國立臺中教育大學資訊工程學系碩士班
碩士論文
指導教授:李宜軒 教授
低頻聽覺訊息對人工電子耳使用者
在噪音環境之影響
A Study of Low Frequency Acoustic Information for
Cochlear Implant Users with Background Noise
研究生:黃柏誠 撰
This thesis would like to pay tribute to all those who provided assistance. Thanks for their guidance, support and encouragement.
I
摘要
近年來許多研究發現,雖然人工電子耳使用者在安靜環境下有不錯的聽辨表現,但在噪 音環境下,由於人工電子耳裝置僅傳遞時域上的振幅包洛線索,導致使用者缺乏頻域線索, 進而嚴重影響使用者在噪音中聽辨目標語音。對於僅在單側裝置人工電子耳的使用者,透過 在對側耳配戴助聽器來提供低頻聽覺訊息,能夠有效提升其在噪音環境下的聽辨表現。推測 是因為低頻聽覺訊息能幫助使用者分離目標語音與噪音。本研究透過人工電子耳語音編碼器 (vocoder)進行聽覺實驗,探討在噪音環境下低頻聽覺訊息對人工電子耳使用者聽辨國語語音 的影響。實驗一的結果顯示,受測者雙耳分別聽取人工電子耳語音與低通濾波語音時能顯著 提升聽辨率。當噪音對人工電子耳干擾較大時,低頻聽覺訊息依舊能讓受測者維持一定的聽 辨表現。然而在此實驗中,並未觀察到雙耳聽覺中的靜噪效應(squelch effect)與雙耳總和效應 (binaural summation effect)。顯示出低頻聽覺訊息並非直接提供語音線索於受測者,而是藉由 提供低頻的頻域線索,進而提升受測者於噪音中聽辨目標語音的能力。實驗二藉由自相關演 算法對目標語音進行基頻提取,以探討基頻對於人工電子耳使用者在噪音環境下聽辨國語語 音的影響。當受測者雙耳分別聽取人工電子耳語音與基頻線索時能顯著提升聽辨率,且與低 頻聽覺訊息相比並未達統計上的顯著差異,顯示出目標語音的基頻為低頻訊息中最主要的聽 辨線索。實驗三探討在變動噪音(fluctuating masker)環境下低頻聽覺訊息對於人工電子耳使用 者聽辨國語語音的影響。結果顯示,低頻聽覺訊息能夠幫助受測者聽辨變動噪音中振幅能量 較小,因而產生較少遮蔽效應的語音區段。進而提升受測者在變動噪音環境中聽辨目標語音 的能力。綜合以上結果,對於人工電子耳使用者提供低頻聽覺能有效提升其在噪音環境下的 語音聽辨表現。 關鍵詞:人工電子耳,低頻聽覺訊息,雙模式聽覺,聽覺實驗II
Abstract
Recent studies have reported speech intelligibility in noisy environment from cochlear implant (CI) users was reduced; due to the CI device only deliver the temporal envelope information, thus eliminated the spectral resolution. For the user who had only implanted one CI in unilateral ear, combined a hearing aid in contralateral ear can improved the speech perception. This is partly true due to the residual low frequency acoustic information provided from hearing aid, can help CI users to segregation the target speech from noise. In this study, vocoder was conducted to evaluate the effect of speech recognition in Taiwanese Mandarin between CI users with and without low frequency acoustic information provided in noise. In experiment 1, result indicates that addition of low frequency acoustic information can significant enhanced the speech intelligibility. When CI was severely interfered by noise, the binaural hearing effect led performance in speech recognition improves to an average level. However, squelch effect and binaural summation effect were not observed, suggested that low frequency acoustic information provided a monaurally based glimpsing and grouping mechanism in speech perception. In experiment 2, the fundamental frequency (F0) of target speech was extracted by using autocorrelation function, to address the contribution of F0 within low frequency region. When comparing to low frequency acoustic information, the result demonstrated that F0 was the main factor in low frequency acoustic information. However, low frequency acoustic information seems contain other robust cues. In experiment 3, the masking release from fluctuating masker in CI users was evaluated. The result shows that low frequency acoustic information increased the masking release, suggested it can aid listener to fuse the glimpsed target speech into a coherent speech stream. These outcomes revealed the important implications for unilateral CI users with residual hearing has the potential to provide substantial benefit in speech intelligibility, when combined with a hearing aid in contralateral ear.
Keywords: cochlear implant (CI), low frequency acoustic information, Bimodal stimulation, normal hearing experiment
III
Table of Contents
Chinese Abstract ... I English Abstract ... II Table of Contents ... III List of Figures ... V 1. Introduction ... 1 1.1 Hearing Impaired ... 1 1.2 Hearing Devices ... 3 1.2.1 Hearing Aids ... 3 1.2.2 Cochlear Implants ... 4
1.3 Motivation and Objectives ... 7
1.4 Organization ... 10
2. Related Work ... 11
2.1 Bimodal Stimulation ... 11
2.2 The Role of Fundamental Frequency ... 14
2.3 Masking Release ... 19
3. Method and Results ... 22
3.1. Materials and Equipment ... 22
3.1.1 Taiwanese Mandarin Material ... 22
3.1.2 Masker ... 23
3.1.3 Vocoder ... 24
3.1.4 Head-Related Transfer Functions... 25
3.2 Experiment 1a ... 26
3.2.1 Subjects and Stimuli... 26
3.2.2 Procedure ... 26
3.2.3 Results ... 28
3.3 Experiment 1b ... 30
3.3.1 Subjects and Stimuli... 30
3.3.2 Procedure ... 30
3.3.3 Results ... 31
3.4 Experiment 2 ... 32
3.4.1 Subjects and Stimuli... 32
3.4.2 Procedure ... 32
3.4.3 Results ... 34
IV
3.5.1 Subjects and Stimuli... 36
3.5.2 Procedure ... 36 3.5.3 Results ... 37 4. Discussion ... 39 4.1 Experiment 1 ... 39 4.2 Experiment 2 ... 48 4.3 Experiment 3 ... 52 4.4 General discussion ... 56
5. Conclusions and Future Work ... 61
References ... 64
Appendix A Mandarin Speech Perception in Noise ... 74
Appendix B Word Recognition Materials for Native Speakers of Taiwanese Mandarin ... 80
Appendix C Results of Experiment 1a ... 81
Appendix D Results of Experiment 1b ... 89
Appendix E Results of Experiment 2 ... 93
V
List of Figures
Figure 1.1 Anatomical structures in ears ... 2
Figure 1.2 The frequency-spatial arrangement in the human cochlea ... 2
Figure 1.3 An overview of the components of the cochlear implant ... 5
Figure 1.4 Schematic diagram of implanted electrode array ... 6
Figure 2.1 The attenuation and distortion factor in Plomp‟s model ... 15
Figure 3.1 The conceptual view of vocoder ... 25
Figure 3.2 The source angle of incidence in experiment 1a and 1b ... 27
Figure 3.3 The listening mode in experiment 1a and 1b ... 28
Figure 3.4 The performance of speech recognition of experiment 1a ... 29
Figure 3.5 The performance of speech recognition of experiment 1b ... 31
Figure 3.6 The listening mode in experiment 2 ... 34
Figure 3.7 The performance of speech recognition of experiment 2 ... 35
1
1. Introduction
1.1 Hearing Impaired
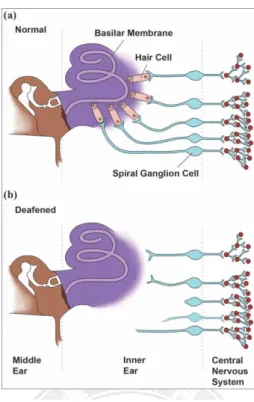
According to World Health Organization (WHO) figures, 360 million people worldwide have moderate to profound hearing loss (328 million adults and 32 million children) as of February, 2013 [1]. Hearing loss is definded as when there is diminished sensitivity to the sounds normally heard, while deafness refers to a degree of impairment such that a person is unable to understand speech even in the presence of amplification. The causes of hearing loss and deafness can be divided into congenital causes and acquired causes. Congenital causes lead to hearing loss being present at or acquired soon after birth. Hearing loss can be caused by hereditary and non-hereditary genetic factors or by certain complications during pregnancy and childbirth, including: (1) maternal rubella, syphilis or certain other infections during pregnancy; (2) low birth weight; (3) a lack of oxygen at the time of birth; (4) inappropriate use of ototoxic drugs during pregnancy; and (5) severe jaundice in the neonatal period, which can damage the hearing nerve in a newborn infant. Whereas, acquired causes can lead to hearing loss at any age, including: (1) infectious diseases; (2) chronic ear infection; (3) head injury or injury to the ear; (4) excessive noise; and (6) age-related hearing loss. These two causes of hearing loss can be categorized into two main types. The first type, conductive hearing loss, is caused by defects in the outer and middle ear, which reduce transmission of sounds to the inner ear. The second type, sensorineural hearing loss, is the most common type of hearing loss and arises from defects in the inner ear, or the auditory nerve. Sensorineural hearing loss is usually the result of degeneration of the hair cells of the organ of Corti in the cochlea. Figure 1.1 shows the absence of sensory hair cells in the (a) normal and (b) (totally) deafened ears. Figure 1.2 shows different frequencies lead to different traveling wave which located of the maximal
2
Figure 1.2 The frequency-spatial arrangement of audio peak responses in the human cochlea. Reprinted from [3].
