國立交通大學
光電工程學系碩士班
碩士論文
利用獨立成份分析法評估
新型電子紙之色料特性
Colorant Estimation of Novel E-Paper
by Independent Component Analysis
研究生:邱郁勛
指導教授:田仲豪教授
利用獨立成份分析法評估
新型電子紙之色料特性
研究生:邱郁勛 指導教授:田仲豪教授
國立交通大學
光電工程系所碩士班
摘 要
電子紙是新型顯示器市場中極具潛力的產品。做為非自發光型的顯示器, 電子紙具有類似印刷製品的閱讀感受,在強光下也能保持畫面對比度;與此同時, 電子紙也具有電子製品的資料傳輸模式及可重複書寫的特性。更重要的是電子紙 具有雙穩態的特性,因此能夠以低耗能維持相同畫面。這些特性使得電子紙在商 業市場上具有廣大的應用範圍,如電子閱讀器、電子報、電子標籤、電子看板等 等。 為了與其他傳統顯示設備進行良好的色彩重建,有必要針對電子紙建立一 套精確的色彩特性化模型。但受限於複雜的混色特性,過去所習之特性化模型難 以應用於新型電子紙的特性化。因此本論文提出盲訊號分離的研究方法,利用量 測到的頻譜資訊評估電子紙的色料特性。 盲訊號分離中的獨立成份分析法是根據高階統計量的方法訂出獨立度的 量測準則,再針對量測準則建立最佳化演算法找到轉換矩陣,並通過此轉換矩陣 將混合訊號轉換至統計上獨立之向量空間。利用獨立成份分析法能夠從量測得到 的頻譜資訊中找到新型電子紙潛在的獨立色料頻譜成份,並以此做為系統的特性 矩陣,建立一套屬於新型電子紙的色彩模型。在本論文中將獨立成份分析法應用 於單色與全彩電泳式電子紙,且成功地得到此複合混色系統的特徵頻譜,並以此 建立能精確描述此電子紙顯色之色彩模型。 IColorant Estimation of Novel E-paper
by Independent Component Analysis
Student:Yu-Hsun chiu Advisor:Dr. Chung-Hao Tien
Institute of Electro-Optical Engineering, Department of Photonics
National Chiao Tung Unversity
Abstract
E-paper is a novel display with several appealing features. Since E-paper is a non-light-emitting display, it performs as hardcopy and holds fine contrast under sunlight, while at the same time, it can deliver or send electronic data as softcopy. Moreover, it has the bi-stable system which can hold the screen with low energy consumption. There are many available applications with these properties, such as E-reader, E-label and E-board.
In order to complete color reproduction, it is necessary to characterize the color performance of E-paper. However, it is too complicated to characterize the hybrid color mixing system with physical model, which is accomplished according to the physical structure. In this paper, we introduce a methodology based on independent component analysis to complete the colorimetric characterization. The independent featuring spectra of E-paper can be found out by applying independent component analysis to the reflectance spectra. After that, the color mixing system can be represented as a linear combination process of featuring spectra.
Two samples will be introduced in this paper: monochrome micro-cup electrophoretic display and full-color micro-encapsulated electrophoretic display.
According to the experimental results, the featuring spectra can be successfully determined by ICA-based methodology. Consequently, a colorimetric characterization of the special EPD with high fidelity has been done.
誌 謝
首先非常感謝指導教授田仲豪老師一直以來給我的指導與鼓勵。在實驗室 的這三年,老師在研究上總是會不斷地與我們討論,並且想盡辦法提供我們新的 想法與資源來提升研究的品質。而除了研究內容外,老師更是強調基礎實力的部 分,並且鼓勵我們多多利用豐富的線上資源,不斷去提升自己的能力。比起在研 究上的成果,我認為這份不斷學習的精神才是我在研究期間最大的收穫。在此對 田仲豪老師致上最高的敬意與謝意。 而在三年的研究生活中,我要特別感謝陸彥行學長對我的指引與幫忙。當 我在研究上一次又一次地陷入迷惘時,學長總是熱心的伸出援手並指點我方向。 也要感謝一起研究色彩學的林孟潔學姐、鐘岳學長,謝謝你們在我學習的過程中 給予我的幫助。還有實驗室的夥伴們:杰恩學長、玉麟學長、昇勳學長、柏宇、 張睿、錫汶、昇達,與你們在實驗室共度的這段時光是我最難忘的回憶,謝謝你 們。而承偉、子豪、少宏各位學弟,雖然只有短短一年的相處,但你們的加入讓 實驗室增加了不少活力,謝謝你們。 最後要感謝我的父母,謝謝你們一直以來對我付出的心力與鼓勵。到口試 為止的這段時間,當我無數次地覺得自己到此為止的時候,多虧有你們在背後支 持我,我才能走到這一步。 僅以此論文獻給我親愛的父母、師長、學長、學姊、學弟們。感謝你們這 段日子以來的支持與鼓勵,謝謝! IV章節目錄
第一章 緒論 ... 1
1.1 前言... 1 1.2 電泳顯示器基本架構... 2 1.3 研究動機與目的... 4 1.4 章節概要... 6第二章 基本理論 ... 7
2.1 反矩陣與廣義反矩陣... 7 2.2 本徵分解與實對稱矩陣... 8 2.3 機率論基本定義... 10 2.4 高斯分佈與中央極限定理... 12 2.5 共變異量與非相關性... 15 2.6 統計上的獨立性... 15 2.7 非高斯度量測準則... 16 2.7.1 峰度 ... 17 2.7.2 負熵 ... 18 2.8 拉格朗日法... 19 2.9 牛頓法... 20第三章 獨立成份分析演算法 ... 22
3.1 分析流程架構... 22 3.2 獨立成份分析法基本模型... 23 V3.3 資料前處理... 25 3.4 獨立度與非高斯度量測準則... 27 3.5 最佳化演算法... 28 3.6 建立特性化模型... 30
第四章 實驗及分析 ... 31
