Anonymizing Multiple K-anonymous Shortest Paths For Social Graphs
Shyue-Liang Wang, Zheng-Ze Tsai, Tzung-Pei
Hong, I-Hsien Ting
National University of KaohsiungKaohsiung, Taiwan 81148 {slwang, tphong, iting}@nuk.edu.tw
Yu-Chuan Tsai
Department of Computer Science and Information Engineering
National Cheng Kung University Tainan, Taiwan 70101 [email protected]
Abstract—To preserve privacy, k-anonymity on relational,
set-valued, and graph data have been studied extensively in recent years. Information on social networks can be modeled as un-weighted or un-weighted graph data for sharing and publishing. We have previously proposed k-anonymous path privacy concept on weighted social graphs to preserve privacy of the shortest path [9]. A published social network graph with
k-anonymous path privacy has at least k indistinguishable
shortest paths between the source and destination vertices. However, previous work only considered modifying
Never-Visited (NV) edges by other shortest paths. In this work, we
further extend the approach and propose a new technique that can modify both NV edges and All-Visited (AV) edges to achieve the k-anonymous path privacy. Experimental results showing the characteristics of each technique are presented. It clearly provides different options to achieve the same level of privacy under different requirements.
Keywords- social networks, privacy preserving, edge weight, shortest path, k-anonymity
I. INTRODUCTION
Social network applications, such as Facebook, MySpace, Linkin and other online communities, collaboration networks, telecommunication networks, have become extremely popular for sharing information in recent years. There are millions of registered users associated with others through friendships, hobbies, professional association, and so on. These user information and relationship can be modeled as vertices, edges, and edge weights in complex graphs and are of significant importance for various application domains such as marketing, psychology, epidemiology and homeland security. As a result, companies and institutions hosting the data are interested and expect to be beneficial in releasing portions of the graphs to communities. However, these social network graphs may contain sensitive personal or institutional information. In order to protect the privacy of users against different types of attacks, graphs should be anonymized before they are published.
Current practices to protect user privacy from published data include removing all identifiable personal information such as names and social security numbers, limiting access, “fuzzing” the data, eliminating unnecessary groupings, augmenting with additional data, etc. However, it is still easy for an attacker to identify the target by performing different structural and non-structural queries.
There are basically three types of sensitive information that one may want to keep private and may be under attack in a social network environment: node information, link information and edge weight information [1, 4, 5]. The node information is the information attached to a vertex. For example, the emails sent by an individual, the personal information such as age, sex, zip code, and transaction data such as purchased items [3, 6-8]. The link information is about the relationships among the individuals which may be considered sensitive. Links can be used to represent financial exchanges, friend relationships, conflict likelihood, sexual relations, and disease transmission [5]. Depending on the application, the edge weight information can semantically represent “degree of friendship”, “trustworthiness”, and “behavior” etc. If considering routing problem, (for information spread and marketing), edge weights may correspond to the cost of information propagation [2]. To protect edge weight privacy, perturbation-based approaches to preserve linear property, such as modifying all edge weights so that the shortest path remained to be the shortest path, have been proposed recently [2, 4, 5]. Previously, we have proposed a new concept of k-anonymous path privacy on weighted social graphs to preserve privacy of the shortest path [9]. A published social network graph with k-anonymous path privacy has at least k indistinguishable shortest paths between the source and destination vertices. However, in that work, we only considered modifying Never-Visited (NV) edges by other shortest paths. In this work, we further extend the approach and propose two new techniques that can modify All-Visited (AV) edges and Partially-Visited (PV) edges to achieve the k-anonymous path privacy respectively. Examples clearly illustrate the differences between the three techniques will be given. Elaborated numerical experiments will be presented to demonstrate the characteristics of each strategy.
The rest of the paper is organized as follows. Section 2 gives the problem description. Section 3 describes the proposed algorithms. Section 4 reports the numerical experiments. Section 5 concludes the paper.
II. PROBLEM DESCRIPTION
In order to protect the privacy of these sensitive information (sensitive edges), three types of work have been proposed. The first type of work tries to preserve the 2011 Second International Conference on Innovations in Bio-inspired Computing and Applications
978-0-7695-4606-3/11 $26.00 © 2011 IEEE DOI 10.1109/IBICA.2011.53
195
2011 Second International Conference on Innovations in Bio-inspired Computing and Applications
978-0-7695-4606-3/11 $26.00 © 2011 IEEE DOI 10.1109/IBICA.2011.53
shortest path characteristic between pairs of source and destination vertices. In another word, the shortest path remains to be the shortest path after all edge weights are minimally modified [2, 5]. The second type of work tries to preserve the privacy of edges emitting from a given vertex [4]. As such, the difference between the weights of the edges emitting from a given vertex are within a predefined parameter. The third type of work tries to preserve the shortest path privacy between pairs of source and destination vertices [9]. In another word, give a pair of source and destination vertices, the edge weights are minimally modified such that there exist at least k shortest paths between the given vertices.
