國立交通大學
資訊科學系
碩
士
論
文
資料探勘技術於病人疼痛自控裝置之應用與分析
Data Mining and Analysis in Patient Controlled Analgesia
研 究 生:吳欣儒
指導教授:胡毓志 教授
資料探勘技術於病人疼痛自控裝置之應用與分析
Data Mining and Analysis in Patient Controlled Analgesia
研 究 生:吳欣儒 Student:Shin-Ru Wu
指導教授:胡毓志 Advisor:Yuh-Jyh Hu
國 立 交 通 大 學
資 訊 科 學 系
碩 士 論 文
A ThesisSubmitted to Department of Computer and Information Science College of Electrical Engineering and Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer and Information Science
July 2011
Hsinchu, Taiwan, Republic of China
i
資料探勘技術於病人疼痛自控裝置之應用與分析
學生:吳欣儒
指導教授:胡毓志教授
國立交通大學資訊科學系(研究所) 碩士班
摘
要
病患在接受手術後通常會發生疼痛的現象,嚴重的疼痛可能會影響到傷口的癒合。 因 此 , 如 何 有 效 地 減 緩 術 後 疼 痛 現 象 是 相 當 重 要 的 。 病 人 疼 痛 自 控 止 痛 法 (Patient-Controlled Analgesia ,PCA) 相 較 於 傳 統 肌 肉 注 射 止 痛 法 (Intramuscular
Injection ,IM)更能有效且快速地減緩疼痛現象。本研究應用資料探勘技術,用以預測病 患短期未來之內使用 PCA 裝置之情況。分析的資料來源為彰化基督教醫院,透過麻醉 醫師的協助,我們收集了 1099 筆病患在術後使用 PCA 裝置的記錄。我們做了以下的預 測分析:(1) 麻醉藥劑量預測,(2) PCA 裝置參數設定調整預測。將預測及屬性分析結果 提供給麻醉醫師參考,藉此更了解病患使用 PCA 裝置之情況,而能更有效地為病患減 輕術後疼痛。 關鍵字:病人疼痛自控、資料探勘、類別不平衡、資料清理
ii
Data Mining and Analysis in Patient Controlled Analgesia
Student:Shin-Ru Wu Advisor:Dr. Yuh-Jyh Hu
Department﹙Institute﹚of Computer Science
National Chiao Tung University
ABSTRACT
Effective pain control is particularly important after surgery, as pain can cause significant distress to patients, and affect wound healing. PCA (Patient-Controlled Analgesia) is more effectively and more quickly than IM (Intramuscular Injection) in the management of postoperative pain. By applying data mining techniques, this study aimed to predict the situation that patients using PCA devices in the short-term future. With the assistance of Changhua Christian Hospital, we collected 1099 PCA patient records. We concentrated on two prediction tasks in this study: (1) postoperative analgesic consumption, and (2) PCA setting readjustment. The result of prediction and feature analysis will be available to the anesthesiologist property reference, to better understand the situation of patients using PCA devices, and more effectively reduce postoperative pain for patients.
iii
目 錄
摘 要 ... i ABSTRACT ... ii 目 錄 ... iii 表目錄 ... v 圖目錄 ... vii 一、 序論 ... 1 1.1 背景介紹 ... 1 1.2 研究動機 ... 2 二、 相關方法研究 ... 3 2.1 困難處 ... 3 2.2 學習演算法(learning algorithms) ... 42.2.1 簡單貝氏分類器(Naive Bayes Classifier) ... 4
2.2.2 類神經網路(Artificial Neural Networks ,ANN) ... 4
2.2.3 支援向量機(Support Vector Machines ,SVM) ... 5
2.2.4 決策表(Decision Table)... 6
2.2.5 決策樹(Decision Tree) ... 7
2.2.6 五種學習演算法之優缺點 ... 8
2.3 整體學習演算法(ensemble learning algorithm) ... 9
2.3.1 Bagging and Random Forest ... 10
2.3.2 AdaBoost ... 11
2.3.3 Stacking ... 12
2.4 類別不平衡(class imbalance) ... 14
2.4.1 減少多數類別取樣法(under sampling) ... 17
2.4.2 增加少數類別取樣法(over sampling with replacement) ... 18
2.4.3 DataBoost-IM ... 18 2.4.4 資料清理(data cleaning) ... 21 三、 實驗說明 ... 23 3.1 資料收集 ... 23 3.2 資料前處理 ... 23 3.3 實驗 ... 26 3.3.1 總劑量預測 ... 26 3.3.2 PCA劑量預測 ... 26 3.3.3 PCA裝置參數設定調整預測 ... 27 3.4 評量準則 ... 28 3.4.1 總劑量預測和PCA劑量預測 ... 28 3.4.2 PCA裝置參數設定調整預測 ... 29 3.4.3 檢定方法 ... 30
iv 四、 結果與討論 ... 32 4.1 預測分析 ... 32 4.2 實驗結果與討論 ... 32 4.2.1 五種學習演算法之結果比較 ... 32 4.2.2 整體學習演算法之結果比較 ... 39 4.2.3 屬性分析 ... 47 4.2.4 Lesion study ... 62 五、 結論 ... 72 參考文獻 ... 75
v
表目錄
表 1. 五種學習演算法之優缺點比較 ... 9 表 2. 所有屬性之說明 ... 24 表 3. Confusion Matrix ... 29 表 4. 總劑量預測的評量準則之說明 ... 29 表 5. Confusion Matrix ... 30 表 6. PCA裝置參數設定調整預測的評量準則之說明 ... 30 表 7. 總劑量預測五種演算法之比較 ... 33 表 8. PCA劑量預測五種演算法之比較 ... 34 表 9. PCA裝置調整設定預測分析五種學習演算法之比較,資料未刪除雜訊 ... 34 表 10. PCA裝置調整設定預測分析五種學習演算法之比較,資料未刪除雜訊,搭配減少 多數類別取樣法(under sampling) ... 35 表 11. PCA裝置調整設定預測分析五種學習演算法之比較,資料未刪除雜訊,搭配增加 少數類別取樣法(over sampling) ... 36 表 12. PCA裝置調整設定預測分析五種學習演算法之比較,資料已刪除雜訊 ... 38 表 13. PCA裝置調整設定預測分析五種學習演算法之比較,資料已刪除雜訊,搭配減少 多數類別取樣法(under sampling) ... 39 表 14. PCA裝置調整設定預測分析五種學習演算法之比較,資料已刪除雜訊,搭配增加 少數類別取樣法(over sampling) ... 39 表 15. 總劑量預測分析之結果 ... 41 表 16. PCA劑量預測分析之結果 ... 42 表 17. PCA裝置調整設定預測分析之結果,資料尚未刪除雜訊 ... 45 表 18. PCA裝置調整設定預測分析之結果,資料已刪除雜訊 ... 46 表 19. 學習演算法和整體學習演算法表現較佳者之相互比較 ... 47 表 20. 總劑量預測分析,前五層中出現頻率為前 10 的屬性名稱及該屬性在該層之出現 頻率 ... 54 表 21. 總劑量預測分析,十個最為關鍵之屬性與分數 ... 54 表 22. 總劑量預測分析,contidose屬性和總劑量分類結果之單因子變異數分析 ... 55 表 23. 總劑量預測分析,pcadose屬性和總劑量分類結果之單因子變異數分析 ... 56 表 24. 總劑量預測分析,生理資訊相關屬性與分類結果之相關性分析 ... 56 表 25. PCA劑量預測分析,前五層中出現頻率為前 10 的屬性名稱及該屬性在該層之出 現頻率 ... 57 表 26. PCA劑量預測分析,十個最為關鍵之屬性與分數 ... 57 表 27. PCA劑量預測分析,pcadose屬性和PCA劑量分類結果之單因子變異數分析 ... 58 表 28. PCA劑量預測分析,p_timediff_mean屬性和PCA劑量分類結果之單因子變異數分 析 ... 59 表 29. PCA劑量預測分析,生理資訊相關屬性與分類結果之相關性分析 ... 59 表 30. PCA裝置調整設定預測分析,資料已刪除雜訊,前五層中出現頻率為前 10 的屬vi 性名稱及該屬性在該層之出現頻率 ... 60 表 31. PCA裝置調整設定預測分析,十個最為關鍵之屬性與分數 ... 60 表 32. PCA裝置調整設定預測分析,p_timediff_var屬性和是否調整PCA裝置參數之單因 子變異數分析 ... 61 表 33. PCA裝置調整設定預測分析,pcamode_set屬性和是否調整PCA裝置參數之單因子 變異數分析 ... 62 表 34. PCA裝置調整設定預測分析,生理資訊相關屬性與分類結果之相關性分析 ... 62 表 35. 總劑量預測分析之結果,屬性使用病患之生理資訊及手術相關屬性 ... 64 表 36. 總劑量預測分析之結果,屬性使用病患使用PCA裝置之相關屬性 ... 64 表 37. PCA劑量預測分析之結果,屬性使用病患之生理資訊及手術相關屬性 ... 66 表 38. PCA劑量預測分析之結果,屬性使用病患使用PCA裝置之相關屬性 ... 66 表 39. PCA裝置調整設定預測分析之結果,資料尚未刪除雜訊,屬性使用病患之生理資 訊及手術相關屬性 ... 68 表 40. PCA裝置調整設定預測分析之結果,資料尚未刪除雜訊,屬性使用病患使用PCA 裝置之相關屬性 ... 69 表 41. PCA裝置調整設定預測分析之結果,資料已刪除雜訊,屬性使用病患之生理資訊 及手術相關屬性 ... 70 表 42. PCA裝置調整設定預測分析之結果,資料已刪除雜訊,屬性使用病患使用PCA裝 置之相關屬性 ... 71
