國立臺中教育大學教育測驗統計研究所理學碩士論文
指導教授:郭伯臣 博士
半監督式線性區別分析應用於
高維度資料分類
A Novel Semisupervised Linear Discriminant
Analysis for High Dimensional Data Classification
研 究 生:朱 慧 珊 撰
謝 辭
感謝每個在我生命中留下身影的人。 曾經以為只要告別青澀的學生生活,進入教育職場工作就可以邁向寬廣的 人生,但無預期的我又再次回到學生的生活,時光飛逝,轉眼間研究所的生活 即將隨著碩士論文的完成而告一個段落。回想這三年來的日子,內心真是百感 交集,縱然有千言萬語,但要下筆寫謝辭之際卻是躊躇再三,早已斑駁的回憶, 經過時間的沈澱與醞釀,如今再次咀嚼已有了不同的風味。 這本論文的誕生,最要感謝的人莫過於恩師郭伯臣教授,無論是在學業或 是在生涯方面,感謝老師的提攜與指導,在專業領域上,其相關知識的傳授、 研究方式的指引及論文寫作的架構上,都給了學生莫大的幫助;在人生規劃上, 老師積極的鼓勵學生繼續升學,平日也不忘叮嚀待人處事的道理,許多的諄諄 教誨,學生都將謹記在心。 由衷感謝張志永教授、陶金旭教授與楊晉民教授,能在所務繁忙之餘願意 抽空擔任學生的口試委員,針對學生研究不足之處,在提供寶貴建議的同時又 不忘加以鼓勵,讓學生獲益匪淺。感謝助教政軒學長,給予程式撰寫的協助與 研究經驗的分享;感謝慧珉學姊、暄博學長、育隆學長、智為學長、筱倩學姊、 佳樺學姊、鈞翔學長、文俊學長、志勝學長、士勛學長、仁傑學長等,在研究 期間的照顧;感謝怡伶、辰育、鎧誌、敏嫻、淑瑜、俊彥、韋任、偉民、宗恩、 芷寧等同學及學弟學妹們,有你們的陪伴,使得原本應該枯燥無味的研究生活 變得生動有趣;感謝K 研究團隊歷屆所有成員們留下的豐富資訊。 感謝曾經一起相處的室友,在我最低潮時伸出友誼的雙手;最後感謝家人 的支持,讓我可以無後顧之憂的完成我的學業;更加感謝妹妹在成長過程中的 真情相伴,而今我將帶著許多祝福及對許多人的感謝,朝向下一座山頭邁進。 朱慧珊 謹致於臺中教育大學教育測驗統計研究所 中華民國 一○○ 年 六 月摘 要
在高光譜遙測影像辨識中,特徵萃取經常扮演著重要的角色。線性區別分析 (Linear Discriminant Analysis, LDA)是一種常見用來減緩Hughes現象的特徵萃取 技術。近年來的研究顯示結合空間資訊之演算法皆能大幅提升高光譜影像辨識的 結果,所以在進行高光譜影像辨識時,不能只考慮光譜資訊而忽略空間資訊的重 要性。非監督式線性區別分析(Unsupervised Linear Discriminant Analysis, UFLDA) 主要是用模糊C-均值(Fuzzy c-means, FCM)隸屬度的概念來修改LDA的組間與組 內分散矩陣的一種特徵萃取法。因此,本研究依據馬可夫隨機域(Markov Random Field, MRF)中鄰居系統的概念取得半監督式樣本,針對未知的樣本運用MRF的概 念或依不同分類器的特性來分別定義UFLDA中的隸屬度,提出一個結合LDA與 UFLDA的特徵萃取演算法,將此以空間資訊搭配光譜資訊的方法命名為半監督式 線性區別分析(Semisupervised Linear Discriminant Analysis, SLDA)。SLDA主要是 利用半監督式樣本來促進LDA的效能,藉由增加樣本數來修正特徵萃取的方向, 使辨識正確率能更為提升。在實驗設計中,本研究所提的方法將分別與半監督式 區別分析(Semisupervised Discriminant Analysis, SDA)及半監督式局部費雪區別分 析(SEmisupervised Local Fisher discriminant analysis, SELF)做比較,其結果顯示, 本研究提出的方法相較於其他半監督式特徵萃取法,在有限的小樣本下,大致上 能獲得較好的辨識效果。
Abstract
Feature extraction often play an important role in hyperspectral image classification. Linear Discriminant Analysis is a commonly used feature extraction techniques to solve Hughes phenomenon. In recent years studies have shown that the algorithm with spatial information can significantly improve classification of hyperspectral images, so a hyperspectral image classification, can not only consider the spectral information and ignores the importance of spatial information. Unsupervised Form Linear Discriminant Analysis was used in Fuzzy c-means membership value of the concept, to modify the linear discriminant analysis of between-calss scatter matrix and within-class scatter matrix of a feature extraction method. Therefore, this study first-order Markov Random Field in the concept of neighborhood systems to get semisupervised samples for these unknown samples, respectively, according to the MRF concept and characteristics of different classifiers to define Unsupervised Linear Discriminant Analysis of the degree of membership value, make a combination of Linear Discriminant Analysis with Unsupervised Linear Discriminant Analysis method, such that the form feature extraction algorithm combining spectral information with spatial information, and this method is named Semisupervised Linear Discriminant Analysis, The method is mainly used semisupervised sample for the performance of linear discriminant analysis, by increasing the number of samples to correct the direction of feature extraction, the recognition accuracy can be more improved. The experiment, Semisupervised Linear Discriminant Analysis with Semisupervised Discriminant Analysis and SEmisupervised Local Fisher discriminant analysis to compare, the results show that the method proposed in this study compared with other
semisupervised feature extraction, small sample size limited, generally to ensure a more better classification results.
