A Semantic-based Concept Clustering Mechanism for Chinese News Ontology Construction
7
0
0
全文
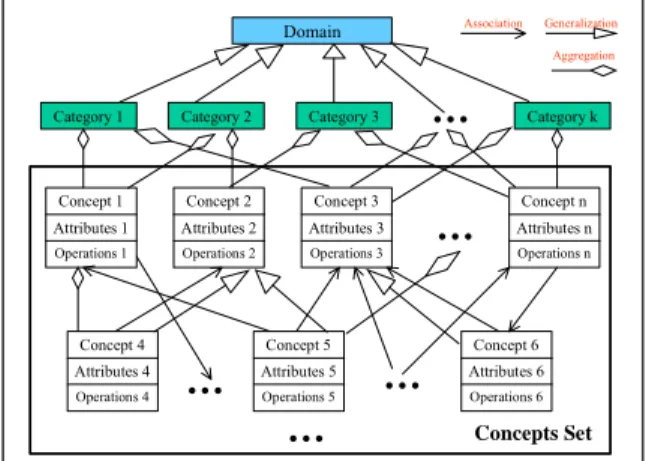
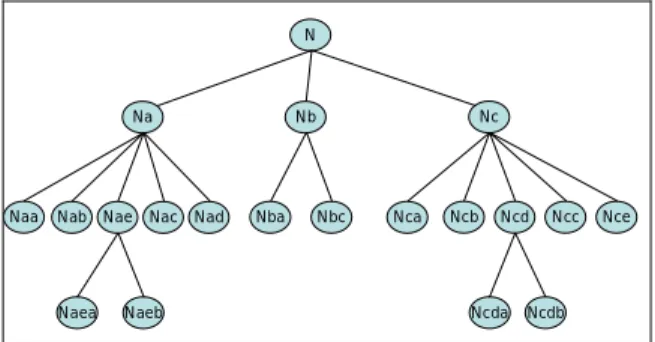
(2) constructed for Chinese News document, so its domain name is Chinese News. Category The second layer is the categories of domain ontology. Each category inherits the domain properties from the domain knowledge, so the relationship between domain and category is a generalization. Furthermore, we also define the aggregation of relationship between each category and concepts. There are seven categories of Chinese News domain ontology in this paper. They are “Political( 政 治 焦 點 )”, “International( 國 際 要 聞 )”, “Finance( 股 市 財 經 )”, “Cross-Strait( 兩 岸 風 雲 )”, “Societal( 社 會 地 方 )”, “Entertainment(運動娛樂)” and “Life(生活新知)”. Concept, Attribute and Operation The following layers are the architecture of the concept hierarchy. We use the object-oriented approach to represent the ontology architecture. We treat each concept node in this ontology as a class, so this structure mode can be treated as a class diagram. Therefore, each concept node contains its concept name, attributes and operations. Furthermore, the relationships between the concepts may be association, generalization or aggregation.. First, the specific class News documents will be previously tagged resulting in each word with its appropriate part-of-speech tag. The CKIP will be used in this step. Second, in refining tagging step, we refer to Academia Sinica Balanced Corpus and Chinese Electronic Dictionary to refine the part-of-speech tags. Therefore, we will have sufficient knowledge in Chinese part-of-speech to analyze what are the useful features in ontology construction. In third step, the stop word filer module will select the useful nouns and verbs terms as the candidate features after our analysis. The fourth step, the term analyzer will analyze the document frequency to help us to select important or representative words from a specific class documents. Concepts clustering play a major role in automatic ontology construction. So, in fifth step, we will evaluate the conceptual resonance of two Chinese terms based on parallel fuzzy inference mechanism [6]. In Chinese terms analysis, we select the more meaningful Chinese nouns in each document such as: Na (普通名詞), Nb (專有名詞) and Nc (地方名詞). Moreover, we filter the un-meaningful nouns such as: Nd (時間名詞), Ne (定詞), Nf (量詞), Ng (方位詞) and Nh (代名詞) for the Chinese News classification.. 3 A Semantic-based Concept Clustering Mechanism for Domain Ontology Construction In this paper, we develop an automatic approach to construct the semantic concepts for Chinese News ontology. First, we use natural language processing technologies to deal with the Chinese News documents that we gathered from WWW. In documents pre-processing, we propose several technologies that contain part-of-speech tagging, refining tagging, stop word filter and term analyzer. We also use some tools in this task such as CKIP [3], Academia Sinica Balanced Corpus [4] and Chinese Electronic Dictionary [5] that help us to deal with documents. Then we will get the Chinese-Terms features to construct Chinese News domain ontology. In addition, the concepts clustering approach based on fuzzy compatibility relation is also proposed. Figure 2 shows the construction architecture for Chinese News ontology. There are several main modules and databases in this architecture.. 