國立臺中教育大學教育測驗統計研究所博士論文
指導教授:郭伯臣 博士
指導教授:
廖晨惠 博士
以 LSA 為基礎之兒童中文語意關聯
輔助學習系統建置
研究生:陳世銘 撰
中
華
民
國
一
○
二
年
六
月
謝辭
本論文的完成,首先感謝指導教授:郭伯臣院長及廖晨惠老師,在論文寫 作時的指導與關懷,其治學嚴謹的態度與亦師亦友,讓我領略到教育家的風範, 也啟發了個人於潛在語意分析的研究興趣;尤其是廖晨惠老師提供 2011 年國科 會計畫所建置之國小兒童中文語料庫,讓本研究得以順利進行。另外感謝張郁 雯老師、陳明蕾老師及楊裕貿老師在論文的編撰與內容的修訂上,提供了許多 寶貴建議與思構方向。 感謝潭子國小全體同仁的體諒與包容,在個人忙碌之際仍兢兢業業於自己 的崗位上,不管行政運作或師生表現,依舊不時創造高峰。有這些夥伴的支持, 終能讓我順利完成學業。 謝謝實驗室的夥伴鎧誌、淑娟,在 meeting 時提供許多的改進建議和想法, 讓論文得以順利完成。 家人的支持與鼓勵,使我的求學過程沒有後顧之憂。內人美智在前五年進 修繁忙之際,除了仍戮力在其工作崗位,亦無怨無悔的處理家務與照顧兒子, 這是讓我能同時兼顧事業與學業的重要因素。僅將完成學位的喜悅與家人分 享:一輩子為子女勞碌的父親、在天之靈的母親、所有關心協助過我的朋友, 均在此致上最衷心的謝意。另特別獻上這份成果,給原訂口試的前一週突然辭 世的內人,併同感恩所有指導與協助的老師和夥伴。陳世銘
中華民國
一○二年六月摘要
本研究旨在建立兒童中文語意空間,並開發以潛在語意分析為基礎之電腦 化語意關聯輔助學習系統。首先透過比較不同年級與不同科目間之兒童中文語 意空間,來描述語意空間特性。其次藉由詞彙語意效度驗證、句子語意效度驗 證、專家關聯度評分以及 LSA 造句自動化計分等四種方式,來評估兒童中文語 意空間的效度。最後再以教學實驗,探討輔助學習系統是否為一有效的輔助教 學與學習工具。 本研究主要發現如下: 一、在不同年級間的兒童中文語意空間之相關性比較,「中-高年級」的相關性 比「低-中年級」及「低-高年級」為高。另外,在不同科目間的相關性比 較亦發現,「國語-社會」的相關性比「國語-自然」及「社會-自然」為高。 二、在詞彙間與句子間的關聯性驗證,兒童中文語意空間與專家評分具高度顯 著相關。在 LSA 以字造句自動化計分評估部分,兒童中文語意空間與專家 評分的高度顯著相關亦優於成人語意空間。 三、使用本研究所開發之「以 LSA 為基礎之電腦化語意關聯輔助學習系統」的 教學活動設計,實驗組的學童對於中文識字量、語詞聯想與造句得分,皆 顯著高於對照組。 四、教學回饋問卷滿意度調查結果顯示,學童對輔助學習系統持正面肯定態度, 代表本系統可用性高,單元的詞彙量適中。 關鍵字:LSA 輔助學習系統、兒童中文語意空間、潛在語意分析Abstract
The purposes of this study were to develop a computerized assistant learning system based on LSA to build children’s Chinese semantic space. First, it describes the characteristics of children’s Chinese semantic space by comparing the semantic space in different grades and in different subjects. Secondly, the validity of children’s Chinese semantic space was verified by semantic correlations between words and words, sentences and sentences, correlating in comparing with human scoring, and LSA-based automated scoring on sentence construction. Furthermore, the effectiveness for an assisted teaching and learning instruction that was developed in present study was evaluated by experimental teaching activities.
The results were as follows:
1. In comparison of the correlation of Chinese semantic space in different grades of students, three groups were divided. Group A was comprised by grades 3 and 4 vs. grades 5 and 6. Group B was comprised by grades 1 and 2 vs. grades 3 and 4. Group C was comprised by grades 1 and 2 vs. grades 5 and 6. This study showed that in the correlation of Chinese semantic space, Group A was higher than Group B and Group C. The similar result was observed in the study of different subjects, Chinese Language and Social Studies with a high number of same words would have higher correlation of Chinese semantic space than Chinese Language and Science. Meanwhile, Chinese Language and Social Studies also had higher correlation of Chinese semantic space than the other two subjects – Science and Social Studies. 2. In the aspect of correlations between words and words, sentences and
scoring. The evaluation of LSA-based automated scoring in sentence construction also showed significantly higher correlation in children’s Chinese semantic space.
3. The experimental group who received the teaching activities with the LSA assisted learning system scored higher than the control group regarding Chinese vocabulary size, the diversity of vocabulary association and sentence construction.
4. Feedback questionnaires indicated that participants have positive attitudes toward teaching activities with the LSA assisted learning system, thus it demonstrated that the system was highly usable and word number of a chapter was applicable.
Keywords: LSA assisted learning system, children’s Chinese semantic space, Latent Semantic Analysis
目錄
