Du-Shiau Tsai, Department of Information Networking Technology, HUST.
On Visual False Positive Secret in 2-out-of-n
Visual Cryptography
Du-Shiau Tsai
Abstract
In 1994, Naor and Shamir proposed a secret sharing scheme with perfect security, called Visual Cryptography. In this paper, we address the issue of visual false positive secret, visual false positive black pixels and visual false positive white pixels, where qualified subsets of participants may visually recognize and accept these pixels as secret which is not true. To our best knowledge, this paper is the first attempt in the literature to demonstrate Visual Cryptography could cause unpredictable damages to qualified subsets of participants and applications based on it without suffering malicious attacks. The experimental results and the analysis demonstrate that visual false positive secret is possible in 2-out-of-n Visual Cryptography.
Keywords: Visual cryptography, Human visual system, Secret sharing, Visual false positive secret.
蔡篤校:修平科技大學資訊網路技術系專任助理教授
2-out-of-n
視覺密碼學之視覺偽分享秘密之研究
蔡篤校
摘 要
1995 年,Naor 和 Shamir 兩位學者共同提出了一個具有絶對安全性的秘密分享機 制:視覺密碼學。在這一篇論文中,我們提出視覺密碼學中存在視覺偽分享秘密。視 覺偽分享秘密將會造成合法使用者透過視覺解密求得不存在的偽秘密。就我們所知, 本篇論文是在文獻中首次嘗試證明,在未受攻擊下視覺密碼學可能將造成合法使用者 和以視覺密碼學為主的應用技術受到不可預料的安全威脅。本文中的實驗和分析結果 說明視覺偽分享秘密確實存在於2-out-of-n 視覺密碼學中。 關鍵詞:視覺密碼學、人類視覺、秘密分享。1. Introduction
A secret sharing scheme is a method to protect a secret K, by distributing partial information, called shares, to a set of participants,P
P1,P2,,Pn
, in a way that only authorized subsets of P can recover K, but any unauthorized subset cannot recover K. Such schemes are useful for protecting important secret data, such as cryptographic keys, from being lost or destroyed without accidental or malicious exposure. Naor and Shamir proposed a variant secret sharing scheme for image, called Visual Cryptography (VC) in 1995, where partial information given to participants are xeroxed onto transparencies [11]. If X is an authorized subset of participants, then the participants in X can visually recover the secret from pattern on the superimposing result of their transparencies. Two special properties distinguish VC from secret sharing scheme [2, 9]. (1) The perfect security of VC is achieved by loosing the contrast and the resolution of the secret image. (2) The decoding process of VC is achieved by Human Visual System (HVS). Due to the unconditional security and the property of decoding without computation, VC quickly became a popular research area for cryptographers and mathematicians. The research area includes optimization andgeneralization. These researchers have devoted themselves to enhancing the contrast and resolution of the reconstructed images [1, 4], and to extending it to general access structures [8]. More researchers proposed non-binary secret image schemes such as gray-level secret images [3, 5, 6] and color secret images [13, 14]. There are also lots of applications based on VC such as steganography [7, 15, 18], and image encryption [12]. Additionally, an issue of cheating in VC was proposed in 2006[10], and then became a new research area for developing cheating prevention schemes [16, 17].
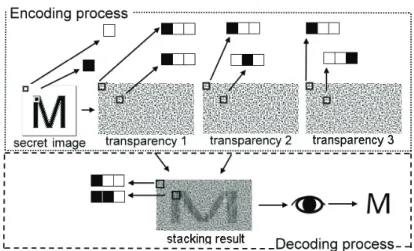
It is necessary to briefly describe the scheme for further discussion. Now, we demonstrate the VC by a 2-out-of-3 scheme. Assume David is the dealer who wants to share the information, letter “M”. Alice, Bob, and Carol are the participants. The information is first represented by a 64 x 64 pixels binary image. The secret image is then transformed into three distinct 64 x 192 subpixels noise-like shares which are later xeroxed onto transparencies, denoted transparency 1, transparency 2, and transparency 3. Transparencies are
delivered to Alice, Bob, and Carol respectively. The pattern on the stacking result of any two of three transparencies will be visually recognized as the secret. Fig. 1 shows the whole secret sharing
process.