4.1 實驗設置... 31 4.2 實驗流程架構... 32 4.3 樣本一:黑白微杯型電泳電子紙... 33 4.4 樣本二:全彩微膠囊型電泳電子紙... 36 4.5 實驗成果討論... 39第五章 結論與未來研究方向 ... 41
5.1 結論... 41 5.2 未來研究方向... 42參考文獻 ... 43
VI圖目錄
圖 1-1
電子紙在商業上具有廣泛的應用範圍... 1
圖 1-2
電泳式電子紙架構示意圖... 3
圖 1-3
(a)減法混色系統與(b)加法混色系統混色機制示意圖... 4
圖 1-4
色彩特性化是以系統特性矩陣描述輸入訊號與輸出端色彩表現的關係. 5
圖 2-1
對直線的反射矩陣而言,其本徵向量就是該直線的指向向量及法向量... 9
圖 2-2
隨機變數 X 的機率密度函數... 11
圖 2-3
標準常態分佈之機率密度函數分佈... 13
圖 2-4
多個獨立變數平均後其機率密度分佈函數將趨近於鐘形。圖為(a)一個骰 子 (b)兩個骰子擲點平均值 之機率分佈函數... 14
圖 2-5
黑色虛線代表函數 F(x1,x2)之等位曲線,綠色實線代表方程式 V(x1,x2)=c 之軌跡,箭號表示斜率... 20
圖 2-6
牛頓法利用對函數做切線來得到新的點,並藉由重複此過程逼近函數的 零點... 21
圖 3-1
特性化模型之分析及建構流程圖... 22
圖 3-2
未知訊號分離流程圖... 24
圖 4-1
實驗儀器配置示意圖... 31
圖 4-2
實驗分析流程圖... 32
圖 4-3
黑白微杯型電泳電子紙結構示意圖... 33
VII圖 4-4
取 1 至 4 個本徵向量之變異量百分比... 34
圖 4-5
獨立特徵頻譜之頻譜曲線(IC1、IC2)及灰階暗態(G0)及亮態(G15)之反射 頻譜曲線... 35
圖 4-6
根據 ICA 模型預測之頻譜與實際灰階反射頻譜之色差值... 36
圖 4-7
E-ink 所生產的全彩微膠囊電泳式電子紙架構示意圖... 36
圖 4-8
取 1 至 6 個本徵向量之變異量百分比... 37
圖 4-9
全彩微膠囊形電泳式電子紙樣本之第一到第四特徵頻譜(IC1~IC4)... 38
圖 4-10
針對(a)全色域資料與 (b)暗態資料的色差分布統計結果,橫軸代表色差 分布區間,縱軸代表數量... 39
VIII表目錄
表 4-1
色彩特性化模型預測準確度表現(ΔE00)... 39
第一章
緒論
1.1 前言
電子紙為一具有雙穩態之反射式顯示器,由於使用性質與傳統紙張頗多相 似,因而得名[1]。做為非自發光型的顯示器,電子紙發展最主要的目標就是在 保留印刷製品的表現特性,同時也具有與其他電子界面交流的功能。此種同時具 有傳統印刷的視覺表現及電子顯示器的操作功能之特殊性質,對於資訊傳遞的便 利性以及製造成本,具有相當的優勢,有機會部分取代紙張印刷或是穿透式顯示 器市場。舉凡一般書籍、海報、標籤等,皆屬於電子紙應用範疇,是故電子紙成 為近年來最熱門的新型顯示器技術之一,如圖 1-1 所示[2]。 圖 1-1 電子紙在商業上具有廣泛的應用範圍 目前電子紙的顯示技術已發展出許多方法來達成雙穩態的功能,包括電泳 (Electrophoretic)[3-8]、電流體(Electrofluidic) [9,10]、電濕潤(Electrowetting) [11,12] 及其他新興技術[12]。在其中又以電泳式顯示材料最受到矚目,並且已經有眾多 相關技術被成功開發,例如 E-Ink 的微膠囊型(micro-encapsulated)、SiPix 的微杯 1型(micro-cup)、以及 Fuji-Xerox 的獨立移動色微粒(independently movable colored particles, IMCP)等等。電泳顯示器具有低耗電量、高對比度、廣視角並可以自由 捲曲等特點[13,14]。隨著電泳材料的相繼開發與製程技術的改良,高階主動式全 彩化預期將主導下一代電子紙的潮流。因此,全彩電子紙所呈現的影像品質也將 成為一項重要的研究議題。本論文的研究目標是建立一套具有物理意義的全彩電 子紙顯色與混色機制之模型,並精準預測與顯色行為對應之特性化方法以及色彩 重現技術,達到良好的影像品質。
1.2 電泳顯示器基本架構
電泳顯示器的顯色原理是依靠電泳現象(Electrophoretic effect)來控制畫面 輸出的亮暗程度,電泳現象意指藉由施加橫向或垂直的電場,控制在溶液或介質 中的粒子進行物理移動。以顯示器或電子名片來說,通常會製作一層薄膜層來嵌 入油墨粒子或色料。這類顯示介面的色階或灰階可以由油墨粒子本身、溶液後方 的反射面或兩者的綜合影響來決定。一般電泳式電子紙的像素架構是由帶電荷的 粒子(單種或多種粒子)、介電流體(單色或透明)、濾光片及電極所組成,藉由包 覆在薄膜層中的粒子分布位置及介電流體的吸收率來決定該像素輸出的色階或 灰階。圖 1-2 是一個簡易的微膠囊型電泳架構示意圖,包含上下電極板、彩色濾 光片、透明介電流體及黑色與白色兩種色料。由於黑白兩色色料分別帶有相反的 極性,透過對上下電極輸入不同電壓調整垂直方向的電場,可以控制色料在微膠 囊中的上下分布位置,並依照整體的分布來決定該子像素最後出光的強度。而不 同強度的反射光透過紅色、綠色、藍色彩色濾光片會呈現不同亮暗的色場,進入 人眼後則透過視網膜後的視覺系統進行混色,進而達成電泳式電子紙全彩化的目 標。另外,在圖 1-2 的結構中除了基礎的紅、綠、藍三原色之外,還在像素組合 中加入了白色子像素來提高電子紙整體的亮度。根據色彩學理論,透過紅、綠、 藍彩色濾光片後的出射光強度即使在完美條件下,最多也只會有原始入射光的 233%,但加入一個白色子像素後就能把整個像素的總體出射光強度提高為 50%, 進而改善亮度不足的問題。 圖 1-2 電泳式電子紙架構示意圖 根據前述架構,此電泳式電子紙的混色原理可以分為兩個部分: (1) 單一子像素的灰階控制 不同灰階的出射光強度主要是藉由調整垂直電場來控制,而出射光的頻譜表 現則是根據入射光通過電泳層時被介電流體及色料吸收的程度所決定。由於 介電流體為透明溶液,我們可以將各灰階的頻譜表現視為黑白兩色色料的吸 收頻譜線性疊加後的結果[15]。而這項特性也說明了電泳式電子紙在灰階控 制的混色原理是依據減法混色系統(subtractive color mixing)的理論模型[16]。 如圖 1-3(a)所示,減法混色系統是利用入射光被紙張上不同厚度的油墨吸收 之後,依照不同色場被吸收程度的線性組合來決定最後呈現之色彩,與電子 紙的灰階特性相符合。 (2) 多個子像素加法混色 第二部分是利用各子像素的反射光穿過彩色濾光片後產生不同的色場,以並 置混色的方式達成全彩化。由於並置混色的結果可以視為反射頻譜做線性疊 加,混合的顯色結果是依據加法混色系統(additive color mixing)來決定[17-19], 如圖 1-3(b)所示。
綜合上述特性,此全彩電泳式電子紙的顯色機制中同時擁有減法混色及加
法混色原理的特性,為一個複合混色系統(hybrid color mixing)。 (a) (b) 圖 1-3 (a)減法混色系統與(b)加法混色系統混色機制示意圖
1.3 研究動機與目的
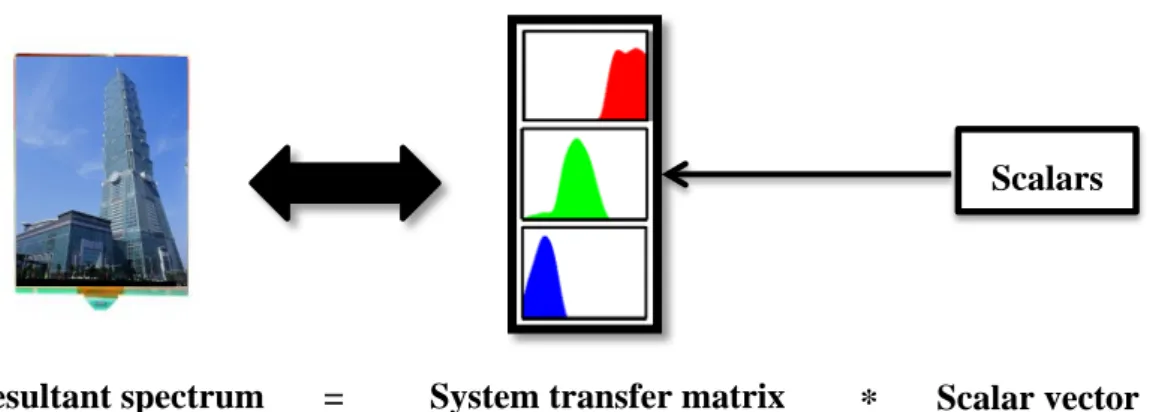