4 Evaluation of Conceptual Resonance of Two Chinese Terms for Concept Clustering Conceptual resonance means the degree of the same concept between two different terms. Hence, two Chinese terms will have a higher possibility with the same concept if they have stronger conceptual resonance strength. In this paper, we proposed four fuzzy variables for conceptual resonance strength of any two Chinese terms, they are resonance in part-of-speech, resonance in term vocabulary, resonance in term association and resonance in common term association. Now we describe them as follows. 4.1 Resonance in Part-of-speech The first fuzzy variable of conceptual resonance is resonance in part-of-speech (POS). First we define the tagging tree according the POS. Figure 3 shows the tagging tree structure that will be used to compute the resonance of POS for any two Chinese terms.. The Flow Chart of Chinese News Ontology Construction Specific Class News Documents (Training Data). Part-of-speech Tagger (CKIP). Academia Sinica Balanced Corpus. Data Mining Association Rule Result. Refining Tagging. Segmentation Standard Dictionary. N. Stop Word Filter. Chinese Electronic Dictionary. Concepts Clustering Processing. Nouns Set. Term Analyzer. Naa. Academia Sinica Balanced Corpus. N ae. Nac. N ad. Nba. N bc. N ca. Ncb. N cd. N cc. Nce. Concepts Set. N aea. Ontology Construction Procedure Chinese Electronic Dictionary. N ab. Nc. Nb. Na. Verbs Set. Concepts Construction Agent. Operations Construction Agent. Attributes Construction Agent. Relations Construction Agent. N aeb. Ncda. Ncdb. Figure 3. The Framework of Tagging Tree Diagram. Domain Ontology. The resonance will be strong when the path. Figure 2. The Flow Chart of Chinese News Ontology Construction.. 2.
(3) distance of any two Chinese terms is near. For example, there are two terms with their POS are “電腦 computer (Nab)” and “ 軟 體 software (Nac)”, and the path distance of two terms is 2 (Nab -> Na -> Nac).. (Nca), 陳水扁(President Chen) (Nb)}. In the human’s viewpoint, these three terms represent similar concept so they will be clustered into together. But in the term’s knowledge viewpoint, just only “總統(President)” and “總統府(The Office of the President)” two terms will be clustered in the same concept, and the term “陳水扁 (President Chen)” will be not clustered into the concept { 總 統 (President), 總 統 府 (The Office of the President)}. So we proposed the evaluative method to decide the strength of resonance in term association. The strength is decided by the confidence value between two terms, so we adopt the average of confidence to be the term association strength. For example, we adopt the two terms {總統(Nab), 陳水扁 (Nb)} from the News category “Political(政治焦點)”. The confidence of (總統 -> 陳水扁) is 0.84, and the confidence of (陳水扁 -> 總統) is 0.80. Therefore, the strength of resonance in term association is (0.84+0.80)/2 = 0.82.. 4.2 Resonance in Term Vocabulary In the viewpoint of characteristic of Chinese language, any two terms with more common words, they will be more similar in semantic meaning. For example, each Chinese term in the terms set {民進黨, 民 進 黨 團 , 民 主 進 步 黨 } has similar semantic meaning since they are composed with the common words “民”, “進” and “黨”. Besides, we also consider another characteristic of Chinese terms in side of term vocabulary. It assumes that because almost every Chinese word is a morpheme with its own meaning, very