Updating Generalized Association Rules with Evolving Taxonomies
6
0
0
全文
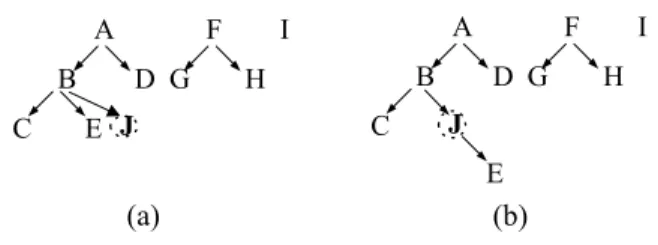
(2) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. In this subsection, we will describe different situations for taxonomy evolution, and clarify the essence of frequent itemsets update for each type of taxonomy evolutions. According to our observation, there are four basic types of item updates that will cause taxonomy evolution: (1) Item insertion: New items are added to the taxonomy. (2) Item deletion: Obsolete items are pruned from the taxonomy. (3) Item rename: Items are renamed for some reasons, such as error correction, product promotion, etc. (4) Item reclassification: Items are classified into different categories. Note that hereafter the term “item” refers to a primitive or a generalized item. Each type of evolutions is further explained in the following.. the taxonomy occurs, apply an updating method to re-build the discovered rules. The challenge thus falls into developing an efficient updating algorithm to facilitate the whole mining process. This problem is nontrivial because updates to the taxonomy not only can reshape the concept hierarchy and the form of generalized items, but also may invalidate some of the discovered association rules, turn previous weak rules into strong ones, and generate import new, undiscovered rules. We propose an algorithm called Taxo_UP (Taxonomy Update) for mining the generalized frequent itemsets, which is capable of effectively reducing the number of candidate sets and database re-scanning, and so can update the generalized association rules efficiently. Detail description of the Taxo_UP algorithm will be given in Section 3. In Section 4, we evaluate the performance of the proposed Taxo_UP with two leading generalized associations mining algorithms, Cumulate and Stratify from [10], on synthetic data. A brief description of previous related work is presented in Section 5. Finally, we summarize our work and future investigation in Section 6.. 2. Update of Generalized Association Rules 2.1. Problem description Let I = {i1, i2, …, ip} be a set of items and DB = {t1, t2, …, tn} be a set of transactions, where each transaction ti = ⟨tid, A⟩ has a unique identifier tid and a set of items A (A⊆I). Assume that a set of taxonomies of items, T, is available and is denoted as a set of hierarchies (trees) on I ∪ J, where J = {j1, j2, …, jp} represents the set of generalized items derived from I. A generalized association rule is an implication of the form A ⇒ B, where A, B ⊂ I ∪ J, A ∩ B = ∅, and no item in B is an ancestor of any item in A. Given a user specified minsup and minconf, the problem of mining generalized association rules is to discover all generalized association rules whose supports and confidence are larger than the specified thresholds. This problem is reduced to the problem of finding all frequent itemsets for a given minimum support [6][10]. Let L be, after an initial discovery of all the generalized association rules in DB, the set of all frequent itemsets with respect to minsup. As time passes, some updated activities may occur to the taxonomies due to some reasons [5]. We denote the updated taxonomies as T’. The problem of updating discovered generalized association rules in DB is to find the set of frequent itemsets L’ with respect to the refined taxonomies T’.. 2.2. Types of taxonomy updates. 369. Type 1: Item insertion. The strategies to handle this type of update operation are different in whether the inserted item is primitive or generalized. When the new inserted item is primitive, we cannot process this item until there is an incremental database update, because the new item does not appear in the original set of frequent itemsets. On the other hand, if the new item represents a generalization, then the insertion itself also has no effect on the discovered associations until the new generalization incurs some item reclassification. Figure 2 shows an example of this type of taxonomy evolution, where a new item “J” is inserted as (a) a primitive item or (b) a generalized item. Note that in Figure 2b item “E” is reclassified to the generalization represented by “J”. A. F D G. B C. E J. A. I B. H C. I. F D G. H. J E. (a). (b). Figure 2. An example of taxonomy evolution caused by item insertion. The inserted item “J” is: (a) primitive; (b) generalized. Type 2: Item deletion. This case is similar to the insertion case. There is nothing to do with the deletion of primitive items if no transaction update to the original database, and the removal of a generalization may also lead to items reclassification. Figure 3 shows an example of this type of taxonomy evolution. Type 3: Item rename. When items are renamed, we do not have to process the database. Instead, we just replace the frequent itemsets with new names and so the association rules..