摘要 ... I Abstract ... III 目 錄 ... V 表 目 錄 ... VII 圖 目 錄 ... VIII 第一章 緒 論 ... 1 第一節 研究背景與動機 ... 1 第二節 研究目的 ... 3 第三節 名詞解釋 ... 4 第二章 文獻探討 ... 7 第一節 潛在語意分析 ... 7 第二節 語料庫與語意空間建置 ... 10 第三節 LSA 語意空間輔助學習系統 ... 13 第四節 兒童詞彙語意發展 ... 16 第三章 研究方法 ... 27 第一節 研究流程 ... 27 第二節 建立兒童中文語意空間 ... 28 第三節 兒童中文語意空間之特性與效度驗證 ... 31 第四節 語意關聯輔助學習系統及評估方式 ... 36 第四章 研究結果與討論 ... 43 第一節 兒童中文語意空間特性描述與比較 ... 43 第二節 兒童中文語意空間效度驗證結果 ... 46 第三節 兒童中文語意空間主要功能介紹 ... 51 第四節 語意關聯輔助學習系統使用探討 ... 65 第五章 結論與未來展望 ... 67 第一節 研究結論 ... 67 第二節 研究限制 ... 69 第三節 後續相關研究建議 ... 69參考文獻 ... 71 中文部分 ... 71 英文部分 ... 77
表目錄
表 3-1 life 在不同語意空間與其他詞彙語意關聯度 ... 32 表 3-2 詞彙語意比對評分範例 ... 33 表 3-3 句子語意比對評分範例 ... 34 表 3-4 以字造句例題 ... 34 表 4-1 兒童中文語意空間-不同年級文章數與詞彙數 ... 44 表 4-2 兒童中文語意空間-不同科目文章數與詞彙數 ... 44 表 4-3 詞彙語意關聯性與專家評分之相關性 ... 47 表 4-4 三組不同句子呈現方式比對之 LSA 語意關聯值的描述性統計 ... 48 表 4-5 均等 Robust 檢定 ... 49 表 4-6 句子語意關聯性與專家評分之相關性 ... 49 表 4-7 專家評分與 LSA 造句自動化計分之相關矩陣-以字造句 ... 50 表 4-8 造詞、以字造句(傳統與 LSA 計分)與閱讀理解之階層式迴歸分析 ... 51 表 4-9 兒童中文語意空間兩兩向量比對範例 ... 54 表 4-10 兒童中文語意空間最接近詞比對範例 ... 55 表 4-11 輔助學習系統修訂歷程 ... 65圖目錄
圖 2-1 LSA 基本架構 ... 8 圖 3-1 研究流程 ... 27 圖 3-2 系統網路架構 ... 28 圖 3-3 有 10 個核心詞彙選單 ... 38 圖 3-4 有 12 個延伸詞彙畫面 ... 38 圖 3-5 詞彙學習排行畫面 ... 39 圖 3-6 有 4 個核心詞彙選單 ... 40 圖 3-7 有 4 個延伸詞彙畫面 ... 40 圖 3-8 第四版修改畫面 ... 41 圖 3-9 包含點選讀音模組 ... 42 圖 3-10 含聲音次數的詞彙排行榜 ... 42 圖 4-1 不同年級的兒童中文語意空間比較 ... 45 圖 4-2 不同科目的兒童中文語意空間比較 ... 46 圖 4-3 詞句語意關聯功能畫面 ... 53 圖 4-4 顯示二個詞彙的語意關聯度 ... 53 圖 4-5 語意最接近詞功能畫面 ... 54 圖 4-6 詞彙重要性篩選畫面 ... 56 圖 4-7 輸入文章內容後,詞彙依重要性由高到低排列 ... 56 圖 4-8 學生登入畫面 ... 57 圖 4-9 選擇要學習的課程 ... 57 圖 4-10 選擇欲學習的核心詞彙 ... 58 圖 4-11 語意關聯輔助學習系統畫面示例 ... 59 圖 4-12 滑鼠移到詞彙上,會提示點選功能說明 ... 59 圖 4-13 滑鼠移到「 」圖示,會提示點選功能說明 ... 60 圖 4-14 重新選取關聯詞彙 ... 61 圖 4-15 顯示詞義及例句 ... 61 圖 4-16 點選 圖示,系統會播放該詞彙念法 ... 62 圖 4-17 學習過之詞彙轉變成開花狀態 ... 62 圖 4-18 點選,回到上一頁 ... 63 圖 4-19 回本單元核心詞彙畫面 ... 63 圖 4-20 點選「住家」後的學習畫面 ... 64 圖 4-21 顯示「詞彙學習排行」 ... 64第一章 緒論
本章第一節介紹研究背景與動機;第二節介紹研究目的,包括建立並瞭解 兒童中文語意空間的特性、驗證其有效性,以及開發並評估本研究所提出之電 腦化語意關聯輔助學習系統的功能;第三節為本研究重要名詞解釋;第四節則 是描述本論文的整體結構。第一節 研究背景與動機
潛在語意分析(Latent Semantic Analysis, LSA)使用關鍵詞來萃取文件中 潛在的概念,試圖從主題文件中的詞句找出重要的潛在語意(Landauer & Dumais, 1997; Landauer, Laham, Rehder, & Schreiner, 1997)。葉鎮源(2002)指出當找到 最佳的維度約化時,LSA 語意模型中的語意推演及擷取的結果會更精準,更能 表現出文件中的潛在語意與字詞間的關聯。Landauer、Foltz 與 Laham(1998)也 認為 LSA 除了可以視為文件的知識表示(knowledge representation)之外,並 可以用來推演隱性的知識關聯。由此可知,LSA 的知識模型與知識推演過程, 已經接近人腦用來理解文件知識的推演與認知機制模型(Landauer et al., 1998; 許富翔,2010;黃永昌,2008;謝佩原,2004)。而近年來,運用大型語料為基 礎,以進行比對及描繪詞彙與詞彙間的語意關係,是心理語言學中新興的研究 取向(陳明蕾、王學誠、柯華葳,2009)。依上述研究顯示,LSA 在心理語言 分析的領域上成為未來重要的發展方向。 語料庫的建置為建立 LSA 語意空間之基礎,許多國內外 LSA 研究使用不 同的語料庫來建立語意空間,在外文語料庫部分例如:科羅拉多大學具有 9 百 萬個詞的的 TASA(Touchstone Applied Science Associates, Inc.)語料庫; Lemaire、Denhiere、Bellissens 與 Jhean-Iarose (2006)建立約 320 萬字的兒童語 料庫;Graesser、Penumatsa、Ventura、Cai 與 Hu (2007)建置合計 30 萬字的電
腦類語料庫。在中文語料庫的部分例如:張國恩與宋曜廷(2005)建了「族群 與群落」及「端午節」兩個主題的語料庫,其詞彙量分別是 1,557 個詞及 2,921 個詞;葉鎮源(2002)收集 100 份台灣新聞週刊雜誌的政壇話題,建置了一個 約有 1,600 個關鍵詞大小的語料庫。中研院之漢語平衡語料庫則是目前國內最 大型的語料庫,共計約 9,277 份文件,500 萬詞。 由上述可知,語料庫的使用相當分歧,且沒有相關研究探討何種應用情境 或使用者特性,所採用的語料庫應具備何種特性?就中文語料庫而言,漢語平 衡語料庫為目前較為完整之語料庫,其語料來源反應了中文環境中,成熟讀者 日常接觸的語彙資料。就本研究的觀點而言,語料庫的收集文件的範圍與文件 適讀年齡與應用的議題及對象息息相關,因本研究的主體為兒童,故本研究擬 使用廖晨惠(2011)所建置的「兒童中文語料庫」來進行語意關聯輔助學習系 統的建置。此外,也將與漢語平衡語料庫進行比較,探討「兒童中文語料庫」 的適用性。 LSA 在教育上已有許多應用,例如建立一個可以自動比對詞彙間複雜語意 間關係的中文語意空間(陳明蕾等人,2009);同義詞及多義詞的測試(Landauer et al., 1998);文件自動化摘要(葉鎮源,2002;汪若文,2004);摘要寫作評 量評分(Landauer et al., 1998;馮樹仁,2002;黃彥博,2008;張國恩、宋曜廷, 2005);測驗題庫的相似性比較(郭榮芳,2005;陳彥霖,2006);以及柯華 葳主持的 Chinese LSA 實驗室建立的語彙比對、斷詞、詞頻分析、寫作評量之 整合式應用網站等。但是對於應用關聯詞彙在教學上的成效評估部分,則尚有 許多值得研究的地方。 過去的詞彙教學程序,是由老師主觀的從短文中提出詞彙表(歐素惠, 2003)。若能運用 LSA 篩選課文內的關鍵詞彙,除了較為客觀以免除老師依據 個人經驗選詞的誤差外,由關鍵核心詞彙依序找出關聯性高的延伸詞彙,可以 讓詞彙學習層面加深加廣。但透過語料庫擷取出來關聯詞彙,一來老師必須自
行編排教學順序,再者若仍如傳統的詞彙教學,其效果也會打折扣。若能透過 系統自動擷取文章中的核心詞彙及延伸詞彙,且運用電腦的多媒體效果,將有 助於提升學生的學習成效(Fletcher-Flinn & Gravatt, 1995)。因此,本研究擬建立 兒童中文語意空間,以瞭解其特性及評估其效度,並比較以漢語平衡語料庫建 立的成人語意空間,分析何者較適合使用在中文環境下的國小兒童學習情境。 最後將開發及評估語意關聯輔助學習系統的成效。
第二節 研究目的
綜合上述研究動機,本研究目的是透過廖晨惠(2011)國科會計畫所建置 之國小兒童中文語料庫,以建立兒童中文語意空間並瞭解其特性以及評估其效 度。最後開發並評估語意關聯輔助學習系統之成效,期望改善傳統詞彙教學及 學習方式。以下為本研究目的:壹、建立兒童中文語意空間