Keyword : Hughes phenomenon, Feature Extraction, Markov Random Field,
目 錄
第一章 緒論 --- 1 第一節 研究動機 --- 1 第二節 研究目的 --- 2 第三節 章節架構 --- 3 第二章 文獻探討 --- 4 第一節 特徵萃取 --- 4 壹、線性區別分析...4 貳、非監督式線性區別分析...5 參、半監督式特徵萃取...8 一、半監督式區別分析...8 二、半監督式局部費雪區別分析...10 第二節 馬可夫隨機域 --- 12 第三節 分類器 --- 14 壹、高斯分類器...14 貳、k 最近鄰分類器 ...15 參、支撐向量機...16 第三章 半監督式線性區別分析 --- 19 第一節 鄰居系統結合空間資訊之線性區別分析 --- 20 第二節 後驗機率結合空間資訊之線性區別分析 --- 22 壹、高斯分類器...22 貳、k 最近鄰分類器 ...23 第四章 實驗設計 --- 25 第一節 資料描述 --- 25 壹、高光譜影像資料...25 貳、教育測驗資料...27 第二節 實驗描述 --- 30 第三節 實驗流程 --- 32第五章 實驗結果 --- 34
第一節 Indian Pines Site 資料集 --- 34
壹、鄰居系統結合空間資訊之線性區別分析...34 貳、後驗機率結合空間資訊之線性區別分析...38 第二節 Washington DC Mall 資料集--- 45 壹、鄰居系統結合空間資訊之線性區別分析...45 貳、後驗機率結合空間資訊之線性區別分析...48 第三節「擴分、約分」單元資料集--- 55 第四節「扇形」單元資料集--- 56 第六章 結論與建議 --- 57 第一節 研究結論 --- 57 第二節 研究建議 --- 58 參考文獻 --- 59 附錄 A:「擴分、約分」單元--- 65 附錄 B:「扇形」單元--- 69
表 目 錄
表4-1 Indian Pines Site 影像各類別所含有圖素...26
表4-2 Washington DC Mall 影像...27
表4-3「擴分、約分」單元的錯誤概念分類表...28
表4-4「擴分、約分」單元資料集實驗設計...29
表4-5「扇形」單元的錯誤概念分類表...29
表4-6「扇形」單元資料集實驗設計...30
表5-1 為在 Indian Pines Site 的資料集上不同特徵萃取法搭配三種單一分類器在三個 case 下的最高分類正確率 ...35
表5-2 為在 Indian Pines Site 的資料集上 GC 及 1NN 分別搭配不同特徵萃取法在三個 case 下的最高分類正確率...39 表5-3 為在 Washington DC Mall 的資料集上不同特徵萃取法搭配三種單一分類器在三 個case 下的最高分類正確率...45 表5-4 為在 Washington DC Mall 的資料集上 GC 及 1NN 分別搭配不同特徵萃取法在三 個case 下的最高分類正確率...49 表5-5「擴分、約分」單元的平均分類正確率...55 表5-6「扇形」單元的平均分類正確率...56
圖 目 錄
圖1-1 Hughes phenomenon...2 圖2-1 說明 LFDA 和 PCA 的例子...10 圖2-2 非正規化圖像資訊,S 的鄰居系統...13 圖2-3 由左到右分別為一階、二階及三階鄰居系統...13 圖3-1 為 MRF 中鄰居系統的一階及二階示意圖 ...20 圖3-2 二階鄰居系統隸屬程度示意圖...21 圖3-3 高斯分類器運作的示意圖...23 圖3-4 k 最近鄰分類器運作的概念圖 ...24圖4-1 Indian Pines Site 影像...26
圖4-2 Indian Pines Site 的 ground truth 影像...26
圖4-3 Washington DC Mall 影像...27
圖4-4 Washington DC Mall 人工定義類別影像...27
圖4-5 研究架構示意圖...32
圖5-1 圖(a)-(d)為 Indian Pines Site 資料集在 case1 中,分別使用不同的特徵萃取法來搭 配任一分類器的thematic maps。 ...36
圖5-2 圖(a)-(d)為 Indian Pines Site 資料集在 case2 中,分別使用不同的特徵萃取法來搭 配任一分類器的thematic maps。 ...37
圖5-3 圖(a)-(d)為 Indian Pines Site 資料集在 case3 中,分別使用不同的特徵萃取法來搭 配任一分類器的thematic maps。 ...37
圖5-4 圖(a)-(d)為 Indian Pines Site 資料集在 case1 中,分別使用不同特徵萃取法來搭配 高斯分類器的thematic maps。 ...40
圖5-5 圖(a)-(d)為 Indian Pines Site 資料集在 case2 中,分別使用不同特徵萃取法來搭配 高斯分類器的thematic maps。 ...41
圖5-6 圖(a)-(d)為 Indian Pines Site 資料集在 case3 中,分別使用不同特徵萃取法來搭配 高斯分類器的thematic maps。 ...42
圖5-7 圖(a)-(d)為 Indian Pines Site 資料集在 case1 中,分別使用不同特徵萃取法來搭配 kNN 分類器的 thematic maps。... 43 圖5-8 圖(a)-(d)為 Indian Pines Site 資料集在 case2 中,分別使用不同特徵萃取法來搭配
kNN 分類器的 thematic maps。... 43 圖5-9 圖(a)-(d)為 Indian Pines Site 資料集在 case3 中,分別使用不同特徵萃取法來搭配
kNN 分類器的 thematic maps。... 44 圖5-10 圖(a)-(d)為 Washington DC Mall 資料集在 case1 中,分別使用不同的特徵萃取
法來搭配任一分類器的thematic maps。 ...47
圖5-11 圖(a)-(d)為 Washington DC Mall 資料集在 case2 中,分別使用不同的特徵萃取 法來搭配任一分類器的thematic maps。 ...47
圖5- 12 圖(a)-(d)為 Washington DC Mall 資料集在 case3 中,分別使用不同的特徵萃取 法來搭配任一分類器的thematic maps。 ...48
圖5-13 圖(a)-(d)為 Washington DC Mall 資料集在 case1 中,分別使用不同特徵萃取法 來搭配高斯分類器的thematic maps。 ...51
圖5-14 圖(a)-(d)為 Washington DC Mall 資料集在 case2 中,分別使用不同特徵萃取法 來搭配高斯分類器的thematic maps。 ...51
圖5-15 圖(a)-(d)為 Washington DC Mall 資料集在 case3 中,分別使用不同特徵萃取法 來搭配高斯分類器的thematic maps。 ...52
圖5-16 圖(a)-(d)為 Washington DC Mall 資料集在 case1 中,分別使用不同特徵萃取法 來搭配 kNN 分類器的 thematic maps。...53
圖5-17 圖(a)-(d)為 Washington DC Mall 資料集在 case2 中,分別使用不同特徵萃取法 來搭配 kNN 分類器的 thematic maps。...54
圖5-18 圖(a)-(d)為 Washington DC Mall 資料集在 case3 中,分別使用不同特徵萃取法 來搭配 kNN 分類器的 thematic maps。...54
符 號 說 明
N 訓練樣本個數 i N 第i類的樣本數 X 所有樣本點 i j x 第i類第 j個樣本 j x 第j個樣本
