國 立 交 通 大 學
資訊科學與工程研究所
博
士
論
文
應用於雜訊網路通道具容錯能力的可調式視訊傳輸
之研究
Efficient Error-Tolerant Design for Scalable Video Transmission over
Error-Prone Channels
研 究 生:何健鵬
指導教授:李素瑛 教授
應用於雜訊網路通道具容錯能力的可調式視訊傳輸之研究
Efficient Error-Tolerant Design for Scalable Video Transmission over
Error-Prone Channels
研 究 生:何健鵬 Student:Chien-Peng Ho
指導教授:李素瑛 Advisor:Suh-Yin Lee
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
博 士 論 文
A DissertationSubmitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Doctor of Philosophy
in
Computer Science
February 2012
應用於雜訊網路通道具容錯能力的可調式視訊傳輸之研
究
研究生: 何健鵬
指導教授: 李素瑛 博士
國立交通大學資訊科學與工程研究所
摘要
近年來因為寬頻服務的日趨成熟,多媒體串流技術和點對點(P2P)分散式
網路架構的隨選視訊點播服務的傳輸與流通量也越來越大,在現有的網
路傳輸系統中,存在封包遺失累積問題,因此穩定可靠的多媒體數據傳
輸方法正成為越來越重要的研究主題。其中,在典型的多媒體通信應用
中高效率容錯和錯誤恢復能力的演算法透過分析和數值方法來實現多目
標優化性能指標的有效技術。與傳統數據通信的特點相較,多媒體串流
有四個方面的主要差別: (1)、封包丟失是視訊串流品質不確定性的主要
原因之一,並可能會導致許多有價值的視訊資訊缺失,進而造成影像品
質嚴重下降。(2)、總頻寬的需求仍遠遠超過了現有的通信網絡基礎設施
(如:支援高品質視訊隨選點播服務)。(3)、雖然在客戶端的緩衝器設計
可以吸收傳輸速率的變化,但這不足以保證多媒體串流的服務品質(如:
網路電視和網路電話)。(4)、雖然大多數的多媒體數據壓縮傳送允許應
用在漏失封包和多錯誤的網路環境,並且由於人類視覺感知系統對於某
些影像的變化不夠敏感,因此能容忍有某些程度的影像品質下降。進
而,在視頻傳輸可調式編碼的基礎上使用錯誤控制和非均等錯誤保護碼
可以是一個廣為被接受的方法來改善接收到的視訊品質。
在本論文中我們針對視訊串流在不斷變化的網路條件中,提出可
擴展性、具錯誤容忍度和有效的錯誤保護的演算法,來達成系統優化性
能之有效視訊傳輸技術。我們針對在漏失封包和多錯誤的網路環境下提
出一個三維小波可調式視訊編碼演算法為基礎的內容自適應之錯誤保護
技術,利用細緻可調式的方式去增強資料錯誤的保護能力。所提出的細
緻可調式之錯誤保護演算法可在視訊編碼率和影像失真之間選擇一個適
當的折衷,以適切決定可調式視訊編碼率和通道編碼-前向錯誤更正碼的
保護安排。實驗結果顯示,確實能達成在多媒體數據傳輸應用中重建視
訊品質和系統容錯能力之間的平衡。在P2P分散式網路架構的視訊串流之
研究中,我們結合非結構性對等網路運算與隨選視訊技術,發展一套以
視訊編碼之失真模型為基礎的複本容錯機制,希望藉由有效的佈建高視
訊品質影響及高點播率之複本於點播視訊流中高失真區
與非連續區域來
提升整體服務成效。根據模擬實驗證明我們所提的方法,相對於其它的
容錯機制,在點對點網路環境中廣泛存在的搭便車 (free-rider) 現象出現
時亦可有效的降低終端使用者間影像品質損失,並在不同點對點網路條
件下能有較穩定的視訊撥放品質。整體而言本方法可以有效降低隨選視
訊服務伺服器的工作負載。
關鍵詞:多媒體通信、錯誤保護、隨選視訊、點對點同儕式網路、容錯設
計。
Efficient Error-Tolerant Design for Scalable Video
Transmission over Error-Prone Channels
Student: Chien-Peng Ho
Advisor: Dr. Suh-Yin Lee
Institute of Computer Science and Information Engineering
National Chiao Tung University
Abstract
Due to the growing maturity of broadband services, multimedia streaming systems and peer-to-peer on demand service are gaining vast popularity in recent times. Stable and reliable transmission of multimedia data is becoming increasingly important for multimedia communication over networks subject to packet erasures. To achieve stability and reliability, efficient fault-tolerant and error-resilience methods for multimedia communication are typical analytical and numerical approaches, so as to attain multi-objective performance metrics. The characteristics of video traffic differ substantially from those of traditional data traffic in four ways. First, packet loss is the major cause of nondeterministic distortion on the Internet and may have significant impact on perceptual quality of the streaming video. Second, aggregate bandwidth requirements, supporting video-on-demand services, are still far in excess of the existing communication network infrastructure. Third, although buffering on the client side can provide an opportunity to absorb variations in transmission rates, it is not sufficient to guarantee the service quality of multimedia streams like IPTV (Internet Protocol television) and VoIP (Voice over IP). Finally, most compressed media data are transmitted over lossy and error-prone networks, and a certain degree of quality degradation is tolerable due to noise in some regions which are below the threshold of human visual perception. Thus, video transmission based on scalable coding and unequal error protection codes can be one of the approaches of maintaining acceptable media quality in a network. Error control for video communication and resource allocation in peer-to-peer multimedia systems remain open issues and are the
focus of this work.
In this thesis, we built scalable, error-resilient, and high-performance multimedia frameworks to adapt to changing network conditions. We developed a framework of fine-level packetization schemes for the streaming of 3D wavelet-based video content over lossy packet networks. An adaptive fine-granularity unequal error protection algorithm was proposed to allow a tradeoff between rate and distortion, and jointly adopt scalable source coding rates and the level of FEC protection. Experimental results show that the proposed framework strikes a fine balance between the reconstructed video quality and the level of error protection under time-varying lossy channels. In the study of P2P video streaming, we developed a replication strategy to optimize resource allocation based on the video-distortion technique for unstructured P2P overlay networks. Failure recovery action can be accomplished by distributing high quality impact and popular replicas to regions of low peers density or discontinuous areas. The results demonstrated the efficiency and robustness of the proposed method at compensating for network-induced errors, and the framework can be applied at a range of different scales of free-riding peers. Moreover, the proposed algorithm was able to handle the load imposed on the system efficiently and improved average visual quality in the overall system.
Keywords: multimedia communication, error protection, video-on-demand, peer-to-peer,
Acknowledgments
I would like to express my sincere gratitude and appreciation to my advisor, Professor Suh-Yin Lee, for her constant advice and guidance in conducting this research work. I have really appreciated the candor and frankness of her comments, and I have learned tremendously from her. It is impossible for me to complete this dissertation without her expert guidance. I would also like to thank my dissertation committee members, Professor Ja-Ling Wu, Kuo-Chin Fan, Long-Wen Chang, Hong-Yuan Mark Liao, Hsueh-Ming Hang, and Hsu-Feng Hsiao for their helpful suggestions, time and advice.
I would like to give a special acknowledgment to Professor Chia-Ling Hsieh and Sheau-Ling Hsieh for encouraging me to finish this work no matter what difficulties I have met. Sincere appreciation extends to all my friends and the members of the Information System Laboratory for sharing their research experiences.
Finally, my deepest thanks go to my family for their encouragement and support. This dissertation is dedicated to them.