本論文最核心的目標就是建立一套電子紙的色彩特性化模型,以矩陣形式 描述全彩電泳式電子紙的顯色機制。特性化的目的在於定義電子紙色彩空間(設 備從屬色彩空間)與 CIE 色度資料(非設備從屬色彩空間)之間的轉換關係[20]。我 們希望能根據電子紙實際的顯色架構及混色原理,建構一個系統特性矩陣 (system transfer matrix),並以線性轉換的形式描述色料特性與電子紙輸出端的色 彩表現的關係,如圖 1-4 所示。藉由建立特性化模型,不但能幫助我們了解電子 紙系統的特性,也有助於未來進行色彩重建時的顏色校正。 �XY Z� = � Xr,max X𝑔𝑔,𝑚𝑚𝑚𝑚𝑚𝑚 X𝑏𝑏,𝑚𝑚𝑚𝑚𝑚𝑚 Y𝑟𝑟,𝑚𝑚𝑚𝑚𝑚𝑚 Y𝑔𝑔,𝑚𝑚𝑚𝑚𝑚𝑚 Y𝑏𝑏,𝑚𝑚𝑚𝑚𝑚𝑚 Z𝑟𝑟,𝑚𝑚𝑚𝑚𝑚𝑚 Z𝑔𝑔,𝑚𝑚𝑚𝑚𝑚𝑚 Z𝑏𝑏,𝑚𝑚𝑚𝑚𝑚𝑚 � �RG B� �DD𝑔𝑔𝑟𝑟 D𝑏𝑏 � = � 1 M𝑟𝑟⁄M𝑔𝑔 Y𝑟𝑟⁄Y𝑏𝑏 C𝑔𝑔⁄C𝑟𝑟 1 Y𝑔𝑔⁄Y𝑏𝑏 C𝑏𝑏⁄C𝑟𝑟 M𝑏𝑏⁄M𝑔𝑔 1 � �MC𝑟𝑟𝑔𝑔 Y𝑏𝑏 � 4圖 1-4 色彩特性化是以系統特性矩陣表現顯示器的混色系統 從電子紙的顯色架構來看,數位訊號會決定輸入的電壓波形,並直接影響 各子像素的灰階變化。因此在理論上可以透過分析子像素的物理特徵建立起灰階 控制的特性化模型,再進一步由單一子像素延伸到多個子像素的並置混色模型, 以達成全彩輸出影像的特性化。但在實際應用上,由於此物理模型為一個同時具 有減法混色及加法混色特性的複合混色系統,若是要直接從灰階控制延伸至全彩 的特性化必須先經過一連串頻譜轉換,而這將會產生非常複雜的特性化模型。為 了解決此問題,我們引入了獨立成份分析法(Independent component analysis, ICA) 作為解決方案。
獨立成份分析屬於盲訊號分離(Blind source separation)的其中一種特殊解 法。盲訊號分離是指在原始訊號及混合方法都未知的場合下,從多個混合訊號中 分析出無法透過觀察得到之原始訊號的方法。而獨立成份分析法則是利用線性變 換,將混合訊號分離成統計上獨立的訊號之線性組合。本研究將把電子紙的反射 頻譜作為訊號分析中的波形,並藉由獨立成份分析法得到一組直接與反射頻譜有 線性關係的特徵頻譜以建立系統特性矩陣。我們希望能透過獨立成份分析找出電 子紙的色料特性,以一個直觀的線性模型來描述複雜的複合混色系統,從而達成 全彩電子紙之色彩特性化。
Resultant spectrum = System transfer matrix * Scalar vector Scalars
1.4 章節概要
本論文共分為五個章節。經前述第一章緒論的簡介後,第二章將介紹在獨 立成份分析中使用到的理論背景。通過對這些背景知識的理解,有助於我們對獨 立成份分析的研究。 在第三章中將深入介紹獨立成份分析的演算法。首先我們會說明整個演算 法的流程,接著根據流程一一詳細敘述獨立成份分析的內容。 第四章進一步地說明我們如何應用獨立成份分析的演算法分析新型電子 紙的反射頻譜及其實驗結果。實驗分為兩個部分,第一個部分是應用於結構較簡 單的黑白微杯型電泳電子紙;第二個部分是應用於全彩微膠囊型電泳電子紙。 最後以第五章歸納本論文的結論,並說明以此方法及迄今達到的成果為基 礎,未來還可以繼續再研究的方向及課題。 6第二章
基本理論
獨立成份分析法的理論基本上可以分為定量及最佳化兩個部份。首先為了定 義何者為此系統的獨立成份,必須建立一套量測準則,定量比較獨立度的高低。 有了量測準則後,接著再依照量測準則建立能尋找具有最高獨立度的最佳化演算 法,以此決定目標系統的獨立成份。由此可知,獨立成份分析法的基礎並非只是 單一核心理論,而是由一連串理論組合而成,其中核心的部分涵蓋了線性代數、 機率與統計的理論。在詳細介紹獨立成份分析的理論之前,本章節將一一說明各 理論的背景知識及意義,其中章節 2.1~2.2 為線性代數相關理論,章節 2.3~2.7 為機率與統計相關理論,章節 2.8~2.9 為最佳化相關理論。2.1
反矩陣與廣義反矩陣
反矩陣是線性代數中解決線性問題的基本方法,其中最常見的線性問題就 是在已知矩陣 A 與向量 b 的條件下,求解 Ax=b 中向量 x 的值。在此問題中, 若已知 A 具有可逆性,此時可藉由求取 A 的反矩陣來得到 x 的唯一解 x=A-1 b。 線性代數中對反矩陣的定義為「當存在一矩陣 A-1使得 A-1 A=I 且 AA-1=I 時,則 矩陣 A 具有可逆性且 A-1為其反矩陣」。在判斷一個矩陣是否具有可逆性時,可 以由該矩陣是否滿足以下條件來檢視: i、 該矩陣必須為方陣 ii、 當一個 n*n 的方陣經過消去法(elimination)處理後必須具有 n 個係數 (pivot) iii、 對方程式 Ax=0 的唯一解只有當向量 x 為零向量的解 iv、 矩陣的行列式(determinant)值不得為零 從以上條件可以看出,當矩陣滿足可逆性的條件時,該矩陣必定為滿秩矩陣(full 7rank matrix),此時該矩陣的行向量互相線性獨立,列向量亦同。
廣義反矩陣(pseudo-inverse matrix)則是在矩陣只有部分滿足可逆性的條件 時,利用矩陣運算所達成的特殊反矩陣。廣義反矩陣的核心理論是將原本無解的 方程式投影到合適的向量空間,以求得具有最小平方誤差(least square error)的最 佳近似解。依照目標投影空間的不同,我們可以將廣義反矩陣分為左反矩陣 (left-inverse)與右反矩陣(right-inverse)。當原矩陣為滿列秩(full column rank)矩陣 時,可以將方程式 Ax=b 投影到原矩陣的列空間上: 𝐀T𝐀𝐱� = 𝐀T𝐛 (2.1) 此投影後的方程式稱為正規方程式(normal equation)。從上式可以發現等號左側 的矩陣 AT A 為滿秩矩陣,符合可逆性的條件,因此乘上反矩陣後就能得到向量𝐱� 的唯一最小平方解: 𝐱� = (𝐀T𝐀)−1𝐀T𝐛 (2.2) 由上式可以定義矩陣 A 的左反矩陣: 𝐀−1𝑙𝑒𝑓𝑡 = (𝐀T𝐀)−1𝐀T (2.3)
同理,當原矩陣為滿行秩(full row rank)矩陣時,可投影到原矩陣的行空間上得到 右反矩陣 Aright-1=AT (AAT)-1。
2.2
本徵分解與實對稱矩陣
本徵分解(eigen decomposition)的意義就如名稱所示,是為了分析矩陣特性 所發展的理論。矩陣在線性代數中可能代表一個向量空間或是線性轉換的過程, 而藉由分析矩陣的本徵向量與本徵值,能夠有效得幫助我們了解隱藏在矩陣中的 特性或是物理意義。本徵分解的理論基礎可以從不變子空間(invariant subspace) 的角度來說明,對一個線性等式 Ax=b 來說,多數的向量 x 在矩陣 A 的定義域及 值域中的方向並不一致,因此經過映射後會改變其方向形成新的向量。但某些特 定的向量經過映射後依然保有相同方向,這些向量所在的空間就是此線性等式的 8不變子空間。依照這個定義,針對這些向量的線性等式可以改寫成 Ax=λx 的形 式,其中向量 x 被稱為矩陣 A 的本徵向量,λ 則是其對應的本徵值。舉例來說, 假如要在 x-y 空間上對一條穿過原點且與 x 軸夾 45 度角的直線做反射,其線性 轉換矩陣如下所示: 𝐀 = �0 11 0� (2.4) 經過運算後可得到其本徵值及本徵向量,如下所示: 𝐀𝐱𝟏= �0 11 0� �11� = 1 ∗ �11� = 𝜆1𝐱1 𝐀𝐱𝟐= �0 11 0� �−1� =1 (−1) ∗ � 1−1� = 𝜆2𝐱2 (2.5) 從上式可以看出,對此線性轉換矩陣來說,其本徵向量分別代表了該直線的指向 向量及法向量。 圖 2-1 對直線的反射矩陣而言,其本徵向量就是該直線的指向向量及法向量 假如定義矩陣 S 為一個將所有本徵向量作為列向量所組成的本徵向量矩 陣,而Λ 為本徵值所組成的本徵值矩陣,則原本的線性等式 Ax=λx 可以改寫成 以下形式: 𝐀𝐒 = [𝐱1 𝐱2 ⋯ 𝐱𝑛] � 𝜆1 0 0 0 ⋱ 0 0 0 𝜆𝑛 � = 𝐒𝚲 (2.6) 當 A 為方正矩陣且本徵向量間彼此線性獨立時,對應的本徵向量矩陣將滿足可 逆性的條件,此時將上式中的矩陣移項就能推得矩陣 A 的本徵分解式:
P
P’
x
2x
1L
9𝐀 = 𝐒𝚲𝐒−1 (2.7) 在 本 徵 分 解 中 有 一 個 經 常 被 使 用 的 矩 陣 形 式 , 稱 為 實 對 稱 矩 陣 (real symmetric matrix)。當一個方陣中的所有元素都為實數,且其轉置矩陣與自身相 等時,該矩陣即為實對稱矩陣。由於其矩陣形式能應用於許多場合,且在本徵分 解上擁有獨特的性質,使得實對稱矩陣成為目前應用範圍最廣的特殊矩陣。假如 對實對稱矩陣做本徵分解,其本徵值及本徵向量將有以下特性: i、 實對稱矩陣的所有本徵值皆為實數,且本徵向量皆為實向量 ii、 實對稱矩陣的所有本徵向量必定互相正交 iii、 任意 n 階實對稱矩陣的本徵分解必定有 n 個標準正交本徵向 量 從以上特性可以看出,一個實對稱矩陣經過本徵分解後得到的本徵向量矩陣必定 為正交矩陣(orthogonal matrix)。由於正交矩陣的反矩陣與其轉置矩陣相等,我們 可以將公式(2.7)的本徵分解式改寫為矩陣 A 的正交對角化表示式: 𝐀 = 𝐐𝚲𝐐−1= 𝐐𝚲𝐐T (2.8) 為了與一般本徵矩陣區別,此處將正交矩陣表示為 Q。
