行政院國家科學委員會專題研究計畫 成果報告
總計畫(3/3)
計畫類別: 整合型計畫
計畫編號: NSC94-2524-S-009-001-
執行期間: 94 年 05 月 01 日至 95 年 04 月 30 日
執行單位: 國立交通大學資訊科學學系(所)
計畫主持人: 曾憲雄
共同主持人: 蔡文能
報告類型: 完整報告
處理方式: 本計畫可公開查詢
中 華 民 國 95 年 7 月 28 日
行政院國家科學委員會專題研究計畫成果報告
智慧型多媒體學習內容管理系統之研製、應用與評估(3/3)
計畫編號:NSC 94-2524-S-009-001
計畫期程:民國九十二年五月至九十五年四月
計畫進度:民國九十四年五月至九十五年四月
主持人: 曾憲雄 教授 國立交通大學 資訊工程學系
共同主持人: 蔡文能 教授 國立交通大學 資訊工程學系
一、中文摘要 隨著網際網路的盛行,網路學習的概念已被廣 泛的接受。然而,各個系統所使用的不同格式教材, 使的難以互相分享彼此間的教學資源,造成教材製 作成本的提高。雖然國際組織所提出的SCORM, IMS, LOM等等標準可些微的解決教材在互操作 性、再用性與分享性上之困難。但在本土化教材、 個人化教學與課程、試題自動化上之定義仍嫌不 足。另外,在個人化教學與課程、試題自動化上, 目前所提出的網路學習系統亦無法呈現出完善的效 能與成果,甚至有些系統根本就忽視此考量。因此, 在本計劃中,我們規劃並建置一套[智慧型多媒體學 習內容管理系統],其中包含3個子計畫,執行成果 分別為:子計畫1:「智慧型個人化多媒體學習內容 管理系統之研製」:研發知識表示、知識資源、知 識管理、知識擷取、知識包裝、及知識探勘等6個模 組。可根據學習者的學習能力與評估後的學習成果 來提供學習者適當的個人化標準學習教材。。子計 畫2:「智慧型個人化題庫系統之建置與管理」:為 了支援智慧型學習診斷系統,延伸數位學習標準中 的教材與試題標準以及增加學習歷程標準。子計畫 3:「行動學習載具上通用型多媒體學習內容存取播 放機制之研發」:研發提出內容調機制、內容傳輸 機制與內容呈現機制,以根據頻寬、使用者喜好、 裝置能力,並即時監視學習與連線狀態,來連續性 地傳輸經過動態調整的適當內容給使用者。而在計 畫執行期間,我們總共發表了21篇期刊論文, 其中 有4篇SSCI與8篇SCI,以及41篇國際會議論文與52 篇中文會議論文。 關鍵詞:網路學習、SCORM、學習內容管理、學 習診斷、內容調適。 AbstractAs internet usage becomes more popular over the world, e-learning system in the past ten years has been accepted globally. However, the different formats of teaching materials among e-learning systems result in difficulty of the sharing the resources and increasing the cost of creating teaching materials. Although the SCORM, IMS, LOM, etc. proposed by international organizations can overcome the issues of interoperability, reusing, and sharing, most existing e-learning systems can not satisfy the personalized instruction, and course and exercise sequencing. Thus, the features of local culture, personalized teaching
strategy, and automatic course and exercise sequencing are still required. Therefore, in this project, Implementation, Application, and Evaluation of an Intelligent Multimedia Content Management System (IAEIMCMS), we try to develop an intelligent multimedia content management system by employing and extending the SCORM/TMML standard. The entire project consists of three subtasks. The executable results are described as follows: Subproject 1-Design and Implementation of an Intelligent Multimedia Content Management System: developed six knowledge modules, i.e., Knowledge Representation, Knowledge Resource, Knowledge Organizer, Knowledge Capturer, Knowledge Packer, and Knowledge Miner, to provide learners with personalized learning contents according to learners’ capabilities and learning results. Subproject 2-Implementation and Management of an Intelligent Personalized Test Bank: extended the standards of teaching materials, test items, learning portfolio in order to support the intelligent learning diagnosis system. Subproject 3-Design and Implementation of a Universal Access Mechanism to Multimedia Learning Content: developed three schemes, i.e., content adaptation, content transmission, and content presentation, to continuously deliver the suitable contents adapted dynamically to learners according to the bandwidth, user preference, device capability, and status of network connection. In addition, during the progress of project, we have published 21 journal papers including 4 SSCI and 8 SCI papers, and 41 international conference papers and 52 Chinese ones.
Keywords: E-Learning、SCORM、Learning Content Management 、 Learning Diagnosis, Content Adaptation.
二、計畫緣由與目的
隨著網際網路的興盛與普及,使的網路學習環 境的設計與開發已廣泛的受到重視,而如何設計一 個適性化的網路學習環境,更成為目前各國發展學 習科技的重要前瞻議題。目前一些國際標準組織已 開始著手規範網路教材文件的標準,以導入文件交 換與共享的概念。目前著名國際組織與教材標準約 有:AICC [1]、IMS[2]、IEEE LOM[3]、ADL SCORM[5]等等。而目前各國際標準中,SCORM (Sharable Content Object Reference Model)因集各家標準之所 長,已成為最受國際廣泛支持與採用的數位學習標 準規範,其目的在於提供可再用與分享的課程元件 撰寫準則。然而,由於目前SCORM在個人化教學 的部分仍存在許多問題,例如: 在本土化教材、個 人化教學與課程、試題自動化上之定義仍嫌不足。 另外,在個人化教學與課程、試題自動化上,目前 所提出的網路學習系統亦無法呈現出完善的效能 與 成 果 , 甚 至 有 些 系 統 根 本 就 忽 視 此 考 量 [7][8][10]。 因此,在本計劃中,我們以開放原始碼的精神 與元件設計方式,來規劃並建置一套[智慧型多媒 體學習內容管理系統],其中包括子計畫 1:「智 慧型個人化多媒體學習內容管理系統之研製」、子 計畫 2:「智慧型個人化題庫系統之建置與管理」 與子計畫 3:「行動學習載具上通用型多媒體學習 內容存取播放機制之研發」等3 個子計劃。其中, 子計畫一與子計畫二皆以 SCORM 國際標準為基 礎,針對個人化、學習歷程與教材內容等標準做延 伸。子計畫一針對多媒體學習內容提供有效的管理 與個人化之教材,而子計畫二根據子計畫一所發展 之多媒體學習內容物件庫與個人資訊來提供子計 畫一所需要的個人化題庫,子計畫三透過所有可能 之行動學習載具,讓學習者能夠在任何時間、任何 地點、利用有線或無線網路,存取子計畫一與二所 提供之多媒體學習內容資訊,以達到延伸學習者的 學習時間與學習空間之目的。 3 個子計畫的工作規劃與進度分別詳述如下: z 子計劃 1-「智慧型個人化多媒體學習內容 管理系統之研製(Design and Implementation of an Intelligent Multimedia Content Management System)」:包含(1).知識表示、(2)知識資源、(3) 知 識管理、(4) 知識擷取、(5) 知識包裝、及(6) 知識 探勘等6 個模組。可根據學習者的學習能力與評估 後的學習成果來提供學習者適當的個人化標準學 習教材。 z 子計劃 2-「智慧型個人化題庫系統之建置與 管 理 (Implementation and Management of an Intelligent Personalized Test Bank)」:為了支援智 慧型學習診斷系統,在數位學習標準中的教材標準 與試題標準加以延伸以及增加學習歷程標準。目的 在於使教材標準能夠支援學習障礙診斷;紀錄與學 習診斷有關的試題屬性,以用以判斷學生的學習障 礙;紀錄診斷結果,供學生或教師參考。 z 子計劃 3-「行動學習載具上通用型多媒體 學 習 內 容 存 取 播 放 機 制 之 研 發 (Design and Implementation of a Universal Access Mechanism to Multimedia Learning Content )」:提出內容調 機制:按照網路頻寬、使用者喜好、裝置能力來動 態調整內容出現的優先順序。提出內容傳輸機制: 即時監視與萃取使用者的學習狀態與網路連線狀 態,以傳輸連續性或同步性的內容。提出內容呈現 機制:管理或產生一個適當的內容給呈現給使用 者。
