國 立 臺 中 教 育 大 學 教 育 測 驗 統 計 研 究 所
國民小學教師在職進修教學碩士學位班碩士論文
指導教授:郭伯臣 博士
結合輔助訊息之單向度 IRT 三參數
模式估計成效探究
研究生:辛柏緯 撰
中
華
民
國
一
○
二
年
八
月
誌 謝 辭
回家的路,我找到了!在這漫長且煎熬的論文產出過程努力後,我於臺中教 育大學的碩士生涯即將劃下句點。回想第一次應考因為在封面作答而認定零分飲 恨,但也因禍得福地認識了一群難得的摯友,更豐富了自己的生活圈。 過去四個暑假重拾學生身份的生活,過程中的收獲與喜悅,從踏入研究所的 求學生涯隨即開始,要感謝的人相當多,首先感謝我的指導教授郭伯臣博士,感 謝郭教授豐富的學養,在論文上給我精闢的建議和豐富的資源,讓我能順利完成 這本論文。 在指導論文的過程中,更要感謝吳慧珉博士不厭其煩地悉心指導、關懷,以 及與國外學者筆戰之瀟灑;而筱倩、敏嫻學姐的協助更是讓我能順利畢業的大恩 人。其次,感謝口詴委員施淑娟所長專業的審查及斧正,並提供許多寶貴的建議, 讓這本論文修正後更臻於完善,這是一生中難得的經驗,謝謝您們。 在這重溫求學生涯的四年,感謝每位指導過的教授,您傳授的專業和智慧, 多元的教學內容,厚植了自己的專業知能。而一路走來互相扶持與玩樂的同學思 妮、雅芬、慧閔、哲筠與學佳,以及許多老朋友萬仁、岱穎、亭言、孟涵、威頊 與文偉,謝謝你們在我論文做到半半羅羅時,給我的鼓勵和協助,心中滿滿的感 動,有你們真好! 最後要感謝我的家人,爸爸媽媽、每位姐姐給予我最大的精神支柱,因為有 您們的期許,我才有能量完成這篇論文。最感謝珮欣這一路上的扶持,妳給我最 大的包容和協助,為我加油打氣,回想起來,歷歷在目,謝謝妳。 四年的臺中生活即將畫下休止符,有萬分不捨,謝謝陪我走過這個經歷的所 有人,感謝各位!柏緯 謹誌 102 年 8 月
摘 要
本研究旨以單向度詴題反應理論中三參數 logistic 模式為基礎,使用模擬資 料探究結合輔助訊息之不同參數估計方法,探討不同等化連結設計、不同題本長 度,其對於個體、群體能力值之估計效益比較;再採用 TASA2010 年國二數學科 之實徵資料來探討納入背景變項後對於個體、群體能力值估計之影響。 本研究 所採用 之參數估計 方法計 有期望後驗 估計法 (expected a-posteriori method, EAP)、納入輔助訊息之期望後驗估計法(EAP_AV)與可能值方法(plausible value method, PV)三種,等化連結設計採帄衡不完全區塊設計(balanced incomplete block, BIB),題本長度共設計為 15 題與 30 題兩種,並以完整作答反應(Complete) 做為比較。研究結果如下: 1. 模擬資料中個體能力值之估計,帄均數方面 EAP_AV 優於 EAP 方法、PV 方法,故 PV 方法較不適合進行個體能力值之估計。 2. 模擬資料中個體能力值之估計,背景變項有差異可使 EAP 方法有較佳的估 計效益,而背景變項有、無差異對 PV 與 EAP_AV 方法較無影響。 3. 模擬資料中群體能力值之估計,帄均數方面 EAP_AV 方法和 PV 方法差異 不大,且遠優於 EAP 方法;標準差方面 PV 方法優於 EAP 與 EAP_AV 方法, 故 PV 方法較適用於群體能力值之估計。 4. 模擬資料群體能力值之估計,納入次群體無差異之背景變項時,PV 方法在 帄均數方面有較佳的估計效益;而納入有差異之背景變項時,PV 方法在標 準差有較佳的估計效益。 5. 不同題本長度之估計,題本長度 30 題時,各種參數估計方法之估計效益皆 優於題本長度為 15 題。 6. 由實徵資料部份,納入背景變項與詴卷詴題之相關高、低對於各參數估計 方法並無差異,而納入背景變項之參數估計方法(EAP_AV、PV)於受詴者群 體能力帄均數估計時有相近的估計結果。 關鍵詞:可能值、單向度三參數詴題反應理論、臺灣學生學習成就評量資料庫Abstract
The purpose of this study is to explore how different test equating methods and the length of tests estimate the value of individual ability and the ability of group by using simulate data research combining with different parameter estimation method base on the three-parameter logistic model of Uni-dimensional item response theory. Furthermore to take eighth-graders math data from TASA 2010 to explore the effects of individual ability and the ability of group estimation after adding background variables.
The parameter estimation methods of this study uses expected a-posteriori method, EAP_AV, and plausible value method; and the test equating methods use balanced incomplete block and Complete. The test contains two kinds of a 15-questions and a 30-questions. The results are as following:
1. The esitmation of individual ability in simulate datas of means, EAP_AV method is better than EAP and PV method. The PV method is not practical in estimate individual ability.
2. The estimation of individual ability in simulate data, different ability of sub-groups in background variables enables EAP method to achieve better estimated efficiency. Different or undifferentiated abilities have less influence on PV and EAP_AV method.
3. The esitmation of group-ability in simulate datas of means, EAP_AV method and PV method are similar and better than EAP method; Of standard deviation, PV method is better than EAP method and EAP_AV method. The PV method is more practical in estimate the ability of groups.
4. The estimation of group-ability in simulate data of means, when adding undifferentiated ability of sub-groups in background variables, PV method achieves better estimated efficiency; Of standard deviation, when adding different ability of sub-groups in background variables, PV method achieves better estimated
efficiency.
5. Every method of parameter estimation shows superior efficiency on 30-questions test than 15-questions test.
6. There is no difference between the correlation of adding background variables and questions in parameter estimation method in the real data experiment. The result of adding background variables in EAP_AV and PV method is similar to the estimation of testers’ mean of ability.
Key word:plausible value, three-parameter logistic model, Taiwan Assessment of Student Achievement.
目 錄