often terms having the same starting or ending word share some common linguistic properties and, thus, can form a term cluster [8][9]. The good examples of starting and ending word are following two terms sets: { 星 期 一 (Monday), 星 期 六 (Saturday), 星期日 (Sunday)} and {昨天 (yesterday), 明天 (tomorrow), 今天 (today), 每天 (everyday)}. We propose the evaluative approach of common words and common starting/ending word to decide the similarity of resonance in term vocabulary as follows. We define strength of similarity be the count of common words number and increasing 0.5 extra strength if they have common starting or ending word. We give an example to evaluate the strength of two terms “民進黨團” and “民主進步黨” as follows. The evaluation method is divided into two parts “evaluation in common words” and “evaluation in common starting or ending word”. They have three common words “民”, “進” and “黨”, and a common starting word “民”. So the total strength is 3.5.. 4.4 Resonance in Common Term Association The common term association represents the strength of two terms according to common term numbers in their corresponding documents. For any two Chinese terms with the same common words or starting/ending words, they may not have the similar meaning. For example, consider the three Chinese terms “ 美 國 (U.S.A.)”, “美 方 (U.S.A.)” and “ 警 方 (police)”, the Chinese term “ 美 方 (U.S.A.)” has common starting word “美” with “美國” and also has common ending word “方” with “警方(police)”. The common document terms with a specific threshold of confidence for “美國”, “美方” and “警方” are as follows: 美 國 (U.S.A.) -> { 白 宮 (White House), 布 希 (Bush), 紐約(New York)} 美 方 (U.S.A.) -> { 白 宮 (White House), 布 希 (Bush), 五角大廈(Pentagon)} 警 方 (police) -> { 警 員 (policeman), 刑 事 組 (criminal investigation), 分局(police station)} Therefore, the common terms for {美國(U.S.A.), 美方 (U.S.A.)} and {警方(police), 美方(U.S.A.)} are as follows: { 美國 (U.S.A.), 美方 (U.S.A.)} -> { 白宮 (White House), 布希(Bush)}, the strength is 2. { 警 方 (police), 美 方 (U.S.A.)} -> Null, the strength is 0. Therefore the term pair { 美 國 (U.S.A.), 美 方 (U.S.A.)} has stronger resonance strength than the term pair {警方(police), 美方(U.S.A.)} in common term association.. 4.3 Resonance in Term Association A large amount of previous research has focused on how to best cluster similar terms together. The proposed methods can be roughly grouped into two categories: knowledge based clustering and data-driven clustering [9]. In Section 4.1 and 4.2, the information for concepts clustering we just focus on term’s knowledge. However, we believe the information of terms knowledge themselves isn’t still enough for concepts clustering. Sometimes, the terms have the similar meaning and without any common properties of their knowledge, hence we must analyze their documents. We used the confidence value between two terms to decide the strength of term relation. The terms with large confidence mean that they have strong relationship and further could be combined into one concept. It will be supplement information for concepts clustering when terms have insufficient in their knowledge but they are similar. Here, we give an example of terms set {總統 (President) (Nab), 總統府(The Office of the President). 5 A Parallel Fuzzy Inference Network Semantic-based Concept Clustering A parallel fuzzy inference network semantic-based concept clustering is proposed in section. The fuzzy variables for computing 3. for for this the.