Table of Contents
摘要... i Abstract...iii Acknowledgments... v Table of Contents ... vi List of Figures... ixList of Tables ...xiii
Chapter 1 Introduction ... 1
1.1 Motivation - the Impacts of Network-based Multimedia Services... 1
1.1.1 Packet Loss ... 2
1.1.2 Bandwidth... 3
1.1.3 Client-side Buffer ... 5
1.1.4 Packet Dependency Control... 7
1.2 Research Objectives and Contributions ... 8
1.3 Synopsis of the Dissertation ... 9
Chapter 2 Background and Survey of Related Work... 11
2.1 Wavelet-based Video Coding System... 11
2.1.1 Overview of the 3D Wavelet Codec... 11
2.1.2 Bitstream and R-D Information ... 14
2.2 Robust Internet Video Transmission based on Scalable Coding Streams ... 17
2.1.1 Two Basic Approaches to Error Correction ... 17
2.1.2 Rate-Distortion Optimized Packet Scheduling... 18
2.2 An Overview on Peer-to-peer Video Systems with Scalable Coding Streams... 20
2.2.1 Comparison between IP Multicast and Peer-to-Peer Networks... 21
2.2.2 Difference between Streaming-based and File-based P2P Media Systems . 22 Chapter 3 Fine-level Packetization and Streaming of Wavelet Video over IP Networks ... 25
3.1 Introduction ... 25
3.2 Investigation of Wavelet Video Bit Streams with Data Losses ... 29
3.2.1 Fine-level adaptive FEC Protection of Wavelet Coefficients... 34
3.2.2 Multiple-adaptation and Fine-level FEC Using R-λ Curve Fitting Function ... 35
3.3 The Proposed Packetization Scheme and Streaming Framework ... 40
3.3.1 Packetization of FEC-protected Data... 41
3.3.2 Streaming Policy... 42
3.4 Experiments... 43
3.4.1 Fine-level FEC Protection Experiments... 45
3.4.2 Fine-level FEC Protection Experiments based on R-λ Curve Fitting Function... 51
3.5 Summary ... 54
Chapter 4 Rate-Distortion Optimized Video Streaming with Smooth Quality Constraint ... 55 4.1 Introduction ... 55 4.2 System Overview... 57 4.2.1 System Architecture... 58 4.2.2 Source Model... 58 4.2.3 Channel Model... 59
4.3 Integrated R-D Optimized Policy Selection... 59
4.3.1 Integration of Quality Smoothness Constraint into the R-D Framework . 60 4.3.2 Importance Function ... 62
4.3.3 Transmitting a GOP of Data Units ... 63
4.4 Experimental Results... 63
4.5 Summary ... 66
Chapter 5 Efficient Data Replication for the Delivery of High-quality Video Content over P2P VoD Advertising Networks... 68
5.2 Previous Studies ... 73
5.3 System Design ... 75
5.3.1 Peer-Attributes Related to Data-sharing ... 75
5.3.1.1 Channel Model of Peers ... 76
5.3.1.2 Channel Sharing Ability of Peers ... 78
5.3.2 The Distortion Estimation in the Packet Bit-stream... 79
5.3.3 Advertising Strategies on the P2P VoD network ... 84
5.4 Proposed Advertising P2P VoD Framework for Wavelet Bit-streams... 85
5.5 Simulation Experiments ... 90
5.5.1 Experimental Setup... 91
5.5.2 Server Load Analysis... 93
5.5.3 Advertising-delivery Rate Analysis ... 95
5.5.4 Analysis of Peer Departure Misses... 96
5.5.5 Impact of Free-riding Peers ... 97
5.6 Summary ... 99
Chapter 6 Concluding Remarks and Future Works ... 100
6.1 Concluding Remarks ... 100
6.1.1 Comments on Fine-level Packetization Design... 100
6.1.2 Comments on Fault-tolerance P2P VoD System Design... 101
6.2 Future Work ... 102
References... 104
List of Figures
Figure 1-1: An example of a Client/Server streaming application. ... 5
Figure 1-2: Client-side buffering... 6
Figure 1-3: Directed acyclic dependency graph. ... 7
Figure 2-1: Wavelet video coding block diagram ... 12
Figure 2-2: Examples of coding block in wavelet video coding... 12
Figure 2-3: 3D ESCOT entropy coding... 13
Figure 2-4: The R-D curve of coding block 0 of subband P(Ht,Y)of STEFAN. ... 13
Figure 2-5: MSRA Wavelet bitstream format (please note that there is no need to enforce layer structure for MCTF-based wavelet bitstreams)... 15
Figure 2-6: An example data of the first GOP of Stefan (2048 kbps, CIF, PSNR: 41.13 db, GOP size: 64)... 15
Figure 2-7: 10% of data loss of blocks 1 on the P(Ht,Y) subband (Stefan, CIF, 150 frames, 15 fps, GOP = 64, target bitrates: 2048k). ... 16
Figure 2-8: The set of R-D pairs, its lower convex hull, and an achievable pair (R, D)... 19
Figure 2-9: Trellis for a Markov decision process. Final state is indicated with double circles... 19
Figure 2-10: An example of P2P overlay network. ... 20
Figure 2-11: A Comparison of the P2P file sharing and P2P streaming scheme. ... 23
Figure 3-1: Reconstructed video when a chunk of TSB data is lost. The loss occurs in coding block 0 of SSB 0 for the TSB in (a)–(d), and coding block 0 of SSB 18 for the TSB in (e)-(f ). ... 30
Figure 3-2: Source data rate in SSB 0 of subband P(Ht, Y) of STEFAN. ... 30
Figure 3-3: Source data rate of coding passes on the convex hull in the block 0 of STEFAN. ... 31
Figure 3-4: R-D curves of STEFAN with 10% loss of coding passes in SSB 0 of the TSB P(Ht, Y). ... 31 Figure 3-5: PSNR of STEFAN with 10% loss of coding passes (CP) in block 0 of SSB 0 of
the TSB P(Ht, Y). ... 32
Figure 3-6: Example overhead of fine-level FEC protection for different rate points within a coding block. ... 33
Figure 3-7: An (n, k) RS codeword with k symbols of video data and 2s symbols of parity. ... 34
Figure 3-8: Two examples of multiple adaptation applications where the same video content is adapted several times down the distribution chains... 36
Figure 3-9: R-λ curve fitting function of STEFAN in block 0 of SSB 0 of the TSB P(Ht, Y) ... 38
Figure 3-10: Packetization for one GOP of video data... 42
Figure 3-11: Data-interleaving scheme for one GOP of video data... 42
Figure 3-12: Redundancy packets for protect source packets one group of video data. ... 43
Figure 3-13: Architecture of the proposed video streaming system. ... 44
Figure 3-14: A comparison of the R-D curves for the fixed FEC and fine-level FEC protection (both protection levels are for 4% packet loss) using the STEFAN sequence. ... 46
Figure 3-15: A comparison of the R-D curves for the fixed FEC and fine-level FEC protection (both protection levels are for 4% packet loss) using the MOBILE sequence. ... 46
Figure 3-16: A comparison of the R-D curves for the fixed FEC and fine-level FEC protection (both protection levels are for 4% packet loss) using the TABLE TENNIS sequence... 47
Figure 3-17: A comparison of the R-D curves for the fixed FEC and fine-level FEC protection (both protection levels are for 4% packet loss) using the FOREMAN sequence. ... 47
Figure 3-18: A comparison of the R-D curves for the fixed FEC and fine-level FEC protection (both protection levels are for 4% packet loss) using the COASTGUARD sequence... 48 Figure 3-19: Comparison of R-D curves of STEFAN without and with different FEC
protections in an error-free environment (FL: Fine-level, FX: Fixed-level). ... 48
Figure 3-20: Comparison of R-D curves of MOBILE without and with different FEC protections in an error-free environment (FL: Fine-level, FX: Fixed-level). ... 49
Figure 3-21: Comparison of R-D curves of TABLE TENNIS without and with different FEC protections in an error-free environment (FL: Fine-level, FX: Fixed-level).49 Figure 3-22: Comparison of R-D curves of FOREMAN without and with different FEC protections in an error-free environment (FL: Fine-level, FX: Fixed-level). ... 50
Figure 3-23: Comparison of R-D curves of COASTGUARD without and with different FEC protections in an error-free environment (FL: Fine-level, FX: Fixed-level).50 Figure 3-24: Fine-level FEC test for the STEFAN sequence ... 51
Figure 3-25: Fine-level FEC test for the MOBILE sequence ... 52
Figure 3-26: Fine-level FEC test for the TABLE TENNIS sequence... 52
Figure 3-27: Fine-level FEC test for the FOREMAN sequence ... 53
Figure 3-28: Fine-level FEC test for the COASTGUARD sequence ... 53
Figure 4-1: An example of video quality change when the network bandwidth varies drastically (Carphone sequence). ... 56
Figure 4-2: System architecture of the proposed streaming system. ... 57
Figure 4-3: Directed acyclic dependence graphs of FGS video... 58
Figure 4-4: Channel model of the proposed scheme. ... 59