vii
圖目錄
圖 1. 具類別不平衡及資料鬆散特性之資料集範例 ... 3 圖 2. 類神經網路之示意圖 ... 5 圖 3. 支援向量機之示意圖 ... 6 圖 4. 決策表之範例 ... 7 圖 5. 根據天氣情況分類「是否適合打網球(PlayTennis)」之決策樹 ... 7 圖 6. 「是否適合打網球(PlayTennis)」決策樹之if-else規則 ... 8 圖 7. Bagging演算法之流程圖 ... 10 圖 8. AdaBoost演算法 ... 12 圖 9. Stacking演算法之流程圖 ... 13 圖 10. Stacking演算法之簡單範例 ... 14 圖 11. 類別不平衡及資料稀疏與學習困難度之相關性探討圖例 ... 17 圖 12. DataBoost-IM演算法 ... 20 圖 13. 資料清理演算法之示意圖例 ... 221
一、 序論
1.1 背景介紹
術後疼痛是一種必然的現象,當病患接受手術後,大多需要一段時間恢復,在這期 間病患必須忍受因為手術造成的疼痛。至於如何讓病患減緩術後疼痛,目前手術後疼痛 控制較好的方式有: (1) 傳統肌肉注射止痛(Intramuscular Injection ,IM),(2) 病人疼痛自 控(Patient-Controlled Analgesia ,PCA)。
傳統肌肉注射止痛(IM)的施用方式為當病患感到疼痛時,須按鈴呼叫麻醉醫師或護 士,經由肌肉注射的方式注射麻醉藥,通常需要花費較長的時間才能達到止痛的效果。 然而病人疼痛自控(PCA),則是透過一台由微電腦控制的裝置。首先將麻醉藥注入藥袋 中,再將藥袋放入 PCA 裝置裡,藉由該裝置控制麻醉藥的注射。當病患感到疼痛時, PCA 裝置可經由病患按壓按鈕的動作,將麻醉藥注射至病患體內,如此便可在較短的時 間內,達到控制術後疼痛的效果。文獻裡提到,使用病人疼痛自控(PCA)比使用傳統肌 肉注射止痛(IM)方式更能有效的達到控制術後疼痛[1,2]。 使用 PCA 裝置並非毫無限制,病患在使用該裝置之前,必須先由麻醉醫師依照病 患的身體狀況,設定適合該病患的麻醉藥劑量和使用該裝置的安全範圍,其中安全範圍
包括「鎖定時間(lockout)」以及「四小時限制(4 hour limit)」兩種設定。「鎖定時間(lockout)」
控制在一定的時間內 PCA 裝置給藥的次數,例如,設定是 10 分鐘,即表示病患在 10 分鐘內,不管做了幾次的按壓動作,PCA 裝置只會給一次的麻醉藥。「四小時限制(4 hour limit)」則是控制在四個小時內,PCA 裝置給藥的總劑量,例如,當其設定是 10ml 時, 即表示 PCA 裝置在四個小時內,只會允許病患被注射 10ml 以內的麻醉藥,若超過該範 圍,PCA 裝置則不給藥。藉由這兩種安全範圍的設定,我們較可確保病患使用病人疼痛 自控(PCA)裝置的安全性。因此,如何設定該裝置的參數以及預測其所影響的麻醉劑量 就益顯重要。 當病患使用 PCA 裝置時,若產生噁心嘔吐的副作用或是無法減輕疼痛等不適的現 象時,醫師必須為病患更改適合該病患的 PCA 裝置參數。為此我們希望透過資料探勘
2 的技術,在病患使用 PCA 裝置的一段時間(例:24 小時)之後,透過病患使用 PCA 的行 為模式,再配合病患的生理資料以及手術相關資料,來預測病患在短期未來之內 (例: 72 小時)所需的麻醉藥劑量為何,以及預測該病患在之後的 PCA 使用上(例:第 24 小時 到第 72 小時)是否需要醫師調整 PCA 裝置的參數。 雖然 PCA 的使用上較方便,但也並非所有病患都適合使用病人疼痛自控止痛法, 因為該方法病患必須透過自行使用 PCA 裝置,所以必須有體力且了解如何操作的病 患才較為適合,像是有癱瘓病症的病患就無法使用。對於年紀較小的兒童,只要了解 操作方式也是適合使用的,在臨床中已有七歲左右的兒童使用該方法改善術後疼痛[3], 不過還是需要麻醉醫師以及護士密切注意因藥物所帶來的副作用。 病人疼痛自控止痛法的目標就是希望透過病患自行控制,在更適合的時候使用麻醉 藥來減輕術後疼痛,如此在術後恢復期間才可以得到更好的休息,且根據一些臨床經 驗,使用病人疼痛自控止痛法的病患所需的麻醉藥劑量大多比使用傳統肌肉注射止痛 (IM)法的所需劑量較少[3]。
1.2 研究動機
此研究的目的,是希望可以透過資料探勘的技術,讓麻醉醫師更能了解病患使用 PCA 裝置的情況,以期更有效的減輕病患的術後疼痛。目前我們完成以下三種預測的分 析:(1)麻醉藥需求總劑量、(2)病患透過按壓 PCA 裝置被注射之麻醉藥需求劑量,和(3) 當病患使用 PCA 裝置一段時間後,是否需要調整 PCA 裝置參數設定。3
二、 相關方法研究
2.1 困難處
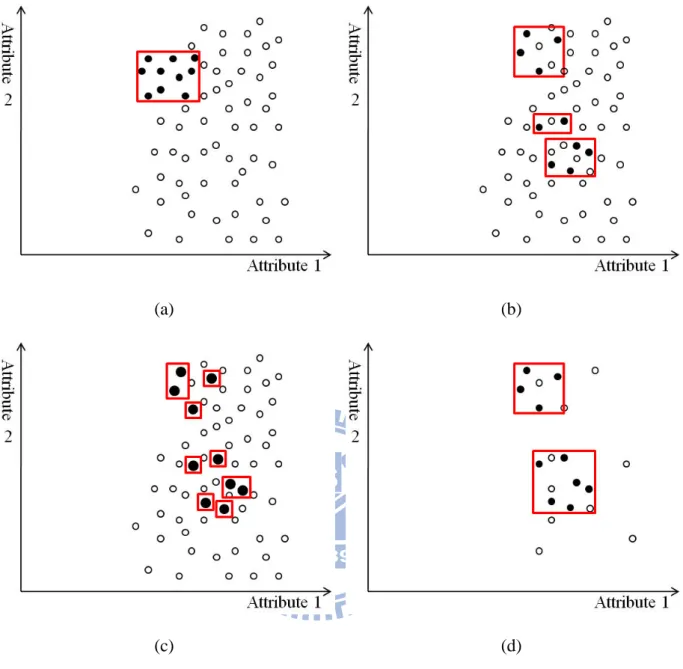
PCA 裝置的按壓與否取決於病患感受到的疼痛程度,但因為疼痛是相當主觀的意 識,因而每個人忍受疼痛的程度有所差異。即使是身體狀況類似的兩個人,對同樣的刺 激也可能有不同疼痛程度的感受,因此,純粹從身體狀況來判斷該病患的 PCA 使用情 況是相當困難的。此外,就 PCA 裝置參數設定調整的預測分析而言,只有少數的病患 在使用該裝置一段時候,PCA 裝置的參數需要被調整,因此我們尚須面對類別不平衡 (class imbalance)的問題,以本篇論文的資料來看,只有 18.9%的病患需要調整 PCA 裝置參數設定。另外,資料中有相當多的雜訊(noise),我們將少數需要調整參數設定的病患 以 1967 年 J. B. MacQueen 提出的 k-means 演算法[4]作分群,再以各群質心為圓心,該 群所有資料中距質心最遠的資料之距離為半徑,發現多數不需要被調整參數設定的病患 有 99.875%都在以此圓心半徑畫出來的邊界之內,如圖 1 所示,由此可看出我們的資料 是相當稀疏的,這些因素更增加了預測工作的困難度。 圖 1. 具類別不平衡及資料鬆散特性之資料集範例 白色的點為多數不需要調整參數設定的病患,黑色的點為少數需要調整參數設定的病患。將少數需要調 整參數設定之病患即黑色點做分群,圓圈為分群後以各群質心為圓心,距質心最遠的資料之距離為半徑 畫出之邊界。多數不需要調整參數設定的病患有 99.875% 都在其邊界之內,可看出資料是相當稀疏的。
4
2.2 學習演算法(learning algorithms)
首先,我們使用幾個資料探勘常見的學習演算法,包括決策樹(Decision Tree)、貝氏 分類器(Bayesian Classifier)、類神經網路(Artificial Neural Networks ,ANN)[7]、支援向量 機(Support Vector Machines ,SVM)和法則歸納法(Rule Induction)。
決策樹使用 Ross Quinlan 發展的 C4.5 演算法[5],貝氏分類器使用簡單貝氏分類器 (Naive Bayes Classifier)[6],支援向量機使用 Chih-Jen Lin 等人發展的 LIBSVM[8],法則
歸納法使用決策表(Decision Table)[9]。
2.2.1 簡單貝氏分類器(Naive Bayes Classifier)
貝氏分類器以貝氏定理(Bayesian Theorem)為基礎,是一種基於統計機率所發展的演 算法,假設有n個屬性X1,X2,...,Xn,t個類別值c1,c2,…,ct,要判斷一筆資料x=(x1,x2,…,xn) 的類別為何,是根據事後機率p(cj|x)來判定,而此機率的計算方式如下: (2.1) 由式(2.1),可以得到以下 (2.2) 若有一類別值ci滿足 (2.3) 則x的類別值就會被判定為ci 而簡單貝氏分類器[ 。 6],是假設在類別值給定的條件下,屬性間彼此互相獨立,在此 假設下,可將式(2.2)轉變成 (2.4) 再利用式(2.3),就可以得到 x 的類別值。
2.2.2 類神經網路(Artificial Neural Networks ,ANN)
5
從外界環境或者其它類神經元取得資訊,並加以簡單的運算,再輸出其結果至外界環境 或者其它類神經元。其主要結構是由神經元(neuron)、層(layer)和網路(network)三個部份 所組成。分為輸入層(Input layer)、輸出層(Output layer)和隱藏層(Hidden layer),如圖 2, 三層連結型成一個神經網路,其中輸入層只從外部環境接收資訊,不做任何計算,只將 資訊傳遞至下一層,而輸出層則是只將資訊輸出至外部環境。而分析計算部分均在隱藏 層完成,隱藏層介於輸入層和輸出層之間,提供類神經網路處理神經元間的交互作用與 問題的內在結構的能力。各層之間的各個神經元之間的連結都有其權重,例如,圖 2 的輸入層的I1和隱藏層的H2之間的連結,其權重記為wi1,h2。類神經網路即是希望透過簡 單的函數計算所有連結之權重。當有未知資料須判定類別時,即可利用已計算出之權重 得到輸出類別為何。 圖 2. 類神經網路之示意圖
2.2.3 支援向量機(Support Vector Machines ,SVM)
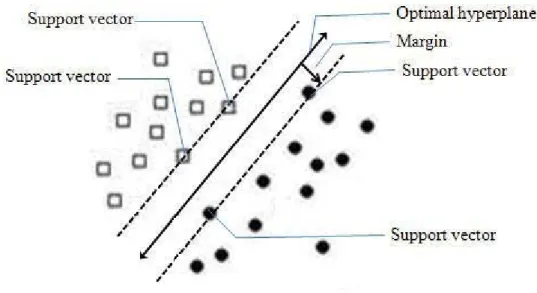
支援向量機[8]是以統計學習理論(Statistical Learning Theory)為基礎發展出來的分類 方 法 。 概 念 為 在 一 群 在 多 維 空 間 中 的 資 料 , 希 望 能 在 該 空 間 中 找 出 一 個 超 平 面 (Hyperplane),使得屬於兩個類別的資料可藉此超平面區分開來。超平面和兩個類別距