三、結果與討論
3.1 子計劃 1:「智慧型個人化多媒體學習內容管理系統之研製(Design and Implementation
of an Intelligent Multimedia Content Management System)」
子計劃1 發展一個智慧型個人化內容管理系統 (Intelligent Multimedia Content Management System, IMCMS),以根據學習者的學習能力與評 估後的學習成果來提供學習者適當的個人化標準 學習教材。IMCMS 包含以下 6 個知識模組。
3.1.1 Knowledge Representation (KR)
教 材 標 記 語 言 (Teaching Material Markup Language, TMML):
前 導 計 畫[19]規 劃 一 兩 層 次 教 材 標 記 語 言 (Teaching Materials Markup Language, TMML),此TMML V1.0 不但承襲了SCORM的標 籤與結構,並詳細規劃其學科之內容。故本子計畫 繼續架構在TMML V1.0 架構上,作其規範上之延 伸與強化,目前規劃版本為TMML V1.5,分為:學 習內容層(Content Level):主要定義與描述學習活 動與相關學習物件。測驗層(Quiz Level): 主要定義 與描述與上層學習活動相關之測驗試題。TMML基 本架構如圖1 所示,左邊為TMML V1.5 版之分層 架 構 示 意 圖 , 目 前TMML V1.5 所 有 延 伸 皆 在 Content Level,共有學科分類(Category)與教育定義 (Pedagogy),而右邊為相對應之學習活動與測驗評 量架構,由圖可知,在TMML架構中,依然保留 SCORM 2004 的學習活動(Activity Tree)架構規劃 與順序規則(Sequencing Rule)定義,且因 2 層式之 規劃,使的QTI的試題架構除保有原有之定義外, 亦可利用上層之順序規則來導引評量測驗活動。 TMML學習診斷的試題描述定義,將鏈結至子計畫 2 所規劃之試題延伸標準規劃描述。 圖 1:TMML 基本架構圖
教學活動模型(Instructional activity Model, IAM): 如前所述,TMML採用SCORM為發展基礎,並 融 入 了Simple Sequence Specification (SSS) 與 Question & Test Interoperability (QTI)等規範。然而 在目前的SSS中,對於龐大的學習活動樹(Activity Tree, AT)存在著不易管理與重新使用的問題,且對 於個人化的學習,如何應用教育理論(Pedagogical Theory)來提供更適性化的學習環境,也是子計畫1 中所關心的。因此,在本計畫中,運用教育理論與 物件導向方法論(OOM)來分別將AT的結構加以延 伸與模組化,使不同之AT彼此具有關聯性與教育 理論之實體意義,可便於管理與重新使用。於是提 出 教 學 活 動 模 型 (Instructional Activity Model,
IAM),此模型由許多具有互關聯性(Inter-relation) 與特殊屬性的小AT節點組成,因此藉由這些互關 聯性與屬性,這些AT節點便可簡易的被管理、重 組與整合,IAM架構之示意圖如圖3所示。此外, 我們也提出AT Selection Algorithm來瀏覽IAM架 構,以動態的產生學習內容(Learning Content)給使 用者。IAM具有延伸性與彈性,因此可以藉由延伸 機制來應用教育理論以符合特殊的需要。 圖2:IAM示意圖 因此,IAM 即為一學習活動或課程之圖形化表 示,其包含一些 AT、包含先備知識(Prerequiste)與 貢 獻(Contribution) 之 能 力 (Capability) 、 包 含 具 有 mReqij的 eij 與 e’ij的關係邊(Relation Edge),及一
些評估函數(Measure Functions),所以,它可以被 表示為 IAM=(ATset, Cset, Eset, E'set),此處:
z ATset = {AT1, AT2, …,ATn}.
z Cset = {c1, c2,…,cn}.
z Eset 為所有 Prerequisite Edges 的集合,被表示為
Eset =
U
E
j, Ej =Ui(eij ,mReqij), eij∈ATj.z E'set 為所有 Contribution Edges 的集合,被表示
為 E'set =
U
E'
j, E'j =Uje'jk, e'jk∈ATj.此外,本子計畫所提出之IAM更融入了Gagne 的Learning Outcome[13] (包含Verbal Information、 Intellectual Skills 、 Cognitive Strategies 、 Motor Skills與Attitude等5種能力)、學習風格[14](包含 Visual、Auditory與Kinesthetic等3種)與Bassing的教 材組織[12] (包含Logical、Psychological與Eclectic Organization等3種組織架構)等教育理論,以提供更 人性化的學習內容給使用者作學習,其詳細的定義 與內容可參考[24]。 物件導向式學習活動模型(OOLA Model) 為了克服目前學習標準(LD、SCORM)之複雜 與不足之處,及提供教師ㄧ個簡易與可套用教學理 論的學習活動規劃環境,並可重新使用既有之學習 資源與分享彼此之教學經驗,因此,子計畫1 提出 了OOLA Model 架構,來達到上述之需求,此模型 具有相當的彈性(Flexibility),主要以一教學活動 中,所應具有之學習目標與內容(Content)、學習工 具 與 互 動 功 能 (Interaction) 以 及 學 習 評 量 (Assessment)等 3 個基本元素為著眼點所規劃而 出,其主要之定義如下: 定義 1 (Definition 1):
Definition 1: OOLA 可表示為一圖形結構(Graph), OOLA = (V, E),此處
z V={N1, N2,…, Nn}. 代 表 ㄧ 學 習 活 動 (Learning
Activity, LA)中之學習單元(Learning Unit)。 OOLA 中之各節點(Node)依照其節點特性可區分 為以下3 種型態:
(1) NLA:代表ㄧ符合 SCORM 標準或 IAM 模型之
一 學 習 活 動(Learning Activity, LA) 或 課 程 單 元 (Single Course)。
(2)NAP: 代 表 ㄧ 可 執 行 之 應 用 程 式 (Application
Program, AP),例如:聊天室(Chat Room)、 搜尋引擎(Searching Engine, SE)、等。 (3) NEA:代表ㄧ課程之學習測驗(Exam Activity,
EA)。
此外,每ㄧ節點具有學習時間(Learning Duration) 之屬性設定,此屬性可讓教師或教學設計者有效的 規畫與控制學習活動之進行。
z E={e1, e2,.., en}. 此為一有向邊(Directed Edge)之
有限集合(Finite Set)。 此有向邊集合中,某些邊具有條件屬性(Condition Attribute, α)可供設定學習活動導引規則(Rules), 以提供學習系統做學習活動之導引控制。目前在 OOLA 定義中,從 NEA至其他三種節點(NLA、 NAP、NEA)的邊集合皆具有條件屬性之設定,即: LA EAN N 、NEANAP、NEANEA。
圖3 則為 OOLA 之架構示意圖(Diagram)。在 OOLA 的彈性架構中,教師或教學設計者可依照其想法或 教學理論來設計與規劃其想要之學習活動,以提供 更妥善之適性化學規劃。
圖 3: OOLA 之示意圖
3.1.2 Knowledge Capturer (KC)
內 容 轉換機制(Content Transformation Scheme, CTS): 為了使子計畫1 所延伸與修訂出的 TMML 教材 標準能快速與方便提供給教師與學習者使用,因此 我們發展了一教材標準化之轉換機制(CTS)來快速 的轉換傳統教材成為符合 SCORM/TMML 的標準 教材。其轉換流程之系統展示如圖4 所示。
圖4:傳統教材標準化之轉換流程 Object Oriented Course Modeling (OOCM):
因SCORM 2004 所 提 出 的 Sequencing & Navigation (SN)規範[6]中,具有複雜的規則與架構 定義,所以要製作出符合SN規範的教材變的相當的 困 難 , 雖 然 有 相 關 之 編 輯 工 具 被 提 出 與 開 發 [4][9][11],但因無考量到SN規範之規則定義與結構 特殊性,故依然難以使用。因此,子計畫1 運用物 件導向的概念,提出了一系統化的方法,稱為物件 導 向 課 程 塑 模(Object Oriented Course Modeling, OOCM)機制。
The Scheme of OOCM:
圖5為OOCM的流程架構,包含以下4個處理: (1) OOAT Modeling with HLPN: 應用 HLPN 來分
析 SN 的規則定義與架構,將 SN 規範與架構 模 組 化成 5 基本的順序元件,稱為 Object Oriented Activity Tree (OOAT)(圖 6)。 每ㄧ OOAT 如同一中介軟體(Middleware),代表在學 習活動中一個基本的課程架構並相對應於在 SCORM 中,一個具有相關順序規則的活動樹 (AT)架構。
(2) Course Construction with OOAT: 使用這些 OOAT 可建構具有複雜順序規則的 SCORM 學 習活動之HLPN 模型架構。 (3) PN2AT Process: 將 HLPN 的課程模型轉換成 符合 SCORM 標準架構且具有相關順序規則 (Rules)的活動樹架構。 (4) AT2CP Process: 將轉換後的 AT 架構與相關 的實體教材資料包裝成SCORM 的教材包裹檔 案(Content Package File)。
圖7為OOCM編輯工具的系統畫面。
圖 5: The Flowchart of Object Oriented Course Modeling (OOCM)
圖7: The Screenshot of the OOCM Authoring Tool
圖6: The Five Sequencing Components of OOATs 3.2.3 OOLA 編輯工具(OOLA Authoring Tool)
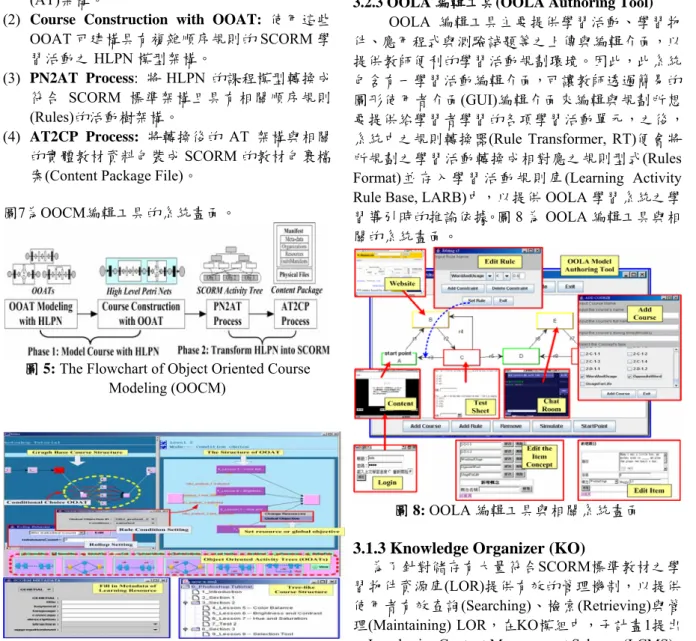
