國立交通大學
電控工程研究所
碩士論文
使用粒子濾波器方法設計適用於不定延遲時間與封包遺失
之網路化控制系統之估測器
Observer Design for Networked Control Systems with
Indefinite Delays and Packet Loss Using Particle Filter
Techniques
研 究 生:林彥良
指導教授:蕭得聖 博士
使用粒子濾波器方法設計適用於不定延遲時間與封包遺失
之網路化控制系統之估測器
Observer Design for Networked Control Systems with Indefinite Delays and
Packet Loss Using Particle Filter Techniques
研 究 生:林彥良 指導教授:蕭得聖 博士 Student:Yan-Liang Lin Advisor:Dr. Te-Sheng Hsiao
國立交通大學 電控工程研究所
碩士論文
A Thesis
Submitted to Institute of Electrical Control Engineering College of Electrical Engineering
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
In
Electrical Control Engineering September 2012
Hsinchu, Taiwan, Republic of China
i
使用粒子濾波器方法設計適用於不定延遲時間與封包遺失
之網路化控制系統之估測器
學生:林彥良
指導教授:蕭得聖 博士
國立交通大學電控工程研究所
摘要
本研究之目的是為網路化控制系統設計估測器方法,首先針對網路化控制系統當中 之網路與受控系統建立一以機率為基礎之模型。其中使用馬可夫鏈隨機變數描述資訊封 包在網路中傳遞之情況,用以表現不定之延遲時間與遺失機率。 由於使用機率進行模型化,因而使用粒子濾波器方法為基礎設計對應之估測器,並 應用粒子濾波器中常見之改良方法如重新取樣法以及正規化方法以及選擇適當之重要 性取樣分布來改善估測效果。同時提出在高階系統與考慮到估測有效視窗長度情況下, 對粒子濾波器當中計算權重之公式之近似,用以減少計算需求以及節省記憶空間,同時 能取得合理之權重更新趨勢。 模擬與實驗時,選取一加熱系統為處理對象,其具有多觀測端點以及應用情境可遠 端之特性,並且能在較少之控制命令下得到多個系統狀態之變化。將此系統所收集到之 觀測數據透過網路傳輸並紀錄,而後送至估測器對估測方法作驗證。並且將估測結果與 傳統之卡曼濾波器作比較,從而驗證此設計方式之可行性與效果。ii
Observer Design for Networked Control Systems with Indefinite
Delays and Packet Loss Using Particle Filter Techniques
Student:Yan-Liang Lin
Advisor:Dr. Te-Sheng Hsiao
Institute of Electrical Control Engineering
National Chiao Tung University
Abstract
The purpose of this research is to design a state observer specifically for networked controlled systems. We propose a probabilistic model for the network controlled system which consists of a Markov-chained random variable to represent the transferring status of each data packet. Because of the inherent probabilistic nature of the proposed model, we design the observer by using particle filtering techniques. To improve the performance, both resampling and
regularization methods are incorporated into the particle filter, and the importance sampling function is carefully selected. In addition, we simplify the way to update the weightings of the samples in order to reduce the demanding computational power and the need for memory space, while to maintain reasonable state estimation accuracy.
In the simulation and experiment parts, a heating system is chosen. The system has multiple sensing nodes for a remote application, and it can change various state variables with a few control commands. After collecting the temperature data of the system, the data are sent through a real network to the observer for state estimation. The result of the estimation is then compared with the outcome of a traditional Kalman filter in order to verify the feasibility and effectiveness of the proposed method.
iii
致謝
首先感謝我的指導教授蕭得聖博士,老師給予的指導使我了解到做研究所應有的思 考方式,以及向他人傳達想法時所應有的表達方向。雖然不敢說能夠達成多少,但是這 份智識我會時刻提醒自己要有所把握。 也感謝口詴時徐保羅老師與陳永帄老師指出我研究說明中遺失的部分,再度告訴我 研究方法的重要性,也使得我有機會將這份研究內容做得更加完整。 同時也感謝我們實驗室,特別是李永洲學長對我研究上所給予的建議,對我幫助良 多。以及翊熏學長還有柏俊、志偉、昌謀、俊傑同學、學弟仲謙、璟沅、維民,大家在 帄日的互相鼓勵與幫助,讓我在研究所的這段時間能夠不斷前進。 最後我感謝我的家人,爸爸媽媽對我的支持是我能完成到目前為止的人生成就所不 可缺少的。實在很感謝大家能夠給我這個機會讓我有這段體驗與成長,不管未來如何變 化,我都會懷念這兩年的時光。iv
目錄