離最近的點之間稱為邊界(Margin),SVM 即是希望找出邊界最大之超平面,即為最佳超 平面(Optimal Hyperplane),如此可明確的區隔兩個類別的資料,如圖 3。而最靠近最佳 超平面之資料稱之為支援向量(Support Vector)。當有未知資料須判定類別時,即是計算
6
該未知資料與最佳超平面之關係,以判定該資料之類別。
圖 3. 支援向量機之示意圖
2.2.4 決策表(Decision Table)
法則歸納法(rule induction)是一種由多個 if-else 規則對資料進行細分的技術,在一系 列有意義的規則中,顯示資料蘊含的關聯性。例如,零售業者可以瞭解百分之七十的顧 客於購買真皮牛仔褲後,均購買塑膠皮帶,因此這兩者間有其一定之關連性,可稱之為 法則。瞭解法則之存在,有助於知道顧客與產品之特質,然而並非每一項法則均有其實 用價值,資料之實用性與否仍須視企業性質而定。 在實際應用上,如何界定該法則是否有實用價值是最大的問題,通常會先將資料中 發生次數太少的項目先予以刪除。利用法則試圖找出最佳特徵值,將包含此特徵值的資 料全部找出來並加以聚合形成一個子集合,反覆執行直到該子集合中的每一個記錄都屬 於同一類別為止,即為所謂的法則歸納法。 而決策表[9]為法則歸納法中其中一種演算法,是透過表格的方式檢視所有條件以及 動作,以找出有實用價值之法則,圖 4 為一決策表之範例,此為印表機故障時的處理方 法決策表,表格上方為印表機故障的條件,下方為排除故障之動作,例如,當印表機無 法列印(Printer dose not print)且紅色警示燈閃爍(A red light is flashing)時,可檢查或更換 墨水匣(check/replace ink)和檢查紙匣(check for paper jam)。
7 圖 4. 決策表之範例
2.2.5 決策樹(Decision Tree)
在這五種學習演算法中,其中決策樹[5]是以樹狀結構為基礎的分類方法,其優點在 於可以轉換成易於了解的決策法則,相較於支援向量機、類神經網路等其它學習演算 法,決策樹具有較高的可讀性,並且可表示為多個 if-else 的規則,圖 5 為一決策樹之範 例 , 這 棵 決 策 樹 根 據 天 氣 情 況 分 類 「 是 否 適 合 打 網 球 (PlayTennis) 」, 例 如 : < Outlook=Sunny,Temperature=Hot,Humidity=High,Wind=Strong >,會被這棵決策樹判 定為 PlayTennis=No,此一決策樹的 if-else 規則如圖 6。決策樹在文獻中已經被證明在 實務應用上是可以運作的,例如: 1993 年加州理工學院噴氣推進實驗室與天文學家合 作開發 SKICAT 系統,成功幫助天文學家發現遙遠的星體[10]以及 1995 年 Lehnert 等人 利用決策樹來做醫療系統上的文字分類(text classification)[11]。 圖 5. 根據天氣情況分類「是否適合打網球(PlayTennis)」之決策樹8 圖 6. 「是否適合打網球(PlayTennis)」決策樹之 if-else 規則
2.2.6 五種學習演算法之優缺點
表 1 為以上五種演算法之優缺點比較,這五種演算法均有分類速度快之優點,簡單 貝氏分類器的訓練速度快,可是該演算法須符合屬性彼此之間需為獨立關係之假設,但 在實務應用上此假設通常不存在,且該演算法無法直接處理連續值之屬性,需假設該屬 性符合常態分配(normal distribution)或是對該連續值之屬性做分類,轉成離散值才可處 理。類神經網路的應用相當廣泛,但訓練時是利用迭代的方式,所以計算量相當大,在 訓練上需要花費較多的時間,而且在訓練時,無法預知需要幾層隱藏層以及多少神經元 為最佳。支援向量機在訓練和分類速度上都很快,但它對雜訊相當的敏感,在求解時會 限制所有訓練資料一定能找出超平面予以切開,因此在執行前使用者需先給定一誤差參 數放寬該限制,此參數對結果通常會有很大的影響。決策表可整理出易懂的 if-else 規則, 有較高之可讀性,但在眾多法則中,如何界定何者才為實用之法則是有其困難的,且該 演算法需要較長的訓練時間,且該演算法也不易處理連續值之屬性。決策樹的優勢在於 有相當高的可讀性,可轉成易懂的 if-else 規則,也可從決策樹中挑選出較為關鍵之屬性, 且訓練和分類速度都快,但是當類別過多時,決策樹的準確度會降低。 因此,為保持預測準確度與預測結果可讀性之間的平衡,我們採用以決策樹為基礎9 的學習演算法,作為資料探勘的工具。 表 1. 五種學習演算法之優缺點比較 學習演算法 訓練 速度 可讀性 處理連續值之 屬性 表達屬性間之 相互關係 缺點 簡單貝氏分 類器 快 低 需作離散化處 理 無 屬性間需為獨立關 係。 類神經網路 慢 低 易 可 隱藏層和神經元數 目須先設定。 支援向量機 快 低 易 無 需先給定一誤差參 數。 決策表 慢 高 需作離散化處 理 可 界定何者為實用法 則有其困難處。 決策樹 快 高 需作離散化處 理 無 類別過多時分類準 確度下降。
2.3 整體學習演算法(ensemble learning algorithm)
整體學習演算法(ensemble learning algorithm)的運作是透過多次執行弱學習演算 法,並且針對每次產生的分類規則進行投票,最後整合投票的結果,透過多次執行可以 整合多個弱學習演算法,使其等價於一個強學習演算法。
1999 年,Bauer & Kohavi 的實驗研究[12]中,說明了使用以決策樹為基礎的整體學
習演算法會比使用單一的弱學習演算法來的準確,其中兩種常見的整體學習演算法有 bagging[13]和 boosting[14]兩種,其中 bagging 是利用不同的訓練資料集合產生不同的分
類規則,最後以投票的方式整合不同的分類規則;而 boosting 則是在每次的迭代中,更 新所有資料的權重,提高分類錯誤的資料權重,反之降低分類正確的資料權重,最後則 以有權重的投票方式整合每次迭代中產生的分類規則。
10
2.3.1 Bagging and Random Forest
1996 年 Breiman 提出 bagging(bootstrap aggregating)方法[13],它是採用投票表決的
方式結合多個分類規則,每個分類規則雖使用相同的學習演算法,但均使用不同的訓練 資料集合,所以每個分類規則彼此之間都有著些許差異。此演算法的流程圖如圖 7,利 用重複取樣(sampling with replacement)的方式產生多組訓練資料集合。例如,原始訓練 資料(training data)若有 n 筆資料,即對該原始訓練資料做 n 次的重複取樣,如此就可產 生一組訓練資料(training data 1),重複此取樣動作 m 次,最後會產生 m 組訓練資料 (training data 1~training data m),其中每一組訓練資料都可以訓練出一棵決策樹,如此就
可產生 m 棵決策樹(decision tree 1~decision tree m),最後,將測試資料(testing data)透過 m 棵決策樹產生 m 個分類結果,再以多數決投票的方式得到最終分類結果。
圖 7. Bagging 演算法之流程圖
2002 年,Breiman 提出 random forest[15],其與 bagging[13]差異之處在於訓練方式
的不同,在利用訓練資料產生決策樹時,bagging 使用的是全部的屬性,而 random forest 則隨機挑選出 M 個屬性,換言之,每一棵決策樹除了使用的訓練資料集合不同之外, 用以訓練決策樹的屬性也不盡相同,根據 Breiman 的建議,M 的值應為屬性數量的平方 根[16]。由於決策樹具高度敏感性,只要訓練資料有些微的不同,其所產生的決策樹就 會有很大的差異。因此,在產生一個決策樹的集合時,我們希望這些決策樹的相異性越 大越好,藉此,該決策樹的集合才能覆蓋包含更多的資訊,就此 random forest 除了強調 訓練資料的差異外,再加上屬性選擇上的差異,以期得到差異性更大的決策樹集合,讓
11 學習演算法可以涵蓋更多的資訊。
2.3.2 AdaBoost
1996 年 Freund 和 Schapire 提出 AdaBoost[17]演算法,AdaBoost 為 boosting 方法中
常被使用的演算法。Boosting 為整體學習演算法中常見的方式之一,boosting 的想法是 透過不斷的迭代執行之後,將一個原本屬於弱學習的演算法,使用有權重的投票機制輸 出結果,透過這樣的機制,不僅可以改善分類的準確度,並可以等價於一個強學習的演 算法。AdaBoost 演算法中,每一筆資料都有其權重,在每一次的迭代(iteration)執行之後, 會更新所有資料的權重,其中,分類錯誤的資料權重會增加,反之分類正確的資料則會 降低其權重,透過這樣的方式,讓學習演算法更重視那些被分類錯誤的資料,以提高分 類的準確度。 AdaBoost 的演算法如圖 8,輸入為 m 筆訓練資料,一個弱學習演算法(WeakLearn) 和最多迭代次數 T,每一筆訓練資料均被預設有相同之權重,進入第一次的迭代使用弱 學習演算法,計算該次分類錯誤率,若錯誤率大於 1/2 則離開迴圈,反之則需利用 計算 ,若 越大,表示該次分類錯誤的程度越高,並利用該值和此次 該筆資料分類正確與否來更新所有資料之權重, 為一小於 1 之數值,因此透過 此公式更新完權重後,會降低分類正確的資料權重, 分類錯誤的資料則會被提高權重。更新完所有資料的權重後,即進入第二次的迭代,會 依照目前的資料權重使用弱學習演算法,因此,弱學習演算法會較為重視在之前的迭代 中被分類錯誤的資料,因為在之前的迭代中被分類錯誤的資料權重會較分類正確的資料 高,直到此次迭代的錯誤率大於 1/2 或是迭代次數等於輸入的最多迭代次數 T 為止即離 開迴圈,最終分類結果是由每一次迭代的分類結果來投票,但每次分類結果的投票權重 並非相等,若該次迭代的分類錯誤率越低,即有越高的投票權重,最後透過有權重的投 票機制得到最終分類結果。
12
Algorithm AdaBoost
Input:sequence of m examples {(x1,y1),…,(xm,ym)} with labels yi Y={1,…,k}
Weak learning algorithm WeakLearn
integer T specifying number of iterations Initialize D1
Do for t=1,2,…,T:
(i)=1/m for all i.