2.3
機率論基本定義
在機率論中將一個 隨機試驗 能得到的所有結果稱為樣本空間(sample space),產生此樣本的機率來源則稱為母體(population)。母體在定義上是無法直 接描述的,只能透過統計的方式進行推論。從母體或樣本空間中抽取出的結果稱 為隨機變數(random variable)。與一般定義的變數不同,機率論中的隨機變數並 非數值而是一個函數,其定義為任意以樣本空間作為定義域的實函數。舉例來說, 假如以一個公正骰子做為母體,則其樣本空間為{1, 2, 3, 4, 5, 6}。若是考慮擲兩 個公正骰子並定義 S 代表樣本空間,X 代表由兩個骰子的和產生的隨機變數,則 S 及 X 分別有以下值: 10S = {(i, j)|i = 1, … ,6; j = 1, … ,6}
𝑋(i, j) = i + j (2.9)
此時隨機變數 X 可能的值為{2, 3, 4, …, 12}。很明顯地,在此隨機變數中每個值 出現的機率並不一樣,而描述隨機變數每個輸出值出現機率的函數就是機率密度 函數(probability density function, pdf)。以上述的例子來說,其機率密度函數 F(X) 的分佈如下圖所示: 圖 2-2 隨機變數 X 的機率密度函數 期望值(expected value)是另一個討論機率問題時經常會使用的結果,其代 表將同一個隨機試驗重複非常多次後,預期會得到的平均值。在機率論中,期望 值的定義為「試驗中所有結果乘上其發生機率的總和」。以上述的隨機變數為例, 根據每個值出現的機率,可計算得到該隨機變數的期望值: 𝐸[𝑋] = 2 ∗361 + 3 ∗362 + 4 ∗363 + ⋯ + 12 ∗361 = 7 (2.10) 其中 E 代表期望值函數。假如所有結果出現的機率都相等,此時根據期望值定
Random variable
P
robabi
li
ty
11義計算的結果就等同於該隨機變數的平均值。期望值也被用於描述一個隨機變數 的離散程度。若以期望值為基準,計算所有資料相對期望值的偏移量,其結果被 稱為該隨機變數的變異量(variance)。變異量的定義如下所示:
𝑉𝑎𝑟(𝑋) = 𝐸[(𝑋 − 𝐸[𝑋])2] (2.11)
變異量就類似於工程應用上的均方誤差(mean square error),只是均方誤差是相對 於均值,而變異量是相對於期望值,但兩者都能用來測量整組數據相對的離散程 度。
2.4
高斯分佈與中央極限定理
高斯分佈(Gaussian distribution)又稱為常態分佈,其機率密度函數的曲線 呈對稱鐘形,因此也被稱為鐘形曲線,是在機率分佈中有著重大影響力的基本模 型。假如以機率密度函數來描述高斯分佈,其表示式為: 𝑔𝑎𝑢𝑠𝑠(𝑋; µ, σ) =𝜎√2𝜋1 𝑒−(𝑋−µ)22𝜎2 (2.12) 其中μ 代表其期望值,σ2代表其變異量。在期望值及變異量已知的情形下,高斯 分佈的熵是所有已知的分布型態中最大的,這使得高斯分佈成為許多物理現象自 然的分佈形式。當期望值為零且變異量為一時,高斯分佈可以被簡化為以下形 式: 𝑔𝑎𝑢𝑠𝑠(𝑋) =√2𝜋1 𝑒−𝑋22 (2.13) 上式被稱為標準常態分佈,其函數分佈如下圖所示: 12圖 2-3 標準常態分佈之機率密度函數分佈
除了一些自然分佈型態外,高斯分佈在統計理論中也是某些情況下的極限分佈形 式,這個現象被稱為中央極限定理(central limit theorem)。
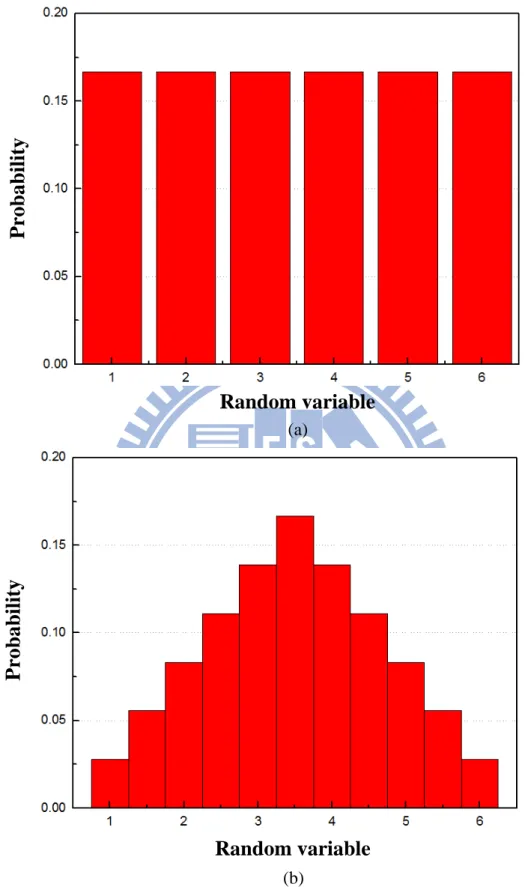
中央極限定理是機率論中一項具有舉足輕重地位的重要定理,也是數理統 計學與誤差分析的理論基礎。根據古典中央極限定理,假如從同一個母體隨機抽 取 n 個獨立隨機變數,當 n 值夠大時,將這些獨立隨機變數做平均後的分佈會近 似於高斯分佈。換句話說,任意兩個獨立隨機變數平均後的機率密度函數曲線, 將比原始變數更接近高斯分佈曲線。以骰子為例,當只有一個骰子時出現數字 1~6 的機率是相等的,但同時骰兩個獨立骰子時,其擲出點數平均後的機率分佈 函數會趨向於鐘形,如圖 2-4 所示。
Random variable
P
robabi
li
ty
13圖 2-4 多個獨立變數平均後其機率密度分佈函數將趨近於鐘形。圖為(a)一個骰子 (b) 兩個骰子擲點平均值 之機率分佈函數。
Random variable
Random variable
P
robabi
li
ty
P
robabi
li
ty
(a) (b) 142.5
共變異量與非相關性
共變異量是用於衡量兩個隨機變數間相似程度的量測工具根據定義,對任 兩個隨機變數 X 與 Y,兩者間的共變異量為: Cov(𝑋, 𝑌) = 𝐸[(𝑋 − 𝐸[𝑋])(𝑌 − 𝐸[𝑌])] = 𝐸[𝑋𝑌] − 𝐸[𝑋]𝐸[𝑌] (2.14) 從上式可以看出,變異量可以視作隨機變數與自身的共變異量,算是一種特殊情 形。共變異量的大小要視情況而定,但變異量的正負與機率密度函數有密切關係。 當兩者的機率密度函數曲線非常相似,則兩者的共變異量為正值;反之,當兩者 的曲線趨勢完全相反,則共變異量為負值。假如需要同時考慮兩組由複數隨機變 數所組成的向量的共變異量,可以將公式(2.14)改寫為共變異數矩陣的形式: Cov(𝐱, 𝐲) = 𝐸[(𝐱 − 𝐸[𝐱])(𝐲 − 𝐸[𝐲])T] (2.15) 當 存 在 兩 個 變 數 的 共 變 異 數 為 零 時 , 代 表 兩 變 數 間 具 有 非 相 關 性 (uncorrelated)。此時公式(2.14)可以改寫為以下形式: 𝐸[𝑋𝑌] = 𝐸[𝑋]𝐸[𝑌] (2.16) 對於具有非相關性的隨機變數來說,兩者間不具有任何線性關係,但不代表兩者 互相垂直。只有當兩個變數至少其中之一的期望值為零的情況下,才能稱一組互 相垂直的變數同時具有非相關性。2.6
統計上的獨立性
定義獨立性可以從很多方面著手,這裡將以機率密度函數的角度進行定義。 假如我們將變數 X 和 Y 的聯合機率密度函數(joint density function)以 F(X,Y)表示, 則 X 和 Y 各自的機率密度函數可以表示成 F(X,Y)的形式:𝐹(𝑋) = ∫ 𝐹(𝑋, 𝑌)d𝑌
𝐹(𝑌) = ∫ 𝐹(𝑋, 𝑌)d𝑋 (2.17)
獨立性的在統計上的定義為「當隨機變數間具有獨立性時,任一變數的機率分佈 不影響其他變數的機率分佈」。根據這個定義,聯合機率密度函數與獨立隨機變 數間有下列關係: 𝐹(𝑋, 𝑌) = 𝐹(𝑋)𝐹(𝑌) (2.18) 從公式(2.18),我們可以延伸出獨立性裡的一個重要特性。假如定義 H1、H2為任 意函數,且隨機變數 X、Y 具有獨立性,則可以得到下列關係式: 𝐸[𝐻1(𝑋)𝐻2(𝑌)] = ∬ 𝐻1(𝑋)𝐻2(𝑌)𝑓(𝑋, 𝑌)𝑑𝑋𝑑𝑌 = ∫ 𝐻1(𝑋)𝐹(𝑋)𝑑𝑋 ∫ 𝐻2(𝑌)𝐹(𝑌)𝑑𝑌 = 𝐸[𝐻1(𝑋)]𝐸[𝐻2(𝑌)] (2.19) 從上式可以看出,當 X 與 Y 互相獨立時,不論將兩個隨機變數經過任何函數轉 換,兩者的共變異量必定為零。 比較公式(2.16)及公式(2.19),可以發現非相關性其實是統計上的獨立性的 一個特例。非相關性只考慮了平均值及變異量的資訊,獨立性則嚴格定義兩個隨 機變數沒有隱含任何關係,在這當中還必須考慮到高階項資訊。舉例來說,假如 隨機變數(X,Y)的值為(0, 1), (0, -1), (1, 0), (-1, 0)的機率各為四分之一,則可以得到 兩變數的共變異量為 E[XY]-E[X]E[Y]=0,具有非相關性。假如考慮平方後的共變 異量,會發現 E[X2 Y2]-E[X2]E[Y2]=-0.25,並不符合前述統計上獨立性的定義。但 反過來說,只要具有獨立性就一定具有非相關性,因此許多獨立成份分析法在計 算過程中都會限制變數間有非相關性,藉此減少自由度並簡化問題[22]。