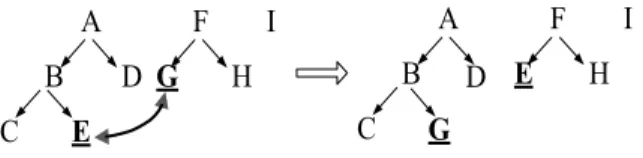
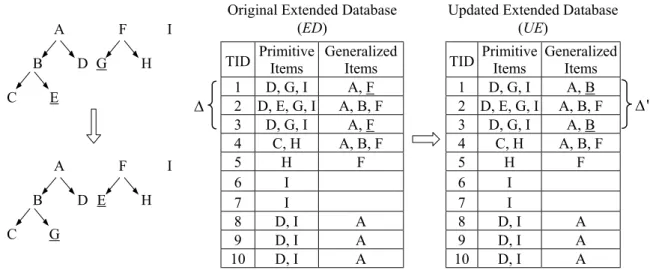
(3) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. A D G. B C. F. A. I. D G. B. H. not change with respect to a taxonomy evolution. Thus, the proposed Taxo_UP algorithm follows a simple guideline: Identify the affected and unaffected generalizations first, and so the affected transactions. Then utilize them to lessen the work of support counting of itemsets as could as possible. An affecting item is a primitive item whose ancestor set changes with respect to a taxonomy evolution. An item is an affected item if its descendent primitive item set changes with respect to a taxonomy evolution. A transaction is called an affected transaction if it contains at least one of affecting items. For a given itemset A, we say A is an affected itemset if it contains at least one of affected items. There are four different cases in dealing with the support counting of A. (1) If A is an unaffected itemset and is frequent in ED, then it is also frequent in UE. (2) If A is an unaffected itemset and is infrequent in ED, then it is also infrequent in UE. (3) If A is an affected itemset and is frequent in ED, then it may be frequent or infrequent in UE. (4) If A is an affected itemset and is infrequent in ED, then it may be frequent or infrequent in UE. Note that only cases 3 and 4 need further database scan to determine the support count of A. Indeed, for case 3, we only have to scan the affected transactions in ED and UE. Then calculate its support to decide whether it is frequent or not. As for case 4, the following lemma provides an effective pruning strategy to reduce the number of candidate itemsets and so can avoid unnecessary database scan. Lemma 2. If an affected itemset A ∉L (frequent itemsets in ED) and δ A' − δ A ≤ 0, then A ∉L’ (frequent itemsets in UE), where ∆ is the set of transactions in ED affected by taxonomy update, ∆' the set of affected transactions in UE, and δ A and δ A' are support counts of A in transactions ∆ and ∆' , respectively. Proof. If A ∉L, then σ A < |ED| × minsup, where σ A denotes the support count of A in ED. Note that |UE| = |ED| = |ED| − |∆| + |∆’| due to |∆| = |∆’|. Hence, σ ′A = σ A + ( δ A' − δ A ) < |ED| × minsup = |UE| × minsup, where σ ′A is the support count of A in UE. Thus, A ∉L’. Thus in case 4, we scan the affected transactions in ED and UE to count the appearances of A. If the support count of A in UE’s affected transactions is greater than that in ED, then we have to scan the rest of UE to decide whether A is frequent or not. An overview of the Taxo_UP algorithm is presented below.. I H. E. C. E. F. (a). (b). Figure 3. An example of taxonomy evolution caused by item deletion: (a) The primitive item “E” is deleted; (b) The generalized item “B” is deleted, and items “C” and “E” are reclassified to “A”. Type 4: Item reclassification. Among the four types of taxonomy updates this is the most profound operation. Once an item, primitive or generalized, is reclassified into another category, all of its ancestor (generalized items) in the old and the new taxonomies are affected. In other words, the supports of these affected generalized items have to be updated and so do the frequent itemsets containing any one of the affected generalized items. For example, in Figure 4, the two shifted items E and G will change the support counts of generalized items A, B, and F, and also affect the support counts of itemsets containing A, B, or F.. A D G. B C. F. E. A. I. D E. B. H C. F. I H. G. Figure 4. An example of taxonomy evolution caused by item reclassification. In this paper, we assume that there is no transaction update to the original database, and so we only have to consider, according to the above discussions, the taxonomy evolution caused by insertion or deletion of generalized items, and reclassification of primitive or generalized items.. 