國 立 臺 中 教 育 大 學 教 育 測 驗 統 計 研 究 所
國民小學教師在職進修教學碩士學位班碩士論文
指導教授:郭伯臣 博士
廖晨惠 博士
兒童文本潛在語意指標
分析系統建置與應用
研究生:蔡亞韋 撰
中
華
民
國
一
○
二
年
六
月
謝辭
兩年的研究所生涯即將邁進尾聲,內心不僅雀躍,並感到如釋重負。身為在 職研究生,雖然有工作、家庭和課業的多重壓力,讓進修的過程倍感艱辛,幸好 ㄧ路上有老師、同學、同事及家人的指導與鼓勵,幫助我的論文得以順利完成, 衷心感謝陪伴我一路成長的師長與夥伴。 首先感謝指導教授郭伯臣老師與廖晨惠老師的諄諄引導。課業上,老師鞭辟 入裡的見解總在我徬徨時,及時給予解惑,讓我能突破瓶頸、茅塞頓開,使我的 論文得以順利完成。生活上,老師常給予我們關懷、鼓勵,幽默風趣的口吻、平 易近人的態度,讓人銘感在心。謝謝楊裕貿老師,百忙中提供語文專業,帶領我 們團隊定義指標中文意義,編製施測試題文本,不厭其煩的一再審題、解惑,點 點滴滴,感恩在心頭。 謝謝口試委員陳明蕾老師,對論文細心審查並提出寶貴的意見,令我獲益匪 淺,也讓這份論文更趨完善。感謝鎧誌學長在研究過程中予以極大的協助,從程 式撰寫到結果分析,都有你精闢的建議。謝謝一路相伴打拼的團隊夥伴,文蘭、 勇媜、筱倩及建宏,有你們的加油打氣、共同努力,才有今日的成果,有你們的 陪伴,減輕不少撰寫論文的艱辛感。還有學校同事們精神上的鼓勵與支持,以及 教學上的協助,讓我在工作上無後顧之憂。 最後對我的家人致上無限的感恩,感謝您們的支持與體貼,我才能完成求學 的夢想。僅在此與所有愛我、關心我的人一起分享這份小小的成就,謝謝你們! 蔡亞韋 謹誌 102.06摘要
本研究應用潛在語意分析(Latent semantic analysis, LSA)技術建置電腦自動化 中文文本指標及線上文本自動化分析系統,並檢視現行教科書在建置指標上的表 現情形。此外以中高年級文本理解測驗,檢視研究指標與閱讀理解層次能力間的 相關。研究結果如下: 一、本研究成功建置潛在語意自動化分析指標。本研究建置四個文本分析指標: 相鄰句潛在語意關係指標(Local LSA)、整篇文章潛在語意關係指標(Global LSA)、句子間新舊訊息潛在語意指標(LSA Given-New)與句間重複動詞潛在 語意關係指標(LSA verb overlap)。
二、研究結果顯示,相鄰句間潛在語意關係及句子間新舊訊息潛在語意關係指標 數值,隨著年級升高有數值上升的趨勢。而文本整體凝聚力指標及句間重複 動詞潛在語意關係指標,隨著年級升高,數值逐漸下降。根據指標發展最佳 預測年級模式,預測文本適讀年級解釋量可達 60.5%。 三、依研究文本理解測驗結果發現:文章中動詞語意重複情況高時,對學生文章 通過率或四個理解層次題目類型回答有正向的作用;而文章中舊訊息較多 時,新舊訊息潛在語意關係指標數值愈高,對學生文章通過率有反向的影 響,但可幫助作答者對直接推論題型的理解。 四、對受試高分組學生而言,影響題本通過率最多的閱讀理解層次是檢驗評估, 影響低分組通過率最多的閱讀理解層次是直接提取。 關鍵字:潛在語意分析、LSA、文本自動化分析、文本內容凝聚力
Abstract
The presented study aimed to develop the computer analyzes indicators of the texts by applying Latent Semantic Analysis and established the web computational system.
We analyzed the cohesions of the texts on different genres for grade1 to grade6 and investigated the trend of the cohesions on different grade levels
1. The study provided four validated indices to measure the characteristics of texts: Local LSA, Global LSA, LSA Given-New and LSA verb overlap.
2. The results show Local LSA and LSA Given-New value increases with grade upward trend. The value of Global LSA and LSA verb overlap decreased gradually with grade level upward. According to the best predictive indicator development Grade model predictive text proper reading grades of up to 60.5% explained. 3.The value of LSA verb overlap is high, the pass rate for students articles or four
types of questions to answer comprehension level has a positive effect; while the value of LSA Given-New indicators is higher, the pass rate for students articles have reverse impact, but those who can help answer questions on direct inference to understand.
4.To the subjects high grouping students, pass rates affect the title of the highest level is to test reading comprehension assessment, impact low group rates up through reading comprehension level is extracted directly.
目次
第一章 緒論 ...1 第一節 研究動機 ...1 第二節 研究目的 ...2 第三節 名詞解釋 ...2 第二章 文獻探討...5 第一節 潛在語意分析 ...5 第二節 線上文本分析系統(Coh-Metrix)...7 第三節 閱讀理解 ...9 第三章 研究方法...12 第一節 研究流程 ...12 第二節 發展文本自動化分析指標 ...14 第三節 中文文本自動化分析系統 ...16 第四節 研究對象與研究限制 ...18 第五節 研究工具 ...19 第六節 資料處理分析 ...23 第四章 研究結果與討論 ...25 第一節 兒童語料庫文本趨勢分析 ...25 第二節 指標分數預測文本適讀年級 ...36 第三節 題本通過率與指標分數分析 ...39 第四節 題本閱讀理解層次與不同年級受試學生、研究建置指標之相關 ..40 第五節 檢視高低分組受試者在題本閱讀理解層次之表現 ...43 第五章 結論與建議...47 第一節 結論 ...47 第二節 建議 ...48 參考文獻...49中文參考文獻...49 英文參考文獻...50
表目次
表 2-1 Coh-Metrix3.0 版指標... 7 表 2-2 Chall 閱讀發展歷程 ...10 表 3-1 修改斷詞標記規則 ...20 表 4-1-1 兒童語料庫及 Coh-Metrix 3.0 語文科文本在相鄰句潛在語意關係指標 數值 ...25 表 4-1-2 兒童語料庫及 Coh-Metrix 3.0 不同類別文本在相鄰句潛在語意關係指 標數值 ...27 表 4-1-3 兒童語料庫及 Coh-Metrix 3.0 語文科文本在整篇文章潛在語意關係指 標數值 ...28 表 4-1-4 兒童語料庫及 Coh-Metrix3.0不同類別文本在整篇文章潛在語意關係指 標數值 ...29 表 4-1-5 兒童語料庫及 Coh-Metrix3.0語文科文本在句子間新舊訊息潛在語意關 係指標數值 ...31 表 4-1-6 兒童語料庫及 Coh-Metrix3.0不同類別文本在句子間新舊訊息潛在語意 關係指標數值 ...32 表 4-1-7 兒童語料庫及 Coh-Metrix3.0語文科文本在句間重複動詞潛在語意關係 指標數值...33 表 4-1-8 兒童語料庫及 Coh-Metrix3.0 不同類別文本句間重複動詞潛在語意關係 指標數值...34 表 4-2-1 個別指標與文本年級之間相關係數表 ...37 表 4-2-3 指標變項預測文本年級模式多元迴歸分析摘要表 ...37 表 4-2-4 計算文本指標變項數值 ...38 表 4-2-5 指標變項預測文本年級模式逐步迴歸分析摘要表 ...38 表 4-3-1 中高年級文本理解測驗在研究建置指標數值 ...39 表 4-3-2 指標分數與不同年級受試學生在題本八篇文章通過率的相關係數摘要表 ...40表 4-4-1 不同年級受試者文本通過率在閱讀理解-直接提取類型題目與研究建置 指標的相關 ...41 表 4-4-2 不同年級受試者文本通過率在閱讀理解-直接推論類型題目與研究建置 指標的相關 ...41 表 4-4-3 不同年級受試者文本通過率在閱讀理解-詮釋整合類型題目與研究建置 指標的相關 ...42 表 4-4-4 不同年級受試者文本通過率在閱讀理解-檢驗評估類型題目與研究建置 指標的相關 ...43 表 4-4-5 閱讀層次 4 個類型題目與研究建置指標的相關 ...43 表 4-5-1 閱讀理解層次預測高低分組一覽表 ...46
