,主 要在強調流程可以執行的事件,及這些事件執行時流程狀態的改變。 掛號 看醫生 批價 檢驗 拿藥 離開
圖<3-2>
在本研究的模式中,將採用以活動為基礎(Activity Based)的模式,這是 因為此種模式是比較便潔的方式,精確地描述出活動之間的關係,對於流程中 活動的執行分析具有重要的價值。
而在以活動為基礎的表示法中,本文參考[WfMC98]所訂定的標準。WfMC (Workflow Management Coalition),工作流程管理協會,是由許多此領域內企 業、組織所共同成立的團體,其研究著重於自動化工作流程的標準制定。在 WfMC 提出的標準裡,包括了 Workflow Enactment Service、Workflow Client/Server Invoked Application、Workflow Interoperability、Process Definition Interchange[WfMC98]。在 1995-1998 年更彙集了各家的說法,統一專有名詞的 定義及應用程式的標準[WfMC94][WfMC96_1][WfMC96_2]。 在 WfMC 的定義中,工作流程是一部份或全部自動化的企業流程。依據 [WfMC98]所制定的標準,流程係以下面七種元件來描述:(1)流程(Process): 企業中依照一定規則進行一連串工作步驟,以達成一特定目標。這一群為達成 一定目標所執行的工作及工作間的傳遞,共同形成一個流程。(2)活動 (Activity):是指流程中的每個邏輯步驟,它可以是一個自動、非自動或半自 動的活動。(3)遞移(Transition):描述不同活動之間的相互關係,活動之間的 連接就是依靠資訊的傳遞(Transition Information)。(4)參與者 (Participant):就是流程中各活動的執行、參與人員以及系統。(5)組織模式 (Organization Model):即參與者在流程中所扮演的角色。例如,業務經理。(6) 應用程式(Application):流程執行中所包括、使用的應用程式。(7)參考資料 (Relevant Data):流程執行中所產生出來並在往後的流程被使用的資料。 S1 S2 S3 S6 S4 S5 S7 R-SR N-SR P-S I-SR F-T L-SR P-S I-SR Event:
R-SR(Recieve Support Request) F-T(Forward Request to Technician) P-S(Perform Service Tasks)
I-SR(Invalidate Support Request) N-SR(Nullify Support Request) L-SR(Log Support Request)
而且,依據流程中常見的進行方式,[WfMC98]的流程表示法包括了以下四 種遞移: 1. 循序(Sequence):活動與活動的執行順序是循序進行的,當前一個活動 執行完成後,下一個活動才能開始執行。 2. 平行(Parallel):流程中,可以同時有一個以上的活動被執行。 3. 迴圈(Loop):流程中,部份活動可以被重覆執行,即這些活動可以執行 一次以上。 4. 子流程(Subflow):流程執行時,有些活動可以再被細分成許多更小、 相關的活動。 在上述 WfMC 所提出的流程進行方式中,我們選擇了前三者。因為本研究 主要是透過使用者介面,提供使用者所有基本、功能性的活動,當使用者準備 執行該項活動時,會點選這個活動,而執行中,這個活動的相關資訊就會被記 錄下來。接下來,本研究則試圖由這些記錄下來的資訊中,找出流程裡眾多活 動之間的執行關係。因此,一個中介(intermediary)、可以再被細分的活動, 其實已包含這個被細分的活動和細分後活動之間的關係,使用者可以直接將這 個被細分的活動和細分後活動視為不同層級、不同群的活動來處理。而同一群 的活動中,當然就只剩下前三項的遞移方式了。
第二節 萃取流程演算法
藉由資訊科技的幫助,在流程執行一段時間後,便可以記錄許多歷史性的 資料。如何利用這些資料,找出流程的定義,是目前許多研究([Agra98][Cook95] [Datt98])的目標。這些研究所使用的模式、演算法都各有不同,因此,以下各 節將分別針對 1.Agrawal 演算法 2.KTAIL 演算法 3.Markov 演算法,這三個不 同的方法,敘述其假設、模式與演算法,並對各法的特性、缺點作一簡單比較。 其中,Agrawal 演算法所找出的是一有向圖(directed graph),類似本論文所採 用的模式;而 KTAIL 和 Markov 演算法,則找出的是有限狀態圖(FSM),類似一 般編譯程式(compiler)所根據的機制。1 . Agrawal 演算法
在[Agra98]的研究中,一個流程是由許多的活動所組成,這些活動是某些 較小單位的工作。假設這些活動的執行時間是”一瞬間(instantaneous)”、沒有 活動的開始時間相同。在這樣的假設下,流程一次執行的記錄(稱為一個流程 例),就會成為一列(list)的活動記錄。如圖 3-3,假設這個流程某次執行活動 A、活動 B、活動 C、活動 E,則所記錄的一個流程例是 ABCE。因此,當收集許 多的流程例後,所得到的資料是許多列的活動記錄,如{ABCE、ACDBE、ACDE… }。 圖<3-3> 因此,在[Agra98]研究中,是將每一次流程執行的記錄分開(成各次流程 例),而每一個流程例所記錄的是一列活動執行先後次序(total order)。所以, 收集了所有流程例資料後,如{ABCE、ACDBE、ACDE、… },就成為演算法的輸入 (input)資料了。 那麼,演算法的輸出呢?演算法的輸出是一個有向圖,圖上的每一個點 (Vertex)代表一個活動,點與點間的邊(Edge)則代表這兩個活動的執行順序。(因 為一個點代表一個活動,所以一個活動在有向圖上只有一點)。如圖 3-3 就是一 個可能輸出的有向圖。 在這樣的輸入假設與輸出要求下,Agrawal 演算法主要的想法(idea)是這樣 的:由流程執行記錄(Workflow log)中的每一個流程例,找出兩兩活動的執行 先後順序的相依性(dependence),若整理全部流程例後,活動間有雙向的相依 性,則刪去這些相依性。利用最後剩下的相依性,就可以找出一相依性的有向 圖(direct graph),即全部活動,也就是整個流程的控制流(control flow)了。
將 Agrawal 演算法列示如下:
1. Start with the graph G=(V,E),with V being the set of activities of the process and E
A
C D
E=ψ. (V is instantiated as the log is scanned in the next step)
2. For each process execution in L, and for each pair of activities u, v such that u terminates before v starts, add the edge (u,v) to E.
3. Remove from E the edges that appear in both directions.
4. For each strongly connected component of G, remove from E all edges between vertices in the same strongly connected component.
5. For each proecss execution in L: (a) Find the induced subgraph of G.
(b) Compute the transitive reduction of the subgraph.
(c) Mark those edges in E that are present in the transitive reduction. 6. Remove the unmarked edges in E.