1. Call WeakLearn, providing it with the distribution Dt
2. Get back a hypothesis h
.
t
3. Calculate the error of h
:X → Y.
t: .
If > 1/2, then set T=t-1 and abort loop.
4. Set
5. Update distribution Dt:
,where Zt is a normalization constant (chosen so that Dt+1
Output the final hypothesis:
will be a
distribution).
圖 8. AdaBoost 演算法
2.3.3 Stacking
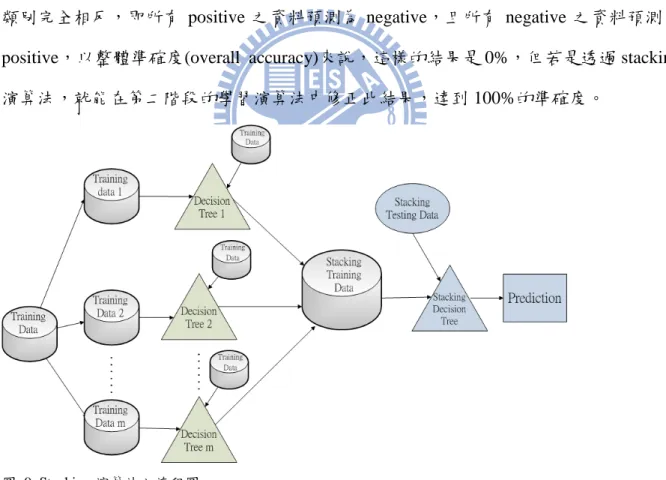
Stacking[18]和 bagging、boosting 不同的地方在於,stacking 可以另一方式整合不同
的學習演算法(例如:決策樹、支援向量機等)的預測結果,圖 9 為 stacking 演算法之流 程圖。以決策樹為例,在產生 m 棵決策樹後,再利用此 m 棵決策樹對訓練資料所做的 預測結果,加以整理完成新的訓練資料(stacking training data)。
13
我們以圖 10 作為一個 stacking 的簡單範例,此範例為根據天氣情況分類「是否適
合打網球(PlayTennis)」,(a)有七筆訓練資料和(b)兩筆測試資料,利用重複取樣的方式產
生五棵決策樹,訓練資料分別利用這五棵決策樹產生五個分類結果。(c)接著則以此分類 結果當作新的訓練資料(stacking training data)之屬性,類別則為原始訓練資料之類別,以 D1 為例,五棵決策樹的分類結果分別為 Yes、Yes、Yes、No 和 No,則這五個分類結果
即為新的訓練資料之屬性,而 D1 原始的類別為 No,所以該資料之類別即為 No;(d)新 的測試資料(stacking testing data)亦然,利用五棵決策樹產生的五個分類結果為屬性,而 其類別即為我們要預測之值。
與 bagging 或 boosting 相較,stacking 的優勢在於其利用兩階段的模式整合不同的預 測結果。舉一較極端之範例,若原使用一階段的整體學習演算法的分類結果和資料正確 類別完全相反,即所有 positive 之資料預測為 negative,且所有 negative 之資料預測為 positive,以整體準確度(overall accuracy)來說,這樣的結果是 0%,但若是透過 stacking
演算法,就能在第二階段的學習演算法中修正此結果,達到 100%的準確度。
14 (a) 訓練資料(Training data)
Day Outlook Temperature Humidity Wind Play Tennis
D1 Sunny Hot High Weak No
D2 Sunny Hot High Strong No
D3 Overcast Hot High Weak Yes
D4 Rain Mild High Weak Yes
D5 Rain Cool Normal Weak Yes
D6 Rain Cool Normal Strong No
(b) 測試資料(testing data)
Day Outlook Temperature Humidity Wind Play Tennis
D7 Overcast Cool Normal Weak Yes
D8 Sunny Mild High Weak No
(c) 新的訓練資料(stacking training data) Day Decision Tree 1 Decision Tree 2 Decision Tree 3 Decision Tree 4 Decision Tree 5 Play Tennis
D1 Yes Yes Yes No No No
D2 Yes No Yes Yes Yes No
D3 No No No No Yes Yes
D4 No No Yes No No Yes
D5 Yes No No No No Yes
D6 Yes No No Yes Yes No
(d) 新的測試資料(stacking testing data) Day Decision Tree 1 Decision Tree 2 Decision Tree 3 Decision Tree 4 Decision Tree 5 Play Tennis
D7 Yes No Yes No No Yes
D8 Yes Yes No Yes Yes No
圖 10. Stacking 演算法之簡單範例
2.4 類別不平衡(class imbalance)
資料探勘在實務的應用上,經常會出現類別不平衡(class imbalance)[19]的問題,此 問題指的是大多數的資料都屬於某一類別,稱之為多數類別(majority class),其數量遠大 於另一類別,此則稱為少數類別(minority class)。然而在日常生活中,我們比較關注的 通常是比較少發生的現象。這些比較少發生的現象大多是比較有趣或重要的,例如:詐 欺偵測(fraud detection)[20]以及漏油偵測(oil spill detection)[21]等兩種類別不平衡之實務 上都是在偵測少數發生的現象。15
在傳統的學習演算法中,對於在學習類別不平衡的資料時,通常會傾向預測為多數 類別(majority class)而忽略了少數類別(minority class),這樣的預測傾向,雖然可以有很 高的多數類別準確度,但少數類別的準確度往往會嚴重降低。而且在大多數的領域中, 少數類別通常是比較被關注的,因此在遇到類別不平衡的資料時,我們希望可以透過一 些方法來改善少數類別的準確度。
過去的文獻中,已提出一些方法來解決類別不平衡的問題,像是 1997 年 Kubat 等 人提出的減少多數類別取樣法(under-sampled examples of the majority class)[22]、1998 年 Ling 等人提出的增加少數類別取樣法(over-sampled examples of the minority class)[23]、
2002 年 Chawla 等人提出的結合減少多數類別和增加少數類別取樣法(over-sampled the
minority class and under-sampled the majority class)[24]、1997 年 Cardie 和 Howe 提出的增
加少數類別之資料權重,使其學習演算法傾向於少數類別[25]、2002 年 Joshi 等人利用 boosting 演算法分類少數類別[26]和 2004 年 Guo 和 Viktor 發展的 DataBoost-IM 演算法,
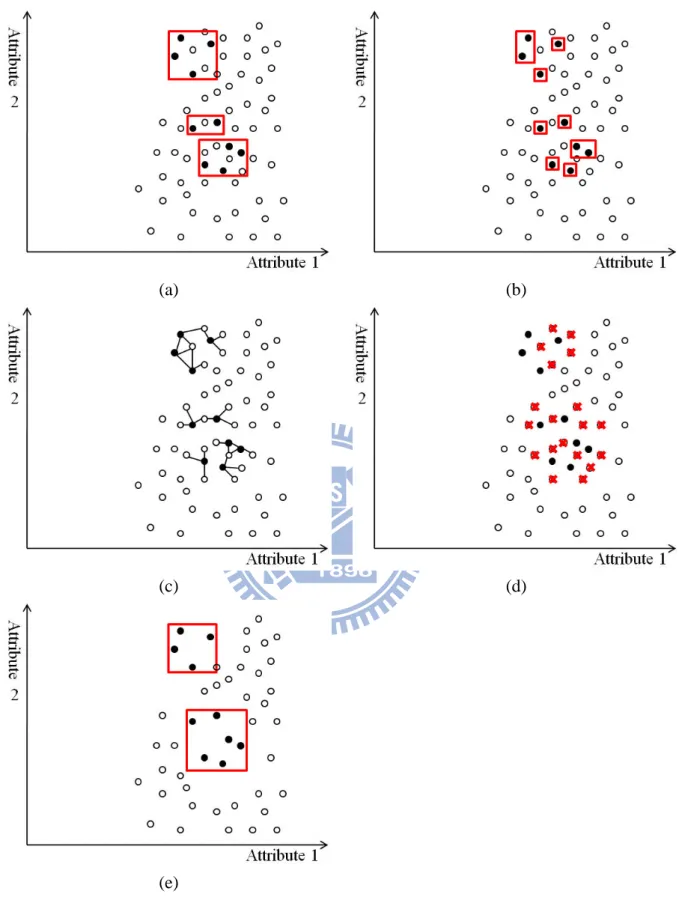
其為整合 boosting 以及產生虛擬資料來提升少數類別的分類準確度[27]等方法。而在此 研究中,我們採用了減少多數類別取樣法、增加少數類別取樣法和 DataBoost-IM。 在一般類別不平衡的資料中,若資料分佈如圖 11(a),少數類別(minority class)的資 料以黑色點表示,白色點則代表多數類別(majority class)之資料,雖然有類別不平衡之問 題,不過兩種類別的資料可被明顯區隔,使用減少多數類別取樣法和增加少數類別取樣 法即可提高少數類別的準確率。但若是資料除了有類別不平衡的問題之外,資料的分佈 還相當的稀疏,如圖 11(b)所示,資料分佈相當稀疏,長方框為其少數類別資料之判定 區間(decision region),可看出框內亦有多數類別之資料,兩種類別之間的邊界相當模 糊。使用傳統解決類別不平衡問題之方法,減少多數類別取樣法和增加少數類別取樣法 後,平衡兩種類別的資料量,希望藉此使得兩種類別彼此的邊界更為明顯,但在分佈相 當稀疏的資料中,圖 11(c)為使用增加少數類別取樣法之示意圖,可以看出在取樣後, 少數類別之判定區間會較為縮小,區間內的多數類別資料也會減少,但文獻中提到,在 使用決策樹學習演算法時,此法會造成少數類別被分割成較多之區塊[24],對決策樹而 言,將資料分割成越多區塊,會造成決策樹的深度越深而有越多的葉子(leaf node),因
