Modeling and Simulation Study of Improving Dynamic Distributed
Systems with Traffic-Shaping Mechanism
1
Chih-Chiang Wang,
2Ren-Hung Hwang,
3Harry Perros,
4Ssu-Wei Huang
1 First Author and Corresponding Author, and 4Department of Computer Science, National Kaohsiung
University of Applied Sciences, Taiwan,
1[email protected] &
4[email protected]
2
Department of Computer Science and Information Engineering, National Chung Cheng
University, Taiwan, [email protected]
3
Department of Computer Science, North Carolina State University, USA, [email protected]
Abstract
With rapid growth in end hosts' processing, storage, and bandwidth capacities, the last decade has witnessed tremendous research efforts in building distributed systems to utilize end-host capacity. However, end-host capacities are known for their inherent dynamics such that the end-host participants may often switch between online and offline status due to join, departure, and failure events. To improve system performance in presence of node dynamics, some researchers have taken the approach of recruiting stable nodes or grouping unstable nodes together in order to form an adequate number of stable servers. Nevertheless, such selection/grouping processes may stifle the system scalability or cause the associated overhead to kick-in. In this paper, we exploit the concept of traffic shaping to improve distributed systems under node dynamics. Our contribution is threefold. First, our simulation results show that node dynamics' effect on the system is not absolute but determined by the input workload's characteristics as well. To the best of our knowledge, no study has yet evaluated such fundamental performance issues of distributed systems under node dynamics. Second, our simulation results show that the long-tailed online-time distribution makes the system more susceptible to performance degradation caused by the bursty workload. Third, based on our observations, we conclude that instead of raising the node-recruiting standard, reducing the job size or smoothing out the job arrival rate can also improve dynamic distributed systems in terms of system throughput and job failure rate at the cost of higher response time. We have also a centralized leaky-bucket controller in our simulation program as proof of concept.
Keywords
: Dynamic Distributed System, Traffic Shaping, Performance Evaluation1. Introduction
With rapid growth in end hosts’ processing, storage, and bandwidth capacities, the last decade has witnessed tremendous research efforts in building distributed systems to utilize end-host capacity. Examples include volunteer grid computing (BOINC [1][2]), globally distributed platform for network service (PlanetLab [3][4]), and various peer-to-peer systems (BitTorrent [5], Skype [6], and other information-sharing and multimedia applications [7][8][9][20]), to name a few. These systems are known for their inherent node dynamics such that the participant nodes often switch between online and offline status due to join, departure, and failure events.
Node dynamics is a major problem in utilizing end-host capacity for computational applications. From the system perspective, nodes with high dynamics are too transient to be useful. As these nodes switch from online to offline status too quickly, most of their assigned jobs will not be finished in time [10]. Therefore, the gain in service capacity does not always outweight the maintenance overhead incurred by high node dynamics. To resolve this problem, some researchers advocate recruiting more stable nodes into the system to reduce the system’s node dynamics [11][12][13][14]. However, node dynamics is actually a measure relative to the system’s offered load. In other words, the same set of nodes may be too transient to serve certain input workload, but they may work just fine when serving another type of workload. From our simulation study, we have observed a relativity relationship between node dynamics, the job size, and the input job arrival rate. Based on this observation, we find instead of raising
This work is partially supported by NSC, Taiwan, ROC under grants NSC 99-2218-E-151-002-MY2.
Journal of Convergence Information Technology(JCIT) Volume8, Number3,Feb 2013
the node-recruiting standard, reducing the job size or smoothing out the job arrival rate can also improve system performance in terms of system throughput and job failure rate.
Our contribution is threefold. First, while it is generally perceived that recruiting more stable nodes might be the only way to alleviate node dynamics’ effect on the system, we show that node dynamics’ effect on the system is not absolute but determined by the input workload’s characteristics as well. Second, we show that the long-tailed online-time distribution makes the system more susceptible to performance degradation caused by the bursty workload. Third, we use simple but valid simulation experiments to prove that applying traffic-shaping mechanisms to highly dynamic distributed systems can effectively improve the system performance at the cost of higher response time. To the best of our knowledge, no study has yet evaluated such fundamental performance issues of distributed systems under node dynamics.
The rest of this paper is organized as follows. In Section 2 we survey existing dynamic distributed systems and some research on node-recruiting mechanisms for dynamic distributed systems. In Section 3 we introduce the basics of our model, the terminology and the assumptions that we make. In Section 4, we study how the job size and the job arrival rate affect a dynamic distributed system. In Section 5, we study how the long-tailed distribution of nodes’ online times affects a dynamic distributed system. Based on our observations from Section 4 and Section 5, in Section 6 we apply a centralized leaky-bucket controller to our model and conduct various simulation experiments as proof of concept. We finally conclude in Section 7.