7. Return(V,E).
上述演算法,可以用一個例子來說明。假設有一個流程 P,其中有五個活 動,分別為 A、B、C、D、E。當這個流程執行一段時間後,得到下列流程資料:{ABCDE、 ACBE、ADBE}。利用 Agrawal 演算法,首先,step1 設有向圖的點為所有活動, 也就是 A、B、C、D、E,而邊則為空集合。 接下來的 step2 則將每一個流程例中,兩兩活動的相依性找出,成為有向 圖的邊。如第一個流程例(ABCDE),可以找出的相依性是 A→B、A→C、A→D、A →E、B→C、B→D、B→E、C→D、C→E、D→E。因此,由第一個流程例所繪出的 有向圖,如圖 3-4(a)所示。 圖<3-4> 同樣的,將第二個流程例(ACBE)、第三個流程例(ADBE)所找出的相依性繪 出。所以 step2 完成後,有向圖如圖 3-4(b)所示。由圖 3-4(b)中,可以很明顯 E A C D B E A C D B E A C D B (a) (b) (c)
發現,活動 B 與活動 C 之間的邊是雙向的,也就是活動 B 與活動 C 有雙向的相 依性。這是因為在某些的流程例中,活動 B 在活動 C 之前執行,而在另外某些 流程例中,活動 C 卻在活動 B 之前執行,所以產生了雙向的相依性。換句話說, 活動 B、C 之間並沒有一定的執行順序,所以應將活動 B、活動 C 之間的相依性 刪去。同樣的道理,如果有數個活動,在有向圖中形成迴圈,則這些活動也難 以肯定彼此間的先後次序,也應刪去。演算法中的 step3、step4 便基於這種特 性,將有向圖中,活動之間沒有固定執行順序的邊刪去。所以圖 3-4(b)在 step3、 step4 執行完成後,如圖 3-4(c)所示。 很明顯的,執行至 step4,演算法已掃描過全部流程例一次,而找出所有 活動兩兩之間的相依性,成一有向圖。接下來,演算法必須考慮,有向圖中有 些邊是因為遞移才產生的。例如,如果活動 X 執行完成,活動 Y 才能開始執行, 活動 Y 執行完成,活動 Z 才能開始執行,則 step4 所完成的有向圖中不僅有(X →Y)、(Y→Z)的邊,也會有(X→Z)的邊。這是因為活動 X 執行的時間當然也會 比活動 Z 開始的時間要早。但實際執行時,並不能直接由活動 X 跳至活動 Z, 所以(X→Z)的邊是多餘的,必須去除。但是不是可以由 step4 中完成的有向圖, 直接將活動間遞移的邊刪去就可以呢?答案當然也是否定的。這可以用圖 3-5(a) 的例子來說明。 圖<3-5> 如果有個流程例是活動 A 執行完成,執行活動 B,活動 B 執行完成,執行 活動 C,活動 C 執行完成,執行活動 D。而另外一個流程例是活動 A 執行完成, 執行活動 C,活動 C 執行完成,執行活動 D。則可以利用前述的演算法(執行至 step4)找出的有向圖如圖 3-5(b)。如果這時將圖 3-5(b)中所有遞移邊刪去如圖 3-5(c),則第二個流程例是不能執行的。也就是說,在活動 A 與活動 C 之間, 其實有執行的順序關係,可以在活動 A 完成後,直接跳至活動 C,因此活動 A、 C 之間應有(A→C)的邊,(A→C)邊並不是遞移。由這個例子,(A→C)邊在第一個 流程例中是遞移,但第二個流程例卻不是,所以有向圖中的邊是不是因為遞移 A B C D (a) A B C D (b) A B C D (c)
而產生,應針對每一個流程例去考慮。 因此,Agrawal 演算法中,step5、step6 即針對每一個流程例去考慮,找 出有向圖中每一個流程例的子圖(subgraph),將不是遞移的邊給予一記號 (mark),待所有流程例處理完後,所有擁有記號的邊自然都是在某些流程例中 不是遞移的邊。如圖 3-4(c)在 step6 完成後,就可以將遞移的邊刪去,而如圖 3-6 所示。 圖<3-6>
因此,Agrawal 演算法須掃描全部流程例二次,step2 至 step4 掃描第一次 以找出所有活動的相依性,若全部有 m 個流程例,而有 n 個活動,則 step2 至 step4 的時間複雜度(tiem complexity)為 O(mn2)。Step5 至 step6 掃描第二次以
去除多餘的遞移相依性,這部份的時間複雜度則為 O(mn3)。所以,整個流程的 時間複雜度為 O(mn3)。 還有一個值得考慮的問題,若流程中有迴圈呢?Agrawal 演算法對於迴圈 的處理方式,主要是將重覆出現的同一個活動視為不同的活動。例如,假設有 一流程例為{ABCBCD},活動 B 與活動 C 重覆執行兩次,則將此流程例改為 {AB1C1B2C2D},第一次執行的活動 B 被改為活動 B1,第二次執行的活動 B 被改為 活動 B2,活動 B1、活動 B2被視為不同的活動(活動 C 也作同樣的處理)。所以接 下來只要利用同樣的方法找出有向圖,最後再把重覆執行的活動合併就可以了, 修改後的演算法如附 1 所示。 綜合上面的說明,本研究認為利用 Agrawal 演算法來萃取流程定義,主要 有下列缺點: (1)模式假設將產生多餘相依性:在 Agrawal 演算法中,假設活動的執行時 間是”一瞬間(instantaneous)”、沒有活動的執行開始時間相同,所以記錄 下來的流程例是一系列活動先後次序(total order),再由一系列的活動先 E A C D B
後次序找兩兩相依性。這樣的作法會產生許多多餘且不必要的相依性,試 以圖 3-7 為例: 圖<3-7> 假設活動 X 與活動 Y 是任意兩個活動,則這兩個活動的執行時間可能存在 圖 3-7 的六種關係。若活動 X 與活動 Y 的執行時間是圖 3-7(b)(c)(d)(e)中 的一種,則活動 X 與活動 Y 必然沒有相依性,兩活動是獨立的。但如果活 動執行時間假設為”一瞬間”呢?則圖 3-7(a)(b)(c)都會認為有 X→Y 的相依 性,而圖 3-7(d)(e)(f)都會認為有 Y→X 的相依性。也就是說,若活動 X 與 活動 Y 的執行時間是圖 3-7(b)(c)(d)(e)的關係時,以 Agrawal 演算法的假 設,就會多出一些相依性。雖然這些相依性可能可以利用其它流程例,而 在兩活動間有雙向相依性時,刪去這些多餘的相依性,可是當然這樣就需 要較多的流程例才能辦到。 再者,活動實際上執行一段時間。因為執行時間有交集的活動,不可能存 在相依性,所以如果能夠善用這些執行時間有交集則兩者獨立的特性,應 該能夠更正確、更快地將流程例中多餘的相依性刪去。但若假設活動的執 行時間是一瞬間,則當然活動執行時間不會有交集,就不能利用這個特性 了。 (2)迴圈處理只適用於簡單迴圈:在 Agrawal 演算法中,對於迴圈的處理方 法,主要是將重覆執行的活動視為不同的活動,在利用同樣的方法找出相 依性後,再合併。但是這樣的處理方式對於迴圈中所有的活動不一定全部 執行時,可能會將許多正確的相依性刪去。 如以圖 3-8 為例,圖 3-8 為一包含迴圈的流程,其中活動 B、C、D、E 形成 一迴圈,可能重覆執行。且活動 C 與活動 D 是平行、OR_Split 的兩個活動, 也就是說,活動 B 執行完成後,可能執行活動 C 之後就執行活動 E,也可 能活動 B 執行完成後,執行活動 D 之後就執行活動 E,當然也有可能,活 動 B 執行完成後,執行活動 C、活動 D,再執行活動 E。 X X X Y Y Y
(a) none(X→Y) (b) overlap(X→Y) (c) contain(X→Y)
X Y (d) contain(Y→X) X Y (e) overlap(Y→X) X Y (f) none(Y→X)
圖<3-8> 因此,假設圖 3-8 二次執行所收集的流程資料為{ABCEBDEF、ABDEBCEF}, 則利用附 1 的演算法執行至 step3 所產生的有向圖如圖 3-9 所示。其中可 以很明顯地發現活動 C1與活動 B2、活動 C1與活動 E1、活動 D1與活動 E1、活 動 D1與活動 B2之間都有雙向的相依性,所以演算法中,step4 將會將這些 相依性刪去。以活動 C1和活動 B2為例,在第一次的流程例中,活動 C1比活 動 B2早執行,所以會有 C1→B2這個相依性,但在第二次的流程例中,活動 B2比活動 C1早執行,所以會有 B2→C1這個相依性,因此雖然這兩個相依性 都是對的,但由於雙向,將會被刪去。 圖<3-9> 這個問題可以利用圖 3-10 的概念來解釋,圖 3-8 迴圈中的活動 B 是迴圈執 行時每次都會執行的活動,因此當迴圈執行第 n 次時,活動 B 會被展開成 Bn。但活動 C 在迴圈中並不一定每次執行,所以在迴圈執行第 n 次時,假 設活動 C 執行第 i 次(i<n),因此,活動 C 被展開成 Ci,也因此,活動 Bn會 在活動 Ci之前執行,而有 Bn→Ci的相依性,如圖 3-10 中(1)的相依性。 A B C D E F A B1 C1 D1 E1 E2 F B2
圖<3-10> 但是在另一個流程例中,假設迴圈執行第 n 次時,活動 C 執行 j 次(i<j<n), 活動 C 會被展開成 Cj,也因此,活動 Bn會在活動 Cj之前執行,而有 Bn→Cj 的相依性,如圖 3-10 中(2)的相依性。但因為 i<j,所以活動 Ci 必在活動 Bn 之前執行,而有 Ci→Bn的相依性,如圖 3-10 中(3)的相依性,所以如果 考慮這二個流程例,則 Bn、Ci之間會有雙向的相依性,而會被去除,因而 有不正確的結果。 所以,這個問題的原因是因為,當迴圈中的某些活動執行次數不固定時(如 有些活動在每一次迴圈執行時不一定執行,或者有巢狀迴圈使得有些活動 在每一次迴圈執行時重覆執行數次),這些活動相對於迴圈中另外一些活動 (如圖 3-8 中的活動 B、活動 E),就有可能在某些流程例中比較早執行,但 在某些流程例中則比較晚執行,使得有向圖有雙向的相依性,而必須刪去, 雖然這些相依性其實都是正確的。因此,Agrawal 演算法對於迴圈的處理 方式,並不適用於迴圈中部份的活動執行次數不定的情形。 2 . KTAIL 演算法