3. The Proposed Taxo_UP Algorithm 3.1. Algorithm description Let ED denote the extended version of DB by adding, in taxonomies T, the ancestors of each primitive item to each transaction, while UE be another extension of DB by adding generalized items in the updated taxonomies T’. A straight-forward way to find updated generalized frequent itemsets would be to run any of the algorithms, such as Cumulate and Stratify [10], for finding generalized frequent itemsets on the updated extended transactions UE. This simple way, however, ignores the fact that many discovered frequent itemsets would not be affected by the taxonomy evolution. Lemma 1. The supports of all primitive items do. Algorithm: Taxo_UP Inputs: (1) DB: the database; (2) ms: the minimum support setting; (3) T: the old item taxonomy; (4) T’: the new item taxonomy; (5) L = UkLk: the set of old. 370.
(4) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. A B C. D G. ∆. A. C. I. F D E. G. H. Primitive Generalized Items Items 1 D, G, I A, F 2 D, E, G, I A, B, F 3 D, G, I A, F 4 C, H A, B, F 5 H F 6 I 7 I 8 D, I A 9 D, I A 10 D, I A. TID. H. E. B. Original Extended Database (ED). I. F. Updated Extended Database (UE) TID 1 2 3 4 5 6 7 8 9 10. Primitive Generalized Items Items D, G, I A, B D, E, G, I A, B, F D, G, I A, B C, H A, B, F H F I I D, I A D, I A D, I A. ∆'. Figure 5. An example of mining generalized association rules caused by item reclassified. frequent itemsets Output: L’ = UkL’k: the set of new frequent itemsets. Method: 1. Load L1; let C1 be the set of items in T’. 2. Divide the set of candidate 1-itemsets C1 into two parts: one X consists of unaffected items in L1, and the other Y contains affected items. 3. Add generalized items in T and T’ into the original database DB to form ED and UE respectively. 4. Compute the count of each 1-itemset A in Y over the affected transactions of ED (∆) and UE (∆’); let the values be δ A and δ A' , respectively. 5. For each 1-itemset A that is in L1 and the affected set Y, i.e., A ∈ Y ∩ L1 , calculate σ’A = σA − δ A + δ A' . 6. For any candidate A ∉ L1 and ( δ A' − δ A ) > 0, count A over the transactions in UE - ∆’ and add the counts to δ A' . 7. Create L’1 by combining X and those itemsets which are frequent in Y. 8. Generate candidates C2 from L’1. 9. Repeat Steps 1-8 for new candidates Ck until no frequent k-itemsets L’k created.. them; we only have to process generalized items A, B and F. Next, transactions 1, 2 and 3 in ED and UE are scanned since these transactions are affected by exchanging items G and E. We then subtract the support counts of items A and F in ED’s affected transactions from and add their counts in UE’s affected transactions to their original support counts. ' For example, we have σ’{F} =σ{F} − δ {F} + δ {F} = 5 − 3 + 1 = 3. Item B is not frequent in ED and may become frequent because δ {' B} − δ {B} = 3 − 1 = 2 > 0 according to Lemma 2. Therefore, we scan transaction 4 to counting item B and add 1 to the count from ' UE. That is, σ’{B} = δ {B } + 1 = 3 + 1 = 