Figure 1.1 Anatomical structures in (a) normal and (b) deafened ears. Note absence of sensory hair cells in (totally) deafened ear. For simplicity, illustrations do not reflect details of structures or use consistent scale
3
amplitude at different placement along basilar membrane (BM). The basal regions along the BM, which are tuned to high frequencies in the auditory input, are generally most affected. Hearing loss is commonly described in terms of reduced sensitivity to low-level sounds. However, damage to the hair cells not only elevates absolute thresholds, but also reduces the frequency selectivity of the system [3].
Even though the degree of hearing loss generally varies with frequency, its severity is commonly described in terms of an overall degree of hearing loss. A common way to quantify the severity of hearing loss is in terms of the pure tone average (PTA), in which absolute thresholds for pure tones (500, 1000, 2000 Hz) are averaged over the frequencies. The following classification system is often used: slight (16 - 25 dB HL), mild (26 - 40 dB HL), moderate (41 - 55 dB HL), moderately severe (56 - 70 dB HL), severe (71 - 90 dB HL), and profound hearing loss (>91 dB HL) [4]. Listeners who have profound hearing loss are also referred to as deaf. In this thesis the term „hearing loss‟ will be taken to mean sensorineural hearing impairment which caused by damage to the hair cells in the cochlea, and focuses on the hearing impaired person with severe to profound hearing loss who must has been implanted to restore the hearing.
1.2 Hearing Devices
Hearing loss caused by cochlear damage is permanent. Hearing impaired (HI) listeners can, however, use hearing devices to aid auditory perception and restore the hearing. Two main types of hearing devices that exist are cochlear implants (CIs) and hearing aids (HAs)
1.2.1 Hearing Aids
Hearing aids (HA) are devices that delieve the amplified sound to user. They are only useful when a region of hair cells in the cochlea is still intact and some residual hearing remains. In the
4
case of severe to profound hearing loss residual hearing is often limited to a small frequency range, for example only up to about 1 kHz. Only the frequencies within this range can be usefully amplified. For individuals with dead regions towards the base of the cochlea, amplification of high frequencies is reported to sound distorted or noise-like [3]. The parameters of the HA are in this case set to attenuate rather than amplify high frequencies.
One of the biggest challenges concerning amplification of sound for people with hearing impairment is loudness recruitment. Absolute thresholds are elevated, whereas the level of uncomfortable loudness remains the same. The dynamic range of people with hearing loss is thus reduced. If all sounds were amplified to the same degree, high level sounds would be uncomfortably loud. Several strategies have been developed to compensate for loudness recruitment. The most commonly used strategy in current HAs is automatic gain control (AGC). This strategy reduces the dynamic range of the signal by means of compression. A wide range of levels at the input is compressed into a smaller range at the output and low-level sounds are amplified more than high level sounds.
An important aspect of HA designs, especially with respect to the perception of speech in noise, is the microphone. Many HAs have omnidirectional microphones that amplify sounds from all directions to the same degree. Directional microphones, on the other hand, are more sensitive to sounds that come from a particular direction. An important benefit of this type of microphone is that it can improve the signal-to-noise ratio (SNR) and thereby aid perception of speech in noisy environment.
1.2.2 Cochlear Implants
People with severe to profound hearing loss in both ears, who do not benefit sufficiently from HAs, may be provided with a CI which is a prosthetic device can partly restore hearing. The
5
device rely on electric current to stimulates the auditory nerve directly via an electrode array which implant into the cochlea, thus bypassing malfunctioning parts of the outer, middle and part of the inner ear. In 1957, Djourno et al. reported a sense of environmental sounds, which was the first device for electric stimulation of the auditory nerve. However, speech could not yet be perceived [5]. The first commercial implant was developed in the 1980s. The House-3 M single electrode implant was developed in 1984 and had several hundred users [6].
Since the 1980s several different CIs have been developed, but all have certain features in common, including: (1) a microphone that picks up the acoustic signal; (2) a signal processor that converts the input signal into a waveform appropriate for electrical stimulation; (3) an external transmission system and an internal receiver which are connected by means of a transcutaneous link and are responsible for the transmission of the electric signal to (4) multiple electrodes inserted into the cochlea [7-8]. Figure 1.3 provides an overview of the components of the CI. The electrode array
Figure 1.3 An overview of the components of the CI. Reprinted from Medical Electronics GmbH, of Innsbruck, Austria.
6
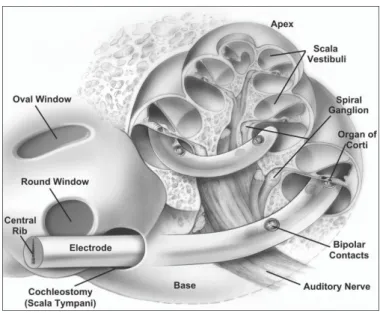
is usually implanted in the scala tympani, which is located close to the auditory nerve, as figure 1.4 shows. The stimulator is connected to the electrodes and transmits the electrical signals to the appropriate electrodes. The mapping between the channels generated by the signal processor and the electrode array is fixed.
The electrodes near the base of the cochlea convey the high frequencies and the electrodes nearest the apex the low frequencies. The number of implanted electrodes varies among different designs, but is usually between 12 and 22 [9]. The electrodes are generally inserted equidistantly up to 25-30 mm from the base of the cochlea, thus stimulating only nerve fibres with characteristic frequencies above 250-500 Hz. The frequency selectivity of the system depends on the number of electrodes as well as the distance between these electrodes. In addition, the limited effect of increasing the number of electrodes may also be explained by distorted frequency-to-place mapping associated with implantation. There is generally a mismatch between the frequency outputs of the speech processor and the CF of the nerve fibres stimulated by the electrode array. The frequency
Figure 1.4 The electrode array is usually implanted in the scala tympani along BM, which located close to the auditory nerve. Reprinted from [13].