KTAIL 演算法[Cook95]是由 Biermann 和 Feldman[Bier72]的演算法(以下簡 稱為 B_F 演算法)修改而來。B_F 演算法原是為了解決 grammar discovery 的問 題(即針對某一種語言,以一些句子為例,由其中找出這個語言的文法),所以 B_F 演算法以句子的各單元字(token)的字串為輸入,而產生 FSM(Finite State Machine)為輸出。 在 KTAIL 的演算法中,認為一個流程是由許多的活動所組成,這些活動是 某些較小單位的工作。每一個活動執行時,會執行一段時間,在這段時間內可 能會記錄下一些事件(event),如活動開始事件(begin event)、活動結束事件(end event)、資源等待事件(wait event)… 等等。這些事件是在某一個時間點發生 Cj Bn Ci (1) (2) (3)
的,沒有事件的時間點相同。所以如果收集流程執行過程發生事件的記錄,就 會得到一連續的事件流(event stream)。
接下來,如果把這些事件流(event stream)中每一個事件(event)視為一個 個的單元字(token),就可以將由這些事件流中找出流程定義的問題轉為前述 grammar discovery 的問題。因此,KTAIL 演算法以事件流(event stream)為輸 入,而以找出的 FSM 圖為輸出,但為了簡化起見,KTAIL 的演算法也假設每一 個活動執行只記錄一個事件(event)。
因此,在以事件流(event stream)為輸入,FSM 圖為輸出的要求下,KTAIL 演算法的主要想法(idea)是:FSM 圖中有許多狀態,每一個狀態可以由將來 (future)會發生的行為來定義。以圖 3-11 的概念來解釋,假設圖 3-11 中(1)、 (2)、..(n)都是一些連續的事件執行(以下簡稱事件列),但這些連續的事件執 行後,接著都會執行某些事件,如圖 3-11 中的(f)。所以,可以認為,圖 3-11 中(1)(2)… (n)的執行可能到達一個相同的狀態,所以接著才會有相同的執行事 件(f)。因此,可以利用這個特性來定義狀態(state),只要將事件流中會有相 同將來行為的事件列分為一類,並用這一類的事件列代表一個狀態,就可以將 FSM 圖中的狀態找出來了。 圖<3-11> 將 KTAIL 演算法列示如下: (1) (2) . . .(n) (f)
1. All the equivalence classes C1、C2、… Cs are extracted form the given sample event streams that characterize the process. Each equivalence class Cj is represented as a unique state Sj of the process. A graph is created with nodes S1,… ,Ss.
2. For each Cj (input state), transitions to destination states Ck upon each event Ai are
determined as follows:
(a) For each history h in Cj, create a concatenated event sequence q, where q =
h.Ai
(b) Now, if q is found to belong to some other equivalence class Ck (i.e., if qεCk),
then Ck is termed as a destination state of event Ai from state Cj.
(c) An edge is created from state Sj to each destination state Sk corresponding to
Ck, and it is labeled as “Ai”.
(d) If no such destionation state can be found, then no transition exists out of state Cj upon the occurrence of event Ai. (It is also possible that there are more than one transitions from an input state upon an event).
3. Merge the initial FSM,then the resultant graph is the final FSM for the process. Each of the states Sj in the FSM is mapped to a set of histories in H.
上述演算法,可以用圖 3-12 來說明。假設圖 3-12 是一個流程執行執行一 次(一個流程例)所收集的事件流(event stream)。由這個事件流可以找出許多 如圖 3-11 中(1)(2)… (n)的先前事件列(prefix),如:{A、AB、ABC、ABCA、… 、 ABCABCBACBACABCBACBACABCBACABCABCBACBA}。 ABCABCBACBACABCBACBACABCBACABCABCBACBA 圖<3-12>
因此,利用 KTAIL 演算法,在 step1 中,首先要將這些先前事件列(prefix) 依這些事件列之後的行為分類。但”之後的行為”如何定義呢?其實最簡單的說 法就是這些事件列之後會執行那些事件(event)。在 KTAIL 演算法中需給予一參 數 K,”之後的行為”由事件列(prefix)之後的 K 個事件(event)來定義。以圖 3-12 為例,假設 K 為 3,則可以由圖 3-3-12 的事件流(event stream)中找出長度為
3 的事件集合:{ABC、BCA、CAB、BCB、CBA、BAC、ACB、ACA}等 8 種。因此, 接下來,就可以很容易地把各先前事件列(prefix)分類了。如先前事件列 A 之 後的事件是 BCA,所以先前事件列 A 就被分到 BCA 這類,而先前事件列 AB 之後 的事件是 CAB,所以先前事件列 AB 就被分到 CAB 這類。依同樣的方法,將所有 先前事件列分類。 由分類結果,可以很明顯地發現,先前事件列(prefix)的分類中,{ABC、 ABCABCBACBAC、ABCABCBACBACABCBACBAC、ABCABCBACBACABCBACBACABCBAC、 ABCABCBACBACABCBACBACABCBACABC}這些事件列之後都會執行事件 ABC,所以這 些先前事件列(prefix)都被分到同一類。這也就是說,這些先前事件列就如同 圖 3-11 的(1)(2)… (n)一般,都到達同一個狀態,所以之後的行為(f)就接著執 行事件 ABC。因此,就把這一個分類稱為一個相同類別(equivalence class),設為 C1,也就利用這一個分類(C1)來代表一個狀態(S1)。 同樣的方法,由圖 3-12 的事件流中,共可找出 8 個相同類別(C1,C2,… C8), 分別代表 8 個狀態(S1,S2,… S8)。因此,可以利用這 8 個相同類別畫出 FSM 圖 中 8 個狀態。 接下來,只需要找出 FSM 圖中各狀態之間的轉換(transition)就可以了, 所以 KTAIL 演算法的 step2,目的便在找出各狀態之間的轉換(transition)。尋 找轉換(transition)的方法很簡單,只要在相同類別(Cj)的既有事件列(history) 之後加上所有可能的事件(Ai),成為新的事件列(h.Ai),若這個新的事件列屬於 另一種相同類別(Ck),則代表這個事件列原來所屬的相同類別(Cj)可以在某個事 件(Ai)發生後變成新的類別(Ck)、新的狀態(Sk)。只要利用這個特性,考慮相同 類別中所有的事件列可能使狀態發生的變化,就可以找出這個類別所代表的狀 態與其它狀態的關係,即與其它狀態之間的轉換。 以相同類別 C1其中既有的事件列 ABC 為例,如果 ABC 之後加上各種可能的 事件,則可能成為新的事件列是 ABCA、ABCB 及 ABCC。而其中 ABCA 屬於相同類 別 C4,代表相同類別 C1可以在事件 A 發生後變成新的類別 C4、新的狀態 S4。所 以,以相同類別 C1為例,演算法 step2(a)中對各既有事件列加上所有可能事件,
整理如表 3-1 中”h.Ai”欄所示,step2(b)中找出新的事件列所屬的相同類別,則
History h.AI Ci ABC ABCA ABCB ABCC C4 -ABCABCBACBAC ABCABCBACBACA ABCABCBACBACB ABCABCBACBACC C4 -ABCABCBACBACABCBACBAC ABCABCBACBACABCBACBACA ABCABCBACBACABCBACBACB ABCABCBACBACABCBACBACC C4 -ABCABCBACBACABCBACBACABCBAC ABCABCBACBACABCBACBACABCBACA ABCABCBACBACABCBACBACABCBACB ABCABCBACBACABCBACBACABCBACC C2 -ABCABCBACBACABCBACBACABCBACABC ABCABCBACBACABCBACBACABCBACABCA ABCABCBACBACABCBACBACABCBACABCB ABCABCBACBACABCBACBACABCBACABCC C4 -表<3-1> 而 step2(c)則利用 step2(a)、(b)所找出的結果,在 FSM 圖中,由狀態 S1