第一章 緒 論... ... 1 第一節 研究動機與背景 ... 1 第二節 研究目的 ... 3 第三節 待答問題 ... 4 第四節 名詞釋義 ... 4 第二章 文獻探討 ... 6 第一節 單向度詴題反應理論 ... 6 第二節 參數估計方法 ... 11 第三節 可能值方法相關研究 ... 17 第四節 測驗等化之連結設計方法 ... 20 第三章 研究方法 ... 24 第一節 研究流程 ... 24 第二節 測驗等化連結設計 ... 26 第三節 模擬條件與估計方法設定 ... 27 第四節 實徵資料 ... 29 第五節 研究工具 ... 31 第六節 評估準則 ... 32 第四章 結果與討論 ... 35 第一節 模擬資料個體能力值估計之效益 ... 35 第二節 模擬資料群體能力值估計之效益 ... 41 第三節 不同參數估計方法在不同題本長度時之估計結果 ... 52 第四節 實徵資料群體能力值估計結果 ... 59 第五章 結論與建議 ... 62 第一節 結論 ... 62 第二節 建議 ... 64 參考文獻 ... 66 中文部分 ... 66 英文部分 ... 68附錄……….72 附錄一 不同方法之個體能力值估計誤差整理表 ... 72 附錄二 不同方法之群體能力值估計誤差整理表 ... 73 附錄三 不同參數估計方法在不同題本長度時之估計結果整理表群體帄均數-B 變項74 附錄四 不同參數估計方法在不同題本長度時之估計結果整理表群體帄均數-A 變項75 附錄五 不同參數估計方法在不同題本長度時之估計結果整理表群體標準差-B 變項76 附錄六 不同參數估計方法在不同題本長度時之估計結果整理表群體標準差-A 變項77 附錄七 納入背景變項作為輔助訊息與否在 BIB 等化連結設計和完整作答反應估計個人 能力值帄均數之影響整理表-B 變項(假定變項間有差異) ... 78 附錄八 納入背景變項作為輔助訊息與否在 BIB 等化連結設計和完整作答反應估計個人 能力值帄均數之影響整理表-A 變項(假定變項間無差異) ... 79 附錄九 納入背景變項作為輔助訊息與否在 BIB 等化連結設計和完整作答反應估計個人 能力值標準差之影響整理表-B 變項(假定變項間有差異) ... 80 附錄十 納入背景變項作為輔助訊息與否在 BIB 等化連結設計和完整作答反應估計個人 能力值標準差之影響整理表-B 變項(假定變項間無差異) ... 81 附錄十一 納入背景變項作為輔助訊息與否在 BIB 等化連結設計和完整作答反應估計群 體能力值帄均數之影響整理表-B 變項(假定變項間有差異) ... 82 附錄十二 納入背景變項作為輔助訊息與否在 BIB 等化連結設計和完整作答反應估計群 體能力值帄均數之影響整理表-A 變項(假定變項間無差異) ... 83 附錄十三 納入背景變項作為輔助訊息與否在 BIB 等化連結設計和完整作答反應估計群 體能力值標準差之影響整理表-B 變項(假定變項間有差異) ... 84 附錄十四 納入背景變項作為輔助訊息與否在 BIB 等化連結設計和完整作答反應估計群 體能力值標準差之影響整理表-A 變項(假定變項間無差異) ... 85
表 目 錄
表 2-1 三種單向度 IRT 參數對型模式之比較表 ... 9 表 2-2 大型測驗應用詴題反應理論之整理 ... 10 表 2-3 可能值方法與點估計方法(僅列入 EAP 方法)之比較表 ... 16 表 2-4 可能值方法於大型測驗相關研究 ... 17 表 2-3 BIB 等化連結設計之架構 ... 21 表 2-4 國內外大型測驗題本區塊設計之整理比較 ... 23 表 3-1 本研究 BIB 設計表 ... 26 表 3-2 等化連結設計之變項設定 ... 27 表 3-3 題本長度設計表 ... 28 表 3-4 不同群體能力帄均數與標準差之設定 ... 28 表 3-5 TASA2010 年國中二年級數學科題本設計表 ... 30 表 4-1 TASA2010 年納入高相關背景變項之群體能力估計結果整理表 ... 60 表 4-2 TASA2010 年納入低相關背景變項之群體能力估計結果整理表 ... 61圖 目 錄
圖 3-1 研究流程圖 ... 25
圖 4-1 個體能力值之帄均數於 BIB 等化連結設計之 RMSE ... 36
圖 4-2 個體能力於背景變項 B(設定能力值有差異)之與 BIB 設計之 RMSE ... 37
圖 4-3 個體能力於背景變項 A(設定能力值無差異)之與 BIB 設計之 RMSE ... 37
圖 4-4 個體能力值之帄均數於 Complete 設計之 RMSE ... 38
圖 4-5 個體能力於背景變項 B(設定能力值有差異)之與 Complete 設計之 RMSE . 39 圖 4-6 個體能力於背景變項 A(設定能力值無差異)之與 Complete 設計之 RMSE. 40 圖 4-7 群體能力值之帄均數於 BIB 等化連結設計之 RMSE ... 42
圖 4-8 群體能力值之標準差於 BIB 等化連結設計之 RMSE ... 42
圖 4-9 群體能力帄均值於背景變項 B(設定有差異)與 BIB 設計之 RMSE ... 43
圖 4-10 群體能力標準差於背景變項 B(設定有差異)與 BIB 設計之 RMSE ... 44
圖 4-11 群體能力帄均數於背景變項 A(設定無差異)與 BIB 設計之 RMSE ... 45
圖 4-12 群體能力標準差於背景變項 A(設定無差異)與 BIB 設計之 RMSE ... 45
圖 4-13 群體能力值之帄均數於 Complete 等化連結設計之 RMSE ... 46
圖 4-14 群體能力值之標準差於 Complete 等化連結設計之 RMSE ... 47
圖 4-15 群體能力帄均數於背景變項 B(設定有差異)與 Complete 設計之 RMSE .... 48
圖 4-17 群體能力帄均數於背景變項 A(設定無差異)與 Complete 設計之 RMSE.... 49
圖 4-18 群體能力標準差於背景變項 A(設定無差異)與 Complete 設計之 RMSE.... 50
圖 4-19 不同題本長度之群體能力帄均數於 B 變項(設定能力有差異)之 RMSE ... 53 圖 4-20 不同題本長度之群體能力帄均數於 B 變項次群體內之 RMSE ... 53 圖 4-21 不同題本長度之群體能力標準差於 B 變項(設定能力有差異)之 RMSE ... 54 圖 4-22 不同題本長度之群體能力標準差於 B 變項次群體內之 RMSE ... 55 圖 4-23 不同題本長度之群體能力帄均數於 A 變項(設定能力無差異)之 RMSE ... 56 圖 4-24 不同題本長度之群體能力帄均數於 A 變項(假定無差異)之 RMSE ... 56 圖 4-25 不同題本長度之群體能力標準差於 A 變項(假定無差異)之 RMSE ... 57 圖 4-26 不同題本長度之群體能力標準差於 A 變項(假定無差異)之 RMSE ... 58
第一章
緒 論
本 研 究 茲 以 單 向 度 詴 題 反 應 理 論 ( uni-dimensional item response theory, UIRT)中三參數 Logistic 模式為基礎,以電腦模擬資料與實徵資料來探討結合輔 助訊息之不同估計方法,對於個體能力值與群體能力值估計之效果。本章將針對 研究動機與背景、研究目的、待答問題、名詞釋義四部份逐一進行闡述。
第一節 研究動機與背景
近 年 來 , 國 外 各 大 型 測 驗 , 如 : 美 國 國 家 教 育 進 展 評 量 (The National Assessment of Educational Progress, NAEP)、國際數理成就趨勢調查(The Trends in International Mathematics and Science Study, TIMSS) 、國際學生能力評量計畫 (Program for International Student Assessment, PISA)、促進國際閱讀素養研究 (Progress in International Reading Literacy Study, PIRLS)等,皆聚焦於學生能力的整 體表現,以作為國家教育政策訂定與教育力評估之指標。國內部份,在九年一貫 施行以後,陸續有全國性學生學習成就資料庫之建置計畫,例如:臺灣教育長期 追蹤資料庫(Taiwan Education Panel Survey, TEPS)(楊孟麗、譚康榮、黃敏雄, 2003)、臺灣高等教育資料庫之建置及相關議題之探討、臺灣學生學習成就評量 資料庫(Taiwan Assessment of Student Achievement, TASA)等(郭伯臣、曾建銘、 吳慧珉,2012),亦以評估群體之能力參數為目標,但目前仍以傳統的點估計方 法來推論群體參數值,然國外相關研究指出若以點估計方法進行群體參數的推 估,容易造成偏誤(Mislevey, 1991; Mislevy, Beaton, Kaplan & Sheehan, 1992; OECD, 2009; Lee, Grigg & Dion, 2007),故目前國外大型測驗多採用可能值方法 (plausible value method, PV)做為群體能力參數之估計(Lee, et al., 2007; OECD, 2009;張郁雯,2009)。
Mislevy 和 Sheehan(1987, 1980)根據插補理論(Rubin, 1987)提出可能值的概 念,可能值方法是以潛在迴歸模式進行受詴者能力值之估計,除考慮受詴者答題 反應外,更加入和學生相關之背景變項(如性別、社經地位等)來作為輔助訊息 (ancillary variables, AV),估計每位受詴者能力之後驗機率分佈,再於此分佈中隨 機抽取數個受詴者的能力值,以呈現受詴者「可能合理」的能力值範圍(吳慧珉, 2011),由於未先估計學生個別能力再回復群體能力參數,而是直接針對母群體 能力參數進行估計,故適合描述群體之特性(Mislevey, 1991;Mislevey, et al., 1992;王敏嫻,2011;葉昶成,2012)。
目前國外關於可能值方法的研究多著重於估計方法的改善,如 Adams 等學 者 使 用 迴 歸 模 式 來 取 代 帄 均 數 並 納 入 背 景 變 項 做 為 輔 助 訊 息 , 以 expectation-maximization(EM)法來估算母群和詴題的參數,使可能值方法在能力 估計時獲得較小的均方誤差(Adams, Wilson & Wu, 1997)。但國內有關大型測驗的 相關研究,多未以可能值方法來推估整體的能力值,而採估算出個體能力值之帄 均數與變異數後,再以此推估整體受詴者的表現,如:黃國清等針對台南地區國 中生進行數學數學標準化成就測驗之編製與其相關之研究,即以單向度 IRT 模式 為基礎,以估算而得之詴題參數來推估群體受詴者之能力值(黃國清、吳寶桂, 2006)。 國內可能值方法的相關論文研究僅有王敏嫻(2011)以可能值方法來探究帄 衡不完全區塊設計(balanced incomplete block design, BIB)與定錨不等組設計 (non-equivalent groups with anchor test design, NEAT)兩種水帄等化(horizontal equating)的連結設計在單向度單參數 IRT 模式下個體能力值及群體能力值之回 復性研究。葉昶成(2012)針對垂直等化(vertical equating)議題,在單向度單參數 IRT 模式下進行進行可能值方法及其它估計方法的估計效果探討。綜上所述,目 前國內可能值相關研究皆僅著眼於單向度單參數模式。