16 而產生過度適應(overfitting)的問題。而使用減少多數類別取樣法如圖 11(d),挑選多數類 別的資料直到數量和少數類別資料量相同為止,但因為挑選多數類別的資料是採用隨機 挑選的方式,從圖 11(d)可看出,兩種類別的資料數量雖然相同,但兩種類別之間還是 無法被明顯的區隔開來,少數類別資料的判定區間內依舊會有多數類別之資料。 除了上述的取樣方法外,在文獻中,亦有使用 k-nearest-neighbor 演算法來做例外偵 測(outlier detection)[28,29],而且如 2.1 所述,因為本篇論文所使用的資料雜訊(noise)過 多,兩種類別的資料是相當稀疏且重疊的,因此我們利用 k-nearest-neighbor 來做資料清 理(data cleaning),刪除部分多數類別的資料,除了可以平衡兩種類別的資料數目外,也 希望類別彼此的邊界更為明顯,讓學習演算法更能區分兩種類別。 而在我們的研究中,大多數的病患在使用 PCA 裝置設定後,都是不需要再調整參 數設定的,只有少部分的病患會有噁心嘔吐等副作用或是無法減輕疼痛的狀況而需要調 整參數,以本篇論文的資料來看,只有 18.9%的病患需要被調整參數設定,因此,在 PCA 裝置參數設定調整的預測分析上,我們會面臨到類別不平衡(class imbalance)的問題,希 望透過減少多數類別取樣法、增加少數類別取樣法或資料清理的方式藉以改善此問題。
17
(a) (b)
(c) (d)
圖 11. 類別不平衡及資料稀疏與學習困難度之相關性探討圖例
說明:白色點為多數類別(majority class),黑色點為少數類別(minority class),長方框為少數類別資料之判 定區間(decision region)。(a) 兩種類別之間有明顯邊界。(b) 兩種類別之間的邊界模糊。 (c) 對(b)進行增 加少數類別取樣法(over sampling),較大的黑色點表示該資料被重複取樣。(d) 對(b)進行減少多數類別取 樣法(under sampling)。
2.4.1 減少多數類別取樣法(under sampling)
減少多數類別取樣法(under-sampled examples of the majority class)[22]的演算法,在 做重複取樣產生訓練資料集合時,分別對兩種類別作取樣,利用降低取樣多數類別的次 數,來減少多數類別的資料數量,以期平均兩種類別的資料數目。例如,多數類別(majority class)的資料有 80 筆,而少數類別(minority class)有 20 筆資料,在使用減少多數類別取
18
樣法時,降低取樣多數類別的次數,僅對多數類別取樣 20 次,取樣完成後,多數類別 和少數類別的資料筆數會是平衡的狀態。
2.4.2 增加少數類別取樣法(over sampling with replacement)
增加少數類別取樣法(over-sampled examples of the minority class)[23],在做重複取樣 產生訓練資料集合時,則是透過重覆取樣的方式提高少數類別的取樣量來增加少數類別 的資料數量,以此平衡兩種類別的資料數量。例如,多數類別(majority class)的資料有 80 筆,而少數類別(minority class)有 20 筆資料,若使用增加少數類別取樣法,重覆少數 類別的取樣次數到 80 次,在取樣完成後,多數類別和少數類別的資料數量則可達到相 同。 減少多數類別取樣法和增加少數類別取樣法不同的地方在於,前者為降低取樣多數 類別的次數,而後者則是提高少數類別的取樣次數。除此之外,兩種演算法的取樣方式 也 略 為 不 同 , 減 少 多 數 類 別 取 樣 法 的 取 樣 方 式 為 取 出 不 放 回 (sampling without replacement),即取樣過的資料不可放回被再次取樣,表示同一筆資料最多只會被取樣一
次,而增加少數類別取樣法的取樣方式則是取出放回(sampling with replacement),表示 資料即使已被取樣過,下次取樣依舊是從全部的資料進行取樣,表示同一筆資料有可能 被取樣兩次以上。兩種方式都是希望可以透過改變取樣次數的方式,平衡兩種類別的資 料個數,讓學習演算法可以由等量的兩種類別資料中學習,以期提高分類的準確度。
2.4.3 DataBoost-IM
2004 年 Guo 和 Viktor 提出 DataBoost-IM[27]演算法,DataBoost-IM 為一整合 boosting
以及產生虛擬資料(data generation)之演算法,其 boosting 的部分和 2.3.2 提到的 AdaBoost 相同,每一筆資料都有其權重,在每一次的迭代(iteration)執行之後,會更新所有資料的 權重,其中,分類錯誤的資料權重會增加,反之分類正確的資料則會降低其權重。除了 針對分類正確與否更新資料的權重外,DataBoost-IM 也結合了產生虛擬資料(data generation)的想法,透過產生虛擬資料來平衡兩種類別的資料數量,並且是針對資料權
19 類錯誤的資料類似。希望透過這樣的方式,除了平衡兩種類別的資料量外,也可以讓學 習演算法更專注在那些被分類錯誤的資料上。 DataBoost-IM 的 演算 法如圖 12 ,輸入為 m 筆訓練資料 ,一個 弱學習演算法 (WeakLearn)和最多迭代次數 T,每一筆訓練資料均被預設有相同之權重,進入迭代後, 分別判斷各個類別的 hard examples,即為資料中權重較高者,意指先前迭代中被分類錯 誤之資料。各類別以各自的 hard examples 為基礎,分別產生虛擬資料(synthetic data)以 平衡各個類別之資料量。虛擬資料(synthetic data)加上原始的訓練資料(original training set)產生新的訓練資料(new training data set)。分別更新各個類別的資料權重,更新後各
個類別的資料權重總合均為相等,目的是希望學習演算法不會傾向預測任一類別。針對 新 的 訓 練 資 料 (new training data set) 和 更 新 後 的 資 料 權 重 使 用 弱 學 習 演 算 法 (WeakLearn),計算該次分類錯誤率,若錯誤率大於 1/2 則離開迴圈,反之則需利用 計算 ,若 越大,表示該次分類錯誤的程度越高,並利用該值和此次 該筆資料分類正確與否來更新所有資料之權重, 為一小於 1 之數值,因此透過 此公式更新完權重後,會降低分類正確的資料權重, 分類錯誤的資料則會被提高權重。更新完所有資料的權重後,即進入下一次的迭代,會 依照目前的資料權重重新判斷 hard examples 以產生虛擬資料。因此,弱學習演算法會 較為重視在之前的迭代中被分類錯誤的資料,因為在之前的迭代中被分類錯誤的資料權 重會較分類正確的資料高,直到此次迭代的錯誤率大於 1/2 或是迭代次數等於輸入的最 多迭代次數 T 為止即離開迴圈,最終分類結果是由每一次迭代的分類結果來投票,但每 次分類結果的投票權重並非相等,若該次迭代的分類錯誤率越低,即有越高的投票權 重,最後透過有權重的投票機制得到最終分類結果。
20
Algorithm DataBoost-IM
Input:sequence of m examples {(x1,y1),…,(xm,ym)} with labels yi Y={1,…,k}
Weak learning algorithm WeakLearn
integer T specifying number of iterations Initialize D1
Do for t=1,2,…,T:
(i)=1/m for all i.
1. Identify hard examples from the original data set for different classes.
2. Generate synthetic data to balance the training knowledge of different classes.
3. Add synthetic data to the original training set to form a new training data set.
4. Update and balance the total weights of the different classes in the new training
data set.
5. Call WeakLearn, providing it with the new training set with synthetic data and
rebalanced weights.
6. Get back a hypothesis ht:X → Y.
7. Calculate the error of ht: .
If > 1/2, then set T=t-1 and abort loop.
8. Set
9. Update distribution Dt:
,where Zt is a normalization constant (chosen so that Dt+1 Output the final hypothesis:
will be a distribution).