依據廖晨惠(2011)國科會計畫所建置之國小兒童中文語料庫,建立一個 20,022 詞彙,5,219 篇文件的詞彙-文件共生矩陣(term-document matrix),經由 LSA 萃取出適合用於語意關聯輔助學習系統的語意空間。貳、探討兒童中文語意空間的特性
本研究依據建立的兒童中文語意空間進行不同類別特性描述與比較,將內 容分為低、中、高不同年級,國語、社會、自然等不同科目分別建立兒童中文 語意空間,並根據 Hu、Cai、Graesser 與 Ventura(2005)所提出的研究方法,進 行不同年級之間與不同科目之間的兒童中文語意空間進行比較。參、評估兒童中文語意空間之效度
在中文環境的教育應用上,除了由中央研究院的現代漢語平衡語料庫所建立的中文語意空間,被印證能反映中文讀者內在心裡表徵的語意空間外,一直 沒有專門適合兒童學習使用的語料來源。若有一個能貼切兒童基礎教育階段的 大型語料庫,未來便能持續探究兒童內在心理詞彙間的語意關聯性,從而進行 後續關於兒童學習與增進閱讀能力等相關應用的可能性。因此,本研究期望能 協助建置一個專為兒童設計之中文語料庫,並透過潛在語意分析技術建立一個 能表徵兒童內在心理知識的語意空間,且針對此語意空間之有效性進行驗證, 探究其是否能有效反應兒童內在知識語意空間型態。
肆、開發語意關聯輔助學習系統及成效評估
配合進行之課程,挑選重要性高的核心詞彙,並由兒童中文語意空間中分 別篩選與核心詞彙關聯性最大的 6 個延伸詞彙,讓教師教學運用或學生透過電 腦進行線上的自主學習,以擴充詞彙量,並掌握詞彙涵義。 評估系統成效部分,將比較傳統的擴充詞彙量教學、教師使用本系統教學 這二種方式,對於學生閱讀能力以及寫作能力提升的差異性。第三節 名詞解釋
針對本論文之重要名詞,說明如下:壹、詞彙重要性指標
採用白鎧誌(2011)「以潛在語意分析評估詞彙重要性及其應用」發展之詞 彙重要性指標。該文章研究發展了「詞彙重要性指標 1」及「詞彙重要性指標 2」, 二者皆與專家評分呈現顯著高度相關,其中以詞彙重要性指標 1 優於指標 2, 故本研究採用「詞彙重要性指標 1」,作為挑選核心詞彙的依據。本文中之詞彙 重要性指標,其公式即採用白鎧誌(2011)研究發展的「詞彙重要性指標 1」。 詞彙重要性指標結合了語意空間中的詞彙向量長度,以及每一個詞彙在詞 彙─文件共生矩陣的出現總次數,藉由運算得到的詞彙重要性,再將其線性轉換使詞彙重要性權重值範圍介於 0~1 之間。
貳、兒童中文語意空間
在中文教育環境下,針對國小學童,運用 LSA 技術所建立的語意空間。其 語料庫來源主要為國小教科書。參、核心詞彙
將學生目前學習的國語課文內容進行斷詞,然後再由兒童中文語意空間計 算前述詞彙的重要性,依計算值篩選出重要性較高的詞彙,這些詞彙就稱為「核 心詞彙」。肆、延伸詞彙
由兒童中文語意空間中分別挑選出與「核心詞彙」關聯性較高的詞彙,這 些詞彙即稱為「延伸詞彙」。因係由兒童中文語意空間中挑選,故延伸詞彙當中, 有可能和「核心詞彙」相同。為了能學習到更多的詞彙,故延伸詞彙若有與核 心詞彙相同者,則不選取該詞彙,而依序往下選取其他不同的詞彙。 所有透過「核心詞彙」以及再透過「延伸詞彙」關聯顯示的下一層詞彙, 均稱為「延伸詞彙」。伍、語意關聯
「語意關聯」意指詞彙與詞彙之間共享的意義。當彼此較緊密時,表示此 詞彙在記憶系統中的儲存位置較近,被提取的速度也相對較快。反之,則表示 彼此的意義較疏遠,則在記憶系統中的儲存距離較遠,被提取的速率也相對較 慢(Collins & Loftus, 1975)。第二章 文獻探討
本章共分為四節,第一節探討潛在語意分析,第二節探究語料庫與語意空 間現況,第三節分析 LSA 語意空間輔助學習系統發展情形,第四節彙整詞彙語 意發展的內容。本論文即根據以上理論來作為相關研究分析之依據。第一節 潛在語意分析
人類語言學習的歷程中,理解日常生活眾多隱含複雜意義的語意關係,是 重要的認知行為之一。例如單純就「老師」和「學生」這二個詞彙而言,雖然 表面上並沒有相同的字,但我們會根據以往閱讀過的許多文章,直覺的認為這 二個詞彙彼此間相當程度的語意關聯性。Deerwester、Dumais、Furnas、Landauer 與 Harshman (1990)所提出的潛在語意分析是一種可以用來分析大量語料資訊 的擷取技術(陳明蕾等人,2009),採用向量空間模式,以數學統計方式表徵關鍵字和原始文件間的關係(Landauer & Dumais, 1997)並將兩者的關係進行轉 換,找出關鍵字在文件中所隱含的概念及關鍵字對應文件的潛在語意。
要建構一個潛在語意分析計算的過程,首先,必須建置一個彼此有關聯性
且相似語意字的語料庫(corpus),再從語料庫中建立一個可以呈現原先文件和
字 詞 之 間 關 聯 的 共 生 矩 陣 ( term-to-document co-occurrence matrix ) (Wang, Pomplun, Chen, Ko, & Rayner, 2010)。為了將隱藏在字詞背後的語意關聯性計算 出來,因此,利用線性代數方法中的奇異值分解法(singular value decomposition, SVD)和維度約化(Dimension Reduction)方式(Landauer & Dumais, 1997),去 除一些不重要的雜訊維度後,再將每一個字詞(word)或一段落(passage)以 向量的方式呈現在一個語意空間(semantic space)中(Wang et al., 2010),將原 本字面看不到的隱含語意挖掘出來,有效的提昇資訊擷取,更精確推演出文件 所隱含的知識。
使用 LSA 建立語意空間的步驟如下(Maletic & Marcus, 2000): 一、 建立詞彙-文件共生矩陣。 二、 以 SVD 方法進行矩陣轉換。 三、 取出特徵奇異值(singular value)進行維度約化 四、 重建矩陣。 LSA 基本的架構流程如圖 2-1 所示: 圖2-1 LSA基本架構
壹、建立詞彙-文件共生矩陣
共生矩陣為一個二維的空間矩陣,是以語料庫中所定義的關鍵詞為列,以 文件為行,當中的元素值為關鍵詞出現在每份文件的次數。語料庫中文件的形 式包括文章、句子,或是研究者自行切割文章為所需大小的新文件。(Quesada, 2006)的研究中指出,在共生矩陣中只出現一次的詞彙會干擾 LSA 語意比對的 效果,因此在關鍵詞的選取上,以在共生矩陣中出現兩次以上的詞彙作為研究 所定義的關鍵詞彙。 建立語料庫 進行 SVD 矩陣分解 語意空間 建立詞彙-文件共生矩陣 維度約化貳、以 SVD 方法進行矩陣轉換
共生矩陣單純呈現每個關鍵詞在每份文件中所出現的次數,並沒有表徵詞 彙間的語意關聯性,若要瞭解各詞彙在矩陣中的關係,可以藉由 SVD 計算每個 詞彙在對角矩陣中的特徵值。愈大向量的特徵值,即具有較大的訊息量,反之 代表訊息量較小。 經 SVD 方法可轉換成 m n 的共生矩陣 A ,將之拆解成: T A=UΣV (2.1) 各變數代表意義:U 為正交矩陣(orthogonal matrix),或稱左奇異向量(left singular value);V 為正交矩陣(orthogonal matrix),或稱右奇異向量(right singular value);為由奇異特徵值組成的對角矩陣( diagonal( , 1 2, , )r , 其餘元素為 0)(Letsche & Berry, 1997)。其中 U 矩陣的列向量稱為「詞彙向量 (type vector)」,而 V 矩陣的列向量稱為「文件向量(document vector)」(Landauer, Foltz, & Laham, 1998)。參、維度約化(dimension reduction)
經由 SVD 進行矩陣轉換後,可以利用維度約化來消除語意空間中不重要之 雜訊(noise),避免矩陣過大的語意空間或是雜訊太多來干擾語意比對的結果。 而維度約化的方式是在取出 SVD 後,將前k個最大的特徵奇異值和U矩陣、V 矩陣前k個行向量( kr),並重建矩陣 T k k k k A U V 。 根據國外 LSA 相關研究指出,當所要進行的研究為大型語料庫時,如果將 維度約化 k 的範圍設定為 100 到 300 個維度之間,在同義詞的測試會有不錯的 效果(Berry, Drmac, & Jessup, 1999;Jessup & Martin, 2001;Landauer & Dumais, 1997;Lizza & Sartoretto, 2001)。因而在本研究中以 300 作為維度約化的維度 數,來重新建置新的中文潛在語意空間。出隱含在字詞下的語意知識,因此可運用這技術建立語意空間,並應用於擴充 詞彙的教學上。
第二節 語料庫與語意空間建置