4. After comparing the supports of A, B, and F to minsup, the new frequent 1-itemsets L'1 are A, B, D, F, G, and I. Next, we use L'1 to generate candidate 2-itemsets C2 , obtaining AF, AI, BD, BF, BI, DF, DG, DI, FG, FI, and GI. However, only AF, AI, BD, BF, BI, DF, FG, and FI undergo support counting, because the others are composed of primitive items. Note that the original frequent 2-itemset AG is deleted in UE due to the existence of item-ancestor relationship. After that, the procedure of generating frequent 2-itemsets is the same as that for generating L'1 . The new frequent 2-itemsets L'2 are AI, BD, BI, DG, DI, and GI. Finally, we use the same approach to generat L'3 , obtaining BDI and DGI. Note that transaction 2 has the same generalized items after the taxonomy evolution; however, we still require processing this transaction in Step 4 of the proposed algorithm. If we do not process this transaction, 2-itemset FG will not become frequent when minsup = 10%. The whole process of running this example using Taxo_UP is illustrated in Figure 6.. 3.2. An example Consider Figure 5. Let minsup = 25% (3 transactions). The set of frequent itemsets L includes: A(7), D(6), F(5), G(3), I(8), AF(4), AG(3), AI(6), DF(3), DG(3), DI(6), FI(3), GI(3), AFI(3), AGI(3), DFI(3), and DGI(3), where the support counts of itemsets are shown within parentheses. The Taxo_UP algorithm first divides all items in C1 into two sets: one consists of unaffected items D, G, and I in L1, and the other contains affected generalized items A, B and F, where A and F are frequent in L1, while B is not. Since items D, G, and I are primitive frequent items and do not change their supports in ED and UE, we do not need to process. 371.
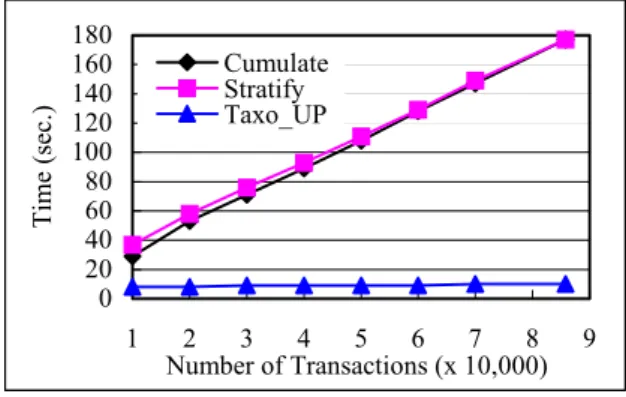
(5) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. C1. performed on an Intel AMD-800 with 512MB RAM, running on Windows 2000.. A, B, C, D, E, F, G, H, I. Unaffected C 1 C 1 in L1. Affected C 1 C1 in L1. Load L1 C1 not in L1. D, G, I. B. * only shows count in UE. Table 1. Default parameter settings for synthetic data generation.. A, F. Scan ED & UE Cal. A B 7. 3*. Parameter Default value 100,000 |DB| Number of original transactions 5 |t| Average size of transactions 200 N Number of items 30 R Number of groups 3 L Number of levels 5 F Fanout. F 3. Scan rest UE B 4. '. Generate L1 '. We first compared the performance of these algorithms with varying minimum supports. As shown in Figure 7, Taxo_UP performs significantly better than Stratify and Cumulate; the improvement ranges from 3 to 6 times and increases as minsup decreases.. A, B, D, F, G, I. L1. Generate C 2 AF, AI, BD, BF, BI, DF, DG, DI, FG, FI, GI. C2. Affected C 2 Load L2 C 2 not in L2 C 2 in L2. Unaffected C 2 C 2 in L2 DG, DI, GI. BD. BI. AF, AI, DF, FI Scan ED & UE Cal. FG AF AI DF. 3*. 3*. 1*. 2. 6. 1. FI 1. Time (sec.). BD, BF, BI, FG. Scan rest UE BD. BI. FG. 3. 3. 1. 700 600 500 400 300 200 100 0. Cumulate Stratify Taxo_UP. 0.5. Generate L2'. 1.0. 1.5 2.0 ms %. 2.5. 