圖次
圖 3-1 研究流程圖 ...13 圖 3-2 句子動詞比對方式...16 圖 3-3 中文文本自動化分析系統登入頁面 ...16 圖 3-4 系統文本輸入與指標選擇頁面...17 圖 3-5 系統分析文本頁面...18 圖 4-1-1 兒童語料庫語文科文本在不同年級相鄰句潛在語意關係指標趨勢 ...26 圖 4-1-2 Coh-Metrix 3.0 語文科文本在不同年級相鄰句潛在語意關係指標趨勢 ...26 圖 4-1-3 兒童語料庫不同類別文本在不同年級相鄰句潛在語意關係指標趨勢...27 圖 4-1-4 Coh-Metrix 3.0 不同類別文本在不同年級相鄰句潛在語意關係指標趨勢 ...27 圖 4-1-5 兒童語料庫語文科文本在不同年級整篇文章潛在語意關係指標趨勢...28 圖 4-1-6 Coh-Metrix 3.0 語文科文本在不同年級整篇文章潛在語意關係指標趨勢 ...29 圖 4-1-7 兒童語料庫不同類別文本在不同年級整篇文章潛在語意關係指標趨勢 ...30 圖 4-1-8 Coh-Metrix 3.0 不同類別文本在不同年級整篇文章潛在語意關係指標趨 勢...30 圖 4-1-9 兒童語料庫語文科文本在不同年級句子間新舊訊息潛在語意關係指標趨 勢...31 圖 4-1-10 Coh-Metrix 3.0 語文科文本在不同年級句子間新舊訊息潛在語意關係指 標趨勢 ...31 圖 4-1-11 兒童語料庫不同類別文本在不同年級句子間新舊訊息潛在語意關係指 標趨勢 ...32 圖 4-1-12 Coh-Metrix3.0 不同類別文本在不同年級句子間新舊訊息潛在語意關係 指標趨勢...33圖 4-1-13 兒童語料庫語文科文本在不同年級句間重複動詞潛在語意關係指標趨 勢...34 圖 4-1-14 Coh-Metrix3.0 語文科文本在不同年級句間重複動詞潛在語意關係指標 趨勢 ...34 圖 4-1-15 兒童語料庫不同類別文本在不同年級句間重複動詞潛在語意關係指標 趨勢 ...35 圖 4-1-16 Coh-Metrix3.0 不同類別文本在不同年級句間重複動詞潛在語意關係指 標趨勢 ...35
第一章 緒論
本章第一節說明研究背景與動機;第二節說明研究目的;第三節為本研究重 要名詞釋義。第一節 研究動機
閱讀是學習的基礎,也是目前各國教育改革的重點。臺灣對學生閱讀教育的 重視反應在近幾年的教育政策上,閱讀政策的施行範圍由弱勢地區擴大為全國, 對象也向下紮根,從 0-3 歲幼童培養起閱讀習慣。但近幾年臺灣學生的閱讀素養 在國際大型閱讀研究測驗中表現起伏不定,測驗結果顯示:臺灣學生喜愛閱讀, 但卻無法有效、重點的閱讀。根據經濟合作暨發展組織(Organization for Economic Co-operation and
evelopment, OECD)(2006)對閱讀素養的定義「個體理解、運用及省思書面文本,
達成個人目標和發展潛能的能力」,由此可知閱讀理解是閱讀者跟閱讀素材間交
互作用的過程(Pearson & Johnson,1978)。閱讀者及閱讀素材也是影響閱讀的最主
要兩個原因(蘇宜芬,2004),閱讀者的能力可經由教學策略來補強(王瓊珠、洪
儷瑜、陳長益,2005),而閱讀素材的選擇就相形重要,如何選擇適合閱讀者能力
的文本,縮短閱讀者搜尋適合本身文本的時間,達到有效的閱讀是推動閱讀教育 的一大重點。
早期對文本的選擇方式常是利用「文本可讀性」公式,以Klare(1974-1975) 的Flesch Reading Ease 和 Flesch- Kincaid Grade Level兩個公式最廣為流傳
(Graesser, McNamara, Louwerse, & Cai, 2004.)。但可讀性公式對文本的分析常流於表 面、直線式分析,如:句子長短、數量及音節多寡等。文本應包含表面、情境模 式和文本基礎等更深層的訊息,單向的理解可能忽略讀者深層的理解。為能多面 向的分析文本,臺中教育大學測驗統計研究所組成一個研究團隊,參考美國 Coh-Metrix線上文本分析系統,分析兒童語料庫文本,發展多項分析文本指標, 包含詞類、詞彙訊息、詞彙多樣性、文章連貫性等。因指標眾多,所以本研究僅 就潛在語意分析(Latent semantic analysis, LSA)指標,分析文本的凝聚力。
近年閱讀相關研究,發現文章凝聚力(cohesion)是選擇文本一項重要的指標。 文章凝聚力及連貫性(coherence)愈高的文本,內含愈多的線索幫助閱讀者了解文 章意義,可讓讀者越容易閱讀理解,反之,若文章凝聚力及連貫性愈低,則較不
易讓讀者理解(McNamara, & Graesser, 2012.)。潛在語意分析技術能測量詞彙間、句
間內含的語意關係,也就是文章的內容凝聚力和文章連貫性。 本研究建置電腦化中文文本分析系統指標,應用潛在語意分析技術,分析現 行教科書文本內容凝聚力趨勢。研究資料引用廖晨惠(2010)國科會計畫:「閱讀研 究議題八:以 LSA 為基礎之電腦化閱讀認知測驗及 AutoTutor 建置」(編號:NSC 100-2420-H-142-001-MY3)所建置的國小語料庫,本研究參考美國曼菲斯大學 Coh-Metrix 系統中的潛在語意分析類別內容,發展中文相鄰句間潛在語意關係指 標(Local LSA)、文本整體凝聚力潛在語意關係指標(Global LSA)、句子之間新舊 訊息潛在語意關係指標(LSA Given-New)及句間重複動詞潛在語意關係指標(LSA verb overlap)(MCnaamara, Graesser, McCarthy, & Cai, 2012)。本研究應用 LSA 統計 方法,觀察現行國小教科書在建置指標上文本分析結果,依文章類別、適用年級 呈現中文文本的內容凝聚力,希望可作為分析閱讀文本的依據,提供閱讀及教學 者更適宜的閱讀文本選擇依據。
第二節 研究目的
根據上述研究動機,本研究應用潛在語意分析技術於 Coh-Metrix 指標,探 討國小現行教科書文本凝聚力,研究目的如下: 一、建置兒童文本分析系統之潛在語意指標。 二、檢視現行教科書文本凝聚力分佈情況。 三、探討指標與閱讀理解的關係。第三節 名詞解釋
針對本研究常見的名詞,說明如下:壹、潛在語意分析(LSA)
LSA 是使用奇異值分解(singular value decomposition, SVD)和維度約化
(dimension reduction)為基礎的資料檢索技術,配合大量文本的語料庫建置潛在語 意空間,能測量詞彙間、句間內含的語意關係。
貳、線上文本分析系統(Coh-Metrix)
Coh-Metrix是一種處理自然語言的線上自動化分析系統,提供多層次的文本 分析指標。此系統可用來理解文本間的差異且探索不同文本類型間的語言特徵。 (MCnaamara,& Graesser, 2012.)參、相鄰句間文本凝聚力及文本整體凝聚力
相鄰句間文本凝聚力為測量句子之間的語意相似程度(similarity),利用 LSA 技術計算文本中相鄰句子之間餘弦值,若比對句間餘弦值愈大,表示在語意空間 中,其兩者的語意愈相似。文本整體凝聚力亦為句子與週遭句子的餘弦值運算, 但比對方式與相鄰句間不同,加上考量句子間距離不同,對語意上影響程度也會 有差距,加以權重計算計算而成。肆、句間新舊訊息
句間新舊訊息(Given-New)為文本中每個句子相對於該文本先前存在訊息的 新/舊資訊程度。Given 表示在句法或情節中,已出現過或是語意相似的訊息,相 對的,New 則是前文中無法找到的訊息(Graesser, MCnaamara, & Kulikowich, 2011)。伍、動詞重複
動詞重複(verb overlap)為動詞在文本中重複的程度,本研究利用 LSA 技術計 算相鄰句間動詞的語意關聯程度。據 MCnaamara 等人(2012)研究發現動詞通 常和文本中的事件、狀態、動作有顯著的關係,當有重複的動詞時,文本可能包 含更連貫的事件結構,可促進和加強情境模式的理解。
陸、閱讀理解
孟艾、羅瑞玉,2005),理解是閱讀的最後目的(董宜俐,2003)。Richek 等人(1996) 認為閱讀理解策略的應用可以激發較高層次的心智活動,使讀者在閱讀的過程中 能積極運用自身的先備知識理解文章、監控自我閱讀理解情況、調整自己的閱讀 方式,進而提升自我對文章的理解。
第二章 文獻探討
本章共分三節,第一節探討潛在語意分析;第二節簡介 Coh-Metrix 電腦自 動化文本分析工具;第三節探討閱讀理解歷程。
第一節 潛在語意分析
LSA 是一種檢索詞彙或句子間相關程度的數學及統計技術,可自動化從文章 的句子中去萃取及推論字詞間的關係(Landauer, Foltz, & Laham, 1998)。LSA 需 使用含大量文本的語料庫(Corpus)建置可表現詞彙上下關係的潛在語意空間。 語意空間建置的基本概念是先建立二維的詞彙及文本相關矩陣,用奇異值分解拆 解此矩陣,以得到詞彙與文本互相對應的語意結構矩陣,接著使用維度約化去除 雜訊,得到具代表性的潛在語意空間(Landauer & Dumais,1997)。在語意空間中, 每個詞彙或文件都是以向量形式呈現,因此可以利用向量的餘弦值(cosine)測量詞 彙與詞彙、詞彙與句子或兩兩句子之間所內含的語意關係。詞彙的語意相似度計 算如公式(1) j i T j i d d d d d d, ) sim( i j (1) di、dj為新矩陣中的兩詞彙,∥di∥為di向量的長度。 文本的語意相似度計算如公式(2),