(4) conceptual resonance of any two Chinese terms will be discussed in the following subsections.. TA_Low. Membership Degree. 0. min TA. maxTA + minTA 2. min TA + 5 p. max TA − 5 p. max TA. The strength of term association between two terms p=. Here. maxTA − minTA 100. Figure 6. The Membership Function of Term Association Strength.. Figure 7 shows the membership functions of fuzzy sets {CTA_Low, CTA_Medium, CTA_High} for fuzzy variable CTA strength. There are three linguistic terms including CTA_Low, CTA_Medium and CTA_High defined in the fuzzy variables. CTA_Low. Membership Degree. POS_High. TA_High. 1. 5.1 Aggregate Term Resonance with Parallel Fuzzy Inference Network In this subsection, we describe how to aggregate four input fuzzy variables into one output fuzzy variable for computing the conceptual resonance strength for each term pair. Now we define the fuzzy variables and theirs linguistic terms as follows. There are four input fuzzy variables including Part-of-speech Similarity (POS), Term-Vocabulary Similarity (TV), Term-Association Strength (TA) and Common Term-Association Strength (CTA), and one output fuzzy variable Conceptual Resonance Strength (CRS) used in this architecture. Figure 4 shows the fuzzy sets {POS_Low, POS_High} for fuzzy variable POS similarity. There are two linguistic terms POS_Low and POS_High defined in the fuzzy variables. Membership Degree. TA_Medium. CTA_Medium. CTA_High. 1. POS_Low. 1. 0. maxCTA + minCTA 2. min CTA + 5 p. min CTA. max CTA − 5 p. max CTA. The numbers of common term between two terms. 0 min POS min POS + 5 p. max POS − 5 p. max POS. Here. The path distance between two tags of term. Here. p=. Figure 8 shows the membership functions of fuzzy sets {CRS_Very Low, CRS_Low, CRS_Medium, CRS_High, CRS_Very High} for fuzzy variable CRS strength. There are five linguistic terms including CRS_Very Low, CRS_Low, CRS_Medium, CRS_High and CRS_Very High defined in the fuzzy variables.. Figure 5 shows the membership functions of fuzzy sets {TV_Low, TV_High} for fuzzy variable TV similarity. There are two linguistic terms TV_Low and TV_High defined in the fuzzy variable. TV_Low. max CTA − minCTA 100. Figure 7. The Membership Function of Term Association Strength.. max POS − min POS 100. Figure 4. The Membership Function of Part-of-speech Similarity.. Membership Degree. p=. TV_High CRS_Very Low. Membership Degree. CRS_Low CRS_Medium. CRS_High. CRS_Very High. 1. 1. 0 min TV. min TV + 5 p. max TV − 5 p. 0. max TV. The path distance between two tags of term Here. p=. min CRS. min. CRS. maxCRS + minCRS max CRS − 5 p max CRS 2 3 maxCRS + minCRS − 10 p. + 5p. maxCRS + 3 minCRS + 10 p 4. 4. The crisp value of conceptual resonance between two terms. max TV − minTV 100. Here. p=. maxCRS − minCRS 100. Figure 5. The Membership Function of Term Vocabulary Similarity.. Figure 8. The Membership Function of Conceptual Resonance Strength.. The membership function of fuzzy sets {TA_Low, TA_Medium, TA_High} for fuzzy variable TA strength are show in figure 6. There are three linguistic terms including TA_Low, TA_Medium and TA_High defined in the fuzzy variables.. After describing the fuzzy variables for computing the conceptual resonance of any Chinese term pair, we will propose the parallel fuzzy inference architecture for semantic concept clustering. Figure 9 shows the architecture.. 4.