中文摘要 ... i 英文摘要 ... ii 致謝 ... iii 目錄 ... iv 第一章 緒論 ... 1 1.1 研究背景與動機 ... 1 1.2 研究目的 ... 1 1.3 研究貢獻 ... 2 1.4 論文架構 ... 2 第二章 相關研究 ... 4 2.1 以馬可夫鏈隨機過程處理 ... 4 2.2 以柏努利隨機過程處理 ... 6 2.3 切換系統 ... 7 2.4 相關研究之總結 ... 10 第三章 系統之假設與模型 ... 11 3.1 系統架構與基本假設 ... 11 3.1.1 系統架構 ... 11 3.1.2 控制命令之假設 ... 12 3.1.3 受控系統之假設 ... 12 3.1.4 網路之假設 ... 13 3.2 系統模型 ... 13 3.2.1 受控系統機率模型 ... 14 3.2.2 網路模型 ... 14 3.2.2.1 網路機率模型 ... 14 3.2.2.2 定義收集到之資訊集合 ... 16 3.3 貝式網路機率模型 ... 17 3.3.1 受控系統之圖形式模型 ... 18v 3.3.2 將網路模型與受控系統模型結合 ... 18 第四章 估測器設計 ... 20 4.1 粒子濾波器 ... 20 4.1.1 基本原理 ... 20 4.1.2 重要性取樣法 ... 21 4.1.3 額外之取樣手段 ... 23 4.1.3.1 重新取樣 ... 23 4.1.3.2 正規化 ... 25 4.2 根據網路化控制系統模型設計估測器 ... 26 4.2.1 使用網路化控制系統模型公式推導 ... 27 4.2.2 網路參數之處理 ... 29 4.3 改進估測器方法 ... 31 4.3.1 重要性分布的選取 ... 31 4.3.2 演算公式的修改 ... 34 4.4 最終版本之粒子濾波器 ... 38 第五章 數據模擬 ... 39 5.1 受控系統之選擇 ... 39 5.2 整體系統架構 ... 39 5.3 受控系統模型 ... 40 5.3.1 暫態熱傳導 ... 40 5.3.2 離散化 ... 41 5.4 模擬的設定 ... 43 5.4.1 加熱系統設定 ... 43 5.4.2 網路設定 ... 45 5.4.3 模擬之傳輸延遲時間 ... 46 5.4.4 有效視窗大小選擇 ... 47 5.5 模擬結果 ... 48 5.5.1 四個網路情況之結果統計圖 ... 50
vi 5.5.2 統計結果說明 ... 52 第六章 實驗驗證 ... 53 6.1 實驗帄台 ... 53 6.2 帄台中各裝置 ... 54 6.2.1 發熱器 ... 54 6.2.2 被加熱銅板 ... 55 6.2.3 熱電耦 ... 55 6.2.4 熱電耦用放大與校正晶片 ... 56 6.2.5 抗交疊濾波器(anti-aliasing filter) ... 57 6.2.6 F2812 數位訊號處理器 ... 57 6.3 網路傳輸紀錄 ... 58 6.4 加熱方程式之改動 ... 59 6.5 實驗進行之設定 ... 60 6.5.1 加熱系統設定 ... 60 6.5.2 加熱命令 ... 61 6.5.3 網路情況 ... 62 6.6 實驗結果 ... 64 6.6.1 三個網路情況之結果統計圖 ... 66 6.6.2 結果說明 ... 68 第七章 結論與未來工作 ... 69 7.1 結論 ... 69 7.2 未來工作 ... 70 參考文獻 ... 71
vii
圖目錄
圖 2-1 J. Nilsson 提出方法處理之系統架構 ... 4 圖 2-2 [11]中所使用之系統架構 ... 7 圖 3-1 系統架構圖 ... 12 圖 3-2 封包傳輸狀態之狀態機 ... 15 圖 3-3 受控系統之圖形化模型 ... 18 圖 3-4 整體系統之圖形化模型 ... 19 圖 4-1 重新取樣示意圖... 24 圖 4-2 正規化示意圖 ... 26 圖 4-3 重要性分布選取示意圖 ... 31 圖 4-4 不同網路情況下之機率密度函數比較圖 ... 35 圖 5-1 模擬用系統架構... 40 圖 5-2 有限差分法示意圖... 41 圖 5-3 模擬用加熱系統帄面圖 ... 44 圖 5-4 I 與 III 號熱源之輸入 ... 44 圖 5-5 II 號熱源之輸入 ... 44 圖 5-6 網路情況2產生之資訊延遲時間 ... 46 圖 5-7 網路情況3產生之資訊延遲時間 ... 47 圖 5-8 網路情況4產生之資訊延遲時間 ... 47 圖 5-9 不同有效視窗大小結果 ... 48 圖 5-10 網路情況沒有延遲(1)之估測目標溫度 ... 49 圖 5-11 網路情況帄均延遲 4 時間(3)之估測目標溫度 ... 50 圖 5-12 網路情況1 沒有延遲 ... 51 圖 5-13 網路情況2 帄均延遲兩個時間單位 ... 51 圖 5-14 網路情況3 帄均延遲四個時間單位 ... 51viii 圖 5-15 網路情況4 帄均延遲六個時間單位 ... 52 圖 6-1 實驗之系統架構... 53 圖 6-2 實驗帄台之實物... 54 圖 6-3 使用之可控溫焊槍與其陶瓷發熱體 ... 54 圖 6-4 熱電耦裝置 ... 55 圖 6-5 單組 AD8494 晶片之應用電路 ... 57 圖 6-6 抗交疊濾波器電路圖... 57 圖 6-7 實驗之網路紀錄方式示意圖 ... 59 圖 6-8 實驗之加熱系統配置... 61 圖 6-9 加熱點 II 之輸入溫度 ... 62 圖 6-10 加熱點 II 之輸入溫度 ... 62 圖 6-11 網路低負載時之延遲時間單位 ... 63 圖 6-12 網路中-高負載之延遲時間單位 ... 63 圖 6-13 網路高負載之延遲時間單位 ... 64 圖 6-14 低負載網路之單次估測結果 ... 65 圖 6-15 網路高負載之單次估測結果 ... 66 圖 6-16 低負載網路之估測結果 ... 67 圖 6-17 中-高負載網路之估測結果 ... 67 圖 6-18 高負載網路之估測結果 ... 67
ix
表目錄
表 4-1 某一時刻以原分布與近似分布計算之有效點數占總點數百分比 ... 36 表 6-1 金屬銅之物理特性... 55 表 6-2 AD8494 特性 ... 56 表 6-3 實際銅板之參數... 61 表 6-4 三種網路情況之帄均延遲 ... 64x
符號表
S :網路封包傳輸參數 R :網路封包傳輸參數轉變為接收機率 D :網路封包傳輸參數維持延遲機率 L :網路封包傳輸參數轉變遺失機率 Z :透過網路傳輸後收取之資料 M :有效視窗大小 s N :粒子濾波器取樣數目 w :權重 w :一般化後之權重 threshold N :重新取樣有效點數閥值 T :端點溫度 :熱傳導率1
第一章 緒論
1.1 研究背景與動機
在一般的即時控制系統中,當感知器之數量較少、容易連接時,通常直接將感知器 之輸出端以直接連接的方式連至估測/控制端。以此方式所獲得之觀測資訊幾乎是即時並 且連續完好。 但隨著感知器數量的增加、或者系統本身與估測/控制端之距離的增加,為了周邊連 接線路的減少與統整、為了將資訊送至估測/控制端,而有以網路作為資訊傳輸介面的方 式。而此種在系統當中包含網路作為傳輸介面的控制系統,便稱為網路化控制系統。以 網路作為傳輸介面後,原先繁雜的連接線路以網路線取代,後續之整合與調整都變得容 易;而難以達成的多端點與遠端監控也可以藉由網路輕易達到。 而在控制系統中,對回授之資訊永遠是希望越接近真實、誤差越少越好,但是在網 路化控制系統中,由於使用網路作為資訊的交換介面,因此資訊的獲得便會受到網路傳 輸的影響。如由網路延遲與資料封包的遺失,則估測端便會因此接收到較舊之資訊或者 沒有收到任何資訊,因此,在估測器當中所使用的演算法,便需要有不同的設計。1.2 研究目的