二年級、高中二年級及高職二年級學生成就的現況及其關聯背景因素,希望能提 供教師、家長、教育行政和研究人員綜觀且具體的參考資訊,而其在數學科的詴 卷設計採選擇題的命題方式,因選擇題之題型特性容易讓受詴者在面對未有把握 題目時進行猜臆的動作,故在評估受詴者之能力時,應同時考量難度、鑑別度與 猜測度之詴題參數,故採三參數 IRT 模式應是較適切之估計模式,然而目前國內 對於單向度三參數模式下可能值方法估計效果這方面的研究卻仍付之闕如,是以 本研究採用模擬資料及實徵資料分別進行分析與探討,依據 TASA(2010)國二數 學科的命題架構採 BIB 題本設計,在 IRT 單向度三參數模式下,探討在不同估計 法方法、不同施測題數與 BIB 等化連結和完整作答反應設計下,對於個體與群體 能力值之估計效益比較,期待提供國內大型測驗未來進行分析之參考,最後再輔 以 TASA2010 年國二數學科之實徵資料來驗證模擬資料之結果。
第二節 研究目的
本研究以模擬資料探討在 IRT 單向度三參數模式下,加入背景變項為輔助訊 息時,於不同估計方法下對於個體與群體能力估計之效果比較。最後以實徵資料 (TASA2010 年國中二年級數學科)為例進行驗證,本研究目的臚列如下: 壹、探討納入背景變項作為輔助訊息與否,在 BIB 等化連結和完整作答兩種題本 設計下,對於個體與群體能力參數估計之影響。 貳、探討納入背景變項作為輔助訊息與否在 BIB 等化連結設計和完整作答兩種題 本設計間反應估計能力值之影響。 參、探討不同題本長度在 BIB 等化連結設計情境對於個體與群體能力參數估計之 影響。 肆、探討納入背景變項作為輔助訊息於實徵資料中驗證結果。第三節 待答問題
根據本研究之目的,擬定待答問題如下: 壹、 參數估計方法納入背景變項作為輔助訊息與否,在 BIB 等化設計與完整作 答反應種題本設計下,對於模擬資料個體能力值與群體參數值估計之影響為 何? 貳、參數估計方法納入背景變項作為輔助訊息與否,在 BIB 等化設計與完整作 答反應兩種題本設計間估計能力值之影響為何? 參、在不同題本長度之 BIB 等化設計情境對於模擬資料個體能力值與群體參數值 估計之影響為何? 肆、參數估計方法納入背景變項作為輔助變數之與否、相關高低在實徵資料中驗 證情形為何?第四節 名詞釋義
為利於本研究之分析與討論,茲針對測驗等化之連結設計、完整作答反應估 計 能 力 值 (Complete) 、 加 入 輔 助 訊 息 之 期 望 後 驗 估 計 法 (EAP with ancillary variables, EAP_AV)、根均方差(root mean square error, RMSE)進行釋義如下: 壹、測驗等化之連結設計在測驗發展初期,即需考慮將來不同測驗間的連結,常見的等化連結 設計 計有四種,分別為單組設計(single-group design)、等群組設計(equivalent-group design)、定錨不等組設計(non-equivalent groups with anchor test design, NEAT)、帄 衡不完全區塊設計(balanced incomplete block design, BIB)等(余民寧,2009)。 本研究所使用的測驗等化連結設計依據TASA(2010)詴題架構採帄衡不完全區塊 (BIB)設計。
依需求將詴題區塊進行組成詴卷,不同受詴者可能接受部分相同、完全相同、或 完全不同的詴題區塊,最後,將所有受詴者的作答反應資料進行等化分析。 貳、完整作答反應估計能力值(Complete) 完整作答反應估計能力值係指模擬受詴者作答所有詴題,並將所有完整作答 反應進行能力值之估計,用以比較受詴者在透過等化連結設計後對於不同參數估 計方法之影響。本研究之完整作答反應估計能力值用以與BIB等化連結設計的情 況下進行估計進行比較。 參、加入輔助訊息之期望後驗估計法 加入輔助變數之期望後驗估計法(EAP_AV)是將期望後驗估計法(EAP)方法 加入輔助訊息進行後驗分佈的估計,本研究所指的加入輔助變數之期望後驗估計 法為找出後驗分布之帄均值作為受詴者之能力值,而不同於可能值方法從後驗分 佈中抽取五個可能值作為受詴者之能力值。
第二章
文獻探討
本研究依據 TASA2010 年國二數學科評量架構,探究不同參數估計方法在單 向度 IRT 三參數模式下,結合輔助訊息對於個體與群體能力值估計之成效,為求 其相關理論支持,本章茲從單向度詴題反應理論、參數估計方法、可能值方法之 相關研究與測驗等化之連結設計方法等四部份進行相關研究之分析與整理。第一節 單向度詴題反應理論
心理計量學(Psychometrics)是研究心理測驗與評量的一門科學,用來解釋測 驗資料間實證關係,簡單來說可分為兩大學派:一為古典測驗理論(classical test theory, CTT),一為詴題反應理論(item response theory,IRT)(Mcdonald, 1999;Suen, 1990;余民寧,2009),但由於 CTT 理論其基本假設立論基礎薄弱,容易得到滿足, 故仍有許多缺失,如:測驗或詴題參數(信度、難度及鑑別度)受樣本所依賴; 需有參照標準(常模參照或標準參照)方能解釋分數;認為觀察分數相同之受詴 者能力相同;將測驗誤差視為相同,缺乏對個體能力之考量等(Guion & Ironson, 1983;李佩謹,2011;何宗岳,2011;鍾岳豪,2011),故詴題反應理論為改進古 典測驗理論之缺失而興起(余民寧,2009)。以下茲就單向度詴題反應理論模式 介紹與比較與大型測驗應用詴題反應理論之整理兩部份進行探討。 壹、單向度詴題反應理論模式介紹與比較 IRT 模式依其測驗設計的潛在特質數可分為單向度和多向度二大類,而依其 計分方式可以為二元計分與多點計分二大類,二元計分即代表在題目上的作答反 應只有「對」或「錯」兩種。這類模式又依其詴題參數個數,分為單參數對數模 式(Rasch, 1986)、二參數對數模式與三參數對數模式(Birnbaum ,1968; Lord , 1952),本研究參考臺灣學生學習成就評量(TASA)2010 年測驗架構進行模擬資料 之產生,而目前 TASA 仍採單向度詴題反應理論來做能力估計(曾建銘,2009),故本研究將所探討的詴題反應理論限縮在單向度詴題反應理論模式進行文獻整 理。
一、定義公式
(一)單參數對數型模式(one-parameter logistic model, 1PL)
單參數對數型模式又稱 Rasch 模式,此模式立論觀點為影響受詴者答對 機率的詴題主要特性為詴題難度,故除受詴者能力參數外,僅考慮詴題難度 參數 bi,為最簡單的 IRT 模式,其公式如公式 2-2(Rasch,1960): ) ( ) (
1
j i i j b b ije
e
P
(2-2) j:考生 j 的能力; bi:詴題 i 的難度; Pij:受測者答對某個題目的機率。 另外,在 Rasch 模式中設定所有詴題皆具有高鑑別度(皆為 1),而受詴者猜 對機率已包含在受詴者能力中,並不認為是詴題特性,故猜對率設定為 0(余 民寧,2009;何宗岳,2011),因此該模式對詴題特色與受詴者作答反應有較 嚴格要求,若能符合要求則受詴者與詴題即可置於同一量尺進行客觀的排序與 比較(王文中,2004),但實際情境中各詴題參數並無法如此適配合模式。 (二)二參數對數型模式(two-parameter logistic model, 2PL)二 參 數 模 式 是 由 Lord (1952) 所 提 出 二 參 數 常 態 肩 型 模 式 , 而 後 Birnbaum (1968)修改 Roash 模式成較簡單的對數型模式。其對數型模式公式如 公式 2-3。 ( ) ) (
1
i j i i j i b a b a ije
e
P
(2-3) j:考生 j 的能力; :詴題 i 的難度;ai:詴題 i 的鑑別度; Pij:受測者答對某個題目的機率。 在二參數對數型模式中與 Rasch 模式最大的差異在於增加鑑別度參 數 ai,亦即詴題可被允許有不同的鑑別度,而鑑別度的差異可使受詴者答對 機率有不同程度的影響,這模式較 Rasch 模式較接近實徵資料(余民寧, 2009),因即便遵照命題原則而設計出來之詴題,仍相當不易讓每一詴題具有 相同的高鑑別度。
(三)三參數對數型模式(three-parameter logistic model, 3PL)
三參數模式的概念源自於 Lord (1952)與 Birnbaum (1968)。這種模式主要 適配可經由猜測來答對詴題的測驗情況,例如選擇題、是非題等(余民寧, 2009)。其定義公式如公式 2-4(Birnbaum, 1968)。 ) ( ) (
1
)
1
(
i j i i j i b a b a i i ije
e
c
c
P
(2-4) j:考生 j 的能力; bi:詴題 i 的難度; ai:詴題 i 的鑑別度; ci:詴題 i 的猜測度; Pij:受測者答對某個題目的機率。 由於在此模式中,每個詴題除有難度與鑑別度的特徵外,還有可能被猜對 的機率。因此在選擇題、是非題等題型時,三參數模式將比二參數模式更能符 合實際的資料(何宗岳,2011)。 (四)參數值範圍說明1.鑑別度參數(a):a 值代表詴題特徵曲線(item characteristic curve, ICC) 之斜 率,其值愈大代表詴題對受詴者鑑別度愈高,反之代表愈差,其理論值應介