n i i i n i i i T n i i i n i i i v b v a v b v a 1 1 1 1 j i ) )( ( ) T , sim(T (2) n 為此語意空間的關鍵詞數 vi表示第 i 個詞彙向量表徵 ai表示在 T1文件中出現的關鍵詞的次數語料庫使用對LSA 研究應用相當重要,國內外對語料庫選用已有一些相關研 究發現。語料庫是包含了大量經過分析整理的文本以及語文資料的大型詞語資料 庫,有既定的格式與標記,可提供語言學相關之研究做分析與與統計(溫文喆, 2008)。LSA以語料庫為基礎,測量學生先備知識表現,是一個測量語意相關的 有用工具,可用來測量摘要和學生文章的品質(Foltz, Gilliam, and Kendall, 2000); 而語料庫的語料來源越多越好,且要和研究目的有一定的相關
(Wiemer-Hastings,2004),當語料來源越能反應讀者所接收的詞彙情形,經由LSA 所建置出的語意空間越能精確表現詞彙間彼此存在的語意關係(劉嘉玲,2012)。
國內外有許多應用不同類別語料庫組成語意空間進行之研究,如Landauer等 人以葛羅里學術百科全書(Grolier Encyclopedia)做為語料庫,建置語意空間, 應用此語意空間比對詞彙之中的語意關係(Landauer , Foltz, & Laham, ,1998); 張國恩、宋曜廷(2005)利用LSA技術建立語意空間,運用此語意空間為基礎,設 計評量國小六年級學生閱讀摘要寫作系統,證明LSA應用在評量敘述文體時,可 區分高低能力的學生,即LSA可協助老師做摘要評量工作。LSA在國內進一步用 於國小教科書分類,黃幀祥(2011)建置一個社會科教材的語意空間,透過社會科 每個學期不同主題的特性,將程度尚未定的社會科文章分類到其所屬的層級,分 類結果準確率近乎8成,顯示LSA以語意為分析的方式,適用於重視語意的中文。 LSA不受語言限制(黃彥博、洪碧霞、蘇義翔,2011),語料庫的建置相對重要, 因此本研究選擇和學生學習關係密切的內含現行教科書文章的兒童語料庫,希望 能精確的反應受試者詞彙與語句的程度。 LSA可提供句子或段落間語意重疊的測量,LSA在Coh-Metrix中的應用,可 用 來 計 量 文 本 在 情 境 模 式 中 的 連 貫 性 (coherence) 及 文 本 內 容 的 凝 聚 力 (cohesion),藉此預測閱讀者理解文本的心理模式,可以作為匹配閱讀者先備知識 及閱讀者未讀過文本難度間的最佳文本閱讀器(Foltz., Kintsch, & Landauer, 1998.)。若LSA測得的相似程度分數下降,即表示該文本對閱讀者在閱讀理解方 面難度較高,反之則是較易閱讀的文本。(Graesser, McNamara, & Kulikowich, 2011) 。
第二節 線上文本分析系統(Coh-Metrix)
Coh-Metrix 是美國曼菲斯大學發展出的一種提供多樣化文本分析電腦自動化 工具。從 2002 年開始發展,當時沒有現成工具可提供文本多樣化的測量指標, 且傳統可讀性測量不包含一些日益被認為對文本難度有影響的因素,尤其缺乏自 動測量文本凝聚力的方法,因而發展 Coh-Metrix 系統。傳統可讀性的限制是只考 慮文本表面特徵,致使只能預測讀者表面對詞或個別句子的理解。例如:傳統可 讀性常使用的 cloze task,評估句子理解是基於詞的聯想和解碼,而非語言理解。 許多理解模式提出理解是有多層面的,包含表面、情境模式和文本基礎。單維的 理解表示忽略了讀者深層的理解,且對教學者想為學生引導對錯及導正學生時幫 助不大。Coh-Metrix 可以評估更深層的語言凝聚力及情境模式,進而評估讀者對 文本深層認知理解的程度。Coh-Metrix 系統的總體目標,希望能提供更多測量文 本複雜性的運算指標,指標包含詞的特性、句子特性及文中意思的關連性。經過 長期發展,目前已開發至 Coh-Metrix 3.0 版,包含 11 類,106 個指標。(McNamara, & Graesser, 2012)表 1 為 Coh-Metrix 3.0 版指標內容。 表 2-1 Coh-Metrix3.0 版指標 類別名稱 指標數量 1 描述性指標 11 2 文本適讀性分數 16 3 參照凝聚力 10 4 潛在語意分析 8 5 詞彙多樣性 4 6 關聯詞 9 7 情境模式 8 8 句法複雜度 7 9 句型密度 8 10 詞彙訊息 22 11 可讀性 3 總計 11 類,106 個指標 (資 料來 源: http://cohmetrix.memphis.edu/cohmetrixpr/index.html)文本凝聚力是Coh-Metrix重要的核心假設,文本凝聚力可以結合文本中事件 和所要傳達的概念,幫助閱讀者理解句子和段落之間的連接。文本概念訊息來自 詞間、句子之間的相關,通常是句子的因果形成的(Graesser, Singer, & Trabasso, 1994)。測量這些文本特徵,如引用、因果、時態和結構,並依據這些特徵所在的 位置(在段落間稱為Local LSA,橫越段落稱為Global LSA),就是文章凝聚力要素 (Givón, T. , 1995., Zwaan, R.A., 1996)。文本中的凝聚力有兩個來源:一為參照凝 聚力和語意上的重疊;當句子中的詞彙、概念,在相鄰句間或段落中重疊時,就 會構成句子之間的聯繫。另一為連接詞,連接詞可告訴閱讀者,兩種想法之間的 關係,幫助閱讀者理解此關係的方向(Graesser , McNamara , & Kulikowich , 2011.)。
高凝聚力的文本,不僅在句子間,也在全文中形成明確的線索,為讀者連接 文本想傳達的意涵。低凝聚力的文本,通常較難理解,因為文中有較少的線索連 結讀者和文本想法(McNamara , & Graesser, 2012)。許多不同模式和相關測量的研 究顯示:文本中凝聚力線索可使閱讀者理解並建構更連貫的心理表徵。因此, Coh-Metrix 提供了多樣性評估文本的指標。 胡夢珂(2010)參考Coh-Metrix 2.0版指標,選取系統中16項指標再加上自行研 究的8項指標,對國小語文科課本作年級分類,研究結果顯示對國小語文科分類 準確率約48%,在低年級文本的預測準確率較高,高年級文本預測較多錯誤。檢 視該研究,發現指標多為文本的表面特徵(字數、筆畫數、詞的種類數等),較少 考量到文本中的語意。本研究以文本中潛在語意為分析主軸,且將學科擴大為語 文科、自然科、社會科,期能考量讀者更深層的閱讀心理模式。 本研究參考 Coh-Metrix3.0 中潛在語意分析指標,加以考量中文語法,修改 計算方式,發展出四個中文文本潛在語意分析指標,含:相鄰句潛在語意關係指 標(Local LSA)、整篇文章潛在語意關係指標(Global LSA)、句子間新舊訊息潛在 語意關係指標(LSA Given-New)、句間重複動詞潛在語意關係指標(LSA verb overlap)。國外對此四個指標與文章閱讀理解曾有相關研究,但中文方面較為缺 乏,故參考國外研究方法,建置研究指標。
順序與文章的凝聚力有關,而相鄰句及整篇文章潛在語意關係指標測出的連貫 性,對文本理解是有差異的,本研究依比對句位置差異發展相鄰句及整篇文章潛 在語意關係指標,並檢視其語意關聯程度。 另文章句子間存在的新舊訊息程度對閱讀理解是一重要環節,若文章中提供 較少的舊訊息(Given),能激發閱讀者更多的詞彙知識(Chafe, 1975),而且可以較 不因依賴文章前面語句而受限(Halliday, 1967),本研究利用 LSA 技術,比對並計 算句子間新舊訊息,發展句子間新舊訊息潛在語意關係指標。而 McNamara 等 (2012)發現文本中若有動詞重複現象,其語意重複產生的凝聚力可用來補償文本 中較低的凝聚力,詞類在之前可讀性公式中是一考量因素,故本研究測量句間動 詞語意重複情況,建置句間重複動詞潛在語意關係指標。
第三節 閱讀理解
壹、閱讀理解的涵義
閱讀是學習的基礎能力,閱讀能力不佳時,對許多科目的學習影響是非常大 的。(蘇宜芬,2004)。研究閱讀的學者相當多,早期行為主義學者認為閱讀僅是 刺激和反應的聯結,只要熟練技巧,就能閱讀;之後,認知心理學家認為閱讀是 個動態的建構歷程,需要經過訊息輸入、編碼、儲存、提取到輸出,讀者在閱讀 時需探索作者表達想法,並建構自己的思維(洪月女譯,1998),即閱讀理解是閱 讀者跟閱讀素材間交互作用的過程,需牽涉到讀者先備知識,以此來解釋閱讀的 內容,建構閱讀的意義(Pearson , Johnson,1978)。由上述可知,閱讀是一種複雜的 心理認知歷程,不能僅由文字表面解碼來探究閱讀素材意義,而是需深入了解讀 者背景及心理歷程。貳、閱讀理解的發展