7
alignment of the electrodes and the auditory nerves is an important factor contributing to speech understanding. A shift in frequency-to-place map leads to degeneration of speech intelligibility [10-11]. It should be mentioned, however, that listeners can to some degree adapt to this shift in frequency-to-place mapping [12].
The signal processor forms an important aspect of implant design. The function of the processor, also known as “signal processing strategy,” is to decompose the signal into different frequency bands, thus attempting to simulate the frequency analyzing functions of a normal cochlea. In comparison with a healthy cochlea, however, the decomposition of the signal into its frequency components is far less precise. The implant provides a limited set of frequency components with a wider bandwidth, resulting in spectral degradation of the signal. The signal processing strategy extracts the envelope for each band by means of rectification and smoothing. Compression is subsequently performed on the output of these channels. This is necessary because the range of the acoustic amplitudes present in the input is larger than the dynamic range of the CI users [7]. The selected envelopes are then used to modulate trains of electric pulses and transmitted to the electrode array.
1.3 Motivation and Objectives
Improvements in technology of CI and speech recognition outcomes have led to some extension of the implantation criteria to include individuals with some residual hearing in one or both ears. Although recent studies have reported that CI have successfully restored hearing performance in quiet in severely hearing loss individuals. However, these individuals still remains several significant difficulties in understanding speech in noise or the presence of competing talkers [13].
8
voice gender and talker identity continues to be challenging for CI users, who have impoverishment spectral resolution [14-16]. The spectral resolution in CI is not high enough to resolve the fundamental frequency (F0) and its harmonics, due to the limited number of electrode number and neural survival. Although the CI encodes the temporal envelope of the acoustic signal and temporal correlates of voice pitch are preserved at least in the low frequency channels [17], the temporal envelope pitch is relatively weak and insufficient for challenging listening environment [18]. The dynamic changes in pitch across an utterance are the primary indicators of intonation and play a critical role in conveying talker‟s voice and emotional states [19] which relayed by the F0 of the target speech, is known to be impoverishment in CIs of today [15-20] but is available within the low frequency acoustic signal for those with residual acoustic hearing. One of the main deficiencies of CIs is that the spectral resolution of the signal is reduced and the lack of pitch perception and another possible is partly because they do not have access to binaural hearing when they only implanted the unilateral side, which these two factors was believed can enable listener to segregation the target speech from noise.
Second, a tonal language is a language that uses tonal cues, which is called lexical tones, to identify word. For example, the syllable /ba/ can have one of four different meanings depending on the F0 contour. Taiwanese Mandarinis a tonal language that variantedof Mandarin and derived from
the official Standard Mandarin spoken in Taiwan. Consider into speech perception of Taiwanese Mandarin in CI users, it would be expected that poor frequency resolution in CI would led poor pitch perception and affect the ability of implant listeners to correctly identify this tonal language.
Third, the fluctuating and irregular nature of the background noise also allows for NH listeners to potentially listen for the target speech in the temporal and spectral „„dips” of the background, to perception the masking release, which also referred as “glimpsing.” While the poor frequency resolution in implanted listeners would reduce their ability to listen in spectral „„dips” as
9
compared to NH [21]. In both listeners with HI [22-23] and CI [14, 20, 24-26] have been suggested that the lack of masking release in fluctuating maskers is partly due to an inability to code F0. In a fluctuating masker, F0 may help by providing stress cues and acoustic landmarks to give a framework that aid listener to fuse the glimpsed target information into a meaningful way. This inability likely arises from reduced temporal fine structure processing [26-32]. The inability of listeners with HI to glimpsing by makes use of temporal fine structure cues is currently a topic of considerable study.
For CI users with low frequency residual hearing may improve pitch perception ability by combined the electric and acoustic stimulation via using the HA with their CI in the same ear, which known as electric-acoustic stimulation (EAS) [33-34], or in opposite ears, which is known as Bimodal stimulation. This benefit is generally attributed to the addition of low frequency acoustic information that is provided by the hearing aid. Despite the low frequency sound is almost unintelligible when presented alone; it is largely unavailable in the electric stimulation with CI. However, it remains a matter of debate which specific cues contained within the low frequency acoustic signal are responsible for the benefits observed. Much of the discussion regarding the Bimodal benefit to CI speech perception has focused on the role of F0.
In this thesis, the overall objective was to evaluate the benefits of speech recognition in Taiwanese Mandarin in noise background with simulation Bimodal stimulation, which combined unprocessed low frequency information and CI simulation in NH listeners. The first aim was to evaluate the hypothesis that residual low frequency acoustic hearing provides phonetic information which, when combined with the CI, produces an improvement in speech intelligibility beyond that of the CI alone. Furthermore, access to the binaural hearing effect in Bimodal stimulation with sound source in different spatial direction, to reveal the important of Bimodal stimulation in binaural hearing. The second aim was to evaluate the hypothesis that the F0 information which
10
available within the low frequency acoustic information can provides the improvement in speech intelligibility with a CI, when comparing the results from low frequency acoustic information. Further addressed a tone that follows the dynamic variation of F0 or amplitude envelope of the low pass speech, extracted from target speech to provide insight into the components of the low frequency region information that are important for achieving this benefit. The third aim was to evaluate the hypothesis that the Bimodal stimulation can benefit from masking release, by using the several acoustic cues within the low frequency acoustic information, to improve the ability of “glimpsing” in CI users.
1.4 Organization
The outline of this study is as follows. Chapter 1 presents some general information regarding HI, hearing aid devices and cochlear implant devices; the motivation, objectives and organization. Chapter 2 provides an overview of the other related studies about the perception of speech in Bimodal stimulation. Chapter 3 is to introduce the methodology of the processing; the settings and results of experiment. Chapter 4 discusses the performance, utility and the extensibility and limitations of the Bimodal stimulation. Finally, Chapter 5 summarizes the dissertation and presents our conclusions and future works.
11
2. Related Work
2.1 Bimodal Stimulation
As adverse as the effects of speech perception with background noise are for individuals with HI, there are perhaps more adverse for CI users, due to the reduced frequency resolution and lack of fine-structure cues provided by the devices [24, 35-37]. CIs work by filtering the incoming signal into a number of frequency bands, and extracting the amplitude envelope in each of the bands [7]. The electrical pulses that are modulated in amplitude with each extracted envelope, emit trains to the electrodes which positioned at various points along the basilar membrane. Because of this process, fine-structure cues are largely discarded.
Previous studies have demonstrated that the addition of low frequency sound provide benefits in terms of speech recognition over the unilateral CI alone in both simulated [38-41] and actual Bimodal stimulation [33-34, 42-56], in noise condition. This may be the low frequency acoustic information contains some cues that help listener to perception phonemic well. As shown by [25], better frequency resolution aids the recognition of speech in backgrounds. Turner et al. demonstrated that high frequency electrical stimulation along with acoustic low frequency hearing in simulated EAS subject had the potential to provide a significant advantage for understanding speech in background noise, particularly when the competing signal was other talkers [34]. Ching showed the low frequency hearing from HA increases consonant voicing and manner of articulation information in Bimodal stimulation [49]. Similarly, Mok et al. demonstrated that increased low frequency phonemes information (e.g. nasals, semivowels, diphthongs and the first formant frequency) were transmitted with Bimodal stimulation relative to the CI alone [52]. Several studies have been suggested that segregation as a possible mechanism for the benefits of Bimodal hearing
12
in noise [39-40, 51]. Chang et al. have suggested that listeners combine the relatively weak pitch information conveyed by the electric stimulation with the stronger pitch cue from the target in the low frequency acoustic to segregate target and background noise. However, the question remains of what low frequency cues are responsible for the Bimodal effect.