To preserve the shortest paths between pairs of vertices, Gaussian randomization perturbation and greedy perturbation techniques that minimally modify the edge weights without adding or deleting any vertices and edges have been proposed. A linear programming abstract model that can preserve linear properties of edge weights (including shortest paths) after anonymization is presented in [2]. To eliminate the distinguishability between edge weights, the k-anonymous weight privacy is defined as [4]: the edge (i j) is k-anonymous if and only if there exist at least k edges in (i) whose weights wi,tl , l = 1, ..., c, and c k, satisfy || wi,j -
wi,tl || ≦ , l=1,..., c. Here, is a predefined positive
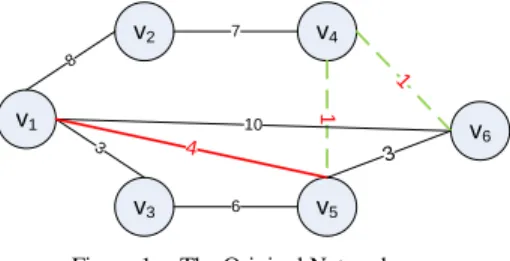
parameter to control the degree of privacy and (i) is the adjacent edge set in which all edges come from the i-th node. To preserve the shortest path privacy, we have introduced the k-anonymous path privacy concept that hiders adversary to infer the sensitive relationship between two entities (vertices) in a social network [9]. The basic idea is to hide the true sensitive information, e.g. the shortest path, by obfuscating it with at least k-1 other paths so that the true path will not be revealed. Figure 1 shows an undirected weighted graph with six vertices. Assuming the relationship represented by the shortest path between vertices v1 and v6 is
sensitive and expected to be hidden. If the weight of edge e5,6 is modified to two, then the graph is anonymized with
two shortest paths between vertices v1 and v6. Therefore,
given a graph G, a set of source and destination nodes H, and privacy level k, the objective of k-anonymous path privacy is to minimally modify the graph such that there exists k shortest paths between each given pair of nodes specified in H, without adding or deleting any vertices or edges. The privacy level k is defined as the number of shortest paths between the specified source and destination vertices.
For a given set of source and destination pair of vertices, certain edges in the shortest paths may overlap with each other. Three categories of edges can be classified according to their involvement in the shortest paths to be preserved [5]. An edge ei,j is a non-visited (NV) edge if ei,j does not belong
to any shortest path to be preserved. An edge ei,j is an
all-visited (AV) edge if all shortest paths pass through it. An edge ei,j is a partially-visited (PV) edge if at least one shortest
path passes through it but not all shortest paths. For example, in Figure 1, the shortest path between v1 and v6 is p1,6 = {(v1,
v5), (v5, v4), (v4, v6)} and the shortest path between v3 and v6
is p3,6 = {(v3, v5), (v5, v4), (v4, v6)}. It can be seen that edges
e5,4 and e4,6 are all-visited edges, e1,5 and e3,5 are
partially-visited edges, and other edges are non-partially-visited edges. It can be observed that modifying the weights of NV and AV edges will not change the characteristic of the shortest path but modifying the weights of AV edges will change the length of all shortest paths.
v1 v2 v3 v5 v4 v6 3 1 10 8 6 4 7 1 3
Figure 1. The Original Network
In this work, we proposed an algorithm for k-anonymous path privacy problem by allowing modifying both NV edges and AV edges. In addition, we propose a lemma to check the condition if a path can be modified to be equal to the shortest path or not.
III. PROPOSED ALGORITHM
For a set of source and destination vertices H on a graph G, a given privacy level k, the k-anonymous path privacy problem is to minimally modify the graph G such that there exists k shortest paths between each given pair of vertices specified in H, without adding or deleting any vertices or edges. We propose a greedy-based approach and modify the edge weights of NV and AV edges in the top-k shortest paths so that they all possess the same path length. The proposed algorithm first finds the second shortest path and reduces proportionally the edge weights of non-overlapping edges between the second shortest and the shortest paths. For example, in Figure 1, the second shortest path between v1
and v6 is p1,6 = {(v1, v5), (v5, v6)}. The non-overlapping edge
is e5,6 which has weight three. The non-overlapping edges in
the shortest path are e5,4 and e4,6 which has total weight of
two. Therefore the edge weight of e5,6 is reduced to two so
that both paths will have the same path length. The process repeats itself after all top-k shortest paths are modified. For k = 2, the two shortest paths for vertex pair (v1, v6) will be
p1,6 = {(v1, v5), (v5, v4), (v4, v6)}and p’1,6 = {(v1, v5), (v5, v6)}.