OOLA 編輯工具主要提供學習活動、學習物 件、應用程式與測驗試題等之上傳與編輯介面,以 提供教師便利的學習活動規劃環境。因此,此系統 包含有一學習活動編輯介面,可讓教師透過簡易的 圖形使用者介面(GUI)編輯介面來編輯與規劃所想 要提供給學習者學習的各項學習活動單元,之後, 系統中之規則轉換器(Rule Transformer, RT)便會將 所規劃之學習活動轉換成相對應之規則型式(Rules Format)並存入學習活動規則庫(Learning Activity Rule Base, LARB)中,以提供 OOLA 學習系統之學 習導引時的推論依據。圖8 為 OOLA 編輯工具與相 關的系統畫面。
圖 8: OOLA 編輯工具與相關系統畫面
3.1.3 Knowledge Organizer (KO)
為了針對儲存有大量符合SCORM標準教材之學 習物件資源庫(LOR)提供有效的管理機制,以提供 使用者有效查詢(Searching)、檢索(Retrieving)與管 理(Maintaining) LOR,在KO模組中,子計畫1提出 ㄧLevel-wise Content Management Scheme (LCMS)。
Level-wise Content Management Scheme (LCMS): 如圖9 所示,LCMS 機制分為 Constructing Phase 與Searching Phase。前者從 SCORM 的教材中利用 CP2CT 處 理 來 建 置 Content Tree(CT) 並 利 用 Clustering 技術來建構與管理一個如同 Directed Acyclic Graph (DAG)的 Multistage Graph 並儲存有 有學習物件(Learning Object, LO)間的關係,稱為 Level-wise Content Clustering Graph (LCCG)。
後者可根據使用者查詢來利用我們所提出的 LCCG Content Searching Algorithm (LCCG-CSAlg) 來搜尋此LCCG 架構,以同時擷取具有ㄧ般概念與 細部概念的學習內容
Constructing Phase 包含以下 3 個處理步驟:
z Content Package to Content Tree (CP2CT) Process: 轉換 SCORM 的教材成為帶有代表性 特徵向量樹狀(Representative Feature Vector)的 Content Tree(CT)。
z Level-wise Content Clustering Process: it clusters LOs according to content trees (CTs) to establish the level-wise content clustering graph (LCCG) for creating the relationships among LOs . 依據 CT 來叢集 LO 以建立 level-wise
content clustering graph (LCCG),其可建構各
LO 間之關係。
z LCCG Maintaining Process: 監督 LCCG 中之 各節點的情況,如需要便進行重建LCCG 之處 理。
Searching Phase 包含以下處理:
z SCORM Metadata Searching:利用 SCORM 的 Metadata 來搜尋 LCCG 的主要進入點。 z Level-wise Content Searching: 從入口節點來
細部搜尋LCCG 的各個相關子點,以提供更精 確的LO 擷取。
圖9: The Flowchart of Level-wise Content Management Scheme (LCMS)
圖10: The Screenshot of LCMS Prototypical System
根據 LCMS 所建構之架構並搭配所提出之搜尋 演算法,便可提供使用者有效查詢(Searching)、檢 索(Retrieving)與管理(Maintaining) LOR。圖 10 為雛 型系統之使用畫面。 3.1.4 Knowledge Packer (KP) 當學習者登入並開始進行學習時,IMCMS 中 的 KP 模組便負責從學習活動資源庫(LAP)中初始 一學習活動,並根據學習者的學習成果來提供適當 的學習內容與服務。因此,此KP 模組包含系統協 調器(System Coordinator, SC)與推論引擎(Inference Engine, IE)來負責協調與推論出使用者適合的學習 內容、服務、與試題測驗。
3.1.5 Knowledge Miner (KMin)
學習歷程探勘(Learning Portfolio Mining, LPM) 學習歷程資料包含許多學生在學習時所留下的有 用資訊,許多研究[15]錯誤! 找不到參照來源。 [16][17][18]已指出學習歷程的分析可幫助教師了 解學生學習成效優劣的成因。因此,子計畫1 提出 4 階段的學習歷程探勘機制來有效分析學習歷程資 料。 圖 11: LPM 流程架構 如圖11 所示,LPM 包含以下 4 階段: 1. User Model Definition Phase: 首先基於教育理 論來定義學習者資訊,例如:性別、學習風格、認知 風格、學習經驗等個人資訊。
2. Learning Pattern Extraction Phase: 應用循序樣 本探勘(Sequential Pattern Mining)技術從學習序列 (Learning Sequence)中來擷取出 Maximal Frequent Learning Patterns。因此,原始的學習者學習序列便 可被對應到一個位元向量(Bit Vector),如果在學習 系列中有包含截取出的學習樣板,則所對應的位元 將設為1。藉由此位元向量,距離式的叢集方法便 可被用來將具有相似學習行為且成績好的學生群 集在一起。
3. Decision Tree Construction Phase: 經過學習樣 式粹取之後,被分群出來的各群體便會被標上識別 碼,接著便可用2/3 好學生的個人資料來建立決策 樹,而剩下的學生資料便可用來做決策樹的測試。 4. Activity Tree Generation Phase: 最後,每ㄧ個群 體所包含的相對應學習樣本,便如同有效的學習規 則,可用來導引相似的學生進行適性化的學習,故 便利用所提出的活動樹轉換演算法來轉換學習樣 本成為個人化的SCORM2004 學習活動樹架構。
兩階層式概念圖建構機制(Two-Phase Concept Map Construction, TP-CMC): 概念圖為表示學習概念之先後備知識間的關 係,利用概念圖可以做有效的適性化學習導引,然 而ㄧ般的概念圖皆為事先定義好的架構,雖可作為 系統的適性導引之用,但製作一個良好的概念圖卻 需花費大量的時間與人力,因此,子計畫1 針對如 何有效的建構出良好的概念圖而提出了兩階層式 概念圖建構機制(TP-CMC)來分析學生的測驗試題 資料,利用分析後的結果來進行概念圖的建構處 理。 TP-CMC 建構流程如圖 12 所示,分為 2 階段, 第一階段-成績關聯規則處理(Grade Association Rule Process):分為 3 個步驟,(1)Grade Fuzzification: 利用模糊集理論來將數值格式的分數資料,轉換成 符號格式,(2)Anomaly Diagnosis:應用常模參照測 驗試題分析(Item Analysis for Norm-Referencing)來 計算各試題的困難度及鑑別度,以剔除不適用的試 題資料,(3)Fuzzy Data Mining:應用 Look Ahead Fuzzy Mining Association Rule algorithm(LFMAlg) 來進行試提資料的概念關係探勘。 在TP-CMC 中,利用如表 1 的試題-概念對應 表來記錄試題與學習概念間的關係,例如:表中 5 個試題包含A, B, C, D 與 E 等 5 個概念,1 表示之 間此試題與此概念之間有關聯存在,0 則沒有。因 此,藉由可關係定義,在 TP-CMC 的第二階段-概 念圖建構處理(Concept Construction Process):將 依據我們針對實際學習與測驗結果間關係的實際 觀察分析,針對在第 1 階段所萃取出的關聯規則 (L-L, L-H, H-H, H-L)做概念間的前後備知識作關 係定義,而提出概念圖建構演算法,來利用萃取出 的關聯規則做概念圖建構。 Historical Testing Records Database Grade
Fuzzification DiagnosisAnomaly Data MiningFuzzy
L-L Rule Type L-H Rule Type H-L Rule Type H-H Rule Type Educational Experts Phase 1:
Grade Association Rule Mining Process
Mined Association Rules
Concept Map Constructor
Phase 2: Concept Map Constructing Process
Test Item-Concept Mapping Database Concept Map Dicussion A C B E D 圖 12: 兩階層式概念圖建構機制(TP-CMC) 表 1: 試題–概念對應表 而利用TP-CMC 所建構出來的概念圖(圖 13), 除可提供給教師做教學策略的參考之外,亦可作為 系統自動學習導引的依據。 圖 13: 概念圖建構雛形系統畫面 3.2 子計劃2:「智慧型個人化題庫系統之建置
與管理(Implementation and Management of
an Intelligent Personalized Test Bank)」
3.2.1 教材標準之延伸 爲使 TMML 能夠支援以概念為基礎之學習障 礙診斷,在 TMML 架構中延伸教材標準,將分別 說明學習概念與概念關係圖表達方式。 學習概念: 假設教師希望能使用以概念為基礎之學習診 斷系統,對學生的測驗成績做診斷分析。則教師必 須 在 教 材 中 清 楚 說 明 整 份 教 材 所 包 含 的 學 習 概 念;每個學習概念都有學習概念編號、學習概念名 稱(表 2)。如此,以概念為基礎之學習診斷系統就 能針對這份教材所出的試題進行學習診斷分析。 表2: 教材延伸標準-學習概念規格說明表 Concept 描述試題所包含的概念編號 Data type:由兩個項目所組成
‧Cid: String // Concept_id identifier
‧Cname:String // Concept_name identifier
Value space: ‧Cid: ASCII set ‧Cname:Unicode set Format: < Concept >
<Value id =" Cid 1" > Cname 1</Value>
<Value id =" Cid 2" > Cname 2</Value>
....