i q x N xi的q個鄰近點 ) (k i x 樣本的第 k 個最近鄰 i 衡量樣本的區域尺度 i a 最近目標樣本點屬於第i類的個數 ij d 最近目標樣本點與第i類第 j個樣本點間的距離 L 樣本的類別數 i m 類別i的平均數 m 所有樣本的總平均數 i c 類別i的加權平均數 ij u 第j個樣本屬於第i類的隸屬度 d 原始空間維度數 p 降維子空間維度數 投影的向量 將資料映射至一個較高維度空間的函數 A 原始空間映射到降維子空間的轉移矩陣D 對角矩陣 用來控制模型複雜性與經驗損失的一個係數 調整LFDA 中 PCA 共變異矩陣所佔的權重 調整光譜資訊的係數 調整空間資訊的係數 錯誤的調節參數為一常數 i 分類錯誤的容許量 w 可分離超平面的法向量 s v 廣義特徵向量 s 廣義特徵值 rlb S 正規化局部組間分散矩陣 rlw S 正規化局部組內分散矩陣 lb S 局部費雪區別分析的組間分散矩陣 lw S 局部費雪區別分析的組內分散矩陣 t S 主成分分析的總變異矩陣 d I dd的單位矩陣 i 類別i的共變異數矩陣 i i的行列式值 ) (u Vc 在鄰居系統c下x的鄰居中有多少個點與x為相同的類別 Z 正規化項 i P 第i類的先驗機率 b 偏誤
第一章 緒論
第一節 研究動機
隨著科技的蓬勃發展,遙感探測(Remote Sensing)技術已普遍應用於日常生活 中。所謂遙感探測技術是指藉由衛星拍攝含有物體光譜反射的地表影像,之後經 由光譜的處理與分析則可辨別地表的地物種類與變化。因遙感探測技術一直朝向 高空間與高光譜解析度發展,故所取得的影像中,每一個像元都包括完整且連續 的光譜資訊,此影像具有數十至數百個較窄的波段資料,故稱之為高光譜影像 (Hyperspectral Image)(徐百輝, 2007)。雖然高光譜影像蘊含有更豐富且細緻的資 訊,但卻容易因為初始訓練樣本取得成本及維度數過高的影響,而造成分類效能 低落。在訓練樣本大小固定下,當維度增加,分類正確率會在某個維度達到極大值後開始下降,此稱之為Hughes phenomenon (Hughes, 1968),如圖 1-1 所示。為
了減緩此種 Hughes 現象的發生,必需設法增加樣本數或者降低維度數。而在降 維的方式中,一般分為特徵選取及特徵萃取兩種,其中,特徵選取是配合適當的 準則,從原始的維度中選出一個最適合的維度子空間。而所謂的特徵萃取則是使 用所有的維度資訊去建構出一個投影矩陣,再將資料投影至擁有較低維度的空間 中。特徵選取與特徵萃取最大的差別在於:特徵選取無論投影到任何原始空間的 軸上,不同類別的資料可能會有重疊的情況;但若將資料投影至特徵萃取的軸 上,則較容易將不同類別的資料分開。以此點為考量,故特徵萃取法用於分類上 會 有 較 好 的 效 能 , 而 最 常 被 使 用 的 特 徵 萃 取 方 法 為 線 性 區 別 分 析(Linear
Discriminant Analysis, LDA)(Fukunaga, 1990),但此方法在有限小樣本的情況下, 常會因為參數無法估計或者估計不精準,使得分類的正確率下降(Qian, 2007; Bandos, Bruzzone & Camps, 2009)。研究顯示結合空間資訊之演算法皆能大幅提升 高光譜影像辨識的結果(Jackson & Landgrebe, 2002;Kuo, Chuang, Huang & Hung, 2009),所以在進行高光譜影像辨識時,不能只考慮光譜資訊而忽略空間資訊的重
要性。有鑑於此,故如何適當的結合空間資訊以增加樣本數的半監督式演算法則 是本研究想要分析及探究的主題。
MEAS URE MENT COMPLEXITY: n (Total Discrete Values)
1 2 5 10 20 50 100 200 500 1000 0.50 0.55 0.60 0.65 0.70 0.75 N =2 5 10 20 50 100 200 1000 500 N = ∞ M E A N RE C O G N IT IO N A C CU RA C Y 圖1-1 Hughes phenomenon
第二節 研究目的
由於半監督式學習是以大量未標記樣本結合已標記樣本資料來訓練模型,可用以解決資料量稀少與分離的問題(Seeger, 2001;Zhu, 2006;Chapelle,
Scholkopf & Zien, 2006),符合實務上的應用。而根據馬可夫隨機域(Markov Random Field, MRF)模型中顯示出資料點間具有相對應的空間關係(Jackson & Landgrebe, 2002;Dell’Acqua, Gamba, Ferrari, Palmason & Benediktsson, 2004;Li & Narayanan, 2004;Fauvel, Benediktsson, Chanussot & Sveinsson, 2008),故可考 量以空間資訊來增加未標記的樣本,嘗試將半監督學習模式導入線性區別分析 中,藉由增加樣本數來修正特徵萃取的方向,如此可以提升分類效能及解決樣 本數不足的問題。非監督式線性區別分析主要是以Fuzzy c-means 隸屬度的概念 來修改線性區別分析中組間與組內分散矩陣的一種特徵萃取法。因此,本研究 依據 MRF 中鄰居系統的概念來取得半監督式樣本,針對此未知的樣本分別以 MRF 的概念或依不同分類器的特性來定義非監督式線性區別分析的隸屬度,提
出一個結合線性區別分析與非監督式線性區別分析的方法,如此即形成以空間 資訊來搭配光譜資訊的特徵萃取演算法,並將此方法命名為半監督式線性區別 分析法,其方法主要是利用半監督式樣本來促進線性區別分析的效能,藉由增 加樣本數來修正特徵萃取的方向,使辨識正確率能更為提升。運用所提及的方 法 實 驗 在 高 光 譜 影 像 資 料 集 及 教 育 測驗 資 料 集 上 , 使 用 傳 統 高 斯 分 類 器 (Gaussian Classifier, GC)、k 最近鄰分類器(k-Nearest-Neighbor classifier, kNN)與 支撐向量機(Support Vector Machine, SVM)三種不同的單一分類器來驗證其效 能,並分別以半監督式區別分析(Semisupervised Discriminant Analysis, SDA)及 半監督式局部費雪區別分析(SEmisupervised Local Fisher discriminant analysis, SELF)二個半監督式的特徵萃取法做比較。
第三節 章節架構
在本研究的第一章首先描述研究的動機,由於實驗所使用的皆為高維度的 資料集,而為了避免因維度數過高,而使分類的效能低落,故於第二章將探討 相關的文獻,其中包含不同學習類型的特徵萃取法,以了解如何適當的降低維 度數與保存有用的資訊,藉由馬可夫隨機域的概念可知樣本位置之間具有關聯 性,故可依據空間資訊來取得半監督式的樣本點,之後針對不同分類器的性質 加以整理。由於初始訓練樣本取得不易,故在線性區別分析中,會因為參數無 法準確的估計而產生Hughes 現象,為了緩和因樣本數不足而導致分類不佳的情 況,故在第三章提出改良的半監督式線性區別分析演算法,主要是利用半監督 式樣本來促進線性區別分析的效能,藉由增加樣本數來修正萃取的方向,使辨 識正確率能更為提升。在第四章實驗設計是將本研究改良的半監督式線性區別 分析的方法,應用於高光譜影像及教育測驗資料集上,說明實驗資料集與流程, 並在第五章敘述實驗的結果,最後於第六章提出本研究的結論及建議。第二章 文獻探討
在第一節將介紹不同的特徵萃取法,可分為監督式特徵萃取(Supervised Feature Extraction)、非監督式特徵萃取(Unsupervised Feature Extraction)及半監督 式特徵萃取(Semisupervised Feature Extraction)。監督式特徵萃取主要介紹線性 區別分析(Linear Discriminant Analysis, LDA),而非監督式特徵萃取將介紹非監 督式線性區別分析(Unsupervised Linear Discriminant Analysis, UFLDA)及半監督
式 特 徵 萃 取 會 介 紹 的 方 法 有 半 監 督 式 區 別 分 析(Semisupervised Discriminant
Analysis, SDA)及 半 監 督 式 局 部 費 雪 區 別 分 析(SEmisupervised Local Fisher discriminant analysis, SELF)。
由於近年來研究指出結合空間資訊可提升分類的正確率,故在第二節將提 及馬可夫隨機域(Markov Random Field, MRF),利用馬可夫隨機域的概念應用於 改良的線性區別分析上。接著在第三節說明三種常使用的分類器,包含高斯分 類器(Gaussian Classifier, SGC)、k 最近鄰分類器(k-Nearest-Neighbor classifier, kNN)與支撐向量機(Support Vector Machine, SVM)。