2. Related Work
As end hosts’ computing resources grow rapidly, many research efforts are devoted to building distributed systems to utilize end-host capacity. For example, BOINC [1][2] is a middleware system for volunteer computing, which allows large numbers of volunteered computers contribute computing and storage resources for scientific computing. Another example is PlanetLab [3][4], which serves as a wide-area testbed for networking and distributed system research. PlanetLab today includes 1,125 nodes spanning 542 sites, and over 1,000 researchers have used PlanetLab to develop new technologies for distributed storage, network mapping, and query processing. The most well-known paradigm is peer-to-peer systems in which each participant computer acts as both a client and a server for the other computer in the same system. Some popular peer-to-peer applications include file-sharing (BitTorrent [5]) and voice-over-Internet (Skype [6]), IPTV [7], information-sharing infrastructure [8], autonomic communication [9], to name a few. Although these systems are built with different design philosophies and serve different purposes, what they share in common is their inherent node dynamics such that the end-host participant may often switch between online and offline status due to join, departure, and failure events.
To improve system performance in presence of node dynamics, some researchers have taken the approach of reducing node dynamics by recruiting relatively stable nodes as system members. In [11], Godfrey et al. investigate several strategies to select stable DHT nodes and explore the performance implications. In [15], Mickens et al. use statistics about nodes’ history to predict their future behavior and use more stable nodes for data placement. In [12], Wang et al. advocate recruiting peer nodes as long as the gain in service scalability outweights the maintenance overhead. In [14], Li et al. propose the idea of grouping unstable nodes together in order to form an adequate number of stable service groups. However, such selection/grouping processes may stifle the system scalability or cause the associated overhead to kick-in.
3. Model for Dynamic Distributed Systems
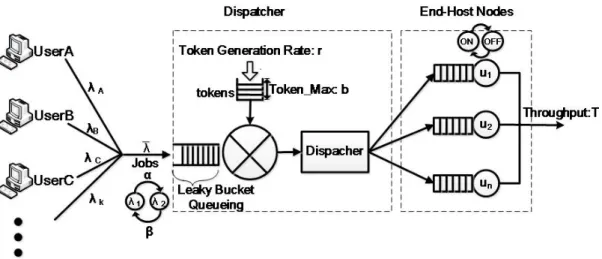
In order to examine the effects of job bursts and traffic-shaping mechanism, we capture the distinguishing characteristics of generic dynamic distributed systems and abstract them into a simple but representative model. At this initial stage of our work, we dismiss network latency, packet loss and retransmissions from our model, and focus on the centralized shaping mechanism as proof of concept. The same concept will be extended to a distributed control mechanism in our future work. Figure 1 shows a schematic description of our model, while the notation for this model is introduced in Table 1.
Figure 1. Model for generic dynamic distributed systems with a centralized leaky-bucket controller
Table 1. Model Parameters and Meaning Parameters Meaning (.) L L D ) , (12 ) , ( i r b CDF of nodes’ ON time mean ON time of nodes
mean OFF time of nodes
job arrival rates of MMPP-2 state transition rates of MMPP-2 mean effective service rate of node Ni
mean job arrival rate of the system mean effective service rate of the system system utilization rate (= / ) token generation rate
maximum number of tokens allowed in the system parameter for long-tailed ON-time distribution
Our model considers a generic distributed system where a centralized dispatcher continuously receives jobs from users. The dispatcher harnesses a fixed population of end-host nodes N = {N1, N2, ..., Nm} to collaboratively serve the jobs, where m is the population size.
Each node cycles between ON (online) state and OFF (offline) state to resemble node dynamics. The dispatcher keeps track of which nodes are ON, and dispatches each received job to at most one ON node based on the join-the-shortest-queue principle. All the ON nodes fully cooperate with the system, enqueueing their assigned jobs and serving them one after another in the first-in-first-out order. When an ON node switches to OFF state, it does not respond to the dispatcher’s request; all the unfinished jobs remaining in its queue will be treated as job failures and purged from the queue. Let L(.) be the cumulative distribution function (CDF) followed by nodes’ ON times and L be the mean ON time. Similarly, let D(.) be the CDF followed by nodes’ OFF times and D be the mean OFF time. Measurement results indicate that nodes’ ON times can be well modeled by a long-tailed distribution [16][17]. We assume that nodes’ ON times are independently distributed and model them using a shifted Pareto with CDF
1
,
)
1
(
1
)
(
tt
U
Equation (1)D=10 L . Because of page limitation, we only present the results for λ1 = 10, C1
/
L=1 and b=10
in Figure 11. However, using other simulation parameters still leads to the same conclusion. Figure 11 confirms that the ON-OFF ratio D/L barely affects the relationship between the token generation rate r and the system throughput; the system produces the maximum throughput at around the point of r = .Figure 10. Simulation of 1,000 nodes (ρ = 0.9). From left to right: C1/L is 10, 1, and 0.1.