2.7
非高斯度量測準則
在獨立成份分析法中,為了找到擁有最少高斯特性的頻譜向量,必須有一 套定量的量測準則決定頻譜的高斯度。在我們的研究中選擇了峰度及負熵作為量 測準則。本章節將說明這兩種方法的理論基礎,且為了簡化問題,我們假設頻譜 向量 u 的平均值為零且變異量為一。在實際操作時為了使資料符合此假設,會先 16對資料進行前處理(preprocessing),詳細內容會在第三章進一步說明。
2.7.1
峰度
峰度(kurtosis)又稱為高階統計量量測法,是最典型的非高斯度量測準則。 峰度的定義如下: 𝑘𝑢𝑟𝑡(𝐮) = 𝐸[𝐮4] − 3{𝐸[𝐮2]}2 (2.20) 由於向量的變異量為一,公式(2.20)可以改寫為: 𝑘𝑢𝑟𝑡(𝐮) = 𝐸[𝐮4] − 3 (2.21) 峰度值在統計學中代表機率分布的曲線特性。當峰度值為正值時,曲線的峰態會 趨向高而尖的形態,稱為超高斯(super-gaussian);當峰度值為負值時,曲線的峰 態會趨向平緩,稱為亞高斯(sub-gaussian)。假如輸入的變數為高斯變數,峰度的 值為零[23]。因此,將頻譜向量 u 輸入峰度公式並取絕對值後,該峰度絕對值越 大則代表該頻譜向量的非高斯特性越強。 在確定頻譜分佈只存在超高斯態的情況下,可以忽略常數部分只考慮四階 項的最大值來簡化等式,假如定義向量 s1、s2彼此間互相獨立,則代入等式可以 得到以下線性特性: 𝑘𝑢𝑟𝑡(𝐬1+ 𝐬2) = 𝑘𝑢𝑟𝑡(𝐬1) + 𝑘𝑢𝑟𝑡(𝐬2) (2.22) 𝑘𝑢𝑟𝑡(𝛼𝐬1) = 𝛼4𝑘𝑢𝑟𝑡(𝐬1) (2.23) 其中α 為任意常數。 在獨立成份分析法的研究中,峰度經常被使用於量測資料的非高斯性,其 原因在於峰度不論是理論上或計算上都非常容易操作。然而當峰度被實際應用於 量測樣本時卻存在一些問題,其中最主要的就是峰度值非常容易受到極端值的影 響。當量測樣本中存在一些錯誤的量測值或是無關的雜訊時,即使只佔總樣本數 的一小部分也有可能極大得左右峰度的計算值[22]。換句話說,峰度並不是一個 穩定的非高斯特性量測準則。 172.7.2 負熵
在資訊理論中,當高斯變數與其他隨機變數有相同變異量時,高斯變數會 有最大的熵值。負熵就是利用此特性,藉由最大化頻譜向量與高斯函數的熵值差 異,來找到具有最大非高斯性的頻譜向量。負熵函數 J 的定義如下[23]: 𝐽(𝐮) = 𝐻(𝛎) − 𝐻(𝐮) (2.24) 其中 H 代表熵值量測函數,ν 是與頻譜向量 u 有相同變異量的高斯分佈函 數。負熵的優勢在於熵值量測在統計理論中已發展的相當完整,因此使用負熵量 測非高斯度的可信度及穩定度相當高。但缺點在於其計算相當複雜,若從定義出 發則必須要計算各參數的機率密度函數(probability density function)。因此在實際 使用上會使用近似函數取代原本負熵函數的定義。我們的研究採用函數為 Hyvärinen 所提出的近似函數[24]: 𝐽(𝐮) = k{𝐸[𝐺(𝐮)] − 𝐸[𝐺(𝛎)]}2 (2.25) 其中 k 為正值常數,G 為任意非二次函數。此近似函數在使用上的限制為 u 與ν 必須是均值為零且變異量為一的狀態,這也是在研究中獨立成份分析法在計算前 必須先經過資料前處理的原因之一。而函數 G 的選擇雖然在理論上並沒有特別 限制,但選擇恰當的函數可以提升運算速度或是運算的穩定性,且獨立成份的分 佈形式也會影響選擇不同函數時的準確性。Hyvärinen 在文章中提出了一些函數 作為選擇: 𝐺1(𝐮) = log cosh(𝐮) (2.26) 𝐺2(𝐮) = −exp (− 𝐮2� ) 2 (2.27) 當泛用性為演算上的重要考量時,G1在大多數的情況下都能有不錯的表現。當 獨立成份的分佈特性為超高斯分佈(super-Gaussian),或是當演算上需要高度穩定 性時,則 G2會是較佳的選擇。在我們的實驗中,兩種函數的表現並沒有明顯差 異,對演算法得到之獨立特徵頻譜的差異也在可忽略的範圍內。 18使用負熵近似式的優勢在於它的概念比原始的負熵定義要來得簡單明瞭, 計算的速度更是快上不少。而它也保留了一些負熵的統計特性,特別是在穩定性 的部分與峰度相較之下有顯著的提升。
2.8
拉格朗日法
拉 格 朗 日 法 (Lagrange method) 是 數 學 上 求 解 約 束 最 佳 化 (constrained optimization)時最常使用的方法。假如在尋找函數極值的過程中,此函數的變數 還同時受到一個或多個條件所限制,這個問題就被稱為約束最佳化。而拉格朗日 法的基礎是將一個有 n 個變數與 k 個限制條件的約束最佳化問題轉換成 n+k 個變 數的方程組的極值問題,其中引入的 k 個純量未知數稱為拉格朗日乘數。舉例來 說,假如需要求取函數 F(x1,x2)的極值,同時必須滿足方程式 V(x1,x2)=c,在此條 件下可以寫出對應的拉格朗日函數: 𝐿(𝑥1, 𝑥2, 𝜅) = 𝐹(𝑥1, 𝑥2) + 𝜅[𝑉(𝑥1, 𝑥2) − 𝑐] (2.28) 其中κ 代表此函數的拉格朗日乘數。而針對此函數,假如對函數的所有變數做偏 微分得到的結果皆為零,此時的解即為原函數 F(x1,x2)的極值。換句話說,函數 的極值可以透過求解下列方程組得到: ∂𝐿 ∂x1 � = 0; ∂𝐿 ∂x� 2 = 0; ∂𝐿 ∂𝜅� = 0 (2.29) 關於拉格朗日法的理論,我們可以從幾何圖形的角度來說明。如圖 2-5 所 示,考慮 F(x1,x2)的等位曲線 F(x1,x2)=di,若要使函數 F 在 V(x1,x2)=c 上有極值, 只有當其等位曲線與函數 V 相切時才可能存在。換句話說,F 與 V 的斜率必定互 相平行,此時可得到以下關係式: ∇{𝐹(𝑥1, 𝑥2) + 𝜅[𝑉(𝑥1, 𝑥2) − 𝑐]} = 0 (2.30) 其中κ 為一個非零純量值。 19
圖 2-5 虛線代表函數 F(x1,x2)之等位曲線,實線代表方程式 V(x1,x2)=c 之軌跡,箭號表 示斜率。 透過拉格朗日法,我們成功將一個約束最佳化問題轉換成計算方程式偏微 分為零的解,而接下來的問題就是該如何求得最佳解,因此我們在此引入另一套 計算方式-牛頓法。
2.9
牛頓法
牛頓法(Newton’s method)是一種近似求解的方法,利用函數的泰勒級數來 逼近方程式 F(x)=0 的解。假設函數 F(x)的軌跡如圖 2-6 所示,首先寫出函數在 x0的一階泰勒展開式: 𝑆(𝑥) = 𝐹(𝑥0) + 𝐹′(𝑥0)(𝑥 − 𝑥0) (2.31) 就幾何上來說,函數在 x0的一階泰勒展開式代表在 x0點對函數的切線。牛頓法 的核心想法就是假設當 x0為函數 F 與 x 軸的交點時,該點同時也是切線與 x 軸 的交點。令 S(x)=0 解變數 x 可得: 𝑥 = 𝑥0− 𝐹(𝑥0) 𝐹′(𝑥 0) � (2.32) 即使得到的變數不是 F(x)=0 的解,通常也會比原始的 x0更接近。只要函數的斜 率是連續的,且做為目標的零點是孤立的,則在零點周圍一定範圍內牛頓法必定 F(x1,x2)=d1 F(x1,x2)=d2 V(x1,x2)=c 20會收斂。因此可以將得到的變數重複代入公式(2.32)中,以迭代的方式逼近最佳 解: 𝑥n+1 = 𝑥n− 𝐹(𝑥n)�𝐹′(𝑥n) (2.33) 上式即是牛頓法的核心計算式。假如將拉格朗日法中得到的偏微分式做為函數代 入公式(2.33),就能夠快速得計算求解。 圖 2-6 牛頓法利用對函數做切線來得到新的點,並藉由重複此過程逼近函數的零點 S(x) x0 x1 F(x1) F(x) x 21
第三章
獨立成份分析演算法
本章節將深入介紹獨立成份分析法及分析流程。首先在 3.1 節簡略的介紹整個 分析流程的架構後,接著再根據獨立成份分析的流程逐一做介紹。雖然獨立成份 分析法的流程在得到獨立成份時便已完成,但為了建立特性化模型,還需要計算 連結系統特性矩陣與反射頻譜的係數,因此在本章節最後 3.6 節的部分會介紹如 何計算特性化模型的係數。3.1 分析流程架構