<Value id =" Cid n"> Cname n</Value>
< /Concept > 概念關係: 各概念間的相互關聯性,包括概念內涵與先後 次序關係,可建構成概念關係圖。故除學習概念 外,明確定義概念繼承關係更是重要。藉此可找出 學生學習的癥結點,提升學生的學習成效。故以 Concept_relevance 標籤來記錄教材中所包含的學 習概念描述,如表3之規格所示。 表 3:教材延伸標準-概念繼承關係規格說明表 Concept_relevance 描述概念間之學習先後順序 Data type:由兩個項目所組成 ‧Fid:String //Farther_concept_id identifier ‧Cid:String // Child_concept_id identifier Value space: ‧Fid:ASCII set ‧Cid:ASCII set Format: < Concept_relevance > <Parent> Fid11,Fid12.... </Parent>
<Child> Cid11,Cid12 ...</Child>
....
<Parent> Fidn1,Fidn2.... </Parent>
<Child> Cidn1,Cid12 ...</Child>
</Concept_relevance > 3.2.2 試題標準之延伸 本節將針對學習障礙診斷的需求,以 TMML 為基礎來延伸試題標準不足部分,使之得以支援智 慧型診斷系統。 基礎試題標準: 目前TMML 在 2005 年在新版試題標準的試題 標準中,一份完整的試題文件架構最主要是由四大 部 分 組 成 , 分 別 是 試 題 資 訊 描 述
(Templateprocessing)、試題內容(Itembody)、記 錄 資 料 來 源(Responseprocessing) 、 變 數 宣 告 (Variabledeclaration)。 z 試題鑑別度:能區別分辨出高學習成就者與低 學習成就者的學生能力程度稱之為鑑別度。子計畫 2 以 Discrimination_level 標籤來記錄試題鑑別度, 數值越高代表此題鑑別度越高,其規格如表4。 表 4:試題延伸標準-試題鑑別度規格說明表 Discrimination_level 描述試題鑑別度 Data type:由一個項目所組成
‧Dsvalue :Float (4) //Discrimination _value
identifier
Value space:
‧Dsvalue:(0~1) a float number greater than or equal to 0 less than 1 Format: <Discrimination_level> Dsvalue </Discrimination_level> z 試題難易度:難易度是指試題在測驗過程中的 測驗困難度。子計畫2 以Difficulty_level標籤來記 錄試題難易度,考量國內教育體制,試題不需過於 複雜的分類,因此將類別加以簡化分為四種狀態: 基礎(Basic)、中等(Middle)、進階(Advanced)、困難 (Difficult),其規格如表 5。 表 5. 試題延伸標準-試題難易度規格說明表 Difficulty_level 描述試題難易度 Data type : ‧Dfvalue:State(basic,middle, advanced,difficult) Value space: ‧Dfvalue 。Basic :試題的難易度等級為”基礎” 。Middle :試題的難易度等級為”中等”。 。Advanced:試題的難易度等級為”進階”。 。Difficult :代表試題的難易度等級為”困難”。 Format: <Difficulty_level> Dfvalue </Difficulty_level > z 支援以概念為基礎之學習障礙診斷之試題延 伸標準:記錄測驗試題中所包含的學習概念,同時 也需記錄出題者對每個學習概念所佔的權重。子計 畫 2 以 Item_Concept 標籤來記錄學習概念與試題 之間的相關程度,如表6 之規格所示。 表 6:試題延伸-概念為基礎之學習障礙診斷規格表 Item_Concept 描述試題包含的概念與概念間相關程度集合 Data type : 由兩個項目組成
‧Cvalue:Floate (4)// Concept_value identifier
‧Cid: String // Concept_id identifier
Value space:
‧Cvalue:(0~1) a float number greater than or equal to 0 less than 1
‧Cid:ASCII set
Format: < Item_Concept > <Value identifier=" Cid 1"> Cvalue 1</Value>
<Value identifier=" Cid 2"> Cvalue 2</Value>
<Value identifier=" Cid 3"> Cvalue 3</Value>
....
<Value identifier=" Cid n"> Cvalue n</Value>
</ Item_Concept > z 支援布魯姆教育分類法之試題延伸標準:教 育分類系統是一種撰寫學習目標的共通語言,布魯 姆分類法﹙B. S. Bloom﹚已儼然成為國際上大家都 所 認 可 的 教 育 分 類 法 。 本 計 畫 以 Revised_Bloom_Taxonomy 標籤來記錄試題中所包 含的布魯姆教育分類法資訊,其規格如表7。 表 7:試題延伸標準-支援布魯姆教育分類法規格表 Revised _Bloom_ Taxonomy 描述試題所涵蓋的布魯姆教育分類法資訊 Data type:由兩個項目組成
‧CPD_id:State(1.1..) //Cognitive Process Dimension_i
identifier
‧KD_id :State(Aa...) // Knowledge Dimension_id
identifier Value space: ‧CPD_id: 。1.1:再認知識(記憶)。1.2:回憶知識(記憶) 。2.1:詮釋知識(了解)。2.2:舉例知識(了解) 。2.3:分類知識(了解)。2.4:摘要知識(了解) 。2.5:推論知識(了解)。2.6:比較知識(了解) 。2.7:解釋知識(了解)。3.1:執行知識(應用) 。3.2:實行知識(應用)。4.1:辨別知識(分析) 。4.2:組織知識(分析)。4.3:歸因知識(分析) 。5.1:檢查知識(評鑑)。5.2:評論知識(評鑑) 。6.1:產生知識(創造)。6.2:計畫知識(創造) 。6.3:製作知識(創造) ‧KD_id: 。Aa:術語的知識 。Ab:特定細節和元素的知識 。Ba:分類和類別的知識 。Bb:原理和通則的知識 。Bc:理論/模式/結構的知識 。Ca:特定學科既能和演算知識 。Cb:特定學科技術與方法知識 。Cc:運用規準的知識 。Da:策略知識 。Db:認知任務知識 。Dc:自我知識 Format: <Revised_Bloom_Taxonomy> < Cognitive_Process_Dimension > CPD_id </ Cognitive_Process_Dimension > < Knowledge_Dimension > KD_id </ Knowledge_Dimension > </Revised_Bloom_Taxonomy> z 支援九年一貫能力指標之試題延伸標準:每 題試題都有其對應的能力指標,且有可能包含一個 或一個以上的能力指標。以Competence_ Indicators 標籤來記錄能力指標編號,其規格如表8。 表 8:試題延伸標準-支援九年一貫能力指標規格表 Competence_ Indicators 描述試題所包含的能力指標 Data type :由一個項目所組成 ‧Cmid:String // Competence_ Indicators_id
identifier
Value space: ‧Cmid:ASCII set
Format: < Competence_ Indicators > Cmid 1,....Cmid n < / Competence_ Indicators > 3.2.3 學習歷程標準之延伸 CMI 特別針對學生的學習歷程提出完整的標 準規範,因而其學習歷程標準成為許多國際標準組 織參考及改進的對象。本計畫亦是在相容於CMI 學習歷程標準的前提下加以延伸。 z 支援以概念為基礎之學習障礙診斷之學習歷 程延伸標準:本計畫以 Concept_cognitive_degree 標 籤來記錄此份試題的認知概念程度,其規格如表9。
表 9:學習歷程延伸標準-概念學習狀況規格說明表 Concept _cognitive_ degree 描述概念學習理解程度 Data type:由兩個項目組成
‧Cdegree:Float (4), // Concept_ degree identifier
‧Cid: String // Concept_id identifier
Value space:
‧Cdegree:(0~1) a float number greater than or equal to 0 less than 1
‧Cid:ASCII SET
Format: <Concept_cognitive_degree > <Value identifier=" Cd 1"> Cdegree 1</Value>
<Value identifier=" Cid 2"> Cdegree 2</Value>
....