在網路化控制系統中,受到以網路為傳輸介面的影響,估測器端接收到的資料有延 遲與遺失的情況。本研究提出一個描述網路延遲與封包遺失的機率化模型,並根據此模2 型設計一基於粒子濾波器(particle filter)的狀態估測器,以減少資料延遲與遺失所帶來的 估測誤差。 為了驗證所提出的網路模型與狀態估測器之效果,本論文將所提出的方法應用於一 加熱系統之溫度估測。該加熱系統有感測資訊量大,且有遠端應用之特性。藉由模擬與 實作,並與傳統卡曼濾波器做比較,凸顯本方法對網路化控制系統狀態估測之效果。
1.3 研究貢獻
本論文針對網路化之控制系統設計了一網路模型與對應之估測方法。而此網路模型 無針對任一網路協定做描述,可適用於已知之多數網路應用情況。而提出之估測法為粒 子濾波器之應用,針對網路模型做適當調整,以及對實際運算情況設計對應的相關處理 手段。 同時,使用一多觀測點之加熱系統以及實際採集之網路資訊做驗證。此驗證提供了 方法應用的可能情境以及運作方式。1.4 論文架構
第一章是為緒論,此章節闡述研究之背景與目的,以及本研究之貢獻。 第二章接著顯示與網路化控制系統相關之研究,注重於估測以及網路之描述。 第三章說明本研究對網路化控制系統當中出現之各個系統方塊之假設以及其對應之模 型推導。 第四章說明本研究所使用之估測器方法的基礎,粒子濾波器的原理與運作方式說明,並 且將前面所定義與推導之各個變數公式應用到估測器的設計當中。同時並討論此估測法 的改進手法。3 第五章將設計一適合網路化控制系統的模擬情境,使用軟體模擬的方式來測詴所設計之 估測器之效果。 第六章將製作一硬體帄台,將前面所提之模擬情境實現,利用此一帄台說明整體系統的 可能應用情境,並且在實際採集數據後用以驗證估測法的效果。 第七章為結論與未來工作,討論本研究所提之成果以及可能之改良與發展方向。
4
第二章 相關研究
網路化控制系統是一個逐漸發展中的課題[1],其中針對以網路為傳輸介面所引起的 延遲與遺失資訊現象,有許多不同的模型化方式及應對的方法。在本章節中,將舉出其 中不同的網路模型化方式以及估測策略,說明其利用上之缺失與可能改進之處。2.1 以馬可夫鏈隨機過程處理
在 1998 年,Johan Nilsson 提出將網路延遲時間以馬可夫鏈的方式模型化[2],在那 之後亦有人利用類似作法發表了相關研究[3][4]。 圖 2-1 J. Nilsson 提出方法處理之系統架構 在此作法中,感測器與控制器之間是以網路傳遞資訊,有延遲時間sc,以及控制器 到制動器之間亦使用網路傳輸,因此有ca的延遲時間,再加上控制命令計算時間 c k , 使得整個控制命令的延遲時間達到 sc c ca k k k k 。 (2.1)5 同時,假設系統可以在接收到控制命令後回傳確切之 ca1 k 資訊,並且此資訊抵達時 間不會晚於下個週期內, 1 1 1 sc ca ca b sc k k k k h (2.2) 其中 ca b1 k 為回傳所需時間,h 為一個取樣週期。 在確認網路延遲的約略變化範圍後,將延遲時間由最小至最大切割成 s 個小單位時 間,rk{1,..., }s 。於是k為一個馬可夫鏈隨機變數,如同r ,並且其狀態轉移矩陣為k
ij Q q ,qij p r
k1 j rk i
(2.3) 於是網路傳輸資訊延遲時間以此方式令其成為馬可夫鏈隨機變數,在得到上一個時刻之 延遲時間後,得到當前延遲時間長短的分布機率,依此將此系統表示如下; (2.4) 其中 k v :系統雜訊 接著此篇研究提出一搭配之 LQG 控制器,並在最後附上穩定性之證明推導。 此篇研究所假設之網路延遲時間被切割成一個離散的時間單位,並且將其變化描述 成馬可夫鏈的形式。並且在估算系統狀態時,考慮到前一個延遲時間的長短,來推斷將 來控制命令的延遲時間,如此之設定使得其效能相當依賴其對網路情況之掌握情形。 同時,此篇研究對於延遲時間長短亦有限制,目標的處理對象為延遲時間小於一個 取樣週期、觀測資訊抵達順序與出發順序相同而無失序,因此也就將適用範圍做出很大 的限制。6
2.2 以柏努利隨機過程處理
在[5]與[6]中,其將網路傳輸情況以柏努利隨機過程的方式來處理。首先,柏努利 隨機過程的敘述如下: 有一個隨機變數為 ,其可能的值為 0 與 1。並且分布符合 (2.5) 首先,假定系統送出觀測資訊 與控制命令時皆通過一有延遲之網路,該延遲的長 短以系統取樣週期分割為二,一個為短於系統取樣週期,一個為長於系統取樣週期。當 延遲時間短於系統取樣週期時,將其視為及時送達;當延遲時間長於系統取樣週期時, 將其視為沒有送達,並且使用前一個時刻的資訊來替代。以此,將系統描述如下: (2.6) 其中,k 與k 為柏努利隨機變數,其分佈符合下列表示 (2.7) 並且根據上述之設定,[5]與[6]皆以 LMI 的方式設計了對應之 H控制器,並且在之後證 明其穩定性。 在此類網路假設中,其對於資訊延遲之處理較為單純,其只設定兩種情況,當延遲 時間短於取樣週期時,視為沒有延遲,而延遲長於取樣週期時則直接將其視為沒有取7 得,而馬上取前一時刻所得之資訊來使用。並且其對網路情況僅以一參數來描述,只表 達比系統取樣週期長或短,無法精確描述大於一個取樣週期之延遲時間。 因此,此方式除對估測法之設計較為單純,僅僅使用即時沒有延遲之資訊,系統之 取樣時間就必頇配合網路情況做設定,無法在網路延遲時間多數大於系統取樣時間的情 況下運作。
2.3 切換系統
在 [11][12]中,將網路化控制系統中網路介面之因素模型化為一個切換系統。並且 此二篇研究所處理之系統架構為在感測器與控制器之間使用網路為傳輸介面,控制器到 制動器之間則無,如下圖。 圖 2-2 [11]中所使用之系統架構 其假設感測器以Ts之週期送出觀測資料,當超過一個週期仍未確認資料之送達時, 則放棄傳送,直接送出下一筆最新之資料。而控制器則是以Ts N/ 之週期運作,較系統 為快,控制器僅收取感測器送出之最新之一筆觀測資訊,上個週期之資訊則被丟棄。當 有控制器收到此最新之觀測數據時,會輸出新的控制命令給以 zero-order- hold 運作之制 動器。於是將此系統表述如下:8 X 是系統狀態,z 則是感測器之輸出,ABCE 都是固定之系統矩陣,d[k]則是系統雜訊。 由於控制器工作較快, 1 2 [ ], [ ],..., N[ ] u k u k u k 即是在此系統周期內每次控制器更新時所下 達之命令。由於感測器與控制器對超過一週期之資料直接以丟棄處理,因此一週期內最 多僅會收取一筆資料,故分成三種情況: 1.當網路無延遲時,整個週期內之控制命令為新的控制命令 u[k], 1 2 [ ] [ ] ... N[ ] [ ] u k u k u k u k 於是系統便可寫為 [ 1] [ ] [ ] [ ] x k Ax k N Bu k Ed k 即與一般控制系統無異。 2.當延遲時間為 h Ts N/ 時,則觀測未抵達前控制命令為 u[k-1],抵達後為 u[k], 1 2 [ ] [ ] ... h[ ] [ 1] u k u k u k u k 1 2 [ ] [ ] ... [ ] [ ] h h N u k u k u k u k 此系統則化為 [ 1] [ ] [ 1] ( ) [ ] [ ] x k Ax k h Bu k N h Bu k Ed k 3.當完全沒有收到延遲資訊時, 1 2 [ ] [ ] ... N[ ] [ 1] u k u k u k u k 於是系統便為 [ 1] [ ] [ 1] [ ] x k Ax k N Bu k Ed k