Von Ilberg et al. reported the speech recognition in quiet results for one patient implanted with a long electrode inserted 20 mm into the cochlea who had some preserved residual hearing 2 months following implantation, this patient‟s sentence recognition scores were 7% with the acoustic hearing alone, and increased to 56% with the addition of electric stimulation. Interestingly, sentence recognition with the CI alone was only 2%, suggesting a strong synergistic effect of the two modes of stimulation [33]. Gantz et al. reported results from a group of six Bimodal users, three implanted with a 6 mm electrode and the remainder with a 10 mm electrode [45]. The 6 mm-electrode patients demonstrated approximately 10% points improvement in the recognition of consonants with the addition of electric stimulation, whereas the patients implanted with the 10mm device improved nearly 40% points. The greatest improvement was noted for the perception of the speech feature place of articulation, which is in agreement with the high-frequency range of speech information assigned to the short-electrode. These authors also noted a strong effect of experience following implantation, with some patients continuing to improve as long as 10 months following implantation. Skarzynski et al. described the speech recognition results for one patient listening under Bimodal stimulation after being implanted with a long electrode of 20 mm insertion depth. Monosyllabic word scores increased from 25% (acoustic-alone) to 90% (EAS) [46]. The electric-only score was 23%, again suggesting a strong synergistic effect for this patient. Gstoettner et al. reported speech results for one patient implanted with a 22 mm electrode who improved from 38% recognition of monosyllables in the acoustic-only mode to 90% with the addition of electric stimulation [48]. Kiefer et al. reported monosyllabic word understanding a group of 11 patients with
13
preserved residual hearing [50]. Mean acoustic-alone scores were 7%-correct, and the addition of electric stimulation increased this to over 60%, with several patients showing scores increasing to over 75%. Of these 11 patients, only four obtained Bimodal scores higher than the electric alone score, suggesting that for many patients, the electric stimulation was providing the primary contribution to speech understanding. James et al. reported word recognition scores for seven subjects whose residual hearing was preserved 6 months postoperatively to 60 dB HL or better at the low frequencies [56]. The mean preoperative score was 22%, CI-alone score 6 months after surgery was 56%, and under Bimodal stimulation scores averaged 68%. For two of these subjects, the implant-alone score was equal to the Bimodal score, suggesting that the bulk of speech recognition was provided by the electric stimulation. At the other end of the spectrum, in two other patients, the implant provided little or no speech recognition alone, nor did it provide an increase over the acoustic-alone score in the Bimodal stimulation. These two patients had long durations of deafness prior to implantation.
Chang et al and Qin et al. both have shown that F0 is seem to play an important role in low frequency region then any first formant may play [39-40]. In their studies, for example, the 300 Hz low-pass speech sound, which should not yield any intelligibility, can significant improved speech recognition in noisy environment, when addition to vocoder stimulation. This seems to suggest that F0 is important, since it is very unlikely that the 300 Hz low-pass speech sound has contain any first formant information [57].
Another report has even showed that CI patients may achieve Bimodal benefit with residual hearing only up to about 125 Hz. For example, Zhang et al., examined Bimodal patients combined the 750, 500, 250 or 125 Hz low-pass speech sound and listened to both monosyllables in quiet and sentences with background noise [58]. Results showed that the majority of the EAS benefit was observed from acoustic information present below 125 Hz. For example, the recognition rate of
14
monosyllables in the vocoder only, EAS-125, and EAS-broadband conditions were 56, 78 and 88 percent correct respectively. Given that the mean F0 was 123 Hz of the male talker, they concluded that perception of F0 plays a major role in Bimodal benefit, due to this low-pass acoustic signal contained only F0 as the major speech cue. Cullington et al. also observed Bimodal benefit with very low frequency acoustic information (150 Hz low-pass) and suggested that much of this benefit provided by F0 information in their study [55].
Plomp had described a model that contained two independent factors that describing the hearing loss [59]. First, the attenuation factor, it represents the threshold shift of a listener with HI. The attenuation factor would show differences in speech intelligibility only at lower noise levels, and a convergence in performance once the level of the noise increased. Second, the distortion factor, it represents supra-threshold deficits, and specifies that performance will always be worse for listeners with HI, once the level of the noise rises to such a level that it becomes the limiting factor in the audibility of the target speech. Figure 2.1 shows the difference between these two factors in speech recognition threshold with conductive hearing loss and sensorineural hearing loss. The distortion factor exhibited by listeners with HI can be observed when fluctuating (amplitude-modulated) maskers are used, such as competing speech. It has been known that normal hearing (NH) listeners can take advantage of the masking release which occurs in the temporal valleys of fluctuating maskers to improve speech intelligibility performance while listeners with HI are less able to [60-65]. This ability has been termed “listening in the dips” or “glimpsing.”
2.2 The Role of Fundamental Frequency
The F0 information is known to be aids listener in segregating the target speech from background noise [66-72]. There are many sources provided evidence that the availability of the target talker's F0 helps improve intelligibility, particularly with competing talker. F0 has also been
15
shown to be important for several linguistic cues, including manner of articulation [73], voicing [74-75] and lexical boundaries [76].
The general term of F0 have often classified into the static mean F0 and the dynamic variations in F0. The static mean F0 is typically thought of when describing the differences in F0 between females and males. The dynamic variation in F0, has known to be F0 contour, is the change in F0 that occurs in time across an utterance.
From Bimodal stimulation, it may be highly informative via residual acoustic hearing to access to F0 information [55, 58, 77-79]. F0 is poorly coded in CI devices [80] but is, in contrast,
Figure 2.1 Factor A describes the attenuation factor and factor D describes The distortion factor in Plomp‟s model [59]. CHL indicates conductive hearing loss and SNHL indicates sensorineural hearing loss. There is a transition between these two areas described. Factor A is a problem only in low noise levels, whereas
16
likely to be well preserved in low frequency residual acoustic hearing. Previous studies have evaluated F0 as a major contributor to the benefit of combined acoustic and electric stimulation in CI users or by simulating Bimodal hearing in NH listeners, in which the acoustic-side was replaced by severely low-pass filtered speech [55, 58] or by a tone that modulated in F0 variations [41, 77-79]. Much of the evidence to support that the Bimodal benefit is a result of the F0 cue present in the low frequency acoustic information [55, 58, 77-78]; however, there is not complete agreement as to the importance of F0.
The earliest work that directly evaluated the contributions of F0 was implemented by [41]. They extracted the dynamic variations in F0 from target speech, and used to frequency modulate a harmonic complex tone. The tone was then combined with vocoder stimuli to form Bimodal hearing which has a masker on the vocoder side only. Their hypothesis was that if the Bimodal benefit has observed by using the modulated complex tone, it can be concluded that F0 is a useful cue. They also evaluated the independent contributions of the voicing cue and the amplitude envelope by according to the voicing of the target speech to turning an unmodulated complex tone on and off to present as the voicing cue, and extracting the amplitude envelope of the target speech to amplitude modulating the complex tone to present as the amplitude envelope. The result have shown that while both of those cues provided benefit over vocoder-only condition, F0 did not. In contrast, they testing at several SNRs, and found that the AMFM complex tone, which used the dynamic variations in F0 to frequency modulate and the amplitude envelope of the target speech to amplitude modulate a harmonic complex tone, only benefit at the lowest SNR (5 dB). Because the F0 cue was not shown to be beneficial in their study, they argued against the segregation was the mechanism for the benefits of Bimodal hearing, and suggested that most Bimodal users are able to access some information about the spectral shape of the speech signal by F0 information, such as formant transition slopes, glides associated with dipthongs and low frequency formant peaks. As well as
17
phonetic cues derived from spectral shape are also present in very low frequency speech stimuli, and are likely to contribute to Bimodal benefit. This information should help listener to identification of many vowels and perhaps some consonants such as nasals with low formant frequencies. They concluded glimpsing as an explanation of Bimodal benefit, and the low frequency stimulus provides an indication may help listeners when to listen or “glimpse” the target.