In the encoding process of the VCs, the 2-out-of-3 scheme shares the information by turning each pixel of the secret image into one black and two transparent adjacent subpixels independently. In the decoding process, every three horizontal and adjacency subpixels of the stacking result is united as a region for representing a pixel. A region consisting of two black and one transparent subpixels is for representing a black pixel; on the contrary, a region consisting of two transparent and one black subpixels is for representing a white pixel. There are totally 64 x 64 non-overlapping regions. For recovering the true information, these 64 x 64 non-overlapping regions should be all decoded correctly. Otherwise, the information could be changed when only one error decoded pixel occurs. For example, the number “1" is unexpectedly recognized as the letter “i”. Fig. 2 demonstrates a special 2-out-of-2 VCs suffering visual false secret. The password is composed of five “1” and five “i”. In this example, to increase the probability that the password can be visually recognized, the password is repeated five times in SI which is a 64 x 64 pixels image. By the observation from the stacking result which is a 128 x 64 pixels image, it is in low probability that the actual password can be
visually recovered.
A VC is designed and considered as a valid k-out-of-n scheme if it satisfies
contrast conditions and security condition
[11]. Both conditions are designed on the basis of a pixel not of an image. When the definition of VC is directly applied to share an image, it implies that HVS should precisely restore every non-overlapping region from the stacking result before averaging every individual black or transparent subpixels contributions within each region. If HVS can not precisely restore every non-overlapping region, it is possible that qualified subsets of participants could recognize some pixels as a part of secret in terms of visual false positive secret (VFPS) from overlapping regions. VC has been widely investigated for decades. Duo to two special properties, there has been lots of applications based VC. In this paper, we address the issue of VFPS in VC. The rest of the paper is organized as follows. Section 2 provides preliminary background on VC. Section 3 illustrates the proposed VFPS. Section 4 provides evidences in favor of VFPS. Finally, conclusions are given in Section 5.
2. Visual cryptography
In 1995, Naor and Shamir proposed a variant of t-out-of-n secret sharing scheme for image. The secret is known to a special
person called dealer. The dealer generates and distributes partial information called
shares to the participants and the shares
given to participants are xeroxed onto transparencies. Therefore, a share is also called a transparency. If X is a qualified subset, then the participants in X can visually recover the secret image by stacking their transparencies without performing any cryptographic computation. To create the transparencies, each black and white pixel of the secret image is handled separately. It appears as a collection of m black and transparent subpixels in each of the n transparencies. Therefore, a pixel of the secret image corresponds to nm subpixels. We can describe the nm subpixels by an n m boolean matrix S=[Sij] such that Sij=1 if and
only if the jth subpixel of the ith share is
black and Sij=0 if and only if the jth
subpixel of the ith share is white. The grey
level of the stack of k shared blocks is determined by the Hamming weight H(V) of the “or”ed m-vector V of the corresponding k rows in S. This grey level is interpreted by the visual system of the users as black if H(V)d and as white if
m d
V
H( )
for some fixed threshold d and relative difference
. The value of m is referred to as the scale of pixel expansion. That is, the size of recovered image m times the size oforiginal secret image. The larger the value of m, the more loss in resolution will be. Therefore we would like the value of m as small as possible. The value of
is referred to as the contrast of the recovered image. We would like
as large as possible. In other words, the larger the value of
is, the more probability of that the correct secret can be recognized will be. More formally, a solution to thek-out-of-n VC consists of two collections C0 and C1of n m boolean matrices. To
share a white pixel, the dealer randomly chooses one of the matrices from C0, and to
share a black pixel, the dealer randomly chooses one of the matrices from C1. The
chosen matrix determines the m subpixels in each one of the n transparencies.
Definition 1 A solution to the k-out-of-n
VC consists of two collections C0 and C1of n m boolean matrices. The solution is
considered valid if the following conditions are met:
Contrast conditions:
1. For any matrix S0in C0, the ''or'' V of
any k of the n rows satisfies
m
d
V
H
(
)
.2. For any matrix
S
1 in C1, the ''or'' V ofany k of the n rows satisfiesH(V)d 3. For any subset
i1,i2,,iq
ofcollections D0, D1 of q m matrices
obtained by restricting each n m matrix in C0, C1 to rows
q
i i
i1, 2,, are indistinguishable in the sense that they contain the same matrices with the same frequencies.