9 接著並假設系統最多連續Dmax次沒有收到任何資料。並且沒有收到資料的情形是以周期 Tm 出現的,此 Tm 是 Ts/N 的倍數,Tm/Ts=m。當 m=1 時沒有遺失,m≧2 時則要同時 考慮遺失與延遲之情況。依照上面所列之三種情形將 x 以每 Ts 時間間隔連續將上列之 系統帶入,最後可以整理出 , , 其為m h D max個模式之切換系統。 此篇研究所提之系統架構僅有觀測端有網路連接,並且處理目標是小於一個取樣週 期之延遲時間以及封包遺失。其對網路運作有設定最大連續遺失限制(Dmax),並沒有任 何機率上的假設,依靠當前收取到之資料來決定此切換系統之切換。 然而此設計隨著 m=Tm/Ts、Dmax 越大,切換系統之模式越多,也就是設計控制時 手續將會更為繁複,並且此設計尚沒有考慮到控制端有網路,也是此方法有所限制之處。
10
2.4 相關研究之總結
經由以上所提之幾種方法可以見到,其所處理之對象通常為較短之延遲時間,使得 系統運作頻率需搭配調整,並在估測時採用之手段多為直接假設當尚未接收時,直接採 用前一時刻的值來當作輸入,或者給予一個依網路機率估算之增益。並且對於網路之描 述甚或採用單一變數、或者依延遲時間分割為切換系統等,落於過於單純或者套用系統 模型複雜。 本研究提出之網路模型可適用之延遲時間並無特別限制,並盡量一般化設定使得可 用於任何表現之網路。所提之對應估測法則善加利用延遲之資料,使用上亦可容易套用 於一般線性之系統,方便設計。11
第三章 系統之假設與模型
本論文之探討對象為網路化控制系統,為了針對此種系統設計估測器,將網路模型 化以及將其與控制系統之模型結合成一完整之描述便是研究之重點。本章節針對設計估 測器方法中所需使用到之系統架構與基本假設以及受控系統模型、網路模型做說明與推 導。並且在最後將受控系統與網路模型以貝式網路機率模型表示法結合表示成一個圖形 式模型。3.1 系統架構與基本假設
本節將說明本研究處理之系統架構以及其中各方塊中所代表之功能以及其基本假 設。假設的產生有些是為事實之物理限制,有些則是由於估測方法的使用限制而產生, 當產生理由是為後者時,無法達成該假設時,便會對估測效果產生影響。3.1.1 系統架構
由於本研究之目標為替網路化控制系統設計估測器,因此在方法的研究中,系統內 包含有:控制命令、受控系統、網路、估測器。其中控制命令採直接連接,以即時的方 式傳送至受控系統,而由受控系統中安置之感測器採集之觀測資訊則透過網路傳送至估 測器端。如此設定是為將研究重點放置在估測器方法,而無考慮到控制器之設計。12 圖 3-1 系統架構圖 在實際使用上的例子有比如大樓之空調系統,空調系統的控制為直接中央控制,而 溫度或濕度感應器則大量散佈在整個建築空間中,這些感應器則使用無線網路通訊;又 或者如以雲端作為遠端大量端點資訊監控,各端點之系統之制動器安置在同地點,而監 控資訊則透過雲端的方式送至監控端。當控制系統中觀測端點數量眾多或與估測端距離 遙遠時,採用網路來傳輸觀測資訊便是一個可能的作法,因此而有了這樣的架構設定。
3.1.2 控制命令之假設
在本研究中,由於沒有控制器之設計,而將重點放在估測效果。因此,控制命令在 所有公式推導中皆視為已知,並且此控制命令以即時、無透過網路的方式傳送至受控系 統中之制動器。3.1.3 受控系統之假設
本研究中所設計之估測方法以受控系統為線性系統之基本假設而推導而成。因此在 此出現之受控系統頇為線性系統,而此系統受到模型之不準確性以及雜訊等影響,在系 統中有系統雜訊以及觀測雜訊此二雜訊影響。此系統之離散時間狀態空間表示式可表示 為如下:13 1 x y n k k k k k n k k k k k x Ax Bu w x y Cx Du v y (3.1) k x 是為系統狀態,u 為控制輸入,k y 為觀測輸出,A,B,C,D 為系統矩陣。 k k w 為系統狀態受到干擾或者模型不準確時,加入之系統雜訊;v 則為觀測雜訊。此二k
雜訊被假設為 White Noise,其為帄均值為 0,並且共變異數矩陣(covariance matrix)分別 為 Q 與 R 之高斯雜訊。
3.1.4 網路之假設
本研究所提出之估測方法頇得知每一筆透過網路所獲得之資訊之個別延遲時間,並 且在每一個來自同一時間之觀測端點之觀測值都抵達時,方將其視為該時間觀測資料之 抵達,無資料之缺漏。若資訊之延遲時間並非實際傳輸所花費之時間,例如受控系統與 估測器兩端之時間並無同步,則估測效果將會受影響。 延遲時間的取得可以透過手動在系統時間附加在封包資訊內獲得,而系統時間之同 步與否除會影響估測結果外,本研究內之公式與理論之推導並無對網路所使用之各種協 定與架設等有特殊之設定或要求。3.2 系統模型
由於本研究所提出之估測方法是以粒子濾波器為基礎所發展之方法,而粒子濾波器 是一個以機率方法為中心概念之估測方法。因此在接下來的推導與說明中,會把受控系 統與網路轉為以機率的方式表達之數學模型,並且在最後將受控系統與網路之機率模型 結合成一整體系統之機率模型,並且以貝氏網路(Bayesian Network)機率模型表示法將其14 圖形化,此圖形化模型可使得判斷各變數間的條件相依性變得容易,幫助後續公式之推 導。
3.2.1 受控系統機率模型
由(3.1)以及 wk與 vk的機率分布可知xk1為帄均值為 Axk+Buk, 共變異數矩陣為 Q 之 高斯隨機變數;y 為帄均值為 Cxkk +Duk,共變數矩陣為 R 之高斯隨機變數,表示如下: 1 ~ ( 1 , ) ~ ( , ) k k k x k k k k x k k k x x Ax Bu Q y y Cx Du R N N (3.2)3.2.2 網路模型
3.2.2.1 網路機率模型
當感測器將資料蒐集後,將數據以封包的形式經由網路送出至估測端。而此封包在 網路傳輸過程中會花費時間,其中有由於傳輸距離與頻寬所造成的物理上的最少所需時 間,以及由於網路其他資訊的封包傳輸壅擠而產生的額外等待時間,或者是由於中間某 段線路的不穩定而造成的封包資料遺失等情況。而最終當封包有抵達估測端時,將可由 封包中附加之時間資訊獲得確定的總延遲時間。 在此設定在一個時間出發的資訊封包,隨著系統時間的前進,封包將會有三種可能 的狀態,分別為接收(Receipt)、延遲(Delay),以及遺失(Loss)。顧名思義,當封包狀態 為接收時,代表封包完好到達估測器端,並且被使用於估測演算法則中、不會在之後的 時間到達;當封包狀態為延遲,代表此封包仍然在網路中傳輸、尚未到達估測器端;當15
封包狀態為遺失,代表此封包已經不會繼續傳輸、永遠不會到達估測器端。
依據這些網路資訊封包的物理表現,假定有一參數 S,使用此參數來表達特定資訊 封包的狀態,並且可以得到此參數之有限狀態機(finite state machine)圖形如下:
圖 3-2 封包傳輸狀態之狀態機 其中R、D、L分別為該資訊封包由延遲轉變為接收、延遲保持為延遲、由延遲 轉變為遺失之機率。而此機率是一個與當前網路傳輸之品質、物理限制,以及由資訊封 包出發至當前時刻已經過之時間有關之函數。於是可以將網路參數 S 定義如下:
, , , k m S R D L , km (3.3) Transition Matrix: 1 0 0 ( ) ( ) ( ) , ( ) ( ) ( ) 1 0 0 1 R k m D k m L k m R k m D k m L k m (3.4) 上式所代表的是:網路參數Sk m, 是由 m 時間出發的資訊封包,在 k 時間點時的狀態, 並且其下一個時刻的狀態轉變機率視乎當前的狀態以及由 m 到 k 已經過時間而定。 於是透過網路傳輸之資料,由於每個封包的延遲時間不一定,在同一時間內可能收 取到來自多個時間點的資訊。而透過網路參數 S,可以定義某一個時間點出發的封包, 在一特定時間是否抵達估測端並被納入估測計算中。 已知一個封包,其當前時刻 k 之狀態為 R(接收),而且其前一個時刻之狀態為 D(延 遲),代表此一封包是在此時間點才抵達,並非抵達許久,因此使一封包之資訊將會被16 納入估測當中。根據此推論,若有封包在 k 時間被收到,其當前網路參數必為 R,而前 一時間點網路參數頇為 D,除非其出發時間便是 k,也就是傳輸花費時間小於一單位系 統時間,此情況被視為即時獲得該資訊。 據上推論,以下定義一集合Z ,其代表的是在 k 時間點所收取到的資料的集合: k , , 1 , , , , k i k i k i k i S R S D k M i k Z y or S R i k (3.5) 其中 M 代表的是估測方法接受的有效視窗大小,當資料的出發時間在有效視窗內, 代表該資料並不是過舊的。過舊的資料給予的狀態資訊由於受控系統不斷的變化而失去 計算價值,因此有效視窗大小應視乎當前網路品質以及系統變化之速度而定。
3.2.2.2 定義收集到之資訊集合
由式子(3.5)可以注意到,收集到之資訊 Z 所代表的是一個集合,這個集合的內容含 有來自何時刻的觀測值 y 是隨著對應的網路參數所改變,並且,y 值的大小則又與系統 狀態 x 有關。也就是說,Z 並不是一般常見之機率分布,而是一個具有離散組合與數值 的連續分布特性的複合分布,因此需要利用先前所提之基本設定以及網路之物理限制來 寫出其定義,如此方可使用在估測器中使用。 Z 中可能收到總視窗長度 M+1 個的 y,是否有收到視乎網路情況,而收到的 y 值為 多少則又與該筆觀測資料出發時刻之系統狀態 x 有關,因此先定義 Z 是一個與 x 和 S 有 關之分布,並且可以將其機率密度函數(probability density function, PDF)展開為所有可能 收取之觀測值 y 分布之連乘:17 : , : 1, : 1 , , 1, 1 ( , , ) ( , ) ( , , ) M k k M k k k M k k k M k k k k k k i k i k k i k k i i p Z x S S p y x S p y x S S
(3.6) 而這當中出現之p y x S( k k, k k, )與p y( k i xk i,Sk k i, ,Sk1,k i )則根據網路參數 S 對資料是否被 接收的定義來寫出如下之定義: , , * ( , ) , ( , ) ( ) , k k k k k k k k k y Cx R S R p y x S y otherwise Ν (3.7) , 1, , 1, * ( , ) , , ( , , ) ,1 ( ) , k i k i k k i k k i k i k i k k i k k i k i y Cx R S R S D p y x S S i M y otherwise N (3.8) 其中 * ( )y 為 impulse 出現在無窮遠處之 Dirac delta 函數,其對任意包含有限值之 y 的集 合積分,結果皆為零,代表有限大小的 y 出現的機率為 0。 於是,根據此定義,
p y x S( k k, k k, )dyk 與
p y( k i xk i,Sk k i, ,Sk1,k i )dyk i 在給予固定 之 x 與 S 之下為 1,便成為一合法之機率密度函數。 當實際計算此分布,且Z 當中並沒有收到某k y 時,則將整體機率密度函數i : , : 1, : 1 ( k k M k, k k M k, k k M k ) p Z x S S 對 yi邊際化(marginalize),以將此缺少之變數自公式中消 去。3.3 貝式網路機率模型
貝式網路機率模型表示法是一種將機率模型中出現之隨機參數以及其之間之相依 性以圖形化表示的方法,也稱作圖形式模型(graphical model)。此方法以圓圈代表隨機變 數,圓圈之間以連線代表參數之間存在條件相依性。在此節,將受控系統與網路模型為 圖形式模型結合表示,幫助了解系統中各參數之間的關係,增進分析與推導的便利性。18
3.3.1 受控系統之圖形式模型
首先,在受控系統中由於輸入命令 u 為已知,因此尚有兩個變動的隨機參數,分別 為系統狀態 x,以及觀測輸出 y。 其中系統狀態 x 之是由前一個時刻之系統狀態以及輸入而得,由於輸入為已知,因 此唯一有相依性之隨機變數僅為前一個時刻之系統狀態,與再過往之系統狀態無關,這 種關係稱之為馬可夫鏈;而當前輸出 y 則是僅與當前系統狀態有關。至此,將受控系統 的圖形化模型表示如下。 圖 3-3 受控系統之圖形化模型 每個 x 皆有來自前一時刻的 x 的連線,代表其與前一時刻之狀態有關;而觀測值 y 則有來自同一時刻之系統狀態 x 的連線,代表除了已知輸入 u 以外,其僅與同一時刻之 變數 x 有關聯。3.3.2 將網路模型與受控系統模型結合
在前面的章節,網路模型部分定義出的p Z x( k k M k : ,Sk k M k, : ,Sk1,k M k : 1)(式 3.5 ),可 以注意到當中所出現之變數僅有 Z、x 以及 S,而觀測數據 y 則因為透過網路傳輸而產 生了條件相依的不確定性,其與 x 的關係仍保持為高斯分布,然而 Z 卻是依靠網路參數19 S 所決定之特定 y 的集合。 因此,將整體模型轉為圖形化表示的時候,y 這個隨機變數被隱藏到 Z 當中,而 Z 需要透過 x 與 S 來得到其內容,於是繪出下面的貝氏網路機率模型: 圖 3-4 整體系統之圖形化模型 此模型代表在 k 時刻,在計算的有效視窗內所出現之隨機變數之間的條件相依性。 x 與 S 本身都是屬於馬可夫鏈的變數,只與前一時刻自己本身的狀態有關。而 Z 則是依 該時刻與前一時刻之網路參數 S 來決定收取到的 y,以及參照那些觀測值 y 所對應之時 刻的系統狀態 x,如此可以看到圖形中 Z 有來自 x 與 S 的連線,而 x 與 S 則有來自前一 時刻自身的連線。如此便完成將系統各個方塊做定義與模型化,模型化之後的公式是配 合為估測器所使用、以機率為基礎來描述。同時,圖形化模型則使得各個隨機變數之間 的條件相依性一目了然,方便在估測器之中做進一步公式推導。
20
第四章 估測器設計
在本章節中,將詳述針對網路化控制系統設計之估測器方法,此方法以粒子濾波器 的理論為基礎,因此將會解釋粒子濾波器之理論原理以及基本的處理過程。並且接著根 據前章所闡述之網路化控制系統模型,設計其對應之估測器。除基礎之估測器公式結果 外,此章節還會包含此估測方法之可能改進方式的說明以及以此得到之最終在模擬以及 實驗中所使用之估測器方法。4.1 粒子濾波器
粒子濾波器是一個以機率方法為基礎所發展之估測方法。以下將從其基本原理開 始,並且講述其中一種發展作法-重要性取樣法,說明其推導過程以及運作時之流程。4.1.1 基本原理
令系統狀態為X ,其為一具有馬可夫鏈特性之隨機變數;觀測為k Y 。並且將其各k 表示為如下之機率表示式 1 ~ ( 1 ) ~ ( ) k k k X k k k X k k X p X X Y p Y X (4.1)21
在 k 時間時,給定觀測值
Y Y1, 2,...,Yk
,可將其寫成Y ,則其對應之最佳估測結果1:k
X X1, 2,...,Xk
,或寫作X1:k,為期望值 X1:k Y1:k。將此條件期望值寫作1:k 1:k ( 1:k 1:k) 1:k
X