(5) y. 0 x<a ( x − a ) /(b − a ) a ≤ x ≤ b b≤x≤c f trapezoidal ( x : a , b, c ) = 1 ( d − x ) /( d − c ) c ≤ x < d x≥d 0. fc(•) Conclusion Layer. f triangular j ≠ 1 or n (3) f ij1 = f j = 1 or n trapezoida l where n is the numbers of linguistic term for i-th linguistic node. Therefore, for each element µ ij1 of. Rule Layer. Premise Layer. x2. x1. x3. x4. Figure 9. A Parallel Fuzzy Inference Architecture for Semantic-based Concept Clustering.. µ1. output vector 1 ij. p. f r = ∑ wi µi. (5). i =1. Conclusion layer: The third layer is called conclusion layer. This layer is also composed of a set of fuzzy linguistic nodes. The fuzzy linguistic node can also operate in a reverse mode, called conclusion node. It should be noted that the reverse mode is only invoked in the rule inference phase. At this phase, the links representing linguistic term set become incoming links, while the link representing base variable becomes outgoing link. In the reverse mode, fuzzy linguistic nodes are responsible for making conclusion and defuzzification. At the end of inference process, defuzzification may be necessary. In our model, the final output y is the crisp value that is produced by combining all inference results with their firing strength. Eq. 6 represents the formula of defuzzification. r. CrispOutput =. input value of ith linguistic node. Then, the output vector of the premise layer will be 2. i =1 j =1 r c. k ij. ∑∑ y i =1 j =1. wijkVij k ij. (6). wijk. n. n. uij1 is the matching degree of the j-th linguistic. Where w k. term in the i-th condition node. In this paper, triangular function and trapezoidal function are adopted as the membership functions of linguistic terms. For triangular and trapezoidal normal membership functions, Eq. 1 and Eq. 2 can be realized by the following formula: x<a 0 ( x − a ) /(b − a ) a ≤ x ≤ b f triangle ( x : a, b, c) = b≤ x≤c (c − x ) /( c − b) x>c 0. c. ∑∑ y. 1 1 µ 1 = (( u11 , u 121 ,..., u 1N 1 ), ( u12 , u 122 ,..., u 1N 2 ),..., (u11n , u 12 n ,..., u 1N n )) 1. is. (4) µ = f ( x) Rule layer: The second layer is called as rule layer where each node is a rule node to represent a fuzzy rule. The links in this layer are used to perform precondition matching of fuzzy logic rules. And the output of a rule node in rule layer will be linked with associated linguistic nodes in the third layer. In our model, the rules are defined by expert’s knowledge previously. In rule node, f r function provides the net input for this node like the Eq. 5. 1 ij. This structure is a three-layered network which can be constructed by directly mapping from a set of specific fuzzy rules, or learned incrementally from a set of training patterns. Here, the rules have been defined by expert’s knowledge. The structure consists of premise layer, rule layer and conclusion layer. There are two kinds of nodes in this model: fuzzy linguistic nodes and rule nodes. A fuzzy linguistic node represents a fuzzy variable and manipulates the information related to that linguistic variable. A rule node represents a rule and decides the final firing strength of that rule during inferring. The premise layer performs the first inference step to compute matching degrees. The conclusion layer is responsible for making conclusion and defuzzification. Now, we will describe each layer in details. Premise layer: The first layer is called as premise layer, which is used to represent the premise part of the fuzzy system we describe. Each fuzzy variable appearing in the premise part is represented with a condition node. Each of the outputs of the condition node is connected to some nodes in the second layer to constitute a condition specified in some rules. Note that the output links must be emitted from proper linguistic terms as specified in fuzzy rules. In other words, a linguistic node is a polymorphic object that can be viewed from different aspects by different fuzzy rules. The premise layer performs the first inference step to compute matching degrees. The input vector is x = ( x1 , x 2 ,..., x n ) , where xi is denoted as the. where. (2). ∑µ , = 1 i. i =1. n. Vij is the center of gravity, r is the numbers of corresponding rule nodes, c is the numbers of linguistic terms of output node, n is the numbers of the fuzzy variable in premise layer and k represents in k-th layer. Therefore in our case, the value of r, c, n and k are 36, 5, 4 and 2.. (1). 5.2 Concepts Clustering Based on Fuzzy Compatibility Relation Approach 5.