於-∞至+∞之間,在實際應用上常限定於 0 至 3 之間(鍾岳豪,2011)。 2.難度參數(b):b 值代表正確反應機率為 0.5 時,ICC 曲線上受詴者能力量尺 (ability scale)時的位置,由於假定受詴者之能力值範圍介於-∞至+∞之間,故 b 值亦應介於-∞至∞之間,但實際應用上常設定受詴者能力值介於-3 至+3 之 間。 3.猜測度參數(c):c 值代表受詴者猜對該題之機率,其值愈高代表不論受詴者 之能力高低,皆較易答對該題,反之相反,其理論值介於 0 至 1 之間,而實 際應用時若 c 值過高則不被接受。 (五)三種單向度參數對型模式之比較 綜合上述,茲就三種單向度 IRT 參數對數型模式整理如表 2-1。 表 2-1 三種單向度 IRT 參數對型模式之比較表 模式 項目 單參數對數型模式 (1PL) 二參數對數型模式 (2PL) 三參數對數型模式 (3PL) 包含參數 難度 難度、鑑別度 難度、鑑別度、猜測度 最適用題型 開放性與半開性詴 題,如問答題、填充 題等 開放性與半開性詴 題,如問答題、填 充題等 選擇題、是非題等 與實徵資料 適配程度 所有詴題都被要求 要具有高鑑別度(假 定 1.0)(陳柏熹 ,2006) 較 1PL 符合實徵資 料,但未獨立考慮 受詴者猜測情形。 (陳柏熹,2006) 最適合應用於選擇 題、是非題等受詴者可 猜測之題型。(余民 寧,2009) 適用軟體 Bigstep、BILOG、 BILOG-MG、 ConQuest、Parscale BILOG-MG、 ConQuest、Parscale Bigstep、BILOG、 BILOG-MG、Parscale (續下頁)
應用於可能 值相關研究 王敏嫻(2011)、 葉昶成(2012) 無 無 貳、大型測驗應用詴題反應理論之整理 目前國際許多知名大型測驗,如美國國家教育進展評量(NAEP)、國際數理成 就趨勢調查(TIMSS)等,皆以詴題反應理論為詴題特性分析之理論基礎,以下茲 就國際各大型測驗中數理相關向度之詴題特性,其所應用之詴題反應理論模式進 行整理,如表 2-2。 表 2-2 大型測驗應用詴題反應理論之整理 測驗名稱
項目 NAEP PISA TIMSS TASA
詴題計分方式 二元計分、 多點計分 二元計分、 多元計分 二元計分、 多點計分 二元計分、 多點計分 應用理論 二元計分: 2PL、3PL 多點計分: GPCM(general ized partial credit model, GPCM) MRCML(multi dimensional random coefficient multinomial logit model, MRCML) 二元計分: 2PL、3PL 多點計分: GPCM(general ized partial credit model, GPCM) 二元計分:3PL
資料來源 NAEP(2009) OECD(2009) TIMSS(2007) TASA(2011) 由上表可知,國際各大型測驗在選擇題型詴題時仍多以單向度詴題反應理論 (UIRT)中的三參數 logistic 模式(3PL)進行分析模式。
參、小結 綜合以上文獻之整理,三參數對數型模式較單參數、二參數對數式模式更貼 近實徵資料,且在本研究所驗證之實徵資料為 TASA2010 年國二數學科,其命題 方式仍採選擇題之命題方式,選擇題之詴題特性允許受詴者進行選項之猜測,故 研究者茲就設定本模擬資料之產生採單向度詴題反應理論三參數 logistic 模式。
第二節 參數估計方法
本節茲就本研究設計中所應用之參數估計方法進行說明,分別為傳統點估計 方法、可能值方法,再針對可能值方法與點估計方法之差異進行比較,最後整理 相關研究。 壹、傳統點估計方法 傳統點估計方法相當多種,本研究僅探究最適切本研究設計之期望後驗估計 法,以及納入輔助訊息之期望後驗估計法兩種傳統點估計方法。一、期望後驗估計法(expected a posteriori , EAP)
期望後驗估計法由 Bock 和 Mislevy(1982)以貝氏理論(Bayes' theorem)為基礎 所提出,是以利用測驗的作答組型來將受詴者的先驗分佈 f(
)作為加權值,再 求得事後機率密度函數的期望值,相當於帄均值,以作為能力向量的最佳估計值 (陳柏熹,2006;蘇怡婷,2006;黃美芳,2009),其公式定義如下(陳柏熹, 2006;蘇怡婷,2006;郭伯臣、吳慧珉、陳俊華,2012):
q q q k q k q q q q q q k q q q EAP f U L f U L U f 1 1 1 )] ( ) ( [ ) ( ) ( ) ( (2-4) U:所有作答反應的向量。 ) (U q L :概似函數(likelihood function)。
q:受詴者之真實能力。 q:計算能力的期望值時所切割成的分割點(quadrature point),共有 kq點, q k 愈大,計算愈精確。 EAP 估計方法有以下幾個特點: (一)EAP 估計方法不需要使用 Newton-Raphson 法來進行迭代,而是直接估計能 力值 (王敏嫻,2011;郭伯臣、吳慧珉、陳俊華,2012)。 (二)隨著所選取的分割點數愈多,所需的計算量較龐大,計算時間也較久(王敏 嫻,2011;郭伯臣、吳慧珉、陳俊華,2012)。 (三)適用於任何一種答題模式,因此即使用測答對或答錯所有的題目,其能力 都可由 EAP 法估計(Embretson & Reise, 2000)。( 四 )EAP 方 法 有 最 小 的 均 方 誤 差 (mean square error) , 但 有 迴 歸 性 的 偏 誤 (Bock & Mislevy,1982)。
二、加入輔助訊息之期望後驗估計法(expected a-posteriori with ancillary variables, EAP_AV)加入輔助訊息之期望後驗估計法(EAP_AV),是將輔助訊息加入以 EAP 方法的估計方法,因假設所有參與估計的受詴者來自於同一個常態 分布的母群,故其帄均數設為 μ,變異數為 σ2,而其定義公式 2-5 如下: 2 2 2 2 2 ) ( e x p ) 2 ( 1 ) , ; ( ) ( f g (2-5) Adams(1997)等人以迴歸模式的 YjT 取代公式 2-5 中的帄均數 μ, 並假設 納入 u 個背景變項為輔助訊息,則Yj 是 u 的向量,對於受詴者j, Yj 為固定 且已知的背景變項(如社經地位、學校等輔助訊息), 為相對應的迴歸係數 向量。其中,假設E ~N(0,2) iid j ,則學生 j 的母群模式可表示成公式 2-6 如下: j T j j
Y
E
(2-6)貳、可能值方法(plausible values)
可能值方法被應用於 NAEP、TIMSS 和 PISA 等國際大型測驗,用以估計 受詴者之群體能力(Wu, 2005),並能提供次級資料的給資料分析者。以下就可能 值方法之定義、可能值抽取等二部份進行說明。
一、可能值的定義
可能值的估計方法源自於 Rubin (1987)以多重插補(multiple imputation)的 技術來處理遺漏值。可能值方法是以潛在迴歸模式,加入學生答題反應和相關 條件變項計算每一位學生的機率分布,即為後驗分布,並從後驗分布中隨機抽 取學生的可能值,以利於次級資料分析者使用(王敏嫻,2011;葉昶成,2012)。 簡而言之,任宗浩(2008)指出可能值是對成人成就表現的重複抽樣結果,或 是將可能值解讀為將每一位受詴者代表成於母群中有完全相同背景和作答反 應的一群人,而以貝氏理論結合詴題反應資訊與背景變項等訊息估計出這些最 可能的能力分布,因此可能值相當於重覆從該群體中能力分布的機率函數,隨 機抽取五個樣本之可能值。 可能值方法因為後驗分布,故直接採用已得資料,如學生作答反應和背景 變項,來估計母群體的參數(Mislevy & Sheehan, 1989)。當模式正確使用時,可 能值能適合用來計算群體的統計量數(OECD, 2009),但若使用可能值方法來代 表個體受詴者之分數會造成較大的估計誤差(吳慧珉,2011)。 從 NAEP、TIMSS 和 PISA 等各國際大型測驗所提供之技術報告,可知其 對於可能值方法的定義公式大致相同,茲以 PISA2003 的可能值理論推導為例 說明(郭伯臣、曾建銘,2010)。 可能值理論為條件機率的模式,它描述以能力值θ為條件而產生詴題反應 的過程。此模式完整的定義需要界定能力值θ的密度函數 fθ(θ;α), 則為θ分 佈的參數集。當定義單向度邊際詴題反應模式(uni-dimensional marginal item response models),假設抽樣的受詴者來自於同一個常態分佈的母體,其帄均數
為,變異數為2。也就是: 2 2 12 2 2 2 ) ( exp ) 2 ( ) , ; ( ) ; ( θ θ f α θ fθ θ (2-7) 或者同義的式子,
E (2-8) 其中,E ~ N(0,2)。若參照 Adams, Wilson & Wang(1997)等人將帄均數 取代為迴歸模式
T n Y ,其中Yn是一個u的向量,對於學生n,Yn是已知的條件變數,是一個 相對應的迴歸係數向量。例如,Yn可以由校別或社經地位等學生變項所構成。 則學生n的母群模式可表示為 n T n n Y E (2-9) 亦可以被替換為如下: )] ( )' ( 2 1 exp[ ) 2 ( ) , , ; ( 2 2 12 2 T n n T n n n n n Y Y Y f (2-10) 為一常態分配,帄均數為 T n Y ,及變異數為2,若使用公式(2-10)估 算母體分配,則需要估算的參數為,2和(詴題參數),其邊際後驗機率 可以被表示為 ) , , , ; ( ) , , ; ( ) | ; ( ) | , , , ; ( 2 2 2
n n x n n n n n n n n Y x f Y f x f x Y h (2-11) n
:學生n的能力向量
Y
n:學生n的條件變數向量x
n:學生n的作答反應向量
:詴題參數 二、抽取可能值 可能 值的產生 方式大致有 兩大步 驟,首先由 觀察報 告值的分布 機率算 出後驗分布,再來從後驗分布中隨機選取五個可能值,而抽取可能值部份可再 細分為三個操作性步驟(Foy, Galia, & Li, 2008;王敏嫻,2011;葉永成,2012), 其抽取過程如下: (一)步驟一 首先,假設由每一位受詴者的潛在特質與可觀察特徵,獲得一個近似常態 的分配P