畫出邊(edge)至狀態 S4,標示為 A,同理,也由狀態 S1畫出邊(edge)至狀態 S2, 標示為 A。依同樣的方法,將所有相同類別處理完成後,就可以得到 FSM 如圖 3-13 所示了。 圖<3-13> 為了使如圖 3-13 的 FSM 圖減少複雜性,KTAIL 演算法加入 step3(B_F 演算 法無此步驟),將圖 3-13 的 FSM 圖中一些狀態合併。合併的方法是:如果一個 狀態 S1,有標示為”t”的轉換(transition)邊至狀態 S2… Sn,而狀態 S2… Sn連出 S1 S2 S4 S3 S5 S7 S6 S8 A A A A B B B B C C
去的轉換(transition)邊標示皆相同,則狀態 S2… Sn合併。以圖 3-13 為例,S2 和 S4合併,而 S3和 S5合併,最後 S7和 S8再合併如圖 3-14 所示。 圖<3-14> 因此,由上述的演算法,就可以由流程執行所記錄下來的事件流資料中找 出流程(以 FSM 圖表示)的定義了。但有一點值得注意的是,在前述 KTAIL 演算 法中所使用的是正確的事件流資料,也就是說並未考慮錯誤資料(noise)的問 題。 所以,在[Datt98]的研究中,針對錯誤資料(noise)的問題,修改 KTAIL 演 算法。主要的不同是加上一個參數 C,作為臨界值(confidence value)。當原來 KTAIL 演算法 step1,由所有事件流中找出所有的相同類別後,[Datt98]的研究 則再加上,計算相同類別中每一個事件列的出現機率,只有超過臨界值者才留 下,不到臨界值的事件列則刪去,而產生新的相同類別。自然,在經過這個修 正後所產生的相同類別,才繼續執行原來 KTAIL 演算法的 step2。 綜合以上的說明,本研究認為利用 KTAIL 演算法來萃取流程定義,主要有 下列缺點: (1)模式假設將產生多餘的狀態及狀態轉換: 在 KTAIL 演算法中,雖然認為 一個活動是由一些事件所組成,但為了簡化起見,也假設一個活動只有一 個事件。但如果一個活動只記錄一個事件,就會如同 Agrawal 演算法的假 設(假設活動的執行時間是”一瞬間(instantaneous)”、沒有活動的執行開 始時間相同),產生許多多餘的相依性(KTAIL 演算法則產生許多多餘的狀 態及狀態轉換)。 如圖 3-15,設圖 3-15 為一個流程,而這個流程的一次流程例為 XABCDY, 則利用 KTAIL 演算法(設 K 值為 1)所找出的 FSM 圖如圖 3-16(a)所示。由圖 3-16(a)中,可以明顯發現,會有 A-B-C-D 的執行順序關係。但是,實際上, 活動 B 與活動 C 之間是獨立的,並沒有一定的執行順序,當然,狀態 S3也 是多餘的。 S1 2/ 4 3/ 5 S6 7/ 8 A A B C B C
圖<3-15> 圖<3-16> 而如果有許多的流程例,對於活動 B 與活動 C 而言,這兩個活動之間可能 是活動 B 之後執行活動 C,或者是活動 C 之後執行活動 B(因為只記錄事件, 事件只有一個時間點,不會有二個事件同時發生),不論何者,都不能使這 個多餘的狀態及狀態間的轉換刪去。例如,圖 3-15 的流程如有另一流程例 為 XACBDY,則利用這兩個流程例,以 KTAIL 演算法所繪出的 FSM 圖如圖 3-16(b)所示,仍有 B→C 或 C→B 的轉換(transition),並未刪去。所以,KTAIL 演算法在流程有平行處理,即有活動彼此之間是獨立、平行的時候,將產 生許多多餘的狀態及狀態間轉換。 (2)參數值設定不易: KTAIL 演算法中需給定一參數值,來決定一個狀態之後 的行為(由狀態之後 K 個事件所定義)。然而,同樣的流程,記錄同樣的事 件,只要 K 值設定不同,則所產生的 FSM 圖並不相同。同樣以圖 3-15 的流 程及圖 3-16 的流程例為例,如果令 K 值為 2,則所繪出的 FSM 圖如圖 3-17 所示。 圖<3-17> 由圖 3-16 與圖 3-17 比較,可以發現兩圖有相當程度不同。因此,KTAIL 演 算法要求 K 值的設定必須由對流程有經驗、熟悉的專家來決定,而且不同 S1 S2 S3 S4 S5 A B C D S1 S2 S3 S4 S5 A C A B B D C (a) (b) A B C D X Y S2 S3 S4 S5 S1 C A B B C
的流程可能就須要設定不同的 K 值。所以,參數 K 值的設定將明顯影響最 後所找出的 FSM 圖,如何適當設定並不容易。 (3)有些狀態不容易合併,模式複雜: KTAIL 演算法以 FSM 圖為輸出,FSM 圖 中表達了狀態及狀態間的轉換。而演算法中,狀態是由”之後的行為”來定 義,所以只要之後執行某些相同的行為,就認為不論前面如何執行,都到 達同一種狀態。由圖 3-17 的例子,可以找到 A-B-C 及 A-C-B 的事件序列, 都到達同樣的狀態 S5,但以流程而言,並不見得真正執行完成事件 A-B-C 與事件 A-C-B 會到達相同的狀態。所以,狀態 S5並沒有辦法提供更多的資 訊,來整理事件 A-B-C、事件 A-C-B 等事件執行順序。 所以,FSM 圖中只是把可能的部份事件順序找出來而己,若可能的事件順 序很多(如有其它事件可以跟事件 B、C 平行處理),則找出的可能事件順序 就有多種可能,而變得複雜,難以進一步整理、合併(merge),而會有一個 較為複雜的 FSM 圖(如圖 3-17 的狀態 S2到狀態 S5就難以再整理、合併)。 因此,KTAIL 演算法所找出的 FSM 圖是一個較為複雜,提供對流程有經驗 者作進一步整理、分析的工具。 而且,進一步考慮,如果流程中的活動包含更多的訊息,如流程中活動實 際上包括一個以上的事件時,以同樣的演算法,因為所找出的是流程部份 的事件執行順序,所以可能一個活動的數個事件被其它活動的事件所隔開, 則要找出同一個活動的事件就更為困難了,當然就更難加以整理、合併了。 3 . Markov 演算法 在[Cook95]的研究中,與 KTAIL 演算法類似地,仍認為一個流程是由許多 的活動所組成,這些活動是某些較小單位的工作。每一個活動執行時,會執行 一段時間,在這段時間內可能會記錄下一些事件(event),如活動開始事件(begin event)、活動結束事件(end event)、資源等待事件(wait event)… 等等。這些 事件是在某一個時間點發生的,沒有事件的時間點相同。所以如果收集流程執 行過程發生事件的記錄,就會得到一連續的事件流(event stream),而為了簡 化起見,Markov 的演算法也假設每一個活動執行只記錄一個事件(event)。在記 錄了流程執行所產生的事件流後,希望能利用演算法由事件流中找出 FSM 圖, 即找出流程的定義來。
因此,在以事件流(event stream)為輸入,FSM 圖為輸出的要求下,Markov 演算法的主要想法(idea)是:找出最可能的事件序列(event sequence),並利 用這些事件序列,轉成 FSM 圖中的狀態和狀態間的轉換。因此,演算法首先要 由事件流中找出較可能的事件序列。而要找出較可能的事件序列,可以由所有 事件組合出許多長度固定的事件列,並計算這些事件列之後執行某事件的機率, 找出其中機率較大者,自然就是較有可能的事件序列了。 將 Markov 演算法列示如下:
1. The event-sequence probability tables are constructed by traversing the event stream.
2. A directed graph, called the event graph, is constructed from the probability tables in the following manner. Each event type is assigned a vertex. Then, for each event sequence that exceeds the threshold probability, a uniquely labeled edge is created from an element in the sequence to the immediately following element in that sequence.
3. The previous step can lead to over-connected vertices that imply event sequences that are otherwise illegal. To correct this, over-connected vertices are split into two or more vertices. (The general definition of this step works by finding disjoint sets of input and output edges for a vertex that have some non-zero sequence probability, and splitting the vertex into as many vertices as there are sets.)