<Value identifier=" Cid n"> Cdegree n</Value>
</Concept_cognitive_degree> z 補救學習路徑:可藉由補救學習路徑,知道如 何有順序性的學習先備知識,補救克服所遇到的學 習障礙。以 To-be-Enhanced_learning_paths 標籤來 記錄補救學習路徑,其規格如表10。 表 10.學習歷程延伸標準-補救學習路徑規格說明表 To-be- Enhanced_ learning_ paths 描述補救學習路徑 Data type:由兩個項目所組成
‧Fid:String // Farther_concept_id identifier
‧Cid:String // Child_concept_id identifier
Value space: ‧Fid:ASCII set ‧Cid:ASCII set
Format: < To-be-Enhanced_learning_paths > <Parent> Fid11,Fid12...</ Parent>
<Child> Cid11,Cid12 </Child>
....
<Parent> Fidn1,Fidn2...</ Parent>
<Child> Cidn1,Cidn2..</Child>
</ To-be-Enhanced_learning_paths > z 關鍵學習路徑:指把先前診斷系統提供的補救 學習路徑中,運算其中一段路徑中比例權重較高的 路 徑 , 即 最 大 學 習 困 難 的 路 徑 。 以 Key_learning_paths 記錄關鍵學習路徑,如表 11。 表 11. 學習歷程延伸標準-關鍵學習路徑規格表 Key_learning_paths 描述關鍵學習路徑 Data type
‧Cid:String // Concept_id identifier
Value space ‧Cid:ASCII set
Format: <Key_learning_paths > Cid1,Cid2 ………Cidn
</Key_learning_paths> z 學習障礙診斷結論:依據輸入值,(鑑別度、難 易度、試題與概念之間的權重關係,試題題目測驗 診斷完的概念學習狀況、補救學習路徑、關鍵學習 路徑)給予學習指導與建議。以 Diagnosis_result 標 籤來記錄學習障礙診斷結論,其規格如表12。 表 12:學習歷程延伸-學習障礙診斷結論規格表 Diagnosis _ result 描述診斷結論 Data type:
‧Drvalue:String // Diagnosis_ result _value
identifier
Data value: ‧Drvalue:Unicode set
Format: <Diagnosis_result> Drvalue </Diagnosis_result> z 支援布魯姆教育分類法之學習歷程延伸標準: 藉由布魯姆分類法資訊,協助幫助學生保留和遷移 所學習獲得的知識並依據分析的結果並給予個人 適 性 化 的 學 習 建 議 。 以 Revised_Bloom _Taxonomy_degree 標籤來記錄試題中隱含布魯姆 教育分類法資訊的了解程度,如表13。 表 13:歷程延伸-bloom 教育分類法學習狀況規格表 Revised_ Bloom_ Taxonomy_ degree 描述布魯姆教育分類法學習狀況理解程度 Data type: 由三個項目組成
‧Ldegree:Interger // Learn_ degree identifier
‧ CPD_id : State(1.1...) //
Cognitive_Process_Dimension_id identifier
‧KD_id: State(Aa...) // Knowledge_Dimension_id
identifier
Value space:
‧
Ldegree:(0%~100%) a integer number greater than or equal to 0 % less than 100% CPD_id:(同支援布魯姆教育分類法規格表) KD_id:(同支援布魯姆教育分類法規格表) Format: < Revised_Bloom_Taxonomy_degree > < Cognitive_Process_Dimension identifier="CPD_id 1 "> Ldegree </ Cognitive_Process_Dimension > < Knowledge_Dimension ="KD_id 1 "> Ldegree </ Knowledge_Dimension > .... <Cognitive_Process_Dimension identifier="CPD_id n "> Ldegree </ Cognitive_Process_Dimension > < Knowledge_Dimension ="KD_id n "> Ldegree </ Knowledge_Dimension > </ Revised_Bloom_Taxonomy_degree > z 支援九年一貫能力指標之學習歷程延伸標準: 以 Competence_ Indicators_degree 標籤來記錄學生 測驗後對能力指標為理解程度,其規格如表14。 表 14:歷程延伸標準-九年一貫能力指標規格表 Competence_ Indicators_degree 描述九年一貫能力指標理解程度 Data type: 由兩個項目組成‧Ldegree:Float (4) // Learn_degree
identifier
‧Cmid:String // Competence_ Indicators_id identifier
Value space: ‧Ldegree:(0~1)
//數值<=1 數值越高代表了解程度越高 ‧Cmid:ASCII set
Format:
< Competence_ Indicators_degree > <Value identifier=" Cmid 1 ">Ldegree
1</Value>
<Value identifier=" Cmid 2 ">Ldegree
2</Value>
....
<Value identifier=" Cmid n ">Ldegree
n</Value> </ Competence_ Indicators_degree > 3.2.4 符合 SCORM 延伸標準的智慧型測驗系統之 規劃 依據所提出的 TMML (SCORM/QTI)延伸標 準,在Windows 2003 作業環境中,以微軟的 C# 發 展 一 套 工 具 試 題 及 學 習 歷 程 匯 入 及 匯 出 工 具 - TELD (TMML-Extension for Learning Diagnosis),系
統架構圖如圖14 所示。系統的功能為:(1)建立教 材延伸標準文件(2)建立試題延伸試題文件(3) 學習歷程資料剖析。 圖 14:TELD 系統架構圖 z 建立教材延伸標準文件:透過 TELD 新增本計 畫所提出之教材延伸標準;會自動將 TMML 教材 文件轉化成教材延伸標準文件。透過TELD 新增概 念編號、概念間之先後順序,如圖 15 所示。 圖 15:編輯教材延伸標準文件
z
建立試題延伸標準文件:當匯入試題標準文件 時,透過TELD 再編輯之。例如新增能力指標、可 選擇參考的教材概念編輯所屬之權重、鑑別度、難 易度、認知歷程向度、知識向度,如圖16 所示。 圖 16:編輯試題延伸標準文件介面 z 學習歷程檔案之剖析:匯入符合學習歷程之標 準文件時,TELD 將匯入的 XML 文件顯示在網頁 上,並檢查XML 文件是否符合學習歷程標準。並 將文件內容顯示在網頁上,如圖17。 圖 17:學習歷程參數瀏覽 子計畫 2 建構的 TMML 學習診斷試題分享系 統 (TMML-Extension for Learning Diagnosis , TELD)可提供使用者便利的標準化教材建構環 境,並能夠支援符合TMML 延伸標準之學習歷程。 同時,TELD 提供編輯試題標準的功能,試題編輯 者只需專注在試題內容,不需記憶延伸標準的細 節。因此,教師在編輯試題時更能得心應手,測驗 的品質提昇及教材的豐富化將有莫大的幫助。 3.3 子計劃 3:「行動學習載具上通用型多媒 體學習內容存取播放機制之研發 (Design andImplementation of a Universal Access Mechanism to Multimedia Learning Content )」 情境導向的內容調整流程是由四個主要的模 組所組合而成:中間代理者、用戶端資訊引擎、內 容引擎與內容可適性引擎。中間代理者是一個與使 用者溝通的入口,使用者資訊引擎將會從情境資料 儲存器裡取出使用者的描述資料,並且更新網路連 線與使用者狀態。內容引擎控制被要求內容的萃 取、分解、與儲存。內容調適引擎執行調適的處理 包含調適規則的產生,物件版本的選擇,資料轉 換,與樣板的安排,整個系統的架構呈現於圖 18 之中。 圖 18:情境導向的內容調整流程架構圖。. 情境組成所有標示使用者傳遞情境的所有資 料,包含個人存取能力,裝置能力,存取環境。子 計畫3 萃取 CC/PP 與 UAProf 中必要的屬性來描述 裝置,而使用者本身存取能力,身處的狀況用來描 述使用者。所以對於內容調適的需求而言產生四類 主要的情境描述: (1) 存取能力(Accessibility):是使用者本身對於媒 體類型可接受的固有的能力,例如視覺障礙者 只能接受聲音類型訊息,耳聾的人可以接受視 覺性質的資訊。 (2) 網路(Network):所指的是使用者的要求與回應 的傳輸網路狀況,我們使用有線與無線來說明 頻寬的限制。 (3) 使用者身處情況(situation)用來說明使用者現 在正處於什麼狀態,這樣的狀態無法呈現哪些 資料,例如使用者正在開會,因此有關聲音