閱讀是學習來的(林寶貴、錡寶香,2000)。Chall(1996,引自王瓊珠、洪儷 瑜、張郁雯與陳秀芬,2008)將閱讀發展歷程分為六階段,如表 2-2,前 3 時期又 稱為「學習閱讀期」,為學習閱讀所需基礎能力階段;後 3 期為「由閱讀中學習時期」,始開始透過閱讀學習,所以本研究選擇四、六年級學生施測,符合閱讀 理解學習階段,並觀察年級差別與閱讀理解能力的關連性。 表 2-2 Chall 閱讀發展歷程 階段 階段名稱 階段年齡 階段特徵 學 習 閱 讀期 0 前閱讀期 0-6 歲 區辨字母、商標 1 識字期 1-2 年級 字母與字音的連結,較無足 夠知識獲知文章意思 2 流暢期 2-3 年級 從文章脈絡可加快閱讀速 度及流暢度 由 閱 讀 中 學 習 時期 3 閱讀新知期 4-8 年級 以閱讀來吸收知識 4 多元觀點期 8-12 年級 閱讀長度、深度及複雜度增 加的文章 5 建構、重建期 12 年級以上 閱讀時會分析、綜合,形成 自己的想法 資料來源:整理自江嘉惠(2009)
參、閱讀理解的歷程
閱讀包含許多複雜的能力,大致可分為識字和理解兩部分。Gagn’e(1993) 將閱讀歷程分為四階段,第一階段:解碼,將文字或訊息辨認出來,Gagn’e 認為 閱讀的首要工作就是認字識義。第二階段:文義理解,也就是將字義與文法結合 以瞭解句子的表面文義。第三階段:推論理解,就是個體為了獲得更深層的理解, 而將閱讀的文章加以統整、摘要或是將新的訊息與舊的知識連結起來使之精緻 化。第四個階段:理解監控。理解監控是為了確保讀者在面對閱讀目標時能夠效 率效能二者兼備(引自陳密桃,1992。) 中文部分也有學者將閱讀理解分為五階段:字彙發展階段、文意理解階段、 推論理解階段(解釋性理解)、評鑑階段(批判性理解)及欣賞性理解階段(胡永 崇,2005)。 參考上述閱讀歷程,發現閱讀理解歷程,由低層至高層能力大致可分為:識 字、推論及理解。本研究依循前述歷程及「促進國際閱讀素養研究」(Progress in International Reading Literacy Study, PIRLS)的四項閱讀理解層次:直接提取、直接學生,期能觀察年級測驗表現與閱讀歷程間的關係。
肆、閱讀理解歷程模式
閱讀理解的分析多由閱讀歷程模式推敲而得,閱讀歷程大致可分為四種模 式: 一、由下而上模式(Bottom-up model):本模式著重文本的解碼,認為閱讀應循 序漸進,由字到句,再進到全文的理解的歷程。(魏靜雯,2004) 二、由上而下模式(Top-down model):強調閱讀時會使用先備知識,不需倚賴字 或句,逐一解構文章內容(柯華葳,1993)。 三、交互模式(Interactive model):結合上述兩個模式,認為閱讀不是單向進 行的歷程,而是同時處理高層次及低層次的認知,認識詞彙可以幫助閱讀,而讀 者的先備知識則能促成閱讀理解(Rumelhart,1985)。 四、建構統整模式(Construction-Integration Model):Kintsch 在 1998 年提出 此模式,認為閱讀者是以「命題」方式來分析文章,理解的歷程是心理表徵被持 續「建構」與「統整」的循環。在建構歷程時,閱讀者會依照自己的先備知識和 文章概念,形成新的命題,接著閱讀者會將新訊息及先備知識統整,以達理解文 章涵義的目標。建構統整模式可分為「文本模式」和「情境模式」兩部份;文本 模式表示閱讀時,閱讀者會受到文章層次的命題表徵影響,情境模式則是閱讀 時,閱讀者加入自己的知識和經驗,提升自己的閱讀理解。(鍾宜軒,2010) 由上述模式可知,影響閱讀理解的因素大致可以從兩方面來看,讀者因素, 及文章方面的因素。讀者方面的因素包括:讀者的認字技能、對句法的掌握、推 論能力(inference)、先備知識或先備經驗等因素。文章方面的因素則可分為: 文章中用語的難度、文章內容連貫性(coherence)及文體結構(引自蘇宜芬, 2004)。本研究目的希望能幫助閱讀者篩選出適讀的文本,故針對會影響閱讀的 文本因素中的文章內容連貫性建置相關指標,期能藉此指標分析文本,更貼合學 生閱讀理解的歷程及能力。第三章 研究方法
本研究目的是建置潛在語意自動化分析指標,分析現行教科書文本凝聚力分 布情形;建置中文文本自動化分析系統,並以中高年級文本理解測驗,探討本研 究建置指標與閱讀間的關係。本章共分為五節,依序為研究流程、發展文本自動 化分析指標、中文文本自動化分析系統、研究對象與研究限制、研究工具及資料 分析處理,分述如下。第一節 研究流程
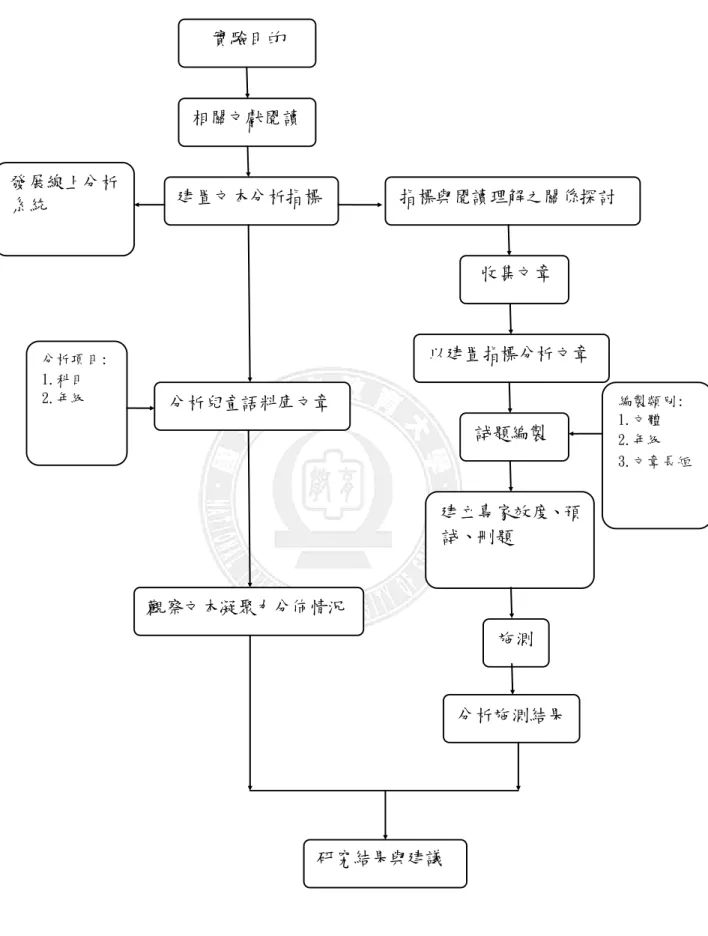
本研究參考 Coh-Metrix3.0 中 LSA 指標,選取與中文語句相關部分,修改計 算方式,使其適用於中文分析並用以建置指標。利用所建置的指標分析兒童語料 庫文章,按科目及年級觀察文章趨勢,了解國內現行兒童學習教材內容在各指標 上的分布情形。同時收集國立編譯館國語科四、六年級文章,使用本研究建置指 標分析後,按分析結果加上考量年級、文體類別及文章長短等因素,依 PIRLS 閱 讀四項理解層次編製『中高年級文本理解測驗』。在臺中市 8 所國小四、六年級 學生實際施測,針對施測結果進行分析與討論,做出結論與建議。本研究流程如 圖 3-1。圖 3-1 研究流程圖 研究結果與建議 分析項 目: 1.科目 2.年級 相關文獻閱讀 建置文本分析指標 分析兒童語料庫文章 觀察文本凝聚力分佈情況 實驗目的 建立專家效度、預 試、刪題 施測 分析施測結果 指標與閱讀理解之關係探討 以建置指標分析文章 收集文章 試題編製 編製類 別: 1.文體 2.年級 3.文章 長短 發展線上分析 系統
第二節 發展文本自動化分析指標
本 研 究 參 考 Coh-Metrix 3.0 版 的 潛 在 語 意 分 析 建 立 文 本 凝 聚 力 指 標
(MCnaamara,et al , 2012.),應用LSA數種不同文本分析指標於中文文本,觀察趨勢
並分析現況。以下就本研究建置之指標分別說明,並說明計算的方法。
壹、相鄰句潛在語意關係指標(Local LSA)
Local LSA為計算兩兩相鄰句間的文本凝聚程度。文本凝聚力即句子間的語 意相似度(similarity),是兩兩比對句子之間的餘弦值。本指標在句子之間比對方 式為:文本中第1句v.s.第2句、第2句v.s.第3句…第n-1句v.s.第n句,比對至該文本 結束。計算文本中,若比對句間餘弦值愈大,表示在語意空間中,其兩者的語意 愈相似。將文本中所有比對的兩句子間餘弦值,帶入公式3,即可計算出句子所 屬文本相鄰句子之間的關聯程度,也就是Local LSA。 1 LSA Local 1 1 1 ,
n sim n i i i (3) n 為文章的句子數,sim 為句子與句子之間的語意相似程度,i 為欲比對的句子。貳、整篇文章潛在語意關係指標(Global LSA)
Global LSA 為計算文本中句子與週遭句子的文本凝聚程度。本指標句子間比 對方式:文本中第 1 句 v.s.第 2 句、第 1 句 v.s.第 3 句…第 1 句 v.s.第 11 句;第 2 句 v.s.第 3 句…第 n 句 v.s.第 n+10 句;以此類推,每句與該句後 10 句兩兩比對, 至文本結束。 句間權重考量:因比對句間的距離不同,對語意上影響程度也會有差距,故 以句間距離倒數作為計算權重。例如:第 3 句與第 5 句間比對出潛在語意的餘弦 值,需乘上 1/(5-3),才是此兩比對句間較合宜的語意相似度。計算權重後的比對 句餘弦值帶入公式 4,公式 4 為計算整篇文章潛在語意相似度的公式。2 1 , LSA Glabol 1 , 1
n n j i sim n j j i n i (4) n 為文章的句子數,sim 為句子與句子之間的語語意相似程度,i 為欲比對的句子。參、句子間新舊訊息潛在語意關係指標(LSA Given-New)
LSA Given-New可以顯示文本中每個句子相對於該文本先前存在訊息的新/ 舊資訊程度。Given表示無論在句法或情節中,已出現過或是語意相似的訊息。 New則表示在前文中無法找到的訊息。指標比對方式:以同一篇文中每一句新句 子和之前所有句子作語意關係比較,判斷是新或舊訊息。如:第1句為文本新訊 息;第2句v.s. 第1句;第3句v.s. 第1~2句;第4句v.s. 第1~3句…第n句v.s.第1~n-1 句。當新句子向量投射到之前句子所形成平面,兩者呈平行時,即判斷該句為 Given,若投射向量為垂直時,則判定為New。(Graesser,et al , 2011.) 公式 5 為計算該文本句子之間新舊訊息潛在語意關係之公式。當文中 Given 訊息愈多,LSA Given-New 會趨近於 1。反之,當文中 Given 訊息愈少,LSA Given-New 會趨近於 0,表示文本凝聚力較低。 G N G New -Given LSA (5) G:相較對比句子,為文中舊訊息 N:相較對比句子,為文中新訊息肆、句間重複動詞潛在語意關係指標(LSA verb overlap)
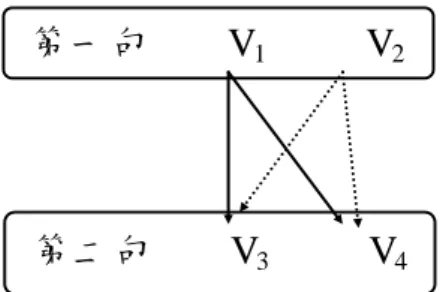
LSA verb overlap 為計算相鄰句間動詞的潛在語意關聯平均值,此為測量句 子間動詞概念相似程度。比對方式為:文本中第 1 句動詞 v.s.第 2 句動詞、第 2 句動詞 v.s.第 3 句動詞…比對至文本結束。若一句中有兩個以上動詞,比對方式 如圖 3-3 所示。V1 v.s. V3、V1 v.s. V4、V2 v.s V3、V2 v.s. V4。
圖 3-2 句子動詞比對方式 動詞通常和文本中的事件、狀態、動作有顯著的關係,當有重複的動詞時,文本 可能包含更連貫的事件結構,可促進和加強情境模式的理解。(Graesser,et al , 2011.)