(6) After fuzzy inference and defuzzification processing, we will get the crisp values of conceptual resonance for all term pairs. We consider the conceptual resonance of terms as fuzzy compatibility relation, because they satisfied the properties of reflexive and symmetric. Therefore, the problem of concepts clustering is equal to find all classes of maximal α-compatibles with fuzzy compatibility relation. Here, α represents a specified membership degree of fuzzy compatibility relation. Then we propose the concepts clustering algorithm based on fuzzy compatibility relation approach as follows: Concept Clustering Algorithm based on Fuzzy Compatibility Relation Approach Input: 1. Fuzzy Compatibility Membership Degree α 2. The Term Set X = {Term[1], Term[2],..., Term[n ]} with n Terms for the Specific Category News, and it’s Corresponding Fuzzy Conceptual Resonance Matrix A = [α ] . ij. Then Break Step 1.7.4: If flag = 0 Then Step 1.7.4.1: Final _ Concept _ Set ← Final _ Concept _ Set ∪ p k. Step 1.7.4.2: Temp _ Set ← Temp _ Set ∪ {P ( p k ) − p k − Φ}. /* P( p ) Denotes the power set of pk */ Step 2: End. k. In our approach, how to decide α is very important. The α value will influence the number of concepts and the compatibility degree of terms for specific concept. The lower α value will form much number of concepts, and strengthen the compatibility degree of terms for specific concept. Therefore, we must decide the scope of number of concepts that are suitable for each News category first. Here, prune-and-search strategy will be used in the problem of α decision. In beginning, we adopt the median of conceptual resonance as the α value. Then concepts will be formed by α . According to the number of concepts, we will adjust α until it satisfies the scope we decide for each News category.. n×n. Output: The Final_Concepts_Set, that is the set of Domain Ontology Concepts. Method: Step 1: For i ← 1 to n Step 1.1: Seti ← Φ /* Set i denotes the Term Set regarding with Term[i ] , and all the compatibility membership degree α ij of the terms in Seti are not. 6 Experiment Results and Analysis In this section, some experiment are made to test the performance of the proposed approach. There are seven categories of News including “Political” (政治焦 點), “International” (國際要聞), “Finance” (股市財經), “Cross-Strait” ( 兩 岸風雲 ), “Societal” (社 會 地方 ), “Entertainment” (運動娛樂) and “Life” (生活新知) used for the experiments. Those documents are gathered from China Times website and the period is between May 2001 from March 2002. After the tagging by CKIP and refining tagging processing, the stop word filter module will filter the stop words from documents. Table 1 lists the filter percent and remaining terms for each News category.. less than α */ Step 1.2: S ← 0 /* S denotes the cardinality of Set */ Step 1.3: Set ← Set ∪ {Term[i]} Step 1.4: Temp _ Set ← Φ , /* Temp _ Set denotes the set of existing Concepts subsets*/ Step 1.5: For j ← i to n Step 1.5.1: If α ij ≥ α Then Step 1.5.1.1: Set = Set ∪ {Term[ j ]} Step 1.5.1.2: S ← S + 1 Step 1.6: Determine the power set pk of Set . Step 1.6.1: S ← | p | , where k = 1,...,2 S i. i. i. i. i. i. i. i. Table 1. The Experimental Results for the Proposed Filter. 政治焦點 國際要聞 股市財經 News Category (Political) (International) (Finance) Number of Doc. 11277 13542 22756 All Terms 25448 25484 18960 Remaining 17091 15367 11346 Terms Filter Percent 32.84% 39.70% 40.16%. i. i. i. pk. k. /* S p Denotes the cardinality of pk */ Step 1.7: For k ← 1 to 2 Step 1.7.1: If p k ∈ Temp _ Set Continue Step 1.7.2: flag ← 0 Step 1.7.3: For l ← 1 to S p − 1 k. Si. 兩岸風雲 (Cross-Strait) 6040 22856 15085 34.00%. k. Step 1.7.3.1: For m ← l + 1 to S pk Step 1.7.3.1.1: n ← Index of p k [l ] in X q ← Index of p k [m ] in X Step 1.7.3.1.2: If α nq < α. 社會地方 (Societal) 13441 35846 24813 30.78%. 運動娛樂 (Entertainment) 5974 24178 16543 31.58%. 生活新知 (Life) 9279 35932 24287 32.41%. After stop word filter, we can select the features from remaining terms, then cluster the semantic concept for ontology construction. Next, we will analyze the results of conceptual resonance for any Chinese term pair. Figure 10(a) shows the partial result of conceptual resonance for the News category “Political” (政治焦點) with highest. Then flag ← 1 and Break Step 1.7.3.2: If flag = 1 6.