(Audio)的多媒體資料就無法被執行,再此,我 們暫時只定義了開會狀態與駕駛狀態來描述使 用者身處的情況。 (4) 最後我們運用原本已既有的裝置描述情境來描 述裝置,在這裡我們分類成筆記型電腦(NB), PDA,與行動電話(Phone)。 針對這些特性來實做內容調適的應用,其情境 資訊的定義如下: Context-profile
CID= {Situation, Accessibility,
Network, Device}
Situation = {office | meeting | driving}
Accessibility = {normal | blind | weak-sighted | deaf | weak-hearing}
Network = {wired | wireless} Device = {NB | PDA | phone}
在此CID表示是用者的身分認證碼。圖19表示 一個實例所舉的情境資訊,其所說明的是Rick是一 位弱視使用者,持PDA在會議狀態中進行內容存 取,其網路狀況是無線網路。
Context-profileRick = {Situation= “office”, Accessibility = “weak-sighted”, Network= “wireless”, Device= “PDA”}
圖19:使用者情境資料的例子 為了提供客製化內容,內容調整伺服器需要準 備資料轉換的導引,提供使用於每個可能的情境描 述,無論如何,完整的情境需求是很難以去設計, 因為這些資訊可能會在未來改變,為了應付將會改 變的情境資訊,子計畫3將各類的情境所延伸出來 的調適規則模組化,未來只要其中有一個情境改 變,我們只需要更改該相關的模組,而不需要整個 修改,最後,在這些情境所制定的規則下,內容調 適機制將會產生調適規則,產生適當的內容服務使 用者。 步驟一、情境定義: 調適規則是一個用來當作多媒體物件版本轉 換的標準,根據使用者需求的情境,必須了解在什 麼情境之下要轉換什麼物件版本服務使用者。圖 20 , 為 所 要 發 展 的 情 境 規 則 。 首 先 定 義 形 式 (Modality)來表示多媒體物件的版本,例如文字 (Text)、聲音(Audio)、影像(Video)、圖片(Image)。 另外定義精確度(Fidelity) 來表示物件的解析度,例 如文字的大小,圖片的大小,聲音的取樣頻率,影 像的解析度等等。其轉換的基本規則如下 Object
OID(Modality, Fidelity) ∩ ContextCID(feature)
=> Object
OID(Modality, Fidelity)
如圖20,我們使用情境資訊的字首“S”、“A”、 “N”、 “D”來個別當作情況(Situation)、存取能力 (Accessibility)、網路(Network)、裝置(Device)的索 引。 步驟二、規則制定: 首先,用戶端所處的狀況例如會議中與駕駛 中,會影響了瀏覽的行為,這會改變到物件形式 (Modality),例如,在開會期間,任何的有聲音性 質的物件如聲音(Audio)與影像(Video)都應該不能 被執行。在情況(Situation)類別中,我們找出十二種 可能的內容調適規則,做為轉換程序的依據,如圖 20(a)所示。以下是一個轉換的規則之一: S2 Object
OID (video, original) ∩ SituationCID(meeting)
→ Object
OID (video, mute)
第 二 , 我 們 考 慮 使 用 者 本 身 的 存 取 能 力 (Accessibility),所描述的是使用者本身的感應狀 態,例如視覺障礙、弱聽、弱視,因此盲人無法接 受視覺類型的資訊,聾者無法接受音效類型的資 訊,對於存取能力而言,有十二種調適規則,如圖 20(b)所示,舉個例子而言,規則A17所指示出,當 一位盲人在讀取文字資訊的時候,這個文字物件就 必須轉成聲音類型物件,其轉換規則如下: A17 Object
OID(text, original) ∩ AccessibilityCID(blind)
→ Object
OID(audio, original).
如果物件轉換碼程式不能提供正確的物件版 本,則這個程序將會被終止,並且在物件的解析度 上會是空白的,舉個例子,因為物件轉換程式不能 將圖片轉換成文字或影像,因此根據規則A12而 言,我們改變圖片得解析度(Fidelity)為空白,其調 適規則如下: A12: Object
OID(image, original) ∩
Accessibility
CID(blind) → ObjectOID(image, blank)
第三,網路狀況(Network)是另外提供物件品 質的條件,事實上,網路的環境包含各種類型,例 如Fast Ethernet、FDDI、wireless LAN與GPRS等等, 在此我們分類成有線與無線兩類,我們假設無線與 有限的傳輸率為10Mbps與1Mbps,因此我們針對這 樣的條件定義出八條規則,如圖20(c)所示,舉個例 子,一個影像可以在有限網路中傳輸的很流暢,但 是他被應用在無線網路時,這個影像檔的每秒傳輸 封包就應該被減少,其規則如下所示: N2: Object
OID(video, original) ∩
Network
CID(wireless) → ObjectOID(video, low)
第四,裝置的能力(Device)用來確定媒體類型 的可執行性,由PDA與手機於計算能力較弱,一些 高品質的影像或是flash被顯示是困難的,大部分的 內容呈現是針對PC或筆記型電腦,但是這樣的內容 較無法平順的呈現在小型螢幕或是解析度較低的 裝置上,因此很多的物件就應該被縮小。。我們使 用三種不同形式的裝置來當做基準,桌上型電腦、 PDA與手機,其轉換的規則有十二條,如圖20(d) 所示,舉個例子,一個文字訊息要被呈現在PDA 上,則他就應該被縮小成PDA所符合的型態之下, 其調適規則如下:
D11: Object
OID(text, orginal) ∩ DeviceCID(PDA) →
Object
OID(text, PDA)
根據以上說明,當使用者有這四種類型所組合 而成的情境時,經由這些調適規則,就可以調適出 符合使用者的內容呈現。 由於深入的探討影響使用者存取內容,甚是學 習效率的因素,不會只有裝置的不同,環境的不一 樣而已,經由以上所訂定的規則,可以讓通用存取 機制獲知使用者更細微的需求,進一步的給予適當 的存取服務,這樣強調個人化的存取機制,可以更 節省資源的使用,增加使用者更多的學習幫助,加 上其他子系統的結合,例如知識分享,群體協同學 習,教學設計等等,更進一步的發展出Ubiquitous learning(U-Learning)。 為了評估內容存取中有調適策略的效率,我們 需要測量調適內容的存取時間與呈現品質,再這報 告中的存取時間表示為服務要求的發送到接收到 呈現畫面的時間區間,被提出的調適策略被建構在 Apache 伺服器上的 PHP 介面與 Mysql 資料庫,測 試平台為IBM 伺服器期 CPU 為 1G 與 1GB 的記憶 體。 所有的執行環境是在於微軟的 Window XP 上 與 Red Hat linux 7.3。所測試的裝置包含了 Compaq 3870 PDA 其作業平台為微軟 Windows C.E3.0 與 smartphone Sony Eriksson P900,所使用的 作 業 系 統 為 Symbian , 另 外 還 包 含 了 一 台 Notebook,其作業系統為 windows XP. 從服務要求 到獲得內容的過程,全部都是經由無線網路。從內 容調適伺服器到Yahoo 的連線是有線網路,而對照 組的測試為沒有使用內容調機制的內容呈現,期間 也是被執行在無線網路的環境之中,我們使用三個 情境來說明單一與多個要求的內容存取。 z 情境一:第一個使用者第一次存取內容。 z 情境二:第二個使用者第二次存取內容。 z 情境三:第一個使用者第二次存取內容。 這個情境為一個學生被指派一個專題作業, 期題目為「在紐約的一天」。該學生很快的透過他 的裝置連線到 Yahoo 旅遊網頁並且瀏覽紐約的圖 片。該學生更近一步的連線到有關於紐約洋基的文 章,並且開始閱讀有關於棒球的歷史,在這個實驗 中,我們利用Notebook、PDA 與 Smartphone 分別 的存取這些網頁內容。 實驗的結果為如圖21(a)、(b)與(c),而圖 21 之(d)則呈現出這些連續測試的總結。在圖 21 中的 實驗都是以五個實驗來做為平均。 而其中有五個情境的評估包含了 NCA-1、 NCA-2、CA-1、CA-2 與 CA-3。NCA-1 表示第一個 使 用 者 第 一 次 存 取 內 容 而 沒 有 經 由 內容調適機 制。NCA-2 表示第一個使用者第二次存取內容而沒 有經由內容調適機制(又快取內容在使用者裝置之 中)。 CA-1 所表示的是第一個使用者第一次存取內 容而且有經過內容調適機制,因此其所花的調適時 間包含了抓取內容,拆解內容與物件管理時間。 CA-2 所表示的是第二個使用者第一次存取內容而 且經由內容調適機制,因為已經有快取機制,因此 較前者少了一個調適時間的花費。CA-3 第一個使 用者第二次存取內容,經由內容調適機制,由於在 使用者的裝置上已經有快取內容了,因此少了內容 調適的時間與內容抓取的時間。 圖 20:依照情境定義所設計之調適規則 圖21(a)、Yahoo Travel 的存取時間。