4. The event graph G is then converted to its dual G’ in the dollowing manner. Each edge in G becomes a vetex in G’ marked by the edge’s unique label. For each in-edge/out-edge pair of a vertex in G, an edge is created in G’ from the vertex in G’ corresponding to the in-edge to the vertex in G’ corresponding to the out-edge. This edge is labeled by the event type.
同樣以圖 3-12 的例子來說明 Markov 演算法。圖 3-12 是一個流程執行執行 一次(一個流程例)所收集的事件流(event stream)。因此,首先由事件流中找 出較可能的事件序列。然而,要找出較可能的事件序列,需要先由所有事件組 合出許多長度固定的事件列,所以 Markov 演算法也需要需給予一參數 K,事件
列的長度由 K 值決定。 以圖 3-12 為例,其中只有 A、B、C 三種事件,所以假設 K 值為 2,則可以 找出所有的事件列為:{AA、AB、AC、BA、BB、BC、CA、CB、CC}等九種事件列。 接下來,則需要計算這些事件列之後執行某事件的機率,因此以這九種事件列 作為表格的縱軸,而以所有可能的事件(A、B、C)作橫軸,繪出表格如表 3-2 所 示。 A B C AA 0.00 0.00 0.00 AB 0.00 0.00 1.00 AC 0.50 0.50 0.00 BA 0.00 0.00 1.00 BB 0.00 0.00 0.00 BC 0.33 0.67 0.00 CA 0.00 1.00 0.00 CB 1.00 0.00 0.00 CC 0.00 0.00 0.00 表<3-2> 接下來,自然要算出表格中各種事件序列的機率了。如表格中第二列為事 件列 AB,圖 3-12 的事件流中事件列 AB 出現 6 次,且之後都執行事件 C,所以 事件列 AB 之後執行事件 C 的機率為 1,而之後執行事件 A、B 的機率皆為 0,如 表 3-2 第二列所示。又如表格中第六列為事件列 BC,圖 3-12 的事件流中事件 列 BC 也出現 6 次,但之後執行事件 A 有 2 次,所以事件列 BC 之後執行事件 A 的機率為 0.33,而之後執行事件 B 有 4 次,所以事件列 BC 之後執行事件 B 的 機率為 0.67,當然,之後執行事件 C 的機率就是 0 了,如表 3-2 第六列所示。 餘類推,完成如表 3-2 所示。 因此,完成表 3-2 後,就可以得到所有可能事件列之後執行某個事件的機 率了。也就是說,Markov 演算法 step1 執行完成,可以得到如同表 3-2 的事件 序列機率表(event-sequence probability table),由表中就可以得知各種事件 序列發生的機率。
當然,接下來只要找出機率較大者,就是較有可能的事件序列了。所以 Markov 演算法 step2,首先由事件序列機率表中找出機率較大的事件序列。因此,Markov 演算法需要另一參數 C,作為門檻值(threshold),只取機率值大於等於這個門 檻值的事件序列。 以表 3-2 為例,設門檻值 C 為 0.5,則可以找到的事件序列是{ABC、ACA、ACB、 BAC、BCB、CAB、CBA}。因此,以這些事件序列畫事件圖(event graph)。即以 事件為點(vertex),事件序列中每一個事件依序相連,繪出圖形如圖 3-18 所示。 圖<3-18> 但由圖 3-18 中可以發現,雖然這些事件和事件之間的邊,是由事件序列機 率表取超過門檻機率值而繪出的,但仍會多出許多的事件序列。例如,可以由 圖 3-18 中找出事件序列 C-B-C,但這個事件序列發生機率並未超過門檻值,所 以應將此事件序列由圖 3-18 中去除。 但如何去除呢?以圖 3-18 上點 B 為例,有連進來的邊(ingoing edge)A→B、 C→B,而有連出去的邊(outgoing edge)B→A、B→C,這些邊是由不同的事件序 列所繪出,所以只要將不同的連進來和連出去的邊分類,使分類後的邊沒有多 出來的事件序列,再將點 B 分裂成數點,以連接分類後的邊即可。 所以,Markov 演算法 step3 的目的,在將如圖 3-18 的事件圖去除多餘的 事件序列。所使用的方法則是藉由圖中的點分裂,使各點所連的邊,不會產生 多餘的事件序列。因此,當 step3 完成,就可以得到一個包含所有超過門檻機 率值的事件序列,但無多餘事件序列的事件圖了。 因此,接下來 step4 只要將這個事件圖轉成 FSM 圖就可以了。因為如圖 3-18 中的點代表事件,所以圖中的邊便代表事件執行前後的狀態了。因此,利用 圖 3-18 分裂後的每一個邊(共有 8 個),繪出 FSM 圖中 8 個狀態。接下來,需要 找出 FSM 圖中狀態之間的轉換(transition)。如(1)-C-(5),便代表了狀態(1) 執行事件 C 後成為狀態(5),所以,FSM 圖中便有一邊由狀態 1 至狀態 5,標示 為 C。這也就是說,由圖 3-18 所完成的分裂圖中,只要找出各點連進來(ingoing A B C
edge)和連出去(outgoing edge)邊的兩兩組合,就可以在 FSM 圖中繪出由連進 來邊所代表的狀態,至連出去邊所代表狀態,而標示為這個點的轉換(transition) 了。最後,完成轉換如圖 3-19 的 FSM 圖(可以再利用一些 FSM 圖合併的方法予 以合併,此處不再討論)。 圖<3-19> 因此,執行 Markov 演算法後,也可以由所記錄下來的事件流,找出流程定 義(以 FSM 圖表示)。且因為 Markov 演算法是利用門檻值的方式,取較有可能的 事件序列來繪 FSM 圖,所以,對於錯誤資料(noise)的問題,已可以處理。但 step3 由事件圖刪去多餘事件序列的方法,在點數較多、K 值較大時,將變得複雜, 所以在[Datt98]的研究中對多餘事件序列刪去的方法作了修改,演算法如附 2 所示。 綜合上面的說明,本研究認為利用 Markov 演算法來萃取流程定義,主要 有下列缺點: (1)模式假設將產生多餘的狀態及狀態轉換: 在 Markov 演算法中,也假設一 個活動只有一個事件。因此,如同 Agrawal 演算法、KTAIL 演算法,會產生 許多多餘的狀態及狀態轉換。 (2)參數值設定不易: 在 Markov 演算法中需給定二參數值,K 值決定事件列 的長度,而 C 值則決定門檻值。這兩個參數值的設定,對於最後所產生的 FSM 圖都有很大的影響。因此,Markov 演算法對於參數值 K、C 的設定也必 須由對流程有經驗、熟悉的專家來決定,而且不同的流程可能就須要設定 不同的 K、C 值。所以,參數值的適當設定並不容易。 (3)有些狀態不容易合併,模式複雜: 就如同 KTAIL 演算法一般,Markov 演 算法也需要對找出的 FSM 圖再合併(merge)、整理。Markov 演算法是取固定 長度的事件列來找尋可能的事件序列,即片段的事件順序找尋事件間順序,
S1
S2
S3
S5
S6
S4
S7
S8
A
A
A
C
C
B
B
A
C
B
所以初步找出的 FSM 圖會很複雜,也需要更進一步的合併、整理。因此, Markov 演算法所找出的 FSM 圖也是一個較為複雜,提供對流程有經驗者作 進一步整理、分析的工具。
第三節 綜合比較