所謂語料庫是指大型的詞語資料庫,記錄了大量語言的使用情形,含有大 量語料分析文本資料,內容經過蒐集彙整和描述標記,以固定標籤與格式儲存, 供研究進行統計分析與測試。由 LSA 基本架構圖 2-1 中,可知 LSA 運作的第 一步是收集和建置所需要的語料庫。由於 LSA 本身是無用的,必須應用在語料 庫上(Lemaire, Denhiere, Bellissens, & Jhean-Iarose, 2006),才能發揮其功用。陳 明蕾等人(2009)認為若有一個大型的語料來源能適當的反映人所擁有的語彙 知識,就可以藉用 LSA 技術建立一個能推演出這些語彙知識背後語意關係的語 意空間。Wiemer-Hastings(2004)提到建置 LSA 所需要的語料庫時,其語料來源 能越大越好,且語料庫要能和研究目的有一定的相關性。Quesada (2006)認為語 料庫是可以反映出一般受試者的思維表現,所以在建立一個 LSA 語意空間的過 程中,語料庫的選擇是非常重要的一部份,能夠讓 LSA 可以精確地計算出詞與 詞、句子與句子或是文章與文章間的語意關聯程度。由此可知,語料庫所包含 的詞彙越貼近研究目的受試者所認知的詞彙越好。故語料來源越能代表族群自 然而真實的語言使用現象,其所建立出來的語意空間就愈能清楚的反應出字 詞、語句與文件彼此間所存在的語意關聯性,進而反映人類內在心理的語彙知 識表徵。因此,建置一個與研究目的相對應的語料庫是相當重要的。另外,語意空間的建置已有許多研究。Landauer 等人(Landauer & Dumais, 1997; Landauer et al., 1998)利用電子版葛羅里學術百科全書(Grolier's Academic American Encyclopedia)中的 30,473 篇文章建立語意空間,其中包含 60,768 個
全書中,每個關鍵詞在每份文件中出現的次數,並沒有涉及到關鍵詞之間彼此 的語意關係。
科羅拉多大學的 LSA 研究團隊採用的 TASA(Touchstone Applied Science Associates, Inc.)語料有 9 百萬個詞。他們也分別與法、德國學者合作,各自採 用有 320 萬個詞的法文語料庫和有 500 萬個詞的德文語料庫(Dennis, 2006),成 功建立兩種不同語系的 LSA 語意空間(Quesada, 2006),驗證 LSA 具有不需使用 文法或事先定義語彙的特性,讓 LSA 技術可以不受限於英語系環境之下。因 此,非英語的語料庫只要建立好關鍵詞與文件間相對應的共生矩陣,就可利用 LSA 技術建立該語系的語意空間(陳明蕾等人,2009)。 Lemaire、Denhiere、Bellissens 與 Jhean-Iarose (2006)建置一個約 320 萬字 的兒童語料庫,其中涵蓋兒童故事和寓言傳說(約 160 萬字)、兒童創作讀物(約 80 萬字)、兒童閱讀課本(約 40 萬字)以及兒童百科全書(約 40 萬字),同時 利用 LSA 技術分析該兒童語料庫,並推演出一個語意空間,再以 9 到 11 歲的 兒童為對象進行實證研究,結果發現從 LSA 語意空間所計算出字詞(word)與 字詞之間的語意關聯程度與兒童以口頭方式實際判斷字詞與字詞的關聯性是相 符合的。 Graesser、Penumatsa、Ventura、Cai 與 Hu (2007)建置的 AutoTutor 系統中, 電腦知識包含電腦硬體、作業系統與網際網路等三個主題,其語料庫是由電腦 素養的教科書、課程腳本和 30 篇文章(其中三個主題各 10 篇,合計 30 萬字) 所組成;在物理學的語料庫則是由課程腳本、觀念物理(Conceptual physics) 中有關的 8 個章節(Hewitt, 1998)、6 冊大學主修的應用和生活科學之通識教材、 2 本高等的電磁學教材以及 2 本電子物理教材(約 1 萬字)共同組成,合計有 6,536 個專門名詞(Olde, Franceschetti, Karnavat, Graesser, & the Tutoring Research Group, 2002)。
(2002)蒐集 100 篇新台灣週刊中關於政治類的文章,建立一個約有 1,600 個 關鍵詞大小的語意空間,透過 LSA 將文件中潛在的語意表現出來,同時藉由找 到最佳的維度約化,讓 LSA 語意模型中的語意推演及擷取更加精準,更能表現 出文件中的潛在語意與字詞間的關聯。 張國恩與宋曜廷(2005)利用 LSA 的理論基礎,以國小三到六年級自然與 生活科技課本及網路上蒐集兩個相關主題(族群與群落、節日)的文章,分別 建立「族群與族落」、「端午節」兩個不同文體的中文語意空間,其詞彙量各自 為 1,557 個詞與 2,921 個詞,並以進行學生閱讀摘要寫作的相關研究。
蘇義翔(2007)所發展的華語文閱讀摘要系統(Electronic Chinese Reading Summarization, ERCS)也是採用 LSA 技術,首先在網路上蒐集與主題(蜜蜂、 袋熊、糞金龜與蝴蝶)相關聯的文章,蒐集到的篇數分別是 22、10、7 與 11 篇,再各自以適當的概念單位個別切分成 354、81、90 與 240 個段落,最後建 構一個有關蜜蜂、袋熊、糞金龜與蝴蝶等四個主題相關知識的潛在語意空間, 並以此計算受試者的摘要和被摘要文章之間的相似度,但因該文本矩陣並不算 大,故計算出的相似度也無法相當精準(黃彥博,2008;黃彥博、洪碧霞、蘇 義翔,2011)。 陳明蕾等人(2009)以中央研究院 2006 年發售的語料版本,中研院漢語平 衡語料庫(Sinica Corpus 3.0),共計 9,277 份文件,500 萬詞,為大型語料來源, 建置步驟為從文件中尋找詞做為矩陣所需要的關鍵詞,此關鍵詞必須在文件中 曾出現兩次以上的詞,每個關鍵詞只要出現兩次以上,就會在矩陣中標記該詞 在該文件裡出現次數。同時,以大學生為研究對象,分別使用自然科學及社會 科學各八篇,主題不同的說明文進行語意關係評定之研究。從研究結果得知, 因採用更大型的語料來源所完成的中文語意空間,能更完整擷取出中文詞彙間 複雜的語意關係,並反映出大學生的內在心理表徵之語意空間。 廖晨惠(2011)的團隊所建置的國小兒童語料庫,涵蓋現行國民小學教科
書與獲得授權的兒童讀物,共 945 篇文章,採用 LSA 技術,建構一個 14,801 詞彙與 1,603 文件(每篇文件約 200 字)的兒童語意空間。劉嘉玲、郭伯臣、 廖晨惠與白鎧誌(2012)從國小三到六年級的國語、社會和自然與生活科技等 三個學習領域中,個別挑選文章進行句子效度驗證初探,各年級各有 36 組句子 進行語意相似度的比對,發現同篇文章的句子順序兩兩呈現與句子隨機兩兩呈 現,其語意關聯程度皆顯著高於不同篇文章的句子隨機方式呈現。一般來說, 同篇文章內的句子會依照文章主題發展而編排,但不同篇文章的句子則會隨著 主題不同,其語意相似度會低於文章內的隨機句子,因此結果顯示廖晨惠建立 的兒童語意空間符合預期推論。 由上述相關文獻得知,語料庫必須能夠呈現自然真實的語言使用現象,且 與研究目的有一定的相關性,內容愈豐富愈好。然而中央研究院建置的平衡語 料庫取材是偏向於一般日常生活中常見的用字與文章,涵蓋六大主題:哲學、 科學、社會藝術、生活及文學等,語式則有五類:書面語、演講稿、劇本台詞、 會話以及會議記錄,內容範圍與程度較適合一般的成人。另外,由語言資料協 會(The Linguistic Data Consortium)製作的中文十億詞語料庫(Chinese Gigaword Corpus)第二版(Graff, Chen, Kong, & Maeda, 2005; Ma & Huang, 2006),總計約
8 億詞,取材來源為台灣中央社(約 4 億 9 千萬詞)、北京新華社(約 3 億 1 千 萬詞)與新加坡早報(約 1 千 8 百萬詞)等三家中文新聞媒體,其文章內容中 的遣詞用字也是較適合一般成人閱讀,較適合應用在成人語意空間之研究。因 此,本研究將協助團隊建置一個兒童中文語料庫,透過 LSA 技術建立兒童中文 語意空間。除了瞭解兒童中文語意空間的特性外,並評估其效度。
第三節 LSA 語意空間輔助學習系統
傳統的詞彙教學,大多透過字典查閱詞義,且生字教學中常使用字首、字尾造詞等方式,因而不容易有系統的學習。但透過資訊科技融入教學,可以促 進教學成效。例如 AutoTutor 是透過電腦提供指導或直接回饋給學生的學習系 統,採用自然語言的對話式教育幫助學習者學習(Graesser, Hu, & McNamara, 2005; Graesser, Lu, Jackson, Mitchell, Ventura, Olney, & Louwerse, 2004; Graesser, Person, Harter, & the Tutoring Research Group, 2001),主要應用 LSA 的 語意關聯度技術,分析學生在對話中的段落或句子所涵蓋或隱匿在其背後的語 意。AutoTutor 會從課程腳本中提出一系列的挑戰性問題,讓學生以建構學習 的方式來獲取答案,在學習過程中強調問題解釋的重要性,幫助學生擁有更完 整的知識概念。