圖21(b)、NY Introduction 網頁的存取時間。
圖21(c)、洋基歷史網頁的存取時間。
圖21(d)、 Yahoo Travel、NY Introduction 到洋 基歷史網頁的存取時間總和。 情境一:第一個使用者第一次存取內容: 當使用者要求內容服務時,利用調適機制去 存取內容有比較好的呈現品質。所延伸的調適成本 會使的存取時間增加,而傳統的方法與調適方法被 表示於圖21 中的(d)分別為 NCA-1 與 CA-1。圖 21 中表示經由Notebool 與 PDA 兩者存取內容,CA-1 的存取時間較為 NCA-1 高,但是透過 Smartphone 的存取,CA-1 所花的存取時間較 NCA-1 少(89.55 秒)。因為來自於情境電話使用上的差異,造成對 應的調適內容產生所以傳輸時間彌補了調適的成 本。 情境二:第二個使用者第一次取內容: 我們使用 NCA-1 與 CA-2 來說明第二個使用 者存取內容。在傳統的模式上存取內容,由於第一 次存取內容而沒有資訊的快取於伺服器上,因此第 一 個 使 用 者 與 第 二 個 使 用 者 的 存 取 時 間 幾 乎 相 等,因此我們使用 NCA-1 來當作傳統的測量,在 調適的模式之中,調適成本花費在第一位使用者的 存取上,因此,第二個使用者會分享到不須調適成 本的好處,如圖21(d),CA-2 相較於 CA-1 中,表 示該情境,在notebook 中改善了 11.59 秒,在 PDA 中改善了40.88 秒,在 Smartphone 中改善了 131.89 秒。 情境三:第一個使用者第二次存取內容: 我們使用 NCA-2 與 CA-3 來說明使用者第二 次存取內容的情況,在第二次的存取中,內容已經 被快取於裝置之中,因此CA-31 與 NCA-2 相比, Notebook 改善了 4.88 秒,PDA 改善了 34.39 秒, smartphone 改善了 19.56 秒。 而使用者所接收到的呈現結果將展示於圖 22,分別為使用傳統方法與經由調適方法,在傳統 模式中,HTML 網頁內容將被設計給桌上型電腦或 是 筆 記 型 電 腦 , 因 此 圖 片 的 呈 現 在 於 PDA 與 Smartphone 之中,其結果會出現不是太大就是太小 的情況,分別呈現於圖 22(a)與(e),而在調適的模 式中,所呈現的圖片在PDA 與 Smartphone 的螢幕 中有最佳的調整,而這樣的結果被顯示在圖 22 的 (c)(f)部分。 圖 22:Yahoo 網頁所調適出來的各種結果
四、計畫成果自評
針對智慧型多媒體內容管理系統相關的標準及 工具等相關研究主題,總計畫共規劃了3 個子計畫 來進行的分析與研究,包含:子計畫 1:智慧型個 人化多媒體學習內容管理系統之研製、子計畫 2: 智慧型個人化題庫系統之建置與管理與子計畫 3: 行動學習載具上通用型多媒體學習內容存取播放 機制之研發。各子計畫間皆互相關聯與支援,以有 效整合各子計畫之研究成果。 本子計畫1 針對前導計畫所提出之 2 層次架構 教 材 標 準 , 教 材 標 示 語 言 (Teaching Material Markup Language, TMML) , 發 展 出 SCORM/TMML 之標準教材轉換與 SCORM 2004 編輯工具,以提供教師與編輯者快速的編輯出符合 SCORM/TMML 的標準化教材。此 TMML 標準規 範與教材轉換與編輯工具,便可提供給子計畫2 與 子計畫 3 使用,進而達到建置標準示範模式之目 的 。 並 針 對 SCORM 1.3 中 ,複雜之學習活動 (Learning Activity)難以管理之問題,提出教學活動 模型(Instructional Activity Model, IAM)架構,以達 到學習活動之管理與再使用,亦提出OOLA 模型來 有效整合課程、互動學習服務、及測驗以架構更適 性化學習活動。針對SCORM 學習元件資源庫發展 LOR 管理機制,以有效的提供各子計畫快速檢索所 欲使用之試題與教材資料。而所提出的學習歷程探 勘(LPM)與兩階層式概念圖建構機制(TP-CMC)可 分析學習歷程資料以建構適性化學習課程與概念 圖,此分析結果將可提供給子計畫2 做適性化試題 測驗診斷與子計畫3 做行動學習。因此,本子計畫 之研究成果皆有效的提供給各子計畫進行研究與 整合。而子計畫2 為了支援智慧型學習診斷系統,在 TMML 中的教材標準與試題標準加以延伸以及增 加學習歷程標準。目的在於使教材標準能夠支援學 習障礙診斷;紀錄與學習診斷有關的試題屬性,以 用以判斷學生的學習障礙;紀錄診斷結果,供學生 或教師參考。以增加 TMML 在智慧型診斷與題庫 系統上之完整性。並利用子計畫1 所發展之教材編 輯工具與子計畫2 所自行發展的輔助工具來製作試 題元件。 子計畫3 萃取 CC/PP 與 UAProf 中必要的屬性 來描述裝置與定義行動學習的情境描述參數,以規 劃 TMML 在行動載據上之規範完整性。並研發提 出內容調機制、內容傳輸機制與內容呈現機制,以 根據頻寬、使用者喜好、裝置能力,並即時監視學 習與連線狀態,來連續性地從子計畫1 資源庫擷取 內容,再經過動態調整成適當內容後,傳輸給使用 者。因此,本計畫有效整合各子計畫之研究成果成 為可支援學習、評量診斷及行動學習的智慧型學習 系統。 本計畫各子計畫主要之成果與貢獻如下: 子計畫 1: 1. 基於 SCORM,提出教學活動模型架構(IAM)與 物件導向學習活動(OOLA)模型,以有效管理及 整合學習內容、服務與測驗,並有效規畫與延伸 教 材 標 示 語 言 (Teaching Material Markup Language, TMML) 2. 提出物件導向課程朔模(OOCM)機制與教材標 準 化 轉 換 機 制 , 以 有 效 編 輯 出 符 合 SCORM 2004/TMML 之標準教材。 3. 針對 SCORM 學習元件資源庫,提出階層式內容 管理機制(LCMS),以有效搜尋與管理大量學習 元件。 4. 針對學習歷程分析,提出學習歷程探勘(LPM)與 兩階層式概念圖建構機制(TP-CMC),來分析學 習歷程資料以建構適性化學習課程與概念圖 子計畫 2: 1. 針對智慧型個人化題庫系統的功能及標準進行 探討,並發表多篇學術論文。 2. 提出支援學習診斷功能之教材延伸標準。 3. 提出支援學習診斷功能之試題延伸標準。 4. 提出能夠支援學習診斷功能之學習歷程標準。 5. 建構試題編輯分享工具,支援所制定之延伸標 準。 子計畫 3: 1. 提出內容調機制:按照網路頻寬、使用者喜好、 裝置能力來動態調整內容出現的優先順序。 2. 提出內容傳輸機制:即時監視與萃取使用者的學 習狀態與網路連線狀態,以傳輸連續性或同步性 的內容。 3. 提出內容呈現機制:管理或產生一個適當的內容 給呈現給使用者。 z 研究內容與原計畫相符的程度、達成預期目標 情況: 本計劃所規劃之 3 個子計畫,針對各項研究 議題所完成的各項成果,皆為根據當初計畫提案的 規劃進行,而成果也符合原始計畫規劃,總計劃並 做有效之整合。 z 研究成果之學術或應用價值、是否適合在學 術期刊發表或申請專利: 在本計畫執行期間,我們總共發表了21 篇期刊 論文[20-40], 其中有 4 篇 SSCI 與 8 篇 SCI,以及 41 篇國際會議論文與 52 篇中文會議論文。 5、參考文獻
[1] Aviation Industry CBT Committee (AICC) 2004, AICC - Aviation Industry CBT Committee. http://www.aicc.org [2] Instructional Management System (IMS) 2004, IMS Global
Learning Consortium. http://www.imsproject.org/
[3] IEEE Learning Technology Standards Committee (LTSC) 2004, IEEE LTSC | WG12. http://ltsc.ieee.org/wg12/
[4] Reload Editor (Reload) 2004, Reload Project,
http://www.reload.ac.uk
[5] Sharable Content Object Reference Model (SCORM) 2004, Advanced Distributed Learning. http://www.adlnet.org/ [6] Sequencing and Navigation (SN) 2004, ‘Sharable Content
Object Reference Model (SCORM) Sequencing and Navigation (SN) Version 1.3’, Advanced Distributed Learning.
http://www.adlnet.org/index.cfm?fuseaction=DownFile&libi d=648&bc=false
[7] P. Brusilovsky and J. Vassileva. Course Sequencing Techniques for Large-Scale Web-based Education. Journal of Engineering Education and Lifelong Learning, Vol. 13, 2003, pp. 75-94.