綜合上節三個演算法的說明,本研究認為在流程模式的假設上,如果假設 一個活動的執行只有一瞬間、一個時間點,不論上述那一種演算法,由記錄下 來的流程歷史資料,來萃取流程定義,都會產生許多多餘的相依順序關係,而 且導致找出的流程定義更為複雜。所以,本研究試圖針對此點進行改善,提供 一個更簡潔的萃取方法。此外,KTAIL 和 Markov 演算法(及其改良方法[Datt98]),所產生的有限狀 態圖(FSM),在很多情況下並不易了解。試以圖 20(a)、(b)、(c)為例,圖 3-20(a),是一個程式撰寫流程([Cook95],ISPW 6/7 process)的一部份。當程式 人員撰寫修改程式(G)後,會編譯程式,如果編譯不成功(H),則重新撰寫修改。 若成功(I),則測式輸出資料是否正確,若不正確(J),同樣重新撰寫修改,當 然,如果輸出結果是正確的(K),則進入下一階段。 圖<3-20> 圖 3-20(b)是利用 KTAIL 演算法所找出來的流程,而圖 3-20(c)是利用 Markov 演算法所找出來的流程。由圖 3-20(b)中,可以清楚發現,KTAIL 演算法所找出 的流程,可以表達當程式人員撰寫程式(G)後,編譯成功(I),但輸出不正確(J), 重新撰寫修改的流程意義(G-I-J)。或是撰寫程式(G)後,編譯不成功(H),重新 Modify Code C_Code S_Test Mod Code[G] Comm Compile_'OK [H] Comm Compile_Ok [I] Comm Test_'OK [J] Comm Test_OK [K] (a) G G G J I H I K (b) G G G H I J K (c)
撰寫修改的流程意義(G-H)。當然,也表達了當程式人員撰寫程式(G)後,編譯 成功(I),輸出正確(K),而進入下一階段的流程意義(G-I-K)。雖然利用 KTAIL 演算法所找出的流程,表達了這些流程意義,但這些流程意義的表達與原來圖 3-20(a)相較,是相當複雜而難以合併、了解的,必須由對這個流程熟悉的專家 來作進一步的解釋與整理。 同樣的情形也發生在 Markov 演算法所找出的流程。在圖 3-20(c)中,也表 達了如 G-I-J、G-H、G-I-K… 等流程執行上的意義(而且更複雜),但與圖 3-20(a) 相較,同樣難以合併、了解,必須由專家解釋。或者說,這二個方法,只是提 供了一個較為初級的流程定義資訊,來供對該流程有經驗的專家參考。這二個 方法所找出的流程較為複雜且必須再由有經驗的專家作進一步的整理。 最後,因為現今商用的工作流程管理系統也很少接受以有限狀態圖所表達 的流程定義。因此本研究將重點放在找出類似有向圖(directed graph)的流程 模式,而且試圖以更簡潔、有效率的方法找出更高品質的流程定義。
第四章.萃取演算法
藉由資訊科技的幫助,應用程式的開發,在流程執行一段時間後,便會留 下一些歷史性的資料(Workflow log),展現和分析這些資料,也很重要。本研 究試圖由這些歷史性的資料中,找出流程的定義。並參考第三章第一節,[WfMC98] 所訂定的流程定義標準,而著重於找出流程的控制流(control flow)部份。 所以,以下簡單將本章分為三個部份: (1)流程模式(Process Model),說 明本研究中對流程、活動、控制流的定義及假設。(2)控制流萃取演算法,利用 這個演算法找出流程的控制流定義,也就是流程中活動執行的順序關係。(3)控 制條件萃取演算法,流程中活動的執行,除了順序關係外,控制條件可以決定 活動是否執行,因此也很重要,利用這個演算法以萃取找出流程的控制條件。第一節 流程模式
企業中有許多的流程(process),執行這些流程可以達成某些企業目標。而 一個流程是由許多的活動(activity)所組成,這些活動是某些較小單位的工作。 例如,保險公司有”客戶索求保險給付”的處理流程,當客戶要求保險給付時, 就可以依這些流程進行處理。這個流程中可能包括”客戶填寫表單”、”表單資料 審查”、”保費費率計算”、”專業審查”...等等的單位工作,這些單位工作就稱 為活動。因此,一個流程可以包含許多的活動,而流程的一次執行則稱為此流 程的一個流程例。 本研究以一個有向圖來代表流程中活動的執行,圖中的每一個點(Vertex) 都 代 表 一 個 活 動 , 點 與 點 間 的 邊 (Edge) , 則 代 表 這 兩 個 活 動 的 執 行 順 序 (Dependence)。同時,邊上也含有一個布林函數(boolean function)。如果, 流程執行時,這個函數值為”真”(true),則下一個活動就會被執行;如果是” 假”(false),則下一個活動就不會被執行了。所以,流程中活動的執行,可以 分為下列三種情形: 1. 循序( Sequence) :流程中的活動依序往下執行,如圖 4-1 所示。活動 A 執行完成後,活動 B 才開始執行,活動 B 執行完成後,活動 C 才開始執 行,以此類推。也就是說,在這樣的有向圖中,這些活動與活動間的邊 上所附的布林函數值都是”真”。因此,這些活動依序往下執行。圖<4-1> 2. 平行( Parallel) :如圖 4-2 所示,活動 A 執行完成後,會測試 A→B 邊 上的布林函數,如果值為”真”,則執行活動 B,如果為”假”,當然活動 B 就不執行了。同樣地,也會測試 A→C、A→D 邊上的布林函數以決定是否 執行活動 C 和活動 D。 圖<4-2> 也就是說,當活動有數個連出去(outgoing)的邊時,每一個邊上的布林 函數都必須被測試,以決定所連的下一個活動是否執行。而且,這些布 林函數測試結果是獨立的,不影響其它布林函數的成立與否。如 A→B 邊 上的測試結果不影響 A→C 邊上的測試結果。所以當一個活動所有可能的 下一個活動都會被執行(函數測試值皆為”真”)時,這種情形稱為 AND;也 可能總是只有一個被執行,這種情形稱為 XOR;當然也有可能介於上述 二者之間,一次有數個不等的活動執行,稱為 OR。 在上述的定義中,活動 B、C、D 的執行與否是彼此獨立的,端視其連進 來邊上的布林函數值是否為真,本研究此項定義是參考[WfMC98]中 AND_SPLIT 的定義而來。當然,目前也有一些不同的定義方法,例如, [WfMC98]中有另一種 XOR_SPLIT 的定義,在這種定義裡,活動之間的執 行不是彼此獨立的(但此種定義也可以用 AND_SPLIT 的定義來處理)。而 在[Atti93]的研究中,更詳細的定義了多種活動之間可能的關係。目前 有許多定義活動間關係的研究提出[Atti93][Adam98],本研究不再於此 贅述,但這些活動間關係較為複雜、適用於特定狀況,所以本研究採用 較為一般化,且廣為工作流程管理系統所接受的平行活動獨立的假設。 另外,上述有許多連出去(outgoing)邊的活動,是一個分支(Split)的活 動,必有一相對應活動,有許多的連進來(incoming)的邊,可以將前面 A B C A B C D E
分支出去的邊合併(Join),如圖 4-2 中的活動 E。這兩個分支(Split)、 合併(Join)活動之間的部份流程,就視為一個區間(Block)。 當然,合併也有兩種情形,一種是必須等前面所有分支出去的流程皆執 行完成,才能往下執行,這種情形稱為 AND_Join。如圖 4-2 中活動 A 執 行後,活動 B、C 執行,而活動 E 必須等到活動 B、C 皆執行完成,才能 開始執行。另一種是只要前面所有分支出去的流程其中之一執行完成, 就可以往下執行,這種情形稱為 XOR_Join。如圖 4-2 中活動 A 執行後, 活動 B、C 執行,而活動 E 只要等到活動 B 或活動 C 執行完成,就可以開 始執行了。 3. 迴圈( Loop) :流程中的活動可以重覆執行,如圖 4-3 所示。活動 A 執 行完成後,執行活動 B,活動 B 執行完成後,會執行活動 C,當活動 C 執 行完成後,有 C→B、C→D 邊上的條件會被測試,若 C→B 邊上條件為”假”, C→D 邊上條件為”真”,則執行活動 D。反之,則重覆執行活動 B、活動 C, 再測試條件,以此類推。因此活動 B、C 可能重覆執行多次。 圖<4-3> 如圖 4-3 中 C→B、C→D 邊上的控制條件,稱為迴圈條件,這兩個條件彼 此不交集,一個成立(為”真”),另一個必不成立(為“假”),且在迴圈執 行完成後測試。至於活動 B、活動 C,則構成迴圈的主體,也將迴圈主體 視為一個區間。在圖 4-3 中的迴圈主體(活動 B、活動 C),是順序執行的, 當然迴圈主體也可以是平行、迴圈(巢狀)的執行方式,如圖 4-4 所示。 圖<4-4> A B C D A B C D E F (a) A B C E F (b)
流程中,每一個活動會執行一段時間,當活動執行期間會留下一些事件 (event)記錄。事件是”瞬間(instantaneous)”發生的、沒有事件的發生時間相 同。在本研究中,並非記錄所有事件,而是對每一個活動,記錄這個活動的開 始(begin)、結束(end)、寫入(write)變數事件。其中的開始、結束事件,每一 個事件以三個資料項(3-tuple)來表示,記錄成[InsNo,AcNo,TS]。其中 InsNo 是流程例代號、AcNo 是活動代號,而 TS 則是這個事件發生的時間。因此就可 以將相同流程例、相同活動的開始、結束時間找出,整理如表 4-1 所示。由表 4-1,就可以得知每一個流程例中,各活動的開始、結束時間。本研究便以表 4-1 的資料作為第二節控制流萃取演算法的輸入資料,以找出流程定義(以有向圖表 示)。