Figure 4-5: An illustrating example to determine how many layers of each frame need to be transmitted. ... 61
Figure 4-6: An example with a truncated group of data units. ... 62
Figure 4-7: PSNR versus each frame at bandwidth of 300kbps. ... 64
Figure 4-8: Variance for different rate-constraint. ... 64
Figure 4-9: Delivered frame size vs. frame number during streaming ... 65
Figure 4-10: The system performance of the variable transmission rate. ... 66
Figure 4-11: The frame size variation during a streaming session. ... 66
Figure 5-1: Existing advertising mechanisms... 71
Figure 5-3: Communication latency experienced on path k within the time-to-live: 2... 77
Figure 5-4: The t+2D coding structure of a wavelet encoder. ... 80
Figure 5-5: Distribution of R-D slopes... 81
Figure 5-6: The distribution of block data rates. ... 81
Figure 5-7: Wavelet Bitstream Format... 83
Figure 5-8: Peers at GOP boundaries. ... 83
Figure 5-9: The operational scenario of a newly joining peer. ... 86
Figure 5-10: The operational scenario of a Tracker. ... 86
Figure 5-11: The proposed replication mechanism. ... 90
Figure 5-12: Workload imposed on the server. ... 94
Figure 5-13: Percentage of requested file received. ... 94
Figure 5-14: Advertisement delivery rate for networks of various sizes. ... 95
Figure 5-15: Comparison of unexpected failure of peer departure misses. ... 96
Figure 5-16: Workload imposed on the server with respect to the rate of free riders... 97
Figure 5-17: Comparison of the proportion of free riders with respect to the averaged PSNR. ... 98
List of Tables
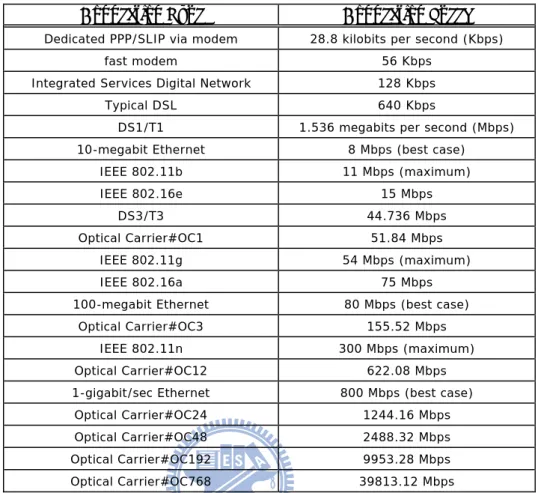
Table 1-1: Digital video bandwidths. ... 3
Table 1-2: Relative network interface speeds... 4
Table 3-1: The amount of R-D information. ... 37
Table 3-2: R-D information overhead vs. GOP size... 37
Chapter 1 Introduction
1.1 Motivation - the Impacts of Network-based
Multimedia Services
Internet based multimedia applications, such as video conferencing, Internet telephony, video-on-demand (VoD), and peer-to-peer (P2P) applications, are a very important trend for future communication and entertainment systems [1]. Streaming media delivery over packet networks is centered on a network layer capable of dynamically selecting a path from the source node to the destination node, with no guarantees on network conditions. In a realistic network, the traffic conditions are dynamically changing, a large variation in bandwidth and end-to-end delays are major problems for supporting multimedia traffic in the network. Hence, multimedia delivery over lossy networks is a challenging task due to bandwidth variation, delay jitter and packet losses [2]. This raises numerous issues that researchers must deal with in order to maintain smooth presentation of video, with visual quality as constant as possible. For smooth streaming presentation, a media source node should track packet losses and adjust media source rates and channel protection levels accordingly. Scalable video coding techniques (such as H.26X, MPEG-4 or wavelet standards) have been standardized on new digital technologies for applications related to streaming media. With scalable video content, a variable bitrate (VBR) source bitstream can be composed on the fly to match the channel bandwidth (assuming the bandwidth can be predicted via some model) and smoothly transmitted to the receivers for presentation. However, if the video quality of the composed stream varies too much it becomes visually unpleasant. Another source of visual degradation comes from packet losses [3]. Unlike distortion from source coding, distortion due to channel loss is more difficult to quantify since the value of a single missing packet depends on the coded data it
contains. Such source and channel distortion removal has not been sufficiently explored until now and needs to be further investigated. Therefore, a more fault tolerant design (with duplicates and redundancies from the given video) may be required, and one should find a way to formulate the distortion and rate impact of packet losses for constructing an rate-distortion (R-D) optimized streaming system that produces smooth video quality streams.
1.1.1 Packet Loss
Packet loss is one of the main factors affecting quality of video in video streaming applications [4]. For instance, it is reasonable to consider a sequence of video-packets transmitting over a route with a packet loss rate varying from 0 to 10 percent [5]. Network congestion is the dominant reason for packet losses, and that causes packet losses in the network router queue buffer [6]. Any packet loss not caused by network congestion is a non-congestive loss, and such segment losses are often assumed to be negligible. Boyce showed that based on MPEG compressed video using the Real-time Transport Protocol (RTP) [7] and User Datagram Protocol (UDP) [8] transport protocols the experimental Internet packet loss rates were quite varied, ranging from 0 to 8.5 percent of the total packets [9].
Over the past half century, the work on loss or error modeling has also paved the way for the distribution of bit errors on communication channels for network related research. One model for packet losses is the Markov or multi-state model. The first generalized model of a burst error channel was presented by Gilbert [10], which is a two-state Markov model. Elliott [11] extended the Gilbert model to the multiple-two-state model. The parameters of the two models can be calculated from the measured error trace by using the mean burst length (the error run) and the mean gap length (the error-free run). In addition, both burst length and gap length are geometrically distributed. Cain et al. [12] studied the distribution of burst lengths over a Gilbert channel. Fritchman [13] enhanced the Gilbert-Elliott model to a partitioned Markov model with partitioning of the state space to several error-free and error states, where the gap length distribution uniquely specifies the model. Nguyen et al. [14] presented a two-state model with segmented exponential
distributed burst lengths and gap lengths. McCullough introduced more channel states (each state represents a specific channel model) to obtain an M-state Markov model, each with a different error rate [15]. Sadeghi et al. introduced and discussed detailed aspects of the finite-state Markov channel and its applications to fading channels [16].
1.1.2 Bandwidth
Table 1-1: Digital video bandwidths.
Compressed Method Format Data Rate
SDTV (480i) 165.9 – 270 megabits per second (Mbps)
EDTV (480p/576p) 540 Mbps
HDTV(1080i/720p) 1.485 gigabits per second (Gbps)
Uncompressed Video HDTV (1080p) 2.970 Gbps SDTV Broadcast (480i) 3 – 6 Mbps HDTV Broadcast (1080i) 12 – 20 Mbps SDTV Production (4:2:2 I-frame only) 18 – 50 Mbps MPEG-2 Video HDTV Production (4:4:4 I-frame 10-bit colour depth)
140 – 500 Mbps
SDTV Broadcast (480i) 1.5 – 3 Mbps
MPEG-4 AVC / H.264
HDTV Broadcast (1080i) 6 – 9 Mbps
Video bitstreams are typically encoded at a predetermined bitrate for a particular application. The audio and video encoded bitstreams consume large amounts of network resources - primarily bandwidth. Moreover, there are many multimedia services which bring a rising tide of increased bandwidth demand over the Internet, including Voice over IP (VoIP), Internet Protocol television (IPTV), High Definition TV streams (HDTV), Standard-definition television (SDTV, 480 lines interlaced), Enhanced definition Television (EDTV, 480 progressive scan) and VoD. Various statistics derived from MPEG-2 and MPEG-4 AVC compressed methods are presented in Table 1-1. Due to high bandwidth needs, there are several technologies available which serve as enabling technologies for satisfying the huge bandwidth demand. We summarize the related network interface technologies and speeds in Table 1-2 [17-19]. For IPTV services, a single SD MPEG-2 stream at the encoding rate of 3.75 Mbps (digital MPEG-2 programs are typical streams over cable television networks) whereas MPEG-4 AVC SD needs approximately 2 Mbps
Table 1-2: Relative network interface speeds.