第三節 中文文本自動化分析系統
本研究建置 LSA 文本自動化分析指標,並發展線上文本分析系統,使用者可 以藉由系統進行文本特徵分析,圖 3-3 到圖 3-5 為系統介面。 圖 3-3 為系統登入頁面,頁面簡述中文及英文版線上文本分析系統內容。系 統使用者需輸入申請之帳號、密碼,始能進行文本分析。 圖 3-3 中文文本自動化分析系統登入頁面 第一句 V1 V2 第二句 V3 V4登入系統後,依據本研究建置指標,點選『文章連貫性指標』標籤,會出現圖 3-4 頁面,請依頁面要求輸入文章標題、資料來源、文章內容,並勾選前在語意分析 相關指標(Local LSA、Global LSA、LSA Given/New、LSA verb overlap),接著點 選『分析文章』按鈕即可進行文章分析。
圖 3-4 系統文本輸入與指標選擇頁面
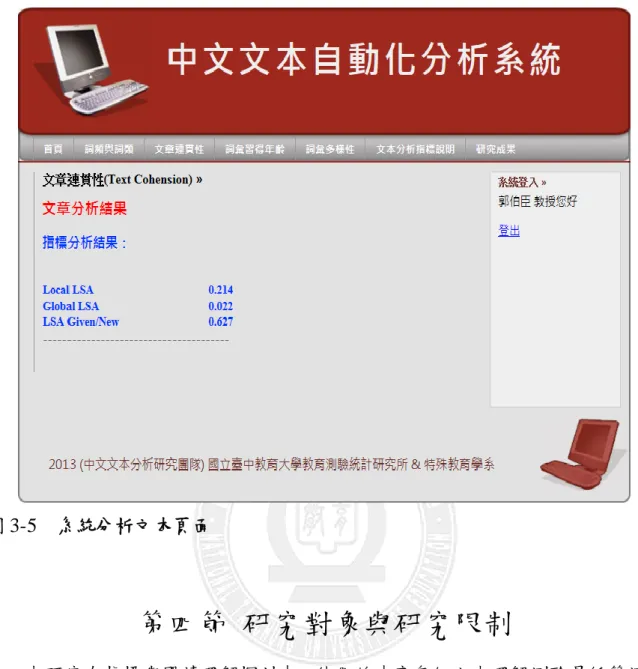
圖 3-5 為文本分析後,呈現點選指標之數值頁面。Local LSA 數值為 0.214,Global LSA 數值為 0.022,LSA Given/New 數值為 0.627。使用者可就指標數值了解文章 語意關聯程度。
圖 3-5 系統分析文本頁面
第四節 研究對象與研究限制
本研究在指標與閱讀理解探討中,使用的中高年級文本理解測驗是紙筆測驗 方式,受試者樣本取自臺中市 8 所國小四、六年級學生。現今學校採 S 型編班, 故學童的先備知識與學習能力皆為常態,測驗結果排除智能及情緒障礙的學童, 有效受試者樣本數共計 796 名學童,其中四年級學生 371 人,六年級學生 425 人。 閱讀是從零歲開始發展的,據 Chall(1996)分類,閱讀發展可分六階段,小學 三年級前為『學習閱讀』階段,需習得閱讀之基礎能力階段,如:識字、基本讀寫 等;小學四年級之後,開始透過閱讀學習,所以本研究選擇四、六年級學生施測, 符合閱讀理解學習階段,並觀察年級差別與閱讀理解能力的關連性。(王瓊珠,洪 儷瑜,張郁雯,陳秀芬,2008)本研究限制可分為對象及文本測驗兩方面探討,因本研究採用立意抽樣,僅 以臺中市國小四、六年級學生作為受試對象,研究結果不適合推論在其他地區的 學生上。而本研究文本理解測驗含八篇文章,因測驗文章樣本數較少,僅作描述 性統計。
第五節 研究工具
壹、兒童語料庫
本研究指標建置資料來源為廖晨惠(2010)之國科會「閱讀研究議題八:以 LSA 為基礎之電腦化閱讀認知測驗及 AutoTutor 建置」計畫(編號:NSC 100-2420-H-142-001-MY3)所建置的國小語料庫,共收錄經授權的 945 篇國小各版 本跨領域之課文及國語日報等文本。本研究主要分析國小一至六年級課文中國 語、自然與社會等科目,計 787 篇文章。貳、斷詞系統
本研究使用中央研究院數位典藏國家型科技計畫建置之中文斷詞系統,完成 兒童語料庫文本第一階段斷詞。中文斷詞系統包含約十萬詞的詞彙庫,另附加詞 類、詞頻、詞類頻率等資料。分詞依據為此一詞彙庫及定量詞、重疊詞等構詞規 律 及 線上 辨識 的新 詞, 並解 決分 詞歧 義問 題。 ( 中研 院中 文斷 詞系 統, http://ckipsvr.iis.sinica.edu.tw/ ) 使用中研院系統初步斷詞後,使用該系統提供的精簡詞類,精簡兒童語料庫 詞類標記,以利後續運算。檢視初步斷詞後的文本內容,發現部分詞類標記與現 代漢語不甚相符,故修改其中部分斷詞規則,完成本次兒童語料庫文本斷詞。表 3-1 為節錄本研究部份修改中研院精簡詞性後斷詞標記規則列表。表 3-1 修改斷詞標記規則 編 號 中文斷詞系統 詞性標記 修改後詞性 標記 中研院斷詞系統 完成斷詞 修改斷詞規則後 斷詞 1 (ADV)(Vi)(M) (N) (ADV)(ADJ) (M) (N) 一(ADV)小(Vi) 根(M)鐵絲(N) 一(ADV)小(ADJ) 根(M)鐵絲(N) 2 (Vi) (N) (T) (N) (ADJ) (N) (T) (N) 傳統(Vi)造形(N) 的(T)布袋戲偶 (N) 傳統(ADJ)造形 (N)的(T)布袋戲 偶(N) 3 (Vi) (Vt) (T) (N) (ADJ)(ADJ) (T) (N) 熱鬧(Vi)喧譁 (Vi)的(T)北管曲 (N) 熱鬧(ADJ)喧譁 (ADJ)的(T)北管 曲(N)
4 (Vi) (T) (N) (ADJ) (N) 快樂(Vi)的(T)
成長(N)
快樂的(ADJ)成長 (N)
5 (Vi) (N) (ADJ)(N) 小(Vi)東西(N) 小(ADJ)東西(N)
6 (Vt) (T) (N) (ADJ) (N) 溫暖(Vt)的(T)地方(N) 溫暖的(ADJ)地方 (N) 7 (Vt) (T) (Vt) (ADV) (Vt) 意想不到(Vt) 的 (T)發現(Vt) 意想不到的(ADV) 發現(Vt)
8 (N)(ADJ)(P) (N)(Vi)(P) 你(N)居住(ADJ)在
(P)
你(N)居住(Vi)在 (P)
9 (N) (ADJ) (ASP) (N)(Vi) (ASP) 小熊(N)醒(ADJ) 了(ASP) 小熊(N)醒(Vi)了 (ASP) 10 (P)(N)(N)(ADJ) (P)(N)(N)(Vi) 在(P)洞(N)裡(N) 過冬(ADJ) 在(P)洞(N)裡(N) 過冬(Vi)
參、電腦軟體應用
一、MATLAB 使用 MATLAB 軟體編寫本研究四個指標程式,並計算指標分析文本數值。 二、SPSS for windows 使用皮爾遜積差相關、迴歸分析及單因子變異數分析等方法,分析研究建置 指標、文本理解測驗及學生能力間的相關。肆、中高年級文本理解測驗
本研究除分析兒童語料庫文章,另收集國立編譯館民國七十八年,國小四、 六年級國語教科書文章。使用研究建置指標分析文章,根據指標計算結果,按年 級、文章長短及文體(記敘文、非記敘文)篩選測驗文章,並仿 PIRLS 四項閱讀理 解層次編製試題,閱讀理解層次包含:直接提取、直接推論、詮釋整合及檢驗評 估。 閱讀理解層次可依內涵性質加以分類,直接提取、直接推論屬於直接理解歷 程,詮釋整合、檢驗評估屬於詮釋理解歷程。直接提取子層次包含:(1)找出與閱 讀目標有關訊息 (2)找出特定觀點 (3)搜尋字詞或句子的定義 (4)指出故事的場 景 (5)當文章明顯陳述出來時,找出主題句或主旨。直接推論子層次包含:(1)推 論出某事件所導致的另一事件 (2)在一串的論點後,歸納出重點 (3)找出代名詞和 主詞的關係(4)歸納文章的主旨 (5)描述人物間的關係。詮釋整合子層次包含:(1) 清楚分辨出文章整體訊息或主旨 (2)考慮文中人物可選擇的其他行動 (3)比較及 對照文章訊息(4)推測故事中的情緒或氣氛(5)詮釋文中訊息在真實世界的適用 性。檢驗評估子層次包含:(1)評估文章所描述事件實際發生的可能性 (2)揣測作 者如何想出讓人出乎意料的結局 (3)評斷文章中訊息的完整性 (4)找出作者的 觀點(引自柯華葳、詹益綾、張建妤、游婷雅,2008)。 初編製中高年級文本理解測驗含中、高年級文章各四篇,記敘文、非記敘文 文章各四篇及長、短文(500 字為界線)各四篇。測驗預試對象為臺中市某國小四、 六年級學生約 60 人,原始測驗題本為 53 題單選題。經預試後,刪除通過率過高 (超過 9 成學生答對)/過低(不滿 2 成學生答對)題目或在不同年級上通過率無明 顯差異的題目,完成中高年級文本理解測驗文本,計 8 篇文章,44 題單選題。題 本內含 PIRLS 閱讀理解層次題數分布:直接提取層次 13 題,直接推論層次 12 題, 詮釋整合層次 13 題及檢驗評估層次 6 題。預試時發現:「詮釋理解層次」題目較 多的文章,通過率低於「直接理解層次」題目較多的文章。 本測驗題本經臺中教育大學三位教授,以及七位平均教學年資達十年以上的 小學現職教師共同編審而成,具有良好的專家效度。使用 SPSS 作為信度分析工具,以 Cronbach α係數檢視題本信度。據 De Vellis (1991)提出若α值大於 0.7, 表示擁有可接受的最小信度;Bryman & Cramer (1997)表示若α值大於 0.8,則是 擁有高信度。本研究中高年級文本理解測驗的信度為 0.85,表示此測驗題本為高 信度的測驗工具。且當任一試題被刪除後,發現結果對題本信度的影響不大,表 示本題本具有不錯的內部一致性。