X p X Y dX (4.2)其中p X( 1:k Y1:k)代表給定Y 時1:k X1:k的條件機率密度函數(conditional probability density function)。若對p X( 1:k Y1:k)進行取樣,令 i m X , m=1,2,…,k 且 i=1,2,…,Ns, 代表 Xm的第 i 個樣本,然後計算取樣帄均值(sample mean)來代替積分,亦即 1: 1: 1: 1: 1: 1: 1 1 ( ) s N i k k k k k k i s X X p X Y dX X N
(4.3) 當其中之N 趨近於無限大時,則其可逼近於實際之期望值條件。 s4.1.2 重要性取樣法
重要性取樣法(Importance Sampling),此方法是由於原先的條件期望值當中之 1: 1: ( k k) p X Y 在實際運算時並不一定是一個可以輕易取樣的機率分佈函數,因此使用另一 容易取樣之機率分佈函數q X( 1:k Y1:k)來取樣,該式稱作 Importance Distribution,或 Proposal Distribution。於是,便將式(4.3) 改寫為 1: 1: 1: 1: 1 1 1: 1: ( ) 1 , ( ) s s i N N k k i i i i k k i i i s k k p X Y X w X w N q X Y
(4.4) 其中 i w 稱為權重, 1 1 s N i i w
,而與(4.3)同樣,當N 趨近於無限大或者足夠大時,便可以s 趨近實際期望值。 並且,利用(4.1)所提之 X 之馬可夫鏈特性,可將p X( 1:k Y1:k)進行如下之拆解22 1: 1: 1: 1: 1 1: 1: 1 1: 1 1: 1: 1 1: 1: 1 1: 1 1: 1 1: 1 1: 1 1 1: 1 1: 1 ( ) ( , ) ( ) ( ) ( , ) ( ) ( ) ( , ) ( ) ( ) ( ) ( ) k k k k k k k k k k k k k k k k k k k k k k k k k k k p X Y p Y X Y p X Y p Y Y p Y X Y p X Y p Y X p X X Y p X Y p Y X p X X p X Y 同時,適當的選用 1: 1: 1 1: 1 1: 1 ( k k) ( k k , k) ( k k ) q X Y q X X Y q X Y 以此將權重改寫 1 1: 1 1: 1 1 1 1 1: 1 1: 1 1 ( ) ( ) ( ) ( ) ( ) ( , ) ( ) ( , ) i i i i i i i k k k k k k k k k k i i k i i i k i i k k k k k k k k p Y X p X X p X Y p Y X p X X w w q X X Y q X Y q X X Y (4.5) 於是,整個粒子濾波器的演算便可以遞迴方式進行,並且由於使用重要性取樣法,此修 改後之粒子濾波器方法亦稱為序列重要性取樣(Sequential Importance Sampling)法。其演 算法流程如下:
Algorithm of Sequential Importance Sampling Method: For Each step k:
1. Draw Xki ~ (q X Xki ki1,Yk) 2. Calculate 1 1 1 ( ) ( ) ( , ) i i i k k k k i i k k i i k k k p Y X p X X w w q X X Y 3. Normalize 1 s i i k k N i k i w w w
4. Estimate 1 s N i i k k k i X w X
並且,在選用重要性分布q X X( k k1,Yk)上,有一簡易的選擇是令其與狀態參數變化分布23 相同,亦即q X X( k k1,Yk) p X X( k k1),此方法又稱為 Bootstrap Filter[10]。若是如此 選擇重要性分布時,權重之更新公式將可簡化為: 1 1 1 1 1 1 1 ( ) ( ) ( ) ( ) ( ) ( , ) ( ) i i i i i i k k k k k k k k i i i i i k k i i k i i k k k k k k k k p Y X p X X p Y X p X X w w w w p Y X q X X Y p X X (4.6)
4.1.3 額外之取樣手段
在實際執行重要性序列取樣法的時候,由於取樣數與樣本數皆是有限的,在連續幾 個遞迴步驟後,會產生一些現象降低演算法的效果,而要應付此些現象,有一些常見之 額外取樣手段,以下將對這些現象與方法做說明。4.1.3.1 重新取樣
隨著遞迴的演算法逐漸進行,每個時刻的權重會被下個時刻所繼承。在一個取樣樣 本數有限以及計算精度有限的實際運作限制下,當演算進行長時間之後,權重越來越往 極少數個樣本集中時,其餘大多數低權重之樣本對期望估測值幾乎沒有影響力,亦即所 謂之「有效點數」降低,此現象亦稱為樣本退化(sample degeneracy),關於有效點數, 可參考[14]。
2 1 1 s eff N i k i N w
(4.7) 當有效點]降低到一定門檻時,此情況便不符合此演算法中大數法則的假設。因此,在 實際進行粒子濾波器方法時,都會需要用到重新取樣的方法。而重新取樣之方法有很多 種[7],在本研究中使用之重新取樣方法為 Multinomial Resampling,此重新取樣之流程24
如下:
Algorithm of Multinomial Resampling For each particle i
1. Draw Ui ~U(0,1], where U is the uniform distribution.
2. jDi U( i), where Di returns the index of the Empirical Function of w . k
3. xk M ki : xk M kj :
After all N particles are assigned s
4. Reset all ki 1 s w N 此重新取樣之方法是為將原先權重集中在少數的幾個樣本,依照其權重比例,重新打散 為N 個樣本,使有效樣本數再度回到s N 。 s 圖 4-1 重新取樣示意圖 如上圖,藍色圓圈代表一個樣本,圓圈的大小代表其權重的高低。左邊的圖代表權重集 中在中間幾個樣本中,其他多數樣本權重極低。而重新取樣後則將原先高權重的單一樣 本依照其權重所占比例複製幾份,並且將樣本之權重重設。
25
4.1.3.2 正規化
而由於重新取樣後之結果,是從將原先過度集中的少數幾個樣本重複進行複製的動 作,因此就結果而言是將樣本的多樣性減少,而當樣本之多樣性太低值時,接下來的取 樣結果仍然會過度集中,也就發生無法正確反映真實分布的情況,使得收斂結果不如預 期,此現象稱為樣本貧化(Sample Impoverishment)現象。 針對此現象有一對應之處理方式,稱之為正規化(Regularization),正規化的基本概 念是:計算重新取樣前之樣本共變異數(sample covariance),並在重新取樣後之樣本上重 新加入此樣本共變異數的一定比例。並且參考[8]獲得建議的比例係數hopt,而實際使用 時再對其進行微調。 Algorithm of Regularization1. Calculated S = sample covariance of k i 1 k
x , and D such that k T
k k k
D D S .