On the other hand, Brown et al. used a pure-tone carrier, as opposed to a harmonic complex, to evaluate the role of the dynamic variations in F0 in simulation Bimodal stimulation [77-78]. They found that, the tone turning by the voicing of the target speech, the tone frequency modulated by the dynamic variations in F0 of target speech and the tone amplitude modulated by the amplitude envelope of low-pass filtered the target speech, all contributed to the Bimodal benefit, and that combining all three cues produced the greatest benefit in simulated Bimodal stimulation [77]. The score was range from 24 to 57 percent correct, depending on using different target and masker materials. Followed by, they replicated in actual Bimodal users [78], the result have shown that presented the F0 information to the ear with residual hearing was significantly improved speech intelligibility over CI-alone condition and was not significantly different to the benefit provided by broadband acoustic speech. These studies both used relatively low SNRs on vocoder only condition, to limit the performance to very low levels, and no masker was applied to the acoustic side, to allow a more sensitive measure of the effects observable from low frequency region information. The authors also found that using a pure tone (113 Hz) which much lower in frequency than the target talker‟s mean static F0 (213 Hz) and modulated by the dynamic variations in F0 and the amplitude envelope cues of the target speech can provide no loss in the amount of Bimodal benefit. They suggested that if listeners are indeed combining the strong F0 cue in the acoustic stimulation with the relatively weak pitch cue from the electric stimulation to segregating the target and masker, then shifting the pitch cue down in frequency should decrease or eliminate the benefit. For the reason
18
that, the authors have argued against segregation as an explanation for the benefits of Bimodal hearing, and concluded the glimpsing account for Bimodal benefits which had proposed previously [41, 81].
Carroll et al. also using the dynamic variations in F0 and the amplitude envelope of low-pass filtered target speech to frequency and amplitude modulated a pure tone to present as the F0 cues [79]. They examined CI users on speech intelligibility, with low-pass speech sound or F0 presented to the ear with residual hearing. For speech recognition in quiet, the result indicated that the F0 didn‟t provide benefit. For speech recognition with a talker masker (at SNR 10 dB), they found that whether presented the low-pass filtered speech combined masker or only the target‟s F0 both provided benefit. In their experiment setup, only the low-pass speech condition had a masker on the acoustic side, indicating the amount of benefit of the F0 cues presented in quiet was equivalent to the amount of Bimodal from acoustic speech with a talker masker. Which particular component of F0 cues provides benefit is unclear.
The data collected in simulation Bimodal have shown that the amplitude envelope in an acoustic signal can provide additive and independent Bimodal benefit to the F0 cue [77-78]; in contrast, Carroll et al. found that the tone which frequency modulated in the dynamic variation of F0 provided benefit in CI users, but not the tone which amplitude modulated in the amplitude envelope of target speech [79]. On the other hand, Kong et al. found just amplitude envelope cue was accounted for the benefit [41]. This may be further possible that, for integration of the signals between devices, the amplitude envelope of the acoustic signal is important, as it is conveyed quite well in both electric and acoustic hearing in Bimodal users.
It is important to note that some useful phonetic cues related to spectral shape may be likely contain in even very severely low-pass filtered acoustic information. For example, it is possible that the proximity of the first formant was indicated by the F0‟s amplitude, even if the F0 is the only
19
audible component, as a lower frequency first formant would indicated by a higher amplitude F0. Li et al. found that low frequency acoustic sound is particularly useful for glimpsing target speech from a background masker in simulated Bimodal stimulation, due to the low frequency spectral information [81]. The higher amplitudes at low-frequencies acoustic sound may tend to indicate voicing, and also is an important cue for manner of consonant articulation, for example, the sudden on/offset of the signal has indicated plosives information, furthermore, it provided some cues that help to convey stress patterns which may aid segmentation, particularly in impoverished listening environment [82]. As stated by Stevens‟ lexical access model [83], the “acoustic discontinuities” at voicing on/offset provide some landmark cues that help listener to segment phonemes and words, providing a structure for lexical recognition. Some studies demonstrated that the F0 contour has also been shown to be a useful cue to speech segmentation [76, 82]. In CI users with residual hearing in the non-implanted ear, it had reduced the ability to segment speech by using syllabic stress cues with removing the F0 contour of the signal.
2.3 Masking Release
NH listeners show a large advantage for the competing talker condition, because they can take advantage of various cues that allow them to separate or „„stream” the multiple sound sources and allowing them to focus on the target speech [84]. These can involve pitch, timing, and in some situations, localization cues. HI listeners and CI users, on the other hand, are most likely unable to perceive some of these cues in competing talker enviornment, making particularly difficult for them to address the target talker since they may not be able to segregate the various talkers. The competing talkers may serve as a type of „„informational masking”. Instead, the linguistic content of the background talkers is mislead or confused with the target talker‟s content [85]. Nelson et al. and Qin et al. demonstrated that reducing the frequency resolution of speech presented to NH listeners
20
produced deficits in speech intelligibility in fluctuating background noise similar to those observed in CI listeners [25, 36]. Thus, they concluded when listening to speech with competing background signals, the primary deficit of CI listeners appears to be related to the poor frequency resolution provided by electrical stimulation in current CI devives.
Over the decades, various studies have demonstrated the differences in the amount of masking release between NH and HI listeners with a range of speech materials. For example, Dubno et al. used CV or VC syllables [86-87], while Eisenberg et al. used nonsense syllables and SPIN sentences [88]. HINT or IEEE sentences were employed in other studies [36, 64, 89]. Furthermore, Jin et al. suggested similar principles of masking release underlying speech recognition in fluctuating noise would be demonstrated, no matter what type of speech stimuli were used [90]. In other words, most listeners are able to benefit from momentary dips in noise, and the amount of masking release varies corresponding to hearing sensitivity of listeners. A simple ANOVA with stimulus type was either CV syllable or IEEE sentence as a dependent variable showed that the differences in masking release for CV syllables and IEEE sentences were not significant, when the SNR is fixed. Speech material types do not seem to be a factor in measuring speech intelligibility in fluctuating noise. However, it does appear that forward masking has significantly stronger relationship to CV identification than to sentence recognition [90].
Access to temporal fine structure information may be particularly important for CI users [91], for whom speech information is impoverished, especially in noisy environment. Nelson et al evaluated the effects of masking release in speech recognition in either CI users, NH listeners listening to vocoder or NH listeners listening to original broadband stimuli [36]. Subjects were tested either in quiet, in a steady noise, or in a gated noise that used a 50% duty cycle. For the gated noise, the modulation rate was varied from 1 to 32 Hz, and using square wave modulated. They found that NH listeners showed masking release as much as 70 percentage points. On the other
21
hand, both NH listeners in vocoder stimulation and CI users showed little to no masking release. The authors argue that the forward masking as an explanation of their result, because of these groups are used the relatively high SNRs (+8 and +16 dB). Therefore, they concluded that even in relatively low level noise, CI users are difficult to fuse the glimpsed target information to forming a coherent auditory image, due to the impoverished spectral information of CI processing, and thus reduce the listeners' speech intelligibility in fluctuating background noise.