本研究使用古典測驗理論(Classical Test Theory, CTT)及試題反應理論(Item Response Theory, IRT)兩種方式分析中高年級文本理解測驗的難度及鑑別度,因兩 理論都是現今測驗文本常使用的分析方法,CTT 題目參數雖易受樣本影響,且受 測者接受不同題目的結果較難互相比較,但 CTT 理論淺顯,實際運用便利;IRT 的參數不受樣本影響,且能估算出受試者的能力值,辨別同分者的能力高低,但 理論較艱深,施行上需有較大的樣本數。以下使用兩種理論分析測驗資料,觀察 數值的趨勢現象。 1.古典測驗理論(CTT): 古典測驗理論又稱『古典信度理論』,用來估計測驗實得分數的信度,也就是估 計實得分數和真實分數間的關聯程度,「實得分數」為「真實分數」加上「誤差 分數」,真實分數為表示研究者觀察不到,但想測量的潛在特質;誤差分數則是 研究者想去避免或降低的部分(引自余民寧,1997)。中高年級文本理解測驗在古 典測驗理論分析的平均難度為 0.6,本研究古典測驗理論的難度亦指通過率,為 所有受試者答對的百分比率,難度(通過率)愈高,表示通過人數愈多,題目愈容 易,難度愈接近 0.5,表示題本的難易適中。中高年級文本理解測驗平均鑑別度 為 0.43,鑑別度計算方法是比較高低分組受試者在個別試題上通過人數的百分 比,鑑別度愈大,愈能鑑別出高低分組的受試者。鑑別度達 0.4 以上,即試題非 常優秀。顯示本試題頗具鑑別度。 2.試題反應理論(IRT): 試題反應理論使用不受樣本影響的參數指標(難度、鑑別度、猜測度),能提供每 位受試者個別差異的測量誤差指標,精準推估每位受試者能力,所以對於相同原 始得分的受試者,可給予不同的能力估計值(引自余民寧,1997)。使用 BILOG-MG
軟體計算中高年級文本理解測驗之三參數,由三參數可得知參加測驗學生的個別 能力值,亦即是受試者答對題目的機率。能力值的計算方法如公式(6)。 ) ( ) (
1
)
1
(
)
(
i i i i b Da b Da i i ie
e
c
c
P
(6) ) ( i P :隨機取樣能力為之受試者答對第 i 題的機率 i a :題目鑑別度 bi:題目難度 i c :題目猜測度 D(scaling factor)=1.7 中高年級文本理解測驗的難度平均值為 0.112,平均鑑別度為 0.768,顯示此測驗 題本的難度適中,鑑別度頗佳。平均猜測度為 0.23,在合理猜測範圍內。 使用兩種理論分析中高年級文本理解測驗,發現學生對於不同年級文章表現 都有高度相關。表示不同年級的文章對中年級、高年級及全體受試者的測驗結果 非常一致,在六年級受試者通過率高的文章,在四年級受試者及全體受試者表 現,也會是通過率高的文章,顯示本研究中高年級文本理解測驗在學生表現上有 相當的一致性。另參與測驗的高年級受試者無論在中年級或高年級的文章,表現 皆優於中年級受試者,符合閱讀學習理論,顯示愈高年級的學生在本文本理解能 力上較佳。 以上「中高年級文本理解測驗」詳細分析數據請參閱中高年級文本理解測驗 技術報告(郭伯臣等,2013)及兒童文本詞類指標分析系統建置與應用(陳建宏, 2013)。第六節 資料處理分析
本研究處理分析的資料包括「兒童語料庫文本趨勢分析」、「建置之指標預測 文本適讀年級」、「理解層次分析」等。統計方法包含皮爾遜積差相關、迴歸與單 因子變異數分析,簡述如下:壹、皮爾遜積差相關(Pearson product-moment correlation)
本研究運用皮爾遜積差相關探討以下幾個項目:二、檢視受試學生文本通過率與研究建置指標間的關係。 三、檢視受試學生能力與閱讀理解層次的關係。
貳、迴歸分析( regression)及逐步迴歸分析(stepwise regression)
本研究使用迴歸分析方法檢視建置指標預測文本適讀年級的解釋量及閱讀理 解層次預測高低分組受試學生表現;再用逐步迴歸找出最好的預測模式。參、單因子變異數分析(One-way ANOVA)
本研究利用單因子變異數分析,檢視指標預測不同類別文本時,文本間是否 有顯著差異。第四章 研究結果與討論
本研究成果可分為兒童語料庫文本趨勢分析、指標分數預測文本適讀年級、 受試學生題本通過率與指標分數分析及受試學生與題本閱讀理解層次的關係,研 究成果分述如下。第一節 兒童語料庫文本趨勢分析
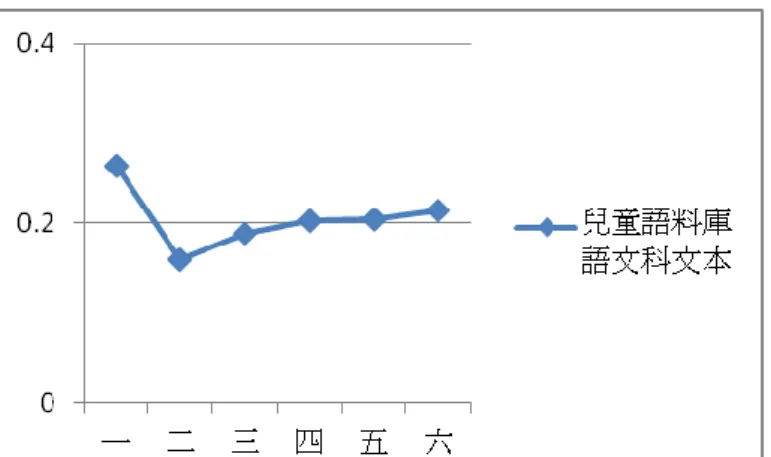
本研究運用 LSA 技術,建置中文文本分析指標,分析國小一至六年級國語、 自然與社會等科目教科書。依 LSA 指標呈現現行教科書在不同類別與年級,文 本內容凝聚力的情況,並與 Coh-Metrix 3.0 版中數據資料比較。本小節比較的 Coh-Metrix 數值,分析的文章來源為 Touchstone Applied Science Associates (TASA),內含 37651 篇文章,分為語文科、社會科及自然科三類。壹、相鄰句潛在語意關係指標(Local LSA)
Local LSA 數值越高,表示文本內容的凝聚力越好。反之,Local LSA 數值 越低,表示文本內容凝聚力愈低,愈不易理解。表4-1-1 為兒童語料庫及 Coh-Metrix 3.0 語文科文本在不同年級之 Local LSA 分析數值。圖 4-1-1 為兒童語料庫結果趨 勢圖,圖 4-1-2 為 Coh-Metrix 3.0 結果趨勢圖。結果顯示兒童語料庫文本除一年級 的 Local LSA 數值較高,其餘年級之 Local LSA 數值有隨著年級平緩上升趨勢, 與 Coh-Metrix 3.0 中 Local LSA 數值隨著年級升高趨勢符合。兒童語料庫文本一 年級數值較其他年級分析數值高,檢視文本內容,發現一年級語文科文本語句 少,用語重複性高,使文本凝聚力相對其他年級偏高。 表 4-1-1 兒童語料庫及 Coh-Metrix 3.0 語文科文本在相鄰句潛在語意關係指標 數值 研究建置 指標 年級 一 二 三 四 五 六 相鄰句潛在語意 關係指標數值 0.264 0.160 0.189 0.203 0.205 0.214 Coh-Metrix 3.0 年級 K-1 2-3 4-5 6-8 Local LSA 0.220 0.232 0.250 0.302
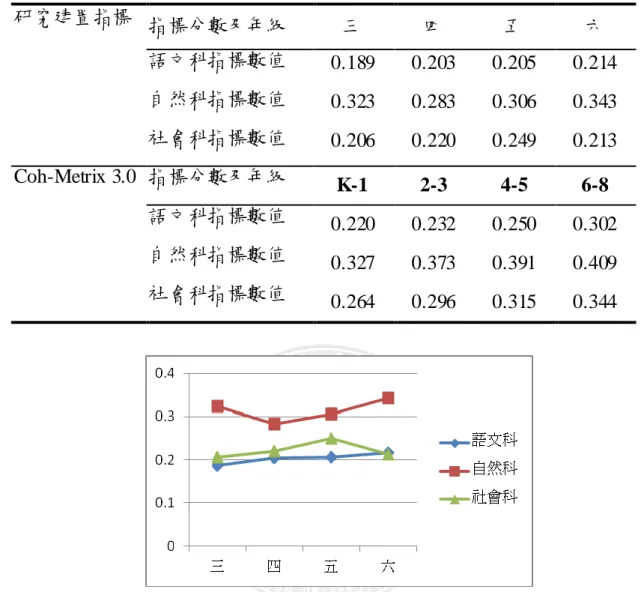
圖 4-1-1 兒童語料庫語文科文本在不同年級相鄰句潛在語意關係指標趨勢 圖 4-1-2 Coh-Metrix 3.0 語文科文本在不同年級相鄰句潛在語意關係指標趨勢 加入文本類別比較指標趨勢,本研究分析國語、自然及社會等 3 個類別並觀察其 趨勢,以了解文本類別與 Local LSA 關係,其分析結果詳見表 4-1-2 與圖 4-1-3、 圖 4-1-4。因自然科及社會科由國小 3 年級開始教授,兒童語料庫文本類別比較 3 至 6 年級。研究結果顯示兒童語料庫中不同類別文本間 Local LSA 測量的凝聚力 為:自然科>社會科>語文科,Local LSA 數值隨著年級升高,與 Coh-Metrix 3.0 趨勢相符。以單因子變異數分析,語文科和自然科、自然科和社會科間皆有顯著 差異 F(2,613)=37.83,p=.000。現行教科書中,3 年級自然數值略高,6 年級社會科 Local LSA 數值下降,語文科則是隨著年級增加而上升。文章若有較高凝聚力, 能幫助閱讀者較易理解其內容,自然科的文本內容凝聚力偏高,推論可能因為讀 者對自然方面的先備知識不足,需要較高凝聚力的內容來幫助其理解文本。