3.0. AI, BD, BI, DG, DI, GI. L2'. Figure 7. Performance comparison of Taxo_UP, Cumulate, and Stratify for different minsups.. Generate C 3 C3 Unaffected C 3 C 3 in L3. BDI, DGI Load L3. DGI. Affected C 3 C3 not in L3. We then compared the three algorithms under varying transaction sizes. The result is depicted in Figure 8. As shown in the figure, Taxo_UP performs significantly better than Cumulate and Stratify. Algorithm Cumulate performs a little better than Stratify. The results also demonstrate that Taxo_UP has better scalability than Cumulate and Stratify.. BDI Scan ED & UE Cal. BDI 3* Scan rest UE BDI 3. Generate L3' '. BDI, DGI. Generate C 4 C4. ∅. Time (sec.). L3. Figure 6. Illustration of algorithm Taxo_UP.. 4. Performance Evaluation In order to examine the performance of Taxo_UP, we conducted experiments to compare its performance with that of Cumulate and Stratify, using the synthetic dataset generated by the IBM data generator [1]. The parameter settings are shown in Table 1. Two items in the taxonomies were randomly chosen to exchange their positions. All experiments were. 180 160 140 120 100 80 60 40 20 0. Cumulate Stratify Taxo_UP. 1. 2 3 4 5 6 7 8 Number of Transactions (x 10,000). 9. Figure 8. Performance comparison of Taxo_UP, Cumulate, and Stratify for different transactions at minsup = 1.0%.. 372.
(6) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. 5. Related Work. evolution.. The problem of mining association rules in the presence of taxonomy information was addressed first in [6] and [10], independently. In [10], the problem is named as mining generalized association rules, which aims to find associations among items at any level of the taxonomy under the minimum support and minimum confidence constraints. In [6], the problem mentioned is somewhat different from that considered in . They generalized the uniform minimum support constraint to a form of level-wise assignment, i.e., items at the same level receive the same minimum support. The objective was mining associations level-by-level in a fixed hierarchy. That is, only associations among items at the same level are examined progressively from the top level to the bottom. The problem of updating association rules incrementally was first addressed by Cheung et al. [2]. They coined the essence of updating the discovered association rules when new transaction records are added into the database over time and proposed an algorithm called FUP (Fast UPdate). They further examined the maintenance of multi-level association rules [3], and extended the model to incorporate the situations of deletion and modification [4]. Their approaches [3][4], however, did not consider the generalized items, and hence could not discover generalized association rules. Since then, a number of techniques have been proposed to improve the efficiency of incremental mining algorithm [7][8][9][11]. But all of them were confined to mining associations between primitive items. The problem of maintaining generalized associations incrementally has been recently investigated in [12], wherein the model of generalized associations was extended to that with non-uniform minimum support. To sum up, all related previous works addressed in part the aspects discussed in this paper; no work, to our knowledge, has considered the issues of evolving taxonomies.. References [1]. R. Agrawal and R. Srikant, “Fast algorithms for mining association rules,” Proc. 20th Int. Conf. Very Large Data Bases, 1994, pp. 487-499. [2] D.W. Cheung, J. Han, V.T. Ng, and C.Y. Wong. “Maintenance of discovered association rules in large databases: An incremental update technique,” Proc. 1996 Int. Conf. Data Engineering, 1996, pp.106-114. [3] D.W. Cheung, V.T. Ng, B.W. Tam, “Maintenance of discovered knowledge: a case in multi-level association rules,” Proc. 1996 Int. Conf. Knowledge Discovery and Data Mining, 1996, pp. 307-310. [4] D.W. Cheung, S.D. Lee, and