22
3. Method and Results
3.1. Materials and Equipment
In this section, the speech materials for NH experiment, the recording settings, the noise masker, the CI simulation and spatial sound direction simulation will be present as follow.
3
.
1.1 Taiwanese Mandarin MaterialThe current study was conducted two testing materials. The Mandarin Speech Perception in Noise (MSPIN) proposed by Tsai et al. [92] and the Word Recognition Materials for Native Speakers of Taiwanese Mandarin (WRMTM) proposed by Nissen et al. [93]. The MSPIN is a sentence list which contains 300 Taiwanese Mandarin sentences for NH speech perception in noise experiment. Each sentence contains 7~10 words and subjects are asked to recognize the key word which is always the last word of each sentence. These sentences are evenly classified into two categories: high predictability (HP) and low predictability (LP). A sentence with HP means that it contains 2~3 cues to predict its last word. In contrast, a LP sentence doesn't contains any cues can predict its last word, which means the subject has to recognize the last word directly. This list contains total 150 key words. All of these words have different syllable structure and were frequently used in daily life. The WRMTM is a word list which contains 200 Taiwanese Mandarin bisyllabic words that can be used to measure the speech perception abilities of native speakers of Taiwanese Mandarin. These words were drawn from the Academia Sinica Balanced Corpus of Modern Chinese which balanced across the topics of philosophy, science, society, art, life, and literature [93]. These words are also most frequently used in daily life and qualified phonetically balanced. The MSPIN was used in experimental 1a and 2, the WRMTM was used in experimental
23
1b and 3.
The experiment was initially conducted to digitally record the MSPIN and WRMTM materials. We recruit a female talker to record the MSPIN material and a male talker to record the WRMTM material. Both of them have received professional training in Taiwanese Mandarin and familiar with the field of Taiwanese Mandarin linguistics. The recording was processed by a Roland R-09HR recorder in a sound-treated booth, at a sampling rate of 44.1k Hz and a bit depth of 16 bits. The file was stored in waveform audio file (wave) format which contains uncompressed pulse-code modulation (PCM) audio. After recording, each sentence and word would verify by five other native speaker of Taiwan Mandarin to ensure that all sentences and words could be fully recognized in quite condition. Any files that were judged to be poorly recorded were re-recorded again.
3.1.2 Masker
Most of studies are used the speech-shaped noise (SSN) or multi-talker babble to evaluate speech perception in noisy environment. SSN is a white noise signal shaped as long-term average spectrum (LTAS) of target speech. Comparison to white noise of the same average intensity, it will have a greater effect on phonemes with low frequency cues than phonemes with high frequency cues, due to it have more intense low frequency components and less intense high frequency components. This type of noise was widely used as masker in vowel, consonant, word and sentence perception test, due to it has approximately equal signal-to-noise ratio over frequency in spectrum.
For generated a SSN, we first calculated the LTAS of target speech that we used in our experimental. The speech signal was processed frame-by-frame with a Hanning window and this window was applied with a half-frame overlap. Followed by use fast fourier transform (FFT) to compute each frame and calculated the root mean square (RMS) of corresponding bin of each frame. The result of calculated the RMS of corresponding bin of each sentence was the LTAS of target
24
speech. Finally, filtered a white noise with a FIR filter which created by the LTAS of target speech. The SSN was used in our experiment 2 and 3. Multi-talker babble simulates the effect of trying to listen to someone speak in a crowded, noisy room which referred to as “cocktail party effect”. The multi-talker babble that we used in experiment 1a and 1b was available from CD (AudiTec Ltd, St Louis) [94].
3.1.3 Vocoder
Considering the large number of factor, such as sound source in spatial, the type of masker and the different cues in acoustic information, and the large number of SNR levels needed to construct psychometric functions in different conditions, a large number of listening tests are often needed to reach reliable conclusions. Vocoder simulation has been widely utilized for assessing the effects of some factors on speech perception in NH listeners, with results well predicting the pattern or trend in the performance observed in CI listeners [6-7, 95].
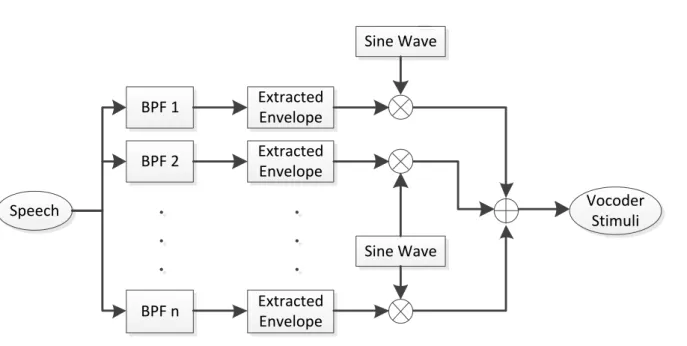
In CI device, the strategy will be converted the extracted acoustic amplitude to electric current and delivered to implanted electrode located in the cochlea. Similar, in a vocoder simulation, the underlying mechanism primarily eliminates the fine-structure information and delivers envelope information contained in the speech signal to NH listeners for identification. The main concept of vocoder is described as follows [95]. (1) The speech signals are band-passed into the several frequency channels, in the light of different strategy; the adjustable parameters include the range of broadband and the number of frequency channels. (2) Using half-rectification and low-pass filtering to extracted the temporal envelope in each frequency band. The adjustable parameters include the slope of low-pass filtering and the cutoff frequency. (3) The extracted envelope is used to modulate a carrier, such as wide-band white noise or sine wave, which is then filtered with a band-pass filter. The adjustable parameters include the slopes of the band-pass filters and the corner frequencies.
25
Adjusting these parameters can effectively simulate the spectral smearing by channel interaction and the spectral shifting by the electrode shallow insertion depth. (4) The modulated bands are then summed and the speech level will be adjusted. Figure 3.1 shows the conceptual view of vocoder.
In this study, we used Advanced Bionics HiRes Fidelity 120 vocoder to simulate the sound that CI users heard [96]. This vocoder has implemented the concept of “virtual channel” which enabled two or more electrodes to be simultaneous stimulation. This technique allows current to be “steered” between electrodes, resulting in 120 spectral bands of sounds.
3.1.4 Head-Related Transfer Functions
In this study, the spatial configurations were applied, using the head-related transfer function (HRTFs) to synthesize binaural sounds from monaural sources. The HRTFs is a transfer function, described as the modifications to a sound from a direction in free sound field that filtered by the
Speech BPF 1 BPF n BPF 2 Extracted Envelope Extracted Envelope Extracted Envelope Sine Wave Sine Wave Vocoder Stimuli
Figure 3.1 The conceptual view of vocoder. The speech signals are band-passed into the several frequency channels then extracted the temporal envelope in each frequency band, used to modulate a sine wave
26
reflection and diffraction of the torso, head and pinnae, before it reaches the transduction machinery of the eardrum and inner ear.
The HRTFs used in our experimental 1a, 1b and 3, was an extensive set of measurements of a KEMAR dummy head microphone that purposed by Massachusetts Institute of Technology Media Laboratory [97]. The measurements were made in MIT's anechoic chamber. The speaker was positioned from the center of bisected the interaural axis of the KEMAR at a distance of 1.4 meters. The spherical space around the KEMAR was sampled at elevations from -40 degrees to +90 degrees. At each elevation, a full 360 degrees of azimuth was sampled in equal increment sizes that were chosen to maintain approximately 5 degree great-circle increments. The input signal which combined target speech and noise was processed by filtering it with the corresponding HRTFs for specific sound source spatial direction.