Contrast conditions are related to the contrast of the decoded image. Security condition indicates that by inspecting fewer than k transparencies, even an infinitely powerful cryptanalyst cannot gain any advantage in deciding whether a shared pixel is white or black. The following serves as an example of how to implement a 2-out-of-n VCs. It can be constructed by the following collections of nn matrices:
C0={all the matrices obtained by permuting
the columns of 0 0 0 1 0 0 0 1 0 0 0 1 }
C1= {all the matrices obtained by
permuting the columns of
1 0 0 0 0 0 1 0 0 0 0 1 }
In the decoding process, m adjacency subpixels of the stacking result are united as a region for representing a pixel. A region consisting of two black and n-2
transparent subpixels is representing a black pixel; on the contrary, a region consisting of one black and n-1 transparent subpixels is representing a white pixel. Therefore, the contrast is n1.
3. The proposed VFPS
3.1 Assumptions and notations
Before introducing VFPS, the following assumptions and notations are defined for the rest of the paper.
Assumption 1 The appearance of each transparency is in a noise form.
Assumption 2 The secret image is a binary image. Furthermore, the secret image is composed of many black pixels and many white pixels.
Assumption 3 The secret will be a password.
So far, we have tacitly assumed that the decoding of VC can be easily executed. This assumption is in order with respect to theoretical model. In general, however, it is well known that VC suffers from a graying effect and the recovered image being much blurrier and darker than the original image. Furthermore, it is not easy to properly align two transparencies. Consequently, we will focus on the scheme in 2-out-of-n VC. And the secret is assumed to be a password.
Notations
SI : it indicates a secret binary image with W H pixels;
tp : it presents the total number of pixels of SI;
Ti: it indicates a transparency, where i =
1,2,…,n; K
i
T : it presents a stacking result of k
transparencies among n transparencies, where i 1, 2, , n k , in k-out-of-n VC;
Rj : a region Rj is defined as a set of j adjacent subpixels, r r1, ,2 rj , of
K i
T ;
BV (WV): the number of black
(transparent) subpixels in a region Rj
represents a black (white) pixel of SI;
R
mW ( Bm
R
) : it presents a region is composed of a set of m adjacent subpixels which were created for sharing adjacent white (black) secret pixels, where m m tp m ). V : it indicates a j- vector which is ' obtained by mapping each black subpixels of a region Rj to 1 and
transparent subpixels of Rj to 0.
According to the constructions in Section 2, the value of m is set to be n, BV
is set to be 2, and WV is set to be 1 in the
2-out-of-n VCs.
3.2 The proposed visual false
positive secret and analysis
VFPS occurs when qualified subsets of participants recognize pattern on stacking result by averaging these tp m indivisual black and transparent subpixels contributions all together. That is, not only non-overlapping regions but also these overlapping-regions will be recognized as black or white pixels of SI. Precisely, it is possible that m adjacent subpixels belonging to different non-overlapping regions are assembled as an overlapping-region Rm , where
( ') V
H V B or H V( ')WV .
VFPS is classified as two categories: visual false positive black pixel and visual false positive white pixel. A VCs is considered as WVFPS-VCs or SVFPS-VCs if it meets the following definition.
Definition 2 A VCs is considered as a weak
visual false positive VCs (WVFPS-VCs) if one of the following conditions is satisfied. Moreover, a VCs is considered as a strong visual false positive VCs(SVFPS-VCs) if the following conditions are both satisfied:
Visual false positive black pixel condition:
region
R
m
R
mW satisfying( ') V
H V B .
Visual false positive white pixel condition:
2. For all regions in SI, there is at least one
region B
m m
R
R
satisfying ( ') VH V W .
Visual false positive black pixel condition indicates that from a region Rm, participants accept black secret pixels which were not sharing from true black pixels; on the contrary, visual false positive white pixel problem indicates that from a region Rm, participants accept white secret pixels which were not sharing from true white pixels. Fig. 3 shows examples following the same scenario in section 1. The first example shows two adjacent white pixels are shared by case 1, case 2, or other 3 3 1 1 cases in 2 1 T . The second example illustrates two adjacent black secret pixels are shared by case 3, case 4, or other 32 32
cases in
2 1
T . In case 2, Alice and Bob recognize a regionR3R6W
consisting ofr2,r3, andr4 as a black pixel
since
H V
( ') 2
. In case 4, Alice and Bob recognize a regionR3R6Bconsisting of2
r , r3 , and r4 as a white pixel since
( ') 1
H V . Precisely, the examples can be extended to the analysis for examining whether the VCs suffers VFPS.