Figure 11. Simulation of 1,000 nodes (ρ = 0.9). From left to right: D/L is 0.1 and 10.
7. Conclusions and Future Work
We made the case that node dynamics’ effect on the system is not absolute but determined by the input workload’s characteristics as well. In presence of high node dynamics, instead of raising the node-recruiting standard, reducing the job size or smoothing out the offered load can also improve the system’s throughput and job failure rate. We also apply a centralized leaky-bucket controller to our model as proof of concept. In future studies, we will formulate the relationship between the input workload, the throughput, and the overall sojourn time. Another natural extension of our work is to push the traffic controller to the end hosts, which calls for a congestion-control-like algorithm to regulate the users’ requests to the dynamic distributed system.
8. References
[1] “Boinc,” http://boinc.berkeley.edu.
[2] David P. Anderson, “Boinc: a System for Public-resource Computing and Storage,” in Proceedings of IEEE GRID, pp.4-10, 2004.
[3] “Planetlab,” http://www.planet-lab.org/.
[4] Larry L. Peterson, Andy C. Bavier, Marc E. Fiuczynski, Steve Muir, “Experiences Building Planetlab,” in Proceedings of OSDI, pp.351-366, 2006.
[5] “Bittorrent,” http://www.bittorrent.org/. [6] “Skype,” http://www.skype.com.
[7] Seungchul Park, “A QoS-based P2P Streaming for Ubiquitous Personal IPTV”, AICIT Internal Journal on Advances in Information Sciences and Service Sciences, Vol. 2, No. 3, pp.82-90, 2010. [8] Jingtao Zhou, Haicheng Yang, Mingwei Wang, “SDDG: a P2P-Semantic-Grid Enabled
Information Sharing Infrastructure”, AICIT Journal of Next Generation Information Technology, Vol. 2, No. 1, pp.27-36, 2011.
[9] Jiaqi Liu, Zhigang Chen, Deng Li, Zhong Ren, “RELO: a Robust, Efficient and Low-cost Peer-to-Peer Overlay for Autonomic Communication”, AICIT International Journal of Advancements in Computing Technology, Vol. 4, No. 6, pp.50-58, 2012.
[10] Derrick Kondo, David P. Anderson, John McLeod, “Performance Evaluation of Scheduling Policies for Volunteer Computing,” in Proceedings of eScience, pp.415-422, 2007.
[11] Brighten Godfrey, Scott Shenker, Ion Stoica, “Minimizing Churn in Distributed Systems,” in Proceedings of ACM SIGCOMM, pp.147-158, 2006.
[12] Chih-Chiang Wang and Khaled Harfoush, “On the Stability-scalability Tradeoff of DHT Deployment,” in Proceedings of IEEE INFOCOM, pp.2207-2215, 2007.
[13] Junfeng Xie, Zhenhua Li, Guihai Chen, Jie Wu, “On Maximum Stability with Enhanced Scalability in High-churn DHT Deployment,” in Proceedings of IEEE ICPP, pp.502-509, 2009. [14] Zhenhua Li, Jie Wu, Junfeng Xie, Tieying Zhang, Guihai Chen, Yafei Dai, “Stability-optimal
Grouping Strategy of Peer-to-Peer Systems,” IEEE Transactions on Parallel and Distributed Systems, pp.2079-2087, 2011.
[15] James Mickens and Brian Noble, “Predicting Node Availability in Peer-to-peer Networks,” in Proceedings of ACM SIGMETRICS POSTERS, pp.378-379, 2005.
[16] Stehan Saroiu, P. Krishna Gummadi, Steven D. Gribble, “A Measurement Study of Peer-to-Peer File Sharing Systems,” in Proceedings of ACM MMCN, pp.156-170, 2002.
[17] Derek Leonard, Vivek Rai, Dmitri Loguinov, “On Lifetime-based Node Failure and Stochastic Resilience of Decentralized Peer-to-Peer Networks,” in Proceedings of SIGMETRICS, pp.26-37, 2005.
[18] Wolfgang Fischer and Kathleen Meier-Hellstern, “The Markov-Modulated Poisson Process (MMPP) Cookbook,” Journal of Performance Evaluation, Vol. 18, Issue 2, pp.149-171 1993. [19] Leonard Kleinrock, “Queueing Systems, ” John Wiley and Sons, USA, 1976.
[20] Chih-Chiang Wang and Khaled Harfoush, “RASTER: A Light-Weight Routing Protocol to Discover Shortest Overlay Routes in Randomized DHT Systems,” in Proceedings of IEEE ICPADS, pp.553-560, 2006.