Connection Type Connection Speed Dedicated PPP/SLIP via modem 28.8 kilobits per second (Kbps)
fast modem 56 Kbps
Integrated Services Digital Network 128 Kbps
Typical DSL 640 Kbps
DS1/T1 1.536 megabits per second (Mbps) 10-megabit Ethernet 8 Mbps (best case)
IEEE 802.11b 11 Mbps (maximum) IEEE 802.16e 15 Mbps DS3/T3 44.736 Mbps Optical Carrier#OC1 51.84 Mbps IEEE 802.11g 54 Mbps (maximum) IEEE 802.16a 75 Mbps
100-megabit Ethernet 80 Mbps (best case)
Optical Carrier#OC3 155.52 Mbps
IEEE 802.11n 300 Mbps (maximum)
Optical Carrier#OC12 622.08 Mbps
1-gigabit/sec Ethernet 800 Mbps (best case)
Optical Carrier#OC24 1244.16 Mbps
Optical Carrier#OC48 2488.32 Mbps
Optical Carrier#OC192 9953.28 Mbps
Optical Carrier#OC768 39813.12 Mbps
for the same quality video program. The video streaming platforms implemented use mainly a family of transport protocols, namely, UDP, RTP, Real-Time Control Protocol (RTCP), and Real Time Streaming Protocol (RTSP). UDP is a best-effort transport protocol over IP networks while RTP and RTCP are the media transport protocols used to transmit and control media data. RTSP is an application-level protocol for initiating and directing delivery of streaming with real-time properties. It could be thought of as a remote network control for multimedia servers (a detail of RTSP is available through RFC 2326 [20]). Current streaming systems for the Internet are based on a best-effort delivery service in the form of UDP, which does not guarantee reliability or the order delivery of the network packets. The most commonly encountered issues of multimedia transmission and streaming applications are unreliable Internet connections and heterogeneous bandwidth of the different end users. When the network bandwidth fluctuates, the coded bit-rate may not match the real bandwidth [21]. Hence, scalable video coding techniques are often used to provide real-time quality adaptation for streaming systems.
1.1.3 Client-side Buffer
DIA Streamer Sensitivity adaptation algorithm Server Controller RTP/ RTCP RTSP muxwith SDP RTSP demux with terminal capability Media Database UDP TCP Packet Buffer UDP TCP Stream Buffer Decoder Packet dependency manager Output Buffer Client Controller Offline Media Encoder Operational error cost function Server Client Network Interface Data Item Information Packet Loss Monitor QoS Decision RTP/ RTCP RTSP muxwith SDP RTSP demux with terminal capability Packet Buffer DIA Streamer Sensitivity adaptation algorithm Server Controller RTP/ RTCP RTSP muxwith SDP RTSP demux with terminal capability Media Database UDP TCP Packet Buffer UDP TCP Stream Buffer Decoder Packet dependency manager Output Buffer Client Controller Offline Media Encoder Operational error cost function Server Client Network Interface Data Item Information Packet Loss Monitor QoS Decision RTP/ RTCP RTSP muxwith SDP RTSP demux with terminal capability Packet BufferFigure 1-1: An example of a Client/Server streaming application.
A video streaming application should allow for short-term network fluctuation. Packet buffers are commonly located in the sending/receiving device. Incoming packets are queued in the packet buffer at the streaming client to overcome the network latency. The structure of a client/server type of streaming application is depicted in Fig. 1-1. We can compute the distortion and the streaming rate that result from a streaming policy, which are implemented in modules including the packet dependency manager, the sensitivity adaptation algorithm, and the operational error cost function. The quality of service (QoS) decision function decides which of the admission control or equivalent bandwidth strategies should be employed. Based on the former policy and updating the policy given the new value, the streamer component splits bit-streams into packets and stores them in the packet buffer memory for transmission to the server side. The Digital item adaptation (DIA) module can be used to describe the usage environment and content format features. The
arriving packet stream is buffered at the destination packet buffer, which temporarily stores the receiving data before providing it to the stream buffer for decoding at the client side (packet losses are monitored for quality assurance purposes). The media decoder fetches coded units from the stream buffer and stores decoded data in the output buffer, then the decoded content is provided to a screen for playback. In particular, the packet buffer can be a shared resource at network nodes, especially for P2P overlay networks (including video sharing applications and P2P video-on-demand applications) [22].
packets generated Cu m ul at iv e da ta time variable network delay Packets
received rate videoconstant bit
playout at client client playout delay bu ffe red video packets generated Cu m ul at iv e da ta time variable network delay Packets received variable network delay Packets
received rate videoconstant bit
playout at client client playout delay bu ffe red video
Figure 1-2: Client-side buffering.
As shown in Fig. 1-2, the packet inter-arrival time is random [23] (inter-arrival time of media sessions and file-transfer sessions may follow a Poisson distribution [24]), or the packet arrival time is fixed time but with explosive, random error bursts. Adaptive media playout (AMP) techniques play one frame at a slower pace, and extend the deadline for the arrival of subsequent frames. Network delay contains transmission delay, propagation delay, processing delay, and queuing delay. It is one of the solutions to reduce the impact of network delays and control the rate of the playout without involvement of the server. Thus, in order to ensure continuous playback of media streams, the client device can adaptively change playout speed to prevent buffer overflow and underflow. Thus, AMP techniques allow the client-device to buffer less data, the playback rate of the streaming media player is varied according to the state of its playout buffer [25]. When designing or
redesigning network-based multimedia systems, minimizing playout delay and keeping a low loss rate are design considerations when deciding which multimedia-service solution is most applicable.
1.1.4 Packet Dependency Control
P
I
I
B
P
B
P
B
P
I
I
B
B
P
B
P
Figure 1-3: Directed acyclic dependency graph.
A certain degree of quality degradation is tolerable for most multimedia applications, and distortion tolerance can be designed to fit human visual perception. Information loss is quantified based on the distortion tolerance and thus the best reconstructed video quality can be obtained at a given bit rate. Packet dependency control (PDC) [26] is designed to provide increased distortion tolerance and elimination of video packet retransmission [27]. Video packets in typical multimedia streaming have potentially strong dependencies between the media packets. If one of the video packets is lost during transmission, then all subsequent packets are dependencies with the lost packet and the follow-up frames may be affected by the error while the decoding procedure is performed at the client. Figure 1-3 shows a dependency of a directed acyclic graph (DAG), each node representing a packetized data unit. Each packetized data unit will be labeled as follows: the actual size of data unit n, distortion reduction if data unit n can be normally decoded at the receiving side, and the decoding deadline of data unit n. The PDC scheme should be used to improve error-resistance capabilities and reduce latency error during the scalable media-streaming phase.
1.2 Research Objectives and Contributions
The major research objectives and goals of this study include the development of error-resilient video communication to mitigate the effects of packet loss and inter-frame error propagation. The study of how active replication [28] can assist fault tolerance and smooth video playback in a P2P overlay network. The study of how perceptual quality-based progressive packet-level transmission on a VBR channel can be used to increase the robustness of video communication systems. The results of this research could help open the way of finding the appropriate solutions for sufficient streaming quality. In summary, there are the following objectives:
‧ Determining a fine-level FEC (forward error correction) packetization protection framework and evaluating the adaptive fine-granularity of FEC protection scheme.
‧ Studying the properties of the parameterized R-D model which is incorporated into the fine-level FEC framework to facilitate multiple adaptations.