Summary Street 系統(Landauer & Psotka, 2000)使用 LSA 技術評量學生的摘 要寫作,分析與理想摘要間的語意關聯度。當學生提交摘要時,文長需達到原 文的 25%左右才能送交,且還能即時性給予摘要內容的修改回饋。當字數超過 預定長度時,系統會找出摘要中意義重疊和不相關的句子助刪除訂正,直到合 乎標準為止,其優勢為能幫助學生進行寫作摘要時學習內容重點的完整性,減 少教師評改的負擔與降低個別回饋的負荷量(Wade-Stein & Kintsch , 2004)。
Interactive Strategy Trainer for Active Reading and Thinking(iSTART)是一 套以網頁為基礎的智能教學系統,用來訓練學生的自我解釋(self-explanation) 能力和閱讀策略(McNamara, Levinstein, & Boonthum, 2004)。在回饋學生自我解 釋的過程中,iSTART 系統是利用 LSA 分析學生自我解釋的含意和挖掘在文件 中所隱含的知識語意 (McNamara, Boonthum, Levinstein, & Millis, 2007)。
在國內,LSA 大多應用在文章摘要的寫作評量上(馮樹仁,2002;丁偉民, 2004;藍敏杰,2007;黃彥博,2008;尹玫君、蘇彥寧,2011;黃彥博、洪碧
霞、蘇義翔,2011),相對於在教學應用上的研究則較少。如黃幀祥(2011)的
「使用潛在語意分析建構文本分類模型-以國小社會科課文為例」,是運用 LSA 中能分析文本的語意特徵,以國小社會科課文為範圍,建立一個社會科的語意
空間模型,利用該語意空間模型再將從網路上搜尋到未知程度的社會科文章進 行分類,其分析結果的準確率達 79.06%,在教學上有助於學生選擇適合自己程 度的社會科文本,以節省學生尋找合適文本的時間。 陳家毅(2011)的「應用中文句法權重於潛在語意分析技術於中文智能教 學系統之對話計分研究」,則是發展以 LSA 為基礎的電腦輔助教學系統,課程 材料採用翰林版的國小二年級國語六課課文,並透過結合中文句法權重函數, 改善 LSA 在語意空間模型所缺乏的字詞順序和句法結構資訊。 劉嘉玲(2012)採用「以 LSA 為基礎之電腦化語意關聯輔助學習系統」(陳 世銘、廖晨惠、郭伯臣,2011)中的詞彙教學系統結合記敘文兒童中文語料庫, 以國小二年級學生為研究對象,進行擴充詞彙量的教學實驗。結果發現在語文 智能、中文識字量、詞彙聯想速度、詞彙聯想多元性及語詞應用能力等五個面 向,以 LSA 詞彙教學系統所選取的詞彙進行補充教學的學習效果,皆顯著優於 傳統生字造詞的詞彙補充教學。不但能提升學生的詞彙量,亦能引發學生學習 詞彙的興趣。 近年來國 外亦將 LSA 應用於文本自動化分析研究,如 McNamara、 Graesser、McCarthy 與 Cai (in preparation)應用 LSA 可以測得句子之間的語意關 聯性之優點,發展 LSA 相關指標並應用於分析文本的連貫性。 綜上所述,顯示 LSA 應用在教育上的範圍已非常廣泛。從 AutoTutor 透過 互動以蒐集使用者更完整的答案,到寫作摘要評分、詞彙教學輔助系統、文本 自動化分析等,可見 LSA 的應用具有研究價值。本研究將開發以 LSA 為基礎 之語意關聯輔助學習系統,持續蒐集教師的使用建議予以改進,以提供在教育 上的詞彙教學應用,最後再評估成效。
第四節 兒童詞彙語意發展
研究閱讀歷程的心理學家認為,人腦中有一個可以長期記憶和存放關於各
種知識的詞庫,稱為心理詞彙庫(mental lexicon)。從心理學的角度看來,當我
們將新概念存放於心理詞彙庫時,代表我們已將一個詞彙表徵一個概念,因此, 在學習新詞彙的過程中,心理詞彙庫會將這些新詞彙與已習得的詞彙進行有系 統的組織,並且以網路型態存在(Collins & Quilian,1972;Just & Carpenter, 1987),形成一種彼此有關係的概念組合,故常共同出現(co-occurrence)或語 意相近的詞彙,其間的距離就越接近,關聯強度也就越強。當我們需要提取某 個概念的詞彙時,會以蔓延激發模式,蔓延擴散至其他與此概念連結的節點, 若提取的詞彙與越多詞彙的關聯性大,那麼被激發的強度也越強,也越容易被 聯 想 與 提 取 (Collins & Loftus, 1975) 。 從 Moss, Ostrin, Tyler 與 Marslen-Wilson(1995)的研究中可知,當人從心理詞彙庫提取一個詞彙時,經由 激發訊息,可將詞彙與詞彙彼此之間的語意關係分成兩種類別: 一、類別的(categorical)語意關係:又分為自然(natural category)與人造(artifact category)兩種。例如,牛(cow)-羊(sheep)是歸屬於自然類別關係; 椅子(chair)-桌子(table)則歸類到人造類別關係。 二、功能的(functional)語意關係:分為腳本關係(script)和工具關係(instrument) 兩種,腳本關係以戲院(theater)-劇本(play)為例,工具關係則是鐵槌 (hammer)-釘子(nail)。 在 Nelson(1974)的研究當中,可以得知在兒童的語意發展上,功能語意關 係會早於類別語意關係。當兒童在學習一個新的詞彙時,會先從在某個事件中 這個詞彙所具備的功能,建立相對應的語意關係。例如,「牙刷」對兒童而言, 是代表早上起床或吃完東西後,一個可以用來清潔牙齒的物品。兒童接觸一個 物件時,最先會去辨識這個物件的功能,包括物件本身的功能、人是如何來使
用該物件,進而在物件知覺歷程的分析上會衍生出功能的概念(Nelson,1974)。 因此,在兒童早期的語意關係當中,功能性的詞彙是比類別語意關係的詞彙較 早發展的(翁巧涵,2010)。隨著年齡的增長,兒童對於詞彙的學習逐漸從功能 語意轉換成類別語意的時間,約是在 5 歲至 9 歲之間(Nelson,1977),因此,兒 童極可能在上小學後,隨著學習經驗的增加,開始進入並發展以類別語意關係 為主的詞彙語意知識。另外,Koo(2002)也對平均年齡為 22.03 歲的成人和 4.1 歲的兒童進行相關研究,認為在心理詞彙庫中的詞彙由功能語意關係轉換到類 別語意關係,是量的改變,而不是質的轉換,是跟語言知識和詞彙量的大小有 關,證明隨著學習詞彙的經驗增加,心理詞彙庫的量越豐富多元,對於在辨識 屬於類別語意關係的詞彙上可以即時的做出語意判斷。 另外,Collins 與 Quillian 早在 1969 年就提出類似的觀點,主張人會將已 習得的詞彙概念建立在語意記憶(semantic memory)系統,並組成涵蓋許多概 念的複雜結構,一個概念就是一個節點,有關係的節點會相互聯結,形成類似 一個知識結構的網路,再加上節點與節點之間會因詞彙類別(categorical)和特 質(property)關係而相互聯結形成一種語意網路。在詞彙語意網路中,當出現 一個詞彙時,會激發在語意記憶中相對應的節點,並平行的自動激發所有連接 的節點,蔓延到具有關連性的詞彙(Chwilla, Hagoort, & Brown, 1998;翁巧涵,
2010)。詞彙之間的語意關係越密切,節點的距離就會越近,關聯強度也會越強, 越快被激發,也就是說,節點網路的連結代表每個詞彙彼此間的聯想關係,故 詞彙之間的連結距離越近,其聯想關係越高,被激發的時間相對也越快。詞彙 聯想可以看成是腦中詞彙蔓延激發的能力,是建構詞彙網路與搜尋需要詞彙的 重要過程,當心理詞彙庫的詞彙越豐富完整,節點網路連結越複雜,就會表現 出較好的詞彙聯想力。 McKeown(1985)研究五年級不同識字能力學童在學習詞彙上的表現,發現
的意義。閱讀能力好的兒童,對於語意處理的正確率會相對提升,對詞彙語意 的反應時間會減少(李姝慧、陳修元、周泰立,2009)。李姝慧等人(2009)設 計不同語意關聯強度(高、低和無關)的實驗,在研究結果中顯示,不管是成 人或是兒童,當語意關聯的距離越遠,其正確率越低,所需要的反應時間也會 增加,而且高閱讀能力的兒童比低閱讀能力的兒童有著較佳的語意判斷表現。 因此,兒童所具備的語意知識會影響對詞彙的正確提取和運用語意知識的處理 能力,造成詞彙和句子理解的困難,無法瞭解文章的意涵,進而形成中文閱讀 障礙。