21
2.4.4 資料清理(data cleaning)
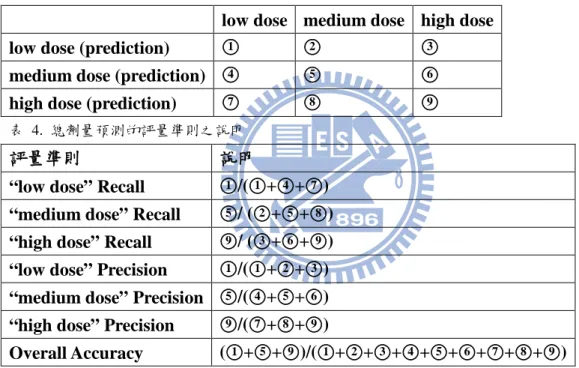
有鑑於相同類別的資料通常較為靠近,我們使用 k-nearest-neighbor 演算法來做資料 清理(data cleaning),若是某一筆資料附近的資料類別都與其類別相異的話,該筆資料極 可能為雜訊(noise)。同時因為 PCA 資料有類別不平衡的問題,所以我們以少數類別 (minority class)的資料為基準,找出離每個少數類別資料最近之 k 筆資料,其距離乃是使用歐幾里得距離(Euclidean distance),在這 k 筆資料中,類別若為多數類別(majority class)的資料即視為雜訊,在檢查過所有較少類別的最近之 k 筆資料後,我們將所有被視 為雜訊之資料予以刪除。透過這樣的方式,兩種類別之間的邊界會更為明顯,就學習演 算法而言,將更能區分兩種類別,以提高分類之準確度。 圖 13 為該演算法之範例,(a)為未做資料清理的原始資料,白色點為多數類別而黑 色點為少數類別之資料,長方框為少數類別資料之判定區間(decision region),可看出有 不少的多數類別資料在區間內,(b)可以透過縮小判定區間的方式,降低區間內多數類別 的資料,但這會造成過度適應(overfitting)的問題,(c)因此,我們利用 k-nearest-neighbor 演算法,當 k=3 時,我們以所有少數類別的資料為基準,找出距離該資料最近之 3 筆資 料,(d)在這 3 筆資料中,若是類別為多數類別者則以 x 記號被標記為雜訊,(e)為刪除所 有被標記為雜訊後之資料。從圖 13(a)及(e)的比較可以看出,在原始資料中,兩種類別 的資料交錯無法明顯區隔,但在刪除雜訊後,兩種類別資料之間的邊界已較為明顯。我 們並且比較圖 13(b)及(e),兩者少數類別的判定區間內都僅有少數的多數類別資料,但 (e)的判定區間明顯比(b)來得大,因此,可以降低造成過度適應(overfitting)的可能性。
22
(a) (b)
(c) (d)
(e)
圖 13. 資料清理演算法之示意圖例
說明:白色點為多數類別(majority class),黑色點為少數類別(minority class),長方框為少數類別資料之判 定區間(decision region)。(a)原始資料。(b) 縮小少數類別之判定區間。 (c)以所有少數類別的資料為基準, 找出距離該點最近之 k 筆資料,k=3。(d) 這 k 筆資料中,類別為多數類別的資料即為雜訊,劃 x 者為所 有被標記為雜訊之資料。(e) 刪除所有被定義為雜訊的資料。
23
三、 實驗說明
實驗分成三個部分,包括總劑量預測、PCA 劑量預測和 PCA 裝置參數設定調整預 測。 針對總劑量預測的部分,我們目前是參考病患前 24 小時的 PCA 使用行為及其基本 生理資料與病歷,用以預測該病患於 72 小時後,其使用的麻醉藥總劑量,這其中包括 了病患透過按壓 PCA 裝置所注射的麻醉藥以及經由點滴被注射的麻醉藥。我們將總劑 量之多寡概分為三類:低劑量(low dose)、一般劑量(medium dose)、高劑量(high dose)。 而 PCA 劑量預測一樣是參考病患前 24 小時的 PCA 使用行為及其基本生理資料與病歷, 但僅僅是預測病患於 72 小時後,透過按壓 PCA 裝置所注射的麻醉藥劑量,相同地,我 們依照劑量之多寡概分為三類:低劑量(low dose)、一般劑量(medium dose)、高劑量(high dose)。至於 PCA 裝置參數設定調整預測,則是以病患前 24 小時的 PCA 使用行為及其基本生理資料與病歷等,預測病患在爾後的 48 小時內,其 PCA 裝置參數的設定是否應 該調整。
3.1 資料收集
此 篇論文所 使用 的資料庫 來自 於彰化基督教醫院,Changhwa Christian Hospital (CCH),2005~2010 的病患使用 PCA 裝置的資料。
3.2 資料前處理
彰化基督教醫院 2005~2010 使用 PCA 裝置總共有 5432 位病患,刪除因 PCA 裝置 暫存空間不足而毀損之檔案後剩餘 4632 位病患,之後再刪除資料庫中無病歷資料之病 患後剩餘 2586 位病患,此外若該病患的病歷資料不完整的比例太高者也將其刪除,最 後可用資料總共有 2207 位病患,其中使用超過 24 小時的病患有 1655 位,而有 1099 位 病患使用 PCA 裝置超過 72 小時。 每一位病患使用 PCA 裝置的狀況不盡相同,所以實驗需要病患的性別和年齡等生 理資料、手術類別和手術時間等手術相關屬性、單位小時成功按壓次數和單位小時失敗 按壓次數等使用 PCA 裝置的情況以及 PCA 裝置參數的設定,像是單位小時的鎖定時間24
(lockout)設定等做為預測的依據。從彰化基督教醫院的資料庫中,我們根據病患的病歷
和使用 PCA 裝置的記錄檔整理出以下的屬性。 每一位病患總共會有 280 個屬性,其中包含了
a. 病患生理資料:BP_HIGH,BP_LOW,PULSE,WEIGHT, SEX, age, DM, HT, AMI,
共 9 個屬性。
b. 手術相關屬性:OP_CLASS, ansTimediff, ASA_TYPE1, ASA_TYPE2,
M1_ANS_WAY, APS,共 6 個屬性。
c. 使用 PCA 情況相關屬性:success_p_1hr~24hr,
failure_p_1hr~24hr,pcadose_1hr~24hr, change_times_1hr~24hr,
p_timediff_mean_1hr~24hr, p_timediff_var_1hr~24hr 共 144 個屬性。
d. PCA 設定相關屬性:loadingdose , contidose _1hr~24hr,pamode_set_1hr~24hr,
pcadose_set_1hr~24hr, lockout_set_1hr~24hr, 4hrlimit_set_1hr~24hr,共 121 個屬
性。 表 2 為所有屬性之詳細說明。 表 2. 所有屬性之說明 屬性名稱 屬性說明 BP_HIGH 收縮壓 BP_LOW 舒張壓 PULSE 心跳 WEIGHT 體重 OP_CLASS 手術的分類 (例如:開膛手術、上腹手術、下腹手術、泌尿系統手術、 主要關節手術、皮膚手術等) ansTimeDiff 手術進行時間 ASA_TYPE1 1:健康 2:輕度全身性疾病 3:重度全身性疾病 4:危及生命的狀況或疾病 5:死亡機率極高之狀況或疾病 6:器官移植
1: healthy 2: mild systemic disease. 3: major systemic disease. 4. life threatening disease or condition. 5. not expect to survive. 6. donor
25 ( transplatation ).