3.2 Experiment 1a
3.2.1 Subjects and Stimuli
16 NH subjects (9 females and 7 males) between the ages of 20 and 29 years old (mean 23.9 years) participated in experimental 1a. All subjects were native speakers of Taiwanese Mandarin. None of the participants had any prior experience with the test materials. Participants signed an informed consent form and were paid for their participation. This experiment consisted of two sessions, each session of 40 minutes. In this experiment, the target speech was MSPIN material and the masker was a multi-talker babble as mentioned before.
3.2.2 Procedure
27
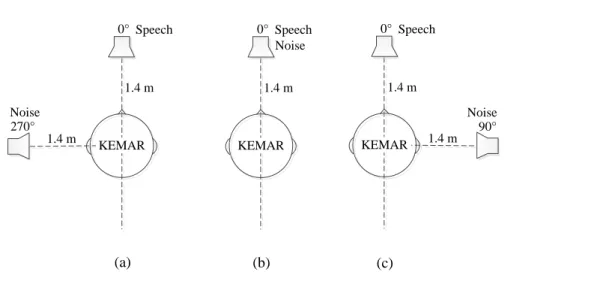
was derived from a 10th-order Butterworth filter with a cutoff frequency at 500 Hz, applied to the input signal which combined target speech and noise to simulated residual low frequency hearing. The assumption for choice to simulate the HA by filtering out high frequencies components, is based on that hearing of HA users generally only remains at low frequencies. The sound source of spatial configurations was simulated by using HRTFs [97]. Figure 3.2 shows how we use HRTFs to produce different sound source angle of incidence. Speech source is always fixedly originated in the front at 0 azimuth, and noise source is placed at an angle of incidence of 0° (S0N0), 90° (S0N90) or 270° (S0N270) azimuth, The distance between source and KEMAR was 1.4 meters. All sentences are mixed by multi-talker babble in SNR 5, 0 or -5 dB. For the listening mode, stimuli were presented either only vocoder in left ear to form unilateral CI-alone condition, or vocoder in left ear and low pass speech in right ear to form Bimodal condition. Figure 3.3 shows CI-alone vs. Bimodal listening mode. All stimuli were presented acoustically with AKG K181DJ headphones. An open-set test was used without feedback provided. Subjects were asked to ignore the masking and recognize the last word of each sentence. Prior to testing, subject were exposed to
Fig. 3.2 The source angle of incidence in this experiment. Speech source is originated in the front at 0 azimuth. Noise source is placed at an angle of incidence of (a) 270°, (b) 0°, or (c) 90° azimuth.
(c) (b) (a) 0° Speech 90° Noise KEMAR 1.4 m 1.4 m 0° Speech 270° Noise KEMAR 1.4 m 1.4 m 0° Speech Noise KEMAR 1.4 m
28
20 sentences in SNR 0 dB, unilateral CI-alone condition and noise on the same side of vocoder, to familiarize the target talker‟s voice and task. During the experimental, subject would test in a total of 36 conditions (3 source angle of incidence x 3 SNR x 2 listening mode x 2 predicted categories), all of these conditions were evaluated in random order for each subject.
3.2.3 Results
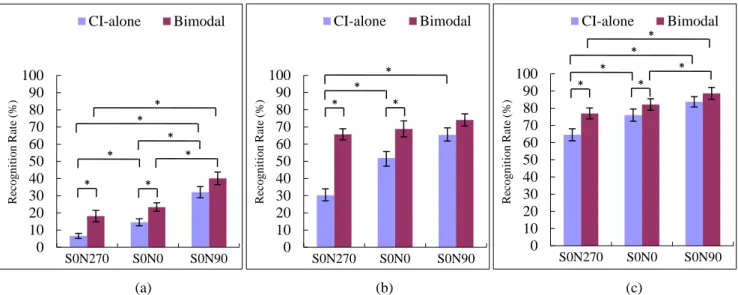
Figure 3.4 shows the result of experiment 1a, conducted by NH subject. Recognition % are plotted as the mean percent correct across subjects with the error bars indicating the standard error of the mean. The upper panel was HP sentence, and lower panel was LP sentence. The left, middle and right panel was the SNR -5, 0 and 5 dB, respectively. One-way repeated-measures analysis of variance (ANOVA) with Fisher‟s Least Significant Difference (LSD) post hoc was conducted to access for differences in recognition rates across SNR, listening mode or sound source angle of incidence. The S0N0, S0N90 and S0N270 indicated that the noise was presented at front, right and left, respectively. Significant differences were found among each SNR level for same listening mode. For S0N0 and S0N270, Bimodal hearing both showed significantly benefit compared with CI-alone at each SNR level. Especially at SNR 0 dB, when vocoder was interfered significantly by noise, the CI-alone only yielded scores ranging from 10-42% and Bimodal condition significantly
CI-alone
Vocoder
Bimodal
Vocoder Low-pass Speech (a) (b)
Figure 3.3 The listening mode in experiment 1a and 1b. (a) CI-alone: only present vocoder stimuli to left ear. (b) Bimodal: present vocoder stimuli to left ear and low pass speech to right ear.
29
improved to 50-70%. For CI-alone, significant differences were found among three sound source angle of incidence at each SNR level, expect between S0N0 and S0N270 at SNR -5 dB. For Bimodal, no significant differences were found among three sound source angle of incidence at SNR 0 and 5 dB, but significant differences were observed at SNR -5 dB, expect between S0N0 and S0N270 of LP sentences. Despite did not return performance to NH levels, the addition of low frequency information was showed an improvement compared with CI-alone. Further detailed
Figure 3.4 The performance of speech recognition as a function of the source angle of incidence with comparing listening mode (CI-alone vs. Bimodal). Recognition rates are plotted as the mean percent correct across subjects with the error bars indicating the standard error of the mean in SNR (a) -5, (b) 0, and (c) 5 dB for HP (upper panel) and LP
(lower panel) sentence. The symbol “*” indicates values that differed significantly between conditions at P<0.05 0 10 20 30 40 50 60 70 80 90 100 S0N270 S0N0 S0N90 R ec o g n it io n R at e (%) CI-alone Bimodal * * * * * * * 0 10 20 30 40 50 60 70 80 90 100 S0N270 S0N0 S0N90 R ec o g n it io n R at e (%) CI-alone Bimodal * * * * * 0 10 20 30 40 50 60 70 80 90 100 S0N270 S0N0 S0N90 R ec o g n it io n R at e (%) * * * * * 0 10 20 30 40 50 60 70 80 90 100 S0N270 S0N0 S0N90 R ec o g n it io n R at e (%) CI-alone Bimodal * * * * * * 0 10 20 30 40 50 60 70 80 90 100 S0N270 S0N0 S0N90 R ec o g n it io n R at e (%) CI-alone Bimodal * * * * * 0 10 20 30 40 50 60 70 80 90 100 S0N270 S0N0 S0N90 R ec o g n it io n R at e (%) CI-alone Bimodal * * * * * (a) (b) (c)
30
results of this experiment was attached as Appendix C.
3.3 Experiment 1b
3.3.1 Subjects and Stimuli
15 NH subjects (7 females and 8 males) between the ages of 22 and 28 years old (mean 24.2 years) participated in experimental 1b. All subjects were native speakers of Taiwanese Mandarin. None of the participants had any prior experience with the test materials. Participants signed an informed consent form and were paid for their participation. This experiment consisted of two sessions, each session of 21 minutes. In this experiment, the target speech was WRMTM material and the masker was a multi-talker babble as mentioned before.