圖 3-1 特性化模型之分析及建構流程圖(1) 設定取樣點量測訊號
在現實中的物理訊號基本上都是連續訊號,例如聲波在時間域上連續、頻 譜在波長上連續。因此在進行分析之前必須先對連續訊號取樣得到離散訊號,並 表示成向量的形式才能進行線性轉換的計算。 資料前處理 設定取樣點量 測混合訊號 輸入最佳化演算法 結果是否具有最 大獨立性? 建立特性化模 型 輸出結果 是 否 22(2) 資料前處理
資料前處理的目的是簡化問題並減少運算時間。通過簡單的運算先行降低 資料複雜度,便能夠大幅得減少後續計算所需要的時間。(3) 輸入最佳化演算法
最佳化演算法的目的是尋找獨立度量測函數的最大值,以此找到具有最大 獨立性的結果。在獨立成份分析中通常會將演算法寫成遞迴式,將向量輸入演算 法後不斷重複更新參數,直到找到使量測函數有最大值的參數為止。(4) 檢查輸出結果
輸出結果的檢查是透過比較每次遞迴的輸出結果來進行。由於遞迴的結果 會逐漸趨向穩定,當遞迴式不再改變參數時,對應參數的向量就是隱藏在系統內 的獨立特徵向量。考慮我們在第一章建立的色彩特性化模型,此處得到的向量就 是系統特性矩陣中的特徵頻譜。(5) 建立特性化模型
由獨立成份分析得到系統特性矩陣後,通過計算得到能描述特徵頻譜與實 際反射頻譜間連結關係的係數,便能聯繫起設備從屬色彩空間與非設備從屬色彩 空間,建立此顯色系統的特性化模型。3.2 獨立成分分析法基本模型
獨立成份分析法是利用高階統計量及資訊理論的方式訂出非高斯性 (non-Gaussianity)或獨立度的量測準則,並以此找出觀察資料中潛在的獨立成份。 獨立成分分析主要被應用於未知訊號分離的領域,其中最典型的就是「雞尾酒會 問題」。當有一群人同時發話時,未知訊號分離能在發話者的聲音波形以及麥克 風與發話者的距離皆未知的情況下,從混合訊號重建回各個發話者原始的聲音波 23形,如圖 3-2 所示。其基本模型的建構,主要是使用統計上的潛在變數(latent variables)模型。 圖 3-2 未知訊號分離流程圖 假設我們對觀察資料依一定間隔取 m 個取樣點,並表示成 n 個潛在變數 的線性組合,則可以寫出下列線性模型: 𝐯𝑗 = 𝑐𝑗1𝐬1+ 𝑐𝑗2𝐬2+ ⋯ + 𝑐𝑗𝑛𝐬𝑛, For all 𝑗 (3.1) 其中 v 是觀察資料,s 是潛在變數且 v 和 s 皆為 m 維向量,cjn是對應的純 量係數。如果定義矩陣 V 是所有向量 v 作為行向量所組成,同理矩陣 S 是由向 量 s 組成,則公式(3.1)可以進一步改寫成: 𝐕 = 𝐒𝐂p (3.2) 其中 Cp是包含所有係數 cjn的矩陣。 公式(3.2)即是獨立成份分析法的一般模型,它描述了此系統是通過何種程 序將潛在成份混合來得到觀察資料。在這個模型中,能被直接得到的只有觀察資 料,而潛在變數和對應的係數只能透過觀察資料計算。理論上只以一條等式同時 解兩個未知數會出現無限多組解,因此在分析之前必須先設定一些前提條件來限 制潛在變數與係數的結果。 混合訊號 A 混合訊號 B 潛在訊號 A 潛在訊號 B 獨立成分 分析 線性轉換 矩陣 24
在獨立成份分析法中的第一個假設為「觀察資料與潛在成份的數量相同」, 此時的矩陣 Cp將為一個滿秩矩陣(full-rank matrix)。若定義矩陣 Bp為矩陣 Cp的 反矩陣,則可以將公式(3.2)改寫為: 𝐒 = 𝐕𝐁p (3.3) 經過改寫後,在公式(3.3)中的等式右側只留下一個未知的矩陣 Bp。假如 設計特定條件來限制向量 si的解,就能根據觀察資料與反矩陣 Bp相乘的結果找 到符合條件的矩陣 Bp。因此獨立成份分析法的第二個假設為「所有潛在成份在 統計學上獨立(statistically independent)」。為了找到在這個條件下能得到的最佳 解,必須挑選一個合適的對照函數(contrast function)作為獨立度量測準則,並依 照此量測準則找到能得到最高獨立度的最佳混合矩陣及對應的獨立成份[21]。 而根據公式(3.2)的基本模型,由於等式中的轉換矩陣與獨立成份都未知, 很明顯地獨立成份分析法具有以下兩個先天上的限制: (i) 無法得到獨立成份真實的變異量(variance) 由於 V 的值是已知的固定項,假如對獨立特徵頻譜 si乘上任一常數得到αsi, 在計算的過程中矩陣 Cp內的向量會產生相應的倒數α-1 (c1i , c2i , … , cni)將常數 抵消。因此為了加速計算,通常會將獨立成份的變異量設為 1。這樣的好處是我 們可以很容易地針對計算結果調整獨立成份的大小或是正負。 (ii) 無法得到獨立成份真實的順序(order) 同樣的,假使調整矩陣 S 內的順序,其等效於乘上一排列矩陣 P,在矩陣 Cp內也會產生相應的反矩陣 P-1,互相抵銷得到 V=CpP-1PS。因此我們無法確認 得到的獨立成份在系統內的排序或重要性。
3.3 資料前處理
在章節 2.6 中,我們提到對任一組具有統計上獨立性的隨機變數來說,該 組變數之間必定同時具有非相關性。基於這個原因,在分析觀察資料的獨立度之 25前通常會先將資料轉換成一組具有非相關性的資料,以降低自由度並加速後續運 算。資料前處理包含兩個部分,第一個部分是集中變數,使觀察資料的均值為零; 第二個部分是資料白化(whitening),使資料間具有非相關性同時變異量為零。白 化為一種利用共變異矩陣的本徵向量達成去相關性的資料處理方法。首先對觀察 資料的共變異矩陣做本徵值分解: E{𝐕T𝐕} = 𝐐𝚲𝐐T (3.4) 其中 Λ 是由本徵值組成的對角矩陣,Q 是本徵向量矩陣。從上式可以看出,此 共變異矩陣實際上是一個實對稱矩陣,分解出的本徵矩陣必定為正交矩陣,其內 部的所有行向量彼此間互相垂直。除此之外,由於前面已先做過集中變數使資料 的均值為零,因此這些本徵向量的期望值也同時為零,彼此間將具有非相關性。 換句話說,只要將原始觀察資料投影至本徵向量矩陣上,就能得到一組具有非相 關性的資料。根據上述理論所寫出的對觀察資料的白化轉換式如下所示: 𝐖 = 𝐕𝐐𝚲−12 (3.5) W 即是觀察資料經過白化轉換後具有非相關性的資料,同時各資料自身的變異 量為零。 在計算本徵分解時,由於本徵值代表資料在本徵向量上的變異量,從本徵 值的大小可以判斷該本徵向量在此觀察資料中的重要性。若本徵值為零,則代表 即使將對應的本徵向量捨棄也不會對觀察資料造成影響。因此在進行資料白化前, 我們可以利用變異量百分比(Percentage variance)檢驗需要多少本徵向量來描述 觀察資料的頻譜向量: Percentage variance = 100% ∗∑𝑘𝑖=1𝜆𝑖 ∑𝑛𝑖=1𝜆𝑖 (3.6) 其中λi是對應各本徵向量的本徵值。取得白化轉換的資料後,公式(3.3)可以改寫 成針對具有非相關性之資料尋找獨立成份的形式: 𝐔 = 𝐖𝐁e (3.7) 26
其中 Be代表對應此非相關矩陣的解混合矩陣,U 則是透過解混合矩陣得到的新 矩陣。根據非相關性的定義,只要該解混合矩陣為正交矩陣,就能保證其與非相 關矩陣相乘後的結果仍然保有非相關性: 𝐸[𝐔T𝐔] = 𝐸[𝐁 e𝐓𝐖𝐓𝐖𝐁e]=I (3.8) 而我們的目標就是找出最佳的解混合矩陣,使矩陣 U 內的向量具有最大獨立性, 此時這些向量就是組成特性化模型的系統特性矩陣之獨立特徵向量。
3.4 獨立度與非高斯度量測準則