ASA_TYPE2 手術類型
E:緊急手術、R:一般手術
E(emergency surgery), R(regular surgery)
M1_ANS_WAY 手術麻醉方式 SA:半身、GA:全身、LE:腰椎硬脊膜外麻醉、NB:神經阻斷 APS 是否在術前接受 PCA SEX 性別 age 年齡 DM 是否患有糖尿病 HT 是否患有高血壓 AMI 是否心肌哽塞 loadingdose 病患在手術後但使用 PCA 裝置之前所被注射的麻醉藥劑量 success_p 單位小時成功按壓次數 成功按壓意指病患該次按壓動作為可被接受的,PCA 裝置會替病患注 射麻醉藥。 failure_p 單位小時失敗按壓次數 失敗按壓意指病患該次按壓動作為不可接受的,可能違反「lockout」 或是「4hrlimit」,PCA 裝置判定不替病患注射麻醉藥。 pcadose 單位小時病人經由按壓 PCA 裝置方式被注射的麻醉藥劑量 contidose 單位小時病人經由點滴方式被注射的麻醉藥劑量 change_times 單位小時 PCA 裝置設定調整次數 p_timediff_mean 單位小時按壓時間差的平均 p_timediff_var 單位小時按壓時間差的變異數
pcamode_set 單位小時 pca mode 設定
PCA:僅透過按壓 PCA 裝置方式被注射麻醉藥。 CONTINUOUS:僅透過點滴方式被注射麻醉藥。
CONTINUOUS+PCA:可透過按壓 PCA 裝置和點滴方式被注射麻醉 藥。
pcadose_set 單位小時 pca dose 設定
pca dose 設定意指病患每次按壓 PCA 裝置,若被判定為成功按壓,PCA 裝置會替病患注射的麻醉藥劑量。
lockout_set 單位小時 lockout 設定
lockout 意指病患該次按壓與下次按壓需間隔時間。 4hrlimit_set 單位小時 4hrlimit 設定
26
3.3 實驗
3.3.1 總劑量預測
總劑量預測的主要目的為病患使用 PCA 裝置一段時間之後,透過病患使用 PCA 的 行為模式,再配合病患的生理資料等,來預測病患在短期未來之內所需麻醉藥劑量的多 寡程度。我們想要預測病患使用 PCA 裝置的 72 小時期間所注射的麻醉藥總劑量,其中 包括了透過按壓 PCA 裝置以及經由點滴方式所注射的麻醉藥。在該預測分析上,總計 有 1099 筆可用資料,由於要預測的內容為病患使用 PCA 裝置 72 小時的麻醉藥總劑量, 因此病患需要使用 PCA 裝置超過 72 小時,該資料才可用於此預測分析。我們依照總劑 量多寡將所有資料分為三個區間,各區間麻醉藥總劑量的標準差類似,表示三種類別的 資料離散程度相似,將其分為低劑量(low dose)、一般劑量(medium dose)和高劑量(high dose),其中低劑量的資料數量為 399 筆,而一般劑量為 551 筆,高劑量的資料數量較少,只有 149 筆。而在屬性的選擇上,我們使用了病患的生理資料以及手術相關屬性。除此 之外,由於疼痛是相當主觀的,即使是相同身體狀況的兩人在疼痛的感受上也會有所差 異,因此單純的從身體狀況來進行預測分析是相當困難的,所以除了上述屬性外,我們 也將病患使用 PCA 裝置 24 小時期間的單位小時使用 PCA 情況和 PCA 設定相關屬性用 於此預測分析。學習演算法的部分,我們會比較決策樹(C4.5)、簡單貝氏分類器(Naive Bayes Classifier)、類神經網路(Artificial Neural Network ,ANN)、支援向量機(Support
Vector Machine ,SVM)和決策表(Decision Table)五種學習演算法,其中除了決策樹(C4.5)
以外,均是使用 WEKA[30]做為實驗的工具。而在整體學習演算法(ensemble learning algorithm)的部分,基於分類規則可讀性、學習速度以及預測準確度之考量下,我們以決
策樹(C4.5)為基礎演算法,搭配 bagging、random forest、bagging + stacking、random forest + stacking 和 Adaboost 共五種整體學習演算法,並加以比較分析。
3.3.2 PCA 劑量預測
PCA 劑量預測和總劑量預測類似,一樣在病患使用 PCA 裝置一段時間之後,透過
27
裝置注射的麻醉藥劑量多寡程度,和總劑量預測不同的地方在於,總劑量預測是預測病 患經由點滴方式和透過按壓 PCA 裝置注射的總麻醉藥劑量多寡,而 PCA 劑量預測僅針 對病患透過按壓 PCA 裝置注射的麻醉藥劑量做預測。我們利用病患的生理資料和手術 相關屬性以及病患使用 PCA 裝置 24 小時期間的單位小時使用 PCA 情況和 PCA 設定相 關屬性,用以預測病患使用 PCA 裝置 72 小時的 PCA 劑量多寡程度。因此,病患需使 用 PCA 裝置超過 72 小時,該資料才為可用資料,因此和總劑量預測相同,總計會有 1099 筆可用資料。我們依照 PCA 劑量多寡將所有資料分為三個區間,各區間麻醉藥總劑量 的標準差類似,表示三種類別的資料離散程度相似,將其分為低劑量(low dose)、一般劑 量(medium dose)和高劑量(high dose),其中低劑量的資料數量為 580 筆,而一般劑量為 373 筆,高劑量的資料數量較少,只有 146 筆。
學習演算法的部分,和總劑量預測相同,我們先比較決策樹(C4.5)、簡單貝氏分類 器(Naive Bayes Classifier)、類神經網路(Artificial Neural Network ,ANN)、支援向量機 (Support Vector Machine ,SVM)和決策表(Decision Table)五種學習演算法,其中除了決策
樹(C4.5)以外,均是使用 WEKA[30]做為實驗的工具。而整體學習演算法(ensemble learning algorithm)的部分,以決策樹(C4.5)為基礎演算法,搭配 bagging、random forest、
bagging + stacking、random forest + stacking 和 Adaboost 共五種整體學習演算法,並加以
比較分析。
3.3.3 PCA 裝置參數設定調整預測
PCA 裝置參數設定調整預測的目的則是在病患使用 PCA 裝置一段時間之後,透過
病患使用 PCA 的行為模式,再配合病患的生理資料等,來預測病患在之後的 PCA 使用 上是否需要醫師調整 PCA 裝置的參數。我們使用了病患的生理資料和手術相關屬性, 以及病患使用 PCA 裝置 24 小時內的單位小時的使用 PCA 情況和 PCA 設定相關屬性, 來預測病患在使用 PCA 裝置第 25 小時到第 72 小時之間,PCA 裝置參數設定是否被調 整。和上述三種預測分析相同,因為是預測病患使用 PCA 裝置 72 小時的情況,所以病 患需使用 PCA 裝置超過 72 小時才可用於此預測分析,可用資料有 1099 筆。我們依照
28 PCA 裝置是否被調整將全部資料分為兩類,其中「未做調整」(negative)的資料有 891 筆,而「有做調整」(positive)的資料僅 208 筆,「未做調整」之資料遠大於「有做調整」 之資料,兩者資料的比例為 0.79:0.21,因此在該預測分析上,有類別不平衡(class imbalance)之問題。 同於上述三種預測分析,我們比較決策樹(C4.5)、簡單貝氏分類器(Naive Bayes Classifier)、類神經網路(Artificial Neural Network ,ANN)、支援向量機(Support Vector
Machine ,SVM)和決策表(Decision Table)五種學習演算法,其中除了決策樹(C4.5)以外,
均是使用 WEKA[30]做為實驗的工具。在此預測分析因有類別不平衡的問題,因此我們 以減少多數類別取樣法(under sampling)和增加少數類別取樣法(over sampling)兩種改變 取樣次數之演算法,搭配上述五種學習演算法。除此之外,我們會利用 k-nearest-neighbor 演算法刪除資料中的雜訊(noise),對資料進行資料清理(data cleaning),藉此方式平衡兩 種類別的資料數量,以提昇分類的準確度。
而整體學習演算法(ensemble learning algorithm)的部分,以決策樹為基礎,使用了 bagging、random forest、bagging + stacking、random forest + stacking 和 AdaBoost 和
DataBoost-IM 五種整體學習演算法,因為在該預設分析上有類別不平衡的問題,所以搭
配了減少多數類別取樣法(under sampling)和增加少數類別取樣法(over sampling),因此除 上述五種整體學習演算法外,還使用了 bagging + over sampling、bagging + under sampling、AdaBoost + over sampling、AdaBoost + under sampling 和 DataBoost-IM 五種方
法,共十種整體學習演算法。除此之外,也使用 k-nearest-neighbor 演算法對資料進行資 料清理(data cleaning),以刪除資料中的雜訊,藉此改善類別不平衡之問題。
3.4 評量準則
3.4.1 總劑量預測和 PCA 劑量預測
總劑量和 PCA 劑量兩種預測分析均使用了 1099 位病患,都是依據麻醉藥劑量的多 寡程度將所有病患分為三個區間,各區間麻醉藥總劑量的標準差類似,意即三類資料的 麻醉藥總劑量離散程度相似,將其分為低劑量(low dose)、一般劑量(medium dose)和高劑29
量(high dose)。在這兩種預測分析中,我們使用整體準確度(overall accuracy)做為主要評 量準則,除此之外,也以各類別的 recall 和 precision 做為評量準則。整體準確度(overall accuracy)為所有資料中,預測正確的比率。各類別的 recall 和 precision 的計算公式如表 3
和表 4,recall 意指在該類別中預測正確的比率,例如,”low dose” Recall 表示類別為 低劑量(low dose)的資料中,有多少比率的資料被預測正確;而 precision 表示被預測為 該類別的資料中,原始類別確實為該類別的比率,例如,”medium dose” Precision 表 示被預測為一般劑量(medium dose)的資料中,其中原始類別亦為一般劑量的資料比率為 何。
表 3. Confusion Matrix
low dose medium dose high dose low dose (prediction) ○1 ○2 ○3
medium dose (prediction) ○4 ○5 ○6
high dose (prediction) ○7 ○8 ○9
表 4. 總劑量預測的評量準則之說明
評量準則 說明
“low dose” Recall ○1 /(○1 +○4 +
“medium dose” Recall
○7 )
○5 / (○2 +○5 +
“high dose” Recall
○8 )
○9 / (○3 +○6 +
“low dose” Precision
○9 )
○1 /(○1 +○2 +
“medium dose” Precision
○3 )
○5 /(○4 +○5 +
“high dose” Precision
○6 ) ○9 /(○7 +○8 + Overall Accuracy ○9 ) (○1 +○5 +○9 )/(○1 +○2 +○3 +○4 +○5 +○6 +○7 +○8 +
3.4.2 PCA 裝置參數設定調整預測
○9 ) 在 PCA 裝置設定調整的預測分析中,由於大多數病患在 PCA 的初次設定之後不再 需要重新調整,因此容易產生預測類別不平衡的問題,例如,在過去的文獻中[31,32]指 出,當資料有類別不平衡的問題時,若只使用整體準確度(overall accuracy)來做為評量準 則是不合理的。例如,多數類別(majority class)的資料筆數佔全數的 95%,而少數類別 (minority class)僅佔全數的 5%,倘若學習演算法將全數預測為多數類別,則其準確度可 高達 95%,然而在此情況之下,所有少數類別的資料都被分類錯誤。在一個分類相當不 平衡的資料中,我們有時更為關注少數類別的資料,因為它們通常俱備特殊意義,因此30