Both have path length, d1,6 = 6. The AV edge for vertex pair
(v1, v6) is e1,5 = (v1, v5). The PV edges are e5,4 = (v5, v4), e5,6 =
(v5, v6) and e4,1 = (v4, v1). For the second pair of vertex pair
(v2, v6), the shortest and second shortest paths are p2,6 = {(v2,
v4), (v4, v6)} and p’2,6 = {(v2, v4), (v4, v5) , (v5, v6)}. However,
the second shortest path cannot be reduced to the same length as the shortest path; due to modifying will make the shortest paths of vertex pair (v1, v6) unequal. Lemma one
provides such a condition that under which a path cannot be modified to be equal to the shortest path. The third shortest path for vertex pair (v2, v6) is p’2,6 = {(v2, v1), (v1, v5) , (v5,
v6)}. If NV and AV edges are considered, then we can modify
the length of e2,1 from 8 to 4, e1,5 from 4 to 2 and find two
paths with same length: p2,6 = {(v2, v4), (v4, v6)} , d2,6 = 8, and
p’2,6 = {(v2, v1), (v1, v5) , (v5, v6)} , d’2,6 = 8. However, since
196 196
AV edge is modified, the shortest paths for vertex pair (v2, v6)
should be updated accordingly. Therefore, p1,6 = {(v1, v5),
(v5, v4), (v4, v6)}, d1,6 = 4, and p’1,6 = {(v1, v5), (v5, v6)}, d’1,6 =
4.
Lemma 1 Let p1,1 and p1,2 be anonymized shortest paths
for vertex pair (v1s, v1d), and p2,1 and p2,2 be paths for vertex
pair (v2s, v2d). Assuming that a=(vi, vj) and b=(vi, vk) are
edges in p1,1 and c=(vj, vk) is a non-overlapping edge in p1,2
such that da + db = dc. If b is an edge of p2,1 and
non-overlapping a, c are edges of p2,2, then p2,2 cannot be
modified to be the shortest path for (v2s, v2d).
The following algorithm heuristically modifies NV edges and AV edges based on greedy approach to achieve k-anonymous path privacy.
K-Multiple Paths Anonymization Algorithm (KMPA) Input: W, weighted adjacency matrix of a given graph G,
H, the set of source and destination vertices for which the shortest paths are to be anonymized, K, number of shortest path between each pair of source and destination vertices,
Output: anonymized weighted adjacency matrix W*, 1. Initialize SPL = ; //shortest path list
2. while (H ) {
3. for (each pair of vertices (vi, vj) in H) //find the
shortest path for each vertex pair
4. find its shortest path pi,j and length di,j; //end of for
5.
d
r,s:
min
Hd
i,j ; //minimum of all shortest paths 6. H := H – (vr, vs);7. TSPL := {pr,s}; //save the shortest path for vertex pair
(vr, vs)
8. while (|TSPL| < k )
{ //there are less than k paths for current vertex pair 9. find next shortest path p’r,s and its length d’r,s;
10. if (d’r,s = dr,s) { //same length
11. TSPL := TSPL + p’r,s ; // add to anonymized list
12. continue; } //to find next shortest path 13. else { // different length
14. If ( d’r,s and dr,s satisfy lemma one) then
continue; // d’r,s cannot be anonymized
15. let diff := d’r,s - dr,s; //the weight to be reduced
16. p’’r,s := p’r,s – {edges in SPL and TSPL} +
{AV edges by previous vertex pairs that appear on p’r,s } ; //consider NV and AV
edges
17. If (p’’r,s and d’’r,s > diff) //enough edge
weight to be modified
18. for (each edge e’’i,j on the p’’r,s )
{ //reduce proportionally 19.
d diff
w w w w rs ij ij ij j i
' " " " ", ;20. update the adjacency matrix;
21. TSPL := TSPL + p’r,s ; //save the
modified path
22. }; // end of for each edge e’’i,j
23. }; //end of else, different length 24. }; // end of while (|TSPL|< k ) 25. SPL := SPL + TSPL;
}; // end of while (H )
IV. NUMERICAL EXPERIMENT
To evaluate the characteristics of the proposed algorithm, we run simulations on a synthetic data set. The data set contains 65 nodes and 1,021 edges. The weights of the edges range from 1 to 4. All data are randomly generated.
All experiments reported in this section were performed on an Intel Core 2 Duo P8700 CPU, 2.53 GHz machine with 4 GB main memory, running Microsoft Windows 7 operating system. All the methods were implemented using Java programming language.