(7) values. Notice that each term pair not only has strong similarity in term knowledge (POS and TV) but also strong strength in term association and common term association. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20. (民主進步黨,民進黨) (親民黨主席,親民黨) (國民黨主席,國民黨) (民進黨主席,民進黨) (親民黨主席,國民黨主席) (行政院長,行政院) (民進黨主席,民主進步黨) (立院,立法院) (立法院,立法院長) (民進黨團,民進黨) (台北市,台北市長) (民進黨籍,民進黨) (民進黨主席,國民黨主席) (高雄市,高雄) (台聯,台灣團結聯盟) (國民黨,民進黨) (國民黨,國民黨籍) (親民黨主席,民進黨主席) (民進黨籍,國民黨籍) (民進黨主席,黨主席). 0.595481543 0.594101448 0.587348993 0.581987023 0.577182427 0.571720293 0.571574542 0.56774317 0.558938037 0.558824035 0.557260479 0.555527542 0.554741061 0.553642597 0.553602148 0.551060166 0.547553789 0.54062093 0.53928488 0.538797148. * * *. * * *. *. 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46. (國民黨主席,連戰) (國民黨,親民黨) (民進黨籍,民進黨團) (副秘書長,秘書長) (親民黨主席,宋楚瑜) (立委,立法委員) (國防部,國防) (馬英九,台北市長) (親民黨,民進黨) (委員會,委員) (縣市長,縣市) (政府,中央政府) (呂秀蓮,副總統) (民主進步黨,民進黨團) (李登輝,前總統) (陳水扁,總統) (副院長,立法院長) (民主進步黨,國民黨) (總統府,總統) (執政黨,政黨) (王金平,立法院長). similarity of any Chinese term pair is presented. By the experimental results, the proposed approach can effectively cluster the semantic concept for the Chinese terms. In the future, we will extend our approach to help construct domain ontology more efficient. Moreover, the Chinese/English documents will also be considered to construct more complex domain ontology.. 0.534303235 0.534003082 0.5338768 0.531714804 0.530113977 0.52974897 0.529134478 0.522650369 0.522529795 0.522146828 0.520918138 0.518259497 0.51637767 0.516346569 0.515308468 0.513920884 0.512207578 0.511493131 0.507264737 0.505084742 0.504385767. Reference [1]. (a) (b) Figure 10. The Partial Result of Conceptual Resonance for “Political” (政治焦點) with Highest Values.. [2] [3]. Figure 10(b) shows the partial result of conceptual resonance for “Political(政治焦點)”, and each term pair still has higher value. The term pairs marked by asterisks represent that they have stronger strength in TA or CTA but without strong similarity in POS or TV. Table 2 shows the results of concept clustering with various α for the News category “Life” (生活新知).. [4] [5] [6]. Table 2. The Analysis of Various α Values for Each News Category. Concept 1 教育 教師 教授 教育部長 α=0.435 Concept 2 學校 學生 學術 大學 台灣大學 Concept 3 學者 學術 大學 教授 教育 教師 教授 教育部長 學生 學校 Concept 1 教育部 Concept 2 學校 學生 學術 大學 台灣大學 校長 α=0.417 Concept 3 學者 學術 大學 教授 研究 Concept 4 學校 家長 老師 學生 Concept 5 科學 學術 大學 Concept 6 學者 科學家 專家 教育 教師 教授 教育部長 學生 學校 Concept 1 教育部 大學 課程 資源 學校 學生 學術 大學 台灣大學 校長 Concept 2 院長 教授 Concept 3 學者 學術 大學 教授 研究 成果 領域 學校 家長 老師 學生 教育部長 教育 α=0.397 Concept 4 部 高中 大學 Concept 5 科學 學術 大學 研究所 研究 Concept 6 學者 專家 科學家 科學 Concept 7 學者 科學 學生 生物 領域 學術 大學 Concept 8 成果 研究 科學 領域 學術 Concept 9 技術 研究 領域 應用 產業. [7]. [8]. [9]. Notice that the concepts with higher α value are the subset of the concepts with lower α value. That is, the lower α value will generate the semantic concept with more Chinese terms. 