3.3.2 Procedure
In this experimental, the whole condition setting was similar with experimental 1a, includes the low pass filtering was applied to the input signal which combined target speech and noise to simulated residual low frequency hearing and the sound source of spatial configurations was also simulated by using HRTFs [97]. The sound source spatial direction setting was also same as experimental 1a (see figure 3.2). All words were mixed by multi-talker babble in SNR 5, 0 or -5 dB. For the listening mode, stimuli were presented as same as experiment 1a (see figure 3.3), either only vocoder in left ear to form unilateral CI-alone condition, or vocoder in left ear and low pass speech in right ear to form Bimodal condition. The stimuli were directly presented to the subject via a AKG K181DJ headphone. An open-set test was used without feedback provided. Subjects were asked to ignore the masking and recognize the whole bisyllabic word. Prior to testing, subject were exposed to 20 MSPIN sentences in SNR 0 dB, unilateral CI-alone condition and noise on the same side of
31
vocoder, to familiarize the test. During the experimental, subject would test in a total of 18 conditions (3 source angle of incidence x 3 SNR x 2 listening mode), all of these conditions were evaluated in random order for each subject.
3.3.3 Results
Figure 3.5 shows the result of experiment 1b, conducted by NH subject. Recognition % are plotted as the mean percent correct across subjects with the error bars indicating the standard error of the mean. The left, middle and right panel shows SNR -5, 0 and 5 dB, respectively. One-way repeated-measures ANOVA with Fisher‟s LSD post hoc was conducted to access for differences in recognition rates across SNR, listening mode or sound source angle of incidence. The S0N0, S0N90 and S0N270 indicated that the noise was presented at front, right and left, respectively. Significant differences were found among each SNR level for same listening mode. For S0N0 and S0N270, Bimodal hearing both showed significantly benefit compared with CI-alone at each SNR level.
Figure 3.5 The performance of speech recognition as a function of the source angle of incidence with comparing listening mode (CI-alone vs. Bimodal). Recognition rates are plotted as the mean percent correct across subjects with
the error bars indicating the standard error of the mean in SNR (a) -5, (b) 0, and (c) 5 dB. The symbol “*” indicates values that differed significantly between conditions at P<0.05
0 10 20 30 40 50 60 70 80 90 100 S0N270 S0N0 S0N90 R ec o g n it io n R at e (%) CI-alone Bimodal * * * * * * * 0 10 20 30 40 50 60 70 80 90 100 S0N270 S0N0 S0N90 R ec o g n it io n R at e (%) CI-alone Bimodal * * * * 0 10 20 30 40 50 60 70 80 90 100 S0N270 S0N0 S0N90 R ec o g n it io n R at e (%) CI-alone Bimodal * * * * * * (a) (b) (c)
32
Especially at SNR 0 dB, when vocoder was interfered significantly by noise, the CI-alone only yielded scores ranging from 30-52% and Bimodal condition significantly improved to 66-69%. For CI-alone, significant differences were found among three sound source angles of incidence at each SNR level, expect between S0N0 and S0N90 at SNR 0 and 5 dB. For Bimodal, no significant differences were found between S0N0 and S0N270 at each SNR level. Significant differences were observed between S0N90 and S0N270; between S0N0 and S0N90 at each SNR level, expect between S0N0 and S0N90 at SNR 0 dB. Although the result of this experimental was slightly difference with experimental 1a, the overall trend was similarly. Further detailed results of this experiment was attached as Appendix D.
3.4 Experiment 2
3.4.1 Subjects and Stimuli
15 NH subjects (10 females and 5 males) between the ages of 20 and 29 years old (mean 24.1 years) participated in experimental 2. All subjects were native speakers of Taiwanese Mandarin. None of the participants had any prior experience with the test materials. Participants signed an informed consent form and were paid for their participation. This experiment consisted of two sessions, each session of 40 minutes. In this experiment, the target speech was MSPIN material and the masker was a SSN as mentioned before.
3.4.2 Procedure
In this experimental, the original speech were initially normalized to an equal long-term RMS amplitude value, and was processed to create five kinds of low frequency information: (1) Low pass speech, (2) F0, (3) Amplitude envelope of F0, (4) Frequency variation of F0 and (5)
33
Voicing cue. The low pass speech was processed as same as experimental 1. The F0 was created by first extracting the dynamic variation of F0 from the original speech using the PRAAT program [98], based on a periodicity detection algorithm with autocorrelation function [99]. The amplitude envelope for the F0 was extracted by low-passing the original speech with a 10th Butterworth filter with a cutoff frequency at 500 Hz then extracted by Hilbert transform. Finally, the extracted amplitude envelope of F0 and dynamic variation of F0 were used to modulate a sinusoidal carrier. These methods resulted in an acoustic sound representation of F0 that provides amplitude, duration, and dynamic variation of frequency cues. For amplitude envelope of F0 and frequency variation of F0 was used the amplitude envelope of F0 and the dynamic variation of F0 to modulate a sinusoidal carrier, respectively. The output only contained information during voiced speech; unvoiced segments were represented as silence. The voicing cue was a sinusoidal wave which has frequency equal to the mean F0 and modulated by the on/offset of the voicing segment of each sentence.
Figure 3.6 shows six listening mode conditions that subjects were tested, named for the type of low frequency acoustic information presented: (1) CI-alone: none of low frequency information was presented, only vocoder in left ear, (2) Bimodal: presented low-passed speech, (3) F0: presented the F0 information of the target speech, (4) AMF0: presented the amplitude envelope of F0, (5) FMF0: presented the frequency variation of F0, (6) Pure tone: presented the voicing cue. Vocoder signal was always presented to the left ear, whereas the acoustic low frequency signals were always presented to the right ear. Subject were tested in a total of 36 conditions (6 listening mode x 3 SNR x 2 predicted categories); all of these conditions were evaluated in random order for each subject. Prior to testing, subject were exposed to 20 sentences in SNR 0 dB, unilateral CI-alone condition and noise on the same side of vocoder, to familiarize the target talker‟s voice and task. Note that for all the acoustic low frequency information signals were always presented in quiet, whereas SSN was presented to the vocoder which were mixed by target speech in
34
signal-to-noise ratio (SNR) 5, 0 or -5 dB. This manipulation was to allow a more sensitive measure of the phonetic contributions from low frequency acoustic information.
3.4.3 Results
Figure 3.7 shows the result of experiment 2, conducted by NH subject. Recognition % are plotted as the mean percent correct across subjects with the error bars indicating the standard error of the mean. The upper panel was HP sentence, and lower panel was LP sentence. The left, middle and right panel was the SNR -5, 0 and 5 dB, respectively. One-way repeated-measures ANOVA with Fisher‟s LSD post hoc revealed that the performance was significantly differences between
CI-alone
Vocoder
AMF0
Vocoder Amplitude Envelope of F0
F0
Vocoder Fundamental Frequency
FMF0
Vocoder Frequency Information of F0
Bimodal
Vocoder Low-pass Speech
Pure tone
Vocoder Voicing cue (1) (3) (5) (2) (4) (6)
Figure 3.6 The listening mode in experiment 2. (1) CI-alone: none of low frequency information was presented, only vocoder in left ear, (2) Bimodal: presented low-passed speech, (3) F0: presented the F0 information of the target speech, (4) AMF0: presented the amplitude envelope of F0, (5) FMF0: presented

![Figure 2.1 Factor A describes the attenuation factor and factor D describes The distortion factor in Plomp‟s model [59]](https://thumb-ap.123doks.com/thumbv2/9libinfo/7447505.109910/23.892.127.807.130.637/figure-factor-describes-attenuation-factor-factor-describes-distortion.webp)