‧ Constraining the analysis of video content complexity with a rate-distortion optimized scalable video streaming system
‧ Characterizing the underlying correlations between peer-network characteristics and video quality impacts over unstructured P2P VoD overlay networks.
‧ Using a distortion-based active replication method for enhancing system scalability and tolerance of peer failures in a P2P VoD system.
‧ Specifying the agent-peers of the overlay P2P VoD system as sources and sinks of internet advertising under robust online marketing communication channels. Scalable video delivery using fault-tolerant and error-resilient techniques has been a subject of study for many years. Nonetheless, although some of the existing error control techniques may establish a different degree of protection based on the degree of importance of the content, unequal error protection is limited to varying degrees in coarsely structured bit-streams, since the error control scheme is based on either a single-layer video coding model or a coarse-granularity layered scalable-video-coding (SVC) mode. The main
contribution of this work is the development of adaptive fine-granularity methodologies to support error-protection in video streaming services with an effective streaming policy. This streaming approach takes into account the R-D information of each block (it is only a chunk of data in a coding block) which is derived doing the encoding process, and searches for an optimal operating point between the scalable source coding rate and the FEC protection level which is dependent on the video content entropy. The content adaptation of the FEC protection has a fine granularity. Therefore, adaption conditions between video content entropy and run-time packet loss rate can be accurately established.
P2P services have been exhibiting a rapid growth in the world. For instance, forecasts from Cisco Visual Networking Index (Cisco VNI) reveal that P2P traffic in 2014 will be more than double the amount of data P2P traffic generated in 2009 (around 7 peta bytes per month). The implementation and validation of a P2P VoD system involves carrying out a performance evaluation of the P2P replication mechanism. P2P multimedia applications claim lower costs and more efficient content distribution than traditional client-server applications. The searching area of P2P services are controlled by the time-to-live (TTL) value, which is decreased each time P2P-related commands are forwarded (to limit the maximum number of intermediate peers) until the command is accepted or the TTL value is zero. Whenever the degree of peer sharing resources drops (such as due to an upload bandwidth outage) below the marginal value at the TTL value in a P2P multimedia system, especially for VoD services, each of the peers is automatically trying to reconnect to the media server for service operations. Heavy traffic leads to high waiting times and a lowered quality of service, which could significantly degrade operational performance and service. In particular, our proposed method provides a reliable set of replica data that can accommodate a large number of free-riding nodes with less jerky video playback.
1.3 Synopsis of the Dissertation
This dissertation is organized as follows. Chapter 2 reviews some related works regarding the techniques of significant effect on video streaming and P2P streaming-based video performance. Section 2.1 gives an introduction to wavelet-based video coding system.
The works related to the error resilience tools is given in Section 2.2, an overview of P2P streaming systems involved in Section 2.3.
Chapter 3 studies error control techniques and fine-level packetization scheme for streaming of 3D wavelet-based video over a lossy packet network. We propose an adaptive fine-granularity unequal error protection algorithm in which the foundation of strategy decision making is based on the tradeoff between rate and distortion, and jointly adapting scalable source coding rate and level of forward error correction (FEC) protection. We also explore the concept of multiple adaptations of video bitstream and fine-level FEC protection in a parameterized R-D model-based approach. The fine-level FEC protection to the granularity of coding pass level is discussed in this chapter.
Chapter 4 studies an approach to integrate smooth quality constraint into a rate-distortion optimized scalable video streaming system over a variable bandwidth channel. Accordingly, a solution is needed to preserve smooth video quality in communication systems in which the available network bandwidth and video data rate may vary. Hence, the scheme takes into account the degree of motion in each frame to an R-D optimized framework for determining the packet scheduling policy.
Chapter 5 further studies the problem of optimizing the media-data replication strategies over unstructured P2P VoD networks in the presence of peer failures or the regions of low resource area. By taking video popularity, uploading bandwidth, supportive buffer into considerations, the proposed mechanism provide a solution on reducing the required video server operations, smoothing playback of videos, and improving the averaged visual quality for overall performance in P2P VoD systems. Finally, Chapter 6 concludes the dissertation and discusses some possible directions for future research.
Chapter 2 Background and Survey of Related Work
In this chapter, we briefly summarize related work on the design of error-resilient video communication. This work is classified into two categories. Section 2.1 gives a brief overview of wavelet-based video coding system. Section 2.2 describes error correction approaches which improve the signal to noise ratio of the transmission link to efficiently support multimedia data transmission over lossy packet networks. Section 2.3 gives an overview of P2P video-on-demand services on network usage.
2.1 Wavelet-based Video Coding System
The fundamentals of 3D wavelet coding which enable temporal, spatial and quality salability are discussed in this section.
2.1.1 Overview of the 3D Wavelet Codec
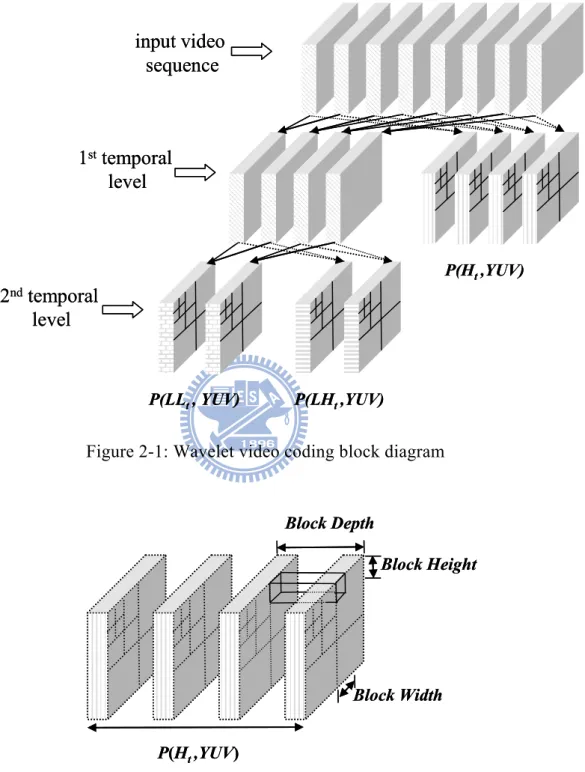
The block diagram of a wavelet-based video coding system is shown in Fig. 2-1. In a t+2D wavelet coder, an input video sequence is temporally decomposed first using motion-compensated temporal filtering (MCTF) [29]. The output of MCTF is then further decomposed by a 2D spatial wavelet transform on a frame-by-frame basis. For example, two-level temporal decomposition results in three temporal subbands, namely, P(Ht, YUV),
P(LHt, YUV), and P(LLt, YUV). When the group of pictures (GOP) size is eight, a typical
set of transformed subband data produced by the t+2D wavelet coder has four P(Ht,YUV)
frames, two P(LHt, YUV) frames, and two P(LLt, YUV) frames. Each frame contains one
luminance component (Y) and two chrominance components (U and V). The coefficients of different subbands are logically segmented into coding blocks, based on the structure of Fig. 2-2, and each coding block is independently coded by an entropy coder. The analysis is presented using the wavelet-based video coder for a CIF resolution sequence. CIF defines a video sequence with a resolution of 352 × 288. For 2-level temporal transform encoding
and GOP=8, a coding block size in Fig. 2-2 has block depth 2 (the number of frames, i.e. two frames), block height 36(=288/23), and block width 44(=352/23).
P(LLt, YUV) P(LHt,YUV) P(Ht,YUV)
1
sttemporal
level
2
ndtemporal
level
input video
sequence
P(LLt, YUV) P(LHt,YUV) P(Ht,YUV)1
sttemporal
level
2
ndtemporal
level
input video
sequence
Figure 2-1: Wavelet video coding block diagram
P(Ht,YUV) Block Depth Block Height Block Width P(Ht,YUV) Block Depth Block Height Block Width
Encode one block
normalization pass get the next bitplane significance propagation pass
magnitude refinement pass normalization pass get the first bitplane
Compute RD Slopes end of bitplane N
Y Encode one block
normalization pass get the next bitplane significance propagation pass
magnitude refinement pass normalization pass get the first bitplane
Compute RD Slopes end of bitplane N
Y
Figure 2-3: 3D ESCOT entropy coding.