為了尋找具有最大獨立性的特徵向量,必須有一套定量量測準則來比較不 同向量的獨立度大小。但依照統計上的獨立性定義設計量測準則的話算式會太過 複雜,作為替代,在獨立成份分析法中選擇了非高斯度作為量測基準。 之所以選擇非高斯度作為替代的量測準則,第一個原因是由於高斯分佈具 有非相關性即獨立的特性。若潛在成分的機率分佈為高斯分佈,經過資料前處理 後將會得到一組具有標準常態分佈的資料,而標準常態分布經過正交線性轉換後 其機率分佈不會有任何改變。換句話說,將存在無限多組正交矩陣可以作為解混 合矩陣求解,而我們無法得知哪一組才能得到真正的系統特性矩陣,因此這些潛 在獨立成份的機率分佈不可為高斯分佈。 而選擇非高斯度的第二個原因,是因為高斯分佈同時是混合訊號的極限分 佈型態。根據中央極限定理,當存在足夠多的獨立隨機變數時,其累加結果的機 率分佈最終將趨向於高斯分佈。換句話說,將任兩個獨立的隨機變數線性組合後, 新變數的分布狀態會比原始的獨立隨機變數有更多高斯特性。由此可知,在公式 (3.2)中任意獨立的潛在成份混合後產生的觀察資料必定具有一定程度的高斯特 性。若將公式(3.2)代入公式(3.7),則可以得到下列關係式: 𝐔 = 𝐒𝐂p𝐁e (3.9) 根據理論,任何獨立成份的線性組合都會提升高斯性,因此要使向量 u 有最低高 27斯性的解必須使其與潛在獨立成分沒有線性組合關係,換句話說,向量 u 自身就 是系統的獨立成份。 基於上述理論,在獨立成份分析中通常會選擇非高斯性的量測準則取代獨 立性,並藉由最大化向量的非高斯性來尋找最合適的解混合矩陣及獨立成份。在 眾多非高斯度量測準則中,峰度及負熵都是經常被使用於獨立成份分析的測量工 具。峰度的優點在於其背景理論較為直觀、公式複雜度低且帶有線性特性,這些 性質使得峰度能很方便得使用於大多數情況。但峰度的缺點在於其穩定性較低, 容易受到少量極端值的影響而改變獨立成份分析的結果。負熵則是源於統計學中 已發展成熟的熵值量測理論,因此在穩定性上具有很高的可信度。雖然負熵公式 較為複雜,但透過近似式簡化能大幅減少計算複雜度,同時保有一定程度的穩定 性。
3.5 最佳化演算法
決定量測準則後,還需要通過計算量測函數的極值,並以此找到具有最大 非高斯性的訊號。在 2.7 節中我們介紹了峰度及負熵的量測公式,若將公式(3.7) 得到的未知矩陣 U 代入量測公式中,並進一步建立最佳化演算法,就能夠找到 使向量具有最大非高斯性的解混合矩陣。由於矩陣 U 內的向量期望值為零且變 異量為一,代入峰度及負熵的量測公式後公式中的 E[u2 ]及 E[G(v)]部分都是常數, 因此可以將原始公式簡化為尋找下列公式的極值: 𝐾(𝐮𝑖) = 𝐸[𝐺(𝐮𝑖)] = 𝐸[𝐺(𝐖𝐛𝑖)] (3.10) 若選擇峰度作為量測準則,則 G(u)=u4;若選擇負熵作為量測準則,則 G(u)可以 是公式(2.26)或(2.27)其中之一。由於我們在尋找最大非高斯性的過程中限制了向 量必須具有非相關性,因此演算法中必須包含限制條件 E[(Wb)2 ]=||b||2=1,依照 定義可以得到對應的拉格朗日函數: 𝐿(𝐛𝑖) = 𝐸[𝐺(𝐖𝐛𝑖)] − 𝜅(‖𝐛𝑖‖2− 1) (3.11) 28其中κ 為拉格朗日乘數。依照定義,當有極值時函數的偏微分為零: 𝐸[𝐖T𝐺′(𝐖𝐛 i)] − 𝜅𝐛i = 0 (3.12) 由於κ 是未知常數,我們將計算中額外產生的常數直接併入 κ 內。從上式可以看 出,當函數有極值時拉格朗日乘數的值如下所示: 𝜅 = 𝐸�𝐛0T𝐖T𝐺′(𝐖𝐛0)� (3.13) 其中 b0代表能使拉格朗日函數有極值的解,對應的獨立向量將具有最大非高斯 性。為了找到公式(3.12)的解,我們利用牛頓法逼近最佳解,並寫出以下遞迴式: 𝐛𝑖+ = 𝐛𝑖 − {𝐸[𝐖 T𝐺′(𝐖𝐛 i)] − 𝜅𝐛i} {𝐸[𝐖𝐖T𝐺′′(𝐖𝐛i)] − 𝜅} � (3.14) 其中 bi+代表每次遞迴後得到的新向量。上式即為基本的非高斯性最佳化演算法, 理論上依照公式做遞迴求解就能得到具有非高斯性的獨立成份。但公式(3.14)太 過複雜,重複遞迴將需要冗長的運算時間,因此我們參考 Hyvärinen 所提出的快 速定點演算法(fast fix-point algorithm)對公式進行優化[24]。首先,由於矩陣 W 具有非相關性,因此可以對公式(3.14)的分母部分做以下近似: 𝐸[𝐖𝐖T𝐺′′(𝐖𝐛 i)] ≈ 𝐸[𝐖𝐖T]𝐸[𝐺′′(𝐖𝐛i)] = 𝐸[𝐺′′(𝐖𝐛i)]𝐈 (3.15) 其次,Hyvärinen 對公式(3.14)乘上κ- E[G’’(Wbi)]做進一步簡化: 𝐛𝑖+ = 𝐸[𝐖T𝐺′(𝐖𝐛i)] − 𝐸[𝐺′′(𝐖𝐛i)]𝐛i (3.16) 上式即為快速定點演算法向量形式的基本遞迴式,只要輸入初始向量並重複將結 果輸入遞迴式,當輸出結果不再改變時就代表已收斂到最佳解。但在我們的演算 法中必須找到複數個獨立成份,若是將向量一個個輸入遞迴式可能會產生重複的 結果,因此需要將基本遞迴式擴充為矩陣形式,並且對每輪遞迴的輸出結果做去 相關性來修正收斂方向: 𝐁𝑒+ = 𝐸[𝐖T𝐺′(𝐖𝐁e)] − 𝐸[𝐺′′(𝐖𝐁e)]𝐁e 𝐁𝑒∗ = 𝐁𝑒+(𝐁𝑒+T𝐁𝑒+)−1 (3.17) 其中 Be*代表經過去相關性的最終輸出結果。公式(3.17)即為獨立成份分析法的最 29
佳化演算法。將初始矩陣輸入遞迴式後,重複遞迴直到收斂至穩定結果,再將輸 出的解混合矩陣代回公式(3.7),就能得到系統的獨立成份。另一方面,這些獨立 成份在電子紙模型中代表系統的特徵頻譜,也就是構成特性化模型的系統特性矩 陣。
3.6 建立特性化模型
求得系統特性矩陣後,下一步是找到重建反射頻譜時各特徵頻譜對應的係 數,再藉以建立特性化模型。由於獨立特徵頻譜的均值為一且變異量為零,在重 建頻譜時我們會先對反射頻譜的均值及變異量作相同處理,並建立標準特性化模 型: 𝐫� = 𝐔 𝐜 (3.18) Where 𝐫 = 𝐫̅ + 𝜎𝑟𝑟𝐫� (3.19) 其中 r 代表電子紙的反射頻譜,𝐫̅代表反射頻譜的平均值,σr代表反射頻譜的變 異量,𝐫�代表標準化的反射頻譜,c 代表對應各特徵向量的純量值所組成的向量。 由於特徵頻譜彼此間互相獨立,此特徵頻譜矩陣為滿列秩矩陣,因此純量向量內 的係數將可以通過廣義反矩陣估計: 𝐜 = (𝐔𝐔T)−1𝐔𝐫� (3.20) 有了系統特性矩陣及對應的純量向量,就可以建立完整的電泳式電子紙之色彩特 性化模型,將電子紙畫面表現的反射頻譜改寫成獨立特徵頻譜的線性組合。 30第四章
實驗及分析
為了驗證此特性化模型的效果及準確性,我們設計了一系列實驗流程來檢驗 此模型對於新型電泳式電子紙的分析結果,以及利用其分析成果所重建的頻譜與 實際頻譜色彩上的差異程度。針對前述研究方法中所建立的特性化模型,我們使 用 CIEDE2000 來評估預測值與量測值之間的誤差。由於人眼對色差的辨識能力 大約是以ΔE00=1 為分界,若是實驗得到的ΔE00<1,則代表我們所提出之特性化 模型具有足夠的準確度。4.1 實驗設置
在量測儀器的設置方面,我們所使用的分光光譜幅度計型號為 TOPCON® SR-UL1R,在亮度 0.005~3000 cd/m2的範圍內亮度量測準確率為+-2%,色度量測 準確率為+-0.002。實驗時幅度計設置在電子紙平面的垂直方向,量測範圍為張 角兩度的圓形區域。實驗使用的標準光源為 CIE illuminant F7,以 45 度角入射電 子紙表面,整體配置如圖 4-1 所示。 圖 4-1 實驗儀器配置示意圖 31為了提高實驗數據的穩定性及準確度,每個數據都是經過五次量測後,取 五個數據平均值做為實驗數據。在實驗樣本的部分,首先會將模型套用於黑白微 杯型電泳電子紙,由於其結構較為單純,可以很容易地比較分析結果與電子紙實 際結構之間是否有連結關係,以此檢驗模型的可行性。接著會將其套用於較複雜 的全彩微膠囊型電泳電子紙建立色彩特性化模型,以實現我們重建全彩顯色機制 及其表現之全彩頻譜的目標。
4.2 實驗流程架構
圖 4-2 實驗分析流程圖 在實驗流程的部分,首先我們會量取一組作為訓練組的頻譜資料,用來分 析電子紙的色料特性。依照在第三章說明過的分析流程,首先對資料進行前處理 轉換成具有非相關性的資料,同時由變異量百分比篩選影響力較小的資料並移除。 前處理完成後將資料輸入最佳化演算法計算獨立特徵頻譜,並以此建立特性化模 型。為了檢驗此特性化模型的準確性,實驗中會另外量取一組頻譜資料作為測試 組,並計算由特性化模型重建之頻譜與實際頻譜之間的色差值。 資料前處理 量取訓練組 獨立成份分析 量取測試組 計算色差 重建頻譜 建立特性化模型 324.3 樣本一:黑白微杯型電泳電子紙