Figure 2 shows the preliminary results of ratios of perturbed edges. The ratio is the number of modified edges over the total number of edges on the k shortest paths. It can be observed that the average percentage of perturbed edges for k >= 5 is about 50%, which is greater than 40% reported in [9]. This is partly due to the previous work only considered modifying the NV edges, but in this work we consider modifying both NV and AV edges. Figure 3 shows the running times of anonymization of k shortest paths for different privacy level k and for multiple pairs of source and destination vertices. It can be observed that anonymizing multiple pairs of source and destination vertices require relatively more running time when k increases to 10. This is due to the fact that it takes longer time to search for extra paths to be anonymized. Comparing to [9], the running times to modify both NV and AV are higher than modifying only NV edges. However, the pattern remains similar for both cases.
To evaluate the information loss between the two approaches (modifying only NV edges vs modifying both NV and AV edges), we adopt the Kullback and Leibler (KL) divergence for random variable of binary values. Intuitively, the KL divergence measures the number of additional bits required when coding a random variable with a probability distribution f(x) while using an alternative probability distribution g(x). It basically compares the entropy of two distributions over the same random variable. The KL divergence used in this work is given as follow:
For each anonymized edge, let f(x) be the ratio of the edge weight over the total weight of all edges to be modified, before modification. Let g(x) be the ratio of the edge weight over the total weight of all edges to be modified, after modification. For anonymizing the vertex pairs H= {(v1, v6),
(v2, v6)}, the K_L Divergence for modifying only the NV
edges is as follow. r s s r s s f g Divergence KL log 1 1 log ) 1 ( ) , ( _ 0466 . 0 2 2 2 3 8 8 log 3 8 8 2 2 2 3 8 8 log 3 8 8 ) , ( _ g f Divergence KL (1) 197 197
The K_L Divergence for modifying both the NV and AV edges is as follow.
Figures 4 and 5 shows the KL divergence for modifying only NV edges and modifying both NV and AV edges respectively. It can be observed the information loss increases as k increases. This is due to more edges must be modified and is consistent with the patterns in Figures 2 and 3.
Figure 2. Ratio of perturbed NV and AV edges for different k
Figure 3. Running time of perturbing NV and AV edges for different k
Figure 4. KL divergence for modifying only NV edges
Figure 5. KL divergence for modifying both NV & AV edges
V. CONCLUSION
In this work, we have studied the problem of preserving sensitive paths in social networks. Based on the concept of k-anonymous path privacy we previously introduced, an algorithm that minimally perturbed both the NV and AV edge weights to achieve the path anonymity is proposed. Examples illustrating the approach and numerical experiments showing the characteristics of the proposed algorithm were given. It clearly provides different options to achieve the same level of privacy under different requirements. In the future, we will consider modifying partially-visited edges and preserving other types of sensitive characteristics and privacy such as minimal cost spanning trees and other.
ACKNOWLEDGMENT
This work was supported in part by the National Science Council, Taiwan, under grant NSC-99-2221-E-390-033.
REFERENCES
[1] J. Cheng, A. Fu, and J. Liu, K-isomorphism: privacy preserving network publication against structural attacks, In SIGMOD conference, pp. 459-470, 2010.
[2] S. Das, O. Egecioglu, A.E. Abbadi, Anonymizing weighted social network graphs, In ICDE, pp. 904-907, 2010..
[3] Y. He and J.F. Naughton, Anonymization of set-valued data via top-down, local generalization, in VLDB 2009.
[4] L. Liu, J. Liu, J. Zhang, Privacy preservation of affinities in social networks, In ICIS, 2010.
[5] L. Liu, J. Wang, J. Liu, J. Zhang, Privacy preservation in social networks with sensitive edge weights, In SDM, pp. 954-965, 2009. [6] A. Meyerson and R. Williams. On the complexity of optimal
k-anonymity. In Proc. of PODS, 2004.
[7] R. Motwani and S.U. Nabar, Anonymizing unstructured data, arXiv: 0810.5582v2, [cs.DB], 2008.
[8] H. Park and K. Shim. Approximate algorithms for k-anonymity. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, pp. 67–78, 2007.
[9] S.L. Wang, Z.Z. Tsai, T.P. Hong, and I.H. Ting. Anonymizing shortest path on social network graphs. In Proc. of ACIIDS, 2011.
003 . 0 2 2 4 2 3 4 8 3 log 3 4 8 3 2 2 4 2 3 4 8 4 log 3 4 8 4 2 2 4 4 3 4 8 8 log 3 4 8 8 ) , ( _ g f Divergence KL 198 198