第一節 特徵萃取
特徵萃取常用來減緩小樣本高維度所造成的Hughes 現象,常用的方法為找 尋一個轉移矩陣(transformation matrix) d p R A ,將原始空間資料xRd,轉換到 維度較小的新特徵空間中,即 T p R x A y ,pd。通常經由特徵萃取轉換後 的特徵向量空間,其資料維度數會比原始萃取的特徵向量空間的資料維度數 小。以下將因機器學習模式的不同,而分別介紹線性區別分析、非監督式線性 區別分析以及將與本研究的方法做比較的二種半監督式特徵萃取。壹、線性區別分析
監督式學習為機器學習的一種類型,其主要的概念為經由訓練資料來進行 學習或者建立一個模式,依據模式去預測可能會出現的輸入值,其中常應用於分類與迴歸分析上。下面將簡述與此學習模式概念相同的特徵萃取技術以線性 區別分析為主。 線性區別分析為一種常用參數型的特徵萃取方法,由於需要使用到樣本的平 均數以及共變異數矩陣,所以被視為一種參數估計型的特徵萃取方法。該方法以 計算組間分散矩陣( LDA b S )以及組內分散矩陣(SwLDA)之比率為估計類別分離程度的 準則,但由於組間分散矩陣的自由度之限制,所以通常使用線性區別分析作特徵 萃取過後的維度數上限為類別數減一。 線性區別分析中的組間分散矩陣的計算公式如下所示:
T i i L i i LDA b m m m m N N S
1 (2-1) 和組內分散矩陣的計算公式如下所示:
T i i j L i N j i i j LDA w x m x m N S i
1 1 1 (2-2) N 訓 練 樣 本 個 數 , Ni 代 表 第 i 類 的 樣 本 數 , L 為 樣 本 的 類 別 數 , L N N N 1 , mi代表類別i的平均數,m代表所有樣本的總平均數, i j x 代 表第i類第 j個樣本,A為轉移矩陣。線性區別分析主要在取得最大的分離量,所 以要求組間的分離量越大越好;組內的分離量則是越小越好。因此最佳化以下的 準則:
A S A A S A
tr T wLDA T bLDA A 1 max arg (2-3) 本研究主要是以線性區別分析為基礎,用以進行特徵萃取演算法的改良,其 詳細的做法將於第三章詳細說明之。貳、非監督式線性區別分析
非監督式學習是機器學習模式的一種,並不需要人力來輸入標籤,依照資 料的分布情形,將性質相似的資料分在同一類,再針對不同群集資料加以分析並定義各群集的意義(Acition, Corsini & Diani, 2003),下面將簡述與此學習模式 概念相同的特徵萃取技術,其中以非監督式線性區別分析為主。
非監督式線性區別分析(Li, Kuo & Lin, 2011),主要是將Fuzzy c-means隸屬度 的概念應用在線性區別分析上的一種特徵萃取方法,並重新定義其組間分散矩陣 ( UFLDA b S )與組內分散矩陣(SwUFLDA),其定義如下所示:
T i L i i N j ij UFLDA b c m c m N u S 1 1 (2-4) 和
L i N j T i j i j ij UFLDA w x c x c N u S 1 1 (2-5) N j N j k ik ij i x u u c 1 1 代表類別i的平均數, 代表第ij j個樣本屬於第i類的隸屬度。則Fisher Linear Discriminant Clustering(FLDC)一般化的目標函數表示法定義 如下所示:
UFLDA
b UFLDA w ij FLDC u tr S S J 1 (2-6) 在費雪規則下,考慮組間與組內分散矩陣的交互作用矩陣,而其資料集的 結果中呈現,FLDC 可以偵測到群集間最大分離量。為了減少組內距離交乘項發生奇異,有一些正規化的技巧(Kuo & Landgrebe, 2003, 2004),可以應用在群集組內分散矩陣。在 FLDC 群集組內分散矩陣其正 規化表示法如下所示:
UFLDA
w UFLDA w UFLDA rw rS r diag S S 1 (2-7)
UFLDA
w S diag 為矩陣SwUFLDA對角線部分,且正規化參數為r
0,1 。FLDC 最優化問 題表示法定義如下所示:
UFLDA
b UFLDA rw U ij FLDC U FLDC J u tr S S限制式為 Lu j N i ij , , 1 , 1 1 。因為最佳化問題為非線性且非凸組合,一些常
用最優化演算法(Waltz, Morales, Nocedal & Orban, 2006;Luenberger & Ye,
2008):“interior-point”、“active-set” and “trust-region-reflective”可應用來解決此類 問題。執行這些演算法,可發現“active-set”演算法的時間成本少於“interior-point” 和“trust-region-reflective” 二 種 演 算 法 , 但 很 容 易 受 起 始 值 的 影 響 。 因 此 , “interior-point”演算法可以找到最佳的UFLDC,然而相對的時間成本高於“active-set” 和 “trust-region-reflective”二種演算法。 UFLDA演算法描述如下所示: 步驟1:起始的隸屬度矩陣為U
uij1iL,1jN,來自隨機值介於零到1之間,使得U 的元素uij滿足 u j N L i ij 1 , 1, , 1
。 步驟2:使用“interior-point”最優化方法,在費雪規則
UFLDA
b UFLDA rw U tr S S 1 max 下找尋 FLDC U 最佳解,其限制式為 u j N L i ij 1 , 1, , 1
且
, ,i , ,L , j , ,N uij 01 1 1 。 步驟3:計算 UFLDA rw S 和SbUFLDA,得到步驟2:UFLDC最佳解。 步驟4:求解特徵值問題 s d UFLDA rw s s UFLDA b S S , 12 。 步驟5:A
1,2,,p
,pd為由原始空間到降維子空間的轉移函數。 本研究嘗試在非監督式線性區別分析中,以鄰居系統或後驗機率的概念來 定義半監督式訓練樣本的隸屬度矩陣,並結合線性區別分析,以形成空間資訊 來搭配光譜資訊的特徵萃取演算法,並將之命名為半監督式線性區別分析演算 法來進行特徵萃取之演算法的改良。參、半監督式特徵萃取
半監督式學習法(Sindhwani, Niyogi & Belkin, 2005)介於監督式學習與非監 督式學習之間,利用大量未標記過的資料結合一些已經標記過的資料來做訓練 的模型,用以解決資料量稀少及分離的問題。在現實生活中,標記資料的取得 非常耗時費力;但相對的,未經過標記的資料量卻是隨手可得。因此,在機器 學習的領域上,如何利用未標記資料是一個重要的課題。倘若未標記資料確實 能讓模型的效能提高,那麼半監督式學習將會相當有助益。下面將簡述與此學 習模式概念相同的特徵萃取技術,分別介紹半監督式區別分析及半監督式局部 費雪區別分析。本研究將與此二種特徵萃取法相比較,用以評估分類的效能。
一、半監督式區別分析
半監督式區別分析(Semisupervised Discriminant Analysis, SDA)(Cai, He, & Han, 2007),主要是以一組未標記樣本來建構正規化的項,避免矩陣發生奇異而 無法求解,以下將簡述該方法。
線性區別分析若沒有足夠的訓練樣本,分散矩陣會發生奇異情況,一般為 了避免分散矩陣產生奇異現象,將進行矩陣正規化(Hastie, Tibshirani & Friedman, 2001),線性區別分析最佳化問題的正規化表示法如下所示:
v J v S v v S v LDA w T LDA b T v max arg (2-9) 代表所投影的向量,是用來控制模型複雜性與經驗損失的一個係數,其中最 常見的正規化形式為Tikhonov正規化(Tikhonov, 1963),表示法如下所示:
2 v v J 線性區別分析模型結合Tikhonov正規化,稱之為正規化區別分析(Regularized Discriminant Analysis, RDA)(Friedman, 1989)。在實務應用層面上,由於所獲得的資料大多為未標記樣本,故運用正規化區