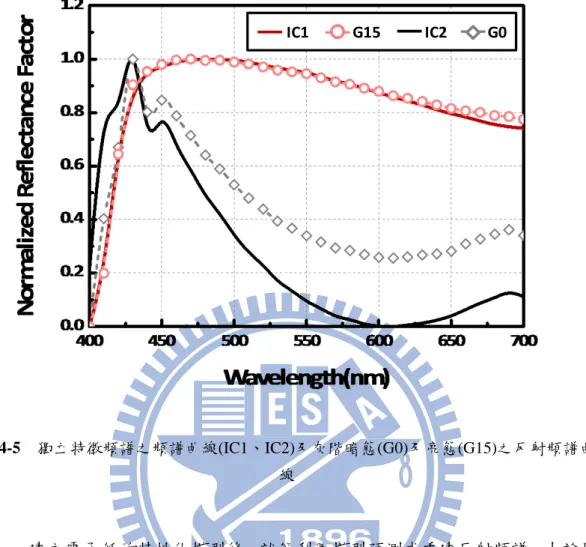
實驗中選擇的第一個樣本是九吋大小的黑白微杯型電泳式電子紙,其結構 如圖 4-3 所示,包含聚合物材質的微杯、透明電泳液及帶有相反極性的黑白色料。 藉由調整上下電極板的電壓,可以使每個獨立像素表現出 16 種灰階。由於在實 際操作時輸入的電壓為交流電,微杯中的色料會隨著電壓變化鬆散分布,而不是 圖 4-3 所描繪的緊密堆積成色料層,因此黑白色料的混合結果很難以一個直觀的 物理模型描述。我們希望利用此種較為單純的黑白樣本,檢驗由獨立成份分析法 所建立的電泳式電子紙之特性化模型是否具有足夠的可靠性。從圖 4-3 的結構可 以發現對於此微杯型電泳電子紙來說,其灰階的變化主要來自黑白色料的頻譜表 現混合結果,可以預期系統特性矩陣內會有兩個主要特徵頻譜決定畫面呈現的灰 階頻譜。 圖 4-3 黑白微杯型電泳電子紙結構示意圖 我們根據前述實驗步驟,量測 16 個灰階的反射頻譜並輸入獨立成份分析 流程,以此找到足以代表電子紙的系統特性矩陣並建立色彩特性化模型。在計算 變異量百分比時,我們發現只要取兩個特徵向量,變異量百分比便已超過 99%, 如圖 4-4 所示。因此我們判斷只需要兩個獨立特徵頻譜就能代表系統的頻譜表現, 此分析結果也符合我們前述的預期結果。 33圖 4-4 取 1 至 4 個本徵向量之變異量百分比 而此黑白電泳電子紙經過獨立成分分析後得到的兩個獨立特徵頻譜,其頻 譜經過正規化的表現如圖 4-5 所示(IC1 與 IC2)。在此黑白樣本中,我們發現使用 前面介紹的所有非高斯度量測準則都會收斂到相同的獨立成份,在遞迴次數上也 沒有明顯差異,顯然使用不同的量測準則並不影響我們分析此黑白樣本的獨立特 徵頻譜。為了更進一步探討獨立特徵頻譜的物理意義,我們將灰階中的最暗態(G0) 及最亮態(G15)的反射頻譜正規化後加入圖 4-5 中比較。其中 IC1 與 G15 的曲線 幾乎完全相同,這表示 IC1 可以被視為子像素中白色色料的色彩表現。另一方面, 從圖 4-5 中可以看出 IC2 頻譜表現的整體強度比 G0 要來得小。由於在電子紙在 實際操作時色料是鬆散分布,且實際結構上白色色料的顆粒比黑色色料大,因此 即使利用電極板將黑色色料控制在溶液上層,其分布密度依然無法完全遮蓋白色 色料的反光而會產生漏光的情形。基於這個原因,我們認為 IC2 的頻譜曲線比起 代表暗態的零階頻譜,更真實地反映了黑色色料的頻譜表現。 34
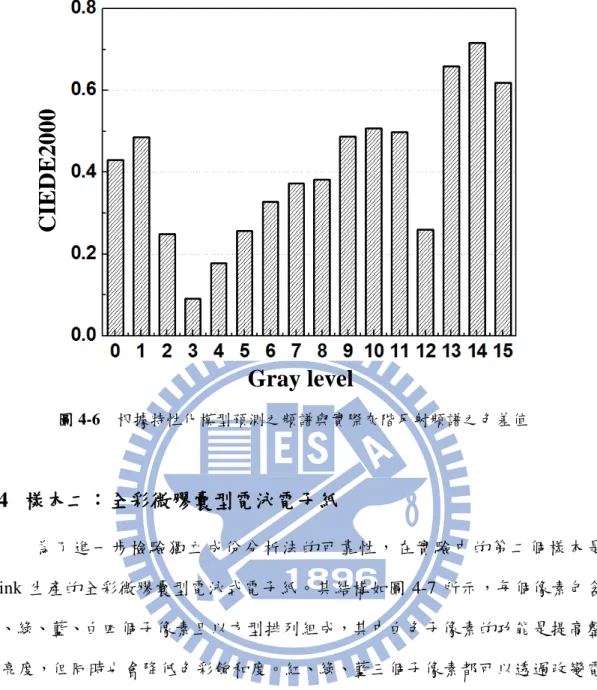
圖 4-5 獨立特徵頻譜之頻譜曲線(IC1、IC2)及灰階暗態(G0)及亮態(G15)之反射頻譜曲 線 建立電子紙的特性化模型後,就能利用模型預測或重建反射頻譜。由於黑 白電子紙只能表現出 16 個灰階,因此在這裡依然是使用灰階頻譜作為樣本。如 章節 3-6 所述,我們透過找到每個灰階對應特徵頻譜的係數,從而實現灰階反射 頻譜的重建,並且以 CIEDE2000 評估與實際反射頻譜的差異,其結果如圖 4-6 所示。平均的 CIEDE2000 色差值為 0.4,且每個灰階單獨的色差值都在 1 以下, 符合我們設定的評估標準。由此可知,對於具多重色料之黑白微杯型電泳式電子 紙,其隱含的色料表現可利用獨立成份分析法來尋找系統特性矩陣,且分析結果 具有相當的可靠性。 IC1 G15 IC2 G0 35
圖 4-6 根據特性化模型預測之頻譜與實際灰階反射頻譜之色差值
4.4 樣本二:全彩微膠囊型電泳電子紙
為了進一步檢驗獨立成份分析法的可靠性,在實驗中的第二個樣本是 E-ink 生產的全彩微膠囊型電泳式電子紙。其結構如圖 4-7 所示,每個像素包含 紅、綠、藍、白四個子像素且以方型排列組成,其中白色子像素的功能是提高整 體亮度,但同時也會降低色彩飽和度。紅、綠、藍三個子像素都可以透過改變電 壓表現出 16 種灰階,一共可以產生 4096 種顏色。 圖 4-7 E-ink 所生產的全彩微膠囊電泳式電子紙架構示意圖Gray level
C
IE
D
E
20
00
36在分析樣本時,我們設定灰階強度為 0, 3, 6, 9, 12, 15,以紅、綠、藍三個 子像素組合產生 216 個頻譜資料作為訓練組資料。依照實驗流程先對資料做前處 理再計算變異量百分比,其結果如圖 4-8 所示。由於變異量百分比在取到第四個 特徵向量時便超過 99%,我們判斷在此系統中一共隱含了四個獨立特徵頻譜。 圖 4-8 取 1 至 6 個本徵向量之變異量百分比 依照實驗流程,經過獨立成份分析後一共會得到四個獨立特徵頻譜 (IC1~IC4),如圖 4-9 所示。與第一個黑白樣本相同,使用前述所有非高斯度量測 準則依然會收斂到相同的獨立成份,在遞迴次數上也沒有明顯差異,這表示即使 是針對較複雜的全彩系統,使用不同的量測準則並不會影響我們分析樣本的獨立 特徵頻譜。圖 4-9 中第一個特徵頻譜表現的是灰階強度變化,其頻譜走向顯示出 反射頻譜的強度變化是由紅、綠、藍三個子像素所共同決定。剩下的三個獨立特 徵頻譜則表現了此顯示系統的色彩變化,在每個特徵頻譜內都有一組對立的頻譜 波段對應一組互補色。舉例來說,第二個特徵頻譜涵蓋了長波段區域(標示為 R) 以及互補的波段區域(標示為 C),因此第二個特徵頻譜所描述的是量測資料中偏 37
紅色及偏青色表現。而第三及第四個特徵頻譜也是類似的情形。由這四個特徵頻 譜的線性組合便能描述此全彩電子紙的反射頻譜特性以及呈現出的色彩表現。 圖 4-9 全彩微膠囊形電泳式電子紙樣本之第一到第四特徵頻譜(IC1~IC4) 我們的實驗中一共量測了兩組測試組資料來檢驗由獨立成份分析法建立 的色彩特性化模型的準確性。第一組資料為「全色域資料」,以等間隔挑選紅、 綠、藍的灰階值並組合形成 5*5*5 的取樣範圍來涵蓋此電子紙能表現的色域。我 們挑選的灰階值分別為 3、6、9、12、15。第二組資料為「暗態資料」,只挑選 最 弱 三 個 灰 階 值 的 組 合 形 成 27 個 暗 態 取 樣 頻 譜 。 實 驗 的 結 果 同 樣 使 用 CIEDE2000 計算色差值並將結果整理後列於圖 4-10 與表 4-1 中。針對兩組不同 的資料,此色彩特性化模型在預測上都有極佳的精確度,有超過半數的重建頻譜 與原始頻譜的色差值在 0.2 以下,所有取樣點中最大的色差值也僅僅只有 0.37。 此驗證結果足以證明,我們所提出利用獨立成份分析法所建立之色彩特性化模型, 能有效且精確地描繪具多重色料之全彩微杯型電泳式電子紙,完成具有可純量化 及可逆性的線性矩陣轉換關係式。 38
圖 4-10 針對(a)全色域資料與 (b)暗態資料的色差分布統計結果,橫軸代表色差分布區 間,縱軸代表數量。 ΔE00 均值 標準差 最大值 全色域資料 0.11 0.07 0.37 暗態資料 0.18 0.04 0.24 表 4-1 色彩特性化模型預測準確度表現(ΔE00)
4.5 實驗成果討論
根據實驗結果,黑白微杯型電泳式電子紙經過獨立成份分析一共會得到兩 個獨立頻譜,分別表現了黑白色料的反射頻譜;而全彩微膠囊型電泳式電子紙經 過獨立成份分析一共會得到四個獨立頻譜,分別表現了灰階強度變化及紅、綠、 藍的顏色變化。這證實了使用獨立成份分析法分析反射頻譜能夠得到電子紙的特 徵頻譜,且特徵頻譜能夠表現出電子紙混色機制的特性。 在做最佳化演算法時,無論是使用峰度還是負熵都會收斂到相同的特徵頻 譜,遞迴次數也都在 20 次以下。我們認為是因為電子紙的頻譜表現較為穩定, 且頻譜曲線與電子訊號不同,不太會有明顯的雜訊或外加因素使波形產生大幅變 (a) (b) 39化,所以峰度會受到少數離峰值影響的缺點沒有被凸顯出來。 在使用獨立成份分析法得到的系統特性矩陣重現頻譜時,黑白電子紙樣本 測試資料的平均色差值為 0.4,全彩電子紙樣本的兩組測試資料平均色差值分別 為 0.11 及 0.18。但不論是黑白樣本還是全彩樣本,所有測試資料的色差值都在 1 以下,符合我們所設定的標準。這代表使用獨立成份分析所建立的色彩特性化模 型具有相當的可靠性,做為樣本的電泳式電子紙其反射頻譜可以被表示成獨立特 徵頻譜的線性組合。 40