Instance_No Activity_No Begin_time End_time 表<4-1>
而寫入變數的事件,則以四個資料項(4-tuple)來表示,記錄成
[InsNo,AcNo,VarName,Value]。其中 InsNo 是流程例代號、AcNo 是活動代號, 而 VarName、Value 則是這個事件所寫入變數的變數名稱和變數值。本研究記錄 了所有寫入事件的資料後,便以此作為第三節控制條件萃取演算法的輸入資料。 因此,在本研究中,首先由使用者列出流程中所有的活動,並假設每個流 程中都可以找到一個開始與結束的活動。如果實際上,流程中的開始活動(start activity)不只一個,則使用者可以加上一個空(null)的開始活動,並由這個空 的開始活動連至原來的開始活動。同樣的,若流程中的結束活動(end activity) 不只一個,則使用者可以加上一個空(null)的結束活動,並由原來的結束活動 連至這個新的結束活動,而使得流程中只有一個開始與一個結束活動。當使用 者列出所有的活動後,工作流程管理系統便可以去收集、記錄如前所述的事件 資料,本研究則試圖由這些資料,利用下節的演算法以找出流程定義。
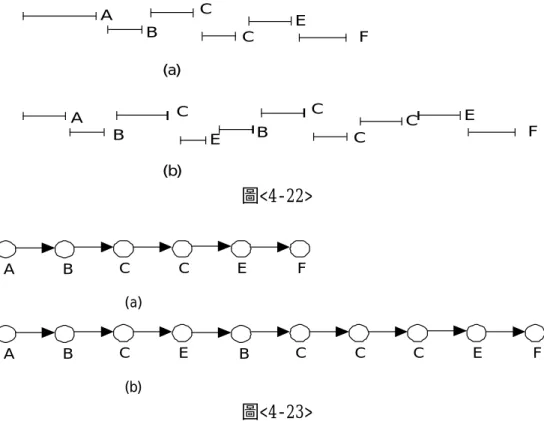
第二節 控制流萃取演算法
為了便於解釋,我們先以圖 4-2 為例,說明流程中活動執行時間的關係。 假設圖 4-2 的流程,某次執行時,活動 A 在 12:00 開始執行,12:30 結束,接下來,活動 B、C、D 可以平行執行,所以活動 B 在 12:40 開始執行,14:40 結束, 而活動 C 在 12:35 開始執行,13:30 結束,活動 D 在 13:45 開始執行,14:20 結 束,最後,活動 E 則在 14:45 開始執行,15:00 結束,利用時間為橫軸,將這 些活動的執行時間表示如圖 4-5 所示。 圖<4-5> 從圖 4-5 中,可以很容易發現,活動與活動的執行時間可能存在三種關係: (1)不交集(none),如活動 A 執行完成後,活動 B 才開始執行,所以這兩個活動 的執行時間並未有交集。(2)部份交集(overlap),如活動 C 與活動 B,活動 C 先 開始執行,但兩活動有一部份的時間是一樣的(因為活動 B、C 是平行的,兩活 動可能平行執行)。(3)包含(contain),如活動 B 和活動 D 的執行時間,因為活 動 B 執行較久,執行時間可以完全包含活動 D 的執行時間。所以從圖 4-2 與圖 4-5 中可以知道,兩兩活動執行時間會有如上述的三種關係。將這三種執行時 間關係整理如圖 4-6 所示。 圖<4-6> 從上述的例子中,可以發現非常重要的一點:在有向圖中,如果活動 X 與 活動 Y 之間有一邊( X →Y ) ,則活動 X 的執行開始時間必然比活動 Y 的執行開始 時間要早, 且 這 兩 個 活 動 的 執 行 時 間,必沒有交集( none) 。如圖 4-2 中,活動 A、活動 B 有一邊 A→B,而圖 4-5 中活動 A 的執行開始時間是 12:00,比活動 B 的執行開始時間 12:40 要早,且活動 A、B 的執行時間不交集。同樣的情形也發 生在活動 A 與活動 C、活動 A 與活動 D、活動 B 與活動 E、活動 C 與活動 E、活 動 D 與活動 E。這些都是因為,如果有向圖中有一邊(設為 X→Y),則必須活動 X 執行完成後,活動 Y 才能開始執行,所以會有這樣的關係。 然而,在圖 4-5 中,活動 A 與活動 E 也滿足這樣的條件,但在圖 4-2 中, Time A 12:00 12:30 B 12:40 14:40 C12:35 13:30 D E 13:45 14:20 14:45 15:00 X X X Y Y Y
卻沒有 A→E 邊。這是因為在圖 4-2 中,活動 E 在其它活動(如活動 B、C、D)之 後執行,而這些活動則在活動 A 之後執行。換句話說,活動 E 是因為遞移,而 在活動 A 之後執行。因此,要找出有向圖中,與活動 A 相連(A→X)的活動 X, 應該由滿足上述條件的活動中,選擇最接近活動 A 的活動。因為在所有滿足條 件的活動中,越靠近活動 A 就越有可能在有向圖中有這個邊。 因此,我們有個想法:在一個活動的執行後,不交集而緊接著執行的活動, 較有可能是這個活動的下一個活動(即有向圖中,這兩個活動間有一邊存在)。 所以,是不是可以利用這樣的想法,由每一個流程例中,找出一個活動可能的 下個活動,最後再將所有流程例合起來,應該就可以找出一個活動所有可能的 下個活動了。
將上述想法說明,整理成演算法 1 如下:
Algorithm 1
Step0. Let Nonegraph = (V,E), V=φ, E=φ
Step1. Let Obverse_list = the ascendant order of all activities by their start time Reverse_list = the descendant order of all activities by their end time Step2. Get first activity(e) from Reverse_list, add node e to Nonegraph
Step3. Get an activity(u) from Reverse_list, add node u to Nonegraph Step4. Search Obverse_list, let I = the position of activity u+1
Step5. Test = 0
While test=0 do
Read I_th activity from Obverse_list as activity v If end time of activity u < start time of activity v Then
Test = 1; Add edge (u,v) to Nonegraph; max= end time of activity v Else
I = I+1 End
Step6. Test = 0; J= I +1; Read I_th activity from Reverse_list as activity t While test=0 and J<=n do
Read J_th activity from Obverse_list as activity o If start time of activity o < end time of activity t Then
J = J+1
If start time of activity o < max Then add edge (u,o) to Nonegraph Else Test= 1
If end time of activity o < max then max = end time of activity o Else
Test = 1 End
Step7. Goto step3 untio no other activity in the Reverse_list Step8. Return E
我們可以利用圖 4-7 的例子來說明這個演算法。假設圖 4-7 是一次流程執 行後所有活動執行時間的記錄,如下所示:
圖<4-7>
演算法 1 中,step0 首先將 Nonegraph 設為一空圖形,而 step1 則先將所有 活動依開始時間由小到大排序,所以,Obverse_list 為{A、B、C、D、E},也將 所有活動依結束時間由大到小排序,所以,Reverse_list 為{E、C、D、B、A}。 接下來,step2 讀取 Reverse_list 中第一個活動E,並將這個節點 E 加入Nonegraph 中,如圖 4-8(a)所示。
圖<4-8>