在強調語意關係的詞彙教學研究上(Bos & Anders, 1990; Kim, Vaughn, Wanzek, & Wei, 2004),發現透過語意特徵分析(semantic feature analysis)和語 意、語法特徵分析(semantic and syntactic analysis),分析詞彙間相關的特徵屬 性,建構詞彙的階層關係,使學童在閱讀測驗上的表現比傳統的詞彙定義教學 (dictionary instruction teaching)較好,並在閱讀和詞彙學習能力上有所進步, 同時也能提升在語文學習障礙的孩童的能力。由此可知,詞彙語意知識的學習, 和建立詞彙之間的語意關係,當語意網路連結的分支越複雜,語意關係相近的 詞彙之間,其連結強度也越緊密,對於語意處理的表現也就會越好,對於增進 學童的閱讀能力是有助益的。底下將就兒童詞彙學習與中文閱讀理解相關研究 與詞彙對中文寫作的相關研究作探討。
壹、兒童詞彙學習
從中文閱讀的角度來看,單字是一個重要的閱讀單位(胡志偉、顏乃欣, 1992),但在眼動追蹤的實驗研究中卻發現,在中文的常態閱讀情境下,詞彙才是最實際的主要閱讀單位(Bai, Yan, Liversedge, Zang, & Rayner, 2008)。國內也有 些學者提出相同的見解,認為中文的詞彙具有心理真實性,同時也是中文閱讀 時基本訊息處理與意義單位(胡志偉,1989;彭瑞元、陳振宇,2004;鄭昭明,
1981)。當兒童已經能辨識單個單字後,字彙量亦逐漸增加,但能讀出或認出文 章中的每一個字,並不代表能理解整篇文章的意義。中文讀者在閱讀過程中, 通常會先辨認出個別文字,再進一步構成詞彙,並且在瞭解詞彙意義後,將多 個詞彙組合成句子,再依照語法結構瞭解整個句子的內涵,爾後進行句與句的 語意整合,以找出段落的意義(柯華葳,1994;王虹琇,2009;林昱成,2009)。 另外,閱讀理解的基礎在於詞彙,因此,詞彙的認識與學習是閱讀理解書 面語言的必要條件(蔡欣儒,2010)。在 Curtis(1981)的研究中,也認為閱讀能 力較差的學童對於詞彙的認識是缺乏廣度和深度。Perfetti(1985)更指出閱讀力 不佳者的文字解碼速度緩慢,在詞彙提取(lexical access)欠缺精準性,所以無 法將詞彙組成句子,進而建構文章,加上詞彙量不足,導致理解部分出現很大 困難。Thorndike(1973)的研究結果顯示,詞彙量和閱讀理解兩者間有.66~.75 的正相關(引自 Aaron & Joshi, 1992)。此外,Aaron 與 Joshi(1992)的研究提 出了優讀者比弱讀者有較多的詞彙量,且詞彙量愈豐富其閱讀理解愈佳。李慧 慧(2006)以逐步迴歸分析和路徑分析(path analysis)探討一般學生的詞彙量 和閱讀理解的關係,研究結果指出兩者間有一條顯著的直接影響路徑,詞彙量 與閱讀理解皆呈現正向高相關,同時也發現閱讀理解困難學生的詞彙量明顯少 於一般學生。且已有研究發現,學童的閱讀理解能力與詞彙能力的相關度會隨 年級的增加而增高,但是其與識字能力的相關度則反之(van der Leij, 1990)。
兒童從 18 個月開始出現詞彙(Hulit & Howard, 2006),終其一生,詞彙的 學習是不會停止的,隨著年齡的增長和生活經驗的增加,兒童會持續地在自己 的心理詞彙庫中加入新的詞彙(Owens, 2005)。當兒童進入小學就讀後,除了繼 續由語言產生的情境中提取詞彙的意義之外,也從閱讀活動中學習更多的新詞 彙和具有多重意義的詞彙(吳雨潔,2007),以及詞彙與詞彙之間的關係。詞彙 習得除了學會詞彙的形、音、義外,更要掌握該詞彙的語法特徵、與其他詞彙
Carnine(1987)從觀察中發現,雖然兩個學生的詞彙庫中具有相同數量的詞彙, 甚至是相同詞彙的情況下,因為在詞彙知識上質(quality)的不同,或對特定 詞彙廣泛性知識上的差異,故藉此認定他們是擁有不同的詞彙知識能力。
Beck 與 McKeown(1991)指出詞彙知識是一個連續量,因此,本研究綜合 多位研究者的觀點(Beck, Perfetti & Mckeown, 1982; Daneman, 1987,1991; Daneman & Carpenter, 1980, 1983; Johnson & Anglin, 1995; Nagy & Herman, 1987; Nagy, Herman, & Anderson, 1985;曾雅瑛、黃秀霜,2002;陳貞佑,2010; 謝玫芳,2011),將詞彙習得過程切割成四個階段: 一、第一階段「完全不認識」:即無法辨識該詞彙,完全不了解或表達出其詞彙 意義(陳貞佑,2010)。 二、第二階段「初步認知」:對該詞彙稍微有些概念,能將其語音和字形做相關 配對連接(謝玫芳,2011),但無法確定其所代表的意義。 三、第三階段「認知詞彙」:對該詞彙有一般概念,如果上下文提供線索,對詞 彙意義能有一般理解(曾雅瑛、黃秀霜,2002),但仍無法主動且正確的運 用該詞彙(Nagy & Herman, 1987; Nagy, Herman, & Anderson, 1985)。
四、第四階段「運用詞彙」:兒童完全理解該詞彙,可以用在上下文中幫助理解 內容,或獨立於內容之外也可以說出其定義,並能在口語或書面語中將其運 用自如(Daneman, 1987,1991; Daneman & Carpenter, 1980, 1983; Johnson & Anglin, 1995;曾雅瑛、黃秀霜,2002)。
在閱讀時所需之最基本能力為認字(柯華葳,1999),其次則是在心理詞彙
庫中積存了一定數量的詞彙,且詞彙量愈多閱讀理解愈佳(Aaron & Joshi,
1992;柯華葳,1999),但除了足夠的詞彙量之外,詞彙知識在閱讀理解中扮演
了更關鍵的角色(Baddeley, Logie, Nimmo-Smith, & Brereton, 1985; Cunningham, Stanovich, & Wilson, 1990; McKeown, Beck, Omanson, & Popel, 1985; Aaron & Joshi, 1992;李慧慧,2006),可以促進理解歷程作用和聽說讀寫的能力(Goldstein,
2004),故建構詞彙知識能力更顯得重要。學生若能具備詞彙習得的第四階段「運 用詞彙」能力,則代表他們已經能理解某個詞彙的定義,並且能將此詞彙運用 自如。 綜合上述研究可知,閱讀理解的基礎在於詞彙,因此,詞彙的認識與學習 是閱讀理解書面語言的必要條件。兒童的認字能力在國小三年級時就已達到自 動化,在閱讀的心理資源處理會以片語、句子或篇章段落為主,因此詞彙能力 較佳的兒童,其閱讀時在處理多詞彙、句子、段落及全文的理解能力也會相對 較高。當學生具備更完整且豐富的詞彙知識,就愈能幫助語句的整合和對全文 的理解。因此,本研究將開發電腦化語意關聯輔助學習系統,讓老師使用於教 學或學生自學,有系統的學習到更多具有關聯性的詞彙並增進本身的詞彙知識。
貳、詞彙對中文造句的相關研究
詞彙知識在閱讀理解歷程中是一項重要的影響因素,尤以具備自動化的解 碼能力卻閱讀理解差的讀者,其造成閱讀困難的基本原因在於不能了解文章中 句子的架構和詞彙(Johnston, Tulbert, Sebastian, Devries & Gompert, 2000),因此 藉由詞彙教學,擴充詞彙量,瞭解詞彙意義與用法,進一步幫助學習者運用詞 彙造句,由詞到句,由句到段,由段到篇章,靈活、順暢的完成文章寫作(楊 裕貿,2006)。 由於詞彙教學並非是一個簡單的教導學生背誦詞彙的過程,其間涉及學習 者對既有詞彙的提取,協助理解新詞彙詞義,建立內在詞彙網絡,因此,需要 一起考慮語義、語用、語法的問題(魏金財,1997)。國外傳統的詞彙教學法的 步驟為老師提出詞彙表,讓學生查字典並寫出詞彙定義,再讓學生抄寫含有該 詞彙的句子,最後進行詞彙測驗來檢驗學生是否以習得詞彙表裡所有的詞彙 (Misulis, 1999)。藉由固定模式的討論、定義和書寫詞彙來幫助學生發展詞彙 (Vacca, Vacca, & Gove, 2000)。而目前國內小學的語文教學流程大多是以先進行概覽課文,生字教學,課文新詞講解,最後課文內容深究及句型練習等步驟。 在該教學過程中,教師會在「生字教學」和「課文新詞」兩部分進行詞彙教學, 但其採用的策略,主要是直接講解由生字造詞和課文新詞的詞義,並無特別針 對詞彙做特定主題的教學活動。在一般教師眼中,所謂的詞彙教學活動中大多 數是指生字和新詞搭配學生查字典的實作活動,讓學生針對不熟悉的詞彙透過 查字典的方式,學會使用工具書和以文釋義的能力。但在這樣的過程中卻發現 學生在使用字典查一個陌生詞彙時,卻在字典的釋義條文中發現更多不懂的詞 彙,使得學生更加陷入詞彙學習的挫敗感中,而且對小學生而言,字典中詞彙 的編排方式呈現條列式,容易讓學生覺得無趣,因此,學生對於課程的學習參 與度低,學習的保留與理解也有限(Dixon, 1990)。 雖然如此,但詞彙教學的重要性已日益受到關注,許多以詞彙教學為主題 的研究紛紛出現,綜合國內外詞彙教學策略的研究來進行說明: 一、詞彙定義教學法 直接教導詞彙本身的意義,讓學生透過查字典來瞭解詞義,並運用同義詞、 反義詞和多義詞幫助學生更熟練詞彙的意義(Dole, Sloan, & Trathen, 1995; Harmon, 1998; Kibby, 1995; Misulis, 1999; Poindexter, 1994; Vacca et al., 2000,歐素 惠、王瓊珠,2004)。羅秋昭(1999)所提出的詞彙教學法就可歸屬為此類,其 方式為(1)充分了解詞義,有一詞一義、一詞多義、比喻義。(2)查字典。(3) 結合上下文來理解詞義。(4)辨析同義詞。(5)掌握單位詞的習慣用法(歐素惠、 王瓊珠,2004)。 二、文句脈絡教學法 教導學生面對陌生的詞彙時,從上下文中推測出詞彙的詞義(Dole et al., 1995; Graves, Juel,& Graves, 2001; Johnson & Steele, 1996; Kibby, 1995;歐素惠、王瓊