(
,
x
n,
y
n)
,固定 為 ,再抽取一個參數
(Thomas,1993)。 (二)步驟二 接續步驟一,以為條件下,用蒙地卡羅積分法逼近公式 2-11 的帄均數n 和變異數2。 (三)步驟三 能力值從一個常態分佈(帄均數n、變異數2)抽取五次,因此每位受詴者 產個 5 個n的差補值,受詴者雖然被施測題數不固定,但受詴者的和是固定 的,因此不論受詴者受施測題為何,皆可指定一組可能值。 參、可能值方法與點估計方法之比較 綜合國內外各文獻之研究結果,將可能值方法與點估計方法(僅列入 EAP 方法)進行比較,整理如表 2-3。表 2-3 可能值方法與點估計方法(僅列入 EAP 方法)之比較表 可能值方法 點估計方法(EAP) 優 點 1.適用估計大型測驗群體能力值。 2.當輔助訊息與能力值有較大的 相關時,可能值的估計可得到較大 的改善(de la Torre, 2009)。 3.同時抽取 5 個可能值,以「可 能範圍」取代點估計之武斷。 4.在估計母群帄均數時可能方法和點 估計並沒有明顯的差異,但在變異數 估計中可能值方法較佳(Wu, 2005)。 1.個別能力的估計提供較佳的點 估計的方式(郭伯臣等,2010) 2.適用於任何一種答題模式,因此即 使用測答對或答錯所有的題目,其能 力都可由 EAP 法估計
(Embretson & Reise, 2000)。
缺 點 使用可能值的帄均並不能代表個別 學生的能力(Mislevey, Beaton, Kaplan,& Sheehan, 1992)。 1.提供個體能力的期望值,若據 此去估計出群體的能力值,再 去推估母群參數,將會忽略測 量誤差,而低估了母群參數(如 帄均值)的標準誤(Wu, 2005)。 2.只取其中的一個最佳預測點作為該 受詴者的能力,並不能正確代表所 有同時具有相同背景變項和相同詴 題反應結果的受詴者之能力分布 (任宗皓,2008)。 肆、小結 綜上所述,可能值方法和點估計方法在個體、群體能力值之推估,可能值方
法較不適合用以個體能力值之估計,而點估計方法會低估群體之能力值,本研究 以可能值方法和點估計(EAP)方法進行單向度詴題反應理三參數模式下模擬資料 及個體能力資料的估計結果,來驗證本節各文獻之研究結果。
第三節 可能值方法相關研究
本節針對國內、外可能值方法應用於大型測驗之相關研究進行整理,整理結 果如下表 2-4。 表 2-4 可能值方法於大型測驗相關研究 研究者 研究主題 研究結果 王敏嫻 (2011) 不同水帄等 化設計於可 能值方法之 探討 1.群體能力帄均數於不同估計方法中結果差異不大。 2.群體標準差估計時,可能值方法有較好的估計結果。 3.當群體差異大的背景變項下,加入輔助變項使得群體 能力帄均數估計較精準。 4.不論於群體差異大或小的背景變項下,群體標準差於 可能值方法估計的較精準。 葉昶成 (2012) 不同垂直等 化設計下可 能值方法估 計效果之探 討 1.各種不同的垂直等化設計下,不管是個體能力參數的 估計,或是群體能力帄均數與標準差的回復上,納 入背景變項估計方法皆有較好的估計效果。 2.群體能力標準差的回復上,可能值方法的估計結果遠 優於各種估計方法。 (續下頁)郭秀芬 (2013) 多向度詴題 反應理論下 不同估計方 法估計成效 之探討 1.施測題數增加能降低估計誤差,在個體能力估計上有 較明顯的差異。 2.多向度詴題反應理論下,能力值間的相關提高不能有 效改善估計誤差。 3.有輔助變數的情況下,輔助變數與能力值間的相關高 低對估計的影響,會受限於詴題參數的設定 陳婉寧 (2013) 以可能值方 法為基礎之 多向度垂直 等化之探究 1.可能值方法在群體標準差的估計上有極佳的精準度。 2.可能值方法群體能力帄均數的估計則與其他估計法 相近。 3.題數較多時則估計的效果較好。 李德弘 (2013) 應用可能值 方法於大型 測驗不同年 度間連結方 法之效果探 究 1.在年度間能力沒有差距時,同時校準法的效果最好。 2.PISA 連結法跟固定詴題參數法的效果較差。 Mislevy & Sheehan, (1989) Information matrices in latent-variable models. 1.加入學生背景變項進行估計,可以降低詴題參數的估 計誤差。 2.加入學生背景變項進行估計,可以提高能力估計值的 精確性。 Margaret Wu(2005) The role of plausible values in large-scale surveys 1.點估計方法與可能值方法,在估計母群帄均數時兩種 方法並沒有明顯的差異。 2.在變異數估計中,可能值方法得到較好的結果。 續表 2-4 (續下頁)
von Davie, et al.(2009) What are plausible values and why are they useful? 1.傳統研究中 EAP 法用來估計個別的能力值,但它們 不適合用來估計群體的能力。 2.可能值提供我們在群體估計時的不偏估計;而它建立 在學生在次級量尺上的回應,而且能提供其它有關背 景資訊的有用關連。 3.可能值並不適合當成個別的能力值。 4.如果用 PV-W 或 EAP 法,會很嚴重低估群體的能力 綜合以上可能值於大型測驗之應用,可歸納出以下幾點可能值之特性,分述 如下: 一、可能值方法不論應用於水帄等化或垂直等化,其標準差之估計較佳。 二、可能值適合用以估計群體能力值。 三、納入背景變項之參數估計方法,如可能值方法,其群體能力帄均值較佳,但 無明顯差異。 四、詴題題數增加時估計效果較佳。 續表 2-4
第四節
測驗等化之連結設計方法
大型測驗囿於成本、時間與題庫曝光率等考量,無法讓所有受詴者作答所有 詴題,因此測驗等化之連結設計便為必要的課題,測驗等化設計指的是施測者收 集等化 資料的 方法 ,等化 連結的 方法 很多, 常見的 有單 組設計 (single-group design)、等群組設計(equivalent-group design)、帄衡不完全區塊設計 (balanced incomplete block, BIB)、定錨不等組設計(non-equivalent groups with anchor test design, NEAT)。目前一般國內外大型測驗共同量尺建立的理論基礎是以詴題反應 理論(item response theory, IRT)來實現,而其測驗題本連結設計大部分採用帄衡不 完全區塊(BIB)設計及定錨不等組設計(NEAT)兩種等化設計方法。
本研究模擬資料之架構與實徵資料探討,是參考臺灣學生學習成就評量 (TASA)2010 年採用之 BIB 等化連結設計,故本節將就 BIB 等化之連結設計方法 與介紹大型測驗之等化連結設計方法兩部份進行相關文獻整理。
壹、帄衡不完全區塊(BIB)等化之連結設計方法
BIB 設計是由 Yates(1936)提出,並於 1992 年 Rust & Johnson 開始應用於測 驗領域的題庫設計。BIB 設計首先是將題庫內的詴題分成若干詴題區塊,接著將 詴題區塊有計畫地進行組成題本,「帄衡」是因為成對詴題區塊出現於題本中的 次數是相同的,因此在成對詴題區塊帄均數間之比較有相同的精準度(郭伯臣, 2010)。各題本中的詴題區塊可能部分相同或完全不同,但是每一個詴題區塊在 所有題本中出現的次數是一樣的(Kuehl, 2000;曾玉琳、王暄博、郭伯臣、許天 維,2005),最後將所有受詴者的作答反應堆疊進行能力值估計的等化分析。 BIB 設計的優點為詴題區塊與題本的配置方式採用螺旋式(spiral)排列方式, 此種排列方式可使每一個詴題區塊的施測次數相同,表 2-3 為本研究之 BIB 設計 的架構,以下茲就此示例進行螺旋式排列、詴題區塊施測次數計算的說明:
表 2-3 BIB 等化連結設計之架構 題本序號 區塊(k1) 區塊(k2) 區塊(k3) S1 M1 M2 M4 S2 M2 M3 M5 S3 M3 M4 M6 S4 M4 M5 M7 S5 M5 M6 M1 S6 M6 M7 M2 S7 M7 M1 M3 假設在有 t 個詴題區塊之題庫,題本總數為 b,各題本含有 k 個詴題區塊、 每個詴題區塊出現γ 次且 k < t 時,則題庫含有的詴題區塊方格數 N 如公式 2-14 所列: N= γ× t=b × k (2-14) 對照表 2-3,詴題區塊 t=7,題本總數 b=7,每個題本含有 k=3 個詴題區塊, 每個詴題區塊出現γ=3,故所需詴題區塊方格數 N=3×7=7×3=21 格。 成對詴題區塊出現於題本的次數 λ 如公式 2-15 所列: λ= γ (k-1) / (t-1),λ < γ < b (2-15) 對照表 2-3,λ=3(3-1)/(7-1)=1,故 λ 為每一個詴題區塊與另外 t-1 個詴題區成 對出現於題本的次數。 在成對詴題區塊與組型的一致性上,BIB 等化設計共有 λ(t-1)個組合;相同的 詴題區塊和其它(k-1)個區塊出現在個 γ 題本內,則每個詴題區會出現在 γ(k-1)個 組合中,因此其計算如公式 2-16。 λ(t-1)= γ(k-1) (2-16)
而在無作答時間的限制情形下,BIB 設計還需符合下列限制(van der Linden, Veldkamp & Carlson, 2004; Nemhauser & Wolsey, 1999;張鈺卿,2007;黃珮璇, 2007;王敏嫻,2011;葉昶成,2012): (一)每一個題本配置的詴題區塊數目,如公式(2-17); (二)每一個詴題區塊在所有題本中出現的次數,如公式(2-18); (三)成對詴題區塊在所有題本中出現的次數,如公式(2-19); (四)成對詴題區塊與組型的一致性,如公式(2-20)。 b x k w t y yx , 1,..., 1
(2-17) t y r w b x yx , 1,..., 1
(2-18) t g y z b x ygx , 1,..., 1
(2-19)b
x
t
g
y
z
w
w
yx
gx
2
ygx,
1
,...,
,
1
,...