7 Conclusions A semantic-based concept clustering mechanism for Chinese News ontology construction is propoed in this paper. The structure of the object-oriented domain ontology is also proposed. In addition, the CKIP provided by Academia Sinica is embedded for Chinese natural language processing. Furthermore, a parallel fuzzy inference mechanism for computing the 7. P.E. van der Vet and N.J.I. Mars, "Bottom-Up Construction Ontologies", IEEE Trans. on Knowledge and data Engineering, Vol. 10, No. 4, pp.513-526, July/August, 1998. N. Guarino, “Formal Ontology and Information System,” Proc. of the First International Conference (FOIS'98), Trento, Italy, June, 1998. “Chinese Knowledge Information Processing Group (CKIP),” Academia Sinica, Taiwan, 2001. “Academia Sinica Balanced Corpus,” Technical Report, No. 95-02/98-04, Academia Sinica, Taiwan, 1998. “Chinese Electronic Dictionary,” Technical Report, No. 93-05, Academia Sinica, Taiwan, 1993. Y. H. Kuo, J. P. Hsu and C. W. Wang, “A Parallel Fuzzy Inference Model with Distributed Prediction Scheme for Reinforcement Learning,” IEEE Trans. on Systems, Man, and Cybernetics, Vol. 28, No. 2, pp.160-172, April, 1998. Y. J. Yang, et al., “An intelligent and efficient word-class-based Chinese language model for Mandarin speech recognition with very large vocabulary.” Proc. of ICSLP-94, Yokohama, Japan, 1994, pp. 1371-1374. J. Gao, J. T. Goodman and J. Miao, “The Use of Clustering Techniques for Language Modeling – Application to Asian Language,” Computational Linguistics and Chinese Language Processing , Vol. 6, No. 1, pp. 27-60, February, 2001. R. C. T. Lee, R. C. Chang, S. S. Tseng and Y. T. Tsai, Introduction to the Design and Analysis of Algorithms, Taipei, Unalis co., 1999..
(8)
數據
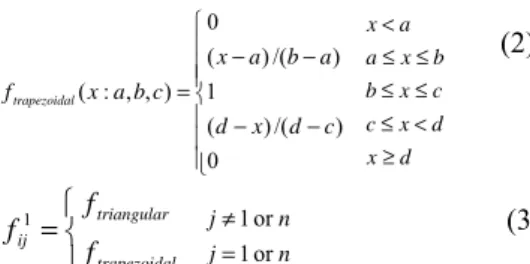

+2

相關文件
• Content demands – Awareness that in different countries the weather is different and we need to wear different clothes / also culture. impacts on the clothing
• Examples of items NOT recognised for fee calculation*: staff gathering/ welfare/ meal allowances, expenses related to event celebrations without student participation,
Based on Cabri 3D and physical manipulatives to study the effect of learning on the spatial rotation concept for second graders..
We propose a primal-dual continuation approach for the capacitated multi- facility Weber problem (CMFWP) based on its nonlinear second-order cone program (SOCP) reformulation.. The
DVDs, Podcasts, language teaching software, video games, and even foreign- language music and music videos can provide positive and fun associations with the language for
● the F&B department will inform the security in advance if large-scaled conferences or banqueting events are to be held in the property.. Relationship Between Food and
• The abstraction shall have two units in terms o f which subclasses of Anatomical structure are defined: Cell and Organ.. • Other subclasses of Anatomical structure shall
First, when the premise variables in the fuzzy plant model are available, an H ∞ fuzzy dynamic output feedback controller, which uses the same premise variables as the T-S