表 4-1-2 兒童語料庫及 Coh-Metrix 3.0 不同類別文本在相鄰句潛在語意關係指 標數值 研究建置指標 指標分數及年級 三 四 五 六 語文科指標數值 0.189 0.203 0.205 0.214 自然科指標數值 0.323 0.283 0.306 0.343 社會科指標數值 0.206 0.220 0.249 0.213 Coh-Metrix 3.0 指標分數及年級 K-1 2-3 4-5 6-8 語文科指標數值 0.220 0.232 0.250 0.302 自然科指標數值 0.327 0.373 0.391 0.409 社會科指標數值 0.264 0.296 0.315 0.344 圖 4-1-3 兒童語料庫不同類別文本在不同年級相鄰句潛在語意關係指標趨勢 圖 4-1-4 Coh-Metrix 3.0 不同類別文本在不同年級相鄰句潛在語意關係指標趨 勢
貳、整篇文章潛在語意關係指標(Global LSA)
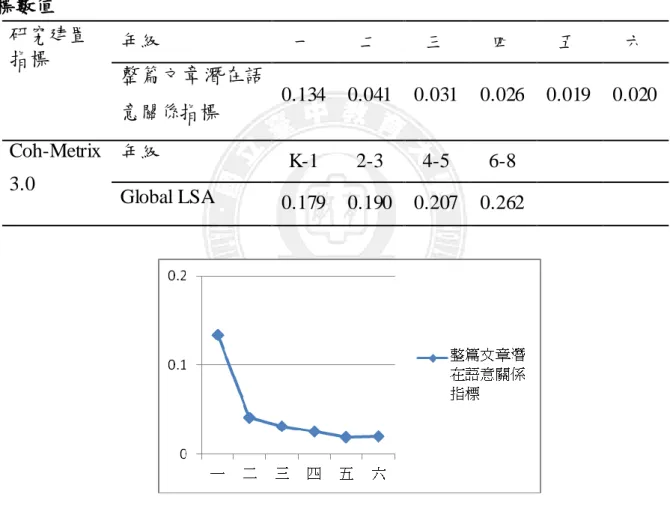
Global LSA 為橫越文本段落,運用 LSA 比對句子之間的語意關聯程度。Global LSA 會受到各段落前置標題、主旨句影響,數值越高,表示文本內容的凝聚力越 好。表 4-1-3 為語文科數值,圖 4-1-5、圖 4-1-6 為趨勢分析圖,顯示國內現行 教科書在語文科的 Global LSA 數值,除一年級數值較高,其餘隨年級升高逐年下 降。與 Coh-Metrix 3.0 Global LSA 數值隨著年級逐漸上升的趨勢相反。
表4-1-3 兒童語料庫及 Coh-Metrix 3.0 語文科文本在整篇文章潛在語意關係指 標數值 研究建置 指標 年級 一 二 三 四 五 六 整篇文章潛在語 意關係指標 0.134 0.041 0.031 0.026 0.019 0.020 Coh-Metrix 3.0 年級 K-1 2-3 4-5 6-8 Global LSA 0.179 0.190 0.207 0.262 圖 4-1-5 兒童語料庫語文科文本在不同年級整篇文章潛在語意關係指標趨勢
圖 4-1-6 Coh-Metrix 3.0 語文科文本在不同年級整篇文章潛在語意關係指標趨 勢
加入文本類別後,比較 Global LSA 在國內現行教科書及 Coh-Metrix 3.0 表現 趨勢,如表 4-1-4 與圖 4-1-7、圖 4-1-8 所示。顯示國內現行教科書在不同類別文 本的 Global LSA 數值都隨著年級逐年下降。文本類別的 Global LSA:自然>社會、 語文,三個科目之間皆有顯著的差異 F(2,613)=24.455,p=.000。文本整體凝聚力指 標,與文章是否有標題或段落前是否有主題句相關(Gernsbacher, 1990.),中文文 本在語文科及社會科中較少此類編排方式,唯自然科在每一小節前,加入實驗關 鍵字、原理名稱,使文本整體凝聚力指標數值較高。 表4-1-4 兒童語料庫及 Coh-Metrix3.0不同類別文本在整篇文章潛在語意關係指 標數值 研究建置指標 指標分數及年級 三 四 五 六 語文科指標數值 0.031 0.026 0.019 0.020 自然科指標數值 0.095 0.087 0.048 0.060 社會科指標數值 0.031 0.036 0.022 0.016 Coh-Metrix 3.0 指標分數及年級 K-1 2-3 4-5 6-8 語文科指標數值 0.179 0.19 0.207 0.262 自然科指標數值 0.205 0.252 0.275 0.31 社會科指標數值 0.156 0.202 0.229 0.277
圖 4-1-7 兒童語料庫不同類別文本在不同年級整篇文章潛在語意關係指標趨勢 圖 4-1-8 Coh-Metrix 3.0 不同類別文本在不同年級整篇文章潛在語意關係指標 趨勢
參、句子間新舊訊息潛在語意關係指標(LSA Given-New)
Given 表示在文本中,已出現過或是語意相似的訊息。New 則表示在前 文中沒有出現過的訊息。因此,當文本 LSA Given-New 越接近 1,表文本中可回 復的舊訊息較多,文本凝聚力會較高,較易閱讀。表 4-1-5 為現行教科書及 Coh-Metrix3.0 在語文科 LSA Given-New 數值,圖 4-1-9、圖 4-1-10 為上述實驗數 值趨勢圖。結果顯示現行教科書隨著年級增加,文本句間新舊訊息潛在語意關係 也會上升,Coh-Metrix 數據顯示國外文本中,句子間新舊訊息潛在語意關係維持 平穩趨勢,不因年級改變而變。表4-1-5 兒童語料庫及 Coh-Metrix3.0語文科文本在句子間新舊訊息潛在語意關 係指標數值 研究建置指標 年級 一 二 三 四 五 六 新舊訊息潛在 語 意關係指標 0.368 0.400 0.478 0.520 0.612 0.613 Coh-Metrix 3.0 年級 K-1 2-3 4-5 6-8 LSA Given-New 0.380 0.352 0.343 0.348 圖 4-1-9 兒童語料庫語文科文本在不同年級句子間新舊訊息潛在語意關係指標 趨勢 圖 4-1-10 Coh-Metrix 3.0 語文科文本在不同年級句子間新舊訊息潛在語意關係 指標趨勢
加入文本類別比較。圖 4-1-11、圖 4-1-12 顯示在 Coh-Metrix 中,不同類別文 本的句間新舊訊息潛在語意關係非常相近,現行教科書版本中,語文科文本在此 項目的關聯性較低。 表4-1-6 兒童語料庫及 Coh-Metrix3.0不同類別文本在句子間新舊訊息潛在語意 關係指標數值 研究建置指標 指標分數及年級 三 四 五 六 語文科指標數值 0.478 0.520 0.612 0.613 自然科指標數值 0.544 0.606 0.657 0.671 社會科指標數值 0.593 0.616 0.786 0.722 Coh-Metrix 3.0 指標分數及年級 K-1 2-3 4-5 6-8 語文科指標數值 0.38 0.352 0.343 0.348 自然科指標數值 0.413 0.421 0.419 0.416 社會科指標數值 0.377 0.376 0.374 0.374 圖 4-1-11 兒童語料庫不同類別文本在不同年級句子間新舊訊息潛在語意關係指 標趨勢
圖 4-1-12 Coh-Metrix3.0 不同類別文本在不同年級句子間新舊訊息潛在語意關 係指標趨勢
肆、句間重複動詞潛在語意關係指標(LSA verb overlap)
LSA verb overlap 為計算相鄰句間動詞的潛在語義餘弦平均值,此為測量句子 間動詞概念相似程度,動詞通常和文本中的事件、狀態、動作有顯著的關係。當 有重複的動詞時,文本可能包含更連貫的事件結構,可促進和加強情境模式的理 解。
從圖 4-1-13、圖 4-1-14 可發現,一、二年級的 LSA verb overlap 數值相當, 且高於其他年級。年級愈高,句間重複動詞潛在語意關係有下降的趨勢。
Coh-Metrix 數值發現 LSA verb overlap 在 2-3 年級語文科文本有下降的的現象。
表 4-1-7 兒童語料庫及 Coh-Metrix3.0 語文科文本在句間重複動詞潛在語意關係 指標數值 研究建置指標 年級 一 二 三 四 五 六 句間重複動詞潛在語意關 係指標 0.254 0.253 0.228 0.221 0.219 0.225 Coh-Metrix 3.0 年級 K-1 2-3 4-5 6-8
圖 4-1-13 兒童語料庫語文科文本在不同年級句間重複動詞潛在語意關係指標趨 勢 圖 4-1-14 Coh-Metrix3.0 語文科文本在不同年級句間重複動詞潛在語意關係指 標趨勢 比較國語、自然及社會科文本,圖 4-1-15、圖 4-1-16 顯示不同類別文本句間 重複動詞潛在語意自然科文本在此項目的關聯性較高,且自然科和社會科間有顯 著差異 F(2,613)=5.4,p=.005。 表 4-1-8 兒童語料庫及 Coh-Metrix3.0 不同類別文本句間重複動詞潛在語意關係 指標數值 研究建置指標 指標分數及年級 三 四 五 六 語文科指標數值 0.228 0.221 0.219 0.225 自然科指標數值 0.257 0.250 0.239 0.242