珠,2004)。Poindexter(1994)讓國中一年級學生以小組方式猜測文章中 6 個生詞,
將文句脈絡結合多義詞彙教學法,以三和五年級學生為實驗對象,發現其詞彙知 識與閱讀理解能力皆有所增進,且詞彙知識增加對閱讀理解更有助益。在研究中 也提出低閱讀能力學生在進行該教學法後,在詞彙知識與閱讀理解上的進步程度 優於高閱讀能力的學生(王虹琇,2009)。在國內則有劉英茂(1978)提出在文 字脈絡中理解的生詞比單獨學習生詞更易熟記,在生詞運用上,單獨學習生詞遠 不及在文句脈絡中學習生詞。李惠珠(1999)以提供注音和上下文語境來輔助學 生對詞彙的認識,發現時常閱讀課外讀物或聽故事的學生,在詞彙能力方面也有 增進。同時,認為教師學歷的高低和教科書版本的不同,也是影響學生詞彙能力 的因素。 三、結合多媒體科技 Yanqing 與 Qi(2004)運用多媒體輔助的教學方式呈現教材內容,發現確實 可以增加兒童的詞彙量。方金雅(2001)實施多媒體詞彙教學來增進國小三年 級學童的詞彙能力,其研究證明多媒體詞彙教學可增進學生的構詞和詞義能 力,發現詞彙能力與認字能力、理解閱讀能力的關係密切。高柏園、黃宜雯、 郭經華與陳俊文(2009)利用以「以字帶詞」組合詞彙的詞彙教學策略,結合 字詞輔助學習系統與線上教學平臺,輔助學習者在閱讀過程中建立和辨別詞 義,同時在學習者識字量有限的情況下,達到在短時間內擴充詞彙量的目的。 另外,國內研究者認為透過多媒體科技的輔助教學方式,可以使詞彙大量且反 覆的練習,讓學生精熟達到自動化的能力,藉此增進詞彙能力(陳密桃、黃秀 霜、陳新豐、方金雅,2006;蘇宜芬、陳學志,2007)。 除此之外,Follman(1990)認為教師直接教導詞彙意義、增加詞彙出現的次 數、運用關鍵字學習詞彙和藉由資訊科技來輔助詞彙教學等方式都可以增進學 生的詞彙量與運用詞彙的能力。另外,在國小語文或華語文教學現場也有一些 擴充詞彙量的策略:
成因,使學生了解詞彙意義,如以「海」為詞根詞素,講解「海嘯」。 二、詞彙聯想法:有同義詞聯想、反義詞聯想、組詞式聯想、義類詞聯想、同根 詞聯想(楊裕貿,2006),利用自己已知的詞彙概念連結擴及至新增的詞彙 上,以統整而非片段的方式進行詞彙學習,如「同意」替換成「贊成」。反 義詞的「冷」,替換成「熱」。組詞式聯想的「跳」,可想出「跳高…」。 義類詞聯想的「山」,可想出「荒山…」。同根詞聯想的「叫」,可想出「吼、 呼…」。 三、直接示意法:利用實物、模型、圖片、動作和手勢直接示範或說明詞彙意義, 如指著滑鼠說明這是「滑鼠」。 四、詞彙搭配法:透過詞彙共同出現(co-occurrence)在一個句子中來呈現詞彙 的「共現」成分(Spence & Owens, 1990),如醫生和護士,因為和所以。 從前述兒童詞彙學習與中文閱讀理解相關研究得知,詞彙與閱讀理解有密 切關係。而閱讀是將文本上的內容轉化成口語符號,寫作則是將口語符號轉譯 為文本內容,但兩者都運用到後設認知能力,將外在訊息建構成對本身有意義 的內容(曾啟瑞,2008)。因此,閱讀與寫作實是一體之兩面(錡寶香,2000), 許多的研究也支持此一論點。陳明彥(2001)以台中縣市四年級和六年級的國 小學童為研究對象,發現不同年級與性別在閱讀理解能力與寫作表現之間存在 中等程度之正相關。而吳憲昌(2002)以問卷調查法探討台中縣國小六年級學 童家庭語文環境、閱讀行為與心得寫作間的關係,得到閱讀行為與心得寫作之 間具有顯著正相關存在。林憲治(2003)也採用問卷調查法,以高雄市公立國 小三年級的學童為研究對象,結果顯示閱讀態度與寫作表現有顯著正相關,而 閱讀態度能部份預測寫作表現。錡寶香(2004)在研究同一年級不同閱讀與寫 作能力的比較方面,結果發現:低閱讀能力學童的寫作能力比一般學童差,且 所使用的總詞彙數、成語數、總共句子數皆較少。邱怡瑛(2005)則以國小五 年級學童為研究對象,探討不同寫作能力學童在記敘文寫作過程中的差異時亦
發現,高寫作能力學生平時閱讀頻率比低寫作能力組高。 綜合上述,寫作要運用語言來表達,而語言的基本單位就是詞(楊裕貿, 2006)。教育部《國民中小學九年一貫課程綱要(國語文)》(2011)國小階段「寫 作能力」指標的整理分析,現行國小的寫作能力的培養教學,第一階段的指標 內涵就提到「能擴充詞彙…」,往後的階段才透過「觀摩、分享與欣賞,培養良 好的寫作態度與興趣」,逐步「…遣詞造句、組織成篇」,終能「精確表達觀察 所得見聞」。由此可知,寫作的成敗端賴能否掌握並熟練詞語的運用,而學童往 往受限於詞彙認識不足,導致語文學習和應用上受阻。因此,欲無礙的學習與 表達語文,必須有豐富的詞彙。應用 LSA 兒童中文語意空間有系統的提供關聯 語詞學習,則在擴充詞彙量的教學上,提供了另一種新方式。
第三章 研究方法
本論文之的目在於建立一個兒童中文語意空間,並運用該語意空間開發一 套電腦化語意關聯輔助學習系統,以下就各研究流程分別說明。第一節 研究流程
依據前述的研究動機、研究目的和文獻探討之後,建立本研究之流程如圖 3-1。透過建立兒童中文語意空間且驗證其有效性之後,開發電腦化語意關聯輔 助學習系統作為詞彙教學輔助工具,並比較傳統詞彙教學,以了解學生在詞彙 量的增加是否有差異。希望未來提供教師一個有效的詞彙教學輔助工具,讓學 生有系統的學習更多關聯詞彙,以提升閱讀能力。 圖3-1 研究流程 本系統所使用的程式語言為 HTML5、JavaScript、AJAX 及 ASP,分述如 閱讀相關文獻 擬定研究主題 學習程式語言 JavaScript、AJAX 及 ASP 協助建置國小一~六年級的兒童中文語料庫 利用兒童中文語意空間 開發電腦化語意關聯輔助學習系統及成效評估 撰寫研究結果 建立並驗證兒童中文語意空間下: 一、 HTML5 以及 JavaScript:製作出互動式的動態網頁。 二、 AJAX:用戶端採用 JavaScript,僅需要向伺服器發送及取回必須處 理的資料,所以畫面回應速度快,web 伺服器處理時間也節省很多。 三、 ASP:將網頁所讀取的資料與資料庫做連結及應用。 四、 MS Access:系統資料庫。 本系統網路架構圖如圖 3-2: 圖3-2 系統網路架構
第二節 建立兒童中文語意空間
Wiemer-Hastings(2004)認為語料庫的建置,內容愈豐富愈佳,而且要能夠 和研究目的及對象有一定的相關。臺灣內容最豐富的語料庫,為中央研究院建 Web Server AJAX Internet ASP Access Database PC 1 PC 2 PC 3置的平衡語料庫,偏向一般生活常見用字與文章來取材,適合一般民眾。在兒 童部分,則有廖晨惠(2011)國科會計畫建置的兒童中文語料庫,其來源為獲 得授權之現行國民小學一到六年級教科書與兒童相關讀物。教科書部分包括: 康軒、南一、翰林三個版本,其餘為國語日報及其他兒童讀物。文章數共有 1,208 篇,詞彙數量為 43,650。本研究即以前述的語料庫(只擷取教科書部分),以 LSA 技術來建立一個 20,022 個詞彙,5,219 篇文件的兒童中文語意空間。 語料庫的建立,必須考慮到未來應用的方向。依照 Wiemer-Hastings(2004) 的研究結果,若要能反應兒童的內在心理詞彙表徵間之語意關聯性,則語料庫 的來源以兒童的造句、作文及投稿內容較適宜,但同樣的也因為兒童使用的詞 彙數較少,語意空間相對較小。另外,就教學與學習的觀點而言,教科書是以 專家的知識概念,希望學生學到什麼內容而去設計規劃,故其詞彙內容多,建 立的語意空間也較大。本研究的目的之一乃在於希望提供國小教師一個有效且 便利的詞彙教學工具,並能切合教科書的內容與進度,故採用以國小教科書為 主的語料庫來建立兒童中文語意空間,並探討其效度。
使用潛在語意分析技術建立語意空間,需要以下四個步驟(Martin & Berry, 2007): 一、字詞與文件共生矩陣建立。 二、詞彙權重計算。 三、執行 SVD 轉換矩陣。 四、維度約化。 底下將分別說明各步驟:
壹、建立字詞與文件共生矩陣
本研究參酌陳明蕾等人(2009)發表之文章,將語料庫中出現兩次以上的 詞彙定義為「關鍵詞」,並以學童教科書文章,以及相關閱讀教材為文件的單位。文件大小是以 200 字左右大小為單位將文章進行切割,最後建置一個字詞與文 件大小為 20,022 個詞彙,5,219 篇文件共生矩陣。
貳、計算詞彙權重
在語料庫裡,詞彙與文件的共生矩陣當中,有些功能詞並無太多意義,必 須透過一個加權以降低對共生矩陣的影響(Landauer & Dumais, 1997)。至於加權 方式分為 local 與 global 二種。local 權重是考慮詞彙在每一份文件中所佔的重 要性,出現次數愈多,local 權重愈大;gloal 權重則是考慮到詞彙在語料庫所有 文件的重要性,與 local 權重相反,在眾多的文件中出現的次數越多,global 權 重則愈小(Dumais, 1991; Landauer & Dumais, 1997)。下列為 m n 的詞彙與文件 共生矩陣 A ,表示詞彙權重加權的公式:
m n
A(fijG i( )L i j( , )) (3.1)
( )
G i 代表第 i 個詞彙在語料庫的 global 權重,而 ( , )L i j 表示第 i 個詞彙在第 j 個文件的 local 權重。一般研究發現使用 log-entropy 方法有較好的效果(Dumais, 1991),其公式給定如下: ( , ) log( ij 1) L i j tf (3.2) ( , ) L i j 表示 local 權重,tfij表示第 i 個詞彙在第 j 個文件出現的次數。 2 j 2 log ( ) ( ) 1 log ij ij p p G i n
, ij ij i tf p gf (3.3) ( ) G i 表示 global 權重,gfi是第 i 個詞彙在所有文件中出現次數的總和。參、執行 SVD 轉換矩陣
藉由 SVD 的運算,來計算出每個關鍵詞在對角矩陣中的特徵值。特徵值的 向量愈大,表示訊息量也較大。經過 SVD 轉換後的矩陣,關鍵詞與文件之間的 關係就不再是次數計量,而變成了表徵關鍵詞在文件中的語意關係。肆、維度約化
Landauer 與 Dumais(1997)提出維度在 100、200 和 300 時,對同義詞有不 錯的效果,因此本研究中將採用 300 作為維度約化的維度數,以重新建立新的 兒童中文語意空間。第三節 兒童中文語意空間之特性與效度驗證
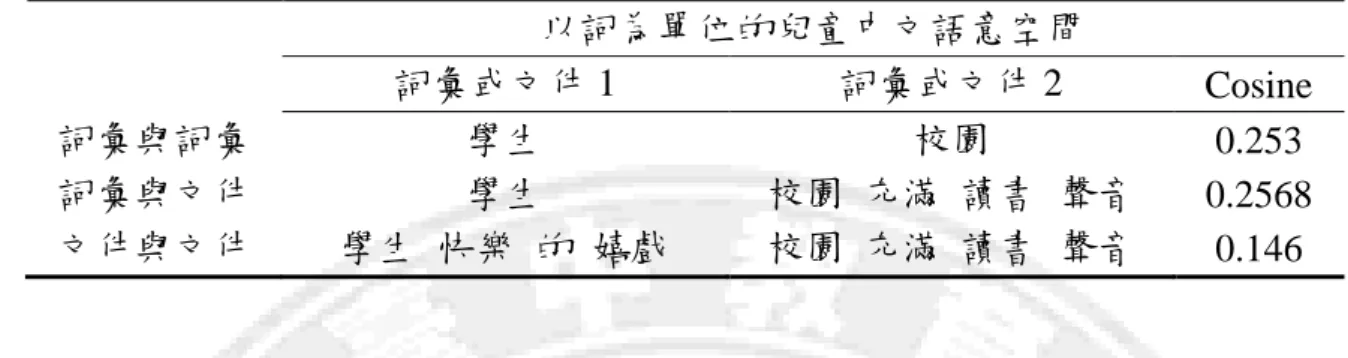
本實驗旨在比較所建立不同年級的兒童中文語意空間之差異,以及不同科 目文章的兒童中文語意空間之差異,並驗證語意空間所計算的詞彙與詞彙間、 以及句子與句子間之語意關聯性,能否反應中文學生內在之心理知識表徵。另 一方式為分別使用兒童中文語意空間與成人語意空間進行造句自動化計分並進 行比較,用以評估本研究建立之兒童中文語意空間是否較適合應用於國小兒童 學習情境中。壹、兒童中文語意空間特性描述與比較
本研究根據所建置的兒童中文語意空間,進行不同類別特性描述與比較。 依內容分為低、中、高不同年級的三個語意空間,國語、自然、社會不同科目 的三個語意空間,分別探討不同年級與不同科目的兒童中文語意空間之差異。 本研究根據 Hu et al.(2005)所提出的研究方法,該研究提出可以比較不同語 意空間之差異的方法:combinatorial similarity,其方法為挑選兩個語意空間之 相同詞彙,從相同詞彙中挑選代表性詞彙,並計算該代表性詞彙與其他詞彙的 語意關聯度,且依語意關聯度由高至低進行排序以進行兩個語意空間相關性之 比較,其兩語意空間之相關性計算公式如下,C 代表兩個語意空間之相關性,x 為所挑選之代表性詞彙,T 為與代表性詞彙進行比對的詞彙數量: 2 1 2 , 1 ,T xT x T x S S C 根據 Hu et al.(2005)的研究,使用「life」這個詞彙為代表性詞彙,計算 3 年級、6 年級、9 年級、12 年級與大學五種語意空間當中,挑選出相同詞彙的 語意關聯度。該研究比較「life」這詞彙與五種語意空間相同詞彙的語意關聯度, 並由高到低排序,取前 50 個詞彙利用上述公式,分別計算出兩個語意空間之相 關性,實驗範例如表 3-1。 表 3-1 為使用「life」這個詞彙與不同語意空間中相同的詞彙進行詞彙語意 關聯度計算並排序選出前 10 個最相近的詞彙(Hu et al., 2005),其研究結果顯示 6 年級與 9 年級語意空間之相關性較為接近。 表 3-1 life 在不同語意空間與其他詞彙語意關聯度 6 年級 9 年級 12 年級 life
reincarnation contemplated death
premiums reincarnation lifetime
policyholder sai hamlin
premium pipal pipal
sai nirvana nirvana
cycles lifetime zarathustra
holdover death ahuramazda
condemning hinduism ahriman
chekhov afterlife policyholder
captial excerpted romantics
本研究依據不同年級與不同科目分別建立的兒童中文語意空間,從相同詞 彙裡依詞頻分別從高、中、低詞頻各挑選出 3 個詞彙當作代表性詞彙,並計算 代表性詞彙與其他詞彙之關聯性並進行排序,再取前 400 個與代表性詞彙語意 關聯度最高之詞彙,由上述公式進行不同語意空間之比較。
貳、詞彙語意效度驗證
一、研究對象 本研究邀請四位國小語文專家進行詞彙語意關聯性評分,以評估本研究建 立的兒童中文語意空間在詞彙語意之效度。 二、研究方法 本研究從國語、社會、自然與生活科技三個領域中,依學習階段從三至六 年級中各挑選一篇文章,再由文章中的詞彙依詞頻高、中、低分別挑選出 2 個 代表性詞彙,並另由該文章內各挑選出 6 個欲比對的詞彙,因此每科目共有 12 組詞彙,每年級共有 36 組詞彙進行語意關聯度計算。 另國語文專家對於詞彙間語意關聯度評分部分,採用問卷形式進行,讓專 家針對詞彙 1 與詞彙 2 的關聯度高低進行評分。其中,詞彙 1 即為代表性詞彙, 詞彙 2 為各文章中欲比對之詞彙。比對評分範例如表 3-2。相關問卷如附錄 1。 本研究除了以兒童中文語意空間計算詞彙間的語意關聯度並與專家評分進 行比較評估之外,同樣也使用現代漢語平衡語料庫 3.1 版建立了大小為 78,444 個詞彙,38,994 份文件的成人語意空間以進行比較。本研究使用皮爾森積差相 關(Pearson product-moment correlation)進行兒童中文語意空間詞彙語意相似 度計算與專家評分之成效評估。 表 3-2 詞彙語意比對評分範例 詞彙 1 詞彙 2 評分區 學校 學生 □低 □中 ■高 校外教學 □低 ■中 □高 足球 ■低 □中 □高參、句子語意效度驗證
一、研究對象 本研究邀請五位國小語文專家進行句子語意關聯性評分以評估本研究所建 立的兒童中文語意空間在句子語意之效度。 二、研究方法 本研究參考陳明蕾等人(2009)之研究進行語意空間句子語意效度驗證, 分別從國語、社會、自然與生活科技三個領域中,依學習階段從三至六年級的 文章中各別挑選出文章,再依據文章各挑選一個段落進行句子比對,經過篩選 後各年級各有 27 組句子以進行語意相似度的比對與專家評分。而研究也使用現 代漢語平衡語料庫 3.1 版建立的成人語意空間以進行比較。 其句子效度驗證方式為將句子以兩兩呈現方式進行句子語意相似度計算, 比對方式以三種方式呈現:(1)同一篇文章內之句子依文章內容順序進行比對, 如:句 1 與句 2 比對,句 2 和句 3 比對,依此類推;(2)同一篇文章內的句子, 以隨機抽選的方式將兩兩句子進行比對,如:句 1 和句 3 相比;句 2 和句 7 相 比對;(3)不同文章間的句子互相比對,本研究以隨機的方式將兩兩句子進行 比對,如:第一篇文章的句 1 和第五篇文章的句 2 相比對。句子語意比對的範 例如表 3-3。相關問卷如附錄 2。 表 3-3 句子語意比對評分範例 句子 1 句子 2 評分區 清潔隊員不怕髒臭的清理垃圾 我們才有乾淨、舒適的環境 □低 □中 ■高 我們要感謝的人太多了 農夫辛苦的耕作 □低 ■中 □高 一大早就吊著絲線盪呀盪的 陽光穿透相思林斜灑過來 ■低 □中 □高本研究進行句子語意效度驗證的方式為請語文專家進行句子之間的關聯性 評分,並使用單因 子變異數分析(ANOVA)與皮爾森積差相關(Pearson product-moment correlation)進行兒童中文語意空間句子語意相似度與專家評分 之成效評估。