The following lemmas serve as the analysis of 2-out-of-3 VCs and 2-out-of-n
VCs.
Lemma 1 The 2-out-of-3 VCs is considered
as SVFPS-VCs.
Proof Assume R6W (R6B) is composed of a set of 6 subpixels which were created for sharing adjacent two white (black) pixels of SI .To visual false positive white pixel condition, 6 B R is created by
C
1. 6 B R is one of 3 3 2 2 cases. Each one of three cases, 'V {110101,110011,101011} is found a R3, where H V( ') 1 . Therefore, the probability to find a 3 6
B
R R satisfying ( ') 1
H V is 1/3. To visual false positive black pixel condition, R6W is created by
0
C
.R6W is one of 3 3 1 1 cases. Each one of three cases , 'V {001010,001100,010100} is found a R3, where H V( ') 2 . Therefore, the probability to find a R3R6W satisfying( ') 2
H V is 1/3. By assumption 2, there are many black pixels and many white pixels in SI, both conditions are met. Therefore, by definition 2, the 2-out-of-3 VCs is considered as SVFPS-VCs.
Lemma 2 The 2-out-of-n VCs is considered
as WVFPS-VCs.
Proof Assume
R
mW is composed of a set of m subpixels which were created for sharing adjacent two white pixels of SI .To visual false positive black pixel condition,W m
R
is created byC
0. W mR
is one of 2 1 1 n n n cases. There are
(
1) / 2
m m
cases to be found a Rm , whereH V
( ') 2
. Since m n , the probability to find aR
m
R
mW satisfying( ') 2
H V
is 1/2-1/2n. By assumption 2, the visual false positive black pixel condition is met. But, to visual false positive white pixel condition in a2-out-of-2 VCs, this condition is not
satisfied because every subpixles in R4B
created by C1
is black. Therefore, the 2-out-of-n VCs is considered as
WVFPS-VCs.
4. Experimental results
To demonstrate the VFPS, we conduct
two experiments of 2-out-of-3 VCs based on the following two 33 matrices:
C0={all the matrices obtained by permuting
the columns of 1 0 0 1 0 0 1 0 0 }
C1= {all the matrices obtained by
permuting the columns of
1 0 0 0 1 0 0 0 1 } The binary image shown in Fig. 4(a) is employed as the 6464 pixels detecting image 1 (DI1). This image is designed for detecting the visual false positive black secret. Fig. 4(b)-(d) are the corresponding 19264 subpixels transparenciesTA ,TB ,
and TC . The results of superimposing any
two of three transparencies are shown in Fig. 4(e)-(g).
Second example uses the detecting image 2 (DI2) shown in Fig. 5(a) which is a complementary image of Fig. 4(a). This image is designed for detecting the visual false positive white secret. Fig. 5(b)-(d) are the corresponding transparencies TA, TB,
and TC . The results of superimposing any
two of three transparencies are shown in Fig. 5(e)-(g). With respect to VFPS, from Fig. 4(e)-(g), there are more than one region in the space between Latitude and Longitude to be visually recognized as
black pixels. For example in Fig.4 (e), that last number of Latitude and Longitude are grouped as the number “2”. Additionally, from Fig. 5(e)-(g), there are also more than one region in the space between Latitude and Longitude to be visually recognized as white pixels. For example in Fig. 5(e), that last number of Latitude and Longitude are grouped as the number “7”. Due to these VFPS, participants may visually recognize and accept these pixels as a part of the secret or boundaries of these reconstructed secrets are unclearly perceptible. The probability of recovering actual secret is decreased.
5. Conclusions
Over the last few years a considerable number of studies have been made on the Visual Cryptography. In this paper, we proposed visual false positive secret which have never been examined. The analysis and experimental results demonstrate that visual false positive secret is possible in 2-out-of-n Visual Cryptography. It is not guaranteed that VCs are useful for protecting important secret data from being lost or destroyed without accidental or malicious exposure. Once the secret data is unexpectedly lost or recognized as different secret, it could cause unpredictable damage to qualified subsets of participants.