別分析的概念,將一組未標記樣本去建構正規化的項J
v ,並假設附近的樣本點具有相同的標籤(Zhou, Bousquet, Lal, Weston & Schölkopf, 2003),其正規化的項表 示法如下所示:
ij ij j T i T S x v x v v J 2 (2-10) 其中
otherwise x N x or x N x if Sij i q j j q i , 0 , 1 (2-11)
j q x N 代表xj的q個鄰近點。此概念想法來自降低維度(Belkin & Niyogi, 2001;He & Niyogi, 2003)、群集 (Ng, Jordan & Weiss, 2001)與圖論的半監督式學習演算法(Chapelle, Weston & Schölkopf, 2003;Sindhwani, Niyogi & Belkin, 2005;Belkin, Niyogi & Sindhwani, 2006)。
v XLX v v X S D X v v x S x v v x D x v S x v x v v J T T T T i ij T j ij i T T i ii i T ij ij j T i T 2 2 2 2 2
(2-12) D為對角矩陣,
j ij ii S D ,X
x1,x2,,xN,xN1,,xNN'
代表所有樣本 點,LDS為拉普拉斯矩陣(Laplacian Matrix)(Chung, 1997)。 則半監督式區別分析目標函數表示法如下所示: )) ( ) ) ( (( max arg 1 A S A A XLX S A tr bLDA T T LDA w T A (2-13) 此篇的特徵萃取法是應用在人臉辨識上,從文章中的實驗結果可以看出SDAConsistency、Laplacian SVM及Laplacian (Recursive Least-Squares, RLS)的方法能有 較高的分類效果。
二、半監督式局部費雪區別分析
半 監 督 式 局 部 費 雪 區 別 分 析 (SEmisupervised Local Fisher discriminant analysis, SELF)(Sugiyama, Ide, Nakajima & Sese, 2010),是結合 LFDA 和 PCA 二 者的優點的一種半監督式特徵萃取方法,以下將簡述該方法。
局部費雪區別分析(Local Fisher Discriminant Analysis, LFDA)(Sugiyama, 2007)為一種監督式特徵萃取法,當標記樣本太少會產生模型過度擬合,即分散
矩 陣 發 生 奇 異 的 情 況 ; 而 主 成 分 分 析(Principal Component Analysis, PCA)
(Jolliffe, 1986)為一種最常見於處理高維度資料的方法,其最主要的目的是降低 資料維度數,並盡可能的保留原始資料的變異以及原始資料在空間中分布的情 形。 以下將舉例說明二者之差異。 圖2-1 說明 LFDA 和 PCA 的例子 在圖2-1(Sugiyama et al., 2010)圓圈和三角形分別表示類別為正與負,實心 和空心分別表示有標記與無標記樣本,實線和虛線分別表示LFDA 與 PCA。由 (a)及(b)可知選擇有標記樣本不同,LFDA 因監督性質影響分類,而 PCA 不受影 響。由(a)與(c)可知選擇具有同樣標記樣本,但垂直縮放的數據多了一倍,此時 LFDA 和 PCA 在分類上同時受影響,而 LFDA 變化不強烈,PCA 有明顯變化。
SELF 的廣義特徵值問題表示法如下所示: s rlw s s rlb v S v S
(2-14) 其中,vs代表廣義特徵向量, 代表廣義特徵值,s rlb S 和S rlw 分別為正規化局 部組間分散矩陣與正規化局部組內分散矩陣,定義如下所示: rlb
lb t S S S =1' ' (2-15) rlw
lw d I S S =1' ' (2-16)
0,1 ' ,
T i N N i i t x x S ' 1 代表主成分分析的總變異矩陣,Id則為一個 d d 的單位矩陣,S lb 和S lw 分別代表局部費雪區別分析的組間及組內分散矩 陣,定義如下所示:
2 1 1 , , T j i j i N j i lb j i lb x x x x W S : (2-17)
T j i j i N j i lw j i lw x x x x W S 1 , , 2 1 : (2-18) lb j i W, 和Wi ,lwj 分別代表局部費雪區別分析的組間及組內分散矩陣的權重矩陣,定義 如下所示:
j i if N j i if N N A Wilbj i j i 1 1 1 , , : (2-19) j i if j i if N A Wilwj ij i 0 , , : (2-20) 其中,Ai j
xi xj
ij
2 , exp ,i: xi xi(k) 為衡量樣本的區域尺度, ) (k i x 則是 樣本的第k個最近鄰。 若' 0,半監督式局部費雪區別分析將退化成局部費雪區別分析,若 1 ' ,半監督式局部費雪區別分析將退化成主成分分析,故LFDA和PCA為SELF 的特例。SELF 最優化問題表示法如下所示:
( ) )]
( [ max
arg SELFT rlb SELF SELFT (rlw) SELF 1
A A S A A S A tr (2-21) SELF A 可由下列式子計算而得: SELF [ 1 1, 2 2, , s s] v v v A (2-22) 此篇的特徵萃取法是應用在人臉辨識上,從文章中的實驗結果可以看出 SELF 相較於 LFDA、PCA、inverted LPP (iLPP)的方法能有較高的分類效果。
第二節 馬可夫隨機域
馬可夫隨機域在近年來應用於影像處理有不錯的效果(Jackson & Landgrebe, 2002;Kuo, Chuang, Huang & Hung, 2009),將影像性質,如亮度、顏色等,視為 圖(graph)位置(site)上的隨機狀態,而位置之間的關係則以圖的邊(edge)表達。馬 可夫隨機域可用來提供這種空間(spatial)過程的一個自然架構。 在圖像資料X
x1,x2,,xN,xN1,,xNN'
中,每個位置的條件機率都只 跟其鄰居(neighborhood)有關,假設
X1,X2,XN
為空間中定義在N 個位置上之 隨機變數,根據與鄰居間的關係建構其空間資訊的條件機率,如下所示:
) , Pr( ) , Pr(Xi xi Xj xj ji Xi xi Xj xj jN xi ,i1 , ,N (2-23)
xi N 代表xi鄰居系統(neighborhood),由上式可知馬可夫隨機域的概念:即為給 定xi位置以外的資訊與只給xi鄰居的資訊所得到的條件機率相等。 假設S為一空間資料,一般鄰居系統(Li, 1995)定義有二種,第一種為非正規 化圖像資訊鄰居系統,定義如下所示:
t S dist(s,t) r ,t s
s (2-24)S 圖2-2 非正規化圖像資訊,S 的鄰居系統 第二種為正規化格點資訊的鄰居系統定義如下所示: s
tS dist(s,t)c2 ,ts
(2-25) 其中c代表c階鄰居系統,其表示法如下圖所示: S S S 圖2-3 由左到右分別為一階、二階及三階鄰居系統 馬可夫隨機域只提供條件機率而不表示存在著條件機率分配,Hammersley和Clifford發現且證明馬可夫隨機域與Gibbs分配(Geman & Geman, 1984)有等價關
係(Hammersley & Clifford, 1971),不但使得模型建構與統計推論更具彈性,而且 可以與統計物理產生關聯性(Besag, 1974)。
of aGibbsdistribution form the has 0 , & field random Markov a is x X P x X P x X (2-26) Gibbs distribution 如下所示:
C c c u V Z x P( ) 1exp ( ) (2-27) u是x的類別,Z為一正規化項使得
( )1 X X x P ;Vc(u)則代表在鄰居系統c下x的 r s鄰居中有多少個點與x為相同的類別, otherwise ) ( ) ( if 0 ) ) ( ), ( (u x u x u x u x , Vc (2-28) x代表x的鄰居點,是一常數係數(由經驗法則決定)。 由上述的方法可將馬可夫隨機域的條件機率分配簡化為如下所示:
) ( 1exp ( ) ( ) ) ( x c x x u x u Z x (2-29) 其中,
) ( ) ( ) ( ) ( 1 0 ) ( ) ( x u x u x u x u x u x u 。 由上面的敘述可知,馬可夫隨機域可用以建立圖像資料點與點之間相關性 的條件空間模型,而此種條件模式乃是架構在空間中任一個格點給定在其鄰居 系統下所產生的機率分配,藉由此法便能容易的透過局部的空間資訊進而描述 任一的格點資訊。基於馬可夫隨機域的性質,本研究將採用此鄰居系統的概念, 以一階鄰居系統的方式來增加未知的樣本點,並以二階鄰居系統的方式來定義 非監督式線性區別分析中的隸屬度矩陣。第三節 分類器
一般的分類器分為兩類,第一類為參數型的分類器,若樣本數夠大或樣本 屬於常態分配時可以準確的估計參數,使得分類器擁有較佳的分類效能,比如 高斯分類器,第二類為非參數型的分類器,則能避免分類樣本不足時,而導致 無法精準估計參數,如 k 最近鄰分類器、支撐向量機,以下將一一作介紹。壹、高斯分類器
在樣本辨識中高斯分類器為一種常見的辨識方法(Fukunaga, 1990),假設將每 筆資料視為在高維度空間中的一點,而這些同一類別的資料點是由一個高斯機率 密度函數(Gaussian probability density function)所產生,則即可使用最大概似估計 法(Maximum Likelihood Estimation, MLE)來求出這個高斯密度函數的最佳參數 值。使用這種方法所求得的分類器,稱為「二次分類器」(Quadratic classifier),因為此方法所產生的決策分界線(Decision Boundaries)都是輸入特徵的二次函 數。相對於一般常用的高斯混合模型(Gaussian Mixture Model, GMM),此方法又 可稱為單一高斯分類器(Single-Gaussian Classifier, SGC)。利用最大後驗機率法
(Maximal a Posteriori, MAP)將一個未知類別的測試樣本x辨識成擁有最大後驗機
率的類別。設有L類其判斷準則表示法如下所示:
i
L i i L i L i P i x P x p P i x P x i P , 1, , 1, , 1, max arg max arg max arg (2-30) 高斯分類器是假設樣本服從高斯分配,因此任意樣本x判別準則經由推論 可轉換成式子如下所示:
i i i i T i L i i i T i i d i L i P m x m x m x m x P ln ln 2 1 2 1 max arg 2 1 exp 2 1 max arg 1 , , 1 1 2 1 2 , , 1 (2-31) i 代表類別i的共變異數矩陣,i 則為i的行列式值,Pi為第i類的先驗 機率。 本研究欲使用傳統的高斯分類器來驗證高光譜影像及教育資料集的分類效 能,並依據此分類器的性質來求得後驗機率,以定義非監督式線性區別分析中 的隸屬度矩陣。貳、k 最近鄰分類器
k 最近鄰分類器其所根據的基礎是「物以類聚」,即同一類的物件應該會聚 集在一起。以數學語言來說,也就是同一類別的物件,若以高維度空間中的點 來表示,則這些點的距離應該會比較接近(Fukunaga, 1990)。在使用 k 個最近鄰 分類器來辨識未知類別樣本x時,kNN 分類器會將測試樣本x根據其 k 個最近相 鄰點所出現之頻率來判斷,將x辨識為出現頻率最高之訓練樣本的類別。因此, 對於一個未知類別的樣本,只要找出在訓練樣本中和此樣本最接近的幾個點,就可以判定此樣本的類別應該和最接近的點之類別是一樣的。值得一提的是, 當 k 個最近相鄰法辨識器的 k 數字增加時,其分類的效果不一定會更好。比較 好的辨識正確率總是發生在 k 的數目較小的情況(Hastie & Tibshirani, 1996)。k 最近鄰分類法是一個很直覺的分類法,在測試各種分類器時,常被當成是最基 礎的分類器,以便和其他更複雜的分類器進行效能比較。與高斯分類器不同, kNN 辨識器是屬於一種無參數形式的辨識器。
本研究欲使用 k 最近鄰分類器的 1NN 來驗證高光譜影像及教育資料集的分 類效能(Kuo, Li & Yang, 2009;Kaya, Ersoy & Kamasak, 2011),並依據此分類器 的性質來求得後驗機率,以定義非監督式線性區別分析中的隸屬度矩陣,而其
中分別以5NN 及 15NN 來做實驗的效果測試。
參、支撐向量機
支撐向量機(Support Vector Machine, SVM)是一種機器學習法用來處理可分 離的資料,它的分類技巧是近年來備受關注的研究主題(Camps, Valls & Bruzzone, 2005;Fauvel, Chanussot & Benediktsson, 2006),理論是基於結構風險最小化 (structural risk minimization)的概念。
在許多應用中,支撐向量機理論比傳統學習機制有更高的效能表現,且在 解決分類問題上已經是強而有力的工具之一。支撐向量機理論將輸入資料映射 至高維度特徵空間且尋找可分離2 個類別的空間中,具有最大邊界(margin)的可 分離超平面(hyperplane)。最大化邊界是二次規劃(quadratic programming)問題。 能經由Lagrangian multipliers 轉變成對偶格式的問題來解決。最佳平面是由少 數的輸入點組合而成,稱為支撐向量,其原始定義如下: N i b x w y w w i i i T i N i i T ,..., 1 . 0 1 ) ) ( ( o subject t 2 1 min , 1 (2-32)
b是偏誤,訓練樣本xi經由函數 映射至一個較高維度空間。w是可分離超平面的 法向量, 是分類錯誤的容許量,i 是代表錯誤的調節參數為一常數,此參數可 以調整變動平衡邊界大小及允許分類錯誤量。找尋最佳超平面,可將問題以 Lagrangian來解決且將原問題轉成對偶形式表示法如下所示: N i y x x y y W i i N i i j i j N i j i N j i N i i ,..., 1 , 0 0 o subject t ) ( ) ( 2 1 ) ( max 1 1 1 1 (2-33) ), ,... (1 N 是非負Lagrange multipliers的向量。Kuhn-Tucker定理在支撐向量 分類器的理論中扮演重要的角色,根據此理論要解決(2-29)的問題,則 的問題 需滿足式子如下所示: N i x w yi( ( i) ) 1 i) 0, 1,..., ( (2-34) N i i i) 0, 1,..., ( (2-35) 從這些等式可知只有在(2-30)非零值的 是滿足限制式i yi(w(xi))1i 且正負相等。資料點對應i 0被稱為支撐向量,可是支撐向量在不可分離的情 形時,有兩種不同的類型。在0i 對應的支撐向量滿足等式yi(w(xi))1 且i 0, 在i 的 情 形 下 則 不是零的且對應的支撐向量不滿足限制式i i i i w x y ( ( ))1 ,此類的支撐向量為錯誤。當資料點xi對應i 0表示分類正 確且能明確的在決策邊界分隔,建構最佳化超平面w(xi) 是以 N i i i i x y w 1 ( ) (2-36)
且純量 是由(2-30)的Kuhn-Tucker條件來決定。在最佳值決定後,其決策函數是 ) ) ( ) ( ( ) ) ( ( ) ( 1
N i i i i i sign y x x x w sign x f (2-37) 在多類的分類問題上,可依據分類的原則歸納為一對多(One-Against-All, OAA)及一對一(One-Against-One, OAO)兩種方法。一對多的方式是將所需解決的 分類問題分解成L個兩類別的分類問題來處理,在訓練過程中必須訓練L個分類 器。當在訓練其中一個分類器時,該類別的資料樣本點為+1類,其餘類別的資料 樣本點為-1類來進行兩類別分類問題的訓練,之後以相同的方式分別去訓練L個 分類器。利用每筆測試資料(Testing Data)分別進入所訓練完的L個分類器測試,比 較L個分類器的輸出值,具最大輸出值的分類器,其+1類所代表的原始類別,即 為最後的分類結果(Bottou, et al., 1994)。而一對一的方式是從L個類別中任意選取 兩個類別為一個組合,因此共有L(L1)/2種組合,依照每兩類別的組合去進行各 兩類別分類問題的分類器訓練,亦即會有L(L1)/2個分類器,每個分類器可以分 出兩個類別,而這兩個類別都是L個類別裡的其中一個。利用每筆測試資料分別 進入由每兩類別組合的分類器去訓練出L(L1)/2個所得的分類結果,經由各分類 器分類結果的投票過程,以獲得最多票數的類別即為此筆測試資料的最後分類結 果(Knerr, Personnaz & Dreyfus, 1990)。在本研究中,將以支撐向量機一對多的方 式來驗證高光譜影像及教育資料集的分類效能(Melgani & Bruzzone, 2004; Bruzzone, Mingmin & Marconcini, 2006)。第三章 半監督式線性區別分析