0 2500 5000 7500 10000 12500 15000 17500 0 100 200 300 400 500 600 700 800 900 Rate (bits) Distor ti on (MSE/bits) P(Ht,Y)- block 0
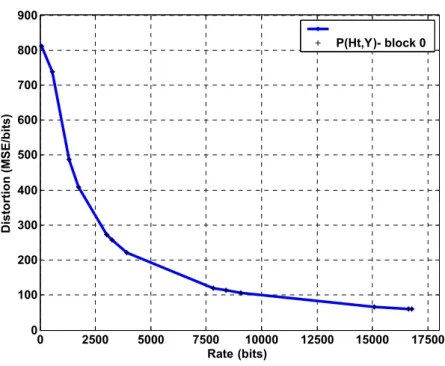
Figure 2-4: The R-D curve of coding block 0 of subband P(Ht,Y)of STEFAN.
Common entropy coding techniques for wavelet video are 3D embedded subband coding with optimized truncation (3D-ESCOT) [30] and 3D set partitioning in hierarchical trees (3D-SPIHT) [31]. The 3D-ESCOT algorithm has higher compression efficiency and better scalability than the 3D-SPIHT algorithm. During the 3D-ESCOT entropy coding process, the entropy coder (fractional bit plane coding and context-based arithmetic coding) operates one coding block at a time, and each coding block consists of N total bit planes.
Three encoding operations of the context-based arithmetic coding (zero coding, sign coding, and magnitude refinement) are used to characterize the significance of coefficients in a bit plane. Following the 3D context modeling, fractional bit plane coding ensures that the bit stream is arranged with fine granularity of signal-to-noise ratio scalability for each coding block. As shown in Fig. 2-3, the fractional bit plane coding procedure consists of three distinct passes: the significant propagation pass, the magnitude refinement pass, and the normalization pass. Since the first bit plane of a coding block can only be processed with the normalization pass, a coding block contains 3N−2 coding passes. After entropy coding, candidate truncation points of a coding block are associated with R-D slopes. Any truncation points that are not on the convex hull are eliminated, and the R-D slopes are λ0, λ1,..., λ3N−2,where |λ0|>|λ1|>...>|λ3N−2|. All coding blocks have R-D curves similar to the
example shown in Fig. 2-4. A single bit error of a top coding pass may cause severe degradation in video quality. Therefore, higher level of protection is required for top coding passes. In addition, the proposed scheme of this dissertation is based on 3D-ESCOT coding technique.
2.1.2 Bitstream and R-D Information
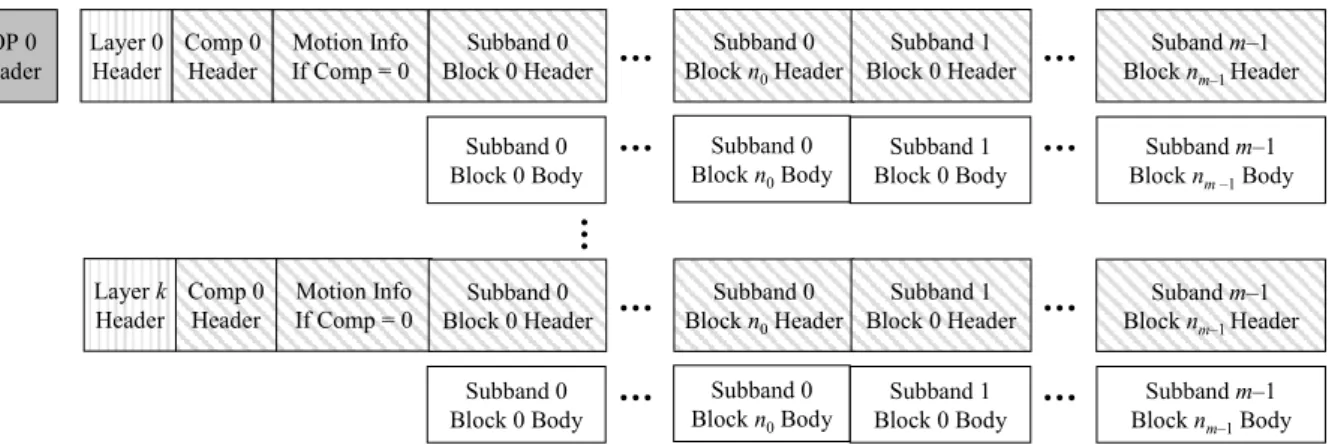
A typical coded video sequence consists of a variable number of GOPs which is composed of a series of consecutive frames. Video encoders can be setting in a static or dynamic GOP length to encode video sequences, and bit-streams are generated based on the selected GOP structure. Each GOP bit-stream comprises four major parts: coded motion vectors, transformed and scaled luminance (Y) and chrominance (UV) data, and the header information (layer header, component header, and block bitplane selection information (e.g. inclusion flag, bit depth information, delta bytes, delta slope)). The R-D information of coding blocks contains rates, distortions, and the Lagrange multiplier values (refer to as the R-D slope λ value). The Lagrange multiplier is used to find the optimal point for different video quality. The video encoded using a 3D wavelet codec [32, 33] (Microsoft Research Asia - VidWav reference software) is organized in the format shown in Fig. 2-5, where m is the total number of temporal and spatial subbands and ni is the number of coding blocks in
subband i. Figure 2-6 depicts an example data of the first GOP of Stefan by using the VidWav codec, the peak signal-to-noise ratio (PSNR) is 41.13 db. The coded motion vectors is 24,218 bytes, Y component is 476,073 bytes, U component is 26,870 bytes, V component is 25,667 bytes, and the header information is 565,278 bytes where the total bytes of the GOP is 1,118,106 bytes, where the header information and Y component are the major amount of data.
GOP 0 Header Layer 0 Header Comp 0 Header Motion Info If Comp = 0 Subband 0 Block 0 Header Subband 0 Block 0 Body Subband 0 Block n0Body Subband m–1 Block nm –1Body Subband 0 Block n0Header Suband m–1 Block nm–1 Header Layer k Header Comp 0 Header Motion Info If Comp = 0 Subband 1 Block 0 Body Subband 1 Block 0 Header Subband 0 Block 0 Header Subband 0 Block 0 Body Subband 0 Block n0Body Subband m–1 Block nm–1Body Subband 0 Block n0Header Suband m–1 Block nm–1 Header Subband 1 Block 0 Body Subband 1 Block 0 Header
Figure 2-5: MSRA Wavelet bitstream format (please note that there is no need to enforce layer structure for MCTF-based wavelet bitstreams)
Figure 2-6: An example data of the first GOP of Stefan (2048 kbps, CIF, PSNR: 41.13 db, GOP size: 64)
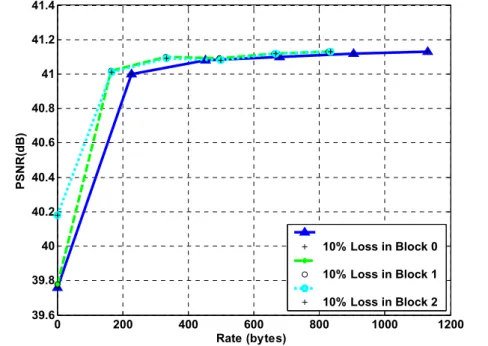
We modeled the data loss ratio in case of partial failures in a bit-stream file. Figure 2-7 shows the different data loss scenarios of block 1 under the same amount of data loss ratio. The lost data is replaced by zero value. As shown in Fig. 2-7(a), the reconstructed video quality on the video will be severely degraded, if the most visually important data is affected by errors. On the other hand, if the less important data is corrupted or lost during transmission, the video frame can be partially reconstructed, as
shown in Fig. 2-7(b). A slightly degraded video-quality but uncorrupted video stream is less annoying to the audiences than a corrupted stream. Figure 2-7(c) shows that the reconstructed frame has less visual quality decrement comparing with the original frame, if the lost data is not critical. This leads to the need of unequal error protection on compressed video bit-stream, in which the more important compressed bit-stream is delivered with a higher degree of error protection [34].