社會科指標數值 0.233 0.232 0.214 0.211 Coh-Metrix 3.0 指標分數及年級 K-1 2-3 4-5 6-8 語文科指標數值 0.082 0.071 0.077 0.080 自然科指標數值 0.112 0.111 0.112 0.114 社會科指標數值 0.121 0.110 0.105 0.102 圖 4-1-15 兒童語料庫不同類別文本在不同年級句間重複動詞潛在語意關係指標 趨勢 圖 4-1-16 Coh-Metrix3.0 不同類別文本在不同年級句間重複動詞潛在語意關係指 標趨勢
伍、綜合討論
利用指標檢視兒童語料庫文章,發現建置指標與文本年級間的變化有關。
Local LSA、LSA Given-New 數值隨著年級升高,Global LSA、LSA verb overlap 數值有隨著年級下降的趨勢。
一年級語文科文本語句少,用語重複性高,使文本凝聚力(Local LSA、Global LSA、LSA verb overlap)相對其他年級偏高。國內教科書編排方式也會影響文本 凝聚力,如 Global LSA 與文章是否有標題或段落前是否有主題句相關,中文文本 較少此類編排方式,唯自然科在每一小節前,加入實驗關鍵字、原理名稱,使文 本整體凝聚力指標數值較高。不同科目間的文本凝聚力也有顯著的差異,通常自 然科的文本內容凝聚力偏高,推論可能因為讀者對自然方面的先備知識不足,需 要較高凝聚力的內容來幫助其理解文本。
第二節 指標分數預測文本適讀年級
本節運用研究建置之中文文本分析指標,分析兒童語料庫文本,計算一到六 年級文本在四個建置指標的數值,檢視指標數值與文本年級間的相關,發展出最 佳指標預測年級模式。為方便呈現,將動詞重複潛在語意關係指標訂為指標 1, 相鄰句潛在語意關係指標為指標 2,全篇文章潛在語意關係指標為指標 3,新舊 訊息潛在語意關係指標為指標 4。壹、檢視個別文本分析指標與兒童語料庫文本適讀年級之相關
表 4-2-1 為 4 個建置指標與一到六年級文本間的相關。所有指標與年級間的 相關係數皆達顯著,表示 4 個指標對於文本年級的判別都有其重要性。相鄰句潛 在 語意 關係指 標與 新舊 訊息潛 在語 意關係 指標 和年級 成正 相關 (r =.104 和.575),表示兩個指標計算文本數值,數值愈高,分析出的文本年級愈高。動 詞重複潛在語意關係指標和全篇文章潛在語意關係指標與對預測文本年級和年 級成負相關(r=-.117 和.-.363),表示指標計算文本的數值愈高,分析出的文本 年級愈低。其中新舊訊息潛在語意關係指標分析年級的能力優於其他三者。表 4-2-1 個別指標與文本年級之間相關係數表 變項 動詞重複數值 相鄰句數值 全篇文章數值 新舊訊息數值 年級 -.117* .104** -.363** .575** *p<.05 **p<.01
貳、檢視文本分析指標與兒童語料庫文本適讀年級之預測度
本小節以多元迴歸分析探討研究建置文本分析指標與兒童語料庫文本適讀 年級之預測度。表 4-2-2 為指標變項預測文本年級模式。結果顯示,4 個指標對 文本年級的整體解釋量可達 60.7%,表示指標對文本年級的預測度頗佳。相鄰句 潛在語意關係指標與新舊訊息潛在語意關係指標和年級成正相關(β=.103 和.594),動詞重複潛在語意關係指標和全篇文章潛在語意關係指標與對預測文本 年級和年級成負相關(β=-.131 和.-.521)。新舊訊息潛在語意關係指標分析年級的 能力優於其他三者。指標預測文本年級公式,迴歸方程式如公式(7)。 Y=1.212 +(-2.073)*指標 1 +1.566*指標 2 +(-13.452)*指標 3 +6.162*指標 4 (7) Y:文本年級 表 4-2-3 指標變項預測文本年級模式多元迴歸分析摘要表 未標準化係數 標準化係數 R2 B 之估計值 標準誤 β 分配 常數 1.212 0.200 動詞重複數值 - 2.073 0.533 -0.131*** .611*** 相鄰句數值 1.556 0.915 0.103*** 全篇文章數值 - 13.452 1.260 - 0.521 新舊訊息數值 6.162 0.443 0.594*** *p<.05 **p<.01 ***p<.001 實測文本時,將文章放入各指標計算數值,文本 A 為選自國編版 4 年級課文,帶 入預測文本年級公式,數值呈現如表 4-2-4。可得到文本 A 的預測結果 Y=3.9, 預測文本為接近 4 年級程度文本。表 4-2-4 計算文本指標變項數值 動詞重複指標 相鄰句指標 全篇文章指標 新舊訊息指標 文本 A 數值 0.219 0.092 0.008 0.510 進一步使用逐步迴歸分析來檢視指標數值與文本年級間的預測度。表 4-2-5 為指標變項預測文本年級模式逐步迴歸分析摘要表。依據逐步迴歸分析模式,可 發展出最佳指標預測年級文本公式,最佳預測迴歸方程式如公式(8)。新舊訊息 潛在語意關係指標與預測文本適讀年級關係最密切,單一指標解釋量為 36.9%, 且達顯著,後依序放入全篇文章潛在語意關係指標、動詞重複潛在語意關係指 標,其二者個別解釋量分別為 22.7%及 1.2%,逐步迴歸分析中排除了相鄰句潛在 語意關係指標,其對文本年級預測的貢獻性最小。 Y=1.129 +(-1.769)*指標 1 + (-11.820)*指標 3 +6.674*指標 4 (8) Y:文本年級 表 4-2-5 指標變項預測文本年級模式逐步迴歸分析摘要表 預測變項 未標準化係數 標準化係數 R2 △R2 B 之估計 值 標準誤 β 分配 常數 1.129 0.195 新舊訊息數值 6.674 0.325 .643*** .369**** .369 全篇文章數值 - 11.820 0.818 –.458*** .596*** .227 動詞重複數值 - 1.769 0.504 –.112*** .608*** .012 *p<.05 **p<.01 將前文中預測的文本 A 放入最佳預測迴歸方程式,文本 A 的預測結果 Y=4.0, 預測文本 A 為 4 年級文本,與文本實際適用年級相符。
第三節 題本通過率與指標分數分析
本節為檢視受試學生在中高年級文本理解測驗上的表現與研究建置指標間 的關係。壹、不同年級受試學生文章通過率與研究建置指標數值的相關
表 4-3-1 為研究建置指標分析中高年級文本理解測驗文本的數值,相鄰句潛 在語意關係指標和新舊訊息潛在語意關係指標數值隨著年級上升,句間重複動詞 潛在語意關係指標數值隨著年級而下降,與兒童語料庫趨勢相似。 表 4-3-1 中高年級文本理解測驗在研究建置指標數值 年級 四 六 相鄰句潛在語意關係指標數值 0.070 0.086 整篇文章潛在語意關係指標 0.005 0.005 新舊訊息潛在語意關係指標 0.406 0.456 句間重複動詞潛在語意關係指標 0.171 0.129 表 4-3-2 為受試學生文章通過率與研究建置指標分析文本數值間的關係。在 古典測驗理論中,動詞重複潛在語意關係指標、相鄰句潛在語意關係指標、全篇 文章潛在語意關係指標與文章通過率成正相關,表示文章通過率高的文章,在動 詞重複、相鄰句及全篇文章潛在語意關係指標數值會越高。其中動詞重複潛在語 意關係指標達中度相關(r =.586 ~.593),顯示文章通過率高低與文章中動詞語 意重複情況有較高的關係。而新舊訊息潛在語意關係指標數值與文章通過率呈現 低度相關,甚至有負相關情形,顯示文章中舊訊息愈多,對文章的通過率影響較 少。 試題反應理論中,也呈現類似情況,動詞重複潛在語意關係指標、相鄰句潛 在語意關係指標、全篇文章潛在語意關係指標與文章通過率成正相關。動詞重複 潛在語意關係指標達中度相關(r =.479 ~.571),對文章通過率的影響較高;新 舊訊息潛在語意關係指標呈負相關,顯示文章中舊訊息越多,對文章通過率會有負向的影響。 表 4-3-2 指標分數與不同年級受試學生在題本八篇文章通過率的相關係數摘要表 古典測驗理論 試題反應理論 中年級 通過率 高年級 通過率 所有受試者 通過率 中年級 通過率 高年級 通過率 所有受試者 通過率 動詞重複數值 .586 .595 .593 .571 .479 .523 相鄰句數值 .219 .308 .270 .199 .199 .200 全篇文章數值 .249 .259 .255 .243 .150 .194 新舊訊息數值 –.028 .057 .020 –.106 –.141 –.125