在高光譜遙測影像辨識中,經常會遭遇到 Hughes 現象,特別容易發生在小 樣本的情況。線性區別分析是一種常見用來解決 Hughes 現象的特徵萃取技術, 主要目的是試圖找到一個特徵空間,在此空間中能夠保留最多的資訊並且降低雜 訊與資料維度數。 近年來,許多研究顯示空間資訊之間具有相關性(Jackson & Landgrebe, 2002;Dell’Acqua, Gamba, Ferrari, Palmason & Benediktsson, 2004;Li & Narayanan, 2004;Fauvel, Benediktsson, Chanussot & Sveinsson, 2008),因此,結合空間資訊 之演算法皆能大幅提升高光譜影像的辨識效果,而其中格點(lattice)空間模型更可 以描述資料點之間相對應的空間關係,藉此可以增加樣本的辨識效果,而馬可夫 隨機域模型(Besag, 1974;Kinderman & Snell, 1980;German & Geman, 1984; Besag, 1986;Li, 1995)對格點圖像問題更是被常拿來運用,且為一有效分類的方 法,故進行高光譜影像辨識時,不能只考慮光譜資訊而忽略空間資訊的重要性。 本研究有鑑於初始訓練樣本取得不易(Camps-Valls, Bandos & Zhou, 2007; Shiguo & Daoqiang, 2011),故嘗試將半監督式學習模式引入線性區別分析中,藉 由空間資訊的概念來增加樣本數,以得到半監督式訓練樣本,並經由迭代來更新 樣本的類別,因為在各種特徵萃取技術中,考量線性區別分析具有簡單易懂及輕 便可解性的優勢,故以此為基礎,本研究提出一個結合線性區別分析與非監督式 線性區別分析的方法,並於非監督線性區別分析中,以鄰居系統或後驗機率的概 念來定義半監督式訓練樣本的隸屬度矩陣,如此即形成以空間資訊來搭配光譜資 訊的特徵萃取演算法,並將之命名為半監督式線性區別分析演算法來進行特徵萃 取之演算法的改良,所提出的方法將可以解決樣本數不足的問題及增加分類的辨 識率。第一節 鄰居系統結合空間資訊之線性區別分析
半監督式線性區別分析主要是利用半監督式樣本來促進線性區別分析的效 能,藉由增加樣本數來修正萃取的方向,使辨識正確率能更為提升。在本研究 中,使用馬可夫隨機域中一階鄰居系統的概念來取得半監督式樣本,圖3-1 的xj 即為初始的訓練樣本,而一階鄰居系統則為半監督式樣本,針對半監督式樣本, 如圖 3-1 所示,本研究以馬可夫隨機域中二階鄰居系統的個數來計算每個樣本 點其歸屬於某類的程度,亦即根據不同的樣本給予相對應的權重,並重新定義 傳統線性區別分析的組間及組內分散矩陣,以費氏準則(Fisher criterion)(Fisher, 1936)來當作目標函數。因為半監督式樣本的類別並不一定是正確的,所以須要 經由迭代來更新樣本的類別,並以二個參數來調整光譜及空間資訊的重要性, 且設定停止的條件,直到樣本的類別收斂,即穩定不再變化為止。其主要的實 驗架構及流程將統一在下一章中描述。 1 j x x j1 x j2 x j3 4 j x x j x j2 x j8 x j x j4 3 j x x j7 x j6 x j5 圖3-1 為 MRF 中鄰居系統的一階及二階示意圖 假設xj為初始的訓練樣本,則藉由馬可夫隨機域中一階鄰居系統的概念來 取得半監督式樣本,即可表示為 1 { 1, 2, 3, 4} j j j j j x x x x x ,針對此未知的樣本,以 馬可夫隨機域二階鄰居系統的個數來計算每個樣本點其歸屬於某類的程度,則 表示為 2 { 1, 2, 3, 4, 5, 6, 7, 8} j j j j j j j j j x x x x x x x x x ,倘若目前有N 個未知樣本, ij u 為第 j 個樣本xj第個鄰居屬於第i類的隸屬程度,即L u j N s i s ij 1, 1,2, , 1,..., 1 1 (3-1) 圖3-2是一個實例,用以說明如何給予每個未知樣本點相對應的權重,令si是 第i類的個數加總,而i1 , ,L且ss1sL,則xj隸屬程度uij定義為 s s u i ij ,因 此,若以馬可夫隨機域中二階鄰居系統的例子而言,即可計算出此樣本點歸屬於 第1類的個數為5、第2類的個數為2、第3類的個數為1及s為鄰居的總個數加總為 8,則其分別的隸屬度si為第i類的鄰居個數如下所示: 故本研究中依據馬可夫隨機域中鄰居系統的概念,分別計算出每個未知樣 本點歸屬於每類的個數,即可得知相對應的隸屬程度,並將此權重加入線性區 別分析的組間及組內分散矩陣中,重新定義以得到新的組間及組內分散矩陣, 最後,將結合傳統線性區別分析與新的半監督式線性區別分析之組間及組內分 散矩陣,以交互驗證法(cross-validation)來挑選 及 二個參數值,用以調整光 譜與空間資訊的重要性,而Fisher criterion 為目標函數。 SLDA 的組間分散矩陣( SLDA b S )定義如下所示: UFLDA b LDA b SLDA b S S S (3-2) 其中, L i T i i N j s ij UFLDA b c m c m N u S 1 1 1 ( )( ) 8 1 8 2 8 5 3 3 2 2 1 1 s s u s s u s s u j j j 圖3-2二階鄰居系統隸屬程度示意圖
SLDA 的組內分散矩陣( SLDA w S )定義如下所示: wUFLDA LDA w SLDA w S S S (3-3) 其中, L i N j s T i j i j N k s q ik ij UFLDA w x c x c u u S q 1 1 1 1 1 ) )( ( 且每類平均計算公式如下所示: N j j s N k s q ik ij i x u u c q 1 1 1 1 (3-4)
N j j x N m 1 1 則代表所有樣本的平均。在求得最佳解uij之後,再計算相對應的 組間與組內分散矩陣,其投影矩陣可以由解廣義特徵值問題 SLDA s w s s SLDA b S S 的特 徵向量組成,將原始空間投影到維度較小的特徵空間之轉置矩陣 SLDA A 定義為 ] ,..., , [ 1 2 p SLDA v v v A 。第二節 後驗機率結合空間資訊之線性區別分析
壹、高斯分類器
高斯分類器為一種參數型分類器,其平均數向量與共變異數矩陣,均假設為 常態高斯分佈,以兩個類別為例,由圖3-3為高斯分類器運作的示意圖,若x是未 知類別的樣本點,屬於類別1的概似程度為L1,屬於類別2的概似程度為L2,由圖 3-3中可知L2大於L1,因此,高斯分類器會將未知類別樣本點x判斷為類別2。圖3-3 高斯分類器運作的示意圖 在本研究中,擬利用高斯分類器的事後機率來重新計算權重矩陣 ij u ,再搭配 實驗的架構,提出後驗機率結合空間資訊之線性區別分析演算法,即可得到分類 結果,其中類別隸屬程度的定義如下:
L i j j j ij i p i x p i p i x p x i p u 1 ) ( ) | ( ) ( ) | ( ) | ( (3-5)貳、k 最近鄰分類器
在處理高維度資料時,k 最近鄰分類器為一種常使用的分類器,演算法的 理論直觀,是個簡潔的無參數形式的分類器。在使用 k 最近鄰分類器時,若想 判斷未知類別的測試樣本中的樣本點x,首先,須找到距離該樣本點x最接近的 k 個訓練樣本點,並根據這 k 個最近鄰訓練樣本點所出現之頻率來判別樣本點x 的隸屬類別,以下將舉例說明之。 由圖3-4 在 kNN 示意圖中,假設灰色代表目標樣本點,則首先利用歐氏距 離找出與目標樣本點最接近的五個樣本點,由下圖可知,紅色表示已知類別的 第1 類最近樣本點有三個,藍色表示已知類別的第 2 類最近樣本點有一個,綠 色表示已知類別的第3 類最近樣本點有一個。則若以 kNN 分類器運作的模式, 此未知類別的樣本點,即目標樣本點將會被判斷為類別1。 Likelihoo d 類別1 類別2 L2 L1 x圖3-4 k 最近鄰分類器運作的概念圖 在本研究中,擬利用kNN分類器的事後機率來重新計算權重矩陣u ,再搭配ij 實驗的架構,提出距離測度結合空間資訊之線性區別分析演算法,即可得到分類 結果,其中類別隸屬程度的定義如下:
L i a j ij a j ij ij i i d d u 1 1 1 1 1 (3-6) 其中dij為最近目標樣本點與第i類第 j個樣本點間的距離, ai為最近目標樣本點 屬於第i類的個數。第四章 實驗設計
此實驗設計的目的在於驗證本研究所提出之半監督式線性區別分析演算 法,在小樣本及高維度的資料辨識上,其分類的效能是否優於傳統的線性區別 分析之演算法,其中,第一節將介紹本研究用來探討特徵萃取要素的兩種不同 資料,一種為高光譜影像資料,另一種為教育測驗資料。介紹所使用的資料後, 將在後面的二小節中說明整個實驗的詳細流程。第一節 資料描述
在實驗中,使用Indian Pines Site 和 Washington DC Mall 兩種不同的高光
譜遙測影像資料,以及「擴分、約分」和「扇形」兩個不同單元的教育測驗資 料。對於相關的資料集分別描述如下。
壹、高光譜影像資料
本研究使用遙測領域研究中常採用之高光譜遙測影像,此影像大多是可以免 費獲得,第一個資料集為農業用地影像「Indian Pines Site (IPS)資料集(Landgrebe, 2003)」,第二個為都市區域 影像「Washington DC Mall 資料集(Landgrebe, 2003) 」。 前 面 的 資 料 集 是 經 由 Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) 感應器測得的資料,後面的資料集為Hyperspectral Digital Imagery Collection Experiment (HYDICE) airborne 高光譜資料。二個資料集的簡介如下。
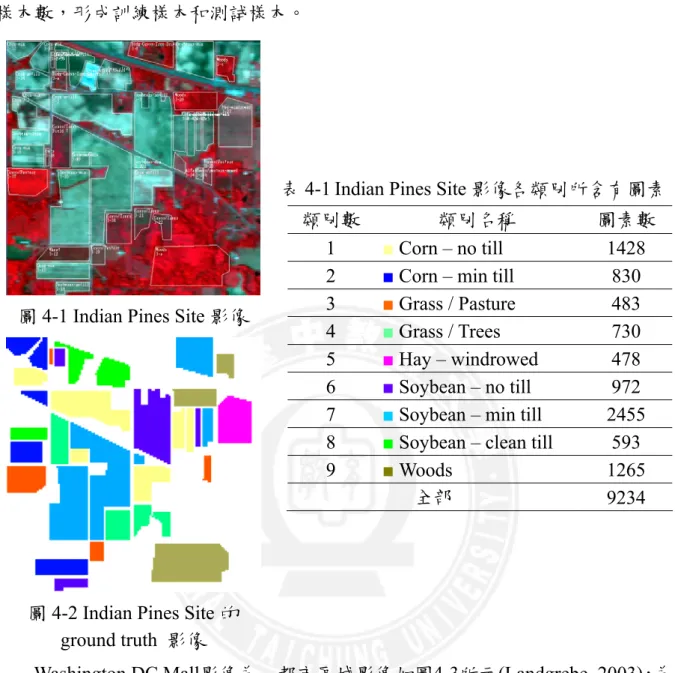
Indian Pines Site 影像是由印第安那州西北部之農業用地中選取一百平方英 里範圍,並於1992年6月蒐集完成,為一混合森林和農業區域的AVIRIS空載高光
譜影像(Landgrebe, 2003),如圖4-1所示。此影像大小為145145、解析度約為20m,
具有220個有效頻譜,包含9個類別,分別為:Corn-no till、Corn-min till、 Grass/Pasture、Grass/Trees、Hay-windrowed、Soybean-no till、Soybean-min till、 Soybean-clean till和Woods。此影像中各類別所含有之圖素(pixels)如表4-1所示,本 研究欲進行之Indian Pines Site影像實驗,則是由各類別中的圖素隨機選取所需之
樣本數,形成訓練樣本和測試樣本。
圖4-1 Indian Pines Site 影像
圖4-2 Indian Pines Site 的
ground truth 影像
表4-1Indian Pines Site 影像各類別所含有圖素
類別數 類別名稱 圖素數
1 ■ Corn – no till 1428
2 ■Corn – min till 830
3 ■ Grass / Pasture 483
4 ■ Grass / Trees 730
5 ■ Hay – windrowed 478
6 ■Soybean – no till 972
7 ■ Soybean – min till 2455
8 ■Soybean – clean till 593
9 ■ Woods 1265 全部 9234 Washington DC Mall影像為一都市區域影像如圖4-3所示(Landgrebe, 2003),為 飛機搭載高光譜儀低空拍攝而成。此影像大小為205307、解析度約為5m,具有 220個頻譜,但部份頻譜被水吸收必須排除,因此僅具有191個有效頻譜。此影像 包含7個類別,分別為:Buildings、Roads、Paths、Lawn、Trees、Water和Shadows, 各類別所含有之圖素(pixels)如表4-2所示,本研究欲進行之Washington DC Mall影 像實驗,乃由各類別中的圖素隨機選取所需之樣本數,形成訓練樣本和測試樣本。
圖4-3 Washington DC Mall 影像 圖4-4 Washington DC Mall 人工定義類別 影像 表4-2 Washington DC Mall 影像 各類別所含有之圖素 類別數 類別名稱 圖素數 1 ■Buildings 3834 2 ■Roads 680 3 ■ Paths 616 4 ■ Lawn 1928 5 ■ Trees 919 6 ■ Water 1224 7 ■ Shadows 221 全部 9422
貳、教育測驗資料
運用樣式辨識技術來建立測驗資料之辨識系統,作為補救教學分類之用,將 學生分為有利於補救教學的分群,可因材施教與縮短補救教學的時間。而教學診 斷的應用亦為小樣本及高維度的問題。數學本身因具有樹狀組織結構,教材內容 通常是依照各重點概念的層級而建構,利用知識結構分析法,參考教育部編列之 國民小學課程標準及相關官方資料,並參考各家教科書出版社的教學指引及課 本,最後交由學科專家開會分析,匯編成一份紙筆診斷評量(郭伯臣、吳慧珉、 楊晉民、柯立偉、白家豪, 2003;郭伯臣, 2006)。 本研究使用兩個不同單元的教育測驗資料集。第一個教育測驗資料為「行 政院國家委員會補助專題研究計畫-國小數學科電腦適性化診斷測驗」第一年施測之紙筆測驗資料,施測單元為康軒文教事業主編之國小科第十一冊第二單元 「擴分、約分」。 施測時所使用的考卷記錄於附錄當中,根據紙筆測驗施測時所得資料,可 將學生的錯誤類型分成15 種類型,表 4-3 是類別所對應需要進行補救教學之概 念。所使用的教育測驗資料集中,有27 個維度,15 個類別(類別 1 到類別 15), 共有1192 個樣本,表 4-4 為「擴分、約分」單元資料集實驗設計。 表4-3「擴分、約分」單元的錯誤概念分類表 組別 人數 需進行補救教學之概念 1 89 「兩異分母比較大小」 2 31 「兩異分母比較大小」、「通分」 3 186 「最簡分數」 4 154 「最簡分數」、「兩異分母比較大小」 5 62 「最簡分數」、「兩異分母比較大小」、「通分」 6 41 「約分」 7 80 「最簡分數」、「約分」、「兩異分母比較大小」 8 59 「最簡分數」、「約分」、「兩異分母比較大小」、「通分」 9 63 「最簡分數」、「約分」、「公因數」、「等值分數」、「兩異分母 比較」、「通分」 10 59 需重新學習「最簡分數」、「約分」、「公因數」、「等值分數」、 「兩異分母比較」、「兩同分母比較」、「公倍數」 11 79 「最簡分數」、「約分」、「兩異分母比較」、「通分」、「兩同分母 比較」 12 77 「最簡分數」、「約分」、「兩異分母比較」、「兩同分母比較」、 「公倍數」、「擴分」
組別 人數 需進行補救教學之概念 13 35 「最簡分數」、「約分」、「公因數」、「等值分數」、「兩異分母 比較」、「兩同分母比較」、「公倍數」、「擴分」 14 150 所以概念都需重新學習 15 27 加強練習(粗心犯錯) 合計 1192 表4-4「擴分、約分」單元資料集實驗設計 第二個教育測驗資料集所採用的教材為康軒出版社所出版的國小數學第 十一冊「扇形」單元,其中,紙筆測驗共有21 題,有效樣本點數總共有 748 個 用以進行實驗。隨機選取出10 個資料集,對於每個類別共有 10 及 20 個訓練樣 本,其餘的樣本點皆為測試樣本。對這些資料集計算其各自的分類正確率,最 後將得到的結果取平均值後,作為最後比較的數據。其中各別錯誤類型以及人 數參照如表4-5,而表 4-6 為「扇形」單元資料集實驗設計。 表4-5「扇形」單元的錯誤概念分類表 組別 人數 需要進行補救教學之概念 1 50 加強練習(粗心犯錯) 2 36 「複合扇形面積」 3 47 「複合扇形面積」、「基本扇形面積」 類別數 15 維度數 27 訓練樣本數 (個別類別) 10 20 總訓練樣本 150 300 總測試樣本 1042 892