(a) The most important 10% data of block 1 is dropped
(b) The less important 10% data of block 1 is dropped
(c) The least important 10% data of block 1 is dropped
Figure 2-7: 10% of data loss of blocks 1 on the P(Ht,Y) subband (Stefan, CIF, 150 frames, 15 fps, GOP = 64, target bitrates: 2048k).
2.2 Robust Internet Video Transmission based on
Scalable Coding Streams
When audio and video streams are transmitted over an unreliable IP network, it is not only the dependency relationship among packets but also the importance of information carried that should be taken into account in the selection of the best video-quality under variable network conditions. Therefore, many research efforts have been made towards improving performance of multimedia transmission systems in general, and designing partial reliability techniques for media content distribution over packet erasure channels which are usually considered on both the forward and feedback links. Efficient transmission over packet erasure channels can be realized by FEC, Automatic Retransmission reQuest (ARQ), error resilience, and error concealment [35]. FEC adds redundancy to the transmitted compressed bit-streams so that the receiver may correct errors and protect the video quality from degradation caused by packet loss and jitter. In ARQ, retransmission is requested when the receiver detects errors, and the most common schemes are: Stop-and-Wait ARQ, Go-Back-N ARQ, and Selective Repeat ARQ. In addition, a number of algorithms have been proposed in the literature for Hybrid ARQ (HARQ) which is essentially a combination of FEC with ARQ in an optimal strategy.
2.1.1 Two Basic Approaches to Error Correction
Automatic Retransmission reQuest (ARQ) is one of the commonly used channel coding approaches for error protection, which is particularly effective against burst channel errors. From a practical viewpoint, the main disadvantages of ARQ are the retransmission costs in terms of huge delays, and some receivers may receive duplicate packets which do not contribute to the quality of the stream due to the long delay propagation. Moreover, ARQ techniques require data stores for incoming packets and a feedback channel. The feedback channel is required to supply for the acknowledgment of error-free packet delivery or for packet retransmission request to the data sender.
error control technique without the need of a feedback channel to reduce or eliminate packet losses in a video communication system. In a FEC scheme, the amount of FEC is pre-determined and based on the probability distribution of the packet loss. However, a larger amount of FEC or redundancy helps to recover from random packet loss event, but FEC codes are not designed to deal with packet burst loss. A burst error may cause substantial degradation to the transmitted video quality [36]. Hence, FEC with adaptive code rate to the importance of bits or frames would be more efficient for controlling errors in data transmission over unreliable channels.
2.1.2 Rate-Distortion Optimized Packet Scheduling
Some recent approaches [37-39] facilitate the selection of optimal channel-adaptive R-D strategies to minimize the expected loss-distortion for different multimedia applications with various quality-of-service requirements and system constraints. An R-D based framework is developed to describe discrete-time Markov chain models in characterizing the random packet-loss process associated with packet network transport system which is then used to analytically investigate the overall efficacy of packet-level protection in improving the end-to-end media quality. One of R-D optimized (RDO) streaming framework was proposed by Chou et al. [26]. RDO can be used to transmit a group of interdependent data unit before a delivery deadline by using feedback information and retransmission strategies. The RDO transmission policies can be obtained by minimizing the Lagrangian cost function of expected rate and distortion.
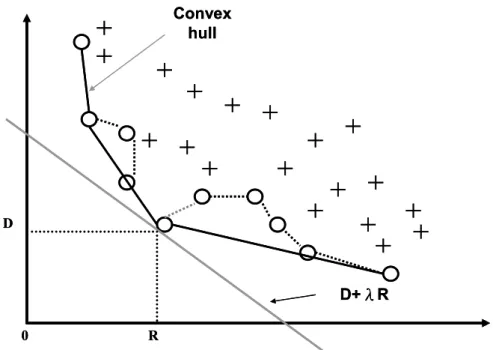
As shown in Fig. 2-8, the slope is the tangent to the convex hull of the R-D curve. The RDO policy that minimizes the overall R-D Lagrangian cost: J(π)=D(π) + λR(π). The parameter λ can control the operation of the basic conditions, such as distortion sensitive or rate sensitive. The expected distortion D(π) depends on the error probabilities, and the expected rate R(π) depends on the size of the data units.
D+λR Convex hull D R 0 D+λR Convex hull D R 0
Figure 2-8: The set of R-D pairs, its lower convex hull, and an achievable pair (R, D)
...
N
transmission opportunities before deadline send: 1 ack: 1 0 0 0 send: 1 0 send: 1 0 ack: 1 0 1 0 1 0 0 1 1 1 0 0 0 0 S0 S1 S2 Action Observation o0 a0 a1 o1 1 1...
N
transmission opportunities before deadline send: 1 ack: 1 0 0 0 send: 1 0 send: 1 0 ack: 1 0 1 0 1 0 0 1 1 1 0 0 0 0 S0 S1 S2 Action Observation o0 a0 a1 o1 1 1Figure 2-9: Trellis for a Markov decision process. Final state is indicated with double circles.
An example of RDO framework is illustrated in Fig. 2-9. In the figure, we assume that the deadline for the delivery (delivery deadline) prior to each discrete interval is the opportunity to send packets in each transmission opportunities S0, S1, ..., Sn-1. The sender will be based on the best strategies to select those data to be transmitted to the client. In the action phrase, the sender selects the data unit, then take action a0 = 1, or not to send data
unit, then take action a0 = 0. In the observation phrase, if the data unit receives feedback
information o0 = 1, or if the unit has not received any information about the feedback
message o0 = 0.In the RDO control streaming system, to decide which opportunities can be
sent in each packet should be transmitted to the client is based on the deadline of this packet, the transmission histories, the channel statistics, feedback information, the interdependencies among packets, and the distortion reduction. The policy can indicate whether the video packet should be transmitted at each transmission opportunity. However, the scheme does not address the issue of reducing video quality variation over loss channels. Furthermore, the RDO mechanism maps probability of packet losses into rate increment of redundant packet transmission. The drawback of this approach is that redundant packet transmission will make the resulting R-D curve impractical.
2.2 An Overview on Peer-to-peer Video Systems with
Scalable Coding Streams
: Internet Router : Peer : Existing network infrastructure : Internet Router : Peer : Existing network infrastructure
Figure 2-10: An example of P2P overlay network.
The P2P overlay network consists of all the participating peers which cooperate to achieve desired functions on top of the physical network topology, as shown in Fig. 2-10. A wave of innovations on P2P multimedia services has been exhibiting a rapid growth in recent years, ranging from easy and efficient operations of home-to-home user to useful and widespread applications for large-scale user communities [40]. The media-resource sharing P2P systems require a large amount of media repositories [41] and contribute bandwidth to serve other peers. Hence, the P2P multimedia services have emerged as a virtual society
that shares and provides access to the resource of peers among P2P community members. Therefore, there has been an increase in research focusing on how to maximize the file availability and minimize the total storage requirements in P2P networks.
2.2.1 Comparison between IP Multicast and Peer-to-Peer
Networks
A unicast video stream is dedicated to a single client. In some internet applications, data delivered from a sender to multiple receivers is required, such as video broadcasts. IP multicast [42-44] provides a network-layer solution, which the data packets are delivered to all nodes with respect to a given scope. The IP multicast service can offer scalable one-point to multipoint delivery necessary in the multicast group communications. However, new set of protocols and mechanisms are needed to build multicast services at the network layer, and the technology is still years away from a large commercial deployment by Internet service providers (ISPs). On the other hand, P2P technologies have gained immense popularity as a form of content distribution activity all over the world. P2P services can be fundamentally more scalable than existing multicast methods, particularly when the bandwidth availability is high at the ISP backbone. Several content providers are using legal P2P networks to reduce operational expenses, such as BBC (British Broadcasting Corporation) iPlayer service [45], Babelgum [46], Jaman [47], and GridNetworks [48]. The primary shortcomings of multicast transmissions are summarized below:
‧ Configuring routers for multicast: Routers perform multicast routing and multicast forwarding functions in the IP multicast.