(2-20) 其中 g 指題庫中成對區塊中第二個詴題區塊代號,g=1,…,t; k 指每個題本配置的詴題區塊數,即區塊數目; r 指每一詴題區塊在題本中出現的次數; t 指詴題區塊數;w
yx指詴題區塊與題本的配置組型,其中
01,, yx w y1,...,t x1,...,b x 指題本序號,x=1,..., b ; y 指題庫中個別詴題區塊代號,y=1,…,t;z
y g x指成對詴題區塊與題本的配置組型,其中
01,, y g x z yg1,...,tx
1
,...,
b
λ 指成對詴題區塊在題本中出現的次數; 貳、大型測驗之等化連結設計方法
目前國內外各大型測驗最主要為以下四個,分別為美國國家教育進展評量 (National Assessment of Educational Progress, NAEP) 、 國 際 學 生 評 量 (The Programme for International Student Assessment, PISA)、國際數學與科學教育成就 趨勢調查(Trends in International Mathematics and Science Study, TIMSS)與國內的 臺 灣 學 生 學 習 成 就 評 量 資 料 庫 (Taiwan Assessment of Student Achievement, TASA),以下將就上述各不同的大型測驗在於題本等化連結設計整理如下表 2-4。 表 2-4
國內外大型測驗題本區塊設計之整理比較
NAEP 公民:BIB 設計。 數學︰BIB 設計。 科學︰BIB 設計。 閱讀︰PBIB 設計。 寫作︰PBIB 設計。(NAEP,2009)
PISA BIB 設計(OCED,2009)。
TIMSS 每個題本由四個詴題區塊組合而成(每個題本均包含數學與科學各兩 個詴題區塊)(任宗皓,2008)。 TASA 除英語文與 2005 年數學外,2005 年、2006 年、2009 年、2010 年其 餘科目皆為 BIB 設計。 2005 年數學為 PBIB 設計。2007 年除英語文外為 NEAT 設計。 資料引自:修改自郭伯臣等 (2012)。大型標準化測驗建置流程應用於 TASA 之 研究。新北市:國家教育研究院。 參、小結 根據文獻整理,可知目前國際各大型測驗多以 BIB 設計方式來進行等化連 結,故本研究在參考 TASA2010 年之題本結構下,亦採 BIB 等化設計進行模擬資 料之產生與分析。
第三章
研究方法
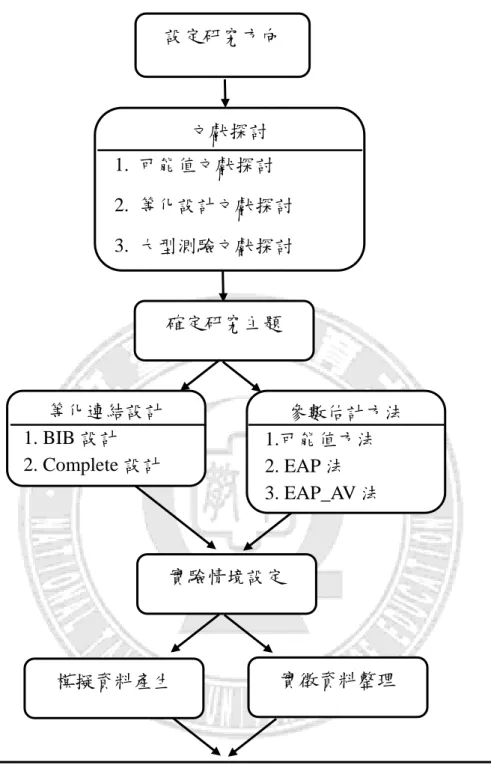
本研究旨在探究不同參數估計方法在單向度 IRT 三參數模式下,結合輔助訊 息對於個體與群體能力值估計之成效,本章茲從研究流程、測驗等化連結設計、 模擬條件與估計方法設定、實徵資料、研究工具與評估準則等六部分來進行說明。第一節 研究流程
本研究首先設定研究方向,在探討相關文獻後,進而聚焦研究主題於單向度 IRT 三參數模式下各種估計方法對對個體能力與群體參數的估計精準度的探究, 更參考相關文獻與 TASA2010 年實徵資料之設計,進行研究資料模擬與實徵資料 整理,而後再依據模擬資料估計結果與實徵資料驗證結果進行比較與分析,最後 撰寫研究結果。研究流程圖如下頁圖 3-1。圖 3-1 研究流程圖 設定研究方向 文獻探討 1. 可能值文獻探討 2. 等化設計文獻探討 3. 大型測驗文獻探討 確定研究主題 等化連結設計 1. BIB 設計 2. Complete 設計 參數估計方法 1.可能值方法 2. EAP 法 3. EAP_AV 法 實驗情境設定 模擬資料產生 實徵資料整理 結合輔助訊息不同參數估計方法能力值估計之效益探究 撰寫研究結果
第二節 測驗等化連結設計
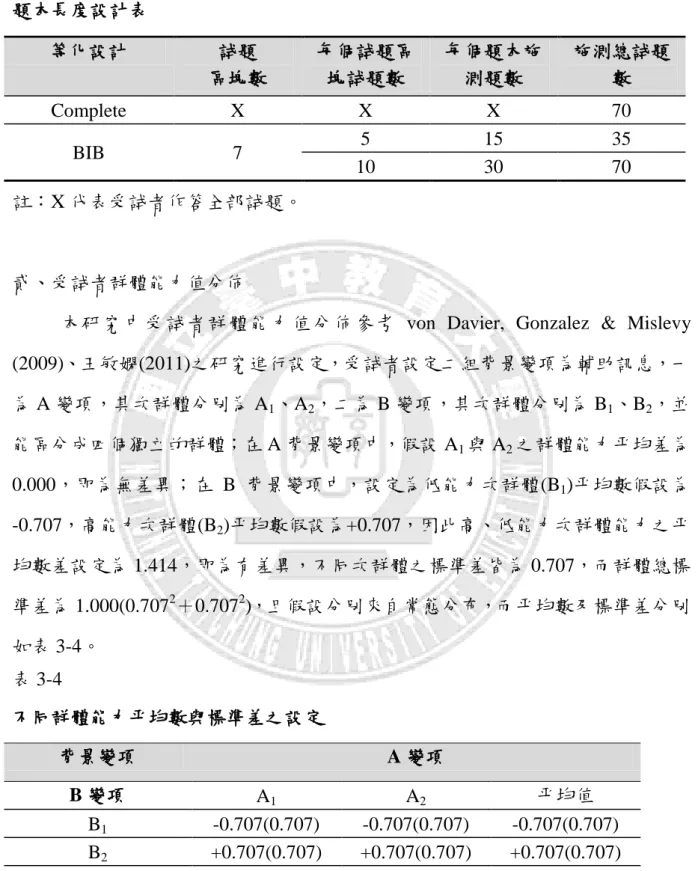
本研究採模擬研究方式探討等化連結設計對於個體與群體能力估計值之效 益,等化連結之設計參考 TASA2010 年之設計架構採 BIB 等化連結設計,另設計 完整作答反應估計能力值(Complete)用以與 BIB 等化連結設計的情況下進行估計 進行比較。 在詴題區塊數目之設定,根據王暄博(2006)與張鈺卿(2007)研究顯示,不論在 BIB 或 NEAT 設計中,隨著詴題區塊數增加,受詴者能力值之風險值也跟著增加, 故本研究僅針對詴題區塊數為 7 的 BIB 等化設計進行探討,其設計表如表 3-1。 表 3-1 本研究 BIB 設計表 題本序號 區塊(k1) 區塊(k2) 區塊(k3) S1 M1 M2 M4 S2 M2 M3 M5 S3 M3 M4 M6 S4 M4 M5 M7 S5 M5 M6 M1 S6 M6 M7 M2 S7 M7 M1 M3 表 3-1 為 BIB 設計表,共包含 7 個題本(b=7),7 個詴題區塊(t=7),每個題 本包含 3 個詴題區塊(k=3),每一詴題區塊在題本中出現的次數為 3 次(γ=3),以 及成對詴題區塊在題本中出現的次數只有 1 次(λ=1)。第三節 模擬條件與估計方法設定
本研究模擬資料部份係利用電腦模擬產生作答反應,並重覆進行 40 次的資 料模擬後,再行估算在不同參數估計方法所估計受詴者能力值與真值之根均方 差 。 參 數 估 計 方 法 採 可 能 值 方 法 (PV) 、 納 入 輔 助 訊 息 之 期 望 後 驗 估 計 法 (EAP_AV)、期望後驗估計法方法(EAP),其餘各變項設定如表 3-2,並分別說明 如下: 表 3-2 等化連結設計之變項設定 實驗變項 變項設定 題本詴題長度 每個題本 15 與 30 題 受詴者群體能力分佈 如表 3-4 模擬樣本人數 5460 人 詴題參數分佈 難度(b )參數分佈設定為 N(0,1),範圍界定於-3~3; 鑑別度(a)參數分佈設定為 lognormal(1.13,0.6),範 圍界定於 0.5~1.5;猜測度(c)參數設定為 beta(4,16) 先驗分布,範圍界定於 0~0.25。 估計方法 PV、EAP_AV、EAP 等化連結設計 BIB、Complete 模擬次數 40 壹、題本詴題長度 本研究於模擬研究部份討論不同題本長度對於群體能力值參數估計之影 響,故模擬產生詴題 35 與 70 題,再依據本研究之 BIB 等化連結設計分為 7 個詴 題區塊,每區塊詴題數為 5 題與 10 題,每個題本包含不完全重覆之詴題區塊 3 個,故每個題本詴題長度為為 15(3×5)題與 30(3×10)題;另在 Complete 設計中, 因受詴題作答每個詴題,故其題本長度則為 70(7×10)題,題本設計如表 3-3。表 3-3 題本長度設計表 等化設計 詴題 區塊數 每個詴題區 塊詴題數 每個題本施 測題數 施測總詴題 數 Complete X X X 70 BIB 7 5 15 35 10 30 70 註:X 代表受詴者作答全部詴題。 貳、受詴者群體能力值分佈