2. After Resampling,
Draw ki~ Epanechnikov Kernel or Gaussian Kernel
1 1
i i i
k k opt k
x x h D k
For Epanechnikov Kernel:
1 ( 4) 8 ( 2)( 4)(2 ) (2 1) x x x n n x x x opt s x n n n n h N n c
For Gaussian Kernel:
1 ( 4) 4 (2 1) x n opt s x h N n x n
c is the volume of the unit n -dimensional sphere. x
26 之擾動後,使原先對應數值較為單調的樣本分布變得更為多樣。 圖 4-2 正規化示意圖 如上圖所示,將原先重新取樣後重複的粒子做微幅的擾動,使其數值並非完全相同,使 重新取樣造成之樣本多樣性減少現象能夠有所改善。
4.2 根據網路化控制系統模型設計估測器
首先,回顧在第三章所推導所得之網路化控制系統模型。其中,受控系統是為線性 系統狀態,其系統狀態x 是一個具有馬可夫鏈性質的隨機變數。 k 1 ~ ( 1 , ) ~ ( , ) k k k x k k k k x k k k x x Ax Bu Q y y Cx Du R N N (4.8) 而感測器輸出y ,透過網路傳送至估測器端。 k , , 1 , , , , k i k i k i k i S R S D k M i k Z y or S R i k (4.9) 每個時間 k 在估測器端都會根據個別資訊封包之狀態來決定確實被收到之觀測值,該時 間內收到之資訊集合稱為Z 。 k : , : 1, : 1 , , 1, 1 ( , , ) ( , ) ( , , ) M k k M k k k M k k k M k k k k k k i k i k k i k k i i p Z x S S p y x S p y x S S
(4.10) 可以注意到,在網路化控制系統當中,系統之輸出的定義已經與原先在粒子濾波器27
當中所推導之定義有些微之不同。因此在進行估測器的演算法時,其計算所使用之公式 必頇經過重新推導與檢查,而此時便是在第三章結尾所獲得之圖形式表示模型帶來益處 的時候,配合貝式球(Bayes Ball Algorithm)的規則[9],在判斷各個隨機變數間的條件相 依性的相當有助益。
4.2.1 使用網路化控制系統模型公式推導
首先,從 1: 1: 1: 1: 1: 1: 1 1 ( ) s N i k k k k k k i s X X p X Y dX X N
當中之p X( 1:k Y1:k)開始,在網路化控 制系統之模型中,由於在經過網路後所得觀測資訊是 Z,因此將p X( 1:k Y1:k)寫作 1: 1: ( k k) p x Z (4.11) 並且,同樣利用得到(4.5)之前置處理方式,由於 x 是馬可夫鏈隨機變數 1: 1: 1: 1: 1 1: 1: 1 1: 1 1: 1: 1 1: 1: 1 1: 1: 1 1: 1 1: 1 1: 1 1: 1 1: 1: 1 1 1: 1 1: 1 ( ) ( , ) ( ) ( ) ( , ) ( ) ( , ) ( , ) ( ) ( , ) ( ) ( ) k k k k k k k k k k k k k k k k k k k k k k k k k k k k k p x Z p Z x Z p x Z p Z Z p Z x Z p x Z p Z x Z p x x Z p x Z p Z x Z p x x p x Z (4.12) 並且選用重要性分布q x( 1:k Z1:k)其符合特性 1: 1: 1 1: 1 1: 1 ( k k) ( k k , k) ( k k ) q x Z q x x Z q x Z (4.13) 於是28 1: 1: 1: 1: 1: 1: 1 1 1: 1 1: 1 1 1: 1 1: 1 1: 1: 1 1 1 1 ( ) ( ) ( , ) ( ) ( ) ( , ) ( ) ( , ) ( ) ( , ) i k k i k i k k i i i i k k k k k k k i i i k k k k k i i i k k k k k i k i i k k k p x Z w q x Z p Z x Z p x x p x Z q x x Z q x Z p Z x Z p x x w q x x Z (4.14) 注意到p Z x( k 1:ik,Z1:k1)並不是如同原始序列重要性取樣濾波器當中出現之p Y X( k ki),其 較為複雜,因為其中出現的 Z 這個複合型的隨機變數的關係,為了實際運算時使用,必 頇設法將其化為常見、已定義的機率分布。由於考慮到運作時之有效視窗大小為 M,如 第三章所提,此 M 代表估測器視多久以前之資料有計算價值,因此令 1: 1: 1 ( k k, k ) p Z x Z p Z x( k k M k : ,Zk M k : 1) (4.15) 參考(4.8)之定義,使用邊際化(Marginize)方式補上此處所缺少之網路參數 S , , 1 : : : 1 : : 1 , : 1, : 1 : , : 1, : 1 : : : 1 : : 1 , : 1, ( , ) ( , , , ,..., ) ... ( , ,..., , ) ( , , , ... k k k k k M k M k k M k k M k k k M k k M k k k M k k k M k k M k M S S S k k M k k k M k k M k M k M k k M k k k M k k M k k k M k k k p Z x Z p Z x Z S S S p S S S x Z p Z x Z S S
, , 1 : : 1 : , : 1, : 1 : : 1 ,..., ) ( , ,..., ) k k k k k M k M M k k M k M S S S k k M k k k M k k M k M k M k S p S S S Z
其中p Z x( k k M k : ,Zk M k :1,Sk k M k, : ,Sk1,k M k : 1,...,Sk M k M : ),根據圖形式模型,當給予 : , , : , 1, : 1,..., : k M k k k M k k k M k k M k M x S S S 時,Z 與k Zk M k : 1彼此不相關,因此 : : 1 ( k k M k, k M k ) p Z x Z , , 1 : : , : 1, : 1 : , : 1, : 1 : : 1 ( , , ,..., ) ... ( , ,..., ) k k k k k M k M k k M k k k M k k k M k k M k M S S S k k M k k k M k k M k M k M k p Z x S S S p S S S Z