‧ Maintenance of the corresponding multicast group: Nodes of a multicast group need to exchange Internet Group Management Protocols (IGMP) [49, 50] among routers.
‧ High complexity and serious scaling constraints at the IP layer: It is almost impossible for clients to receive the same video quality during different multicast sessions. The majority of high complexity requirements are caused by potentially
large numbers of clients and sessions [51].
‧ Not widely deployed: The implementation of multicast protocols needs special commercial routers which need to be PIM-compatible (Protocol Independent Multicast [52, 53]).
‧ Error, flow and congestion control is more complex than in unicast
applications: Advanced features in reliability, congestion control, flow control,
and security have been shown to be more difficult than in the unicast case [54, 55].
2.2.2 Difference between Streaming-based and File-based P2P
Media Systems
An appropriate fault-tolerant design for P2P VoD systems can help moderate performance degradation during peer failure [56]. This is important especially because continuous operation is an essential feature of P2P VoD systems (e.g. video playback). Another challenging aspect of P2P VoD systems is fault-tolerant design to replicate multimedia files in proper quantities. Replication can hold the greater share of media repositories during high service demand [57]. Thus, numerous P2P replication schemes have been developed for various performance objectives, such as improved startup time, media-file availability, and response time. As shown in Fig. 2-11, P2P replication schemes can be classified into two major types: file-based and media streaming-based data replication. File-based data replication systems are designed for file sharing through downloads, with a typical focus on maximizing file availability or hit rate [58]. There are usually no time-critical constraints associated with transmission (e.g. BitTorrent (BT) [59]). In contrast, media streaming-based data replication systems should determine which data has to be received in time for continuously streaming delivery. In addition, a gracefully degradable quality of video and audio play-back is acceptable, so the transmission of the video and audio stream usually allows some packets to be dropped. For this reason, the BT-like model is less suitable for media streaming-based systems. The remaining differences between file-based and media streaming-based data replications are described as follows.
‧ Point-to-Point connections: The UDP is typically the default network transport protocol used by streaming-based applications. In order to guarantee delivery, the Transmission Control Protocol (TCP) is often used for file-based P2P systems (pull operation) applications.
‧ Resolution, frame rate, and bitrate: For streaming-based P2P systems, the content provider can use flexible approaches to adapt the dynamic QoS requirements of fine granularity scalability by controlling resolution, frame rate, bitrate and video dimension. In contrast, file-based applications are less able to dynamically adapt after the encoding procedure.
‧ Quality of streaming session: In case of severe bandwidth fluctuations or packet losses in the network, TCP-based media delivery may lead to a large number of TCP retransmissions that lead to a higher average delay and jitter. Streaming-based P2P systems are better suited for supporting the playback quality of a streaming session.
whole file
sliding window
P2P file sharing
(random part of a file)
P2P media streaming
playback point
whole file
sliding window
P2P file sharing
(random part of a file)
P2P media streaming
playback point
Figure 2-11: A Comparison of the P2P file sharing and P2P streaming scheme.
The problem of streaming-based data replication has been addressed in the past. Ghandeharizadeh et al. [60] developed a home-to-home (H2O) optimized replication framework in a P2P environment. The system minimizes startup-latency and replica-blocks of clips among H2O devices in a hybrid way that replicates partial urgently-blocks and perfecting. A key issue in an H2O-based replication framework is that all video segments are treated equally without discrimination. Such a framework typically relies on the use of
non-scalable bit-streams. On the other hand, a scalable bit-stream allows graceful degradation when the smaller distortion of the bit-stream gets lost. Each scalable bit-stream contains a base layer and one or more enhancement layers. Moreover, the base layer is encoded at a lower bit-rate, which is critical in perceptual errors of media data. Hence, the base layer shall have stronger protection against packet losses than the enhancement-layer.
Wan et al. [61] employed local active rendezvous servers (LARS) to coordinate external other LARS and control availability of clips for the P2P streaming in a hierarchical overlay network. Additionally, each LARS is responsible to provide good coverage in its own subgroup. Here network bandwidth and peer capabilities are major factors when generating replicas. The scalability of peers and movies is limited by the special applications. Also a request-rate minimization policy was proposed by Poon et al. [62]. In particular, they studied different replication strategies and showed that the better approach for replication is not only maximizing file availability but also adapting to bandwidth constraints of peers. Ye and Chiu [63] study decentralized and cooperative resource allocation problems with preferential replication in unstructured P2P systems. It is shown that the availability and importance of files are both significant factors in the management of replication service systems. The above types of data replication schemes show that the overlay path length, heterogeneous peer availability and packet loss rates are major factors of perceptual errors of media data in P2P systems. In addition, the replication design of video clips in P2P systems should be postulated based on the popularities and quality impact of video.
Chapter 3 Fine-level Packetization and Streaming
of Wavelet Video over IP Networks
This chapter presents a framework of fine-level packetization scheme for streaming of 3D wavelet-based video content over lossy IP networks. The tradeoff between rate and distortion are controlled by jointly adapting scalable source coding rate and level of FEC protection. A content-dependent packetization mechanism with data-interleaving and Reed-Solomon protection for wavelet-based video codecs is proposed to provide unequal error protection. This chapter also tries to answer an important question for scalable video streaming systems. Given extra bandwidth on the systems, should one increase the level of channel protection for the most important packets, or transmit more scalable source data? Experimental results show that the proposed framework achieves good balance between quality of the received video and level of error protection under bandwidth-varying lossy IP networks.
The rest of this chapter is organized as follows. Section 3.1 gives the introduction. Section 3.2 presents a detail analysis on the wavelet compressed video bit stream and the bit stream architecture for fine-level protection. The details of the proposed packetization scheme and streaming framework are described in Section 3.3. Some experimental results of the proposed system are shown in Section 3.4. Finally, some conclusions and discussions are given in Section 3.5.
3.1 Introduction
There is a growing demand for video transmission over heterogeneous networks for communication and entertainment applications. SVC techniques are often proposed for such systems since, ideally, a video sequence can be encoded once and adapted on the fly to different frame rate, bitrate, and resolution for different applications. Although scalable
video is an interesting concept, it takes end-to-end system design to show the advantage of SVC over single-layer coding techniques. With single-layer coding, techniques like bitstream switching can be used to achieve video adaptations. However, it is easier to achieve good rate versus source-and-channel distortion tradeoff with scalable coding techniques.
The mainstream video compression techniques are based on hybrid motion compensated transform coding approach, where the transform algorithms are typically either Discrete Cosine Transform (DCT) or 3D wavelet transform. So far, DCT-based SVC approaches have demonstrated better coding efficiency than wavelet-based SVC techniques [64], especially for low bitrate applications. However, a wavelet-based SVC framework can provide fine-granularity bitrate scalability with less system complexity than that of an FGS-based (Fine Granularity Scalability) DCT framework. In addition, many on-going efforts show that wavelet-based SVC approaches still have room for improvement [65]. Therefore, in this chapter, wavelet-based SVC is used as the core codec for the development of a scalable video streaming framework.
The most challenging problem for scalable video streaming over IP networks is about how to optimally adapt source data rate and degree of packet loss protection to real-time network conditions. Video packetization and scheduling algorithms are mostly responsible for mitigating the effects of bandwidth variation and packet losses in the network. The packetization and scheduling algorithms are mainly based on resource-versus-distortion optimization [66-68], where resource can be available computation power, rate, delay, and so forth. A general resource allocation treatment for streaming systems is presented in [69]. Some researches try to apply the rate-distortion optimization (RDO) principle [70] of source coding theories to video streaming over lossy networks [66]. For a streaming system, the distortion is a result from both source coding and channel losses. A key issue in an RDO-based streaming system is that the distortion due to packet losses is much more difficult to quantify than the distortion due to lossy source coding.
Several frameworks for 3D wavelet based video streaming system have been proposed recently. Chu and Xiong [71] introduced a combined packetized wavelet video