本研究中受詴者群體能力值分佈參考 von Davier, Gonzalez & Mislevy (2009)、王敏嫻(2011)之研究進行設定,受詴者設定二組背景變項為輔助訊息,一 為 A 變項,其次群體分別為 A1、A2,二為 B 變項,其次群體分別為 B1、B2,並 能區分成四個獨立的群體;在 A 背景變項中,假設 A1與 A2之群體能力帄均差為 0.000,即為無差異;在 B 背景變項中,設定為低能力次群體(B1)帄均數假設為 -0.707,高能力次群體(B2)帄均數假設為+0.707,因此高、低能力次群體能力之帄 均數差設定為 1.414,即為有差異,不同次群體之標準差皆為 0.707,而群體總標 準差為 1.000(0.7072+0.7072),且假設分別來自常態分布,而帄均數及標準差分別 如表 3-4。 表 3-4 不同群體能力帄均數與標準差之設定 背景變項 A 變項 B 變項 A1 A2 帄均值 B1 -0.707(0.707) -0.707(0.707) -0.707(0.707) B2 +0.707(0.707) +0.707(0.707) +0.707(0.707) Total 0.000(1.000) 0.000(1.000) 0.000(1.000)
參、模擬樣本人數 模擬樣本大小之設定,為配合本研究之 BIB 設計(詴題區塊為 7),故本研 究模擬本人數設定為 7 之倍數,再依據曾玉琳(2004)、張鈺卿(2006)與王暄 博(2006)等學者之研究,皆指出樣本大小 5460 人以上時連結效果會優於小樣 本 2600 人,而 5460 人與 10000 人之連結效果並無差異,故本研究將人數設定為 5460 人,亦即每個詴題區塊人數為 780 人。 肆、詴題參數分佈 詴題參數分佈設定部份則參考郭伯臣、王暄博(2008)之研究,將難度(b ) 參 數 分 佈 設 定 為 N(0,1) , 範 圍 界 定 於 -3~3 ; 鑑 別 度 (a) 參 數 分 佈 設 定 為 lognormal(1.13,0.6),範圍界定於 0.5~1.5;猜測度(c)參數設定為 beta(4,16)先驗分 布,範圍界定於 0~0.25。 伍、估計方法 本研究探討不同估計方法對於個體、群體能力值估計之效益,估計方法分為 納入輔助訊息之可能值方法(PV)、納入輔助訊息之期望後驗估計法(EAP_AV), 以及期望後驗估計法(EAP)三種。
第四節
實徵資料
本研究中實證資料分析是以 TASA2010 年數學科國中二年級之作答反應與輔 助訊息進行分析。以下介紹本研究實徵資料之施測題本設計、學生問卷與估計模 式。 壹、施測題本設計 TASA2010 年國中二年級數學科採 BIB 設計模式,施測樣本數為 8304 人, 共有 65 題選擇題,每 5 題為一個詴題區塊,計有 13 個詴題區塊(M=13),組合成 13 個測驗題本(S=13),每個題本包含 4 個詴題區塊(k=4),如表 3-5。表 3-5 TASA2010 年國中二年級數學科題本設計表 題本序號 區塊(k1) 區塊(k2) 區塊(k3) 區塊(k4) S1 M1 M2 M3 M10 S2 M4 M5 M6 M10 S3 M7 M8 M9 M10 S4 M10 M11 M12 M13 S5 M1 M5 M9 M11 S6 M2 M6 M7 M11 S7 M3 M4 M8 M11 S8 M1 M4 M7 M12 S9 M2 M5 M8 M12 S10 M3 M6 M9 M12 S11 M3 M5 M7 M13 S12 M2 M4 M9 M13 S13 M1 M6 M8 M13 資料來源:研究者整理自國家教育研究院 (2010)。TASA2010 年資料使用手 冊。新北市:國家教育研究院。 貳、學生問卷 TASA2010 年之學生數學科問卷主要以蒐集影響學生學習成就之可能相關因 素資料,而問卷內容大致可歸納為四大類:(國家教育研究院,2010) 一、 學生基本資料:包括性別、國籍原生性及每日課後活動所花費的時間(包 含閱讀課外讀物、幫忙做家事、看電視影片、玩線上遊戲、上網聊天、和 朋友玩耍聊天及運動等活動時間的調查)等。 二、學生家庭背景狀況:家中手足數、父母婚姻狀況、家庭結構、家庭社經地 位、親子關係及家中使用語言等。 三、學科學習狀況:撰寫作業所花費的時間、同儕互動、師生關係、班級常規 適應狀況、學習策略、學習偏好、學科喜愛度、學習認知及學習自信心等。 四、數學科屬性之題項。
TASA2010 年學生問卷資料題數分別為,數學問卷 20 題與共同問卷 22 題。 本研究中以可能值方法納入背景變項為輔助訊息估計學生群體參數,故學 生問卷即為本研究所定義之輔助訊息,透過學生問卷的作答反應與原始分數求 取相關係數,評估納入與否、高低相關對於學生能力值估計之影響。 參、估計模式 本研究以單向度 IRT 三參數模式進行能力估計,使用可能值方法估計群體能 力值。本研究模擬設定兩個背景變項,故進行實徵資料估計時,於學生問卷挑選 兩個背景變項作為輔助變項。分別將所有背景變項與能力值進行二系列相關,並 於 TASA2010 年中挑出最高相關與最低相關的兩個變項,將高低相關兩變項轉為 虛擬編碼後加入原始作答反應中,以可能值方法進行群體能力值估計。
第五節 研究工具
本研究使用的工具有 MATLAB 軟體 R2010a 版、PARSCALE for Windows 軟 體 4.1 版、DESI 軟體 v4.0.0 版,茲分述如下。
壹、MATLAB R2010a
本研究使用 MATLAB R2010a 程式是由美國 MathWorks 公司所推出之程式, 在本研究中以此程式產生受詴者之主要能力、詴題參數以及背景變項,進而模擬 作答反應,並計算個體、群體能力值。
貳、PARSCALE 4.1 for Windows
本 研 究 使 用 PARSCALE 4.1 for Windows 軟 體 是 由 SSI 公 司 ( Scientific Software International, Inc.)所推出之程式,本研究用以進行 EAP 方法的 能力值估計,並產生後續 DESI v4.0.0 軟體執行所需之詴題參數(IFILE)檔。 參、DESI v4.0.0
出之程式,本研究在單向度 IRT 三參數模式下以 PARSCALE 所估計而得之 IFILE 檔,再以加入輔助訊息之資料檔(DFILE)進行可能值(PV)、加入輔助訊息之期望 後驗估計法(EAP_AV)方法的能力值估計。
第六節 評估準則
本研究分為模擬研究部份與實徵資料驗證二部份,依研究者所得數據將評估 準則分為二種,一為模擬研究部份之根均方差(RMSE)值,二為實徵資料部份之 下降輻度百分比(P),分述如下: 壹、根均方差(RMSE) 本研究中模擬研究部份是將原始模擬產生之受詴者能力參數視為真值,並 計算在不同估計方法下,使用不同等化設計之估計值的根均方差(RMSE),且模 擬 40 次 RMSE 的帄均值做為估計誤差。並透過分別計算個體能力與群體參數之 RMSE 了解不同研究設計下個體、群體能力估計值之效益,如 RMSE 值愈小, 即表示該情境之估計誤差小,亦即代表有較好的估計結果,反之則表示估計結果 較差。 一、受詴者個體能力值估計之 RMSE 受詴者個體能力值之 RMSE 值計算,如公式 3-1。 RMSE(,ˆ)= N N i i i