B. Kao, “A general incremental technique for maintaining discovered association rules,” Proc. DASFAA'97, 1997, pp. 185-194. [5] J. Han and Y. Fu, “Dynamic generation and refinement of concept hierarchies for knowledge discovery in databases,” Proc. AAAI’94 Workshop on Knowledge Discovery in Databases (KDD’94), 1994, pp. 157-168. [6] J. Han and Y. Fu, “Discovery of multiple-level association rules from large databases,” Proc. 21st Int. Conf. Very Large Data Bases, 1995, pp. 420-431. [7] T.P. Hong, C.Y. Wang, Y.H. Tao, “Incremental data mining based on two support thresholds,” Proc. 4 Int. Conf. Knowledge-Based Intelligent Engineering Systems and Allied Technologies, 2000, pp.436-439. [8] K.K. Ng and W. Lam, “Updating of association rules dynamically,” Proc. 1999 Int. Symp. Database Applications in Non-Traditional Environments, 2000, pp. 84-91. [9] N.L. Sarda and N.V. Srinivas, “An adaptive algorithm for incremental mining of association rules,” Proc. 9th Int. Workshop on Database and Expert Systems Applications (DEXA'98), 1998, pp. 240-245. [10] R. Srikant and R. Agrawal, “Mining generalized association rules,” Proc. 21st Int. Conf. Very Large Data Bases, 1995, pp. 407-419. [11] S. Thomas, S. Bodagala, K. Alsabti, and S. Ranka, “An efficient algorithm for the incremental updation of association rules in large databases,” Proc. 3rd Int. Conf. Knowledge Discovery and Data Mining, 1997. [12] M.C. Tseng and W.Y. Lin, “Maintenance of generalized association rules with multiple minimum supports,” Intelligent Data Analysis, in print.. 6. Conclusions We have investigated in this paper the problem of updating generalized association rules under evolving taxonomy. We presented an algorithm, Taxo_UP, for updating generalized frequent itemsets. Empirical evaluation showed that the Taxo_UP algorithm is very effective and has good linear scale-up characteristic. In the future, we will extend the problem of updating generalized association rule to a more general model that deals with an incremental database update and fuzzy taxonomic structure. We will also investigate the problem of on-line discovery and maintenance of multi-dimensional association rules from data warehouse data under taxonomy or attribute. 373.
(7)
數據
相關文件
Reading Task 6: Genre Structure and Language Features. • Now let’s look at how language features (e.g. sentence patterns) are connected to the structure
Promote project learning, mathematical modeling, and problem-based learning to strengthen the ability to integrate and apply knowledge and skills, and make. calculated
Now, nearly all of the current flows through wire S since it has a much lower resistance than the light bulb. The light bulb does not glow because the current flowing through it
In this paper, we have shown that how to construct complementarity functions for the circular cone complementarity problem, and have proposed four classes of merit func- tions for
The case where all the ρ s are equal to identity shows that this is not true in general (in this case the irreducible representations are lines, and we have an infinity of ways
This kind of algorithm has also been a powerful tool for solving many other optimization problems, including symmetric cone complementarity problems [15, 16, 20–22], symmetric
Due to the limitation of space, this paper only deals with the above-mentioned problems by referring to the `sutras` and
– Assume that there is no concept with significan t correlation to Mountain..