同樣地,step3 由 Reverse_list 中讀取活動 C,將節點 C 加入 Nonegraph 中。接著執行 step4,搜尋 Obverse_list,找到活動 C 在 Obverse_list 中所處 的位置。因為活動 C 是 Obverse_list 的第三個活動,所以 I 值被設為 4。接下 來的 step5,目的在找出開始時間晚於活動 C 的結束時間、且最接近的活動。 因為 Obverse_list 是依所有活動的開始時間由小到大來排列的,所以尋找符合 目的的活動,只要由活動 C 所處的位置繼續往前找即可。因此時 I 值為 4,所 以讀取 Obverse_list 中第四個活動 D,因為活動 D 的開始時間比活動 C 的結束 時間早,所以並不符合要求。I 值加上 1 成為 5 且重覆 step5 迴圈,讀取 Obverse_list 中第五個活動 E,因為活動 E 的開始時間比活動 C 的結束時間晚, 所以,活動 E 是第一個找到符合要求的活動,所以也是最接近的。將 C→E 邊加 入 Nonegraph 中,如圖 4-8(b)所示。接著執行 step6,step6 的目的,在找出所 有比活動 E 晚開始、執行時間與活動 E 有交集、且與活動 C 之間並非遞移的活 動。要找出比活動 E 晚開始的活動,而現在的 I 值,是活動 E 在 Obverse_list 中的位置,所以也只要由位置 I 繼續往前找即可。因此,設 J 值等於 I+1(而為 6)。此時,因為 J 值為 6,超過這個流程例中活動個數(設為 n),代表沒有活動 比活動 E 晚開始,所以直接結束 step6 迴圈。接著執行 step7,而回到 step3。
A B C D E E (a) E C (b) E D C E (c) B (d) A C D (e) B D C E
接下來,step3 中由 Reverse_list 中讀取活動 D,將節點 D 加入 Nonegraph 中。執行 step4,搜尋 Obverse_list,找到活動 D 在 Obverse_list 中所處的位 置。因為活動 D 是 Obverse_list 的第四個活動,所以 I 值被設為 5。接下來的 step5,因此時 I 值為 5,所以讀取 Obverse_list 中第五個活動 E,因為活動 E 的開始時間比活動 D 的結束時間晚,所以,活動 E 是找到最接近而符合要求的 活動。將 D→E 邊加入 Nonegraph 中,如圖 4-8(c)所示。接著執行 step6,因此 時,J 值等於 I+1 而為 6,代表也沒有活動比活動 E 晚開始,所以直接結束 step6 迴圈。接著執行 step7,而回到 step3。
此時,step3 由 Reverse_list 中所讀取的活動是 B,將節點 B 加入 Nonegraph 中。執行 step4,搜尋 Obverse_list,找到活動 B 在 Obverse_list 中所處的位 置。因為活動 B 是 Obverse_list 的第二個活動,所以 I 值被設為 3。接下來的 step5,因此時 I 值為 3,所以讀取 Obverse_list 中第三個活動 C,因為活動 C 的開始時間比活動 B 的結束時間早,不符合要求,所以 I 值加 1 成為 4 且重覆 迴圈。因此時 I 值為 4,所以讀取 Obverse_list 中第四個活動 D,因為活動 D 的開始時間比活動 B 的結束時間晚,所以活動 D 是找到最接近而符合要求的活 動。將 B→D 邊加入 Nonegraph 中,如圖 4-8(d)所示。接著執行 step6,因此時, J 值等於 I+1(而為 5),所以讀取 Obverse_list 中第五個活動 E,但活動 E 並不 滿足與活動 D 有交集的條件,所以直接結束 step6 迴圈。接著執行 step7,而 回到 step3。
同樣的方法,step3 由 Reverse_list 中讀取活動 A,將節點 A 加入 Nonegraph 中。執行 step4,搜尋 Obverse_list,找到活動 A 在 Obverse_list 中所處的位 置。因為活動 A 是 Obverse_list 的第一個活動,所以 I 值被設為 2。接下來的 step5,因此時 I 值為 2,所以讀取 Obverse_list 中第二個活動 B,因為活動 B 的開始時間比活動 A 的結束時間晚,所以活動 B 是找到最接近而符合要求的活 動。將 A→B 邊加入 Nonegraph 中。接著執行 step6,因此時,J 值等於 I+1(而 為 3),所以讀取 Obverse_list 中第三個活動 C,活動 C 的開始時間早於活動 B 的結束時間(代表二活動有交集),所以活動 C 也滿足條件,將 A→C 邊加入 Nonegraph 中,如圖 4-8(e)所示。重覆迴圈,讀取 Obverse_list 中第四個活動 D。活動 D 的執行時間與活動 B 沒有交集,所以結束 step6 迴圈。接著執行 step7, 因 Reverse_list 中沒有其它活動而結束。因此,最後所傳回的邊是:{A→B、A
→C、B→D、C→E、D→E}。 綜合以上所述,演算法 1 的主要方法是先找出一個活動(設為 X)結束之後, 第一個執行時間不交集的活動(設為 Y),並考慮那些開始時間介於活動 Y 的執 行時間的所有活動(設為 Z),而認為活動 Y、活動 Z 是活動 X 符合前述條件且非 遞移而產生的活動。 這個概念可以用圖 4-9 來說明,對活動 X 而言,所有比活動 X 晚開始的活 動,可以分為二類,第一類執行時間與活動 X 有交集,如圖 4-9 的活動 B、C、 D。這一類因為與活動 X 執行時間交集,所以不可能與活動 X 有執行順序關係。 第二類則是執行時間與活動 X 沒有交集,如活動 Y、活動 E、活動 F、活動 G。 這類才是可能與活動 X 有執行順序關係的活動,所以演算法 1 的 step5,目的 就在跳過第一類的活動,直到第二類的第一個活動。 圖<4-9> 如圖 4-9,活動 Y 是第二類最早開始的活動,如果第二類活動中,有活動 與活動 Y 的執行時間沒有交集,如活動 G,則這些活動的開始時間必晚於活動 Y 的結束時間,而且這些活動必因活動 Y 而遞移於活動 X,所以這些活動也不用 列入考慮。因此真正值得考慮的是,第二類活動中與活動 Y 有交集的活動,即 第二類活動中,開始時間介於活動 Y 的開始(T1)、結束時間(T2)點之間的活動, 如活動 E、活動 F。所以當演算法 1 的 step5 完成時,會找到第二類活動中的第 一個活動 Y(此時的 I 值代表 Obverse_list 中活動 Y 的位置),接著執行的step6, 就準備由第二類活動中的第二個活動開始找起(所以一開始設 J 值為 I+1),找 出開始時間介於 T1、T2之間的活動。 但有一點值得注意的是,如活動 E、活動 F 這些與活動 Y 執行時間有交集 而被列入考慮的活動,其中如果有活動的執行時間可以被活動 Y 的執行時間所 X E Y F G T1 T3 T2 C D B
包括,如活動 E,則考慮的時間點 T2應該被改成活動 E 的結束時間點(T3)。這 是因為,如果有活動的開始時間介於 T3與 T2之間,則這些活動雖然與活動 Y 有 交集,但會因為活動 E 而遞移,如活動 F。所以在考慮這些與活動 Y 有交集的 活動時,如果有活動的執行時間可以被活動 Y 所包括,則應將考慮區間的結束 時間點往前移至這個活動的結束時間。因此,在演算法 1 的 step5、step6 中, 變數 max 一開始被設為第一個活動(Y)的結束時間,如果與活動 Y 有交集的活動 中,有比活動 Y 早結束的活動,則重新設定 max 值為這個活動的結束時間,而 使得尋找時間區間縮小,開始時間超過 max 值的活動不再被列入考慮。 因此,如圖 4-10(a)的流程例,所找出的 Nonegraph 如圖 4-10(b),對活動 A 而言,不會有 A→D 的邊。 圖<4-10> 綜合以上的說明,演算法 1 可以用來找出各流程例中,每一個活動之後可 能的下一個活動,如圖 4-10(b)中,傳回的邊是:{A→B、A→C、B→D、C→E、D →E},即從圖 4-10(a)的流程例中,利用演算法所找出的結果,活動 A 之後可 能的下個活動是活動 B、活動 C,而活動 B 之後下個活動可能是活動 D,活動 C 之後可能的活動是活動 E,活動 D 之後可能的活動是活動 E。因此,從這個流程 例中,演算法 1 就可以找出每個活動可能的下個活動。如果能將所有的流程例 依同樣的演算法,找出每一個活動執行後可能執行的下個活動,聯集起來,應 該就可以得到每一個活動執行之後所有可能的下個活動了。 而在找到每一個活動執行之後所有可能的下個活動後,如果可以把其中不 正確的部份刪去,當然就可以利用剩下的部份找出正確的有向圖。但是那些是 不正確的部份呢?可以用圖 4-11 的例子來說明。 圖<4-11> E A C D B A B C D E (a) (b) A B C E