在有類別不平衡問題的資料中,少數類別的預測準確度才是我們想要改善的重點。就 此,我們除了使用整體準確度(overall accuracy)以及各類別的 recall 和 precision 作為參考 之外,在該預測分析上,我們增加了幾何平均(geometric mean)[33]和 F-score[34]作為評 量準則,其中幾何平均為 positive recall 和 negative recall 的幾何平均。各評量準則之詳 細計算方式如表 5 和表 6。
表 5. Confusion Matrix
Positive Negative
Positive(prediction) True Positive(TP) False Positive(FP)
Negative(prediction) False Negative(FN) True Negative(TN)
表 6. PCA 裝置參數設定調整預測的評量準則之說明 評量準則 說明 Positive Recall TP/(TP+FN) Positive Precision TP/(TP+FP) Positive F-score Negative Recall TN/(FP+TN) Negative Precision TN/(TN+FN) Negative F-score Geometric Mean Overall Accuracy (TP+TN)/(TP+FP+FN+TN)
3.4.3 檢定方法
在上述三種預測分析中,總劑量預測和 PCA 劑量預測是以整體準確度(overall accuracy) 為 主 要 評 量 準 則 , PCA 裝 置 參 數 設 定 調 整 預 測 因 為 有 類 別 不 平 衡 (classimbalance)之問題,若使用整體準確度為主要評量準則會有不合理之情況,應以少數類
別的預測準確值為其主要改善之重點,而在 PCA 資料中,僅少數病患在 PCA 初始設定 後,需要重新調整設定,因此「有做調整」(positive)為少數類別(minority class),故此預 測分析是以 positive F-score 為其主要評量準則。
在總劑量預測、PCA 劑量預測和 PCA 裝置參數設定調整預測上,三種預測分析皆 會比較決策樹(C4.5)、簡單貝氏分類器(Naive Bayes Classifier)、類神經網路(Artificial
31
Neural Network ,ANN)、支援向量機(Support Vector Machine ,SVM)和決策表(Decision
Table)五種學習演算法,比較方式是以五種學習演算法中表現最好之演算法為基準,使
用 paired t-test 檢定,比較該演算法和其餘四種學習演算法之差異,若其差異之 p-value 小於 0.05,即認為兩者演算法之準確值有顯著差異,以此方式比較五種學習演算法。而 整體學習演算法(ensemble learning algorithm)的部分,一樣會以所有整體學習演算法中表 現最好之演算法為基準,與其餘之整體學習演算法以 paired t-test 檢定,藉此得知個別演 算法之準確值彼此間的差異性。
而在 PCA 裝置調整預測分析上,我們以 k-nearest-neighbor 演算法刪除雜訊(noise), 對資料進行資料清理(data cleaning),希望藉此方式改善類別不平衡的問題。為檢測資料 清理對個別演算法預測類別不平衡之資料是否有幫助,我們會針對相同的演算法,包含 五種學習演算法以及十種整體學習演算法,以 paired t-test 檢定,比較未作資料清理和已 作資料清理之結果,若已作資料清理之表現優於未作資料清理之結果,且其差異之 p-value 小於 0.05,則表示資料清理對該演算法而言,確實可達到改善之效果。
32
四、 結果與討論
4.1 預測分析
我們希望可以透過資料探勘的技術,讓麻醉醫師更能了解病患使用 PCA 裝置的情 況,以期更有效的減輕病患的術後疼痛。因此透過總劑量預測、PCA 劑量預測以及 PCA 裝置參數設定調整預測三種預測分析,希望可以提供給麻醉醫師更多病患使用 PCA 裝 置的資訊,譬如,若是預測病患的麻醉藥需求為高劑量,但目前使用的劑量設定較低, 可能表示未來該病患會有較多的麻醉藥需求,或是若病患被預測為需要做 PCA 設定的 調整,表示該病患在未來可能會有噁心嘔吐等副作用或是無法減輕疼痛等不適的現象, 可以提醒麻醉醫師需要特別注意該病患的狀況。4.2 實驗結果與討論
實驗結果的部分,都是採用 10-fold 交叉驗證(cross validation)法,評估各方法的優 劣,而在 bagging 和 random forest 兩種整體學習演算法(ensemble learning algorithm)或是 以這兩者搭配其他演算法(stacking、under sampling 和 over sampling)之方法時,例如, bagging + stacking 或 random forest + under sampling 整體學習演算法時,在每次實驗中我
們會透過重複取樣以產生 200 組訓練資料,並做十次的 10-fold 交叉驗證求其平均。 而在評量準則的選擇上,總劑量預測分析和 PCA 劑量預測分析是以整體準確度 (overall accuracy)為主要評量準則。在 PCA 裝置參數設定調整預測分析上,由於多數病
患不需要參數調整,因此有類別不平衡(class imbalance)的問題,不適合使用整體準確度 作為主要評量準則,其中我們以 positive class 作為少數類別(minority class),意即 positive class 的病患需要 PCA 參數的調整。因此,我們以 positive F-score 和幾何平均(geometric
mean)做為主要的評量準則。
4.2.1
五種學習演算法之結果比較
我們針對獨立的學習演算法,使用決策樹(C4.5)、簡單貝氏分類器(Naive Bayes Classifier)、類神經網路(Artificial Neural Network ,ANN)、支援向量機(Support Vector
33
Machine ,SVM)和決策表(Decision Table)五種學習演算法,比較在兩種預測分析上,各學
習演算法在預測準確值上之表現,並加以分析結果。
4.2.1.1 總劑量預測
總劑量預測五種學習演算之結果如表 7,其中表現最好之演算法為決策表(Decision Table),我們將決策表和其餘四種學習演算法的結果作 paired t-test 檢定,若其差異之
p-value 小於 0.05,則在表 7 該演算法上以星號”*”標記之,而 p-value 小於 0.001 者,
會於表 7 該演算法上標記”〒”,表示該演算法和決策表之結果有顯著差異。 表 7. 總劑量預測五種演算法之比較
總劑量預測(%) C4.5 Naive Bayes ANN SVM Decision Table
“low dose” Recall 77.4* 79.0〒 69.8 8.0〒 74.9
“medium dose” Recall 72.8〒 67.7〒 79.6 96.1〒 78.9
“high dose” Recall 60.6〒 38.0〒 21.6〒 0.0〒 48.3
“low dose” Precision 76.3 71.8〒 80.2* 59.4〒 75.6
“medium dose” Precision 73.5* 70.2〒 66.1〒 50.6〒 72.4
“high dose” Precision 62.8〒 46.3〒 56.9* 0.0〒 73.4
Overall Accuracy 72.8 67.9〒 68.5〒 50.7〒 73.3
註:與 Decision Table 之比較:* 表示 p-value < 0.05,〒表示 p-value < 0.001。
4.2.1.2 PCA 劑量預測
PCA 劑量預測五種學習演算之結果如表 8,簡單貝氏分類器(Naive Bayes)為其中表
現最好之演算法,我們將簡單貝氏分類器和其餘四種學習演算法的結果作 paired t-test 檢定,以星號”*” 在表 8 上標記差異之 p-value 小於 0.05 之演算法,並以”〒”標記 差異之 p-value 小於 0.001 之演算法,表示該演算法和簡單貝氏分類器之結果有顯著差異。
34 表 8. PCA 劑量預測五種演算法之比較
PCA 劑量預測(%) C4.5 Naive Bayes ANN SVM Decision Table
“low dose” Recall 76.9〒 81.4 89.2* 99.9〒 82.8
“medium dose” Recall
*
51.5〒 48.1 19.1〒 0.0〒 42.3
“high dose” Recall
〒
45.4〒 50.8 8.4〒 0.0〒 26.8
“low dose” Precision
〒
76.1 75.4 62.0〒 52.8〒 68.4 “medium dose” Precision
〒
51.2〒 55.6 20.7〒 0.0〒 49.1
“high dose” Precision
〒
49.3* 51.2 22.8〒 0.0〒 54.4
Overall Accuracy 64.1 65.4 54.7〒 52.7〒 61.1
註:與 Naive Bayes 之比較:* 表示 p-value < 0.05,〒表示 p-value < 0.001。 〒
4.2.1.3 PCA 裝置參數設定調整預測
表 9 為五種學習演算法針對 PCA 裝置參數設定調整預測分析之結果,其中表現最 好的為簡單貝氏分類器(Naive Bayes),我們利用 paired t-test 檢定比較簡單貝氏分類器 (Naive Bayes)和其餘四種學習演算法結果之差異,若其差異之 p-value 小於 0.05,則在表
9 該演算法上以星號”*”標記之若小於 0.001 則以”〒”標記,表示該演算法和簡單貝
氏分類器(Naive Bayes)的結果有顯著差異。
從表 9 可以看出,單一的學習演算法在該預測分析上表現大多不佳,明顯受到類別 不平衡(class imbalance)問題之影響,預測結果大多傾向於預測多數類別(negative class), 其中類神經網路(ANN)和支援向量機(SVM)在少數類別(positive class)的表現最差,幾乎 是全數預測為多數類別(negative class)。
表 9. PCA 裝置調整設定預測分析五種學習演算法之比較,資料未刪除雜訊
PCA 裝置調整設定預測(%) C4.5 Naive Bayes ANN SVM Decision Table
Positive Recall 25.5〒 65.8 0.0〒 0.0〒 0.8 Positive Precision 〒 25.4* 23.6 0.0〒 1.0〒 4.8 Positive F-score 〒 25.2〒 34.5 0.0〒 0.1〒 1.3 Negative Recall 〒 82.5〒 49.7 100.0〒 100.0〒 99.0 Negative Precision 〒 82.6〒 86.2 81.1〒 81.1〒 81.0 Negative F-score 〒 82.5〒 62.7 89.5〒 89.5〒 89.1 Geometric Mean 〒 45.8〒 56.6 0.0〒 0.2〒 3.2 Overall Accuracy 〒 71.7〒 52.7 81.1〒 81.1〒 78.9
註:與 Naive Bayes 之比較:* 表示 p-value < 0.05,〒表示 p-value < 0.001。 〒


![圖 10. Stacking 演算法之簡單範例 2.4 類別不平衡(class imbalance) 資料探勘在實務的應用上,經常會出現類別不平衡(class imbalance)[19]的問題,此 問題指的是大多數的資料都屬於某一類別,稱之為多數類別(majority class),其數量遠大 於另一類別,此則稱為少數類別(minority class)。然而在日常生活中,我們比較關注的 通常是比較少發生的現象。這些比較少發生的現象大多是比較有趣或重要的,例如:詐 欺偵測(fraud detecti](https://thumb-ap.123doks.com/thumbv2/9libinfo/8736120.203123/23.892.117.815.116.833/不平衡在實務不平衡類別其數量遠於另一類則稱較少少發生現象大多.webp)