若將第三章定義之(3.6)式代入其中,則可得到 : : 1 ( k k M k, k M k ) p Z x Z , , 1 : , , 1, 1 , : 1, : 1 : : 1 ( , ) ( , , ) ... ( , ,..., ) k k k k k M k M M k k k k k i k i k k i k k i i S S S k k M k k k M k k M k M k M k p y x S p y x S S p S S S Z
(4.16)29 得到此式後,便可在確定Z 之後進行計算。 k
4.2.2 網路參數之處理
在上面最後所得到之(4.14)式,其中出現之p S( k k M k, : ,Sk1,k M k : 1,...,Sk M k M : Zk M k : 1) 項目,由於當Zk M k : 確定時,可以透過其中所包含之y來將對應之 , : , 1, : 1,..., : k k M k k k M k k M k M S S S 分成是 「R」還是「D 或 L」兩種情形。 並且, , , 1, 1 ( , ) ( , , ) M k k k k k i k i k k i k k i i p y x S p y x S S
在定義中,若是確實有收到某一時間 之資料y ,然而對應之i Sk i,,Sk1,k i 卻為 D 或 L 時,則出現 * ( )yi ,使得整個項目化為 0。 因此只有當全部之網路參數 S 與 Z 當中顯示之 y 的情況相符合時,稱這個網路參數組合 為S,以及此時有收到的 y 對應的 x 為x' ,舉例而言,當Zk {y yk, k1}時,使 , , 1, 1 ( , ) ( , , ) M k k k k k i k i k k i k k i i p y x S p y x S S
不等於 0 的 S 組合其中必含有 , , , 1 , 1, 1 k k k k k k S R S R S D,並以此可得到 , 1 1 , 1 1, 1 1 1 ( , ) ( , , ) ( , ) ( , ) k k k k k k k k k k k k k k p y x S R p y x S R S D y Cx R y Cx R N N 將 y 值帶入則可將其轉為x' 的高斯分布相乘,亦即 1 1 1 1 1 1 1 1 ( , ) ( , ) ( , ) ( , ) k k k k T T k k k k y Cx R y Cx R x C y C R C x C y C R C N N N N 將此結果表示為 ( 'p x u ,)。 於是,將這個非 0 的 ( 'p x u ,)高斯 PDF 提出,也就相當於:30 , , 1 : : : 1 , , 1, 1 , : 1, : 1 : : 1 : 1 : ( , ) ( , ) ( , , ) ... ( , ,..., ) 0 ... ( ' , ) ( ) ... ( ' , ) ( k k k k k M k M k k M k k M k M k k k k k i k i k k i k k i i S S S k k M k k k M k k M k M k M k k M k k M k p Z x Z p y x S p y x S S p S S S Z p x u p S Z p x u p S Z
1) ... 0 ... , , 1 : : 1 ( ' , ) ... ( ) k k k k k M k M k M k S S S p x u p S Z
(4.17) 可以發現,後半部網路參數的部分與樣本x'無關。 因此在權重的標準化時 , , 1 : , , 1 : 1 : 1 1 1 : 1 1 1 1 ( ' , ) ... ( ) ( , ) ( ' , ) ... ( ) ( , ) s k k k k k M k M s k k k k k M k M i i k k N i k i i k M k S S S i k i i k k k i k M k N S S S i k i i i k k k w w w p x u p S Z w q x x Z p x u p S Z w q x x Z
, , 1 : , , 1 : 1 : 1 1 : 1 1 1 1 1 1 1 ( ' , ) ... ( ) ( , ) ... ( ) ( ' , ) ( , ) ( ' , ) ( , ) ( k k k k k M k M s k k k k k M k M i i k i i k M k S S S k k k i N k M k i S S S k i i i k k k i i k i i k k k i k p x u w p S Z q x x Z p S Z p x u w q x x Z p x u w q x x Z p w
1 1 ' , ) ( , ) s i N i i i k k k x u q x x Z
(4.18) 可以發現,網路參數 S 的狀態變化機率實際上並不會包含在計算當中,換句話說,估測 器在計算權重時,注重的是收取到之資料內容與該資料之延遲時間,在某一資料尚未被 收取到時,估測器無法對該資料做任何利用。31
4.3 改進估測器方法
雖然已經將網路化控制系統之模型套用到粒子濾波器上,但是此方式仍然存有許多 改進空間。如重要性分布(Importance Distribution)的選取、演算公式的修改等,以下逐 步對各個手段說明。4.3.1 重要性分布的選取
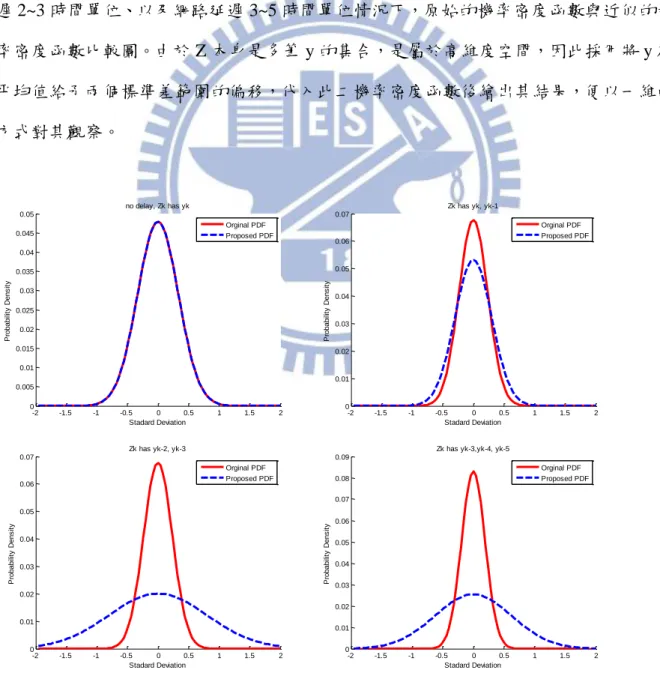
在粒子濾波器中,重要性分布的功能是用來抽取樣本估測值,而當抽取到的樣本範 圍越接近真實分布時,自然會增加演算法所得之估測結果的收斂速度。 圖 4-3 重要性分布選取示意圖 上圖是一個簡易的示意圖,使用實線來代表真實分布,虛線是選取的重要性分布,其中 四張圖各代表的情形說明如下: 1:雖然真實分布複雜,但是選取的重要性分布仍適當涵蓋了大部分的真實分布,並且32 也沒有過度地包含到多餘的範圍,算是適當的分布。 2:選取的重要性分布無法確實表達到全部的真實分布,當估測目標在特定範圍內時可 能使得收斂速度較慢。 3:選取的重要性分布涵蓋太多多餘的範圍,大部分的取樣落在真實分布之外,使得收 斂較慢,假若取樣都落在真實範圍之外時更會使得情況惡化。 4:選取的重要性分布範圍太小,使得取樣過於集中,無法確實反映真實的分布,在系 統不準確性高時收斂效果緩慢。 當設定q X X( k k1,Yk) p X X( k k1)時,由於取樣時僅僅只依靠Xk1,假若模型之不 準確性較大,或者複雜度較高時,可能取樣出來的X 的範圍並不能有效涵蓋住真實的k k X 分布範圍,使得演算法沒有辦法迅速收斂到較佳的結果。 配合網路化控制系統模型所得之濾波器當中,在套用下一章加熱系統模型進行數據 模擬時,由於系統階數較高,使用q x x( k k1,Zk) p x x( k k1)時無法確實取樣到足夠多且 接近真實系統狀態的樣本,因此遭遇收斂結果緩慢之情形。 於是,設想一重要性取樣分布 1 1 ( k k , k) ( k k , k) q x x Z p x x Z (4.17) 此分布由於參考到當前收取到的資料來取樣,因此理論上新的取樣值會朝向最新的觀測 結果靠攏,使得取樣值更能落在真實分布內。 1 1 1 1 1 ( , ) ( , ) ( , ) ( ) ( ) k k k k k k k k k k k k k q x x Z p x x Z p Z x x p x x p Z x