[8] L. Sheremetov and A.G. Arenas, EVA: An Interactive Web-based Collaborative Learning Environment. Computers & Education, Vol. 39, Issue 2, 2002, pp. 161-182.
[9] Timothy K. Shih, J. C.S. Hung, W.C. Ko, W.C. Chang, and N. H. Lin, “COLLABORATIVE COURSEWARE AUTHORING BASED ON SCORM METADATA”, Proceedings of the IEEE International Conference on Multimedia & Expo 2003 (ICME 2003), Taipei, Taiwan, July, 2003. Retrieved 4 September 2004 from
http://www.mine.tku.edu.tw/scorm/
[10] J. Vassileva and R. Deters, Dynamic Courseware Generation on The WWW. British Journal of Educational Technology, Vol. 29, Issue. 1, 1998, pp. 5-14.
[11] J.T. D. Yang, C.Y. Tsai, and T.H. Wu, “Visualized Online Simple Sequencing Authoring Tool for SCORM-compliant Content Package”, Proceedings of the 4th IEEE International
Conference on Advanced Learning technologies (ICALT 2004), Finland, August, 2004.
[12] Nelson L. Bassing, Teaching in Secondary Schools, Boston: Houghton Mifflin Company, pp. 51-55. 1963.
[13] R.M. Gagne, “Learning Outcomes and Their Effects,” American Psychologist, No.4, 1984.
[14] R. Sternberg and E. Grigorenko, Styles of Thinking in the School, Branco Weiss Institute, May 1998.
[15] S. Beekhoven, U.D. Jong, and H.V. Hout, “Different Course, Different Students, Same Results? An Examination of Differences in Study Progress of Students in Different Courses,” Higher Education, Vol. 46, 2003, pp. 37-59. [16] D.A. Kolb, “Learning Style Inventory: Technical Manual”,
Boston, Mass: McBer originally published in 1976, 1985. [17] K. Smith and H. Tillema, “Evaluating Portfolio Use As A
Learning Tool For Professionals,” Scandinavian Journal research, Vol. 42, No. 2, 1998, pp.193-205.
[18] F.H. Wang and H.M. Shao, “Effective Personalized Recommendation Based on Time-Framed Navigation Clustering and Association Mining,” Expert Systems with Applications, Vol. 27, 2004, pp. 365–377.
[19] 總計畫:網路教學平台與內容標準化, 子計畫三:通用型教
材 內 容 標 準 之 規 劃 , NSC91-2520-S-009-005
[20] S.S. Tseng, P.C. Sue, J.M. Su, J.F. Weng, and W.N. Tsai, “A New Approach for Constructing the Concept Map,“ to appear in Journal of Computers & Education. (Article In Press) (SSCI, SCI, EI)
[21] J.M. Su, S.S. Tseng, W. Wang, J.F. Weng, J.T.D. Yang, and W.N. Tsai, "Learning Portfolio Analysis and Mining for SCORM Compliant Environment, " Journal of Educational Technology & Society (ETS), Vol. 9, Issue 1, 2006, pp. 262-275. (SSCI)
[22] J.M. Su, S.S. Tseng, C.Y. Chen, J.F. Weng, and W.N. Tsai, "Constructing SCORM Compliant Course Based on High Level Petri Nets, " International Journal Computer Standards & Interfaces, Vol. 28, Issue 3, 2006, pp. 336-355. (SCI)
[23] J.M. Su, S.S. Tseng, C.Y. Wang, Y.C. Lei, Y.C. Sung, and W.N. Tsai, "A Content Management Scheme in SCORM Compliant Learning Object Repository," Journal of Information Science and Engineering (JISE), Vol. 21, No. 5, September, 2005, pp. 1053-1075. (SCI)
[24] J.M. Su, S.S. Tseng, C.T. Chen, and W.N. Tsai, "Adaptive Learning Environment for Pedagogical Needs," Journal of Information Science and Engineering (JISE), Vol. 20, No. 6, November, 2004, pp.1057-1077. (SCI)
[25] J.M. Su, J.H Chen, Wei Wang, J,Y Chen, P.C. Sue, S. S. Tseng, and W.N. Tsai, “Design and Implementation of SCORM Compliant Intelligent Learning System,” Global Chinese Journal for Computers in Education (GCJCE), Vol. 2, No. 1, 2004, pp. 45-58.
[26] Gwo-Jen Hwang, Peng-Yeng Yin and Shu-Heng Yeh (2006), “A Tabu Search Approach to Generating Test Sheets for Multiple Assessment Criteria”, accepted by IEEE Transactions on Education. (SCI, EI)
[27] Gwo-Haur Hwang, Jun-Ming Chen, Gwo-Jen Hwang and Hui-Chun Chu (2006), “A Time Scale-Oriented Approach for Building Medical Expert Systems”, Expert Systems with Applications, Vol. 31, No. 2, pp. 299-308. (SCI, EI) [28] Judy C.R. Tseng, Gwo-Jen Hwang and Ying Chan (2005),
“An Efficient Approach to Restructuring Subject Materials in Mobile Learning Environments”, WSEAS Transactions on Advances in Engineering Education, Vol. 4, No. 2, pp. 302-308. (EI)
[29] Judy C.R. Tseng & Gwo-Jen Hwang (2005), “Development of an Intelligent Internet Shopping Agent based on a Novel Personalization Approach”, Journal of Internet Technology, Vol. 6, No. 4, pp. 477-485. (EI)
[30] Gwo-Jen Hwang (2005), “A Data Mining Algorithm for Diagnosing Student Learning Problems in Science Courses”, International Journal of Distance Education Technology, Vol. 3, No. 4, pp. 35-50. (EI)
[31] Judy C.R. Tseng and Gwo-Jen Hwang (2004), “A Novel Approach to Diagnosing Student Learning Problems in E-Learning Environments”, WSEAS Transactions on Information Science and Applications, Vol. 1, No. 5, November 2004, pp. 1295-1300. (EI)
[32] Gwo-Jen Hwang, Bertrand M.T. Lin, Hsien-Hao Tseng, Tsung-Liang Lin (2005), “On the Development of a Computer-Assisted Testing System with Genetic Test Sheet-Generating Approach”, IEEE Transactions on Systems, Man, and Cybernetics: Part C, Vol. 35, No.4, pp. 590-594. (SCI, EI)
[33] S.J.H. Yang, “Context Aware Ubiquitous Learning Environments for Peer-to-Peer Collaborative Learning,” Educational Technology & Society, Vol. 9, No. 1, 2006, pp. 188-201.(SSCI)
[34] S.J.H. Yang, I.Y.L. Chen, and N.W.Y. Shao, “Ontology Enabled Annotation and Knowledge Management for Collaborative Learning in Virtual Learning Community,“ Educational Technology & Society, Vol. 7, No. 4, 2004, pp. 70-81. (SSCI)
[35] S.J.H. Yang and N.W.Y. Shao, “An Ontology-Based Content Model for Intelligent Web Content Access Services,” International Journal of Web Services Research, Vol. 3, No. 2, 2006, pp. 59-78. (EI)
[36] S.J.H. Yang and N.W.Y. Shao, “Enhancing Pervasive Web Accessibility with Rule-Based Adaptation Strategy,” to appear in Expert System with Applications, Vol. 32, No. 4, August 2007 (SCI).
[37] S.J.H. Yang, B.C.W. Lan, B.J.D. Wu, and A.C.N. Chang, “Context Aware Service Oriented Architecture for Web Based Learning,” in Journal of Advanced Technology for Learning, Vol. 2, No. 4, pp. 216-222, Oct. 2005.
[38] S.J.H. Yang, J.S.F. Hsieh, B.C.W. Lan and J.Y. Chung, “Composition and Evaluation of Trustworthy Web Services,” in International Journal of Web and Grid Services. Vol. 2, No. 1, pp. 5-24, Jan. 2006.
[39] S.J.H. Yang, B.C.W. Lan and J.Y. Chung, “Trustworthy Service-Oriented Business Process Integration,” to appear in International Journal of Simulation and Process Modeling. Vol. 3, 2007.
[40] S.J.H Yang, J.J.P. Tsai, and C.C. Chen, “Fuzzy Rule Base Systems Verification Using High Level Petri Nets,” IEEE Trans. on Knowledge and Data Engineering, Vol. 15, No. 2, March-April 2003, pp. 457-473. (SCI)