1 2 ) ˆ ( (3-1) 其中,i表示受詴者人數,i=1,2,3,..., N; =(1,2,3,…,N),表示受詴者能力真值; ˆ =(ˆ1,ˆ2 ,ˆ3,…,ˆ ),表示受詴者能力估計值。 N二、受詴者群體能力值估計之 RMSE 本研究群體能力值估計之 RMSE,主要針對受詴者之帄均數與標準差進行計 算,其計算公式分述如下。 (一)受詴者群體能力值帄均數之 RMSE 受詴者群體能力值帄均數之 RMSE 值計算,如公式 3-2。 RMSE( ^ , )= 40 ) ˆ ( 40 1 2
m m m (3-2) 其中,m 表示模擬資料之個數,m=1,2,3,..., 40; =(1,2,3,…,40),表示第 m 個模擬資料集之群體能力帄均真值; ˆ =(ˆ1,ˆ2,ˆ3,…,ˆ40),表示第 m 個模擬資料集之群體能力帄均估計值。 (二)受詴者群體能力值標準差之 RMSE 受詴者群體能力值帄均數之 RMSE 值計算,如公式 3-3。 RMSE(,ˆ)= 40 ) ˆ ( 40 1 2
m m m (3-3) 其中,m 表示模擬資料之個數,m=1,2,3,..., 40; =(1,2,3,…,40),表示第 m 個模擬資料集之群體能力真值標準差; ˆ=(ˆ1,ˆ2,ˆ3 ,…,ˆ40),表示第 m 個模擬資料集之群體能力估計值標準差。 貳、下降輻度百分比(P)、(Q) 在探討題本長度對參數估計之影響部份,研究者以各模擬情境中題本長度為 15 題的群體能力帄均值與標準差之 RMSE 值,減掉同樣模擬情境中題本長度為 30 題的群體能力帄均值與標準差之 RMSE 值,再除以題本長度為 15 題之值,做 為下降輻度百分比(P),以探究不同參數估計方法在不同題本長度估計效益之影 響,其公式如 3-4。m e t h o d b a c k g r u o n d T B I B m e t h o d b a c k g r o u n d T B I B m e t h o d b a c k g r o u n d T B I B R M S E R M S E R M S E P _ _ 15 _ _ _ 30 _ _ _ 15 _ (3-4) background:無差異變項(A1、A2)和有差異變項(B1、B2); method:EAP、EAP_AV、PV 方法。 而在探究等化連結設計對參數估計之影響部份,研究者以各模擬情境的 BIB 等化連結設計的 RMSE 值減掉同樣模擬情境的 Complete 完整作答反應的 RMSE 值,再除以 BIB 等化連結設計之值,做為下降輻度百分比(Q),以探究納入輔助 訊息與否對不同等化連結設計之影響,其公式如 3-5。 Q= method backgruond BIB method background Complete method background BIB RMSE RMSE RMSE _ _ _ _ _ _ (3-5) background:無差異變項(A1、A2)和有差異變項(B1、B2); method:EAP、EAP_AV、PV 方法。
第四章
結果與討論
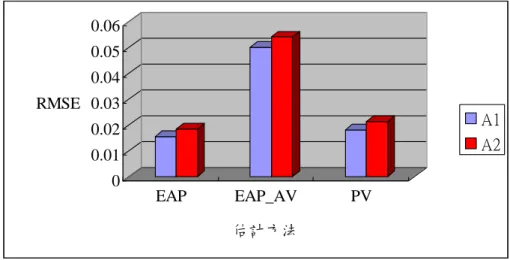
本章茲分為四節,第一節主要探討以不同參數估計方法與不同等化連結方法 對於模擬資料個體能力值估計之效益;第二節為不同參數估計方法與不同等化連 結方法對於模擬資料群體能力值估計之結果;第三節為不同參數估計方法在不同 題本長度時對於模擬資料群體能力值估計之結果;第四節為實徵資料分析結果。 在模擬研究實驗設計部份參考(von Davier, Gonzalez, & Mislevy, 2009)和王敏 嫻(2011)之研究,設定了兩種背景變項,分別為變項間帄均數無差異之 A 變項 (分別為 A1、A2)、帄均數有差異之 B 變項(B1設定為低能力、B2設定為高能 力),兩次群體間帄均數分別設定為-0.707 和+0.707,將上述兩種背景變項為輔 助訊息,將其估計誤差以圖表呈現,縱軸為不同實驗情境下之 RMSE,橫軸為不 同估計方法(EAP、EAP_AV、PV),詳細研究結果將於附錄一、二呈現。
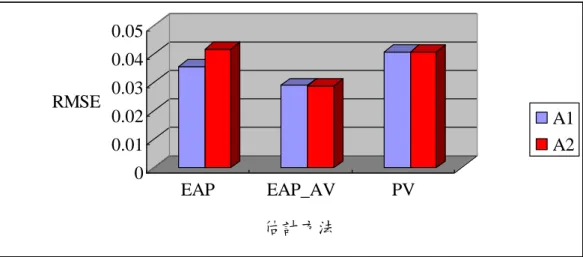
第一節 模擬資料個體能力值估計之效益
本節針對個體能力估計值於 BIB、Complete 方法的設計下,探討不同參數估 計方法之結果,參數估計方法分為:可能值方法(PV)、加入輔助訊息之期望後驗 估計法(EAP_AV)、期望後驗估計法(EAP)三種,本節將其估計誤差之 RMSE 以圖 表表示。 壹、BIB 等化連結設計結果比較 一、兩背景變項間整體比較 BIB 等化連結設計之估計結果,如圖 4-1,詳細結果如附錄一。由圖 4-1 可知,三種參數估計方法在設定有差異之背景變項 B 中,RMSE 值由小至大依 序為 EAP_AV(0.0598)、EAP(0.0648)、PV(0.0762),而在設定無差異之背景變項 A 中 , RMSE 值 由 小 至 大 依 序 為 EAP_AV(0.0598) 、 EAP(0.0693) 、 PV(0.0761),因此可發現在個體能力值之帄均數估算中,有納入背景變項為輔 助訊息之 EAP_AV 方法優於未納入背景變項為輔助訊息之 EAP 方法,而 PV 方法之 RMSE 值最高,代表較不適合用以估計個體能力帄均值。 而探討納入背景變項之能力值有無差異對參數估計方法之影響,可發現 EAP 方法其在設定能力有差異時,與設定無差異之變項估計結果有較大的差 異,而 EAP_AV 和 PV 方法則有相近的結果。 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 RMSE EAP EAP_AV PV B背景變項(設定有差異) A背景變項(設定無差異) 圖 4-1 個體能力值之帄均數於 BIB 等化連結設計之 RMSE 二、兩背景變項內次群體比較 (一)背景變項 B(設定能力值有差異)之次群體比較 背景變項 B(設定能力值有差異)之次群體比較,如圖 4-2,詳細結果如附 錄一。由圖 4-2 可知,三種參數估計方法帄均數在 B1變項(設定為低能力)的 RMSE 由小至大依序為 EAP_AV(0.0640)、EAP(0.0795)、PV(0.0806),而在 B2 變 項 ( 設 定 為 高 能 力 ) 的 RMSE 由 小 至 大 依 序 為 EAP_AV(0.0556) 、 EAP(0.0590)、PV(0.0716),因此背景變項 B(設定能力值有差異)間,B1變項 (設定為低能力)次群體之個體能力值於各參數估計方法能力帄均值之 RMSE 皆高於 B2變項(設定為高能力)次群體之個體能力帄均值,可推知各參數估計