Acknowledgements
This work was partially supported by the National Science Council, Taiwan, R.O.C., under contract No. NSC100-2221-E-164-010.
References
[1] A. Shamir and M. Naor. Visual Cryptography II: Improving the Contrast via the Cover Base, Security in Communication Networks, September 16-17. (1996).
[2] A. Shamir, How to share a secret, Comm. ACM, Vol. 22 (1979) pp. 612-613.
[3] C. Blundo, A. De Santis and M. Naor, Visual cryptography for grey level images, Information Processing Letters, Vol. 75, No.6, 255-259. (2000)
[4] C. Blundo, P. D'Arco, A. De Santis, D. R. Stinson, Contrast optimal Threshold Visual Cryptography Schemes, SIAM J. Discrete Math. 16(2) 224-261(2003).
[5] C.C. Chang, and J.C. Chuang, An image intellectual property protection scheme for gray-level image using visual secret sharing strategy, Pattern Recognition Letters, Vol. 23 931-941(2002).
cryptography for gray-level images by dithering techniques, Pattern Recognition Letters. Vol. 24 (1-3) 349-358 (2003).
[7] C.C. Wang, S.C. Tai and C.S. Yu, Repeating image watermarking technique by the visual cryptography, IEICE Transactions on Fundamentals, Vol. E83-A 1589-1598(2000). [8] G. Ateniese, C. Blundo, A. De Santis
and D. R. Stinson, Visual Cryptography for General Access Structures, Information and Computation 86-106(1996).
[9] G. Blakley, Safeguarding cryptographic keys, Proc. AFIPS 1979 Natl. Conf., New York , Vol. 48 (1979) pp. 313-317.
[10] G. Horng, T. H. Chen and D. S. Tsai, Cheating in Visual Cryptography, Designs, Codes and Cryptography, Vol. 38, No. 2 219-236(2006).
[11] M. Naor and A. Shamir, Visual Cryptography, In Proceedings of
Advances in Cryptography-EUROCRYOT’94,
LNCS 950 1-12(1994).
[12] Rastislav Lukac, Konstantinos N. Plataniotis, Bit-level based secret sharing for image encryption, Pattern
Recognition Vol. 38(5) 767-772(2005).
[13] V. Rijmen, B. Preneel, ELcient colour visual encryption for shared colors of Benetton, Eurocrypto’96, Rump Session, Berlin (1996).
[14] Y. C. Hou, Visual cryptography for color images, Pattern Recognition, Vol. 36 1619 – 1629(2003).
[15] T. H. Chen, and D. S. Tsai, Owner-Customer Right Protection Mechanism using a Watermarking Scheme and a Watermarking Protocol, Pattern Recognition, Vol. 39, Issue 8, pp. 1530-1541(2006).
[16] C. M. Hu and W. G. Tzeng, Cheating Prevention in Visual Cryptography, IEEE Transactions on Image Processing, Vol. 16, No. 1, pp. 36-45 (2007)
[17] D. S. Tsai, T. H. Chen and G. Horng, A Cheating Prevention Scheme for Binary Visual Cryptography with Homogeneous Secret Images. Pattern Recognition. Vol. 40, Issue 8, pp. 2356-2366 (2007).
[18] T. H. Chen, T. H. Hung, G. Horng, and C. M. Chang, Multiple Watermarking Based on Visual Secret Sharing, International Journal of Innovative Computing Information and Control, Vol. 4, No. 11, pp. 3005-3026 (2008).
Figure 1: A simulated example of 2-out-of-3 VCs by image processing software
Figure 2: The experimental result based on a 2-out-of-2 VC suffering visual false secret
(a)Detecting image 1
(b)Transparency TA (c) Transparency TB
(d) Transparency TC (e)The result of superimposing TA and TB
(f)Secret message by superimposing share
C
T and share TB
(g)Secret message by superimposing share
C
T and share TA
(a)Detecting Image 2
(b)Transparency TA (c) Transparency TB
(d) Transparency TC (e)The result of superimposing TA and TB
(f)Secret message by superimposing share
C
T and share TB
(g)Secret message by superimposing share
C
T and share TA
Figure 5: The experimental results based on a 2-out-of-3 VC with complementary image of Fig. 4(a)